
Praise for Software Architecture: The Hard Parts
Cuốn sách này cung cấp cuốn cẩm nang thiếu sót liên quan đến việc xây dựng microservices và phân tích những sắc thái của các quyết định kiến trúc trong toàn bộ hệ thống công nghệ. Trong cuốn sách này, bạn sẽ có một danh mục các quyết định kiến trúc mà bạn có thể đưa ra khi xây dựng hệ thống phân tán của mình và những ưu nhược điểm liên quan đến từng quyết định. Cuốn sách này là điều cần thiết cho mọi kiến trúc sư đang xây dựng các hệ thống phân tán hiện đại.
Aleksandar Serafimoski, Tư vấn viên chính, Thoughtworks
“Đây là một cuốn sách phải đọc cho các nhà công nghệ đam mê kiến trúc. Diễn đạt tuyệt vời các mẫu.”
Vanya Seth, Trưởng bộ phận Công nghệ, Thoughtworks Ấn Độ
"Dù bạn là một kiến trúc sư đang hứa hẹn thành công hay một kiến trúc sư dày dạn kinh nghiệm đang dẫn dắt một đội ngũ, không chỉ là những câu nói xuông, cuốn sách này sẽ hướng dẫn bạn những chi tiết về cách thành công trong hành trình tạo ra các ứng dụng doanh nghiệp và microservices."
Tiến sĩ Venkat Subramaniam, Tác giả đoạt giải thưởng và Người sáng lập Agile Developer, Inc.
"Kiến trúc Phần mềm: Những Khó Khăn Cung cấp cho người đọc cái nhìn quý giá, các thực hành và ví dụ thực tế về việc tách rời các hệ thống liên kết chặt chẽ và xây dựng chúng trở lại. Bằng cách phát triển kỹ năng phân tích cân nhắc hiệu quả, bạn sẽ bắt đầu đưa ra những quyết định kiến trúc tốt hơn."
Joost van Wenen, Đối tác quản lý & Đồng sáng lập, Infuze Consulting
“Tôi rất thích đọc tác phẩm toàn diện này về kiến trúc phân tán! Một sự kết hợp tuyệt vời giữa những cuộc thảo luận vững chắc về các khái niệm căn bản, cùng với nhiều lời khuyên thực tiễn.”
David Kloet, Kiến trúc sư phần mềm độc lập
“Chia tách một đống bùn lớn không phải là công việc dễ dàng. Bắt đầu từ mã nguồn và đến với dữ liệu, cuốn sách này sẽ giúp bạn thấy những dịch vụ nào nên được tách ra và những dịch vụ nào nên được giữ lại với nhau.”
Rubén Díaz-Martínez, Nhà phát triển phần mềm tại Codesai
“Cuốn sách này sẽ trang bị cho bạn nền tảng lý thuyết và một khuôn khổ thực tiễn để giúp trả lời những câu hỏi khó nhất trong kiến trúc phần mềm hiện đại.”
James Lewis, Giám đốc Kỹ thuật, Thoughtworks
Software Architecture: The Hard Parts
Phân tích Trao đổi Hiện đại cho Kiến trúc Phân tán
Neal Ford, Mark Richards, Pramod Sadalage, và Zhamak Dehghani
Software Architecture: The Hard Parts
bởi Neal Ford, Mark Richards, Pramod Sadalage và Zhamak Dehghani
Bản quyền © 2022 Neal Ford, Mark Richards, Pramod Sadalage và Zhamak Dehghani. Tất cả các quyền được bảo lưu.
In ấn tại Canada.
Được xuất bản bởi O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472.
Sách O'Reilly có thể được mua cho mục đích giáo dục, kinh doanh hoặc sử dụng trong chương trình khuyến mãi bán hàng. Phiên bản trực tuyến cũng có sẵn cho hầu hết các tựa sách (http://oreilly.com). Để biết thêm thông tin, vui lòng liên hệ với bộ phận bán hàng doanh nghiệp/cơ sở của chúng tôi: 800-998-9938 hoặc corporate@oreilly.com.
- Acquisitions Editor: Melissa Duffield
- Development Editor: Nicole Taché
- Production Editor: Christopher Faucher
- Copyeditor: Sonia Saruba
- Proofreader: Sharon Wilkey
- Indexer: Sue Klefstad
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: O’Reilly Media, Inc.
- October 2021: First Edition
Revision History for the First Edition
- 2021-09-23: First Release
Xem http://oreilly.com/catalog/errata.csp?isbn=9781492086895 để biết thông tin phát hành.
Logo O’Reilly là một dấu hiệu đã đăng ký của O’Reilly Media, Inc. Kiến trúc Phần mềm: Những phần khó khăn, hình ảnh bìa và các phong cách thương mại liên quan là các thương hiệu của O’Reilly Media, Inc.
Các quan điểm được thể hiện trong tác phẩm này là của các tác giả và không đại diện cho quan điểm của nhà xuất bản. Mặc dù nhà xuất bản và các tác giả đã nỗ lực tốt để đảm bảo rằng thông tin và hướng dẫn chứa trong tác phẩm này là chính xác, nhà xuất bản và các tác giả từ chối mọi trách nhiệm đối với các lỗi hoặc thiếu sót, bao gồm nhưng không giới hạn trách nhiệm đối với thiệt hại phát sinh từ việc sử dụng hoặc dựa vào tác phẩm này. Việc sử dụng thông tin và hướng dẫn chứa trong tác phẩm này là rủi ro của chính bạn. Nếu bất kỳ mẫu mã hoặc công nghệ nào mà tác phẩm này chứa hoặc mô tả thuộc quyền sở hữu trí tuệ hoặc giấy phép mã nguồn mở của người khác, bạn có trách nhiệm đảm bảo rằng việc sử dụng của bạn tuân thủ các giấy phép và/hoặc quyền đó.
978-1-492-08689-5
[MBP]
Preface
Khi hai tác giả của bạn, Neal và Mark, đang viết cuốn sách "Những nguyên tắc cơ bản về Kiến trúc Phần mềm", chúng tôi liên tục gặp phải những ví dụ phức tạp trong kiến trúc mà chúng tôi muốn đề cập nhưng lại quá khó khăn. Mỗi ví dụ đều không đưa ra giải pháp dễ dàng mà chỉ là một tập hợp các sự đánh đổi lộn xộn. Chúng tôi đã xếp những ví dụ đó vào một đống mà chúng tôi gọi là "Những Phần Khó". Sau khi cuốn sách đó hoàn thành, chúng tôi nhìn vào đống phần khó khổng lồ và cố gắng tìm hiểu: Tại sao những vấn đề này lại khó giải quyết đến vậy trong các kiến trúc hiện đại?
Chúng tôi đã lấy tất cả các ví dụ và làm việc với chúng như những kiến trúc sư, áp dụng phân tích đánh đổi cho từng tình huống, nhưng cũng chú ý đến quy trình mà chúng tôi đã sử dụng để đạt được các đánh đổi đó. Một trong những sự nhận thức sớm của chúng tôi là tầm quan trọng ngày càng tăng của dữ liệu trong các quyết định kiến trúc: ai có thể/nên truy cập dữ liệu, ai có thể/nên ghi dữ liệu vào đó, và làm thế nào để quản lý sự tách biệt giữa dữ liệu phân tích và dữ liệu vận hành. Để đạt được điều đó, chúng tôi đã mời các chuyên gia trong những lĩnh vực đó tham gia cùng chúng tôi, điều này cho phép cuốn sách này hoàn toàn tích hợp quá trình ra quyết định từ cả hai góc độ: kiến trúc đến dữ liệu và dữ liệu đến kiến trúc.
Kết quả là cuốn sách này: một tập hợp các bài toán khó trong kiến trúc phần mềm hiện đại, những đánh đổi khiến cho các quyết định trở nên khó khăn, và cuối cùng là một hướng dẫn minh họa để chỉ cho bạn cách áp dụng phân tích đánh đổi giống như vậy vào những vấn đề độc đáo của riêng bạn.
Conventions Used in This Book
Các quy ước kiểu chữ sau được sử dụng trong cuốn sách này:
- Italic
-
Chỉ định các điều khoản mới, URL, địa chỉ email, tên tệp và đường dẫn tệp.
Constant width-
Được sử dụng cho danh sách chương trình, cũng như trong các đoạn văn để tham chiếu đến các yếu tố chương trình như tên biến hoặc tên hàm, cơ sở dữ liệu, loại dữ liệu, biến môi trường, câu lệnh và từ khóa.
Constant width bold-
Hiển thị các lệnh hoặc văn bản khác mà người dùng nên gõ một cách chính xác.
Constant width italic-
Hiển thị văn bản cần được thay thế bằng các giá trị do người dùng cung cấp hoặc bởi các giá trị được xác định theo ngữ cảnh.
Tip
Yếu tố này biểu thị một mẹo hoặc gợi ý.
Using Code Examples
Tài liệu bổ sung (ví dụ mã, bài tập, v.v.) có sẵn để tải xuống tại http://architecturethehardparts.com.
Nếu bạn có câu hỏi kỹ thuật hoặc vấn đề khi sử dụng các ví dụ mã, vui lòng gửi email đến bookquestions@oreilly.com.
Cuốn sách này ở đây để giúp bạn hoàn thành công việc của mình. Nói chung, nếu có mã ví dụ kèm theo cuốn sách này, bạn có thể sử dụng nó trong các chương trình và tài liệu của mình. Bạn không cần liên hệ với chúng tôi để xin phép trừ khi bạn đang sao chép một phần lớn mã. Ví dụ, viết một chương trình sử dụng nhiều đoạn mã từ cuốn sách này không yêu cầu sự cho phép. Việc bán hoặc phân phối các ví dụ từ sách của O'Reilly thì cần có sự cho phép. Trả lời một câu hỏi bằng cách trích dẫn cuốn sách này và trích dẫn mã ví dụ không cần sự cho phép. Việc tích hợp một lượng lớn mã ví dụ từ cuốn sách này vào tài liệu của sản phẩm của bạn thì cần phải có sự cho phép.
Chúng tôi đánh giá cao, nhưng thường không yêu cầu ghi nguồn. Một ghi nguồn thường bao gồm tiêu đề, tác giả, nhà xuất bản và ISBN. Ví dụ: “Kiến trúc phần mềm: Những phần khó khăn do Neal Ford, Mark Richards, Pramod Sadalage và Zhamak Dehghani (O’Reilly) viết. Bản quyền 2022 của Neal Ford, Mark Richards, Pramod Sadalage và Zhamak Dehghani, 978-1-492-08689-5.”
Nếu bạn cảm thấy việc sử dụng các ví dụ mã của mình vượt ra ngoài phạm vi sử dụng hợp lý hoặc quyền đã được cấp ở trên, hãy liên hệ với chúng tôi theo địa chỉ permissions@oreilly.com.
O’Reilly Online Learning
Note
Trong hơn 40 năm qua, O'Reilly Media đã cung cấp đào tạo công nghệ và kinh doanh, tri thức và hiểu biết để giúp các công ty thành công.
Mạng lưới độc đáo của chúng tôi gồm các chuyên gia và nhà đổi mới chia sẻ kiến thức và kinh nghiệm của họ thông qua sách, bài viết và nền tảng học tập trực tuyến của chúng tôi. Nền tảng học tập trực tuyến của O'Reilly cung cấp cho bạn quyền truy cập theo yêu cầu vào các khóa đào tạo trực tiếp, các lộ trình học chuyên sâu, môi trường lập trình tương tác, và một bộ sưu tập khổng lồ các tài liệu văn bản và video từ O'Reilly và hơn 200 nhà xuất bản khác. Để biết thêm thông tin, hãy truy cập http://oreilly.com.
How to Contact Us
Vui lòng gửi các ý kiến và câu hỏi liên quan đến cuốn sách này tới nhà xuất bản:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
Chúng tôi có một trang web cho cuốn sách này, nơi chúng tôi liệt kê các lỗi, ví dụ và bất kỳ thông tin bổ sung nào. Bạn có thể truy cập trang này tại https://oreil.ly/sa-the-hard-parts.
Gửi email đến bookquestions@oreilly.com để góp ý hoặc đặt câu hỏi kỹ thuật về cuốn sách này.
Để biết tin tức và thông tin về sách và khóa học của chúng tôi, hãy truy cập http://oreilly.com.
Tìm chúng tôi trên Facebook: http://facebook.com/oreilly
Theo dõi chúng tôi trên Twitter: http://twitter.com/oreillymedia
Xem chúng tôi trên YouTube: http://youtube.com/oreillymedia
Acknowledgments
Mark và Neal xin cảm ơn tất cả những người đã tham gia các lớp học, hội thảo, phiên hội nghị và các cuộc họp nhóm người dùng (hầu như hoàn toàn trực tuyến) của chúng tôi, cũng như tất cả những người khác đã lắng nghe các phiên bản của tài liệu này và cung cấp phản hồi vô giá. Việc lặp lại tài liệu mới đặc biệt khó khăn khi chúng tôi không thể thực hiện trực tiếp, vì vậy chúng tôi trân trọng những người đã bình luận về nhiều phiên bản khác nhau. Chúng tôi cảm ơn đội ngũ xuất bản tại O’Reilly, những người đã làm cho trải nghiệm này trở nên ít đau đớn nhất có thể khi viết một cuốn sách. Chúng tôi cũng cảm ơn một vài nhóm ngẫu nhiên giữ gìn sự tỉnh táo và gợi ý ý tưởng có tên như Pasty Geeks và Hacker B&B.
Xin cảm ơn những người đã thực hiện việc đánh giá kỹ thuật cho cuốn sách của chúng tôi—Vanya Seth, Venkat Subramanian, Joost van Weenen, Grady Booch, Ruben Diaz, David Kloet, Matt Stein, Danilo Sato, James Lewis, và Sam Newman. Những ý kiến và phản hồi quý báu của các bạn đã giúp xác thực nội dung kỹ thuật của chúng tôi và làm cho cuốn sách này trở nên tốt hơn.
Chúng tôi đặc biệt muốn ghi nhận những người lao động và gia đình bị ảnh hưởng bởi đại dịch toàn cầu bất ngờ. Là những người lao động tri thức, chúng tôi đã đối mặt với những bất tiện có phần không đáng kể so với sự gián đoạn và tàn phá to lớn gây ra cho rất nhiều bạn bè và đồng nghiệp của chúng tôi từ đủ mọi tầng lớp trong xã hội. Chúng tôi xin bày tỏ tình cảm và sự trân trọng đặc biệt tới các nhân viên y tế, nhiều người trong số họ chưa bao giờ nghĩ rằng họ sẽ ở tuyến đầu của một bi kịch toàn cầu khủng khiếp nhưng đã xử lý tình huống một cách đáng ngưỡng mộ. Lời cảm ơn của chúng tôi không bao giờ có thể được diễn đạt đầy đủ.
Acknowledgments from Mark Richards
Ngoài những lời cảm ơn đã được đề cập trước đó, tôi một lần nữa cảm ơn người vợ đáng yêu của tôi, Rebecca, vì đã kiên nhẫn với tôi trong một dự án sách nữa. Sự hỗ trợ và lời khuyên không ngừng của bạn đã giúp cuốn sách này trở thành hiện thực, ngay cả khi điều đó có nghĩa là phải dành thời gian cho việc viết tiểu thuyết của bạn. Bạn có ý nghĩa rất lớn đối với tôi, Rebecca. Tôi cũng cảm ơn người bạn tốt và đồng tác giả của tôi, Neal Ford. Sự hợp tác với bạn trong các tài liệu cho cuốn sách này (cũng như cuốn trước đó) thực sự là một trải nghiệm quý giá và đầy ý nghĩa. Bạn là, và luôn luôn là, bạn của tôi.
Acknowledgments from Neal Ford
Tôi muốn cảm ơn gia đình mở rộng của mình, Thoughtworks như một tập thể, và Rebecca Parsons cùng Martin Fowler như những phần cá nhân trong đó. Thoughtworks là một nhóm người phi thường, họ có khả năng tạo ra giá trị cho khách hàng trong khi luôn chú ý đến lý do tại sao mọi thứ hoạt động để chúng ta có thể cải thiện chúng. Thoughtworks đã hỗ trợ cuốn sách này theo nhiều cách và tiếp tục nuôi dưỡng những Thoughtworkers thách thức và truyền cảm hứng cho tôi mỗi ngày. Tôi cũng cảm ơn câu lạc bộ cocktail khu phố của chúng tôi vì những giờ thoát khỏi nhịp sống thường nhật, bao gồm cả các phiên họp ngoài trời hàng tuần, khoảng cách xã hội mà đã giúp tất cả chúng tôi vượt qua khoảng thời gian kỳ lạ vừa qua. Tôi cảm ơn người bạn lâu năm của tôi, Norman Zapien, người luôn mang đến những cuộc trò chuyện thú vị. Cuối cùng, tôi cảm ơn vợ tôi, Candy, người tiếp tục hỗ trợ lối sống này mà khiến tôi phải tập trung vào những thứ như viết sách hơn là chú ý quá nhiều đến những chú mèo của chúng tôi.
Acknowledgments from Pramod Sadalage
Tôi cảm ơn vợ tôi, Rupali, vì tất cả sự hỗ trợ và hiểu biết, và hai cô gái đáng yêu của tôi, Arula và Arhana, vì sự khuyến khích; bố yêu cả hai con. Tất cả công việc tôi làm sẽ không thể thực hiện được nếu không có các khách hàng mà tôi làm việc cùng và các hội nghị khác nhau đã giúp tôi phát triển các khái niệm và nội dung. Tôi cảm ơn AvidXchange, khách hàng mới nhất mà tôi đang làm việc, vì sự hỗ trợ và cung cấp không gian tuyệt vời để phát triển các khái niệm mới. Tôi cũng cảm ơn Thoughtworks vì sự hỗ trợ liên tục trong cuộc sống của tôi, và Neal Ford, Rebecca Parsons, và Martin Fowler vì đã là những người cố vấn tuyệt vời; các bạn làm tôi trở thành một người tốt hơn. Cuối cùng, tôi xin cảm ơn cha mẹ tôi, đặc biệt là mẹ tôi, Shobha, người mà tôi nhớ mỗi ngày. Con nhớ mẹ, MẸ.
Acknowledgments from Zhamak Dehghani
Tôi cảm ơn Mark và Neal vì lời mời mở để đóng góp vào tác phẩm tuyệt vời này. Đóng góp của tôi cho cuốn sách này sẽ không thể thực hiện được nếu không có sự hỗ trợ liên tục của chồng tôi, Adrian, và sự kiên nhẫn của con gái tôi, Arianna. Tôi yêu cả hai người.
Chapter 1. What Happens When There Are No “Best Practices”?
Tại sao một nhà công nghệ như kiến trúc sư phần mềm lại thuyết trình tại một hội nghị hoặc viết một cuốn sách? Bởi vì họ đã phát hiện ra cái mà thường được gọi là “thực tiễn tốt nhất,” một thuật ngữ đã bị lạm dụng đến mức những người sử dụng nó ngày càng phải đối mặt với phản ứng ngược. Dù gọi là gì đi nữa, các nhà công nghệ viết sách khi họ đã tìm ra một giải pháp mới cho một vấn đề chung và muốn truyền bá nó đến một đối tượng rộng rãi hơn.
Nhưng điều gì xảy ra với tập hợp lớn các vấn đề mà không có giải pháp tốt? Các lớp vấn đề hoàn toàn tồn tại trong kiến trúc phần mềm mà không có giải pháp tốt chung, mà thay vào đó đưa ra một loạt các sự đánh đổi rối rắm đặt so sánh với một bộ phận (gần như) cũng rối rắm.
Các nhà phát triển phần mềm phát triển những kỹ năng xuất sắc trong việc tìm kiếm trực tuyến các giải pháp cho một vấn đề hiện tại. Ví dụ, nếu họ cần tìm hiểu cách cấu hình một công cụ cụ thể trong môi trường của họ, việc sử dụng thành thạo Google sẽ tìm ra câu trả lời.
Nhưng điều đó không đúng với các kiến trúc sư.
Đối với các kiến trúc sư, nhiều vấn đề đặt ra những thách thức độc đáo vì chúng kết hợp chính xác môi trường và hoàn cảnh của tổ chức của bạn—có khả năng nào mà có ai đó đã gặp phải chính kịch bản này và viết blog hoặc đăng lên Stack Overflow không?
Các kiến trúc sư có thể tự hỏi tại sao chỉ có rất ít sách về kiến trúc so với các chủ đề kỹ thuật như khung, API, và những thứ tương tự. Các kiến trúc sư hiếm khi gặp phải những vấn đề phổ biến nhưng lại phải đối mặt với việc ra quyết định trong những tình huống mới mẻ. Đối với các kiến trúc sư, mỗi vấn đề là một bông tuyết. Trong nhiều trường hợp, vấn đề không chỉ mới mẻ trong một tổ chức cụ thể mà còn trên toàn thế giới. Không có sách hay phiên hội thảo nào tồn tại cho những vấn đề đó!
Các kiến trúc sư không nên liên tục tìm kiếm những giải pháp thần kỳ cho các vấn đề của họ; chúng hiếm như vào năm 1986, khi Fred Brooks đặt ra thuật ngữ này.
Không có sự phát triển đơn lẻ nào, trong cả công nghệ lẫn kỹ thuật quản lý, mà chỉ riêng nó hứa hẹn một sự cải thiện gấp mười lần trong một thập kỷ về năng suất, độ tin cậy và sự đơn giản.
Fred Brooks từ “Không có viên đạn bạc”
Bởi vì gần như mọi vấn đề đều đặt ra những thách thức mới, công việc thực sự của một kiến trúc sư nằm ở khả năng khách quan đánh giá và xác định các lựa chọn cân nhắc ở cả hai phía của một quyết định quan trọng để giải quyết vấn đề một cách tốt nhất có thể. Các tác giả không nói về “các giải pháp tốt nhất” (trong cuốn sách này hay trong thế giới thực) vì “tốt nhất” ngụ ý rằng một kiến trúc sư đã quản lý để tối đa hóa tất cả các yếu tố cạnh tranh có thể trong thiết kế. Thay vào đó, lời khuyên châm biếm của chúng tôi là như sau:
Tip
Đừng cố gắng tìm kiếm thiết kế tốt nhất trong kiến trúc phần mềm; thay vào đó, hãy phấn đấu cho sự kết hợp các thỏa hiệp ít tệ nhất.
Thường thì, thiết kế tốt nhất mà một kiến trúc sư có thể tạo ra là bộ sưu tập các hệ số bù trừ tồi tệ nhất - không có đặc điểm kiến trúc nào vượt trội như khi nó hoạt động một mình, nhưng sự cân bằng của tất cả các đặc điểm kiến trúc cạnh tranh thúc đẩy thành công của dự án.
Điều này đặt ra câu hỏi: “Làm thế nào một kiến trúc sư có thể tìm ra sự kết hợp khó khăn nhất trong các đổi chác (và ghi chép chúng một cách hiệu quả)?” Cuốn sách này chủ yếu nói về việc ra quyết định, giúp các kiến trúc sư đưa ra quyết định tốt hơn khi đối mặt với những tình huống mới.
Why “The Hard Parts”?
Tại sao chúng tôi lại đặt tên cuốn sách này là Kiến trúc Phần mềm: Những Phần Khó? Thực ra, "khó" trong tiêu đề mang ý nghĩa kép. Đầu tiên, khó ngụ ý đến sự khó khăn, và các kiến trúc sư thường phải đối mặt với những vấn đề khó khăn mà thực sự (và hình tượng) không ai đã từng gặp phải trước đây, liên quan đến vô số quyết định công nghệ có ảnh hưởng lâu dài chồng lên môi trường quan hệ cá nhân và chính trị nơi quyết định đó phải được đưa ra.
Thứ hai, cứng mang ý nghĩa là sự vững chắc—giống như trong sự phân chia giữa phần cứng và phần mềm, phần cứng nên thay đổi ít hơn nhiều vì nó cung cấp nền tảng cho phần mềm. Tương tự, các kiến trúc sư thảo luận về sự phân biệt giữa kiến trúc và thiết kế, trong đó kiến trúc là cấu trúc còn thiết kế thì dễ thay đổi hơn. Do đó, trong cuốn sách này, chúng tôi nói về các phần cơ bản của kiến trúc.
Định nghĩa về kiến trúc phần mềm đã tạo ra nhiều giờ trò chuyện không hiệu quả giữa các chuyên gia trong lĩnh vực này. Một định nghĩa hài hước yêu thích là “kiến trúc phần mềm là những thứ khó thay đổi sau này.” Những thứ đó chính là nội dung mà cuốn sách của chúng tôi đề cập.
Giving Timeless Advice About Software Architecture
Hệ sinh thái phát triển phần mềm liên tục và hỗn loạn thay đổi và phát triển. Những chủ đề từng được ưa chuộng cách đây vài năm đã bị hệ sinh thái tiếp nhận và biến mất hoặc được thay thế bằng thứ gì đó khác/ tốt hơn. Chẳng hạn, 10 năm trước, phong cách kiến trúc chủ đạo cho các doanh nghiệp lớn là kiến trúc hướng dịch vụ, điều khiển bằng trình tự. Bây giờ, hầu như không ai còn xây dựng theo phong cách kiến trúc đó nữa (vì những lý do chúng ta sẽ khám phá trong quá trình này); phong cách hiện tại được ưa chuộng cho nhiều hệ thống phân tán là microservices. Sự chuyển đổi đó đã xảy ra như thế nào và tại sao?
Khi các kiến trúc sư nhìn vào một phong cách cụ thể (đặc biệt là phong cách lịch sử), họ phải xem xét các rào cản tồn tại đã dẫn đến kiến trúc đó trở nên thống trị. Vào thời điểm đó, nhiều công ty đang sáp nhập để trở thành các tập đoàn, với tất cả những khó khăn trong việc tích hợp đi kèm với sự chuyển đổi đó. Thêm vào đó, mã nguồn mở không phải là một lựa chọn khả thi (thường vì lý do chính trị hơn là lý do kỹ thuật) cho các công ty lớn. Do đó, các kiến trúc sư đã nhấn mạnh việc chia sẻ tài nguyên và điều phối tập trung như một giải pháp.
Tuy nhiên, trong những năm qua, mã nguồn mở và Linux đã trở thành các lựa chọn khả thi, khiến cho các hệ điều hành trở nên miễn phí về mặt thương mại. Tuy nhiên, điểm chuyển mình thực sự xảy ra khi Linux trở nên miễn phí về mặt vận hành với sự ra đời của các công cụ như Puppet và Chef, cho phép các đội phát triển có thể lập trình để tạo ra môi trường của họ như một phần của quá trình xây dựng tự động. Khi khả năng đó xuất hiện, nó đã thúc đẩy một cuộc cách mạng kiến trúc với microservices và hạ tầng containers cùng với các công cụ điều phối như Kubernetes đang nhanh chóng nổi lên.
Điều này minh họa rằng hệ sinh thái phát triển phần mềm mở rộng và tiến hóa theo những cách hoàn toàn bất ngờ. Một khả năng mới dẫn đến một khả năng khác, điều này lại tạo ra những khả năng mới một cách bất ngờ. Qua thời gian, hệ sinh thái hoàn toàn thay thế bản thân, từng phần một.
Điều này đặt ra một vấn đề từ lâu cho các tác giả sách về công nghệ nói chung và kiến trúc phần mềm nói riêng - làm thế nào chúng ta có thể viết một cái gì đó mà không trở nên cũ ngay lập tức?
Chúng tôi không tập trung vào công nghệ hay các chi tiết triển khai trong cuốn sách này. Thay vào đó, chúng tôi tập trung vào cách các kiến trúc sư đưa ra quyết định, và cách đánh giá khách quan các giao dịch khi gặp phải những tình huống mới. Chúng tôi sử dụng các tình huống và ví dụ đương thời để cung cấp chi tiết và bối cảnh, nhưng các nguyên tắc cơ bản tập trung vào phân tích giao dịch và ra quyết định khi đối mặt với các vấn đề mới.
The Importance of Data in Architecture
Dữ liệu là một thứ quý giá và sẽ tồn tại lâu hơn chính các hệ thống.
Tim Berners-Lee
Đối với nhiều người trong ngành kiến trúc, dữ liệu là tất cả. Mỗi doanh nghiệp xây dựng bất kỳ hệ thống nào đều phải xử lý dữ liệu, vì nó có xu hướng tồn tại lâu hơn hệ thống hoặc kiến trúc, đòi hỏi sự cân nhắc và thiết kế kỹ lưỡng. Tuy nhiên, nhiều bản năng của các kiến trúc sư dữ liệu trong việc xây dựng các hệ thống gắn kết chặt chẽ tạo ra xung đột trong các kiến trúc phân tán hiện đại. Chẳng hạn, các kiến trúc sư và DBA phải đảm bảo rằng dữ liệu doanh nghiệp vẫn tồn tại sau khi các hệ thống monolith bị phá vỡ và rằng doanh nghiệp vẫn có thể khai thác giá trị từ dữ liệu của mình bất kể sự biến động của kiến trúc.
Người ta đã nói rằng dữ liệu là tài sản quan trọng nhất trong một công ty. Các doanh nghiệp muốn khai thác giá trị từ dữ liệu mà họ có và đang tìm kiếm những cách mới để triển khai dữ liệu trong việc ra quyết định. Mỗi phần của doanh nghiệp hiện nay đều dựa vào dữ liệu, từ việc phục vụ khách hàng hiện tại, đến việc thu hút khách hàng mới, tăng cường giữ chân khách hàng, cải thiện sản phẩm, dự đoán doanh số bán hàng và các xu hướng khác. Sự phụ thuộc vào dữ liệu này có nghĩa là tất cả kiến trúc phần mềm đều phục vụ cho dữ liệu, đảm bảo rằng dữ liệu đúng được cung cấp và có thể sử dụng bởi tất cả các bộ phận trong doanh nghiệp.
Các tác giả đã xây dựng nhiều hệ thống phân tán cách đây vài thập kỷ khi chúng lần đầu tiên trở nên phổ biến, nhưng việc ra quyết định trong các microservices hiện đại dường như khó khăn hơn, và chúng tôi muốn tìm hiểu lý do tại sao. Cuối cùng, chúng tôi nhận ra rằng, vào những ngày đầu của kiến trúc phân tán, chúng tôi chủ yếu vẫn lưu trữ dữ liệu trong một cơ sở dữ liệu quan hệ duy nhất. Tuy nhiên, trong microservices và sự tuân thủ triết lý về ngữ cảnh giới hạn từ Thiết kế theo miền, như một cách để giới hạn phạm vi của sự liên kết chi tiết thực hiện, dữ liệu đã trở thành một mối quan tâm kiến trúc, cùng với tính vụ giao dịch. Nhiều phần khó khăn của kiến trúc hiện đại phát sinh từ những căng thẳng giữa dữ liệu và các mối quan tâm kiến trúc, mà chúng tôi sẽ giải quyết trong cả Phần I và Phần II.
Một sự phân biệt quan trọng mà chúng tôi đề cập trong nhiều chương là sự phân tách giữa dữ liệu hoạt động và dữ liệu phân tích:
- Operational data
-
Dữ liệu được sử dụng cho hoạt động của doanh nghiệp, bao gồm doanh số, dữ liệu giao dịch, tồn kho, và các thông tin khác. Đây là dữ liệu mà công ty hoạt động dựa vào—nếu có điều gì đó làm gián đoạn dữ liệu này, tổ chức sẽ không thể hoạt động trong thời gian dài. Loại dữ liệu này được định nghĩa là Xử lý Giao dịch Trực tuyến (OLTP), thường liên quan đến việc chèn, cập nhật và xóa dữ liệu trong cơ sở dữ liệu.
- Analytical data
-
Dữ liệu được sử dụng bởi các nhà khoa học dữ liệu và các nhà phân tích kinh doanh khác để dự đoán, phân tích xu hướng và các thông tin kinh doanh khác. Dữ liệu này thường không phải là dữ liệu giao dịch và thường không phải là dữ liệu quan hệ - nó có thể nằm trong cơ sở dữ liệu đồ thị hoặc dưới dạng ảnh chụp ở định dạng khác với hình thức giao dịch ban đầu. Dữ liệu này không quan trọng cho hoạt động hàng ngày mà chủ yếu cho định hướng chiến lược lâu dài và các quyết định.
Chúng tôi đề cập đến tác động của cả dữ liệu vận hành và dữ liệu phân tích trong toàn bộ cuốn sách.
Architectural Decision Records
Một trong những cách hiệu quả nhất để tài liệu hóa các quyết định kiến trúc là thông qua Hồ sơ Quyết định Kiến trúc (ADRs). ADRs lần đầu tiên được Michael Nygard quảng bá trong một bài blog và sau đó được đánh dấu là “được chấp nhận” trong Radar Công nghệ của Thoughtworks. Một ADR bao gồm một tệp văn bản ngắn (thường dài từ một đến hai trang) mô tả một quyết định kiến trúc cụ thể. Mặc dù ADR có thể được viết bằng văn bản thông thường, nhưng chúng thường được viết dưới dạng định dạng tài liệu văn bản nào đó như AsciiDoc hoặc Markdown. Ngoài ra, một ADR cũng có thể được viết sử dụng mẫu trang wiki. Chúng tôi đã dành một chương hoàn toàn cho ADR trong cuốn sách trước đây của mình, Cơ bản về Kiến trúc Phần mềm (O’Reilly).
Chúng tôi sẽ sử dụng ADR như một cách để ghi chép các quyết định kiến trúc khác nhau được đưa ra trong cuốn sách. Đối với mỗi quyết định kiến trúc, chúng tôi sẽ sử dụng định dạng ADR sau với giả định rằng mỗi ADR đều được phê duyệt:
ADR: Một cụm danh từ ngắn chứa quyết định kiến trúc
Ngữ cảnh Trong phần này của ADR, chúng tôi sẽ thêm một mô tả ngắn gọn một hoặc hai câu về vấn đề và liệt kê các giải pháp thay thế.
Quyết định Trong phần này, chúng tôi sẽ nêu rõ quyết định kiến trúc và cung cấp lý do chi tiết cho quyết định đó.
Hệ quả Trong phần này của ADR, chúng tôi sẽ mô tả bất kỳ hệ quả nào sau khi quyết định được áp dụng, và cũng sẽ thảo luận về các giao dịch mà đã được xem xét.
Danh sách tất cả các Hồ sơ Quyết định Kiến trúc được tạo ra trong cuốn sách này có thể được tìm thấy trong Phụ lục B.
Việc ghi chép quyết định là quan trọng đối với một kiến trúc sư, nhưng việc quản lý việc sử dụng đúng đắn của quyết định đó là một chủ đề riêng biệt. May mắn thay, các phương pháp kỹ thuật hiện đại cho phép tự động hóa nhiều mối quan tâm chung về quản trị bằng cách sử dụng các chức năng phù hợp với kiến trúc.
Architecture Fitness Functions
Khi một kiến trúc sư đã xác định mối quan hệ giữa các thành phần và mã hóa điều đó thành thiết kế, làm thế nào họ có thể đảm bảo rằng những người thực hiện sẽ tuân thủ thiết kế đó? Nói rộng hơn, làm thế nào các kiến trúc sư có thể đảm bảo rằng các nguyên tắc thiết kế mà họ định nghĩa trở thành hiện thực nếu họ không phải là những người thực hiện chúng?
Những câu hỏi này thuộc về lĩnh vực quản trị kiến trúc, áp dụng cho bất kỳ sự giám sát có tổ chức nào về một hoặc nhiều khía cạnh của phát triển phần mềm. Vì cuốn sách này chủ yếu đề cập đến cấu trúc kiến trúc, chúng tôi sẽ đề cập đến cách tự động hóa thiết kế và các nguyên tắc chất lượng thông qua các hàm phù hợp ở nhiều nơi.
Phát triển phần mềm đã dần dần tiến hóa theo thời gian để thích ứng với các phương pháp kỹ thuật độc đáo. Trong những ngày đầu của phát triển phần mềm, một phép ẩn dụ về sản xuất thường được áp dụng cho các thực tiễn phần mềm, cả trong quy mô lớn (như quy trình phát triển Waterfall) và nhỏ (các phương pháp tích hợp trên các dự án). Vào những năm 1990, một sự suy nghĩ lại về các phương pháp kỹ thuật phát triển phần mềm, được dẫn dắt bởi Kent Beck và các kỹ sư khác trong dự án C3, gọi là Lập trình Cực đoan (XP), đã nêu bật tầm quan trọng của phản hồi gia tăng và tự động hóa như những yếu tố then chốt cho năng suất phát triển phần mềm. Vào những năm 2000, những bài học tương tự được áp dụng cho giao điểm của phát triển phần mềm và vận hành, từ đó khởi nguồn cho vai trò mới của DevOps và tự động hóa nhiều công việc vận hành trước đây vốn được thực hiện bằng tay. Như trước đây, tự động hóa cho phép các đội nhóm tiến nhanh hơn vì họ không phải lo lắng về việc gặp phải sự cố mà không có phản hồi hợp lý. Do đó, tự động hóa và phản hồi đã trở thành những nguyên tắc trung tâm cho phát triển phần mềm hiệu quả.
Hãy xem xét các môi trường và tình huống dẫn đến những bước đột phá trong tự động hóa. Trong thời đại trước khi có tích hợp liên tục, hầu hết các dự án phần mềm bao gồm một giai đoạn tích hợp kéo dài. Mỗi nhà phát triển được kỳ vọng làm việc ở một mức độ tách biệt nào đó với những người khác, sau đó tích hợp toàn bộ mã vào cuối giai đoạn tích hợp. Những dấu vết của thực tiễn này vẫn còn tồn tại trong các công cụ quản lý phiên bản buộc phải tạo nhánh và ngăn chặn tích hợp liên tục. Không có gì ngạc nhiên khi có một mối tương quan mạnh mẽ giữa kích thước dự án và nỗi đau của giai đoạn tích hợp. Bằng cách tiên phong trong tích hợp liên tục, nhóm XP đã minh họa giá trị của phản hồi nhanh chóng, liên tục.
Cuộc cách mạng DevOps cũng diễn ra theo một con đường tương tự. Khi Linux và các phần mềm mã nguồn mở khác trở nên “đủ tốt” cho các doanh nghiệp, kết hợp với sự xuất hiện của các công cụ cho phép định nghĩa chương trình (cuối cùng) của các máy ảo, nhân viên vận hành nhận ra rằng họ có thể tự động hóa định nghĩa máy và nhiều nhiệm vụ lặp đi lặp lại khác.
Trong cả hai trường hợp, những tiến bộ trong công nghệ và hiểu biết đã dẫn đến việc tự động hóa một công việc lặp đi lặp lại mà trước đây được xử lý bởi một vai trò tốn kém—điều này mô tả trạng thái hiện tại của quản trị kiến trúc trong hầu hết các tổ chức. Ví dụ, nếu một kiến trúc sư chọn một phong cách kiến trúc hoặc phương tiện giao tiếp cụ thể, họ có thể làm gì để đảm bảo rằng một lập trình viên thực hiện nó một cách chính xác? Khi thực hiện thủ công, các kiến trúc sư thực hiện việc xem xét mã hoặc có thể tổ chức các hội đồng xem xét kiến trúc để đánh giá tình trạng quản trị. Tuy nhiên, cũng giống như trong việc cấu hình máy tính một cách thủ công trong hoạt động, những chi tiết quan trọng có thể dễ dàng rơi qua những đánh giá hời hợt.
Using Fitness Functions
Trong cuốn sách năm 2017 "Xây dựng Kiến trúc Tiến hóa" (O’Reilly), các tác giả (Neal Ford, Rebecca Parsons và Patrick Kua) đã định nghĩa khái niệm về hàm thích nghi kiến trúc: bất kỳ cơ chế nào thực hiện đánh giá tính toàn vẹn khách quan của một số đặc điểm kiến trúc hoặc sự kết hợp của các đặc điểm kiến trúc. Dưới đây là phân tích từng điểm của định nghĩa đó:
- Any mechanism
-
Các kiến trúc sư có thể sử dụng một loạt các công cụ để triển khai các hàm fitness; chúng tôi sẽ trình bày nhiều ví dụ trong suốt cuốn sách. Ví dụ, có những thư viện kiểm thử chuyên dụng để kiểm tra cấu trúc kiến trúc, các kiến trúc sư có thể sử dụng các công cụ giám sát để kiểm tra các đặc điểm kiến trúc hoạt động như hiệu suất hoặc khả năng mở rộng, và các khung kỹ thuật chắn tán kiểm tra độ tin cậy và khả năng phục hồi.
- Objective integrity assessment
-
Một yếu tố quan trọng cho quản trị tự động nằm ở các định nghĩa khách quan cho các đặc điểm kiến trúc. Ví dụ, một kiến trúc sư không thể chỉ định rằng họ muốn một trang web "hiệu suất cao"; họ phải cung cấp một giá trị đối tượng có thể được đo lường bằng một bài kiểm tra, giám sát hoặc chức năng phù hợp khác.
Các kiến trúc sư cần chú ý đến các đặc điểm của kiến trúc tổng hợp—những đặc điểm không thể đo lường một cách khách quan nhưng thực sự là sự tổng hợp của các yếu tố có thể đo lường khác. Chẳng hạn, "tính linh hoạt" không thể đo lường được, nhưng nếu một kiến trúc sư bắt đầu phân tích khái niệm rộng này, mục tiêu là các đội ngũ có thể phản ứng nhanh chóng và tự tin với sự thay đổi, bất kể là trong hệ sinh thái hay lĩnh vực nào. Do đó, một kiến trúc sư có thể tìm ra các đặc điểm có thể đo lường góp phần vào tính linh hoạt: khả năng triển khai, khả năng kiểm tra, thời gian chu trình, và nhiều hơn nữa. Thường thì, việc thiếu khả năng đo lường một đặc điểm kiến trúc cho thấy định nghĩa đó quá mơ hồ. Nếu các kiến trúc sư hướng tới các thuộc tính có thể đo lường, điều này cho phép họ tự động hóa việc áp dụng chức năng phù hợp.
- Some architecture characteristic or combination of architecture characteristics
-
Đặc điểm này mô tả hai phạm vi cho các hàm fitness:
- Atomic
-
Các hàm fitness này xử lý một đặc điểm kiến trúc đơn lẻ một cách tách biệt. Ví dụ, một hàm fitness kiểm tra vòng lặp thành phần trong một mã nguồn là có phạm vi nguyên tử.
- Holistic
-
Các chức năng thể dục toàn diện xác thực sự kết hợp của các đặc điểm kiến trúc. Một yếu tố làm phức tạp các đặc điểm kiến trúc là sự hợp tác mà chúng đôi khi thể hiện với các đặc điểm kiến trúc khác. Ví dụ, nếu một kiến trúc sư muốn cải thiện bảo mật, có khả năng cao rằng điều đó sẽ ảnh hưởng đến hiệu suất. Tương tự, tính mở rộng và tính linh hoạt đôi khi mâu thuẫn với nhau - việc hỗ trợ một số lượng lớn người dùng đồng thời có thể khiến việc xử lý các đột biến đột ngột trở nên khó khăn hơn. Các chức năng thể dục toàn diện vận hành một sự kết hợp của các đặc điểm kiến trúc liên kết để đảm bảo rằng hiệu ứng kết hợp sẽ không ảnh hưởng tiêu cực đến kiến trúc.
Một kiến trúc sư triển khai các hàm fitness để xây dựng các biện pháp bảo vệ xung quanh sự thay đổi bất ngờ trong các đặc điểm kiến trúc. Trong thế giới phát triển phần mềm Agile, các nhà phát triển triển khai các bài kiểm tra đơn vị, chức năng và chấp nhận người dùng để xác thực các khía cạnh khác nhau của thiết kế miền. Tuy nhiên, cho đến nay, chưa có cơ chế tương tự nào tồn tại để xác thực phần đặc điểm kiến trúc của thiết kế. Thật vậy, sự tách biệt giữa các hàm fitness và các bài kiểm tra đơn vị cung cấp một hướng dẫn phạm vi tốt cho các kiến trúc sư. Các hàm fitness xác thực các đặc điểm kiến trúc, không phải tiêu chí miền; các bài kiểm tra đơn vị thì ngược lại. Do đó, một kiến trúc sư có thể quyết định xem cần hàm fitness hay bài kiểm tra đơn vị bằng cách đặt câu hỏi: “Có cần bất kỳ kiến thức miền nào để thực hiện bài kiểm tra này không?” Nếu câu trả lời là “có”, thì bài kiểm tra đơn vị/chức năng/chấp nhận người dùng là phù hợp; nếu “không”, thì một hàm fitness là cần thiết.
Chẳng hạn, khi các kiến trúc sư nói về tính đàn hồi, đó là khả năng của ứng dụng để chịu đựng một lượng người dùng đột ngột tăng cao. Lưu ý rằng kiến trúc sư không cần biết bất kỳ chi tiết nào về miền—điều này có thể là một trang web thương mại điện tử, một trò chơi trực tuyến, hoặc một thứ gì khác. Do đó, tính đàn hồi là mối quan tâm về kiến trúc và nằm trong phạm vi của một hàm sức khỏe. Ngược lại, nếu kiến trúc sư muốn xác thực các phần đúng của một địa chỉ gửi thư, điều đó được bao phủ thông qua một bài kiểm tra truyền thống. Tất nhiên, sự phân tách này không hoàn toàn nhị nguyên—một số hàm sức khỏe sẽ chạm đến miền và ngược lại, nhưng các mục tiêu khác nhau cung cấp một cách tốt để tách biệt chúng một cách tâm lý.
Dưới đây là một vài ví dụ để làm cho khái niệm bớt trừu tượng.
Một mục tiêu phổ biến của kiến trúc sư là duy trì tính toàn vẹn cấu trúc nội bộ tốt trong mã nguồn. Tuy nhiên, những lực lượng xấu hoạt động chống lại ý định tốt của kiến trúc sư trên nhiều nền tảng. Ví dụ, khi lập trình trong bất kỳ môi trường phát triển Java hoặc .NET phổ biến nào, ngay khi một lập trình viên tham chiếu đến một lớp chưa được nhập khẩu, IDE sẽ hữu ích trình bày một hộp thoại hỏi lập trình viên xem họ có muốn tự động nhập tham chiếu không. Điều này xảy ra thường xuyên đến mức hầu hết các lập trình viên phát triển thói quen gạt bỏ hộp thoại tự động nhập như một phản xạ.
Tuy nhiên, việc nhập khẩu tùy tiện các lớp hoặc thành phần với nhau sẽ dẫn đến thảm họa cho tính module. Ví dụ, Hình 1-1 minh họa một mẫu phản tác dụng đặc biệt nghiêm trọng mà các kiến trúc sư mong muốn tránh.
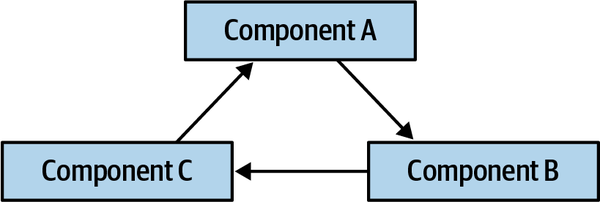
Figure 1-1. Cyclic dependencies between components
Trong mẫu chống ví dụ này, mỗi thành phần tham chiếu đến một thứ gì đó trong các thành phần khác. Việc có một mạng lưới các thành phần như vậy làm hỏng tính mô-đun vì một nhà phát triển không thể tái sử dụng một thành phần đơn lẻ mà không mang theo các thành phần khác. Và, dĩ nhiên, nếu các thành phần khác được liên kết với các thành phần khác, kiến trúc có xu hướng ngày càng tiến tới mẫu chống ví dụ Big Ball of Mud. Làm thế nào các kiến trúc sư có thể quản lý hành vi này mà không phải liên tục nhìn qua vai của các nhà phát triển nhanh nhạy? Đánh giá mã giúp nhưng diễn ra quá muộn trong chu kỳ phát triển để có hiệu quả. Nếu một kiến trúc sư cho phép một nhóm phát triển tự do nhập khẩu qua mã trong một tuần cho đến khi đánh giá mã, thiệt hại nghiêm trọng đã xảy ra trong mã.
Giải pháp cho vấn đề này là viết một hàm phù hợp để tránh các chu trình thành phần, như được trình bày trong Ví dụ 1-1.
Example 1-1. Fitness function to detect component cycles
publicclassCycleTest{privateJDependjdepend;@BeforeEachvoidinit(){jdepend=newJDepend();jdepend.addDirectory("/path/to/project/persistence/classes");jdepend.addDirectory("/path/to/project/web/classes");jdepend.addDirectory("/path/to/project/thirdpartyjars");}@TestvoidtestAllPackages(){Collectionpackages=jdepend.analyze();assertEquals("Cycles exist",false,jdepend.containsCycles());}}
Trong mã, một kiến trúc sư sử dụng công cụ đo lường JDepend để kiểm tra các phụ thuộc giữa các gói. Công cụ này hiểu cấu trúc của các gói Java và sẽ thất bại trong bài kiểm tra nếu có bất kỳ chu kỳ nào tồn tại. Một kiến trúc sư có thể kết nối bài kiểm tra này vào quá trình xây dựng liên tục của một dự án và ngừng lo lắng về việc các nhà phát triển dễ dàng tạo ra các chu kỳ một cách tình cờ. Đây là một ví dụ tuyệt vời về một hàm fitness bảo vệ các thực hành quan trọng hơn là khẩn cấp trong phát triển phần mềm: đó là một mối quan tâm quan trọng đối với các kiến trúc sư, nhưng lại có ít tác động đến việc lập trình hàng ngày.
Ví dụ 1-1 cho thấy một hàm fitness rất cấp thấp, tập trung vào mã nguồn. Nhiều công cụ bảo trì mã nguồn phổ biến (chẳng hạn như SonarQube) triển khai nhiều hàm fitness thường gặp theo cách sẵn có. Tuy nhiên, các kiến trúc sư cũng có thể muốn xác nhận cấu trúc vĩ mô của kiến trúc cũng như cấu trúc vi mô. Khi thiết kế một kiến trúc theo lớp như trong Hình 1-2, kiến trúc sư xác định các lớp để đảm bảo sự tách biệt của các mối quan tâm.
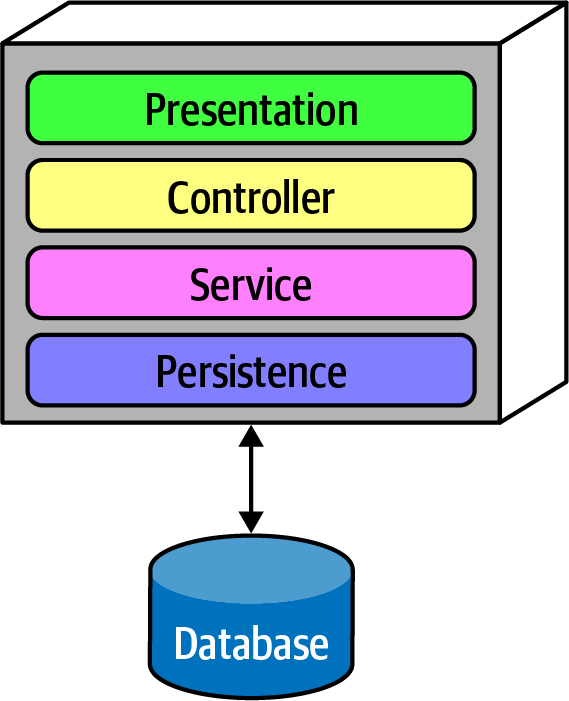
Figure 1-2. Traditional layered architecture
Tuy nhiên, làm thế nào kiến trúc sư có thể đảm bảo rằng các lập trình viên sẽ tôn trọng những lớp này? Một số lập trình viên có thể không hiểu tầm quan trọng của các mẫu, trong khi những người khác có thể áp dụng thái độ "thà xin lỗi còn hơn xin phép" do một số mối quan tâm địa phương vượt trội, chẳng hạn như hiệu suất. Nhưng cho phép những người thực hiện làm yếu đi lý do cho kiến trúc sẽ gây hại cho sức khỏe lâu dài của kiến trúc.
ArchUnit cho phép các kiến trúc sư giải quyết vấn đề này thông qua một hàm đánh giá, được trình bày trong Ví dụ 1-2.
Example 1-2. ArchUnit fitness function to govern layers
layeredArchitecture().layer("Controller").definedBy("..controller..").layer("Service").definedBy("..service..").layer("Persistence").definedBy("..persistence..").whereLayer("Controller").mayNotBeAccessedByAnyLayer().whereLayer("Service").mayOnlyBeAccessedByLayers("Controller").whereLayer("Persistence").mayOnlyBeAccessedByLayers("Service")
Trong Ví dụ 1-2, kiến trúc sư xác định mối quan hệ mong muốn giữa các lớp và viết một hàm kiểm tra độ phù hợp để quản lý điều đó. Điều này cho phép kiến trúc sư thiết lập các nguyên tắc kiến trúc bên ngoài các sơ đồ và các tài liệu thông tin khác, cũng như xác minh chúng một cách liên tục.
Một công cụ tương tự trong không gian .NET, NetArchTest, cho phép thực hiện các bài kiểm tra tương tự cho nền tảng đó. Một xác minh lớp trong C# xuất hiện trong Ví dụ 1-3.
Example 1-3. NetArchTest for layer dependencies
// Classes in the presentation should not directly reference repositoriesvarresult=Types.InCurrentDomain().That().ResideInNamespace("NetArchTest.SampleLibrary.Presentation").ShouldNot().HaveDependencyOn("NetArchTest.SampleLibrary.Data").GetResult().IsSuccessful;
Các công cụ tiếp tục xuất hiện trong lĩnh vực này với mức độ tinh vi ngày càng tăng. Chúng tôi sẽ tiếp tục làm nổi bật nhiều kỹ thuật trong số này khi chúng tôi minh họa các hàm thích nghi cùng với nhiều giải pháp của chúng tôi.
Việc tìm kiếm một kết quả khách quan cho một hàm fitness là rất quan trọng. Tuy nhiên, khách quan không có nghĩa là tĩnh. Một số hàm fitness sẽ có giá trị trả về phi ngữ cảnh, chẳng hạn như đúng/sai hoặc một giá trị số như ngưỡng hiệu suất. Tuy nhiên, các hàm fitness khác (được coi là động) sẽ trả về một giá trị dựa trên một số ngữ cảnh. Ví dụ, khi đo lường khả năng mở rộng, các kiến trúc sư đo lường số lượng người dùng đồng thời và cũng thường đo lường hiệu suất cho mỗi người dùng. Thường thì, các kiến trúc sư thiết kế hệ thống sao cho khi số lượng người dùng tăng lên, hiệu suất mỗi người dùng giảm nhẹ — nhưng không rơi mạnh. Do đó, đối với những hệ thống này, các kiến trúc sư thiết kế các hàm fitness về hiệu suất tính đến số lượng người dùng đồng thời. Chừng nào mà việc đo lường một đặc điểm kiến trúc là khách quan, các kiến trúc sư có thể kiểm tra nó.
Trong khi hầu hết các hàm thích nghi nên được tự động hóa và chạy liên tục, một số hàm sẽ cần phải được thực hiện thủ công. Một hàm thích nghi thủ công yêu cầu một người xử lý việc xác thực. Ví dụ, đối với các hệ thống có thông tin pháp lý nhạy cảm, một luật sư có thể cần kiểm tra các thay đổi ở các phần quan trọng để đảm bảo tính hợp pháp, mà việc này không thể tự động hóa. Hầu hết các pipeline triển khai hỗ trợ các giai đoạn thủ công, cho phép các nhóm điều chỉnh các hàm thích nghi thủ công. Lý tưởng nhất, những giai đoạn này nên được thực hiện thường xuyên nhất có thể - một xác thực không chạy thì không thể xác thực được gì. Các nhóm thực hiện các hàm thích nghi theo yêu cầu (hiếm khi) hoặc như một phần của quy trình tích hợp liên tục (thường gặp). Để đạt được đầy đủ lợi ích của các xác thực như hàm thích nghi, chúng nên được thực hiện liên tục.
Tính liên tục là quan trọng, như được minh họa trong ví dụ về quản trị cấp doanh nghiệp sử dụng các hàm fitness. Hãy xem xét kịch bản sau: công ty sẽ làm gì khi phát hiện một lỗ hổng zero-day trong một trong các framework hoặc thư viện phát triển mà doanh nghiệp sử dụng? Nếu giống như hầu hết các công ty, các chuyên gia bảo mật sẽ rà soát các dự án để tìm phiên bản gây ra vấn đề của framework và đảm bảo nó được cập nhật, nhưng quy trình đó hiếm khi được tự động hóa, phụ thuộc vào nhiều bước thủ công. Đây không phải là một câu hỏi trừu tượng; kịch bản chính xác này đã ảnh hưởng đến một tổ chức tài chính lớn được mô tả trong Vụ rò rỉ dữ liệu của Equifax. Giống như quản trị kiến trúc được mô tả trước đó, các quy trình thủ công dễ mắc sai sót và cho phép các chi tiết bị bỏ qua.
Hãy tưởng tượng một thế giới khác, trong đó mọi dự án đều có một pipeline triển khai, và nhóm bảo mật có một “slot” trong pipeline triển khai của từng nhóm, nơi họ có thể triển khai các chức năng kiểm tra. Hầu hết thời gian, những kiểm tra này sẽ là những kiểm tra thông thường nhằm bảo đảm như ngăn cản các lập trình viên lưu trữ mật khẩu trong cơ sở dữ liệu và những công việc quản lý thông thường khác. Tuy nhiên, khi một lỗ hổng zero-day xuất hiện, việc có cùng một cơ chế ở mọi nơi cho phép nhóm bảo mật chèn một bài kiểm tra vào từng dự án nhằm kiểm tra một phiên bản và framework nhất định; nếu phát hiện phiên bản nguy hiểm, nó sẽ làm hỏng quá trình biên dịch và thông báo cho nhóm bảo mật. Các đội ngũ cấu hình pipeline triển khai để kích hoạt bất kỳ thay đổi nào trong hệ sinh thái: mã nguồn, sơ đồ cơ sở dữ liệu, cấu hình triển khai và các chức năng kiểm tra. Điều này cho phép các doanh nghiệp tự động hóa một cách phổ quát các nhiệm vụ quản lý quan trọng.
Các hàm đánh giá mang lại nhiều lợi ích cho các kiến trúc sư, không chỉ đơn thuần là cơ hội để họ lại có thể lập trình! Một trong những phàn nàn chung của các kiến trúc sư là họ ít có cơ hội lập trình hơn trước—nhưng các hàm đánh giá thường chính là mã nguồn! Bằng cách xây dựng một đặc tả có thể thực thi của kiến trúc, mà bất kỳ ai cũng có thể xác minh bất cứ lúc nào bằng cách chạy quá trình xây dựng của dự án, các kiến trúc sư phải hiểu rõ hệ thống và sự phát triển liên tục của nó, điều này có sự trùng lặp với mục tiêu cốt lõi là theo kịp mã nguồn của dự án khi nó phát triển.
Tuy nhiên, bất kỳ hàm fitness nào mạnh mẽ đến đâu, các kiến trúc sư cũng nên tránh lạm dụng chúng. Các kiến trúc sư không nên hình thành một nhóm và rút lui vào một tháp ngà để xây dựng một tập hợp các hàm fitness phức tạp, liên kết với nhau đến mức không thể nào thực hiện được, chỉ gây frust cho các nhà phát triển và các nhóm. Thay vào đó, đây là cách để các kiến trúc sư xây dựng một danh sách kiểm tra có thể thực thi của các nguyên tắc quan trọng nhưng không khẩn cấp trong các dự án phần mềm. Nhiều dự án chìm trong sự cấp bách, khiến một số nguyên tắc quan trọng bị rơi rụng. Điều này thường là nguyên nhân của nợ kỹ thuật: "Chúng tôi biết đây là xấu, nhưng chúng tôi sẽ quay lại để sửa chữa sau"—và sau đó không bao giờ đến. Bằng cách quy định các quy tắc về chất lượng mã, cấu trúc, và các biện pháp bảo vệ khác chống lại sự xuống cấp thành các hàm fitness chạy liên tục, các kiến trúc sư xây dựng một danh sách kiểm tra chất lượng mà các nhà phát triển không thể bỏ qua.
Vài năm trước, cuốn sách tuyệt vời "The Checklist Manifesto" của Atul Gawande (Picador) đã nhấn mạnh việc sử dụng danh sách kiểm tra của các chuyên gia như bác sĩ phẫu thuật, phi công và những lĩnh vực khác mà thường xuyên sử dụng (đôi khi theo yêu cầu của pháp luật) danh sách kiểm tra như một phần trong công việc của họ. Điều này không phải vì họ không biết công việc của mình hay đặc biệt hay quên; khi các chuyên gia thực hiện cùng một nhiệm vụ lặp đi lặp lại, rất dễ để tự lừa dối bản thân khi vô tình bỏ qua, và danh sách kiểm tra ngăn chặn điều đó. Các chức năng thể hình đại diện cho một danh sách kiểm tra các nguyên tắc quan trọng được định nghĩa bởi các kiến trúc sư và được thực thi như một phần của quy trình xây dựng để đảm bảo các nhà phát triển không vô tình (hoặc có chủ đích, do các yếu tố bên ngoài như áp lực về tiến độ) bỏ qua chúng.
Chúng tôi sử dụng các hàm fitness xuyên suốt cuốn sách khi có cơ hội để minh họa việc quản lý một giải pháp kiến trúc cũng như thiết kế ban đầu.
Architecture Versus Design: Keeping Definitions Simple
Một lĩnh vực đấu tranh liên tục cho các kiến trúc sư là giữ cho kiến trúc và thiết kế là những hoạt động riêng biệt nhưng có liên quan. Trong khi chúng tôi không muốn tham gia vào cuộc tranh luận không bao giờ kết thúc về sự khác biệt này, chúng tôi cố gắng trong cuốn sách này giữ vững vị trí ở phía kiến trúc của phổ này vì một số lý do.
Đầu tiên, các kiến trúc sư phải hiểu các nguyên tắc kiến trúc cơ bản để đưa ra quyết định hiệu quả. Chẳng hạn, quyết định giữa giao tiếp đồng bộ và giao tiếp không đồng bộ có một số sự đánh đổi trước khi các kiến trúc sư đưa vào các chi tiết triển khai. Trong cuốn sách "Những nguyên tắc cơ bản của Kiến trúc Phần mềm", các tác giả đã đặt ra định luật thứ hai của kiến trúc phần mềm: lý do quan trọng hơn cách thức. Mặc dù cuối cùng các kiến trúc sư phải hiểu cách triển khai các giải pháp, nhưng trước hết họ phải hiểu lý do tại sao một sự lựa chọn có sự đánh đổi tốt hơn so với sự lựa chọn khác.
Thứ hai, bằng cách tập trung vào các khái niệm kiến trúc, chúng ta có thể tránh việc thực hiện nhiều lần các khái niệm đó. Các kiến trúc sư có thể triển khai giao tiếp bất đồng bộ theo nhiều cách khác nhau; chúng ta tập trung vào lý do tại sao một kiến trúc sư lại chọn giao tiếp bất đồng bộ và để chi tiết thực hiện ở một nơi khác.
Thứ ba, nếu chúng ta bắt đầu thực hiện tất cả các loại tùy chọn mà chúng tôi đã trình bày, điều này sẽ trở thành cuốn sách dài nhất từng được viết. Tập trung vào các nguyên tắc kiến trúc cho phép chúng ta giữ mọi thứ ở mức độ tổng quát nhất có thể.
Để giữ cho các chủ đề bám sát vào kiến trúc nhất có thể, chúng tôi sử dụng các định nghĩa đơn giản nhất cho các khái niệm chính. Ví dụ, kết nối trong kiến trúc có thể lấp đầy cả những cuốn sách (và đã có). Để đạt được điều đó, chúng tôi sử dụng các định nghĩa đơn giản sau đây, gần như là giản đơn:
- Service
-
Nói theo cách thông thường, một dịch vụ là một tập hợp các chức năng gắn kết được triển khai dưới dạng một tệp thực thi độc lập. Hầu hết các khái niệm mà chúng ta thảo luận liên quan đến dịch vụ đều áp dụng rộng rãi cho các kiến trúc phân tán, và cụ thể là các kiến trúc vi dịch vụ.
Theo các thuật ngữ chúng tôi định nghĩa trong Chương 2, một dịch vụ là một phần của một lượng kiến trúc, bao gồm các định nghĩa thêm về cả sự liên kết tĩnh và động giữa các dịch vụ và các lượng khác.
- Coupling
-
Hai hiện vật (bao gồm cả dịch vụ) được gắn kết nếu một sự thay đổi ở cái này có thể yêu cầu một sự thay đổi ở cái kia để duy trì chức năng hoạt động đúng.
- Component
-
Một khối xây dựng kiến trúc của ứng dụng thực hiện một chức năng kinh doanh hoặc hạ tầng nào đó, thường được thể hiện qua cấu trúc gói (Java), không gian tên (C#), hoặc một nhóm mã nguồn vật lý trong một cấu trúc thư mục nào đó. Ví dụ, thành phần Lịch Sử Đơn Hàng có thể được triển khai thông qua một tập hợp các tệp lớp nằm trong không gian tên app.business.order.history.
- Synchronous communication
-
Hai hiện vật giao tiếp đồng bộ nếu người gọi phải chờ phản hồi trước khi tiếp tục.
- Asynchronous communication
-
Hai thực thể giao tiếp không đồng bộ nếu người gọi không chờ phản hồi trước khi tiếp tục. Tùy chọn, người gọi có thể được thông báo bởi người nhận qua một kênh riêng khi yêu cầu đã hoàn tất.
- Orchestrated coordination
-
Một quy trình làm việc được điều phối nếu nó bao gồm một dịch vụ có trách nhiệm chính là điều phối quy trình làm việc.
- Choreographed coordination
-
Một quy trình làm việc được sắp xếp khi nó thiếu một người điều phối; thay vào đó, các dịch vụ trong quy trình làm việc chia sẻ trách nhiệm phối hợp của quy trình đó.
- Atomicty
-
Một quy trình làm việc được coi là nguyên tử nếu tất cả các phần của quy trình đó duy trì trạng thái nhất quán trong mọi lúc; điều ngược lại được thể hiện bởi phổ tính nhất quán cuối cùng, được đề cập trong Chương 6.
- Contract
-
Chúng tôi sử dụng thuật ngữ hợp đồng theo nghĩa rộng để định nghĩa giao diện giữa hai phần mềm, có thể bao gồm các cuộc gọi phương thức hoặc hàm, kiến trúc tích hợp các cuộc gọi từ xa, phụ thuộc, và nhiều hơn nữa. Bất cứ nơi nào hai phần mềm kết nối, một hợp đồng đều có liên quan.
Kiến trúc phần mềm vốn dĩ mang tính trừu tượng: chúng ta không thể biết những sự kết hợp độc đáo của các nền tảng, công nghệ, phần mềm thương mại và nhiều khả năng khác mà độc giả của chúng ta có, ngoại trừ việc không có hai cái nào hoàn toàn giống nhau. Chúng ta đề cập đến nhiều ý tưởng trừu tượng, nhưng cần phải cụ thể hóa chúng với một số chi tiết triển khai để làm cho chúng trở nên rõ ràng. Để đạt được điều đó, chúng ta cần một vấn đề để minh họa các khái niệm kiến trúc – điều này dẫn chúng ta đến đội Sysops.
Introducing the Sysops Squad Saga
- saga
Một câu chuyện dài về những thành tựu anh hùng.
Từ điển Tiếng Anh Oxford
Chúng tôi thảo luận về một số câu chuyện trong cuốn sách này, cả theo nghĩa đen lẫn nghĩa bóng. Các kiến trúc sư đã mượn thuật ngữ câu chuyện để mô tả hành vi giao dịch trong các kiến trúc phân tán (mà chúng tôi sẽ đề cập chi tiết trong Chương 12). Tuy nhiên, các cuộc thảo luận về kiến trúc thường trở nên trừu tượng, đặc biệt là khi xem xét những vấn đề trừu tượng như những phần khó khăn của kiến trúc. Để giúp giải quyết vấn đề này và cung cấp một bối cảnh thực tế cho những giải pháp mà chúng tôi thảo luận, chúng tôi bắt đầu một câu chuyện theo nghĩa đen về Đội Sysops.
Chúng tôi sử dụng câu chuyện về nhóm Sysops trong mỗi chương để minh họa các kỹ thuật và sự trao đổi được mô tả trong cuốn sách này. Trong khi nhiều cuốn sách về kiến trúc phần mềm đề cập đến các nỗ lực phát triển mới, rất nhiều vấn đề thực tế tồn tại trong các hệ thống hiện có. Do đó, câu chuyện của chúng tôi bắt đầu từ kiến trúc nhóm Sysops hiện tại được nêu bật ở đây.
Penultimate Electronics là một tập đoàn điện tử lớn có nhiều cửa hàng bán lẻ trên khắp cả nước. Khi khách hàng mua máy tính, TV, dàn âm thanh và các thiết bị điện tử khác, họ có thể chọn mua một kế hoạch hỗ trợ. Khi xảy ra sự cố, các chuyên gia công nghệ trực tiếp phục vụ khách hàng (đội Sysops) sẽ đến nhà (hoặc văn phòng làm việc) của khách hàng để khắc phục sự cố với thiết bị điện tử.
Bốn người dùng chính của ứng dụng ticketing của Sysops Squad như sau:
- Administrator
-
Quản trị viên duy trì người dùng nội bộ của hệ thống, bao gồm danh sách các chuyên gia và bộ kỹ năng tương ứng, vị trí và tình trạng sẵn có của họ. Quản trị viên cũng quản lý tất cả quy trình thanh toán cho khách hàng sử dụng hệ thống, và duy trì dữ liệu tham chiếu tĩnh (chẳng hạn như sản phẩm được hỗ trợ, cặp tên-giá trong hệ thống, và vân vân).
- Customer
-
Khách hàng đăng ký dịch vụ Sysops Squad và duy trì hồ sơ khách hàng, hợp đồng hỗ trợ và thông tin thanh toán của họ. Khách hàng nhập ticket vấn đề vào hệ thống và cũng điền vào các bài khảo sát sau khi công việc đã hoàn thành.
- Sysops Squad expert
-
Các chuyên gia được phân công các vé sự cố và sửa chữa các vấn đề dựa trên vé. Họ cũng tương tác với cơ sở dữ liệu tri thức để tìm kiếm giải pháp cho các vấn đề của khách hàng và ghi chú về các sửa chữa.
- Manager
-
Người quản lý theo dõi các hoạt động vé vấn đề và nhận báo cáo vận hành và phân tích về hệ thống vé vấn đề tổng thể của Nhóm Sysops.
Nonticketing Workflow
Các quy trình không liên quan đến vé bao gồm những hành động mà các quản trị viên, quản lý và khách hàng thực hiện không liên quan đến một vé vấn đề. Các quy trình này được mô tả như sau:
-
Các chuyên gia của Đội ngũ Sysops được thêm vào và duy trì trong hệ thống thông qua một quản trị viên, người nhập khu vực, tính khả dụng và kỹ năng của họ.
-
Khách hàng đăng ký với hệ thống Sysops Squad và có nhiều kế hoạch hỗ trợ dựa trên các sản phẩm họ đã mua.
-
Khách hàng sẽ được tự động tính phí hàng tháng dựa trên thông tin thẻ tín dụng trong hồ sơ của họ. Khách hàng có thể xem lịch sử thanh toán và bảng sao kê qua hệ thống.
-
Các quản lý yêu cầu và nhận các báo cáo hoạt động và phân tích đa dạng, bao gồm báo cáo tài chính, báo cáo hiệu suất chuyên gia và báo cáo vé.
Ticketing Workflow
Quy trình ticket bắt đầu khi một khách hàng nhập một vé vấn đề vào hệ thống và kết thúc khi khách hàng hoàn thành khảo sát sau khi sửa chữa xong. Quy trình này được phác thảo như sau:
-
Khách hàng đã mua gói hỗ trợ sẽ tạo một vé báo lỗi bằng cách sử dụng trang web Sysops Squad.
-
Ngay khi một phiếu yêu cầu sự cố được nhập vào hệ thống, hệ thống sẽ xác định chuyên gia của Đội Sysops nào sẽ phù hợp nhất với công việc dựa trên kỹ năng, vị trí hiện tại, khu vực dịch vụ và khả năng sẵn sàng.
-
Khi được phân công, vé sự cố sẽ được tải lên một ứng dụng di động tùy chỉnh trên thiết bị di động của chuyên gia trong Đội ngũ Sysops. Chuyên gia cũng sẽ nhận được thông báo qua tin nhắn văn bản rằng họ có một vé sự cố mới.
-
Khách hàng được thông báo qua tin nhắn SMS hoặc email (dựa trên sở thích trong hồ sơ của họ) rằng chuyên gia đang trên đường đến.
-
Chuyên gia sử dụng ứng dụng di động tùy chỉnh trên điện thoại của họ để lấy thông tin vé và vị trí. Chuyên gia của nhóm Sysops cũng có thể truy cập cơ sở kiến thức thông qua ứng dụng di động để tìm hiểu những gì đã được thực hiện trong quá khứ để khắc phục vấn đề.
-
Khi chuyên gia khắc phục vấn đề, họ sẽ đánh dấu vé là “hoàn thành.” Chuyên gia của nhóm sysops có thể sau đó thêm thông tin về vấn đề và sửa chữa cơ sở dữ liệu tri thức.
-
Sau khi hệ thống nhận được thông báo rằng vé đã hoàn thành, nó sẽ gửi email đến khách hàng với liên kết đến một cuộc khảo sát, mà khách hàng sau đó sẽ điền vào.
-
Hệ thống nhận bảng khảo sát đã hoàn thành từ khách hàng và ghi lại thông tin khảo sát.
A Bad Scenario
Gần đây, tình hình với ứng dụng xử lý vé sự cố của đội Sysops không tốt. Hệ thống vé sự cố hiện tại là một ứng dụng khổng lồ, được phát triển cách đây nhiều năm. Khách hàng phàn nàn rằng các tư vấn viên không bao giờ xuất hiện vì vé bị mất, và thường thì tư vấn viên sai xuất hiện để sửa chữa những thứ họ không biết gì về nó. Khách hàng cũng đã phàn nàn rằng hệ thống không luôn sẵn sàng để nhập vé sự cố mới.
Thay đổi cũng khó khăn và rủi ro trong tổ chức lớn này. Mỗi khi có một thay đổi được thực hiện, thường mất quá nhiều thời gian và thường có một thứ khác bị hỏng. Do các vấn đề về độ tin cậy, hệ thống Đội ngũ Sysops thường xuyên "bị đóng băng" hoặc gặp sự cố, dẫn đến việc toàn bộ tính năng ứng dụng không khả dụng từ năm phút đến hai giờ trong khi vấn đề được xác định và ứng dụng được khởi động lại.
Nếu không có biện pháp gì được thực hiện sớm, Penultimate Electronics sẽ buộc phải từ bỏ mảng kinh doanh hợp đồng hỗ trợ rất có lãi và sa thải tất cả các quản trị viên, chuyên gia, quản lý và nhân viên phát triển CNTT của đội Sysops Squad—bao gồm cả các kiến trúc sư.
Sysops Squad Architectural Components
Hệ thống đơn thể cho ứng dụng Sysops Squad xử lý quản lý vé, báo cáo hoạt động, đăng ký khách hàng và lập hóa đơn, cũng như các chức năng hành chính chung như bảo trì người dùng, đăng nhập, và duy trì kỹ năng và hồ sơ chuyên gia. Hình 1-3 và Bảng 1-1 tương ứng minh họa và mô tả các thành phần của ứng dụng đơn thể hiện có (phần ss. của không gian tên xác định ngữ cảnh ứng dụng Sysops Squad).
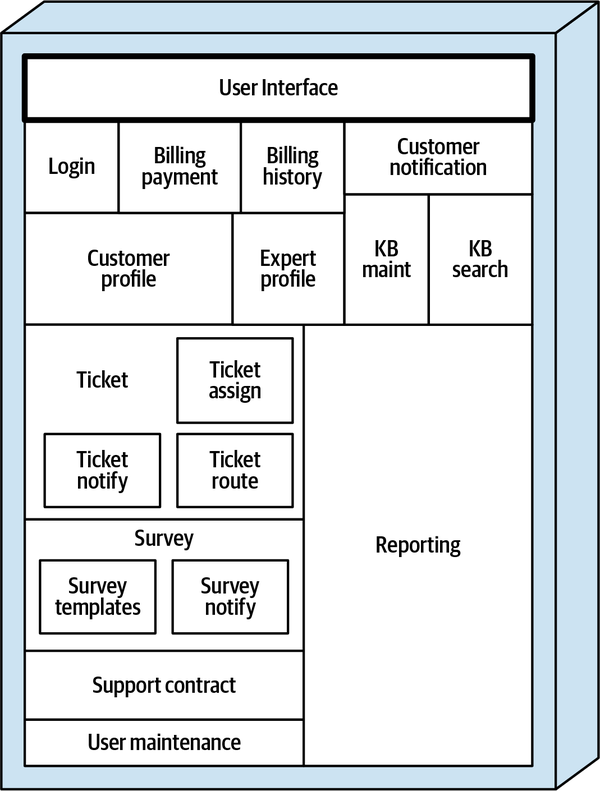
Figure 1-3. Components within the existing Sysops Squad application
| Component | Namespace | Responsibility |
|---|---|---|
Đăng nhập | Đăng nhập | Logic đăng nhập và bảo mật của người dùng nội bộ và khách hàng |
Thanh toán hóa đơn | thanh toán hóa đơn | Thông tin thanh toán hàng tháng của khách hàng và thông tin thẻ tín dụng của khách hàng |
Lịch sử thanh toán | lịch sử thanh toán | Lịch sử thanh toán và các hóa đơn trước đây |
Thông báo khách hàng | thông báo của khách hàng | Thông báo cho khách hàng về thanh toán, thông tin chung |
Hồ sơ khách hàng | hồ sơ khách hàng | Duy trì hồ sơ khách hàng, đăng ký khách hàng |
Hồ sơ chuyên gia | chuyên gia hồ sơ | Duy trì hồ sơ chuyên gia (tên, vị trí, kỹ năng, v.v.) |
Bảo trì KB | bảo trì ss.kb. | Duy trì và xem các mục trong cơ sở tri thức |
Tìm kiếm KB | Tìm kiếm ss.kb | Công cụ truy vấn để tìm kiếm cơ sở tri thức |
Báo cáo | báo cáo.ss | Tất cả các báo cáo (chuyên gia, vé, tài chính) |
Vé | vé ss | Tạo vé, bảo trì, hoàn thành, mã chung |
Gán vé | gán.thẻ.vé | Tìm một chuyên gia và gán vé. |
Thông báo vé | Thông báo vé ss. | Thông báo cho khách hàng rằng chuyên gia đang trên đường đến. |
Tuyến vé | lịch trình vé | Gửi vé đến ứng dụng di động của chuyên gia. |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ | Hợp đồng hỗ trợ cho khách hàng, sản phẩm trong kế hoạch |
Khảo sát | khảo sát | Duy trì các khảo sát, ghi nhận và ghi lại kết quả khảo sát. |
Thông báo khảo sát | thông báo khảo sát | Gửi email khảo sát cho khách hàng |
Mẫu khảo sát | mẫu khảo sát ss | Duy trì các khảo sát khác nhau dựa trên loại dịch vụ |
Bảo trì người dùng | người dùng.ss | Duy trì người dùng và vai trò nội bộ |
Các thành phần này sẽ được sử dụng trong các chương tiếp theo để minh họa các kỹ thuật và sự đánh đổi khác nhau khi xử lý việc chia nhỏ các ứng dụng thành kiến trúc phân tán.
Sysops Squad Data Model
Ứng dụng Sysops Squad cùng với các thành phần khác nhau được liệt kê trong Bảng 1-1 sử dụng một lược đồ duy nhất trong cơ sở dữ liệu để lưu trữ tất cả các bảng và mã cơ sở dữ liệu liên quan. Cơ sở dữ liệu này được sử dụng để lưu trữ thông tin về khách hàng, người dùng, hợp đồng, thanh toán, hóa đơn, cơ sở kiến thức và khảo sát khách hàng; các bảng được liệt kê trong Bảng 1-2, và mô hình ER được minh họa trong Hình 1-4.
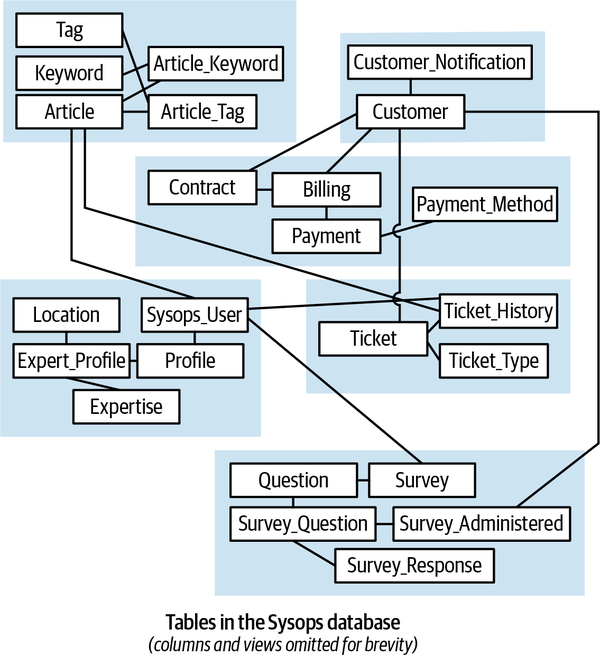
Figure 1-4. Data model within the existing Sysops Squad application
| Table | Responsibility |
|---|---|
Khách hàng | Các thực thể cần hỗ trợ Sysops |
Thông báo Khách hàng | Tùy chọn thông báo cho khách hàng |
Khảo sát | Khảo sát về sự hài lòng của khách hàng sau hỗ trợ |
Câu hỏi | Câu hỏi trong một cuộc khảo sát |
"Câu_Hỏi_Khảo_Sát" | Một câu hỏi được gán cho khảo sát. |
Khảo sát được thực hiện | Câu hỏi khảo sát được giao cho khách hàng. |
Khảo sát_Phản hồi | Phản hồi của khách hàng đối với cuộc khảo sát |
Hóa đơn | Thông tin thanh toán cho hợp đồng hỗ trợ |
Hợp đồng | Hợp đồng giữa một thực thể và Sysops để hỗ trợ |
Phương_Thức_Thanh_Toán | Các phương thức thanh toán được hỗ trợ để thực hiện thanh toán |
Thanh toán | Thanh toán đã được xử lý cho các hóa đơn |
Người dùng SysOps | Các người dùng khác nhau trong Sysops |
Hồ sơ | Thông tin hồ sơ cho người dùng Sysops |
Hồ_sơ_Chuyên_gia | Hồ sơ của các chuyên gia |
Chuyên môn | Nhiều chuyên môn trong Sysops |
Vị trí | Các địa điểm được phục vụ bởi chuyên gia |
bài viết | Bài viết cho cơ sở kiến thức |
Thẻ | Thẻ trên bài viết |
Từ khóa | Từ khóa cho một bài viết |
Thẻ_Bài_Viết | Những thẻ liên quan đến bài viết |
Từ_khoá_Bài_viết | Bảng kết hợp cho từ khóa và bài viết |
Vé | Các vé hỗ trợ được tạo bởi khách hàng |
Loại vé | Các loại vé khác nhau |
Lịch sử vé | Lịch sử của các vé hỗ trợ |
Mô hình dữ liệu Sysops là một mô hình dữ liệu chuẩn ở dạng chuẩn ba bình thường với chỉ một vài thủ tục lưu trữ hoặc kích hoạt. Tuy nhiên, có khá nhiều view tồn tại chủ yếu được sử dụng bởi thành phần Báo cáo. Khi nhóm kiến trúc cố gắng phân tách ứng dụng và hướng tới kiến trúc phân tán, họ sẽ phải làm việc với nhóm cơ sở dữ liệu để hoàn thành các nhiệm vụ ở cấp độ cơ sở dữ liệu. Cấu trúc của các bảng và view trong cơ sở dữ liệu này sẽ được sử dụng xuyên suốt cuốn sách để thảo luận về các kỹ thuật và sự đánh đổi khác nhau nhằm thực hiện nhiệm vụ phân tách cơ sở dữ liệu.
Part I. Pulling Things Apart
Như nhiều người trong số chúng ta đã phát hiện khi còn nhỏ, một cách tuyệt vời để hiểu cách một cái gì đó ghép lại với nhau là trước tiên phải tháo rời nó. Để hiểu các chủ đề phức tạp (như là sự đánh đổi trong kiến trúc phân tán), một kiến trúc sư phải tìm ra điểm bắt đầu để gỡ rối.
Trong cuốn sách "Những điều mỗi lập trình viên nên biết về Thiết kế Đối tượng" (Dorset House), Meilir Page-Jones đã đưa ra một quan sát sáng suốt rằng sự kết hợp trong kiến trúc có thể được chia thành hai loại: kết hợp tĩnh và kết hợp động. Kết hợp tĩnh đề cập đến cách mà các phần của kiến trúc (các lớp, thành phần, dịch vụ, và vân vân) được kết nối với nhau: các phụ thuộc, mức độ kết hợp, các điểm kết nối, và vân vân. Một kiến trúc sư có thể thường đo lường kết hợp tĩnh tại thời điểm biên dịch vì nó đại diện cho các phụ thuộc tĩnh trong kiến trúc.
Kết nối động đề cập đến cách mà các phần của kiến trúc gọi lẫn nhau: loại hình giao tiếp, thông tin được truyền, độ chặt chẽ của hợp đồng, v.v.
Mục tiêu của chúng tôi là khám phá cách thực hiện phân tích thỏa hiệp trong các kiến trúc phân tán; để làm điều đó, chúng tôi phải tách rời các phần di chuyển ra để có thể thảo luận về chúng một cách độc lập nhằm hiểu rõ trước khi lắp ráp chúng lại với nhau.
Phần I chủ yếu bàn về cấu trúc kiến trúc, cách mà các yếu tố được kết nối một cách tĩnh. Trong Chương 2, chúng tôi giải quyết vấn đề xác định phạm vi của sự kết nối tĩnh và động trong các kiến trúc, và trình bày bức tranh toàn diện mà chúng ta phải phân tích để hiểu. Chương 3 bắt đầu quá trình đó, định nghĩa tính mô-đun và sự tách biệt trong kiến trúc. Chương 4 cung cấp các công cụ để đánh giá và phân tích mã nguồn, và Chương 5 cung cấp các mẫu để hỗ trợ quá trình này.
Dữ liệu và giao dịch đã trở nên ngày càng quan trọng trong kiến trúc, thúc đẩy nhiều quyết định thỏa hiệp của các kiến trúc sư và DBA. Chương 6 đề cập đến những ảnh hưởng kiến trúc của dữ liệu, bao gồm cách hòa hợp ranh giới dịch vụ và dữ liệu. Cuối cùng, Chương 7 liên kết việc ghép nối kiến trúc với các mối quan tâm về dữ liệu để định nghĩa các bộ tích hợp và giải thể—các lực lượng khuyến khích kích thước và ranh giới dịch vụ lớn hơn hoặc nhỏ hơn.
Chapter 2. Discerning Coupling in Software Architecture
Thứ Tư, ngày 3 tháng 11, 13:00
Logan, kiến trúc sư chính của Penultimate Electronics, đã cắt ngang một nhóm nhỏ các kiến trúc sư trong căng tin, đang thảo luận về kiến trúc phân tán. “Austen, cậu lại đeo băng bó lần nữa à?”
“Không, chỉ là một cái nẹp,” Austen trả lời. “Tôi bị trật cổ tay khi chơi golf đĩa cực vào cuối tuần - nó gần như đã lành.”
"Cái gì... thôi khỏi đi. Cuộc trò chuyện đầy cảm xúc mà tôi đã xộc vào là gì vậy?"
“Tại sao ai đó không luôn chọn mẫu saga trong microservices để kết nối các giao dịch?” Austen hỏi. “Bằng cách đó, các kiến trúc sư có thể làm cho các dịch vụ nhỏ như họ muốn.”
“Nhưng bạn không phải sử dụng orchestration với sagas sao?” Addison hỏi. “Thế còn những lúc chúng ta cần giao tiếp không đồng bộ? Và, các giao dịch sẽ trở nên phức tạp đến mức nào? Nếu chúng ta phân chia mọi thứ quá nhiều, liệu chúng ta có thể thực sự đảm bảo tính toàn vẹn của dữ liệu không?”
“Bạn biết đấy,” Austen nói, “nếu chúng ta sử dụng một bus dịch vụ doanh nghiệp, chúng ta có thể để nó quản lý hầu hết những thứ đó cho chúng ta.”
"Tôi nghĩ không ai còn sử dụng ESB nữa - phải chăng chúng ta nên sử dụng Kafka cho những thứ như vậy?"
"Chúng chẳng phải là cùng một thứ!" Austen nói.
Logan đã cắt ngang cuộc trò chuyện đang trở nên căng thẳng. “Đây là một so sánh không hợp lý, nhưng không có công cụ hoặc phương pháp nào là giải pháp hoàn hảo. Kiến trúc phân tán như microservices rất khó khăn, đặc biệt nếu các kiến trúc sư không thể gỡ rối tất cả các lực lượng đang hoạt động. Điều chúng ta cần là một phương pháp hoặc mô hình giúp chúng ta tìm ra những vấn đề khó khăn trong kiến trúc của mình.”
"Chà," Addison nói, "dù chúng ta làm gì, nó phải được tách rời càng nhiều càng tốt - mọi thứ tôi đã đọc đều nói rằng các kiến trúc sư nên đón nhận việc tách rời nhiều nhất có thể."
“Nếu bạn làm theo lời khuyên đó,” Logan nói, “Mọi thứ sẽ bị tách rời đến mức không cái nào có thể giao tiếp với cái nào khác—thật khó để xây dựng phần mềm theo cách đó! Giống như nhiều thứ khác, sự liên kết không phải lúc nào cũng xấu; các kiến trúc sư chỉ cần biết cách áp dụng nó một cách phù hợp. Thực ra, tôi nhớ một câu nói nổi tiếng về điều đó từ một triết gia Hy Lạp….”
Tất cả mọi thứ đều là độc, và không có gì là không có độc; chỉ có liều lượng mới khiến một thứ không trở thành độc.
Paracelsus
Một trong những nhiệm vụ khó khăn nhất mà một kiến trúc sư sẽ phải đối mặt là gỡ rối các lực lượng và sự đánh đổi khác nhau trong kiến trúc phân tán. Những người cung cấp lời khuyên thường ca ngợi lợi ích của các hệ thống "không liên kết chặt chẽ", nhưng làm thế nào mà các kiến trúc sư có thể thiết kế các hệ thống mà không có gì kết nối với cái gì khác? Các kiến trúc sư thiết kế các microservices tinh tế để đạt được sự tách biệt, nhưng sau đó, việc điều phối, giao dịch và bất đồng bộ trở thành những vấn đề lớn. Lời khuyên chung nói "tách biệt", nhưng không cung cấp hướng dẫn nào về cách đạt được mục tiêu đó trong khi vẫn xây dựng các hệ thống hữu ích.
Các kiến trúc sư gặp khó khăn trong việc đưa ra quyết định về độ chi tiết và giao tiếp vì không có hướng dẫn phổ quát rõ ràng cho việc ra quyết định—không có các phương pháp tốt nhất nào có thể áp dụng cho các hệ thống phức tạp trong thế giới thực. Cho đến giờ, các kiến trúc sư đã thiếu một cái nhìn và thuật ngữ đúng đắn để tiến hành phân tích cẩn thận, từ đó xác định bộ thỏa hiệp tốt nhất (hoặc ít tồi tệ nhất) theo từng trường hợp.
Tại sao các kiến trúc sư lại gặp khó khăn với các quyết định trong kiến trúc phân tán? Cuối cùng, chúng ta đã xây dựng các hệ thống phân tán từ thế kỷ trước, sử dụng nhiều cơ chế giống nhau (hàng đợi tin nhắn, sự kiện, và vân vân). Tại sao sự phức tạp lại tăng lên đến vậy với microservices?
Câu trả lời nằm ở triết lý cơ bản của các dịch vụ vi mô, được cảm hứng từ ý tưởng về một ngữ cảnh giới hạn. Xây dựng các dịch vụ mô hình hóa các ngữ cảnh giới hạn đòi hỏi một sự thay đổi tinh tế nhưng quan trọng đối với cách mà các kiến trúc sư thiết kế các hệ thống phân tán, vì giờ đây tính transactionality trở thành một mối quan tâm kiến trúc hàng đầu. Trong nhiều hệ thống phân tán mà các kiến trúc sư thiết kế trước khi có dịch vụ vi mô, các trình xử lý sự kiện thường kết nối với một cơ sở dữ liệu quan hệ duy nhất, cho phép nó xử lý các chi tiết như tính toàn vẹn và các giao dịch. Việc di chuyển cơ sở dữ liệu vào trong ranh giới dịch vụ chuyển các mối quan tâm về dữ liệu thành các mối quan tâm về kiến trúc.
Như chúng tôi đã nói trước đây, "Kiến trúc phần mềm" là những thứ mà bạn không thể tra cứu trên Google được. Một kỹ năng mà các kiến trúc sư hiện đại phải phát triển là khả năng phân tích các sự đánh đổi. Mặc dù đã có nhiều khung lý thuyết tồn tại trong nhiều thập kỷ (chẳng hạn như Phương pháp Phân tích Sự đánh đổi Kiến trúc, hay ATAM), nhưng chúng thiếu sự tập trung vào những vấn đề thực tế mà các kiến trúc sư phải đối mặt hàng ngày.
Cuốn sách này tập trung vào cách các kiến trúc sư có thể thực hiện phân tích trade-off cho bất kỳ số lượng kịch bản nào độc đáo cho tình huống của họ. Như trong nhiều lĩnh vực của kiến trúc, lời khuyên là đơn giản; những phần khó nằm ở chi tiết, đặc biệt là cách các phần khó trở nên rối ren, khiến cho việc nhìn thấy và hiểu các phần riêng lẻ trở nên khó khăn, như được minh họa trong Hình 2-1.
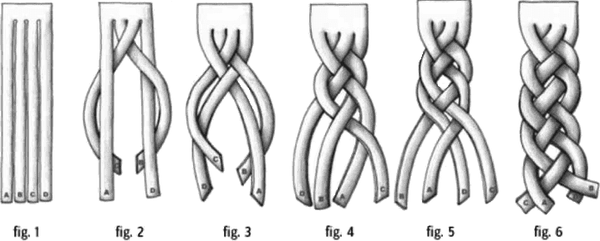
Figure 2-1. A braid entangles hair, making the individual strands hard to identify
Khi các kiến trúc sư nhìn vào những vấn đề phức tạp, họ gặp khó khăn trong việc thực hiện phân tích giao dịch vì những khó khăn trong việc tách rời các mối quan tâm, để có thể xem xét chúng một cách độc lập. Do đó, bước đầu tiên trong phân tích giao dịch là gỡ rối các khía cạnh của vấn đề, phân tích những phần nào liên kết với nhau và tác động của mối liên kết đó đến sự thay đổi. Để mục đích này, chúng tôi sử dụng định nghĩa đơn giản nhất của từ liên kết:
- Coupling
-
Hai phần của một hệ thống phần mềm được liên kết nếu một sự thay đổi ở một phần có thể gây ra một sự thay đổi ở phần kia.
Thường thì, kiến trúc phần mềm tạo ra những vấn đề đa chiều, nơi mà nhiều lực tương tác với nhau theo những cách phụ thuộc lẫn nhau. Để phân tích các sự đánh đổi, một kiến trúc sư phải trước tiên xác định những lực nào cần phải đánh đổi với nhau.
Vì vậy, đây là lời khuyên của chúng tôi cho việc phân tích trao đổi hiện đại trong kiến trúc phần mềm:
-
Tìm những phần nào bị rối nhau.
-
Phân tích cách mà chúng liên kết với nhau.
-
Đánh giá các thỏa hiệp bằng cách xác định tác động của sự thay đổi đối với các hệ thống liên kết phụ thuộc lẫn nhau.
Mặc dù các bước rất đơn giản, nhưng những phần khó khăn ẩn chứa trong chi tiết. Do đó, để minh họa khung này trong thực tế, chúng tôi sẽ lấy một trong những vấn đề khó khăn nhất (và có lẽ gần với tính tổng quát nhất) trong kiến trúc phân tán, đó là liên quan đến microservices.
- How do architects determine the size and communication styles for microservices?
-
Xác định kích thước phù hợp cho các dịch vụ vi mô dường như là một vấn đề phổ biến—các dịch vụ quá nhỏ tạo ra các vấn đề về giao dịch và tổ chức, trong khi các dịch vụ quá lớn gây ra các vấn đề về quy mô và phân phối.
Để đạt được điều đó, phần còn lại của cuốn sách này sẽ giải quyết nhiều khía cạnh cần xem xét khi trả lời câu hỏi trước đó. Chúng tôi cung cấp thuật ngữ mới để phân biệt các mẫu tương tự nhưng khác biệt và cho thấy các ví dụ thực tiễn về việc áp dụng các mẫu này và những mẫu khác.
Tuy nhiên, mục tiêu chính của cuốn sách này là cung cấp cho bạn những kỹ thuật dựa trên ví dụ để học cách xây dựng phân tích đánh đổi của riêng bạn cho những vấn đề đặc thù trong lĩnh vực của bạn. Chúng ta bắt đầu với việc phân tích những lực lượng lớn đầu tiên trong các kiến trúc phân tán: xác định quantum kiến trúc cùng với hai loại liên kết, tĩnh và động.
Architecture (Quantum | Quanta)
Thuật ngữ quantum, tất nhiên, được sử dụng rất nhiều trong lĩnh vực vật lý được gọi là cơ học lượng tử. Tuy nhiên, các tác giả đã chọn từ này vì những lý do tương tự như các nhà vật lý. Quantum bắt nguồn từ từ Latin quantus, có nghĩa là “bao nhiêu” hoặc “bao nhiêu nhiều.” Trước khi vật lý chiếm lấy nó, ngành pháp lý đã sử dụng nó để đại diện cho “số lượng yêu cầu hoặc cho phép” (ví dụ, trong các khoản bồi thường được trả). Thuật ngữ này cũng xuất hiện trong lĩnh vực toán học của topo, liên quan đến các thuộc tính của các dạng hình. Vì có nguồn gốc từ Latin, số ít là quantum, và số nhiều là quanta, tương tự như sự đối xứng giữa datum/data.
Một kiến trúc lượng tử đo lường nhiều khía cạnh của cả hình thức và hành vi trong kiến trúc phần mềm liên quan đến cách các phần kết nối và giao tiếp với nhau.
- Architecture quantum
-
Một quantum kiến trúc là một artifact có thể triển khai độc lập với độ kết hợp chức năng cao, độ kết nối tĩnh cao và độ kết nối động đồng bộ. Một ví dụ phổ biến của một quantum kiến trúc là một microservice được hình thành tốt trong một quy trình công việc.
- Static coupling
-
Đại diện cho cách các phụ thuộc tĩnh được giải quyết trong kiến trúc thông qua các hợp đồng. Những phụ thuộc này bao gồm hệ điều hành, các framework và/hoặc thư viện được cung cấp thông qua quản lý phụ thuộc truyền sinh, và bất kỳ yêu cầu vận hành nào khác để cho phép lượng tử hoạt động.
- Dynamic coupling
-
Đại diện cho cách mà quanta giao tiếp trong thời gian chạy, có thể là đồng bộ hoặc không đồng bộ. Do đó, các hàm fitness cho những đặc điểm này phải liên tục, thường sử dụng các bộ giám sát.
Mặc dù cả kết nối tĩnh và kết nối động đều có vẻ tương tự, các kiến trúc sư phải phân biệt hai điểm khác biệt quan trọng. Một cách dễ dàng để hiểu sự khác biệt là kết nối tĩnh mô tả cách các dịch vụ được kết nối với nhau, trong khi kết nối động mô tả cách các dịch vụ gọi lẫn nhau trong quá trình chạy. Ví dụ, trong kiến trúc vi dịch vụ, một dịch vụ phải chứa các thành phần phụ thuộc như cơ sở dữ liệu, đại diện cho kết nối tĩnh — dịch vụ đó không hoạt động nếu không có dữ liệu cần thiết. Dịch vụ đó có thể gọi các dịch vụ khác trong quá trình thực hiện một quy trình công việc, điều này đại diện cho kết nối động. Không dịch vụ nào yêu cầu dịch vụ khác hiện diện để hoạt động, ngoại trừ quy trình công việc tại thời điểm chạy này. Do đó, kết nối tĩnh phân tích các phụ thuộc hoạt động, và kết nối động phân tích các phụ thuộc giao tiếp.
Các định nghĩa này bao gồm những đặc điểm quan trọng; hãy cùng xem xét từng điểm một cách chi tiết vì chúng giúp thông tin cho hầu hết các ví dụ trong sách.
Independently Deployable
Cái gọi là có thể triển khai độc lập ngụ ý nhiều khía cạnh của một quantum kiến trúc - mỗi quantum đại diện cho một đơn vị có thể triển khai riêng biệt trong một kiến trúc cụ thể. Do đó, một kiến trúc đơn khối - một kiến trúc được triển khai như một đơn vị duy nhất - theo định nghĩa là một quantum kiến trúc đơn. Trong một kiến trúc phân tán như microservices, các nhà phát triển có xu hướng hướng tới khả năng triển khai các dịch vụ một cách độc lập, thường là theo cách tự động hóa cao. Do đó, từ góc độ có thể triển khai độc lập, một dịch vụ trong kiến trúc microservices đại diện cho một quantum kiến trúc (tùy thuộc vào mức độ kết nối - như sẽ được thảo luận sau).
Việc làm cho mỗi kiến trúc lượng tử trở thành một tài sản có thể triển khai trong kiến trúc phục vụ nhiều mục đích hữu ích. Đầu tiên, ranh giới được đại diện bởi một kiến trúc lượng tử đóng vai trò như một ngôn ngữ chung hữu ích giữa các kiến trúc sư, nhà phát triển và đội ngũ vận hành. Mỗi người đều hiểu phạm vi chung đang được thảo luận: các kiến trúc sư hiểu các đặc tính liên kết, các nhà phát triển hiểu phạm vi hành vi, và đội ngũ vận hành hiểu các đặc tính có thể triển khai.
Thứ hai, kiến trúc lượng tử đại diện cho một trong những lực (kết hợp tĩnh) mà các kiến trúc sư phải xem xét khi cố gắng đạt được độ phân granularity phù hợp cho các dịch vụ trong một kiến trúc phân tán. Thường thì, trong các kiến trúc microservices, các nhà phát triển phải đối mặt với câu hỏi khó khăn về độ granularity của dịch vụ nào mang lại tập hợp tối ưu các sự trao đổi. Một số trong những sự trao đổi đó xoay quanh khả năng triển khai: chu kỳ phát hành mà dịch vụ này yêu cầu, những dịch vụ khác có thể bị ảnh hưởng, những thực tiễn kỹ thuật nào liên quan, và những điều tương tự. Các kiến trúc sư hưởng lợi từ việc hiểu rõ chính xác ranh giới triển khai nằm ở đâu trong các kiến trúc phân tán. Chúng tôi thảo luận về độ granularity của dịch vụ và các sự trao đổi liên quan trong Chương 7.
Thứ ba, khả năng triển khai độc lập buộc kiến trúc tách biệt phải bao gồm các điểm kết nối chung như cơ sở dữ liệu. Hầu hết các cuộc thảo luận về kiến trúc thường tiện lợi bỏ qua các vấn đề như cơ sở dữ liệu và giao diện người dùng, nhưng các hệ thống trong thế giới thực thường phải đối mặt với những vấn đề đó. Do đó, bất kỳ hệ thống nào sử dụng cơ sở dữ liệu chung đều không đạt tiêu chí kiến trúc cho khả năng triển khai độc lập trừ khi việc triển khai cơ sở dữ liệu diễn ra đồng bộ với ứng dụng. Nhiều hệ thống phân tán, nếu không chia sẻ cơ sở dữ liệu chung, sẽ đủ điều kiện cho nhiều phần kiến trúc nhưng lại không đạt yêu cầu triển khai độc lập nếu chúng chia sẻ một cơ sở dữ liệu chung có chu kỳ triển khai riêng. Do đó, chỉ đơn giản xem xét các ranh giới triển khai không cung cấp một thước đo hữu ích. Các kiến trúc sư cũng nên xem xét tiêu chí thứ hai cho một phần kiến trúc, đó là sự gắn kết chức năng cao, để giới hạn phần kiến trúc trong một phạm vi hữu ích.
High Functional Cohesion
Sự gắn kết chức năng cao về mặt cấu trúc đề cập đến sự gần gũi của các yếu tố liên quan: các lớp, thành phần, dịch vụ, và v.v. Trong suốt lịch sử, các nhà khoa học máy tính đã định nghĩa nhiều loại gắn kết, được giới hạn trong trường hợp này cho mô-đun tổng quát, có thể được đại diện dưới dạng các lớp hoặc thành phần, tùy thuộc vào nền tảng. Từ góc độ miền, định nghĩa kỹ thuật về sự gắn kết chức năng cao trùng lặp với các mục tiêu của ngữ cảnh giới hạn trong thiết kế theo miền: hành vi và dữ liệu thực hiện một quy trình làm việc cụ thể trong miền.
Từ góc độ khả năng triển khai độc lập hoàn toàn, một kiến trúc khổng lồ đơn thể đủ tư cách là một lượng kiến trúc. Tuy nhiên, nó gần như chắc chắn không có sự gắn kết chức năng cao, mà thay vào đó bao gồm chức năng của toàn bộ hệ thống. Kiến trúc đơn thể càng lớn, khả năng gắn kết chức năng đơn lẻ càng thấp.
Lý tưởng, trong kiến trúc microservices, mỗi dịch vụ mô hình hóa một miền hoặc quy trình đơn lẻ, do đó thể hiện sự gắn kết chức năng cao. Sự gắn kết trong bối cảnh này không phải là về cách các dịch vụ tương tác để thực hiện công việc, mà là cách một dịch vụ độc lập và liên kết với dịch vụ khác như thế nào.
High Static Coupling
Coupling tĩnh cao ngụ ý rằng các yếu tố bên trong kiến trúc lượng tử được kết nối chặt chẽ với nhau, điều này thực sự là một khía cạnh của các hợp đồng. Các kiến trúc sư nhận ra những điều như REST hoặc SOAP là các định dạng hợp đồng, nhưng các chữ ký phương thức và các phụ thuộc hoạt động (thông qua các điểm kết nối như địa chỉ IP hoặc URL) cũng đại diện cho các hợp đồng. Do đó, các hợp đồng là một phần khó của kiến trúc; chúng tôi sẽ đề cập đến các vấn đề liên quan đến việc kết nối bao gồm tất cả các loại hợp đồng, bao gồm cách chọn các hợp đồng phù hợp, trong Chương 13.
Một lượng kiến trúc (architecture quantum) là một phần của đo lường sự liên kết tĩnh, và phép đo này khá đơn giản cho hầu hết các topo kiến trúc. Ví dụ, các sơ đồ sau đây cho thấy các kiểu kiến trúc được đề cập trong cuốn "Nền tảng Kiến trúc Phần mềm", với sự liên kết tĩnh của lượng kiến trúc được minh họa.
Bất kỳ kiểu kiến trúc đơn khối nào cũng sẽ có một lượng bằng một, như được minh họa trong Hình 2-2.
Figure 2-2. Monolithic architectures always have a quantum of one
Như bạn có thể thấy, bất kỳ kiến trúc nào triển khai như một đơn vị duy nhất và sử dụng một cơ sở dữ liệu duy nhất sẽ luôn có một quantum duy nhất. Đo lường quantum kiến trúc của việc gắn kết tĩnh bao gồm cơ sở dữ liệu, và một hệ thống dựa vào một cơ sở dữ liệu duy nhất không thể có nhiều hơn một quantum. Do đó, đo lường gắn kết tĩnh của một quantum kiến trúc giúp xác định các điểm gắn kết trong kiến trúc, không chỉ trong các thành phần phần mềm đang phát triển. Hầu hết các kiến trúc đơn thể chứa một điểm gắn kết duy nhất (thường là một cơ sở dữ liệu) khiến cho đo lường quantum của nó bằng một.
Cấu trúc phân tán thường có đặc điểm tách rời ở cấp độ thành phần; hãy xem xét bộ các kiểu kiến trúc tiếp theo, bắt đầu với kiến trúc dựa trên dịch vụ được trình bày trong Hình 2-3.
Figure 2-3. Architecture quantum for a service-based architecture
Mặc dù mô hình dịch vụ cá nhân này cho thấy sự phân tách thường thấy trong kiến trúc microservices, nhưng kiến trúc vẫn sử dụng một cơ sở dữ liệu quan hệ duy nhất, khiến điểm số kiến trúc của nó chỉ đạt một.
Cho đến nay, việc đo lường sự ghép đôi tĩnh của kiến trúc lượng tử đã đánh giá tất cả các topo thành một. Tuy nhiên, các kiến trúc phân tán tạo ra khả năng có nhiều quanta nhưng không nhất thiết bảo đảm điều đó. Ví dụ, kiểu trung gian của kiến trúc điều khiển theo sự kiện sẽ luôn được đánh giá thành một kiến trúc lượng tử duy nhất, như được minh họa trong Hình 2-4.
Mặc dù kiểu kiến trúc này đại diện cho một kiến trúc phân tán, nhưng hai điểm kết nối kéo nó về phía một lượng kiến trúc đơn lẻ: cơ sở dữ liệu, giống như với các kiến trúc đơn thể trước đó, nhưng cũng là Bộ điều phối Yêu cầu chính nó - bất kỳ điểm kết nối toàn diện nào cần thiết cho kiến trúc hoạt động đều tạo thành một lượng kiến trúc xung quanh nó.
Figure 2-4. A mediated EDA has a single architecture quantum
Kiến trúc dựa trên sự kiện (không có trung gian trung tâm) ít bị phụ thuộc hơn, nhưng điều đó không đảm bảo sự tách biệt hoàn toàn. Hãy xem xét kiến trúc dựa trên sự kiện được minh họa trong Hình 2-5.
Kiến trúc theo kiểu môi giới (broker-style) dựa trên sự kiện này (không có một người trung gian trung tâm) vẫn được coi là một quantum kiến trúc duy nhất vì tất cả các dịch vụ đều sử dụng một cơ sở dữ liệu quan hệ duy nhất, đóng vai trò là một điểm nối chung. Câu hỏi được phân tích tĩnh cho một quantum kiến trúc là: “Liệu sự phụ thuộc này của kiến trúc có cần thiết để khởi động dịch vụ này không?” Ngay cả trong trường hợp một kiến trúc dựa trên sự kiện, nơi một số dịch vụ không truy cập cơ sở dữ liệu, nếu chúng phụ thuộc vào các dịch vụ mà có truy cập cơ sở dữ liệu, thì chúng trở thành một phần của sự kết nối tĩnh của quantum kiến trúc.
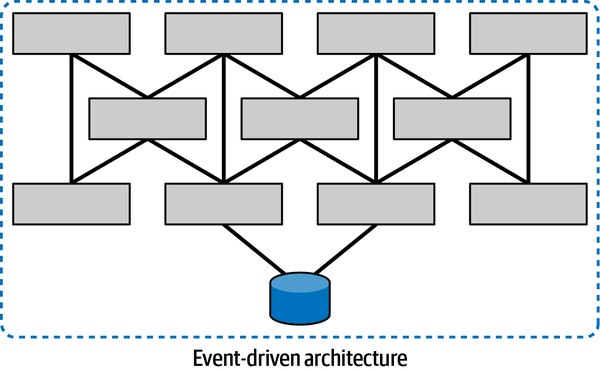
Figure 2-5. Even a distributed architecture such as broker-style event-driven architecture can be a single quantum
Tuy nhiên, còn những tình huống trong các kiến trúc phân tán mà không có các điểm kết nối chung thì sao? Hãy xem xét kiến trúc hướng sự kiện được minh họa trong Hình 2-6.
Các kiến trúc sư đã thiết kế hệ thống dựa trên sự kiện này với hai kho dữ liệu và không có sự phụ thuộc tĩnh giữa các tập dịch vụ. Lưu ý rằng mỗi khối lượng kiến trúc có thể hoạt động trong một hệ sinh thái giống như sản xuất. Nó có thể không tham gia vào tất cả các quy trình công việc yêu cầu của hệ thống, nhưng nó vẫn hoạt động thành công và vận hành—gửi yêu cầu và nhận chúng trong kiến trúc.
Đo lường mối liên kết tĩnh của một quantum kiến trúc đánh giá các sự phụ thuộc liên kết giữa các thành phần kiến trúc và hoạt động. Do đó, hệ điều hành, kho dữ liệu, trình môi giới tin nhắn, quản lý chứa và tất cả các sự phụ thuộc vận hành khác hình thành các điểm liên kết tĩnh của một quantum kiến trúc, sử dụng các hợp đồng chặt chẽ nhất có thể, các sự phụ thuộc vận hành (thêm thông tin về vai trò của các hợp đồng trong quantum kiến trúc sẽ có trong Chương 13).
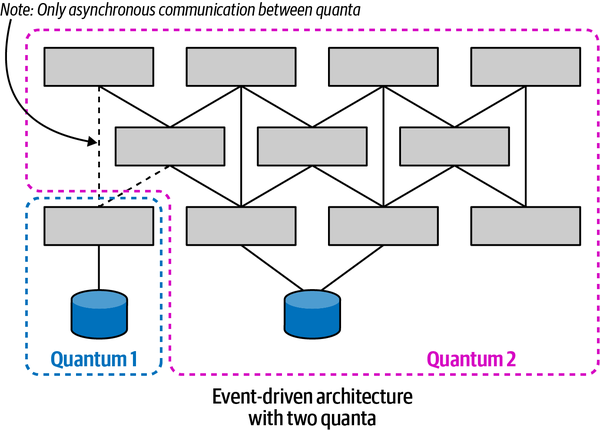
Figure 2-6. An event-driven architecture with multiple quanta
Kiến trúc microservices có đặc điểm là các dịch vụ được tách rời cao, bao gồm cả các phụ thuộc về dữ liệu. Các kiến trúc sư trong những kiến trúc này ưa chuộng mức độ tách rời cao và chú ý không tạo ra các điểm kết nối giữa các dịch vụ, cho phép mỗi dịch vụ riêng lẻ hình thành các khối lượng riêng của nó, như được minh họa trong Hình 2-7.
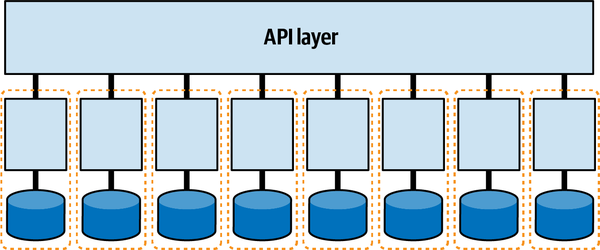
Figure 2-7. Microservices may form their own quanta
Mỗi dịch vụ (được xem như một ngữ cảnh giới hạn) có thể có những đặc điểm kiến trúc riêng—một dịch vụ có thể có mức độ scalability hoặc bảo mật cao hơn dịch vụ khác. Mức độ chi tiết này trong việc xác định các đặc điểm kiến trúc là một trong những lợi thế của phong cách kiến trúc microservices. Mức độ tách rời cao cho phép các nhóm làm việc trên một dịch vụ di chuyển nhanh nhất có thể, mà không cần lo lắng về việc làm hỏng các phụ thuộc khác.
Tuy nhiên, nếu hệ thống gắn chặt với giao diện người dùng, kiến trúc sẽ hình thành một khối lượng kiến trúc duy nhất, như được minh họa trong Hình 2-8.
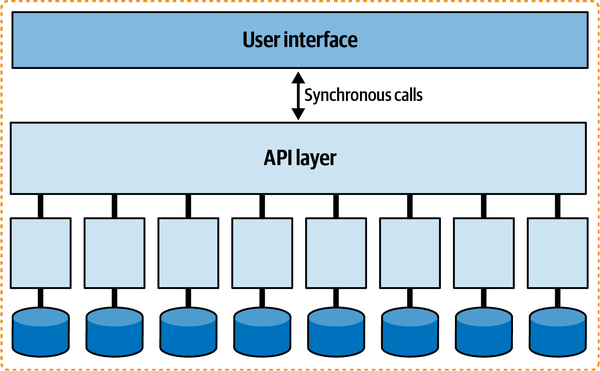
Figure 2-8. A tightly coupled user interface can reduce a microservices architecture quantum to one
Giao diện người dùng tạo ra các điểm kết nối giữa phía trước và phía sau, và hầu hết các giao diện người dùng sẽ không hoạt động nếu các phần của backend không khả dụng.
Hơn nữa, sẽ rất khó cho một kiến trúc sư để thiết kế các đặc điểm kiến trúc vận hành khác nhau (hiệu suất, quy mô, tính linh hoạt, độ tin cậy, v.v.) cho mỗi dịch vụ nếu chúng đều phải hợp tác với nhau trong một giao diện người dùng duy nhất (đặc biệt trong trường hợp các cuộc gọi đồng bộ, được đề cập trong “Liên kết năng động lượng tử”).
Các kiến trúc sư thiết kế giao diện người dùng sử dụng tính bất đồng bộ mà không tạo ra sự liên kết giữa phía trước và phía sau. Một xu hướng trong nhiều dự án vi dịch vụ là sử dụng một khung micro frontend cho các yếu tố giao diện người dùng trong kiến trúc vi dịch vụ. Trong một kiến trúc như vậy, các yếu tố giao diện người dùng tương tác thay mặt cho các dịch vụ được phát ra từ chính các dịch vụ đó. Bề mặt giao diện người dùng hoạt động như một bức tranh vẽ, nơi các yếu tố giao diện người dùng có thể xuất hiện, và cũng tạo điều kiện cho việc giao tiếp lỏng lẻo giữa các thành phần, thường sử dụng các sự kiện. Kiến trúc như vậy được minh họa trong Hình 2-9.
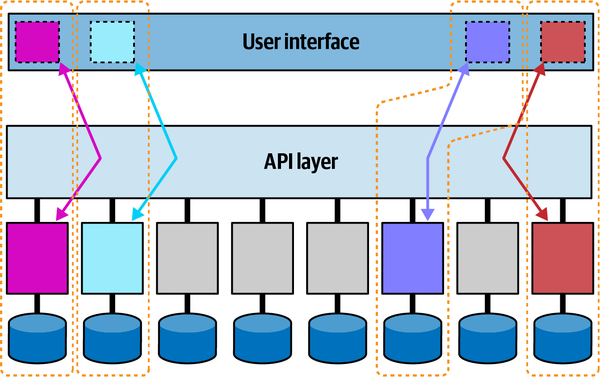
Figure 2-9. In a micro-frontend architecture, each service + user interface component forms an architecture quantum
Trong ví dụ này, bốn dịch vụ có màu sắc cùng với các micro-frontend tương ứng tạo thành các quanta kiến trúc: mỗi dịch vụ này có thể có những đặc điểm kiến trúc khác nhau.
Bất kỳ điểm kết nối nào trong một kiến trúc có thể tạo ra các điểm kết nối tĩnh từ quan điểm lượng tử. Hãy xem xét tác động của một cơ sở dữ liệu chung giữa hai hệ thống, như được minh họa trong Hình 2-10.
Sự kết nối tĩnh của một hệ thống cung cấp cái nhìn quý giá, ngay cả trong những hệ thống phức tạp liên quan đến kiến trúc tích hợp. Ngày càng nhiều, một kỹ thuật phổ biến của kiến trúc sư để hiểu kiến trúc kế thừa là tạo ra một sơ đồ lượng tử tĩnh về cách mọi thứ được "kết nối" với nhau, điều này giúp xác định những hệ thống nào sẽ bị ảnh hưởng bởi sự thay đổi và cung cấp một cách hiểu (và tiềm năng tách rời) kiến trúc.
Liên kết tĩnh chỉ là một nửa của các lực đang hoạt động trong kiến trúc phân tán. Nửa còn lại là liên kết động.
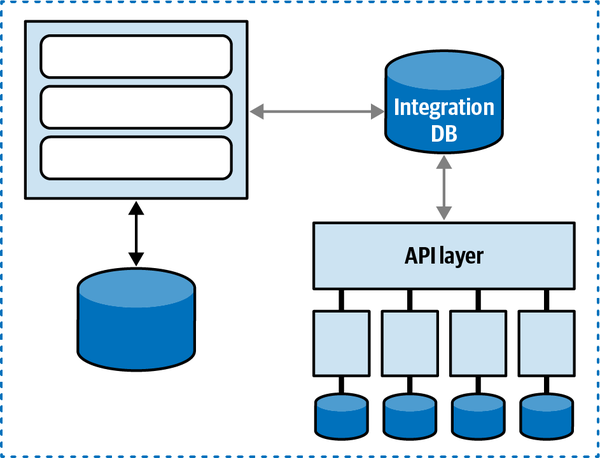
Figure 2-10. A shared database forms a coupling point between two systems, creating a single quantum
Dynamic Quantum Coupling
Phần cuối cùng của định nghĩa lượng kiến trúc liên quan đến việc kết hợp đồng bộ trong thời gian thực - nói cách khác, hành vi của các lượng kiến trúc khi chúng tương tác với nhau để hình thành các quy trình công việc trong một kiến trúc phân tán.
Bản chất của cách thức các dịch vụ gọi lẫn nhau tạo ra những quyết định đánh đổi khó khăn vì nó đại diện cho một không gian quyết định đa chiều, bị ảnh hưởng bởi ba lực lượng liên kết lẫn nhau:
- Communication
-
Đề cập đến loại đồng bộ kết nối được sử dụng: đồng bộ hoặc bất đồng bộ.
- Consistency
-
Mô tả liệu giao tiếp trong quy trình làm việc có yêu cầu tính nguyên tử hay có thể sử dụng tính nhất quán cuối cùng.
- Coordination
-
Mô tả liệu quy trình làm việc có sử dụng bộ điều phối hay các dịch vụ giao tiếp thông qua hợp xướng.
Communication
Khi hai dịch vụ giao tiếp với nhau, một trong những câu hỏi cơ bản đối với một kiến trúc sư là liệu sự giao tiếp đó nên là đồng bộ hay bất đồng bộ.
Giao tiếp đồng bộ yêu cầu người yêu cầu phải chờ phản hồi từ người nhận, như đã thể hiện trong Hình 2-11.
Figure 2-11. A synchronous call waits for a result from the receiver
Dịch vụ gọi thực hiện một cuộc gọi (sử dụng một trong số các giao thức hỗ trợ các cuộc gọi đồng bộ, chẳng hạn như gRPC) và giữ chặn (không thực hiện xử lý thêm) cho đến khi người nhận trả về một giá trị (hoặc trạng thái chỉ ra sự thay đổi trạng thái hoặc điều kiện lỗi).
Giao tiếp bất đồng bộ xảy ra giữa hai dịch vụ khi người gọi gửi một tin nhắn đến người nhận (thường thông qua một cơ chế như hàng đợi tin nhắn) và, khi người gọi nhận được xác nhận rằng tin nhắn sẽ được xử lý, họ trở lại làm việc. Nếu yêu cầu cần một giá trị phản hồi, người nhận có thể sử dụng một hàng đợi phản hồi để (bất đồng bộ) thông báo cho người gọi về kết quả, như được minh họa trong Hình 2-12.
Figure 2-12. Asynchronous communication allows parallel processing
Người gọi gửi một tin nhắn tới hàng đợi tin nhắn và tiếp tục xử lý cho đến khi được thông báo bởi người nhận rằng thông tin yêu cầu đã có sẵn qua cuộc gọi trả lại. Thông thường, các kiến trúc sư sử dụng hàng đợi tin nhắn (được minh họa qua ống hình trụ màu x gray trong sơ đồ trên cùng của Hình 2-12) để thực hiện giao tiếp bất đồng bộ, nhưng hàng đợi là phổ biến và tạo ra tiếng ồn trong các sơ đồ, vì vậy nhiều kiến trúc sư không đưa chúng vào, như được hiển thị trong sơ đồ dưới. Và, tất nhiên, các kiến trúc sư có thể thực hiện giao tiếp bất đồng bộ mà không cần hàng đợi tin nhắn bằng cách sử dụng nhiều thư viện hoặc khung khác nhau. Mỗi loại sơ đồ đều ngụ ý thông điệp bất đồng bộ; sơ đồ thứ hai cung cấp rút gọn trực quan và ít chi tiết triển khai hơn.
Các kiến trúc sư phải xem xét các sự đánh đổi quan trọng khi chọn cách thức các dịch vụ sẽ giao tiếp. Những quyết định liên quan đến giao tiếp ảnh hưởng đến sự đồng bộ, xử lý lỗi, tính chất giao dịch, khả năng mở rộng và hiệu suất. Phần còn lại của cuốn sách này sẽ đi sâu vào nhiều vấn đề này.
Consistency
Tính nhất quán đề cập đến mức độ nghiêm ngặt của tính toàn vẹn giao dịch mà các cuộc gọi giao tiếp phải tuân thủ. Các giao dịch nguyên tử (giao dịch toàn bộ hoặc không có gì yêu cầu tính nhất quán trong quá trình xử lý yêu cầu) nằm ở một bên của phổ, trong khi các mức độ nhất quán cuối cùng khác nhau nằm ở bên kia.
Tính giao dịch—khi có nhiều dịch vụ tham gia vào một giao dịch tất cả hoặc không có gì—là một trong những vấn đề khó khăn nhất để mô hình hóa trong các kiến trúc phân tán, dẫn đến lời khuyên chung là nên cố gắng tránh các giao dịch giữa các dịch vụ. Chúng tôi sẽ thảo luận về tính nhất quán và sự giao thoa của dữ liệu và kiến trúc trong các Chương 6, 9, 10 và 12.
Coordination
Sự phối hợp đề cập đến mức độ phối hợp mà quy trình làm việc được mô hình hóa bởi giao tiếp yêu cầu. Hai mẫu chung phổ biến cho microservices là tổ chức và biên đạo, mà chúng tôi sẽ mô tả trong Chương 11. Quy trình làm việc đơn giản - một dịch vụ đơn lẻ trả lời một yêu cầu - không cần sự xem xét đặc biệt từ khía cạnh này. Tuy nhiên, khi độ phức tạp của quy trình làm việc gia tăng, nhu cầu phối hợp càng lớn.
Ba yếu tố này - giao tiếp, tính nhất quán và sự phối hợp - đều ảnh hưởng đến quyết định quan trọng mà một kiến trúc sư phải đưa ra. Tuy nhiên, một cách quan trọng, các kiến trúc sư không thể đưa ra những lựa chọn này một cách độc lập; mỗi lựa chọn đều có ảnh hưởng lẫn nhau. Ví dụ, tính giao dịch dễ dàng hơn trong các kiến trúc đồng bộ có trung gian, trong khi các mức độ mở rộng cao hơn có thể đạt được với các hệ thống được phối hợp bất đồng bộ có tính nhất quán cuối cùng.
Suy nghĩ về những lực này như liên quan đến nhau tạo thành một không gian ba chiều, như được minh họa trong Hình 2-13.
Mỗi lực lượng trong giao tiếp dịch vụ xuất hiện như một chiều. Đối với một quyết định cụ thể, một kiến trúc sư có thể vẽ biểu đồ vị trí trong không gian đại diện cho sức mạnh của những lực lượng này.
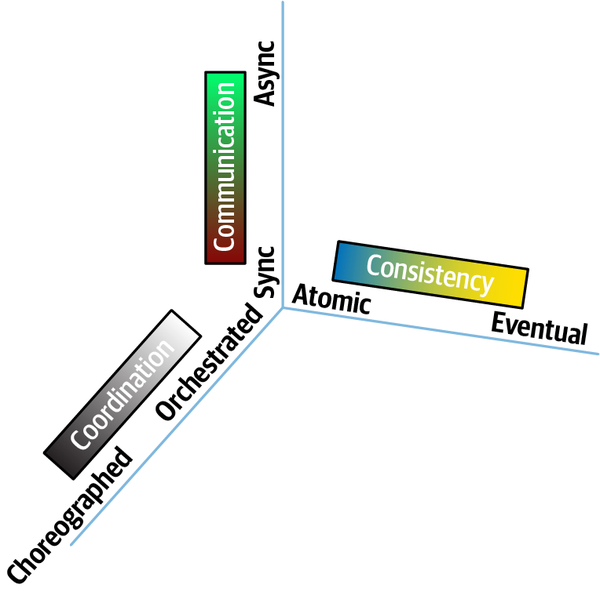
Figure 2-13. The dimensions of dynamic quantum coupling
Khi một kiến trúc sư có thể xây dựng một hiểu biết rõ ràng về các lực tác động trong một tình huống nhất định, điều đó tạo ra các tiêu chí cho phân tích đánh đổi. Trong trường hợp của sự kết nối động, Bảng 2-1 cho thấy một khuôn khổ để xác định tên các mẫu cơ bản dựa trên tám tổ hợp có thể.
| Pattern name | Communication | Consistency | Coordination | Coupling |
|---|---|---|---|---|
Trường ca sử thi | đồng bộ | nguyên tử | được tổ chức | rất cao |
Trò Chơi Tag Điện Thoại | đồng bộ | nguyên tử | được biên đạo | cao |
Huyền Thoại Cổ Tích | đồng bộ | cuối cùng | điều phối | cao |
Cuộc Phiêu Lưu Du Hành Thời Gian | đồng bộ | cuối cùng | được dàn dựng | trung bình |
Huyền ảo Tiểu thuyết Saga | không đồng bộ | nguyên tử | dàn dựng | cao |
Truyện kinh dị | không đồng bộ | nguyên tử | dàn dựng | trung bình |
Huyền thoại song song | bất đồng bộ | cuối cùng | được sắp xếp tài tình | thấp |
"Huyền Thoại Tập" | không đồng bộ | cuối cùng | biên đạo | rất thấp |
Để hiểu đầy đủ về ma trận này, chúng ta trước tiên phải xem xét từng chiều một cách riêng biệt. Do đó, các chương tiếp theo sẽ giúp bạn xây dựng bối cảnh để hiểu những đánh đổi riêng lẻ cho giao tiếp, tính nhất quán và phối hợp, sau đó gộp chúng lại với nhau trong Chương 12.
Trong các chương còn lại của Phần I, chúng tôi sẽ tập trung vào sự kết nối tĩnh và hiểu các khía cạnh khác nhau trong kiến trúc phân tán, bao gồm quyền sở hữu dữ liệu, tính giao dịch và độ granularity của dịch vụ. Trong Phần II, Ghép lại mọi thứ, chúng tôi tập trung vào sự kết nối động và hiểu các mẫu giao tiếp trong microservices.
Sysops Squad Saga: Understanding Quanta
Thứ Ba, ngày 23 tháng 11, 14:32
Austen đến văn phòng của Addison với vẻ mặt khó chịu không giống thường ngày. “Này, Addison, mình có thể làm phiền bạn một chút được không?”
“Chắc chắn rồi, có chuyện gì vậy?”
“Tôi đã đọc về những thứ liên quan đến kiến trúc lượng tử này, và tôi chỉ...không...hiểu...nó!”
Addison cười, “Tôi hiểu ý bạn. Tôi đã gặp khó khăn với nó khi nó hoàn toàn trừu tượng, nhưng khi bạn gắn nó vào những thứ thực tiễn, thì hóa ra nó lại là một tập hợp quan điểm hữu ích.”
"Bạn có ý gì?"
"Ừm," Addison nói, "quanta kiến trúc cơ bản định nghĩa một bối cảnh giới hạn DDD dưới góc độ kiến trúc."
“Tại sao không chỉ sử dụng bối cảnh giới hạn chứ?” Austen hỏi.
"Bối cảnh giới hạn có định nghĩa cụ thể trong DDD, và việc làm rối nó với những thông tin về kiến trúc chỉ khiến mọi người phải phân biệt liên tục. Chúng tương tự nhau, nhưng không giống nhau. Phần đầu tiên về sự kết hợp chức năng và triển khai độc lập chắc chắn phù hợp với dịch vụ dựa trên bối cảnh giới hạn. Nhưng định nghĩa kiến trúc lượng tử đi xa hơn bằng cách xác định các loại coupling—đó là nơi mà các vấn đề tĩnh và động xuất hiện."
"Cái đó là về cái gì? Liệu ghép nối chỉ là ghép nối thôi sao? Tại sao phải phân biệt?"
“Có rất nhiều mối quan tâm khác nhau xoay quanh các loại khác nhau,” Addison nói. “Hãy bắt đầu với loại tĩnh, mà tôi thích nghĩ là cách mọi thứ được kết nối với nhau. Một cách khác để nghĩ về nó: hãy xem xét một trong những dịch vụ mà chúng tôi đang xây dựng trong kiến trúc mục tiêu của chúng tôi. Tất cả những kết nối cần thiết để khởi động dịch vụ đó là gì?”
"Vâng, nó được viết bằng Java, sử dụng cơ sở dữ liệu Postgres, và chạy trong Docker—chỉ thế thôi, đúng không?"
“Bạn đang bỏ lỡ rất nhiều.” Addison nói. “Thế nếu bạn phải xây dựng dịch vụ đó từ đầu, giả sử chúng ta không có gì trong tay? Nó là Java, nhưng cũng sử dụng SpringBoot và, khoảng 15 hoặc 20 khung công tác và thư viện khác nhau?”
“Đúng vậy, chúng ta có thể xem trong tệp POM của Maven để tìm ra tất cả các phụ thuộc đó. Còn gì nữa?”
Ý tưởng đứng sau việc kết nối lượng tử tĩnh là việc kết nối cần thiết để hoạt động. Chúng tôi đang sử dụng các sự kiện để giao tiếp giữa các dịch vụ—vậy còn trung gian sự kiện thì sao?
“Nhưng đó không phải là phần động đó sao?”
“Không phải sự hiện diện của môi giới. Nếu dịch vụ (hoặc, rộng hơn, kiến trúc quantum) mà tôi muốn khởi động sử dụng một môi giới tin nhắn để hoạt động, thì môi giới phải có mặt. Khi dịch vụ gọi một dịch vụ khác qua môi giới, chúng ta rơi vào khía cạnh động.”
“Được rồi, điều đó có lý,” Austen nói. “Nếu tôi nghĩ về những gì cần thiết để khởi tạo từ đầu, đó chính là sự ghép nối lượng tử tĩnh.”
"Đúng vậy. Và chỉ thông tin đó đã rất hữu ích. Gần đây, chúng tôi đã xây dựng một sơ đồ về sự liên kết lượng tử tĩnh cho từng dịch vụ của chúng tôi theo cách phòng vệ."
Austen cười. “Phòng thủ à? Cậu đang nói gì vậy…”
"Chúng tôi đang thực hiện một phân tích độ tin cậy để xác định nếu tôi thay đổi điều này, cái gì có thể bị hỏng, trong đó điều đó có thể là bất kỳ thứ gì trong kiến trúc hoặc hoạt động của chúng tôi. Họ đang cố gắng giảm thiểu rủi ro — nếu chúng tôi thay đổi một dịch vụ, họ muốn biết cái gì phải được kiểm tra."
“Tôi hiểu - đó là mối liên kết lượng tử tĩnh. Tôi có thể thấy cách mà đó là một cách nhìn hữu ích. Nó cũng cho thấy các đội có thể ảnh hưởng lẫn nhau như thế nào. Điều đó có vẻ thực sự hữu ích. Có công cụ nào chúng ta có thể tải xuống để tính toán điều đó cho chúng ta không?”
“Điều đó thật tuyệt vời!” Addison cười. “Thật không may, không ai với sự pha trộn kiến trúc độc đáo của chúng ta đã xây dựng và mã nguồn mở chính xác công cụ mà chúng ta muốn. Tuy nhiên, một số thành viên trong nhóm nền tảng đang làm việc trên một công cụ để tự động hóa điều này, được tùy chỉnh cần thiết cho kiến trúc của chúng ta. Họ đang sử dụng các tệp manifest container, tệp POM, các phụ thuộc NPM và các công cụ phụ thuộc khác để xây dựng và duy trì danh sách các phụ thuộc xây dựng. Chúng tôi cũng đã thiết lập khả năng quan sát cho tất cả các dịch vụ của mình, vì vậy giờ đây chúng tôi có các tệp log nhất quán về việc các hệ thống gọi nhau như thế nào, khi nào và thường xuyên ra sao. Họ đang sử dụng điều đó để xây dựng một đồ thị cuộc gọi để xem các thứ kết nối với nhau như thế nào.”
“Được rồi, vậy liên kết tĩnh là cách mà mọi thứ được kết nối với nhau. Còn liên kết động thì sao?”
“Liên kết động liên quan đến cách mà các quanta giao tiếp với nhau, đặc biệt là các cuộc gọi đồng bộ và bất đồng bộ và tác động của chúng đến các đặc điểm kiến trúc hoạt động—những điều như hiệu suất, quy mô, tính đàn hồi, độ tin cậy, và v.v. Hãy xem xét tính đàn hồi trong một khoảnh khắc—nhớ sự khác biệt giữa khả năng mở rộng và tính đàn hồi chứ?”
Austen cười nhếch mép. “Tôi không biết sẽ có bài kiểm tra. Hãy xem nào…khả năng mở rộng là khả năng hỗ trợ một số lượng lớn người dùng đồng thời; tính linh hoạt là khả năng hỗ trợ một đợt yêu cầu từ người dùng trong một khoảng thời gian ngắn.”
“Đúng rồi! Ngôi sao vàng cho bạn. Được rồi, hãy nghĩ về tính đàn hồi. Giả sử trong kiến trúc trạng thái tương lai của chúng ta, có hai dịch vụ như Ticketing và Assignment, và hai loại cuộc gọi. Chúng ta đã thiết kế cẩn thận các dịch vụ của mình để có độ tách biệt tĩnh cao với nhau, để chúng có thể đàn hồi độc lập. Đó là tác dụng phụ khác của việc tách biệt tĩnh, bởi vì nó xác định phạm vi của những thứ như đặc điểm kiến trúc vận hành. Giả sử rằng Ticketing đang hoạt động với quy mô đàn hồi gấp 10 lần Assignment, và chúng ta cần thực hiện một cuộc gọi giữa chúng. Nếu chúng ta thực hiện một cuộc gọi đồng bộ, toàn bộ quy trình làm việc sẽ bị chậm lại, khi người gọi phải chờ dịch vụ chậm hơn xử lý và trả về. Nếu ngược lại, chúng ta thực hiện một cuộc gọi bất đồng bộ, sử dụng hàng đợi tin nhắn như một bộ đệm, chúng ta có thể cho phép hai dịch vụ hoạt động độc lập về mặt vận hành, cho phép người gọi thêm tin nhắn vào hàng đợi và tiếp tục làm việc, nhận thông báo khi quy trình làm việc hoàn tất.”
“À, tôi hiểu, tôi hiểu! Tư duy kiến trúc định nghĩa phạm vi của các đặc điểm kiến trúc - thật rõ ràng là sự kết nối tĩnh có thể ảnh hưởng đến điều đó. Nhưng bây giờ tôi nhận ra rằng, tùy thuộc vào loại gọi mà bạn thực hiện, bạn có thể tạm thời kết nối hai dịch vụ với nhau.”
“Đúng vậy,” Addison nói. “Các quanta kiến trúc có thể liên kết với nhau tạm thời, trong quá trình cuộc gọi, nếu bản chất của cuộc gọi liên kết các yếu tố như hiệu suất, phản hồi, quy mô và nhiều yếu tố khác."
"Được rồi, tôi nghĩ tôi hiểu cái gì là lượng kiến trúc và cách các định nghĩa liên kết hoạt động. Nhưng tôi sẽ không bao giờ làm cho chuyện lượng/những lượng đó trở nên rõ ràng!"
“Cũng giống như datum/data, nhưng không ai sử dụng datum cả!” Addison cười nói. “Bạn sẽ thấy nhiều hơn về ảnh hưởng của kết nối động lên quy trình làm việc và các sự việc giao dịch khi bạn tiếp tục tìm hiểu về kiến trúc của chúng tôi.”
“Tôi không thể chờ đợi được!”
Chapter 3. Architectural Modularity
Thứ Ba, ngày 21 tháng 9, 09:33
Đó là cùng một phòng hội nghị mà họ đã từng ở hàng trăm lần trước, nhưng hôm nay bầu không khí lại khác. Rất khác. Khi mọi người tập trung lại, không có cuộc trò chuyện nhỏ nào được trao đổi. Chỉ có sự im lặng. Cái kiểu im lặng chết chóc mà bạn có thể cắt bằng dao. Vâng, đó thực sự là một phép ẩn dụ thích hợp với chủ đề của cuộc họp.
Các lãnh đạo doanh nghiệp và nhà tài trợ của ứng dụng ticketing Sysops Squad đang gặp khó khăn đã có cuộc họp với các kiến trúc sư ứng dụng, Addison và Austen, với mục đích bày tỏ mối quan ngại và sự thất vọng về khả năng của bộ phận CNTT trong việc khắc phục những vấn đề không bao giờ kết thúc liên quan đến ứng dụng ticket trouble. “Nếu không có một ứng dụng hoạt động,” họ đã nói, “chúng tôi không thể tiếp tục hỗ trợ dòng sản phẩm này.”
Khi cuộc họp căng thẳng kết thúc, các nhà tài trợ doanh nghiệp lặng lẽ rời đi một cách lần lượt, để lại Addison và Austen một mình trong phòng hội nghị.
“Đó là một cuộc họp tồi tệ,” Addison nói. “Tôi không thể tin họ thực sự đổ lỗi cho chúng ta về tất cả những vấn đề mà chúng ta đang gặp phải với ứng dụng xử lý vé. Đây là một tình huống thật tồi tệ.”
"Ừ, tôi biết," Austen nói. "Đặc biệt là phần về việc có thể đóng cửa dòng sản phẩm hỗ trợ. Chúng tôi sẽ được phân công sang các dự án khác, hoặc tệ hơn, có thể bị sa thải. Mặc dù tôi thích dành toàn bộ thời gian của mình trên sân bóng đá hoặc trên các sườn đồi trượt tuyết vào mùa đông, tôi thực sự không thể đủ khả năng để đánh mất công việc này."
“Cả tôi cũng không thể,” Addison nói. “Hơn nữa, tôi thực sự thích đội phát triển mà chúng ta có, và tôi không muốn thấy nó bị tan rã.”
“Em cũng vậy,” Austen nói. “Tôi vẫn nghĩ rằng việc tách rời ứng dụng sẽ giải quyết hầu hết những vấn đề này.”
“Em đồng ý với anh,” Addison nói, “nhưng làm thế nào chúng ta thuyết phục doanh nghiệp chi thêm tiền và thời gian để tái cấu trúc kiến trúc? Anh thấy họ đã phàn nàn trong cuộc họp về số tiền mà chúng ta đã chi để vá lỗi ở đây ở đó, chỉ để tạo ra thêm các vấn đề trong quá trình đó.”
“Bạn đúng,” Austen nói. “Họ sẽ không bao giờ đồng ý với một nỗ lực di chuyển kiến trúc tốn kém và mất thời gian vào thời điểm này.”
“Nhưng nếu chúng ta đều đồng ý rằng chúng ta cần phải tách rời ứng dụng để giữ cho nó tồn tại, thì làm thế nào chúng ta có thể thuyết phục doanh nghiệp và có được nguồn tài chính cũng như thời gian mà chúng ta cần để hoàn toàn tái cấu trúc ứng dụng của Đội Sysops?” Addison hỏi.
“Không rõ,” Austen nói. “Hãy xem liệu Logan có thể available để thảo luận về vấn đề này với chúng ta không.”
Addison đã tra cứu trực tuyến và thấy rằng Logan, kiến trúc sư trưởng của Penultimate Electronics, đã sẵn sàng. Addison đã gửi một tin nhắn giải thích rằng họ muốn phá vỡ ứng dụng đơn khối hiện có, nhưng không chắc làm thế nào để thuyết phục doanh nghiệp rằng cách tiếp cận này sẽ hiệu quả. Addison đã giải thích trong tin nhắn rằng họ đang gặp khó khăn và cần một số lời khuyên. Logan đã đồng ý gặp gỡ họ và đã tham gia cùng họ trong phòng hội nghị.
“Điều gì khiến bạn chắc chắn rằng việc tách rời ứng dụng Sysops Squad sẽ giải quyết tất cả các vấn đề?” Logan hỏi.
“Bởi vì,” Austen nói, “chúng tôi đã cố gắng sửa mã nhiều lần, và dường như không có tác dụng. Chúng tôi vẫn có quá nhiều vấn đề.”
“Bạn hoàn toàn không hiểu ý tôi,” Logan nói. “Để tôi hỏi bạn một câu khác. Bạn có đảm bảo gì rằng việc chia tách hệ thống sẽ đạt được điều gì hơn là chỉ làm tăng chi phí và lãng phí thêm thời gian quý báu?”
“Chà,” Austen nói, “thật ra, chúng tôi không làm vậy.”
“Vậy làm thế nào bạn biết rằng việc chia tách ứng dụng là phương pháp đúng đắn?” Logan hỏi.
“Chúng tôi đã nói với bạn rồi,” Austen nói, “bởi vì không có cách nào khác mà chúng tôi thử dường như có hiệu quả!”
“Xin lỗi,” Logan nói, “nhưng bạn biết rõ như tôi rằng đó không phải là lý do hợp lý cho việc kinh doanh. Bạn sẽ không bao giờ có được khoản tài trợ cần thiết với kiểu lý do đó.”
“Vậy, lý do kinh doanh hợp lý sẽ là gì?” Addison hỏi. “Chúng ta phải trình bày cách tiếp cận này với doanh nghiệp như thế nào để có được sự phê duyệt cho khoản tài trợ bổ sung?”
“Chà,” Logan nói, “để xây dựng một lý do kinh doanh tốt cho một vấn đề lớn như thế này, trước tiên bạn cần phải hiểu những lợi ích của tính mô-đun kiến trúc, khớp những lợi ích đó với các vấn đề bạn đang gặp phải với hệ thống hiện tại, và cuối cùng phân tích và ghi chép các thỏa hiệp liên quan đến việc tách rời ứng dụng.”
Các doanh nghiệp ngày nay phải đối mặt với một cơn lũ thay đổi; sự phát triển của thị trường dường như đang thúc đẩy với tốc độ kinh khủng. Các yếu tố thúc đẩy kinh doanh (chẳng hạn như sáp nhập và mua lại), sự gia tăng cạnh tranh trên thị trường, nhu cầu tiêu dùng gia tăng và đổi mới sáng tạo (chẳng hạn như tự động hóa thông qua học máy và trí tuệ nhân tạo) tất yếu yêu cầu thay đổi các hệ thống máy tính cơ bản. Trong nhiều trường hợp, những thay đổi trong hệ thống máy tính do đó cũng yêu cầu thay đổi các kiến trúc cơ bản hỗ trợ chúng.
Tuy nhiên, không chỉ doanh nghiệp đang trải qua những thay đổi liên tục và nhanh chóng - mà cả môi trường kỹ thuật mà các hệ thống máy tính đó hoạt động cũng vậy. Việc đóng gói ứng dụng, chuyển sang cơ sở hạ tầng dựa trên đám mây, việc áp dụng DevOps và ngay cả những tiến bộ mới trong các kênh phát hành liên tục đều ảnh hưởng đến kiến trúc cơ bản của những hệ thống máy tính đó.
Thật khó trong thế giới ngày nay để quản lý tất cả những thay đổi liên tục và nhanh chóng này liên quan đến kiến trúc phần mềm. Kiến trúc phần mềm là cấu trúc nền tảng của một hệ thống, và do đó thường được coi là điều nên giữ ổn định và không thay đổi thường xuyên, giống như các khía cạnh cấu trúc cơ bản của một tòa nhà lớn hoặc tòa nhà chọc trời. Tuy nhiên, không giống như kiến trúc cấu trúc của một tòa nhà, kiến trúc phần mềm phải liên tục thay đổi và thích nghi để đáp ứng những yêu cầu mới của môi trường kinh doanh và công nghệ ngày nay.
Xem xét số lượng ngày càng tăng các vụ sáp nhập và mua lại diễn ra trên thị trường hiện nay. Khi một công ty mua lại một công ty khác, không chỉ có được các yếu tố vật lý của công ty (chẳng hạn như nhân viên, tòa nhà, hàng hóa, v.v.) mà còn có thêm nhiều khách hàng. Các hệ thống hiện có trong mỗi công ty có thể mở rộng để đáp ứng sự gia tăng khối lượng người dùng do vụ sáp nhập hoặc mua lại không? Tính mở rộng là một phần lớn của các vụ sáp nhập và mua lại, cũng như tính linh hoạt và khả năng mở rộng, tất cả đều là những mối quan tâm về kiến trúc.
Các hệ thống đơn thể lớn (triển khai một lần) thường không cung cấp mức độ khả năng mở rộng, tính linh hoạt và khả năng mở rộng cần thiết để hỗ trợ hầu hết các vụ sáp nhập và mua lại. Khả năng bổ sung tài nguyên máy (luồng, bộ nhớ và CPU) nhanh chóng bị giới hạn. Để minh họa điểm này, hãy xem xét hình ảnh của cốc nước trong Hình 3-1. Cốc đại diện cho máy chủ (hoặc máy ảo), và nước đại diện cho ứng dụng. Khi các ứng dụng đơn thể phát triển để xử lý nhu cầu tiêu dùng và tải người dùng ngày càng tăng (cho dù từ sự sáp nhập, mua lại hay sự phát triển của công ty), chúng bắt đầu tiêu thụ nhiều tài nguyên hơn. Khi nước được thêm vào cốc (đại diện cho ứng dụng đơn thể đang phát triển), cốc bắt đầu đầy lên. Việc thêm một cốc khác (được đại diện như một máy chủ hoặc máy ảo khác) không mang lại tác dụng gì, vì cốc mới sẽ chứa cùng một lượng nước như cốc đầu tiên.

Figure 3-1. A full glass representing a large monolithic application close to capacity
Một khía cạnh của tính mô-đun trong kiến trúc là chia nhỏ những ứng dụng lớn, đồ sộ thành những phần riêng biệt và nhỏ hơn để cung cấp nhiều khả năng mở rộng và phát triển hơn, đồng thời tạo điều kiện cho sự thay đổi liên tục và nhanh chóng. Ngược lại, những khả năng này có thể giúp đạt được các mục tiêu chiến lược của một công ty.
Bằng cách thêm một cốc trống khác vào ví dụ về cốc nước của chúng ta và chia ứng dụng (nước) thành hai phần riêng biệt, một nửa lượng nước bây giờ có thể được đổ vào cốc trống mới, cung cấp 50% dung tích nhiều hơn, như được minh họa trong Hình 3-2. Sự tương tự về cốc nước là một cách tuyệt vời để giải thích về tính mô-đun của kiến trúc (việc chia nhỏ các ứng dụng đơn thể) cho các bên liên quan trong kinh doanh và các giám đốc cấp cao, những người sẽ không thể tránh khỏi việc trả tiền cho nỗ lực tái cấu trúc kiến trúc.
Figure 3-2. Two half-full glasses representing an application broken apart with plenty of capacity for growth
Sự mở rộng quy mô tăng cường chỉ là một lợi ích của sự mô-đun kiến trúc. Một lợi ích quan trọng khác là tính linh hoạt, khả năng phản ứng nhanh với sự thay đổi. Một bài viết từ Forbes vào tháng 1 năm 2020 của David Benjamin và David Komlos đã nêu rõ như sau:
Có một điều sẽ tách biệt những người chiến thắng và kẻ thua cuộc: khả năng đáp ứng kịp thời để thực hiện những điều chỉnh táo bạo và quyết đoán một cách hiệu quả và khẩn trương.
Các doanh nghiệp phải trở nên linh hoạt để tồn tại trong thế giới ngày nay. Tuy nhiên, trong khi các bên liên quan trong doanh nghiệp có thể đưa ra quyết định nhanh chóng và thay đổi hướng đi một cách nhanh chóng, đội ngũ công nghệ của công ty có thể không thể thực hiện những chỉ đạo mới đó đủ nhanh để tạo ra sự khác biệt. Việc cho phép công nghệ hoạt động nhanh như doanh nghiệp (hoặc ngược lại, ngăn chặn công nghệ làm chậm doanh nghiệp) yêu cầu một mức độ linh hoạt kiến trúc nhất định.
Modularity Drivers
Các kiến trúc sư không nên chia hệ thống thành các phần nhỏ hơn trừ khi có các động lực kinh doanh rõ ràng. Các động lực kinh doanh chính để chia nhỏ các ứng dụng bao gồm tốc độ đưa ra thị trường (đôi khi được gọi là thời gian đến thị trường) và đạt được một mức độ lợi thế cạnh tranh trên thị trường.
Tốc độ đưa sản phẩm ra thị trường đạt được thông qua khả năng linh hoạt kiến trúc—khả năng phản ứng nhanh với sự thay đổi. Tính linh hoạt là một đặc tính kiến trúc phức hợp bao gồm nhiều đặc tính kiến trúc khác, bao gồm khả năng bảo trì, khả năng kiểm thử và khả năng triển khai.
Lợi thế cạnh tranh đạt được thông qua tốc độ ra thị trường kết hợp với khả năng mở rộng và mức độ sẵn có tổng thể cũng như khả năng chịu lỗi của ứng dụng. Càng tốt hơn một công ty hoạt động, nó càng phát triển, do đó cần có khả năng mở rộng nhiều hơn để hỗ trợ hoạt động của người dùng gia tăng. Khả năng chịu lỗi, tức là khả năng của một ứng dụng bị lỗi nhưng vẫn tiếp tục hoạt động, là cần thiết để đảm bảo rằng khi các phần của ứng dụng bị lỗi, các phần khác vẫn có khả năng hoạt động bình thường, giảm thiểu tác động toàn diện đến người dùng cuối. Hình 3-3 minh họa mối quan hệ giữa các yếu tố kỹ thuật và các yếu tố kinh doanh dẫn xuất cho tính mô-đun (được bao bọc trong các ô).
Các doanh nghiệp phải linh hoạt để tồn tại trong thị trường đầy biến động và nhanh chóng ngày nay, điều này có nghĩa là các kiến trúc cơ bản cũng phải linh hoạt. Như được minh họa trong Hình 3-3, năm đặc điểm kiến trúc chính để hỗ trợ tính linh hoạt, tốc độ đưa ra thị trường và, cuối cùng, lợi thế cạnh tranh trong thị trưởng hiện nay là khả năng sẵn sàng (chịu lỗi), khả năng mở rộng, khả năng triển khai, khả năng kiểm tra và khả năng bảo trì.
Figure 3-3. The drivers for modularity and the relationships among them
Lưu ý rằng tính mô-đun kiến trúc không nhất thiết phải chuyển sang kiến trúc phân tán. Khả năng bảo trì, khả năng kiểm tra và khả năng triển khai (được định nghĩa trong các phần tiếp theo) cũng có thể đạt được thông qua các kiến trúc đơn thể như mô-đun đơn thể hoặc thậm chí kiến trúc vi hạt nhân (xem Phụ lục B để có danh sách tài liệu cung cấp thêm thông tin về các kiểu kiến trúc này). Cả hai kiểu kiến trúc này đều cung cấp một mức độ tính mô-đun kiến trúc dựa trên cách mà các thành phần được cấu trúc. Ví dụ, với mô-đun đơn thể, các thành phần được nhóm lại thành các miền có cấu trúc tốt, cung cấp cho cái được gọi là kiến trúc phân vùng miền (xem Các nguyên tắc cơ bản của Kiến trúc Phần mềm, Chương 8, trang 103). Với kiến trúc vi hạt nhân, chức năng được phân tách thành các thành phần plug-in riêng biệt, cho phép một phạm vi kiểm tra và triển khai nhỏ hơn nhiều.
Maintainability
Khả năng bảo trì liên quan đến sự dễ dàng trong việc thêm, thay đổi hoặc loại bỏ các tính năng, cũng như áp dụng các thay đổi nội bộ như các bản sửa lỗi bảo trì, nâng cấp framework, nâng cấp phần mềm của bên thứ ba, và nhiều hơn nữa. Giống như hầu hết các đặc điểm kiến trúc tổng hợp, khả năng bảo trì rất khó để định nghĩa một cách khách quan. Alexander von Zitzewitz, kiến trúc sư phần mềm và người sáng lập hello2morrow, đã viết một bài viết về một chỉ số mới nhằm định nghĩa khách quan mức độ khả năng bảo trì của một ứng dụng. Mặc dù chỉ số khả năng bảo trì của von Zitzewitz tương đối phức tạp và liên quan đến nhiều yếu tố, hình thức ban đầu của nó như sau:
Trong đó, ML là mức độ khả năng bảo trì của toàn bộ hệ thống (tỷ lệ phần trăm từ 0% đến 100%), k là tổng số thành phần logic trong hệ thống, và ci là mức độ kết nối cho bất kỳ thành phần nào, với sự chú ý đặc biệt đến mức độ kết nối chảy vào. Phương trình này về cơ bản chỉ ra rằng mức độ kết nối chảy vào giữa các thành phần càng cao thì mức độ khả năng bảo trì tổng thể của mã nguồn càng thấp.
Gác lại những toán học phức tạp, một số chỉ số điển hình được sử dụng để xác định khả năng bảo trì tương đối của một ứng dụng dựa trên các thành phần (các khối xây dựng kiến trúc của một ứng dụng) bao gồm những điều sau đây:
- Component coupling
-
Mức độ và cách thức mà các thành phần biết về nhau.
- Component cohesion
-
Mức độ và cách thức mà các hoạt động của một thành phần tương tác với nhau.
- Cyclomatic complexity
-
Mức độ gián tiếp và lồng ghép tổng thể trong một thành phần
- Component size
-
Số lượng các câu lệnh tổng hợp trong một thành phần
- Technical versus domain partitioning
-
Các thành phần được sắp xếp theo cách sử dụng kỹ thuật hoặc theo mục đích miền - xem Phụ lục A
Trong ngữ cảnh của kiến trúc, chúng tôi định nghĩa một thành phần là một khối xây dựng kiến trúc của ứng dụng thực hiện một số loại chức năng kinh doanh hoặc hạ tầng, thường được thể hiện thông qua cấu trúc gói (Java), không gian tên (C#) hoặc tập hợp vật lý của các tệp (lớp) trong một cấu trúc thư mục nào đó. Ví dụ, thành phần Lịch sử Đơn hàng có thể được triển khai thông qua một tập hợp các tệp lớp nằm trong không gian tên app.business.order.history.
Các kiến trúc monolithic lớn thường có mức độ bảo trì thấp do việc phân chia chức năng thành các lớp kỹ thuật, sự liên kết chặt chẽ giữa các thành phần, và độ kết dính yếu của các thành phần từ góc độ miền. Ví dụ, hãy xem xét một yêu cầu mới trong một kiến trúc monolithic truyền thống có nhiều lớp để thêm ngày hết hạn cho các mục trong danh sách ước muốn của khách hàng (các mục trong danh sách có thể được mua sau này). Lưu ý trong Hình 3-4 rằng phạm vi thay đổi của yêu cầu mới là ở mức ứng dụng vì sự thay đổi được propogate đến tất cả các lớp trong ứng dụng.
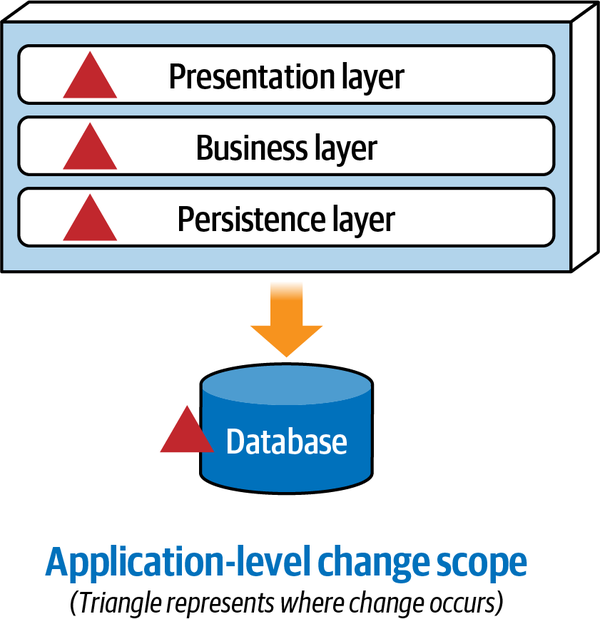
Figure 3-4. With monolithic layered architectures, change is at an application level
Tùy thuộc vào cấu trúc đội ngũ, việc thực hiện thay đổi đơn giản này để thêm ngày hết hạn cho các mục trong danh sách ước nguyện trong một kiến trúc phân lớp nguyên khối có thể cần phối hợp của ít nhất ba đội.
-
Một thành viên từ đội ngũ giao diện người dùng sẽ cần thiết để thêm trường hết hạn mới vào màn hình.
-
Một thành viên từ nhóm backend sẽ cần thiết để thêm các quy tắc kinh doanh liên quan đến ngày hết hạn và thay đổi hợp đồng để thêm trường hết hạn mới.
-
Một thành viên từ đội ngũ cơ sở dữ liệu sẽ cần thiết để thay đổi cấu trúc bảng để thêm cột thời hạn mới vào bảng Danh sách mong muốn.
Vì miền Danh sách mong muốn được phân bổ khắp toàn bộ kiến trúc, việc duy trì một miền hoặc tiểu miền cụ thể (chẳng hạn như Danh sách mong muốn) trở nên khó khăn hơn. Ngược lại, các kiến trúc mô-đun phân chia các miền và tiểu miền thành những đơn vị phần mềm nhỏ hơn, có thể triển khai riêng biệt, từ đó dễ dàng hơn trong việc sửa đổi một miền hoặc tiểu miền. Lưu ý rằng với kiến trúc dịch vụ phân tán, như được hiển thị trong Hình 3-5, phạm vi thay đổi của yêu cầu mới nằm ở cấp độ miền trong một dịch vụ miền cụ thể, giúp dễ dàng hơn trong việc cô lập đơn vị triển khai cụ thể cần thay đổi.
Chuyển sang tính mô-đun kiến trúc thậm chí nhiều hơn, chẳng hạn như kiến trúc microservices, như được minh họa trong Hình 3-6, đặt yêu cầu mới ở mức độ thay đổi chức năng, tách biệt sự thay đổi vào một dịch vụ cụ thể chịu trách nhiệm cho chức năng danh sách mong muốn.
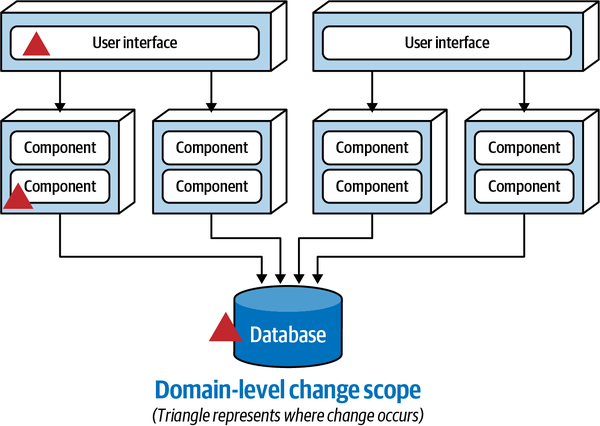
Figure 3-5. With service-based architectures, change is at a domain level
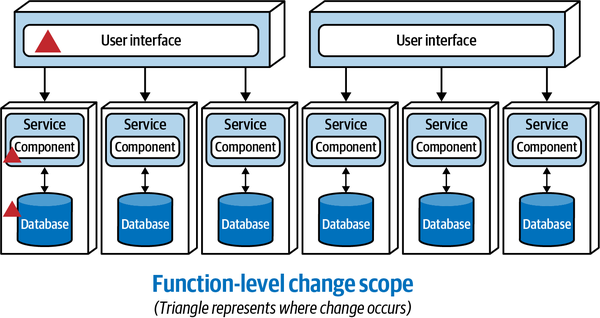
Figure 3-6. With microservices architectures, change is at a function level
Ba quá trình tiến tới tính mô-đun này cho thấy rằng khi mức độ tính mô-đun của kiến trúc tăng lên, khả năng bảo trì cũng tăng theo, khiến việc thêm, thay đổi hoặc loại bỏ chức năng trở nên dễ dàng hơn.
Testability
Khả năng kiểm tra được định nghĩa là mức độ dễ dàng trong việc kiểm tra (thường được thực hiện thông qua các bài kiểm tra tự động) cũng như độ hoàn chỉnh của việc kiểm tra. Khả năng kiểm tra là một thành phần thiết yếu cho sự linh hoạt trong kiến trúc. Các kiểu kiến trúc lớn như kiến trúc phân lớp hỗ trợ mức độ khả năng kiểm tra (và do đó là tính linh hoạt) tương đối thấp do khó khăn trong việc đạt được kiểm tra hồi quy đầy đủ và hoàn chỉnh cho tất cả các tính năng trong đơn vị triển khai lớn. Ngay cả khi một ứng dụng monolithic có một bộ kiểm tra hồi quy đầy đủ, hãy tưởng tượng sự thất vọng khi phải thực hiện hàng trăm hoặc thậm chí hàng nghìn bài kiểm tra đơn vị cho một thay đổi mã đơn giản. Không chỉ mất nhiều thời gian để thực hiện tất cả các bài kiểm tra, mà nhà phát triển tội nghiệp sẽ phải đau đầu nghiên cứu lý do tại sao hàng chục bài kiểm tra thất bại khi thực tế các bài kiểm tra thất bại đó không liên quan gì đến thay đổi.
Tính mô-đun kiến trúc—việc chia nhỏ các ứng dụng thành các đơn vị triển khai nhỏ hơn—giảm đáng kể phạm vi kiểm tra tổng thể cho các thay đổi được thực hiện đối với một dịch vụ, cho phép độ hoàn thiện của việc kiểm tra tốt hơn cũng như dễ dàng hơn trong việc kiểm tra. Không chỉ mô-đun hóa dẫn đến các bộ kiểm tra nhỏ hơn, nhắm mục tiêu hơn, mà việc duy trì các bài kiểm tra đơn vị cũng trở nên dễ dàng hơn.
Trong khi tính mô-đun kiến trúc thường cải thiện khả năng kiểm thử, nó đôi khi có thể dẫn đến những vấn đề tương tự như những vấn đề tồn tại với các ứng dụng đơn thể, triển khai đơn. Ví dụ, hãy xem xét một ứng dụng được chia thành ba đơn vị triển khai nhỏ tự chứa (dịch vụ), như được minh họa trong Hình 3-7.
Việc thay đổi Dịch vụ A chỉ giới hạn phạm vi kiểm thử cho dịch vụ đó, vì Dịch vụ B và Dịch vụ C không liên kết với Dịch vụ A. Tuy nhiên, khi sự giao tiếp giữa các dịch vụ này tăng lên, như được thể hiện ở cuối Hình 3-7, khả năng kiểm thử giảm nhanh chóng vì phạm vi kiểm thử cho một thay đổi đối với Dịch vụ A hiện bao gồm cả Dịch vụ B và Dịch vụ C, do đó ảnh hưởng đến cả sự dễ dàng trong kiểm thử và độ đầy đủ của kiểm thử.
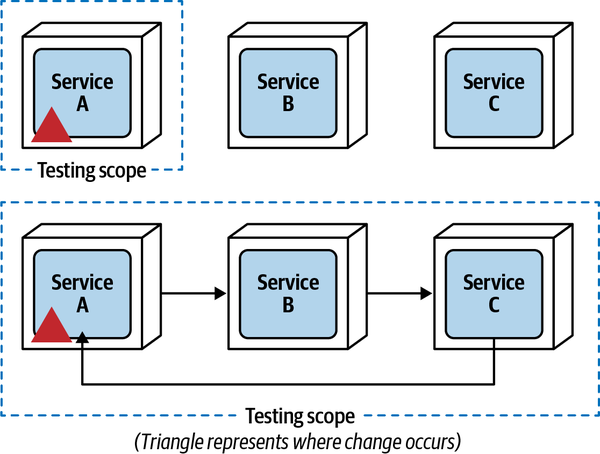
Figure 3-7. Testing scope is increased as services communicate with one another
Deployability
Khả năng triển khai không chỉ liên quan đến sự dễ dàng trong quá trình triển khai – mà còn liên quan đến tần suất triển khai và mức độ rủi ro tổng thể của việc triển khai. Để hỗ trợ sự linh hoạt và phản ứng nhanh với sự thay đổi, các ứng dụng phải hỗ trợ cả ba yếu tố này. Triển khai phần mềm mỗi hai tuần (hoặc thường xuyên hơn) không chỉ làm gia tăng rủi ro tổng thể trong việc triển khai (do việc nhóm nhiều thay đổi lại với nhau), mà trong hầu hết các trường hợp, còn làm chậm trễ không cần thiết các tính năng mới hoặc sửa lỗi đã sẵn sàng để được phát hành cho khách hàng. Tất nhiên, tần suất triển khai phải được cân bằng với khả năng của khách hàng (hoặc người dùng cuối) để có thể tiếp nhận thay đổi nhanh chóng.
Kiến trúc monolithic thường hỗ trợ mức độ triển khai thấp do lượng thủ tục cần thiết trong việc triển khai ứng dụng (chẳng hạn như đóng băng mã, triển khai giả, và những việc tương tự), rủi ro cao rằng điều gì đó khác có thể gặp trục trặc khi các tính năng mới hoặc sửa lỗi được triển khai, và thời gian dài giữa các lần triển khai (tuần đến tháng). Các ứng dụng có một mức độ modularity kiến trúc nhất định theo các đơn vị phần mềm được triển khai riêng lẻ có ít thủ tục triển khai hơn, ít rủi ro khi triển khai, và có thể được triển khai thường xuyên hơn so với một ứng dụng monolithic lớn, đơn lẻ.
Cũng giống như khả năng kiểm tra, khả năng triển khai cũng bị ảnh hưởng tiêu cực khi các dịch vụ trở nên nhỏ hơn và giao tiếp nhiều hơn với nhau để hoàn thành một giao dịch kinh doanh. Rủi ro triển khai tăng lên, và việc triển khai một thay đổi đơn giản trở nên khó khăn hơn vì sợ làm hỏng các dịch vụ khác. Để trích dẫn kiến trúc sư phần mềm Matt Stine trong bài viết của ông về việc phối hợp các microservices:
Nếu các microservices của bạn phải được triển khai như một bộ hoàn chỉnh theo thứ tự cụ thể, xin hãy đưa chúng trở lại thành một monolith và tiết kiệm cho bản thân một số đau đớn.
Kịch bản này dẫn đến cái gọi là "quả bóng lớn của sự hỗn độn phân tán," nơi rất ít (nếu không muốn nói là không có) lợi ích của tính mô-đun kiến trúc được hiện thực hóa.
Scalability
Khả năng mở rộng được định nghĩa là khả năng của một hệ thống duy trì phản hồi khi tải người dùng tăng dần theo thời gian. Liên quan đến khả năng mở rộng là tính đàn hồi, được định nghĩa là khả năng của một hệ thống duy trì phản hồi trong các đỉnh tải người dùng cao và bất ngờ. Hình 3-8 minh họa sự khác biệt giữa khả năng mở rộng và tính đàn hồi.
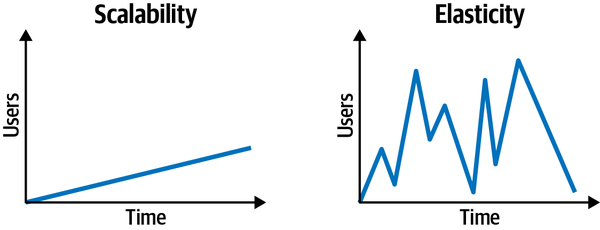
Figure 3-8. Scalability is different from elasticity
Trong khi cả hai đặc điểm kiến trúc này đều bao gồm khả năng phản hồi như một chức năng của số lượng yêu cầu đồng thời (hoặc người dùng trong hệ thống), chúng được xử lý khác nhau từ góc độ kiến trúc và triển khai. Khả năng mở rộng thường xảy ra trong một khoảng thời gian dài hơn như một chức năng của sự tăng trưởng bình thường của công ty, trong khi tính co giãn là phản ứng ngay lập tức đối với một đợt tăng tải người dùng.
Một ví dụ tuyệt vời để làm rõ sự khác biệt là hệ thống bán vé concert. Giữa các sự kiện concert lớn, thường có một tải người dùng đồng thời tương đối nhẹ. Tuy nhiên, ngay khi vé bắt đầu được bán cho một buổi hòa nhạc nổi tiếng, tải người dùng đồng thời sẽ tăng vọt một cách đáng kể. Hệ thống có thể từ 20 người dùng đồng thời tăng lên 3,000 người sử dụng chỉ trong vài giây. Để duy trì tính phản hồi, hệ thống phải có khả năng xử lý các đỉnh cao trong tải người dùng, và cũng phải có khả năng khởi động ngay lập tức các dịch vụ bổ sung để xử lý sự gia tăng lưu lượng. Tính linh hoạt phụ thuộc vào việc các dịch vụ có thời gian khởi động trung bình rất nhỏ (MTTS), điều này đạt được bằng cách kiến trúc hệ thống với các dịch vụ rất nhỏ, tinh vi. Với một giải pháp kiến trúc phù hợp, MTTS (và do đó tính linh hoạt) có thể được quản lý thêm thông qua các kỹ thuật thiết kế như các nền tảng nhẹ nhỏ gọn và môi trường thực thi.
Mặc dù cả khả năng mở rộng và tính linh hoạt đều cải thiện với các dịch vụ có độ chi tiết cao hơn, nhưng tính linh hoạt chủ yếu là chức năng của độ chi tiết (kích thước của một đơn vị triển khai), trong khi khả năng mở rộng chủ yếu là chức năng của tính mô-đun (cách tách rời các ứng dụng thành các đơn vị triển khai riêng biệt). Hãy xem xét các kiểu kiến trúc truyền thống lớp, kiến trúc dựa trên dịch vụ và kiến trúc microservices cùng với các đánh giá sao tương ứng cho khả năng mở rộng và tính linh hoạt của chúng, như được minh họa trong Hình 3-9 (các chi tiết về các kiểu kiến trúc này và các đánh giá sao tương ứng của chúng có thể được tìm thấy trong cuốn sách trước của chúng tôi, Cơ bản về Kiến trúc Phần mềm. Lưu ý rằng một sao có nghĩa là khả năng này không được hỗ trợ tốt bởi kiểu kiến trúc, trong khi năm sao có nghĩa là khả năng đó là một tính năng chính của kiểu kiến trúc và được hỗ trợ tốt.
Lưu ý rằng khả năng mở rộng và tính đàn hồi tương đối thấp với kiến trúc phân layered đơn khối. Các kiến trúc phân layered đơn khối lớn vừa khó vừa tốn kém để mở rộng vì tất cả các chức năng của ứng dụng phải mở rộng ở cùng một mức độ (khả năng mở rộng ở cấp ứng dụng và thời gian khởi động trung bình kém). Điều này có thể trở nên đặc biệt tốn kém trong các hạ tầng dựa trên đám mây. Tuy nhiên, với kiến trúc dựa trên dịch vụ, lưu ý rằng khả năng mở rộng cải thiện, nhưng không nhiều như tính đàn hồi. Điều này là do các dịch vụ miền trong kiến trúc dựa trên dịch vụ có kích thước lớn và thường chứa toàn bộ miền trong một đơn vị triển khai (chẳng hạn như xử lý đơn hàng hoặc quản lý kho), và thường có thời gian khởi động trung bình (MTTS) quá lâu để phản ứng nhanh với nhu cầu tức thì về tính đàn hồi do kích thước lớn của chúng (khả năng mở rộng ở cấp miền và MTTS hợp lý). Lưu ý rằng với vi dịch vụ, cả khả năng mở rộng và tính đàn hồi đều được tối đa hóa nhờ vào tính chất nhỏ, một mục đích, và chi tiết của mỗi dịch vụ được triển khai riêng lẻ (khả năng mở rộng ở cấp chức năng và MTTS xuất sắc).
Như khả năng kiểm tra và khả năng triển khai, càng nhiều dịch vụ giao tiếp với nhau để hoàn thành một giao dịch kinh doanh đơn lẻ, thì tác động tiêu cực đến khả năng mở rộng và tính đàn hồi càng lớn. Vì lý do này, điều quan trọng là giảm thiểu giao tiếp đồng bộ giữa các dịch vụ khi yêu cầu mức độ khả năng mở rộng và tính đàn hồi cao.
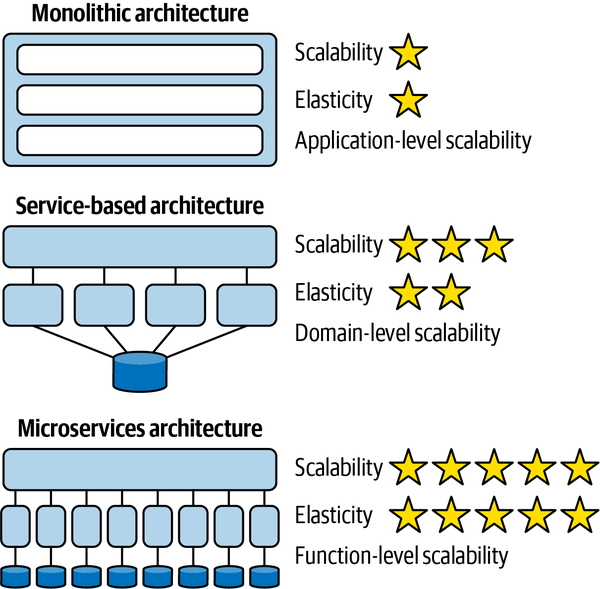
Figure 3-9. Scalability and elasticity improve with modularity
Availability/Fault Tolerance
Giống như nhiều đặc điểm kiến trúc khác, tính chịu lỗi có những định nghĩa khác nhau. Trong bối cảnh của tính mô-đun kiến trúc, chúng tôi định nghĩa tính chịu lỗi là khả năng của một số bộ phận của hệ thống vẫn giữ được khả năng phản hồi và sẵn có khi các bộ phận khác của hệ thống gặp lỗi. Ví dụ, nếu xảy ra một lỗi nghiêm trọng (như tình huống hết bộ nhớ) trong phần xử lý thanh toán của một ứng dụng bán lẻ, người dùng của hệ thống vẫn nên có khả năng tìm kiếm các mặt hàng và đặt hàng, mặc dù việc xử lý thanh toán không khả dụng.
Tất cả các hệ thống đơn khối đều gặp phải mức độ chịu lỗi thấp. Mặc dù khả năng chịu lỗi có thể được giảm bớt trong một hệ thống đơn khối bằng cách có nhiều phiên bản của toàn bộ ứng dụng được cân bằng tải, nhưng kỹ thuật này vừa tốn kém vừa không hiệu quả. Nếu lỗi xuất phát từ một lỗi lập trình, lỗi đó sẽ tồn tại trong cả hai phiên bản, do đó có khả năng làm sập cả hai phiên bản.
Tính mô-đun kiến trúc là cần thiết để đạt được khả năng chịu lỗi ở cấp độ miền và cấp độ chức năng trong một hệ thống. Bằng cách tách rời hệ thống thành nhiều đơn vị triển khai, sự cố nghiêm trọng chỉ giới hạn trong đơn vị triển khai đó, do đó cho phép phần còn lại của hệ thống hoạt động bình thường. Tuy nhiên, có một điều cần lưu ý: nếu các dịch vụ khác phụ thuộc đồng bộ vào một dịch vụ đang gặp lỗi, khả năng chịu lỗi không được đảm bảo. Đây là một trong những lý do mà giao tiếp không đồng bộ giữa các dịch vụ là rất quan trọng để duy trì một mức độ khả năng chịu lỗi tốt trong một hệ thống phân tán.
Sysops Squad Saga: Creating a Business Case
Thứ Năm, ngày 30 tháng 9, 12:01
Với sự hiểu biết tốt hơn về những gì được gọi là tính modular của kiến trúc và các yếu tố tương ứng để tách rời một hệ thống, Addison và Austen đã gặp nhau để thảo luận về các vấn đề của đội Sysops và cố gắng khớp chúng với các yếu tố modularity nhằm xây dựng một lý do kinh doanh vững chắc để trình bày với các nhà tài trợ kinh doanh.
“Chúng ta hãy xem xét từng vấn đề mà chúng ta đang đối mặt và xem liệu chúng ta có thể ghép chúng với một số yếu tố thúc đẩy tính mô-đun hay không,” Addison nói. “Bằng cách đó, chúng ta có thể chứng minh cho doanh nghiệp thấy rằng việc tách rời ứng dụng thực sự sẽ giải quyết các vấn đề mà chúng ta đang gặp phải.”
“Ý kiến hay,” Austen nói. “Hãy bắt đầu với vấn đề đầu tiên mà họ đã bàn luận trong cuộc họp—thay đổi. Chúng ta dường như không thể áp dụng thay đổi một cách hiệu quả cho hệ thống đơn khối hiện tại mà không có cái gì đó bị hỏng. Hơn nữa, việc thay đổi mất quá nhiều thời gian, và việc kiểm tra các thay đổi thực sự là một cơn ác mộng.”
“Và các nhà phát triển đang liên tục phàn nàn rằng mã nguồn quá lớn, và rất khó để tìm đúng chỗ để áp dụng thay đổi cho các tính năng mới hoặc sửa lỗi,” Addison nói.
“Được rồi,” Austen nói, “rõ ràng, khả năng bảo trì tổng thể là một vấn đề quan trọng ở đây.”
“Đúng vậy,” Addison nói. “Vì vậy, bằng cách tách rời ứng dụng, nó không chỉ làm giảm sự kết nối của mã, mà còn cách ly và phân chia chức năng thành các dịch vụ được triển khai riêng biệt, giúp các nhà phát triển dễ dàng áp dụng thay đổi hơn.”
“Khả năng kiểm tra là một đặc điểm quan trọng khác liên quan đến vấn đề này, nhưng chúng tôi đã giải quyết điều đó vì tất cả các bài kiểm tra đơn vị tự động của chúng tôi,” Austen nói.
"Thực ra, không phải vậy," Addison trả lời. "Hãy xem cái này."
Addison đã chỉ cho Austen thấy rằng hơn 30% các trường hợp kiểm tra đã bị chú thích hoặc trở nên lỗi thời, và có những trường hợp kiểm tra bị thiếu cho một số phần quan trọng của quy trình làm việc trong hệ thống. Addison cũng giải thích rằng các nhà phát triển liên tục phàn nàn rằng toàn bộ bộ kiểm tra đơn vị phải được chạy cho bất kỳ thay đổi nào (lớn hay nhỏ), điều này không chỉ mất nhiều thời gian, mà các nhà phát triển còn phải đối mặt với việc sửa chữa các vấn đề không liên quan đến thay đổi của họ. Đây là một trong những lý do khiến việc áp dụng ngay cả những thay đổi đơn giản nhất mất nhiều thời gian.
"Khả năng kiểm thử liên quan đến độ dễ dàng trong việc kiểm thử, nhưng cũng liên quan đến sự đầy đủ của việc kiểm thử," Addison nói. "Chúng ta không có cả hai điều đó. Bằng cách tách ứng dụng ra, chúng ta có thể giảm đáng kể phạm vi kiểm thử cho những thay đổi được thực hiện đối với ứng dụng, nhóm các bài kiểm thử tự động liên quan lại với nhau và đạt được sự đầy đủ hơn trong việc kiểm thử - do đó ít lỗi hơn."
“Điều tương tự cũng đúng với khả năng triển khai,” Addison tiếp tục. “Bởi vì chúng tôi có một ứng dụng đơn khối, chúng tôi phải triển khai toàn bộ hệ thống, ngay cả khi chỉ là một sửa lỗi nhỏ. Bởi vì rủi ro triển khai của chúng tôi rất cao, Parker khăng khăng yêu cầu thực hiện các bản phát hành sản xuất hàng tháng. Điều mà Parker không hiểu là bằng cách đó, chúng tôi tích tụ nhiều thay đổi vào mỗi bản phát hành, một số trong số đó thậm chí còn chưa được kiểm tra cùng nhau.”
“Đúng vậy,” Austen nói, “và ngoài ra, những lần giả lập triển khai và việc đóng mã mà chúng tôi thực hiện cho mỗi bản phát hành tốn thời gian quý báu—thời gian mà chúng tôi không có. Tuy nhiên, điều chúng ta đang nói ở đây không phải là vấn đề kiến trúc, mà hoàn toàn là vấn đề đường ống triển khai.”
“Tôi không đồng ý,” Addison nói. “Chắc chắn nó cũng liên quan đến kiến trúc. Hãy suy nghĩ một chút, Austen. Nếu chúng ta tách hệ thống thành các dịch vụ được triển khai riêng biệt, thì một thay đổi cho bất kỳ dịch vụ nào sẽ chỉ ảnh hưởng đến dịch vụ đó mà thôi. Ví dụ, giả sử chúng ta thực hiện một thay đổi khác trong quy trình phân công vé. Nếu quy trình đó là một dịch vụ riêng biệt, không chỉ phạm vi kiểm tra sẽ được giảm thiểu, mà chúng ta còn giảm thiểu nguy cơ khi triển khai một cách đáng kể. Điều đó có nghĩa là chúng ta có thể triển khai thường xuyên hơn với ít nghi thức hơn, cũng như giảm thiểu số lượng lỗi.”
“Tôi hiểu ý bạn,” Austen nói, “và trong khi tôi đồng ý với bạn, tôi vẫn khẳng định rằng ở một thời điểm nào đó chúng ta sẽ phải điều chỉnh quy trình triển khai hiện tại của mình.”
Thỏa mãn rằng việc tách rời ứng dụng Sysops Squad và chuyển sang kiến trúc phân tán sẽ giải quyết các vấn đề thay đổi, Addison và Austen đã chuyển sang các mối quan tâm khác của nhà tài trợ doanh nghiệp.
"Được rồi," Addison nói, "vấn đề lớn khác mà các nhà tài trợ doanh nghiệp phàn nàn trong cuộc họp là sự hài lòng tổng thể của khách hàng. Đôi khi hệ thống không khả dụng, hệ thống dường như bị sập vào những thời điểm nhất định trong ngày, và chúng ta đã gặp quá nhiều vấn đề về mất vé và định tuyến vé. Thật không ngạc nhiên khi khách hàng bắt đầu hủy bỏ kế hoạch hỗ trợ của họ."
“Chờ một chút,” Austen nói. “Tôi có một số số liệu mới nhất ở đây cho thấy không phải tính năng bán vé cốt lõi đang khiến hệ thống bị sập, mà là tính năng khảo sát khách hàng và báo cáo.”
“Đây là một tin tuyệt vời,” Addison nói. “Vì vậy, bằng cách tách chức năng của hệ thống thành các dịch vụ riêng biệt, chúng ta có thể cô lập những lỗi đó, giữ cho chức năng quản lý vé chính vẫn hoạt động. Đó là một lý do hợp lý tự nó!”
“Chính xác,” Austen nói. “Vậy là chúng ta đồng ý rằng khả năng sẵn sàng tổng thể thông qua việc chịu lỗi sẽ giải quyết vấn đề ứng dụng không phải lúc nào cũng sẵn sàng cho khách hàng, vì họ chỉ tương tác với phần hệ thống đặt vé.”
“Nhưng còn việc hệ thống bị đông lại thì sao?” Addison hỏi. “Chúng ta giải thích phần đó như thế nào khi chia nhỏ ứng dụng?”
“Thật trùng hợp, tôi đã nhờ Sydney từ đội phát triển Sysops Squad thực hiện một số phân tích cho tôi về chính vấn đề đó,” Austen nói. “Hóa ra đây là sự kết hợp của hai yếu tố. Đầu tiên, mỗi khi chúng tôi có hơn 25 khách hàng tạo vé cùng một lúc, hệ thống bị treo. Nhưng, hãy kiểm tra điều này—mỗi khi họ chạy các báo cáo hoạt động trong suốt cả ngày khi khách hàng đang gửi vé vấn đề, hệ thống cũng bị treo.”
"Vậy," Addison nói, "có vẻ như chúng ta đang gặp cả vấn đề về khả năng mở rộng và tải cơ sở dữ liệu ở đây."
“Chính xác!” Austen nói. “Và hãy nghe này—bằng cách tách rời ứng dụng và cơ sở dữ liệu đơn khối, chúng ta có thể phân tách báo cáo thành một hệ thống riêng và cũng cung cấp khả năng mở rộng thêm cho chức năng quản lý vé hướng tới khách hàng.”
Hài lòng vì họ có một trường hợp kinh doanh tốt để trình bày trước các nhà tài trợ doanh nghiệp và tự tin rằng đây là cách tiếp cận đúng đắn để cứu vãn dòng kinh doanh này, Addison đã tạo ra một Hồ sơ Quyết định Kiến trúc (ADR) cho quyết định tách biệt hệ thống và tạo một bài thuyết trình trường hợp kinh doanh tương ứng cho các nhà tài trợ doanh nghiệp.
ADR: Di chuyển Ứng dụng Đội Sysops sang Kiến trúc Phân tán
Bối cảnh Đội Sysops hiện tại là một ứng dụng xử lý vé vấn đề monolithic hỗ trợ nhiều chức năng kinh doanh khác nhau liên quan đến vé vấn đề, bao gồm đăng ký khách hàng, nhập và xử lý vé vấn đề, báo cáo hoạt động và phân tích, xử lý thanh toán và lập hóa đơn, cùng với các chức năng bảo trì hành chính khác nhau. Ứng dụng hiện tại có nhiều vấn đề liên quan đến khả năng mở rộng, khả năng sẵn sàng và khả năng duy trì.
Quyết định Chúng tôi sẽ chuyển đổi ứng dụng Sysops Squad hiện tại từ kiến trúc đơn giản sang kiến trúc phân tán. Việc chuyển sang kiến trúc phân tán sẽ đạt được những điều sau:
Làm cho chức năng ticketing chính trở nên sẵn sàng hơn cho khách hàng bên ngoài, từ đó cung cấp khả năng chịu lỗi tốt hơn.
Cung cấp khả năng mở rộng tốt hơn cho sự phát triển của khách hàng và việc tạo vé, giải quyết các vấn đề thường xuyên bị treo ứng dụng mà chúng tôi đang gặp phải.
Tách chức năng báo cáo và tải báo cáo trên cơ sở dữ liệu, giải quyết vấn đề ứng dụng thường xuyên bị treo mà chúng tôi đã gặp phải.
Cho phép các nhóm triển khai các tính năng mới và sửa lỗi nhanh hơn nhiều so với ứng dụng đơn thể hiện tại, từ đó cung cấp sự linh hoạt tổng thể tốt hơn.
Giảm số lượng lỗi được đưa vào hệ thống khi có sự thay đổi, do đó cung cấp khả năng kiểm thử tốt hơn.
Cho phép chúng tôi triển khai các tính năng mới và sửa lỗi với tốc độ nhanh hơn nhiều (hàng tuần hoặc thậm chí hàng ngày), từ đó cung cấp khả năng triển khai tốt hơn.
Hệ quả Nỗ lực di cư sẽ gây ra sự chậm trễ cho các tính năng mới được giới thiệu vì hầu hết các nhà phát triển sẽ cần thiết cho việc di cư kiến trúc.
Nỗ lực di cư sẽ phát sinh chi phí bổ sung (ước tính chi phí sẽ được xác định sau).
Cho đến khi quy trình triển khai hiện tại được sửa đổi, các kỹ sư phát hành sẽ phải quản lý việc phát hành và giám sát nhiều đơn vị triển khai khác nhau.
Nỗ lực di cư sẽ yêu cầu chúng ta tách rời cơ sở dữ liệu đơn thể.
Addison và Austen đã gặp gỡ các nhà tài trợ kinh doanh cho hệ thống ghi vé sự cố của Đội Sysops và trình bày trường hợp của họ một cách rõ ràng và ngắn gọn. Các nhà tài trợ kinh doanh đã hài lòng với bài thuyết trình và đồng ý với cách tiếp cận, thông báo cho Addison và Austen tiếp tục với việc di chuyển.
Chapter 4. Architectural Decomposition
Thứ Hai, ngày 4 tháng 10, 10:04
Bây giờ mà Addison và Austen đã có sự chấp thuận để chuyển sang kiến trúc phân tán và tách rời ứng dụng Sysops Squad monolithic, họ cần xác định cách tiếp cận tốt nhất để bắt đầu.
"Ứng dụng này lớn đến nỗi tôi thậm chí không biết bắt đầu từ đâu. Nó lớn như một con voi!" Addison kêu lên.
"Ồ," Austen nói. "Bạn ăn một con voi như thế nào?"
“Ha, tôi đã nghe câu chuyện cười đó trước đây, Austen. Từng miếng một, tất nhiên rồi!” Addison cười.
"Chính xác. Vậy hãy áp dụng nguyên tắc tương tự với ứng dụng Sysops Squad," Austen nói. "Tại sao chúng ta không bắt đầu tách nó ra, từng phần một? Nhớ rằng tôi đã nói báo cáo là một trong những nguyên nhân khiến ứng dụng bị treo? Có lẽ chúng ta nên bắt đầu từ đó."
“Điều đó có thể là một khởi đầu tốt,” Addison nói, “nhưng còn dữ liệu thì sao? Chỉ việc tách báo cáo thành một dịch vụ riêng không giải quyết được vấn đề. Chúng ta cũng cần chia tách dữ liệu, hoặc thậm chí tạo một cơ sở dữ liệu báo cáo riêng với các bơm dữ liệu để cung cấp cho nó. Tôi nghĩ đó là một miếng quá lớn để bắt đầu.”
“Bạn nói đúng,” Austen nói. “Này, còn chức năng cơ sở tri thức thì sao? Nó tương đối độc lập và có thể dễ dàng tách ra hơn.”
“Điều đó đúng. Vậy còn chức năng khảo sát thì sao? Chắc hẳn là cũng dễ tách ra,” Addison nói. “Vấn đề là, tôi không thể không cảm thấy rằng chúng ta nên tiếp cận vấn đề này một cách có hệ thống hơn là chỉ ăn từng miếng một.”
"Có thể Logan có thể cho chúng ta một số lời khuyên," Austen nói.
Addison và Austen đã gặp Logan để thảo luận về một số cách tiếp cận mà họ đang xem xét để tách rời ứng dụng. Họ đã giải thích với Logan rằng họ muốn bắt đầu với cơ sở tri thức và chức năng khảo sát nhưng không chắc chắn phải làm gì tiếp theo.
"Cách tiếp cận mà bạn đang đề xuất," Logan nói, "được gọi là Mô hình chống Di chuyển Voi. Việc ăn voi từng miếng một có vẻ là một cách tiếp cận tốt lúc ban đầu, nhưng trong hầu hết các trường hợp, nó dẫn đến một cách tiếp cận không có cấu trúc và tạo ra một đống hỗn độn phân tán, mà một số người cũng gọi là một khối phân tán. Tôi không khuyến nghị cách tiếp cận đó."
“Vậy, còn những cách tiếp cận nào khác tồn tại? Có những mô hình nào chúng ta có thể sử dụng để phân tách ứng dụng?” Addison hỏi.
"Bạn cần xem xét toàn diện ứng dụng và áp dụng hoặc phân nhánh chiến thuật hoặc phân tách theo thành phần," Logan nói. "Đó là hai cách tiếp cận hiệu quả nhất mà tôi biết."
Addison và Austen nhìn Logan. "Nhưng làm thế nào chúng ta biết nên sử dụng cái nào?"
Trong khi tính mô-đun kiến trúc mô tả lý do cho việc tách rời một ứng dụng khối đơn, việc phân rã kiến trúc mô tả cách thực hiện. Việc tách rời các ứng dụng khối đơn lớn và phức tạp có thể là một nhiệm vụ phức tạp và tốn thời gian, và quan trọng là phải biết liệu có khả thi để bắt đầu một nỗ lực như vậy hay không và cách tiếp cận như thế nào.
Phân tách dựa trên thành phần và phân nhánh chiến thuật là hai phương pháp phổ biến để tách rời các ứng dụng nguyên khối. Phân tách dựa trên thành phần là một phương pháp khai thác, áp dụng các mẫu tái cấu trúc khác nhau để tinh chỉnh và khai thác các thành phần (những khối xây dựng logic của một ứng dụng) nhằm hình thành kiến trúc phân tán theo cách tăng dần và có kiểm soát. Phương pháp phân nhánh chiến thuật liên quan đến việc tạo ra các bản sao của một ứng dụng và loại bỏ các phần không mong muốn để hình thành các dịch vụ, tương tự như cách một nghệ sĩ điêu khắc tạo nên một tác phẩm nghệ thuật đẹp từ một khối granit hoặc đá cẩm thạch.
Phương pháp nào là hiệu quả nhất? Câu trả lời cho câu hỏi này là, tất nhiên, điều đó phụ thuộc. Một trong những yếu tố chính trong việc chọn lựa phương pháp phân tách là cách mà mã ứng dụng đơn thể hiện có được cấu trúc tốt. Có tồn tại các thành phần và ranh giới thành phần rõ ràng trong mã nguồn hay mã nguồn chủ yếu là một đống lộn xộn không có cấu trúc?
Như biểu đồ trong Hình 4-1 minh họa, bước đầu tiên trong nỗ lực phân rã kiến trúc là xác định liệu mã nguồn có thể được phân rã hay không. Chúng tôi sẽ đề cập đến chủ đề này một cách chi tiết trong phần tiếp theo. Nếu mã nguồn có thể phân rã, bước tiếp theo là xác định xem mã nguồn có phần lớn là một mớ hỗn độn không có các thành phần rõ ràng hay không. Nếu đúng như vậy, thì việc phân nhánh chiến thuật (xem “Phân Nhánh Chiến Thuật”) có thể là cách tiếp cận phù hợp. Tuy nhiên, nếu các tệp mã nguồn được cấu trúc theo cách kết hợp chức năng tương tự trong các thành phần được định nghĩa rõ ràng (hoặc thậm chí là định nghĩa lỏng lẻo), thì phương pháp phân rã dựa trên thành phần (xem “Phân Rã Dựa Trên Thành Phần”) là con đường nên theo.
Figure 4-1. The decision tree for selecting a decomposition approach
Chúng tôi mô tả cả hai phương pháp này trong chương này, và sau đó dành một chương hoàn toàn (Chương 5) để mô tả chi tiết từng mẫu phân rã dựa trên thành phần.
Is the Codebase Decomposable?
Điều gì xảy ra khi một mã nguồn thiếu cấu trúc bên trong? Liệu nó có thể được phân tách không? Phần mềm như vậy có một cái tên thông dụng - Mô hình Chống-Mái Nhà Lớn, được Brian Foote đặt ra trong bài tiểu luận cùng tên vào năm 1999. Ví dụ, một ứng dụng web phức tạp với các trình xử lý sự kiện được kết nối trực tiếp với các lệnh gọi cơ sở dữ liệu và không có sự mô-đun hóa có thể được coi là kiến trúc Mái Nhà Lớn. Nói chung, các kiến trúc sư không dành nhiều thời gian để tạo ra các mẫu cho những loại hệ thống này; kiến trúc phần mềm liên quan đến cấu trúc bên trong, và những hệ thống này thiếu đặc điểm định nghĩa đó.
Rất tiếc, nếu không có quản lý cẩn thận, nhiều hệ thống phần mềm sẽ trở thành những khối hỗn độn, để lại cho những kiến trúc sư sau này (hoặc có thể là một phiên bản không được yêu thích của chính họ) phải sửa chữa. Bước đầu tiên trong bất kỳ bài tập tái cấu trúc kiến trúc nào yêu cầu một kiến trúc sư xác định kế hoạch cho việc tái cấu trúc, điều này đồng thời yêu cầu kiến trúc sư phải hiểu cấu trúc bên trong. Câu hỏi then chốt mà kiến trúc sư phải trả lời là liệu mã nguồn này có thể cứu vãn được không? Nói cách khác, nó có phải là ứng cử viên cho các mẫu phân rã hay không, hoặc một phương pháp khác có phù hợp hơn không?
Không có một tiêu chí nào có thể xác định liệu một mã nguồn có cấu trúc nội bộ hợp lý hay không—việc đánh giá đó thuộc về một hoặc nhiều kiến trúc sư. Tuy nhiên, các kiến trúc sư có công cụ để giúp xác định các đặc điểm vĩ mô của mã nguồn, đặc biệt là các chỉ số coupling, nhằm đánh giá cấu trúc nội bộ.
Afferent and Efferent Coupling
Vào năm 1979, Edward Yourdon và Larry Constantine đã xuất bản cuốn sách Thiết kế có cấu trúc: Những nguyên tắc cơ bản của một ngành thiết kế chương trình và hệ thống máy tính (Yourdon), định nghĩa nhiều khái niệm cốt lõi, bao gồm các chỉ số coupling vào (afferent) và coupling ra (efferent). Coupling vào đo lường số lượng kết nối đến một đối tượng mã (thành phần, lớp, hàm, v.v.). Coupling ra đo lường các kết nối ra ngoài đến các đối tượng mã khác.
Lưu ý giá trị của chỉ hai biện pháp này khi thay đổi cấu trúc của một hệ thống. Ví dụ, khi phân tách một kiến trúc monolith thành một kiến trúc phân tán, kiến trúc sư sẽ tìm thấy các lớp chia sẻ như Địa chỉ. Khi xây dựng một monolith, việc tái sử dụng các khái niệm cốt lõi như Địa chỉ là điều phổ biến và được khuyến khích cho các nhà phát triển, nhưng khi tách rời monolith, giờ đây kiến trúc sư phải xác định có bao nhiêu phần khác của hệ thống sử dụng tài sản chia sẻ này.
Hầu như mọi nền tảng đều có các công cụ cho phép các kiến trúc sư phân tích các đặc điểm liên kết của mã để hỗ trợ trong việc tái cấu trúc, di chuyển hoặc hiểu biết về một mã nguồn. Nhiều công cụ tồn tại cho các nền tảng khác nhau cung cấp cái nhìn ma trận về các mối quan hệ giữa các lớp và/hoặc thành phần, như được minh họa trong Hình 4-2.
Trong ví dụ này, plug-in Eclipse cung cấp một hình ảnh trực quan của đầu ra của JDepend, bao gồm phân tích sự kết nối theo gói, cùng với một số chỉ số tổng hợp được làm nổi bật trong phần tiếp theo.
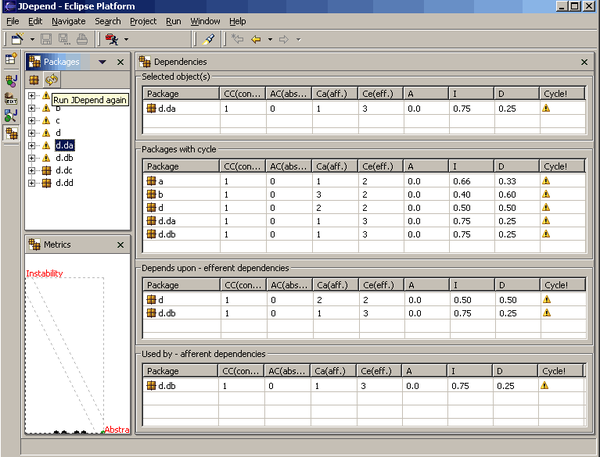
Figure 4-2. JDepend in Eclipse analysis view of coupling relationships
Abstractness and Instability
Robert Martin, một nhân vật nổi tiếng trong lĩnh vực kiến trúc phần mềm, đã tạo ra một số chỉ số dẫn xuất cho một cuốn sách C++ vào cuối những năm 1990, có thể áp dụng cho bất kỳ ngôn ngữ lập trình hướng đối tượng nào. Các chỉ số này—độ trừu tượng và độ không ổn định—đo lường sự cân bằng của các đặc điểm nội tại của một mã nguồn.
Độ trừu tượng là tỷ lệ giữa các đối tượng trừu tượng (các lớp trừu tượng, giao diện, v.v.) và các đối tượng cụ thể (các lớp triển khai). Nó đại diện cho một thước đo giữa trừu tượng và triển khai. Các yếu tố trừu tượng là các tính năng của một cơ sở mã cho phép các lập trình viên hiểu chức năng tổng thể tốt hơn. Ví dụ, một cơ sở mã chỉ bao gồm một phương thức main() và 10.000 dòng mã sẽ có điểm gần bằng không trong chỉ số này và sẽ khá khó hiểu.
Công thức cho tính trừu tượng xuất hiện trong Phương trình 4-1.
Equation 4-1. Abstractness
Trong phương trình, m a đại diện cho các yếu tố trừu tượng (giao diện hoặc lớp trừu tượng) trong mã nguồn, và m c đại diện cho các yếu tố cụ thể. Các kiến trúc sư tính toán độ trừu tượng bằng cách tính tỷ lệ giữa tổng của các đối tượng trừu tượng và tổng của các đối tượng cụ thể.
Một chỉ số suy diễn khác, độ không ổn định, là tỷ lệ giữa sự liên kết ra (efferent coupling) và tổng của cả sự liên kết ra và sự liên kết vào (afferent coupling), được trình bày trong Phương trình 4-2.
Equation 4-2. Instability
Trong phương trình, C e đại diện cho sự kết nối hướng ra (hoặc hướng đi ra), và C a đại diện cho sự kết nối hướng vào (hoặc hướng đi vào).
Chỉ số không ổn định xác định sự biến động của một mã nguồn. Một mã nguồn thể hiện mức độ không ổn định cao sẽ dễ bị hỏng hơn khi có sự thay đổi do sự liên kết chặt chẽ. Xem xét hai kịch bản, mỗi kịch bản có C a = 2. Đối với kịch bản đầu tiên, C e = 0, cho ra chỉ số không ổn định bằng không. Trong kịch bản khác, C e = 3, cho ra chỉ số không ổn định là 3/5. Do đó, chỉ số không ổn định cho một thành phần phản ánh số lượng thay đổi tiềm năng có thể xảy ra khi có sự thay đổi ở các thành phần liên quan. Một thành phần có giá trị không ổn định gần bằng một là rất không ổn định, còn giá trị gần bằng không có thể ổn định hoặc cứng nhắc: nó ổn định nếu mô-đun hoặc thành phần chứa chủ yếu các yếu tố trừu tượng, và cứng nhắc nếu nó chủ yếu bao gồm các yếu tố cụ thể. Tuy nhiên, sự đánh đổi cho độ ổn định cao là thiếu khả năng tái sử dụng—nếu mỗi thành phần đều độc lập, thì sự trùng lặp là điều có khả năng xảy ra.
Một thành phần có giá trị I gần với 1, chúng ta có thể đồng ý, là rất không ổn định. Tuy nhiên, một thành phần có giá trị I gần với 0 có thể là ổn định hoặc cứng. Tuy nhiên, nếu nó chủ yếu chứa các yếu tố bê tông, thì nó là cứng.
Do đó, nói chung, điều quan trọng là xem xét giá trị của I và A cùng nhau thay vì tách rời. Vì vậy, lý do để xem xét chuỗi chính được trình bày trên trang tiếp theo.
Distance from the Main Sequence
Một trong số ít các chỉ số toàn diện mà các kiến trúc sư có cho cấu trúc kiến trúc là khoảng cách từ chuỗi chính, một chỉ số được suy ra dựa trên sự không ổn định và tính trừu tượng, được trình bày trong Phương trình 4-3.
Equation 4-3. Distance from the main sequence
Trong phương trình, A = trừu tượng và I = bất ổn.
Métric khoảng cách từ chuỗi chính tưởng tượng mối quan hệ lý tưởng giữa tính trừu tượng và sự không ổn định; các thành phần nằm gần đường lý tưởng này thể hiện sự kết hợp lành mạnh của hai mối quan tâm đối lập này. Ví dụ, việc vẽ đồ thị một thành phần cụ thể cho phép các nhà phát triển tính toán métric khoảng cách từ chuỗi chính, được minh họa trong Hình 4-3.
Figure 4-3. Normalized distance from the main sequence for a particular component
Các nhà phát triển vẽ đồ thị thành phần ứng viên, sau đó đo khoảng cách từ đường lý tưởng. Càng gần đến đường, thành phần càng được cân bằng tốt. Những thành phần rơi quá xa vào góc trên bên phải sẽ rơi vào cái mà các kiến trúc sư gọi là vùng vô dụng: mã quá trừu tượng trở nên khó sử dụng. Ngược lại, mã rơi vào góc dưới bên trái sẽ rơi vào vùng đau đớn: mã có quá nhiều triển khai và không đủ trừu tượng trở nên giòn và khó bảo trì, như được minh họa trong Hình 4-4.
Các công cụ tồn tại trên nhiều nền tảng để cung cấp các biện pháp này, giúp các kiến trúc sư khi phân tích mã nguồn do sự không quen thuộc, di chuyển hoặc đánh giá nợ kỹ thuật.
Metric "distance-from-the-main-sequence" cho các kiến trúc sư đang tìm cách cấu trúc lại ứng dụng có ý nghĩa gì? Giống như trong các dự án xây dựng, việc di chuyển một cấu trúc lớn có nền tảng kém sẽ mang lại những rủi ro. Tương tự, nếu một kiến trúc sư mơ ước cấu trúc lại một ứng dụng, việc cải thiện cấu trúc bên trong sẽ giúp dễ dàng hơn trong việc di chuyển thực thể đó.
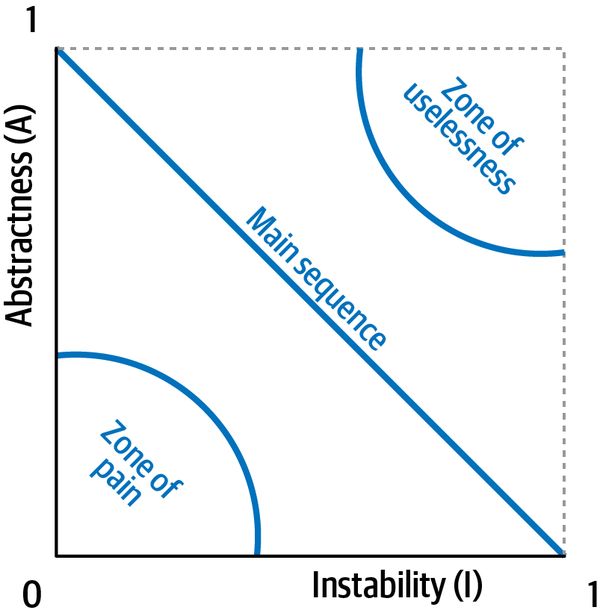
Figure 4-4. Zones of uselessness and pain
Chỉ số này cũng cung cấp một manh mối tốt về sự cân bằng của cấu trúc nội bộ. Nếu một kiến trúc sư đánh giá một mã nguồn mà nhiều thành phần rơi vào các khu vực vô dụng hoặc đau đớn, có lẽ không đáng để dành thời gian cố gắng cải thiện cấu trúc nội bộ đến mức có thể được sửa chữa.
Theo sơ đồ luồng trong Hình 4-1, một khi kiến trúc sư quyết định rằng mã nguồn có thể được phân tách, bước tiếp theo là xác định cách tiếp cận để phân tách ứng dụng. Các phần sau đây mô tả hai cách tiếp cận để phân tách một ứng dụng: phân tách dựa trên thành phần và phân tách chiến thuật.
Component-Based Decomposition
Kinh nghiệm của chúng tôi cho thấy hầu hết những khó khăn và phức tạp liên quan đến việc di chuyển các ứng dụng nguyên khối sang kiến trúc phân tán cao như microservices đến từ các thành phần kiến trúc được định nghĩa kém. Ở đây, chúng tôi định nghĩa một thành phần là một khối xây dựng của ứng dụng có vai trò và trách nhiệm rõ ràng trong hệ thống và một tập hợp các thao tác được xác định rõ. Các thành phần trong hầu hết các ứng dụng được biểu hiện thông qua không gian tên hoặc cấu trúc thư mục và được thực hiện thông qua các tệp thành phần (hoặc tệp nguồn). Ví dụ, trong Hình 4-5, cấu trúc thư mục penultimate/ss/ticket/assign sẽ đại diện cho một thành phần gọi là Ticket Assign với không gian tên penultimate.ss.ticket.assign.
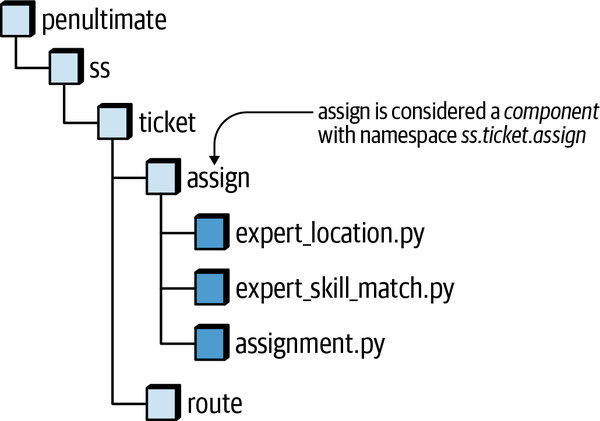
Figure 4-5. The directory structure of a codebase becomes the namespace of the component
Tip
Khi tách các ứng dụng đơn khối thành các kiến trúc phân tán, hãy xây dựng dịch vụ từ các thành phần, không phải từ các lớp riêng lẻ.
Trong nhiều năm tập thể di chuyển ứng dụng monolithic sang kiến trúc phân tán (chẳng hạn như microservices), chúng tôi đã phát triển một bộ các mẫu phân decompositer dựa trên thành phần được mô tả trong Chương 5, giúp chuẩn bị một ứng dụng monolithic cho việc di chuyển. Các mẫu này liên quan đến việc tái cấu trúc mã nguồn để đạt được một tập hợp các thành phần được xác định rõ ràng có thể cuối cùng trở thành các dịch vụ, giảm bớt nỗ lực cần thiết để di chuyển ứng dụng sang kiến trúc phân tán.
Các mẫu phân rã dựa trên thành phần này về cơ bản cho phép việc di chuyển từ kiến trúc monolithic sang kiến trúc dựa trên dịch vụ, điều này được định nghĩa trong Chương 2 và mô tả chi tiết hơn trong Cơ bản về Kiến trúc Phần mềm. Kiến trúc dựa trên dịch vụ là một dạng lai của phong cách kiến trúc microservices, nơi một ứng dụng được chia thành các dịch vụ miền, là các dịch vụ thô và được triển khai riêng lẻ, chứa tất cả logic kinh doanh cho một miền cụ thể.
Chuyển sang kiến trúc dựa trên dịch vụ là phù hợp như một mục tiêu cuối cùng hoặc như một bước tiến đến hệ thống vi dịch vụ.
-
Là một bước đệm, điều này cho phép một kiến trúc sư xác định những lĩnh vực nào cần có mức độ chi tiết cao hơn về microservices và những lĩnh vực nào có thể giữ nguyên dưới dạng dịch vụ miền thô (quyết định này được thảo luận chi tiết trong Chương 7).
-
Kiến trúc dựa trên dịch vụ không yêu cầu phải tách biệt cơ sở dữ liệu, do đó cho phép các kiến trúc sư tập trung vào phân chia miền và chức năng trước khi giải quyết việc phân tách cơ sở dữ liệu (được thảo luận chi tiết trong Chương 6).
-
Kiến trúc dựa trên dịch vụ không yêu cầu tự động hóa vận hành hay đóng gói trong container. Mỗi dịch vụ miền có thể được triển khai bằng cùng một artefact triển khai như ứng dụng gốc (chẳng hạn như tệp EAR, tệp WAR, Assembly, và vân vân).
-
Việc chuyển sang kiến trúc dựa trên dịch vụ là một vấn đề kỹ thuật, có nghĩa là nó thường không liên quan đến các bên liên quan trong kinh doanh và không yêu cầu bất kỳ thay đổi nào đối với cấu trúc tổ chức của bộ phận CNTT cũng như các môi trường thử nghiệm và triển khai.
Tip
Khi di chuyển các ứng dụng monolithic sang microservices, hãy cân nhắc chuyển đổi sang kiến trúc dựa trên dịch vụ trước tiên như một bước đệm đến microservices.
Nhưng nếu mã nguồn là một đống hỗn độn không có cấu trúc và không chứa nhiều thành phần có thể quan sát được? Đó là lúc việc phân nhánh chiến thuật phát huy tác dụng.
Tactical Forking
Mô hình phân nhánh chiến thuật được Fausto De La Torre đặt tên là một cách tiếp cận thực dụng để tái cấu trúc các kiến trúc mà về cơ bản là những đống bùn lớn.
Thông thường, khi các kiến trúc sư nghĩ về việc tái cấu trúc một mã nguồn, họ nghĩ đến việc tách các phần ra, như được minh họa trong Hình 4-6.
Figure 4-6. Extracting a part of a system
Tuy nhiên, một cách khác để suy nghĩ về việc cách ly một phần của hệ thống là xóa bỏ những phần không còn cần thiết, như được minh họa trong Hình 4-7.
Figure 4-7. Deleting what’s not wanted is another way to isolate parts of a system
Trong Hình 4-6, các nhà phát triển phải liên tục đối mặt với những mạch liên kết phức tạp xác định kiến trúc này; khi họ trích xuất các phần, họ phát hiện ra rằng ngày càng nhiều phần của mã nguồn lớn (monolith) phải được mang theo do các phụ thuộc. Trong Hình 4-7, các nhà phát triển xóa bỏ những đoạn mã không cần thiết, nhưng các phụ thuộc vẫn còn, tránh được hiệu ứng giải tỏa liên tục do việc trích xuất.
Sự khác biệt giữa việc trích xuất và xóa ảnh hưởng đến mẫu phân nhánh chiến thuật. Đối với phương pháp phân tách này, hệ thống bắt đầu như một ứng dụng đơn khối, như được mô tả trong Hình 4-8.
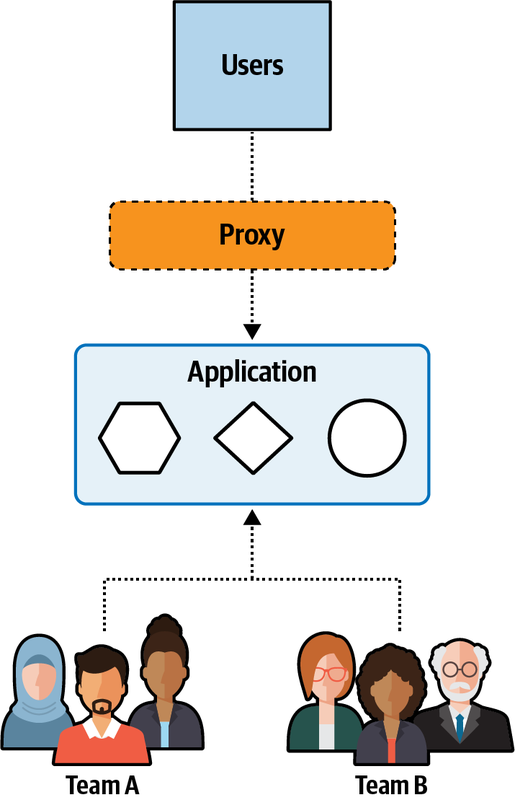
Figure 4-8. Before restructuring, a monolith includes several parts
Hệ thống này bao gồm một số hành vi miền (được xác định trong hình dưới dạng các hình học đơn giản) mà không có tổ chức nội bộ nhiều. Thêm vào đó, trong kịch bản này, mục tiêu mong muốn bao gồm hai đội để tạo ra hai dịch vụ, một với miền hình lục giác và hình vuông, và một với miền hình tròn, từ monolith hiện có.
Bước đầu tiên trong việc phân nhánh chiến thuật là sao chép toàn bộ công trình, và cung cấp cho mỗi nhóm một bản sao của toàn bộ mã nguồn, như được minh họa trong Hình 4-9.
Figure 4-9. Step one clones the monolith
Mỗi đội nhận một bản sao của toàn bộ mã nguồn, và họ bắt đầu xóa (như đã minh hoạ trước đó trong Hình 4-7) những đoạn mã không cần thiết thay vì trích xuất mã mong muốn. Các nhà phát triển thường thấy điều này dễ dàng hơn trong một mã nguồn có độ kết nối chặt chẽ vì họ không phải lo lắng về việc trích xuất một số lượng lớn các phụ thuộc mà việc kết nối cao tạo ra. Thay vào đó, trong chiến lược xóa, một khi tính năng đã được tách biệt, hãy xóa bất kỳ đoạn mã nào không làm hỏng bất kỳ điều gì.
Khi mẫu tiếp tục phát triển, các nhóm bắt đầu cách ly các phần mục tiêu, như thể hiện trong Hình 4-10. Sau đó, mỗi nhóm tiếp tục loại bỏ dần các mã không mong muốn.
Figure 4-10. Teams constantly refactor to remove unwanted code
Khi hoàn thành mô hình phân nhánh chiến thuật, các nhóm đã chia ứng dụng nguyên khối ban đầu thành hai phần, giữ nguyên cấu trúc thô của hành vi trong mỗi phần, như được minh họa trong Hình 4-11.
Figure 4-11. The end state of tactical forking features two services
Bây giờ việc tái cấu trúc đã hoàn tất, để lại hai dịch vụ thô làm kết quả.
Trade-Offs
Tách nhánh chiến thuật là một phương pháp thay thế khả thi cho cách tiếp cận phân tích chính thức hơn, thích hợp nhất cho các mã nguồn có ít hoặc không có cấu trúc nội bộ. Giống như tất cả các thực hành trong kiến trúc, nó có những nhược điểm của riêng mình.
- Benefits
-
-
Các nhóm có thể bắt đầu làm việc ngay lập tức mà hầu như không cần phân tích trước.
-
Các lập trình viên cảm thấy việc xóa mã dễ hơn là trích xuất nó. Việc trích xuất mã từ một cơ sở mã hỗn độn gặp khó khăn do sự liên kết chặt chẽ, trong khi mã không cần thiết có thể được xác minh bằng biên dịch hoặc thử nghiệm đơn giản.
-
- Shortcomings
-
-
Các dịch vụ thu được có thể vẫn chứa một lượng lớn mã chủ yếu là tiềm ẩn còn sót lại từ kiến trúc đơn thể.
-
Nếu các nhà phát triển không thực hiện thêm nỗ lực, mã bên trong các dịch vụ mới được tạo ra sẽ không tốt hơn mã hỗn loạn từ monolith—chỉ là có ít hơn.
-
Sự không nhất quán có thể xảy ra giữa tên của mã chia sẻ và các tệp thành phần chia sẻ, dẫn đến khó khăn trong việc xác định mã chung và giữ cho nó nhất quán.
-
Tên của mẫu này rất hợp lý (như tất cả các tên mẫu tốt nên có) - nó cung cấp một cách tiếp cận chiến thuật hơn là chiến lược để cấu trúc lại các kiến trúc, cho phép các đội nhóm nhanh chóng di chuyển các hệ thống quan trọng hoặc thiết yếu lên thế hệ tiếp theo (mặc dù theo một cách không có cấu trúc).
Sysops Squad Saga: Choosing a Decomposition Approach
Thứ Sáu, 29 tháng 10, 10:01
Bây giờ mà Addison và Austen đã hiểu cả hai cách tiếp cận, họ đã gặp nhau trong phòng hội nghị chính để phân tích ứng dụng của đội Sysops bằng cách sử dụng các chỉ số trừu tượng và không ổn định nhằm xác định cách tiếp cận nào là phù hợp nhất với tình huống của họ.
“Nhìn vào điều này,” Addison nói. “Hầu hết mã nằm dọc theo chuỗi chính. Tất nhiên có một vài ngoại lệ, nhưng tôi nghĩ chúng ta có thể kết luận rằng việc tách rời ứng dụng này là khả thi. Vậy bước tiếp theo là xác định phương pháp nào sẽ sử dụng.”
“Tôi thật sự thích cách tiếp cận chia nhánh có tính chiến thuật,” Austen nói. “Nó gợi nhớ đến những nghệ sĩ điêu khắc nổi tiếng, khi được hỏi làm thế nào họ có thể chạm trổ những tác phẩm đẹp mắt từ đá cẩm thạch rắn, họ đã trả lời rằng họ chỉ đơn giản là loại bỏ những phần đá cẩm thạch không nên có ở đó. Tôi cảm thấy ứng dụng Sysops Squad có thể là tác phẩm điêu khắc của tôi!”
“Đợi đã, Michelangelo,” Addison nói. “Đầu tiên là thể thao, giờ đến điêu khắc? Bạn cần phải quyết định xem bạn thích dành thời gian không làm việc vào cái gì. Điều tôi không thích về cách tiếp cận phân nhánh chiến thuật là tất cả mã trùng lặp và chức năng chung trong mỗi dịch vụ. Hầu hết các vấn đề của chúng ta liên quan đến khả năng duy trì, khả năng kiểm thử, và độ tin cậy tổng thể. Bạn có thể tưởng tượng phải áp dụng cùng một thay đổi cho nhiều dịch vụ khác nhau cùng lúc không? Điều đó sẽ là một cơn ác mộng!”
“Nhưng thực sự có bao nhiêu chức năng chung?” Austen hỏi.
“Em không chắc,” Addison nói, “nhưng em biết có khá nhiều mã nguồn chung cho các thứ hạ tầng như ghi nhật ký và bảo mật, và em biết nhiều lệnh gọi cơ sở dữ liệu được chia sẻ từ lớp duy trì của ứng dụng.”
Austen dừng lại và suy nghĩ về lập luận của Addison một chút. “Có thể bạn đúng. Vì chúng ta đã xác định được các ranh giới thành phần rõ ràng, tôi đồng ý với phương pháp phân rã dựa trên thành phần chậm hơn và từ bỏ sự nghiệp điêu khắc của mình. Nhưng tôi sẽ không từ bỏ thể thao!”
Addison và Austen đã đạt được thỏa thuận rằng phương pháp phân tách thành phần sẽ là phương pháp thích hợp cho ứng dụng Sysops Squad. Addison đã viết một ADR cho quyết định này, phác thảo các yếu tố cần cân nhắc và lý do cho phương pháp phân tách dựa trên thành phần.
ADR: Di cư sử dụng phương pháp phân rã dựa trên thành phần
Bối cảnh Chúng tôi sẽ tách ứng dụng Sysops Squad monolithic thành các dịch vụ được triển khai riêng biệt. Hai phương pháp mà chúng tôi đã xem xét cho việc di chuyển sang kiến trúc phân tán là phân nhánh chiến thuật và phân tích dựa trên các thành phần.
Quyết định Chúng tôi sẽ sử dụng phương pháp phân rã dựa trên thành phần để di chuyển ứng dụng Sysops Squad monolithic hiện có sang kiến trúc phân tán.
Ứng dụng có các ranh giới thành phần được xác định rõ ràng, phù hợp với phương pháp phân tích dựa trên thành phần.
Cách tiếp cận này giảm khả năng phải duy trì mã trùng lặp trong mỗi dịch vụ.
Với phương pháp chia tách chiến thuật, chúng ta cần xác định các ranh giới dịch vụ ngay từ đầu để biết cần tạo bao nhiêu ứng dụng bị chia tách. Với phương pháp phân rã dựa trên thành phần, các định nghĩa dịch vụ sẽ tự nhiên xuất hiện thông qua việc nhóm các thành phần lại với nhau.
Với bản chất của các vấn đề mà chúng tôi đang phải đối mặt với ứng dụng hiện tại về độ tin cậy, khả năng sẵn có, khả năng mở rộng và quy trình làm việc, việc sử dụng phương pháp phân rã dựa trên thành phần mang lại một quá trình di chuyển từng bước an toàn và có kiểm soát hơn so với phương pháp phân nhánh chiến thuật.
Hậu quả Nỗ lực di cư có thể sẽ mất nhiều thời gian hơn với phương pháp phân tích dựa trên thành phần so với việc phân nhánh chiến thuật. Tuy nhiên, chúng tôi cảm thấy các lý do trong phần trước nặng ký hơn so với sự đánh đổi này.
Cách tiếp cận này cho phép các nhà phát triển trong nhóm làm việc hợp tác để xác định chức năng chung, ranh giới của các thành phần và ranh giới miền. Việc phân nhánh chiến thuật sẽ yêu cầu chúng tôi tách rời đội ngũ thành các nhóm nhỏ riêng biệt cho mỗi ứng dụng đã phân nhánh và tăng cường mức độ phối hợp cần thiết giữa các nhóm nhỏ hơn.
Chapter 5. Component-Based Decomposition Patterns
Thứ Hai, ngày 1 tháng 11, 11:53
Addison và Austen đã chọn sử dụng phương pháp phân tích dựa trên thành phần, nhưng không chắc chắn về các chi tiết của từng mẫu phân tích. Họ đã cố gắng nghiên cứu về phương pháp này, nhưng không tìm thấy nhiều thông tin trên internet về nó. Một lần nữa, họ đã gặp Logan trong phòng hội nghị để xin lời khuyên về những mẫu này là gì và cách sử dụng chúng.
“Nghe này, Logan,” Addison nói, “Tôi muốn bắt đầu bằng việc nói rằng cả hai chúng tôi đều rất trân trọng quỹ thời gian mà bạn đã dành cho chúng tôi để bắt đầu quá trình chuyển giao này. Tôi biết bạn đang rất bận rộn với những công việc của riêng mình.”
“Không có vấn đề gì,” Logan nói. “Chúng tôi những người lính cứu hỏa phải luôn bên nhau. Tôi đã từng ở trong trường hợp của bạn trước đây, nên tôi hiểu cảm giác bay mù trong những tình huống như thế này. Hơn nữa, đây là một nỗ lực di cư rất nổi bật, và điều quan trọng là cả hai bạn phải làm đúng ngay từ lần đầu tiên. Bởi vì sẽ không có lần thứ hai.”
“Cảm ơn, Logan,” Austin nói. “Mình có một trận đấu khoảng hai giờ nữa, nên chúng ta sẽ cố gắng làm cho nó ngắn gọn. Bạn đã nói về phân rã dựa trên thành phần trước đó, và chúng mình đã chọn cách tiếp cận đó, nhưng không tìm thấy nhiều thông tin về nó trên internet.”
“Tôi không ngạc nhiên,” Logan nói. “Chưa có nhiều điều được viết về chúng, nhưng tôi biết có một cuốn sách sắp ra mắt mô tả chi tiết các mô hình này vào khoảng cuối năm nay. Tôi lần đầu tiên biết về những mẫu phân rã này tại một hội nghị cách đây khoảng bốn năm trong một phiên làm việc với một kiến trúc sư phần mềm có kinh nghiệm. Tôi thực sự ấn tượng với cách tiếp cận lặp đi lặp lại và có hệ thống để di chuyển an toàn từ kiến trúc monolithic sang một kiến trúc phân tán như kiến trúc dựa trên dịch vụ và microservices. Kể từ đó, tôi đã sử dụng những mẫu này với khá nhiều thành công.”
“Bạn có thể chỉ cho chúng tôi cách mà những mô hình này hoạt động không?” Addison hỏi.
“Chắc chắn rồi,” Logan nói. “Hãy để chúng ta giải quyết từng mô hình một.”
Phân tích dựa trên thành phần (được giới thiệu trong Chương 4) là một kỹ thuật rất hiệu quả để tách rời một ứng dụng đơn thể khi mã nguồn được cấu trúc và nhóm lại theo không gian tên (hoặc thư mục). Chương này giới thiệu một tập hợp các mẫu, được gọi là mẫu phân tích dựa trên thành phần, mô tả việc tái cấu trúc mã nguồn đơn thể để tạo ra một tập hợp các thành phần được định nghĩa rõ ràng, có thể trở thành các dịch vụ trong tương lai. Những mẫu phân tích này giúp giảm đáng kể nỗ lực di chuyển các ứng dụng đơn thể sang kiến trúc phân tán.
Hình 5-1 cho thấy lược đồ cho các mẫu phân rã dựa trên thành phần được mô tả trong chương này và cách chúng được sử dụng cùng nhau để tách biệt một ứng dụng đơn thể. Ban đầu, các mẫu này được sử dụng cùng nhau theo trình tự khi chuyển đổi một ứng dụng đơn thể sang một ứng dụng phân tán, và sau đó được sử dụng riêng lẻ khi thực hiện bảo trì cho ứng dụng đơn thể trong quá trình di cư. Các mẫu phân rã này được tóm tắt như sau:
- “Identify and Size Components Pattern”
-
Thông thường, mẫu đầu tiên được áp dụng khi tách rời một ứng dụng nguyên khối. Mẫu này được sử dụng để xác định, quản lý và định kích thước hợp lý các thành phần.
- “Gather Common Domain Components Pattern”
-
Được sử dụng để hợp nhất logic miền kinh doanh chung có thể bị trùng lặp trong ứng dụng, giảm số lượng dịch vụ có khả năng bị trùng lặp trong kiến trúc phân tán kết quả.
- “Flatten Components Pattern”
-
Được sử dụng để thu gọn hoặc mở rộng các miền, miền con và các thành phần, từ đó đảm bảo rằng các tệp mã nguồn chỉ nằm trong các thành phần đã được định nghĩa rõ ràng.
- “Determine Component Dependencies Pattern”
-
Được sử dụng để xác định các phụ thuộc của thành phần, tinh chỉnh những phụ thuộc đó, và xác định tính khả thi cũng như mức độ nỗ lực tổng thể cho việc di chuyển từ kiến trúc đơn khối sang kiến trúc phân tán.
- “Create Component Domains Pattern”
-
Được sử dụng để nhóm các thành phần thành các miền hợp lý trong ứng dụng và để định cấu trúc lại namespace và/hoặc thư mục của thành phần để phù hợp với một miền cụ thể.
- “Create Domain Services Pattern”
-
Được sử dụng để tách rời một kiến trúc đơn thể bằng cách di chuyển các miền logic trong ứng dụng đơn thể đến các dịch vụ miền triển khai riêng biệt.
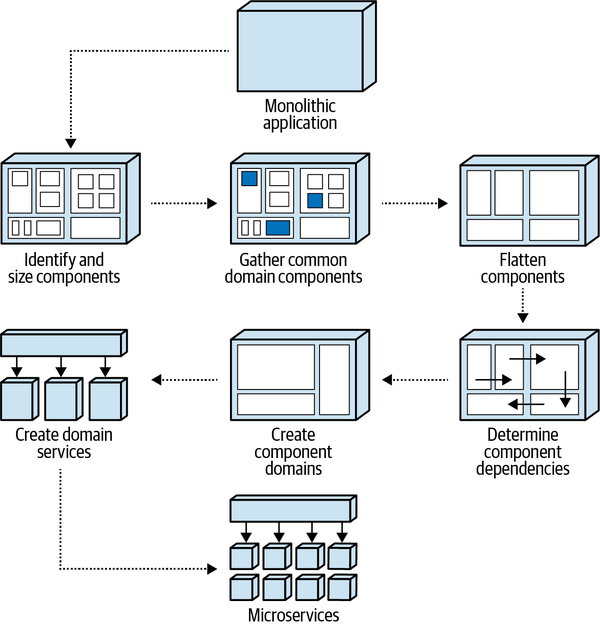
Figure 5-1. Component-based decomposition pattern flow and usage
Mỗi mẫu được mô tả trong chương này được chia thành ba phần. Phần đầu tiên, “Mô Tả Mẫu”, mô tả cách hoạt động của mẫu, tại sao mẫu đó quan trọng và kết quả của việc áp dụng mẫu. Biết rằng hầu hết các hệ thống là những mục tiêu di chuyển trong quá trình di cư, phần thứ hai, “Chức Năng Thích Hợp cho Quản Trị,” mô tả cách quản trị tự động có thể được sử dụng sau khi áp dụng mẫu để liên tục phân tích và xác minh tính chính xác của mã nguồn trong suốt quá trình bảo trì. Phần thứ ba sử dụng ứng dụng Sysops Squad trong thực tế (xem “Giới Thiệu Saga của Sysops Squad”) để minh họa việc sử dụng mẫu và minh họa các biến đổi của ứng dụng sau khi mẫu được áp dụng.
Identify and Size Components Pattern
Bước đầu tiên trong bất kỳ quá trình di cư monolithic nào là áp dụng mẫu Nhận diện và Kích thước Thành phần. Mục đích của mẫu này là để nhận diện và lập danh mục các thành phần kiến trúc (khối xây dựng logic) của ứng dụng và sau đó kích thước các thành phần một cách hợp lý.
Pattern Description
Vì các dịch vụ được xây dựng từ các thành phần, việc xác định không chỉ các thành phần trong một ứng dụng mà còn phải định kích thước chính xác cho chúng là rất quan trọng. Mẫu này được sử dụng để xác định các thành phần có kích thước quá lớn (thực hiện quá nhiều) hoặc quá nhỏ (không thực hiện đủ). Các thành phần quá lớn so với các thành phần khác thường liên kết chặt chẽ hơn với các thành phần khác, khó tách ra thành các dịch vụ riêng biệt và dẫn đến một kiến trúc ít mô-đun hơn.
Thật không may, việc xác định kích thước của một thành phần là khá khó khăn. Số lượng tệp nguồn, lớp và tổng số dòng mã không phải là những chỉ số tốt vì mỗi lập trình viên thiết kế lớp, phương thức và hàm theo cách riêng của họ. Một chỉ số mà chúng tôi thấy hữu ích cho việc đo kích thước thành phần là tính tổng số câu lệnh trong một thành phần nhất định (tổng số câu lệnh trong tất cả các tệp nguồn nằm trong một không gian tên hoặc thư mục). Một câu lệnh là một hành động hoàn chỉnh duy nhất được thực hiện trong mã nguồn, thường kết thúc bằng một ký tự đặc biệt (như dấu chấm phẩy trong các ngôn ngữ như Java, C, C++, C#, Go và JavaScript; hoặc một dòng mới trong các ngôn ngữ như F#, Python và Ruby). Mặc dù không phải là một chỉ số hoàn hảo, ít nhất nó là một chỉ số tốt về mức độ mà thành phần đang thực hiện và độ phức tạp của thành phần đó.
Việc có kích thước thành phần tương đối đồng nhất trong một ứng dụng là rất quan trọng. Nói chung, kích thước của các thành phần trong một ứng dụng nên rơi vào khoảng từ một đến hai độ lệch chuẩn so với kích thước thành phần trung bình (hoặc mean). Bên cạnh đó, tỷ lệ mã mà mỗi thành phần đại diện nên được phân bổ khá đều giữa các thành phần của ứng dụng và không nên thay đổi đáng kể.
Trong khi nhiều công cụ phân tích mã tĩnh có thể cho thấy số lượng câu lệnh trong một tệp nguồn, nhiều công cụ trong số đó không tổng hợp số câu lệnh tổng cộng theo thành phần. Vì lý do này, kiến trúc sư thường phải thực hiện xử lý sau bằng tay hoặc tự động để tổng hợp số câu lệnh tổng cộng theo thành phần và sau đó tính toán tỷ lệ phần trăm mã mà thành phần đó đại diện.
Bất kể công cụ hoặc thuật toán nào được sử dụng, thông tin và các chỉ số quan trọng cần thu thập và tính toán cho mẫu này được trình bày trong Bảng 5-1 và được định nghĩa trong danh sách sau.
| Component name | Component namespace | Percent | Statements | Files |
|---|---|---|---|---|
Thanh toán hóa đơn | thanh toán hóa đơn | 5 | bốn nghìn ba trăm mười hai | 23 |
Lịch sử thanh toán | lịch sử thanh toán | 4 | ba nghìn hai trăm chín | 17 |
Thông báo Khách hàng | Thông báo của khách hàng ss. | 2 | một nghìn bốn trăm ba mươi ba | 7 |
- Component name
-
Một tên mô tả và định danh của thành phần cần phải nhất quán trong toàn bộ các sơ đồ ứng dụng và tài liệu. Tên thành phần nên rõ ràng đủ để có thể tự mô tả. Ví dụ, thành phần Lịch sử Thanh toán được hiển thị trong Bảng 5-1 rõ ràng là một thành phần chứa các tệp mã nguồn được sử dụng để quản lý lịch sử thanh toán của khách hàng. Nếu vai trò và trách nhiệm cụ thể của thành phần không thể xác định ngay lập tức, hãy cân nhắc thay đổi thành phần (và có thể cả không gian tên tương ứng) thành một cái tên mô tả hơn. Ví dụ, một thành phần được gọi là Quản lý Vé để lại quá nhiều câu hỏi chưa có lời giải thích về vai trò và trách nhiệm của nó trong hệ thống, và nên được đổi tên để mô tả rõ hơn vai trò của nó.
- Component namespace
-
Sự xác định vật lý (hoặc logic) của thành phần đại diện cho nơi các tệp mã nguồn thực hiện thành phần đó được nhóm và lưu trữ. Nhận dạng này thường được thể hiện thông qua một không gian tên, cấu trúc gói (Java) hoặc cấu trúc thư mục. Khi một cấu trúc thư mục được sử dụng để chỉ định thành phần, chúng ta thường chuyển đổi ký tự phân cách tệp thành dấu chấm (.) và tạo ra một không gian tên logic tương ứng. Ví dụ, không gian tên của thành phần cho các tệp mã nguồn trong cấu trúc thư mục ss/customer/notification sẽ có giá trị không gian tên ss.customer.notification. Một số ngôn ngữ yêu cầu rằng không gian tên phải khớp với cấu trúc thư mục (chẳng hạn như Java với một gói), trong khi các ngôn ngữ khác (chẳng hạn như C# với một không gian tên) không thực thi ràng buộc này. Dù bất kỳ nhận diện không gian tên nào được sử dụng, hãy đảm bảo loại nhận diện này nhất quán giữa tất cả các thành phần trong ứng dụng.
- Percent
-
Kích thước tương đối của thành phần dựa trên tỷ lệ phần trăm của mã nguồn tổng thể chứa thành phần đó. Đo lường phần trăm này hữu ích trong việc xác định các thành phần có vẻ quá lớn hoặc quá nhỏ trong ứng dụng tổng thể. Đo lường này được tính bằng cách lấy tổng số câu lệnh trong các tệp mã nguồn đại diện cho thành phần đó và chia con số đó cho tổng số câu lệnh trong toàn bộ mã nguồn của ứng dụng. Ví dụ, giá trị phần trăm 5 cho thành phần ss.billing.payment trong Bảng 5-1 có nghĩa là thành phần này chiếm 5% của toàn bộ mã nguồn.
- Statements
-
Tổng số câu lệnh mã nguồn trong tất cả các tệp nguồn chứa trong thành phần đó. Chỉ tiêu này hữu ích không chỉ để xác định kích thước tương đối của các thành phần trong một ứng dụng, mà còn để xác định độ phức tạp tổng thể của thành phần. Ví dụ, một thành phần đơn giản có mục đích duy nhất mang tên Danh sách mong muốn của Khách hàng có thể có tổng cộng 12.000 câu lệnh, cho thấy rằng việc xử lý các mục trong danh sách mong muốn có thể phức tạp hơn những gì nó thể hiện. Chỉ tiêu này cũng cần thiết để tính toán chỉ tiêu phần trăm đã được mô tả trước đó.
- Files
-
Tổng số tệp mã nguồn (chẳng hạn như lớp, giao diện, kiểu, và những thứ khác) có trong thành phần. Trong khi chỉ số này ít liên quan đến kích thước của một thành phần, nó cung cấp thông tin bổ sung về thành phần từ góc độ cấu trúc lớp. Ví dụ, một thành phần có 18,409 câu lệnh và chỉ có 2 tệp là một ứng cử viên tốt để tái cấu trúc thành các lớp nhỏ hơn, có ngữ cảnh hơn.
Khi điều chỉnh kích thước một thành phần lớn, chúng tôi khuyên bạn nên sử dụng phương pháp phân rã chức năng hoặc phương pháp định hướng miền để xác định các miền phụ có thể tồn tại trong thành phần lớn đó. Ví dụ, giả sử ứng dụng Sysops Squad có một thành phần Ticket Trouble chứa 22% mã nguồn chịu trách nhiệm cho việc tạo, phân công, định tuyến và hoàn thành vé. Trong trường hợp này, có thể hợp lý khi chia thành phần Ticket Trouble duy nhất thành bốn thành phần riêng biệt (Tạo Vé, Phân Công Vé, Định Tuyến Vé và Hoàn Thành Vé), giảm tỷ lệ phần trăm mã mà mỗi thành phần đại diện, từ đó tạo ra một ứng dụng mô-đun hơn. Nếu không có miền phụ rõ ràng nào tồn tại trong một thành phần lớn, thì hãy giữ nguyên thành phần đó.
Fitness Functions for Governance
Khi mẫu phân rã này đã được áp dụng và các thành phần đã được xác định và kích thước đúng, điều quan trọng là áp dụng một hình thức quản trị tự động để xác định các thành phần mới và đảm bảo rằng các thành phần không trở nên quá lớn trong quá trình bảo trì ứng dụng bình thường, từ đó tạo ra các phụ thuộc không mong muốn hoặc không dự kiến. Các hàm đánh giá tự động toàn diện có thể được kích hoạt trong quá trình triển khai để cảnh báo kiến trúc sư nếu các ràng buộc được chỉ định bị vi phạm (chẳng hạn như số liệu phần trăm đã được thảo luận trước đó hoặc việc sử dụng độ lệch chuẩn để xác định các trường hợp ngoại lệ).
Các hàm tính toán fitness có thể được triển khai thông qua mã viết tùy chỉnh hoặc thông qua việc sử dụng các công cụ mã nguồn mở hoặc COTS như một phần của quy trình CI/CD. Một số hàm tính toán tự động có thể được sử dụng để giúp quản lý mẫu phân rã này như sau.
Fitness function: Maintain component inventory
Chức năng fitness tự động toàn diện này, thường được kích hoạt khi triển khai thông qua quy trình CI/CD, giúp giữ cho danh mục các thành phần được cập nhật. Nó được sử dụng để thông báo cho kiến trúc sư về các thành phần có thể đã được thêm hoặc gỡ bỏ bởi nhóm phát triển. Việc xác định các thành phần mới hoặc đã bị gỡ bỏ không chỉ quan trọng đối với mẫu này mà còn cho các mẫu phân hoạch khác. Ví dụ 5-1 trình bày mã giả và thuật toán cho một triển khai khả thi của chức năng fitness này.
Example 5-1. Pseudocode for maintaining component inventory
# Get prior component namespaces that are stored in a datastoreLISTprior_list=read_from_datastore()# Walk the directory structure, creating namespaces for each complete pathLISTcurrent_list=identify_components(root_directory)# Send an alert if new or removed components are identifiedLISTadded_list=find_added(current_list,prior_list)LISTremoved_list=find_removed(current_list,prior_list)IFadded_listNOTEMPTY{add_to_datastore(added_list)send_alert(added_list)}IFremoved_listNOTEMPTY{remove_from_datastore(removed_list)send_alert(removed_list)}
Fitness function: No component shall exceed <some percent> of the overall codebase
Chức năng thể lực tổng thể tự động này, thường được kích hoạt khi triển khai thông qua một pipeline CI/CD, xác định các thành phần vượt ngưỡng nhất định về tỷ lệ phần trăm mã nguồn tổng thể được đại diện bởi thành phần đó, và cảnh báo kiến trúc sư nếu bất kỳ thành phần nào vượt quá ngưỡng đó. Như đã đề cập trước đây trong chương này, giá trị tỷ lệ phần trăm ngưỡng sẽ thay đổi tùy thuộc vào kích thước của ứng dụng, nhưng nên được thiết lập để xác định các ngoại lệ đáng kể. Ví dụ, đối với một ứng dụng tương đối nhỏ chỉ có 10 thành phần, việc thiết lập ngưỡng phần trăm ở mức 30% sẽ đủ để nhận diện một thành phần quá lớn, trong khi đối với một ứng dụng lớn có 50 thành phần, ngưỡng 10% sẽ hợp lý hơn. Ví dụ 5-2 cho thấy mã giả và thuật toán cho một sự triển khai khả thi của chức năng thể lực này.
Example 5-2. Pseudocode for maintaining component size based on percent of code
# Walk the directory structure, creating namespaces for each complete pathLISTcomponent_list=identify_components(root_directory)# Walk through all of the source code to accumulate total statementstotal_statements=accumulate_statements(root_directory)# Walk through the source code for each component, accumulating statements# and calculating the percentage of code each component represents. Send# an alert if greater than 10%FOREACHcomponentINcomponent_list{component_statements=accumulate_statements(component)percent=component_statements/total_statementsIFpercent>.10{send_alert(component,percent)}}
Fitness function: No component shall exceed <some number of standard deviations> from the mean component size
Chức năng fitness tự động toàn diện này, thường được kích hoạt khi triển khai thông qua một đường ống CI/CD, xác định các thành phần vượt ngưỡng cho trước về số lượng độ lệch chuẩn so với trung bình của tất cả các kích thước thành phần (dựa trên tổng số câu lệnh trong thành phần), và cảnh báo cho kiến trúc sư nếu bất kỳ thành phần nào vượt quá ngưỡng đó.
Độ lệch chuẩn là một phương pháp hữu ích để xác định các giá trị ngoại lệ liên quan đến kích thước thành phần. Độ lệch chuẩn được tính như sau:
nơi N là số giá trị quan sát, x i là các giá trị quan sát, và x ¯ là giá trị trung bình của các giá trị quan sát. Giá trị trung bình của các giá trị quan sát ( x ¯ ) được tính như sau:
Độ lệch chuẩn có thể được sử dụng cùng với sự khác biệt từ giá trị trung bình để xác định số lượng độ lệch chuẩn mà kích thước thành phần nằm xa giá trị trung bình. Ví dụ 5-3 trình bày mã giả cho hàm đánh giá này, sử dụng ba độ lệch chuẩn từ giá trị trung bình làm ngưỡng.
Example 5-3. Pseudocode for maintaining component size based on number of standard deviations
# Walk the directory structure, creating namespaces for each complete pathLISTcomponent_list=identify_components(root_directory)# Walk through all of the source code to accumulate total statements and number# of statements per componentSETtotal_statementsTO0MAPcomponent_size_mapFOREACHcomponentINcomponent_list{num_statements=accumulate_statements(component)ADDnum_statementsTOtotal_statementsADDcomponent,num_statementsTOcomponent_size_map}# Calculate the standard deviationSETsquare_diff_sumTO0num_components=get_num_entries(component_list)mean=total_statements/num_componentsFOREACHcomponent,sizeINcomponent_size_map{diff=size-meanADDsquare(diff)TOsquare_diff_sum}std_dev=square_root(square_diff_sum/(num_components-1))# For each component calculate the number of standard deviations from the# mean. Send an alert if greater than 3FOREACHcomponent,sizeINcomponent_size_map{diff_from_mean=absolute_value(size-mean);num_std_devs=diff_from_mean/std_devIFnum_std_devs>3{send_alert(component,num_std_devs)}}
Sysops Squad Saga: Sizing Components
Thứ Ba, ngày 2 tháng 11, 09:12
Sau cuộc thảo luận với Logan (kiến trúc sư trưởng) về các mẫu phân hoạch dựa trên thành phần, Addison quyết định áp dụng mẫu Nhận diện và Định kích thước Các thành phần để xác định tất cả các thành phần trong ứng dụng ticketing của Đội Sysops và tính toán kích thước của mỗi thành phần dựa trên tổng số câu lệnh trong mỗi thành phần.
Addison đã thu thập tất cả thông tin cần thiết về các thành phần và đưa thông tin này vào Bảng 5-2, tính toán phần trăm mã cho mỗi thành phần dựa trên tổng số câu lệnh trong toàn bộ ứng dụng (trong trường hợp này, có 82.931 câu lệnh).
| Component name | Component namespace | Percent | Statements | Files |
|---|---|---|---|---|
Đăng nhập | đăng nhập | 2 | 1865 | 3 |
Thanh toán hóa đơn | thanh toán hóa đơn | 5 | bốn nghìn ba trăm mười hai | 23 |
Lịch sử thanh toán | lịch sử thanh toán | 4 | ba nghìn hai trăm chín | 17 |
Thông báo cho khách hàng | thông báo khách hàng | 2 | một nghìn bốn trăm ba mươi ba | 7 |
Hồ sơ khách hàng | Hồ sơ khách hàng | 5 | bốn ngàn không trăm mười hai | 16 |
Hồ sơ chuyên gia | chuyên gia.ss.hồ sơ | 6 | năm nghìn không trăm chín mươi chín | 32 |
Bảo trì KB | ss.kb.bảo trì | 2 | một nghìn bảy trăm lẻ một | 14 |
Tìm kiếm KB | tìm kiếm ss.kb | 3 | hai nghìn tám trăm bảy mươi một | 4 |
Báo cáo | báo cáo.ss | 33 | Hai mươi bảy nghìn bảy trăm sáu mươi lăm | 162 |
Vé |
| 8 | bảy nghìn không trăm chín | 45 |
Chỉ định vé | ss.ticket.assign translates to "gán vé". | 9 | bảy nghìn tám trăm bốn mươi lăm | 14 |
Thông báo vé | Thông báo vé ss. | 2 | Một nghìn bảy trăm sáu mươi lăm | 3 |
Lộ trình vé | chuyến đi của vé | 2 | một nghìn bốn trăm sáu mươi tám | 4 |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ | 5 | bốn nghìn một trăm bốn | 24 |
Khảo sát | khảo sát | 3 | hai nghìn hai trăm linh bốn | 5 |
Thông báo Khảo sát | Thông báo khảo sát | 2 | một nghìn hai trăm chín mươi chín | 3 |
Mẫu khảo sát | Mẫu khảo sát | 2 | Một nghìn sáu trăm bảy mươi hai | 7 |
Bảo trì người dùng | người dùng.ss | 4 | ba nghìn hai trăm chín mươi tám | 12 |
Addison nhận thấy rằng hầu hết các thành phần được liệt kê trong Bảng 5-2 có kích thước tương đối giống nhau, ngoại trừ thành phần Báo cáo (ss.reporting) chiếm 33% mã nguồn. Vì thành phần Báo cáo lớn hơn đáng kể so với các thành phần khác (được minh họa trong Hình 5-2), Addison đã quyết định tách thành phần này ra để giảm kích thước tổng thể của nó.
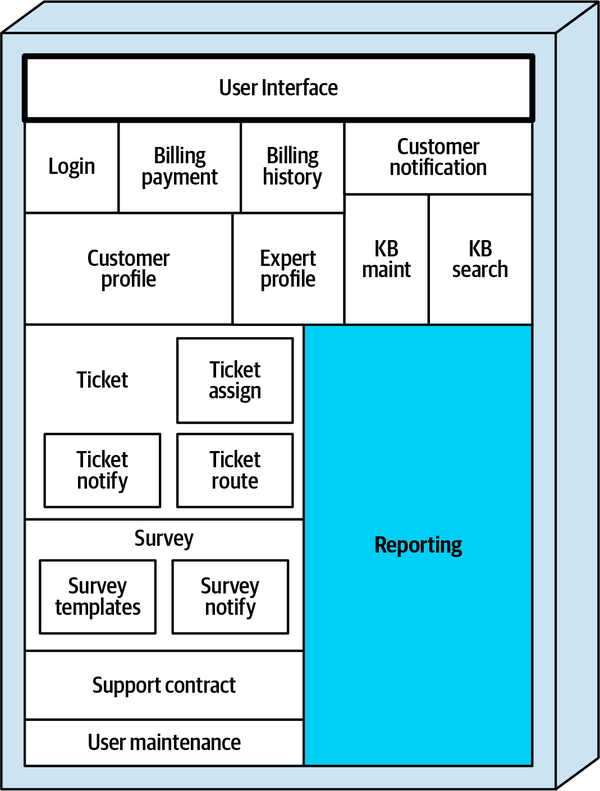
Figure 5-2. The Reporting component is too big and should be broken apart
Sau khi thực hiện phân tích, Addison nhận thấy rằng thành phần báo cáo chứa mã nguồn thực hiện ba loại báo cáo:
-
Báo cáo vé (báo cáo nhân khẩu học vé, báo cáo số vé theo ngày/tuần/tháng, báo cáo thời gian giải quyết vé, v.v.)
-
Báo cáo chuyên gia (báo cáo sử dụng chuyên gia, báo cáo phân phối chuyên gia, và các báo cáo khác)
-
Báo cáo tài chính (báo cáo chi phí sửa chữa, báo cáo chi phí chuyên gia, báo cáo lợi nhuận, v.v.)
Addison cũng đã xác định mã code chung (chung) mà tất cả các danh mục báo cáo sử dụng, chẳng hạn như tiện ích chung, máy tính, truy vấn dữ liệu chung, phân phối báo cáo và định dạng dữ liệu chung. Addison đã tạo ra một câu chuyện kiến trúc (xem “Câu chuyện Kiến trúc”) cho việc tái cấu trúc này và giải thích nó cho nhóm phát triển. Sydney, một trong những lập trình viên của Đội Sysops được giao câu chuyện kiến trúc, đã tái cấu trúc mã code để tách rời thành phần Báo cáo đơn thành bốn thành phần riêng biệt—một thành phần Chung của Báo cáo chứa mã chung và ba thành phần khác (Báo cáo Vé, Báo cáo Chuyên gia và Báo cáo Tài chính), mỗi thành phần đại diện cho một khu vực báo cáo chức năng, như minh họa trong Hình 5-3.
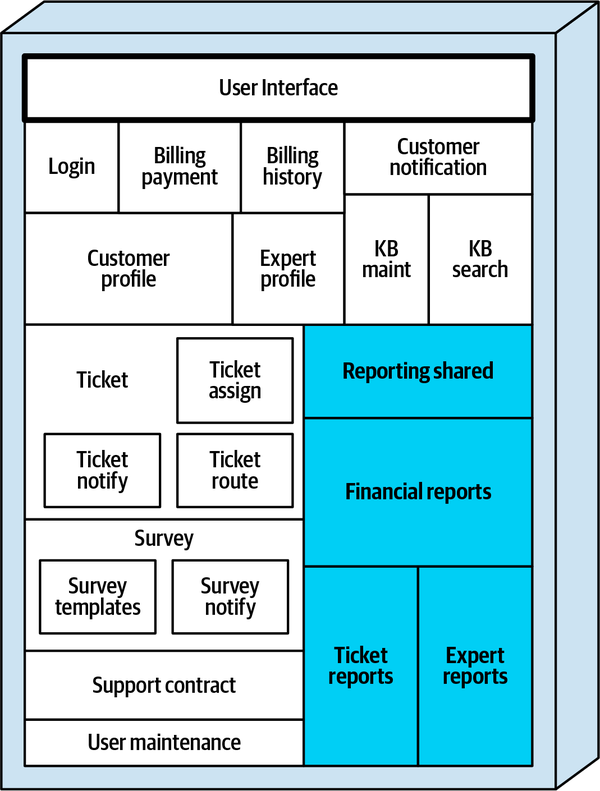
Figure 5-3. The large Reporting component broken into smaller reporting components
Sau khi Sydney thực hiện các thay đổi, Addison đã phân tích lại mã và xác minh rằng tất cả các thành phần bây giờ đã được phân phối khá đồng đều về kích thước. Addison đã ghi lại kết quả của việc áp dụng mẫu phân rã này trong Bảng 5-3.
| Component name | Component namespace | Percent | Statements | Files |
|---|---|---|---|---|
Đăng nhập | Đăng nhập | 2 | 1865 | 3 |
Thanh toán hóa đơn | thanh toán hoá đơn | 5 | bốn ngàn ba trăm mười hai | 23 |
Lịch sử thanh toán | lịch sử thanh toán ss | 4 | ba nghìn hai trăm chín | 17 |
Thông báo Khách hàng | thông báo khách hàng | 2 | một nghìn bốn trăm ba mươi ba | 7 |
Hồ sơ khách hàng | Hồ sơ khách hàng | 5 | bốn nghìn không trăm mười hai | 16 |
Hồ sơ chuyên gia | chuyên gia.ss.hồ_sơ | 6 | năm nghìn không trăm chín mươi chín | 32 |
Bảo trì KB | bảo trì ss.kb | 2 | một nghìn bảy trăm linh một | 14 |
Tìm kiếm KB | Tìm kiếm ss.kb | 3 | hai nghìn tám trăm bảy mươi một | 4 |
Báo cáo Chia sẻ | báo cáo.sở hữu.chia sẻ | 7 | năm nghìn ba trăm chín | 20 |
Báo cáo vé | bảng báo cáo vé | 8 | sáu nghìn chín trăm năm mươi lăm | 58 |
Báo cáo chuyên gia | chuyên gia báo cáo ss | 9 | bảy nghìn bảy trăm ba mươi bốn | 48 |
Báo cáo tài chính | báo cáo.tài chính | 9 | bảy nghìn bảy trăm sáu mươi bảy | 36 |
Vé | vé ss | 8 | bảy nghìn không trăm chín | 45 |
Bảng phân công vé | ss.ticket.assign: giao vé ss | 9 | bảy nghìn tám trăm bốn mươi lăm | 14 |
Thông báo vé | thông báo vé.ss | 2 | Một nghìn bảy trăm sáu mươi lăm | 3 |
Lộ trình vé | lộ trình vé ss | 2 | một nghìn bốn trăm sáu mươi tám | 4 |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ | 5 | bốn nghìn một trăm bốn | 24 |
Khảo sát | khảo sát | 3 | hai nghìn hai trăm linh bốn | 5 |
Thông báo Khảo sát | Thông báo khảo sát | 2 | một nghìn hai trăm chín mươi chín | 3 |
Mẫu khảo sát | mẫu khảo sát.ss | 2 | một nghìn sáu trăm bảy mươi hai | 7 |
Bảo trì người dùng | người dùng.ss | 4 | ba nghìn hai trăm chín mươi tám | 12 |
Lưu ý trong Saga Đội Sysops trước đó rằng phần Báo cáo không còn tồn tại như một thành phần trong Bảng 5-3 hoặc Hình 5-3. Mặc dù không gian tên vẫn tồn tại (ss.reporting), nhưng nó không còn được coi là một thành phần, mà là một miền con. Các thành phần đã được tái cấu trúc được liệt kê trong Bảng 5-3 sẽ được sử dụng khi áp dụng mẫu phân rã tiếp theo, Tập Hợp Các Thành Phần Miền Chung.
Gather Common Domain Components Pattern
Khi chuyển từ kiến trúc đơn khối sang kiến trúc phân tán, việc xác định và hợp nhất các chức năng miền chung thường mang lại lợi ích, giúp dễ dàng nhận diện và tạo ra các dịch vụ chung hơn. Mẫu Gather Common Domain Components được sử dụng để xác định và thu thập logic miền chung và tập trung nó vào một thành phần duy nhất.
Pattern Description
Chức năng miền được phân biệt với chức năng hạ tầng ở chỗ chức năng miền là một phần của logic xử lý kinh doanh của một ứng dụng (như thông báo, định dạng dữ liệu và xác thực dữ liệu) và chỉ chung cho một số quy trình, trong khi chức năng hạ tầng mang tính chất vận hành (như ghi log, thu thập số liệu và bảo mật) và chung cho tất cả các quy trình.
Việc hợp nhất các chức năng miền chung giúp loại bỏ các dịch vụ trùng lặp khi tách rời một hệ thống monolithic. Thường thì chỉ có những khác biệt rất tinh tế giữa các chức năng miền chung được sao chép trong toàn bộ ứng dụng, và những khác biệt này có thể được giải quyết dễ dàng trong một dịch vụ chung duy nhất (hoặc thư viện chia sẻ).
Việc tìm kiếm chức năng miền chung chủ yếu là một quy trình thủ công, nhưng một số tự động hóa có thể được sử dụng để hỗ trợ trong nỗ lực này (xem “Chức năng Fitness cho Quản trị”). Một gợi ý cho thấy việc xử lý miền chung tồn tại trong ứng dụng là việc sử dụng các lớp chia sẻ giữa các thành phần hoặc cấu trúc kế thừa chung được nhiều thành phần sử dụng. Lấy ví dụ, một tệp lớp có tên SMTPConnection trong một mã nguồn lớn được sử dụng bởi năm lớp, tất cả nằm trong các namespace khác nhau (các thành phần). Kịch bản này là một chỉ báo tốt cho thấy chức năng thông báo email chung đã lan rộng khắp ứng dụng và có thể là một ứng cử viên tốt cho việc hợp nhất.
Một cách khác để xác định chức năng miền chung là thông qua tên của một thành phần logic hoặc không gian tên tương ứng của nó. Hãy xem xét các thành phần sau (được biểu thị dưới dạng không gian tên) trong một mã nguồn lớn:
-
Kiểm toán vé (penultimate.ss.ticket.audit)
-
Kiểm toán hóa đơn
-
Kiểm toán khảo sát (penultimate.ss.survey.audit)
Lưu ý rằng mỗi thành phần trong số này (Kiểm toán Vé, Kiểm toán Thanh toán và Kiểm toán Khảo sát) đều có điểm chung là ghi lại hành động đã thực hiện và người dùng yêu cầu hành động vào một bảng kiểm toán. Mặc dù ngữ cảnh có thể khác nhau, nhưng kết quả cuối cùng là giống nhau - chèn một hàng vào bảng kiểm toán. Chức năng miền chung này có thể được hợp nhất vào một thành phần mới có tên penultimate.ss.shared.audit, dẫn đến việc giảm thiểu sự trùng lặp mã và cũng giảm số lượng dịch vụ trong kiến trúc phân tán kết quả.
Không phải tất cả các chức năng miền chung đều trở thành dịch vụ chia sẻ. Thay vào đó, mã chung có thể được tập hợp vào một thư viện chia sẻ, được liên kết với mã trong quá trình biên dịch. Những ưu và nhược điểm của việc sử dụng dịch vụ chia sẻ thay vì thư viện chia sẻ được thảo luận chi tiết trong Chương 8.
Fitness Functions for Governance
Tự động hóa việc quản lý chức năng miền chung là khá khó khăn do tính chủ quan trong việc xác định chức năng chung và phân loại nó thành chức năng miền so với chức năng hạ tầng. Hầu hết, các hàm sinh sản được sử dụng để quản lý mẫu này vì vậy thường là bán tự động. Tuy nhiên, có một số cách để tự động hóa việc quản lý nhằm hỗ trợ trong việc giải thích thủ công các chức năng miền chung. Các hàm sinh sản sau đây có thể hỗ trợ trong việc tìm kiếm chức năng miền chung.
Fitness function: Find common names in leaf nodes of component namespace
Chức năng thể chất toàn diện tự động này có thể được kích hoạt khi triển khai thông qua pipeline CI/CD để xác định các tên chung trong không gian tên của một thành phần. Khi một tên nút không gian tên kết thúc chung được tìm thấy giữa hai hoặc nhiều thành phần, kiến trúc sư sẽ nhận được thông báo và có thể phân tích chức năng để xác định xem đó có phải là logic miền chung hay không. Để tránh việc thông báo giống nhau bị gửi đi liên tục như một "dương tính giả," một tệp loại trừ có thể được sử dụng để lưu trữ những không gian tên có tên nút kết thúc chung nhưng không được coi là logic miền chung (chẳng hạn như nhiều không gian tên kết thúc bằng .calculate hoặc .validate). Ví dụ 5-4 cho thấy mã giả cho chức năng thể chất này.
Example 5-4. Pseudocode for finding common namespace leaf node names
# Walk the directory structure, creating namespaces for each complete pathLISTcomponent_list=identify_components(root_directory)# Locate possible duplicate component node names that are not in the exclusion# list stored in a datastoreLISTexcluded_leaf_node_list=read_datastore()LISTleaf_node_listLISTcommon_component_listFOREACHcomponentINcomponent_list{leaf_name=get_last_node(component)IFleaf_nameINleaf_node_listANDleaf_nameNOTINexcluded_leaf_node_list{ADDcomponentTOcommon_component_list}ELSE{ADDleaf_nameTOleaf_node_list}}# Send an alert if any possible common components were foundIFcommon_component_listNOTEMPTY{send_alert(common_component_list)}
Fitness function: Find common code across components
Chức năng thể dục tự động toàn diện này có thể được kích hoạt khi triển khai thông qua một pipeline CI/CD để xác định các lớp chung được sử dụng giữa các không gian tên. Mặc dù không luôn chính xác, chức năng này giúp thông báo cho kiến trúc sư về khả năng có tính năng miền trùng lặp. Giống như chức năng thể dục trước đó, một tệp loại trừ được sử dụng để giảm số lượng "dương tính giả" cho mã chung đã biết không được coi là logic miền trùng lặp. Ví dụ 5-5 cho thấy pseudocode cho chức năng thể dục này.
Example 5-5. Pseudocode for finding common source files between components
# Walk the directory structure, creating namespaces for each complete path and a list# of source file names for each componentLISTcomponent_list=identify_components(root_directory)LISTsource_file_list=get_source_files(root_directory)MAPcomponent_source_file_mapFOREACHcomponentINcomponent_list{LISTcomponent_source_file_list=get_source_files(component)ADDcomponent,component_source_file_listTOcomponent_source_file_map}# Locate possible common source file usage across components that are not in# the exclusion list stored in a datastoreLISTexcluded_source_file_list=read_datastore()LISTcommon_source_file_listFOREACHsource_fileINsource_file_list{SETcountTO0FOREACHcomponent,component_source_file_listINcomponent_source_file_map{IFsource_fileINcomponent_source_file_list{ADD1TOcount}}IFcount>1ANDsource_fileNOTINexcluded_source_file_list{ADDsource_fileTOcommon_source_file_list}}# Send an alert if any source files are used in multiple componentsIFcommon_source_file_listNOTEMPTY{send_alert(common_source_file_list)}
Sysops Squad Saga: Gathering Common Components
Thứ Sáu, ngày 5 tháng 11, 10:34
Sau khi xác định và phân loại các thành phần trong ứng dụng Sysops Squad, Addison đã áp dụng mẫu Tập hợp Các thành phần Miền Chung để xem có chức năng chung nào giữa các thành phần không. Từ danh sách các thành phần trong Bảng 5-3, Addison nhận thấy có ba thành phần liên quan đến việc thông báo cho khách hàng của Sysops Squad và đã liệt kê chúng trong Bảng 5-4.
| Component | Namespace | Responsibility |
|---|---|---|
Thông báo Khách hàng | thông báo khách hàng | Thông báo chung |
Thông báo vé | thông báo vé | Thông báo rằng chuyên gia đang trên đường đến. |
Thông báo Khảo sát | thông báo khảo sát | Gửi email khảo sát |
Khi mỗi thành phần thông báo này có một ngữ cảnh khác nhau để thông báo cho khách hàng, Addison nhận ra rằng chúng đều có một điểm chung – chúng đều gửi thông tin cho khách hàng. Hình 5-4 minh họa các thành phần thông báo chung này trong ứng dụng Sysops Squad.
Nhận thấy rằng mã nguồn chứa trong các thành phần này cũng rất giống nhau, Addison đã tham khảo ý kiến của Austen (kiến trúc sư khác trong nhóm Sysops). Austen thích ý tưởng về một thành phần thông báo duy nhất, nhưng lo ngại về việc ảnh hưởng đến mức độ kết nối tổng thể giữa các thành phần. Addison đồng ý rằng đây có thể là một vấn đề và đã điều tra thêm về sự đánh đổi này.
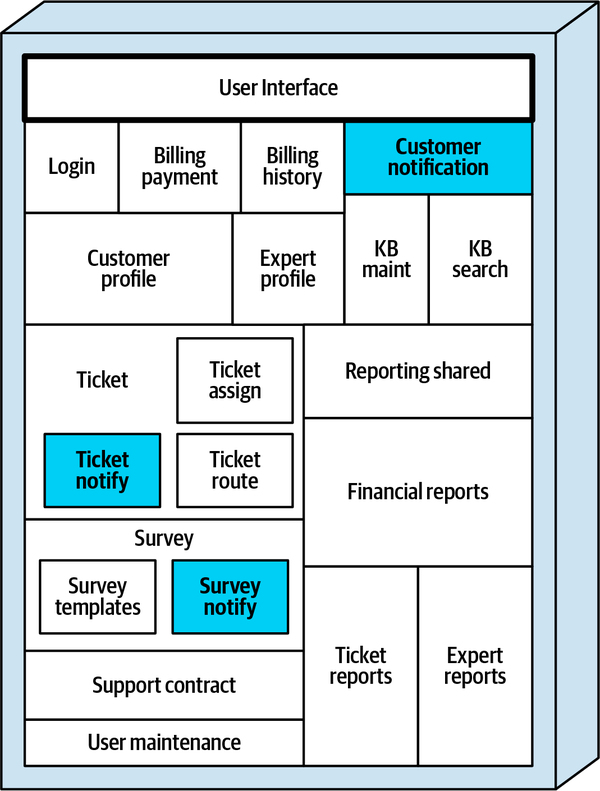
Figure 5-4. Notification functionality is duplicated throughout the application
Addison đã phân tích mức độ kết nối vào (kết nối đến) của các thành phần thông báo trong nhóm Sysops hiện tại và đưa ra các chỉ số kết nối kết quả được liệt kê trong Bảng 5-5, trong đó “CA” đại diện cho số lượng các thành phần khác yêu cầu thành phần đó (kết nối đến).
| Component | CA | Used by |
|---|---|---|
Thông báo khách hàng | 2 | Thanh toán hóa đơn, Hợp đồng hỗ trợ |
Thông báo vé | 2 | Vé, Đường vé |
Thông báo Khảo sát | 1 | Khảo sát |
Addison sau đó nhận thấy rằng nếu chức năng thông báo khách hàng được hợp nhất vào một thành phần duy nhất, mức độ liên kết cho thành phần duy nhất đó tăng lên mức độ liên kết đầu vào là 5, như được trình bày trong Bảng 5-6.
| Component | CA | Used by |
|---|---|---|
Thông báo | 5 | Thanh toán hóa đơn, Hợp đồng hỗ trợ, Vé, Lộ trình vé, Khảo sát |
Addison đã mang những phát hiện này đến cho Austen, và họ đã thảo luận về kết quả. Những gì họ phát hiện là, trong khi thành phần hợp nhất mới có mức độ kết nối vào khá cao, nhưng điều đó không ảnh hưởng đến mức độ kết nối vào tổng thể để thông báo cho khách hàng. Nói cách khác, ba thành phần riêng biệt có tổng mức độ kết nối vào là 5, nhưng thành phần hợp nhất duy nhất cũng có mức độ kết nối vào là 5.
Addison và Austen đều nhận ra tầm quan trọng của việc phân tích mức độ kết nối sau khi hợp nhất các chức năng miền chung. Trong một số trường hợp, việc kết hợp các chức năng miền chung thành một thành phần hợp nhất duy nhất đã làm tăng mức độ kết nối của thành phần đó, dẫn đến việc có quá nhiều phụ thuộc vào một thành phần chung trong ứng dụng. Tuy nhiên, trong trường hợp này, cả Addison và Austen đều cảm thấy thoải mái với phân tích kết nối, và đã đồng ý hợp nhất chức năng thông báo để giảm sự trùng lặp cả về mã lệnh lẫn chức năng.
Addison đã viết một câu chuyện kiến trúc để kết hợp tất cả các chức năng thông báo vào một không gian tên duy nhất đại diện cho một thành phần Thông báo chung. Sydney, được giao nhiệm vụ cho câu chuyện kiến trúc, đã tái cấu trúc mã nguồn, tạo ra một thành phần duy nhất cho thông báo khách hàng, như được minh họa trong Hình 5-5.
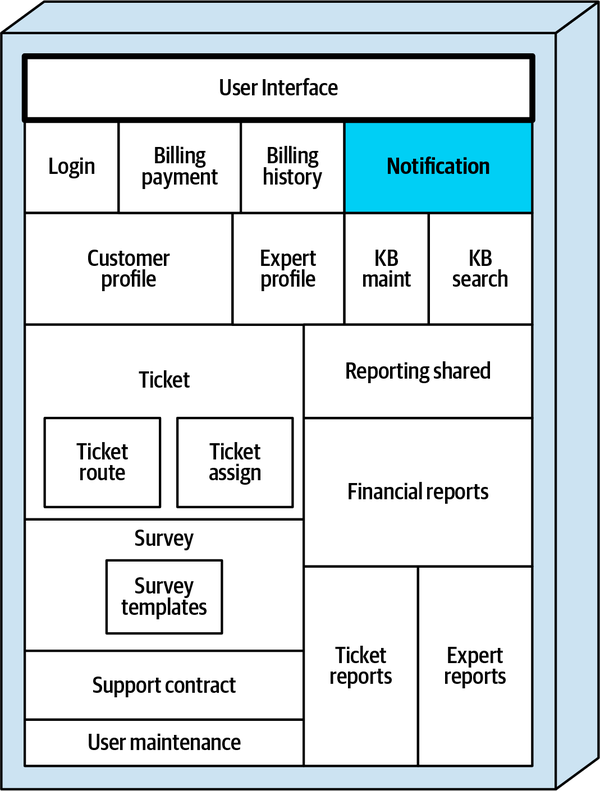
Figure 5-5. Notification functionality is consolidated into a new single component called Notification
Bảng 5-7 cho thấy các thành phần đã được tạo ra sau khi Sydney triển khai câu chuyện kiến trúc mà Addison đã tạo ra. Lưu ý rằng các thành phần Thông báo Khách hàng (ss.customer.notification), Thông báo Vé (ss.ticket.notify), và Thông báo Khảo sát (ss.survey.notify) đã bị xóa, và mã nguồn đã được chuyển đến thành phần Thông báo hợp nhất mới (ss.notification).
| Component | Namespace | Responsibility |
|---|---|---|
Đăng nhập | đăng nhập | Đăng nhập người dùng và khách hàng |
Thanh toán hóa đơn | thanh toán hóa đơn | Hóa đơn hàng tháng của khách hàng |
Lịch sử thanh toán | lịch sử thanh toán | Lịch sử thanh toán |
Hồ sơ khách hàng | Hồ sơ khách hàng | Duy trì hồ sơ khách hàng |
Hồ sơ Chuyên gia | hồ sơ.chuyên gia.ss | Duy trì hồ sơ chuyên gia |
Bảo trì KB | ss.kb.bảo trì | Duy trì và xem kho tri thức |
Tìm kiếm KB | Tìm kiếm ss.kb | Tìm kiếm cơ sở tri thức |
Thông báo | thông báo | Tất cả thông báo cho khách hàng |
Báo cáo Chia sẻ | báo cáo.chia sẻ | Chức năng chia sẻ |
Báo cáo vé | báo cáo.vé | Tạo báo cáo vé |
Báo cáo Chuyên gia | chuyên gia báo cáo ss | Tạo báo cáo chuyên gia |
Báo cáo tài chính | báo cáo.tài chính | Tạo báo cáo tài chính |
Vé | ss.ticket in Vietnamese is "vé ss". | Tạo và duy trì vé |
Gán vé | `ss.ticket.assign` in Vietnamese can be translated as `gán vé`. | Giao chuyên gia cho vé hỗ trợ |
Lộ trình vé | vé.ss.lộ trình | Gửi vé cho chuyên gia |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ | Bảo trì hợp đồng hỗ trợ |
Khảo sát | khảo sát ss | Gửi và nhận khảo sát |
Mẫu khảo sát | mẫu khảo sát ss | Duy trì các mẫu khảo sát |
Bảo trì người dùng | người dùng.ss | Duy trì người dùng nội bộ |
Flatten Components Pattern
Như đã đề cập trước đó, các thành phần—các khối xây dựng của một ứng dụng—thường được xác định thông qua không gian tên, cấu trúc gói hoặc cấu trúc thư mục và được triển khai thông qua các tệp lớp (hoặc tệp mã nguồn) chứa trong những cấu trúc này. Tuy nhiên, khi các thành phần được xây dựng dựa trên các thành phần khác, mà lại được xây dựng dựa trên các thành phần khác nữa, chúng bắt đầu đánh mất bản sắc của mình và ngừng trở thành các thành phần theo định nghĩa của chúng ta. Mẫu Flatten Components được sử dụng để đảm bảo rằng các thành phần không được xây dựng chồng lên nhau, mà thay vào đó được làm phẳng và được đại diện như các nút lá trong một cấu trúc thư mục hoặc không gian tên.
Pattern Description
Khi không gian tên đại diện cho một thành phần cụ thể được mở rộng (nói cách khác, một nút khác được thêm vào không gian tên hoặc cấu trúc thư mục), không gian tên hoặc thư mục trước đó sẽ không còn đại diện cho một thành phần nữa, mà thay vào đó là một miền con. Để minh họa cho điểm này, hãy xem chức năng khảo sát khách hàng trong ứng dụng Sysops Squad được đại diện bởi hai thành phần: Khảo sát (ss.survey) và Mẫu khảo sát (ss.survey.templates). Lưu ý trong Bảng 5-8 cách không gian tên ss.survey, chứa năm tệp lớp được sử dụng để quản lý và thu thập các cuộc khảo sát, được mở rộng với không gian tên ss.survey.templates để bao gồm bảy lớp đại diện cho từng loại khảo sát gửi đến khách hàng.
| Component name | Component namespace | Files |
|---|---|---|
→ Khảo sát | khảo sát ss | 5 |
Mẫu khảo sát | mẫu khảo sát | 7 |
Trong khi cấu trúc này có vẻ hợp lý từ quan điểm của nhà phát triển để giữ mã mẫu tách biệt với quy trình khảo sát, nó tạo ra một số vấn đề vì Mẫu Khảo sát, như một thành phần, sẽ được coi là một phần của thành phần Khảo sát. Người ta có thể bị cám dỗ để xem Mẫu Khảo sát như một tiểu thành phần của Khảo sát, nhưng sau đó các vấn đề phát sinh khi cố gắng hình thành các dịch vụ từ những thành phần này—cả hai thành phần nên nằm trong một dịch vụ duy nhất gọi là Khảo sát, hay Mẫu Khảo sát nên là một dịch vụ riêng biệt so với dịch vụ Khảo sát?
Chúng tôi đã giải quyết tình huống này bằng cách định nghĩa một thành phần là nút cuối cùng (hoặc nút lá) của cấu trúc không gian tên hoặc thư mục. Với định nghĩa này, ss.survey.templates là một thành phần, trong khi ss.survey sẽ được coi là một miền con, không phải là một thành phần. Chúng tôi cũng định nghĩa các không gian tên như ss.survey là không gian tên gốc vì chúng được mở rộng với các nút không gian tên khác (trong trường hợp này, .templates).
Lưu ý rằng không gian tên gốc ss.survey trong Bảng 5-8 chứa năm tệp lớp. Chúng tôi gọi những tệp lớp này là các lớp mồ côi vì chúng không thuộc về bất kỳ thành phần nào có thể xác định được. Nhớ rằng một thành phần được xác định bởi một nút lá không gian tên chứa mã nguồn. Bởi vì không gian tên ss.survey đã được mở rộng để bao gồm .templates, ss.survey không còn được coi là một thành phần và do đó không nên chứa bất kỳ tệp lớp nào.
Các thuật ngữ và định nghĩa tương ứng sau đây rất quan trọng để hiểu và áp dụng mẫu phân rã Flatten Components:
- Component
-
Một tập hợp các lớp được nhóm lại trong một không gian tên nút lá, thực hiện một số chức năng cụ thể nào đó trong ứng dụng (chẳng hạn như xử lý thanh toán hoặc chức năng khảo sát khách hàng).
- Root namespace
-
Một nút không gian tên đã được mở rộng bởi một nút không gian tên khác. Ví dụ, với các không gian tên ss.survey và ss.survey.templates, ss.survey sẽ được coi là một không gian tên gốc vì nó được mở rộng bởi .templates. Các không gian tên gốc đôi khi cũng được gọi là các tên miền con.
- Orphaned classes
-
Các lớp nằm trong một không gian tên gốc và do đó không có thành phần xác định nào liên quan đến chúng.
Các định nghĩa này được minh họa trong Hình 5-6, nơi hộp có ký hiệu C đại diện cho mã nguồn nằm trong không gian tên đó. Sơ đồ này (và tất cả các sơ đồ tương tự) được vẽ từ dưới lên nhằm nhấn mạnh khái niệm về các ngọn đồi trong ứng dụng, cũng như nhấn mạnh khái niệm về việc các không gian tên xây dựng dựa vào nhau.
Figure 5-6. Components, root namespaces, and orphaned classes (C box denotes source code)
Lưu ý rằng vì cả ss.survey và ss.ticket đều được mở rộng qua các nút không gian tên khác, nên những không gian tên đó được xem là không gian tên gốc, và các lớp chứa trong những không gian tên gốc đó do đó được xem là các lớp mồ côi (thuộc về không thành phần nào được xác định). Vì vậy, các thành phần duy nhất được biểu thị trong Hình 5-6 là ss.survey.templates, ss.login, ss.ticket.assign và ss.ticket.route.
Mô hình phân rã Các thành phần Phẳng được sử dụng để di chuyển các lớp mồ côi nhằm tạo ra các thành phần xác định rõ ràng chỉ tồn tại như là các nút lá trong một thư mục hoặc không gian tên, từ đó tạo ra các miền phụ xác định rõ ràng (không gian tên gốc). Chúng tôi gọi việc làm phẳng các thành phần là việc phân tách (hoặc xây dựng) các không gian tên trong một ứng dụng để loại bỏ các lớp mồ côi. Ví dụ, một cách để làm phẳng không gian tên gốc ss.survey trong Hình 5-6 và loại bỏ các lớp mồ côi là chuyển mã nguồn chứa trong không gian tên ss.survey.templates xuống không gian tên ss.survey, do đó biến ss.survey thành một thành phần duy nhất (.survey giờ đây là nút lá của không gian tên đó). Tùy chọn làm phẳng này được minh họa trong Hình 5-7.
Figure 5-7. Survey is flattened by moving the survey template code into the .survey namespace
Ngoài ra, việc làm phẳng cũng có thể được áp dụng bằng cách lấy mã nguồn trong ss.survey và áp dụng phân tích chức năng hoặc thiết kế hướng miền để xác định các lĩnh vực chức năng riêng biệt trong không gian tên gốc, từ đó hình thành các thành phần từ những lĩnh vực chức năng đó. Ví dụ, giả sử chức năng trong không gian tên ss.survey tạo và gửi một khảo sát cho khách hàng, và sau đó xử lý một khảo sát hoàn thành nhận từ khách hàng. Hai thành phần có thể được tạo ra từ không gian tên ss.survey: ss.survey.create, thành phần tạo và gửi khảo sát, và ss.survey.process, thành phần xử lý một khảo sát nhận từ khách hàng. Hình thức làm phẳng này được minh họa trong Hình 5-8.
Figure 5-8. Survey is flattened by moving the orphaned classes to new leaf nodes ( components)
Tip
Bất kể hướng làm phẳng nào, hãy đảm bảo rằng các tệp mã nguồn chỉ nằm trong các không gian tên hoặc thư mục lá, để mã nguồn có thể luôn được xác định trong một thành phần cụ thể.
Một kịch bản phổ biến khác mà mã nguồn mồ côi có thể tồn tại trong không gian tên gốc là khi mã được chia sẻ bởi các thành phần khác trong không gian tên đó. Hãy xem xét ví dụ trong Hình 5-9, nơi chức năng khảo sát khách hàng nằm trong ba thành phần (ss.survey.templates, ss.survey.create và ss.survey.process), nhưng mã chung (chẳng hạn như giao diện, lớp trừu tượng, tiện ích chung) nằm trong không gian tên gốc ss.survey.
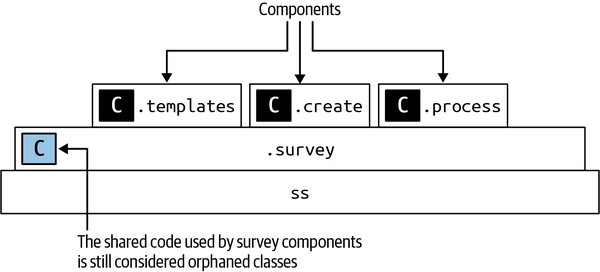
Figure 5-9. Shared code in .survey is considered orphaned classes and should be moved
Các lớp chia sẻ trong ss.survey vẫn được coi là lớp mồ côi, mặc dù chúng đại diện cho mã chia sẻ. Áp dụng mẫu Phẳng các Thành phần sẽ di chuyển những lớp mồ côi chia sẻ đó vào một thành phần mới gọi là ss.survey.shared, do đó loại bỏ tất cả các lớp mồ côi khỏi phân miền ss.survey, như được mô tả trong Hình 5-10.
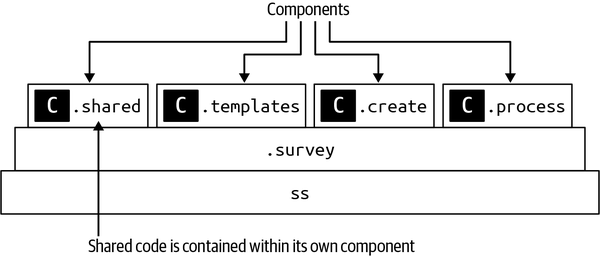
Figure 5-10. Shared survey code is moved into its own component
Lời khuyên của chúng tôi khi di chuyển mã chia sẻ sang một thành phần riêng biệt (tên không gian nút lá) là chọn một từ không được sử dụng trong bất kỳ mã nguồn nào hiện có trong miền, chẳng hạn như .sharedcode, .commoncode, hoặc một tên duy nhất nào đó. Điều này cho phép kiến trúc sư tạo ra các chỉ số dựa trên số lượng thành phần được chia sẻ trong mã nguồn, cũng như tỷ lệ phần trăm mã nguồn được chia sẻ trong ứng dụng. Đây là một chỉ báo tốt về khả năng tách biệt ứng dụng đơn thể. Ví dụ, nếu tổng số lệnh trong tất cả các không gian tên kết thúc bằng .sharedcode chiếm 45% tổng mã nguồn, khả năng cao là việc chuyển sang kiến trúc phân tán sẽ dẫn đến quá nhiều thư viện chung và trở nên khó khăn để duy trì vì các phụ thuộc vào thư viện chung.
Một chỉ số tốt khác liên quan đến việc phân tích mã chia sẻ là số lượng thành phần kết thúc bằng .sharedcode (hoặc bất kỳ nút không gian tên chia sẻ chung nào được sử dụng). Chỉ số này cung cấp cho kiến trúc sư cái nhìn về số lượng thư viện chia sẻ (JAR, DLL, và những thứ tương tự) hoặc dịch vụ chia sẻ sẽ hình thành từ việc phân tách ứng dụng đơn khối.
Fitness Functions for Governance
Việc áp dụng mô hình phân rã Flatten Components liên quan đến một lượng chủ quan khá lớn. Ví dụ, mã từ các nút lá có nên được hợp nhất vào không gian tên gốc hay mã trong không gian tên gốc có nên được chuyển vào các nút lá? Tuy nhiên, hàm fitness sau đây có thể hỗ trợ trong việc tự động hóa quản lý việc giữ cho các thành phần phẳng (chỉ ở các nút lá).
Fitness function: No source code should reside in a root namespace
Chức năng thể dục tự động toàn diện này có thể được kích hoạt khi triển khai qua một pipeline CI/CD để tìm kiếm các lớp mồ côi - các lớp nằm trong không gian tên gốc. Việc sử dụng chức năng thể dục này giúp giữ cho các thành phần phẳng trong quá trình chuyển đổi monolithic, đặc biệt là khi thực hiện bảo trì liên tục cho ứng dụng monolithic trong suốt quá trình chuyển đổi. Ví dụ 5-6 cho thấy pseudocode mà thông báo cho kiến trúc sư khi xuất hiện các lớp mồ côi ở bất kỳ đâu trong cơ sở mã.
Example 5-6. Pseudocode for finding code in root namespaces
# Walk the directory structure, creating namespaces for each complete pathLISTcomponent_list=identify_components(root_directory)# Send an alert if a non-leaf node in any component contains source filesFOREACHcomponentINcomponent_list{LISTcomponent_node_list=get_nodes(component)FOREACHnodeINcomponent_node_list{IFcontains_code(node)ANDNOTlast_node(component_node_list){send_alert(component)}}}
Sysops Squad Saga: Flattening Components
Thứ tư, ngày 10 tháng 11, 11:10
Sau khi áp dụng “Mô hình Tập hợp các Thành phần Miền Chung”, Addison đã phân tích kết quả trong Bảng 5-7 và nhận thấy rằng các thành phần Khảo sát và Vé chứa các lớp mồ côi. Addison đã làm nổi bật những thành phần này trong Bảng 5-9 và Hình 5-11.
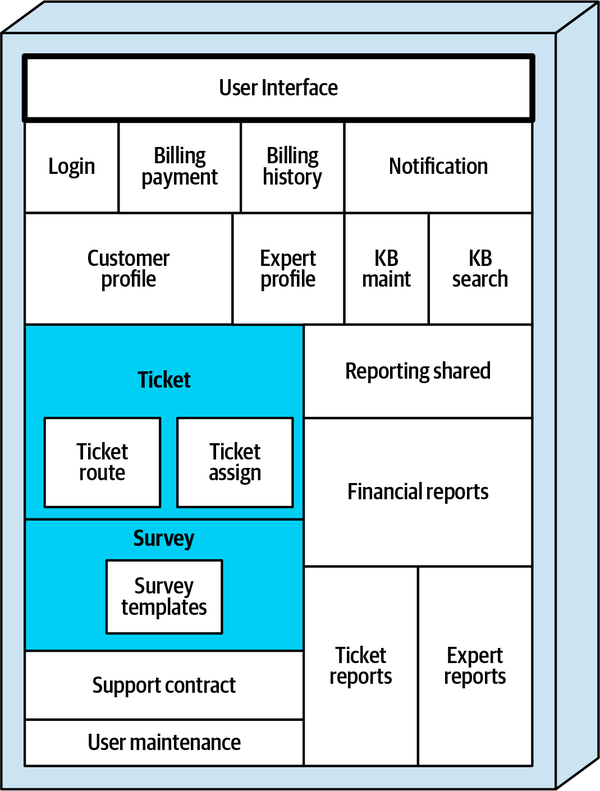
Figure 5-11. The Survey and Ticket components contain orphaned classes and should be flattened
| Component name | Component namespace | Statements | Files |
|---|---|---|---|
Vé | vé ss | bảy nghìn không trăm chín | 45 |
Gán vé | ss.ticket.assign translates to "gán vé". | bảy nghìn tám trăm bốn mươi lăm | 14 |
Lộ trình vé | Đường đi vé ss | Một nghìn bốn trăm sáu mươi tám | 4 |
Khảo sát | khảo sát | Hai ngàn hai trăm bốn. | 5 |
Mẫu Khảo Sát | mẫu khảo sát | Một nghìn sáu trăm bảy mươi hai | 7 |
Addison quyết định giải quyết các thành phần ticketing trước. Biết rằng việc làm phẳng các thành phần có nghĩa là loại bỏ mã nguồn ở các nút không lá, Addison có hai lựa chọn: hợp nhất mã contained trong các thành phần phân bổ vé và định tuyến vé vào thành phần ss.ticket, hoặc chia nhỏ 45 lớp trong thành phần ss.ticket thành các thành phần riêng biệt, từ đó biến ss.ticket thành một miền con. Addison đã thảo luận về những lựa chọn này với Sydney (một trong những lập trình viên của đội Sysops), và dựa trên sự phức tạp và sự thay đổi thường xuyên trong chức năng phân bổ vé, đã quyết định giữ các thành phần đó tách biệt và di chuyển mã bị bỏ rơi từ không gian tên gốc ss.ticket vào các không gian tên khác, từ đó hình thành nên các thành phần mới.
Với sự giúp đỡ từ Sydney, Addison đã phát hiện rằng 45 lớp trẻ mồ côi nằm trong không gian tên ss.ticket đã triển khai các chức năng quản lý vé sau đây:
-
Tạo và bảo trì vé (tạo vé, cập nhật vé, hủy vé, v.v.)
-
Logic hoàn thành vé
-
Mã chia sẻ chung cho hầu hết các chức năng đặt vé.
Vì chức năng phân công vé và định tuyến vé đã có trong các thành phần riêng (ss.ticket.assign và ss.ticket.route, tương ứng), Addison đã tạo một câu chuyện kiến trúc để chuyển mã nguồn chứa trong không gian tên ss.ticket sang ba thành phần mới, như được trình bày trong Bảng 5-10.
| Component | Namespace | Responsibility |
|---|---|---|
Vé đã được chia sẻ |
| Mã chung và tiện ích |
Bảo trì vé | ss.ticket.bảo trì | Thêm và duy trì vé |
Hoàn thành vé | ss.ticket.completion dịch sang tiếng Việt là "hoàn thành vé ss". | Hoàn thành vé và bắt đầu khảo sát |
Gán vé | gán vé ss | Gán chuyên gia cho vé |
Lộ trình vé | đường đi vé số | Gửi vé cho chuyên gia |
Addison sau đó đã xem xét chức năng khảo sát. Làm việc với Sydney, Addison nhận thấy rằng chức năng khảo sát hiếm khi thay đổi và không quá phức tạp. Sydney đã nói chuyện với Skyler, nhà phát triển của đội Sysops đã tạo ra không gian tên ss.survey.templates, và phát hiện ra rằng không có lý do thuyết phục để tách các mẫu khảo sát thành không gian tên riêng (“Nó chỉ có vẻ là một ý tưởng hay vào thời điểm đó,” Skyler nói). Với thông tin này, Addison đã tạo ra một câu chuyện kiến trúc để di chuyển bảy tệp lớp từ ss.survey.templates vào không gian tên ss.survey và loại bỏ thành phần ss.survey.template, như được trình bày trong Bảng 5-11.
| Component | Namespace | Responsibility |
|---|---|---|
Khảo sát | khảo sát | Gửi và nhận khảo sát |
Sau khi áp dụng mẫu Flatten Components (được minh họa trong Hình 5-12), Addison nhận thấy rằng không có “đồi” (các thành phần chồng lên nhau) hoặc các lớp mồ côi và tất cả các thành phần chỉ được chứa trong các nút lá của không gian tên tương ứng.
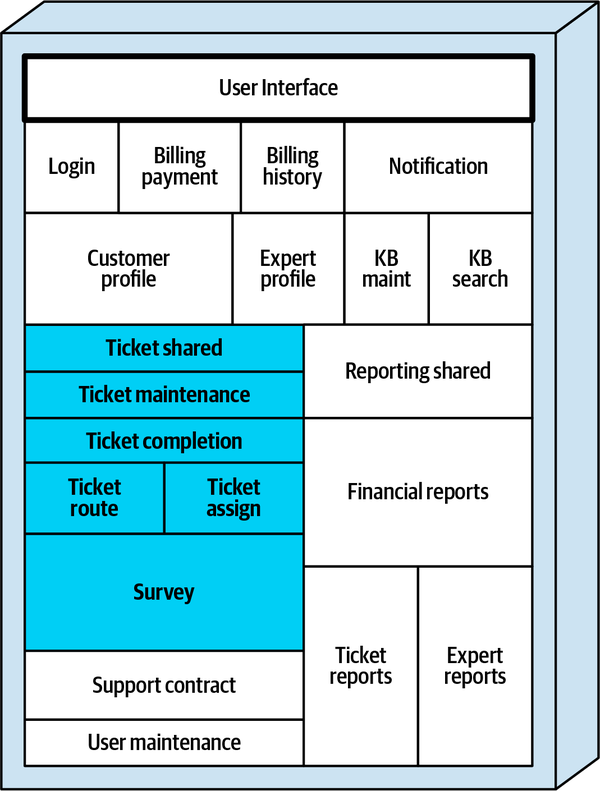
Figure 5-12. The Survey component was flattened into a single component, whereas the Ticket component was raised up and flattened, creating a Ticket subdomain
Addison đã ghi lại kết quả của những nỗ lực tái cấu trúc cho đến nay trong việc áp dụng các mẫu phân tách này và liệt kê chúng trong Bảng 5-12.
| Component | Namespace |
|---|---|
Đăng nhập | đăng nhập |
Thanh toán hóa đơn | Thanh toán hóa đơn |
Lịch sử thanh toán | lịch sử thanh toán ss |
Hồ sơ Khách hàng | Hồ sơ khách hàng |
Hồ sơ Chuyên gia | chuyên gia hồ sơ |
Bảo trì KB | Bảo trì ss.kb. |
Tìm kiếm KB | tìm kiếm.ss.kb |
Thông báo | Thông báo ss. |
Báo cáo chia sẻ | báo cáo.chia sẻ |
Báo cáo vé | báo cáo.thẻ vé |
Báo cáo chuyên gia | chuyên gia báo cáo |
Báo cáo tài chính | báo cáo.tài chính |
Vé đã được chia sẻ | vé chia sẻ |
Bảo trì vé | bảo trì vé ss |
Hoàn thành vé | ss.ticket.completion = hoàn thành vé ss |
Gán vé | ss.ticket.assign translates to "gán vé ss" in Vietnamese. |
Lộ trình vé | ss.ticket.route: tuyến vé ss |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ |
Khảo sát | khảo sát |
Bảo trì người dùng | người dùng.ss |
Determine Component Dependencies Pattern
Ba câu hỏi phổ biến nhất thường được đặt ra khi xem xét việc chuyển đổi từ ứng dụng đơn khối sang kiến trúc phân tán như sau:
-
Có khả thi để tách rời ứng dụng đơn thể hiện tại không?
-
Mức độ nỗ lực tổng thể ước chừng cho việc này là gì?
-
Điều này có yêu cầu phải viết lại mã hoặc tái cấu trúc mã không?
Một trong những tác giả của bạn đã tham gia vào một nỗ lực di chuyển lớn cách đây vài năm để chuyển một ứng dụng phức tạp từ kiến trúc đơn khối sang microservices. Vào ngày đầu tiên của dự án, CIO chỉ muốn biết một điều duy nhất—nỗ lực di chuyển này là một quả bóng golf, một quả bóng rổ hay một máy bay chở khách? Tác giả của bạn cảm thấy tò mò về những so sánh kích thước này, nhưng CIO khăng khăng rằng câu trả lời cho câu hỏi đơn giản này không nên khó đến vậy, xét về kích thước thô. Như đã diễn ra, việc áp dụng mô hình Xác định sự phụ thuộc giữa các thành phần đã nhanh chóng và dễ dàng trả lời câu hỏi này cho CIO—nỗ lực này thật không may lại giống như một máy bay chở khách, nhưng chỉ là một cuộc di chuyển nhỏ của chiếc Embraer 190 chứ không phải là một cuộc di chuyển lớn của chiếc Boeing 787 Dreamliner.
Pattern Description
Mục đích của mẫu Xác định Các phụ thuộc Thành phần là phân tích các phụ thuộc đến và đi (sự kết nối) giữa các thành phần để xác định hình dạng của đồ thị phụ thuộc dịch vụ có thể trông như thế nào sau khi tách rời ứng dụng nguyên khối. Mặc dù có nhiều yếu tố trong việc xác định mức độ chi tiết đúng cho một dịch vụ (xem Chương 7), mỗi thành phần trong ứng dụng nguyên khối đều có thể là một ứng cử viên dịch vụ (tuỳ thuộc vào kiểu kiến trúc phân tán mục tiêu). Vì lý do này, việc hiểu rõ các tương tác và phụ thuộc giữa các thành phần là rất quan trọng.
Cần lưu ý rằng mẫu này đề cập đến sự phụ thuộc của các thành phần, chứ không phải sự phụ thuộc của các lớp riêng lẻ trong một thành phần. Một sự phụ thuộc thành phần được hình thành khi một lớp từ một thành phần (tên không gian) tương tác với một lớp từ một thành phần khác (tên không gian). Ví dụ, giả sử lớp CustomerSurvey trong thành phần ss.survey gọi một phương thức trong lớp CustomerNotification trong thành phần ss.notification để gửi khảo sát khách hàng, như được minh họa trong mã giả ở Ví dụ 5-7.
Example 5-7. Pseudocode showing a dependency between the Survey and Notification components
namespacess.surveyclassCustomerSurvey{functioncreateSurvey{...}functionsendSurvey{...ss.notification.CustomerNotification.send(customer_id,survey)}}
Lưu ý sự phụ thuộc giữa các thành phần Khảo sát và Thông báo, vì lớp CustomerNotification được sử dụng bởi lớp CustomerSurvey nằm ngoài không gian tên ss.survey. Cụ thể, thành phần Khảo sát sẽ có một sự phụ thuộc efferent (hoặc outgoing) vào thành phần Thông báo, và thành phần Thông báo sẽ có một sự phụ thuộc afferent (hoặc incoming) vào thành phần Khảo sát.
Lưu ý rằng các lớp trong một thành phần cụ thể có thể là một mớ hỗn độn liên kết chặt chẽ của nhiều phụ thuộc, nhưng điều đó không quan trọng khi áp dụng mẫu này—điều quan trọng chỉ là những phụ thuộc giữa các thành phần.
Nhiều công cụ có sẵn có thể hỗ trợ trong việc áp dụng mẫu này và hình dung các phụ thuộc của thành phần. Ngoài ra, nhiều IDE hiện đại có các plug-in sẽ tạo ra các sơ đồ phụ thuộc của các thành phần hoặc không gian tên trong một mã nguồn cụ thể. Những hình ảnh trực quan này có thể hữu ích trong việc trả lời ba câu hỏi chính được đặt ra ở đầu phần này.
Ví dụ, hãy xem xét sơ đồ phụ thuộc được hiển thị trong Hình 5-13, nơi các hộp đại diện cho các thành phần (không phải lớp), và các đường thẳng đại diện cho các điểm kết nối giữa các thành phần. Lưu ý rằng chỉ có một phụ thuộc duy nhất giữa các thành phần trong sơ đồ này, làm cho ứng dụng này trở thành một ứng viên tốt để phân tách vì các thành phần này độc lập về mặt chức năng với nhau.
Figure 5-13. A monolithic application with minimal component dependencies takes less effort to break apart (golf ball sizing)
Với một sơ đồ phụ thuộc như Hình 5-13, câu trả lời cho ba câu hỏi chính là như sau:
-
Có khả thi để tách rời ứng dụng monolithic hiện có không? Có.
-
Mức độ nỗ lực tổng thể cho việc di chuyển này là khoảng nào? Một quả bóng golf (tương đối đơn giản).
-
Điều này sẽ là viết lại mã hay là tái cấu trúc mã? Tái cấu trúc (di chuyển mã hiện có vào các dịch vụ được triển khai riêng biệt)
Bây giờ hãy nhìn vào sơ đồ phụ thuộc được hiển thị trong Hình 5-14. Thật không may, sơ đồ này là điển hình cho các phụ thuộc giữa các thành phần trong hầu hết các ứng dụng doanh nghiệp. Lưu ý đặc biệt rằng bên trái của sơ đồ này có mức độ gắn bó cao nhất, trong khi bên phải trông khả thi hơn nhiều để tách rời.
Figure 5-14. A monolithic application with a high number of component dependencies takes more effort to break apart (basketball sizing)
Với mức độ gắn bó chặt chẽ giữa các thành phần này, câu trả lời cho ba câu hỏi quan trọng không được lạc quan lắm:
-
Có khả thi để tách rời ứng dụng đơn khối hiện tại không? Có thể...
-
Mức độ nỗ lực tổng thể cho việc di chuyển này là gì? Một quả bóng rổ (khó hơn nhiều).
-
Đây sẽ là việc viết lại mã hay cải tiến mã? Có khả năng là một sự kết hợp giữa một số cải tiến và một số viết lại mã hiện có.
Cuối cùng, hãy xem xét sơ đồ phụ thuộc được minh họa trong Hình 5-15. Trong trường hợp này, kiến trúc sư nên quay lại và chạy theo hướng ngược lại nhanh nhất có thể!
Figure 5-15. A monolithic application with too many component dependencies is not feasible to break apart (airliner sizing)
Câu trả lời cho ba câu hỏi chính đối với các ứng dụng có ma trận phụ thuộc thành phần kiểu này không có gì bất ngờ:
-
Không, việc tách rời ứng dụng đơn khối hiện tại là không khả thi.
-
Mức độ nỗ lực tổng thể cho việc chuyển giao này là gì? Một hãng hàng không.
-
Điều này sẽ là viết lại mã hay tái cấu trúc mã? Viết lại hoàn toàn ứng dụng.
Chúng tôi không thể nhấn mạnh đủ tầm quan trọng của những loại sơ đồ hình ảnh này khi tách rời một ứng dụng nguyên khối. Về bản chất, những sơ đồ này hình thành một radar để xác định vị trí của kẻ thù (sự kết nối chặt chẽ giữa các thành phần), và cũng tạo ra một bức tranh về cách mà ma trận phụ thuộc dịch vụ sẽ như thế nào nếu ứng dụng nguyên khối được tách ra thành một kiến trúc phân tán cao.
Theo kinh nghiệm của chúng tôi, sự liên kết giữa các thành phần là một trong những yếu tố quan trọng nhất trong việc xác định thành công (và tính khả thi) của nỗ lực di cư từ monolithic. Việc xác định và hiểu mức độ liên kết giữa các thành phần không chỉ cho phép kiến trúc sư xác định tính khả thi của nỗ lực di cư, mà còn cho họ biết nên mong đợi điều gì về mức độ công sức tổng thể. Đáng tiếc, rất thường xuyên chúng tôi thấy các đội ngũ lao vào việc phân tách một ứng dụng monolithic thành các microservices mà không có bất kỳ phân tích hay hình ảnh nào về hình thức của ứng dụng monolithic. Và không có gì ngạc nhiên, những đội ngũ đó gặp khó khăn trong việc phá vỡ các ứng dụng monolithic của họ.
Mô hình này không chỉ hữu ích cho việc xác định mức độ liên kết tổng thể của các thành phần trong một ứng dụng, mà còn để xác định cơ hội tái cấu trúc các phụ thuộc trước khi tách rời ứng dụng. Khi phân tích mức độ liên kết giữa các thành phần, điều quan trọng là phải phân tích cả liên kết đến (afferent) (thường được ký hiệu là CA trong hầu hết các công cụ), và liên kết đi (efferent) (thường được ký hiệu là CE trong hầu hết các công cụ). CT, hoặc liên kết tổng, là tổng của cả liên kết đến và liên kết đi.
Nhiều lần, việc tách rời một thành phần có thể giảm mức độ kết nối của thành phần đó. Ví dụ, giả sử thành phần A có mức độ kết nối hướng vào là 20 (nghĩa là, 20 thành phần khác phụ thuộc vào chức năng của thành phần này). Điều này không nhất thiết có nghĩa là tất cả 20 thành phần khác đều cần tất cả chức năng từ thành phần A. Có thể 14 trong số các thành phần khác chỉ cần một phần nhỏ chức năng có trong thành phần A. Việc tách thành phần A thành hai thành phần khác nhau (thành phần A1 chứa chức năng nhỏ hơn, kết nối với nhau, và thành phần A2 chứa phần lớn chức năng) làm giảm mức độ kết nối hướng vào của thành phần A2 xuống còn 6, trong khi thành phần A1 có mức độ kết nối hướng vào là 14.
Fitness Functions for Governance
Hai cách để tự động hóa việc quản lý các thành phần phụ thuộc là đảm bảo không có thành phần nào có "quá nhiều" phụ thuộc, và hạn chế một số thành phần không được kết hợp với các thành phần khác. Các hàm đánh giá được mô tả dưới đây là một số cách để quản lý các loại phụ thuộc này.
Fitness function: No component shall have more than <some number> of total dependencies
Hàm chức năng thể hình tự động toàn diện này có thể được kích hoạt khi triển khai thông qua một pipeline CI/CD để đảm bảo rằng mức độ kết nối của bất kỳ thành phần nào không vượt quá một ngưỡng nhất định. Tùy thuộc vào kiến trúc sư để xác định rằng ngưỡng tối đa này nên dựa trên mức độ kết nối tổng thể trong ứng dụng và số lượng thành phần. Một cảnh báo được tạo ra từ hàm chức năng này cho phép kiến trúc sư thảo luận về bất kỳ sự gia tăng nào trong kết nối với nhóm phát triển, có thể thúc đẩy hành động để tách biệt các thành phần nhằm giảm mức độ kết nối. Hàm chức năng này cũng có thể được sửa đổi để tạo ra một cảnh báo cho giới hạn ngưỡng chỉ đến, chỉ đi hoặc cả hai (như các hàm chức năng riêng biệt). Ví dụ 5-8 cho thấy mã giả để gửi cảnh báo nếu tổng kết nối (đến và đi) vượt quá một mức tổng hợp là 15, mà đối với hầu hết các ứng dụng sẽ được coi là tương đối cao.
Example 5-8. Pseudocode for limiting the total number of dependencies of any given component
# Walk the directory structure, gathering components and the source code files# contained within those componentsLISTcomponent_list=identify_components(root_directory)MAPcomponent_source_file_mapFOREACHcomponentINcomponent_list{LISTcomponent_source_file_list=get_source_files(component)ADDcomponent,component_source_file_listTOcomponent_source_file_map}# Determine how many references exist for each source file and send an alert if# the total dependency count is greater than 15FOREACHcomponent,component_source_file_listINcomponent_source_file_map{FOREACHsource_fileINcomponent_source_file_list{incomingcount=used_by_other_components(source_file,component_source_file_map){outgoing_count=uses_other_components(source_file){total_count=incomingcount+outgoingcount}IFtotal_count>15{send_alert(component,total_count)}}
Fitness function: <some component> should not have a dependency on <another component>
Chức năng kiểm tra thể chất tự động này có thể được kích hoạt khi triển khai thông qua một đường ống CI/CD để hạn chế một số thành phần không phụ thuộc vào những thành phần khác. Trong hầu hết các trường hợp, sẽ có một chức năng kiểm tra thể chất cho mỗi hạn chế phụ thuộc, vì vậy nếu có 10 hạn chế khác nhau cho các thành phần, sẽ có 10 chức năng kiểm tra thể chất khác nhau, một cho mỗi thành phần liên quan. Ví dụ 5-9 cho thấy một ví dụ sử dụng ArchUnit để đảm bảo rằng thành phần Bảo trì Vé (ss.ticket.maintenance) không có phụ thuộc vào thành phần Hồ sơ Chuyên gia (ss.expert.profile).
Example 5-9. ArchUnit code for governing dependency restrictions between components
publicvoidticket_maintenance_cannot_access_expert_profile(){noClasses().that().resideInAPackage("..ss.ticket.maintenance..").should().accessClassesThat().resideInAPackage("..ss.expert.profile..").check(myClasses);}
Sysops Squad Saga: Identifying Component Dependencies
Thứ Hai, ngày 15 tháng 11, 09:45
Sau khi đọc về mô hình Xác định Phụ thuộc Thành phần, Addison tự hỏi ma trận phụ thuộc ứng dụng của đội Sysops Squad trông như thế nào và liệu có khả thi để tách ứng dụng ra hay không. Addison đã sử dụng một tiện ích mở rộng IDE để tạo ra một sơ đồ phụ thuộc thành phần của ứng dụng Sysops Squad hiện tại. Ban đầu, Addison cảm thấy hơi nản lòng vì Hình 5-16 cho thấy nhiều phụ thuộc giữa các thành phần của ứng dụng Sysops Squad.
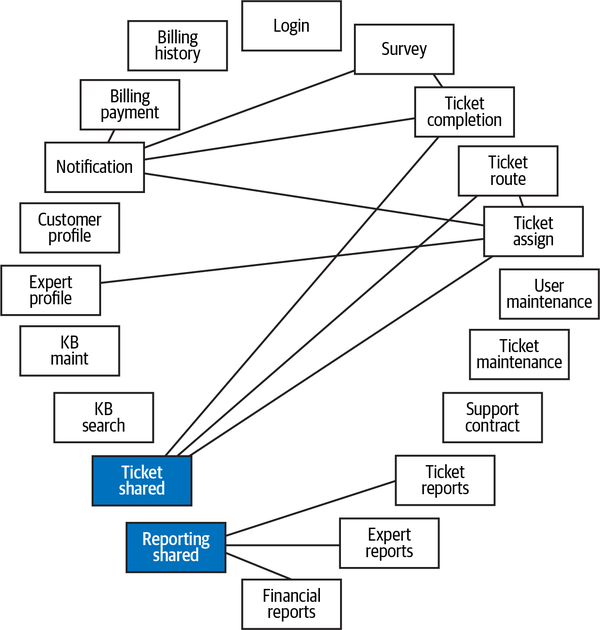
Figure 5-16. Component dependencies in the Sysops Squad application
Tuy nhiên, sau khi phân tích thêm, Addison nhận thấy rằng thành phần Thông báo có nhiều phụ thuộc nhất, điều này không có gì ngạc nhiên vì đây là thành phần dùng chung. Tuy nhiên, Addison cũng nhận thấy có nhiều phụ thuộc trong các thành phần Xử lý vé và Báo cáo. Cả hai lĩnh vực miền này đều có một thành phần cụ thể cho mã dùng chung (giao diện, lớp trợ giúp, lớp thực thể, và v.v.). Nhận ra rằng cả mã dùng chung của hệ thống xử lý vé và báo cáo chủ yếu chứa các tham chiếu lớp dựa trên biên dịch và có khả năng sẽ được triển khai dưới dạng thư viện chia sẻ hơn là dịch vụ, Addison đã lọc bỏ các thành phần này để có cái nhìn tốt hơn về các phụ thuộc giữa chức năng cốt lõi của ứng dụng, điều này được minh hoạ trong Hình 5-17.
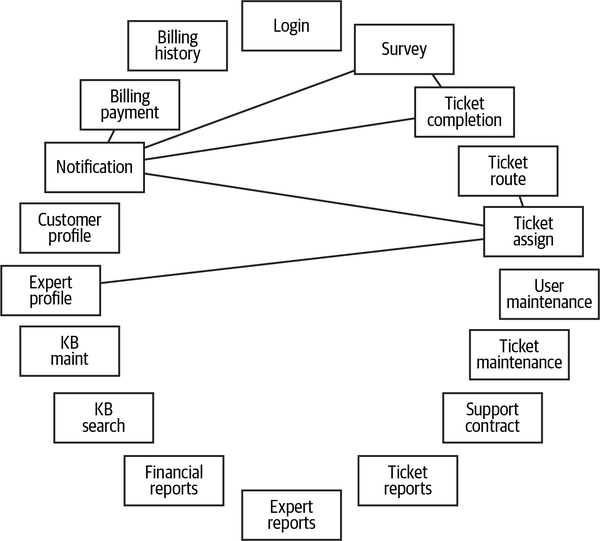
Figure 5-17. Component dependencies in the Sysops Squad application without shared library dependencies
Sau khi các thành phần chung được lọc ra, Addison nhận thấy rằng các phụ thuộc khá tối thiểu. Addison đã trình bày kết quả này cho Austen, và cả hai đều đồng ý rằng hầu hết các thành phần đều tương đối độc lập và có vẻ như ứng dụng Sysops Squad là một ứng cử viên tốt để tách ra thành một kiến trúc phân tán.
Create Component Domains Pattern
Trong khi mỗi thành phần được xác định trong một ứng dụng đơn thể có thể được coi là một ứng cử viên khả thi cho một dịch vụ riêng biệt, trong hầu hết các trường hợp, mối quan hệ giữa một dịch vụ và các thành phần là mối quan hệ một-nhiều—tức là, một dịch vụ có thể chứa một hoặc nhiều thành phần. Mục đích của mẫu Tạo Miền Thành Phần là nhóm các thành phần lại với nhau một cách hợp lý để có thể tạo ra các dịch vụ miền thô hơn khi phân tách một ứng dụng.
Pattern Description
Xác định các miền thành phần—nhóm các thành phần thực hiện một số chức năng liên quan—là một phần quan trọng trong việc tách rời bất kỳ ứng dụng đơn khối nào. Nhớ lại lời khuyên từ Chương 4:
Khi tách rời các ứng dụng đơn khối, hãy xem xét việc chuyển sang kiến trúc dựa trên dịch vụ như một bước đệm để đến các kiến trúc phân tán khác.
Tạo ra các miền thành phần là một cách hiệu quả để xác định những gì sẽ trở thành dịch vụ miền trong kiến trúc dựa trên dịch vụ.
Các miền thành phần được thể hiện vật lý trong một ứng dụng thông qua các không gian tên (hoặc thư mục) thành phần. Bởi vì các nút không gian tên có tính chất phân cấp, chúng trở thành một cách tuyệt vời để đại diện cho các miền và tiểu miền chức năng. Kỹ thuật này được minh họa trong Hình 5-18, nơi nút thứ hai trong không gian tên (.customer) đề cập đến miền, nút thứ ba đại diện cho một tiểu miền dưới miền khách hàng (.billing), và nút lá (.payment) đề cập đến thành phần. .MonthlyBilling ở cuối không gian tên này đề cập đến một tệp lớp nằm trong thành phần Payment.
Figure 5-18. Component domains are identified through the namespace nodes
Vì nhiều ứng dụng monolithic cũ được triển khai trước khi thiết kế theo miền trở nên phổ biến, trong nhiều trường hợp việc tái cấu trúc các không gian tên là cần thiết để xác định cấu trúc các miền trong ứng dụng. Ví dụ, hãy xem xét các thành phần được liệt kê trong Bảng 5-13 tạo thành miền Khách hàng trong ứng dụng Sysops Squad.
| Component | Namespace |
|---|---|
Thanh toán hóa đơn | thanh toán hóa đơn |
Lịch sử thanh toán | lịch sử thanh toán |
Hồ sơ khách hàng | hồ sơ khách hàng |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ |
Chú ý rằng mỗi thành phần đều liên quan đến chức năng của khách hàng, nhưng các không gian tên tương ứng không phản ánh sự liên kết đó. Để nhận diện đúng miền Khách hàng (được thể hiện qua không gian tên ss.customer), các không gian tên cho các thành phần Thanh toán Hoá đơn, Lịch sử Hoá đơn và Hợp đồng Hỗ trợ sẽ phải được sửa đổi để thêm nút .customer ở đầu không gian tên, như đã trình bày trong Bảng 5-14.
| Component | Namespace |
|---|---|
Thanh toán hóa đơn | thanh toán hóa đơn khách hàng |
Lịch sử thanh toán | lịch sử thanh toán của khách hàng |
Hồ sơ khách hàng | Hồ sơ khách hàng |
Hợp đồng hỗ trợ | hợp đồng hỗ trợ khách hàng |
Lưu ý trong bảng trước rằng tất cả các chức năng liên quan đến khách hàng (thanh toán, duy trì hồ sơ và duy trì hợp đồng hỗ trợ) hiện được nhóm lại dưới .customer, để mỗi thành phần được sắp xếp theo miền cụ thể đó.
Fitness Functions for Governance
Sau khi đã được tái cấu trúc, việc quản lý các miền thành phần là rất quan trọng để đảm bảo rằng các quy tắc không gian tên được thực thi và không có mã nào tồn tại ngoài bối cảnh của một miền thành phần hoặc miền con. Hàm kiểm tra tự động sau đây có thể được sử dụng để giúp quản lý các miền thành phần khi chúng đã được thiết lập trong ứng dụng đơn thể.
Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
Chức năng thể lực toàn diện tự động này có thể được kích hoạt khi triển khai thông qua một quy trình CI/CD để hạn chế các miền có trong một ứng dụng. Chức năng thể lực này giúp ngăn ngừa việc phát sinh thêm các miền một cách không ý thức bởi các nhóm phát triển và thông báo cho kiến trúc sư nếu có bất kỳ không gian tên (hoặc thư mục) mới nào được tạo ra ngoài danh sách miền đã được phê duyệt. Ví dụ 5-10 minh họa một ví dụ sử dụng ArchUnit để đảm bảo rằng chỉ có các miền ticket, customer và admin tồn tại trong một ứng dụng.
Example 5-10. ArchUnit code for governing domains within an application
publicvoidrestrict_domains(){classes().should().resideInAPackage("..ss.ticket..").orShould().resideInAPackage("..ss.customer..").orShould().resideInAPackage("..ss.admin..").check(myClasses);}
Sysops Squad Saga: Creating Component Domains
Thứ Năm, 18 tháng 11, 13:15
Addison và Austen đã tham khảo ý kiến của Parker, chủ sở hữu sản phẩm của đội Sysops Squad, và cùng nhau xác định năm lĩnh vực chính trong ứng dụng: lĩnh vực Ticketing (ss.ticket) chứa tất cả các chức năng liên quan đến vé, bao gồm xử lý vé, khảo sát khách hàng và chức năng cơ sở tri thức (KB); lĩnh vực Reporting (ss.reporting) chứa tất cả các chức năng báo cáo; lĩnh vực Customer (ss.customer) chứa hồ sơ khách hàng, thanh toán và hợp đồng hỗ trợ; lĩnh vực Admin (ss.admin) chứa việc bảo trì người dùng và các chuyên gia của đội Sysops Squad; và cuối cùng, lĩnh vực Shared (ss.shared) chứa các chức năng đăng nhập và thông báo được các lĩnh vực khác sử dụng.
Addison đã tạo ra một sơ đồ miền (xem Hình 5-19) cho thấy các miền khác nhau và các nhóm thành phần tương ứng trong mỗi miền, và hài lòng với việc phân nhóm này vì không có thành phần nào bị bỏ sót, và có sự gắn kết tốt giữa các thành phần trong mỗi miền.
Bài tập mà Addison thực hiện trong việc lập sơ đồ và phân nhóm các thành phần là rất quan trọng vì nó đã xác thực các ứng viên miền đã xác định và cũng cho thấy sự cần thiết phải hợp tác với các bên liên quan trong kinh doanh (chẳng hạn như người sở hữu sản phẩm hoặc người tài trợ ứng dụng kinh doanh). Nếu các thành phần không được sắp xếp đúng cách hoặc Addison còn lại với những thành phần không thuộc về đâu, sẽ cần phải hợp tác thêm với Parker (người sở hữu sản phẩm).
Hài lòng rằng tất cả các thành phần đều phù hợp với các miền này, Addison sau đó đã nhìn vào các không gian tên thành phần khác nhau trong Bảng 5-12 sau khi áp dụng “Mô hình Làm phẳng Các Thành phần” và xác định việc cải tiến miền thành phần cần phải diễn ra.
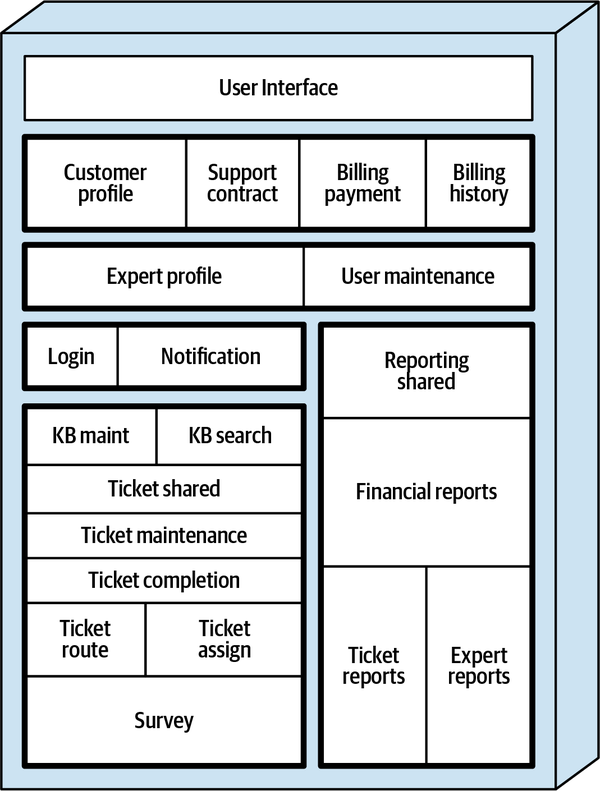
Figure 5-19. The five domains identified (with darkened borders) within the Sysops Squad application
Addison bắt đầu với miền Ticket và thấy rằng trong khi chức năng vé cốt lõi bắt đầu với không gian tên ss.ticket, các thành phần khảo sát và cơ sở kiến thức thì không. Do đó, Addison đã viết một câu chuyện kiến trúc để tái cấu trúc các thành phần được liệt kê trong Bảng 5-15 để phù hợp với miền vé.
| Component | Domain | Current namespace | Target namespace |
|---|---|---|---|
Bảo trì KB | Vé | bảo trì ss.kb | ss.ticket.kb.bảo trì |
Tìm kiếm KB | Vé | tìm kiếm.ss.kb | ss.ticket.kb.search chuyển sang tiếng Việt là "tìm kiếm.kb.vé". |
Vé đã được chia sẻ | Vé | ss.ticket.chia sẻ | Không thay đổi |
Bảo trì vé | Vé | ss.ticket.bảo trì | Cũng vậy (không thay đổi) |
Hoàn thành vé | Vé | ss.ticket.completion: hoàn thành vé ss | Cũng vậy (không thay đổi) |
Gán vé | Vé | phiếu.chỉ định | Giống nhau (không thay đổi) |
Lộ trình vé | Vé | Đường đi vé số ss. | Cũng vậy (không thay đổi) |
Khảo sát | Vé | Khảo sát ss. | đánh giá vé ss |
Tiếp theo, Addison đã xem xét các thành phần liên quan đến khách hàng và phát hiện rằng các thành phần thanh toán và khảo sát cần được tái cấu trúc để đưa chúng vào miền Khách hàng, đồng thời tạo ra một tiểu miền Thanh toán. Addison đã viết một câu chuyện kiến trúc cho việc tái cấu trúc chức năng miền Khách hàng, như được trình bày trong Bảng 5-16.
| Component | Domain | Current namespace | Target namespace |
|---|---|---|---|
Thanh toán hoá đơn | Khách hàng | thanh toán hóa đơn | Thanh toán hóa đơn khách hàng |
Lịch sử thanh toán | Khách hàng | lịch sử thanh toán ss | "Lịch sử thanh toán của khách hàng" |
Hồ sơ khách hàng | Khách hàng | hồ sơ khách hàng | Không thay đổi |
Hợp đồng hỗ trợ | Khách hàng | hợp đồng hỗ trợ | hợp đồng hỗ trợ khách hàng |
Bằng cách áp dụng “Mô hình Xác định và Định cỡ các Thành phần”, Addison đã phát hiện rằng miền báo cáo đã được căn chỉnh và không cần hành động nào thêm với các thành phần báo cáo được liệt kê trong Bảng 5-17.
| Component | Domain | Current namespace | Target namespace |
|---|---|---|---|
Báo cáo chia sẻ | Báo cáo | Báo cáo chia sẻ | Cũng vậy (không thay đổi) |
Báo cáo vé | Báo cáo | ss.báo cáo. vé | Cũng vậy (không thay đổi) |
Báo cáo Chuyên gia | Báo cáo | chuyên gia báo cáo ss | Giống nhau (không thay đổi) |
Báo cáo tài chính | Báo cáo | báo cáo tài chính | Không thay đổi |
Addison nhận thấy rằng cả miền Quản trị (Admin) và Chung (Shared) cũng cần được đồng bộ hóa, và quyết định tạo ra một câu chuyện kiến trúc duy nhất cho nỗ lực tái cấu trúc này và liệt kê các thành phần này trong Bảng 5-18. Addison cũng quyết định đổi tên không gian tên ss.expert.profile thành ss.experts để tránh tạo ra một miền con Expert không cần thiết dưới miền Quản trị.
| Component | Domain | Current namespace | Target namespace |
|---|---|---|---|
Đăng nhập | Chia sẻ | đăng nhập | đăng nhập aa.shared |
Thông báo | Chia sẻ | thông báo | thông báo chia sẻ |
Hồ sơ Chuyên gia | Quản trị viên | hồ sơ chuyên gia ss | chuyên gia quản trị hệ thống |
Bảo trì người dùng | Quản trị viên | người dùng.ss | người dùng quản trị viên |
Với mẫu này đã hoàn thành, Addison nhận ra họ đã sẵn sàng để tách rời ứng dụng đơn thể và chuyển sang giai đoạn đầu tiên của kiến trúc phân tán bằng cách áp dụng mẫu Tạo Dịch vụ Miền (được mô tả ở phần tiếp theo).
Create Domain Services Pattern
Khi các thành phần đã được xác định kích thước đúng cách, làm phẳng và nhóm lại thành các miền, các miền đó có thể được chuyển đến các dịch vụ miền được triển khai riêng biệt, tạo ra cái được gọi là kiến trúc dựa trên dịch vụ (xem Phụ lục A). Dịch vụ miền là các đơn vị phần mềm thô hơn, được triển khai tách biệt, chứa tất cả các chức năng cho một miền cụ thể (chẳng hạn như Đặt vé, Khách hàng, Báo cáo, v.v.).
Pattern Description
Mẫu “Tạo miền thành phần” trước đó tạo ra các miền thành phần được định nghĩa rõ ràng trong một ứng dụng nguyên khối và thể hiện những miền đó thông qua các không gian tên thành phần (hoặc cấu trúc thư mục). Mẫu này lấy những miền thành phần được định nghĩa rõ ràng đó và tách các nhóm thành phần thành các dịch vụ triển khai riêng biệt, được gọi là dịch vụ miền, từ đó tạo ra một kiến trúc dựa trên dịch vụ.
Dưới dạng đơn giản nhất, kiến trúc dựa trên dịch vụ bao gồm một giao diện người dùng mà truy cập từ xa vào các dịch vụ miền thô, tất cả đều chia sẻ một cơ sở dữ liệu đơn khối. Mặc dù có nhiều kiểu hình trong kiến trúc dựa trên dịch vụ (chẳng hạn như tách rời giao diện người dùng, tách cơ sở dữ liệu, thêm cổng API, v.v.), kiểu hình cơ bản được thể hiện trong Hình 5-20 là một điểm khởi đầu tốt cho việc chuyển đổi một ứng dụng đơn khối.
Figure 5-20. The basic topology for a service-based architecture
Ngoài những lợi ích được đề cập trong "Phân tách dựa trên thành phần", việc chuyển sang kiến trúc dựa trên dịch vụ trước tiên cho phép kiến trúc sư và đội ngũ phát triển tìm hiểu thêm về từng dịch vụ miền để xác định xem nó có nên được phân nhỏ thành các dịch vụ nhỏ hơn trong kiến trúc microservices hay để lại dưới dạng dịch vụ miền lớn hơn. Quá nhiều đội ngũ mắc sai lầm khi bắt đầu quá chi tiết, và kết quả là phải chấp nhận tất cả những yếu tố phức tạp của microservices (chẳng hạn như phân tách dữ liệu, quy trình làm việc phân tán, giao dịch phân tán, tự động hóa hoạt động, đóng gói container, v.v.) mà không cần tất cả các dịch vụ microservices chi tiết đó.
Hình 5-21 mô tả cách hoạt động của mô hình Tạo Dịch vụ Miền. Lưu ý trong sơ đồ cách mà miền thành phần Báo cáo được định nghĩa trong "Mô hình Tạo Miền Thành Phần" được tách ra khỏi ứng dụng đơn khối, tạo thành dịch vụ Báo cáo được triển khai riêng biệt.
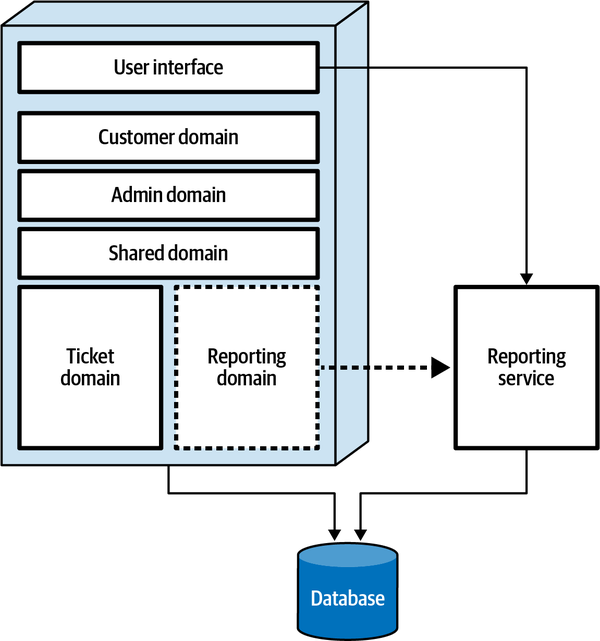
Figure 5-21. Component domains are moved to external domain services
Một lời khuyên, tuy nhiên: đừng áp dụng mẫu này cho đến khi tất cả các miền thành phần đã được xác định và tái cấu trúc. Điều này giúp giảm số lượng sửa đổi cần thiết cho mỗi dịch vụ miền khi di chuyển các thành phần (và do đó là mã nguồn) xung quanh. Ví dụ, giả sử tất cả các chức năng về đăng ký vé và cơ sở kiến thức trong ứng dụng của Nhóm Sysops được nhóm và tái cấu trúc thành một miền Ticket, và một dịch vụ Ticket mới được tạo ra từ miền đó. Bây giờ giả sử rằng thành phần khảo sát khách hàng (được xác định thông qua không gian tên ss.customer.survey) được coi là một phần của miền Ticket. Vì miền Ticket đã được di chuyển, nên dịch vụ Ticket bây giờ sẽ phải được sửa đổi để bao gồm thành phần Khảo sát. Tốt hơn là hãy sắp xếp và tái cấu trúc tất cả các thành phần vào các miền thành phần trước, sau đó mới bắt đầu di chuyển các miền thành phần đó đến các dịch vụ miền.
Fitness Functions for Governance
Điều quan trọng là giữ cho các thành phần trong mỗi dịch vụ miền phù hợp với miền, đặc biệt nếu dịch vụ miền sẽ được chia nhỏ thành các microservices. Loại hình quản trị này giúp giữ cho các dịch vụ miền không trở thành những dịch vụ đơn thể không có cấu trúc riêng. Hàm kiểm tra phù hợp sau đây đảm bảo rằng không gian tên (và do đó các thành phần) được giữ nhất quán trong một dịch vụ miền.
Fitness function: All components in <some domain service> should start with the same namespace
Chức năng fitness tự động toàn diện này có thể được kích hoạt khi triển khai thông qua pipeline CI/CD để đảm bảo rằng các không gian tên cho các thành phần trong một dịch vụ miền vẫn đồng nhất. Ví dụ, tất cả các thành phần trong dịch vụ miền Ticket nên bắt đầu bằng ss.ticket. Ví dụ 5-11 sử dụng ArchUnit để đảm bảo ràng buộc này. Mỗi dịch vụ miền sẽ có chức năng fitness tương ứng dựa trên miền cụ thể của nó.
Example 5-11. ArchUnit code for governing components within the Ticket domain service
publicvoidrestrict_domain_within_ticket_service(){classes().should().resideInAPackage("..ss.ticket..").check(myClasses);}
Sysops Squad Saga: Creating Domain Services
Thứ Ba, ngày 23 tháng 11, 09:04
Addison và Austen đã làm việc chặt chẽ với đội ngũ phát triển của Sysops Squad để xây dựng một kế hoạch di chuyển nhằm giai đoạn chuyển đổi từ các miền thành phần sang dịch vụ miền. Họ nhận ra rằng nỗ lực này không chỉ yêu cầu mã trong mỗi miền thành phần được trích xuất khỏi cấu trúc đơn và chuyển đến một không gian làm việc dự án mới, mà còn cần giao diện người dùng giờ đây có thể truy cập từ xa các chức năng trong miền đó.
Dựa trên các miền thành phần được xác định trước đó trong Hình 5-19, nhóm đã di chuyển từng thành phần một, cuối cùng đạt được kiến trúc dựa trên dịch vụ, như được hiển thị trong Hình 5-22. Lưu ý cách mỗi miền đã được xác định trong mẫu trước giờ trở thành một dịch vụ triển khai riêng biệt.
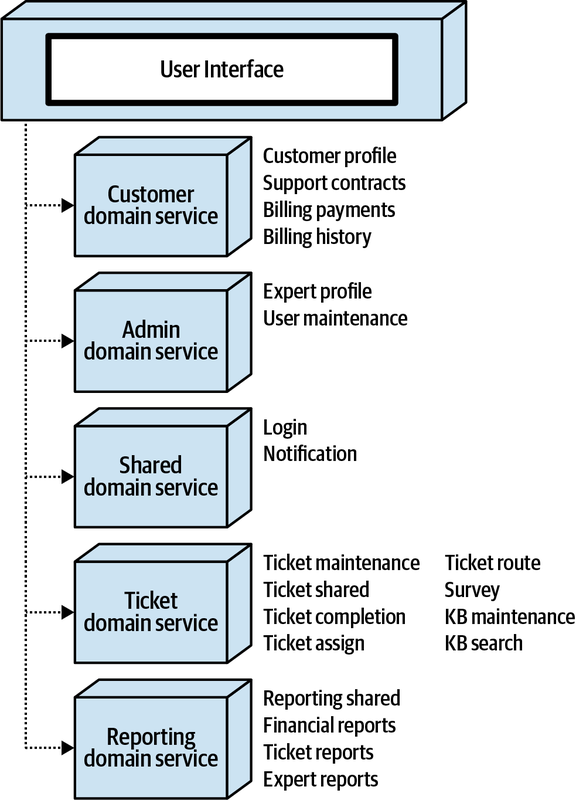
Figure 5-22. Separately deployed domain services result in a distributed Sysops Squad application
Summary
Chúng tôi đã thấy rằng những nỗ lực di cư “theo cảm hứng” hiếm khi mang lại kết quả tích cực. Việc áp dụng các mẫu phân tách dựa trên thành phần cung cấp một phương pháp có cấu trúc, có kiểm soát và từng bước để phá vỡ các kiến trúc đơn khối. Sau khi áp dụng những mẫu này, các nhóm có thể làm việc để phân tách dữ liệu đơn khối (xem Chương 6) và bắt đầu phá vỡ các dịch vụ miền thành các microservices chi tiết hơn (xem Chương 7) khi cần thiết.
Chapter 6. Pulling Apart Operational Data
Thứ Năm, 7 tháng 10, 08:55
Bây giờ khi ứng dụng Sysops Squad đã được chia tách thành các dịch vụ miền được triển khai riêng biệt, Addison và Austen đều nhận ra rằng đã đến lúc bắt đầu suy nghĩ về việc tách rời cơ sở dữ liệu Sysops Squad dạng đơn khối. Addison đồng ý bắt đầu nỗ lực này, trong khi Austen bắt đầu làm việc để cải thiện quy trình triển khai CI/CD. Addison đã gặp Dana, kiến trúc sư dữ liệu của Sysops Squad, và Devon, một trong những DBA hỗ trợ các cơ sở dữ liệu của Penultimate Electronics.
“Tôi muốn nghe ý kiến của bạn về cách chúng ta có thể phân chia cơ sở dữ liệu của đội Sysops.” Addison nói.
“Chờ một chút,” Dana nói. “Ai nói gì về việc tách rời cơ sở dữ liệu?”
“Addison và tôi đã đồng ý vào tuần trước rằng chúng tôi cần phải chia tách cơ sở dữ liệu của Sysops Squad,” Devon nói. “Như bạn biết, ứng dụng Sysops Squad đang trải qua một cuộc đại tu lớn, và việc tách rời dữ liệu là một phần của cuộc đại tu đó.”
“Tôi nghĩ rằng cơ sở dữ liệu đơn khối là hoàn toàn ổn,” Dana nói. “Tôi không thấy lý do gì để nó bị chia tách. Nếu bạn không thể thuyết phục tôi ngược lại, tôi sẽ không thay đổi quan điểm về vấn đề này. Hơn nữa, bạn có biết việc chia tách cơ sở dữ liệu đó khó khăn như thế nào không?”
“Tất nhiên, sẽ khó khăn,” Devon nói, “nhưng tôi biết một quy trình năm bước sử dụng các miền dữ liệu mà sẽ hoạt động rất tốt trên cơ sở dữ liệu này. Bằng cách đó, chúng ta thậm chí có thể bắt đầu điều tra việc sử dụng các loại cơ sở dữ liệu khác nhau cho một số phần của ứng dụng, như cơ sở tri thức và thậm chí là chức năng khảo sát khách hàng.”
“Đừng đi trước một bước,” Dana nói. “Và cũng đừng quên rằng tôi là người chịu trách nhiệm cho tất cả những cơ sở dữ liệu này.”
Addison nhanh chóng nhận ra mọi thứ đang trở nên mất kiểm soát, và nhanh chóng áp dụng một số kỹ năng đàm phán và điều phối quan trọng. “Được rồi,” Addison nói, “chúng tôi lẽ ra nên đưa bạn vào các cuộc thảo luận ban đầu của chúng tôi, và vì điều đó tôi xin lỗi. Tôi lẽ ra nên biết tốt hơn. Chúng ta có thể làm gì để đưa bạn tham gia và giúp chúng tôi phân tích cơ sở dữ liệu của đội Sysops?”
“Điều đó thật dễ,” Dana nói. “Thuyết phục tôi rằng cơ sở dữ liệu của Sysops Squad thực sự cần phải được tách rời. Hãy cung cấp cho tôi một lý do thuyết phục. Nếu bạn có thể làm điều đó, thì chúng ta sẽ nói về quy trình năm bước của Devon. Nếu không, nó sẽ giữ nguyên như hiện tại.”
Việc tách rời một cơ sở dữ liệu là rất khó - thực tế còn khó hơn nhiều so với việc tách rời tính năng ứng dụng. Bởi vì dữ liệu thường là tài sản quan trọng nhất trong công ty, nên có nguy cơ lớn hơn về sự gián đoạn trong kinh doanh và ứng dụng khi tách rời hoặc restructure dữ liệu. Ngoài ra, dữ liệu có xu hướng gắn bó chặt chẽ với tính năng ứng dụng, khiến việc xác định các ranh giới rõ ràng trong một mô hình dữ liệu lớn trở nên khó khăn hơn.
Theo cách tương tự, khi một ứng dụng đơn khối được chia thành các đơn vị triển khai riêng biệt, có lúc việc tách rời một cơ sở dữ liệu đơn khối cũng là điều mong muốn (hoặc thậm chí cần thiết). Một số kiểu kiến trúc, chẳng hạn như microservices, yêu cầu dữ liệu phải được tách ra để hình thành các bối cảnh giới hạn được định nghĩa rõ ràng (nơi mà mỗi dịch vụ sở hữu dữ liệu riêng của nó), trong khi các kiến trúc phân tán khác, chẳng hạn như kiến trúc dựa trên dịch vụ, cho phép các dịch vụ chia sẻ một cơ sở dữ liệu chung.
Điều thú vị là, một số kỹ thuật giống như những kỹ thuật được sử dụng để phân tách chức năng ứng dụng cũng có thể được áp dụng để phân tách dữ liệu. Ví dụ, các thành phần chuyển thành các miền dữ liệu, các tệp lớp chuyển thành các bảng cơ sở dữ liệu, và các điểm kết nối giữa các lớp chuyển thành các đối tượng cơ sở dữ liệu như khóa ngoại, view, trigger, hoặc thậm chí là các thủ tục lưu trữ.
Trong chương này, chúng tôi khám phá một số yếu tố thúc đẩy việc phân tách dữ liệu và trình bày các kỹ thuật để hiệu quả phân chia dữ liệu khối thành các miền dữ liệu, lược đồ và thậm chí là các cơ sở dữ liệu riêng biệt theo cách diễn tiến và có kiểm soát. Biết rằng thế giới cơ sở dữ liệu không chỉ là quan hệ, chúng tôi cũng thảo luận về các loại cơ sở dữ liệu khác nhau (quan hệ, đồ thị, tài liệu, khóa-giá trị, cột, NewSQL và gốc đám mây) và phác thảo những ưu nhược điểm liên quan đến từng loại cơ sở dữ liệu này.
Data Decomposition Drivers
Việc phân tách một cơ sở dữ liệu đơn khối có thể là một nhiệm vụ đầy thách thức, vì vậy điều quan trọng là phải hiểu xem (và khi nào) một cơ sở dữ liệu nên được phân tách, như được minh họa trong Hình 6-1. Các kiến trúc sư có thể biện minh cho nỗ lực phân tách dữ liệu bằng cách hiểu và phân tích các yếu tố phân tách dữ liệu (các yếu tố thúc đẩy việc phân tách dữ liệu) và các yếu tố tích hợp dữ liệu (các yếu tố thúc đẩy việc giữ lại dữ liệu cùng nhau). Cố gắng đạt được sự cân bằng giữa hai lực thúc đẩy này và phân tích các đánh đổi của từng yếu tố là chìa khóa để điều chỉnh độ chi tiết của dữ liệu đúng cách.
Figure 6-1. Under what circumstances should a monolithic database be decomposed?
Trong phần này, chúng ta sẽ khám phá các bộ phân tách dữ liệu và bộ tích hợp dữ liệu được sử dụng để giúp đưa ra sự lựa chọn đúng đắn khi xem xét việc tách rời dữ liệu monolithic.
Data Disintegrators
Các yếu tố thúc đẩy sự phân tách dữ liệu cung cấp câu trả lời và lý do cho câu hỏi “Khi nào tôi nên xem xét tách rời dữ liệu của mình?” Sáu yếu tố chính thúc đẩy sự phân tách dữ liệu bao gồm:
- Change control
-
Bao nhiêu dịch vụ bị ảnh hưởng bởi sự thay đổi của bảng cơ sở dữ liệu?
- Connection management
-
Cơ sở dữ liệu của tôi có thể xử lý các kết nối cần thiết từ nhiều dịch vụ phân tán không?
- Scalability
-
Cơ sở dữ liệu có thể mở rộng để đáp ứng nhu cầu của các dịch vụ truy cập vào nó không?
- Fault tolerance
-
Có bao nhiêu dịch vụ bị ảnh hưởng bởi sự cố cơ sở dữ liệu hoặc thời gian bảo trì?
- Architectural quanta
-
Một cơ sở dữ liệu chung đơn lẻ có khiến tôi bị ép vào một kiến trúc lượng tử đơn không mong muốn không?
- Database type optimization
-
Tôi có thể tối ưu hóa dữ liệu của mình bằng cách sử dụng nhiều loại cơ sở dữ liệu không?
Mỗi trong những yếu tố gây ra sự phân hủy này sẽ được thảo luận chi tiết trong các phần sau.
Change control
Một trong những nguyên nhân chính dẫn đến sự phân tán dữ liệu là việc kiểm soát các thay đổi trong cấu trúc bảng cơ sở dữ liệu. Việc xóa bảng hoặc cột, thay đổi tên bảng hoặc cột, và thậm chí thay đổi kiểu cột trong bảng sẽ làm hỏng các câu lệnh SQL tương ứng truy cập các bảng đó, và do đó làm hỏng các dịch vụ tương ứng sử dụng các bảng đó. Chúng tôi gọi những loại thay đổi này là thay đổi phá vỡ, trái ngược với việc thêm bảng hoặc cột trong cơ sở dữ liệu, điều này thường không ảnh hưởng đến các truy vấn hoặc ghi hiện có. Không ngạc nhiên khi việc kiểm soát thay đổi bị ảnh hưởng nhiều nhất khi sử dụng cơ sở dữ liệu quan hệ, nhưng các loại cơ sở dữ liệu khác cũng có thể tạo ra vấn đề về kiểm soát thay đổi (xem “Chọn loại cơ sở dữ liệu”).
Như được minh họa trong Hình 6-2, khi có những thay đổi đột phá xảy ra với cơ sở dữ liệu, nhiều dịch vụ phải được cập nhật, kiểm tra và triển khai cùng với những thay đổi của cơ sở dữ liệu. Việc phối hợp này có thể nhanh chóng trở nên khó khăn và dễ xảy ra lỗi khi số lượng các dịch vụ triển khai riêng lẻ chia sẻ cùng một cơ sở dữ liệu gia tăng. Hãy tưởng tượng việc cố gắng phối hợp 42 dịch vụ được triển khai riêng lẻ cho một thay đổi đột phá trong cơ sở dữ liệu!
Figure 6-2. Services impacted by the database change must be deployed together with the database
Việc phối hợp các thay đổi đối với nhiều dịch vụ phân tán cho một thay đổi cơ sở dữ liệu chung chỉ là một phần của câu chuyện. Mối nguy thực sự khi thay đổi một cơ sở dữ liệu chung trong bất kỳ kiến trúc phân tán nào là quên không tính đến các dịch vụ truy cập vào bảng vừa được thay đổi. Như đã minh họa trong Hình 6-3, những dịch vụ đó trở nên không hoạt động trong môi trường sản xuất cho đến khi chúng được thay đổi, kiểm tra và triển khai lại.
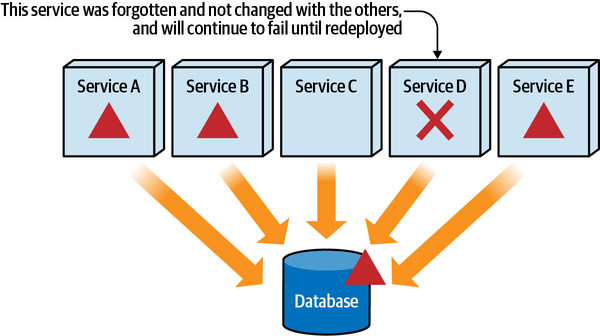
Figure 6-3. Services impacted by a database change but forgotten will continue to fail until redeployed
Trong hầu hết các ứng dụng, mối nguy cơ từ các dịch vụ bị quên được giảm thiểu nhờ vào phân tích tác động cẩn thận và kiểm thử hồi quy mạnh mẽ. Tuy nhiên, hãy xem xét một hệ sinh thái microservices với 400 dịch vụ, tất cả đều chia sẻ cùng một cơ sở dữ liệu quan hệ phân cụm cực kỳ sẵn sàng. Hãy tưởng tượng phải chạy quanh tất cả các nhóm phát triển trong nhiều lĩnh vực khác nhau, cố gắng tìm ra dịch vụ nào đang sử dụng bảng đang được thay đổi. Cũng hãy tưởng tượng rằng bạn phải phối hợp, kiểm thử và triển khai tất cả những dịch vụ này cùng nhau như một đơn vị duy nhất, cùng với cơ sở dữ liệu. Suy nghĩ về kịch bản này bắt đầu trở thành một bài tập khiến đầu óc choáng váng, thường dẫn đến một mức độ điên rồ nào đó.
Việc chia nhỏ một cơ sở dữ liệu thành các ngữ cảnh rạch ròi giúp kiểm soát những thay đổi lớn trong cơ sở dữ liệu một cách hiệu quả. Khái niệm ngữ cảnh ranh giới này bắt nguồn từ cuốn sách nổi bật "Thiết kế dựa trên miền" của Eric Evans (Addison-Wesley) và mô tả mã nguồn, logic kinh doanh, cấu trúc dữ liệu và dữ liệu tất cả đều được gắn kết với nhau - được bao bọc - trong một ngữ cảnh cụ thể. Như được minh họa trong Hình 6-4, các ngữ cảnh rành mạch xung quanh các dịch vụ và dữ liệu tương ứng của chúng giúp kiểm soát sự thay đổi, vì sự thay đổi chỉ giới hạn trong các dịch vụ đó trong ngữ cảnh rành mạch đó.
Thông thường, các ngữ cảnh giới hạn được hình thành xung quanh các dịch vụ và dữ liệu mà các dịch vụ sở hữu. Bằng "sở hữu", chúng tôi ý nói đến một dịch vụ có quyền ghi vào cơ sở dữ liệu (khác với việc chỉ có quyền truy cập đọc vào dữ liệu). Chúng tôi sẽ thảo luận về quyền sở hữu dữ liệu phân tán chi tiết hơn ở Chương 9.
Figure 6-4. Database changes are isolated to only those services within the associated bounded context
Lưu ý trong Hình 6-4 rằng Dịch vụ C cần truy cập một số dữ liệu trong Cơ sở dữ liệu D nằm trong một ngữ cảnh giới hạn với Dịch vụ D. Vì Cơ sở dữ liệu D nằm trong một ngữ cảnh giới hạn khác, Dịch vụ C không thể truy cập trực tiếp dữ liệu. Điều này không chỉ vi phạm quy tắc ngữ cảnh giới hạn, mà còn tạo ra sự lộn xộn liên quan đến việc kiểm soát thay đổi. Do đó, Dịch vụ C phải yêu cầu Dịch vụ D cung cấp dữ liệu. Có nhiều cách để truy cập dữ liệu mà dịch vụ không sở hữu trong khi vẫn duy trì ngữ cảnh giới hạn. Những kỹ thuật này sẽ được thảo luận chi tiết trong Chương 10.
Một khía cạnh quan trọng của một ngữ cảnh giới hạn liên quan đến kịch bản giữa Service C cần dữ liệu và Service D sở hữu dữ liệu đó trong ngữ cảnh giới hạn của nó là sự trừu tượng hóa cơ sở dữ liệu. Lưu ý rằng trong Hình 6-5, Service D đang truyền dữ liệu mà Service C đã yêu cầu thông qua một dạng hợp đồng nào đó (chẳng hạn như JSON, XML, hoặc có thể là một đối tượng).
Lợi thế của bối cảnh giới hạn là dữ liệu được gửi đến Service C có thể là một hợp đồng khác với sơ đồ của Database D. Điều này có nghĩa là một thay đổi phá vỡ đối với một bảng nào đó trong Database D chỉ ảnh hưởng đến Service D và không nhất thiết làm ảnh hưởng đến hợp đồng của dữ liệu được gửi đến Service C. Nói cách khác, Service C được trừu tượng hóa khỏi cấu trúc sơ đồ thực tế của Database D.
Figure 6-5. The contract from a service call abstracts the caller from the underlying database schema
Để minh họa sức mạnh của việc trừu tượng bối cảnh giới hạn này trong một kiến trúc phân tán, hãy giả định rằng Cơ sở dữ liệu D có một bảng Danh sách mong muốn với cấu trúc sau:
CREATETABLEWishlist(CUSTOMER_IDVARCHAR(10),ITEM_IDVARCHAR(20),QUANTITYINT,EXPIRATION_DTDATE);
Hợp đồng JSON tương ứng mà Dịch vụ D gửi đến Dịch vụ C để yêu cầu các mục trong danh sách mong muốn như sau:
{"$schema":"http://json-schema.org/draft-04/schema#","properties":{"cust_id":{"type":"string"},"item_id":{"type":"string"},"qty":{"type":"number"},"exp_dt":{"type":"number"}},}
Lưu ý rằng trường dữ liệu ngày hết hạn (exp_dt) trong lược đồ JSON được đặt tên khác so với tên cột trong cơ sở dữ liệu và được chỉ định dưới dạng số (một giá trị dài đại diện cho thời gian epoch - số mili giây kể từ nửa đêm ngày 1 tháng 1 năm 1970), trong khi trong cơ sở dữ liệu nó được đại diện dưới dạng trường DATE. Bất kỳ thay đổi nào về tên cột hoặc loại cột trong cơ sở dữ liệu đều không còn ảnh hưởng đến Dịch vụ C vì có hợp đồng JSON riêng biệt.
Để minh họa cho điểm này, giả sử doanh nghiệp quyết định không còn hết hạn các mục trong danh sách ước muốn. Điều này đòi hỏi phải thay đổi cấu trúc bảng của cơ sở dữ liệu.
ALTERTABLEWishlistDROPCOLUMNEXPIRATION_DT;
Dịch vụ D sẽ phải được sửa đổi để phù hợp với sự thay đổi này vì nó nằm trong cùng một ngữ cảnh ràng buộc với cơ sở dữ liệu, nhưng hợp đồng tương ứng sẽ không cần phải thay đổi ngay lập tức. Cho đến khi hợp đồng cuối cùng được thay đổi, Dịch vụ D có thể chỉ định một ngày xa trong tương lai hoặc đặt giá trị thành zero để chỉ ra rằng sản phẩm không có hạn sử dụng. Điểm chính là Dịch vụ C được trừu tượng hóa khỏi những thay đổi đột phá được thực hiện với Cơ sở D do ngữ cảnh ràng buộc.
Connection management
Thiết lập kết nối đến cơ sở dữ liệu là một thao tác tốn kém. Một bộ kết nối cơ sở dữ liệu thường được sử dụng không chỉ để tăng hiệu suất mà còn để giới hạn số lượng kết nối đồng thời mà một ứng dụng được phép sử dụng. Trong các ứng dụng đơn khối, bộ kết nối cơ sở dữ liệu thường thuộc về ứng dụng (hoặc máy chủ ứng dụng). Tuy nhiên, trong các kiến trúc phân tán, mỗi dịch vụ—hay cụ thể hơn, mỗi phiên bản dịch vụ—thường có bộ kết nối riêng. Như được minh họa trong Hình 6-6, khi nhiều dịch vụ chia sẻ cùng một cơ sở dữ liệu, số lượng kết nối có thể nhanh chóng trở nên bão hòa, đặc biệt khi số lượng dịch vụ hoặc phiên bản dịch vụ tăng lên.
Figure 6-6. Database connections can quickly get saturated with multiple service instances
Việc đạt (hoặc vượt) số lượng kết nối cơ sở dữ liệu tối đa có sẵn là một yếu tố khác cần xem xét khi quyết định có nên tách rời cơ sở dữ liệu hay không. Thời gian chờ kết nối (thời gian chờ để có được một kết nối có sẵn) thường là dấu hiệu đầu tiên cho thấy số lượng kết nối cơ sở dữ liệu tối đa đã được đạt đến. Vì thời gian chờ kết nối cũng có thể biểu hiện dưới dạng thời gian yêu cầu hết hạn hoặc các cầu dao bị ngắt, việc tìm kiếm thời gian chờ kết nối thường là điều đầu tiên chúng tôi khuyên bạn nên làm nếu những điều kiện này thường xuyên xảy ra khi sử dụng một cơ sở dữ liệu chung.
Để minh họa các vấn đề liên quan đến kết nối cơ sở dữ liệu và kiến trúc phân tán, hãy xem xét ví dụ sau: một ứng dụng đơn thể với 200 kết nối cơ sở dữ liệu được chia thành một kiến trúc phân tán gồm 50 dịch vụ, mỗi dịch vụ có 10 kết nối cơ sở dữ liệu trong hồ bơi kết nối của nó.
Ứng dụng monolithic gốc | 200 kết nối |
Dịch vụ phân tán | 50 |
Kết nối cho mỗi dịch vụ | 10 |
Số lượng cài đặt dịch vụ tối thiểu | 2 |
Tổng số kết nối dịch vụ | một nghìn |
Chú ý rằng số lượng kết nối cơ sở dữ liệu trong cùng một ngữ cảnh ứng dụng đã tăng từ 200 lên 1,000, và các dịch vụ còn chưa bắt đầu mở rộng! Giả sử một nửa các dịch vụ mở rộng lên trung bình 5 phiên bản mỗi cái, số lượng kết nối cơ sở dữ liệu nhanh chóng tăng lên 1,700.
Nếu không có một chiến lược kết nối hoặc kế hoạch quản trị nào đó, các dịch vụ sẽ cố gắng sử dụng nhiều kết nối nhất có thể, thường xuyên gây ra tình trạng thiếu kết nối cho các dịch vụ khác đang cần. Vì lý do này, việc quản lý cách sử dụng kết nối cơ sở dữ liệu trong kiến trúc phân tán là rất quan trọng. Một phương pháp hiệu quả là phân bổ cho từng dịch vụ một hạn mức kết nối để quản lý sự phân phối các kết nối cơ sở dữ liệu có sẵn giữa các dịch vụ. Hạn mức kết nối xác định số lượng kết nối cơ sở dữ liệu tối đa mà một dịch vụ được phép sử dụng hoặc cung cấp trong bể kết nối của nó.
Bằng cách chỉ định một hạn ngạch kết nối, các dịch vụ sẽ không được phép tạo ra nhiều kết nối cơ sở dữ liệu hơn số lượng đã được phân bổ cho nó. Nếu một dịch vụ đạt đến số lượng kết nối cơ sở dữ liệu tối đa trong hạn ngạch của nó, nó phải chờ cho một trong các kết nối mà nó đang sử dụng trở nên khả dụng. Phương pháp này có thể được thực hiện bằng hai cách: phân phối đều hạn ngạch kết nối giống nhau cho mỗi dịch vụ, hoặc phân bổ một hạn ngạch kết nối khác nhau cho mỗi dịch vụ dựa trên nhu cầu của nó.
Cách tiếp cận phân phối đồng đều thường được sử dụng khi lần đầu triển khai dịch vụ, và chưa biết được mỗi dịch vụ sẽ cần bao nhiêu kết nối trong hoạt động bình thường và cao điểm. Mặc dù đơn giản, cách tiếp cận này không hiệu quả lắm vì một số dịch vụ có thể cần nhiều kết nối hơn so với những dịch vụ khác, trong khi một số kết nối do các dịch vụ khác giữ có thể không được sử dụng.
Mặc dù phức tạp hơn, phương pháp phân phối biến động là hiệu quả hơn nhiều trong việc quản lý các kết nối cơ sở dữ liệu đến một cơ sở dữ liệu chung. Với phương pháp này, mỗi dịch vụ được chỉ định một hạn ngạch kết nối khác nhau dựa trên tính năng và yêu cầu khả năng mở rộng của nó. Lợi ích của phương pháp này là tối ưu hóa việc sử dụng các kết nối cơ sở dữ liệu có sẵn trên các dịch vụ phân tán, đảm bảo rằng những dịch vụ cần nhiều kết nối cơ sở dữ liệu hơn có chúng sẵn sàng để sử dụng. Tuy nhiên, nhược điểm là nó cần có kiến thức về bản chất của tính năng và yêu cầu khả năng mở rộng của từng dịch vụ.
Chúng tôi thường khuyên bạn nên bắt đầu với phương pháp phân phối đồng đều và tạo các hàm fitness để đo lường mức sử dụng kết nối đồng thời cho mỗi dịch vụ. Chúng tôi cũng khuyến nghị giữ các giá trị hạn ngạch kết nối trong một máy chủ (hoặc dịch vụ) cấu hình bên ngoài để các giá trị có thể dễ dàng điều chỉnh hoặc thủ công hoặc lập trình thông qua các thuật toán học máy đơn giản. Kỹ thuật này không chỉ giúp giảm thiểu nguy cơ bão hòa kết nối mà còn cân bằng hợp lý các kết nối cơ sở dữ liệu có sẵn giữa các dịch vụ phân tán để đảm bảo rằng không có kết nối nhàn rỗi nào bị lãng phí.
Bảng 6-1 cho thấy một ví dụ về việc bắt đầu sử dụng phương pháp phân phối đều cho một cơ sở dữ liệu có thể hỗ trợ tối đa 100 kết nối đồng thời. Lưu ý rằng Dịch vụ A chỉ bao giờ cần tối đa 5 kết nối, Dịch vụ C chỉ cần 15 kết nối và Dịch vụ E chỉ cần 14 kết nối, trong khi Dịch vụ B và Dịch vụ D đã đạt giới hạn kết nối tối đa của chúng và đã trải qua thời gian chờ kết nối.
| Service | Quota | Max used | Waits | |
|---|---|---|---|---|
A | 20 | 5 | Không | |
→ | B | 20 | 20 | Có |
C | 20 | 15 | Không | |
→ | D | 20 | 20 | Có |
E | 20 | 14 | Không |
Vì Service A đang thấp hơn hạn mức kết nối của nó, đây là một địa điểm tốt để bắt đầu phân bổ lại các kết nối cho các dịch vụ khác. Di chuyển năm kết nối cơ sở dữ liệu đến Service B và năm kết nối cơ sở dữ liệu đến Service D đem lại kết quả như được trình bày trong Bảng 6-2.
| Service | Quota | Max used | Waits | |
|---|---|---|---|---|
A | 10 | 5 | Không | |
→ | B | 25 | 25 | Có |
C | 20 | 15 | Không | |
D | 25 | 25 | Không | |
E | 20 | 14 | Không |
Điều này đã tốt hơn, nhưng Dịch vụ B vẫn gặp phải tình trạng chờ kết nối, cho thấy rằng nó cần nhiều kết nối hơn mức cho phép trong hạn ngạch kết nối của nó. Việc điều chỉnh lại các hạn ngạch một cách thậm chí còn sâu hơn bằng cách lấy hai kết nối từ Dịch vụ A và Dịch vụ E mang lại kết quả tốt hơn nhiều, như được thể hiện trong Bảng 6-3.
| Service | Quota | Max used | Waits |
|---|---|---|---|
A | 8 | 5 | Không |
B | 29 | 27 | Không |
C | 20 | 15 | Không |
D | 25 | 25 | Không |
E | 18 | 14 | Không |
Phân tích này, có thể được rút ra từ các hàm fitness liên tục thu thập dữ liệu thông số đã được phát trực tiếp từ mỗi dịch vụ, cũng có thể được sử dụng để xác định mức độ gần gũi giữa số lượng kết nối tối đa đã sử dụng và số lượng kết nối tối đa có sẵn, cũng như lượng bộ đệm tồn tại cho mỗi dịch vụ về hạn ngạch và số kết nối tối đa đã sử dụng.
Scalability
Một trong những lợi thế của kiến trúc phân tán là khả năng mở rộng - khả năng cho các dịch vụ xử lý sự gia tăng về khối lượng yêu cầu trong khi vẫn duy trì thời gian phản hồi nhất quán. Hầu hết các sản phẩm liên quan đến cơ sở hạ tầng trên đám mây và tại chỗ đều làm tốt trong việc đảm bảo rằng các dịch vụ, container, máy chủ HTTP và máy ảo có thể mở rộng để đáp ứng sự gia tăng nhu cầu. Nhưng còn cơ sở dữ liệu thì sao?
Như được minh họa trong Hình 6-7, khả năng mở rộng dịch vụ có thể gây áp lực lớn lên cơ sở dữ liệu, không chỉ về số lượng kết nối cơ sở dữ liệu (như đã thảo luận ở phần trước), mà còn về thông lượng và khả năng lưu trữ của cơ sở dữ liệu. Để một hệ thống phân tán có thể mở rộng, tất cả các phần của hệ thống cần phải mở rộng, bao gồm cả cơ sở dữ liệu.
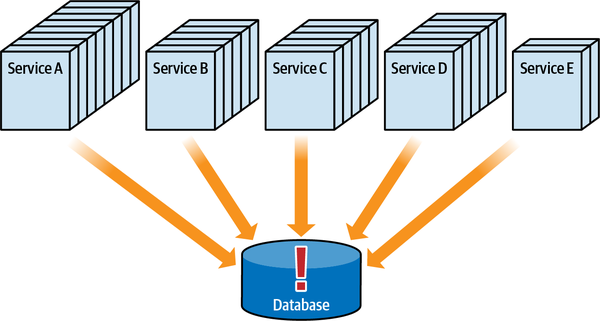
Figure 6-7. The database must also scale when services scale
Khả năng mở rộng là một yếu tố khác cần xem xét khi nghĩ đến việc tách một cơ sở dữ liệu. Kết nối cơ sở dữ liệu, dung lượng, thông lượng và hiệu suất đều là những yếu tố trong việc xác định liệu một cơ sở dữ liệu chia sẻ có thể đáp ứng các yêu cầu của nhiều dịch vụ trong một kiến trúc phân tán hay không.
Xem xét các hạn ngạch kết nối cơ sở dữ liệu đã tinh chỉnh trong Bảng 6-3 ở phần trước. Khi các dịch vụ mở rộng bằng cách thêm nhiều phiên bản, bức tranh thay đổi một cách rõ rệt, như được thể hiện trong Bảng 6-4, nơi tổng số kết nối cơ sở dữ liệu là 100.
| Service | Quota | Max used | Instances | Total used |
|---|---|---|---|---|
A | 8 | 5 | 2 | 10 |
B | 29 | 27 | 3 | 81 |
C | 20 | 15 | 3 | 45 |
D | 25 | 25 | 2 | 50 |
E | 18 | 14 | 4 | 56 |
TỔNG CỘNG | 100 | 86 | 14 | 242 |
Xin lưu ý rằng mặc dù hạn ngạch kết nối được phân bổ để phù hợp với 100 kết nối cơ sở dữ liệu có sẵn, nhưng khi các dịch vụ bắt đầu mở rộng, hạn ngạch không còn hợp lệ vì tổng số kết nối được sử dụng tăng lên 242, tức là nhiều hơn 142 kết nối so với số lượng có sẵn trong cơ sở dữ liệu. Điều này có khả năng dẫn đến việc chờ kết nối, từ đó sẽ gây ra suy giảm hiệu suất tổng thể và thời gian chờ của yêu cầu.
Việc chia nhỏ dữ liệu thành các miền dữ liệu riêng biệt hoặc thậm chí một cơ sở dữ liệu cho mỗi dịch vụ, như được minh họa trong Hình 6-8, yêu cầu ít kết nối đến từng cơ sở dữ liệu hơn, từ đó cung cấp khả năng mở rộng và hiệu suất cơ sở dữ liệu tốt hơn khi các dịch vụ phát triển.
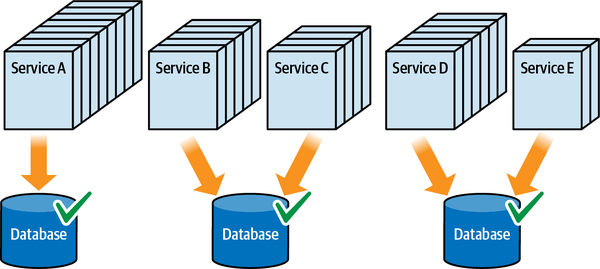
Figure 6-8. Breaking apart the database provides better database scalability
Ngoài kết nối cơ sở dữ liệu, một yếu tố cần xem xét liên quan đến khả năng mở rộng là tải trọng đặt lên cơ sở dữ liệu. Bằng cách chia tách một cơ sở dữ liệu, tải trọng đặt lên mỗi cơ sở dữ liệu sẽ giảm, do đó cũng cải thiện hiệu suất tổng thể và khả năng mở rộng.
Fault tolerance
Khi nhiều dịch vụ chia sẻ cùng một cơ sở dữ liệu, hệ thống tổng thể trở nên kém khả năng chịu lỗi hơn vì cơ sở dữ liệu trở thành một điểm lỗi duy nhất (SPOF). Ở đây, chúng tôi định nghĩa khả năng chịu lỗi là khả năng của một số phần của hệ thống tiếp tục hoạt động không bị gián đoạn khi một dịch vụ hoặc cơ sở dữ liệu gặp sự cố. Lưu ý trong Hình 6-9 rằng khi chia sẻ một cơ sở dữ liệu duy nhất, khả năng chịu lỗi tổng thể là thấp vì nếu cơ sở dữ liệu bị ngừng hoạt động, tất cả các dịch vụ trở nên không hoạt động.
Figure 6-9. If the database goes down, all services become nonoperational
Tính chịu lỗi là một động lực khác để xem xét việc tách rời dữ liệu. Nếu tính chịu lỗi được yêu cầu cho một số phần của hệ thống, việc tách rời dữ liệu có thể loại bỏ điểm thất bại duy nhất trong hệ thống, như được trình bày trong Hình 6-10. Điều này đảm bảo rằng một số phần của hệ thống vẫn hoạt động dù có sự cố xảy ra với cơ sở dữ liệu.
Figure 6-10. Breaking apart the database achieves better fault tolerance
Lưu ý rằng kể từ khi dữ liệu được tách rời, nếu Cơ sở dữ liệu B gặp sự cố, chỉ có Dịch vụ B và Dịch vụ C bị ảnh hưởng và không hoạt động, trong khi các dịch vụ khác tiếp tục hoạt động không bị gián đoạn.
Architectural quantum
Nhớ lại từ Chương 2 rằng một lượng kiến trúc được định nghĩa là một hiện vật có thể triển khai độc lập với sự kết nối chức năng cao, kết nối tĩnh cao và kết nối động đồng bộ. Lượng kiến trúc giúp cung cấp hướng dẫn về thời điểm cần tách rời một cơ sở dữ liệu, làm cho nó trở thành một yếu tố thúc đẩy phân tán dữ liệu khác.
Xem xét các dịch vụ trong Hình 6-11, nơi Dịch vụ A và Dịch vụ B yêu cầu các đặc điểm kiến trúc khác với các dịch vụ khác. Lưu ý trong sơ đồ rằng mặc dù Dịch vụ A và Dịch vụ B được nhóm lại với nhau, nhưng chúng không tạo thành một thực thể kiến trúc riêng biệt so với các dịch vụ khác do cùng chia sẻ một cơ sở dữ liệu. Do đó, cả năm dịch vụ, cùng với cơ sở dữ liệu, tạo thành một thực thể kiến trúc duy nhất.
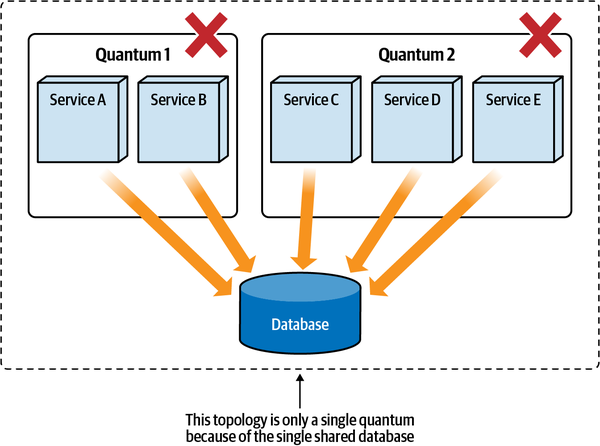
Figure 6-11. The database is part of the architectural quantum
Vì cơ sở dữ liệu được đưa vào phần sự kết hợp chức năng của định nghĩa kiến trúc quantum, nên cần phải tách dữ liệu ra để mỗi phần kết quả có thể nằm trong quantum riêng của nó. Lưu ý trong Hình 6-12 rằng, do cơ sở dữ liệu bị tách ra, Dịch vụ A và Dịch vụ B, cùng với dữ liệu tương ứng, hiện nay nằm trong một quantum riêng biệt so với quantum được hình thành với các dịch vụ C, D và E.
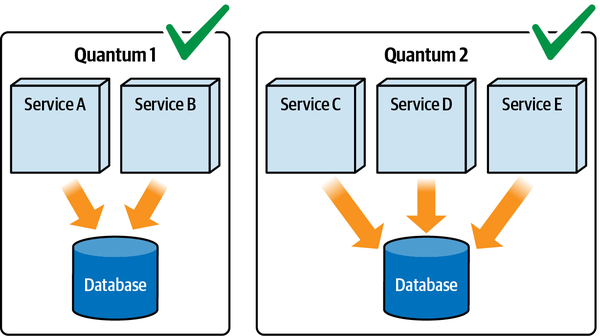
Figure 6-12. Breaking up the database forms two architectural quanta
Database type optimization
Thường thì không phải tất cả dữ liệu đều được xử lý giống nhau. Khi sử dụng một cơ sở dữ liệu đơn nhất, tất cả dữ liệu phải tuân theo loại cơ sở dữ liệu đó, do đó có thể tạo ra các giải pháp không tối ưu cho một số loại dữ liệu nhất định.
Việc phân tách dữ liệu đơn lẻ cho phép kiến trúc sư di chuyển một số dữ liệu đến loại cơ sở dữ liệu tối ưu hơn. Ví dụ, giả sử một cơ sở dữ liệu quan hệ đơn lẻ lưu trữ dữ liệu giao dịch liên quan đến ứng dụng, bao gồm dữ liệu tham chiếu dưới dạng cặp khóa-giá trị (chẳng hạn như mã quốc gia, mã sản phẩm, mã kho, v.v.). Loại dữ liệu này khó quản lý trong một cơ sở dữ liệu quan hệ vì dữ liệu không có tính chất quan hệ, mà là dạng khóa-giá trị. Do đó, một cơ sở dữ liệu khóa-giá trị (xem “Các cơ sở dữ liệu khóa-giá trị”) sẽ tạo ra giải pháp tối ưu hơn so với cơ sở dữ liệu quan hệ.
Data Integrators
Các trình tích hợp dữ liệu thực hiện điều hoàn toàn ngược lại so với các trình phân tách dữ liệu đã được thảo luận ở phần trước. Những yếu tố này cung cấp câu trả lời và lý do cho câu hỏi "Khi nào tôi nên xem xét việc kết hợp dữ liệu trở lại?" Cùng với các trình phân tách dữ liệu, các trình tích hợp dữ liệu cung cấp sự cân bằng và các sự đánh đổi khi phân tích khi nào nên tách rời dữ liệu và khi nào không nên.
Hai động lực tích hợp chính để gộp dữ liệu lại với nhau là:
- Data relationships
-
Có khóa ngoại, trigger hay view nào hình thành mối quan hệ chặt chẽ giữa các bảng không?
- Database transactions
-
Một đơn vị công việc giao dịch đơn lẻ có cần thiết để đảm bảo tính toàn vẹn và nhất quán của dữ liệu không?
Mỗi trình điều khiển tích hợp này sẽ được thảo luận chi tiết trong các phần tiếp theo.
Data relationships
Giống như các thành phần trong một kiến trúc, các bảng cơ sở dữ liệu cũng có thể được kết hợp, đặc biệt là đối với các cơ sở dữ liệu quan hệ. Các đối tượng như khóa ngoại, trigger, view và thủ tục lưu trữ liên kết các bảng lại với nhau, làm cho việc tách dữ liệu trở nên khó khăn; xem Hình 6-13.
Hãy tưởng tượng bạn tiếp cận DBA hoặc kiến trúc sư dữ liệu của mình và nói với họ rằng vì cơ sở dữ liệu cần phải được phân tách để hỗ trợ các bối cảnh biên chặt chẽ trong một hệ sinh thái microservices, mọi khóa ngoại và chế độ xem trong cơ sở dữ liệu cần phải bị loại bỏ! Đó không phải là một kịch bản khả thi (hoặc thậm chí hợp lý), nhưng đó chính xác là những gì sẽ cần diễn ra để hỗ trợ mô hình cơ sở dữ liệu-theo-dịch vụ trong microservices.
Figure 6-13. Foreign keys (FK), triggers, and views create tightly coupled relationships between data
Những artefact này là cần thiết trong hầu hết các cơ sở dữ liệu quan hệ để hỗ trợ tính nhất quán và tính toàn vẹn của dữ liệu. Ngoài những artefact vật lý này, dữ liệu cũng có thể có mối quan hệ logic, chẳng hạn như bảng vé vấn đề và bảng trạng thái vé vấn đề tương ứng của nó. Tuy nhiên, như minh họa trong Hình 6-14, những artefact này phải được loại bỏ khi di chuyển dữ liệu sang một lược đồ hoặc cơ sở dữ liệu khác để hình thành các ngữ cảnh bó hẹp.
Figure 6-14. Data artifacts must be removed when breaking apart data
Lưu ý rằng mối quan hệ khóa ngoại (FK) giữa các bảng trong Dịch vụ A có thể được giữ nguyên vì dữ liệu nằm trong cùng một bối cảnh ràng buộc, sơ đồ hoặc cơ sở dữ liệu. Tuy nhiên, các khóa ngoại (FK) giữa các bảng trong Dịch vụ B và Dịch vụ C phải được loại bỏ (cũng như view được sử dụng trong Dịch vụ C) vì những bảng đó liên kết với các cơ sở dữ liệu hoặc sơ đồ khác nhau.
Mối quan hệ giữa dữ liệu, dù là logic hay vật lý, là một động lực tích hợp dữ liệu, do đó tạo ra sự đánh đổi giữa các tác nhân phân tách dữ liệu và các tác nhân tích hợp dữ liệu. Chẳng hạn, việc kiểm soát thay đổi (một tác nhân phân tách dữ liệu) có quan trọng hơn việc bảo tồn các mối quan hệ khóa ngoại giữa các bảng (một tác nhân tích hợp dữ liệu) không? Sự chống chịu lỗi (một tác nhân phân tách dữ liệu) có quan trọng hơn việc bảo tồn các view vật liệu giữa các bảng (một tác nhân tích hợp dữ liệu) không? Việc xác định điều gì quan trọng hơn giúp đưa ra quyết định về việc liệu dữ liệu có nên được tách ra hay không và độ chi tiết của schema kết quả nên như thế nào.
Database transactions
Một bộ tích hợp dữ liệu khác là giao dịch cơ sở dữ liệu, một điều chúng tôi thảo luận chi tiết trong “Giao dịch phân tán”. Như được thể hiện trong Hình 6-15, khi một dịch vụ đơn lẻ thực hiện nhiều hành động ghi cơ sở dữ liệu vào các bảng riêng biệt trong cùng một cơ sở dữ liệu hoặc lược đồ, những cập nhật đó có thể được thực hiện trong một giao dịch Atomicity, Consistency, Isolation, Durability (ACID) và được xác nhận hoặc hoàn tác như một đơn vị công việc duy nhất.
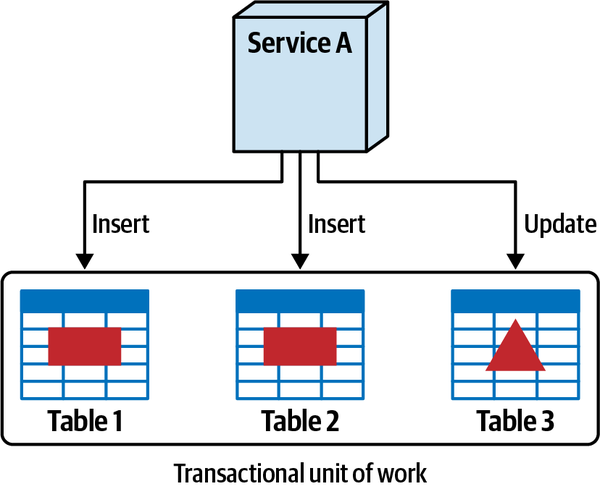
Figure 6-15. A single transactional unit of work exists when the data is together
Tuy nhiên, khi dữ liệu được phân tách thành các sơ đồ hoặc cơ sở dữ liệu riêng biệt, như được minh họa trong Hình 6-16, một đơn vị giao dịch duy nhất không còn tồn tại nữa do các cuộc gọi từ xa giữa các dịch vụ. Điều này có nghĩa là một thao tác chèn hoặc cập nhật có thể được cam kết trong một bảng, nhưng không trong các bảng khác do các điều kiện lỗi, dẫn đến các vấn đề về tính nhất quán và tính toàn vẹn của dữ liệu.
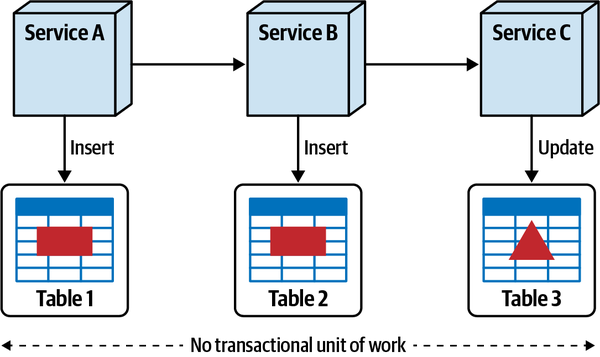
Figure 6-16. Single unit of work transactions don’t exist when data is broken apart
Trong khi chúng ta đi sâu vào các chi tiết về quản lý giao dịch phân tán và các saga giao dịch trong Chương 12, điểm ở đây là nhấn mạnh rằng giao dịch cơ sở dữ liệu là một yếu tố tích hợp dữ liệu khác và cần được xem xét khi cân nhắc việc tách rời một cơ sở dữ liệu.
Sysops Squad Saga: Justifying Database Decomposition
Thứ Hai, ngày 15 tháng 11, 15:55
Được trang bị những lý do của họ, Addison và Devon đã gặp nhau để thuyết phục Dana rằng việc tách rời cơ sở dữ liệu Sysops Squad đơn nhất là cần thiết.
“Chào, Dana,” Addison nói. “Chúng tôi nghĩ rằng chúng tôi có đủ chứng cứ để thuyết phục bạn rằng cần phải tách rời cơ sở dữ liệu của đội Sysops Squad.”
“Em đang lắng nghe,” Dana nói, hai tay khoanh lại và sẵn sàng tranh luận rằng cơ sở dữ liệu nên giữ nguyên như hiện tại.
“Em sẽ bắt đầu,” Addison nói. “Chú ý rằng những bản ghi này liên tục cho thấy mỗi khi các báo cáo hoạt động chạy, chức năng ghi vé trong ứng dụng bị đơ?”
“Vâng,” Dana nói, “Tôi thừa nhận rằng ngay cả tôi cũng nghi ngờ điều đó. Rõ ràng là có điều gì đó sai với cách mà chức năng đặt vé truy cập vào cơ sở dữ liệu, không phải báo cáo.”
“Thực ra,” Addison nói, “đó là sự kết hợp của cả việc bán vé và báo cáo. Nhìn đây.”
Addison đã cho Dana xem các chỉ số và nhật ký cho thấy một số truy vấn buộc phải được bao bọc trong các luồng, và rằng các truy vấn từ chức năng đặt vé đã bị hết thời gian chờ do trạng thái chờ khi các truy vấn báo cáo được thực thi. Addison cũng đã chỉ cho cách phần báo cáo của hệ thống sử dụng các luồng song song để truy vấn các phần của các báo cáo phức tạp cùng một lúc, về cơ bản chiếm hết tất cả các kết nối cơ sở dữ liệu.
“Được rồi, tôi có thể thấy cách việc có một cơ sở dữ liệu báo cáo riêng sẽ giúp tình hình từ góc độ kết nối cơ sở dữ liệu. Nhưng điều đó vẫn không thuyết phục tôi rằng dữ liệu không báo cáo nên được tách rời,” Dana nói.
“Nhắc đến kết nối cơ sở dữ liệu,” Devon nói, “hãy nhìn vào ước lượng kết nối pool này khi chúng ta bắt đầu tách rời các dịch vụ miền.”
Devon đã chỉ cho Dana số lượng dịch vụ ước tính trong ứng dụng phân phối Sysops Squad cuối cùng, bao gồm số lượng phiên bản được dự kiến cho mỗi dịch vụ khi ứng dụng mở rộng. Dana đã giải thích cho Devon rằng pool kết nối được chứa trong mỗi phiên bản dịch vụ riêng biệt, không giống như trong giai đoạn hiện tại của quá trình di chuyển, nơi mà máy chủ ứng dụng sở hữu pool kết nối.
“Vì vậy, bạn thấy đấy, Dana,” Devon nói, “với những ước lượng dự kiến này, chúng ta sẽ cần thêm 2.000 kết nối đến cơ sở dữ liệu để cung cấp khả năng mở rộng mà chúng ta cần để xử lý lượng vé, và chúng ta đơn giản là không có đủ với một cơ sở dữ liệu duy nhất.”
"Dana đã dành một chút thời gian để nhìn qua các con số. 'Bạn có đồng ý với những con số này không, Addison?'"
“Tôi có,” Addison nói. “Devon và tôi đã tự mình nghĩ ra chúng sau nhiều phân tích dựa trên lượng lưu lượng HTTP cũng như tỷ lệ tăng trưởng dự kiến được Parker cung cấp.”
“Tôi phải thừa nhận,” Dana nói, “đây là những thứ tốt mà hai bạn đã chuẩn bị. Tôi đặc biệt thích việc các bạn đã suy nghĩ về việc không để các dịch vụ kết nối với nhiều cơ sở dữ liệu hoặc lược đồ. Như các bạn biết, trong cuốn sách của tôi, điều đó là không chấp nhận.”
“Chúng tôi cũng vậy. Tuy nhiên, chúng tôi có một lý do nữa để nói chuyện với bạn,” Addison nói. “Như bạn có thể biết hoặc không biết, chúng tôi đã gặp rất nhiều vấn đề liên quan đến việc hệ thống không khả dụng cho khách hàng của chúng tôi. Mặc dù việc tách rời các dịch vụ mang lại cho chúng tôi một mức độ chống lỗi nào đó, nhưng nếu một cơ sở dữ liệu đơn thể bị ngừng hoạt động do bảo trì hoặc do sự cố máy chủ, tất cả các dịch vụ sẽ trở thành không hoạt động.”
"Devon thêm vào, 'Điều Addison đang nói là bằng cách tách rời cơ sở dữ liệu, chúng ta có thể cung cấp khả năng chịu lỗi tốt hơn bằng cách tạo ra các silo miền cho dữ liệu. Nói cách khác, nếu cơ sở dữ liệu khảo sát gặp sự cố, chức năng bán vé vẫn sẽ có sẵn.'"
“Chúng tôi gọi đó là một quantum kiến trúc,” Addison nói. “Nói cách khác, vì cơ sở dữ liệu là một phần của việc liên kết tĩnh của một hệ thống, việc tách nó ra sẽ khiến chức năng đặt vé cốt lõi trở thành độc lập và không phụ thuộc đồng thời vào các phần khác của hệ thống.”
“Nghe này,” Dana nói, “bạn đã thuyết phục tôi rằng có lý do chính đáng để tách rời cơ sở dữ liệu của đội Sysops, nhưng hãy giải thích cho tôi cách mà bạn có thể nghĩ tới việc làm điều đó. Bạn có nhận ra có bao nhiêu khóa ngoại và view trong cơ sở dữ liệu đó không? Không có cách nào bạn có thể loại bỏ tất cả những thứ đó.”
"Chúng ta không nhất thiết phải loại bỏ tất cả những hiện vật đó. Đó là lý do tại sao các miền dữ liệu và quy trình năm bước lại quan trọng," Devon nói. "Để tôi giải thích..."
Decomposing Monolithic Data
Việc phân tách một cơ sở dữ liệu đơn thể là khó khăn và đòi hỏi một kiến trúc sư phải hợp tác chặt chẽ với nhóm cơ sở dữ liệu để an toàn và hiệu quả tách rời dữ liệu. Một kỹ thuật đặc biệt hiệu quả để tách rời dữ liệu là tận dụng quy trình năm bước. Như được minh họa trong Hình 6-17, quy trình tiến hóa và lặp đi lặp lại này tận dụng khái niệm miền dữ liệu như một phương tiện để di chuyển dữ liệu một cách có phương pháp vào các sơ đồ riêng biệt, và do đó, vào các cơ sở dữ liệu vật lý khác nhau.
Figure 6-17. Five-step process for decomposing a monolithic database
Một miền dữ liệu là một tập hợp các đối tượng cơ sở dữ liệu liên kết với nhau - bảng, chế độ xem, khóa ngoại và bộ kích hoạt - tất cả đều liên quan đến một miền cụ thể và thường được sử dụng cùng nhau trong một phạm vi chức năng hạn chế. Để minh họa khái niệm về miền dữ liệu, hãy xem xét các bảng của nhóm Sysops đã được giới thiệu trong Bảng 1-2 và các phân bổ miền dữ liệu đề xuất tương ứng được hiển thị trong Bảng 6-5.
| Table | Proposed data domains |
|---|---|
khách hàng | Khách hàng |
thông_báo_khách_hàng | Khách hàng |
khảo sát | Khảo sát |
câu hỏi | Khảo sát |
khảo sát được thực hiện | Khảo sát |
câu_hỏi_chiến_khảo_sát | Khảo sát |
khảo sát phản hồi | Khảo sát |
hóa đơn | Thanh toán |
hợp đồng | Thanh toán |
phương thức thanh toán | Thanh toán |
thanh toán | Thanh toán |
người dùng quản trị hệ thống | Hồ sơ |
hồ sơ | Hồ sơ |
hồ sơ chuyên gia | Hồ sơ |
chuyên môn | Hồ sơ |
địa điểm | Hồ sơ |
bài viết | Cơ sở tri thức |
thẻ | Cơ sở tri thức |
từ khóa | Cơ sở kiến thức |
thẻ_bài_viết | Cơ sở tri thức |
từ khóa bài viết | Cơ sở tri thức |
vé | Vé máy bay |
loại vé | Vé máy bay |
lịch sử vé | Vé máy bay |
Bảng 6-5 liệt kê sáu miền dữ liệu trong ứng dụng Sysops Squad: Khách hàng, Khảo sát, Thanh toán, Hồ sơ, Cơ sở kiến thức và Xử lý vé. Bảng thanh toán thuộc miền dữ liệu Thanh toán, bảng vé và bảng loại vé thuộc miền dữ liệu Xử lý vé, và vân vân.
Một cách để tưởng tượng về các miền dữ liệu là nghĩ về cơ sở dữ liệu như một quả bóng đá, trong đó mỗi hình lục giác màu trắng đại diện cho một miền dữ liệu riêng biệt. Như được minh họa trong Hình 6-18, mỗi hình lục giác màu trắng của quả bóng đá chứa một tập hợp các bảng liên quan đến miền cùng với tất cả các artefact liên kết (chẳng hạn như khóa ngoại, view, thủ tục lưu trữ, v.v...).
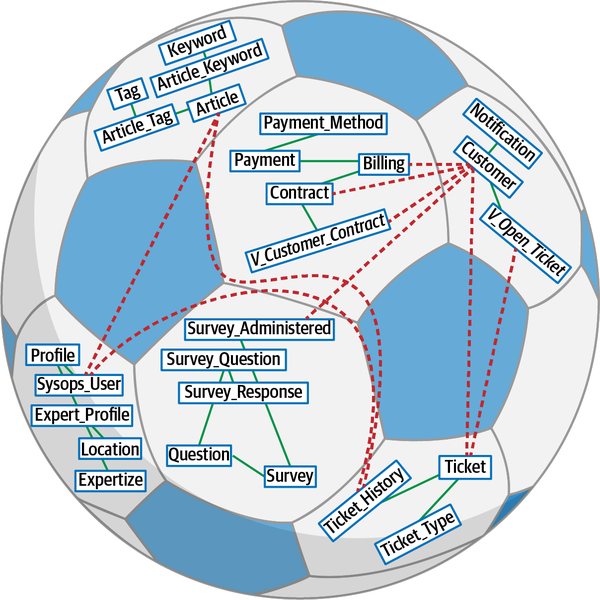
Figure 6-18. Database objects in a hexagon belong in a data domain
Việc trực quan hóa cơ sở dữ liệu theo cách này cho phép kiến trúc sư và nhóm cơ sở dữ liệu dễ dàng thấy được ranh giới miền dữ liệu cũng như các phụ thuộc giữa các miền (chẳng hạn như khóa ngoại, views, thủ tục lưu trữ, v.v.) cần phải được gỡ bỏ. Lưu ý trong Hình 6-18 rằng trong mỗi hình lục giác màu trắng, tất cả các phụ thuộc và mối quan hệ của bảng dữ liệu đều có thể được bảo tồn, nhưng không phải giữa các hình lục giác màu trắng. Ví dụ, trong sơ đồ, hãy lưu ý rằng các đường kẻ đặc đại diện cho các phụ thuộc tự chứa trong miền dữ liệu, trong khi các đường kẻ nét đứt vượt qua các miền dữ liệu và phải được loại bỏ khi các miền dữ liệu được trích xuất vào các sơ đồ riêng biệt.
Khi trích xuất một miền dữ liệu, các phụ thuộc giữa các miền phải được loại bỏ. Điều này có nghĩa là loại bỏ các ràng buộc khóa ngoại, các chế độ xem, các trình kích hoạt, các hàm và các thủ tục lưu trữ giữa các miền dữ liệu. Các nhóm cơ sở dữ liệu có thể tận dụng các mẫu tái cấu trúc được tìm thấy trong cuốn sách "Refactoring Databases: Evolutionary Database Design" của Scott Ambler và Pramod Sadalage (Addison-Wesley) để loại bỏ an toàn và lặp đi lặp lại những phụ thuộc dữ liệu này.
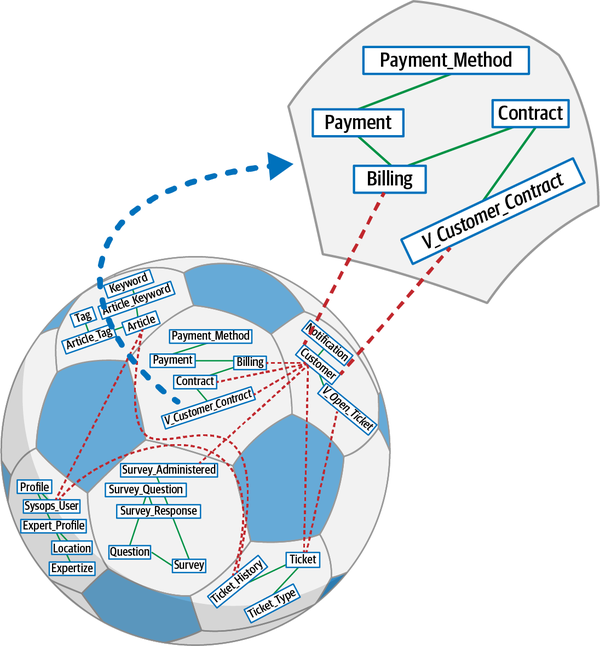
Figure 6-19. Tables belonging to data domains, extracted out, and connections that need to be broken
Để minh họa quy trình xác định một miền dữ liệu và loại bỏ các tham chiếu giữa các miền, hãy xem xét sơ đồ trong Hình 6-19, nơi một miền dữ liệu đại diện cho Thanh toán được tạo ra. Vì bảng khách hàng thuộc về một miền dữ liệu khác với v_customer_contract, bảng khách hàng phải được loại bỏ khỏi chế độ xem trong miền Thanh toán. Chế độ xem gốc v_customer_contract trước khi xác định miền dữ liệu được định nghĩa trong Ví dụ 6-1.
Example 6-1. Database view to get open tickets for customer with cross-domain joins
CREATEVIEW[payment].[v_customer_contract]ASSELECTcustomer.customer_id,customer.customer_name,contract.contract_start_date,contract.contract_duration,billing.billing_date,billing.billing_amountFROMpayment.contractAScontractINNERJOINcustomer.customerAScustomerON(contract.customer_id=customer.customer_id)INNERJOINpayment.billingASbillingON(contract.contract_id=billing.contract_id)WHEREcontract.auto_renewal=0
Lưu ý trong chế độ xem cập nhật được hiển thị trong Ví dụ 6-2 rằng mối kết nối giữa bảng khách hàng và bảng thanh toán đã bị xóa, cũng như cột tên khách hàng (customer.customer_name).
Example 6-2. Database view to get open tickets in ticket domain for a given customer
CREATEVIEW[payment].[v_customer_contract]ASSELECTbilling.customer_id,contract.contract_start_date,contract.contract_duration,billing.billing_date,billing.billing_amountFROMpayment.contractAScontractINNERJOINpayment.billingASbillingON(contract.contract_id=billing.contract_id)WHEREcontract.auto_renewal=0
Các quy tắc bối cảnh giới hạn cho các miền dữ liệu áp dụng giống như các bảng riêng lẻ—một dịch vụ không thể nói chuyện với nhiều miền dữ liệu. Do đó, bằng cách loại bỏ bảng này khỏi cái nhìn, dịch vụ Thanh toán giờ đây phải gọi dịch vụ Khách hàng để lấy tên khách hàng mà nó đã có từ cái nhìn ban đầu.
Khi các kiến trúc sư và nhóm cơ sở dữ liệu hiểu khái niệm về miền dữ liệu, họ có thể áp dụng quy trình năm bước để phân tách một cơ sở dữ liệu nguyên khối. Năm bước đó được trình bày trong các phần tiếp theo.
Step 1: Analyze Database and Create Data Domains
Như minh họa trong Hình 6-20, tất cả các dịch vụ đều có quyền truy cập vào tất cả dữ liệu trong cơ sở dữ liệu. Thực hành này, được gọi là phong cách tích hợp cơ sở dữ liệu chia sẻ mà Gregor Hohpe và Bobby Woolf mô tả trong cuốn sách Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions (Addison-Wesley), tạo ra một sự kết nối chặt chẽ giữa dữ liệu và các dịch vụ truy cập dữ liệu đó. Như đã thảo luận trong “Các yếu tố phân tách dữ liệu”, sự kết nối chặt chẽ này trong cơ sở dữ liệu làm cho việc quản lý thay đổi trở nên rất khó khăn.
Figure 6-20. Multiple services use the same database, accessing all the tables necessary for read or write purposes
Bước đầu tiên trong việc phân chia cơ sở dữ liệu là xác định các nhóm miền cụ thể trong cơ sở dữ liệu. Ví dụ, như được thể hiện trong Bảng 6-5, các bảng liên quan được nhóm lại với nhau để giúp xác định các miền dữ liệu có thể có.
Step 2: Assign Tables to Data Domains
Bước tiếp theo là nhóm các bảng theo một ngữ cảnh giới hạn cụ thể, phân bổ các bảng thuộc về một miền dữ liệu cụ thể vào lược đồ riêng của chúng. Lược đồ là một cấu trúc logic trong các máy chủ cơ sở dữ liệu. Lược đồ chứa các đối tượng như bảng, chế độ xem, hàm, v.v. Trong một số máy chủ cơ sở dữ liệu, như Oracle, lược đồ là giống như người dùng, trong khi ở các cơ sở dữ liệu khác, như SQL Server, lược đồ là không gian logic cho các đối tượng cơ sở dữ liệu nơi người dùng có quyền truy cập vào các lược đồ này.
Như được minh họa trong Hình 6-21, chúng tôi đã tạo ra các sơ đồ cho mỗi miền dữ liệu và di chuyển các bảng đến các sơ đồ mà chúng thuộc về.
Figure 6-21. Services use the primary schema according to their data domain needs
Khi các bảng thuộc các miền dữ liệu khác nhau được kết nối chặt chẽ và liên quan đến nhau, các miền dữ liệu phải được kết hợp, tạo ra một ngữ cảnh có giới hạn rộng hơn mà nhiều dịch vụ sở hữu một miền dữ liệu cụ thể. Việc kết hợp các miền dữ liệu sẽ được thảo luận chi tiết hơn trong Chương 9.
Để minh hoạ việc gán bảng cho các lược đồ, hãy xem xét ví dụ về Đội Sysops, trong đó bảng thanh toán phải được chuyển từ lược đồ gốc của nó sang một lược đồ miền dữ liệu khác gọi là thanh toán.
ALTERSCHEMApaymentTRANSFERsysops.billing;
Ngoài ra, một nhóm cơ sở dữ liệu có thể tạo ra các từ đồng nghĩa cho các bảng không thuộc về lược đồ của họ. Từ đồng nghĩa là các cấu trúc trong cơ sở dữ liệu, tương tự như liên kết tượng trưng, cung cấp một tên thay thế cho một đối tượng cơ sở dữ liệu khác có thể tồn tại trong cùng một lược đồ hoặc lược đồ khác hoặc máy chủ khác. Mặc dù ý tưởng của từ đồng nghĩa là nhằm loại bỏ các truy vấn giữa các lược đồ, nhưng quyền đọc hoặc ghi cần thiết để truy cập vào chúng.
Để minh họa cho thực tiễn này, hãy xem xét truy vấn đa miền sau đây:
SELECThistory.ticket_id,history.notes,agent.nameFROMticket.ticket_historyAShistoryINNERJOINprofile.sysops_userASagentON(history.assigned_to_sysops_user_id=agent.sysops_user_id)
Tiếp theo, tạo một từ đồng nghĩa cho bảng profile.sysops_user trong schema ticketing:
CREATESYNONYMticketing.sysops_userFORprofile.sysops_user;GO
Do đó, truy vấn có thể tận dụng từ đồng nghĩa sysops_user thay vì bảng liên miền:
SELECThistory.ticket_id,history.notes,agent.nameFROMticket.ticket_historyAShistoryINNERJOINticket.sysops_userASagentON(history.assigned_to_sysops_user_id=agent.sysops_user_id)
Rất tiếc, việc tạo các từ đồng nghĩa theo cách này cho các bảng được truy cập qua các schema cung cấp cho các nhà phát triển ứng dụng những điểm gộp. Để hình thành các miền dữ liệu thích hợp, những điểm gộp này cần phải được tách rời tại một thời điểm nào đó trong tương lai, do đó chuyển các điểm tích hợp từ lớp cơ sở dữ liệu sang lớp ứng dụng.
Mặc dù từ đồng nghĩa không thực sự loại bỏ các truy vấn chéo giữa các sơ đồ, nhưng chúng cho phép kiểm tra phụ thuộc và phân tích mã dễ dàng hơn, giúp việc tách chúng ra sau này trở nên dễ dàng hơn.
Step 3: Separate Database Connections to Data Domains
Trong bước này, logic kết nối cơ sở dữ liệu trong mỗi dịch vụ được tái cấu trúc để đảm bảo các dịch vụ kết nối với một sơ đồ cụ thể và có quyền đọc và ghi chỉ đối với các bảng thuộc về miền dữ liệu của chúng. Sự chuyển đổi này, được minh họa trong Hình 6-22, là khó khăn nhất vì tất cả việc truy cập đa sơ đồ phải được giải quyết ở cấp độ dịch vụ.
Lưu ý rằng cấu hình cơ sở dữ liệu đã được thay đổi để tất cả việc truy cập dữ liệu được thực hiện nghiêm ngặt thông qua các dịch vụ và các lược đồ kết nối của chúng. Trong ví dụ này, Dịch vụ C giao tiếp với Dịch vụ D chứ không phải với Lược đồ D. Không có truy cập chéo giữa các lược đồ; tất cả các đồng nghĩa được tạo trong "Bước 2: Gán Bảng vào miền Dữ liệu" đều bị xóa.
Figure 6-22. Move the cross-schema object access to the services, away from direct cross-schema access
Tip
Khi cần dữ liệu từ các lĩnh vực khác, đừng truy cập vào cơ sở dữ liệu của họ. Thay vào đó, hãy truy cập chúng thông qua dịch vụ sở hữu miền dữ liệu.
Sau khi hoàn thành bước này, cơ sở dữ liệu sẽ ở trạng thái chủ quyền dữ liệu theo dịch vụ, điều này xảy ra khi mỗi dịch vụ sở hữu dữ liệu của chính nó. Chủ quyền dữ liệu theo dịch vụ là trạng thái lý tưởng cho một kiến trúc phân tán. Giống như tất cả các thực hành trong kiến trúc, nó bao gồm lợi ích và nhược điểm:
- Benefits
-
-
Các nhóm có thể thay đổi sơ đồ cơ sở dữ liệu mà không cần lo lắng về việc ảnh hưởng đến các thay đổi ở các miền khác.
-
Mỗi dịch vụ có thể sử dụng công nghệ cơ sở dữ liệu và loại cơ sở dữ liệu phù hợp nhất với trường hợp sử dụng của họ.
-
- Shortcomings
-
-
Các vấn đề về hiệu suất xảy ra khi các dịch vụ cần truy cập vào một khối lượng dữ liệu lớn.
-
Tính toàn vẹn tham chiếu không thể được duy trì trong cơ sở dữ liệu, dẫn đến khả năng chất lượng dữ liệu kém.
-
Tất cả mã cơ sở dữ liệu (thủ tục lưu trữ, hàm) truy cập các bảng thuộc về các miền khác phải được chuyển đến lớp dịch vụ.
-
Step 4: Move Schemas to Separate Database Servers
Khi các đội cơ sở dữ liệu đã tạo ra và phân tách các miền dữ liệu, và đã cô lập các dịch vụ để chúng truy cập vào dữ liệu của riêng mình, họ có thể di chuyển các miền dữ liệu đến các cơ sở dữ liệu vật lý riêng biệt. Đây thường là một bước cần thiết vì ngay cả khi các dịch vụ truy cập vào các lược đồ của chúng, việc truy cập một cơ sở dữ liệu duy nhất tạo ra một lượng kiến trúc duy nhất, như đã đề cập trong Chương 2, điều này có thể có ảnh hưởng xấu đến các đặc điểm hoạt động, chẳng hạn như khả năng mở rộng, khả năng chịu lỗi và hiệu suất.
Khi chuyển các lược đồ đến các cơ sở dữ liệu vật lý riêng biệt, các nhóm cơ sở dữ liệu có hai lựa chọn: sao lưu và phục hồi, hoặc sao chép. Các tùy chọn này được trình bày như sau:
- Backup and restore
-
Với tùy chọn này, các nhóm trước tiên sao lưu mỗi schema với các miền dữ liệu, sau đó thiết lập máy chủ cơ sở dữ liệu cho mỗi miền dữ liệu. Họ sau đó phục hồi các schema, kết nối các dịch vụ với các schema trong các máy chủ cơ sở dữ liệu mới, và cuối cùng xóa các schema khỏi máy chủ cơ sở dữ liệu ban đầu. Cách tiếp cận này thường yêu cầu thời gian ngừng hoạt động cho quá trình di chuyển.
- Replicate
-
Sử dụng tùy chọn sao chép, các nhóm trước tiên thiết lập các máy chủ cơ sở dữ liệu cho mỗi miền dữ liệu. Tiếp theo, họ sao chép các schema, chuyển kết nối sang các máy chủ cơ sở dữ liệu mới, và sau đó xóa các schema khỏi máy chủ cơ sở dữ liệu gốc. Mặc dù phương pháp này tránh được thời gian ngừng hoạt động, nhưng nó đòi hỏi nhiều công việc hơn để thiết lập việc sao chép và quản lý sự phối hợp tăng lên.
Hình 6-23 cho thấy một ví dụ về tùy chọn sao chép, trong đó đội ngũ cơ sở dữ liệu thiết lập nhiều máy chủ cơ sở dữ liệu để có một máy chủ cơ sở dữ liệu cho mỗi miền dữ liệu.
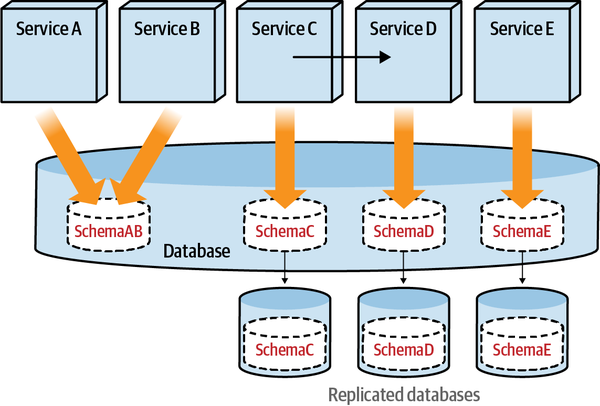
Figure 6-23. Replicate schemas (data domains) to their own database servers
Step 5: Switch Over to Independent Database Servers
Khi các lược đồ đã được sao chép hoàn toàn, các kết nối dịch vụ có thể được chuyển đổi. Bước cuối cùng trong việc làm cho các miền dữ liệu và dịch vụ hoạt động như những đơn vị triển khai độc lập của riêng chúng là loại bỏ kết nối với các máy chủ cơ sở dữ liệu cũ và xóa các lược đồ khỏi các máy chủ cơ sở dữ liệu cũ. Trạng thái cuối cùng được thấy trong Hình 6-24.
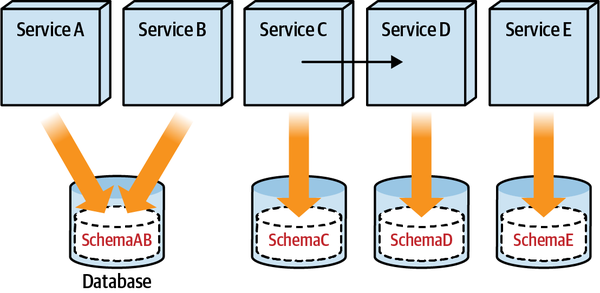
Figure 6-24. Independent database servers for each data domain
Khi nhóm cơ sở dữ liệu đã phân tách các miền dữ liệu, cô lập các kết nối cơ sở dữ liệu và cuối cùng chuyển các miền dữ liệu sang các máy chủ cơ sở dữ liệu riêng biệt, họ có thể tối ưu hóa từng máy chủ cơ sở dữ liệu cho tính khả dụng và khả năng mở rộng. Các đội cũng có thể phân tích dữ liệu để xác định loại cơ sở dữ liệu phù hợp nhất để sử dụng, giới thiệu việc sử dụng nhiều loại cơ sở dữ liệu trong hệ sinh thái.
Selecting a Database Type
Kể từ khoảng năm 2005, một cuộc cách mạng đã diễn ra trong công nghệ cơ sở dữ liệu. Thật không may, số lượng sản phẩm xuất hiện trong thời gian này đã tạo ra một vấn đề được gọi là Nghịch lý của sự Lựa chọn. Việc có quá nhiều sản phẩm và sự lựa chọn có nghĩa là phải đưa ra nhiều quyết định về sự đánh đổi hơn. Vì mỗi sản phẩm được tối ưu hóa cho những sự đánh đổi nhất định, nên phụ thuộc vào cả kiến trúc sư phần mềm và dữ liệu để chọn sản phẩm phù hợp với những sự đánh đổi này liên quan đến không gian vấn đề của họ.
Trong phần này, chúng tôi giới thiệu xếp hạng sao cho các loại cơ sở dữ liệu khác nhau, sử dụng các đặc điểm sau trong phân tích của chúng tôi:
- Ease-of-learning curve
-
Đặc điểm này đề cập đến mức độ dễ dàng mà các nhà phát triển mới, kiến trúc sư dữ liệu, người mô hình hóa dữ liệu, DBA vận hành và các người dùng khác của cơ sở dữ liệu có thể học tập và áp dụng. Ví dụ, người ta giả định rằng hầu hết các nhà phát triển phần mềm đều hiểu SQL, trong khi một ngôn ngữ truy vấn như Gremlin (một ngôn ngữ truy vấn đồ thị) có thể là một kỹ năng ngách. Đánh giá cao hơn có nghĩa là mức độ học tập dễ hơn. Đánh giá thấp hơn có nghĩa là mức độ học tập khó hơn.
- Ease of data modeling
-
Đặc điểm này đề cập đến độ dễ dàng mà các nhà mô hình hóa dữ liệu có thể đại diện cho miền dưới dạng một mô hình dữ liệu. Đánh giá sao cao hơn có nghĩa là mô hình hóa dữ liệu phù hợp với nhiều trường hợp sử dụng, và khi đã được mô hình hóa, nó dễ dàng thay đổi và áp dụng.
- Scalability/throughput
-
Đặc điểm này đề cập đến mức độ và độ dễ dàng mà một cơ sở dữ liệu có thể mở rộng để xử lý lưu lượng tăng lên. Có dễ dàng để mở rộng cơ sở dữ liệu không? Cơ sở dữ liệu có thể mở rộng theo chiều ngang, chiều dọc, hay cả hai? Điểm xếp hạng sao cao hơn có nghĩa là dễ dàng hơn để mở rộng và có được lưu lượng cao hơn.
- Availability/partition tolerance
-
Đặc điểm này đề cập đến việc cơ sở dữ liệu có hỗ trợ các cấu hình có khả năng sẵn sàng cao hay không (chẳng hạn như replica-sets trong MongoDB hoặc khả năng điều chỉnh tính nhất quán trong Apache Cassandra). Nó có cung cấp các tính năng để xử lý các phân vùng mạng không? Sao càng cao, cơ sở dữ liệu càng hỗ trợ tốt hơn cho khả năng sẵn sàng cao hơn và/hoặc khả năng chịu đựng phân vùng tốt hơn.
- Consistency
-
Đặc điểm này đề cập đến việc cơ sở dữ liệu có hỗ trợ mô hình "luôn nhất quán" hay không. Cơ sở dữ liệu có hỗ trợ giao dịch ACID hay nghiêng về giao dịch BASE với mô hình nhất quán theo thời gian không? Nó có cung cấp các tính năng để có các mô hình nhất quán có thể điều chỉnh cho các loại ghi khác nhau không? Xếp hạng sao càng cao, cơ sở dữ liệu càng hỗ trợ nhiều tính nhất quán hơn.
- Programming language support, product maturity, SQL support, and community
-
Đặc điểm này đề cập đến việc cơ sở dữ liệu hỗ trợ những ngôn ngữ lập trình nào (và bao nhiêu ngôn ngữ), mức độ trưởng thành của cơ sở dữ liệu và kích thước của cộng đồng cơ sở dữ liệu. Một tổ chức có dễ dàng tuyển dụng những người biết cách làm việc với cơ sở dữ liệu không? Xếp hạng sao cao hơn có nghĩa là có hỗ trợ tốt hơn, sản phẩm đã trưởng thành, và dễ dàng tuyển dụng nhân tài.
- Read/write priority
-
Tính năng này đề cập đến việc cơ sở dữ liệu ưu tiên việc đọc hơn việc ghi, hay việc ghi hơn việc đọc, hoặc nếu nó có cách tiếp cận cân bằng giữa hai. Đây không phải là một lựa chọn nhị phân - mà thực chất là một thang đo hướng mà cơ sở dữ liệu tối ưu hóa.
Relational Databases
Cơ sở dữ liệu quan hệ (còn được gọi là RDBMS) đã là lựa chọn cơ sở dữ liệu trong hơn ba thập kỷ. Có giá trị đáng kể trong việc sử dụng chúng và sự ổn định mà chúng cung cấp, đặc biệt là trong hầu hết các ứng dụng liên quan đến kinh doanh. Các cơ sở dữ liệu này nổi tiếng với Ngôn ngữ Truy vấn Có cấu trúc (SQL) phổ biến và các thuộc tính ACID mà chúng cung cấp. Giao diện SQL mà chúng cung cấp làm cho chúng trở thành lựa chọn ưu tiên để triển khai các mô hình đọc khác nhau dựa trên cùng một mô hình ghi. Xếp hạng sao cho các cơ sở dữ liệu quan hệ xuất hiện trong Hình 6-25.

Figure 6-25. Relational databases rated for various adoption characteristics
- Ease-of-learning curve
-
Cơ sở dữ liệu quan hệ đã tồn tại nhiều năm. Chúng thường được dạy trong các trường học, và có nhiều tài liệu cũng như hướng dẫn trưởng thành. Do đó, chúng dễ học hơn nhiều so với các loại cơ sở dữ liệu khác.
- Ease of data modeling
-
Cơ sở dữ liệu quan hệ cho phép mô hình hóa dữ liệu linh hoạt. Chúng cho phép mô hình hóa các cấu trúc khóa-giá trị, tài liệu, giống như đồ thị, và cho phép thay đổi trong các mẫu đọc bằng cách thêm các chỉ mục mới. Một số mô hình thực sự khó đạt được, chẳng hạn như các cấu trúc đồ thị có độ sâu tùy ý. Cơ sở dữ liệu quan hệ tổ chức dữ liệu thành các bảng và hàng (tương tự như bảng tính), điều này là tự nhiên đối với hầu hết các nhà lập mô hình cơ sở dữ liệu.
- Scalability/throughput
-
Cơ sở dữ liệu quan hệ thường được mở rộng theo chiều dọc bằng cách sử dụng các máy lớn. Tuy nhiên, việc thiết lập với các bản sao và chuyển đổi tự động khá phức tạp, yêu cầu sự phối hợp và thiết lập cao hơn.
- Availability/partition tolerance
-
Cơ sở dữ liệu quan hệ ưu tiên tính nhất quán hơn khả năng sẵn có và khả năng chịu phân đoạn, được thảo luận trong “Kỹ thuật chia bảng”.
- Consistency
-
Cơ sở dữ liệu quan hệ đã thống trị trong nhiều năm bởi vì sự hỗ trợ cho các thuộc tính ACID. Các tính năng ACID xử lý nhiều vấn đề trong các hệ thống đồng thời và cho phép phát triển ứng dụng mà không cần lo lắng về các chi tiết cấp thấp của tính đồng thời và cách mà các cơ sở dữ liệu xử lý chúng.
- Programming language support, product maturity, SQL support, and community
-
Vì cơ sở dữ liệu quan hệ đã tồn tại trong nhiều năm, các mẫu thiết kế, thực hiện và vận hành đã được biết đến có thể được áp dụng cho chúng, do đó, chúng trở nên dễ dàng để áp dụng, phát triển và tích hợp trong một kiến trúc. Nhiều cơ sở dữ liệu quan hệ thiếu hỗ trợ cho các API luồng phản ứng và các khái niệm mới tương tự; các khái niệm kiến trúc mới hơn mất nhiều thời gian hơn để triển khai trong các cơ sở dữ liệu quan hệ đã được thiết lập vững chắc. Nhiều giao diện ngôn ngữ lập trình hoạt động với cơ sở dữ liệu quan hệ, và cộng đồng người dùng thì lớn (mặc dù bị phân tán giữa tất cả các nhà cung cấp).
- Read/write priority
-
Trong các cơ sở dữ liệu quan hệ, mô hình dữ liệu có thể được thiết kế theo cách mà hoặc là đọc trở nên hiệu quả hơn, hoặc là ghi trở nên hiệu quả hơn. Cùng một cơ sở dữ liệu có thể xử lý nhiều loại khối lượng công việc khác nhau, cho phép ưu tiên đọc-ghi được cân bằng. Ví dụ, không phải tất cả các trường hợp sử dụng đều cần các thuộc tính ACID, đặc biệt là trong các kịch bản dữ liệu lớn và lưu lượng truy cập cao, hoặc khi mong muốn có một cấu trúc linh hoạt thực sự, chẳng hạn như trong quản trị khảo sát. Trong những trường hợp này, các loại cơ sở dữ liệu khác có thể là một lựa chọn tốt hơn.
MySQL, Oracle, Microsoft SQL Server và PostgreSQL là những cơ sở dữ liệu quan hệ phổ biến nhất và có thể được cài đặt độc lập hoặc có sẵn dưới dạng Dịch vụ Cơ sở dữ liệu trên các nền tảng cung cấp điện toán đám mây lớn.
Key-Value Databases
Cơ sở dữ liệu khóa-giá trị tương tự như cấu trúc dữ liệu bảng băm, giống như các bảng trong RDBMS với một cột ID làm khóa và một cột blob làm giá trị, do đó có thể lưu trữ bất kỳ loại dữ liệu nào. Cơ sở dữ liệu khóa-giá trị là một phần của một gia đình được gọi là cơ sở dữ liệu NoSQL. Trong cuốn sách NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence (Addison-Wesley), Pramod Sadalage (một trong những tác giả) và Martin Fowler mô tả sự phát triển của các cơ sở dữ liệu NoSQL và các động lực, cách sử dụng, và các thỏa hiệp khi sử dụng loại cơ sở dữ liệu này, và là một tài liệu tham khảo tốt để tìm hiểu thêm về loại cơ sở dữ liệu này.
Cơ sở dữ liệu key-value dễ hiểu nhất trong số các cơ sở dữ liệu NoSQL. Một ứng dụng client có thể chèn một khóa và một giá trị, lấy giá trị cho một khóa đã biết, hoặc xóa một khóa đã biết cùng với giá trị của nó. Cơ sở dữ liệu key-value không biết nội dung bên trong phần giá trị, cũng như không quan tâm đến nội dung bên trong, có nghĩa là cơ sở dữ liệu chỉ có thể truy vấn bằng khóa và không gì khác.
Không giống như cơ sở dữ liệu quan hệ, cơ sở dữ liệu key-value nên được lựa chọn dựa trên nhu cầu. Có những cơ sở dữ liệu key-value bền vững như Amazon DynamoDB hoặc Riak KV, cơ sở dữ liệu không bền vững như MemcacheDB, và các cơ sở dữ liệu khác như Redis có thể được cấu hình để bền vững hoặc không. Các cấu trúc cơ sở dữ liệu quan hệ khác như joins, where, và order by không được hỗ trợ, mà thay vào đó là các thao tác get, put và delete. Xếp hạng cho các cơ sở dữ liệu key-value xuất hiện trong Hình 6-26.
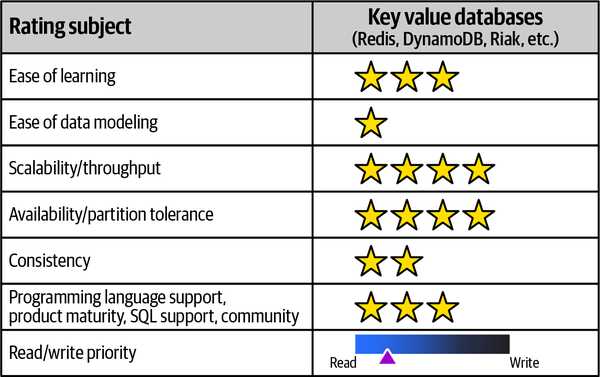
Figure 6-26. Key-value databases rated for various adoption characteristics
- Ease-of-learning curve
-
Cơ sở dữ liệu key-value rất dễ hiểu. Vì chúng sử dụng "Hướng tổng hợp", nên việc thiết kế tổng hợp là rất quan trọng vì bất kỳ thay đổi nào trong tổng hợp đều có nghĩa là phải ghi lại tất cả dữ liệu. Việc chuyển từ cơ sở dữ liệu quan hệ sang bất kỳ cơ sở dữ liệu NoSQL nào cần phải tập luyện và quên đi những thói quen quen thuộc. Ví dụ, một nhà phát triển không thể đơn giản truy vấn "Lấy cho tôi tất cả các khóa."
- Ease of data modeling
-
Vì các cơ sở dữ liệu key-value được định hướng theo tổng hợp, chúng có thể sử dụng các cấu trúc bộ nhớ như mảng, bản đồ, hoặc bất kỳ loại dữ liệu nào khác, bao gồm cả blob lớn. Dữ liệu chỉ có thể được truy vấn bằng khóa hoặc ID, có nghĩa là khách hàng cần phải có quyền truy cập vào khóa bên ngoài cơ sở dữ liệu. Một số ví dụ tốt về khóa bao gồm session_id, user_id và order_id.
- Scalability/throughput
-
Vì các cơ sở dữ liệu key-value được lập chỉ mục theo khóa hoặc ID, việc tra cứu khóa rất nhanh chóng vì không có các phép nối hoặc sắp xếp. Giá trị được lấy và trả về cho khách hàng, điều này cho phép dễ dàng mở rộng và tăng khả năng thông lượng.
- Availability/partition tolerance
-
Vì có nhiều loại cơ sở dữ liệu key-value và mỗi loại có những đặc tính khác nhau, ngay cả cùng một cơ sở dữ liệu cũng có thể được cấu hình để hoạt động theo nhiều cách khác nhau, cả cho một cài đặt lẫn cho mỗi lần đọc. Ví dụ, trong Riak, người dùng có thể sử dụng các thuộc tính quorum như all, one, quorum và default. Khi chúng ta sử dụng quorum là one, truy vấn có thể trả về thành công khi bất kỳ một nút nào phản hồi. Khi sử dụng quorum là all, tất cả các nút phải phản hồi để truy vấn trả về thành công. Mỗi truy vấn có thể điều chỉnh độ khoan dung của phân vùng và khả năng sẵn có. Do đó, giả định rằng tất cả các kho lưu trữ key-value đều giống nhau là một sai lầm.
- Consistency
-
Trong mỗi thao tác ghi, chúng ta có thể áp dụng các cấu hình tương tự như khi áp dụng quorum trong các thao tác đọc; các cấu hình này cung cấp cái được gọi là độ nhất quán có thể điều chỉnh. Độ nhất quán cao hơn có thể đạt được bằng cách đánh đổi độ trễ. Để một thao tác ghi được coi là rất nhất quán, tất cả các nút phải phản hồi, điều này làm giảm khả năng chịu partition. Sử dụng quorum đa số được coi là một sự đánh đổi hợp lý.
- Programming language support, product maturity, SQL support, and community
-
Cơ sở dữ liệu khóa-giá trị có hỗ trợ tốt cho ngôn ngữ lập trình, và nhiều cơ sở dữ liệu mã nguồn mở có cộng đồng tích cực để giúp học hỏi và hiểu chúng. Vì hầu hết các cơ sở dữ liệu đều có API REST HTTP, nên chúng dễ dàng hơn rất nhiều để liên kết.
- Read/write priority
-
Vì các cơ sở dữ liệu kiểu key-value tập trung vào việc tổng hợp, việc truy cập dữ liệu thông qua khóa hoặc ID hướng đến ưu tiên đọc. Cơ sở dữ liệu key-value có thể được sử dụng cho lưu trữ phiên và cũng có thể được sử dụng để lưu cache các thuộc tính và sở thích của người dùng.
Document Databases
Tài liệu như JSON hoặc XML là cơ sở của cơ sở dữ liệu tài liệu. Tài liệu có thể đọc được bởi con người, tự mô tả và là cấu trúc cây phân cấp. Cơ sở dữ liệu tài liệu là một loại cơ sở dữ liệu NoSQL khác, mà xếp hạng của nó xuất hiện trong Hình 6-27. Những cơ sở dữ liệu này hiểu cấu trúc của dữ liệu và có thể lập chỉ mục nhiều thuộc tính của các tài liệu, cho phép linh hoạt hơn trong việc truy vấn.

Figure 6-27. Document databases rated for various adoption characteristics
- Ease-of-learning curve
-
Cơ sở dữ liệu tài liệu giống như cơ sở dữ liệu key-value, trong đó giá trị có thể đọc được bằng con người. Điều này giúp việc học cách sử dụng cơ sở dữ liệu trở nên dễ dàng hơn. Các doanh nghiệp quen làm việc với tài liệu, chẳng hạn như XML và JSON trong các ngữ cảnh khác nhau, chẳng hạn như payload API và giao diện front-end JavaScript.
- Ease of data modeling
-
Cũng giống như các cơ sở dữ liệu kiểu key-value, mô hình hóa dữ liệu liên quan đến việc mô hình hóa các tập hợp như đơn hàng, vé và các đối tượng miền khác. Các cơ sở dữ liệu tài liệu khá linh hoạt khi nói đến thiết kế tập hợp, vì các phần của tập hợp có thể được truy vấn và có thể được lập chỉ mục.
- Scalability/throughput
-
Cơ sở dữ liệu tài liệu tập trung vào tập hợp và dễ dàng mở rộng. Chỉ số phức tạp làm giảm khả năng mở rộng, và kích thước dữ liệu tăng lên dẫn đến nhu cầu phân vùng hoặc chia nhỏ. Khi phân chia nhỏ được giới thiệu, nó làm tăng độ phức tạp và cũng buộc phải chọn một khóa phân chia.
- Availability/partition tolerance
-
Giống như các cơ sở dữ liệu kiểu key-value, cơ sở dữ liệu tài liệu có thể được cấu hình cho khả năng sẵn có cao hơn. Việc thiết lập trở nên phức tạp khi có các cụm sao chép cho các bộ sưu tập phân mảnh. Các nhà cung cấp dịch vụ đám mây đang cố gắng làm cho những thiết lập này dễ sử dụng hơn.
- Consistency
-
Một số cơ sở dữ liệu tài liệu đã bắt đầu hỗ trợ giao dịch ACID trong một bộ sưu tập, nhưng điều này có thể không hoạt động trong một số trường hợp biên. Giống như các cơ sở dữ liệu khóa-giá trị, các cơ sở dữ liệu tài liệu cung cấp khả năng tinh chỉnh các hoạt động đọc và ghi bằng cách sử dụng cơ chế số phiếu bầu.
- Programming language support, product maturity, SQL support, and community
-
Cơ sở dữ liệu tài liệu là loại cơ sở dữ liệu NoSQL phổ biến nhất, với một cộng đồng người dùng năng động, nhiều hướng dẫn học trực tuyến và nhiều trình điều khiển ngôn ngữ lập trình cho phép dễ dàng áp dụng hơn.
- Read/write priority
-
Cơ sở dữ liệu tài liệu thiên về tập hợp và có các chỉ mục thứ cấp để truy vấn, vì vậy các cơ sở dữ liệu này ưu tiên cho việc đọc.
Column Family Databases
Cơ sở dữ liệu dạng cột, còn được gọi là cơ sở dữ liệu cột rộng hoặc cơ sở dữ liệu bảng lớn, có các hàng với số lượng cột khác nhau, trong đó mỗi cột là một cặp tên-giá trị. Với các cơ sở dữ liệu dạng cột, tên được gọi là khóa cột, giá trị được gọi là giá trị cột, và khóa chính của một hàng được gọi là khóa hàng. Cơ sở dữ liệu dạng cột là một loại cơ sở dữ liệu NoSQL khác nhóm dữ liệu liên quan có thể được truy cập cùng một lúc, và các đánh giá của chúng xuất hiện trong Hình 6-28.

Figure 6-28. Column family databases rated for various adoption characteristics
- Ease-of-learning curve
-
Cơ sở dữ liệu dạng cột là khó hiểu. Vì một tập hợp các cặp tên-giá trị thuộc về một hàng, nên mỗi hàng có thể có các cặp tên-giá trị khác nhau. Một số cặp tên-giá trị có thể có một bản đồ các cột và được gọi là siêu cột. Hiểu cách sử dụng chúng cần có thời gian và thực hành.
- Ease of data modeling
-
Mô hình dữ liệu với cơ sở dữ liệu dạng cột cần thời gian để làm quen. Dữ liệu cần được sắp xếp thành các nhóm cặp tên-giá trị có một định danh hàng duy nhất, và thiết kế khóa hàng này cần nhiều vòng lặp. Một số cơ sở dữ liệu dạng cột như Apache Cassandra đã giới thiệu một ngôn ngữ truy vấn giống SQL được gọi là Cassandra Query Language (CQL), giúp cho việc mô hình hóa dữ liệu trở nên dễ tiếp cận hơn.
- Scalability/throughput
-
Tất cả các cơ sở dữ liệu dạng gia đình cột đều có khả năng mở rộng cao và phù hợp với các trường hợp sử dụng cần thông lượng ghi hoặc đọc cao. Các cơ sở dữ liệu dạng gia đình cột có thể mở rộng ngang cho các hoạt động đọc và ghi.
- Availability/partition tolerance
-
Cơ sở dữ liệu dạng cột tự nhiên hoạt động trong các cụm, và khi một số nút của cụm gặp sự cố, điều này là xuyên suốt với khách hàng. Hệ số sao chép mặc định là ba, có nghĩa là ít nhất ba bản sao dữ liệu được tạo ra, nâng cao khả năng sẵn sàng và khả năng chịu phân vùng. Tương tự như cơ sở dữ liệu key-value và tài liệu, cơ sở dữ liệu dạng cột có thể điều chỉnh việc ghi và đọc dựa trên nhu cầu đa số.
- Consistency
-
Cơ sở dữ liệu dạng cột, giống như các cơ sở dữ liệu NoSQL khác, tuân theo khái niệm tính nhất quán có thể điều chỉnh. Điều này có nghĩa là, tùy thuộc vào nhu cầu, mỗi thao tác có thể quyết định mức độ nhất quán mong muốn. Ví dụ, trong các kịch bản ghi cao, nơi một số mất mát dữ liệu có thể được chấp nhận, mức độ nhất quán ghi là ANY có thể được sử dụng, có nghĩa là ít nhất một nút đã chấp nhận ghi, trong khi mức độ nhất quán ALL có nghĩa là tất cả các nút phải chấp nhận ghi và phản hồi thành công. Các mức độ nhất quán tương tự có thể áp dụng cho các thao tác đọc. Đây là một sự đánh đổi—các mức độ nhất quán cao hơn làm giảm khả năng sẵn có và khả năng phân đoạn.
- Programming language support, product maturity, SQL support, and community
-
Cơ sở dữ liệu kiểu cột như Cassandra và Scylla có cộng đồng hoạt động năng nổ, và việc phát triển các giao diện tương tự SQL đã giúp việc áp dụng những cơ sở dữ liệu này dễ dàng hơn.
- Read/write priority
-
Cơ sở dữ liệu dạng gia đình cột sử dụng các khái niệm về SSTables, nhật ký cam kết (commit logs) và memtables, và vì các cặp tên-giá trị được lấp đầy khi có dữ liệu, chúng có thể xử lý dữ liệu thưa thớt tốt hơn nhiều so với cơ sở dữ liệu quan hệ. Chúng lý tưởng cho các kịch bản có khối lượng ghi cao.
Tất cả các cơ sở dữ liệu NoSQL đều được thiết kế để hiểu được định hướng tổng hợp. Việc có các tập hợp dữ liệu (aggregates) cải thiện hiệu suất đọc và ghi, và cũng cho phép có khả năng sẵn sàng cao hơn và độ tolérance phân tán khi các cơ sở dữ liệu được chạy trong dạng cụm. Khái niệm định lý CAP được đề cập chi tiết hơn trong "Kỹ thuật phân tách bảng".
Graph Databases
Khác với cơ sở dữ liệu quan hệ, nơi mà các quan hệ được ngầm hiểu dựa trên các tham chiếu, cơ sở dữ liệu đồ thị sử dụng các nút để lưu trữ các thực thể và thuộc tính của chúng. Các nút này được kết nối bằng các cạnh, còn được gọi là quan hệ, là những đối tượng rõ ràng. Các nút được tổ chức theo các quan hệ và cho phép phân tích dữ liệu kết nối bằng cách duyệt theo các cạnh cụ thể.

Figure 6-29. In graph databases, direction of the edge has significance when querying
Các cạnh trong cơ sở dữ liệu đồ thị có ý nghĩa hướng. Trong Hình 6-29, một cạnh loại TICKET_CREATED kết nối một nút vé với ID 4235143 đến một nút khách hàng với ID Neal. Chúng ta có thể đi qua từ nút vé qua cạnh hướng ra TICKET_CREATED hoặc từ nút khách hàng qua cạnh hướng vào TICKET_CREATED. Khi các hướng bị lẫn lộn, việc truy vấn đồ thị trở nên rất khó khăn. Các đánh giá cho cơ sở dữ liệu đồ thị được minh họa trong Hình 6-29.
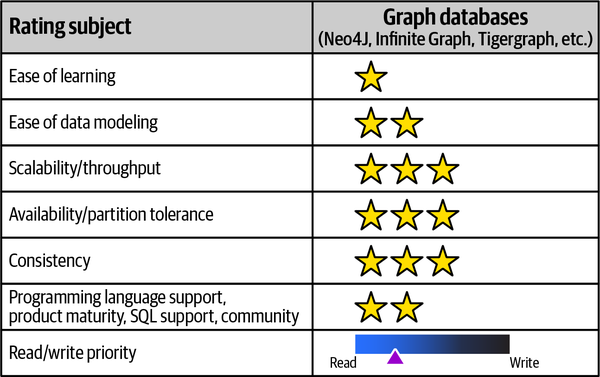
Figure 6-30. Graph databases rated for various adoption characteristics
- Ease-of-learning curve
-
Cơ sở dữ liệu đồ thị có một đường cong học tập dốc. Việc hiểu cách sử dụng các nút, mối quan hệ, loại mối quan hệ và thuộc tính mất thời gian.
- Ease of data modeling
-
Hiểu cách mô hình hóa các miền và chuyển đổi chúng thành các nút và quan hệ là rất khó. Ban đầu, xu hướng là thêm thuộc tính vào các quan hệ. Khi kiến thức mô hình cải thiện, việc sử dụng ngày càng nhiều các nút và quan hệ, và chuyển đổi một số thuộc tính quan hệ thành nút với loại quan hệ bổ sung diễn ra, điều này cải thiện việc duyệt đồ thị.
- Scalability/throughput
-
Các nút sao chép cải thiện khả năng mở rộng đọc, và thông lượng có thể được điều chỉnh cho các tải đọc. Vì việc chia tách hoặc phân đoạn đồ thị là khó khăn, thông lượng ghi bị hạn chế bởi loại cơ sở dữ liệu đồ thị được chọn. Việc duyệt các mối quan hệ rất nhanh chóng, vì việc lập chỉ mục và lưu trữ được duy trì và không được tính toán tại thời gian truy vấn.
- Availability/partition tolerance
-
Một số cơ sở dữ liệu đồ thị có khả năng phân vùng cao và tính khả dụng cao là phân tán. Các cụm cơ sở dữ liệu đồ thị có thể sử dụng các nút có thể được thăng chức thành lãnh đạo khi các lãnh đạo hiện tại không có sẵn.
- Consistency
-
Nhiều cơ sở dữ liệu đồ thị hỗ trợ giao dịch ACID. Một số cơ sở dữ liệu đồ thị, chẳng hạn như Neo4j, hỗ trợ giao dịch, để dữ liệu luôn nhất quán.
- Programming language support, product maturity, SQL support, and community
-
Cơ sở dữ liệu đồ thị có nhiều hỗ trợ từ cộng đồng. Nhiều thuật toán, như thuật toán Dijkstra hoặc độ tương đồng của nút, được triển khai trong cơ sở dữ liệu, giảm nhu cầu viết chúng từ đầu. Khung ngôn ngữ được gọi là Gremlin hoạt động trên nhiều cơ sở dữ liệu khác nhau, giúp dễ sử dụng hơn. Neo4J hỗ trợ một ngôn ngữ truy vấn được gọi là Cypher, cho phép các nhà phát triển dễ dàng truy vấn cơ sở dữ liệu.
- Read/write priority
-
Trong cơ sở dữ liệu đồ thị, việc lưu trữ dữ liệu được tối ưu hóa cho việc duyệt các mối quan hệ, trái ngược với các cơ sở dữ liệu quan hệ, nơi chúng ta phải truy vấn các mối quan hệ và suy luận chúng tại thời điểm truy vấn. Cơ sở dữ liệu đồ thị tốt hơn cho các kịch bản yêu cầu đọc dữ liệu nhiều.
Cơ sở dữ liệu đồ thị cho phép cùng một nút có nhiều loại mối quan hệ khác nhau. Trong ví dụ của Đội Sysops, một đồ thị mẫu có thể trông như sau: một knowledge_base được tạo ra bởi người dùng sysops_user và knowledge_base được sử dụng bởi sysops_user. Do đó, các mối quan hệ created_by và used_by kết nối các nút giống nhau cho các loại mối quan hệ khác nhau.
NewSQL Databases
Matthew Aslett lần đầu tiên sử dụng thuật ngữ NewSQL để định nghĩa các cơ sở dữ liệu mới nhằm cung cấp khả năng mở rộng của các cơ sở dữ liệu NoSQL đồng thời hỗ trợ các tính năng của cơ sở dữ liệu quan hệ như ACID. Các cơ sở dữ liệu NewSQL sử dụng các loại cơ chế lưu trữ khác nhau, và tất cả chúng đều hỗ trợ SQL.
Cơ sở dữ liệu NewSQL, có xếp hạng xuất hiện trong Hình 6-31, cải thiện các cơ sở dữ liệu quan hệ bằng cách cung cấp phân vùng dữ liệu tự động hoặc sharding, cho phép mở rộng theo chiều ngang và tăng cường khả năng sẵn sàng, trong khi vẫn cho phép các nhà phát triển dễ dàng chuyển đổi sang việc sử dụng mô hình quen thuộc của SQL và ACID.
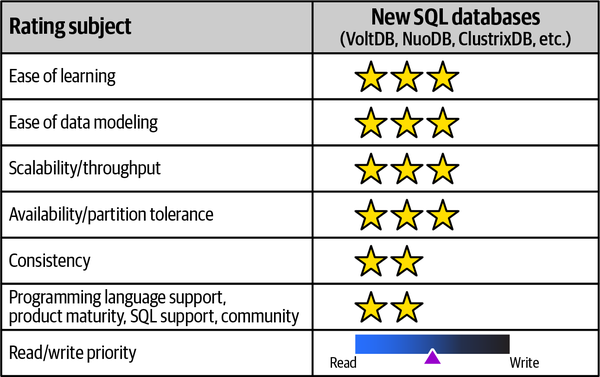
Figure 6-31. New SQL databases rated for various adoption characteristics
- Ease-of-learning curve
-
Vì các cơ sở dữ liệu NewSQL giống như các cơ sở dữ liệu quan hệ (với giao diện SQL, có thêm tính năng mở rộng theo chiều ngang, tuân thủ ACID), nên việc học sẽ dễ dàng hơn. Một số trong số đó chỉ có sẵn dưới dạng Dịch vụ Cơ sở dữ liệu (DBaaS), điều này có thể khiến việc học trở nên khó khăn hơn.
- Ease of data modeling
-
Vì các cơ sở dữ liệu NewSQL tương tự như cơ sở dữ liệu quan hệ, việc mô hình hóa dữ liệu là quen thuộc đối với nhiều người và dễ tiếp thu hơn. Đặc điểm thêm là thiết kế phân mảnh, cho phép đặt dữ liệu phân mảnh tại các vị trí địa lý khác nhau.
- Scalability/throughput
-
Cơ sở dữ liệu NewSQL được thiết kế để hỗ trợ mở rộng theo chiều ngang cho các hệ thống phân tán, cho phép có nhiều nút hoạt động, khác với cơ sở dữ liệu quan hệ chỉ có một lãnh đạo hoạt động và các nút còn lại là các nút theo sau. Nhiều nút hoạt động cho phép cơ sở dữ liệu NewSQL có khả năng mở rộng cao và đạt được hiệu suất tốt hơn.
- Availability/partition tolerance
-
Nhờ vào thiết kế nhiều nút hoạt động, lợi ích về tính sẵn sàng có thể rất cao với khả năng chịu phân vùng tốt hơn. CockroachDB là một cơ sở dữ liệu NewSQL phổ biến có khả năng sống sót qua các sự cố về đĩa, máy móc và trung tâm dữ liệu.
- Consistency
-
Cơ sở dữ liệu NewSQL hỗ trợ các giao dịch ACID đồng nhất mạnh mẽ. Dữ liệu luôn nhất quán, điều này cho phép người dùng cơ sở dữ liệu quan hệ dễ dàng chuyển sang cơ sở dữ liệu NewSQL.
- Programming language support, product maturity, SQL support, and community
-
Có nhiều cơ sở dữ liệu NewSQL mã nguồn mở, vì vậy việc học chúng là dễ dàng. Một số cơ sở dữ liệu cũng hỗ trợ các giao thức tương thích với các cơ sở dữ liệu quan hệ hiện có, cho phép chúng thay thế các cơ sở dữ liệu quan hệ mà không gặp phải vấn đề tương thích nào.
- Read/write priority
-
Cơ sở dữ liệu NewSQL được sử dụng giống như cơ sở dữ liệu quan hệ, với những lợi ích bổ sung về lập chỉ mục và phân phối địa lý, nhằm cải thiện hiệu suất đọc hoặc hiệu suất ghi.
Cloud Native Databases
Với việc tăng cường sử dụng đám mây, các cơ sở dữ liệu đám mây như Snowflake, Amazon Redshift, Datomic và Azure CosmosDB đã trở nên phổ biến hơn. Những cơ sở dữ liệu này giảm bớt gánh nặng vận hành, cung cấp sự minh bạch về chi phí và là một cách dễ dàng để thử nghiệm vì không cần đầu tư ban đầu. Các đánh giá về cơ sở dữ liệu gốc đám mây xuất hiện trong Hình 6-32.
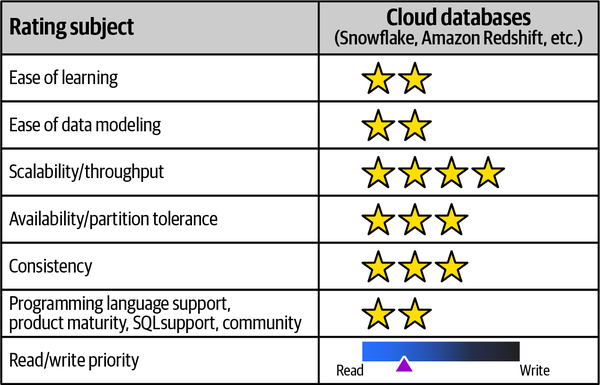
Figure 6-32. Cloud native databases rated for various adoption characteristics
- Ease-of-learning curve
-
Một số cơ sở dữ liệu đám mây như AWS Redshift giống như các cơ sở dữ liệu quan hệ và do đó dễ hiểu hơn. Các cơ sở dữ liệu như Snowflake, có giao diện SQL nhưng có cơ chế lưu trữ và tính toán khác nhau, cần một chút thời gian luyện tập. Datomic hoàn toàn khác biệt về mặt mô hình và sử dụng các sự thật nguyên tử không thay đổi. Do đó, độ dốc của việc học tập thay đổi tùy thuộc vào từng sản phẩm cơ sở dữ liệu.
- Ease of data modeling
-
Datomic không có khái niệm về bảng hoặc cần xác định thuộc tính trước. Cần định nghĩa các thuộc tính của từng thuộc tính cá nhân, và các thực thể có thể có bất kỳ thuộc tính nào. Snowflake và Redshift thường được sử dụng cho các khối lượng công việc kiểu kho dữ liệu. Hiểu loại mô hình mà cơ sở dữ liệu cung cấp là rất quan trọng trong việc lựa chọn cơ sở dữ liệu để sử dụng.
- Scalability/throughput
-
Vì tất cả các cơ sở dữ liệu này chỉ có trên đám mây, việc mở rộng chúng tương đối đơn giản vì các tài nguyên có thể được phân bổ tự động với một mức giá. Trong những quyết định này, sự đánh đổi thường liên quan đến giá cả.
- Availability/partition tolerance
-
Các cơ sở dữ liệu trong danh mục này (như Datomic) có khả năng sẵn sàng cao khi được triển khai theo Topology Sản xuất. Chúng không có điểm lỗi đơn lẻ và được hỗ trợ bởi bộ đệm mở rộng. Snowflake, chẳng hạn, sao chép các cơ sở dữ liệu của mình qua các khu vực và tài khoản. Các cơ sở dữ liệu khác trong danh mục này hỗ trợ khả năng sẵn sàng cao hơn với nhiều tùy chọn cấu hình khác nhau. Ví dụ, Redshift hoạt động trong một khu vực khả dụng duy nhất và cần được chạy trên nhiều cụm để hỗ trợ khả năng sẵn sàng cao hơn.
- Consistency
-
Datomic hỗ trợ giao dịch ACID bằng cách sử dụng các động cơ lưu trữ để lưu trữ các khối trong lưu trữ khối. Các cơ sở dữ liệu khác, như Snowflake và Redshift, cũng hỗ trợ giao dịch ACID.
- Programming language support, product maturity, SQL support, and community
-
Nhiều cơ sở dữ liệu trong số này còn mới, và việc tìm kiếm sự trợ giúp có kinh nghiệm có thể khó khăn. Thực nghiệm với các cơ sở dữ liệu này yêu cầu một tài khoản đám mây, điều này có thể tạo ra một rào cản khác. Trong khi các cơ sở dữ liệu gốc đám mây giảm bớt khối lượng công việc vận hành cho các DBA vận hành, chúng có một đường cong học tập cao hơn đối với các nhà phát triển. Datomic sử dụng Clojure trong tất cả các ví dụ của nó, và các thủ tục lưu trữ được viết bằng Clojure, vì vậy không biết Clojure có thể là một rào cản để sử dụng.
- Read/write priority
-
Các cơ sở dữ liệu này có thể được sử dụng cho cả tải nặng về đọc hoặc tải nặng về ghi. Snowflake và Redshift chủ yếu hướng đến các khối lượng công việc kiểu kho dữ liệu, do đó ưu tiên đọc, trong khi Datomic có thể hỗ trợ cả hai loại tải với các chỉ mục khác nhau như EAVT (Thực thể, Thuộc tính, Giá trị, sau đó là Giao dịch) trước.
Time-Series Databases
Dựa trên các xu hướng hiện tại, chúng tôi thấy sự gia tăng trong việc sử dụng IoT, microservices, xe tự lái và khả năng quan sát, tất cả đều đã thúc đẩy một sự gia tăng phi thường trong phân tích chuỗi thời gian. Xu hướng này đã dẫn đến sự ra đời của các cơ sở dữ liệu được tối ưu hóa để lưu trữ các chuỗi điểm dữ liệu được thu thập trong một khoảng thời gian, cho phép người dùng theo dõi các thay đổi trong bất kỳ khoảng thời gian nào. Các xếp hạng cho loại cơ sở dữ liệu này xuất hiện trong Hình 6-33.
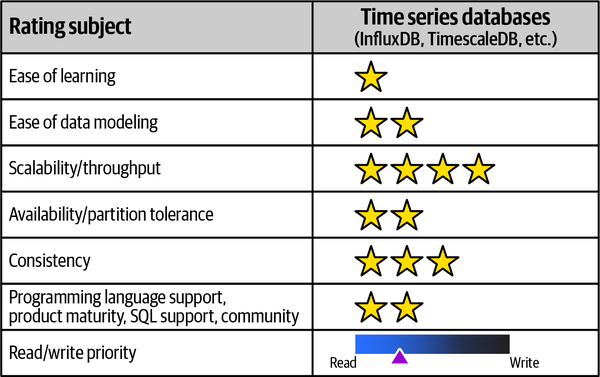
Figure 6-33. Time-series databases rated for various adoption characteristics
- Ease-of-learning curve
-
Hiểu dữ liệu theo chuỗi thời gian thường dễ dàng—mỗi điểm dữ liệu gắn liền với một mốc thời gian, và dữ liệu gần như luôn được chèn vào và không bao giờ được cập nhật hoặc xóa. Hiểu các thao tác chỉ thêm đòi hỏi một số sự từ bỏ những gì đã học từ việc sử dụng cơ sở dữ liệu khác, nơi mà các lỗi trong dữ liệu có thể được sửa chữa bằng một lần cập nhật. InfluxDB, Kx, và TimeScale là một số cơ sở dữ liệu theo chuỗi thời gian phổ biến.
- Ease of data modeling
-
Khái niệm cơ bản của cơ sở dữ liệu chuỗi thời gian là phân tích sự thay đổi của dữ liệu theo thời gian. Ví dụ, với ví dụ về Đội Sysops, những thay đổi được thực hiện đối với một đối tượng vé có thể được lưu trữ trong cơ sở dữ liệu chuỗi thời gian, nơi mà thời gian thay đổi và ticket_id được đánh dấu. Việc thêm nhiều thông tin vào một thẻ được coi là thực hành không tốt. Ví dụ, ticket_status=Open, ticket_id=374737 thì tốt hơn là ticket_info=Open.374737.
- Scalability/throughput
-
Timescale được xây dựng dựa trên PostgreSQL và cho phép mở rộng chuẩn và cải thiện thông lượng. Chạy InfluxDB ở chế độ cluster bằng cách sử dụng các nút meta để quản lý siêu dữ liệu và các nút dữ liệu để lưu trữ dữ liệu thực tế mang lại sự cải thiện về khả năng mở rộng và thông lượng.
- Availability/partition tolerance
-
Một số cơ sở dữ liệu như InfluxDB có sự lựa chọn về khả năng sẵn có và độ chịu phân vùng tốt hơn với cấu hình cho các nút meta và dữ liệu, cùng với các yếu tố sao chép.
- Consistency
-
Cơ sở dữ liệu chuỗi thời gian sử dụng cơ sở dữ liệu quan hệ làm động cơ lưu trữ của chúng đạt được các thuộc tính ACID để đảm bảo tính nhất quán, trong khi các cơ sở dữ liệu khác có thể điều chỉnh tính nhất quán bằng cách sử dụng mức độ nhất quán là bất kỳ, một hoặc đa số. Cấu hình mức độ nhất quán cao hơn thường dẫn đến tính nhất quán cao hơn và khả năng sẵn có thấp hơn, vì vậy đây là một sự đánh đổi cần được cân nhắc.
- Programming language support, product maturity, SQL support, and community
-
Cơ sở dữ liệu chuỗi thời gian đã trở nên phổ biến gần đây, và có nhiều tài nguyên để học hỏi. Một số cơ sở dữ liệu này, chẳng hạn như InfluxDB, cung cấp một ngôn ngữ truy vấn giống SQL được gọi là InfluxQL.
- Read/write priority
-
Cơ sở dữ liệu theo chuỗi thời gian chỉ cho phép thêm dữ liệu và thường phù hợp hơn cho các khối lượng công việc chủ yếu đọc.
Khi sử dụng cơ sở dữ liệu thời gian, cơ sở dữ liệu tự động gán một dấu thời gian vào mỗi dữ liệu được tạo, và dữ liệu chứa các thẻ hoặc thuộc tính thông tin. Dữ liệu được truy vấn dựa trên một số yếu tố giữa các khoảng thời gian cụ thể. Do đó, cơ sở dữ liệu thời gian không phải là cơ sở dữ liệu đa năng.
Tóm tắt tất cả các loại cơ sở dữ liệu đã được thảo luận trong phần này, Bảng 6-6 cho thấy một số sản phẩm cơ sở dữ liệu phổ biến cho loại cơ sở dữ liệu đó.
| Database type | Products |
|---|---|
Quan hệ | PostgreSQL, Oracle, Microsoft SQL |
Khóa-giá trị | Riak KV, Amazon DynamoDB, Redis |
Tài liệu | MongoDB, Couchbase, AWS DocumentDB |
Họ cột | Cassandra, Scylla, Amazon SimpleDB |
Đồ thị | Neo4j: Neo4j Infinite Graph: Đồ thị vô hạn Tiger Graph: Tiger Graph |
NewSQL translates to "NewSQL" in Vietnamese as there is no direct translation for this term. It is commonly used as is in the context of technology. | VoltDB, ClustrixDB, SimpleStore (còn được gọi là MemSQL) |
Đám mây gốc | Snowflake: Bông tuyết Datomic: Datomic Redshift: Redshift |
Chuỗi thời gian | InfluxDB, kdb+, Amazon Timestream |
Sysops Squad Saga: Polyglot Databases
Thứ Năm, ngày 16 tháng 12, 16:05
Bây giờ khi đội ngũ đã hình thành các miền dữ liệu từ cơ sở dữ liệu của đội Sysops monolithic, Devon nhận thấy miền dữ liệu Khảo sát sẽ là một ứng cử viên tuyệt vời để chuyển đổi từ cơ sở dữ liệu quan hệ truyền thống sang cơ sở dữ liệu tài liệu sử dụng JSON. Tuy nhiên, Dana, người đứng đầu kiến trúc dữ liệu, không đồng ý và muốn giữ các bảng dưới dạng quan hệ.
“Tôi đơn giản không đồng ý,” Dana nói. “Các bảng khảo sát luôn hoạt động như các bảng quan hệ trong quá khứ, vì vậy tôi không thấy lý do gì để thay đổi mọi thứ.”
“Thực ra,” Skyler nói, “nếu bạn đã trò chuyện với chúng tôi về điều này khi hệ thống đang được phát triển ban đầu, bạn sẽ hiểu rằng từ góc độ giao diện người dùng, thật sự rất khó để xử lý dữ liệu quan hệ cho một cái gì đó như khảo sát khách hàng. Vì vậy, tôi không đồng ý. Nó có thể mang lại lợi ích cho bạn, nhưng từ góc độ phát triển giao diện người dùng, việc xử lý dữ liệu quan hệ cho các vấn đề khảo sát đã trở thành một điểm khó khăn lớn.”
“Thấy chưa, đó là lý do tại sao chúng ta cần chuyển sang cơ sở dữ liệu tài liệu.”
“Có vẻ như bạn quên rằng với vai trò kiến trúc sư dữ liệu cho công ty này, tôi là người có trách nhiệm cuối cùng đối với tất cả những cơ sở dữ liệu khác nhau này. Bạn không thể chỉ bắt đầu thêm các loại cơ sở dữ liệu khác nhau vào hệ thống,” Dana nói.
“Nhưng đó sẽ là một giải pháp tốt hơn nhiều,” Devon nói.
Xin lỗi, nhưng tôi sẽ không gây rối cho đội cơ sở dữ liệu chỉ để Skyler có công việc dễ dàng hơn trong việc duy trì giao diện người dùng. Mọi thứ không hoạt động theo cách đó.
“Chờ đã,” Skyler nói, “chúng ta không phải đã đồng ý rằng một phần của vấn đề với ứng dụng Sysops Squad monolithic hiện tại là các đội phát triển không làm việc đủ gần gũi với các đội cơ sở dữ liệu sao?”
"Vâng," Dana nói.
“Vậy thì,” Skyler nói, “hãy làm điều đó. Hãy cùng nhau làm việc để giải quyết việc này.”
“Được rồi,” Dana nói, “nhưng những gì tôi cần từ bạn và Devon là một lý do chính đáng để đưa một loại cơ sở dữ liệu khác vào bộ phối hợp.”
“Bạn đã hiểu,” Devon nói. “Chúng ta sẽ bắt tay vào làm ngay lập tức.”
Devon và Skyler biết rằng cơ sở dữ liệu tài liệu sẽ là một giải pháp tốt hơn nhiều cho dữ liệu khảo sát khách hàng, nhưng họ không chắc chắn làm thế nào để xây dựng các lý do thuyết phục để Dana đồng ý di chuyển dữ liệu. Skyler đã gợi ý họ nên gặp Addison để nhận trợ giúp, vì cả hai đều nhất trí rằng đây là một mối quan tâm về kiến trúc. Addison đã đồng ý giúp đỡ và sắp xếp một cuộc họp với Parker (chủ sở hữu sản phẩm của đội Sysops) để xác nhận xem có lý do kinh doanh nào để di chuyển các bảng khảo sát khách hàng sang cơ sở dữ liệu tài liệu hay không.
"Cảm ơn bạn đã gặp gỡ với chúng tôi, Parker," Addison nói. "Như tôi đã đề cập với bạn trước đó, chúng tôi đang nghĩ đến việc thay đổi cách lưu trữ dữ liệu khảo sát khách hàng và có một vài câu hỏi dành cho bạn."
“Chà,” Parker nói, “đó là một trong những lý do khiến tôi đồng ý tham gia cuộc họp này. Bạn thấy đấy, phần khảo sát khách hàng của hệ thống đã là một điểm đau lớn cho bộ phận marketing, cũng như cho tôi.”
“Hả?” Skyler hỏi. “Bạn có ý gì?”
“Bạn mất bao lâu để áp dụng ngay cả những yêu cầu thay đổi nhỏ nhất vào các khảo sát khách hàng?” Parker hỏi.
“À thì,” Devon nói, “không tệ lắm từ phía cơ sở dữ liệu. Ý tôi là, chỉ cần thêm một cột mới cho một câu hỏi mới hoặc thay đổi loại câu trả lời.”
“Chờ một chút,” Skyler nói. “Xin lỗi, nhưng đối với tôi, đây là một thay đổi lớn, ngay cả khi bạn thêm một câu hỏi nữa. Bạn không biết việc truy vấn tất cả dữ liệu quan hệ đó và hiển thị một khảo sát khách hàng trong giao diện người dùng khó khăn như thế nào. Vì vậy, câu trả lời của tôi là, sẽ rất lâu.”
“Nghe này,” Parker nói. “Chúng tôi ở mảng kinh doanh cũng rất thất vọng khi ngay cả những thay đổi đơn giản nhất cũng mất của các bạn hẳn vài ngày để thực hiện. Điều đó thực sự là không chấp nhận được.”
“Tôi nghĩ tôi có thể giúp ở đây,” Addison nói. “Vậy Parker, những gì bạn đang nói là khảo sát khách hàng thay đổi thường xuyên, và việc thực hiện những thay đổi đó mất quá nhiều thời gian?”
“Đúng vậy,” Parker nói. “Bộ phận tiếp thị không chỉ muốn có sự linh hoạt tốt hơn trong khảo sát khách hàng, mà còn muốn có phản hồi tốt hơn từ bộ phận CNTT. Nhiều lần họ không gửi yêu cầu thay đổi vì họ biết rằng điều đó chỉ dẫn đến sự thất vọng và chi phí bổ sung mà họ không tính toán trước.”
"Điều gì sẽ xảy ra nếu tôi nói với bạn rằng việc thiếu linh hoạt và khả năng phản hồi với các yêu cầu thay đổi có liên quan đến công nghệ được sử dụng để lưu trữ khảo sát khách hàng, và rằng bằng cách thay đổi cách chúng ta lưu trữ dữ liệu, chúng ta có thể cải thiện đáng kể tính linh hoạt cũng như thời gian phản hồi cho các yêu cầu thay đổi?" Addison hỏi.
“Vậy thì tôi sẽ là người hạnh phúc nhất trên Trái đất, cũng như phòng marketing vậy,” Parker nói.
“Devon và Skyler, tôi nghĩ chúng ta đã có lý do kinh doanh của mình,” Addison nói.
Với lý do kinh doanh được xác định, Devon, Skyler và Addison đã thuyết phục Dana sử dụng một cơ sở dữ liệu tài liệu. Giờ đây, nhóm cần phải tìm ra cấu trúc tối ưu cho dữ liệu khảo sát khách hàng. Các bảng cơ sở dữ liệu quan hệ hiện có được minh họa trong Hình 6-34. Mỗi khảo sát khách hàng bao gồm hai bảng chính - bảng Khảo sát và bảng Câu hỏi, với mối quan hệ một-nhiều giữa hai bảng này.
Figure 6-34. Tables and relationships in the sysops survey data domain
Một ví dụ về dữ liệu chứa trong mỗi bảng được trình bày trong Hình 6-35, trong đó bảng Câu hỏi chứa câu hỏi, các tùy chọn trả lời và kiểu dữ liệu cho câu trả lời.
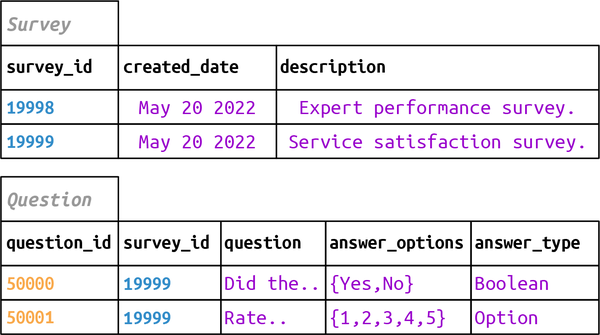
Figure 6-35. Relational data in tables for survey and question in the survey data domain
“Vì vậy, về cơ bản chúng ta có hai tùy chọn để mô hình hóa các câu hỏi khảo sát trong một cơ sở dữ liệu tài liệu,” Devon nói. “Một tài liệu tổng hợp duy nhất hoặc một tài liệu được chia nhỏ.”
“Làm thế nào chúng ta biết được nên sử dụng cái nào?” Skyler hỏi, vui mừng vì các nhóm phát triển cuối cùng cũng đang làm việc với các nhóm cơ sở dữ liệu để đạt được một giải pháp thống nhất.
“Tôi biết,” Addison nói, “hãy mô hình hóa cả hai để chúng ta có thể nhìn thấy rõ sự đánh đổi với từng phương pháp.”
Devon đã cho nhóm thấy rằng với tùy chọn tổng hợp đơn, như được hiển thị trong Hình 6-36, cùng với danh sách mã nguồn tương ứng trong Ví dụ 6-3, cả dữ liệu khảo sát và tất cả dữ liệu câu hỏi liên quan được lưu trữ dưới dạng một tài liệu. Do đó, toàn bộ khảo sát của khách hàng có thể được truy xuất từ cơ sở dữ liệu bằng cách sử dụng một thao tác lấy đơn, giúp Skyler và những người khác trong nhóm phát triển dễ dàng làm việc với dữ liệu.
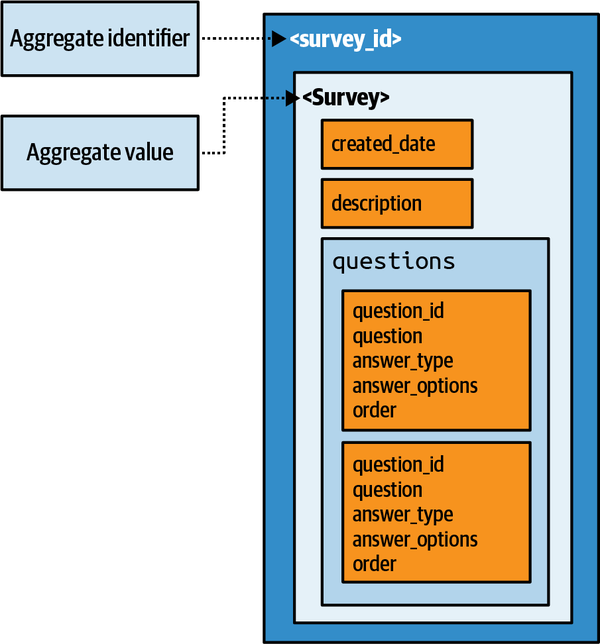
Figure 6-36. Survey model with single aggregate
Example 6-3. JSON document for single aggregate design with children embedded
#Surveyaggregatewithembeddedquestions{"survey_id":"19999","created_date":"Dec 28 2021","description":"Survey to gauge customer...","questions":[{"question_id":"50001","question":"Rate the expert","answer_type":"Option","answer_options":"1,2,3,4,5","order":"2"},{"question_id":"50000","question":"Did the expert fix the problem?","answer_type":"Boolean","answer_options":"Yes,No","order":"1"}]}
“Tôi thực sự thích cách tiếp cận đó,” Skyler nói. “Về cơ bản, tôi sẽ không phải lo lắng quá nhiều về việc tổng hợp mọi thứ trên giao diện người dùng, có nghĩa là tôi chỉ cần hiển thị tài liệu mà tôi lấy được trên trang web.”
“Ừ,” Devon nói, “nhưng điều đó sẽ cần thêm công việc ở phía cơ sở dữ liệu vì các câu hỏi sẽ được sao chép trong mỗi tài liệu khảo sát. Bạn biết đấy, lập luận về việc tái sử dụng. Để tôi cho bạn xem cách tiếp cận khác.”
Skyler giải thích rằng một cách khác để nghĩ về tập hợp là chia mô hình khảo sát và câu hỏi để các câu hỏi có thể được vận hành độc lập, như được chỉ ra trong Hình 6-37, với danh sách mã nguồn tương ứng trong Ví dụ 6-4. Điều này sẽ cho phép cùng một câu hỏi được sử dụng trong nhiều khảo sát, nhưng sẽ khó để trình bày và truy xuất hơn so với một tập hợp đơn.
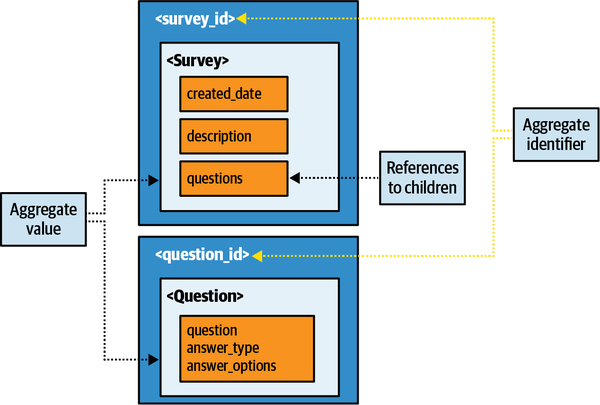
Figure 6-37. Survey model with multiple aggregates with references
Example 6-4. JSON document with aggregates split and parent document showing references to children
#SurveyaggregatewithreferencestoQuestions{"survey_id":"19999","created_date":"Dec 28","description":"Survey to gauge customer...","questions":[{"question_id":"50001","order":"2"},{"question_id":"50000","order":"1"}]}#Questionaggregate{"question_id":"50001","question":"Rate the expert","answer_type":"Option","answer_options":"1,2,3,4,5"}{"question_id":"50000","question":"Did the expert fix the problem?","answer_type":"Boolean","answer_options":"Yes,No"}
Bởi vì hầu hết các vấn đề phức tạp và thay đổi đều nằm ở giao diện người dùng, Skyler thích mô hình tổng hợp đơn lẻ hơn. Devon thích mô hình tổng hợp nhiều để tránh trùng lặp dữ liệu câu hỏi trong mỗi khảo sát. Tuy nhiên, Addison chỉ ra rằng chỉ có năm loại khảo sát (mỗi loại dành cho một danh mục sản phẩm), và hầu hết các thay đổi liên quan đến việc thêm hoặc xóa câu hỏi. Nhóm đã thảo luận về các yếu tố đánh đổi, và tất cả đều đồng ý rằng họ sẵn sàng chấp nhận một số trùng lặp dữ liệu câu hỏi để dễ dàng thay đổi và hiển thị ở phía giao diện người dùng. Bởi vì tính khó khăn của quyết định này và bản chất cấu trúc của việc thay đổi dữ liệu, Addison đã tạo ra một ADR để ghi lại những lý do cho quyết định này.
ADR: Sử dụng Cơ sở dữ liệu Tài liệu cho Khảo sát Khách hàng
Ngữ cảnh Khách hàng nhận một cuộc khảo sát sau khi công việc đã hoàn thành, được hiển thị trên một trang web để khách hàng điền vào và gửi đi. Khách hàng nhận một trong năm loại khảo sát dựa trên loại sản phẩm điện tử được sửa chữa hoặc cài đặt. Cuộc khảo sát hiện đang được lưu trữ trong một cơ sở dữ liệu quan hệ, nhưng nhóm muốn chuyển đổi cuộc khảo sát sang một cơ sở dữ liệu tài liệu sử dụng JSON.
Quyết định Chúng tôi sẽ sử dụng cơ sở dữ liệu tài liệu cho khảo sát khách hàng.
Bộ phận Marketing cần nhiều sự linh hoạt và kịp thời hơn cho các thay đổi đối với khảo sát khách hàng. Chuyển sang cơ sở dữ liệu tài liệu không chỉ mang lại sự linh hoạt tốt hơn, mà còn giúp kịp thời hơn cho các thay đổi cần thiết đối với khảo sát khách hàng.
Sử dụng cơ sở dữ liệu tài liệu sẽ đơn giản hóa giao diện người dùng của khảo sát khách hàng và tạo điều kiện tốt hơn cho việc thay đổi các khảo sát.
Hậu quả Vì chúng ta sẽ sử dụng một tổng hợp duy nhất, nên cần phải thay đổi nhiều tài liệu khi một câu hỏi khảo sát chung được cập nhật, thêm vào hoặc xóa bỏ.
Chức năng khảo sát sẽ cần phải tạm ngừng trong quá trình di chuyển dữ liệu từ cơ sở dữ liệu quan hệ sang cơ sở dữ liệu tài liệu.
Chapter 7. Service Granularity
Thứ Năm, 14 tháng 10, 13:33
Khi nỗ lực di chuyển bắt đầu, cả Addison và Austen đều cảm thấy quá tải với tất cả các quyết định liên quan đến việc tách rời các dịch vụ miền đã được xác định trước đó. Đội phát triển cũng có những ý kiến riêng, điều này làm cho việc quyết định về độ chi tiết của dịch vụ trở nên khó khăn hơn.
“ Tôi vẫn chưa chắc phải làm gì với chức năng quản lý vé chính,” Addison nói. “Tôi không thể quyết định liệu việc tạo vé, hoàn thành, phân công chuyên gia và định tuyến chuyên gia nên là một, hai, ba hoặc thậm chí bốn dịch vụ. Taylen khăng khăng muốn làm mọi thứ chi tiết, nhưng tôi không chắc đó có phải là cách tiếp cận đúng hay không.”
“Em cũng vậy,” Austen nói. “Và em còn đang gặp khó khăn trong việc xác định xem chức năng đăng ký khách hàng, quản lý hồ sơ và thanh toán có nên tách rời ra không. Chưa hết, tối nay em còn có một trận đấu nữa.”
"Bạn lúc nào cũng có một trò chơi để tham gia," Addison nói. "Nói về chức năng khách hàng, bạn đã bao giờ tìm ra xem chức năng đăng nhập của khách hàng có trở thành một dịch vụ riêng biệt không?"
“Không,” Austen nói, “Tôi vẫn đang làm việc về điều đó. Skyler nói rằng nó nên tách biệt, nhưng không đưa cho tôi lý do nào khác ngoài việc nói rằng đó là chức năng tách biệt.”
“Đây là một vấn đề khó,” Addison nói. “Bạn có nghĩ rằng Logan có thể làm sáng tỏ điều này không?”
“Ý kiến hay,” Austen nói, “Phân tích dựa trên cảm tính này thật sự đang làm chậm lại mọi thứ.”
Addison và Austen đã mời Taylen, trưởng nhóm Sysops Squad, tham gia cuộc họp với Logan để tất cả họ có thể hiểu rõ về các vấn đề liên quan đến độ chi tiết của dịch vụ mà họ đang gặp phải.
“Tôi đang nói với bạn,” Taylen nói, “chúng ta cần phải chia nhỏ các dịch vụ miền thành các dịch vụ nhỏ hơn. Chúng quá lớn để phù hợp với microservices. Như tôi nhớ, micro có nghĩa là nhỏ. Cuối cùng, chúng ta đang chuyển sang microservices. Những gì Addison và Austen đề xuất đơn giản là không phù hợp với mô hình microservices.”
“Không phải phần nào của một ứng dụng cũng phải là microservices,” Logan nói. “Đó là một trong những cạm bẫy lớn nhất của phong cách kiến trúc microservices.”
“Nếu vậy, thì làm thế nào bạn xác định được dịch vụ nào nên và không nên tách ra?” Taylen hỏi.
“Cho tôi hỏi bạn điều này, Taylen,” Logan nói. “Lý do bạn muốn làm tất cả các dịch vụ nhỏ lại là gì?”
"Nguyên tắc trách nhiệm đơn lẻ," Taylen trả lời. "Hãy tra cứu nó. Đó là cơ sở của microservices."
“ Tôi biết nguyên tắc trách nhiệm đơn lẻ là gì,” Logan nói. “Và tôi cũng biết nó có thể mang tính chủ quan như thế nào. Hãy lấy dịch vụ thông báo khách hàng của chúng ta làm ví dụ. Chúng ta có thể thông báo cho khách hàng qua SMS, email, và thậm chí gửi thư bưu điện. Vậy mọi người hãy cho tôi biết, một dịch vụ hay ba dịch vụ?”
“Ba,” Taylen lập tức trả lời. “Mỗi phương thức thông báo đều là một thứ riêng biệt. Đó chính là bản chất của microservices.”
“Một,” Addison trả lời. “Thông báo rõ ràng là một trách nhiệm duy nhất.”
“Tôi không chắc,” Austen trả lời. “Tôi có thể thấy cả hai cách. Chúng ta nên tung đồng xu không?”
“Đây chính là lý do tại sao chúng ta cần giúp đỡ,” Addison thở dài.
“Chìa khóa để có được độ chi tiết của dịch vụ đúng,” Logan nói, “là loại bỏ ý kiến và cảm tính, và sử dụng các bộ phân tách và tích hợp độ chi tiết để phân tích khách quan các giao dịch và hình thành lý do rõ ràng cho việc có nên tách rời dịch vụ hay không.”
“Các bộ phân rã độ tinh vi và bộ tích hợp là gì?” Austen hỏi.
"Để tôi cho bạn xem," Logan nói.
Các kiến trúc sư và nhà phát triển thường nhầm lẫn các thuật ngữ modularity và granularity, và trong một số trường hợp thậm chí coi chúng là giống nhau. Hãy xem xét các định nghĩa từ điển của từng thuật ngữ này:
- Modularity
-
Được thiết kế với các đơn vị hoặc kích thước tiêu chuẩn để linh hoạt và đa dạng trong việc sử dụng.
- Granularity
-
Gồm hoặc có vẻ như bao gồm một trong nhiều hạt tạo thành một đơn vị lớn hơn.
Không có gì ngạc nhiên khi có nhiều sự nhầm lẫn giữa các thuật ngữ này! Mặc dù các thuật ngữ có định nghĩa từ điển tương tự, chúng tôi muốn phân biệt giữa chúng vì chúng có ý nghĩa khác nhau trong bối cảnh kiến trúc phần mềm. Trong cách sử dụng của chúng tôi, tính mô-đun liên quan đến việc chia hệ thống thành các phần riêng biệt (xem Chương 3), trong khi độ granularity liên quan đến kích thước của những phần riêng biệt đó. Thú vị thay, hầu hết các vấn đề và thách thức trong các hệ thống phân tán thường không liên quan đến tính mô-đun, mà chủ yếu là độ granularity.
Xác định mức độ chi tiết phù hợp – kích thước của một dịch vụ – là một trong những phần khó khăn trong kiến trúc phần mềm mà các kiến trúc sư và đội ngũ phát triển luôn gặp phải. Mức độ chi tiết không được định nghĩa bởi số lượng lớp hoặc số dòng mã trong một dịch vụ, mà là dựa vào những gì dịch vụ đó thực hiện – đó là lý do tại sao việc đạt được mức độ chi tiết của dịch vụ là rất khó khăn.
Các kiến trúc sư có thể tận dụng các chỉ số để theo dõi và đo lường các khía cạnh khác nhau của một dịch vụ nhằm xác định mức độ phân granularity dịch vụ phù hợp. Một chỉ số như vậy được sử dụng để đo lường khách quan kích thước của một dịch vụ là tính toán số lượng câu lệnh trong một dịch vụ. Mỗi lập trình viên có phong cách và kỹ thuật lập trình khác nhau, vì vậy số lượng lớp và số dòng mã là những chỉ số kém để đo lường độ granularity. Ngược lại, số lượng câu lệnh ít nhất cho phép một kiến trúc sư hoặc đội phát triển đo lường khách quan những gì dịch vụ đang thực hiện. Nhớ lại từ Chương 4 rằng một câu lệnh là một hành động hoàn chỉnh được thực hiện trong mã nguồn, thường kết thúc bằng một ký tự đặc biệt (như dấu chấm phẩy trong các ngôn ngữ như Java, C, C++, C#, Go, JavaScript; hoặc một dòng mới trong các ngôn ngữ như F#, Python và Ruby).
Một chỉ số khác để xác định độ tinh tế của dịch vụ là đo lường và theo dõi số lượng giao diện công khai hoặc các hoạt động mà một dịch vụ cung cấp. Dù vẫn còn một chút chủ quan và biến đổi với hai chỉ số này, nhưng đây là điều gần nhất mà chúng ta đã phát triển được cho đến nay để đo lường và đánh giá độ tinh tế của dịch vụ một cách khách quan.
Hai lực lượng đối kháng cho độ chi tiết dịch vụ là các giải thể độ chi tiết và các tích hợp độ chi tiết. Những lực lượng đối kháng này được minh họa trong Hình 7-1. Các giải thể độ chi tiết trả lời câu hỏi “Khi nào tôi nên xem xét việc tách một dịch vụ thành các phần nhỏ hơn?”, trong khi các tích hợp độ chi tiết trả lời câu hỏi “Khi nào tôi nên xem xét việc ghép các dịch vụ lại với nhau?” Một sai lầm phổ biến mà nhiều đội phát triển mắc phải là tập trung quá nhiều vào các giải thể độ chi tiết trong khi bỏ qua các tích hợp độ chi tiết. Bí quyết để đến được mức độ chi tiết phù hợp cho một dịch vụ là đạt được sự cân bằng giữa hai lực lượng đối kháng này.
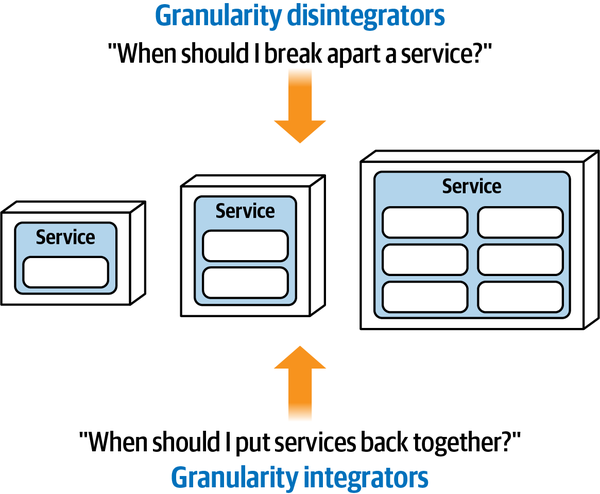
Figure 7-1. Service granularity depends on a balance of disintegrators and integrators
Granularity Disintegrators
"Các bộ phân tách độ chi tiết cung cấp hướng dẫn và lý do để khi nào nên chia nhỏ một dịch vụ thành các phần nhỏ hơn. Trong khi lý do để chia nhỏ một dịch vụ có thể chỉ liên quan đến một yếu tố duy nhất, trong hầu hết các trường hợp, lý do sẽ dựa trên nhiều yếu tố. Sáu yếu tố chính cho việc phân tách độ chi tiết như sau:"
- Service scope and function
-
Dịch vụ có đang làm quá nhiều việc không liên quan không?
- Code volatility
-
Các thay đổi có được hạn chế chỉ ở một phần của dịch vụ không?
- Scalability and throughput
-
Các phần của dịch vụ có cần mở rộng khác nhau không?
- Fault tolerance
-
Có lỗi nào gây ra sự cố cho các chức năng quan trọng trong dịch vụ không?
- Security
-
Một số phần của dịch vụ có cần mức độ bảo mật cao hơn những phần khác không?
- Extensibility
-
Dịch vụ có luôn mở rộng để thêm các ngữ cảnh mới không?
Các phần sau đây sẽ chi tiết từng yếu tố phân mảnh độ chi tiết này.
Service Scope and Function
Phạm vi và chức năng dịch vụ là yếu tố đầu tiên và phổ biến nhất để chia nhỏ một dịch vụ đơn thành các dịch vụ nhỏ hơn, đặc biệt là liên quan đến microservices. Có hai khía cạnh cần xem xét khi phân tích phạm vi và chức năng dịch vụ. Khía cạnh đầu tiên là độ gắn kết: mức độ và cách mà các hoạt động của một dịch vụ cụ thể liên quan đến nhau. Khía cạnh thứ hai là kích thước tổng thể của một thành phần, thường được đo bằng tổng số câu lệnh được cộng lại từ các lớp tạo nên dịch vụ đó, số điểm vào công khai vào dịch vụ, hoặc cả hai.
Xem xét một dịch vụ Thông báo điển hình, dịch vụ này thực hiện ba việc: thông báo cho khách hàng qua SMS (Dịch vụ Tin nhắn Ngắn), email, hoặc một bức thư in gửi qua đường bưu điện đến khách hàng. Mặc dù rất hấp dẫn để chia dịch vụ này thành ba dịch vụ đơn mục đích riêng biệt (một cho SMS, một cho email, và một cho thư bưu chính) như được minh họa trong Hình 7-2, nhưng điều này một mình không đủ để biện minh cho việc tách dịch vụ ra, vì nó đã có sự kết hợp tương đối mạnh - tất cả các chức năng này liên quan đến một điều, đó là thông báo cho khách hàng. Vì “mục đích đơn” để lại cho ý kiến và diễn giải cá nhân, nên rất khó để biết có nên tách dịch vụ này hay không.
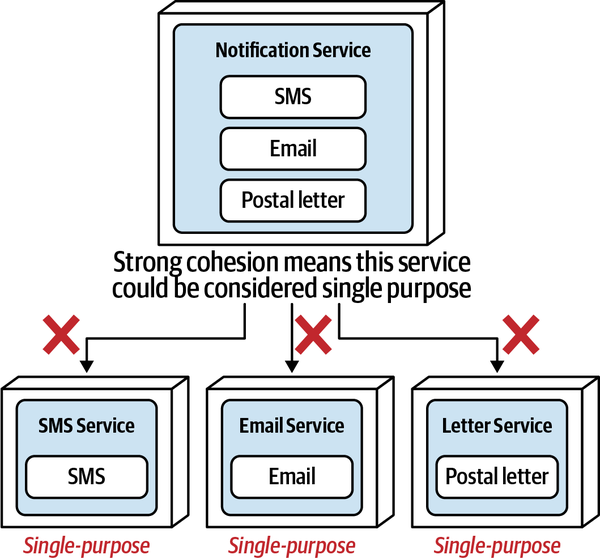
Figure 7-2. A service with relatively strong cohesion is not a good candidate for disintegration based on functionality alone
Bây giờ hãy xem xét một dịch vụ đơn lẻ quản lý thông tin hồ sơ khách hàng, sở thích của khách hàng và cả những bình luận của khách hàng được thực hiện trên trang web. Khác với ví dụ Dịch vụ Thông báo trước đó, dịch vụ này có độ kết hợp tương đối yếu vì ba chức năng này liên quan đến một phạm vi rộng hơn - khách hàng. Dịch vụ này có thể đang đảm nhận quá nhiều công việc, và do đó có lẽ nên được chia thành ba dịch vụ riêng biệt, như được minh họa trong Hình 7-3.
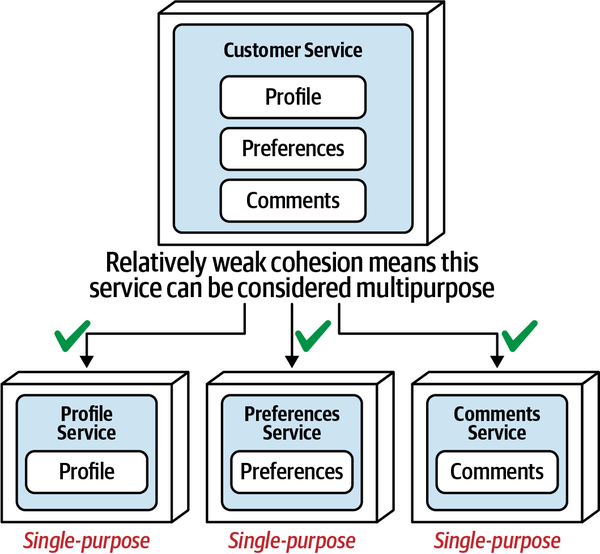
Figure 7-3. A service with relatively weak cohesion is a good candidate for disintegration
Thiết bị phân tán độ chi tiết này có liên quan đến nguyên tắc trách nhiệm đơn lẻ được đặt tên bởi Robert C. Martin như một phần của các nguyên tắc SOLID của ông, nguyên tắc này tuyên bố rằng “mỗi lớp nên có trách nhiệm với một phần chức năng duy nhất của chương trình, mà nó nên bao bọc. Tất cả các dịch vụ của mô-đun, lớp hoặc hàm đó nên được định hướng chặt chẽ với trách nhiệm đó.” Trong khi nguyên tắc trách nhiệm đơn lẻ ban đầu được áp dụng trong bối cảnh các lớp, trong những năm gần đây, nó đã mở rộng để bao gồm các thành phần và dịch vụ.
Trong kiến trúc microservices, một microservice được định nghĩa là một đơn vị phần mềm phục vụ một mục đích duy nhất, được triển khai riêng biệt và thực hiện một nhiệm vụ rất tốt. Không có gì ngạc nhiên khi các lập trình viên có xu hướng thu nhỏ các dịch vụ càng nhiều càng tốt mà không xem xét lý do tại sao họ lại làm như vậy! Sự chủ quan liên quan đến việc cái gì là và không phải là trách nhiệm đơn lẻ chính là nơi mà hầu hết các lập trình viên gặp rắc rối liên quan đến độ granularity của dịch vụ. Mặc dù có một số chỉ số (chẳng hạn như LCOM) để đo lường độ kết hợp, nhưng nó vẫn rất chủ quan khi nói đến dịch vụ - việc thông báo cho khách hàng có phải là một nhiệm vụ duy nhất hay thông báo qua email có phải là một nhiệm vụ duy nhất không? Vì lý do này, việc hiểu các yếu tố phân tán độ granularity khác là vô cùng quan trọng để xác định mức độ granularity phù hợp.
Code Volatility
Độ biến động của mã - tỷ lệ thay đổi mã nguồn - là một yếu tố tốt khác để tách một dịch vụ thành các dịch vụ nhỏ hơn. Điều này cũng được gọi là phân tách dựa trên độ biến động. Đo lường khách quan tần suất thay đổi mã trong một dịch vụ (dễ dàng thực hiện thông qua các phương tiện chuẩn trong bất kỳ hệ thống kiểm soát phiên bản mã nguồn nào) đôi khi có thể dẫn đến một lý do tốt để tách biệt một dịch vụ. Hãy xem lại ví dụ về dịch vụ thông báo từ phần trước. Phạm vi dịch vụ (tính gắn kết) một mình không đủ để biện minh cho việc tách biệt dịch vụ. Tuy nhiên, bằng cách áp dụng các chỉ số thay đổi, thông tin liên quan được tiết lộ về dịch vụ.
-
Tần suất thay đổi chức năng thông báo SMS: trung bình mỗi sáu tháng
-
Tần suất thay đổi chức năng thông báo qua email: mỗi sáu tháng (trung bình)
-
Chức năng thông báo thư bưu điện tỷ lệ thay đổi: hàng tuần (trung bình)
Lưu ý rằng tính năng thư bưu chính thay đổi hàng tuần (trung bình), trong khi đó tính năng SMS và email hiếm khi thay đổi. Là một dịch vụ đơn lẻ, bất kỳ thay đổi nào đối với mã thư bưu chính sẽ yêu cầu nhà phát triển phải kiểm tra và triển khai lại toàn bộ dịch vụ, bao gồm cả tính năng SMS và email. Tùy thuộc vào môi trường triển khai, điều này cũng có thể có nghĩa là tính năng SMS và email sẽ không khả dụng khi các thay đổi về thư bưu chính được triển khai. Do đó, với tư cách là một dịch vụ đơn lẻ, phạm vi kiểm tra bị mở rộng và rủi ro triển khai cao. Tuy nhiên, bằng cách chia nhỏ dịch vụ này thành hai dịch vụ riêng biệt (Thông báo điện tử và Thông báo thư bưu chính), như được minh họa trong Hình 7-4, các thay đổi thường xuyên giờ đây được tách biệt vào một dịch vụ nhỏ hơn. Điều này có nghĩa là phạm vi kiểm tra được giảm đáng kể, rủi ro triển khai giảm thấp hơn, và tính năng SMS cùng email không bị gián đoạn trong quá trình triển khai các thay đổi thư bưu chính.
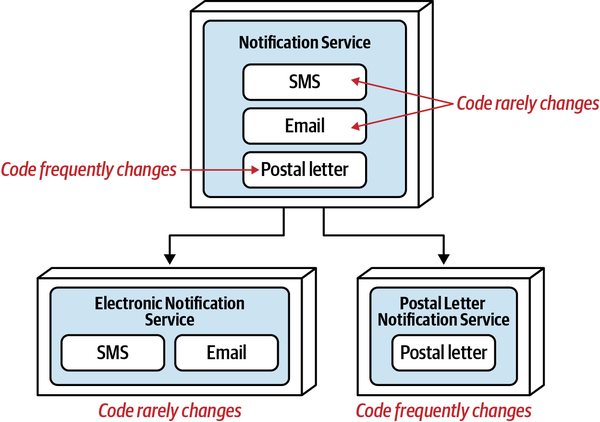
Figure 7-4. An area of high code change in a service is a good candidate for disintegration
Scalability and Throughput
Một lý do khác cho việc chia một dịch vụ thành các dịch vụ nhỏ hơn là khả năng mở rộng và thông lượng. Các yêu cầu về khả năng mở rộng của các chức năng khác nhau của một dịch vụ có thể được đo lường một cách khách quan để xác định xem dịch vụ đó có nên được tách rời hay không. Hãy xem lại ví dụ về Dịch vụ Thông báo, nơi một dịch vụ duy nhất thông báo cho khách hàng qua SMS, email và thư gửi qua đường bưu điện. Đo lường các yêu cầu về khả năng mở rộng của dịch vụ duy nhất này tiết lộ thông tin sau đây:
-
Thông báo SMS: 220.000/phút
-
Thông báo qua email: 500/phút
-
Thông báo thư bưu điện: 1/phút
Lưu ý sự biến đổi cực kỳ giữa việc gửi thông báo SMS và thông báo bằng thư bưu điện. Là một dịch vụ duy nhất, chức năng email và thư bưu điện phải mở rộng không cần thiết để đáp ứng nhu cầu của thông báo SMS, ảnh hưởng đến chi phí và cả tính đàn hồi về thời gian khởi động trung bình (MTTS). Việc chia tách Dịch vụ Thông báo thành ba dịch vụ riêng biệt (SMS, Email và Thư), như được minh họa trong Hình 7-5, cho phép mỗi dịch vụ này có thể mở rộng độc lập để đáp ứng các yêu cầu lưu lượng khác nhau của chúng.
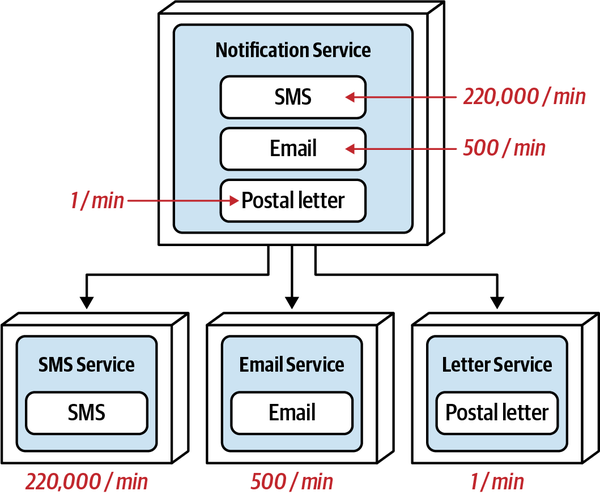
Figure 7-5. Differing scalability and throughput needs is a good disintegration driver
Fault Tolerance
Tính chịu lỗi mô tả khả năng của một ứng dụng hoặc chức năng trong một lĩnh vực cụ thể tiếp tục hoạt động, ngay cả khi xảy ra một sự cố nghiêm trọng (chẳng hạn như tình trạng hết bộ nhớ). Tính chịu lỗi là một động lực tốt khác cho sự phân rã độ chi tiết.
Xem xét ví dụ về Dịch vụ Thông báo hợp nhất tương tự, thông báo cho khách hàng qua SMS, email và thư bưu chính (Hình 7-6). Nếu chức năng email tiếp tục gặp vấn đề với tình trạng hết bộ nhớ và bị sập nghiêm trọng, toàn bộ dịch vụ sẽ ngừng hoạt động, bao gồm cả xử lý SMS và thư bưu chính.
Việc tách dịch vụ Thông báo hợp nhất này thành ba dịch vụ riêng biệt cung cấp một mức độ chịu lỗi cho lĩnh vực thông báo khách hàng. Giờ đây, một lỗi nghiêm trọng trong chức năng của dịch vụ email sẽ không ảnh hưởng đến SMS hoặc thư gửi bưu điện.
Xin lưu ý rằng trong ví dụ này, Dịch vụ Thông báo được chia thành ba dịch vụ riêng biệt (SMS, Email và Thư Bưu chính), mặc dù chức năng email là vấn đề duy nhất liên quan đến các sự cố thường xuyên (hai dịch vụ còn lại rất ổn định). Vì chức năng email là vấn đề duy nhất, tại sao không kết hợp chức năng SMS và thư bưu chính vào một dịch vụ duy nhất?
Xem xét ví dụ về tính không ổn định của mã từ phần trước. Trong trường hợp này, Thư Bưu Chính thay đổi liên tục, trong khi hai dịch vụ còn lại (SMS và Email) thì không. Việc chia nhỏ dịch vụ này thành chỉ hai dịch vụ là hợp lý vì Thư Bưu Chính là chức năng gây ra vấn đề, nhưng Email và SMS có liên quan – cả hai đều liên quan đến việc thông báo cho khách hàng qua điện tử. Bây giờ hãy xem xét ví dụ về khả năng chịu lỗi. SMS thông báo và thông báo Thư Bưu Chính có điểm gì chung ngoài việc thông báo cho khách hàng? Tên gọi tự mô tả phù hợp của dịch vụ kết hợp đó sẽ là gì?
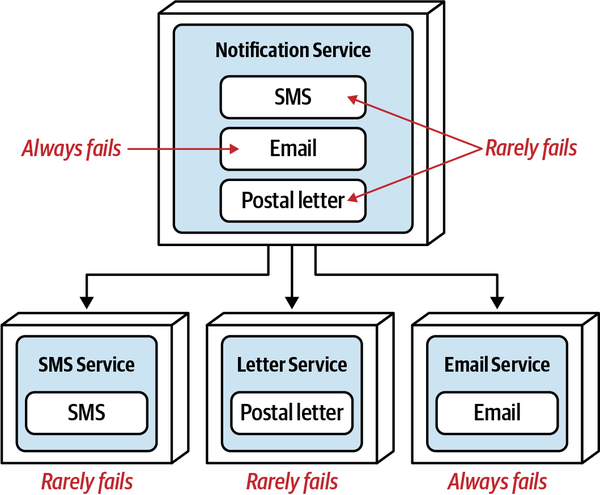
Figure 7-6. Fault tolerance and service availability are good disintegration drivers
Việc chuyển chức năng email sang một dịch vụ riêng biệt làm mất đi sự liên kết tổng thể trong miền, vì sự liên kết giữa chức năng SMS và thư bưu điện trở nên yếu. Hãy cân nhắc những cái tên dịch vụ có thể có: Dịch vụ Email và…Dịch vụ Thông báo Khác? Dịch vụ Email và…Dịch vụ Thông báo SMS-Thư? Dịch vụ Email và…Dịch vụ Không phải Email? Vấn đề đặt tên này liên quan đến phạm vi dịch vụ và mức độ chi tiết của chức năng—nếu một dịch vụ quá khó để đặt tên vì nó làm nhiều việc, hãy cân nhắc phân tách dịch vụ đó. Những sự phân tách dưới đây giúp hình dung điểm quan trọng này:
-
Dịch vụ Thông báo → Dịch vụ Email, Dịch vụ Thông báo Khác (tên không hay)
-
Dịch vụ Thông báo → Dịch vụ Email, Dịch vụ Không Email (tên không hay)
-
Dịch vụ Thông báo → Dịch vụ Email, Dịch vụ SMS-Thư (tên không hay)
-
Dịch vụ Thông báo → Dịch vụ Email, Dịch vụ SMS, Dịch vụ Thư (tên hay)
Trong ví dụ này, chỉ có sự phân tách cuối cùng là hợp lý, đặc biệt khi xem xét việc thêm một thông báo từ mạng xã hội khác - điều đó sẽ được đặt ở đâu? Bất cứ khi nào phân tách một dịch vụ, bất kể động lực phân tách là gì, luôn kiểm tra xem liệu có thể tạo ra sự kết hợp mạnh mẽ với các chức năng "còn lại" hay không.
Security
Một cạm bẫy phổ biến khi bảo vệ dữ liệu nhạy cảm là chỉ nghĩ đến việc lưu trữ dữ liệu đó. Ví dụ, việc bảo vệ dữ liệu PCI (Ngành Thẻ Thanh Toán) khỏi dữ liệu không phải PCI có thể được thực hiện thông qua các sơ đồ hoặc cơ sở dữ liệu tách riêng nằm ở các khu vực bảo mật khác nhau. Tuy nhiên, điều thường bị thiếu sót trong thực tiễn này là cũng phải bảo vệ cách thức truy cập vào dữ liệu đó.
Hãy xem xét ví dụ được minh họa trong Hình 7-7 mô tả Dịch vụ Hồ sơ Khách hàng chứa hai chức năng chính: duy trì hồ sơ khách hàng để thêm, thay đổi hoặc xóa thông tin hồ sơ cơ bản (tên, địa chỉ, v.v.); và duy trì thông tin thẻ tín dụng của khách hàng để thêm, xóa và cập nhật thông tin thẻ tín dụng.
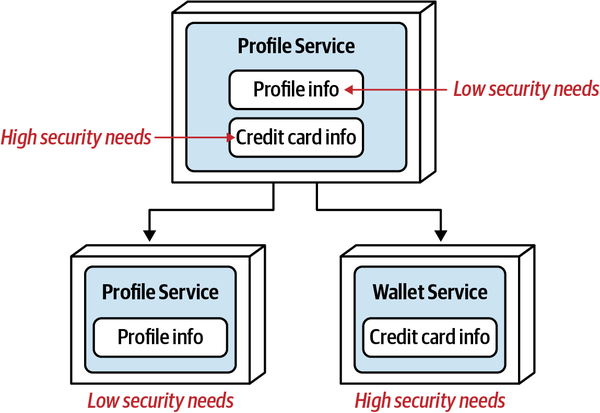
Figure 7-7. Security and data access are good disintegration drivers
Mặc dù dữ liệu thẻ tín dụng có thể được bảo vệ, nhưng việc truy cập vào dữ liệu đó đang gặp rủi ro vì chức năng thẻ tín dụng gắn liền với chức năng hồ sơ khách hàng cơ bản. Mặc dù các điểm truy cập API vào dịch vụ hồ sơ khách hàng hợp nhất có thể khác nhau, nhưng vẫn có rủi ro rằng ai đó truy cập vào dịch vụ để lấy tên khách hàng cũng có thể có quyền truy cập vào chức năng thẻ tín dụng. Bằng cách tách dịch vụ này thành hai dịch vụ riêng biệt, quyền truy cập vào chức năng được sử dụng để duy trì thông tin thẻ tín dụng có thể được bảo mật hơn vì tập hợp các hoạt động thẻ tín dụng chỉ đi vào một dịch vụ duy nhất.
Extensibility
Một yếu tố chính khác thúc đẩy sự phân tách độ chi tiết là khả năng mở rộng - khả năng thêm chức năng bổ sung khi ngữ cảnh dịch vụ phát triển. Hãy xem xét một dịch vụ thanh toán quản lý các giao dịch thanh toán và hoàn tiền qua nhiều phương thức thanh toán, bao gồm thẻ tín dụng, thẻ quà tặng và giao dịch PayPal. Giả sử công ty muốn bắt đầu hỗ trợ các phương thức thanh toán khác, như điểm thưởng, tín dụng cửa hàng từ các giao dịch trả lại; và các dịch vụ thanh toán bên thứ ba khác, như ApplePay, SamsungPay, và như vậy. Việc mở rộng dịch vụ thanh toán để thêm các phương thức thanh toán bổ sung này dễ dàng đến mức nào?
Các phương thức thanh toán bổ sung này chắc chắn có thể được thêm vào một dịch vụ thanh toán tập trung duy nhất. Tuy nhiên, mỗi khi một phương thức thanh toán mới được thêm vào, toàn bộ dịch vụ thanh toán sẽ cần phải được kiểm tra (bao gồm cả các loại hình thanh toán khác), và chức năng cho tất cả các phương thức thanh toán khác sẽ bị triển khai lại không cần thiết vào sản xuất. Do đó, với dịch vụ thanh toán tập trung duy nhất, phạm vi kiểm tra được mở rộng và rủi ro triển khai cao hơn, làm cho việc thêm các loại hình thanh toán bổ sung trở nên khó khăn hơn.
Bây giờ hãy xem xét việc tách dịch vụ hợp nhất hiện tại thành ba dịch vụ riêng biệt (Xử lý thẻ tín dụng, Xử lý thẻ quà tặng và Xử lý giao dịch PayPal), như được minh họa trong Hình 7-8.
Bây giờ, khi dịch vụ thanh toán đơn lẻ được chia thành các dịch vụ riêng biệt theo phương thức thanh toán, việc thêm một phương thức thanh toán khác (như điểm thưởng) chỉ là vấn đề phát triển, kiểm tra và triển khai một dịch vụ riêng biệt so với các dịch vụ khác. Kết quả là, quá trình phát triển nhanh hơn, phạm vi kiểm tra được rút gọn và rủi ro khi triển khai thấp hơn.
Lời khuyên của chúng tôi là chỉ áp dụng driver này nếu biết trước rằng các chức năng ngữ cảnh tích hợp bổ sung đang được lên kế hoạch, mong muốn hoặc là một phần của miền bình thường. Ví dụ, với thông báo, có thể nghi ngờ rằng các phương tiện thông báo sẽ không liên tục mở rộng vượt ra ngoài các phương tiện thông báo cơ bản (SMS, email hoặc thư). Tuy nhiên, với xử lý thanh toán, rất có khả năng rằng các loại thanh toán bổ sung sẽ được thêm vào trong tương lai, và do đó cần có các dịch vụ riêng biệt cho mỗi loại thanh toán. Vì thường khó để "đoán" xem liệu (và khi nào) chức năng ngữ cảnh có thể mở rộng (chẳng hạn như các phương thức thanh toán bổ sung), lời khuyên của chúng tôi là chờ đợi driver này như một phương tiện chính để biện minh cho việc phân tách chi tiết cho đến khi một mô hình có thể được thiết lập hoặc xác nhận về khả năng mở rộng liên tục có thể được xác nhận.
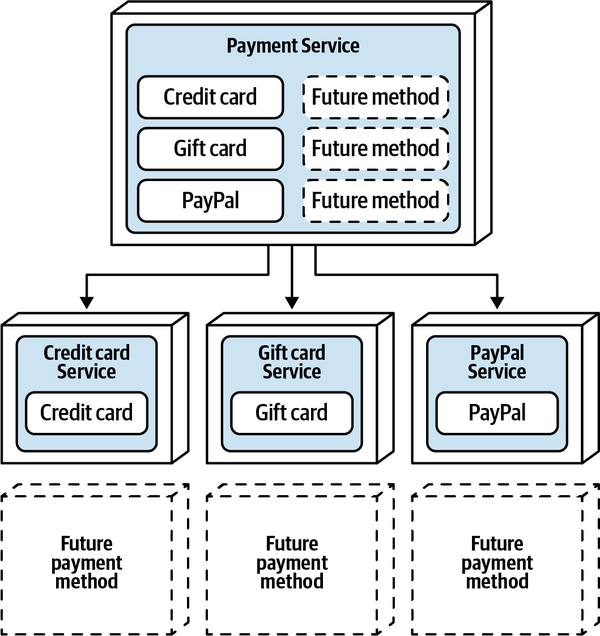
Figure 7-8. Planned extensibility is a good disintegration driver
Granularity Integrators
Trong khi các thiết bị phân tán độ chi tiết cung cấp hướng dẫn và lý do cho việc khi nào nên chia một dịch vụ thành những phần nhỏ hơn, thì các thiết bị tích hợp độ chi tiết hoạt động theo cách ngược lại - chúng cung cấp hướng dẫn và lý do cho việc gộp lại các dịch vụ (hoặc không tách rời một dịch vụ ngay từ đầu). Phân tích các thỏa hiệp giữa các yếu tố thúc đẩy phân tán và các yếu tố thúc đẩy tích hợp là bí quyết để có được độ chi tiết dịch vụ đúng. Bốn yếu tố chính thúc đẩy tích hợp độ chi tiết như sau:
- Database transactions
-
Có cần một giao dịch ACID giữa các dịch vụ riêng biệt không?
- Workflow and choreography
-
Các dịch vụ có cần giao tiếp với nhau không? Mã chia sẻ: Các dịch vụ có cần chia sẻ mã với nhau không? Mối quan hệ cơ sở dữ liệu: Mặc dù một dịch vụ có thể được tách rời, nhưng dữ liệu mà nó sử dụng có thể được tách rời không?
Các phần sau sẽ chi tiết từng yếu tố tích hợp độ granularity này.
Database Transactions
Hầu hết các hệ thống đơn khối và dịch vụ miền thô sử dụng cơ sở dữ liệu quan hệ dựa vào các giao dịch cơ sở dữ liệu theo đơn vị công việc duy nhất để duy trì tính toàn vẹn và nhất quán của dữ liệu; xem “Giao dịch Phân tán” để biết chi tiết về giao dịch ACID (cơ sở dữ liệu) và cách chúng khác với giao dịch BASE (phân tán). Để hiểu cách các giao dịch cơ sở dữ liệu ảnh hưởng đến độ granularity của dịch vụ, hãy xem xét tình huống được minh họa trong Hình 7-9, nơi chức năng khách hàng đã được chia thành Dịch vụ Hồ sơ Khách hàng duy trì thông tin hồ sơ khách hàng và Dịch vụ Mật khẩu duy trì thông tin và chức năng liên quan đến bảo mật khác.
Lưu ý rằng việc có hai dịch vụ riêng biệt cung cấp một mức độ kiểm soát truy cập bảo mật tốt đối với thông tin mật khẩu vì quyền truy cập ở mức dịch vụ chứ không phải ở mức yêu cầu. Quyền truy cập vào các thao tác như thay đổi mật khẩu, đặt lại mật khẩu và truy cập mật khẩu của khách hàng để đăng nhập có thể được giới hạn trong một dịch vụ duy nhất (và do đó quyền truy cập có thể được giới hạn trong dịch vụ duy nhất đó). Tuy nhiên, trong khi điều này có thể là một động lực tốt để phân tách, hãy xem xét thao tác đăng ký khách hàng mới, như được minh họa trong Hình 7-10.
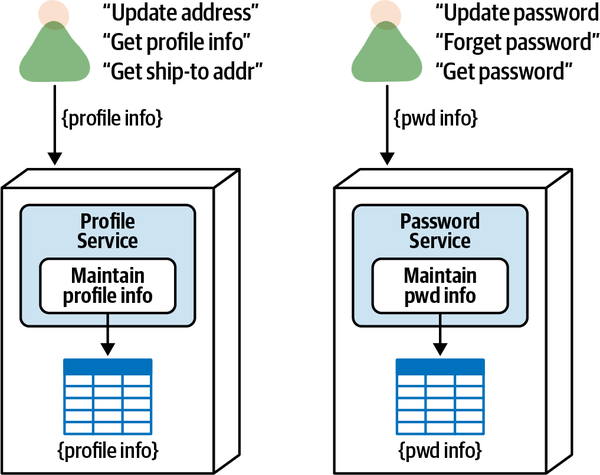
Figure 7-9. Separate services with atomic operations have better security access control
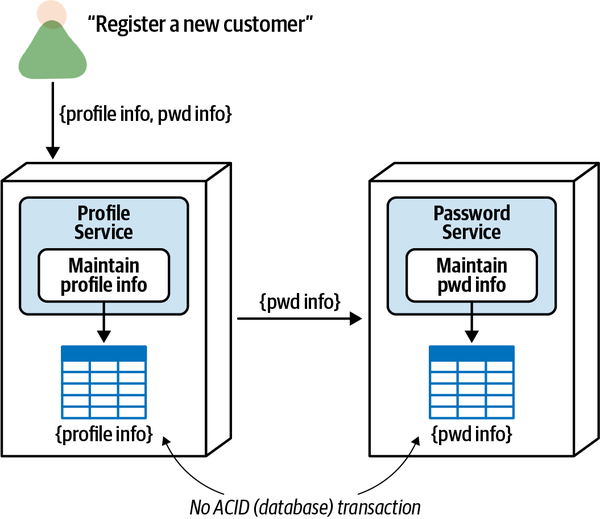
Figure 7-10. Separate services with combined operations do not support database (ACID) transactions
Khi đăng ký một khách hàng mới, cả thông tin hồ sơ và mật khẩu được mã hóa đều được chuyển vào Dịch vụ Hồ sơ từ một màn hình giao diện người dùng. Dịch vụ Hồ sơ chèn thông tin hồ sơ vào bảng cơ sở dữ liệu tương ứng của nó, thực hiện cam kết công việc đó, và sau đó chuyển thông tin mật khẩu được mã hóa cho Dịch vụ Mật khẩu, dịch vụ này sau đó chèn thông tin mật khẩu vào bảng cơ sở dữ liệu tương ứng của nó và thực hiện cam kết công việc của riêng nó.
Trong khi việc tách biệt các dịch vụ cung cấp kiểm soát truy cập bảo mật tốt hơn cho thông tin mật khẩu, nhược điểm là không có giao dịch ACID cho các hành động như đăng ký một khách hàng mới hoặc hủy đăng ký (xóa) một khách hàng khỏi hệ thống. Nếu dịch vụ mật khẩu gặp sự cố trong bất kỳ thao tác nào trong số này, dữ liệu sẽ bị để lại trong trạng thái không nhất quán, dẫn đến việc xử lý lỗi phức tạp (cũng rất dễ có lỗi) để đảo ngược việc chèn hồ sơ ban đầu hoặc thực hiện các hành động khắc phục khác (xem “Mô hình Giao dịch Saga” để biết chi tiết về tính nhất quán cuối cùng và xử lý lỗi trong các giao dịch phân tán). Do đó, nếu cần có một giao dịch ACID theo đơn vị công việc duy nhất từ góc độ kinh doanh, các dịch vụ này nên được hợp nhất thành một dịch vụ duy nhất, như mô tả trong Hình 7-11.
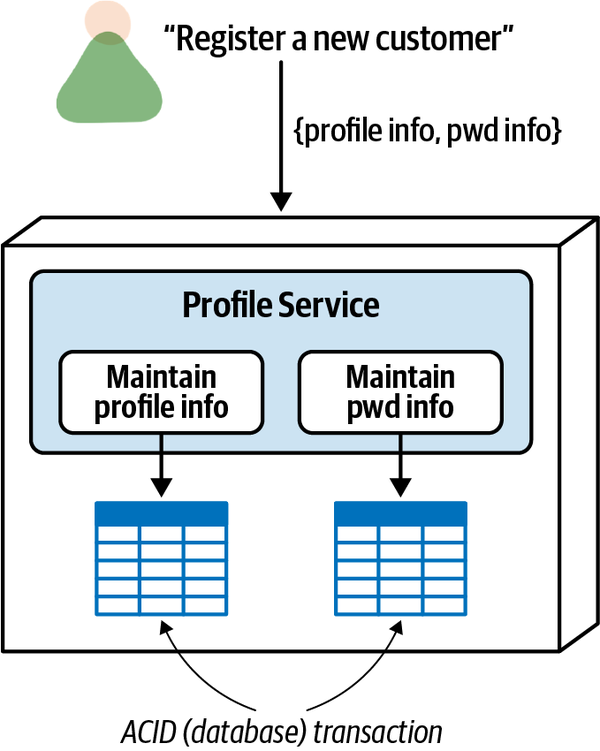
Figure 7-11. A single service supports database (ACID) transactions
Workflow and Choreography
Một tích hợp độ granularity phổ biến khác là quy trình làm việc và khiêu vũ - các dịch vụ giao tiếp với nhau (đôi khi cũng được gọi là giao tiếp giữa các dịch vụ hoặc giao tiếp theo hướng đông-tây). Giao tiếp giữa các dịch vụ là khá phổ biến và trong nhiều trường hợp là cần thiết trong các kiến trúc phân tán cao như microservices. Tuy nhiên, khi các dịch vụ tiến tới mức độ granularity tinh vi hơn dựa trên các yếu tố phân tán được nêu ở phần trước, giao tiếp giữa các dịch vụ có thể gia tăng đến mức mà các tác động tiêu cực bắt đầu xảy ra.
Vấn đề với khả năng chịu lỗi tổng thể là tác động đầu tiên của việc có quá nhiều giao tiếp đồng bộ giữa các dịch vụ. Hãy xem xét sơ đồ trong Hình 7-12: Dịch vụ A giao tiếp với các dịch vụ B và C, dịch vụ B giao tiếp với dịch vụ C, dịch vụ D giao tiếp với dịch vụ E, và cuối cùng dịch vụ E giao tiếp với dịch vụ C. Trong trường hợp này, nếu dịch vụ C bị sập, tất cả các dịch vụ khác sẽ trở nên không hoạt động do phụ thuộc tranh chấp vào dịch vụ C, tạo ra vấn đề về khả năng chịu lỗi tổng thể, khả năng sẵn sàng và độ tin cậy.
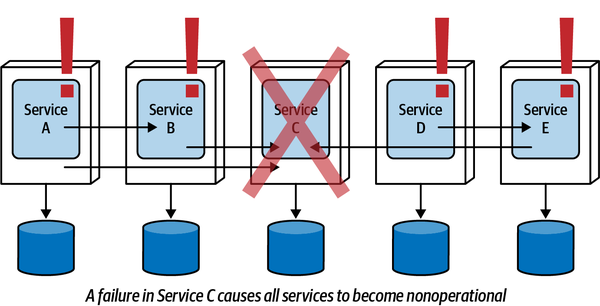
Figure 7-12. Too much workflow impacts fault tolerance
Thú vị là, khả năng chịu lỗi là một trong những yếu tố thúc đẩy sự phân tách mức độ tinh vi từ phần trước - nhưng khi những dịch vụ đó cần trò chuyện với nhau, thực sự không có gì được cải thiện từ góc độ khả năng chịu lỗi. Khi tách rời các dịch vụ, luôn kiểm tra xem các chức năng có liên kết chặt chẽ và phụ thuộc vào nhau hay không. Nếu có, thì khả năng chịu lỗi tổng thể từ góc độ yêu cầu kinh doanh sẽ không đạt được, và có thể tốt hơn nếu xem xét giữ các dịch vụ lại với nhau.
Hiệu suất tổng thể và khả năng phản hồi là một yếu tố khác thúc đẩy việc tích hợp granular (tập hợp các dịch vụ lại với nhau). Hãy xem xét kịch bản trong Hình 7-13: một dịch vụ khách hàng lớn được chia thành năm dịch vụ riêng biệt (từ A đến E). Trong khi mỗi dịch vụ này có bộ yêu cầu nguyên tử nhất quán riêng, việc lấy tất cả thông tin khách hàng một cách tập hợp từ một yêu cầu API duy nhất vào một giao diện người dùng duy nhất sẽ cần năm lần truy cập riêng biệt khi sử dụng kiểu phối hợp (xem Chương 11 để có giải pháp thay thế cho vấn đề này bằng cách sử dụng điều phối). Giả sử có độ trễ mạng và bảo mật 300 ms cho mỗi yêu cầu, thì yêu cầu đơn lẻ này sẽ phải chịu thêm 1500 ms chỉ riêng về độ trễ! Việc hợp nhất tất cả các dịch vụ này thành một dịch vụ duy nhất sẽ loại bỏ độ trễ, từ đó tăng cường hiệu suất tổng thể và khả năng phản hồi.
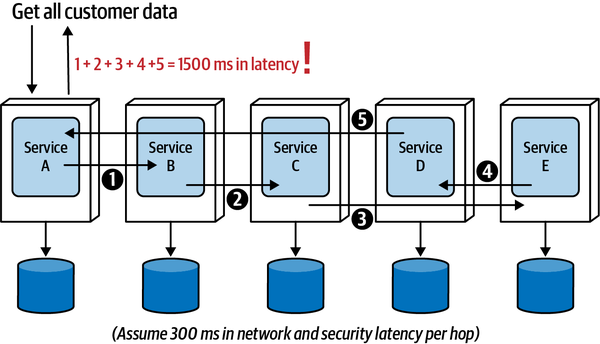
Figure 7-13. Too much workflow impacts overall performance and responsiveness
Về tổng thể hiệu suất, sự đánh đổi cho trình điều khiển tích hợp này là cân bằng giữa nhu cầu tách rời một dịch vụ với sự mất mát hiệu suất tương ứng nếu các dịch vụ đó cần giao tiếp với nhau. Một quy tắc tốt là xem xét số lượng yêu cầu cần nhiều dịch vụ giao tiếp với nhau, đồng thời tính đến mức độ quan trọng của những yêu cầu đó cần giao tiếp giữa các dịch vụ. Ví dụ, nếu 30% các yêu cầu cần một quy trình làm việc giữa các dịch vụ để hoàn tất yêu cầu và 70% là hoàn toàn nguyên tử (chỉ dành cho một dịch vụ mà không cần bất kỳ giao tiếp bổ sung nào), thì có thể hợp lý để giữ các dịch vụ tách biệt. Tuy nhiên, nếu tỷ lệ phần trăm bị đảo ngược, thì hãy xem xét việc ghép chúng lại với nhau. Điều này giả định, tất nhiên, rằng hiệu suất tổng thể là quan trọng. Có nhiều sự dễ dãi hơn trong trường hợp chức năng backend, nơi mà người dùng cuối không phải chờ đợi yêu cầu hoàn tất.
Yếu tố hiệu suất khác cần xem xét là mức độ quan trọng của yêu cầu đòi hỏi quy trình làm việc. Hãy xem xét ví dụ trước đó, trong đó 30% các yêu cầu cần một quy trình làm việc giữa các dịch vụ để hoàn thành yêu cầu, và 70% là hoàn toàn nguyên tử. Nếu một yêu cầu quan trọng cần thời gian phản hồi cực nhanh là một phần trong 30%, thì có thể hợp lý hơn khi gộp lại các dịch vụ, mặc dù 70% các yêu cầu hoàn toàn nguyên tử.
Tính đáng tin cậy tổng thể và độ toàn vẹn dữ liệu cũng bị ảnh hưởng bởi sự gia tăng giao tiếp dịch vụ. Xem xét ví dụ trong Hình 7-14: thông tin khách hàng được tách thành năm dịch vụ khách hàng riêng biệt. Trong trường hợp này, việc thêm một khách hàng mới vào hệ thống đòi hỏi sự phối hợp của cả năm dịch vụ khách hàng. Tuy nhiên, như đã giải thích trong một phần trước, mỗi dịch vụ này có giao dịch cơ sở dữ liệu riêng của nó. Lưu ý trong Hình 7-14 rằng các dịch vụ A, B và C đã cam kết một phần dữ liệu khách hàng, nhưng Dịch vụ D thì không thành công.
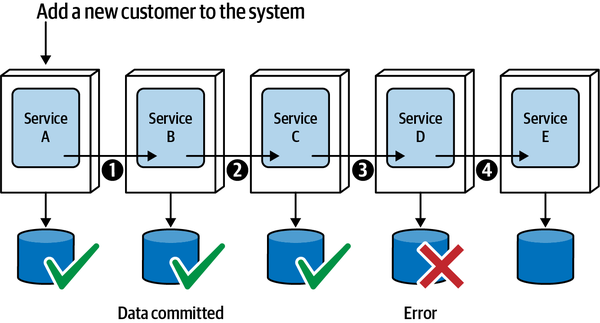
Figure 7-14. Too much workflow impacts reliability and data integrity
Điều này tạo ra vấn đề về tính nhất quán và tính toàn vẹn của dữ liệu bởi vì một phần dữ liệu khách hàng đã được cam kết và có thể đã được tác động thông qua việc truy xuất thông tin đó từ một quy trình khác hoặc thậm chí là một tin nhắn được gửi từ một trong những dịch vụ đó phát đi hành động dựa trên dữ liệu đó. Trong cả hai trường hợp, dữ liệu đó hoặc phải được hoàn tác thông qua các giao dịch bù đắp hoặc được đánh dấu với một trạng thái cụ thể để biết giao dịch đã dừng lại ở đâu nhằm khởi động lại. Đây là một tình huống rất rối rắm, một tình huống mà chúng tôi mô tả chi tiết trong “Mô hình Giao dịch Saga”. Nếu tính toàn vẹn và tính nhất quán của dữ liệu là quan trọng hoặc chủ chốt cho một hoạt động, có thể là khôn ngoan khi xem xét việc gộp lại những dịch vụ đó.
Shared Code
Mã nguồn chia sẻ là một thực tiễn phổ biến (và cần thiết) trong phát triển phần mềm. Các chức năng như ghi log, bảo mật, tiện ích, định dạng, chuyển đổi, trích xuất, và nhiều thứ khác đều là những ví dụ tốt về mã chia sẻ. Tuy nhiên, mọi thứ có thể trở nên phức tạp khi xử lý mã chia sẻ trong kiến trúc phân tán và đôi khi có thể ảnh hưởng đến độ granularity của dịch vụ.
Mã chia sẻ thường được chứa trong một thư viện chia sẻ, chẳng hạn như tệp JAR trong hệ sinh thái Java, một GEM trong môi trường Ruby, hoặc một DLL trong môi trường .NET, và thường được liên kết với một dịch vụ vào thời điểm biên dịch. Trong khi chúng ta đi sâu vào các mẫu tái sử dụng mã chi tiết trong Chương 8, ở đây chúng tôi chỉ minh họa cách mà mã chia sẻ đôi khi có thể ảnh hưởng đến độ granularity của dịch vụ và có thể trở thành một yếu tố tích hợp độ granularity (tập hợp lại các dịch vụ).
Xem xét tập hợp năm dịch vụ được hiển thị trong Hình 7-15. Mặc dù có thể đã có một trình điều khiển phân tách tốt để chia tách các dịch vụ này, nhưng tất cả chúng đều chia sẻ một mã nguồn chung của chức năng miền (trái ngược với các tiện ích chung hoặc chức năng hạ tầng). Nếu có sự thay đổi xảy ra trong thư viện chung, điều này cuối cùng sẽ yêu cầu sự thay đổi trong các dịch vụ tương ứng sử dụng thư viện chung đó. Chúng tôi nói "cuối cùng" vì việc phiên bản hóa đôi khi có thể được sử dụng với các thư viện chung để cung cấp sự linh hoạt và khả năng tương thích ngược (xem Chương 8). Do đó, tất cả những dịch vụ đã được triển khai riêng này sẽ phải được thay đổi, kiểm tra và triển khai cùng nhau. Trong những trường hợp này, có thể là khôn ngoan khi hợp nhất năm dịch vụ này thành một dịch vụ duy nhất để tránh nhiều lần triển khai, cũng như để chức năng dịch vụ không bị lệch nhau do việc sử dụng các phiên bản khác nhau của một thư viện.
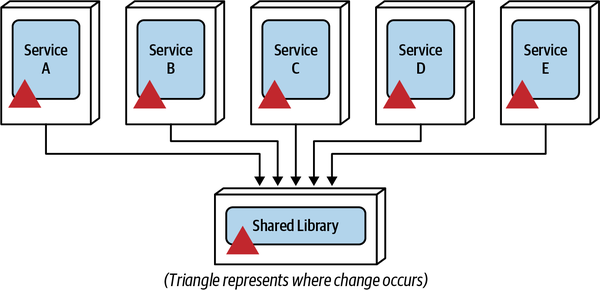
Figure 7-15. A change in shared code requires a coordinated change to all services
Không phải tất cả các việc sử dụng mã chia sẻ đều thúc đẩy sự tích hợp về độ chi tiết. Ví dụ, các chức năng cắt chéo liên quan đến cơ sở hạ tầng như ghi log, kiểm toán, xác thực, ủy quyền và giám sát mà tất cả các dịch vụ cùng sử dụng không phải là một động lực tốt để gộp lại các dịch vụ hoặc thậm chí chuyển về kiến trúc đơn thể. Một số hướng dẫn để xem xét mã chia sẻ như một yếu tố tích hợp độ chi tiết như sau:
- Specific shared domain functionality
-
Chức năng miền chung là mã chia sẻ chứa logic kinh doanh (khác với chức năng liên quan đến hạ tầng). Chúng tôi khuyến nghị xem xét yếu tố này như một bộ phận tích hợp có thể nếu tỷ lệ mã miền chung tương đối cao. Ví dụ, giả sử mã chung (chia sẻ) cho một nhóm chức năng liên quan đến khách hàng (duy trì hồ sơ, duy trì sở thích và thêm hoặc xóa bình luận) chiếm hơn 40% tổng mã nguồn. Phân tách chức năng tập hợp thành các dịch vụ riêng biệt sẽ có nghĩa là gần một nửa mã nguồn nằm trong một thư viện chung chỉ được sử dụng bởi ba dịch vụ đó. Trong ví dụ này, có thể là hợp lý khi xem xét giữ chức năng liên quan đến khách hàng này trong một dịch vụ hợp nhất cùng với mã chia sẻ (đặc biệt nếu mã chia sẻ thay đổi thường xuyên, như đã thảo luận ở phần tiếp theo).
- Frequent shared code changes
-
Bất kể kích thước của thư viện chia sẻ, việc thay đổi thường xuyên các chức năng chia sẻ yêu cầu các thay đổi phối hợp thường xuyên đối với các dịch vụ sử dụng chức năng miền chia sẻ đó. Mặc dù việc phiên bản hóa có thể được sử dụng để giảm thiểu các thay đổi phối hợp, cuối cùng các dịch vụ sử dụng chức năng chia sẻ đó sẽ cần phải áp dụng phiên bản mới nhất. Nếu mã chia sẻ thay đổi thường xuyên, có thể là khôn ngoan khi xem xét hợp nhất các dịch vụ sử dụng mã chia sẻ đó để giúp giảm thiểu sự phối hợp thay đổi phức tạp của nhiều đơn vị triển khai.
- Defects that cannot be versioned
-
Trong khi việc phiên bản hóa có thể giúp hạn chế các thay đổi đồng bộ và cho phép tính tương thích ngược cũng như tính linh hoạt (khả năng phản ứng nhanh với thay đổi), đôi khi một số chức năng kinh doanh nhất định phải được áp dụng cho tất cả các dịch vụ cùng một lúc (chẳng hạn như một lỗi hoặc thay đổi trong quy tắc kinh doanh). Nếu điều này xảy ra thường xuyên, có thể đã đến lúc xem xét việc kết hợp các dịch vụ trở lại với nhau để đơn giản hóa các thay đổi.
Data Relationships
Một sự đánh đổi khác trong sự cân bằng giữa các yếu tố phân tán mức độ chi tiết và các yếu tố tích hợp là mối quan hệ giữa dữ liệu mà một dịch vụ hợp nhất duy nhất sử dụng so với dữ liệu mà các dịch vụ riêng lẻ sẽ sử dụng. Yếu tố tích hợp này giả định rằng dữ liệu có được từ việc tách rời một dịch vụ là không được chia sẻ, mà thay vào đó được hình thành thành các ngữ cảnh giới hạn chặt chẽ trong mỗi dịch vụ để tạo điều kiện cho việc kiểm soát thay đổi và hỗ trợ cho tính sẵn có và độ tin cậy tổng thể.
Xem xét ví dụ trong Hình 7-16: một dịch vụ hợp nhất duy nhất có ba chức năng (A, B và C) và các mối quan hệ bảng dữ liệu tương ứng. Các đường solid chỉ vào các bảng đại diện cho việc ghi vào các bảng (do đó là quyền sở hữu dữ liệu), và các đường chấm chấm chỉ ra từ các bảng đại diện cho quyền truy cập chỉ đọc vào bảng. Việc thực hiện một hoạt động ánh xạ giữa các chức năng và các bảng tiết lộ các kết quả được hiển thị trong Bảng 7-1, trong đó "chủ sở hữu" có nghĩa là ghi (và các truy vấn tương ứng) và "quyền truy cập" có nghĩa là quyền truy cập chỉ đọc vào một bảng không thuộc quyền sở hữu của chức năng đó.
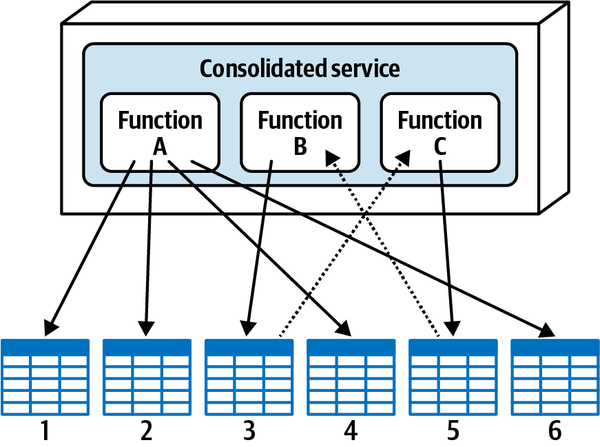
Figure 7-16. The database table relationships of a consolidated service
| Function | Table 1 | Table 2 | Table 3 | Table 4 | Table 5 | Table 6 |
|---|---|---|---|---|---|---|
A | chủ sở hữu | chủ sở hữu | chủ sở hữu | chủ sở hữu | ||
B | chủ sở hữu | truy cập | ||||
C | Truy cập | chủ sở hữu |
Giả sử rằng dựa trên một số yếu tố phân tán được nêu trong phần trước, dịch vụ này đã được chia thành ba dịch vụ riêng biệt (mỗi dịch vụ cho một chức năng trong dịch vụ hợp nhất); xem Hình 7-17. Tuy nhiên, việc tách dịch vụ hợp nhất thành ba dịch vụ riêng biệt hiện yêu cầu các bảng dữ liệu tương ứng được gán cho mỗi dịch vụ trong một ngữ cảnh giới hạn.
Lưu ý ở đầu Hình 7-17 rằng Dịch vụ A sở hữu các bảng 1, 2, 4 và 6 như một phần của bối cảnh giới hạn; Dịch vụ B sở hữu bảng 3; và Dịch vụ C sở hữu bảng 5. Tuy nhiên, hãy lưu ý trong sơ đồ rằng mọi thao tác trong Dịch vụ B đều yêu cầu truy cập vào dữ liệu trong bảng 5 (do Dịch vụ C sở hữu), và mọi thao tác trong Dịch vụ C đều yêu cầu truy cập vào dữ liệu trong bảng 3 (do Dịch vụ B sở hữu). Do bối cảnh giới hạn, Dịch vụ B không thể đơn giản gọi ra và truy vấn trực tiếp bảng 5, cũng như Dịch vụ C không thể truy vấn trực tiếp bảng 3.
Để hiểu rõ hơn về ngữ cảnh giới hạn và lý do tại sao Dịch vụ C không thể đơn giản truy cập bảng 3, giả sử Dịch vụ B (nắm giữ bảng 3) quyết định thực hiện một thay đổi trong quy tắc kinh doanh của mình yêu cầu phải loại bỏ một cột khỏi bảng 3. Việc này sẽ làm hỏng Dịch vụ C và bất kỳ dịch vụ nào khác sử dụng bảng 3. Đây là lý do tại sao khái niệm ngữ cảnh giới hạn lại quan trọng trong các kiến trúc phân tán cao như microservices. Để giải quyết vấn đề này, Dịch vụ B sẽ phải yêu cầu Dịch vụ C cung cấp dữ liệu của nó, và Dịch vụ C sẽ phải yêu cầu Dịch vụ B cung cấp dữ liệu của nó, dẫn đến việc giao tiếp qua lại giữa các dịch vụ này, như được mô tả ở dưới hình 7-17.
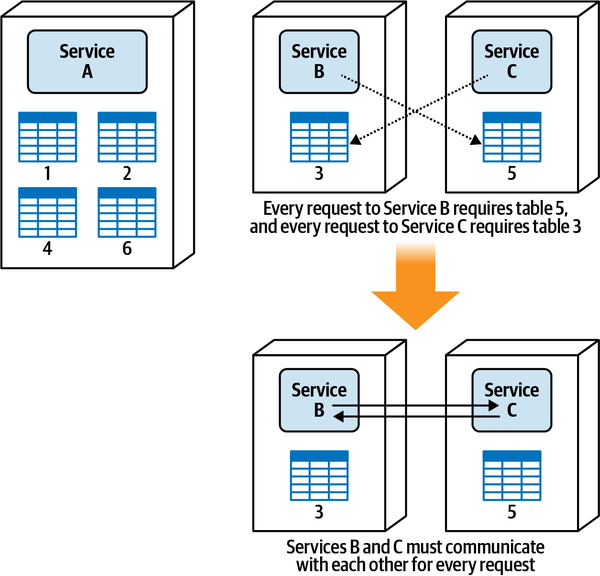
Figure 7-17. Database table relationships impact service granularity
Dựa trên sự phụ thuộc của dữ liệu giữa các dịch vụ B và C, sẽ là khôn ngoan khi hợp nhất những dịch vụ này thành một dịch vụ duy nhất để tránh các vấn đề về độ trễ, độ tin cậy và khả năng mở rộng liên quan đến việc giao tiếp giữa các dịch vụ này, cho thấy rằng mối quan hệ giữa các bảng có thể ảnh hưởng đến độ chi tiết của dịch vụ. Chúng tôi đã để trình điều khiển tích hợp độ chi tiết này ở lại cuối cùng vì đây là trình điều khiển tích hợp độ chi tiết với ít sự đánh đổi nhất. Mặc dù đôi khi việc di chuyển từ một hệ thống nguyên khối yêu cầu phải cải tiến cách tổ chức dữ liệu, trong hầu hết các trường hợp, không khả thi để tổ chức lại các mối quan hệ thực thể của bảng cơ sở dữ liệu chỉ để tách một dịch vụ. Chúng tôi sẽ đi vào chi tiết về việc tách dữ liệu trong Chương 6.
Finding the Right Balance
Tìm mức độ chi tiết dịch vụ phù hợp là điều khó khăn. Bí quyết để có được mức độ chi tiết đúng là hiểu cả các yếu tố tách rời chi tiết (khi nào tách một dịch vụ ra) và các yếu tố kết hợp chi tiết (khi nào ghép chúng lại), và phân tích các thỏa hiệp tương ứng giữa hai yếu tố này. Như đã minh họa trong các kịch bản trước, điều này đòi hỏi một kiến trúc sư không chỉ xác định các thỏa hiệp, mà còn hợp tác chặt chẽ với các bên liên quan trong doanh nghiệp để phân tích những thỏa hiệp đó và tìm ra giải pháp phù hợp cho mức độ chi tiết dịch vụ.
Bảng 7-2 và 7-3 tóm tắt các yếu tố thúc đẩy cho các máy phân tách và máy tổng hợp.
| Disintegrator driver | Reason for applying driver |
|---|---|
Phạm vi dịch vụ | Dịch vụ đơn mục đích với sự kết nối chặt chẽ |
Biến động mã | Tính linh hoạt (giảm phạm vi kiểm tra và rủi ro triển khai) |
Khả năng mở rộng | Giảm chi phí và phản ứng nhanh hơn |
Khả năng chịu lỗi | Thời gian hoạt động tổng thể tốt hơn |
Truy cập an ninh | Kiểm soát truy cập an ninh tốt hơn đến một số chức năng. |
Tính mở rộng | Tính linh hoạt (dễ dàng thêm chức năng mới) |
| Integrator driver | Reason for applying driver |
|---|---|
Giao dịch cơ sở dữ liệu | Tính toàn vẹn và nhất quán của dữ liệu |
Luồng công việc | Tính chịu lỗi, hiệu suất, và độ tin cậy |
Mã chia sẻ | Tính duy trì |
Mối quan hệ dữ liệu | Tính toàn vẹn và độ chính xác của dữ liệu |
Các kiến trúc sư có thể sử dụng các yếu tố trong các bảng này để tạo ra các tuyên bố thương lượng, sau đó có thể được thảo luận và giải quyết bằng cách hợp tác với một chủ sở hữu sản phẩm hoặc nhà tài trợ doanh nghiệp.
Ví dụ 1:
Kiến trúc sư: “Chúng tôi muốn tách rời dịch vụ của mình để cô lập những thay đổi mã thường xuyên, nhưng khi làm như vậy, chúng tôi sẽ không thể duy trì một giao dịch cơ sở dữ liệu. Điều nào quan trọng hơn dựa trên nhu cầu kinh doanh của chúng tôi—tính linh hoạt tổng thể tốt hơn (có thể bảo trì, kiểm thử và triển khai), điều này tương đương với thời gian ra thị trường nhanh hơn, hay tính toàn vẹn và nhất quán dữ liệu mạnh mẽ hơn?”
Người tài trợ dự án: “Dựa trên nhu cầu kinh doanh của chúng ta, tôi sẵn sàng hy sinh một chút thời gian đưa sản phẩm ra thị trường chậm hơn để có được sự toàn vẹn và nhất quán dữ liệu tốt hơn, vì vậy chúng ta hãy giữ nó như một dịch vụ duy nhất cho bây giờ.”
Ví dụ 2:
Kiến trúc sư: “Chúng ta cần giữ dịch vụ hợp nhất để hỗ trợ giao dịch cơ sở dữ liệu giữa hai hoạt động nhằm đảm bảo tính nhất quán của dữ liệu, nhưng điều đó có nghĩa là chức năng nhạy cảm trong dịch vụ kết hợp đơn lẻ sẽ kém an toàn hơn. Điều gì quan trọng hơn dựa trên nhu cầu kinh doanh của chúng ta—tính nhất quán dữ liệu tốt hơn hay an ninh tốt hơn?”
Người tài trợ dự án: “Giám đốc CNTT của chúng tôi đã trải qua một số tình huống khó khăn liên quan đến bảo mật và bảo vệ dữ liệu nhạy cảm, và điều này luôn nằm ở vị trí hàng đầu trong tâm trí họ và là một phần trong hầu hết các cuộc thảo luận. Trong trường hợp này, việc bảo mật dữ liệu nhạy cảm là quan trọng hơn, vì vậy hãy giữ cho các dịch vụ tách biệt và tìm cách để giảm thiểu một số vấn đề về tính nhất quán của dữ liệu.”
Ví dụ 3:
Kiến trúc sư: “Chúng ta cần tách biệt dịch vụ thanh toán của mình để cung cấp khả năng mở rộng tốt hơn cho việc thêm các phương thức thanh toán mới, nhưng điều đó có nghĩa là chúng ta sẽ có quy trình làm việc phức tạp hơn, ảnh hưởng đến khả năng phản hồi khi nhiều loại thanh toán được sử dụng cho một đơn hàng (điều này xảy ra thường xuyên). Theo nhu cầu kinh doanh của chúng ta, điều nào quan trọng hơn - khả năng mở rộng tốt hơn trong quy trình thanh toán, do đó tăng cường tính linh hoạt và thời gian đưa sản phẩm ra thị trường tổng thể, hay tính phản hồi tốt hơn khi thực hiện thanh toán?"
Nhà tài trợ dự án: “Vì tôi thấy chúng ta chỉ thêm được hai, có thể ba loại hình thanh toán nữa trong vài năm tới, tôi muốn chúng ta tập trung vào khả năng phản hồi tổng thể, vì khách hàng phải chờ hoàn tất quá trình xử lý thanh toán trước khi mã đơn hàng được phát hành.”
Sysops Squad Saga: Ticket Assignment Granularity
Thứ Hai, ngày 25 tháng 10 lúc 11:08
Khi một vé hỗ trợ được tạo bởi khách hàng và được hệ thống chấp nhận, nó phải được phân công cho một chuyên gia của nhóm Sysops dựa trên bộ kỹ năng, vị trí và khả năng sẵn có của họ. Việc phân công vé bao gồm hai thành phần chính - một thành phần Phân công Vé xác định tư vấn viên nào nên được phân công công việc, và thành phần Điều hướng Vé tìm kiếm chuyên gia của nhóm Sysops, chuyển tiếp vé đến thiết bị di động của chuyên gia (qua một ứng dụng di động Sysops Squad tùy chỉnh), và thông báo cho chuyên gia qua tin nhắn SMS rằng một vé mới đã được phân công.
Đội phát triển Sysops Squad gặp khó khăn trong việc quyết định liệu hai thành phần này (phân công và định tuyến) nên được triển khai như một dịch vụ hợp nhất hay hai dịch vụ riêng biệt, như đã minh họa trong Hình 7-18. Đội phát triển đã tham khảo ý kiến của Addison (một trong những kiến trúc sư của Sysops Squad) để quyết định lựa chọn nào nên theo.
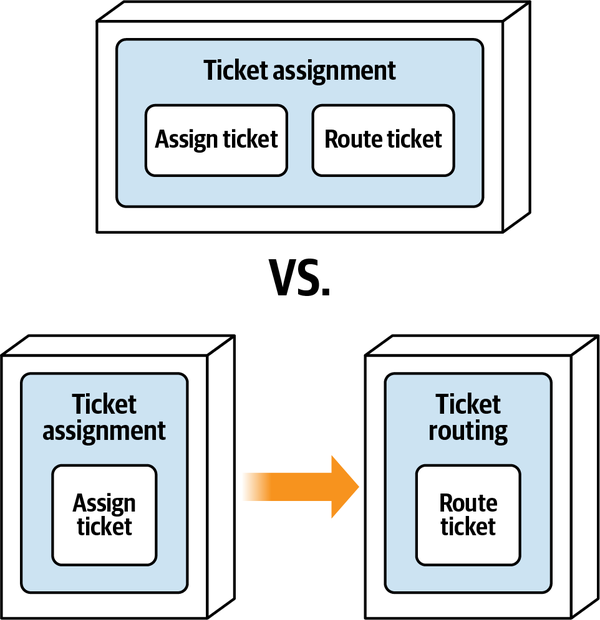
Figure 7-18. Options for ticket assignment and routing
"Vậy bạn thấy đấy," Taylen nói, "các thuật toán phân bổ vé rất phức tạp, và do đó nên được tách biệt khỏi chức năng định tuyến vé. Bằng cách đó, khi những thuật toán đó thay đổi, tôi không phải lo lắng về tất cả chức năng định tuyến."
“Vâng, nhưng có bao nhiêu thay đổi đối với các thuật toán phân công đó?” Addison hỏi. “Và chúng ta dự đoán sẽ có bao nhiêu thay đổi trong tương lai?”
“Tôi áp dụng các thay đổi cho những thuật toán đó ít nhất hai đến ba lần một tháng. Tôi đọc về phân tích dựa trên biến động, và tình huống này phù hợp hoàn hảo,” Taylen nói.
“Nhưng nếu chúng ta tách chức năng phân công và định tuyến thành hai dịch vụ, sẽ cần có sự giao tiếp liên tục giữa chúng,” Skyler nói. “Hơn nữa, phân công và định tuyến thực sự là một chức năng, chứ không phải hai.”
“Không,” Taylen nói, “chúng là hai chức năng riêng biệt.”
"Chờ một chút," Addison nói. "Tôi hiểu điều Skyler muốn nói. Hãy suy nghĩ một chút. Khi một chuyên gia được tìm thấy và có sẵn trong một khoảng thời gian nhất định, vé sẽ ngay lập tức được chuyển đến chuyên gia đó. Nếu không có chuyên gia nào có sẵn, vé sẽ quay trở lại hàng đợi và chờ cho đến khi tìm được một chuyên gia."
“Vâng, đúng vậy,” Taylen nói.
“Xem này,” Skyler nói, “bạn không thể thực hiện một nhiệm vụ vé mà không chuyển nó đến chuyên gia. Vì vậy, hai chức năng là một.”
"Không, không, không," Taylen nói. "Bạn không hiểu. Nếu một chuyên gia được thấy có sẵn trong một khoảng thời gian nhất định, thì chuyên gia đó sẽ được phân công. Chấm hết. Định tuyến chỉ là một vấn đề vận chuyển."
“Điều gì xảy ra trong chức năng hiện tại nếu một vé không thể được chuyển đến chuyên gia?” Addison hỏi.
“Sau đó, một chuyên gia khác được chọn,” Taylen nói.
“Được rồi, hãy suy nghĩ về điều đó một chút, Taylen,” Addison nói. “Nếu phân công và định tuyến là hai dịch vụ riêng biệt, thì dịch vụ định tuyến sẽ phải giao tiếp lại với dịch vụ phân công, thông báo rằng không thể tìm thấy chuyên gia và yêu cầu chọn một người khác. Điều đó cần nhiều sự phối hợp giữa hai dịch vụ.”
“Có, nhưng chúng vẫn là hai chức năng tách biệt, không phải là một như Skyler đang gợi ý,” Taylen nói.
“Tôi có một ý tưởng,” Addison nói. “Chúng ta có thể đồng ý rằng phân công và định tuyến là hai hoạt động riêng biệt, nhưng lại gắn bó chặt chẽ với nhau một cách đồng bộ không? Nghĩa là, một chức năng không thể tồn tại nếu không có chức năng kia?”
“Có,” cả Taylen và Skyler đều trả lời.
“Trong trường hợp đó,” Addison nói, “hãy phân tích các lợi ích và trade-off. Điều nào quan trọng hơn—tách biệt chức năng phân công để kiểm soát thay đổi, hay kết hợp phân công và định tuyến thành một dịch vụ duy nhất để cải thiện hiệu suất, xử lý lỗi và kiểm soát quy trình làm việc?”
“Ừm,” Taylen nói, “khi bạn nói như vậy, rõ ràng là dịch vụ đơn. Nhưng tôi vẫn muốn tách biệt mã bài tập.”
“Được rồi,” Addison nói, “trong trường hợp đó, sao chúng ta không tạo ba thành phần kiến trúc khác biệt trong một dịch vụ duy nhất. Chúng ta có thể phân định phân công, định tuyến và mã chia sẻ với các không gian tên riêng biệt trong mã. Điều đó có giúp ích không?”
"Ừ," Taylen nói, "điều đó có thể. Được rồi, cả hai bạn đều thắng. Chúng ta sẽ chọn một dịch vụ duy nhất."
“Taylor,” Addison nói, “không phải là về việc chiến thắng, mà là phân tích các sự đánh đổi để tìm ra giải pháp thích hợp nhất; chỉ có vậy thôi.”
Với việc mọi người đồng ý với một dịch vụ duy nhất cho việc phân công và định tuyến, Addison đã viết bản ghi quyết định kiến trúc (ADR) sau cho quyết định này:
ADR: Dịch vụ hợp nhất cho việc phân công và định tuyến vé
Bối cảnh Khi một vé được tạo và chấp nhận bởi hệ thống, nó phải được gán cho một chuyên gia và sau đó được gửi đến thiết bị di động của chuyên gia đó. Điều này có thể được thực hiện thông qua một dịch vụ gán vé tổng hợp hoặc các dịch vụ riêng biệt cho việc gán vé và định tuyến vé.
Quyết định Chúng tôi sẽ tạo ra một dịch vụ phân công vé hợp nhất duy nhất cho các chức năng phân công và định tuyến của vé.
Các vé sẽ ngay lập tức được chuyển đến chuyên gia của Đội ngũ Sysops ngay khi chúng được phân công, vì vậy hai hoạt động này có mối liên hệ chặt chẽ và phụ thuộc lẫn nhau.
Cả hai chức năng phải có khả năng mở rộng như nhau, vì vậy không có sự khác biệt về thông lượng giữa các dịch vụ này, cũng như không cần thiết phải có áp lực ngược giữa các chức năng này.
Vì cả hai chức năng đều hoàn toàn phụ thuộc vào nhau, khả năng chịu lỗi không phải là yếu tố quyết định để tách rời các chức năng này.
Việc tách các chức năng này thành các dịch vụ riêng biệt sẽ yêu cầu có quy trình làm việc giữa chúng, dẫn đến các vấn đề về hiệu suất, khả năng chống lỗi và độ tin cậy có thể xảy ra.
Hệ quả Các thay đổi đối với thuật toán phân công (xảy ra thường xuyên) và thay đổi đối với cơ chế định tuyến (thay đổi không thường xuyên) sẽ yêu cầu thử nghiệm và triển khai cả hai chức năng, dẫn đến tăng phạm vi thử nghiệm và rủi ro triển khai.
Sysops Squad Saga: Customer Registration Granularity
Thứ Sáu, ngày 14 tháng 1, 13:15
Khách hàng phải đăng ký với hệ thống để có quyền truy cập vào kế hoạch hỗ trợ của Đội ngũ Sysops. Trong quá trình đăng ký, khách hàng phải cung cấp thông tin hồ sơ (tên, địa chỉ, tên doanh nghiệp nếu có, v.v.), thông tin thẻ tín dụng (được thanh toán hàng tháng), thông tin mật khẩu và câu hỏi bảo mật, cũng như danh sách các sản phẩm đã mua mà họ muốn được bảo hiểm dưới kế hoạch hỗ trợ của Đội ngũ Sysops.
Một số thành viên trong nhóm phát triển khăng khăng rằng đây nên là một Dịch vụ Khách hàng hợp nhất duy nhất chứa tất cả thông tin khách hàng, trong khi các thành viên khác trong nhóm không đồng ý và cho rằng nên có một dịch vụ riêng cho mỗi chức năng này (dịch vụ Hồ sơ, dịch vụ Thẻ tín dụng, dịch vụ Mật khẩu và dịch vụ Sản phẩm Hỗ trợ). Skyler, với kinh nghiệm trước đây về dữ liệu PCI và PII, cho rằng thông tin về thẻ tín dụng và mật khẩu nên được tách ra thành một dịch vụ riêng so với phần còn lại, và do đó chỉ có hai dịch vụ (một dịch vụ Hồ sơ chứa thông tin hồ sơ và sản phẩm và một dịch vụ Khách hàng Bảo mật riêng chứa thông tin thẻ tín dụng và mật khẩu). Ba tùy chọn này được minh họa trong Hình 7-19.
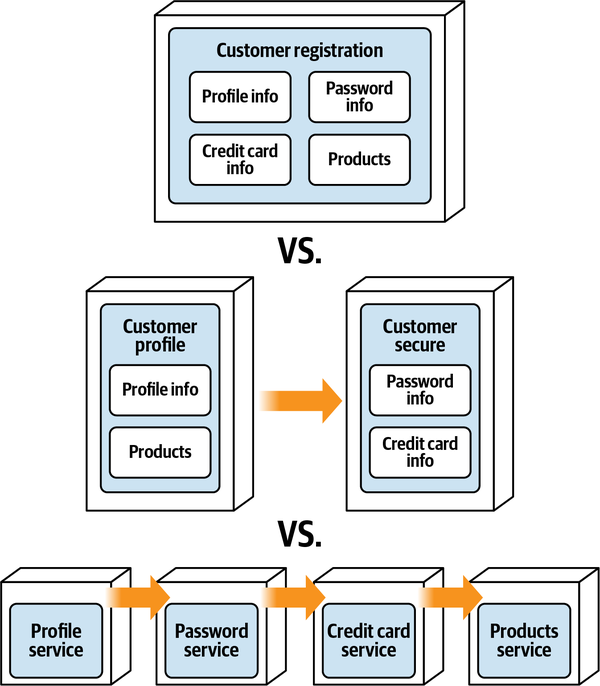
Figure 7-19. Options for customer registration
Bởi vì Addison bận rộn với chức năng ticketing chính, nhóm phát triển đã nhờ đến sự giúp đỡ của Austen trong việc giải quyết vấn đề độ chi tiết này. Dự đoán rằng đây sẽ không phải là một quyết định dễ dàng, đặc biệt là vì nó liên quan đến an ninh, Austen đã sắp xếp một cuộc họp với Parker, (chủ sở hữu sản phẩm), và Sam, chuyên gia an ninh của Penultimate Electronics để thảo luận về những lựa chọn này.
“Được rồi, vậy chúng tôi có thể làm gì cho bạn?” Parker hỏi.
“Vâng,” Austen nói, “chúng tôi đang gặp khó khăn trong việc xác định số dịch vụ cần tạo ra để đăng ký khách hàng và duy trì thông tin liên quan đến khách hàng. Bạn thấy đấy, có bốn loại dữ liệu chính mà chúng tôi đang xử lý ở đây: thông tin hồ sơ, thông tin thẻ tín dụng, thông tin mật khẩu và thông tin sản phẩm đã mua.”
“Chờ đã, khoan đã,” Sam ngắt lời. “Bạn biết rằng thông tin thẻ tín dụng và mật khẩu phải được bảo mật, đúng không?”
“Dĩ nhiên, chúng tôi biết điều đó phải được bảo mật,” Austen nói. “Điều chúng tôi đang gặp khó khăn là thực tế có một API đăng ký khách hàng duy nhất cho backend, vì vậy nếu chúng tôi có các dịch vụ riêng biệt, tất cả đều phải được phối hợp cùng nhau khi đăng ký một khách hàng, điều này sẽ đòi hỏi một giao dịch phân tán.”
“Ý bạn là gì?” Parker hỏi.
“Chà,” Austen nói, “chúng ta sẽ không thể đồng bộ hóa tất cả dữ liệu lại với nhau như một đơn vị công việc nguyên tử.”
“Điều đó không phải là một lựa chọn,” Parker nói. “Tất cả thông tin của khách hàng đều được lưu trữ trong cơ sở dữ liệu, hoặc là không. Để tôi nói một cách khác. Chúng ta tuyệt đối không thể có tình huống mà chúng ta có hồ sơ khách hàng mà không có hồ sơ thẻ tín dụng hoặc mật khẩu tương ứng. Không bao giờ.”
“Được rồi, nhưng còn về việc bảo mật thông tin thẻ tín dụng và mật khẩu thì sao?” Sam hỏi. “Có vẻ như, việc có các dịch vụ riêng biệt sẽ cho phép kiểm soát an ninh tốt hơn đối với loại thông tin nhạy cảm đó.”
“Tôi nghĩ tôi có thể có một ý tưởng.” Austen nói. “Thông tin thẻ tín dụng được mã hóa trong cơ sở dữ liệu, đúng không?”
“Được mã hóa và mã thông báo,” Sam nói.
"Rất tốt. Còn thông tin mật khẩu thì sao?" Austen hỏi.
“Cũng vậy,” Sam nói.
"Được rồi," Austen nói, "nên tôi nghĩ điều chúng ta thực sự cần tập trung ở đây là kiểm soát quyền truy cập vào mật khẩu và thông tin thẻ tín dụng tách biệt với các yêu cầu khác liên quan đến khách hàng—bạn biết đấy, như là lấy và cập nhật thông tin hồ sơ, và vân vân."
“Tôi nghĩ tôi hiểu vấn đề của bạn,” Parker nói. “Bạn đang nói với tôi rằng nếu tách tất cả các chức năng này thành các dịch vụ riêng biệt, bạn có thể bảo mật việc truy cập vào dữ liệu nhạy cảm tốt hơn, nhưng bạn không thể đảm bảo yêu cầu 'tất cả hoặc không có gì' của tôi. Tôi có đúng không?”
"Chính xác. Đó là sự đánh đổi," Austen nói.
“Chờ đã,” Sam nói. “Bạn có đang sử dụng thư viện bảo mật Tortoise để bảo vệ các cuộc gọi API không?”
"Vâng. Chúng tôi sử dụng những thư viện đó không chỉ ở lớp API, mà còn trong từng dịch vụ để kiểm soát quyền truy cập thông qua lưới dịch vụ. Cho nên về cơ bản, đó là một sự kiểm tra kép," Austen nói.
"Hmmm," Sam nói. "Được rồi, tôi đồng ý với một dịch vụ miễn là bạn sử dụng khung bảo mật Tortoise."
"Có tôi cũng vậy, miễn là chúng ta vẫn có quy trình đăng ký khách hàng tất cả hoặc không có gì," Parker nói.
“Vậy thì tôi nghĩ chúng ta đều đồng ý rằng việc đăng ký khách hàng hoàn toàn là một yêu cầu tuyệt đối và chúng ta sẽ duy trì quyền truy cập bảo mật nhiều cấp với Tortoise,” Austen nói.
"Đã thống nhất," Parker nói.
"Đồng ý," Sam nói.
Parker nhận thấy cách mà Austen điều hành cuộc họp bằng cách tạo điều kiện cho cuộc trò chuyện thay vì kiểm soát nó. Đây là một bài học quan trọng đối với một kiến trúc sư trong việc xác định, hiểu và thương lượng các sự đánh đổi. Parker cũng hiểu rõ hơn sự khác biệt giữa thiết kế và kiến trúc ở chỗ an ninh có thể được kiểm soát thông qua thiết kế (sử dụng một thư viện tùy chỉnh với mã hóa đặc biệt) thay vì kiến trúc (chia nhỏ chức năng thành các đơn vị triển khai riêng biệt).
Dựa trên cuộc trò chuyện với Parker và Sam, Austen đã quyết định rằng chức năng liên quan đến khách hàng sẽ được quản lý thông qua một dịch vụ miền hợp nhất duy nhất (thay vì các dịch vụ được triển khai riêng biệt) và đã viết ADR sau cho quyết định này:
ADR: Dịch vụ hợp nhất cho các chức năng liên quan đến khách hàng
Ngữ cảnh Khách hàng phải đăng ký với hệ thống để có quyền truy cập vào kế hoạch hỗ trợ của Sysops Squad. Trong quá trình đăng ký, khách hàng phải cung cấp thông tin hồ sơ, thông tin thẻ tín dụng, thông tin mật khẩu và các sản phẩm đã mua. Điều này có thể được thực hiện thông qua một dịch vụ khách hàng tổng hợp, một dịch vụ riêng biệt cho từng chức năng hoặc một dịch vụ riêng cho dữ liệu nhạy cảm và không nhạy cảm.
Quyết định Chúng tôi sẽ tạo ra một dịch vụ khách hàng hợp nhất cho việc quản lý hồ sơ, thẻ tín dụng, mật khẩu và các sản phẩm được hỗ trợ.
Chức năng đăng ký và hủy đăng ký của khách hàng yêu cầu một đơn vị công việc nguyên tử duy nhất. Một dịch vụ đơn lẻ sẽ hỗ trợ các giao dịch ACID để đáp ứng yêu cầu này, trong khi các dịch vụ tách biệt sẽ không làm được điều đó.
Việc sử dụng các thư viện bảo mật Tortoise trong lớp API và mạng dịch vụ sẽ giảm thiểu rủi ro truy cập bảo mật đối với thông tin nhạy cảm.
Hậu quả Chúng tôi sẽ yêu cầu thư viện bảo mật Tortoise để đảm bảo quyền truy cập an toàn trong cả cổng API và mesh dịch vụ.
Bởi vì đây là một dịch vụ đơn lẻ, việc thay đổi mã nguồn cho thông tin hồ sơ, thẻ tín dụng, mật khẩu hoặc sản phẩm đã mua sẽ làm tăng phạm vi kiểm tra và tăng rủi ro triển khai.
Chức năng kết hợp (hồ sơ, thẻ tín dụng, mật khẩu và sản phẩm đã mua) sẽ phải mở rộng như một đơn vị.
Sự đánh đổi được thảo luận trong một cuộc họp với chủ sở hữu sản phẩm và chuyên gia bảo mật là tính giao dịch so với bảo mật. Việc chia nhỏ chức năng của khách hàng thành các dịch vụ riêng biệt cung cấp quyền truy cập bảo mật tốt hơn, nhưng không hỗ trợ giao dịch cơ sở dữ liệu "tất cả hoặc không có gì" cần thiết cho việc đăng ký hoặc hủy đăng ký của khách hàng. Tuy nhiên, các mối quan tâm về bảo mật được giảm thiểu thông qua việc sử dụng thư viện bảo mật Tortoise tùy chỉnh.
Part II. Putting Things Back Together
Việc cố gắng chia nhỏ một mô-đun gắn kết chỉ dẫn đến việc tăng độ phụ thuộc và giảm khả năng đọc hiểu.
Larry Constantine
Khi một hệ thống bị tách rời, các kiến trúc sư thường thấy cần phải nối lại để nó hoạt động như một đơn vị gắn kết. Như Larry Constantine đã suy luận một cách trau chuốt trong câu trích trước đó, không dễ dàng như vẻ bề ngoài, với nhiều sự đánh đổi liên quan khi tách rời mọi thứ.
Trong phần thứ hai của cuốn sách này, chúng tôi thảo luận về các kỹ thuật khác nhau để vượt qua một số thách thức khó khăn liên quan đến kiến trúc phân tán, bao gồm quản lý giao tiếp dịch vụ, hợp đồng, quy trình làm việc phân tán, giao dịch phân tán, quyền sở hữu dữ liệu, quyền truy cập dữ liệu và dữ liệu phân tích.
Phần I nói về cấu trúc; Phần II nói về sự giao tiếp. Khi một kiến trúc sư hiểu về cấu trúc và những quyết định đã dẫn đến nó, đã đến lúc suy nghĩ về cách mà các phần cấu trúc tương tác với nhau.
Chapter 8. Reuse Patterns
Thứ Tư, ngày 2 tháng 2, 15:15
Khi các thành viên trong nhóm phát triển làm việc để phân tách các dịch vụ miền, họ bắt đầu gặp phải những bất đồng về cách xử lý tất cả mã và chức năng chia sẻ. Taylen, bực bội với những gì Skyler đang làm liên quan đến mã chia sẻ, đã đi đến bàn làm việc của Skyler.
“Cậu đang làm cái quái gì vậy?” Taylen hỏi.
“Tôi sẽ chuyển tất cả mã nguồn chia sẻ sang một không gian làm việc mới để chúng ta có thể tạo ra một DLL chia sẻ từ đó,” Skyler trả lời.
“Một DLL chia sẻ duy nhất?”
“Đó là điều tôi đang lên kế hoạch,” Skyler nói. “Hầu hết các dịch vụ đều cần những thứ này, vì vậy tôi sẽ tạo ra một DLL duy nhất mà tất cả các dịch vụ có thể sử dụng.”
"Cách đó là ý kiến tệ nhất mà tôi từng nghe," Taylen nói. "Mọi người đều biết rằng bạn nên có nhiều thư viện chia sẻ trong kiến trúc phân tán!"
“Không theo ý kiến của tôi,” Sydney nói. “Có vẻ như tôi nghĩ dễ quản lý hơn một thư viện DLL chia sẻ duy nhất thay vì hàng chục thư viện khác nhau.”
"Vì tôi là người dẫn dắt công nghệ cho ứng dụng này, tôi muốn bạn tách chức năng đó thành các thư viện chia sẻ riêng biệt."
“Được rồi, được rồi, tôi nghĩ tôi có thể di chuyển tất cả quyền xác thực vào một DLL riêng biệt nếu điều đó làm bạn vui,” Skyler nói.
"Cái gì?" Taylen nói. "Mã ủy quyền phải là một dịch vụ chia sẻ, bạn biết đấy——không phải trong thư viện chia sẻ."
“Không,” Skyler nói. “Mã đó nên nằm trong một DLL chia sẻ.”
"Có chuyện gì ồn ào ở đó vậy?" Addison hỏi.
“Taylen muốn chức năng ủy quyền nằm trong một dịch vụ chia sẻ. Thật điên rồ. Tôi nghĩ nó nên nằm trong DLL chia sẻ chung,” Skyler nói.
“Không đời nào,” Taylen nói. “Nó phải được đặt trong một dịch vụ chia sẻ riêng biệt.”
“Và,” Skyler nói, “Taylen khăng khăng rằng phải có nhiều thư viện chia sẻ cho chức năng chung thay vì chỉ một thư viện chia sẻ.”
“Để tôi nói với bạn,” Addison nói. “Hãy cùng xem xét những ưu nhược điểm của độ chi tiết của thư viện chia sẻ, và cũng xem xét những ưu nhược điểm giữa một thư viện chia sẻ và một dịch vụ chia sẻ để xem liệu chúng ta có thể giải quyết những vấn đề này một cách hợp lý và chu đáo hơn không.”
Tái sử dụng mã là một phần bình thường của phát triển phần mềm. Các chức năng trong lĩnh vực kinh doanh phổ biến, như định dạng, máy tính, bộ xác thực và kiểm toán, thường được chia sẻ giữa nhiều thành phần, cũng như các chức năng hạ tầng chung, như bảo mật, ghi nhật ký và thu thập số liệu. Trong hầu hết các kiến trúc đơn khối, việc tái sử dụng mã thường không được suy nghĩ nhiều—đó chỉ là vấn đề đơn giản của việc nhập khẩu hoặc tự động tiêm các tệp lớp được chia sẻ. Tuy nhiên, trong các kiến trúc phân tán, như được hiển thị trong Hình 8-1, mọi thứ trở nên phức tạp hơn, khi xuất hiện các câu hỏi về cách xử lý các chức năng chia sẻ.
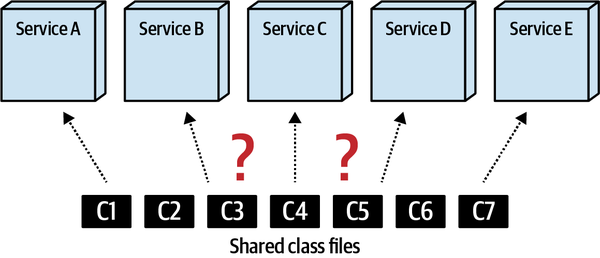
Figure 8-1. Code reuse is a hard part of distributed architecture
Thường xuyên trong các kiến trúc phân tán cao như microservices và môi trường serverless, những câu như "tái sử dụng là lạm dụng!" và "chia sẻ không gì cả!" được các kiến trúc sư ca ngợi nhằm giảm bớt lượng mã chia sẻ trong các loại kiến trúc này. Các kiến trúc sư trong những môi trường này thậm chí đã được phát hiện đưa ra lời khuyên trái ngược với nguyên tắc DRY nổi tiếng (Đừng lặp lại bản thân) bằng cách sử dụng một từ viết tắt đối lập gọi là WET (Viết mỗi lần hoặc Viết mọi thứ hai lần).
Trong khi các nhà phát triển nên cố gắng hạn chế việc tái sử dụng mã trong các kiến trúc phân tán, thì đây vẫn là một sự thật trong phát triển phần mềm và phải được giải quyết, đặc biệt là trong các kiến trúc phân tán. Trong chương này, chúng tôi giới thiệu một số kỹ thuật để quản lý mã tái sử dụng trong một kiến trúc phân tán, bao gồm sao chép mã, thư viện chia sẻ, dịch vụ chia sẻ và sidecar trong một mạng dịch vụ. Đối với mỗi tùy chọn này, chúng tôi cũng thảo luận về những ưu điểm, nhược điểm và sự đánh đổi của từng phương pháp.
Code Replication
Trong việc sao chép mã, mã chia sẻ được sao chép vào mỗi dịch vụ (hoặc cụ thể hơn, vào từng kho mã nguồn dịch vụ), như được thể hiện trong Hình 8-2, do đó hoàn toàn tránh việc chia sẻ mã. Mặc dù có thể nghe có vẻ điên rồ, nhưng kỹ thuật này đã trở nên phổ biến trong những ngày đầu của microservices khi có rất nhiều sự nhầm lẫn và hiểu lầm về khái niệm ngữ cảnh giới hạn, do đó dẫn đến việc tạo ra một “kiến trúc không chia sẻ.” Về lý thuyết, sao chép mã dường như là một cách tiếp cận tốt vào thời điểm đó để giảm chia sẻ mã, nhưng trên thực tế, nó nhanh chóng thất bại.

Figure 8-2. With replication, shared functionality is copied into each service
Mặc dù việc sao chép mã không còn được sử dụng nhiều ngày nay, nhưng nó vẫn là một kỹ thuật hợp lệ để giải quyết việc tái sử dụng mã qua nhiều dịch vụ phân tán. Kỹ thuật này cần được tiếp cận với sự cẩn trọng cực kỳ cao bởi lý do rõ ràng là nếu một lỗi được phát hiện trong mã hoặc một thay đổi quan trọng cho mã là cần thiết, sẽ rất khó khăn và tốn thời gian để cập nhật tất cả các dịch vụ chứa mã đã được sao chép.
Đôi khi, kỹ thuật này có thể chứng tỏ hữu ích, đặc biệt là đối với mã tĩnh một lần mà hầu hết (hoặc tất cả) các dịch vụ cần. Chẳng hạn, hãy xem xét mã Java trong Ví dụ 8-1 và mã C# tương ứng trong Ví dụ 8-2 xác định lớp trong dịch vụ đại diện cho điểm vào của dịch vụ (thường là lớp API RESTful trong một dịch vụ).
Example 8-1. Source code defining a service entry point annotation (Java)
@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.TYPE)public@interfaceServiceEntrypoint{}/* Usage:@ServiceEntrypointpublic class PaymentServiceAPI {...}*/
Example 8-2. Source code defining a service entry point attribute (C#)
[AttributeUsage(AttributeTargets.Class)]classServiceEntrypoint:Attribute{}/* Usage:[ServiceEntrypoint]class PaymentServiceAPI {...}*/
Lưu ý rằng mã nguồn trong Ví dụ 8-1 thực sự không chứa bất kỳ chức năng nào. Chú thích chỉ đơn giản là một dấu hiệu (hoặc thẻ) được sử dụng để xác định một lớp nhất định là đại diện cho điểm vào dịch vụ. Tuy nhiên, chú thích đơn giản này rất hữu ích để thêm các chú thích siêu dữ liệu khác về một dịch vụ cụ thể, bao gồm loại dịch vụ, miền, ngữ cảnh giới hạn, v.v.; xem Chương 89 trong 97 Điều Mọi Lập Trình Viên Java Nên Biết của Kevlin Henney và Trisha Gee (O’Reilly) để biết mô tả về các chú thích tùy chỉnh siêu dữ liệu này.
Loại mã nguồn này là một ứng viên tốt cho việc sao chép vì nó tĩnh và không chứa lỗi (và có khả năng cao là sẽ không có lỗi trong tương lai). Nếu đây là một lớp duy nhất, có thể đáng để sao chép vào mỗi kho mã dịch vụ thay vì tạo một thư viện chia sẻ cho nó. Tuy nhiên, chúng tôi thường khuyến khích điều tra các kỹ thuật chia sẻ mã khác được trình bày trong chương này trước khi chọn phương pháp sao chép mã.
Trong khi kỹ thuật sao chép bảo tồn ngữ cảnh giới hạn, nó làm cho việc áp dụng các thay đổi trở nên khó khăn nếu mã cần phải được sửa đổi. Bảng 8-1 liệt kê các giao dịch khác nhau liên quan đến kỹ thuật này.
When to Use
Kỹ thuật sao chép là một phương pháp tốt khi các nhà phát triển có mã tĩnh đơn giản (như chú thích, thuộc tính, tiện ích chung đơn giản, v.v.) mà là một lớp chỉ được tạo ra một lần hoặc mã mà ít có khả năng thay đổi do các lỗi hoặc thay đổi chức năng. Tuy nhiên, như đã đề cập trước đó, chúng tôi khuyến khích khám phá các tùy chọn tái sử dụng mã khác trước khi áp dụng kỹ thuật sao chép mã.
Khi chuyển đổi từ kiến trúc đơn lẻ sang kiến trúc phân tán, chúng tôi cũng nhận thấy rằng kỹ thuật sao chép đôi khi có thể hoạt động cho các lớp tiện ích tĩnh phổ biến. Ví dụ, bằng cách sao chép lớp Utility.cs C# đến tất cả các dịch vụ, mỗi dịch vụ giờ đây có thể loại bỏ (hoặc nâng cao) lớp Utility.cs để phù hợp với nhu cầu cụ thể của mình, do đó loại bỏ mã không cần thiết và cho phép lớp tiện ích phát triển cho từng ngữ cảnh cụ thể (tương tự như kỹ thuật nhánh chiến thuật được mô tả trong Chương 3). Một lần nữa, rủi ro với kỹ thuật này là một lỗi hoặc thay đổi rất khó để lan truyền đến tất cả các dịch vụ vì mã bị sao chép cho mỗi dịch vụ.
Shared Library
Một trong những kỹ thuật phổ biến nhất để chia sẻ mã là sử dụng thư viện chung. Thư viện chung là một sản phẩm bên ngoài (chẳng hạn như tệp JAR, DLL, v.v.) chứa mã nguồn được nhiều dịch vụ sử dụng, thường được liên kết với dịch vụ tại thời điểm biên dịch (xem Hình 8-3). Mặc dù kỹ thuật thư viện chung có vẻ đơn giản và dễ hiểu, nhưng nó có những phức tạp và đánh đổi của riêng mình, không kém phần quan trọng là độ chi tiết và quản lý phiên bản của thư viện chung.
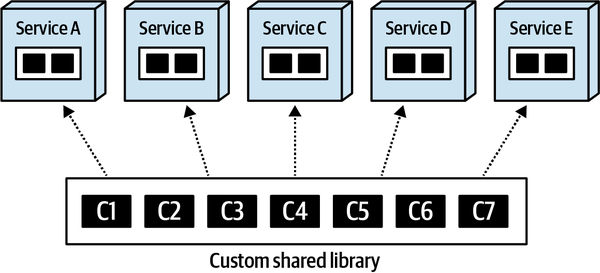
Figure 8-3. With the shared library technique, common code is consolidated and shared at compile time
Dependency Management and Change Control
Tương tự như độ phân granularity của dịch vụ (được thảo luận trong Chương 7), có những sự đánh đổi liên quan đến độ phân granularity của thư viện chia sẻ. Hai lực đối kháng tạo ra sự đánh đổi với thư viện chia sẻ là quản lý phụ thuộc và kiểm soát thay đổi.
Xem xét thư viện chia sẻ được phân mảnh thô được minh họa trong Hình 8-4. Lưu ý rằng trong khi quản lý phụ thuộc là tương đối đơn giản (mỗi dịch vụ sử dụng một thư viện chia sẻ duy nhất), việc kiểm soát thay đổi thì không. Nếu có sự thay đổi xảy ra ở bất kỳ tệp lớp nào trong thư viện chia sẻ thô, mọi dịch vụ, dù có quan tâm đến sự thay đổi hay không, đều phải cuối cùng áp dụng sự thay đổi đó vì lý do ngưng hỗ trợ phiên bản của thư viện chia sẻ. Điều này buộc phải kiểm thử lại và triển khai lại tất cả các dịch vụ sử dụng thư viện đó, do đó tăng đáng kể phạm vi kiểm thử tổng thể của một thay đổi thư viện chia sẻ.
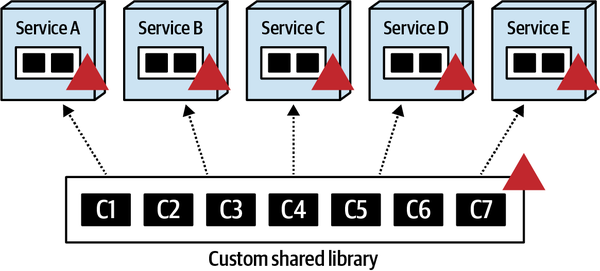
Figure 8-4. Changes to coarse-grained shared libraries impact multiple services but keep dependencies low
Việc chia mã chung thành các thư viện chia sẻ nhỏ hơn dựa trên chức năng (chẳng hạn như bảo mật, định dạng, chú thích, máy tính, v.v.) thì tốt hơn cho việc kiểm soát thay đổi và khả năng duy trì tổng thể, nhưng không may tạo ra sự lộn xộn về quản lý phụ thuộc. Như được thể hiện trong Hình 8-5, một thay đổi trong lớp chung C7 chỉ ảnh hưởng đến Dịch vụ D và Dịch vụ E, nhưng việc quản lý ma trận phụ thuộc giữa các thư viện chung và dịch vụ nhanh chóng bắt đầu trông như một đống bùn phân tán lớn (hoặc những gì một số người gọi là một khối đơn phân tán).
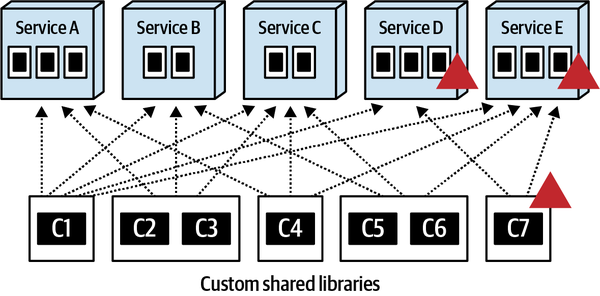
Figure 8-5. Changes to fine-grained shared libraries impact fewer services but increase dependencies
Lựa chọn độ chi tiết của thư viện chia sẻ có thể không quan trọng nhiều khi chỉ có vài dịch vụ, nhưng khi số lượng dịch vụ tăng lên, các vấn đề liên quan đến kiểm soát thay đổi và quản lý phụ thuộc cũng gia tăng. Chỉ cần tưởng tượng một hệ thống có 200 dịch vụ và 40 thư viện chia sẻ—nó sẽ nhanh chóng trở nên phức tạp và không thể bảo trì.
Xét những đánh đổi giữa kiểm soát thay đổi và quản lý phụ thuộc, lời khuyên của chúng tôi là thường xuyên tránh các thư viện chia sẻ lớn và thô, và cố gắng hướng tới các thư viện nhỏ hơn với phân chia chức năng khi có thể, qua đó ưu tiên kiểm soát thay đổi hơn là quản lý phụ thuộc. Ví dụ, việc tách ra các chức năng tương đối tĩnh như định dạng và bảo mật (xác thực và phân quyền) vào các thư viện chia sẻ riêng biệt sẽ tách biệt mã tĩnh này, do đó giảm quy mô thử nghiệm và các đợt triển khai phiên bản không cần thiết cho các chức năng chia sẻ khác.
Versioning Strategies
Lời khuyên chung của chúng tôi về việc phiên bản thư viện chia sẻ là luôn sử dụng phiên bản! Việc phiên bản hóa các thư viện chia sẻ không chỉ cung cấp tính tương thích ngược mà còn mang lại mức độ linh hoạt cao—khả năng phản ứng nhanh chóng với sự thay đổi.
Để minh họa cho điểm này, hãy xem xét một thư viện chia sẻ chứa các quy tắc xác thực trường chung có tên là Validation.jar, được sử dụng bởi 10 dịch vụ. Giả sử một trong những dịch vụ đó cần thay đổi ngay lập tức một trong các quy tắc xác thực. Bằng cách phiên bản hóa tệp Validation.jar, dịch vụ cần thay đổi có thể ngay lập tức tích hợp phiên bản Validation.jar mới và được triển khai đến môi trường sản xuất ngay lập tức, mà không ảnh hưởng đến 9 dịch vụ còn lại. Nếu không có phiên bản, cả 10 dịch vụ sẽ phải được kiểm tra và triển khai lại khi thực hiện thay đổi thư viện chia sẻ, từ đó làm tăng thời gian và sự phối hợp cho thay đổi thư viện chia sẻ (do đó giảm tính linh hoạt).
Mặc dù những lời khuyên trước đó có thể có vẻ hiển nhiên, nhưng có những đánh đổi và sự phức tạp ẩn chứa trong việc quản lý phiên bản. Thực tế là, việc quản lý phiên bản có thể phức tạp đến nỗi các tác giả của bạn thường xem quản lý phiên bản như một sai lầm thứ chín của điện toán phân tán: “quản lý phiên bản là đơn giản.”
Một trong những phức tạp đầu tiên của việc phiên bản hóa thư viện chia sẻ là việc thông báo một thay đổi phiên bản. Trong một kiến trúc phân tán cao với nhiều đội ngũ, thường rất khó để thông báo một thay đổi phiên bản cho một thư viện chia sẻ. Làm thế nào để các đội khác biết rằng Validation.jar vừa nâng cấp lên phiên bản 1.5? Những thay đổi là gì? Những dịch vụ nào bị ảnh hưởng? Những đội ngũ nào bị ảnh hưởng? Ngay cả với rất nhiều công cụ quản lý thư viện chia sẻ, phiên bản và tài liệu thay đổi (chẳng hạn như JFrog Artifactory), các thay đổi phiên bản vẫn phải được phối hợp và thông báo đến đúng người vào đúng thời điểm.
Một phức tạp khác là việc ngừng hỗ trợ các phiên bản cũ hơn của một thư viện chia sẻ—loại bỏ những phiên bản không còn được hỗ trợ sau một ngày nhất định. Các chiến lược ngừng hỗ trợ dao động từ tùy chỉnh (cho các thư viện chia sẻ riêng lẻ) cho đến toàn cầu (cho tất cả các thư viện chia sẻ). Và, không có gì đáng ngạc nhiên, có những cân nhắc giữa hai cách tiếp cận này.
Gán một chiến lược giảm hạng tùy chỉnh cho từng thư viện chia sẻ thường là cách tiếp cận mong muốn vì các thư viện thay đổi với tốc độ khác nhau. Ví dụ, nếu thư viện chia sẻ Security.jar không thay đổi thường xuyên, thì việc duy trì chỉ hai hoặc ba phiên bản là một chiến lược hợp lý. Tuy nhiên, nếu thư viện chia sẻ Calculators.jar thay đổi hàng tuần, việc duy trì chỉ hai hoặc ba phiên bản có nghĩa là tất cả các dịch vụ sử dụng thư viện chia sẻ đó sẽ phải tích hợp một phiên bản mới hơn hàng tháng (hoặc thậm chí hàng tuần) — gây ra nhiều lần kiểm tra và triển khai lại không cần thiết. Do đó, việc duy trì 10 phiên bản của Calculators.jar sẽ là một chiến lược hợp lý hơn nhiều do tần suất thay đổi. Tuy nhiên, nhược điểm của cách tiếp cận này là ai đó phải duy trì và theo dõi việc giảm hạng cho từng thư viện chia sẻ. Điều này đôi khi có thể là một nhiệm vụ khó khăn và chắc chắn không dành cho những người nhút nhát.
Bởi vì sự thay đổi là biến động giữa các thư viện chia sẻ khác nhau, chiến lược gỡ bỏ toàn cầu, mặc dù đơn giản hơn, lại là một phương pháp kém hiệu quả hơn. Chiến lược gỡ bỏ toàn cầu quy định rằng tất cả các thư viện chia sẻ, bất kể tốc độ thay đổi, sẽ không hỗ trợ nhiều hơn một số phiên bản ngược nhất định (ví dụ: bốn phiên bản). Mặc dù điều này dễ duy trì và quản lý, nhưng nó có thể gây ra sự đảo lộn đáng kể - việc liên tục kiểm tra lại và triển khai lại các dịch vụ - chỉ để duy trì khả năng tương thích với phiên bản mới nhất của một thư viện chia sẻ thường xuyên thay đổi. Điều này có thể khiến các đội ngũ cảm thấy nản lòng và giảm đáng kể tốc độ và năng suất tổng thể của đội.
Bất kể chiến lược loại bỏ nào được sử dụng, các lỗi nghiêm trọng hoặc thay đổi làm hỏng mã chia sẻ đều làm mất hiệu lực bất kỳ loại chiến lược loại bỏ nào, khiến tất cả các dịch vụ phải áp dụng phiên bản mới nhất của một thư viện chia sẻ một lần (hoặc trong một khoảng thời gian rất ngắn). Đây là một lý do khác mà chúng tôi khuyến nghị giữ các thư viện chia sẻ càng chi tiết càng tốt và tránh các thư viện loại lớn như SharedStuff.jar chứa tất cả chức năng chia sẻ trong hệ thống.
Một lời khuyên cuối cùng về phiên bản: hãy tránh sử dụng phiên bản MỚI NHẤT khi chỉ định phiên bản nào của thư viện mà dịch vụ cần. Theo kinh nghiệm của chúng tôi, các dịch vụ sử dụng phiên bản MỚI NHẤT thường gặp vấn đề khi thực hiện các sửa lỗi nhanh hoặc triển khai nóng khẩn cấp vào môi trường sản xuất, vì một số điều trong phiên bản MỚI NHẤT có thể không tương thích với dịch vụ, do đó gây thêm nỗ lực phát triển và kiểm thử cho đội ngũ để phát hành dịch vụ vào sản xuất.
Trong khi kỹ thuật thư viện chia sẻ cho phép thay đổi được phiên bản hóa (do đó cung cấp mức độ linh hoạt cao cho các thay đổi mã chia sẻ), việc quản lý phụ thuộc có thể khó khăn và rắc rối. Bảng 8-2 liệt kê các sự đánh đổi khác nhau liên quan đến kỹ thuật này.
When To Use
Kỹ thuật thư viện chia sẻ là một phương pháp tốt cho các môi trường đồng nhất, nơi thay đổi mã chia sẻ ít đến vừa phải. Khả năng phiên bản (mặc dù đôi khi phức tạp) cho phép mức độ linh hoạt tốt khi thực hiện các thay đổi mã chia sẻ. Bởi vì các thư viện chia sẻ thường được gắn với dịch vụ tại thời điểm biên dịch, các đặc tính vận hành như hiệu suất, khả năng mở rộng và khả năng chịu lỗi không bị ảnh hưởng, và rủi ro làm hỏng các dịch vụ khác do thay đổi mã chung là thấp nhờ vào việc phiên bản.
Shared Service
Phương pháp thay thế chính để sử dụng thư viện chia sẻ cho các chức năng chung là sử dụng dịch vụ chia sẻ thay vào đó. Kỹ thuật dịch vụ chia sẻ, được minh họa trong Hình 8-6, tránh việc tái sử dụng bằng cách đặt chức năng chia sẻ vào một dịch vụ được triển khai riêng biệt.
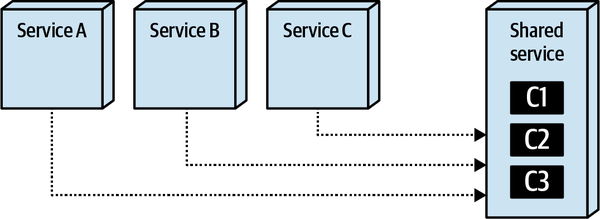
Figure 8-6. With the shared service technique, common functionality is made available at runtime through separate services
Một yếu tố phân biệt về kỹ thuật dịch vụ chia sẻ là mã chia sẻ phải ở dạng thành phần, không phải kế thừa. Mặc dù có rất nhiều tranh cãi về việc sử dụng thành phần hơn là kế thừa từ quan điểm thiết kế mã nguồn (xem bài viết của Thoughtworks “Thành phần so với Kế thừa: Cách để Chọn” và bài viết của Martin Fowler “Kế thừa được Thiết kế”), nhưng về mặt kiến trúc, thành phần so với kế thừa có tầm quan trọng khi chọn kỹ thuật tái sử dụng mã, đặc biệt là với kỹ thuật dịch vụ chia sẻ.
Vào thời điểm trước đây, dịch vụ chia sẻ là một phương pháp phổ biến để giải quyết các chức năng chung trong kiến trúc phân tán. Những thay đổi đối với chức năng chia sẻ không còn yêu cầu phải triển khai lại các dịch vụ; thay vào đó, vì những thay đổi được cô lập trong một dịch vụ riêng biệt, chúng có thể được triển khai mà không cần phải triển khai lại các dịch vụ khác cần chức năng chia sẻ. Tuy nhiên, như mọi thứ trong kiến trúc phần mềm, việc sử dụng dịch vụ chia sẻ đi kèm với nhiều yêu cầu trao đổi, bao gồm rủi ro thay đổi, hiệu suất, khả năng mở rộng và khả năng chịu lỗi.
Change Risk
Việc thay đổi chức năng chia sẻ bằng cách sử dụng kỹ thuật dịch vụ chia sẻ hóa ra là một con dao hai lưỡi. Như được minh họa trong Hình 8-7, việc thay đổi chức năng chia sẻ đơn giản chỉ là việc sửa đổi mã chia sẻ được chứa trong một dịch vụ riêng biệt (như một máy tính giảm giá), redeploy dịch vụ đó, và voilà—các thay đổi giờ đây đã có sẵn cho tất cả các dịch vụ, mà không cần phải kiểm tra lại và redeploy bất kỳ dịch vụ nào khác cần chức năng chia sẻ đó.
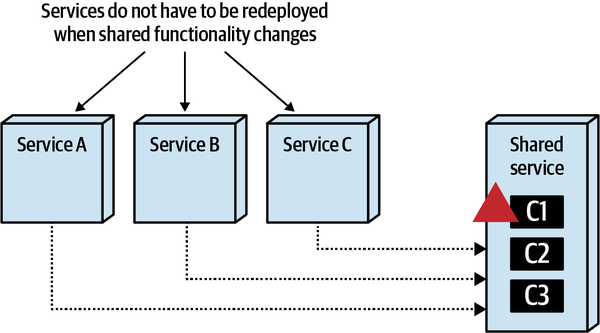
Figure 8-7. Shared functionality changes are isolated to only the shared service
Giá mà cuộc sống đơn giản như vậy! Vấn đề, tất nhiên, là sự thay đổi đối với một dịch vụ chung là một thay đổi trong thời gian thực, trái ngược với việc thay đổi dựa trên biên dịch với kỹ thuật thư viện chung. Do đó, một sự thay đổi "đơn giản" trong một dịch vụ chung có thể gây sập toàn bộ hệ thống, như được mô phỏng trong Hình 8-8.
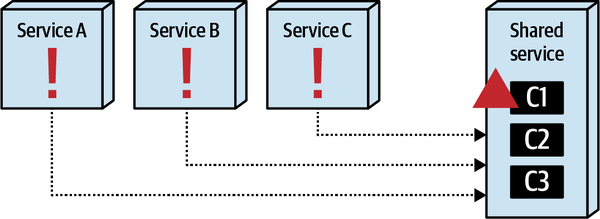
Figure 8-8. Changes to a shared service can break other services at runtime
Điều này tất yếu đưa ra vấn đề phiên bản. Trong kỹ thuật thư viện chia sẻ, việc quản lý phiên bản được thực hiện thông qua các liên kết thời gian biên dịch, làm giảm đáng kể rủi ro liên quan đến việc thay đổi một thư viện chia sẻ. Tuy nhiên, làm thế nào để phiên bản hóa một thay đổi dịch vụ chia sẻ đơn giản?
Phản ứng ngay lập tức, tất nhiên, là sử dụng phiên bản của điểm cuối API—nói cách khác, tạo một điểm cuối mới chứa mỗi thay đổi dịch vụ chia sẻ, như được thể hiện trong Ví dụ 8-3.
Example 8-3. Discount calendar with versioning for shared service endpoint
app/1.0/discountcalc?orderid=123app/1.1/discountcalc?orderid=123app/1.2/discountcalc?orderid=123app/1.3/discountcalc?orderid=123latest change -> app/1.4/discountcalc?orderid=123
Sử dụng cách tiếp cận này, mỗi khi một dịch vụ chia sẻ thay đổi, nhóm sẽ tạo một điểm cuối API mới chứa phiên bản mới của URI. Không khó để thấy những vấn đề phát sinh với thực tiễn này. Đầu tiên, các dịch vụ truy cập dịch vụ tính toán giảm giá (hoặc cấu hình tương ứng cho từng dịch vụ) phải thay đổi để chỉ định tới phiên bản chính xác. Thứ hai, khi nào nhóm nên tạo một điểm cuối API mới? Thế còn việc thay đổi một thông điệp lỗi đơn giản thì sao? Còn việc tính toán mới thì sao? Việc phiên phiên bản bắt đầu trở nên phần lớn là chủ quan vào thời điểm này, và các dịch vụ sử dụng dịch vụ chia sẻ vẫn phải thay đổi để chỉ định tới điểm cuối chính xác.
Một vấn đề khác với việc phiên bản hóa điểm cuối API là nó giả định rằng tất cả truy cập vào dịch vụ chia sẻ đều thông qua một cuộc gọi API RESTful đi qua một cổng hoặc thông qua giao tiếp điểm-điểm. Tuy nhiên, trong một số trường hợp, việc truy cập vào dịch vụ chia sẻ thông qua giao tiếp giữa các dịch vụ thường được thực hiện thông qua các giao thức khác như nhắn tin và gRPC (ngoài một cuộc gọi API RESTful). Điều này càng làm phức tạp chiến lược phiên bản cho một thay đổi, khiến cho việc phối hợp các phiên bản giữa nhiều giao thức trở nên khó khăn.
Điều quan trọng là với kỹ thuật dịch vụ chia sẻ, các thay đổi đối với dịch vụ chia sẻ thường mang tính chất thời gian chạy, vì vậy mang nhiều rủi ro hơn so với thư viện chia sẻ. Mặc dù việc quản lý phiên bản có thể giúp giảm thiểu rủi ro này, nhưng nó phức tạp hơn nhiều để áp dụng và quản lý so với thư viện chia sẻ.
Performance
Bởi vì các dịch vụ yêu cầu chức năng chia sẻ phải thực hiện cuộc gọi giữa các dịch vụ đến một dịch vụ chia sẻ, hiệu suất bị ảnh hưởng do độ trễ mạng (và độ trễ bảo mật, giả sử các điểm cuối đến dịch vụ chia sẻ là an toàn). Sự đánh đổi này, như được thể hiện trong Hình 8-9, không tồn tại với kỹ thuật thư viện chia sẻ khi truy cập mã chia sẻ.
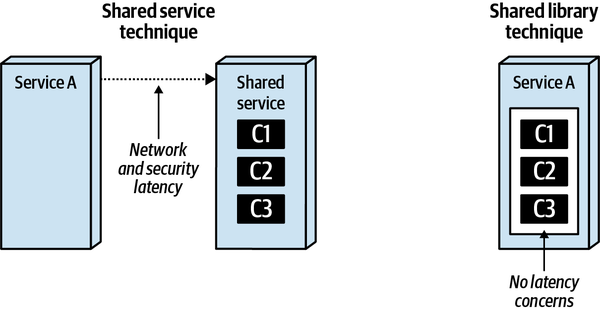
Figure 8-9. Shared service introduces network and security latency
Việc sử dụng gRPC có thể giúp giảm bớt một số vấn đề về hiệu suất bằng cách giảm đáng kể độ trễ mạng, cũng như việc sử dụng các giao thức không đồng bộ như nhắn tin. Với nhắn tin, dịch vụ cần chức năng chia sẻ có thể gửi yêu cầu thông qua một hàng đợi yêu cầu, thực hiện các công việc khác, và khi cần thiết, có thể nhận lại kết quả thông qua một hàng đợi phản hồi riêng bằng cách sử dụng ID tương quan (tham khảo Java Message Service, Ấn bản thứ hai của Mark Richards và đồng tác giả (O’Reilly) để biết thêm thông tin về các kỹ thuật nhắn tin).
Scalability
Một nhược điểm khác của kỹ thuật dịch vụ chia sẻ là dịch vụ chia sẻ phải mở rộng theo quy mô của các dịch vụ sử dụng dịch vụ chia sẻ. Điều này đôi khi có thể gây rắc rối trong việc quản lý, đặc biệt là khi nhiều dịch vụ truy cập đồng thời vào cùng một dịch vụ chia sẻ. Tuy nhiên, như được minh họa trong Hình 8-10, kỹ thuật thư viện chia sẻ không gặp phải vấn đề này vì chức năng chia sẻ được chứa trong dịch vụ tại thời điểm biên dịch.
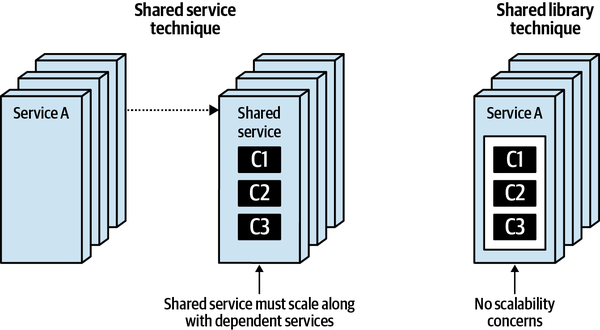
Figure 8-10. Shared services must scale as dependent services scale
Fault Tolerance
Mặc dù các vấn đề về độ tin cậy có thể thường được giảm thiểu thông qua nhiều phiên bản của một dịch vụ, tuy nhiên đây vẫn là một sự đánh đổi cần xem xét khi sử dụng kỹ thuật dịch vụ chia sẻ. Như được minh hoạ trong Hình 8-11, nếu dịch vụ chia sẻ trở nên không khả dụng, các dịch vụ yêu cầu chức năng chia sẻ sẽ không hoạt động cho đến khi dịch vụ chia sẻ sẵn có. Kỹ thuật thư viện chia sẻ không gặp phải vấn đề này vì chức năng chia sẻ được chứa trong dịch vụ tại thời điểm biên dịch, do đó được truy cập thông qua các lệnh gọi phương thức hoặc hàm tiêu chuẩn.
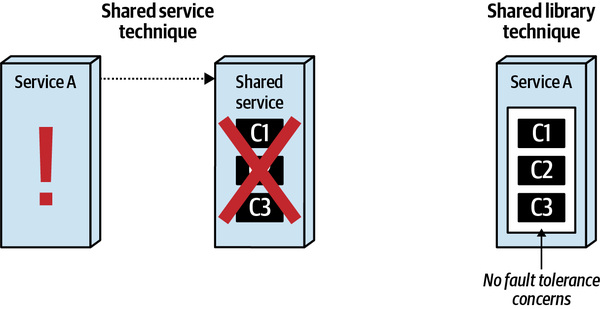
Figure 8-11. Shared services introduce fault-tolerance issues
Kỹ thuật dịch vụ chia sẻ giữ nguyên ngữ cảnh giới hạn và tốt cho mã chia sẻ thay đổi thường xuyên, nhưng các đặc điểm vận hành như hiệu suất, khả năng mở rộng và tính sẵn có bị ảnh hưởng. Bảng 8-3 liệt kê các trade-off khác nhau liên quan đến kỹ thuật này.
When to Use
Kỹ thuật dịch vụ chia sẻ rất hữu ích trong các môi trường đa ngôn ngữ (những môi trường có nhiều ngôn ngữ và nền tảng khác nhau), và cũng khi chức năng chia sẻ có xu hướng thay đổi thường xuyên. Mặc dù những thay đổi trong một dịch vụ chia sẻ thường linh hoạt hơn nhiều so với kỹ thuật thư viện chia sẻ, nhưng cần cẩn thận với các tác động tại thời gian thực và rủi ro đối với các dịch vụ cần chức năng chia sẻ.
Sidecars and Service Mesh
Có lẽ phản ứng phổ biến nhất đối với bất kỳ câu hỏi nào từ một kiến trúc sư là "Nó phụ thuộc!" Không có vấn đề nào trong kiến trúc phân tán minh họa sự mập mờ này tốt hơn là sự liên kết vận hành.
Một trong những mục tiêu thiết kế của kiến trúc microservices là mức độ tách biệt cao, thường được thể hiện qua lời khuyên “Sự lặp lại còn tốt hơn là sự kết nối.” Ví dụ, giả sử rằng hai dịch vụ của Đội Sysops cần truyền thông tin khách hàng, nhưng ngữ cảnh được định nghĩa bởi thiết kế hướng miền yêu cầu các chi tiết triển khai phải được giữ kín trong dịch vụ. Do đó, một giải pháp chung cho phép mỗi dịch vụ có đại diện nội bộ riêng của các thực thể như Khách hàng, truyền tải thông tin đó theo cách lỏng lẻo, chẳng hạn như cặp tên-nội dung trong JSON. Lưu ý rằng điều này cho phép mỗi dịch vụ thay đổi đại diện nội bộ của mình theo ý muốn, bao gồm cả công nghệ sử dụng, mà không làm hỏng sự tích hợp. Các kiến trúc sư thường không thích việc lặp lại mã vì nó gây ra các vấn đề đồng bộ, sai lệch ngữ nghĩa và nhiều vấn đề khác, nhưng đôi khi có những lực lượng tồn tại có ảnh hưởng tồi tệ hơn những vấn đề của sự lặp lại, và việc kết nối trong microservices thường nằm trong số đó. Do đó, trong kiến trúc microservices, câu trả lời cho câu hỏi “chúng ta nên lặp lại hay kết nối với một khả năng nào đó?” có khả năng là lặp lại, trong khi trong một kiểu kiến trúc khác như kiến trúc dựa trên dịch vụ, câu trả lời chính xác có khả năng là kết nối. Tùy thuộc vào tình huống!
Khi thiết kế microservices, các kiến trúc sư đã chấp nhận thực tế về việc lặp lại triển khai để bảo tồn sự tách rời. Nhưng còn những loại khả năng nào hưởng lợi từ việc kết nối chặt chẽ? Chẳng hạn, hãy xem xét những khả năng vận hành chung như giám sát, ghi nhật ký, xác thực và phân quyền, bộ ngắt mạch, và nhiều khả năng vận hành khác mà mỗi dịch vụ nên có. Tuy nhiên, việc cho phép mỗi nhóm quản lý những phụ thuộc này thường dẫn đến hỗn loạn. Ví dụ, hãy xem xét một công ty như Penultimate Electronics cố gắng tiêu chuẩn hóa một giải pháp giám sát chung để dễ dàng triển khai các dịch vụ khác nhau. Nhưng nếu mỗi nhóm chịu trách nhiệm thực hiện giám sát cho dịch vụ của họ, làm thế nào nhóm vận hành có thể chắc chắn rằng họ đã làm được? Ngoài ra, vấn đề như nâng cấp đồng nhất thì sao? Nếu công cụ giám sát cần được nâng cấp trên toàn tổ chức, các nhóm có thể phối hợp điều đó như thế nào?
Giải pháp phổ biến đã xuất hiện trong hệ sinh thái microservices trong vài năm qua giải quyết vấn đề này một cách thanh lịch, bằng cách sử dụng mẫu Sidecar. Mẫu này dựa trên một mẫu kiến trúc lâu đời do Alistair Cockburn định nghĩa, được biết đến với tên gọi kiến trúc lục giác, như được minh họa trong Hình 8-12.
Trong mô hình hình lục giác này, những gì chúng ta bây giờ gọi là logic miền nằm ở trung tâm của hình lục giác, được bao quanh bởi các cổng và bộ thích ứng tới các phần khác của hệ sinh thái (thực tế, mô hình này còn được gọi là Mô hình Cổng và Bộ Thích Ứng). Mặc dù có trước microservices nhiều năm, mô hình này có những điểm tương đồng với các microservices hiện đại, với một sự khác biệt quan trọng: tính chính xác của dữ liệu. Kiến trúc hình lục giác coi cơ sở dữ liệu như một bộ thích ứng khác có thể được kết nối, nhưng một trong những hiểu biết từ DDD gợi ý rằng các sơ đồ dữ liệu và tính giao dịch nên nằm bên trong—giống như các microservices.
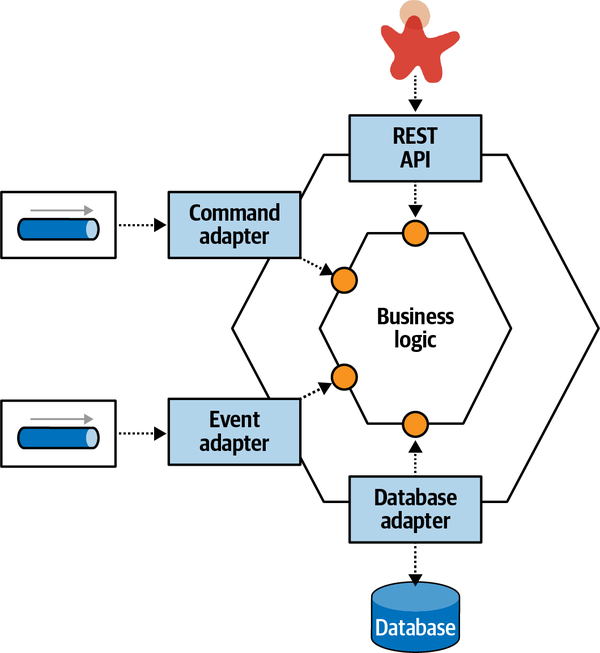
Figure 8-12. The Hexagonal pattern separated domain logic from technical coupling
Mẫu Sidecar tận dụng cùng một khái niệm như kiến trúc lục giác ở chỗ nó tách rời logic miền khỏi logic kỹ thuật (hạ tầng). Ví dụ, xem xét hai microservices, như được hiển thị trong Hình 8-13.
Figure 8-13. Two microservices that share the same operational capabilities
Ở đây, mỗi dịch vụ bao gồm sự phân tách giữa các vấn đề vận hành (các thành phần lớn hơn ở phía dưới của dịch vụ) và các vấn đề miền, được thể hiện trong các hộp ở phía trên của dịch vụ được ghi là “miền.” Nếu các kiến trúc sư mong muốn sự nhất quán trong các khả năng vận hành, các phần tách biệt sẽ được đưa vào một thành phần bên cạnh, được đặt tên ẩn dụ cho sidecar gắn liền với xe máy, việc thực hiện được chia sẻ trách nhiệm giữa các nhóm hoặc được quản lý bởi một nhóm cơ sở hạ tầng tập trung. Nếu các kiến trúc sư có thể giả định rằng mọi dịch vụ đều bao gồm sidecar, điều này tạo ra một giao diện vận hành nhất quán giữa các dịch vụ, thường được gắn qua một mặt dịch vụ, như được mô tả trong Hình 8-14.
Figure 8-14. When each microservice includes a common component, architects can establish links between them for consistent control
"Nếu các kiến trúc sư và hoạt động có thể an toàn giả định rằng mọi dịch vụ đều bao gồm thành phần sidecar (được điều chỉnh bởi các hàm fitness), nó hình thành một lưới dịch vụ, như được minh họa trong Hình 8-15. Các hộp bên phải của mỗi dịch vụ đều kết nối với nhau, tạo thành một 'lưới'."
Có một mạng cho phép các kiến trúc sư và DevOps tạo ra bảng điều khiển, kiểm soát các đặc điểm hoạt động như quy mô và nhiều khả năng khác.
Mô hình Sidecar cho phép các nhóm quản trị như kiến trúc sư doanh nghiệp có sự kiểm soát hợp lý đối với quá nhiều môi trường đa ngôn ngữ: một trong những lợi ích của microservices là dựa vào tích hợp thay vì một nền tảng chung, cho phép các nhóm chọn mức độ phức tạp và khả năng phù hợp trên cơ sở dịch vụ. Tuy nhiên, khi số lượng nền tảng gia tăng, việc quản lý thống nhất trở nên khó khăn hơn. Do đó, các nhóm thường sử dụng tính nhất quán của service mesh như một yếu tố thúc đẩy để hỗ trợ hạ tầng và các mối quan tâm chéo khác trên nhiều nền tảng khác nhau. Ví dụ, nếu không có service mesh, nếu các kiến trúc sư doanh nghiệp muốn thống nhất xung quanh một giải pháp giám sát chung, thì các nhóm phải xây dựng một sidecar cho mỗi nền tảng hỗ trợ giải pháp đó.
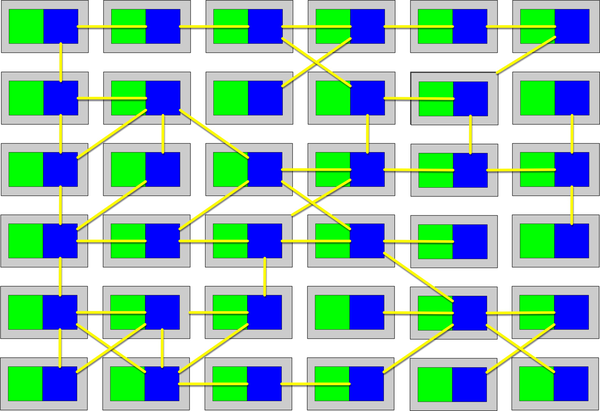
Figure 8-15. A service mesh is an operational link among services
Mô hình Sidecar không chỉ đại diện cho cách tách rời khả năng vận hành khỏi các miền mà còn là một mẫu tái sử dụng trực giao để giải quyết một loại kết nối cụ thể (xem “Kết nối Trực giao”). Thường thì, các giải pháp kiến trúc yêu cầu nhiều loại kết nối, chẳng hạn như ví dụ hiện tại về kết nối miền so với kết nối hoạt động. Một mẫu tái sử dụng trực giao cung cấp một cách để tái sử dụng một số khía cạnh trái ngược với một hoặc nhiều đường nối trong kiến trúc. Ví dụ, các kiến trúc microservices được tổ chức xung quanh các miền, nhưng kết nối hoạt động yêu cầu cắt ngang qua những miền đó. Một sidecar cho phép kiến trúc sư tách biệt những mối quan tâm đó trong một lớp cắt ngang, nhưng nhất quán, xuyên suốt kiến trúc.
Trong khi mẫu Sidecar cung cấp một lớp trừu tượng tốt, nó có những đánh đổi như tất cả các phương pháp kiến trúc khác, như được trình bày trong Bảng 8-4.
When to Use
Mô hình Sidecar và lưới dịch vụ cung cấp một cách sạch sẽ để phân bổ một số loại mối quan tâm cắt ngang trong kiến trúc phân tán, và có thể được sử dụng không chỉ cho sự liên kết hoạt động (xem Chương 14). Nó cung cấp một tương đương kiến trúc với Mẫu Thiết Kế Decorator trong cuốn sách Mẫu Thiết Kế của Gang of Four (Addison Wesley)—nó cho phép kiến trúc sư "trang trí" hành vi trong một kiến trúc phân tán độc lập với khả năng kết nối thông thường.
Sysops Squad Saga: Common Infrastructure Logic
Thứ Năm, ngày 10 tháng 2, 10:34
"Sydney nhìn vào văn phòng của Taylen vào một buổi sáng sương mù. “Này, bạn có đang sử dụng thư viện Gửi Tin nhắn chung không?”"
Taylen đã trả lời, “Vâng, chúng tôi đang cố gắng tập trung vào điều đó để đạt được sự nhất quán trong việc giải quyết thông điệp.”
Sydney nói, “Được rồi, nhưng bây giờ chúng ta đang nhận được thông điệp ghi lại gấp đôi - có vẻ như thư viện ghi vào nhật ký, nhưng dịch vụ của chúng ta cũng ghi vào nhật ký. Điều đó có đúng như vậy không?”
“Không,” Taylen trả lời. “Chúng ta chắc chắn không muốn có các mục ghi nhật ký trùng lặp. Điều đó chỉ làm mọi thứ trở nên rối rắm. Chúng ta nên hỏi Addison về điều đó.”
Do đó, Sydney và Taylen đã đến gõ cửa Addison. “Này, bạn có một phút không?”
Addison trả lời, “Luôn vì bạn—có chuyện gì vậy?”
Sydney nói, “Chúng tôi đã hợp nhất một số mã trùng lặp của mình thành các thư viện chung, và điều đó đang hoạt động tốt – chúng tôi ngày càng giỏi hơn trong việc xác định các phần ít khi thay đổi. Nhưng bây giờ, chúng tôi gặp phải vấn đề đưa chúng tôi đến đây – ai là người nên viết các thông điệp ghi log? Thư viện, dịch vụ, hay cái gì khác? Và, làm thế nào chúng tôi có thể làm cho điều đó nhất quán?”
Addison nói, “Chúng tôi đã gặp phải hành vi chia sẻ hoạt động. Ghi log chỉ là một trong số đó. Còn giám sát, phát hiện dịch vụ, bộ ngắt mạch, thậm chí một số hàm tiện ích của chúng tôi, như thư viện JSONtoXML mà một vài đội đang chia sẻ thì sao? Chúng tôi cần một cách tốt hơn để xử lý điều này nhằm ngăn chặn các vấn đề. Đó là lý do tại sao chúng tôi đang trong quá trình triển khai một service mesh với hành vi chung này trong một thành phần sidecar.”
Sydney nói: “Tôi đã đọc về sidecars và service mesh - đó là cách chia sẻ thông tin giữa nhiều microservices, đúng không?”
Addison nói, “Có một phần nào đó, nhưng không phải tất cả các loại vấn đề. Mục đích của service mesh và sidecar là để hợp nhất sự kết nối vận hành, chứ không phải sự kết nối miền. Ví dụ, giống như trong trường hợp của chúng tôi, chúng tôi muốn có sự nhất quán cho việc ghi log và giám sát giữa tất cả các dịch vụ của chúng tôi, nhưng không muốn mỗi đội phải lo lắng về điều đó. Nếu chúng tôi hợp nhất mã ghi log vào sidecar chung mà mỗi dịch vụ đều triển khai, chúng tôi có thể đảm bảo tính nhất quán.”
Taylen hỏi, “Ai sở hữu thư viện chung? Trách nhiệm chung giữa tất cả các đội?”
Addison trả lời, “Chúng tôi đã suy nghĩ về điều đó, nhưng hiện tại chúng tôi có đủ đội ngũ; chúng tôi đã tạo ra một đội ngũ hạ tầng chung sẽ quản lý và duy trì thành phần sidecar. Họ đã xây dựng quy trình triển khai để tự động kiểm tra sidecar khi nó được liên kết vào dịch vụ với một tập hợp các hàm kiểm tra khả năng hoạt động.”
Sydney nói: “Vậy nếu chúng ta cần chia sẻ thư viện giữa các dịch vụ, chỉ cần yêu cầu họ đưa nó vào sidecar thôi?”
Addison nói: "Hãy cẩn thận - cái sidecar này không được sử dụng cho bất cứ điều gì, chỉ dành cho nối ghép hoạt động."
“Tôi không chắc sự phân biệt đó là gì,” Taylen nói.
“Khớp nối vận hành bao gồm những điều chúng ta đã thảo luận—ghi log, giám sát, phát hiện dịch vụ, xác thực và phân quyền, và những thứ tương tự. Nói chung, nó bao gồm tất cả các phần cơ sở hạ tầng không có trách nhiệm về miền. Nhưng bạn không nên để các thành phần chia sẻ miền, như lớp Địa chỉ hoặc Khách hàng, trong sidecar.”
Sydney hỏi: "Nhưng tại sao? Nếu tôi cần cùng một định nghĩa lớp trong hai dịch vụ thì sao? Đưa nó vào sidecar có làm cho nó khả dụng cho cả hai không?"
Addison trả lời, “Có, nhưng bây giờ bạn đang tăng cường sự kết nối theo cách mà chúng tôi cố gắng tránh trong microservices. Trong hầu hết các kiến trúc, một triển khai duy nhất của dịch vụ đó sẽ được chia sẻ giữa các đội cần nó. Tuy nhiên, trong microservices, điều đó tạo ra một điểm kết nối, gắn nhiều dịch vụ lại với nhau theo cách không mong muốn - nếu một đội thay đổi mã chia sẻ, mọi đội phải phối hợp với thay đổi đó. Tuy nhiên, các kiến trúc sư có thể quyết định đặt thư viện chia sẻ trong sidecar - đó là, sau tất cả, một khả năng kỹ thuật. Cả hai câu trả lời đều không hoàn toàn chính xác, điều này làm cho đây trở thành một quyết định của kiến trúc sư và xứng đáng với phân tích đánh đổi. Ví dụ, nếu lớp Address thay đổi và cả hai dịch vụ đều phụ thuộc vào nó, cả hai đều phải thay đổi - định nghĩa của sự kết nối. Chúng tôi xử lý những vấn đề đó bằng hợp đồng. Vấn đề khác liên quan đến kích thước: chúng tôi không muốn sidecar trở thành phần lớn nhất của kiến trúc. Ví dụ, hãy xem xét thư viện JSONtoXML mà chúng tôi đã thảo luận trước đó. Có bao nhiêu đội sử dụng cái đó?”
Taylen nói, “Chà, bất kỳ đội nào phải tích hợp với hệ thống mainframe cho bất kỳ điều gì—có lẽ 5 trong số, cái gì, 16 hoặc 17 đội?”
Addison nói, "Hoàn hảo. Được rồi, cái giá phải trả khi đưa JSONtoXML vào sidecar là gì?"
Sydney trả lời, “Vậy có nghĩa là mọi đội đều tự động có thư viện và không cần phải kết nối nó qua các phụ thuộc.”
“Và mặt xấu thì sao?” Addison hỏi.
“Chà, việc thêm nó vào sidecar làm nó lớn hơn, nhưng không nhiều lắm - đó là một thư viện nhỏ.” Sydney nói.
“Đó là sự đánh đổi then chốt đối với mã tiện ích chung—bao nhiêu đội cần nó so với mức độ chi phí bổ sung mà nó thêm vào mỗi dịch vụ, đặc biệt là những dịch vụ không cần đến nó.”
“Và nếu ít hơn một nửa số đội sử dụng nó, thì có lẽ nó không xứng đáng với chi phí đi kèm,” Sydney nói.
"Đúng vậy! Vậy thì, bây giờ, chúng ta sẽ để điều đó ra khỏi sidecar và có thể xem xét lại trong tương lai," Addison nói.
ADR: Sử dụng Sidecar để Kết nối Vận hành
Ngữ cảnh Mỗi dịch vụ trong kiến trúc vi dịch vụ của chúng tôi yêu cầu hành vi vận hành chung và nhất quán; việc để trách nhiệm đó cho từng đội sẽ dẫn đến những sự không nhất quán và vấn đề phối hợp.
Quyết định Chúng tôi sẽ sử dụng một thành phần sidecar kết hợp với một service mesh để hợp nhất các mối liên kết vận hành chia sẻ.
Đội ngũ hạ tầng chia sẻ sẽ sở hữu và duy trì sidecar cho các đội ngũ dịch vụ; các đội ngũ dịch vụ đóng vai trò là khách hàng của họ. Các dịch vụ sau sẽ được cung cấp bởi sidecar:
Giám sát
Ghi chép nhật ký
phát hiện dịch vụ
Xác thực
Ủy quyền
Hệ quả Các nhóm không nên thêm các lớp miền vào sidecar, điều này khuyến khích sự liên kết không thích hợp.
Các nhóm làm việc với nhóm hạ tầng chia sẻ để đặt các thư viện hoạt động chung vào sidecar nếu đủ số lượng nhóm yêu cầu.
Code Reuse: When Does It Add Value?
Nhiều kiến trúc sư không đánh giá đúng các sự đánh đổi khi họ gặp phải một số tình huống, điều này không nhất thiết là một thiếu sót—nhiều sự đánh đổi chỉ trở nên rõ ràng sau khi sự việc đã xảy ra.
Tái sử dụng là một trong những sự trừu tượng bị lạm dụng nhiều nhất, vì quan điểm chung trong các tổ chức là tái sử dụng đại diện cho một mục tiêu đáng khen mà các nhóm nên cố gắng đạt được. Tuy nhiên, nếu không đánh giá tất cả các sự đánh đổi liên quan đến việc tái sử dụng, có thể dẫn đến những vấn đề nghiêm trọng trong kiến trúc.
Sự nguy hiểm của việc tái sử dụng quá nhiều là một trong những bài học mà nhiều kiến trúc sư đã rút ra từ xu hướng kiến trúc hướng dịch vụ điều phối trong thế kỷ 20, nơi một trong những mục tiêu chính của nhiều tổ chức là tối đa hóa việc tái sử dụng.
Xem xét kịch bản từ một công ty bảo hiểm, được minh họa trong Hình 8-16.
Figure 8-16. Each domain within a large insurance company has a view of the customer
Mỗi bộ phận trong công ty đều có một khía cạnh nào đó về khách hàng mà họ quan tâm. Nhiều năm trước, các kiến trúc sư đã được hướng dẫn để chú ý đến loại sự tương đồng này; một khi được phát hiện, mục tiêu là tập trung cái nhìn tổ chức về khách hàng vào một dịch vụ duy nhất, như được trình bày trong Hình 8-17.
Figure 8-17. Unifying on a centralized Customer service
Trong khi hình ảnh trong Hình 8-17 có vẻ hợp lý, nhưng đó lại là một thảm họa kiến trúc vì hai lý do. Đầu tiên, nếu tất cả thông tin về một thực thể quan trọng như Khách hàng phải nằm ở một nơi duy nhất, thì thực thể đó phải đủ phức tạp để xử lý mọi miền và kịch bản, khiến nó trở nên khó sử dụng cho những điều đơn giản.
Thứ hai, điều này tạo ra sự giòn manh trong kiến trúc. Nếu mọi miền cần thông tin khách hàng phải lấy nó từ một nơi duy nhất, khi nơi đó thay đổi, mọi thứ sẽ bị hỏng. Ví dụ, trong trường hợp của chúng ta, điều gì xảy ra khi CustomerService cần thêm các khả năng mới cho một trong các miền? Thay đổi đó có thể ảnh hưởng đến tất cả các miền khác, đòi hỏi sự phối hợp và kiểm tra để đảm bảo rằng thay đổi đó không "rippled" trong toàn bộ kiến trúc.
Các kiến trúc sư đã không nhận ra rằng việc tái sử dụng có hai khía cạnh quan trọng; họ đã đúng về khía cạnh đầu tiên: trừu tượng. Cách mà các kiến trúc sư và nhà phát triển tìm ra các ứng cử viên cho việc tái sử dụng là thông qua trừu tượng. Tuy nhiên, yếu tố thứ hai là điều quyết định tính hữu ích và giá trị: tỉ lệ thay đổi.
Quan sát rằng một số tái sử dụng gây ra sự giòn gãy làm dấy lên câu hỏi về cách mà loại tái sử dụng đó khác biệt với những loại mà chúng ta rõ ràng có lợi. Hãy xem xét những thứ mà mọi người đều tái sử dụng thành công: hệ điều hành, các framework và thư viện mã nguồn mở, và tương tự. Điểm khác biệt nào phân biệt chúng với tài sản mà các nhóm dự án xây dựng? Câu trả lời là tỷ lệ thay đổi chậm. Chúng ta được lợi từ sự kết hợp kỹ thuật, như hệ điều hành và các framework bên ngoài, vì chúng có tỷ lệ thay đổi và chu kỳ cập nhật được hiểu rõ. Các khả năng miền nội bộ hoặc các framework công nghệ thay đổi nhanh tạo ra những mục tiêu kết hợp kém.
Tip
Tái sử dụng được hình thành thông qua trừu tượng nhưng được thực hiện bởi tỷ lệ thay đổi chậm.
Reuse via Platforms
Có nhiều bài báo ca ngợi giá trị của các nền tảng trong tổ chức, gần như đến mức phân tán ngữ nghĩa. Tuy nhiên, hầu hết mọi người đều đồng ý rằng nền tảng là mục tiêu mới của sự tái sử dụng trong các tổ chức, có nghĩa là đối với mỗi khả năng miền phân biệt, tổ chức sẽ xây dựng một nền tảng với API được định nghĩa rõ ràng để ẩn đi các chi tiết thực hiện.
Tốc độ thay đổi chậm thúc đẩy lý do này. Như chúng tôi đã thảo luận trong Chương 13, một API có thể được thiết kế để liên kết lỏng lẻo với các caller, cho phép tỷ lệ thay đổi nội bộ về chi tiết thực hiện diễn ra mạnh mẽ mà không làm vỡ API. Điều này, tất nhiên, không bảo vệ tổ chức khỏi những thay đổi về ngữ nghĩa của thông tin mà nó phải truyền giữa các miền, nhưng bằng cách thiết kế cẩn thận về đóng gói và hợp đồng, các kiến trúc sư có thể hạn chế lượng thay đổi gây gãy và sự mong manh trong kiến trúc tích hợp.
Sysops Squad Saga: Shared Domain Functionality
Thứ ba, ngày 8 tháng 2, 12:50
Với sự chấp thuận của Addison, đội phát triển đã quyết định tách chức năng quản lý vé cốt lõi thành ba dịch vụ riêng biệt: một dịch vụ Tạo Vé hướng tới khách hàng, một dịch vụ Phân Công Vé và một dịch vụ Hoàn Thành Vé. Tuy nhiên, cả ba dịch vụ đều sử dụng logic cơ sở dữ liệu chung (các truy vấn và cập nhật) và chia sẻ một tập hợp các bảng cơ sở dữ liệu trong miền dữ liệu quản lý vé.
Taylen muốn tạo ra một dịch vụ dữ liệu chia sẻ mà sẽ chứa logic cơ sở dữ liệu chung, do đó hình thành một lớp trừu tượng cơ sở dữ liệu, như được thể hiện trong Hình 8-18.
Figure 8-18. Option using a shared Ticket Data service for common database logic for the Sysops Squad ticketing services
Skyler ghét ý tưởng này và muốn sử dụng một thư viện chia sẻ duy nhất (DLL) mà mỗi dịch vụ sẽ bao gồm như một phần của việc xây dựng và triển khai, như được minh họa trong Hình 8-19.
Figure 8-19. Option using a shared library for common database logic for the Sysops Squad ticketing services
Cả hai nhà phát triển đã gặp Addison để giải quyết trở ngại này.
“Vậy, Addison, bạn có ý kiến gì không? Logic của cơ sở dữ liệu chung nên nằm trong một dịch vụ dữ liệu chung hay một thư viện chung?” Taylen hỏi.
“Không phải là về ý kiến,” Addison nói. “Mà là về việc phân tích các sự đánh đổi để đạt được giải pháp phù hợp nhất cho chức năng cơ bản của cơ sở dữ liệu vé chia sẻ. Hãy áp dụng phương pháp dự đoán và giả thuyết rằng giải pháp phù hợp nhất là sử dụng dịch vụ dữ liệu chia sẻ.”
“Chờ đã,” Skyler nói. “Đó đơn giản không phải là một giải pháp kiến trúc tốt cho vấn đề này.”
“Làm sao vậy?” Addison hỏi, khiến Skyler bắt đầu suy nghĩ theo cách cân nhắc qua lại.
“Trước hết,” Skyler nói, “cả ba dịch vụ sẽ cần thực hiện một cuộc gọi liên dịch vụ tới dịch vụ dữ liệu chung cho mỗi truy vấn hoặc cập nhật cơ sở dữ liệu. Chúng ta sẽ gặp phải sự sụt giảm hiệu suất nghiêm trọng nếu làm như vậy. Hơn nữa, nếu dịch vụ dữ liệu chung bị ngưng hoạt động, cả ba dịch vụ đó sẽ không còn hoạt động.”
“Vậy thì sao?” Taylen nói. “Đó chỉ là chức năng phía sau, nên ai mà quan tâm? Chức năng phía sau không cần phải quá nhanh, và các dịch vụ có thể khởi động lại khá nhanh nếu chúng thất bại.”
"Thật ra," Addison nói, "không phải tất cả đều là chức năng ở backend. Đừng quên, dịch vụ Tạo Vé là giao diện khách hàng, và nó sẽ sử dụng cùng một dịch vụ dữ liệu chia sẻ như chức năng ticketing ở backend."
“Ừ, nhưng hầu hết các chức năng vẫn là phía backend,” Taylen nói, với một chút thiếu tự tin hơn trước.
“Cho đến nay,” Addison nói, “có vẻ như sự đánh đổi khi sử dụng dịch vụ dữ liệu chung là hiệu suất và khả năng chịu lỗi cho các dịch vụ đặt vé.”
"Chúng ta cũng đừng quên rằng bất kỳ thay đổi nào được thực hiện đối với dịch vụ dữ liệu chia sẻ đều là thay đổi trong thời gian chạy. Nói cách khác," Skyler nói, "nếu chúng ta thực hiện một thay đổi và triển khai dịch vụ dữ liệu chia sẻ, chúng ta có thể phá vỡ một cái gì đó."
"Đó là lý do tại sao chúng tôi kiểm tra," Taylen nói.
"Vâng, nhưng nếu bạn muốn giảm thiểu rủi ro, bạn sẽ phải kiểm tra tất cả các dịch vụ ticketing cho mỗi thay đổi đối với dịch vụ dữ liệu chung, điều này sẽ làm tăng thời gian kiểm tra đáng kể. Với một thư viện DLL chia sẻ, chúng ta có thể phiên bản hóa thư viện chung để cung cấp khả năng tương thích ngược." Skyler nói.
“Được rồi, chúng ta sẽ thêm rủi ro tăng thêm cho các thay đổi và nỗ lực kiểm tra tăng thêm vào những đánh đổi này,” Addison nói. “Ngoài ra, đừng quên rằng chúng ta sẽ cần thêm sự phối hợp từ góc độ khả năng mở rộng. Mỗi khi chúng ta tạo thêm nhiều phiên bản của dịch vụ tạo vé, chúng ta cũng phải đảm bảo rằng tạo thêm nhiều phiên bản của dịch vụ dữ liệu chia sẻ.”
“Đừng tập trung quá nhiều vào những điều tiêu cực.” Taylen nói. “Thế còn những lợi ích của việc sử dụng dịch vụ dữ liệu chia sẻ thì sao?”
“Được rồi,” Addison nói, “hãy nói về lợi ích của việc sử dụng dịch vụ dữ liệu chung.”
“Trừu tượng hóa dữ liệu, tất nhiên rồi,” Taylen nói. “Các dịch vụ sẽ không phải lo lắng về bất kỳ logic cơ sở dữ liệu nào. Tất cả những gì họ cần làm chỉ là thực hiện một cuộc gọi dịch vụ từ xa tới dịch vụ dữ liệu chung.”
"Có lợi ích nào khác không?" Addison hỏi.
“Ờ,” Taylen nói, “tôi định nói về việc tập trung quản lý kết nối, nhưng chúng ta vẫn cần nhiều phiên bản để hỗ trợ dịch vụ tạo vé khách hàng. Nó sẽ hữu ích, nhưng không phải là một thay đổi lớn vì chỉ có ba dịch vụ mà không có nhiều phiên bản của mỗi dịch vụ. Tuy nhiên, việc kiểm soát thay đổi sẽ dễ dàng hơn rất nhiều với một dịch vụ dữ liệu chung. Chúng ta sẽ không phải triển khai lại bất kỳ dịch vụ nào trong số dịch vụ liên quan đến vé khi có thay đổi về logic cơ sở dữ liệu.”
“Chúng ta hãy xem qua các tệp lớp chung trong kho lưu trữ và xem lịch sử thay đổi thực sự có bao nhiêu cho đoạn mã đó,” Addison nói.
Addison, Taylen và Skyler đều nhìn vào lịch sử kho lưu trữ của các tệp lớp logic dữ liệu chia sẻ.
“Hmm…” Taylen nói, “Mình tưởng có nhiều thay đổi hơn nữa trong đoạn mã đó so với những gì hiển thị trong kho lưu trữ. Được rồi, vậy có lẽ những thay đổi cho logic cơ sở dữ liệu chung cũng khá tối giản sau tất cả.”
Qua cuộc trò chuyện về việc thảo luận các nhượng bộ, Taylen bắt đầu nhận ra rằng những bất lợi của một dịch vụ chia sẻ dường như vượt xa những lợi ích, và không có lý do thuyết phục thực sự để đặt logic cơ sở dữ liệu chia sẻ vào một dịch vụ chia sẻ. Taylen đã đồng ý đặt logic cơ sở dữ liệu chia sẻ vào một DLL chia sẻ, và Addison đã viết một ADR cho quyết định kiến trúc này.
ADR: Sử dụng thư viện chia sẻ cho logic cơ sở dữ liệu vé chung
Ngữ cảnh Chức năng tạo vé được chia thành ba dịch vụ: Tạo vé, Gán vé và Hoàn thành vé. Cả ba dịch vụ đều sử dụng mã chung cho phần lớn các truy vấn cơ sở dữ liệu và các lệnh cập nhật. Hai tùy chọn là sử dụng một thư viện chia sẻ hoặc tạo một dịch vụ dữ liệu chia sẻ.
Quyết định Chúng tôi sẽ sử dụng một thư viện chung cho logic cơ sở dữ liệu vé chung.
Việc sử dụng một thư viện chia sẻ sẽ cải thiện hiệu suất, khả năng mở rộng và khả năng chịu lỗi của dịch vụ Tạo vé mặt khách hàng, cũng như dịch vụ Phân bổ vé.
Chúng tôi nhận thấy rằng mã logic cơ sở dữ liệu chung không thay đổi nhiều và do đó là mã tương đối ổn định. Hơn nữa, việc thay đổi có ít rủi ro hơn đối với logic cơ sở dữ liệu chung vì các dịch vụ cần phải được kiểm tra và triển khai lại. Nếu cần thay đổi, chúng tôi sẽ áp dụng phiên bản khi thích hợp để không phải triển khai lại tất cả các dịch vụ khi logic cơ sở dữ liệu chung thay đổi.
Việc sử dụng thư viện chia sẻ giảm sự kết nối giữa các dịch vụ và loại bỏ các phụ thuộc dịch vụ bổ sung, lưu lượng HTTP và băng thông tổng thể.
Hậu quả Những thay đổi đối với logic cơ sở dữ liệu chung trong DLL chia sẻ sẽ yêu cầu các dịch vụ cấp vé phải được kiểm tra và triển khai, do đó làm giảm tính linh hoạt tổng thể cho logic cơ sở dữ liệu chung đối với chức năng cấp vé.
Các phiên dịch vụ sẽ cần quản lý bộ kết nối cơ sở dữ liệu của riêng chúng.
Chapter 9. Data Ownership and Distributed Transactions
Thứ Sáu, ngày 10 tháng 12, 09:12
Trong khi đội cơ sở dữ liệu làm việc để phân tách cơ sở dữ liệu monolithic của Đội Sysops, đội phát triển Sysops, cùng với Addison, kiến trúc sư của Đội Sysops, đã bắt đầu làm việc để hình thành các bối cảnh giới hạn giữa các dịch vụ và dữ liệu, phân công quyền sở hữu bảng cho các dịch vụ trong quá trình này.
“Giáo sư, tại sao bạn lại thêm bảng hồ sơ chuyên gia vào bối cảnh bị giới hạn của dịch vụ Gán vé?” Addison hỏi.
"Bởi vì," Sydney nói, "việc phân bổ vé phụ thuộc vào bảng đó cho các thuật toán phân bổ. Nó liên tục truy vấn bảng đó để lấy thông tin về vị trí và kỹ năng của chuyên gia."
“Nhưng nó chỉ thực hiện truy vấn đến bảng chuyên gia,” Addison nói. “Dịch vụ Quản lý Người dùng chứa chức năng để thực hiện cập nhật cơ sở dữ liệu nhằm duy trì thông tin đó. Vì vậy, tôi nghĩ bảng hồ sơ chuyên gia nên thuộc về dịch vụ Quản lý Người dùng và nên được đưa vào bối cảnh giới hạn đó.”
"Tôi không đồng ý," Sydney nói. "Chúng ta đơn giản không thể chi trả cho việc dịch vụ phân công thực hiện các cuộc gọi từ xa tới dịch vụ bảo trì người dùng cho mỗi truy vấn mà nó cần. Nó đơn giản sẽ không khả thi."
“Trong trường hợp đó, bạn thấy việc cập nhật bảng sẽ diễn ra như thế nào khi một chuyên gia có được kỹ năng mới hoặc thay đổi địa điểm cung cấp dịch vụ? Còn khi chúng tôi thuê một chuyên gia mới thì sao?” Addison hỏi. “Việc đó sẽ diễn ra như thế nào?”
“Đơn giản thôi,” Sydney nói. “Dịch vụ Bảo trì Người dùng vẫn có thể truy cập vào bảng chuyên gia. Tất cả những gì nó cần làm là kết nối với một cơ sở dữ liệu khác. Vấn đề là gì chứ?”
“Cậu không nhớ Dana đã nói gì trước đây sao? Việc nhiều dịch vụ kết nối đến cùng một lược đồ cơ sở dữ liệu là chấp nhận được, nhưng một dịch vụ không được phép kết nối đến nhiều cơ sở dữ liệu hoặc lược đồ. Dana đã nói rằng điều đó là không thể chấp nhận và sẽ không cho phép điều đó xảy ra,” Addison nói.
“Ôi, đúng rồi, mình quên quy tắc đó. Vậy chúng ta sẽ làm gì?” Sydney hỏi. “Chúng ta có một dịch vụ cần thực hiện các cập nhật thỉnh thoảng, và một dịch vụ hoàn toàn khác trong một miền hoàn toàn khác để thực hiện các thao tác đọc thường xuyên từ bảng.”
“Chị không biết câu trả lời đúng là gì,” Addison nói. “Rõ ràng điều này sẽ cần có thêm sự hợp tác giữa nhóm cơ sở dữ liệu và chúng ta để tìm ra những vấn đề này. Để tôi xem Dana có thể cung cấp bất kỳ lời khuyên nào về việc này không.”
Khi dữ liệu đã được tách ra, nó phải được ghép lại để cho hệ thống hoạt động. Điều này có nghĩa là phải xác định dịch vụ nào sở hữu dữ liệu nào, cách quản lý các giao dịch phân tán, và cách các dịch vụ có thể truy cập dữ liệu họ cần (nhưng không còn sở hữu). Trong chương này, chúng ta sẽ khám phá các khía cạnh sở hữu và giao dịch của việc ghép lại dữ liệu phân tán.
Assigning Data Ownership
Sau khi phân tách dữ liệu trong một kiến trúc phân tán, một kiến trúc sư phải xác định dịch vụ nào sở hữu dữ liệu nào. Thật không may, việc gán quyền sở hữu dữ liệu cho một dịch vụ không đơn giản như nghe có vẻ, và nó trở thành một phần khó khăn khác của kiến trúc phần mềm.
Quy tắc chung để xác định quyền sở hữu bảng quy định rằng các dịch vụ thực hiện các thao tác ghi trên một bảng sẽ sở hữu bảng đó. Mặc dù quy tắc chung này hoạt động tốt cho sở hữu đơn (chỉ một dịch vụ thực hiện ghi trên một bảng), nhưng nó trở nên phức tạp khi các đội có quyền sở hữu chung (nhiều dịch vụ thực hiện ghi trên cùng một bảng) hoặc tệ hơn, quyền sở hữu chung (hầu hết hoặc tất cả các dịch vụ đều ghi vào bảng).
Tip
Nguyên tắc chung về quyền sở hữu dữ liệu là dịch vụ thực hiện các thao tác ghi vào bảng là chủ sở hữu của bảng đó. Tuy nhiên, quyền sở hữu chung làm cho quy tắc đơn giản này trở nên phức tạp!
Để minh họa một số phức tạp liên quan đến quyền sở hữu dữ liệu, hãy xem xét ví dụ được minh họa trong Hình 9-1 cho thấy ba dịch vụ: Dịch vụ Danh sách Ước vọng quản lý tất cả các danh sách ước vọng của khách hàng, Dịch vụ Danh mục duy trì danh mục sản phẩm, và Dịch vụ Tồn kho duy trì chức năng tồn kho và bổ sung hàng hóa cho tất cả các sản phẩm trong danh mục sản phẩm.
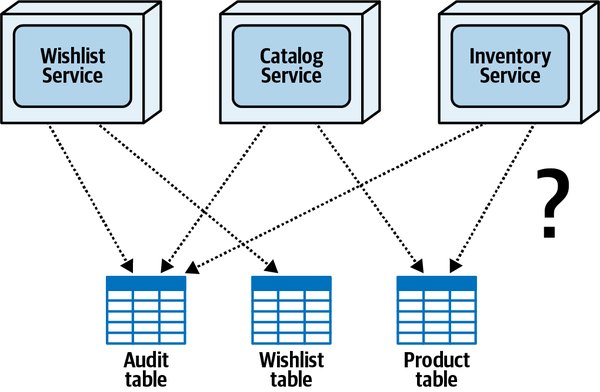
Figure 9-1. Once data is broken apart, tables must be assigned to services that own them
Để làm cho vấn đề trở nên phức tạp hơn, hãy lưu ý rằng Dịch vụ Wishlist ghi vào cả bảng Audit và bảng Wishlist, Dịch vụ Catalog ghi vào bảng Audit và bảng Product, và Dịch vụ Inventory ghi vào bảng Audit và bảng Product. Đột nhiên, ví dụ đơn giản này trở thành một nhiệm vụ phức tạp và khó hiểu để phân định quyền sở hữu dữ liệu.
Trong chương này, chúng tôi giải thích sự phức tạp này bằng cách thảo luận về ba kịch bản gặp phải khi phân công quyền sở hữu dữ liệu cho các dịch vụ (quyền sở hữu đơn, quyền sở hữu chung và quyền sở hữu chung), và khám phá các kỹ thuật để giải quyết những kịch bản này, sử dụng Hình 9-1 làm điểm tham chiếu chung.
Single Ownership Scenario
Quyền sở hữu bảng đơn xảy ra khi chỉ có một dịch vụ ghi vào một bảng. Đây là kịch bản quyền sở hữu dữ liệu đơn giản nhất và tương đối dễ giải quyết. Nhắc lại Hình 9-1, lưu ý rằng bảng Wishlist chỉ có một dịch vụ ghi vào nó - Dịch vụ Wishlist.
Trong kịch bản này, rõ ràng rằng Dịch vụ Danh sách mong muốn nên là chủ sở hữu của bảng Danh sách mong muốn (bất chấp các dịch vụ khác cần quyền truy cập chỉ đọc vào bảng Danh sách mong muốn), xem Hình 9-2. Lưu ý rằng ở bên phải của sơ đồ này, bảng Danh sách mong muốn trở thành một phần của bối cảnh giới hạn của Dịch vụ Danh sách mong muốn. Kỹ thuật lập sơ đồ này là một cách hiệu quả để chỉ ra quyền sở hữu bảng và bối cảnh giới hạn được hình thành giữa dịch vụ và dữ liệu tương ứng của nó.
Figure 9-2. With single ownership, the service that writes to the table becomes the table owner
Vì tính đơn giản của kịch bản này, chúng tôi khuyến nghị giải quyết trước các mối quan hệ sở hữu một bảng để làm sạch sân chơi nhằm giải quyết tốt hơn những kịch bản phức tạp hơn phát sinh: sở hữu chung và sở hữu liên kết.
Common Ownership Scenario
Sở hữu bảng chung xảy ra khi hầu hết (hoặc tất cả) các dịch vụ cần ghi vào cùng một bảng. Ví dụ, Hình 9-1 cho thấy tất cả các dịch vụ (Danh sách mong muốn, Danh mục và Kho) cần ghi vào bảng Audit để ghi lại hành động thực hiện bởi người dùng. Vì tất cả các dịch vụ cần ghi vào bảng, nên rất khó để xác định ai thực sự nên sở hữu bảng Audit. Trong khi ví dụ đơn giản này chỉ bao gồm ba dịch vụ, hãy tưởng tượng một ví dụ thực tế hơn khi có khả năng hàng trăm (hoặc thậm chí hàng nghìn) dịch vụ phải ghi vào cùng một bảng Audit.
Giải pháp đơn giản là đặt bảng Audit vào một cơ sở dữ liệu hoặc lược đồ chung được sử dụng bởi tất cả các dịch vụ, đáng tiếc đã tái giới thiệu tất cả các vấn đề chia sẻ dữ liệu được mô tả ở đầu chương 6, bao gồm kiểm soát thay đổi, tình trạng thiếu kết nối, khả năng mở rộng và khả năng chịu lỗi. Do đó, cần một giải pháp khác để giải quyết vấn đề quyền sở hữu dữ liệu chung.
Một kỹ thuật phổ biến để giải quyết vấn đề sở hữu bảng chung là gán một dịch vụ riêng biệt làm chủ sở hữu chính (và duy nhất) của dữ liệu đó, có nghĩa là chỉ có một dịch vụ chịu trách nhiệm ghi dữ liệu vào bảng. Các dịch vụ khác cần thực hiện các hành động ghi sẽ gửi thông tin đến dịch vụ riêng biệt, sau đó dịch vụ này sẽ thực hiện thao tác ghi thực tế trên bảng.
Nếu không cần thông tin hoặc xác nhận từ các dịch vụ gửi dữ liệu, các dịch vụ có thể sử dụng hàng đợi đã lưu trữ để gửi tin nhắn không đồng bộ theo kiểu "bắn và quên". Ngoài ra, nếu cần trả lại thông tin cho người gọi dựa trên một hành động ghi (chẳng hạn như trả về một số xác nhận hoặc khóa cơ sở dữ liệu), các dịch vụ có thể sử dụng một cái gì đó như REST, gRPC hoặc tin nhắn yêu cầu-phản hồi (giả đồng bộ) cho một cuộc gọi đồng bộ.
Quay trở lại với ví dụ về bảng kiểm toán, hãy chú ý trong Hình 9-3 rằng kiến trúc sư đã tạo ra một Dịch vụ Kiểm toán mới và giao quyền sở hữu cho bảng Kiểm toán, có nghĩa là nó là dịch vụ duy nhất thực hiện các hành động đọc hoặc ghi trên bảng. Trong ví dụ này, vì không cần thông tin trả về, kiến trúc sư đã sử dụng phương pháp nhắn tin không đồng bộ "bắn và quên" với một hàng đợi bền vững, để Dịch vụ Danh sách mong muốn, Dịch vụ Danh mục và Dịch vụ Kho hàng không cần chờ đợi cho bản ghi kiểm toán được ghi vào bảng. Việc làm cho hàng đợi trở nên bền vững (có nghĩa là tin nhắn được lưu trên ổ đĩa bởi nhà môi giới) đảm bảo việc giao hàng được đảm bảo trong trường hợp có sự cố dịch vụ hoặc nhà môi giới và giúp đảm bảo rằng không có tin nhắn nào bị mất.
Figure 9-3. Common ownership uses a dedicated service owner
Trong một số trường hợp, có thể cần thiết cho các dịch vụ đọc dữ liệu chung mà họ không sở hữu. Các kỹ thuật truy cập chỉ đọc này được mô tả chi tiết trong Chương 10.
Joint Ownership Scenario
Một trong những kịch bản phổ biến (và phức tạp) liên quan đến quyền sở hữu dữ liệu là quyền sở hữu chung, xảy ra khi nhiều dịch vụ thực hiện các hành động ghi vào cùng một bảng. Kịch bản này khác với kịch bản quyền sở hữu phổ biến trước đó ở chỗ trong quyền sở hữu chung, chỉ có một vài dịch vụ trong cùng một miền ghi vào cùng một bảng, trong khi với quyền sở hữu phổ biến, hầu hết hoặc tất cả các dịch vụ đều thực hiện các thao tác ghi vào cùng một bảng. Ví dụ, hãy chú ý trong Hình 9-1 rằng tất cả các dịch vụ đều thực hiện các thao tác ghi vào bảng Audit (quyền sở hữu phổ biến), trong khi chỉ có các dịch vụ Catalog và Inventory thực hiện các thao tác ghi vào bảng Product (quyền sở hữu chung).
Hình 9-4 cho thấy ví dụ về quyền sở hữu chung tách biệt từ Hình 9-1. Dịch vụ Danh mục sẽ chèn các sản phẩm mới vào bảng, loại bỏ các sản phẩm không còn được cung cấp và cập nhật thông tin sản phẩm tĩnh khi có thay đổi, trong khi Dịch vụ Tồn kho chịu trách nhiệm đọc và cập nhật tồn kho hiện tại cho mỗi sản phẩm khi các sản phẩm được truy vấn, bán hoặc trả lại.
Figure 9-4. Joint ownership occurs when multiple services within the same domain perform write operations on the same table
May mắn thay, có một số kỹ thuật tồn tại để giải quyết tình huống sở hữu này - kỹ thuật chia bảng, kỹ thuật miền dữ liệu, kỹ thuật ủy quyền và kỹ thuật hợp nhất dịch vụ. Mỗi kỹ thuật sẽ được thảo luận chi tiết trong các phần tiếp theo.
Table Split Technique
Kỹ thuật phân tách bảng chia một bảng duy nhất thành nhiều bảng sao cho mỗi dịch vụ sở hữu một phần dữ liệu mà nó chịu trách nhiệm. Kỹ thuật này được mô tả chi tiết trong cuốn sách Refactoring Databases và trên trang web kèm theo.
Để minh họa kỹ thuật chia bảng, hãy xem xét ví dụ bảng Sản phẩm được minh họa trong Hình 9-4. Trong trường hợp này, kiến trúc sư hoặc nhà phát triển sẽ đầu tiên tạo một bảng Hàng tồn kho riêng biệt chứa ID sản phẩm (khóa) và số lượng hàng tồn kho (số lượng mặt hàng có sẵn), trước khi điền dữ liệu vào bảng Hàng tồn kho từ bảng Sản phẩm hiện có, sau đó cuối cùng là xóa cột số lượng hàng tồn kho khỏi bảng Sản phẩm. Mẫu mã nguồn trong Ví dụ 9-1 cho thấy cách mà kỹ thuật này có thể được triển khai bằng cách sử dụng ngôn ngữ định nghĩa dữ liệu (DDL) trong một cơ sở dữ liệu quan hệ điển hình.
Example 9-1. DDL source code for splitting up the Product table and moving inventory counts to a new Inventory table
CREATETABLEInventory(product_idVARCHAR(10),inv_cntINT);INSERTINTOInventoryVALUES(product_id,inv_cnt)ASSELECTproduct_id,inv_cntFROMProduct;COMMIT;ALTERTABLEProductDROPCOLUMNinv_cnt;
Việc chia tách bảng cơ sở dữ liệu chuyển quyền sở hữu chung thành kịch bản sở hữu một bảng đơn: Dịch vụ Danh mục sở hữu dữ liệu trong bảng Sản phẩm, và Dịch vụ Tồn kho sở hữu dữ liệu trong bảng Tồn kho. Tuy nhiên, như shown trong Hình 9-5, kỹ thuật này yêu cầu có sự giao tiếp giữa Dịch vụ Danh mục và Dịch vụ Tồn kho khi sản phẩm được tạo ra hoặc loại bỏ để đảm bảo dữ liệu giữ được sự nhất quán giữa hai bảng.
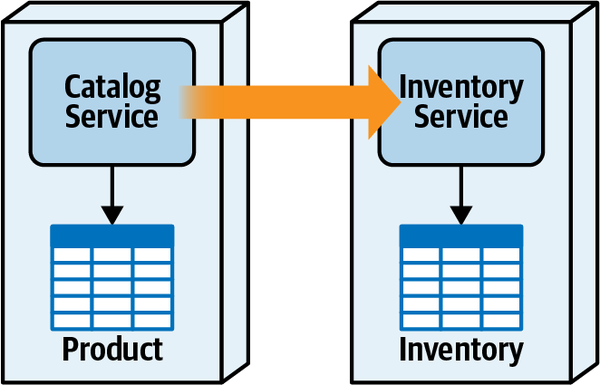
Figure 9-5. Joint ownership can be addressed by breaking apart the shared table
Ví dụ, nếu một sản phẩm mới được thêm vào, Dịch vụ Danh mục sẽ tạo ra một ID sản phẩm và chèn sản phẩm mới vào bảng Sản phẩm. Sau đó, Dịch vụ Danh mục phải gửi ID sản phẩm mới đó (và có thể là số lượng hàng tồn kho ban đầu) đến Dịch vụ Hàng tồn kho. Nếu một sản phẩm bị xóa, Dịch vụ Danh mục trước tiên sẽ xóa sản phẩm khỏi bảng Sản phẩm, sau đó phải thông báo cho Dịch vụ Hàng tồn kho để xóa dòng hàng tồn kho khỏi bảng Hàng tồn kho.
Việc đồng bộ hóa dữ liệu giữa các bảng phân tách không phải là một vấn đề đơn giản. Liệu việc giao tiếp giữa Dịch vụ Danh mục và Dịch vụ Tồn kho nên là đồng bộ hay bất đồng bộ? Dịch vụ Danh mục nên làm gì khi thêm hoặc xóa sản phẩm và phát hiện rằng Dịch vụ Tồn kho không khả dụng? Đây là những câu hỏi khó để trả lời, và thường bị ảnh hưởng bởi sự đánh đổi giữa tính khả dụng và tính nhất quán mà thường thấy trong các kiến trúc phân tán. Chọn tính khả dụng có nghĩa là quan trọng hơn là Dịch vụ Danh mục luôn có khả năng thêm hoặc xóa sản phẩm, mặc dù một bản ghi tồn kho tương ứng có thể không được tạo trong bảng Tồn kho. Chọn tính nhất quán có nghĩa là quan trọng hơn là hai bảng luôn phải đồng bộ với nhau, điều này sẽ khiến cho thao tác tạo hoặc xóa sản phẩm thất bại nếu Dịch vụ Tồn kho không khả dụng. Vì phân tách mạng là điều cần thiết trong các kiến trúc phân tán, định lý CAP tuyên bố rằng chỉ một trong hai lựa chọn này (tính nhất quán hoặc tính khả dụng) là có thể.
Loại giao thức truyền thông (đồng bộ so với bất đồng bộ) cũng quan trọng khi tách một bảng. Dịch vụ Catalog có cần xác nhận rằng bản ghi Inventory tương ứng được thêm khi tạo sản phẩm mới hay không? Nếu có, thì giao tiếp đồng bộ là cần thiết, cung cấp tính nhất quán dữ liệu tốt hơn nhưng hy sinh hiệu suất. Nếu không cần xác nhận, Dịch vụ Catalog có thể sử dụng giao tiếp bất đồng bộ theo kiểu "bắn và quên", cung cấp hiệu suất tốt hơn nhưng hy sinh tính nhất quán dữ liệu. Có rất nhiều sự đánh đổi cần cân nhắc!
Bảng 9-1 tóm tắt các sự đánh đổi liên quan đến kỹ thuật chia bảng cho quyền sở hữu chung.
Data Domain Technique
Một kỹ thuật khác để sở hữu chung là tạo ra một miền dữ liệu chia sẻ. Điều này được hình thành khi quyền sở hữu dữ liệu được chia sẻ giữa các dịch vụ, từ đó tạo ra nhiều chủ sở hữu cho bảng. Với kỹ thuật này, các bảng được chia sẻ bởi các dịch vụ cùng nhau sẽ được đưa vào cùng một cấu trúc hoặc cơ sở dữ liệu, do đó hình thành một bối cảnh hạn chế rộng hơn giữa các dịch vụ và dữ liệu.
Lưu ý rằng Hình 9-6 trông giống với sơ đồ gốc trong Hình 9-4 với một điểm khác biệt đáng chú ý - sơ đồ miền dữ liệu có bảng Sản phẩm trong một ô riêng biệt bên ngoài ngữ cảnh của mỗi dịch vụ sở hữu. Kỹ thuật vẽ sơ đồ này làm rõ rằng bảng này không thuộc sở hữu hay là phần của ngữ cảnh giới hạn của bất kỳ dịch vụ nào, mà được chia sẻ giữa chúng trong một ngữ cảnh giới hạn rộng hơn.
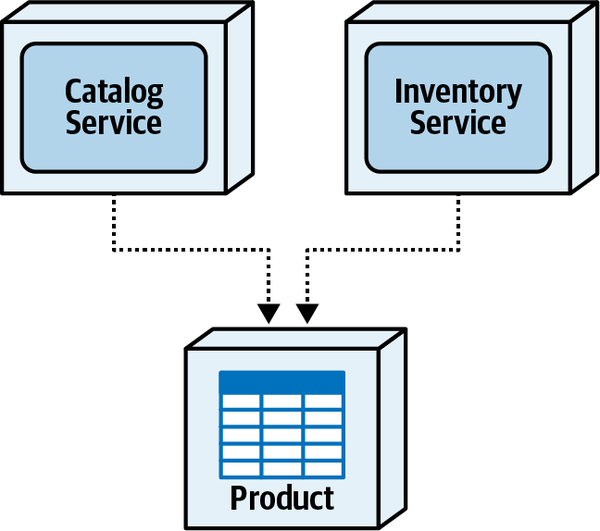
Figure 9-6. With joint ownership, services can share data by using the data domain technique (shared schema)
Mặc dù việc chia sẻ dữ liệu thường không được khuyến khích trong các kiến trúc phân tán (đặc biệt là với microservices), nhưng điều này giải quyết một số vấn đề về hiệu suất, khả năng sẵn có và tính nhất quán của dữ liệu mà các kỹ thuật sở hữu chung khác gặp phải. Bởi vì các dịch vụ không phụ thuộc vào nhau, Dịch vụ Danh mục có thể tạo hoặc xóa sản phẩm mà không cần phối hợp với Dịch vụ Kho, và Dịch vụ Kho có thể điều chỉnh tồn kho mà không cần Dịch vụ Danh mục. Cả hai dịch vụ hoàn toàn độc lập với nhau.
Tip
Khi chọn kỹ thuật miền dữ liệu, luôn đánh giá lại lý do tại sao cần các dịch vụ riêng biệt vì dữ liệu là chung cho mỗi dịch vụ. Các lý do có thể bao gồm sự khác biệt về khả năng mở rộng, nhu cầu về khả năng chịu lỗi, sự khác biệt về băng thông, hoặc cách ly sự biến động của mã (xem Chương 7).
Thật không may, việc chia sẻ dữ liệu trong một kiến trúc phân tán gây ra một số vấn đề, vấn đề đầu tiên trong số đó là tăng cường nỗ lực cho các thay đổi được thực hiện đối với cấu trúc dữ liệu (chẳng hạn như thay đổi sơ đồ của một bảng). Bởi vì một ngữ cảnh giới hạn rộng hơn được hình thành giữa các dịch vụ và dữ liệu, các thay đổi đối với cấu trúc bảng chia sẻ có thể yêu cầu những thay đổi đó phải được phối hợp giữa nhiều dịch vụ. Điều này dẫn đến việc tăng cường nỗ lực phát triển, phạm vi thử nghiệm và rủi ro triển khai.
Một vấn đề khác với kỹ thuật miền dữ liệu liên quan đến quyền sở hữu dữ liệu là kiểm soát các dịch vụ nào có trách nhiệm ghi vào dữ liệu nào. Trong một số trường hợp, điều này có thể không quan trọng, nhưng nếu việc kiểm soát các hoạt động ghi vào dữ liệu nhất định là quan trọng, thì cần nỗ lực bổ sung để áp dụng các quy tắc quản trị cụ thể nhằm duy trì quyền sở hữu ghi vào bảng hoặc cột cụ thể.
Bảng 9-2 tóm tắt các lợi thế và nhược điểm liên quan đến kỹ thuật miền dữ liệu cho kịch bản sở hữu chung.
Delegate Technique
Một phương pháp thay thế để giải quyết tình huống sở hữu chung là kỹ thuật ủy quyền. Với kỹ thuật này, một dịch vụ được giao quyền sở hữu duy nhất của bảng và trở thành người ủy quyền, trong khi dịch vụ (hoặc dịch vụ) khác giao tiếp với người ủy quyền để thực hiện các cập nhật thay mặt cho mình.
Một trong những thách thức của kỹ thuật ủy quyền là biết dịch vụ nào nên được chỉ định là người ủy quyền (chủ sở hữu duy nhất của bảng). Tùy chọn đầu tiên, được gọi là ưu tiên miền chính, chỉ định quyền sở hữu bảng cho dịch vụ đại diện gần nhất cho miền chính của dữ liệu—nói cách khác, dịch vụ thực hiện hầu hết các thao tác CRUD của thực thể chính cho thực thể cụ thể trong miền đó. Tùy chọn thứ hai, được gọi là ưu tiên đặc điểm hoạt động, chỉ định quyền sở hữu bảng cho dịch vụ cần các đặc điểm kiến trúc hoạt động cao hơn, chẳng hạn như hiệu suất, tính mở rộng, khả năng sẵn sàng và thông lượng.
Để minh họa hai tùy chọn này và các yếu tố đánh đổi tương ứng với mỗi tùy chọn, hãy xem xét kịch bản sở hữu chung giữa Dịch vụ Danh mục và Dịch vụ Tồn kho như được thể hiện trong Hình 9-4. Trong ví dụ này, Dịch vụ Danh mục chịu trách nhiệm tạo, cập nhật và xoá các sản phẩm, cũng như truy xuất thông tin sản phẩm; Dịch vụ Tồn kho chịu trách nhiệm truy xuất và cập nhật số lượng tồn kho sản phẩm cũng như biết khi nào cần bổ sung hàng nếu tồn kho quá thấp.
Với tùy chọn ưu tiên miền chính, dịch vụ thực hiện phần lớn các hoạt động CRUD trên thực thể chính sẽ trở thành chủ sở hữu của bảng. Như được minh họa trong Hình 9-7, vì Dịch vụ Danh mục thực hiện phần lớn các hoạt động CRUD trên thông tin sản phẩm, Dịch vụ Danh mục sẽ được chỉ định là chủ sở hữu duy nhất của bảng. Điều này có nghĩa là dịch vụ Tồn kho phải giao tiếp với Dịch vụ Danh mục để lấy hoặc cập nhật số lượng tồn kho vì nó không sở hữu bảng.
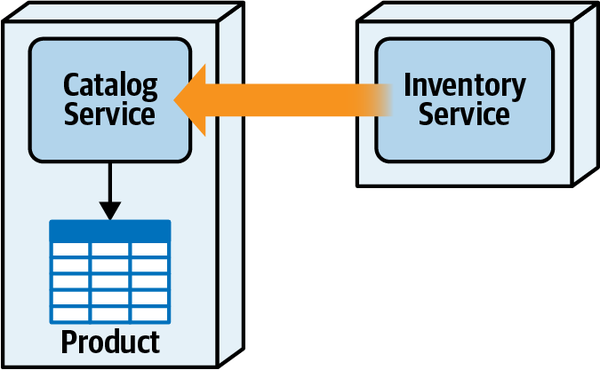
Figure 9-7. Table ownership is assigned to the Catalog service because of domain priority
Giống như kịch bản sở hữu chung đã được mô tả ở trên, kỹ thuật uỷ quyền luôn buộc phải có sự giao tiếp giữa các dịch vụ khác cần cập nhật dữ liệu. Lưu ý rằng trong Hình 9-7, Dịch vụ Quản lý Kho phải gửi các cập nhật hàng tồn kho thông qua một loại giao thức truy cập từ xa nào đó đến Dịch vụ Danh Mục để nó có thể thực hiện các cập nhật và đọc hàng tồn kho thay mặt cho Dịch vụ Quản lý Kho. Giao tiếp này có thể là đồng bộ hoặc không đồng bộ. Như luôn thấy trong kiến trúc phần mềm, cần phải xem xét thêm nhiều phân tích đánh đổi.
Với giao tiếp đồng bộ, Dịch vụ Quản lý hàng tồn kho phải chờ đợi để Dịch vụ Danh mục cập nhật hàng tồn kho, điều này ảnh hưởng đến hiệu suất tổng thể nhưng đảm bảo tính一致 của dữ liệu. Việc sử dụng giao tiếp không đồng bộ để gửi cập nhật hàng tồn kho giúp Dịch vụ Quản lý hàng tồn kho hoạt động nhanh hơn nhiều, nhưng dữ liệu chỉ nhất quán ở mức độ cuối cùng. Hơn nữa, với giao tiếp không đồng bộ, vì có thể xảy ra lỗi trong Dịch vụ Danh mục khi cố gắng cập nhật hàng tồn kho, Dịch vụ Quản lý hàng tồn kho không có đảm bảo rằng hàng tồn kho đã được cập nhật, cũng ảnh hưởng đến tính toàn vẹn của dữ liệu.
Với tùy chọn ưu tiên các đặc tính hoạt động, các vai trò sở hữu sẽ bị đảo ngược vì việc cập nhật tồn kho xảy ra với tốc độ nhanh hơn nhiều so với dữ liệu sản phẩm tĩnh. Trong trường hợp này, quyền sở hữu bảng sẽ được giao cho Dịch vụ Tồn kho, lý do là việc cập nhật tồn kho sản phẩm là một phần của quy trình giao dịch theo thời gian thực thường xuyên hơn trong việc mua sắm sản phẩm, trái ngược với nhiệm vụ hành chính ít xảy ra hơn là cập nhật thông tin sản phẩm hoặc thêm và xoá sản phẩm (xem Hình 9-8).
Với tùy chọn này, việc cập nhật thường xuyên số lượng hàng tồn kho có thể sử dụng các cuộc gọi trực tiếp tới cơ sở dữ liệu thay vì các giao thức truy cập từ xa, từ đó làm cho các hoạt động hàng tồn kho nhanh hơn và đáng tin cậy hơn. Thêm vào đó, dữ liệu có tính biến động cao nhất (số lượng hàng tồn kho) được giữ rất nhất quán.
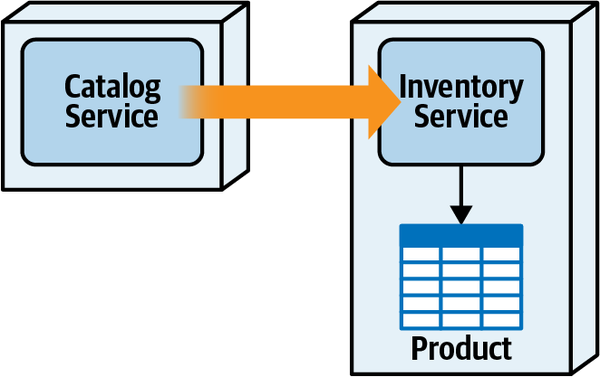
Figure 9-8. Table ownership is assigned to the Inventory Service because of operational characteristics priority
Tuy nhiên, một vấn đề lớn với sơ đồ được minh họa trong Hình 9-8 là vấn đề trách nhiệm quản lý miền. Dịch vụ Kho hàng chịu trách nhiệm quản lý tồn kho sản phẩm, không phải hoạt động cơ sở dữ liệu (và xử lý lỗi tương ứng) để thêm, xóa và cập nhật thông tin sản phẩm tĩnh. Vì lý do này, chúng tôi thường khuyến nghị tùy chọn ưu tiên miền, và tận dụng các thứ như bộ đệm trong bộ nhớ được nhân bản hoặc bộ đệm phân tán để giúp giải quyết các vấn đề về hiệu suất và khả năng chịu lỗi.
Bất kể dịch vụ nào được chỉ định làm đại diện (chủ sở hữu bảng duy nhất), kỹ thuật đại diện đều có một số bất lợi, lớn nhất là sự liên kết giữa các dịch vụ và nhu cầu giao tiếp giữa các dịch vụ. Điều này dẫn đến các vấn đề khác cho các dịch vụ không phải đại diện, bao gồm việc thiếu giao dịch nguyên tử khi thực hiện các thao tác ghi, hiệu suất thấp do độ trễ mạng và xử lý, và khả năng chịu lỗi thấp. Vì những vấn đề này, kỹ thuật đại diện thường phù hợp hơn cho các kịch bản ghi dữ liệu mà không yêu cầu giao dịch nguyên tử và có thể chịu đựng sự nhất quán cuối cùng thông qua các giao tiếp bất đồng bộ.
Bảng 9-3 tóm tắt những đánh đổi tổng thể của kỹ thuật ủy quyền.
Service Consolidation Technique
Phương pháp ủy quyền được thảo luận trong phần trước làm nổi bật vấn đề chính liên quan đến việc sở hữu chung—sự phụ thuộc vào dịch vụ. Kỹ thuật hợp nhất dịch vụ giải quyết sự phụ thuộc vào dịch vụ và xử lý việc sở hữu chung bằng cách kết hợp nhiều chủ sở hữu bảng (dịch vụ) thành một dịch vụ hợp nhất duy nhất, do đó chuyển việc sở hữu chung thành một kịch bản sở hữu duy nhất (xem Hình 9-9).
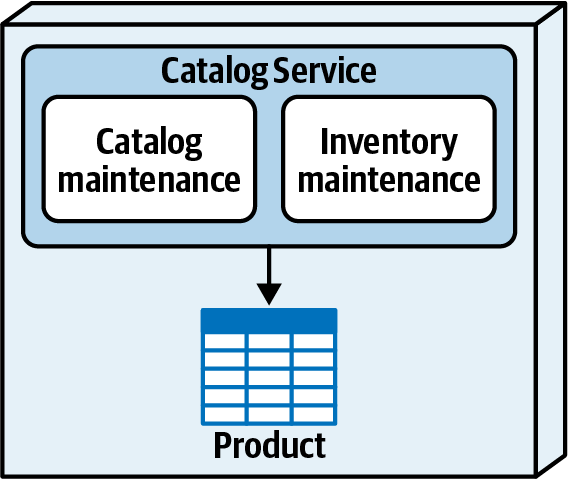
Figure 9-9. Table ownership is resolved by combining services
Giống như kỹ thuật miền dữ liệu, kỹ thuật này giải quyết các vấn đề liên quan đến sự phụ thuộc vào dịch vụ và hiệu suất, đồng thời giải quyết vấn đề quyền sở hữu chung. Tuy nhiên, giống như các kỹ thuật khác, nó cũng có những nhược điểm riêng.
Việc kết hợp các dịch vụ tạo ra một dịch vụ thô hơn, do đó tăng cường phạm vi kiểm thử tổng thể cũng như rủi ro triển khai tổng thể (khả năng làm hỏng một phần khác của dịch vụ khi một tính năng mới được thêm vào hoặc một lỗi được sửa). Việc hợp nhất các dịch vụ cũng có thể ảnh hưởng đến khả năng chịu lỗi tổng thể vì tất cả các phần của dịch vụ cùng lỗi với nhau.
Tính khả thi tổng thể cũng bị ảnh hưởng khi sử dụng kỹ thuật hợp nhất dịch vụ vì tất cả các phần của dịch vụ phải mở rộng như nhau, mặc dù một số chức năng có thể không cần mở rộng ở cùng một mức độ như các chức năng khác. Ví dụ, trong Hình 9-9, chức năng bảo trì danh mục (trước đây là trong một dịch vụ Danh mục riêng biệt) phải mở rộng một cách không cần thiết để đáp ứng nhu cầu cao của chức năng truy xuất và cập nhật hàng tồn kho.
Bảng 9-4 tóm tắt các thỏa hiệp tổng thể của kỹ thuật hợp nhất dịch vụ.
Data Ownership Summary
Hình 9-10 hiển thị các phân công quyền sở hữu bảng kết quả từ Hình 9-1 sau khi áp dụng các kỹ thuật được mô tả trong phần này. Đối với kịch bản một bảng liên quan đến Dịch vụ Danh sách Mong muốn, chúng tôi đơn giản đã phân công quyền sở hữu cho Dịch vụ Danh sách Mong muốn, tạo ra một bối cảnh ràng buộc chặt chẽ giữa dịch vụ và bảng. Đối với kịch bản sở hữu chung liên quan đến bảng kiểm toán, chúng tôi đã tạo ra một Dịch vụ Kiểm toán mới, với tất cả các dịch vụ khác gửi một thông điệp bất đồng bộ đến một hàng đợi được lưu trữ. Cuối cùng, đối với kịch bản sở hữu chung phức tạp hơn liên quan đến bảng sản phẩm với Dịch vụ Danh mục và Dịch vụ Tồn kho, chúng tôi đã chọn sử dụng kỹ thuật ủy quyền, phân công quyền sở hữu duy nhất của bảng sản phẩm cho Dịch vụ Danh mục, với Dịch vụ Tồn kho gửi yêu cầu cập nhật đến Dịch vụ Danh mục.
Khi quyền sở hữu bảng đã được giao cho các dịch vụ, kiến trúc sư phải xác thực các phân công quyền sở hữu bảng bằng cách phân tích các quy trình làm việc kinh doanh và các yêu cầu giao dịch tương ứng của chúng.
Figure 9-10. Resulting data ownership using delegate technique for joint ownership
Distributed Transactions
Khi các kiến trúc sư và nhà phát triển nghĩ về giao dịch, họ thường nghĩ đến một đơn vị công việc nguyên tử duy nhất, nơi nhiều cập nhật cơ sở dữ liệu sẽ được cam kết cùng nhau hoặc tất cả sẽ bị hoàn trả khi xảy ra lỗi. Loại giao dịch nguyên tử này thường được gọi là giao dịch ACID. Như đã đề cập trong Chương 6, ACID là một từ viết tắt mô tả các thuộc tính cơ bản của một giao dịch cơ sở dữ liệu đơn vị công việc nguyên tử: nguyên tử, nhất quán, tách biệt và bền vững.
Để hiểu cách thức hoạt động của giao dịch phân tán và những đánh đổi liên quan đến việc sử dụng giao dịch phân tán, cần phải nắm rõ bốn thuộc tính của một giao dịch ACID. Chúng tôi tin tưởng rằng nếu không hiểu rõ về giao dịch ACID, một kiến trúc sư sẽ không thể thực hiện phân tích đánh đổi cần thiết để biết khi nào (và khi nào không) nên sử dụng giao dịch phân tán. Do đó, chúng ta sẽ đi sâu vào chi tiết về giao dịch ACID trước, sau đó mô tả cách chúng khác biệt so với giao dịch phân tán.
Tính nguyên tử có nghĩa là một giao dịch phải commit hoặc rollback tất cả các cập nhật của nó trong một đơn vị công việc duy nhất, bất kể số lượng cập nhật được thực hiện trong giao dịch đó. Nói cách khác, tất cả các cập nhật được coi là một tổng thể chung, vì vậy tất cả các thay đổi đều được commit hoặc rollback như một đơn vị. Ví dụ, giả sử việc đăng ký một khách hàng liên quan đến việc chèn thông tin hồ sơ khách hàng vào bảng Hồ Sơ Khách Hàng, chèn thông tin thẻ tín dụng vào bảng Ví, và chèn thông tin liên quan đến bảo mật vào bảng Bảo Mật. Giả sử thông tin hồ sơ và thẻ tín dụng được chèn thành công, nhưng việc chèn thông tin bảo mật bị lỗi. Với tính nguyên tử, các chèn thông tin hồ sơ và thẻ tín dụng sẽ được rollback, giữ cho các bảng cơ sở dữ liệu đồng bộ.
Tính nhất quán có nghĩa là trong suốt quá trình thực hiện giao dịch, cơ sở dữ liệu sẽ không bao giờ bị để lại trong một trạng thái không nhất quán hoặc vi phạm bất kỳ ràng buộc toàn vẹn nào được chỉ định trong cơ sở dữ liệu. Ví dụ, trong một giao dịch ACID, hệ thống không thể thêm một bản ghi chi tiết (chẳng hạn như một mặt hàng) mà không đầu tiên thêm bản ghi tóm tắt tương ứng (chẳng hạn như một đơn hàng). Mặc dù một số cơ sở dữ liệu hoãn việc kiểm tra này cho đến thời điểm cam kết, nhưng nói chung, các lập trình viên không thể vi phạm các ràng buộc tính nhất quán như ràng buộc khóa ngoại trong quá trình thực hiện giao dịch.
Isolasi đề cập đến mức độ mà các giao dịch cá nhân tương tác với nhau. Isolasi bảo vệ dữ liệu giao dịch chưa hoàn thành khỏi việc bị nhìn thấy bởi các giao dịch khác trong quá trình xử lý yêu cầu kinh doanh. Ví dụ, trong quá trình một giao dịch ACID, khi thông tin hồ sơ khách hàng được chèn vào bảng Hồ sơ Khách hàng, không có dịch vụ nào bên ngoài phạm vi giao dịch ACID có thể truy cập vào thông tin vừa chèn cho đến khi toàn bộ giao dịch được hoàn tất.
Độ bền có nghĩa là khi một phản hồi thành công từ việc cam kết giao dịch xảy ra, tất cả các cập nhật dữ liệu sẽ được đảm bảo là vĩnh viễn, bất chấp các sự cố hệ thống xảy ra sau đó.
Để minh họa một giao dịch ACID, giả sử một khách hàng đăng ký cho ứng dụng Sysops Squad nhập tất cả thông tin hồ sơ của họ, các sản phẩm điện tử mà họ muốn được bảo hiểm trong kế hoạch hỗ trợ, và thông tin thanh toán của họ trên một màn hình giao diện người dùng duy nhất. Thông tin này sau đó được gửi đến dịch vụ khách hàng duy nhất, như được trình bày trong Hình 9-11, sau đó thực hiện tất cả các hoạt động cơ sở dữ liệu liên quan đến yêu cầu kinh doanh đăng ký khách hàng.
Figure 9-11. With ACID transactions, an error on the billing insert causes a rollback to the other table inserts
Đầu tiên, hãy lưu ý rằng với một giao dịch ACID, vì đã xảy ra lỗi khi cố gắng chèn thông tin thanh toán, cả thông tin hồ sơ và thông tin hợp đồng hỗ trợ đã được chèn trước đó giờ đây sẽ bị quay lại (đó là phần nguyên tử và nhất quán của ACID). Mặc dù không được minh họa trong biểu đồ, dữ liệu được chèn vào mỗi bảng trong quá trình giao dịch sẽ không hiển thị cho các yêu cầu khác (đó là phần cách ly của ACID).
Lưu ý rằng các giao dịch ACID có thể tồn tại trong bối cảnh của mỗi dịch vụ trong một kiến trúc phân tán, nhưng chỉ khi cơ sở dữ liệu tương ứng cũng hỗ trợ các thuộc tính ACID. Mỗi dịch vụ có thể thực hiện các cam kết và hoàn tác của riêng nó đối với các bảng mà nó sở hữu trong phạm vi của giao dịch kinh doanh nguyên tử. Tuy nhiên, nếu yêu cầu kinh doanh trải dài qua nhiều dịch vụ, toàn bộ yêu cầu kinh doanh đó không thể là một giao dịch ACID - thay vào đó, nó trở thành một giao dịch phân tán.
Giao dịch phân tán xảy ra khi một yêu cầu kinh doanh nguyên tử chứa nhiều cập nhật cơ sở dữ liệu được thực hiện bởi các dịch vụ từ xa được triển khai riêng biệt. Lưu ý trong Hình 9-12 rằng cùng một yêu cầu đăng ký khách hàng mới (được đánh dấu bởi hình ảnh laptop đại diện cho khách hàng thực hiện yêu cầu) hiện đã trải rộng trên ba dịch vụ được triển khai riêng biệt - Dịch vụ Hồ sơ Khách hàng, Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn.
Figure 9-12. Distributed transactions do not support ACID properties
Như bạn có thể thấy, các giao dịch phân tán không hỗ trợ các thuộc tính ACID.
Tính nguyên tử không được hỗ trợ vì mỗi dịch vụ được triển khai riêng lẻ sẽ cam kết dữ liệu của riêng nó và chỉ thực hiện một phần của yêu cầu kinh doanh nguyên tử tổng thể. Trong một giao dịch phân tán, tính nguyên tử gắn liền với dịch vụ, không phải với yêu cầu kinh doanh (như đăng ký khách hàng).
Tính nhất quán không được hỗ trợ vì sự cố trong một dịch vụ gây ra dữ liệu không đồng bộ giữa các bảng chịu trách nhiệm cho yêu cầu kinh doanh. Như đã trình bày trong Hình 9-12, do việc chèn vào Dịch vụ Thanh toán Hóa đơn không thành công, bảng Hồ sơ và bảng Hợp đồng hiện không đồng bộ với bảng Hóa đơn (chúng tôi sẽ chỉ rõ cách giải quyết những vấn đề này sau trong phần này). Tính nhất quán cũng bị ảnh hưởng bởi vì các ràng buộc của cơ sở dữ liệu quan hệ truyền thống (chẳng hạn như khóa ngoại luôn khớp với khóa chính) không thể được áp dụng trong mỗi lần cam kết dịch vụ riêng lẻ.
Sự tách biệt không được hỗ trợ vì một khi Dịch vụ Hồ sơ Khách hàng chèn dữ liệu hồ sơ trong quá trình giao dịch phân tán để đăng ký một khách hàng, thông tin hồ sơ đó sẽ có sẵn cho bất kỳ dịch vụ hoặc yêu cầu nào khác, ngay cả khi quá trình đăng ký khách hàng (giao dịch hiện tại) chưa hoàn thành.
Độ bền không được hỗ trợ trong toàn bộ yêu cầu kinh doanh - nó chỉ được hỗ trợ cho từng dịch vụ riêng lẻ. Nói cách khác, bất kỳ cam kết dữ liệu cá nhân nào cũng không đảm bảo rằng tất cả dữ liệu trong phạm vi toàn bộ giao dịch kinh doanh đều là vĩnh viễn.
Thay vì ACID, các giao dịch phân tán hỗ trợ một thứ gọi là BASE. Trong hóa học, một chất axit và một chất bazơ hoàn toàn đối lập nhau. Điều tương tự cũng đúng với giao dịch nguyên tử và giao dịch phân tán—giao dịch ACID là đối lập với giao dịch BASE. BASE miêu tả các thuộc tính của một giao dịch phân tán: khả năng sẵn có cơ bản, trạng thái mềm, và tính nhất quán cuối cùng.
Sự sẵn có cơ bản (phần “BA” của BASE) có nghĩa là tất cả các dịch vụ hoặc hệ thống trong giao dịch phân tán đều phải có sẵn để tham gia vào giao dịch phân tán. Mặc dù giao tiếp không đồng bộ có thể giúp tách rời các dịch vụ và giải quyết các vấn đề về sẵn có có liên quan đến các bên tham gia giao dịch phân tán, nhưng điều này không may ảnh hưởng đến thời gian mà dữ liệu cần để trở nên nhất quán cho giao dịch kinh doanh nguyên tử (xem tính nhất quán cuối cùng ở phần sau trong mục này).
Trạng thái mềm (phần S của BASE) mô tả tình huống khi một giao dịch phân tán đang diễn ra và trạng thái của yêu cầu kinh doanh nguyên tử chưa hoàn tất (hoặc trong một số trường hợp còn chưa được biết đến). Trong ví dụ đăng ký khách hàng được trình bày ở Hình 9-12, trạng thái mềm xảy ra khi thông tin hồ sơ khách hàng được chèn (và cam kết) vào bảng Hồ sơ, nhưng hợp đồng hỗ trợ và thông tin thanh toán thì chưa. Phần chưa biết của trạng thái mềm có thể xảy ra nếu, sử dụng cùng một ví dụ, cả ba dịch vụ hoạt động song song để chèn dữ liệu tương ứng của chúng - trạng thái chính xác của yêu cầu kinh doanh nguyên tử không được biết đến vào bất kỳ thời điểm nào cho đến khi cả ba dịch vụ báo cáo lại rằng dữ liệu đã được xử lý thành công. Trong trường hợp một quy trình làm việc sử dụng giao tiếp không đồng bộ (xem Chương 11), trạng thái đang diễn ra hoặc trạng thái cuối cùng của giao dịch phân tán thường khó xác định.
Tính nhất quán cuối cùng (phần E của BASE) có nghĩa là sau một khoảng thời gian đủ lâu, tất cả các phần của giao dịch phân tán sẽ hoàn thành thành công và tất cả dữ liệu sẽ đồng bộ với nhau. Loại mẫu tính nhất quán cuối cùng được sử dụng và cách xử lý lỗi quy định thời gian cần thiết cho tất cả các nguồn dữ liệu liên quan trong giao dịch phân tán trở nên nhất quán.
Phần tiếp theo mô tả ba loại mẫu nhất quán cuối cùng và các đánh đổi tương ứng với mỗi mẫu.
Eventual Consistency Patterns
Các kiến trúc phân tán phụ thuộc nhiều vào tính nhất quán cuối cùng như một sự đánh đổi cho các đặc điểm kiến trúc hoạt động tốt hơn như hiệu suất, khả năng mở rộng, tính đàn hồi, độ chịu lỗi và tính sẵn có. Mặc dù có nhiều cách để đạt được tính nhất quán cuối cùng giữa các nguồn dữ liệu và hệ thống, ba mô hình chính đang được sử dụng hiện nay là mô hình đồng bộ hóa nền, mô hình yêu cầu có tổ chức và mô hình dựa trên sự kiện.
Để mô tả tốt hơn từng mẫu và minh họa cách chúng hoạt động, hãy xem lại quá trình đăng ký khách hàng từ ứng dụng Sysops Squad mà chúng ta đã thảo luận trước đó trong Hình 9-13. Trong ví dụ này, có ba dịch vụ riêng biệt tham gia vào quá trình đăng ký khách hàng: một Dịch vụ Hồ sơ Khách hàng duy trì thông tin hồ sơ cơ bản, một Dịch vụ Hợp đồng Hỗ trợ duy trì các sản phẩm được bảo hiểm dưới kế hoạch sửa chữa của Sysops Squad cho từng khách hàng, và một Dịch vụ Thanh toán Hóa đơn tính phí khách hàng cho kế hoạch hỗ trợ. Lưu ý trong hình rằng khách hàng 123 là một người đăng ký dịch vụ Sysops Squad, do đó có dữ liệu trong từng bảng tương ứng thuộc sở hữu của mỗi dịch vụ.
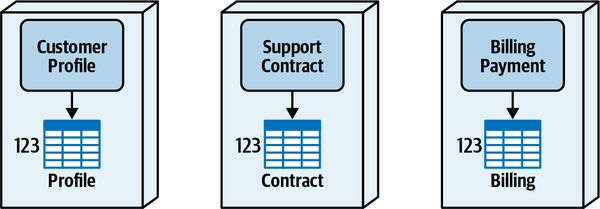
Figure 9-13. Customer 123 is a subscriber in the Sysops Squad application
Khách hàng 123 quyết định họ không còn quan tâm đến kế hoạch hỗ trợ của Đội ngũ Sysops, vì vậy họ hủy đăng ký dịch vụ. Như được hiển thị trong Hình 9-14, Dịch vụ Hồ sơ Khách hàng nhận yêu cầu này từ giao diện người dùng, loại bỏ khách hàng khỏi bảng Hồ sơ và trả về xác nhận cho khách hàng rằng họ đã hủy đăng ký thành công và sẽ không còn bị tính phí. Tuy nhiên, dữ liệu cho khách hàng đó vẫn tồn tại trong bảng Hợp đồng thuộc sở hữu của Dịch vụ Hợp đồng Hỗ trợ và bảng Thanh toán thuộc sở hữu của Dịch vụ Thanh toán.
Figure 9-14. Data is out of sync after the customer unsubscribes from the support plan
Chúng tôi sẽ sử dụng kịch bản này để mô tả từng mẫu nhất quán cuối cùng nhằm đưa tất cả dữ liệu vào đồng bộ cho yêu cầu kinh doanh nguyên tử này.
Background Synchronization Pattern
Mô hình đồng bộ hóa nền tảng sử dụng một dịch vụ hoặc quá trình bên ngoài riêng biệt để kiểm tra định kỳ các nguồn dữ liệu và giữ chúng đồng bộ với nhau. Thời gian để các nguồn dữ liệu trở nên nhất quán cuối cùng khi sử dụng mô hình này có thể khác nhau tùy thuộc vào việc quá trình nền được thực hiện như một công việc theo lô chạy vào giữa đêm hay một dịch vụ thức dậy định kỳ (chẳng hạn, mỗi giờ) để kiểm tra tính nhất quán của các nguồn dữ liệu.
Bất kể cách thức quy trình nền được triển khai như thế nào (dữ liệu theo lô hàng đêm hoặc định kỳ), mẫu này thường có thời gian dài nhất để các nguồn dữ liệu trở nên đồng nhất. Tuy nhiên, trong nhiều trường hợp, các nguồn dữ liệu không cần phải được giữ đồng bộ ngay lập tức. Hãy xem xét ví dụ về việc khách hàng hủy đăng ký trong Hình 9-14. Khi một khách hàng hủy đăng ký, thực sự không quan trọng là thông tin hợp đồng hỗ trợ và thông tin thanh toán cho khách hàng đó vẫn tồn tại. Trong trường hợp này, tính đồng nhất cuối cùng thực hiện vào ban đêm là thời gian đủ để đồng bộ dữ liệu.
Một trong những thách thức của mẫu này là quá trình nền được sử dụng để giữ cho tất cả dữ liệu đồng bộ phải biết dữ liệu nào đã thay đổi. Điều này có thể được thực hiện thông qua một luồng sự kiện, một nút kích hoạt cơ sở dữ liệu, hoặc đọc dữ liệu từ các bảng nguồn và điều chỉnh các bảng đích với dữ liệu nguồn. Bất kể kỹ thuật nào được sử dụng để xác định sự thay đổi, quá trình nền phải có kiến thức về tất cả các bảng và nguồn dữ liệu liên quan đến giao dịch.
Hình 9-15 minh họa việc sử dụng mẫu đồng bộ nền cho ví dụ hủy đăng ký của Đội Sysops. Lưu ý rằng vào lúc 11:23:00, khách hàng gửi yêu cầu hủy đăng ký khỏi gói hỗ trợ. Dịch vụ Hồ sơ Khách hàng nhận yêu cầu, xóa dữ liệu và một giây sau (11:23:01) phản hồi lại khách hàng rằng họ đã hủy đăng ký thành công khỏi hệ thống. Sau đó, vào lúc 23:00, quy trình đồng bộ nền theo lô bắt đầu. Quy trình đồng bộ nền phát hiện rằng khách hàng 123 đã bị xóa thông qua việc truyền sự kiện hoặc so sánh thay đổi giữa bảng chính và bảng thứ cấp, và xóa dữ liệu khỏi bảng Hợp đồng và Bảng Thanh toán.
Mẫu này tốt cho khả năng phản hồi tổng thể vì người dùng cuối không phải chờ đợi toàn bộ giao dịch kinh doanh hoàn thành (trong trường hợp này, hủy đăng ký kế hoạch hỗ trợ). Nhưng, thật không may, có một số đánh đổi nghiêm trọng với mô hình nhất quán cuối cùng này.
Figure 9-15. The background synchronization pattern uses an external process to ensure data consistency
Nhược điểm lớn nhất của mô hình đồng bộ hóa nền là nó kết hợp tất cả các nguồn dữ liệu lại với nhau, do đó làm phá vỡ mọi bối cảnh giới hạn giữa dữ liệu và các dịch vụ. Lưu ý trong Hình 9-16 rằng quy trình đồng bộ hóa lô nền phải có quyền ghi cho từng bảng thuộc sở hữu của các dịch vụ tương ứng, có nghĩa là tất cả các bảng đều có quyền sở hữu chung giữa các dịch vụ và quy trình đồng bộ hóa nền.
Sự sở hữu dữ liệu chia sẻ giữa các dịch vụ và quy trình đồng bộ hóa nền tảng đầy rẫy vấn đề, và nhấn mạnh sự cần thiết phải có các bối cảnh ràng buộc chặt chẽ trong một kiến trúc phân tán. Các thay đổi cấu trúc được thực hiện đối với các bảng do mỗi dịch vụ sở hữu (thay đổi tên cột, xóa cột, v.v.) cũng phải được phối hợp với một quy trình nền tảng bên ngoài, khiến việc thay đổi trở nên khó khăn và tốn thời gian.
Ngoài những khó khăn trong việc kiểm soát thay đổi, các vấn đề xảy ra liên quan đến sự lặp lại của logic kinh doanh. Khi xem Hình 9-15, có thể thấy rằng quá trình nền có vẻ khá đơn giản khi thực hiện thao tác DELETE trên tất cả các hàng trong bảng Hợp đồng và Thanh toán chứa khách hàng 123. Tuy nhiên, có thể tồn tại một số quy tắc kinh doanh trong các dịch vụ này cho thao tác cụ thể đó.
Figure 9-16. The background synchronization pattern is coupled to the data sources, therefore breaking the bounded context and data ownership
Ví dụ, khi một khách hàng huỷ đăng ký, các hợp đồng hỗ trợ hiện tại và lịch sử thanh toán của họ sẽ được giữ trong ba tháng trong trường hợp khách hàng quyết định đăng ký lại gói hỗ trợ. Do đó, thay vì xóa các hàng trong những bảng đó, một cột remove_date sẽ được thiết lập với một giá trị dài đại diện cho ngày mà các hàng sẽ bị xóa (một giá trị bằng không trong cột này chỉ ra một khách hàng đang hoạt động). Cả hai dịch vụ đều kiểm tra remove_date hàng ngày để xác định các hàng nào nên bị xóa khỏi các bảng tương ứng của chúng. Câu hỏi là, logic kinh doanh đó nằm ở đâu? Câu trả lời, dĩ nhiên, nằm trong Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn—ồ, và cũng trong quy trình hàng loạt nền!
Mô hình nhất quán muộn với sự đồng bộ nền tảng không phù hợp cho các kiến trúc phân tán yêu cầu các ngữ cảnh giới hạn chặt chẽ (như microservices) nơi sự gắn kết giữa quyền sở hữu dữ liệu và chức năng là một phần quan trọng của kiến trúc. Các tình huống mà mô hình này hữu ích là các hệ thống không đồng nhất đóng (tự chứa) không giao tiếp với nhau hoặc chia sẻ dữ liệu.
Ví dụ, hãy xem xét một hệ thống nhập đơn hàng cho nhà thầu chấp nhận đơn hàng vật liệu xây dựng, và một hệ thống riêng biệt khác (được triển khai trên nền tảng khác) thực hiện việc lập hóa đơn cho nhà thầu. Khi một nhà thầu đặt hàng cung ứng, một quy trình đồng bộ hóa nền sẽ chuyển những đơn hàng đó sang hệ thống lập hóa đơn để tạo hóa đơn. Khi một nhà thầu thay đổi đơn hàng hoặc hủy bỏ nó, quy trình đồng bộ hóa nền sẽ chuyển những thay đổi đó sang hệ thống lập hóa đơn để cập nhật hóa đơn. Đây là một ví dụ tốt về việc các hệ thống trở nên nhất quán theo thời gian, với đơn hàng của nhà thầu luôn đồng bộ giữa hai hệ thống.
Bảng 9-5 tóm tắt các trao đổi cho mẫu đồng bộ hóa nền tảng để đạt được tính nhất quán cuối cùng.
Orchestrated Request-Based Pattern
Một phương pháp phổ biến để quản lý giao dịch phân tán là đảm bảo rằng tất cả các nguồn dữ liệu được đồng bộ trong suốt quá trình yêu cầu của doanh nghiệp (nói cách khác, trong khi người dùng cuối đang chờ đợi). Phương pháp này được thực hiện thông qua cái gọi là mẫu yêu cầu được tổ chức.
Không giống như mẫu đồng bộ hóa nền tảng trước đó hoặc mẫu dựa trên sự kiện được mô tả trong phần tiếp theo, mẫu dựa trên yêu cầu có tổ chức cố gắng xử lý toàn bộ giao dịch phân tán trong quá trình yêu cầu kinh doanh, do đó yêu cầu một loại nhạc trưởng nào đó để quản lý giao dịch phân tán. Nhạc trưởng, có thể là một dịch vụ hiện có được chỉ định hoặc một dịch vụ riêng biệt mới, chịu trách nhiệm quản lý tất cả công việc cần thiết để xử lý yêu cầu, bao gồm kiến thức về quy trình kinh doanh, kiến thức về các bên tham gia, logic phát đa, xử lý lỗi và quyền sở hữu hợp đồng.
Một cách để thực hiện mẫu này là chỉ định một trong các dịch vụ chính (giả sử có một dịch vụ như vậy) để quản lý giao dịch phân tán. Kỹ thuật này, như được minh họa trong Hình 9-17, chỉ định một trong các dịch vụ đảm nhận vai trò là người điều phối bên cạnh các trách nhiệm khác của nó, trong trường hợp này là Dịch vụ Hồ sơ Khách hàng.
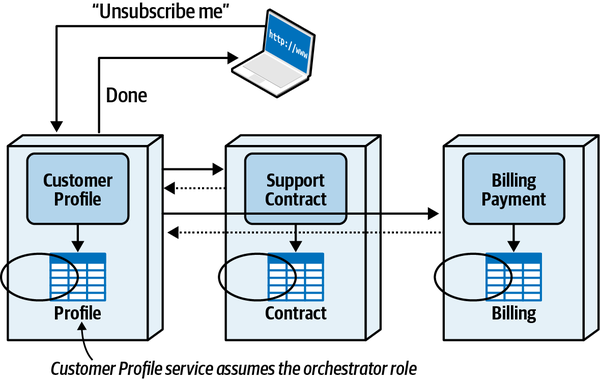
Figure 9-17. The Customer Profile Service takes on the role of an orchestrator for the distributed transaction
Mặc dù phương pháp này tránh khỏi việc cần một dịch vụ quản lý phối hợp riêng biệt, nhưng nó có xu hướng làm quá tải trách nhiệm của dịch vụ được chỉ định làm bộ điều phối giao dịch phân tán. Ngoài vai trò của một bộ điều phối, dịch vụ được chỉ định quản lý giao dịch phân tán còn phải thực hiện các trách nhiệm riêng của nó. Một nhược điểm khác của phương pháp này là nó dễ dẫn đến sự gắn kết chặt chẽ và phụ thuộc đồng bộ giữa các dịch vụ.
Cách tiếp cận mà chúng tôi thường ưa thích khi sử dụng mô hình dựa trên yêu cầu điều phối là sử dụng một dịch vụ điều phối chuyên biệt cho yêu cầu kinh doanh. Cách tiếp cận này, như được minh họa trong Hình 9-18, giải phóng Dịch vụ Hồ sơ Khách hàng khỏi trách nhiệm quản lý giao dịch phân tán và chuyển trách nhiệm đó cho một dịch vụ điều phối riêng biệt.
Chúng tôi sẽ sử dụng phương pháp dịch vụ phối hợp riêng biệt này để mô tả cách mà mô hình nhất quán cuối cùng này hoạt động và những thỏa hiệp tương ứng với mô hình này.
Figure 9-18. A dedicated orchestration service takes on the role of an orchestrator for the distributed transaction
Xin lưu ý rằng vào lúc 11:23:00, khách hàng đã gửi yêu cầu hủy đăng ký khỏi kế hoạch hỗ trợ Sysops Squad. Yêu cầu này được nhận bởi Dịch vụ Điều phối Hủy đăng ký, sau đó chuyển tiếp yêu cầu một cách đồng bộ đến Dịch vụ Hồ sơ Khách hàng để xóa khách hàng khỏi bảng Hồ sơ. Một giây sau, Dịch vụ Hồ sơ Khách hàng gửi lại một sự xác nhận cho Dịch vụ Điều phối Hủy đăng ký, sau đó gửi các yêu cầu song song (qua các luồng hoặc một loại giao thức bất đồng bộ nào đó) đến cả Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn. Cả hai dịch vụ này xử lý yêu cầu hủy đăng ký và sau đó gửi lại một sự xác nhận một giây sau đó cho Dịch vụ Điều phối Hủy đăng ký, cho biết họ đã hoàn tất việc xử lý yêu cầu. Bây giờ mà tất cả dữ liệu đã đồng bộ, Dịch vụ Điều phối Hủy đăng ký phản hồi lại khách hàng vào lúc 11:23:02 (hai giây sau khi yêu cầu ban đầu được đưa ra), thông báo cho khách hàng biết rằng họ đã hủy đăng ký thành công.
Sự đánh đổi đầu tiên cần lưu ý là phương pháp điều phối thường ủng hộ tính nhất quán của dữ liệu hơn là khả năng phản hồi. Việc thêm một dịch vụ điều phối chuyên dụng không chỉ gây thêm các bước nhảy mạng và lời gọi dịch vụ, mà tùy thuộc vào việc bộ điều phối thực hiện các cuộc gọi theo tuần tự hay song song, thời gian bổ sung sẽ cần thiết cho việc giao tiếp qua lại giữa bộ điều phối và các dịch vụ mà nó đang gọi.
Thời gian phản hồi có thể được cải thiện trong Hình 9-18 bằng cách thực hiện yêu cầu Hồ sơ Khách hàng cùng lúc với các dịch vụ khác, nhưng chúng tôi đã chọn thực hiện hoạt động đó một cách đồng bộ vì lý do xử lý lỗi và tính nhất quán. Ví dụ, nếu khách hàng không thể bị xóa khỏi bảng Hồ sơ do có một khoản phí hóa đơn chưa thanh toán, sẽ không cần phải thực hiện hành động nào khác để đảo ngược các hoạt động trong Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn. Đây là một ví dụ khác về tính nhất quán so với tính phản hồi.
Ngoài tính linh hoạt, một sự đánh đổi khác với mẫu này là việc xử lý lỗi phức tạp. Trong khi mẫu dựa trên yêu cầu được điều phối có vẻ đơn giản, hãy xem xét điều gì sẽ xảy ra khi khách hàng bị xóa khỏi bảng Hồ sơ và bảng Hợp đồng, nhưng có một lỗi xảy ra khi cố gắng xóa thông tin thanh toán từ bảng Thanh toán, như minh họa trong Hình 9-19. Vì các Dịch vụ Hồ sơ và Hợp đồng Hỗ trợ đã xác nhận các hoạt động của chúng một cách riêng lẻ, nên Dịch vụ Điều phối Hủy bỏ hiện phải quyết định hành động nào sẽ thực hiện trong khi khách hàng đang chờ yêu cầu được xử lý.
-
Liệu người điều phối có nên gửi lại yêu cầu đến Dịch vụ Thanh toán Hóa đơn để thử lại không?
-
Liệu người điều phối có nên thực hiện một giao dịch bồi thường và yêu cầu Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Hồ sơ Khách hàng hoàn tác các hoạt động cập nhật của chúng không?
-
Liệu người điều phối có nên thông báo cho khách hàng rằng đã xảy ra lỗi và yêu cầu họ chờ một chút trước khi thử lại, trong khi cố gắng khôi phục lại sự nhất quán không?
-
Liệu người điều phối có nên bỏ qua lỗi với hy vọng rằng một quy trình khác sẽ xử lý vấn đề và phản hồi cho khách hàng rằng họ đã được hủy đăng ký thành công không?
Tình huống thực tế này tạo ra một tình huống rối rắm cho bộ điều phối. Bởi vì đây là mẫu nhất quán cuối cùng được sử dụng, không có phương tiện nào khác để chỉnh sửa dữ liệu và đưa mọi thứ trở lại đồng bộ (do đó loại trừ các tùy chọn 3 và 4 trong danh sách trước). Trong trường hợp này, lựa chọn thực sự duy nhất cho bộ điều phối là cố gắng đảo ngược giao dịch phân tán - nói cách khác, thực hiện một cập nhật bồi thường để chèn lại khách hàng trong bảng Hồ sơ và đặt cột remove_date trong bảng Hợp đồng về số không. Điều này sẽ yêu cầu bộ điều phối có tất cả thông tin cần thiết để chèn lại khách hàng, và không có tác động phụ nào xảy ra khi tạo một khách hàng mới (như khởi tạo thông tin thanh toán hoặc hợp đồng hỗ trợ).
Figure 9-19. Error conditions are very hard to address when using the orchestrated request-based pattern
Một phức tạp khác với các giao dịch bù đắp trong kiến trúc phân tán là các lỗi xảy ra trong quá trình bù đắp. Ví dụ, giả sử một giao dịch bù đắp được phát hành cho Dịch vụ Hồ sơ Khách hàng để chèn lại khách hàng, và hoạt động đó đã thất bại. Giờ thì sao? Dữ liệu thực sự đã không còn đồng bộ, và không có dịch vụ hoặc quy trình nào khác xung quanh để sửa chữa vấn đề. Hầu hết các trường hợp như thế này thường đòi hỏi sự can thiệp của con người để sửa chữa các nguồn dữ liệu và đưa chúng trở lại đồng bộ. Chúng tôi sẽ đi vào chi tiết hơn về các giao dịch bù đắp và các saga giao dịch trong "Mẫu Saga Giao dịch".
Bảng 9-6 tóm tắt các đánh đổi cho mô hình yêu cầu có tổ chức dựa trên yêu cầu để đạt được tính nhất quán cuối cùng.
Event-Based Pattern
Mô hình dựa trên sự kiện là một trong những mô hình nhất quán cuối cùng phổ biến và đáng tin cậy nhất cho hầu hết các kiến trúc phân tán hiện đại, bao gồm vi dịch vụ và kiến trúc dựa trên sự kiện. Với mô hình này, các sự kiện được sử dụng kết hợp với mô hình nhắn tin công khai và đăng ký (pub/sub) bất đồng bộ để đăng thông báo sự kiện (chẳng hạn như khách hàng hủy đăng ký) hoặc tin nhắn lệnh (chẳng hạn như hủy đăng ký khách hàng) đến một chủ đề hoặc luồng sự kiện. Các dịch vụ tham gia vào giao dịch phân tán lắng nghe các sự kiện nhất định và phản hồi lại các sự kiện đó.
Thời gian nhất quán cuối cùng thường ngắn để đạt được sự nhất quán dữ liệu nhờ vào tính chất song song và tách biệt của việc xử lý tin nhắn không đồng bộ. Các dịch vụ rất tách biệt với nhau theo mô hình này, và tính nhạy bén là tốt vì dịch vụ kích hoạt sự kiện nhất quán cuối cùng không cần phải chờ đợi quá trình đồng bộ hóa dữ liệu diễn ra trước khi trả thông tin cho khách hàng.
Hình 9-20 minh họa cách mà mô hình dựa trên sự kiện cho tính nhất quán cuối cùng hoạt động. Lưu ý rằng khách hàng đưa ra yêu cầu hủy đăng ký cho Dịch vụ Hồ sơ Khách hàng vào lúc 11:23:00. Dịch vụ Hồ sơ Khách hàng nhận yêu cầu, xóa khách hàng khỏi bảng Hồ sơ, công bố một tin nhắn tới một chủ đề tin nhắn hoặc luồng sự kiện, và trả lại thông tin sau một giây cho khách hàng biết rằng họ đã hủy đăng ký thành công. Xung quanh thời điểm này, cả Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn đều nhận được sự kiện hủy đăng ký và thực hiện các chức năng cần thiết để hủy đăng ký khách hàng, làm cho tất cả các nguồn dữ liệu cuối cùng nhất quán.
Figure 9-20. The event-based pattern uses asynchronous publish-and-subscribe messaging or event streams to achieve eventual consistency
Đối với các triển khai sử dụng hệ thống nhắn tin theo chủ đề tiêu chuẩn (chẳng hạn như ActiveMQ, RabbitMQ, AmazonMQ, và các hệ thống tương tự), các dịch vụ phản hồi sự kiện phải được thiết lập dưới dạng người đăng ký bền vững để đảm bảo không có thông điệp nào bị mất nếu máy chủ nhắn tin hoặc dịch vụ nhận thông điệp gặp lỗi. Một người đăng ký bền vững tương tự như khái niệm về hàng đợi tồn tại vì người đăng ký (trong trường hợp này là Dịch vụ Hợp đồng Hỗ trợ và Dịch vụ Thanh toán Hóa đơn) không cần phải có mặt tại thời điểm thông điệp được phát hành, và các người đăng ký được đảm bảo nhận được thông điệp ngay khi họ trở nên có sẵn. Trong trường hợp các triển khai truyền phát sự kiện, máy chủ nhắn tin (chẳng hạn như Apache Kafka) phải luôn lưu trữ thông điệp và đảm bảo rằng nó có sẵn trong chủ đề trong một khoảng thời gian hợp lý.
Những lợi ích của mô hình dựa trên sự kiện là khả năng phản hồi, tính kịp thời của sự nhất quán dữ liệu và sự tách rời dịch vụ. Tuy nhiên, giống như tất cả các mô hình nhất quán cuối cùng, sự đánh đổi chính của mô hình này là xử lý lỗi. Nếu một trong các dịch vụ (ví dụ, Dịch vụ Thanh toán Hóa đơn được minh họa trong Hình 9-20) không sẵn có, thực tế rằng nó là một người đăng ký bền bỉ có nghĩa là cuối cùng nó sẽ nhận và xử lý sự kiện khi nó trở nên sẵn có. Tuy nhiên, nếu dịch vụ đang xử lý sự kiện và gặp sự cố, mọi chuyện trở nên phức tạp nhanh chóng.
Hầu hết các trình xử lý tin nhắn sẽ cố gắng gửi tin nhắn một số lần nhất định, và sau nhiều lần không thành công từ phía người nhận, trình xử lý sẽ gửi tin nhắn đến hàng đợi thư chết (DLQ). Đây là một địa điểm có thể cấu hình để lưu trữ sự kiện cho đến khi một quy trình tự động đọc tin nhắn và cố gắng sửa chữa vấn đề. Nếu không thể sửa chữa theo chương trình, tin nhắn sẽ thường được gửi đến một người để xử lý thủ công.
Bảng 9-7 liệt kê các sự đánh đổi cho mẫu dựa trên sự kiện nhằm đạt được tính nhất quán cuối cùng.
Sysops Squad Saga: Data Ownership for Ticket Processing
Thứ Ba, ngày 18 tháng Giêng, 09:14
Sau khi nói chuyện với Dana và tìm hiểu về quyền sở hữu dữ liệu và quản lý giao dịch phân tán, Sydney và Addison nhanh chóng nhận ra rằng việc tách rời dữ liệu và phân công quyền sở hữu dữ liệu để hình thành các ngữ cảnh hạn chế chặt chẽ là không thể nếu không có sự hợp tác giữa hai đội trong việc giải quyết vấn đề.
“Không có gì ngạc nhiên khi mọi thứ ở đây dường như không hoạt động,” Sydney nhận xét. “Chúng ta luôn gặp vấn đề và tranh cãi giữa chúng ta và đội ngũ cơ sở dữ liệu, và bây giờ tôi thấy kết quả của việc công ty chúng ta đối xử với chúng ta như hai đội ngũ riêng biệt.”
"Chính xác," Addison nói. "Tôi rất vui vì chúng ta đang làm việc chặt chẽ hơn với nhóm dữ liệu bây giờ. Vậy, từ những gì Dana nói, dịch vụ thực hiện các hành động ghi trên bảng dữ liệu sở hữu bảng đó, bất kể những dịch vụ khác cần truy cập dữ liệu theo kiểu chỉ đọc. Trong trường hợp đó, có vẻ như Dịch vụ Bảo trì Người dùng cần phải sở hữu dữ liệu."
Sydney đã đồng ý, và Addison đã tạo một bản ghi quyết định kiến trúc tổng thể mô tả những điều cần làm cho các kịch bản sở hữu bảng đơn.
ADR: Quyền sở hữu một bảng cho các bối cảnh giới hạn
Bối cảnh Khi xác định các ngữ cảnh giới hạn giữa các dịch vụ và dữ liệu, các bảng phải được gán quyền sở hữu cho một dịch vụ hoặc nhóm dịch vụ cụ thể.
Quyết định Khi chỉ có một dịch vụ ghi vào một bảng, bảng đó sẽ được giao quyền sở hữu cho dịch vụ đó. Hơn nữa, các dịch vụ cần truy cập chỉ đọc vào một bảng trong một bối cảnh giới hạn khác không thể truy cập trực tiếp vào cơ sở dữ liệu hoặc sơ đồ chứa bảng đó.
Theo đội ngũ cơ sở dữ liệu, quyền sở hữu bảng được định nghĩa là dịch vụ thực hiện các phép ghi vào một bảng. Do đó, đối với các tình huống sở hữu bảng đơn, bất kể có bao nhiêu dịch vụ khác cần truy cập vào bảng, chỉ có một dịch vụ được gán làm chủ sở hữu, và chủ sở hữu đó là dịch vụ duy trì dữ liệu.
Hậu quả Tùy thuộc vào kỹ thuật được sử dụng, các dịch vụ yêu cầu quyền truy cập chỉ đọc vào một bảng trong một ngữ cảnh giới hạn khác có thể gặp phải các vấn đề về hiệu suất và khả năng chịu lỗi khi truy cập dữ liệu trong một ngữ cảnh giới hạn khác.
Bây giờ mà Sydney và Addison hiểu rõ hơn về quyền sở hữu bảng và cách tạo ra các ngữ cảnh giới hạn giữa dịch vụ và dữ liệu, họ bắt đầu làm việc trên chức năng khảo sát. Dịch vụ Hoàn thành Vé sẽ ghi lại thời gian hoàn thành vé và chuyên gia đã thực hiện công việc vào bảng khảo sát. Dịch vụ Khảo sát sẽ ghi lại thời gian khảo sát được gửi cho khách hàng, và cũng sẽ chèn tất cả các kết quả khảo sát một khi khảo sát được nhận.
“Cái này không khó lắm khi tôi đã hiểu rõ hơn về bối cảnh giới hạn và quyền sở hữu bảng,” Sydney nói.
“Được rồi, hãy chuyển sang chức năng khảo sát,” Addison nói.
“Ôi, Sydney nói. “Cả Dịch vụ Hoàn thành Vé và Dịch vụ Khảo sát đều ghi vào bảng Khảo sát.”
“Đó là điều mà Dana gọi là sở hữu bàn chung,” Addison nói.
"Vậy, chúng ta có những lựa chọn nào?" Sydney hỏi.
“Vì việc chia tách bảng không hiệu quả, nên cuối cùng chúng ta chỉ còn lại hai lựa chọn,” Addison nói. “Chúng ta có thể sử dụng một miền dữ liệu chung để cả hai dịch vụ cùng sở hữu dữ liệu, hoặc chúng ta có thể sử dụng kỹ thuật ủy quyền và chỉ định một dịch vụ làm chủ sở hữu.”
"Tôi thích miền dữ liệu chung. Hãy để cả hai dịch vụ ghi vào bảng và chia sẻ một sơ đồ chung," Sydney nói.
“Trừ khi điều đó không hoạt động trong tình huống này,” Addison nói. “Dịch vụ Hoàn thành Vé đã đang giao tiếp với miền dữ liệu vé chung. Nhớ rằng, một dịch vụ không thể kết nối với nhiều lược đồ.”
“Ôi, đúng rồi,” Sydney nói. “Chờ đã, tôi biết rồi, chỉ cần thêm các bảng khảo sát vào sơ đồ miền dữ liệu vé.”
“Nhưng bây giờ chúng ta đang bắt đầu ghép tất cả các bảng lại với nhau.” Addison nói. “Chẳng mấy chốc chúng ta sẽ quay lại với một cơ sở dữ liệu đơn thể một lần nữa.”
“Vậy chúng ta làm gì?” Sydney hỏi.
“Chờ một chút, tôi nghĩ tôi thấy một giải pháp tốt ở đây,” Addison nói. “Bạn biết rằng Dịch vụ Hoàn thành Vé phải gửi một thông điệp đến Dịch vụ Khảo sát để bắt đầu quá trình khảo sát khi một vé hoàn tất không? Vậy nếu chúng ta chuyển dữ liệu cần thiết cùng với thông điệp đó để Dịch vụ Khảo sát có thể chèn dữ liệu khi nó tạo khảo sát cho khách hàng thì sao?”
“Thật tuyệt vời,” Sydney nói. “Như vậy, Ticket Completion không cần quyền truy cập vào bảng Khảo sát.”
Addison và Sydney đã thống nhất rằng Dịch vụ Khảo sát sẽ sở hữu bảng Khảo sát, và sẽ sử dụng kỹ thuật ủy quyền để truyền dữ liệu khi bảng thông báo cho Dịch vụ Khảo sát để bắt đầu quy trình khảo sát như được minh họa trong Hình 9-21. Addison đã viết một bản ghi quyết định kiến trúc cho quyết định này.
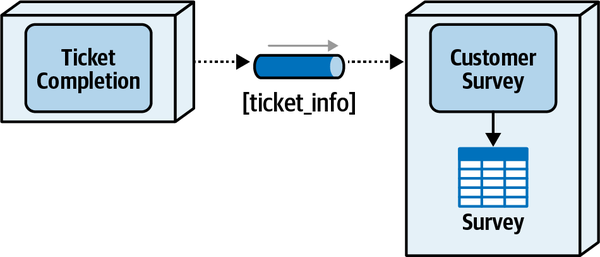
Figure 9-21. Survey Service owns the data using the delegation technique
ADR: Dịch vụ khảo sát sở hữu bảng khảo sát
Ngữ cảnh Cả Dịch vụ Hoàn thành Vé và Dịch vụ Khảo sát đều ghi vào bảng Khảo sát. Vì đây là một tình huống sở hữu chung, các lựa chọn là sử dụng một miền dữ liệu chia sẻ chung hoặc sử dụng kỹ thuật ủy quyền. Việc tách bảng không phải là một lựa chọn do cấu trúc của bảng Khảo sát.
Quyết định Dịch vụ Khảo sát sẽ là chủ sở hữu duy nhất của bảng Khảo sát, có nghĩa là nó là dịch vụ duy nhất có thể thực hiện các thao tác ghi lên bảng đó.
Khi một vé được đánh dấu là đã hoàn thành và được hệ thống chấp nhận, Dịch vụ Hoàn thành Vé cần gửi một tin nhắn đến Dịch vụ Khảo sát để khởi động quy trình khảo sát khách hàng. Vì Dịch vụ Hoàn thành Vé đã gửi một sự kiện thông báo, thông tin vé cần thiết có thể được truyền kèm theo sự kiện đó, do đó loại bỏ nhu cầu Dịch vụ Hoàn thành Vé phải có quyền truy cập vào bảng Khảo sát.
Hậu quả Tất cả dữ liệu cần thiết mà Dịch vụ Hoàn thành Vé cần nhập vào bảng Khảo sát sẽ cần được gửi như một phần của payload khi kích hoạt quy trình khảo sát khách hàng.
Trong hệ thống đơn khối, việc hoàn thành vé đã chèn bản ghi khảo sát như một phần của quy trình hoàn thành. Với quyết định này, việc tạo ra bản ghi khảo sát trở thành một hoạt động riêng biệt so với quy trình tạo vé và hiện nay được xử lý bởi Dịch vụ Khảo sát.
Chapter 10. Distributed Data Access
Thứ Hai, ngày 3 tháng 1, 12:43
“Bây giờ mà chúng ta đã giao quyền sở hữu của bảng hồ sơ chuyên gia cho Dịch vụ Quản lý Người dùng,” Sydney nói, “thì Dịch vụ Phân công Vé nên lấy dữ liệu về vị trí và kỹ năng của chuyên gia như thế nào? Như tôi đã nói trước đó, với số lần đọc mà nó thực hiện đến cơ sở dữ liệu, thực sự không khả thi để thực hiện một cuộc gọi từ xa mỗi khi nó cần truy vấn bảng.”
“Bạn có thể sửa đổi cách hoạt động của thuật toán phân công để giảm số lượng truy vấn cần thiết không?” Addison hỏi.
“Sydney trả lời, “Tôi cũng không biết. Taylen là người thường xuyên duy trì những thuật toán đó.”
Addison và Sydney đã gặp Taylen để thảo luận về vấn đề truy cập dữ liệu và xem liệu Taylen có thể điều chỉnh các thuật toán phân công chuyên gia để giảm số lần gọi đến bảng hồ sơ chuyên gia hay không.
“Bạn đang đùa phải không?” Taylen hỏi. “Không thể nào tôi có thể viết lại các thuật toán bài tập để làm những gì bạn đang yêu cầu. Hoàn toàn không có cách nào cả.”
“Nhưng lựa chọn duy nhất của chúng ta là thực hiện các cuộc gọi từ xa đến Dịch vụ Quản lý Người dùng mỗi khi thuật toán phân công cần dữ liệu chuyên gia,” Addison nói.
“Cái gì?” Taylen hét lên. “Chúng ta không thể làm vậy!”
“Điều đó tôi cũng đã nói,” Sydney nói. “Điều đó có nghĩa là chúng ta lại quay về điểm bắt đầu. Mô hình kiến trúc phân tán này thật khó. Tôi không muốn nói điều này, nhưng tôi thực sự bắt đầu cảm thấy nhớ ứng dụng đơn khối. Đợi đã, tôi biết rồi. Sao chúng ta không thực hiện các cuộc gọi nhắn tin đến Dịch vụ Quản lý Người dùng thay vì sử dụng REST?”
"Đó là điều giống nhau," Taylen nói. "Tôi vẫn phải chờ thông tin quay trở lại, dù chúng ta sử dụng messaging, REST, hay bất kỳ giao thức truy cập từ xa nào khác. Bảng đó đơn giản cần phải nằm trong cùng một miền dữ liệu với các bảng vé."
"Còn phải có một giải pháp khác để truy cập dữ liệu mà chúng ta không còn sở hữu," Addison nói. "Để tôi kiểm tra với Logan."
Trong hầu hết các hệ thống monolithic sử dụng một cơ sở dữ liệu duy nhất, các nhà phát triển không phải suy nghĩ thêm về việc đọc các bảng cơ sở dữ liệu. Các phép nối bảng SQL là điều thường thấy, và với một truy vấn đơn giản, tất cả dữ liệu cần thiết có thể được truy xuất trong một cuộc gọi cơ sở dữ liệu duy nhất. Tuy nhiên, khi dữ liệu được phân tách thành các cơ sở dữ liệu hoặc lược đồ riêng biệt thuộc về các dịch vụ khác nhau, việc truy cập dữ liệu cho các thao tác đọc bắt đầu trở nên khó khăn.
Chương này mô tả các cách mà các dịch vụ có thể lấy quyền truy cập để đọc dữ liệu mà họ không sở hữu—nói cách khác, là bên ngoài bối cảnh giới hạn của các dịch vụ cần dữ liệu. Bốn mẫu truy cập dữ liệu mà chúng tôi thảo luận trong chương này bao gồm mẫu Giao tiếp giữa các dịch vụ, mẫu Nhân bản Lược đồ Cột, mẫu Bộ nhớ đệm Nhân bản và mẫu Miền Dữ liệu.
Mỗi mẫu truy cập dữ liệu này đều có những lợi thế và bất lợi riêng của nó. Đúng vậy, một lần nữa, phải có sự đánh đổi. Để mô tả rõ hơn về từng mẫu này, chúng ta sẽ trở lại ví dụ về Dịch vụ Danh sách Mong muốn và Dịch vụ Danh mục từ Chương 9. Dịch vụ Danh sách Mong muốn được hiển thị trong Hình 10-1 duy trì một danh sách các mặt hàng mà một khách hàng có thể muốn mua trong tương lai, và chứa ID khách hàng, ID mặt hàng và ngày mà mặt hàng được thêm vào trong bảng Danh sách Mong muốn tương ứng. Dịch vụ Danh mục chịu trách nhiệm duy trì tất cả các mặt hàng mà công ty bán, và bao gồm ID mặt hàng, mô tả mặt hàng, và thông tin kích thước sản phẩm tĩnh, chẳng hạn như trọng lượng, chiều cao, chiều dài, v.v.
Trong ví dụ này, khi một yêu cầu được gửi từ khách hàng để hiển thị trong danh sách mong muốn của họ, cả ID mặt hàng và mô tả mặt hàng (item_desc) đều được trả về cho khách hàng. Tuy nhiên, Dịch vụ Danh sách mong muốn không có mô tả mặt hàng trong bảng của mình; dữ liệu đó thuộc quyền sở hữu của Dịch vụ Danh mục trong một bối cảnh hạn chế chặt chẽ, cung cấp kiểm soát thay đổi và quyền sở hữu dữ liệu. Do đó, kiến trúc sư phải sử dụng một trong những mẫu truy cập dữ liệu được nêu trong chương này để đảm bảo Dịch vụ Danh sách mong muốn có thể lấy mô tả sản phẩm từ Dịch vụ Danh mục.
Figure 10-1. Wishlist Service needs item descriptions but doesn’t have access to the product table containing the data
Interservice Communication Pattern
Mô hình Giao tiếp Liên dịch vụ là mô hình phổ biến nhất để truy xuất dữ liệu trong một hệ thống phân tán. Nếu một dịch vụ (hoặc hệ thống) cần đọc dữ liệu mà nó không thể truy cập trực tiếp, nó chỉ cần yêu cầu dịch vụ hoặc hệ thống sở hữu dữ liệu đó bằng cách sử dụng một loại giao thức truy cập từ xa nào đó. Điều gì có thể đơn giản hơn?
Cũng như hầu hết mọi thứ trong kiến trúc phần mềm, mọi thứ không hoàn toàn như nó có vẻ. Mặc dù đơn giản, kỹ thuật truy cập dữ liệu phổ biến này đáng tiếc lại tồn đọng nhiều bất lợi. Xem Hình 10-2: Dịch vụ Wishlist thực hiện một cuộc gọi truy cập từ xa đồng bộ tới Dịch vụ Catalog, truyền vào một danh sách các ID mặt hàng để nhận về một danh sách mô tả các mặt hàng tương ứng.
Lưu ý rằng đối với mỗi yêu cầu lấy danh sách mong muốn của khách hàng, Dịch vụ Danh sách Mong muốn phải thực hiện một cuộc gọi từ xa đến Dịch vụ Danh mục để lấy mô tả mặt hàng. Vấn đề đầu tiên xảy ra với cách tiếp cận này là hiệu suất chậm hơn do độ trễ mạng, độ trễ bảo mật và độ trễ dữ liệu. Độ trễ mạng là thời gian truyền gói dữ liệu đến và từ một dịch vụ (thường nằm trong khoảng từ 30 ms đến 300 ms). Độ trễ bảo mật xảy ra khi điểm cuối của dịch vụ mục tiêu yêu cầu xác thực bổ sung để thực hiện yêu cầu. Độ trễ bảo mật có thể thay đổi lớn tùy thuộc vào mức độ bảo mật của điểm cuối đang được truy cập, nhưng có thể nằm trong khoảng từ 20 ms đến 400 ms cho hầu hết các hệ thống. Độ trễ dữ liệu mô tả tình huống mà nhiều cuộc gọi cơ sở dữ liệu cần được thực hiện để lấy thông tin cần thiết để trả lại cho người dùng cuối. Trong trường hợp này, thay vì một câu lệnh nối bảng SQL đơn, một cuộc gọi cơ sở dữ liệu bổ sung phải được Dịch vụ Danh mục thực hiện để lấy mô tả mặt hàng. Điều này có thể thêm từ 10 ms đến 50 ms thời gian xử lý bổ sung. Cộng tất cả lại, và độ trễ có thể lên đến một giây chỉ để lấy mô tả mặt hàng.
Figure 10-2. Interservice communication data access pattern
Một bất lợi lớn khác của kiểu mẫu này là sự liên kết dịch vụ. Bởi vì Danh sách mong muốn phải phụ thuộc vào việc Dịch vụ Danh mục có sẵn, nên các dịch vụ này do đó vừa liên kết ngữ nghĩa vừa liên kết tĩnh, có nghĩa là nếu Dịch vụ Danh mục không có sẵn, thì Dịch vụ Danh sách mong muốn cũng sẽ không hoạt động. Hơn nữa, do sự liên kết tĩnh chặt chẽ giữa Dịch vụ Danh sách mong muốn và Dịch vụ Danh mục, khi Dịch vụ Danh sách mong muốn mở rộng để đáp ứng khối lượng nhu cầu bổ sung, thì Dịch vụ Danh mục cũng phải mở rộng theo.
Bảng 10-1 tóm tắt các đánh đổi liên quan đến mẫu truy cập dữ liệu giao tiếp giữa các dịch vụ.
Column Schema Replication Pattern
Với mẫu Tái tạo Lược đồ Cột, các cột được sao chép qua các bảng, do đó sao chép dữ liệu và làm cho nó có sẵn cho các ngữ cảnh giới hạn khác. Như được thể hiện trong Hình 10-3, cột item_desc được thêm vào bảng Wishlist, làm cho dữ liệu đó có sẵn cho Dịch vụ Wishlist mà không cần phải yêu cầu Dịch vụ Catalog cung cấp dữ liệu.
Figure 10-3. With the Column Schema Replication data access pattern, data is replicated to other tables
Đồng bộ hóa dữ liệu và tính nhất quán của dữ liệu là hai vấn đề lớn nhất liên quan đến mẫu truy cập dữ liệu Lập bản sao Schema Cột. Mỗi khi một sản phẩm được tạo ra, loại bỏ khỏi danh mục, hoặc mô tả sản phẩm bị thay đổi, Dịch vụ Danh mục phải thông báo cho Dịch vụ Danh sách yêu thích (và bất kỳ dịch vụ nào khác đang sao chép dữ liệu) về sự thay đổi đó. Điều này thường được thực hiện thông qua các giao tiếp bất đồng bộ sử dụng hàng đợi, chủ đề hoặc streaming sự kiện. Trừ khi cần đồng bộ hóa giao dịch ngay lập tức, giao tiếp bất đồng bộ là lựa chọn ưu tiên hơn so với giao tiếp đồng bộ vì nó tăng cường khả năng đáp ứng và giảm thiểu sự phụ thuộc vào khả năng có sẵn giữa các dịch vụ.
Một thách thức khác với mô hình này là đôi khi rất khó để quản lý quyền sở hữu dữ liệu. Bởi vì dữ liệu được sao chép trong các bảng thuộc về các dịch vụ khác, nên các dịch vụ đó có thể cập nhật dữ liệu, mặc dù họ không chính thức sở hữu dữ liệu. Điều này lại tạo ra nhiều vấn đề về tính nhất quán của dữ liệu hơn nữa.
Dù các dịch vụ vẫn được kết hợp do sự đồng bộ dữ liệu, dịch vụ yêu cầu quyền truy cập đọc có thể truy cập ngay lập tức vào dữ liệu và có thể thực hiện các phép nối SQL đơn giản hoặc truy vấn đến bảng của chính nó để lấy dữ liệu. Điều này tăng hiệu suất, khả năng chịu lỗi và khả năng mở rộng, tất cả đều là những nhược điểm trong mô hình giao tiếp giữa các dịch vụ.
Trong khi nhìn chung, chúng tôi cảnh báo về việc sử dụng mẫu truy cập dữ liệu này cho các tình huống như Dịch vụ Danh sách Mong muốn và Dịch vụ Danh mục, thì một số tình huống mà nó có thể được xem xét là tổng hợp dữ liệu, báo cáo, hoặc những trường hợp mà các mẫu truy cập dữ liệu khác không phù hợp do khối lượng dữ liệu lớn, yêu cầu phản hồi cao, hoặc yêu cầu độ tin cậy cao.
Bảng 10-2 tóm tắt các thỏa hiệp liên quan đến mô hình truy cập dữ liệu Lập bản sao lược đồ cột.
Replicated Caching Pattern
Hầu hết các nhà phát triển và kiến trúc sư coi caching là một kỹ thuật để tăng cường khả năng phản hồi tổng thể. Bằng cách lưu trữ dữ liệu trong bộ nhớ cache, việc truy xuất dữ liệu từ hàng chục mili giây giảm xuống chỉ còn vài nano giây. Tuy nhiên, caching cũng có thể là một công cụ hiệu quả cho việc truy cập và chia sẻ dữ liệu phân tán. Mô hình này tận dụng cache in-memory được sao chép để dữ liệu cần thiết cho các dịch vụ khác được cung cấp cho mỗi dịch vụ mà không cần chúng phải yêu cầu. Một cache được sao chép khác với các mô hình cache khác ở chỗ dữ liệu được lưu giữ trong bộ nhớ trong mỗi dịch vụ và được đồng bộ hóa liên tục để tất cả các dịch vụ có cùng một dữ liệu chính xác vào mọi thời điểm.
Để hiểu rõ hơn về mô hình bộ nhớ đệm đã được sao chép, việc so sánh nó với các mô hình bộ nhớ đệm khác sẽ hữu ích để thấy sự khác biệt giữa chúng. Mô hình bộ nhớ đệm đơn giản trong bộ nhớ là hình thức đơn giản nhất của việc bộ nhớ đệm, nơi mỗi dịch vụ có bộ nhớ đệm trong bộ nhớ nội bộ riêng của nó. Với mô hình bộ nhớ đệm này (được minh họa trong Hình 10-4), dữ liệu trong bộ nhớ không được đồng bộ giữa các bộ nhớ đệm, nghĩa là mỗi dịch vụ có dữ liệu duy nhất riêng biệt thuộc về dịch vụ đó. Mặc dù mô hình bộ nhớ đệm này giúp tăng cường khả năng phản hồi và khả năng mở rộng trong từng dịch vụ, nhưng nó không hữu ích cho việc chia sẻ dữ liệu giữa các dịch vụ do sự thiếu đồng bộ bộ nhớ đệm giữa các dịch vụ.
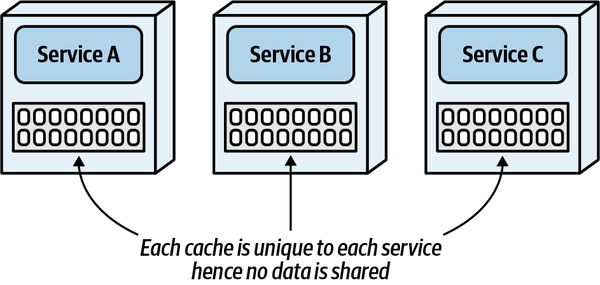
Figure 10-4. With a single in-memory cache, each service contains its own unique data
Mô hình caching khác được sử dụng trong kiến trúc phân tán là caching phân tán. Như được minh họa trong Hình 10-5, với mô hình caching này, dữ liệu không được giữ trong bộ nhớ của từng dịch vụ, mà được lưu trữ bên ngoài trong một máy chủ caching. Các dịch vụ, sử dụng một giao thức riêng, thực hiện yêu cầu đến máy chủ caching để truy xuất hoặc cập nhật dữ liệu chung. Lưu ý rằng, không giống như mô hình caching trong bộ nhớ đơn, dữ liệu có thể được chia sẻ giữa các dịch vụ.
Mô hình bộ nhớ đệm phân tán không phải là một mô hình bộ nhớ đệm hiệu quả để sử dụng cho mô hình truy cập dữ liệu bộ nhớ đệm sao chép vì nhiều lý do. Đầu tiên, không có lợi ích nào từ các vấn đề về khả năng chịu lỗi mà chúng ta thấy trong mô hình Giao tiếp giữa các dịch vụ. Thay vì phụ thuộc vào một dịch vụ để truy xuất dữ liệu, sự phụ thuộc chỉ đơn giản là đã chuyển sang máy chủ bộ nhớ đệm.
Bởi vì dữ liệu cache được tập trung và chia sẻ, mô hình cache phân tán cho phép các dịch vụ khác cập nhật dữ liệu, do đó phá vỡ bối cảnh ràng buộc về quyền sở hữu dữ liệu. Điều này có thể gây ra sự không nhất quán dữ liệu giữa cache và cơ sở dữ liệu sở hữu. Mặc dù điều này đôi khi có thể được giải quyết thông qua việc quản lý chặt chẽ, nhưng nó vẫn là một vấn đề với mô hình cache này.
Cuối cùng, vì việc truy cập vào bộ nhớ đệm phân tán tập trung thực hiện thông qua một cuộc gọi từ xa, độ trễ mạng làm tăng thêm thời gian truy xuất dữ liệu, từ đó ảnh hưởng đến khả năng phản hồi tổng thể so với bộ nhớ đệm sao chép trong bộ nhớ.
Figure 10-5. A distributed cache is external from the services
Với bộ nhớ cache được sao chép, mỗi dịch vụ có dữ liệu trong bộ nhớ của riêng mình, được giữ đồng bộ giữa các dịch vụ, cho phép dữ liệu giống nhau được chia sẻ giữa nhiều dịch vụ. Lưu ý trong Hình 10-6 rằng không có sự phụ thuộc vào bộ nhớ cache bên ngoài. Mỗi phiên bản bộ nhớ cache giao tiếp với nhau để khi một cập nhật được thực hiện trên bộ nhớ cache, cập nhật đó ngay lập tức (ẩn sau các màn hình) được truyền đạt một cách không đồng bộ đến các dịch vụ khác sử dụng cùng một bộ nhớ cache.
Figure 10-6. With a replicated cache, each service contains the same in-memory data
Không phải tất cả các sản phẩm caching đều hỗ trợ caching sao chép, vì vậy điều quan trọng là kiểm tra với nhà cung cấp sản phẩm caching để đảm bảo hỗ trợ cho mô hình caching sao chép. Một số sản phẩm phổ biến hỗ trợ caching sao chép bao gồm Hazelcast, Apache Ignite và Oracle Coherence.
Để xem cách bộ nhớ đệm sao chép có thể giải quyết việc truy cập dữ liệu phân tán, chúng ta sẽ trở lại với ví dụ về Dịch vụ Danh sách mong muốn và Dịch vụ Danh mục. Trong Hình 10-7, Dịch vụ Danh mục sở hữu một bộ nhớ đệm trong bộ nhớ về mô tả sản phẩm (nghĩa là nó là dịch vụ duy nhất có thể sửa đổi bộ nhớ đệm), và Dịch vụ Danh sách mong muốn chứa một bản sao chỉ đọc trong bộ nhớ của cùng một bộ nhớ đệm.
Figure 10-7. Replicated caching data access pattern
Với mẫu này, Dịch vụ Danh sách mong muốn không còn cần gọi đến Dịch vụ Danh mục để lấy mô tả sản phẩm - chúng đã được lưu trong bộ nhớ của Dịch vụ Danh sách mong muốn. Khi có bản cập nhật mô tả sản phẩm được thực hiện bởi Dịch vụ Danh mục, sản phẩm trong bộ nhớ đệm sẽ cập nhật bộ nhớ đệm trong Dịch vụ Danh sách mong muốn để đảm bảo dữ liệu nhất quán.
Những lợi thế rõ ràng của mô hình cache sao chép là khả năng phản hồi, tính chịu lỗi và khả năng mở rộng. Bởi vì không cần giao tiếp giữa các dịch vụ một cách rõ ràng, dữ liệu có sẵn ngay trong bộ nhớ, cung cấp truy cập nhanh nhất có thể đến dữ liệu mà dịch vụ không sở hữu. Tính chịu lỗi cũng được hỗ trợ tốt với mô hình này. Ngay cả khi Dịch vụ Danh mục (Catalog Service) bị sập, Dịch vụ Danh sách Ưu tiên (Wishlist Service) vẫn có thể tiếp tục hoạt động. Khi Dịch vụ Danh mục khôi phục, các cache kết nối với nhau mà không gây gián đoạn cho Dịch vụ Danh sách Ưu tiên. Cuối cùng, với mô hình này, Dịch vụ Danh sách Ưu tiên có thể mở rộng độc lập với Dịch vụ Danh mục.
Với tất cả những lợi thế rõ ràng này, làm sao lại có thể tồn tại một sự đánh đổi với mô hình này? Như luật đầu tiên của kiến trúc phần mềm đã nêu trong cuốn sách của chúng tôi, Những Nguyên Tắc Cơ Bản Của Kiến Trúc Phần Mềm, mọi thứ trong kiến trúc phần mềm đều là một sự đánh đổi, và nếu một kiến trúc sư nghĩ rằng họ đã phát hiện ra điều gì đó không phải là sự đánh đổi, điều đó có nghĩa là họ chỉ chưa xác định được sự đánh đổi đó mà thôi.
Một sự đánh đổi đầu tiên với mẫu này là sự phụ thuộc vào dịch vụ liên quan đến dữ liệu bộ nhớ cache và thời gian khởi động. Vì Dịch vụ Danh mục sở hữu bộ nhớ cache và chịu trách nhiệm làm đầy bộ nhớ cache, nó phải đang chạy khi Dịch vụ Danh sách Ưu tiên ban đầu khởi động. Nếu Dịch vụ Danh mục không khả dụng, Dịch vụ Danh sách Ưu tiên ban đầu phải vào trạng thái chờ cho đến khi kết nối với Dịch vụ Danh mục được thiết lập. Lưu ý rằng chỉ có phiên bản Dịch vụ Danh sách Ưu tiên ban đầu bị ảnh hưởng bởi sự phụ thuộc khởi động này; nếu Dịch vụ Danh mục bị lỗi, các phiên bản Dịch vụ Danh sách Ưu tiên khác vẫn có thể được khởi động, với dữ liệu bộ nhớ cache được chuyển từ một trong những phiên bản Dịch vụ Danh sách Ưu tiên khác. Cũng cần lưu ý rằng một khi Dịch vụ Danh sách Ưu tiên đã khởi động và có dữ liệu trong bộ nhớ cache, không cần thiết phải có Dịch vụ Danh mục khả dụng. Khi bộ nhớ cache được cung cấp trong Dịch vụ Danh sách Ưu tiên, Dịch vụ Danh mục có thể khởi động và ngừng mà không ảnh hưởng đến Dịch vụ Danh sách Ưu tiên (hoặc bất kỳ phiên bản nào của nó).
Sự đánh đổi thứ hai với mô hình này là về khối lượng dữ liệu. Nếu khối lượng dữ liệu quá lớn (chẳng hạn vượt quá 500 MB), tính khả thi của mô hình này nhanh chóng giảm sút, đặc biệt là khi có nhiều phiên bản dịch vụ cần dữ liệu. Mỗi phiên bản dịch vụ có bộ nhớ cache nhân bản riêng, nghĩa là nếu kích thước cache là 500 MB và cần 5 phiên bản dịch vụ, tổng bộ nhớ sử dụng là 2.5 GB. Các kiến trúc sư phải phân tích cả kích thước của bộ nhớ cache và tổng số phiên bản dịch vụ cần dữ liệu cache để xác định tổng yêu cầu bộ nhớ cho bộ nhớ cache nhân bản.
Một sự đánh đổi thứ ba là mô hình cache sao chép thường không thể giữ cho dữ liệu hoàn toàn đồng bộ giữa các dịch vụ nếu tỷ lệ thay đổi của dữ liệu (tỷ lệ cập nhật) quá cao. Điều này có sự khác biệt dựa trên kích thước dữ liệu và độ trễ sao chép, nhưng nhìn chung, mô hình này không phù hợp cho dữ liệu có độ biến động cao (như số lượng hàng tồn kho sản phẩm). Tuy nhiên, đối với dữ liệu tương đối tĩnh (như mô tả sản phẩm), mô hình này hoạt động tốt.
Sự đánh đổi cuối cùng liên quan đến mô hình này là quản lý cấu hình và thiết lập. Các dịch vụ nhận biết lẫn nhau trong mô hình bộ nhớ cache sao chép thông qua các bản phát sóng và tra cứu TCP/IP. Nếu phạm vi bản phát sóng và tra cứu TCP/IP quá rộng, có thể mất nhiều thời gian để thiết lập quy trình bắt tay cấp socket giữa các dịch vụ. Các môi trường dựa trên đám mây và container hóa làm cho vấn đề này đặc biệt khó khăn do thiếu khả năng kiểm soát đối với địa chỉ IP và tính chất động của các địa chỉ IP liên quan đến những môi trường này.
Bảng 10-3 liệt kê các giao dịch liên quan đến mẫu truy cập dữ liệu cache được sao chép.
Data Domain Pattern
Trong chương trước, chúng ta đã thảo luận về việc sử dụng một miền dữ liệu để giải quyết vấn đề quyền sở hữu chung, trong đó nhiều dịch vụ cần ghi dữ liệu vào cùng một bảng. Các bảng được chia sẻ giữa các dịch vụ được đưa vào một lược đồ duy nhất mà sau đó được chia sẻ bởi cả hai dịch vụ. Mô hình tương tự cũng có thể được sử dụng cho việc truy cập dữ liệu.
Xem xét lại vấn đề Dịch vụ Danh sách Ước và Dịch vụ Danh mục, nơi Dịch vụ Danh sách Ước cần truy cập vào mô tả sản phẩm nhưng không có quyền truy cập vào bảng chứa những mô tả đó. Giả sử mô hình Giao tiếp Giữa Các Dịch vụ không phải là giải pháp khả thi do vấn đề độ tin cậy của Dịch vụ Danh mục cũng như vấn đề hiệu suất với độ trễ mạng và việc truy xuất dữ liệu bổ sung. Cũng giả sử rằng mô hình Nhân bản Lược đồ Cột không khả thi vì yêu cầu về mức độ nhất quán dữ liệu cao. Cuối cùng, giả sử rằng mô hình Bộ đệm Nhân bản không phải là một lựa chọn vì khối lượng dữ liệu lớn. Giải pháp duy nhất còn lại là tạo một miền dữ liệu, kết hợp bảng Danh sách Ước và bảng Sản phẩm trong cùng một lược đồ chia sẻ, có thể truy cập được cho cả Dịch vụ Danh sách Ước và Dịch vụ Danh mục.
Hình 10-8 minh họa việc sử dụng mẫu truy cập dữ liệu này. Lưu ý rằng bảng Wishlist và bảng Product không còn thuộc sở hữu của dịch vụ nào, mà được chia sẻ giữa chúng, hình thành một bối cảnh giới hạn rộng hơn. Với mẫu này, việc truy cập vào mô tả sản phẩm trong Dịch vụ Wishlist chỉ là một phép nối SQL đơn giản giữa hai bảng.
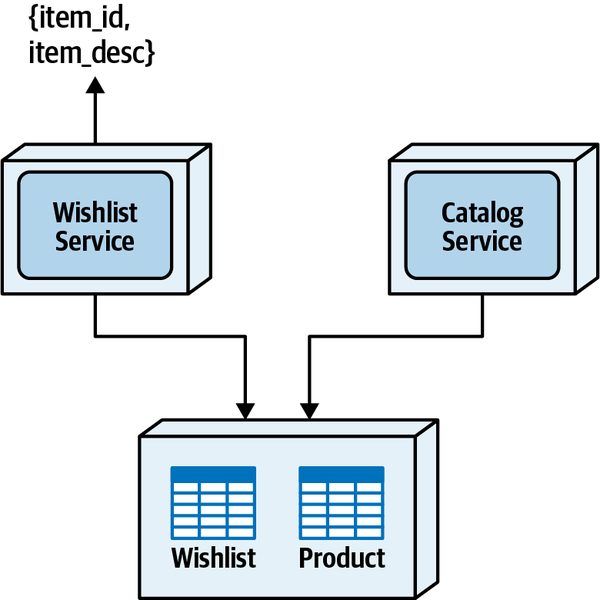
Figure 10-8. Data domain data access pattern
Trong khi việc chia sẻ dữ liệu thường không được khuyến khích trong kiến trúc phân tán, mẫu này mang lại nhiều lợi ích lớn hơn so với các mẫu truy cập dữ liệu khác. Trước hết, các dịch vụ hoàn toàn tách rời nhau, do đó giải quyết bất kỳ sự phụ thuộc nào về khả năng sẵn sàng, khả năng phản hồi, thông lượng và mở rộng. Khả năng phản hồi rất tốt với mẫu này vì dữ liệu có sẵn thông qua một cuộc gọi SQL bình thường, loại bỏ nhu cầu thực hiện các tổng hợp dữ liệu bổ sung trong chức năng của dịch vụ (như được yêu cầu với mẫu Bộ đệm Nhân bản).
Cả tính nhất quán dữ liệu và tính toàn vẹn dữ liệu đều rất cao với mẫu Data Domain. Do nhiều dịch vụ truy cập cùng một bảng dữ liệu, dữ liệu không cần phải được chuyển giao, sao chép hoặc đồng bộ hóa. Tính toàn vẹn dữ liệu được duy trì trong mẫu này theo nghĩa là các ràng buộc khóa ngoại giờ đây có thể được thực thi giữa các bảng. Ngoài ra, các đối tượng cơ sở dữ liệu khác, chẳng hạn như views, stored procedures và triggers, có thể tồn tại trong miền dữ liệu. Thực tế, việc bảo tồn những ràng buộc toàn vẹn này và các đối tượng cơ sở dữ liệu là một động lực khác cho việc sử dụng mẫu Data Domain.
Với mô hình này, không cần hợp đồng bổ sung nào để chuyển dữ liệu giữa các dịch vụ - sơ đồ bảng trở thành hợp đồng. Trong khi đây là một lợi thế cho mô hình này, nó cũng là một sự đánh đổi. Các hợp đồng được sử dụng với mô hình giao tiếp giữa các dịch vụ và mô hình Bộ nhớ Cache Nhân bản tạo thành một lớp trừu tượng trên sơ đồ bảng, cho phép các thay đổi đối với cấu trúc bảng vẫn nằm trong một ngữ cảnh giới hạn chặt chẽ và không ảnh hưởng đến các dịch vụ khác. Tuy nhiên, mô hình này tạo thành một ngữ cảnh giới hạn rộng hơn, yêu cầu nhiều dịch vụ có thể thay đổi khi cấu trúc của bất kỳ bảng nào trong miền dữ liệu thay đổi.
Một nhược điểm khác của mẫu này là nó có thể mở ra các vấn đề bảo mật liên quan đến quyền truy cập dữ liệu. Ví dụ, trong Hình 10-8, Dịch vụ Wishlist có quyền truy cập hoàn toàn vào tất cả dữ liệu trong miền dữ liệu. Mặc dù điều này là chấp nhận được trong ví dụ về Dịch vụ Wishlist và Dịch vụ Catalog, nhưng có thể có những thời điểm mà các dịch vụ truy cập vào miền dữ liệu không nên có quyền truy cập vào một số dữ liệu nhất định. Một bối cảnh hạn chế hơn với quyền sở hữu dịch vụ nghiêm ngặt có thể ngăn các dịch vụ khác truy cập vào một số dữ liệu nhất định thông qua các hợp đồng được sử dụng để truyền dữ liệu qua lại.
Bảng 10-4 liệt kê các sự đánh đổi liên quan đến mẫu truy cập dữ liệu của miền dữ liệu.
Sysops Squad Saga: Data Access for Ticket Assignment
Thứ Năm, 3 tháng 3, 14:59
Logan đã giải thích các phương pháp khác nhau để truy cập dữ liệu trong một kiến trúc phân tán, và cũng phác thảo những đánh đổi tương ứng của mỗi kỹ thuật. Addison, Sydney và Taylen sau đó đã phải đưa ra quyết định về kỹ thuật nào để sử dụng.
“Trừ khi chúng ta bắt đầu hợp nhất tất cả các dịch vụ này, tôi đoán chúng ta sẽ phải chấp nhận rằng việc Giao phó Vé cần phải đến được với dữ liệu hồ sơ chuyên gia một cách nhanh chóng,” Taylen nói.
"Được rồi," Addison nói. "Vậy việc hợp nhất dịch vụ là không khả thi vì những dịch vụ này nằm trong các miền hoàn toàn khác nhau, và tùy chọn miền dữ liệu chia sẻ cũng không khả thi vì lý do mà chúng ta đã bàn luận trước đó—chúng ta không thể để Dịch vụ Gán Vé kết nối với hai cơ sở dữ liệu khác nhau."
"Vậy thì, chúng ta có hai lựa chọn." Sydney nói. "Chúng ta có thể sử dụng giao tiếp giữa các đơn vị quân đội hoặc bộ nhớ đệm sao chép."
“Chờ đã. Hãy xem xét tùy chọn bộ nhớ đệm sao chép trong một phút,” Taylen nói. “Chúng ta đang nói về bao nhiêu dữ liệu ở đây?”
“Vậy,” Sydney nói, “chúng ta có 900 chuyên gia trong cơ sở dữ liệu. Dịch vụ Phân bổ Vé cần dữ liệu gì từ bảng hồ sơ chuyên gia?”
“Đó chủ yếu là thông tin tĩnh vì chúng tôi nhận các nguồn thông tin vị trí chuyên gia hiện tại từ nơi khác. Vì vậy, đó sẽ là kỹ năng của chuyên gia, khu vực dịch vụ của họ và lịch trình sẵn có tiêu chuẩn của họ,” Taylen nói.
“Được rồi, vậy thì đó khoảng 1,3 KB dữ liệu cho mỗi chuyên gia. Và vì chúng ta có tổng cộng 900 chuyên gia, thì sẽ là… khoảng 1200 KB tổng dữ liệu. Và dữ liệu này tương đối tĩnh,” Sydney nói.
“Hmm, điều đó không phải là nhiều dữ liệu để lưu trữ trong bộ nhớ,” Taylen nói.
“Đừng quên rằng nếu chúng ta sử dụng bộ nhớ cache sao chép, chúng ta sẽ phải xem xét số lượng các phiên bản mà chúng ta sẽ có cho Dịch vụ Quản lý Người dùng cũng như Dịch vụ Gán Vé,” Addison nói. “Chỉ để chắc chắn, chúng ta nên sử dụng số lượng phiên bản tối đa của mỗi dịch vụ mà chúng ta mong đợi.”
“Tôi đã có thông tin đó,” Taylen nói. “Chúng tôi dự kiến chỉ có tối đa hai phiên bản của Dịch vụ Quản lý Người dùng và tối đa bốn phiên bản trong cao điểm nhất của Dịch vụ Phân công Vé.”
"Đó không phải là một lượng dữ liệu trong bộ nhớ lớn." Sydney nhận xét.
“Không, không phải vậy,” Addison nói. “Được rồi, hãy phân tích các sự đánh đổi bằng cách tiếp cận dựa trên giả thuyết mà chúng ta đã thử trước đó. Tôi đề xuất rằng chúng ta nên chọn tùy chọn bộ nhớ đệm nhân bản trong bộ nhớ để chỉ lưu trữ dữ liệu cần thiết cho Dịch vụ Gán Vé. Còn sự đánh đổi nào khác mà bạn có thể nghĩ đến không?”
Cả Taylen và Sydney ngồi đó một lúc để cố gắng nghĩ ra một số điểm tiêu cực cho phương pháp bộ nhớ đệm sao chép.
“Vậy nếu Dịch vụ Quản lý Người dùng bị sập thì sao?” Sydney hỏi.
“Miễn là bộ nhớ cache được lấp đầy, thì Dịch vụ Giao nhận Vé sẽ hoạt động tốt,” Addison nói.
“Chờ đã, bạn có ý nói rằng dữ liệu sẽ được lưu trữ trong bộ nhớ, ngay cả khi Dịch vụ Quản lý Người dùng không khả dụng sao?” Taylen hỏi.
"Miễn là Dịch vụ Quản lý Người dùng khởi động trước Dịch vụ Phân công Vé, thì có," Addison nói.
“À!" Taylen nói. "Vậy thì đó là sự đánh đổi đầu tiên của chúng ta. Việc phân bổ vé không thể hoạt động nếu không khởi động Dịch vụ Quản lý Người dùng. Điều đó không tốt.”
“Nhưng,” Addison nói, “nếu chúng ta gọi từ xa đến Dịch vụ Quản lý Người dùng và nó bị sập, Dịch vụ Phân bổ Vé sẽ không hoạt động. Ít nhất với tùy chọn bộ nhớ đệm sao chép, một khi Quản lý Người dùng đã hoạt động trở lại, chúng ta không còn phụ thuộc vào nó nữa. Vì vậy, bộ nhớ đệm sao chép thực sự có khả năng chịu lỗi tốt hơn trong trường hợp này.”
"Đúng vậy," Taylen nói. "Chúng ta chỉ cần cẩn thận về sự phụ thuộc vào khởi động."
“Còn điều gì khác mà bạn nghĩ là tiêu cực?” Addison hỏi, biết rằng có một sự đánh đổi rõ ràng khác nhưng muốn nhóm phát triển tự mình nghĩ ra.
“Um,” Sydney nói, “vâng. Tôi có một cái. Chúng ta sẽ sử dụng sản phẩm caching nào?”
“À,” Addison nói, “đó thực sự là một sự đánh đổi khác. Có ai trong hai người đã từng làm với bộ nhớ đệm nhân bản chưa? Hay bất kỳ ai trong nhóm phát triển thì sao?”
Cả Taylen và Sydney đều lắc đầu.
"Vậy thì chúng ta có một số rủi ro ở đây," Addison nói.
“Thực ra,” Taylen nói, “Tôi đã nghe nói nhiều về kỹ thuật cache này một thời gian và rất muốn thử nghiệm. Tôi sẽ tình nguyện nghiên cứu một số sản phẩm và thực hiện một số chứng minh khái niệm về phương pháp này.”
“Rất tốt,” Addison nói. “Trong thời gian chờ đợi, tôi sẽ nghiên cứu chi phí cấp phép cho những sản phẩm đó, cũng như xem có bất kỳ giới hạn kỹ thuật nào liên quan đến môi trường triển khai của chúng ta không. Bạn biết đấy, những thứ như chồng chéo vùng khả dụng, tường lửa, những thứ đại loại như vậy.”
Nhóm bắt đầu nghiên cứu và thực hiện công việc chứng minh khái niệm, và đã nhận thấy rằng đây không chỉ là một giải pháp khả thi về chi phí và nỗ lực, mà còn giải quyết vấn đề truy cập dữ liệu vào bảng hồ sơ chuyên gia. Addison đã thảo luận về phương pháp này với Logan, người đã phê duyệt giải pháp. Addison đã tạo ra một ADR phác thảo và biện minh cho quyết định này.
ADR: Sử dụng bộ nhớ đệm sao chép trong bộ nhớ cho dữ liệu hồ sơ chuyên gia
Bối cảnh Dịch vụ Giao nhiệm vụ cần truy cập liên tục vào bảng hồ sơ chuyên gia, được sở hữu bởi Dịch vụ Quản lý Người dùng trong một bối cảnh giới hạn khác. Truy cập thông tin hồ sơ chuyên gia có thể được thực hiện thông qua giao tiếp giữa các dịch vụ, bộ nhớ cache nhân bản trong bộ nhớ hoặc một miền dữ liệu chung.
Quyết định Chúng tôi sẽ sử dụng bộ nhớ đệm sao chép giữa Dịch vụ Quản lý Người dùng và Dịch vụ Phân bổ Vé, với Dịch vụ Quản lý Người dùng là người sở hữu duy nhất cho các thao tác ghi.
Vì Dịch vụ Gán Vé đã kết nối với lược đồ dữ liệu miền vé chia sẻ, nó không thể kết nối với một lược đồ bổ sung. Hơn nữa, do chức năng quản lý người dùng và chức năng ticketing cốt lõi nằm trong hai miền riêng biệt, chúng tôi không muốn kết hợp các bảng dữ liệu trong một lược đồ duy nhất. Do đó, việc sử dụng một miền dữ liệu chung không phải là một lựa chọn.
Sử dụng một bộ nhớ cache sao chép trong bộ nhớ giải quyết các vấn đề về hiệu suất và khả năng chịu lỗi liên quan đến tùy chọn giao tiếp giữa các dịch vụ.
Hậu quả Ít nhất một phiên bản của Dịch vụ Quản lý Người dùng phải đang chạy khi khởi động phiên bản đầu tiên của Dịch vụ Gán Vé.
Chi phí cấp phép cho sản phẩm caching sẽ được yêu cầu cho tùy chọn này.
Chapter 11. Managing Distributed Workflows
Thứ Ba, ngày 15 tháng 2, 14:34
Austen chạy nhanh vào văn phòng của Logan ngay sau bữa trưa. “Tôi đã xem xét các thiết kế kiến trúc mới, và tôi muốn giúp đỡ. Bạn có cần tôi viết một số ADR hoặc giúp đỡ với một số spikes không? Tôi sẵn sàng viết lên ADR tuyên bố rằng chúng ta chỉ sử dụng choreography trong kiến trúc mới để giữ cho mọi thứ không bị ràng buộc.”
“Ôi, dừng lại đi, tên điên,” Logan nói. “Bạn nghe điều đó ở đâu? Điều gì khiến bạn có ấn tượng như vậy?”
"Chà, tôi đã đọc rất nhiều về microservices, và lời khuyên của mọi người dường như là giữ cho mọi thứ tách rời cao. Khi tôi nhìn vào các mô hình giao tiếp, có vẻ như choreography là phương thức tách rời nhất, vì vậy chúng ta nên luôn sử dụng nó, đúng không?"
"Luôn luôn là một thuật ngữ khó khăn trong kiến trúc phần mềm. Tôi có một người hướng dẫn có quan điểm đáng nhớ về điều này, người luôn nói, Đừng bao giờ sử dụng các từ tuyệt đối khi nói về kiến trúc, ngoại trừ khi nói về các từ tuyệt đối. Nói cách khác, đừng bao giờ nói 'không bao giờ'. Tôi không thể nghĩ ra nhiều quyết định trong kiến trúc mà 'luôn luôn' hoặc 'không bao giờ' áp dụng."
"Được rồi," Austen nói. "Vậy các kiến trúc sư quyết định giữa các kiểu giao tiếp khác nhau như thế nào?"
Là một phần trong phân tích liên tục của chúng tôi về những cân nhắc đi kèm với các kiến trúc phân tán hiện đại, chúng tôi đi đến phần động của sự liên kết lượng tử, nhận ra nhiều mẫu mà chúng tôi đã mô tả và đặt tên trong Chương 2. Thực tế, ngay cả những mẫu mà chúng tôi đã đặt tên chỉ chạm đến nhiều hoán vị có thể với các kiến trúc hiện đại. Do đó, một kiến trúc sư nên hiểu các lực lượng đang hoạt động để có thể thực hiện phân tích cân nhắc một cách khách quan nhất.
Trong Chương 2, chúng tôi đã xác định ba lực liên kết khi xem xét các mô hình tương tác trong kiến trúc phân tán: giao tiếp, nhất quán và phối hợp, như đã được trình bày trong Hình 11-1.
Figure 11-1. The dimensions of dynamic quantum coupling
Trong chương này, chúng tôi sẽ thảo luận về sự phối hợp: kết hợp hai hoặc nhiều dịch vụ trong kiến trúc phân tán để tạo thành một công việc theo miền cụ thể, cùng với nhiều vấn đề liên quan.
Có hai mẫu phối hợp cơ bản trong kiến trúc phân tán: điều phối và biên đạo. Sự khác biệt cơ bản về mặt hình thái giữa hai phong cách này được minh họa trong Hình 11-2.
Sự điều phối được phân biệt bởi việc sử dụng một người điều phối, trong khi một giải pháp được vũ công hóa thì không sử dụng một người nào.
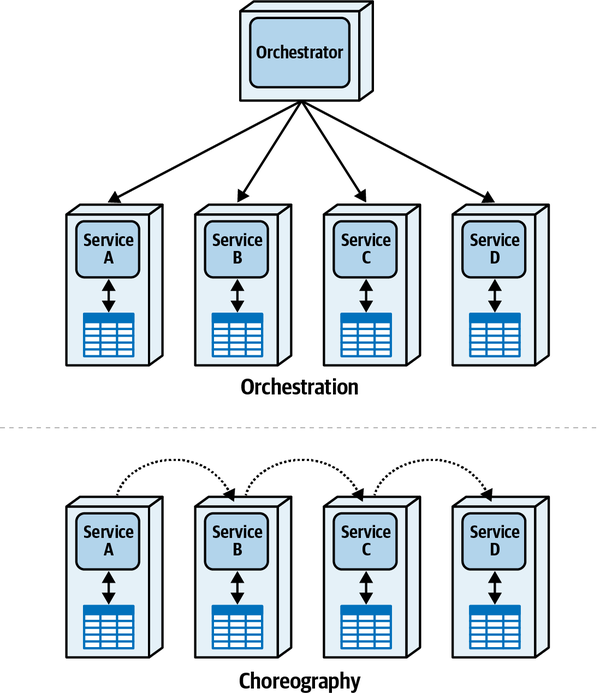
Figure 11-2. Orchestration versus choreography in distributed architectures
Orchestration Communication Style
Mô hình điều phối sử dụng một thành phần điều phối (đôi khi được gọi là môi giới) để quản lý trạng thái luồng công việc, hành vi tùy chọn, xử lý lỗi, thông báo và rất nhiều công việc bảo trì luồng công việc khác. Nó được đặt tên theo đặc điểm phân biệt của một dàn nhạc, sử dụng một nhạc trưởng để đồng bộ hóa các phần chưa hoàn chỉnh của bản nhạc tổng thể nhằm tạo ra một tác phẩm âm nhạc thống nhất. Sự điều phối được minh họa trong biểu diễn tổng quát nhất trong Hình 11-3.
Trong ví dụ này, các dịch vụ A-D là các dịch vụ miền, mỗi dịch vụ chịu trách nhiệm về bối cảnh gói gọn, dữ liệu và hành vi riêng của nó. Thành phần Orchestrator thường không bao gồm bất kỳ hành vi miền nào ngoài quy trình công việc mà nó trung gian. Lưu ý rằng kiến trúc microservices có một orchestrator cho mỗi quy trình công việc, không có một orchestrator toàn cầu như bus dịch vụ doanh nghiệp (ESB). Một trong những mục tiêu chính của kiểu kiến trúc microservices là giảm thiểu sự phụ thuộc lẫn nhau, và việc sử dụng một thành phần toàn cầu như ESB tạo ra một điểm liên kết không mong muốn. Do đó, microservices có xu hướng có một orchestrator cho mỗi quy trình công việc.
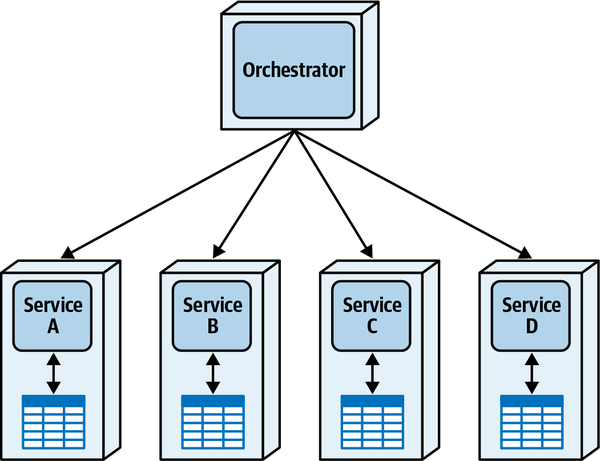
Figure 11-3. Orchestration among distributed microservices
Điều phối là hữu ích khi một kiến trúc sư phải mô hình hóa một quy trình làm việc phức tạp bao gồm không chỉ "đường đi hạnh phúc" đơn lẻ mà còn các đường đi thay thế và các điều kiện lỗi. Tuy nhiên, để hiểu hình dạng cơ bản của mẫu, chúng ta bắt đầu với đường đi hạnh phúc không có lỗi. Hãy xem xét một ví dụ rất đơn giản về Công ty Điện tử Penultimate bán một thiết bị cho một trong những khách hàng của mình trực tuyến, như được thể hiện trong Hình 11-4.
Hệ thống này chuyển yêu cầu Đặt Hàng đến Bộ Điều Phối Đặt Hàng, bộ điều phối này thực hiện một cuộc gọi đồng bộ đến Dịch Vụ Đặt Hàng, nơi ghi lại đơn hàng và trả về một thông điệp trạng thái. Tiếp theo, bộ trung gian gọi đến Dịch Vụ Thanh Toán, nơi cập nhật thông tin thanh toán. Sau đó, bộ điều phối thực hiện một cuộc gọi bất đồng bộ đến Dịch Vụ Thực Hiện để xử lý đơn hàng. Cuộc gọi là bất đồng bộ vì không có những phụ thuộc thời gian nghiêm ngặt nào cho việc thực hiện đơn hàng, trái ngược với việc xác minh thanh toán. Ví dụ, nếu việc thực hiện đơn hàng chỉ xảy ra vài lần một ngày, thì không có lý do gì để phải chịu overhead của một cuộc gọi đồng bộ. Tương tự, bộ điều phối sau đó gọi đến Dịch Vụ Gửi Thư để thông báo cho người dùng về một đơn hàng điện tử thành công.
Nếu thế giới chỉ bao gồm những con đường hạnh phúc, kiến trúc phần mềm sẽ rất dễ dàng. Tuy nhiên, một trong những khó khăn chính của kiến trúc phần mềm là các điều kiện và đường dẫn lỗi.
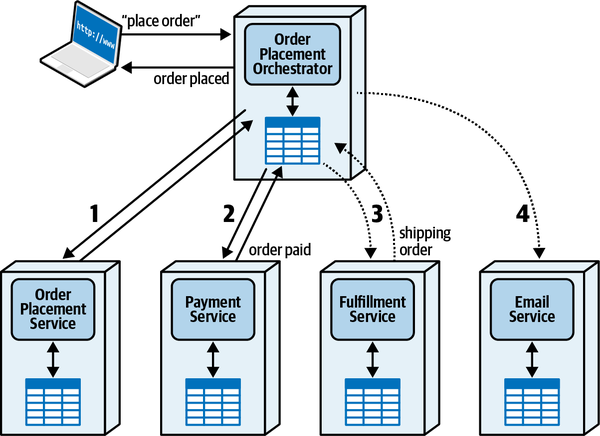
Figure 11-4. A “happy path” workflow using an orchestrator to purchase electronic equipment (note the asynchronous calls denoted by dotted lines for less time-sensitive calls)
Xem xét hai kịch bản lỗi tiềm năng trong việc mua sắm điện tử. Đầu tiên, điều gì sẽ xảy ra nếu phương thức thanh toán của khách hàng bị từ chối? Kịch bản lỗi này xuất hiện trong Hình 11-5.
Ở đây, Bộ điều phối Đặt hàng cập nhật đơn hàng qua Dịch vụ Đặt hàng như trước. Tuy nhiên, khi cố gắng thực hiện thanh toán, nó bị từ chối bởi dịch vụ thanh toán, có thể là do số thẻ tín dụng đã hết hạn. Trong trường hợp đó, Dịch vụ Thanh toán thông báo cho bộ điều phối, và sau đó bộ điều phối thực hiện một cuộc gọi (thông thường là) không đồng bộ để gửi thông điệp cho Dịch vụ Email nhằm thông báo cho khách hàng về đơn hàng không thành công. Thêm vào đó, bộ điều phối cập nhật trạng thái của Dịch vụ Đặt hàng, mà vẫn nghĩ rằng đây là một đơn hàng đang hoạt động.
Lưu ý trong ví dụ này, chúng ta cho phép mỗi dịch vụ duy trì trạng thái giao dịch riêng của nó, mô hình hóa "Mô hình Sagu Fairy Tale" của chúng ta. Một trong những phần khó khăn nhất của kiến trúc hiện đại là quản lý giao dịch, điều này chúng ta sẽ đề cập trong Chương 12.
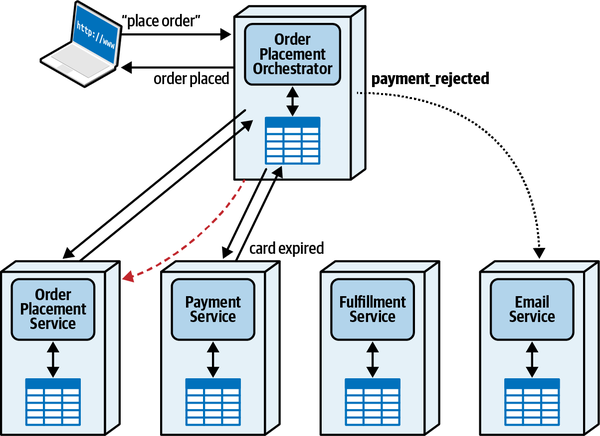
Figure 11-5. Payment rejected error condition
Trong kịch bản lỗi thứ hai, quy trình đã tiến xa hơn: điều gì sẽ xảy ra khi Dịch vụ Thực hiện báo cáo một đơn hàng bị thiếu hàng? Kịch bản lỗi này xuất hiện trong Hình 11-6.
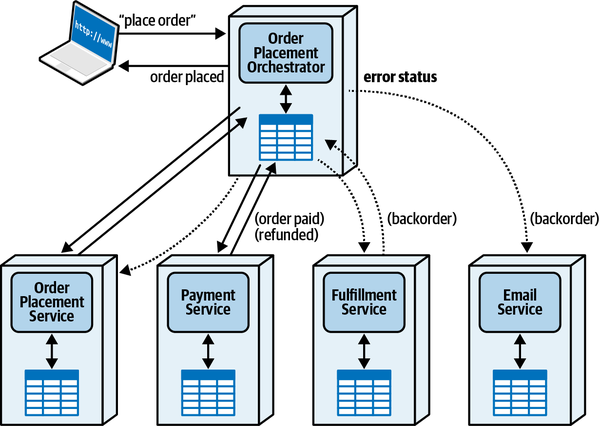
Figure 11-6. When an item is back-ordered, the orchestrator must rectify the state
Như bạn có thể thấy, quy trình làm việc diễn ra bình thường cho đến khi Dịch vụ hoàn tất thông báo cho người điều phối rằng mặt hàng hiện tại đã hết hàng, cần phải đặt hàng lại. Trong trường hợp đó, người điều phối phải hoàn lại tiền (đây là lý do tại sao nhiều dịch vụ trực tuyến không thu phí cho đến khi giao hàng, không phải vào thời điểm đặt hàng) và cập nhật trạng thái của Dịch vụ Đặt hàng.
Một đặc điểm thú vị cần lưu ý trong Hình 11-6: ngay cả trong những kịch bản lỗi phức tạp nhất, kiến trúc sư không cần phải thêm các đường truyền thông bổ sung mà không có sẵn để hỗ trợ quy trình làm việc bình thường, điều này khác với "Phong cách Giao tiếp Choreography".
Các lợi ích chung của phong cách giao tiếp phối hợp bao gồm những điểm sau:
- Centralized workflow
-
Khi độ phức tạp tăng lên, việc có một thành phần thống nhất cho trạng thái và hành vi trở nên có lợi.
- Error handling
-
Xử lý lỗi là một phần quan trọng trong nhiều quy trình làm việc của miền, được hỗ trợ bởi việc có một người sở hữu trạng thái cho quy trình làm việc.
- Recoverability
-
Vì một bộ điều phối theo dõi trạng thái của quy trình làm việc, một kiến trúc sư có thể thêm logic để thử lại nếu một hoặc nhiều dịch vụ miền gặp phải sự cố tạm thời.
- State management
-
Việc có một bộ điều phối làm cho trạng thái của quy trình làm việc có thể truy vấn được, cung cấp một nơi cho các quy trình làm việc khác và các trạng thái tạm thời khác.
Những bất lợi chung của phong cách giao tiếp tổ chức bao gồm những điều sau:
- Responsiveness
-
Tất cả giao tiếp phải thông qua người hòa giải, tạo ra một nút thắt tiềm ẩn cho năng suất có thể ảnh hưởng đến khả năng phản hồi.
- Fault tolerance
-
Mặc dù việc điều phối nâng cao khả năng phục hồi cho các dịch vụ miền, nhưng nó tạo ra một điểm thất bại tiềm ẩn cho quy trình làm việc, điều này có thể được giải quyết bằng cách thêm độ dư thừa nhưng lại làm tăng độ phức tạp.
- Scalability
-
Phong cách giao tiếp này không mở rộng tốt như vũ đạo vì nó có nhiều điểm phối hợp hơn (người điều phối), làm giảm khả năng song song. Như chúng ta đã thảo luận trong Chương 2, một số mẫu coupling động sử dụng vũ đạo và do đó đạt được quy mô cao hơn (đặc biệt là "Mẫu Cuộc Hành Trình Thời Gian" và "Mẫu Hành Trình Tuyển Tập").
- Service coupling
-
Việc có một bộ điều phối trung tâm tạo ra sự kết nối chặt chẽ hơn giữa nó và các thành phần miền, điều này đôi khi là cần thiết. Các thỏa thuận về kiểu giao tiếp điều phối xuất hiện trong Bảng 11-1.
Choreography Communication Style
Trong khi Phong cách Giao tiếp Điều phối được đặt tên dựa trên phép ẩn dụ về sự phối hợp trung tâm do một người điều phối cung cấp, thì mẫu vũ đạo minh họa trực quan ý định của phong cách giao tiếp không có sự điều phối trung tâm. Thay vào đó, mỗi dịch vụ tham gia với những dịch vụ khác, giống như những đối tác khiêu vũ. Không phải là một buổi biểu diễn tạm thời—các động tác đã được lên kế hoạch trước bởi người biên đạo/kiến trúc sư nhưng được thực hiện mà không có một người điều phối trung tâm.
Hình 11-4 mô tả quy trình phối hợp cho một khách hàng mua sắm điện tử từ Penultimate Electronics; quy trình tương tự được mô hình hóa theo phong cách truyền thông khiêu vũ xuất hiện trong Hình 11-7.
Trong quy trình làm việc này, yêu cầu khởi tạo sẽ được gửi đến dịch vụ đầu tiên trong chuỗi trách nhiệm - trong trường hợp này là Dịch vụ Đặt Hàng. Sau khi cập nhật các bản ghi nội bộ về đơn hàng, dịch vụ này gửi một yêu cầu không đồng bộ mà Dịch vụ Thanh Toán nhận được. Khi thanh toán đã được áp dụng, Dịch vụ Thanh Toán tạo ra một thông điệp được Dịch vụ Hoàn Tất nhận, dịch vụ này lập kế hoạch cho việc giao hàng và gửi một thông điệp đến Dịch vụ Email.
Thoạt nhìn, giải pháp phối hợp có vẻ đơn giản hơn—ít dịch vụ hơn (không có trình điều phối), và một chuỗi sự kiện/câu lệnh đơn giản (tin nhắn). Tuy nhiên, như với nhiều vấn đề trong kiến trúc phần mềm, những khó khăn không nằm ở các con đường mặc định mà ở các điều kiện giới hạn và lỗi.
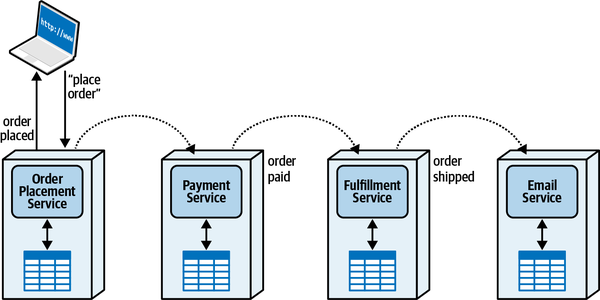
Figure 11-7. Purchasing electronics using choreography
Như trong phần trước, chúng tôi sẽ đề cập đến hai kịch bản lỗi tiềm năng. Kịch bản đầu tiên xảy ra do thanh toán không thành công, như được minh họa trong Hình 11-8.
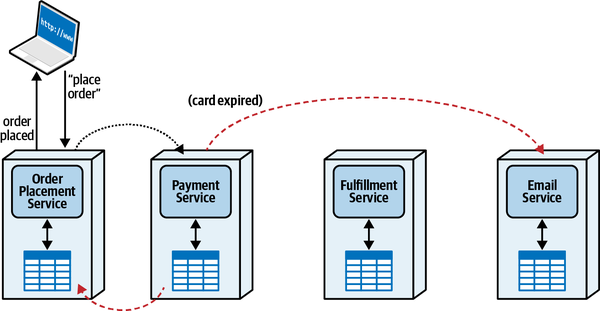
Figure 11-8. Error in payment in choreography
Thay vì gửi một thông điệp dành cho Dịch vụ Hoàn thành, Dịch vụ Thanh toán gửi các thông điệp chỉ ra sự cố cho Dịch vụ Email và quay lại Dịch vụ Đặt hàng để cập nhật trạng thái đơn hàng. Quy trình làm việc thay thế này có vẻ không quá phức tạp, với một liên kết truyền thông mới duy nhất mà trước đây không tồn tại.
Tuy nhiên, hãy xem xét sự phức tạp ngày càng tăng do tình huống lỗi khác đối với đơn hàng sản phẩm bị thiếu, như được thể hiện trong Hình 11-9.
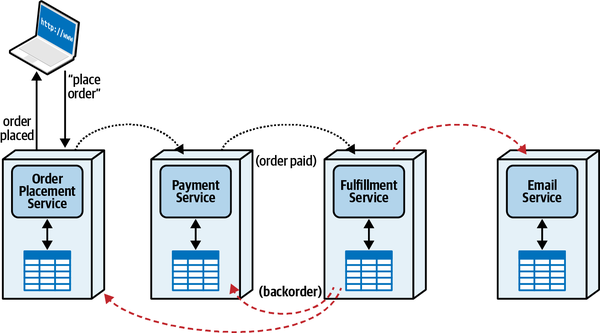
Figure 11-9. Managing the workflow error condition of product backlog
Nhiều bước trong quy trình này đã hoàn thành trước sự kiện (hết hàng) gây ra lỗi. Bởi vì mỗi dịch vụ này thực hiện tính linh hoạt riêng của nó (đây là một ví dụ về “Mô hình Saga Anthology”), khi một lỗi xảy ra, mỗi dịch vụ phải phát hành các thông điệp bồi thường đến các dịch vụ khác. Khi Dịch vụ Thực hiện nhận ra tình trạng lỗi, nó nên tạo ra các sự kiện phù hợp với bối cảnh giới hạn của nó, có thể là một thông điệp phát sóng mà các dịch vụ Email, Thanh toán và Đặt hàng đã đăng ký.
Ví dụ được trình bày trong Hình 11-9 minh họa mối quan hệ phụ thuộc giữa các quy trình phức tạp và các trung gian. Trong khi quy trình ban đầu trong bài múa trình bày trong Hình 11-7 có vẻ đơn giản hơn so với Hình 11-4, trường hợp lỗi (và các trường hợp khác) đã làm tăng thêm độ phức tạp cho giải pháp được biên đạo. Trong Hình 11-10, mỗi kịch bản lỗi buộc các dịch vụ miền phải tương tác với nhau, thêm vào các liên kết giao tiếp mà trước đây không cần thiết cho con đường suôn sẻ.
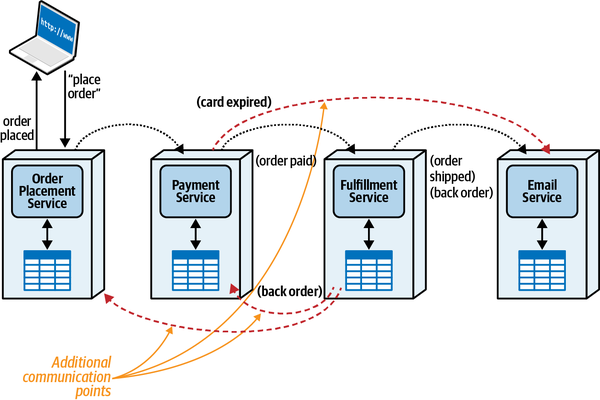
Figure 11-10. Error conditions in choreography typically add communication links
Mỗi quy trình làm việc mà các kiến trúc sư cần mô hình hóa trong phần mềm đều có một mức độ kết nối ngữ nghĩa nhất định - sự kết nối vốn có tồn tại trong miền vấn đề. Ví dụ, quá trình gán một vé cho thành viên của đội Sysops có một quy trình làm việc nhất định: một khách hàng phải yêu cầu dịch vụ, kỹ năng phải được khớp với các chuyên gia cụ thể, sau đó được đối chiếu với lịch trình và địa điểm. Cách mà một kiến trúc sư mô hình hóa tương tác đó chính là sự kết nối thực thi.
Sự liên kết ngữ nghĩa của một quy trình làm việc được quy định bởi các yêu cầu của miền giải pháp và phải được mô hình hóa theo một cách nào đó. Dù một kiến trúc sư có thông minh đến đâu, họ cũng không thể giảm bớt lượng liên kết ngữ nghĩa, nhưng các lựa chọn triển khai của họ có thể làm tăng nó. Điều này không có nghĩa là một kiến trúc sư không thể phản đối những ngữ nghĩa không thực tế hoặc không thể thực hiện được do người dùng kinh doanh xác định—một số yêu cầu của miền tạo ra những vấn đề vô cùng khó khăn trong kiến trúc.
Dưới đây là một ví dụ phổ biến. Hãy xem xét kiến trúc monolithic lớp tiêu chuẩn so với kiểu hiện đại hơn của một monolith mô-đun, như được minh họa trong Hình 11-11.
Kiến trúc bên trái đại diện cho kiến trúc phân lớp truyền thống, được phân tách bởi các khả năng kỹ thuật như lưu trữ, quy tắc kinh doanh, v.v. Ở bên phải, cùng một giải pháp xuất hiện, nhưng được phân tách theo các mối quan tâm miền như Thanh toán Danh mục và Cập nhật Tồn kho thay vì các khả năng kỹ thuật.
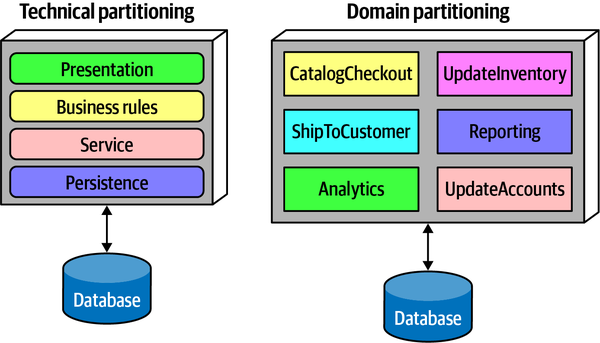
Figure 11-11. Technical versus domain partitioning in architecture
Cả hai kiểu kiến trúc đều là cách hợp lý để tổ chức một mã nguồn. Tuy nhiên, hãy xem xét vị trí của các khái niệm miền như Thanh toán Danh mục nằm trong mỗi kiến trúc, như được minh hoạ trong Hình 11-12.

Figure 11-12. Catalog Checkout is smeared across implementation layers in a technically partitioned architecture
Quy trình thanh toán của danh mục bị “nhòe” qua các tầng của kiến trúc kỹ thuật, trong khi nó chỉ xuất hiện trong thành phần miền phù hợp và cơ sở dữ liệu trong ví dụ được phân vùng miền. Tất nhiên, việc căn chỉnh một miền với kiến trúc phân vùng miền không phải là một phát hiện mới—một trong những hiểu biết của thiết kế hướng miền là sự ưu tiên của các quy trình công việc miền. Dù thế nào đi chăng nữa, nếu một kiến trúc sư muốn mô hình hóa một quy trình công việc, họ phải làm cho các phần chuyển động đó hoạt động cùng nhau. Nếu kiến trúc sư đã tổ chức kiến trúc của họ giống như các miền, thì việc thực hiện quy trình công việc sẽ có độ phức tạp tương tự. Tuy nhiên, nếu kiến trúc sư đã áp đặt các lớp bổ sung (như trong phân vùng kỹ thuật, như được thể hiện trong Hình 11-12), điều này sẽ làm tăng độ phức tạp tổng thể của việc thực hiện vì giờ đây kiến trúc sư phải thiết kế cho độ phức tạp ngữ nghĩa cùng với độ phức tạp thực hiện bổ sung.
Đôi khi, sự phức tạp thêm là cần thiết. Ví dụ, nhiều kiến trúc phân tầng xuất phát từ mong muốn của các kiến trúc sư nhằm tiết kiệm chi phí bằng cách hợp nhất các mẫu kiến trúc, chẳng hạn như kết nối cơ sở dữ liệu bằng cách sử dụng pooling. Trong trường hợp đó, một kiến trúc sư đã xem xét các giao dịch giữa việc tiết kiệm chi phí liên quan đến việc phân tách tính kết nối cơ sở dữ liệu về mặt kỹ thuật so với sự phức tạp và chi phí mà điều này mang lại, và trong nhiều trường hợp, sự tiết kiệm này đã chiến thắng.
Bài học lớn nhất trong thập kỷ qua của thiết kế kiến trúc là mô hình hóa ngữ nghĩa của quy trình làm việc càng gần với việc triển khai càng tốt.
Tip
Một kiến trúc sư không bao giờ có thể giảm thiểu sự kết nối ngữ nghĩa thông qua việc triển khai, nhưng họ có thể làm cho nó tồi tệ hơn.
Do đó, chúng ta có thể thiết lập mối quan hệ giữa sự liên kết ngữ nghĩa và nhu cầu phối hợp—càng nhiều bước cần thiết trong quy trình làm việc, càng có nhiều khả năng xảy ra lỗi và các con đường tùy chọn khác xuất hiện.
Workflow State Management
Hầu hết các luồng công việc đều bao gồm trạng thái tạm thời về tình trạng của luồng công việc: những yếu tố nào đã thực thi, những yếu tố nào còn lại, thứ tự, điều kiện lỗi, các lần thử lại, và những điều khác. Đối với các giải pháp được phối hợp, người sở hữu trạng thái luồng công việc rõ ràng là bộ điều phối (mặc dù một số giải pháp kiến trúc tạo ra các bộ điều phối không trạng thái để có quy mô lớn hơn). Tuy nhiên, đối với việc phối hợp, không có người sở hữu trạng thái luồng công việc rõ ràng nào. Nhiều tùy chọn phổ biến để quản lý trạng thái trong việc phối hợp; dưới đây là ba tùy chọn phổ biến.
Đầu tiên, mẫu Front Controller đặt trách nhiệm về trạng thái lên dịch vụ được gọi đầu tiên trong chuỗi trách nhiệm, trong trường hợp này là Dịch vụ Đặt Hàng. Nếu dịch vụ đó chứa thông tin về cả đơn hàng và trạng thái của quy trình làm việc, một số dịch vụ miền phải có một liên kết giao tiếp để truy vấn và cập nhật trạng thái đơn hàng, như minh họa trong Hình 11-13.
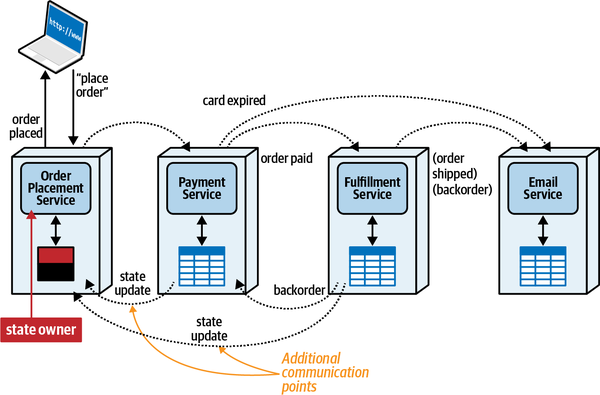
Figure 11-13. In choreography, a Front Controller is a domain service that owns workflow state in addition to domain behavior
Trong kịch bản này, một số dịch vụ phải giao tiếp trở lại với Dịch vụ Đặt hàng để cập nhật trạng thái của đơn hàng, vì nó là chủ sở hữu trạng thái. Mặc dù điều này đơn giản hóa quy trình làm việc, nhưng nó làm tăng chi phí giao tiếp và làm cho Dịch vụ Đặt hàng trở nên phức tạp hơn so với một dịch vụ chỉ xử lý hành vi miền. Trong khi mẫu Front Controller có một số đặc điểm thuận lợi, nó cũng có những đánh đổi, như được chỉ ra trong Bảng 11-2.
Một cách thứ hai để một kiến trúc sư quản lý trạng thái giao dịch là không lưu trữ bất kỳ trạng thái công việc tạm thời nào, mà dựa vào việc truy vấn các dịch vụ cá nhân để xây dựng một ảnh chụp thời gian thực. Điều này được gọi là điệu nhảy không trạng thái. Trong khi điều này đơn giản hóa trạng thái của dịch vụ đầu tiên, nó làm tăng đáng kể chi phí mạng liên quan đến việc trao đổi giữa các dịch vụ để xây dựng một ảnh chụp trạng thái. Ví dụ, hãy xem xét một quy trình làm việc như con đường điệu nhảy vui vẻ đơn giản trong Hình 11-7 mà không có trạng thái bổ sung. Nếu một khách hàng muốn biết trạng thái đơn hàng của họ, kiến trúc sư phải xây dựng một quy trình làm việc truy vấn trạng thái của từng dịch vụ miền để xác định trạng thái đơn hàng mới nhất. Mặc dù điều này tạo ra một giải pháp linh hoạt cao, nhưng việc tái xây dựng trạng thái có thể phức tạp và tốn kém về các đặc điểm kiến trúc vận hành như khả năng mở rộng và hiệu suất. Điệu nhảy không trạng thái đánh đổi hiệu suất cao để lấy kiểm soát quy trình làm việc, như được minh họa trong Bảng 11-3.
Một giải pháp thứ ba sử dụng kết nối dấu hiệu (được mô tả chi tiết hơn trong “Kết nối dấu hiệu cho Quản lý Quy trình làm việc”), lưu trữ trạng thái quy trình làm việc bổ sung trong hợp đồng tin nhắn được gửi giữa các dịch vụ. Mỗi dịch vụ miền cập nhật phần của mình trong trạng thái tổng thể và chuyển nó cho dịch vụ tiếp theo trong chuỗi trách nhiệm. Do đó, bất kỳ người tiêu dùng nào của hợp đồng đó có thể kiểm tra trạng thái của quy trình làm việc mà không cần truy vấn mỗi dịch vụ.
Đây là một giải pháp tạm thời, vì nó vẫn chưa cung cấp một nơi duy nhất cho người dùng để truy vấn trạng thái của quy trình làm việc đang diễn ra. Tuy nhiên, nó cung cấp cách để truyền trạng thái giữa các dịch vụ như một phần của quy trình làm việc, cung cấp cho mỗi dịch vụ bối cảnh bổ sung có thể hữu ích. Như trong tất cả các tính năng của kiến trúc phần mềm, sự kết nối đóng dấu có những đặc điểm tốt và xấu, được thể hiện trong Bảng 11-4.
Trong Chương 13, chúng tôi thảo luận về cách các hợp đồng có thể giảm hoặc tăng cường sự kết nối quy trình làm việc trong các giải pháp được phối hợp.
Những lợi thế của phong cách giao tiếp qua vũ đạo bao gồm:
- Responsiveness
-
Phong cách giao tiếp này có ít điểm nghẽn đơn, do đó cung cấp nhiều cơ hội cho sự song song hóa hơn.
- Scalability
-
Tương tự như khả năng phản hồi, việc thiếu các điểm phối hợp như nhạc trưởng cho phép việc mở rộng độc lập hơn.
- Fault tolerance
-
Việc thiếu một trình điều phối đơn lẻ cho phép kiến trúc sư tăng cường khả năng chịu lỗi bằng cách sử dụng nhiều phiên bản.
- Service decoupling
-
Không có bộ điều phối đồng nghĩa với việc giảm sự liên kết.
Những nhược điểm của phong cách giao tiếp vũ đạo bao gồm:
- Distributed workflow
-
Không có người quản lý quy trình nào khiến việc quản lý lỗi và các điều kiện ranh giới trở nên khó khăn hơn.
- State management
-
Không có người đại diện nhà nước tập trung cản trở quản lý nhà nước đang diễn ra.
- Error handling
-
Xử lý lỗi trở nên khó khăn hơn mà không có người điều phối vì các dịch vụ miền phải có nhiều kiến thức về quy trình làm việc hơn.
- Recoverability
-
Tương tự, khả năng phục hồi trở nên khó khăn hơn mà không có một người điều phối để thực hiện các nỗ lực thử lại và khắc phục khác.
Giống như "Phong cách giao tiếp lập trình", điệu nhảy có một số lợi ích và bất lợi, thường là trái ngược nhau, được tóm tắt trong Bảng 11-5.
Trade-Offs Between Orchestration and Choreography
Như với mọi thứ trong kiến trúc phần mềm, cả điều phối và vũ đạo đều không đại diện cho giải pháp hoàn hảo cho mọi khả năng. Một số đánh đổi chính, bao gồm một số điều đã được phác thảo ở đây, sẽ dẫn dắt kiến trúc sư đến một trong hai giải pháp này.
State Owner and Coupling
Như minh họa trong Hình 11-13, quyền sở hữu nhà nước thường nằm ở một vị trí nào đó, hoặc trong một trung gian chính thức hoạt động như một người điều phối, hoặc một bộ điều khiển chính trong một giải pháp được phối hợp. Trong giải pháp phối hợp, việc loại bỏ trung gian buộc các dịch vụ phải giao tiếp ở mức độ cao hơn. Đây có thể là một sự đánh đổi hoàn toàn hợp lý. Ví dụ, nếu một kiến trúc sư có một quy trình làm việc cần quy mô lớn hơn và thường có ít điều kiện lỗi, thì việc đánh đổi giữa quy mô lớn hơn của việc phối hợp với độ phức tạp của xử lý lỗi có thể là điều đáng giá.
Tuy nhiên, khi độ phức tạp của quy trình làm việc tăng lên, nhu cầu về một bộ điều phối cũng tăng theo tỷ lệ, như được minh họa trong Hình 11-14.
Hơn nữa, càng có nhiều độ phức tạp ngữ nghĩa trong một quy trình làm việc, thì vai trò của điều phối viên càng trở nên thiết thực. Hãy nhớ rằng, việc kết nối thực hiện không thể cải thiện kết nối ngữ nghĩa, chỉ có thể làm cho nó tồi tệ hơn.
Cuối cùng, điểm tối ưu cho biên đạo nằm ở những quy trình làm việc cần tính phản hồi và khả năng mở rộng, và hoặc không có các kịch bản lỗi phức tạp hoặc chúng xảy ra không thường xuyên. Phong cách giao tiếp này cho phép thông lượng cao; nó được sử dụng bởi các mẫu liên kết động như “Mẫu Câu Chuyện Điện Thoại”, “Mẫu Câu Chuyện Du Hành Thời Gian”, và “Mẫu Câu Chuyện Tuyển Tập”. Tuy nhiên, nó cũng có thể dẫn đến việc triển khai cực kỳ khó khăn khi các yếu tố khác được đưa vào, dẫn đến “Mẫu Câu Chuyện Kinh Hoàng”.
Figure 11-14. As the complexity of the workflow rises, orchestration becomes more useful
Mặt khác, điều phối (orchestration) phù hợp nhất cho các quy trình làm việc phức tạp bao gồm điều kiện ranh giới và lỗi. Trong khi kiểu này không cung cấp nhiều khả năng mở rộng như biên đạo (choreography), nó giảm bớt độ phức tạp trong hầu hết các trường hợp. Kiểu giao tiếp này xuất hiện trong các mẫu "Epic Saga", "Fairy Tale Saga", "Fantasy Fiction Saga" và "Parallel Saga".
Sự phối hợp là một trong những lực chính tạo ra độ phức tạp cho các kiến trúc sư khi xác định cách tốt nhất để giao tiếp giữa các microservices. Tiếp theo, chúng ta sẽ khảo sát cách mà lực này giao thoa với một lực chính khác, sự nhất quán.
Sysops Squad Saga: Managing Workflows
Thứ Năm, ngày 15 tháng 3, 11:00
Addison và Austen đã đến văn phòng của Logan đúng giờ, mang theo một bài thuyết trình và một bình cà phê từ trong bếp.
“Bạn có sẵn sàng cho chúng tôi chưa?” Addison hỏi.
“Chắc rồi,” Logan nói. “Thời gian thật hợp lý—mới kết thúc một cuộc gọi hội nghị. Các bạn đã sẵn sàng để bàn về các tùy chọn quy trình làm việc cho dòng ticket chính chưa?”
“Vâng!” Austen nói. “Tôi nghĩ chúng ta nên sử dụng vũ đạo, nhưng Addison thì nghĩ là phối khí, và chúng ta không thể quyết định.”
"Cho tôi một cái nhìn tổng quan về quy trình làm việc mà chúng ta đang xem xét."
"Đây là quy trình làm việc chính của vé," Addison nói. "Nó liên quan đến bốn dịch vụ; đây là các bước."
Hoạt động đối mặt với khách hàng
-
Khách hàng gửi một yêu cầu hỗ trợ qua Dịch vụ Quản lý Vé và nhận được số vé.
Các hoạt động nền
-
Dịch vụ phân công vé tìm đúng chuyên gia Sysops cho vé sự cố.
-
Dịch vụ Gán Phiếu Khó khăn chuyển phiếu khó khăn đến thiết bị di động của chuyên gia hệ thống.
-
Khách hàng được thông báo qua Dịch vụ Thông báo rằng chuyên gia Sysops đang trên đường đến để khắc phục vấn đề.
-
Chuyên gia khắc phục vấn đề và đánh dấu vé là hoàn thành, sau đó được gửi đến Dịch vụ Quản lý Vé.
-
Dịch vụ Quản lý Vé giao tiếp với Dịch vụ Khảo sát để thông báo cho khách hàng điền vào khảo sát.
“Bạn đã mô hình hóa cả hai giải pháp chưa?” Logan hỏi.
"Có. Bản vẽ cho vũ đạo nằm ở Hình 11-15."
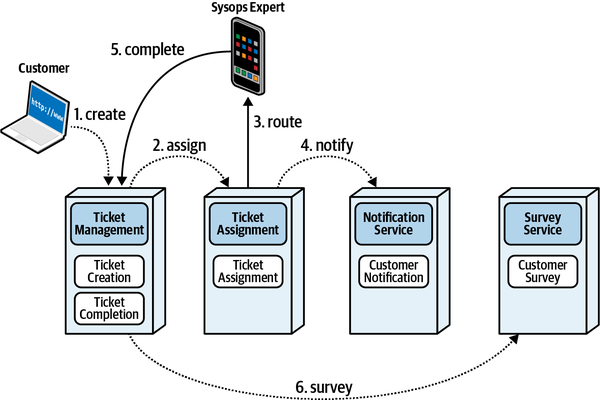
Figure 11-15. Primary ticket flow modeled as choreography
“…và mô hình cho quá trình orchestrate nằm trong Hình 11-16.”
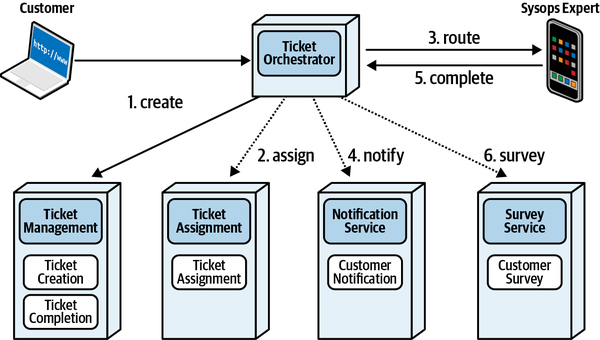
Figure 11-16. Primary ticket workflow modeled as orchestration
Logan suy nghĩ về các hình vẽ trong một lúc, rồi tuyên bố: “Chà, có vẻ như không có người chiến thắng rõ ràng ở đây. Bạn biết điều đó có nghĩa là gì.”
Austen lên tiếng, “Sự đánh đổi!”
“Chắc chắn rồi,” Logan cười. “Hãy nghĩ về các kịch bản có khả năng xảy ra và xem mỗi giải pháp phản ứng như thế nào với chúng. Những vấn đề chính nào bạn đang quan tâm?”
"Đầu tiên là vé bị mất hoặc gửi nhầm. Doanh nghiệp đã phàn nàn về vấn đề này, và nó đã trở thành một ưu tiên," Addison nói.
“Được rồi, cái nào giải quyết vấn đề đó tốt hơn - điều phối hay vũ đạo?”
“Kiểm soát quy trình làm việc dễ hơn có vẻ như phiên bản điều phối viên tốt hơn - chúng ta có thể xử lý tất cả các vấn đề trong quy trình làm việc ở đó.” Austen đã tình nguyện nói.
"Được rồi, hãy xây dựng một bảng các vấn đề và giải pháp ưu tiên trong Bảng 11-6."
“Vấn đề tiếp theo chúng ta nên mô hình hóa là gì?” Addison hỏi.
"Chúng tôi cần biết trạng thái của một vé sự cố tại bất kỳ thời điểm nào—doanh nghiệp đã yêu cầu tính năng này, và nó giúp dễ dàng theo dõi nhiều chỉ số. Điều đó ngụ ý rằng chúng tôi cần một bộ điều phối để có thể truy vấn trạng thái của quy trình làm việc."
“Nhưng bạn không cần có một bộ điều phối cho điều đó—chúng ta có thể truy vấn bất kỳ dịch vụ nào để xem liệu nó đã xử lý một phần nào đó của quy trình làm việc hay sử dụng coupling dấu.” Addison nói.
“Đúng vậy—đây không phải là một trò chơi có tổng bằng không,” Logan nói. “Có thể cả hai hoặc không có giải pháp nào cũng hoạt động tốt như nhau. Chúng tôi sẽ ghi nhận cả hai giải pháp trong bảng cập nhật của chúng tôi ở Bảng 11-7.”
“Được rồi, còn gì nữa?”
“Chỉ còn một điều nữa mà tôi có thể nghĩ đến,” Addison nói. “Khách hàng có thể hủy vé, và vé có thể được phân công lại vì lý do sự sẵn có của chuyên gia, mất kết nối với thiết bị di động của chuyên gia, hoặc sự chậm trễ của chuyên gia tại địa điểm của khách hàng. Do đó, việc xử lý lỗi đúng cách là rất quan trọng. Điều đó có nghĩa là điều phối đúng không?”
“Vâng, nói chung là như vậy. Các quy trình phức tạp phải được đặt ở đâu đó, hoặc trong một bộ điều phối hoặc rải rác qua các dịch vụ. Thật tốt khi có một nơi duy nhất để tập trung xử lý lỗi. Và chắc chắn là vũ đạo không ghi điểm tốt ở đây, vì vậy chúng tôi sẽ cập nhật bảng của mình trong Bảng 11-8.”
"Cái đó trông khá tốt. Còn gì nữa không?"
“Không có gì không rõ ràng,” Addison nói. “Chúng ta sẽ ghi lại điều này trong một tài liệu ADR; nếu chúng ta nghĩ ra bất kỳ vấn đề nào khác, chúng ta có thể thêm chúng vào đó.”
ADR: Sử dụng Orchestration cho Quy trình Vé Chính
Ngữ cảnh Đối với quy trình xử lý ticket chính, kiến trúc phải hỗ trợ việc theo dõi dễ dàng các tin nhắn bị mất hoặc không được theo dõi đúng cách, xử lý lỗi xuất sắc và khả năng theo dõi trạng thái ticket. Một giải pháp điều phối như minh họa trong Hình 11-16 hoặc một giải pháp phối hợp như minh họa trong Hình 11-15 đều có thể hoạt động.
Quyết định Chúng tôi sẽ sử dụng điều phối cho quy trình làm việc chính của vé.
Chúng tôi đã mô hình hóa sự phối hợp và điệu múa và đã đạt được các sự đánh đổi trong Bảng 11-8.
Hệ quả Quy trình xử lý vé có thể gặp vấn đề về khả năng mở rộng xung quanh một bộ điều khiển đơn lẻ, điều này nên được xem xét lại nếu các yêu cầu về khả năng mở rộng hiện tại thay đổi.
Chapter 12. Transactional Sagas
Thứ Năm, ngày 31 tháng 3, 16:55
Austen đến văn phòng của Logan muộn vào chiều thứ Năm gió lùa. “Addison vừa gửi tôi đến đây để hỏi bạn về một câu chuyện kinh dị nào đó?”
Logan dừng lại và nhìn lên. “Đó có phải là mô tả về môn thể thao mạo hiểm điên rồ nào mà bạn sẽ tham gia vào cuối tuần này không? Lần này là gì vậy?”
“Bây giờ là cuối xuân, vì vậy một nhóm chúng tôi đang đi trượt băng trên hồ đang tan băng. Chúng tôi mặc bộ đồ bó, vì vậy thật sự là sự kết hợp giữa trượt băng và bơi lội. Nhưng đó không phải là điều mà Addison định nói. Khi tôi cho Addison xem thiết kế của mình cho quy trình bán vé, tôi ngay lập tức được chỉ định phải đến gặp bạn và nói rằng tôi đã tạo ra một câu chuyện kinh dị.”
Logan cười. “À, tôi hiểu chuyện gì đang xảy ra—bạn đã tình cờ rơi vào mẫu giao tiếp của saga Câu chuyện Kinh dị. Bạn đã thiết kế một quy trình làm việc với giao tiếp bất đồng bộ, tính giao dịch nguyên tử, và vũ đạo, đúng không?”
"Bạn làm sao biết?"
“Đó là mô hình câu chuyện kinh dị, hoặc thực sự, mô hình ngược. Có tám mô hình saga tổng quát mà chúng ta bắt đầu từ đó, vì vậy thật tốt khi biết chúng là gì, vì mỗi mô hình có một sự cân bằng khác nhau về các đánh đổi.”
Khái niệm về saga trong kiến trúc tồn tại trước microservices, ban đầu liên quan đến việc hạn chế phạm vi của các khóa cơ sở dữ liệu trong các kiến trúc phân tán sớm—bài báo thường được cho là đã đặt ra khái niệm này là từ Biên bản hội nghị ACM năm 1987. Trong cuốn sách Microservices Patterns (Nhà xuất bản Manning) và cũng được phác thảo trong phần "Saga Pattern" trên trang web của mình, Chris Richardson mô tả mẫu saga cho microservices như một chuỗi các giao dịch cục bộ, nơi mỗi cập nhật công bố một sự kiện, do đó kích hoạt cập nhật tiếp theo trong chuỗi. Nếu bất kỳ cập nhật nào trong số đó thất bại, saga sẽ phát hành một loạt các cập nhật bồi thường để hoàn tác các thay đổi trước đó đã được thực hiện trong saga.
Tuy nhiên, hãy nhớ từ Chương 2 rằng đây chỉ là một trong tám loại saga có thể có. Trong phần này, chúng ta sẽ đi sâu hơn và xem xét cách hoạt động bên trong của các saga giao dịch và cách quản lý chúng, đặc biệt là khi xảy ra lỗi. Cuối cùng, vì các giao dịch phân tán thiếu tính nguyên tử (xem “Giao dịch phân tán”), điều làm cho chúng trở nên thú vị là khi các vấn đề xảy ra.
Transactional Saga Patterns
Trong Chương 2, chúng tôi đã giới thiệu một ma trận đối chiếu từng chiều giao thoa khi các kiến trúc sư phải chọn cách triển khai một câu chuyện giao dịch, được tái hiện trong Bảng 12-1.
| Pattern name | Communication | Consistency | Coordination |
|---|---|---|---|
Huyền thoại sử thi | Đồng bộ | Nguyên tử | Điều phối |
Cuộc Phiêu Lưu Đánh Đu Điện Thoại | Đồng bộ | Nguyên tử | Được dàn dựng |
Huyền thoại cổ tích | Đồng bộ | Cuối cùng | Dàn xếp |
Hành Trình Thời Gian | Đồng bộ | Cuối cùng | Biên đạo múa |
Huyền bí tiểu thuyết sử thi | Không đồng bộ | Nguyên tử | Đã tổ chức |
Câu chuyện kinh dị | Không đồng bộ | Nguyên tử | Được dàn dựng |
Huyền Thoại Song Song | Không đồng bộ | Cuối cùng | Được phối hợp |
Truyền thuyết Tập hợp | Không đồng bộ | Cuối cùng | Được biên đạo |
Chúng tôi cung cấp những cái tên kỳ quặc cho mỗi sự kết hợp, tất cả đều được lấy cảm hứng từ các loại sử thi. Tuy nhiên, các tên mẫu tồn tại để giúp phân biệt các khả năng, và chúng tôi không muốn cung cấp một bài kiểm tra ghi nhớ để liên kết một tên mẫu với một tập hợp các đặc điểm, vì vậy chúng tôi đã thêm một ký hiệu trên mỗi loại sử thi chỉ ra giá trị của ba chiều được liệt kê theo thứ tự chữ cái (như trong Bảng 12-1). Ví dụ, mẫu Sử thi chỉ ra giá trị của đồng bộ, nguyên tử, và được điều phối cho giao tiếp, nhất quán, và phối hợp. Các ký hiệu giúp bạn dễ dàng liên kết tên với các tập hợp đặc trưng hơn.
Trong khi các kiến trúc sư sẽ sử dụng một số mẫu nhiều hơn những mẫu khác, tất cả chúng đều có công dụng hợp pháp và các tập hợp thỏa hiệp khác nhau.
Chúng tôi minh họa mỗi kết hợp giao tiếp có thể có với cả một đại diện ba chiều về sự giao nhau của ba lực trong không gian cùng với một ví dụ về quy trình làm việc sử dụng các dịch vụ phân tán chung, mà chúng tôi gọi là các sơ đồ đồng cấu. Những sơ đồ này cho thấy các tương tác giữa các dịch vụ một cách tổng quát nhất, nhằm đạt được mục tiêu của chúng tôi là thể hiện các khái niệm kiến trúc ở dạng đơn giản nhất. Trong mỗi sơ đồ này, chúng tôi sử dụng bộ ký hiệu tổng quát được hiển thị trong Hình 12-1.
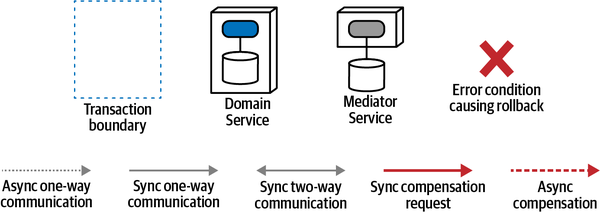
Figure 12-1. Legend for ISO architecture interaction diagrams
Đối với mỗi mô hình kiến trúc, chúng tôi không hiển thị tất cả các tương tác có thể có, điều này sẽ trở nên lặp lại. Thay vào đó, chúng tôi xác định và minh họa những đặc điểm phân biệt của mô hình - điều gì làm cho hành vi của nó trở nên độc đáo trong số các mô hình.
Epic Saga(sao) Pattern
Loại hình giao tiếp này là mô hình saga “truyền thống” như nhiều kiến trúc sư hiểu, còn được gọi là Saga Dàn Hợp Tác vì loại hình phối hợp của nó. Các mối quan hệ không gian của nó xuất hiện trong Hình 12-2.
Mô hình này sử dụng giao tiếp đồng bộ, tính nhất quán nguyên tử và sự phối hợp có tổ chức. Mục tiêu của kiến trúc sư khi chọn mô hình này giống với hành vi của các hệ thống đơn thể - thực tế, nếu một hệ thống đơn thể được thêm vào sơ đồ này trong Hình 12-2, nó sẽ là gốc (0, 0, 0), hoàn toàn thiếu phân phối. Do đó, kiểu giao tiếp này rất quen thuộc với các kiến trúc sư và nhà phát triển của các hệ thống giao dịch truyền thống.
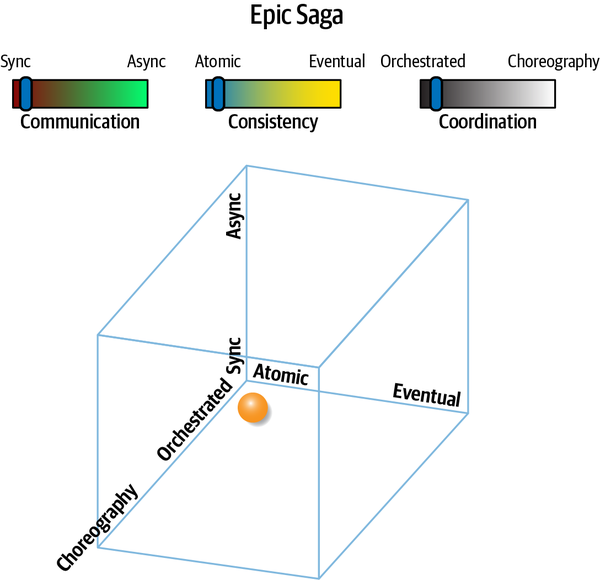
Figure 12-2. The Epic Saga(sao) pattern’s dynamic coupling (communication, consistency, coordination) relationships
Biểu diễn đồng cấu của mẫu Epic Saga xuất hiện trong Hình 12-3.
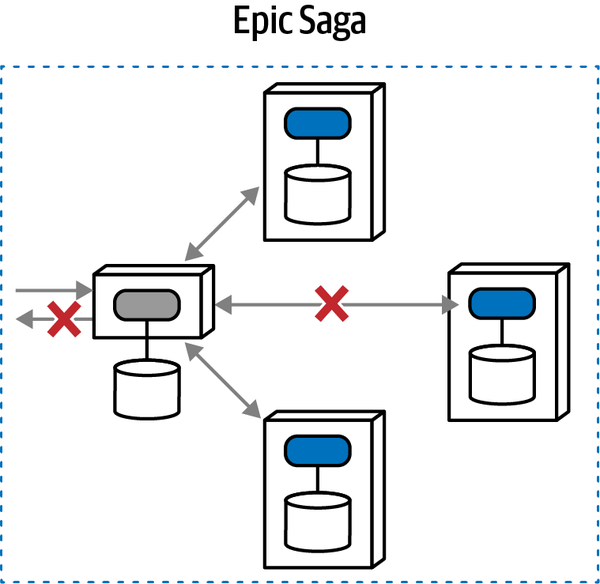
Figure 12-3. The isomorphic communication illustration of the Epic Saga(sao) pattern
Ở đây, một dịch vụ điều phối điều phối một quy trình công việc bao gồm các bản cập nhật cho ba dịch vụ, được dự kiến sẽ xảy ra theo cách giao dịch - hoặc tất cả ba cuộc gọi thành công hoặc không cuộc gọi nào thành công. Nếu một trong các cuộc gọi thất bại, thì tất cả đều thất bại và trở lại trạng thái trước đó. Một kiến trúc sư có thể giải quyết vấn đề phối hợp này theo nhiều cách, tất cả đều phức tạp trong các kiến trúc phân tán. Tuy nhiên, các giao dịch như vậy giới hạn sự lựa chọn cơ sở dữ liệu và có những chế độ thất bại nổi tiếng.
Nhiều kiến trúc sư mới vào nghề hoặc còn thiếu kinh nghiệm thường tin rằng, vì một mẫu tồn tại cho một vấn đề, nó đại diện cho một giải pháp rõ ràng. Tuy nhiên, mẫu đó chỉ là sự nhận diện sự phổ biến, chứ không phải khả năng giải quyết. Các giao dịch phân tán cung cấp một ví dụ xuất sắc cho hiện tượng này—các kiến trúc sư quen với việc mô hình hóa giao dịch trong các hệ thống không phân tán đôi khi tin rằng việc chuyển khả năng đó sang thế giới phân tán chỉ là một thay đổi gia tăng. Tuy nhiên, các giao dịch trong kiến trúc phân tán gặp phải một số thách thức, những thách thức này trở nên tồi tệ hơn một cách tỷ lệ thuận với độ phức tạp của sự kết hợp ngữ nghĩa của vấn đề.
Xem xét một triển khai phổ biến của mẫu Epic Saga, sử dụng các giao dịch bồi thường. Một cập nhật bồi thường là một hành động đảo ngược một hành động ghi dữ liệu mà một dịch vụ khác đã thực hiện (chẳng hạn như đảo ngược một cập nhật, chèn lại một hàng đã bị xóa trước đó, hoặc xóa một hàng đã được chèn trước đó) trong quá trình thực hiện phạm vi giao dịch phân tán. Trong khi các cập nhật bồi thường cố gắng đảo ngược các thay đổi nhằm đưa các nguồn dữ liệu phân tán trở lại trạng thái ban đầu của chúng trước khi bắt đầu giao dịch phân tán, chúng lại chứa đựng nhiều vấn đề phức tạp, thách thức và sự đánh đổi.
Một mô hình giao dịch bù đắp gán một dịch vụ để giám sát tính hoàn chỉnh của giao dịch của một yêu cầu, như được trình bày trong Hình 12-4.
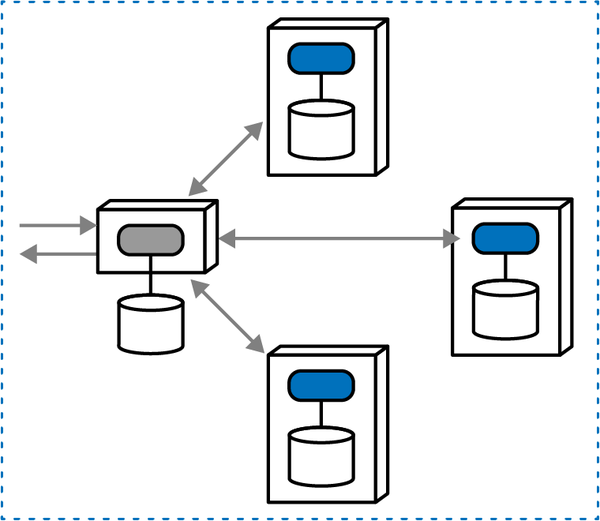
Figure 12-4. A successful orchestrated transactional Epic Saga using a compensating transaction
Tuy nhiên, cũng như nhiều vấn đề trong kiến trúc, các điều kiện lỗi gây ra khó khăn. Trong một khuôn khổ giao dịch bù đắp, người trung gian theo dõi sự thành công của các cuộc gọi và phát hành các cuộc gọi bù đắp tới các dịch vụ khác nếu một hoặc nhiều yêu cầu thất bại, như được trình bày trong Hình 12-5.
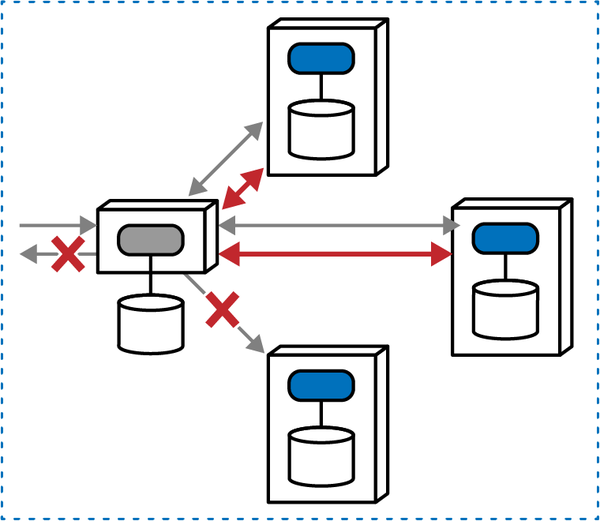
Figure 12-5. When an error occurs, a mediator must send compensating requests to other services
Một môi giới vừa chấp nhận các yêu cầu vừa trung gian hóa quy trình công việc, và các cuộc gọi đồng bộ đến hai dịch vụ đầu tiên thành công. Tuy nhiên, khi cố gắng gọi đến dịch vụ cuối cùng, cuộc gọi thất bại (do có thể nhiều lý do cả về miền lẫn hoạt động). Vì mục tiêu của Epic Saga là tính nhất quán nguyên tử, người môi giới phải sử dụng các giao dịch bồi thường và yêu cầu hai dịch vụ còn lại hoàn tác hoạt động trước đó, đưa trạng thái tổng thể trở về như trước khi giao dịch bắt đầu.
Mẫu này được sử dụng rộng rãi: nó mô hình hóa hành vi quen thuộc và có tên mẫu đã được thiết lập rõ ràng. Nhiều kiến trúc sư mặc định theo mẫu Epic Saga vì nó cảm thấy quen thuộc với các kiến trúc đơn khối, kết hợp với yêu cầu (đôi khi là sự đòi hỏi) từ các bên liên quan rằng các thay đổi trạng thái phải được đồng bộ hóa, bất chấp các hạn chế kỹ thuật. Tuy nhiên, nhiều mẫu liên kết động lượng khác có thể cung cấp một bộ điều chỉnh giao dịch tốt hơn.
Lợi thế rõ ràng của Epic Saga là sự phối hợp giao dịch mô phỏng các hệ thống đơn khối, kết hợp với người sở hữu quy trình rõ ràng được đại diện qua một bộ điều phối. Tuy nhiên, những bất lợi là đa dạng. Thứ nhất, việc điều phối cộng với tính giao dịch có thể ảnh hưởng đến các đặc điểm kiến trúc hoạt động như hiệu suất, quy mô, tính đàn hồi, v.v.—người điều phối phải đảm bảo rằng tất cả các bên tham gia trong giao dịch đều thành công hoặc thất bại, gây ra các nút thắt thời gian. Thứ hai, các mẫu khác nhau được sử dụng để triển khai tính giao dịch phân tán (chẳng hạn như các giao dịch bồi thường) dễ bị ảnh hưởng bởi nhiều chế độ thất bại và điều kiện biên khác nhau, cùng với việc thêm độ phức tạp vốn có thông qua các thao tác hoàn tác. Các giao dịch phân tán gặp rất nhiều khó khăn và do đó tốt nhất là nên tránh nếu có thể.
Mô hình Truyền thuyết Vĩ đại có các đặc điểm sau đây:
- Coupling level
-
Mẫu này thể hiện mức độ kết nối cực kỳ cao trên tất cả các chiều có thể có: giao tiếp đồng bộ, tính nhất quán nguyên tử và phối hợp có tổ chức - thực tế đây là mẫu kết nối cao nhất trong danh sách. Điều này không gây ngạc nhiên, vì nó mô hình hóa hành vi của giao tiếp trong hệ thống monolithic được kết nối chặt chẽ, nhưng tạo ra một số vấn đề trong kiến trúc phân tán.
- Complexity level
-
Các điều kiện lỗi và các phối hợp chặt chẽ khác được thêm vào yêu cầu về tính nguyên tử làm tăng độ phức tạp cho kiến trúc này. Các cuộc gọi đồng bộ mà kiến trúc này sử dụng làm giảm bớt một số phức tạp, vì các kiến trúc sư không phải lo lắng về các điều kiện tranh chấp và tình trạng chết trong quá trình gọi.
- Responsiveness/availability
-
Sự điều phối tạo ra một nút thắt cổ chai, đặc biệt khi nó cũng phải phối hợp tính nguyên tử của giao dịch, điều này làm giảm khả năng phản hồi. Mô hình này sử dụng các cuộc gọi đồng bộ, ảnh hưởng thêm đến hiệu suất và khả năng phản hồi. Nếu bất kỳ dịch vụ nào không có sẵn hoặc xảy ra lỗi không thể khôi phục, mô hình này sẽ thất bại.
- Scale/elasticity
-
Tương tự như sự linh hoạt, nút thắt và sự phối hợp cần thiết để thực hiện mô hình này khiến cho việc mở rộng quy mô và các mối quan tâm về vận hành khác trở nên khó khăn.
Trong khi Epic Saga rất phổ biến nhờ sự quen thuộc, nó đã tạo ra một số thách thức, cả từ góc độ thiết kế lẫn đặc điểm vận hành, như được trình bày trong Bảng 12-2.
| Epic Saga(sao) pattern | Ratings |
|---|---|
Giao tiếp | Đồng bộ |
Tính nhất quán | Nguyên tử |
Phối hợp | Dàn dựng |
Ghép đôi | Rất cao |
Phức tạp | Thấp |
Độ nhạy/khả năng có mặt | Thấp |
Quy mô/tính đàn hồi | Rất thấp |
Rất may, các kiến trúc sư không cần phải mặc định vào các mẫu mà, mặc dù có vẻ quen thuộc, lại tạo ra sự phức tạp ngẫu nhiên - có nhiều mẫu khác nhau với các bộ thỏa hiệp khác nhau. Hãy tham khảo "Huyền thoại Đội Sysops: Giao dịch Nguyên tử và Cập nhật Bù" để có một ví dụ cụ thể về Huyền thoại Huyền thoại và một số thách thức phức tạp mà nó mang lại (cũng như cách giải quyết những thách thức đó).
Phone Tag Saga(sac) Pattern
Mô hình Phone Tag Saga thay đổi một trong những khía cạnh của Epic Saga, chuyển đổi sự phối hợp từ được điều phối sang được biên đạo; sự thay đổi này được minh họa trong Hình 12-6.
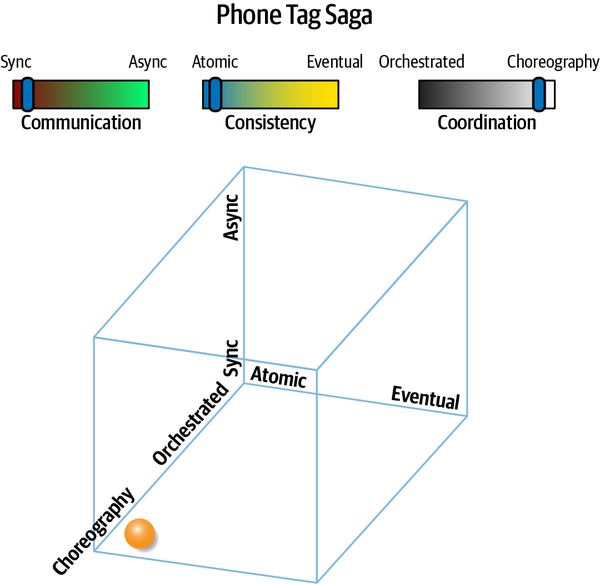
Figure 12-6. The Phone Tag pattern utilizes loosely coupled communication
Tên mẫu là Phone Tag vì nó giống với một trò chơi trẻ em nổi tiếng được gọi là Telephone ở Bắc Mỹ: trẻ em tạo thành một vòng tròn, và một người thì thầm một bí mật cho người tiếp theo, người này tiếp tục truyền đạt cho người tiếp theo, cho đến khi phiên bản cuối cùng được nói ra bởi người cuối cùng. Trong Hình 12-6, sự phối hợp được ưa chuộng hơn so với sự chỉ huy, tạo ra sự thay đổi tương ứng trong cấu trúc giao tiếp như được thể hiện trong Hình 12-7.
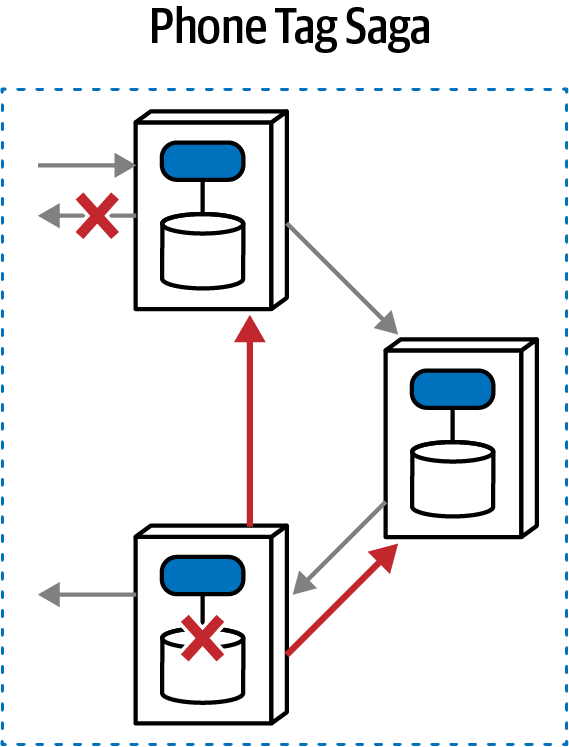
Figure 12-7. Because of a lack of orchestration, each participant must coordinate status
Mô hình Phone Tag Saga có tính chất nguyên tử nhưng cũng có sự phụ thuộc, nghĩa là kiến trúc sư không chỉ định một bộ điều khiển chính thức. Tuy nhiên, tính nguyên tử yêu cầu một mức độ phối hợp nào đó. Trong Hình 12-7, dịch vụ được gọi ban đầu trở thành điểm phối hợp (đôi khi được gọi là bộ điều khiển phía trước). Khi nó hoàn thành công việc của mình, nó sẽ chuyển yêu cầu cho dịch vụ tiếp theo trong quy trình làm việc, tiếp tục cho đến khi quy trình thành công. Tuy nhiên, nếu xảy ra điều kiện lỗi, mỗi dịch vụ phải có logic tích hợp để gửi các yêu cầu bù lại dọc theo chuỗi.
Bởi vì mục tiêu kiến trúc là tính nguyên tử giao dịch, logic để phối hợp tính nguyên tử đó phải tồn tại ở đâu đó. Do đó, các dịch vụ miền phải chứa nhiều logic hơn về ngữ cảnh quy trình mà chúng tham gia, bao gồm cả xử lý lỗi và định tuyến. Đối với các quy trình phức tạp, bộ điều khiển phía trước trong mẫu này sẽ trở nên phức tạp như hầu hết các trình điều phối, làm giảm sức hấp dẫn và tính ứng dụng của mẫu này. Do đó, mẫu này thường được sử dụng cho các quy trình đơn giản cần quy mô lớn hơn, nhưng có thể ảnh hưởng đến hiệu suất.
Cách thức phối hợp so với kiến trúc điều phối cải thiện các đặc điểm kiến trúc hoạt động như khả năng mở rộng? Việc sử dụng phối hợp ngay cả với giao tiếp đồng bộ giúp giảm thiểu các nút thắt—trong các điều kiện không có lỗi, dịch vụ cuối cùng trong quy trình làm việc có thể trả kết quả, cho phép lưu lượng cao hơn và ít điểm nghẽn hơn. Hiệu suất cho các quy trình làm việc bình thường có thể nhanh hơn trong một Epic Saga do thiếu sự phối hợp. Tuy nhiên, trong các điều kiện lỗi sẽ chậm hơn nhiều mà không có người trung gian—mỗi dịch vụ phải giải phóng chuỗi gọi, điều này cũng làm tăng độ kết nối giữa các dịch vụ.
Thông thường, Phone Tag Saga cung cấp quy mô tốt hơn một chút so với Epic Saga do không có một bên trung gian, điều này đôi khi có thể trở thành một nút thắt hạn chế. Tuy nhiên, mẫu này cũng thể hiện hiệu suất thấp hơn cho các điều kiện lỗi và những độ phức tạp của quy trình làm việc khác—không có bên trung gian, quy trình làm việc phải được giải quyết thông qua giao tiếp giữa các dịch vụ, điều này ảnh hưởng đến hiệu suất.
Một đặc điểm tốt của kiến trúc không điều phối là không có sự đơn đôi trong việc kết nối, tức là không có một nơi duy nhất mà luồng công việc gắn kết với nhau. Mặc dù mẫu này sử dụng các yêu cầu đồng bộ, nhưng có ít điều kiện chờ hơn cho các luồng công việc diễn ra thuận lợi, cho phép mở rộng quy mô cao hơn. Nói chung, việc giảm sự kết nối sẽ tăng khả năng mở rộng.
Với khả năng mở rộng được cải thiện do thiếu sự điều phối, đi kèm là sự phức tạp gia tăng của các dịch vụ miền để quản lý các mối quan tâm về quy trình làm việc bên cạnh trách nhiệm chính của chúng. Đối với các quy trình làm việc phức tạp, sự phức tạp gia tăng và giao tiếp giữa các dịch vụ có thể khiến các kiến trúc sư trở lại với việc điều phối và các khoản đánh đổi của nó.
Cuộc chiến điện thoại có một sự kết hợp tính năng khá hiếm — nói chung, nếu một kiến trúc sư chọn phối hợp, họ cũng chọn bất đồng bộ. Tuy nhiên, trong một số trường hợp mà một kiến trúc sư có thể chọn sự kết hợp này thay vào đó: các gọi đồng bộ đảm bảo rằng mỗi dịch vụ miền hoàn thành phần của nó trong quy trình trước khi gọi đến cái tiếp theo, loại bỏ các điều kiện tranh chấp. Nếu các điều kiện lỗi dễ giải quyết, hoặc các dịch vụ miền có thể sử dụng tính idempotence và thực hiện lại, thì các kiến trúc sư có thể xây dựng quy mô song song cao hơn bằng cách sử dụng mẫu này so với Epic Saga.
Mô hình Telephone Tag Saga có các đặc điểm sau:
- Coupling level
-
Mô hình này giảm bớt một trong những chiều liên kết của mô hình Epic Saga, sử dụng một quy trình công việc được phối hợp thay vì được điều phối. Do đó, mô hình này ít bị liên kết hơn một chút, nhưng vẫn giữ yêu cầu giao dịch giống nhau, có nghĩa là sự phức tạp của quy trình làm việc phải được phân phối giữa các dịch vụ miền.
- Complexity level
-
Mô hình này phức tạp hơn nhiều so với Epic Saga; độ phức tạp trong mô hình này tăng lên tỷ lệ thuận với độ phức tạp ngữ nghĩa của quy trình: quy trình càng phức tạp, càng nhiều logic phải xuất hiện trong mỗi dịch vụ để bù đắp cho sự thiếu hụt của bộ điều phối. Mặt khác, một kiến trúc sư có thể thêm thông tin quy trình vào chính các tin nhắn như một hình thức gắn kết đóng dấu (xem “Gắn Kết Đóng Dấu cho Quản Lý Quy Trình”) để duy trì trạng thái, nhưng việc này lại làm tăng thêm bối cảnh phụ thuộc mà mỗi dịch vụ cần.
- Responsiveness/availability
-
Ít sự điều phối thường dẫn đến khả năng phản hồi tốt hơn, nhưng các điều kiện lỗi trong mô hình này trở nên khó khăn hơn để mô hình hóa mà không có người điều phối, đòi hỏi nhiều sự phối hợp thông qua các callback và các hoạt động tốn thời gian khác.
- Scale/elasticity
-
Thiếu sự phối hợp dẫn đến ít điểm nghẽn hơn, thường làm tăng khả năng mở rộng, nhưng chỉ một chút. Mô hình này vẫn sử dụng sự kết nối chặt chẽ xung quanh hai trong ba chiều, vì vậy khả năng mở rộng không phải là một điểm nổi bật, đặc biệt nếu các điều kiện lỗi xảy ra thường xuyên.
Các xếp hạng cho Phone Tag Saga xuất hiện trong Bảng 12-3.
| Phone Tag Saga(sac) | Ratings |
|---|---|
Giao tiếp | Đồng bộ |
Tính nhất quán | Nguyên tử |
Sự phối hợp | Dàn dựng |
Ghép nối | Cao |
Độ phức tạp | Cao |
Tính phản hồi/khả dụng | Thấp |
Quy mô/độ co giãn | Thấp |
Mô hình Phone Tag Saga thích hợp hơn cho các quy trình làm việc đơn giản không có nhiều điều kiện lỗi phổ biến. Mặc dù nó cung cấp một số đặc điểm tốt hơn so với Epic Saga, nhưng độ phức tạp do thiếu một bộ điều phối đã bù đắp cho nhiều lợi thế.
Fairy Tale Saga(seo) Pattern
Câu chuyện cổ tích điển hình cung cấp những câu chuyện vui vẻ với cốt truyện dễ theo dõi, do đó có tên là Fairy Tale Saga, sử dụng giao tiếp đồng bộ, tính nhất quán cuối cùng và phối hợp, như được thể hiện trong Hình 12-8.
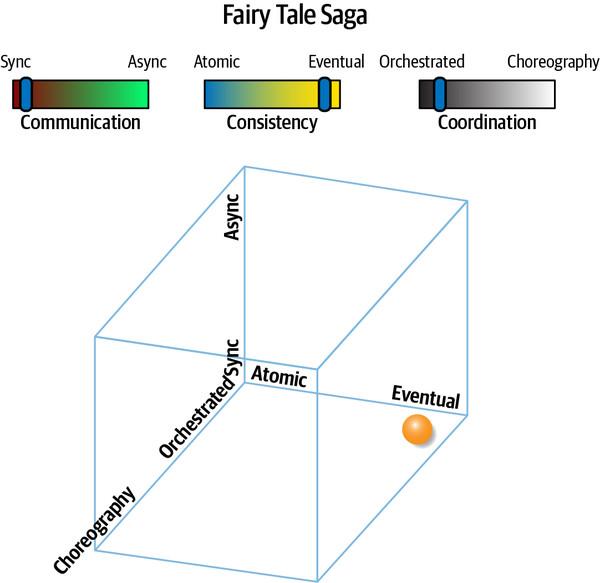
Figure 12-8. The Fairy Tale Saga(seo) illustrates eventual consistency
Mô hình giao tiếp này làm giảm yêu cầu nguyên tử khó khăn, cung cấp nhiều tùy chọn hơn cho các kiến trúc sư để thiết kế hệ thống. Ví dụ, nếu một dịch vụ tạm thời không hoạt động, tính nhất quán cuối cùng cho phép lưu trữ một thay đổi cho đến khi dịch vụ được khôi phục. Cấu trúc giao tiếp cho Fairy Tale Saga được minh họa trong Hình 12-9.
Trong mô hình này, có một bộ điều phối để phối hợp yêu cầu, phản hồi và xử lý lỗi. Tuy nhiên, bộ điều phối không chịu trách nhiệm quản lý giao dịch, mà mỗi dịch vụ miền giữ trách nhiệm đó (để xem các ví dụ về quy trình làm việc thông dụng, hãy xem Chương 11). Do đó, bộ điều phối có thể quản lý các cuộc gọi bồi thường, nhưng không yêu cầu phải xảy ra trong một giao dịch đang hoạt động.
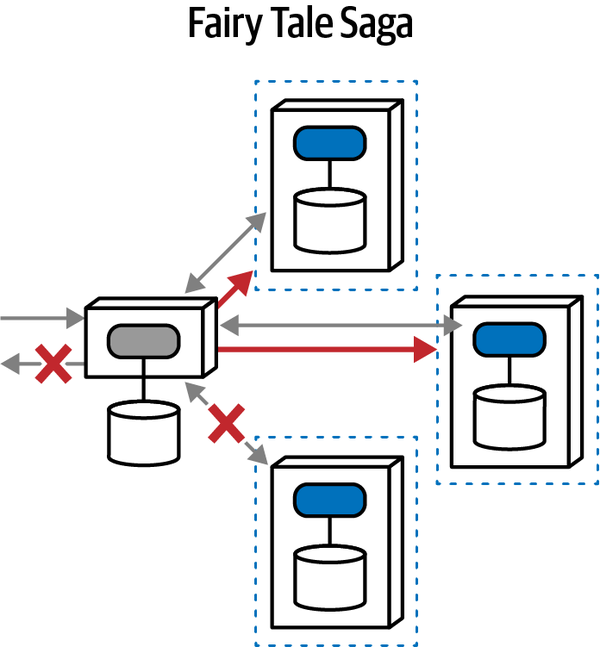
Figure 12-9. Isomorphic illustration of a Fairy Tale interaction
Đây là một mẫu mã hấp dẫn hơn nhiều và thường xuất hiện trong nhiều kiến trúc microservices. Có một trung gian giúp quản lý quy trình làm việc dễ hơn, giao tiếp đồng bộ là lựa chọn dễ hơn trong hai lựa chọn, và tính nhất quán cuối cùng loại bỏ thách thức phối hợp khó khăn nhất, đặc biệt là đối với xử lý lỗi.
Lợi thế hấp dẫn nhất của Fairy Tale Saga là sự thiếu vắng các giao dịch toàn diện. Mỗi dịch vụ miền quản lý hành vi giao dịch của riêng nó, dựa vào tính nhất quán cuối cùng cho quy trình làm việc tổng thể.
So với nhiều mẫu khác, mẫu này thường thể hiện sự cân bằng tốt về các sự đánh đổi.
- Coupling level
-
Cuộc Saga Cổ Tích có tính gắn kết cao, với hai trong số ba yếu tố gắn kết được tối đa hóa trong mô hình này (giao tiếp đồng bộ và phối hợp có tổ chức). Tuy nhiên, yếu tố tồi tệ hơn về độ phức tạp của sự gắn kết—tính giao dịch—biến mất trong mô hình này để nhường chỗ cho tính nhất quán cuối cùng. Người điều phối phải vẫn quản lý các quy trình làm việc phức tạp, nhưng không bị ràng buộc bởi việc phải thực hiện trong một giao dịch.
- Complexity level
-
Độ phức tạp của Fairy Tale Saga khá thấp; nó bao gồm các tùy chọn tiện lợi nhất (được tổ chức, đồng bộ hóa) với giới hạn lỏng lẻo nhất (tính nhất quán cuối cùng). Do đó, cái tên Fairy Tale Saga - một câu chuyện đơn giản với kết thúc hạnh phúc.
- Responsiveness/availability
-
Khả năng phản hồi thường tốt hơn trong các phong cách giao tiếp như thế này vì, mặc dù các cuộc gọi là đồng bộ, người trung gian cần chứa ít trạng thái nhạy cảm với thời gian về các giao dịch đang diễn ra, cho phép cân bằng tải tốt hơn. Tuy nhiên, sự khác biệt thực sự trong hiệu suất đến từ tính không đồng bộ, được minh họa trong các mô hình tương lai.
- Scale/elasticity
-
Việc thiếu sự kết nối thường dẫn đến khả năng mở rộng cao hơn; việc loại bỏ sự kết nối giao dịch cho phép mỗi dịch vụ mở rộng độc lập hơn.
Các đánh giá cho Fairy Tale Saga xuất hiện trong Bảng 12-4.
| Fairy Tale Saga(seo) | Ratings |
|---|---|
Giao tiếp | Đồng bộ |
Tính nhất quán | Cuối cùng |
Phối hợp | Được phối hợp |
Liên kết | Cao |
Độ phức tạp | Rất thấp |
Tính nhạy bén/sự có mặt | Trung bình |
Tỷ lệ/độ co giãn | Cao |
Nếu một kiến trúc sư có thể tận dụng tính nhất quán tạm thời, mô hình này trở nên khá hấp dẫn, kết hợp các thành phần di chuyển dễ dàng với những hạn chế đáng sợ tối thiểu, biến nó thành một lựa chọn phổ biến trong số các kiến trúc sư.
Time Travel Saga(sec) Pattern
Mô hình Cuộc phiêu lưu Thời gian có đặc điểm là giao tiếp đồng bộ và tính nhất quán cuối cùng, nhưng quy trình được dàn dựng. Nói cách khác, mô hình này tránh sử dụng người điều trung tâm, và đặt hoàn toàn trách nhiệm về quy trình vào các dịch vụ miền tham gia, như được minh hoạ trong Hình 12-10.
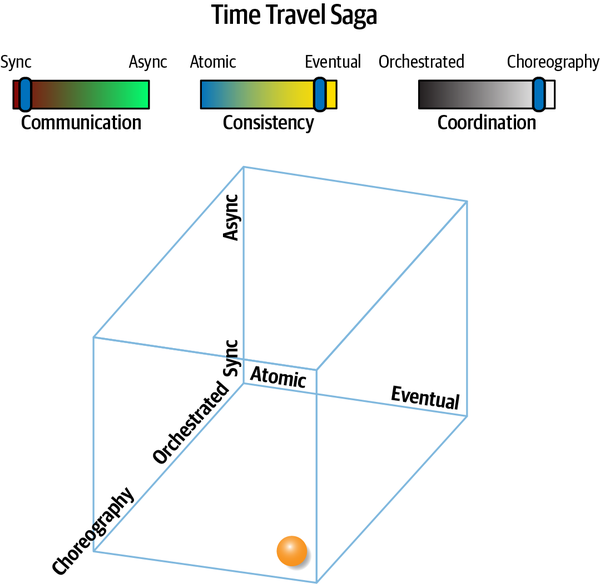
Figure 12-10. The Time Travel Saga(sec) pattern uses two of three decoupling techniques
Cấu trúc hình học minh họa sự thiếu phối hợp, như được trình bày trong Hình 12-11.
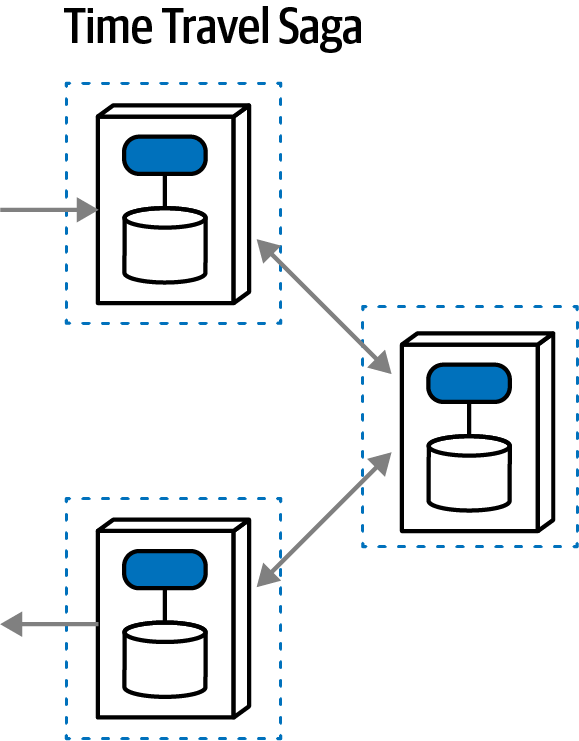
Figure 12-11. Complex workflows become difficult to manage without orchestration
Trong quy trình làm việc này, mỗi dịch vụ chấp nhận một yêu cầu, thực hiện một hành động và sau đó chuyển tiếp yêu cầu đó đến một dịch vụ khác. Kiến trúc này có thể triển khai mẫu thiết kế Chuỗi Trách Nhiệm hoặc phong cách kiến trúc Ống và Bộ Lọc—bất kỳ quy trình làm việc nào với một chuỗi bước một chiều. Mỗi dịch vụ trong mô hình này “sở hữu” tính giao dịch riêng của nó, vì vậy các kiến trúc sư phải thiết kế các điều kiện lỗi trong quy trình làm việc vào trong thiết kế miền. Nói chung, tồn tại một mối quan hệ phức tạp tỷ lệ giữa độ phức tạp của quy trình làm việc và giải pháp được dàn dựng vì thiếu sự phối hợp tích hợp thông qua một trung gian—quy trình làm việc càng phức tạp thì việc dàn dựng càng trở nên khó khăn. Nó được gọi là Saga Du Hành Thời Gian vì mọi thứ đều được tách rời từ góc độ thời gian: mỗi dịch vụ sở hữu ngữ cảnh giao dịch riêng của nó, khiến tính nhất quán của quy trình làm việc trở nên dần dần theo thời gian—trạng thái sẽ trở nên nhất quán theo thời gian dựa trên thiết kế của sự tương tác.
Sự thiếu vắng các giao dịch trong mẫu Time Travel Saga làm cho việc mô hình hóa các quy trình làm việc trở nên dễ dàng hơn; tuy nhiên, việc thiếu một bộ điều phối nghĩa là mỗi dịch vụ miền phải bao gồm hầu hết trạng thái và thông tin của quy trình làm việc. Như trong tất cả các giải pháp được phối hợp, có một mối tương quan trực tiếp giữa độ phức tạp của quy trình làm việc và tiện ích của một bộ điều phối; do đó, mẫu này phù hợp nhất cho các quy trình làm việc đơn giản.
Đối với các giải pháp hưởng lợi từ thông lượng cao, mẫu này hoạt động cực kỳ hiệu quả cho các quy trình làm việc theo kiểu "bắn và quên", như nạp dữ liệu điện tử, giao dịch số lượng lớn, và các việc tương tự. Tuy nhiên, vì không có bộ điều phối, các dịch vụ miền phải xử lý các điều kiện lỗi và phối hợp.
Sự thiếu liên kết làm tăng khả năng mở rộng với mẫu này; chỉ cần thêm tính không đồng bộ sẽ làm cho nó trở nên mở rộng hơn (như trong mẫu Anthology Saga). Tuy nhiên, vì mẫu này thiếu sự điều phối giao dịch toàn diện, các kiến trúc sư phải nỗ lực thêm để đồng bộ hóa dữ liệu.
Dưới đây là đánh giá định tính về mô típ Hành trình Thời gian:
- Coupling level
-
Mức độ liên kết nằm trong khoảng trung bình với Saga du hành thời gian, với sự giảm bớt liên kết do sự vắng mặt của một bộ điều phối được cân bằng bởi sự liên kết vẫn còn của giao tiếp đồng bộ. Như với tất cả các mẫu nhất quán cuối cùng, việc thiếu sự liên kết giao dịch giúp giảm bớt nhiều mối quan tâm về dữ liệu.
- Complexity level
-
Sự mất mát tính giao dịch làm giảm độ phức tạp cho mẫu này. Mẫu này là kiểu gần như đặc thù, cực kỳ phù hợp với các kiến trúc truyền thông một chiều, có tốc độ thông lượng nhanh, và mức độ liên kết phù hợp với kiểu kiến trúc đó.
- Responsiveness/availability
-
Điểm số phản hồi đạt mức trung bình với mẫu kiến trúc này: nó khá cao đối với các hệ thống được xây dựng theo mục đích, như đã mô tả trước đó, và khá thấp đối với việc xử lý lỗi phức tạp. Bởi vì không có bộ điều phối nào tồn tại trong mẫu này, mỗi dịch vụ miền phải xử lý tình huống để khôi phục tính nhất quán cuối cùng trong trường hợp có lỗi, điều này sẽ gây ra nhiều overhead với các cuộc gọi đồng bộ, ảnh hưởng đến phản hồi và hiệu suất.
- Scale/elasticity
-
Mô hình kiến trúc này cung cấp khả năng mở rộng và tính linh hoạt cực kỳ tốt; nó chỉ có thể được cải thiện hơn nữa với tính bất đồng bộ (xem mô hình Anthology Saga).
Các xếp hạng cho mẫu Hành Trình Thời Gian xuất hiện trong Bảng 12-5.
| Time Travel Saga(sec) | Ratings |
|---|---|
Giao tiếp | Đồng bộ |
Nhất quán | Cuối cùng |
Phối hợp | Dàn dựng |
Ghép đôi | Trung bình |
Sự phức tạp | Thấp |
Độ nhạy/khả năng sẵn có | Trung bình |
Quy mô/độ co giãn | Cao |
Mô hình Cuộc Phiêu Lưu Thời Gian cung cấp một lối vào cho mô hình Cuộc Phiêu Lưu Tuyển Tập phức tạp hơn nhưng cuối cùng có thể mở rộng. Các kiến trúc sư và nhà phát triển thấy việc xử lý giao tiếp đồng bộ dễ dàng hơn để lý luận, triển khai và gỡ lỗi; nếu mô hình này cung cấp khả năng mở rộng đủ, các đội không cần phải chấp nhận các lựa chọn thay thế phức tạp hơn nhưng có khả năng mở rộng hơn.
Fantasy Fiction Saga(aao) Pattern
Saga tiểu thuyết giả tưởng sử dụng tính nhất quán nguyên tử, giao tiếp không đồng bộ và phối hợp điều phối, như được thể hiện trong Hình 12-12.
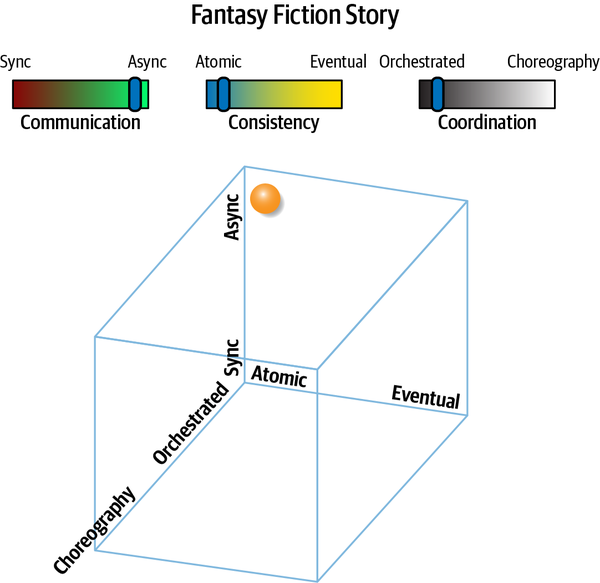
Figure 12-12. Asynchronous communication makes transactionality difficult in this pattern
Cấu trúc đại diện được hiển thị trong Hình 12-13 bắt đầu cho thấy một số khó khăn với mẫu này.
Chỉ vì một sự kết hợp của các yếu tố kiến trúc tồn tại không có nghĩa là nó tạo thành một mô hình hấp dẫn, tuy nhiên sự kết hợp tương đối khó xảy ra này vẫn có những ứng dụng. Mô hình này giống như Epic Saga ở tất cả các khía cạnh ngoại trừ giao tiếp—mô hình này sử dụng giao tiếp bất đồng bộ thay vì đồng bộ. Truyền thống, một trong những cách mà các kiến trúc sư tăng cường khả năng phản hồi của các hệ thống phân tán là bằng cách sử dụng sự không đồng bộ, cho phép các hoạt động xảy ra song song thay vì tuần tự. Điều này có thể có vẻ như là một cách tốt để tăng cường hiệu suất cảm nhận so với Epic Saga.
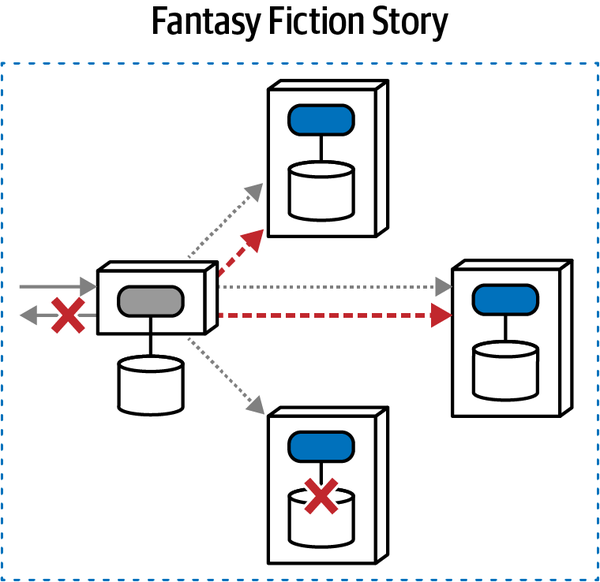
Figure 12-13. The Fantasy Fiction Saga(aao) pattern is far-fetched because transaction coordination for asynchronous communication presents difficulties
Tuy nhiên, việc không đồng bộ không phải là một thay đổi đơn giản - nó thêm nhiều lớp phức tạp vào kiến trúc, đặc biệt là xung quanh sự phối hợp, đòi hỏi nhiều phức tạp hơn ở môi giới. Ví dụ, giả sử một quy trình giao dịch Alpha bắt đầu. Bởi vì mọi thứ là không đồng bộ, trong khi Alpha đang chờ, quy trình giao dịch Beta bắt đầu. Bây giờ, môi giới phải theo dõi trạng thái của tất cả các giao dịch đang diễn ra trong trạng thái chờ.
Nó trở nên tồi tệ hơn. Giả sử rằng quy trình làm việc Gamma bắt đầu, nhưng cuộc gọi đầu tiên đến dịch vụ miền phụ thuộc vào kết quả của Alpha vẫn đang chờ xử lý — một kiến trúc sư có thể mô hình hóa hành vi này như thế nào? Mặc dù có thể, nhưng độ phức tạp ngày càng gia tăng.
Thêm tính không đồng bộ vào các quy trình được điều phối sẽ tạo ra trạng thái giao dịch không đồng bộ, xóa bỏ những giả định tuần tự về thứ tự và thêm vào những khả năng về deadlock, điều kiện đua và một loạt các thách thức hệ thống song song khác.
Mẫu này đặt ra những thách thức sau:
- Coupling level
-
Mức độ kết nối trong mẫu này rất cao, sử dụng một bộ điều phối và tính nguyên tử nhưng với giao tiếp bất đồng bộ, điều này làm cho việc phối hợp trở nên khó khăn hơn vì các kiến trúc sư và nhà phát triển phải đối mặt với tình trạng đua và các vấn đề ngoài thứ tự khác do giao tiếp bất đồng bộ gây ra.
- Complexity level
-
Bởi vì sự kết nối rất khó khăn, độ phức tạp cũng tăng lên trong mô hình này. Không chỉ có độ phức tạp trong thiết kế, yêu cầu các kiến trúc sư phát triển các quy trình làm việc quá phức tạp, mà còn có độ phức tạp trong việc gỡ lỗi và vận hành khi xử lý các quy trình làm việc không đồng bộ ở quy mô lớn.
- Responsiveness/availability
-
Bởi vì mô hình này cố gắng phối hợp giao dịch giữa các cuộc gọi, khả năng phản hồi sẽ bị ảnh hưởng tổng thể và sẽ cực kỳ tồi tệ nếu một hoặc nhiều dịch vụ không khả dụng.
- Scale/elasticity
-
Mở rộng quy mô là gần như không thể trong các hệ thống giao dịch, ngay cả với sự bất đồng bộ. Quy mô tốt hơn nhiều trong mô hình tương tự Parallel Saga, chuyển từ tính nhất quán nguyên tử sang tính nhất quán cuối cùng.
Các đánh giá cho mô hình Saga Tiểu Thuyết Huyền Bí xuất hiện trong Bảng 12-6.
| Fantasy Fiction | Ratings |
|---|---|
Giao tiếp | Không đồng bộ |
Sự nhất quán | Nguyên tử |
Phối hợp | Dàn xếp |
Ghép đôi | Cao |
Phức tạp | Cao |
Tính phản hồi/khả dụng | Thấp |
Quy mô/độ co giãn | Thấp |
Mô hình này thật không may phổ biến hơn mức nó nên có, chủ yếu là do nỗ lực sai lầm nhằm cải thiện hiệu suất của Epic Saga trong khi vẫn duy trì tính giao dịch; một lựa chọn tốt hơn thường là Parallel Saga.
Horror Story(aac) Pattern
Một trong những mẫu phải là sự kết hợp tồi tệ nhất có thể; nó được gọi là mô hình Câu chuyện kinh dị, được đặc trưng bởi giao tiếp không đồng bộ, tính nhất quán nguyên tử và phối hợp theo kịch bản, được minh họa trong Hình 12-14.
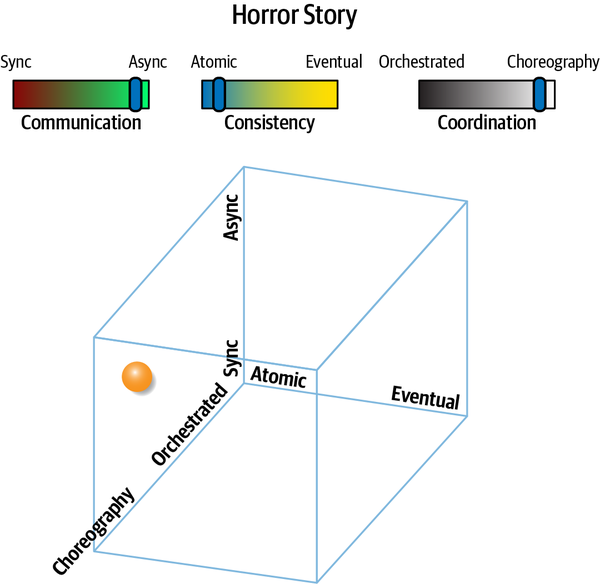
Figure 12-14. The most difficult combination: achieving transactionality while asynchronous and choreographed
Tại sao sự kết hợp này lại tồi tệ như vậy? Nó kết hợp sự kết nối chặt chẽ nhất xung quanh tính nhất quán (nguyên tử) với hai kiểu kết nối lỏng lẻo nhất, bất đồng bộ và biên đạo. Giao tiếp cấu trúc cho mẫu này xuất hiện trong Hình 12-15.
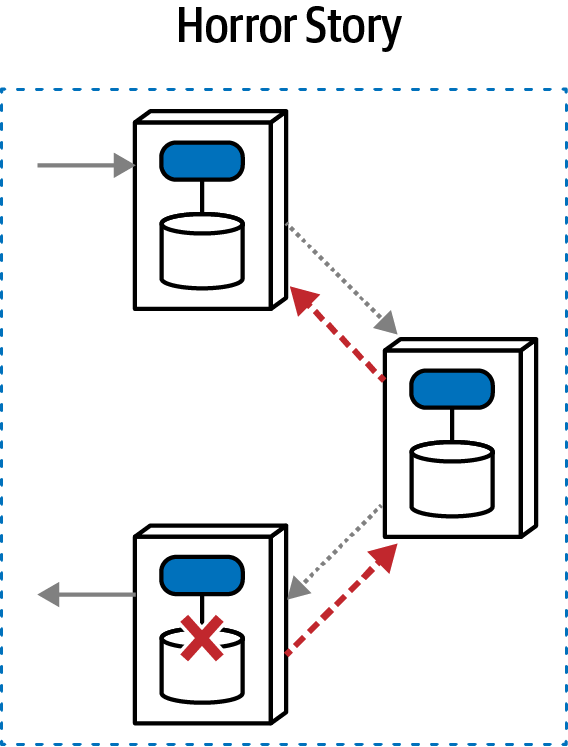
Figure 12-15. This pattern requires a lot of interservice communication because of required transactionality and the lack of a mediator
Trong mẫu này, không có bên trung gian nào để quản lý tính nhất quán giao dịch giữa nhiều dịch vụ—trong khi sử dụng giao tiếp bất đồng bộ. Do đó, mỗi dịch vụ miền phải theo dõi thông tin hoàn tác về nhiều giao dịch chờ, có thể diễn ra không theo thứ tự do tính bất đồng bộ, và phối hợp với nhau trong các điều kiện lỗi. Chỉ cần một trong nhiều ví dụ tồi tệ có thể xảy ra, hãy tưởng tượng rằng giao dịch Alpha bắt đầu và, trong khi đang chờ, giao dịch Beta bắt đầu. Một trong những cuộc gọi cho giao dịch Alpha thất bại—giờ đây, các dịch vụ được lên kế hoạch phải đảo ngược thứ tự thực hiện, hoàn tác từng phần tử của giao dịch (có thể không theo thứ tự) dọc theo đường đi. Sự đa dạng và phức tạp của các điều kiện lỗi làm cho điều này trở thành một lựa chọn khó khăn.
Tại sao một kiến trúc sư có thể chọn tùy chọn này? Tính không đồng bộ hấp dẫn vì nó đem lại hiệu suất cao, nhưng kiến trúc sư vẫn có thể cố gắng duy trì tính toàn vẹn giao dịch, điều này có nhiều chế độ thất bại khác nhau. Thay vào đó, một kiến trúc sư sẽ tốt hơn nếu chọn mẫu Anthology Saga, mẫu này loại bỏ tính giao dịch toàn bộ.
Đánh giá định tính cho mẫu Chuyện Kinh Dị như sau:
- Coupling level
-
Thật bất ngờ, mức độ coupling cho mẫu này không phải là tồi tệ nhất (danh hiệu “vinh dự” đó thuộc về mẫu Epic Saga). Mặc dù mẫu này cố gắng thực hiện loại coupling đơn lẻ tồi tệ nhất (tính giao dịch), nó làm giảm bớt hai mẫu còn lại, thiếu cả một phương tiện trung gian và coupling - làm tăng giao tiếp đồng bộ.
- Complexity level
-
Cũng như tên gọi của nó, độ phức tạp của mẫu này thực sự là khủng khiếp, tồi tệ nhất so với bất kỳ mẫu nào khác vì nó yêu cầu tiêu chuẩn khắt khe nhất (tính giao dịch) với sự kết hợp khó khăn nhất của các yếu tố khác để đạt được điều đó (tính bất đồng bộ và sự phối hợp).
- Scale/elasticity
-
Mô hình này cho phép mở rộng tốt hơn so với những mô hình có vai trò trung gian, và tính bất đồng bộ cũng cung cấp khả năng thực hiện nhiều công việc hơn đồng thời.
- Responsiveness/availability
-
Độ phản hồi thấp đối với mẫu này, tương tự như các mẫu khác yêu cầu các giao dịch toàn diện: sự phối hợp cho quy trình làm việc đòi hỏi một lượng lớn “thông tin trao đổi” giữa các dịch vụ, làm giảm hiệu suất và độ phản hồi.
Các thỏa hiệp cho mẫu Câu chuyện Kinh dị xuất hiện trong Bảng 12-7.
| Horror Story(aac) | Ratings |
|---|---|
Giao tiếp | Không đồng bộ |
Sự nhất quán | Nguyên tử |
Sự phối hợp | Biên đạo |
Ghép nối | Trung bình |
Độ phức tạp | Rất cao |
Khả năng phản hồi/có mặt | Thấp |
Quy mô/độ đàn hồi | Trung bình |
Mô hình được đặt tên đúng là Câu Chuyện Kinh Dị thường là kết quả của một kiến trúc sư có ý tốt bắt đầu với mô hình Truyền Thuyết Huyền Bí, nhận thấy hiệu suất chậm do các quy trình phức tạp, và nhận ra rằng các kỹ thuật để cải thiện hiệu suất bao gồm giao tiếp bất đồng bộ và vũ điệu hợp tác. Tuy nhiên, suy nghĩ này cung cấp một ví dụ tuyệt vời về việc không xem xét tất cả các chiều không gian vấn đề liên quan. Khi tách biệt, giao tiếp bất đồng bộ cải thiện hiệu suất. Tuy nhiên, với tư cách là các kiến trúc sư, chúng ta không thể xem xét nó một cách tách biệt khi nó liên quan đến các chiều kiến trúc khác, chẳng hạn như tính nhất quán và sự phối hợp.
Parallel Saga(aeo) Pattern
Mô hình Saga Song Song được đặt tên theo mô hình Saga Epic "truyền thống" với hai điểm khác biệt chính làm giảm bớt các ràng buộc và do đó khiến nó trở thành một mô hình dễ triển khai hơn: giao tiếp bất đồng bộ và tính nhất quán cuối cùng. Sơ đồ hình học của mô hình Saga Song Song xuất hiện trong Hình 12-16.
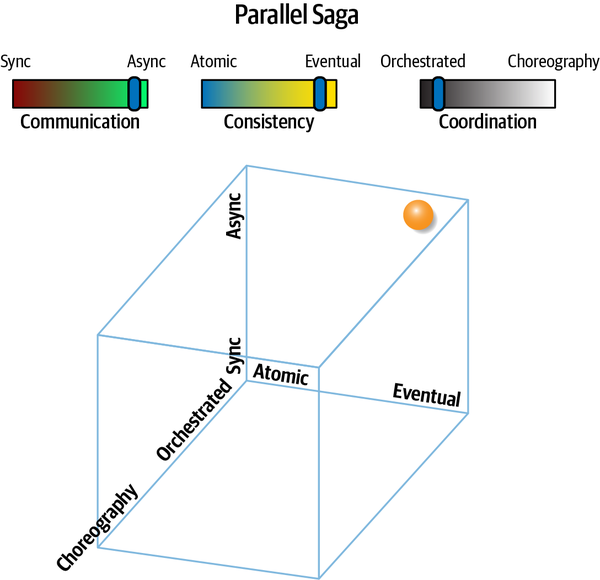
Figure 12-16. Parallel Saga(aeo) offers performance improvements over traditional sagas
Các mục tiêu khó nhất trong mẫu Epic Saga xoay quanh giao dịch và giao tiếp đồng bộ, cả hai đều gây ra tắc nghẽn và suy giảm hiệu suất. Như đã trình bày trong Hình 12-16, mẫu này nới lỏng cả hai ràng buộc.
Biểu diễn đồng hình của Parallel Saga xuất hiện trong Hình 12-17.
Mô hình này sử dụng một trung gian, làm cho nó phù hợp với các quy trình công việc phức tạp. Tuy nhiên, nó sử dụng giao tiếp bất đồng bộ, cho phép cải thiện khả năng phản hồi và thực thi song song. Sự nhất quán trong mô hình nằm ở các dịch vụ miền, có thể yêu cầu một số đồng bộ hóa dữ liệu chia sẻ, hoặc trong nền tảng hoặc được điều khiển thông qua trung gian. Cũng như trong các vấn đề kiến trúc khác cần sự phối hợp, một trung gian trở nên rất hữu ích.
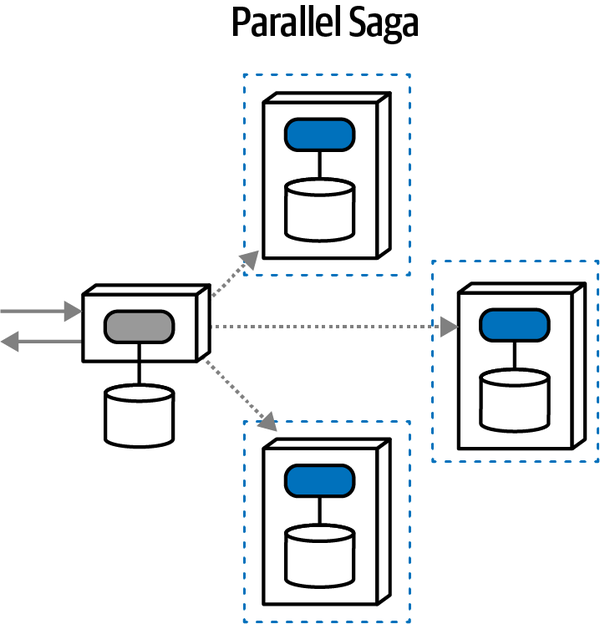
Figure 12-17. Each service owns its own transactionality; the mediator coordinates request and response
Ví dụ, nếu một lỗi xảy ra trong quá trình thực thi một luồng công việc, bộ trung gian có thể gửi các thông điệp bất đồng bộ đến từng dịch vụ miền liên quan để bù đắp cho sự thay đổi không thành công, điều này có thể bao gồm việc thử lại, đồng bộ hóa dữ liệu, hoặc một loạt các biện pháp khắc phục khác.
Tất nhiên, việc nới lỏng các ràng buộc đồng nghĩa với việc một số lợi ích sẽ phải đánh đổi, đó là bản chất của kiến trúc phần mềm. Thiếu tính giao dịch đặt thêm gánh nặng lên trung gian để giải quyết các lỗi và vấn đề trong quy trình công việc. Giao tiếp không đồng bộ, mặc dù đem lại khả năng đáp ứng tốt hơn, nhưng khiến việc giải quyết các vấn đề về thời gian và đồng bộ hóa trở nên khó khăn—các tình huống tranh chấp, tình trạng chết, độ tin cậy của hàng đợi và nhiều vấn đề khác trong kiến trúc phân tán tồn tại trong lĩnh vực này.
Mô hình Saga song song thể hiện các điểm số chất lượng sau:
- Coupling level
-
Mẫu này có mức độ coupling thấp, cách ly sức mạnh làm tăng coupling của các giao dịch trong phạm vi của các dịch vụ miền riêng lẻ. Nó cũng sử dụng giao tiếp bất đồng bộ, further decoupling các dịch vụ khỏi trạng thái chờ, cho phép xử lý song song nhiều hơn nhưng lại thêm một yếu tố thời gian vào phân tích coupling của kiến trúc sư.
- Complexity level
-
Độ phức tạp của Parallel Saga cũng thấp, phản ánh sự giảm thiểu sự liên kết đã được đề cập trước đó. Mẫu này khá dễ hiểu đối với các kiến trúc sư, và việc điều phối cho phép thiết kế quy trình làm việc và xử lý lỗi đơn giản hơn.
- Scale/elasticity
-
Sử dụng giao tiếp bất đồng bộ và ranh giới giao dịch nhỏ hơn cho phép kiến trúc này mở rộng rất tốt, và với mức độ tách biệt tốt giữa các dịch vụ. Ví dụ, trong kiến trúc vi dịch vụ, một số dịch vụ hướng ra công chúng có thể cần mức độ mở rộng và tính linh hoạt cao hơn, trong khi các dịch vụ văn phòng không cần mở rộng nhưng lại cần mức độ bảo mật cao hơn. Tách biệt các giao dịch ở mức độ miền giải phóng kiến trúc để mở rộng xung quanh các khái niệm miền.
- Responsiveness/availability
-
Do tính chất không đồng bộ của các giao dịch và giao tiếp không được phối hợp, khả năng phản hồi của kiến trúc này là rất cao. Thực tế, vì mỗi dịch vụ trong số này duy trì ngữ cảnh giao dịch riêng của nó, kiến trúc này rất phù hợp với sự biến động hiệu suất dịch vụ cao giữa các dịch vụ, cho phép các kiến trúc sư mở rộng một số dịch vụ nhiều hơn những dịch vụ khác do nhu cầu.
Các đánh giá liên quan đến mẫu Parallel Saga xuất hiện trong Bảng 12-8.
| Parallel Saga(aeo) | Ratings |
|---|---|
Giao tiếp | Không đồng bộ |
Nhất quán | Cuối cùng |
Sự phối hợp | Được tổ chức |
Ghép nối | Thấp |
phức tạp | Thấp |
Phản hồi/sự sẵn có | Cao |
Tỉ lệ/mặc đàn hồi | Cao |
Tổng thể, mẫu Parallel Saga cung cấp một tập hợp hấp dẫn các sự đánh đổi cho nhiều kịch bản, đặc biệt với các quy trình làm việc phức tạp cần quy mô lớn.
Anthology Saga(aec) Pattern
Mô hình Anthology Saga cung cấp một tập hợp các đặc điểm hoàn toàn trái ngược với mô hình Epic Saga truyền thống: nó sử dụng giao tiếp bất đồng bộ, tính nhất quán theo thời gian, và phối hợp theo cách dàn dựng, tạo ra ví dụ ít liên kết nhất trong tất cả các mô hình này. Quan điểm hình học của mô hình Anthology Saga xuất hiện trong Hình 12-18.
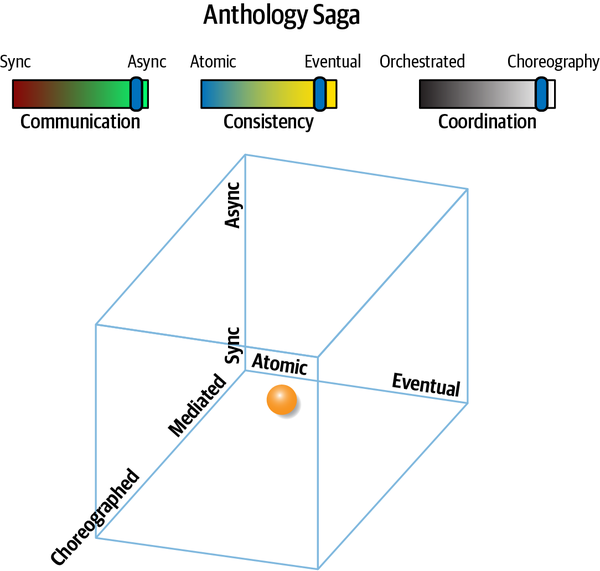
Figure 12-18. The Anthology Saga(aec) pattern offers the opposite extremes of the Epic Saga, and is therefore the least coupled pattern
Mô hình tuyển tập sử dụng hàng đợi tin nhắn để gửi tin nhắn bất đồng bộ đến các dịch vụ miền khác mà không cần điều phối, như minh họa trong Hình 12-19.
Như bạn có thể thấy, mỗi dịch vụ duy trì tính toàn vẹn giao dịch riêng của nó, và không có bộ điều phối nào tồn tại, buộc mỗi dịch vụ miền phải bao gồm nhiều bối cảnh hơn về các quy trình công việc mà chúng tham gia, bao gồm xử lý lỗi và các chiến lược phối hợp khác.
Figure 12-19. Lack of orchestration, eventual consistency, and asynchronicity make this pattern highly decoupled but a challenge for coordination
Sự thiếu hụt trong việc phối hợp khiến các dịch vụ trở nên phức tạp hơn nhưng cho phép thông lượng, khả năng mở rộng, tính linh hoạt và các đặc điểm kiến trúc vận hành có lợi khác cao hơn nhiều. Không có điểm thắt cổ chai hoặc sự liên kết nào tồn tại trong kiến trúc này, cho phép tính phản hồi và khả năng mở rộng cao.
Tuy nhiên, mẫu này không hoạt động tốt lắm cho các quy trình phức tạp, đặc biệt là trong việc giải quyết các lỗi nhất quán dữ liệu. Mặc dù có vẻ như không thể thực hiện điều này mà không có một bộ điều khiển, việc kết nối theo kiểu stamp ("Stamp Coupling for Workflow Management") có thể được sử dụng để mang trạng thái quy trình, như đã được mô tả trong mẫu Phone Tag Saga tương tự.
Mẫu này hoạt động tốt nhất cho các quy trình làm việc đơn giản, chủ yếu là tuyến tính, nơi các kiến trúc sư mong muốn có khả năng xử lý cao. Mẫu này cung cấp tiềm năng lớn nhất cho cả hiệu suất cao và khả năng mở rộng, khiến nó trở thành một lựa chọn hấp dẫn khi những yếu tố đó là động lực chính cho hệ thống. Tuy nhiên, mức độ tách rời làm cho việc phối hợp trở nên khó khăn, thậm chí là cản trở đối với các quy trình làm việc phức tạp hoặc quan trọng.
Mô hình Anthology Saga lấy cảm hứng từ truyện ngắn có các đặc điểm sau:
- Coupling level
-
"Cặp đôi cho mẫu này là thấp nhất so với bất kỳ tổ hợp lực nào khác, tạo ra một kiến trúc tách rời cao phù hợp cho quy mô lớn và tính linh hoạt."
- Complexity level
-
Trong khi mối liên kết cực kỳ thấp, độ phức tạp tương ứng cao, đặc biệt là đối với các quy trình làm việc phức tạp, nơi một bộ điều phối (không có ở đây) là tiện lợi.
- Scale/elasticity
-
Mẫu này đạt điểm cao nhất trong danh mục khả năng mở rộng và đàn hồi, tương ứng với việc thiếu sự liên kết tổng thể được tìm thấy trong mẫu này.
- Responsiveness
-
Độ phản hồi cao trong kiến trúc này do thiếu các bộ điều chỉnh tốc độ (tính nhất quán giao dịch, giao tiếp đồng bộ) và việc sử dụng các tăng tốc độ phản hồi (phối hợp có kịch bản).
Bảng đánh giá cho mẫu Anthology Saga xuất hiện trong Bảng 12-9.
| Anthology Saga(aec) | Ratings |
|---|---|
Giao tiếp | Không đồng bộ |
Tính nhất quán | Cuối cùng |
Phối hợp | Được biên đạo |
Ghép đôi | Rất thấp |
Độ phức tạp | Cao |
Tính phản hồi/khả dụng | Cao |
Quy mô/độ co giãn | Rất cao |
Mô hình Anthology Saga rất phù hợp cho việc truyền thông với lưu lượng cực kỳ cao với các điều kiện lỗi đơn giản hoặc hiếm gặp. Ví dụ, kiến trúc Pipes and Filters sẽ hoàn toàn phù hợp với mô hình này.
Các kiến trúc sư có thể triển khai các mẫu được mô tả trong phần này theo nhiều cách khác nhau. Ví dụ, các kiến trúc sư có thể quản lý các giao dịch sagas thông qua các giao dịch nguyên tử bằng cách sử dụng các cập nhật bù trừ hoặc bằng cách quản lý trạng thái giao dịch với tính nhất quán cuối cùng. Phần này đã trình bày những ưu điểm và nhược điểm của mỗi phương pháp, điều này sẽ giúp một kiến trúc sư quyết định mẫu giao dịch saga nào nên sử dụng.
State Management and Eventual Consistency
Quản lý trạng thái và tính nhất quán cuối cùng sử dụng các máy trạng thái hữu hạn (xem “Máy Trạng Thái Saga”) để luôn biết trạng thái hiện tại của saga giao dịch, và cũng để cuối cùng khắc phục điều kiện lỗi thông qua việc thử lại hoặc một hình thức hành động khắc phục tự động hoặc thủ công. Để minh họa cách tiếp cận này, hãy xem xét việc triển khai Saga Cổ Tích trong ví dụ hoàn thành vé được minh họa trong Hình 12-20.
Figure 12-20. The Fairy Tale Saga leads to better responsiveness, but leaves data sources out of sync with one another until they can be corrected
Lưu ý rằng Dịch vụ Khảo sát không khả dụng trong phạm vi của giao dịch phân tán. Tuy nhiên, với loại saga này, thay vì phát hành một bản cập nhật bù, trạng thái của saga được thay đổi thành NO_SURVEY và một phản hồi thành công được gửi đến Chuyên gia Sysops (bước 7 trong biểu đồ). Dịch vụ Điều phối Vé sau đó làm việc bất đồng bộ (sau cánh gà) để giải quyết lỗi một cách chương trình qua việc thử lại và phân tích lỗi. Nếu không thể giải quyết lỗi, Dịch vụ Điều phối Vé sẽ gửi lỗi đến một quản trị viên hoặc giám sát viên để sửa chữa và xử lý thủ công.
Bằng cách quản lý trạng thái của saga thay vì phát hành các cập nhật bồi thường, người dùng cuối (trong trường hợp này là chuyên gia của đội Sysops) không cần phải lo lắng rằng cuộc khảo sát chưa được gửi đến khách hàng—trách nhiệm đó thuộc về Dịch vụ Điều phối Vé. Sự nhạy bén là tốt từ góc nhìn của người dùng cuối, và người dùng có thể làm việc trên các nhiệm vụ khác trong khi các lỗi được hệ thống xử lý.
Saga State Machines
Một máy trạng thái là một mẫu mô tả tất cả các con đường có thể tồn tại trong một kiến trúc phân tán. Một máy trạng thái luôn bắt đầu với một trạng thái khởi đầu để khởi động hành trình giao dịch, sau đó chứa các trạng thái chuyển tiếp và hành động tương ứng nên xảy ra khi trạng thái chuyển tiếp xảy ra.
Để minh họa cách hoạt động của máy trạng thái saga, hãy xem xét quy trình sau đây của một vé vấn đề mới được tạo ra bởi một khách hàng trong hệ thống Sysops Squad:
-
Khách hàng nhập một phiếu yêu cầu vấn đề mới vào hệ thống.
-
Vé được giao cho chuyên gia Sysops Squad tiếp theo có sẵn.
-
Vé sau đó được chuyển đến thiết bị di động của chuyên gia.
-
Chuyên gia nhận vé và xử lý vấn đề.
-
Chuyên gia hoàn thành việc sửa chữa và đánh dấu vé là đã hoàn tất.
-
Một cuộc khảo sát được gửi đến khách hàng.
Các trạng thái khác nhau có thể tồn tại trong câu chuyện giao dịch này, cũng như các hành động chuyển tiếp tương ứng, được minh họa trong Hình 12-21. Lưu ý rằng câu chuyện giao dịch bắt đầu với nút BẮT ĐẦU chỉ ra điểm vào của câu chuyện và kết thúc với nút ĐÓNG chỉ ra điểm ra của câu chuyện.
Figure 12-21. State diagram for creating a new problem ticket
Các mục sau đây mô tả chi tiết hơn về hành trình giao dịch này và các trạng thái cũng như các hành động chuyển tiếp xảy ra trong từng trạng thái:
- START
-
Cuộc hành trình giao dịch bắt đầu khi một khách hàng nhập một yêu cầu hỗ trợ mới vào hệ thống. Kế hoạch hỗ trợ của khách hàng được xác thực và dữ liệu yêu cầu được xác minh. Khi yêu cầu được chèn vào bảng yêu cầu trong cơ sở dữ liệu, trạng thái hành trình giao dịch chuyển sang TRẢI NGHIỆM và khách hàng được thông báo rằng yêu cầu đã được tạo thành công. Đây là kết quả duy nhất có thể cho sự chuyển trạng thái này—mọi lỗi trong trạng thái này đều ngăn cản hành trình bắt đầu.
- CREATED
-
Khi vé được tạo thành công, nó sẽ được giao cho một chuyên gia của Đội Sysops. Nếu không có chuyên gia nào có sẵn để phục vụ vé, nó sẽ được giữ trong trạng thái chờ cho đến khi có một chuyên gia sẵn sàng. Khi một chuyên gia được giao, trạng thái của saga sẽ chuyển sang trạng thái ĐƯỢC GIAO. Đây là kết quả duy nhất cho chuyển đổi trạng thái này, có nghĩa là vé sẽ được giữ ở trạng thái ĐƯỢC TẠO cho đến khi nó có thể được giao.
- ASSIGNED
-
Khi một vé được phân công cho một chuyên gia, kết quả duy nhất có thể xảy ra là chuyển vé đến chuyên gia đó. Giả định rằng trong quá trình thuật toán phân công, chuyên gia đã được xác định và đang có sẵn. Nếu vé không thể được chuyển tiếp vì không thể xác định được chuyên gia hoặc chuyên gia không có mặt, tiến trình sẽ ở trạng thái này cho đến khi có thể chuyển tiếp. Khi đã được chuyển tiếp, chuyên gia phải xác nhận rằng vé đã được nhận. Khi điều này xảy ra, trạng thái tiến trình giao dịch sẽ chuyển sang ĐƯỢC CHẤP NHẬN. Đây là kết quả duy nhất có thể cho sự chuyển tiếp trạng thái này.
- ACCEPTED
-
Có hai trạng thái khả thi một khi vé đã được chấp nhận bởi chuyên gia của Đội Sysops: ĐÃ HOÀN THÀNH hoặc CHUYỂN GIAO. Khi chuyên gia hoàn thành sửa chữa và đánh dấu vé là "hoàn thành," trạng thái của saga chuyển sang ĐÃ HOÀN THÀNH. Tuy nhiên, nếu vì lý do nào đó vé bị phân công sai hoặc chuyên gia không thể hoàn thành sửa chữa, chuyên gia sẽ thông báo cho hệ thống và trạng thái sẽ chuyển sang CHUYỂN GIAO.
- REASSIGN
-
Khi ở trong trạng thái saga này, hệ thống sẽ phân công lại vé cho một chuyên gia khác. Giống như trạng thái ĐƯỢC TẠO, nếu không có chuyên gia nào có sẵn, saga giao dịch sẽ ở lại trong trạng thái PHÂN CÔNG LẠI cho đến khi một chuyên gia được chỉ định. Khi một chuyên gia khác được tìm thấy và vé lại được phân công, trạng thái sẽ chuyển sang trạng thái ĐƯỢC GIAO, chờ được chấp nhận bởi chuyên gia khác. Đây là kết quả duy nhất có thể cho sự chuyển tiếp trạng thái này, và saga vẫn ở trong trạng thái này cho đến khi một chuyên gia được chỉ định cho vé.
- COMPLETED
-
Hai trạng thái có thể xảy ra khi một chuyên gia hoàn thành một vé là ĐÃ ĐÓNG hoặc KHÔNG KHẢO SÁT. Khi vé ở trạng thái này, một khảo sát được gửi đến khách hàng để đánh giá chuyên gia và dịch vụ, và trạng thái saga được chuyển sang ĐÃ ĐÓNG, do đó kết thúc saga giao dịch. Tuy nhiên, nếu Dịch vụ Khảo sát không khả dụng hoặc xảy ra lỗi trong quá trình gửi khảo sát, trạng thái sẽ chuyển sang KHÔNG KHẢO SÁT, cho thấy rằng vấn đề đã được khắc phục nhưng không có khảo sát nào được gửi đến khách hàng.
- NO_SURVEY
-
Trong trạng thái lỗi này, hệ thống tiếp tục cố gắng gửi khảo sát đến khách hàng. Khi đã gửi thành công, trạng thái sẽ chuyển sang ĐÓNG, đánh dấu kết thúc của chuỗi giao dịch. Đây là kết quả duy nhất có thể xảy ra trong giao dịch trạng thái này.
Trong nhiều trường hợp, việc liệt kê danh sách tất cả các chuyển trạng thái có thể và các hành động chuyển tiếp tương ứng trong một bảng nào đó là rất hữu ích. Các nhà phát triển sau đó có thể sử dụng bảng này để triển khai các kích hoạt chuyển trạng thái và các điều kiện lỗi có thể xảy ra trong dịch vụ điều phối (hoặc các dịch vụ tương ứng nếu sử dụng nhảy múa). Một ví dụ về thực tiễn này được thể hiện trong Bảng 12-10, liệt kê tất cả các trạng thái và hành động có thể xảy ra khi chuyển trạng thái diễn ra.
| Initiating state | Transition state | Transaction action |
|---|---|---|
BẮT ĐẦU | TẠO RA | Gán vé cho chuyên gia |
TẠO RA | GIAO PHÓ | Chuyền vé cho chuyên gia được phân công |
ĐƯỢC GIAO GIAI ĐOẠN | ĐƯỢC CHẤP NHẬN | Chuyên gia khắc phục sự cố |
ĐƯỢC CHẤP NHẬN | HOÀN THÀNH | Gửi khảo sát khách hàng |
ĐƯỢC CHẤP NHẬN | Chuyển giao | Chuyển giao cho một chuyên gia khác |
Chuyển giao lại | GIAO RỒI | Chuyển ticket đến chuyên gia được phân công |
HOÀN THÀNH | Đã đóng | Đã hoàn thành saga vé |
ĐÃ HOÀN THÀNH | KHÔNG_CÓ_KHẢO_SÁT | Gửi khảo sát khách hàng |
KHÔNG_CÓ_KHẢO_SÁT | ĐÃ ĐÓNG | Cuộc phiêu lưu vé đã hoàn thành |
Sự lựa chọn giữa việc sử dụng cập nhật bù hoặc quản lý trạng thái cho các quy trình giao dịch phân tán phụ thuộc vào tình huống cũng như phân tích sự đánh đổi giữa tính phản hồi và tính nhất quán. Bất kể kỹ thuật nào được sử dụng để quản lý lỗi trong một giao dịch phân tán, trạng thái của giao dịch phân tán đó cần được biết đến và cũng cần được quản lý.
Bảng 12-11 tóm tắt những lợi ích và đánh đổi liên quan đến việc sử dụng quản lý trạng thái thay vì giao dịch phân tán nguyên tử với các cập nhật bù trừ.
Techniques for Managing Sagas
Giao dịch phân tán không phải là thứ có thể đơn giản "thả vào" một hệ thống. Chúng không thể được tải xuống hoặc mua bằng một loại khung hoặc sản phẩm nào đó như các trình quản lý giao dịch ACID - chúng phải được thiết kế, lập trình và bảo trì bởi các nhà phát triển và kiến trúc sư.
Một trong những kỹ thuật mà chúng tôi thích sử dụng để quản lý các giao dịch phân tán là tận dụng các chú thích (Java) hoặc thuộc tính tùy chỉnh (C#), hoặc các đối tượng tương tự khác trong các ngôn ngữ khác. Mặc dù các đối tượng ngôn ngữ này tự chúng không chứa bất kỳ chức năng thực tế nào, nhưng chúng cung cấp một cách có thể lập trình để ghi lại và tài liệu hóa các biên niên sử giao dịch trong hệ thống, cũng như cung cấp một phương tiện để kết nối các dịch vụ với các biên niên sử giao dịch.
Các danh sách nguồn trong Ví dụ 12-1 (Java) và Ví dụ 12-2 (C#) cho thấy một ví dụ về việc triển khai các chú thích và thuộc tính tùy chỉnh này. Lưu ý rằng trong cả hai triển khai, các saga giao dịch (NEW_TICKET, CANCEL_TICKET, và các saga khác) được chứa trong enum Transaction, cung cấp một nơi duy nhất trong mã nguồn để liệt kê và tài liệu hóa các saga khác nhau tồn tại trong ngữ cảnh ứng dụng.
Example 12-1. Source code defining a transactional saga annotation (Java)
@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.TYPE)public@interfaceSaga{publicTransaction[]value();publicenumTransaction{NEW_TICKET,CANCEL_TICKET,NEW_CUSTOMER,UNSUBSCRIBE,NEW_SUPPORT_CONTRACT}}
Example 12-2. Source code defining a transactional saga attribute (C#)
[AttributeUsage(AttributeTargets.Class)]classSaga:System.Attribute{publicTransaction[]transaction;publicenumTransaction{NEW_TICKET,CANCEL_TICKET,NEW_CUSTOMER,UNSUBSCRIBE,NEW_SUPPORT_CONTRACT};}
Khi đã được xác định, các chú thích hoặc thuộc tính này có thể được sử dụng để xác định các dịch vụ liên quan đến saga giao dịch. Ví dụ, đoạn mã nguồn trong Ví dụ 12-3 cho thấy Dịch vụ Khảo sát (được xác định bởi lớp SurveyServiceAPI như là điểm vào dịch vụ) tham gia vào saga NEW_TICKET, trong khi Dịch vụ Vé (được xác định bởi lớp TicketServiceAPI như là điểm vào dịch vụ) tham gia vào hai saga: NEW_TICKET và CANCEL_TICKET.
Example 12-3. Source code showing the use of the transactional saga annotation (Java)
@ServiceEntrypoint@Saga(Transaction.NEW_TICKET)publicclassSurveyServiceAPI{...}@ServiceEntrypoint@Saga({Transaction.NEW_TICKET,)Transaction.CANCEL_TICKET})publicclassTicketServiceAPI{...}
Lưu ý rằng chuỗi NEW_TICKET bao gồm Dịch vụ Khảo sát và Dịch vụ Vé. Đây là thông tin quý giá đối với một nhà phát triển vì nó giúp họ xác định phạm vi kiểm tra khi thực hiện các thay đổi cho một quy trình làm việc hoặc chuỗi cụ thể, và cũng cho phép họ biết những dịch vụ khác có thể bị ảnh hưởng bởi một thay đổi trong một trong các dịch vụ trong chuỗi giao dịch.
Sử dụng các chú thích và thuộc tính tùy chỉnh này, các kiến trúc sư và nhà phát triển có thể viết các công cụ giao diện dòng lệnh (CLI) đơn giản để duyệt qua mã nguồn hoặc kho lưu trữ mã nguồn nhằm cung cấp thông tin về saga trong thời gian thực. Ví dụ, bằng cách sử dụng một công cụ duyệt mã tùy chỉnh đơn giản, một nhà phát triển, kiến trúc sư hoặc thậm chí một nhà phân tích kinh doanh có thể truy vấn các dịch vụ nào liên quan đến saga NEW_TICKET:
$./sagatool.sh NEW_TICKET -services -> Ticket Service -> Assignment Service -> Routing Service -> Survey Service$
Một công cụ đi bộ mã tùy chỉnh có thể xem xét từng tệp lớp trong ngữ cảnh ứng dụng chứa chú thích (hoặc thuộc tính) @ServiceEntrypoint và kiểm tra chú thích @Saga xem có sự hiện diện của kịch bản cụ thể (trong trường hợp này, Transaction.NEW_TICKET). Loại công cụ tùy chỉnh này không khó để viết và có thể cung cấp thông tin quý giá khi quản lý các kịch bản giao dịch.
Sysops Squad Saga: Atomic Transactions and Compensating Updates
Thứ ba, ngày 5 tháng 4, 09:44
Addison và Austen đã gặp Logan ngay từ đầu để thảo luận về các vấn đề xung quanh tính giao dịch trong kiến trúc microservices mới trong phòng hội nghị dài.
Logan bắt đầu, “Tôi biết rằng không phải ai cũng đồng quan điểm về cách mà những gì bạn đã đọc áp dụng vào những gì chúng ta đang làm ở đây. Vì vậy, tôi đã chuẩn bị một số quy trình làm việc và sơ đồ để giúp mọi người đồng nhất. Hôm nay, chúng ta sẽ thảo luận về việc đánh dấu một ticket là hoàn thành trong hệ thống. Đối với quy trình này, chuyên gia của đội Sysops hoàn thành một công việc và đánh dấu ticket là “hoàn thành” bằng cách sử dụng ứng dụng di động trên thiết bị di động của chuyên gia. Tôi muốn nói về mẫu Epic Saga và các vấn đề liên quan đến việc cập nhật bồi thường. Tôi đã tạo một sơ đồ để minh họa quy trình này trong Hình 12-22. Mọi người có nhìn thấy không?”
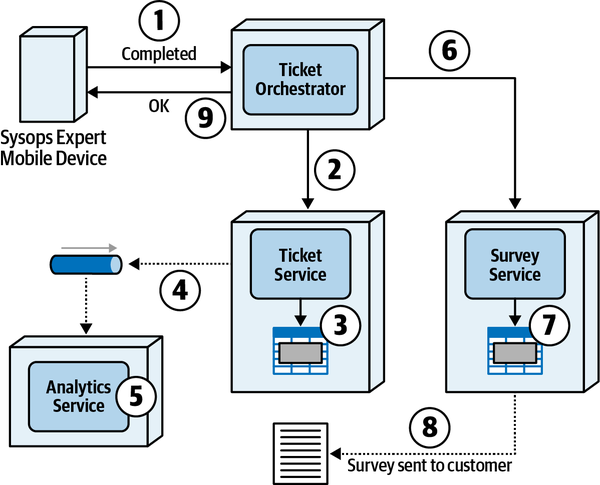
Figure 12-22. The epic saga requires the ticket status to be updated and survey to be sent in one synchronous atomic operation
Logan tiếp tục, “Tôi cũng đã tạo ra một danh sách mô tả từng bước. Các số được khoanh tròn trên sơ đồ khớp với quy trình làm việc.”
-
Đội ngũ Sysops đánh dấu vé là hoàn thành bằng cách sử dụng một ứng dụng trên thiết bị di động của họ, và điều này được nhận một cách đồng bộ bởi Dịch vụ Điều phối Vé.
-
Dịch vụ Điều phối Vé gửi một yêu cầu đồng bộ đến Dịch vụ Vé để thay đổi trạng thái của vé từ “đang xử lý” sang “hoàn thành.”
-
Dịch vụ vé cập nhật số vé thành "hoàn tất" trong bảng cơ sở dữ liệu và thực hiện cam kết cập nhật.
-
Trong quá trình hoàn thành vé, Dịch vụ Vé gửi thông tin liên quan đến vé (chẳng hạn như thời gian sửa chữa vé, thời gian chờ vé, thời gian, v.v.) một cách bất đồng bộ đến một hàng đợi để được Dịch vụ Phân tích lấy. Khi đã gửi, Dịch vụ Vé gửi một xác nhận tới Dịch vụ Điều phối Vé rằng việc cập nhật đã hoàn tất.
-
Vào khoảng thời gian đó, Dịch vụ Phân tích nhận thông tin phân tích vé cập nhật một cách bất đồng bộ và bắt đầu xử lý thông tin vé.
-
Dịch vụ Orchestrator vé sau đó gửi một yêu cầu đồng bộ đến Dịch vụ Khảo sát để chuẩn bị và gửi khảo sát cho khách hàng.
-
Dịch vụ Khảo sát chèn dữ liệu vào bảng với thông tin khảo sát (khách hàng, thông tin vé và dấu thời gian) và thực hiện cam kết chèn dữ liệu.
-
Dịch vụ Khảo sát sau đó gửi khảo sát đến khách hàng qua email và trả về một xác nhận cho Dịch vụ Điều phối Vé rằng quá trình xử lý khảo sát đã hoàn tất.
-
Cuối cùng, Dịch vụ Điều phối Vé gửi phản hồi về thiết bị di động của chuyên gia nhóm Sysops nói rằng quá trình hoàn tất vé đã xong. Khi điều này xảy ra, chuyên gia có thể chọn vé vấn đề tiếp theo được giao cho họ.
“Wow, điều này thực sự hữu ích. Bạn đã mất bao lâu để tạo ra cái này?” Addison nói.
“Không phải là ít thời gian, nhưng nó đã được sử dụng hữu ích. Các bạn không phải là nhóm duy nhất bối rối về cách để tất cả những phần này hoạt động cùng nhau. Đây là phần khó khăn của kiến trúc phần mềm. Mọi người có hiểu những điều cơ bản của quy trình làm việc không?”
Trước một biển gật đầu, Logan tiếp tục, “Một trong những vấn đề đầu tiên xảy ra với các cập nhật bù là do không có sự cách ly giao dịch trong một giao dịch phân tán (xem “Giao dịch phân tán”), các dịch vụ khác có thể đã thực hiện hành động trên dữ liệu được cập nhật trong phạm vi của giao dịch phân tán trước khi giao dịch phân tán hoàn tất. Để minh họa cho vấn đề này, hãy xem xét ví dụ Epic Saga giống như trong Hình 12-23: chuyên gia của Đội Sysops đánh dấu một vé là đã hoàn thành, nhưng lần này Dịch vụ Khảo sát không khả dụng. Trong trường hợp này, một cập nhật bù (bước 7 trong sơ đồ) được gửi đến Dịch vụ Vé để đảo ngược cập nhật, thay đổi trạng thái của vé từ đã hoàn thành trở lại đang tiến hành (bước 8 trong sơ đồ).”
“Cũng lưu ý trong Hình 12-23 rằng vì đây là một giao dịch phân tán nguyên tử, một lỗi sẽ được gửi trở lại cho chuyên gia nhóm Sysops thông báo rằng hành động không thành công và cần thử lại. Bây giờ, một câu hỏi cho bạn: tại sao chuyên gia nhóm Sysops lại phải lo lắng rằng khảo sát không được gửi?”
Austen suy nghĩ một lúc. “Nhưng không phải đó là một phần của quy trình làm việc trong monolith sao? Tất cả những thứ đó xảy ra trong một giao dịch, nếu tôi nhớ đúng.”
“Ừ, nhưng tôi luôn nghĩ điều đó thật kỳ lạ, chỉ là chưa bao giờ nói ra,” Addison nói. “Tôi không thấy lý do gì mà chuyên gia lại phải lo lắng về cuộc khảo sát. Chuyên gia chỉ muốn chuyển sang nhiệm vụ tiếp theo mà họ được giao.”
"Đúng vậy," Logan nói. "Đây là vấn đề với các giao dịch phân tán nguyên tử - người dùng cuối không cần thiết phải liên kết ngữ nghĩa với quy trình kinh doanh. Nhưng hãy lưu ý rằng Hình 12-23 cũng minh họa vấn đề với việc thiếu cách ly giao dịch trong một giao dịch phân tán. Hãy chú ý rằng như một phần của việc cập nhật ban đầu để đánh dấu vé là hoàn thành, Dịch vụ Vé đã gửi thông tin vé đến một hàng đợi một cách không đồng bộ (bước 4 trong sơ đồ) để được xử lý bởi Dịch vụ Phân tích (bước 5). Tuy nhiên, khi cập nhật bồi thường được phát hành đến Dịch vụ Vé (bước 7), thông tin vé đã được Dịch vụ Phân tích xử lý ở bước 5."
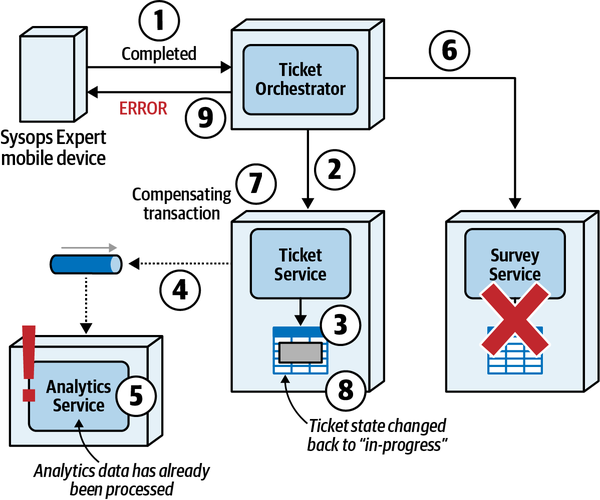
Figure 12-23. Epic Saga(sao) requires compensation, but side effects can occur
"Chúng tôi gọi đây là tác dụng phụ trong các kiến trúc phân tán. Bằng cách đảo ngược giao dịch trong Dịch vụ Vé, các hành động được thực hiện bởi các dịch vụ khác sử dụng dữ liệu từ bản cập nhật trước có thể đã xảy ra và có thể không thể đảo ngược. Tình huống này cho thấy tầm quan trọng của sự cách ly trong một giao dịch, điều mà các giao dịch phân tán không hỗ trợ. Để giải quyết vấn đề này, Dịch vụ Vé có thể gửi một yêu cầu khác qua bơm dữ liệu đến Dịch vụ Phân tích, yêu cầu dịch vụ đó bỏ qua thông tin vé trước đó, nhưng hãy tưởng tượng khối lượng mã phức tạp và logic thời gian mà Dịch vụ Phân tích sẽ cần để xử lý sự thay đổi bù trừ này. Hơn nữa, có thể đã có các hành động downstream bổ sung được thực hiện trên dữ liệu phân tích đã được xử lý bởi Dịch vụ Phân tích, làm phức tạp thêm chuỗi sự kiện cần đảo ngược và sửa chữa. Với các kiến trúc phân tán và các giao dịch phân tán, thực sự đôi khi là "rùa hết lần này đến lần khác"."
Logan dừng lại một lúc, sau đó tiếp tục, “Một vấn đề khác—”
Austen ngắt lời, “Một vấn đề khác sao?”
Logan mỉm cười. “Một vấn đề khác liên quan đến các cập nhật bồi thường là những lỗi bồi thường. Giữ nguyên ví dụ Epic Saga về việc hoàn thành một vé, hãy chú ý trong Hình 12-24 rằng ở bước 7, một cập nhật bồi thường được gửi đến Dịch vụ Vé để thay đổi trạng thái từ đã hoàn thành trở lại đang tiến hành. Tuy nhiên, trong trường hợp này, Dịch vụ Vé phát sinh một lỗi khi cố gắng thay đổi trạng thái của vé (bước 8).”
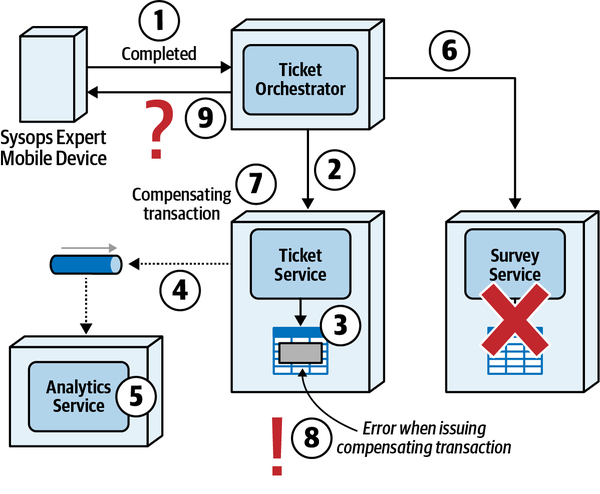
Figure 12-24. Compensating updates within an Epic Saga can fail, leading to inconsistency and confusion about what action to take in the event of a compensation failure
“Tôi đã thấy chuyện đó xảy ra! Mất cả đời để tìm ra điều đó,” Addison nói.
“Các kiến trúc sư và nhà phát triển thường giả định rằng các cập nhật bù sẽ luôn hoạt động,” Logan nói. “Nhưng đôi khi chúng không hoạt động. Trong trường hợp này, như được trình bày ở Hình 12-24, có sự nhầm lẫn về loại phản hồi nào nên gửi lại cho người dùng cuối (trong trường hợp này là chuyên gia của Đội Sysops). Trạng thái vé đã được đánh dấu là hoàn thành vì việc bù đắp đã thất bại, vì vậy việc cố gắng yêu cầu “đánh dấu là hoàn thành” một lần nữa có thể chỉ dẫn đến một lỗi khác (chẳng hạn như Vé đã được đánh dấu là hoàn thành). Nói về sự nhầm lẫn từ phía người dùng cuối!”
"Ừ, mình có thể tưởng tượng ra các nhà phát triển sẽ đến hỏi chúng ta cách giải quyết vấn đề này," Addison nói.
“Thường thì các nhà phát triển là những người kiểm tra tốt cho các giải pháp kiến trúc chưa hoàn chỉnh hoặc gây nhầm lẫn. Nếu họ cảm thấy bối rối, có thể có lý do chính đáng,” Logan nói. “Được rồi, một vấn đề nữa. Giao dịch phân tán nguyên tử và các cập nhật bồi thường tương ứng cũng ảnh hưởng đến khả năng phản hồi. Nếu xảy ra lỗi, người dùng cuối phải chờ cho đến khi tất cả các hành động khắc phục được thực hiện (thông qua các cập nhật bồi thường) trước khi có phản hồi gửi đến người dùng về lỗi."
"Không phải đó là nơi mà việc chuyển sang tính nhất quán cuối cùng giúp ích cho độ nhạy bén sao?" Austen hỏi.
"Đúng vậy, mặc dù tính nhạy bén có thể đôi khi được giải quyết bằng cách phát hành các cập nhật bù đắp một cách không đồng bộ thông qua tính nhất quán cuối cùng (như với mẫu Parallel Saga và Anthology Saga), nhưng nhìn chung, hầu hết các giao dịch phân tán nguyên tử có tính nhạy bén kém hơn khi có sự tham gia của các cập nhật bù đắp."
“Được rồi, điều đó có lý—điều phối nguyên tử sẽ luôn có chi phí,” Austen nói.
“Đó là rất nhiều thông tin. Hãy tạo một bảng để tóm tắt một số sự đánh đổi liên quan đến giao dịch phân tán nguyên tử và các cập nhật bù trừ.” (Xem Bảng 12-12.)
Logan nói, “Khi mẫu giao dịch bù đắp này tồn tại, nó cũng mang lại một số thách thức. Ai muốn nêu một thách thức nào?”
“Tôi biết: một dịch vụ không thể thực hiện hoàn tác,” Austen nói. “Thế nếu một trong các dịch vụ không thể hoàn tác thành công thao tác trước đó? Bộ điều phối phải có mã phối hợp để chỉ ra rằng giao dịch không thành công.”
"Đúng rồi—còn cái khác thì sao?"
"Để khóa hay không khóa các dịch vụ tham gia?" Addison nói. “Khi trung gian thực hiện cuộc gọi đến một dịch vụ và nó cập nhật một giá trị, trung gian sẽ thực hiện các cuộc gọi đến các dịch vụ tiếp theo là một phần của quy trình công việc. Tuy nhiên, điều gì sẽ xảy ra nếu một yêu cầu khác xuất hiện cho dịch vụ đầu tiên phụ thuộc vào kết quả của việc giải quyết yêu cầu đầu tiên, có thể từ cùng một trung gian hoặc từ một ngữ cảnh khác? Vấn đề kiến trúc phân tán này trở nên tồi tệ hơn khi các cuộc gọi là không đồng bộ thay vì đồng bộ (được minh họa trong "Mô hình Saga Chơi Điện Thoại"). Hoặc, trung gian có thể yêu cầu rằng các dịch vụ khác không nhận cuộc gọi trong quá trình thực hiện quy trình công việc, điều này đảm bảo một giao dịch hợp lệ nhưng phá hủy hiệu suất và khả năng mở rộng.”
Logan nói, “Đúng vậy. Hãy cùng nhau suy ngẫm một chút. Về mặt khái niệm, các giao dịch buộc người tham gia phải dừng lại thế giới cá nhân của họ và đồng bộ hóa với một giá trị cụ thể. Điều này rất dễ dàng để mô hình hóa với kiến trúc đơn khối và cơ sở dữ liệu quan hệ đến nỗi các kiến trúc sư lạm dụng giao dịch trong các hệ thống đó. Nhiều phần của thế giới thực không phải là giao dịch, như được quan sát trong bài tiểu luận nổi tiếng của Gregor Hohpe, “Starbucks Không Sử Dụng Commit Hai Giai Đoạn”. Việc tổ chức giao dịch là một trong những phần khó khăn nhất của kiến trúc, và càng rộng thì càng tồi tệ.”
“Có cách nào thay thế việc sử dụng Epic Saga không?” Addison hỏi.
“Có!” Logan nói. “Một cách tiếp cận thực tế hơn cho kịch bản được mô tả trong Hình 12-24 có thể là sử dụng một trong hai mẫu Fairy Tale Saga hoặc Parallel Saga. Những saga này dựa vào tính nhất quán cuối cùng không đồng bộ và quản lý trạng thái thay vì các giao dịch phân tán nguyên tử với các cập nhật bù trừ khi xảy ra lỗi. Với những loại saga này, người dùng ít bị ảnh hưởng bởi các lỗi có thể xảy ra trong giao dịch phân tán, vì lỗi được giải quyết một cách âm thầm, không có sự tham gia của người dùng cuối. Tính phản hồi cũng tốt hơn với cách tiếp cận quản lý trạng thái và tính nhất quán cuối cùng, vì người dùng không phải chờ đợi để có hành động điều chỉnh trong giao dịch phân tán. Nếu chúng ta gặp vấn đề với tính nguyên tử, chúng ta có thể xem xét những mẫu này như những lựa chọn thay thế.”
"Cảm ơn—đó là một lượng tài liệu lớn, nhưng bây giờ tôi thấy tại sao các kiến trúc sư lại đưa ra một số quyết định trong kiến trúc mới," Addison nói.
Chapter 13. Contracts
Thứ Sáu, ngày 15 tháng 4, 12:01
Addison đã gặp Sydney trong bữa trưa ở căng tin để nói chuyện về việc phối hợp giữa Ticket Orchestrator và các dịch vụ mà nó tích hợp để quản lý quy trình làm việc của vé.
“Tại sao không chỉ sử dụng gRPC cho tất cả các giao tiếp? Tôi nghe nói nó thực sự nhanh,” Sydney nói.
"Chà, đó là một cách triển khai, không phải là kiến trúc," Addison nói. "Chúng ta cần quyết định loại hợp đồng mà chúng ta muốn trước khi chọn cách triển khai chúng. Trước tiên, chúng ta cần quyết định giữa hợp đồng chặt chẽ hoặc lỏng lẻo. Khi chúng ta quyết định về loại hợp đồng, tôi sẽ để bạn quyết định cách triển khai chúng, miễn là chúng đáp ứng các chức năng kiểm tra của chúng ta."
“Điều gì xác định loại hợp đồng nào chúng ta cần?” Sydney nói.
Trong Chương 2, chúng ta đã bắt đầu thảo luận về giao điểm của ba lực lượng quan trọng—truyền thông, tính nhất quán và sự phối hợp—và cách phát triển các biện pháp thỏa hiệp cho chúng. Chúng tôi đã mô hình hóa không gian giao thoa của ba lực lượng trong một không gian ba chiều kết hợp, được thể hiện lại trong Hình 13-1. Trong Chương 12, chúng ta đã quay lại với ba lực lượng này với một cuộc thảo luận về các phong cách giao tiếp khác nhau và các biện pháp thỏa hiệp của chúng.
Dù kiến trúc có thể nhận ra một mối quan hệ như thế này đến đâu, một số lực cắt ngang qua không gian khái niệm và ảnh hưởng đến tất cả các chiều khác một cách bình đẳng. Nếu theo đuổi phép ẩn dụ ba chiều trực quan, những lực cắt ngang này hoạt động như một chiều bổ sung, giống như thời gian là trực giao với ba chiều vật lý.
Figure 13-1. Three-dimensional intersecting space for messaging forces in distributed architectures
Một yếu tố không đổi trong kiến trúc phần mềm có ảnh hưởng đến hầu hết mọi khía cạnh của quyết định kiến trúc là hợp đồng, được định nghĩa rộng rãi là cách mà các phần khác nhau của một kiến trúc kết nối với nhau. Định nghĩa từ điển về một hợp đồng như sau:
- contract
-
Một thỏa thuận bằng văn bản hoặc lời nói, đặc biệt liên quan đến việc làm, bán hàng hoặc thuê mướn, được dự định có hiệu lực pháp lý.
Trong phần mềm, chúng ta sử dụng hợp đồng một cách rộng rãi để mô tả những thứ như điểm tích hợp trong kiến trúc, và nhiều định dạng hợp đồng là một phần của quá trình thiết kế trong phát triển phần mềm: SOAP, REST, gRPC, XMLRPC và một mớ các chữ cái khác. Tuy nhiên, chúng ta mở rộng định nghĩa đó và làm cho nó nhất quán hơn:
- hard parts contract
-
"Cách định dạng được sử dụng bởi các phần của kiến trúc để truyền đạt thông tin hoặc các phụ thuộc."
Định nghĩa này về hợp đồng bao gồm tất cả các kỹ thuật được sử dụng để "kết nối" các phần của một hệ thống, bao gồm các phụ thuộc chuyển tiếp cho các framework và thư viện, các điểm tích hợp nội bộ và bên ngoài, bộ nhớ đệm, và bất kỳ giao tiếp nào giữa các phần.
Chương này minh họa tác động của hợp đồng lên nhiều phần của kiến trúc, bao gồm kết nối lượng tĩnh và động, cũng như cách để cải thiện (hoặc làm hại) hiệu quả của quy trình làm việc.
Strict Versus Loose Contracts
Giống như nhiều thứ trong kiến trúc phần mềm, các hợp đồng không tồn tại trong một phạm vi nhị phân mà nằm trên một phổ rộng, từ nghiêm ngặt đến lỏng lẻo. Hình 13-2 minh họa phổ này, sử dụng các loại hợp đồng ví dụ.

Figure 13-2. The spectrum of contract types, from strict to loose
Một hợp đồng nghiêm ngặt yêu cầu tuân thủ tên, kiểu, thứ tự và tất cả các chi tiết khác, không để lại sự mơ hồ. Một ví dụ về hợp đồng nghiêm ngặt nhất có thể có trong phần mềm là một lệnh gọi phương thức từ xa, sử dụng một cơ chế nền tảng như RMI trong Java. Trong trường hợp đó, lệnh gọi từ xa mô phỏng một lệnh gọi phương thức nội bộ, khớp với tên, tham số, kiểu và tất cả các chi tiết khác.
Nhiều định dạng hợp đồng nghiêm ngặt bắt chước ngữ nghĩa của các phương thức gọi. Ví dụ, các nhà phát triển thấy một loạt các giao thức bao gồm một số biến thể của RPC, vốn là viết tắt của Remote Procedure Call. gRPC là một ví dụ về một khung gọi từ xa phổ biến mặc định sử dụng các hợp đồng nghiêm ngặt.
Nhiều kiến trúc sư thích các hợp đồng nghiêm ngặt vì chúng mô hình hóa hành vi ngữ nghĩa giống hệt của các cuộc gọi phương thức nội bộ. Tuy nhiên, các hợp đồng nghiêm ngặt tạo ra sự dễ gãy trong kiến trúc tích hợp - điều cần tránh. Như đã thảo luận trong Chương 8, một thứ đang thay đổi đồng thời và được sử dụng bởi nhiều phần kiến trúc khác nhau có thể tạo ra vấn đề trong kiến trúc. Các hợp đồng phù hợp với mô tả đó vì chúng tạo nên sự kết dính trong một kiến trúc phân tán: càng thường xuyên thay đổi, chúng càng gây ra nhiều vấn đề lan tỏa cho các dịch vụ khác. Tuy nhiên, các kiến trúc sư không bị buộc phải sử dụng các hợp đồng nghiêm ngặt và nên chỉ làm như vậy khi có lợi.
Ngay cả một định dạng lỏng lẻo như JSON cũng cung cấp cách để chọn lọc thêm thông tin về schema vào các cặp tên-giá trị đơn giản. Ví dụ 13-1 cho thấy một hợp đồng JSON chặt chẽ với thông tin schema được đính kèm.
Example 13-1. Strict JSON contract
{"$schema":"http://json-schema.org/draft-04/schema#","properties":{"acct":{"type":"number"},"cusip":{"type":"string"},"shares":{"type":“number", "minimum": 100}},"required": ["acct", "cusip", "shares"]}
Dòng đầu tiên đề cập đến định nghĩa schema mà chúng tôi sử dụng và sẽ được xác thực. Chúng tôi định nghĩa ba thuộc tính (acct, cusip và shares), cùng với các loại của chúng và, ở dòng cuối, các thuộc tính nào là bắt buộc. Điều này tạo ra một hợp đồng nghiêm ngặt, với các trường bắt buộc và loại đã được chỉ định.
Các ví dụ về hợp đồng lỏng lẻo bao gồm các định dạng như REST và GraphQL, là những định dạng rất khác nhau nhưng tương tự nhau trong việc thể hiện sự gắn kết lỏng lẻo hơn các định dạng dựa trên RPC. Đối với REST, kiến trúc sư mô hình hóa các tài nguyên thay vì các điểm cuối phương thức hoặc quy trình, tạo ra các hợp đồng ít dễ gãy hơn. Chẳng hạn, nếu một kiến trúc sư xây dựng một tài nguyên RESTful mô tả các bộ phận của một chiếc máy bay để hỗ trợ các truy vấn về chỗ ngồi, thì truy vấn đó sẽ không bị hỏng trong tương lai nếu ai đó thêm thông tin về động cơ vào tài nguyên—việc thêm thông tin không làm hỏng những gì đã có.
Tương tự, GraphQL được sử dụng bởi các kiến trúc phân tán để cung cấp dữ liệu tổng hợp chỉ đọc thay vì thực hiện các cuộc gọi phối hợp tốn kém qua nhiều dịch vụ khác nhau. Hãy xem hai biểu diễn GraphQL trong Ví dụ 13-2 và 13-3, cung cấp hai cái nhìn khác nhau nhưng hiệu quả về hợp đồng Hồ sơ.
Example 13-2. Customer Wishlist Profile representation
typeProfile{name:String}
Example 13-3. Customer Profile representation
typeProfile{name:Stringaddr1:Stringaddr2:Stringcountry:String...}
Khái niệm hồ sơ xuất hiện trong cả hai ví dụ nhưng với các giá trị khác nhau. Trong kịch bản này, Danh sách mong muốn của khách hàng không có quyền truy cập nội bộ vào tên của khách hàng, chỉ có một định danh duy nhất. Do đó, nó cần quyền truy cập vào Hồ sơ Khách hàng, cái mà ánh xạ định danh đến tên khách hàng. Ngược lại, Hồ sơ Khách hàng bao gồm một lượng lớn thông tin về khách hàng ngoài tên. Theo như Danh sách mong muốn, điều duy nhất thú vị trong Hồ sơ là tên.
Một mẫu chống mẫu thường gặp mà một số kiến trúc sư gặp phải là giả định rằng Wishlist có thể cuối cùng sẽ cần tất cả các phần khác, vì vậy các kiến trúc sư bao gồm chúng trong hợp đồng ngay từ đầu. Đây là một ví dụ về sự kết hợp không hiệu quả và là một mẫu chống trong hầu hết các trường hợp, vì nó giới thiệu những thay đổi gây rối mà không cần thiết, làm cho kiến trúc trở nên dễ bị gãy nhưng mang lại ít lợi ích. Ví dụ, nếu Wishlist chỉ quan tâm đến tên khách hàng từ Profile, nhưng hợp đồng quy định mọi trường trong Profile (phòng trường hợp), thì một thay đổi trong Profile mà Wishlist không quan tâm sẽ gây ra sự cố hợp đồng và phải phối hợp để khắc phục. Giữ hợp đồng ở mức “cần biết” đạt được sự cân bằng giữa kết hợp ngữ nghĩa và thông tin cần thiết mà không tạo ra sự dễ bị gãy không cần thiết trong kiến trúc tích hợp.
Ở đầu xa của phổ hợp đồng, có những hợp đồng rất lỏng lẻo, thường được diễn đạt dưới dạng các cặp tên-giá trị trong các định dạng như YAML hoặc JSON, như được minh họa trong Ví dụ 13-4.
Example 13-4. Name-value pairs in JSON
{"name":"Mark","status":"active","joined":"2003"}
Chỉ có sự thật thô trong ví dụ này! Không có thông tin siêu dữ liệu bổ sung, thông tin kiểu, hay bất cứ điều gì khác, chỉ là các cặp tên-giá trị.
Sử dụng các hợp đồng lỏng lẻo như vậy cho phép các hệ thống cực kỳ tách biệt, thường là một trong những mục tiêu trong kiến trúc, chẳng hạn như microservices. Tuy nhiên, tính lỏng lẻo của hợp đồng đi kèm với các nhượng bộ như thiếu tính chắc chắn của hợp đồng, khả năng xác minh và tăng cường logic ứng dụng. Chúng tôi minh họa trong “Hợp đồng trong Microservices” cách các kiến trúc sư giải quyết vấn đề này bằng cách sử dụng các hàm độ phù hợp của hợp đồng.
Trade-Offs Between Strict and Loose Contracts
Khi nào một kiến trúc sư nên sử dụng hợp đồng nghiêm ngặt và khi nào họ nên sử dụng hợp đồng lỏng lẻo? Giống như tất cả những phần khó khăn trong kiến trúc, không có câu trả lời chung cho câu hỏi này, vì vậy điều quan trọng là các kiến trúc sư hiểu khi nào mỗi loại là phù hợp nhất.
Strict contracts
Các hợp đồng nghiêm ngặt có một số ưu điểm, bao gồm những điều sau đây:
- Guaranteed contact fidelity
-
Việc xây dựng xác minh lược đồ trong các hợp đồng đảm bảo tuân thủ chính xác các giá trị, kiểu và các siêu dữ liệu được quản lý khác. Một số lĩnh vực vấn đề có lợi từ việc liên kết chặt chẽ cho các thay đổi hợp đồng.
- Versioned
-
Các hợp đồng nghiêm ngặt thường yêu cầu một chiến lược quản lý phiên bản để hỗ trợ hai điểm cuối chấp nhận các giá trị khác nhau hoặc để quản lý sự phát triển của miền theo thời gian. Điều này cho phép thay đổi dần dần các điểm tích hợp trong khi hỗ trợ một số lượng phiên bản quá khứ chọn lọc để làm cho việc hợp tác tích hợp trở nên dễ dàng hơn.
- Easier to verify at build time
-
Nhiều công cụ schema cung cấp cơ chế để xác minh hợp đồng vào thời điểm xây dựng, thêm một cấp độ kiểm tra kiểu cho các điểm tích hợp.
- Better documentation
-
"Các tham số và loại khác nhau cung cấp tài liệu xuất sắc mà không có sự mơ hồ."
Hợp đồng nghiêm ngặt cũng có một số nhược điểm:
- Tight coupling
-
Theo định nghĩa chung của chúng tôi về coupling, các hợp đồng nghiêm ngặt tạo ra các điểm kết nối chặt chẽ. Nếu hai dịch vụ chia sẻ một hợp đồng nghiêm ngặt và hợp đồng đó thay đổi, cả hai dịch vụ đều phải thay đổi.
- Versioned
-
Điều này xuất hiện cả ở mặt lợi và mặt hại. Trong khi việc giữ các phiên bản riêng biệt cho phép độ chính xác, nó có thể trở thành một cơn ác mộng trong việc tích hợp nếu đội ngũ không có chiến lược gỡ bỏ rõ ràng hoặc cố gắng hỗ trợ quá nhiều phiên bản.
Các sự đánh đổi cho các hợp đồng nghiêm ngặt được tóm tắt trong Bảng 13-1.
Loose contracts
Các hợp đồng lỏng lẻo, chẳng hạn như cặp tên-giá trị, cung cấp các điểm tích hợp ít liên kết nhất, nhưng chúng cũng có những đánh đổi, như được tóm tắt trong Bảng 13-2.
Đây là một số lợi thế của hợp đồng lỏng.
- Highly decoupled
-
Nhiều kiến trúc sư có một mục tiêu rõ ràng cho kiến trúc microservices đó là bao gồm mức độ tách biệt cao, và các hợp đồng linh hoạt mang lại sự linh hoạt tối đa.
- Easier to evolve
-
Bởi vì thông tin về sơ đồ ít hoặc không tồn tại, các hợp đồng này có thể phát triển tự do hơn. Tất nhiên, sự thay đổi về sự kết nối ngữ nghĩa vẫn cần sự phối hợp giữa tất cả các bên liên quan—thực hiện không thể làm giảm sự kết nối ngữ nghĩa—nhưng các hợp đồng lỏng lẻo cho phép sự phát triển thực hiện dễ dàng hơn.
Hợp đồng lỏng cũng có một số nhược điểm:
- Contract management
-
Hợp đồng lỏng lẻo theo định nghĩa không có các đặc điểm hợp đồng nghiêm ngặt, điều này có thể gây ra các vấn đề như tên bị đánh sai, thiếu cặp giá trị tên, và các thiếu sót khác mà các sơ đồ sẽ khắc phục.
- Requires fitness functions
-
Để giải quyết những vấn đề hợp đồng vừa mô tả, nhiều đội sử dụng hợp đồng do người tiêu dùng thúc đẩy như một chức năng thích ứng kiến trúc để đảm bảo rằng các hợp đồng lỏng lẻo vẫn chứa đủ thông tin cho hợp đồng hoạt động.
Ví dụ về những đánh đổi phổ biến mà kiến trúc sư gặp phải, hãy xem xét ví dụ về hợp đồng trong kiến trúc microservice.
Contracts in Microservices
Các kiến trúc sư phải liên tục đưa ra quyết định về cách thức các dịch vụ tương tác với nhau, thông tin nào sẽ được truyền (ngữ nghĩa), cách thức truyền tải (thực hiện) và mức độ liên kết chặt chẽ giữa các dịch vụ.
Coupling levels
Xem xét hai dịch vụ vi mô với tính chất giao dịch độc lập cần chia sẻ thông tin miền như Địa chỉ Khách hàng, như được thể hiện trong Hình 13-3.
Figure 13-3. Two services that must share domain information about the customer
Kiến trúc sư có thể triển khai cả hai dịch vụ trong cùng một công nghệ và sử dụng một hợp đồng được kiểu hóa chặt chẽ, hoặc là một giao thức gọi thủ tục từ xa cụ thể cho nền tảng (như RMI) hoặc một cái không phụ thuộc vào thực hiện như gRPC, và truyền thông tin khách hàng từ dịch vụ này sang dịch vụ khác với độ tin cậy cao về sự chính xác của hợp đồng. Tuy nhiên, sự liên kết chặt chẽ này vi phạm một trong những mục tiêu hướng tới của kiến trúc microservices, nơi các kiến trúc sư cố gắng tạo ra các dịch vụ không bị phụ thuộc lẫn nhau.
Xem xét phương pháp thay thế, nơi mỗi dịch vụ có cách biểu diễn nội bộ riêng cho Khách hàng, và việc tích hợp sử dụng cặp tên-giá trị để truyền thông tin từ dịch vụ này sang dịch vụ khác, như được minh họa trong Hình 13-4.
Ở đây, mỗi dịch vụ có định nghĩa về Khách hàng trong bối cảnh giới hạn của riêng nó. Khi truyền tải thông tin, kiến trúc sư sử dụng cặp tên-giá trị trong JSON để truyền tải thông tin liên quan theo một hợp đồng lỏng.
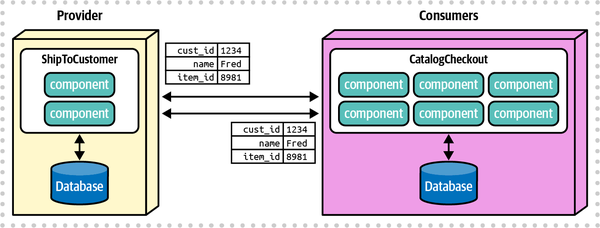
Figure 13-4. Microservices with their own internal semantic representation can pass values in simple messages
Sự liên kết lỏng lẻo này đáp ứng nhiều mục tiêu tổng thể của microservices. Đầu tiên, nó tạo ra các dịch vụ có độ phân tách cao được mô hình hóa dựa trên các ngữ cảnh được giới hạn, cho phép mỗi đội có thể phát triển các biểu diễn nội bộ một cách mạnh mẽ như cần thiết. Thứ hai, nó tạo ra sự phân tách thực hiện. Nếu cả hai dịch vụ bắt đầu trong cùng một ngăn xếp công nghệ, nhưng đội trong dịch vụ thứ hai quyết định chuyển sang nền tảng khác, điều đó có thể sẽ không ảnh hưởng gì đến dịch vụ đầu tiên. Tất cả các nền tảng đang được sử dụng phổ biến đều có thể tạo ra và tiêu thụ các cặp tên-giá trị, làm cho chúng trở thành ngôn ngữ chung của kiến trúc tích hợp.
Nhược điểm lớn nhất của các hợp đồng lỏng là độ trung thành của hợp đồng—như một kiến trúc sư, làm thế nào tôi có thể biết rằng các nhà phát triển truyền đúng số lượng và loại tham số cho các cuộc gọi tích hợp? Một số giao thức, chẳng hạn như JSON, bao gồm các công cụ lược đồ để cho phép các kiến trúc sư phủ lên các hợp đồng lỏng bằng nhiều siêu dữ liệu hơn. Các kiến trúc sư cũng có thể sử dụng một kiểu hàm phù hợp của kiến trúc gọi là hợp đồng điều khiển bởi người tiêu dùng.
Consumer-driven contracts
Một vấn đề phổ biến trong kiến trúc microservices là các mục tiêu dường như mâu thuẫn giữa việc giảm thiểu sự phụ thuộc lẫn nhau và duy trì độ trung thành với hợp đồng. Một phương pháp sáng tạo sử dụng những tiến bộ trong phát triển phần mềm là hợp đồng do người tiêu dùng điều khiển, thường thấy trong kiến trúc microservices.
Trong nhiều kịch bản tích hợp kiến trúc, một dịch vụ quyết định thông tin nào sẽ phát ra cho các đối tác tích hợp khác (mô hình đẩy - nhà cung cấp dịch vụ đẩy hợp đồng đến người tiêu dùng). Khái niệm hợp đồng do người tiêu dùng điều khiển đảo ngược mối quan hệ đó thành một mô hình kéo; ở đây, người tiêu dùng chuẩn bị một hợp đồng cho những mục mà họ cần từ nhà cung cấp, và chuyển hợp đồng đó cho nhà cung cấp, người sẽ bao gồm nó trong bản xây dựng của họ và giữ cho bài kiểm tra hợp đồng luôn đạt yêu cầu. Hợp đồng bao gồm thông tin mà người tiêu dùng cần từ nhà cung cấp. Điều này có thể hoạt động cho một mạng lưới các yêu cầu liên kết mà Nhà cung cấp phải tuân thủ, như được minh họa trong Hình 13-5.
Figure 13-5. Consumer-driven contracts allow the provider and consumers to stay in sync via automated architectural governance
Trong ví dụ này, nhóm bên trái cung cấp những phần thông tin (có khả năng) trùng lặp cho từng nhóm tiêu dùng bên phải. Mỗi nhóm tiêu dùng tạo một hợp đồng chỉ định thông tin cần thiết và chuyển nó cho nhà cung cấp, người sẽ bao gồm các bài kiểm tra của họ như một phần của quy trình tích hợp liên tục hoặc triển khai. Điều này cho phép mỗi nhóm chỉ định hợp đồng một cách nghiêm ngặt hoặc lỏng lẻo tùy theo nhu cầu, đồng thời đảm bảo tính chính xác của hợp đồng như một phần của quy trình xây dựng. Nhiều công cụ kiểm tra hợp đồng do người tiêu dùng điều khiển cung cấp các tiện ích tự động hóa kiểm tra hợp đồng trong thời gian xây dựng, cung cấp một lớp lợi ích khác tương tự như các hợp đồng nghiêm ngặt hơn.
Hợp đồng do người tiêu dùng quyết định khá phổ biến trong kiến trúc microservices vì chúng cho phép các kiến trúc sư giải quyết hai vấn đề là sự tách rời lỏng lẻo và tích hợp được kiểm soát. Các bước đánh đổi của hợp đồng do người tiêu dùng quyết định được trình bày trong Bảng 13-3.
Lợi ích của các hợp đồng do người tiêu dùng điều khiển như sau:
- Allow loose contract coupling between services
-
Việc sử dụng cặp tên-giá trị là cách kết nối lỏng lẻo nhất giữa hai dịch vụ, cho phép thay đổi thực hiện với ít khả năng xảy ra sự cố nhất.
- Allow variability in strictness
-
Nếu các đội sử dụng các hàm kiểm tra kiến trúc, các kiến trúc sư có thể xây dựng các xác minh nghiêm ngặt hơn so với những gì thường được cung cấp bởi các sơ đồ hoặc các công cụ kiểu tốp khác. Ví dụ, hầu hết các sơ đồ cho phép các kiến trúc sư chỉ định các kiểu số nhưng không phải các khoảng giá trị chấp nhận được. Việc xây dựng các hàm kiểm tra cho phép các kiến trúc sư xây dựng độ chính xác mà họ muốn.
- Evolvable
-
Sự kết nối lỏng lẻo có nghĩa là khả năng tiến hóa. Việc sử dụng các cặp tên-giá trị đơn giản cho phép các điểm tích hợp thay đổi chi tiết triển khai mà không làm đứt gãy ý nghĩa của thông tin được truyền giữa các dịch vụ.
Đây là những bất lợi của hợp đồng do người tiêu dùng điều khiển:
- Require engineering maturity
-
Các hàm fitness trong kiến trúc là một ví dụ tuyệt vời về một khả năng hoạt động tốt chỉ khi các đội ngũ có kỷ luật thực hiện các thực hành tốt và không bỏ qua các bước. Ví dụ, nếu tất cả các đội đều thực hiện tích hợp liên tục bao gồm các bài kiểm tra hợp đồng, thì các hàm fitness cung cấp một cơ chế xác minh tốt. Mặt khác, nếu nhiều đội bỏ qua các bài kiểm tra thất bại hoặc không kịp thời thực hiện các bài kiểm tra hợp đồng, các điểm tích hợp có thể bị hỏng trong kiến trúc lâu hơn mong muốn.
- Two interlocking mechanisms rather than one
-
Các kiến trúc sư thường tìm kiếm một cơ chế duy nhất để giải quyết vấn đề, và nhiều công cụ lập sơ đồ có khả năng phức tạp để tạo ra kết nối từ đầu đến cuối. Tuy nhiên, đôi khi hai cơ chế đơn giản liên kết với nhau có thể giải quyết vấn đề một cách đơn giản hơn. Do đó, nhiều kiến trúc sư sử dụng sự kết hợp của các cặp tên-giá trị và hợp đồng dựa trên người tiêu dùng để xác thực các hợp đồng. Tuy nhiên, điều này có nghĩa là các đội ngũ cần hai cơ chế thay vì một.
Giải pháp tốt nhất của kiến trúc sư cho sự đánh đổi này phụ thuộc vào độ trưởng thành của đội ngũ và sự tách biệt với các hợp đồng lỏng lẻo so với độ phức tạp cộng với tính chắc chắn với các hợp đồng chặt chẽ hơn.
Stamp Coupling
Một mẫu chung và đôi khi là mẫu phản tại trong kiến trúc phân tán là sự kết hợp đóng dấu, mô tả việc truyền một cấu trúc dữ liệu lớn giữa các dịch vụ, nhưng mỗi dịch vụ chỉ tương tác với một phần nhỏ của cấu trúc dữ liệu đó. Hãy xem xét ví dụ về bốn dịch vụ được hiển thị trong Hình 13-6.
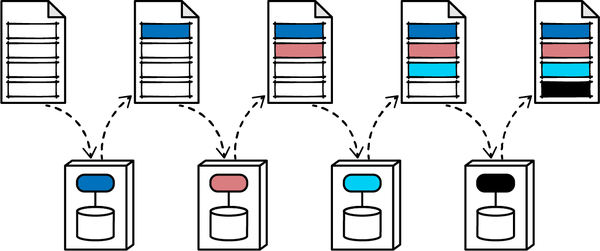
Figure 13-6. Stamp coupling between four services
Mỗi dịch vụ chỉ truy cập (đọc, ghi hoặc cả hai) một phần nhỏ của cấu trúc dữ liệu được truyền giữa các dịch vụ. Mẫu này rất phổ biến khi tồn tại một định dạng tài liệu tiêu chuẩn của ngành, thường là XML. Ví dụ, ngành du lịch có một định dạng tài liệu XML tiêu chuẩn toàn cầu quy định chi tiết về các lịch trình du lịch. Nhiều hệ thống làm việc với các dịch vụ liên quan đến du lịch truyền toàn bộ tài liệu xung quanh, chỉ cập nhật các phần liên quan của chúng.
Tuy nhiên, kết nối dấu (Stamp coupling) thường là một mẫu phản chống vô tình, nơi một kiến trúc sư đã chỉ định quá mức chi tiết trong một hợp đồng mà không cần thiết hoặc vô tình tiêu tốn quá nhiều băng thông cho những cuộc gọi tầm thường.
Over-Coupling via Stamp Coupling
Quay trở lại với danh sách mong muốn và dịch vụ hồ sơ của chúng ta, hãy xem xét việc gắn kết hai thứ này với nhau bằng một hợp đồng nghiêm ngặt kết hợp với sự kết hợp đóng dấu, như minh họa trong Hình 13-7.
Trong ví dụ này, mặc dù Dịch vụ Danh sách mong muốn chỉ cần tên (được truy cập thông qua một ID duy nhất), kiến trúc sư đã liên kết toàn bộ cấu trúc dữ liệu của Hồ sơ như một hợp đồng, có thể là do nỗ lực sai lầm để đảm bảo tính lâu dài trong tương lai. Tuy nhiên, tác động tiêu cực của việc liên kết quá chặt chẽ trong các hợp đồng là tính dễ vỡ. Nếu Hồ sơ thay đổi một trường mà Danh sách mong muốn không quan tâm, chẳng hạn như trạng thái, thì nó vẫn làm hỏng hợp đồng.
Figure 13-7. The Wishlist Service is stamp coupled to the Profile Service
Việc quy định quá nhiều chi tiết trong hợp đồng thường là một mẫu hình ngược nhưng dễ rơi vào khi cũng sử dụng sự kết hợp theo kiểu stamp cho các mối quan tâm hợp lý, bao gồm những ứng dụng như quản lý quy trình công việc (xem “Sự kết hợp theo kiểu Stamp cho Quản lý Quy trình Công việc”).
Bandwidth
Mô hình sai lầm khác mà một số kiến trúc sư rơi vào là một trong những sai lầm nổi tiếng của điện toán phân tán: băng thông là vô hạn. Các kiến trúc sư và nhà phát triển hiếm khi phải xem xét kích thước tổng cộng của số lượng các cuộc gọi phương thức mà họ thực hiện trong một kiến trúc đơn nhất vì có những rào cản tự nhiên tồn tại. Tuy nhiên, nhiều rào cản đó biến mất trong các kiến trúc phân tán, vô tình tạo ra những vấn đề.
Xem xét ví dụ trước đó cho 2.000 yêu cầu mỗi giây. Nếu mỗi payload có kích thước 500 KB, thì băng thông cần thiết cho yêu cầu này bằng 1.000.000 KB mỗi giây! Đây rõ ràng là một sự lãng phí băng thông nghiêm trọng mà không có lý do chính đáng. Mặt khác, nếu sự kết nối giữa Wishlist và Profile chỉ chứa thông tin cần thiết, tên, thì overhead sẽ chuyển thành 200 byte mỗi giây, với tổng băng thông hợp lý là 400 KB.
Sự kết nối kiểu tem có thể gây ra vấn đề khi sử dụng quá mức, bao gồm cả các vấn đề do kết nối quá chặt vào băng thông. Tuy nhiên, như mọi thứ trong kiến trúc, nó cũng có những ứng dụng có lợi.
Stamp Coupling for Workflow Management
Trong Chương 12, chúng ta đã đề cập đến một số mẫu giao tiếp lượng tử động, bao gồm một vài mẫu có phong cách phối hợp là biên đạo. Các kiến trúc sư thường có xu hướng trung gian cho các quy trình phức tạp vì nhiều lý do mà chúng ta đã chỉ ra. Tuy nhiên, điều gì sẽ xảy ra nếu các yếu tố khác, chẳng hạn như khả năng mở rộng, khiến một kiến trúc sư hướng tới một giải pháp vừa được biên đạo vừa phức tạp?
Các kiến trúc sư có thể sử dụng sự gán nhãn để quản lý trạng thái luồng công việc giữa các dịch vụ, truyền đạt cả kiến thức miền và trạng thái luồng công việc như một phần của hợp đồng, như được minh họa trong Hình 13-8.
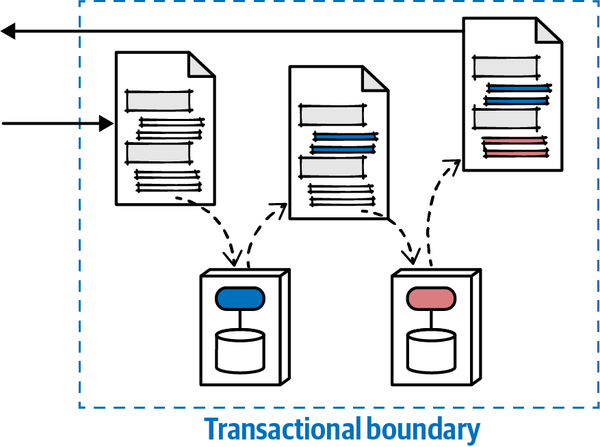
Figure 13-8. Using stamp coupling for workflow management
Trong ví dụ này, một kiến trúc sư thiết kế hợp đồng để bao gồm thông tin quy trình làm việc: trạng thái của quy trình làm việc, trạng thái giao dịch, và v.v. Khi mỗi dịch vụ miền chấp nhận hợp đồng, nó cập nhật phần của mình trong hợp đồng và trạng thái cho quy trình làm việc, sau đó truyền tiếp. Ở cuối quy trình làm việc, người nhận có thể truy vấn hợp đồng để xác định thành công hay thất bại, cùng với trạng thái và thông tin như thông báo lỗi. Nếu hệ thống cần thực hiện tính nhất quán giao dịch trong toàn bộ, thì các dịch vụ miền nên phát lại hợp đồng cho các dịch vụ đã truy cập trước đó để khôi phục tính nhất quán nguyên tử.
Việc sử dụng kết nối dấu để quản lý quy trình làm việc tạo ra sự kết nối cao hơn giữa các dịch vụ so với mức bình thường, nhưng sự kết nối ngữ nghĩa phải được giải quyết ở đâu đó - nhớ rằng, một kiến trúc sư không thể giảm sự kết nối ngữ nghĩa thông qua thực thi. Tuy nhiên, trong nhiều trường hợp, việc chuyển sang điệu nhảy có thể cải thiện thông lượng và khả năng mở rộng, khiến cho việc lựa chọn kết nối dấu thay vì trung gian trở thành một lựa chọn hấp dẫn. Bảng 13-4 cho thấy các sự đánh đổi cho kết nối dấu.
Sysops Squad Saga: Managing Ticketing Contracts
Thứ Ba, ngày 10 tháng 5, 10:10
Sydney và Addison gặp lại nhau ở căng tin để uống cà phê và thảo luận về các hợp đồng trong quy trình quản lý vé.
Addison nói, “Hãy xem xét quy trình làm việc đang được thảo luận, quy trình quản lý vé. Tôi đã phác thảo các loại hợp đồng mà chúng ta nên sử dụng, và tôi muốn chạy qua với bạn để đảm bảo rằng tôi không bỏ sót điều gì. Nó được minh họa trong Hình 13-9.”
"Các hợp đồng giữa bộ điều phối và hai dịch vụ vé, Quản lý Vé và Phân bổ Vé, là rất chặt chẽ; thông tin đó có mối liên kết ngữ nghĩa cao và có khả năng thay đổi cùng nhau," Addison nói. "Ví dụ, nếu chúng tôi thêm các loại đối tượng mới để quản lý, việc phân bổ phải đồng bộ. Dịch vụ Thông báo và Khảo sát có thể lỏng lẻo hơn nhiều - thông tin thay đổi chậm hơn và không được hưởng lợi từ sự kết nối dễ đổ bể."
Sydney nói, "Tất cả những quyết định đó đều hợp lý - nhưng còn hợp đồng giữa người điều phối và chuyên gia ứng dụng của Đội Sysops thì sao? Có vẻ như hợp đồng đó cũng cần chặt chẽ như hợp đồng giao nhiệm vụ."
“Điều này rất hay—về danh nghĩa, chúng tôi muốn hợp đồng với ứng dụng di động khớp với việc phân công vé. Tuy nhiên, chúng tôi triển khai ứng dụng di động thông qua một cửa hàng ứng dụng công cộng, và quy trình phê duyệt của họ đôi khi mất nhiều thời gian. Nếu chúng tôi giữ hợp đồng linh hoạt hơn, chúng tôi sẽ có được linh hoạt và tốc độ thay đổi chậm hơn.”
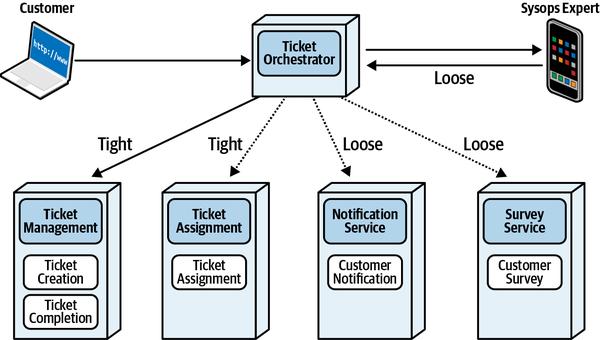
Figure 13-9. Types of contracts between collaborators in the ticket management workflow
Họ đều viết một ADR cho điều này:
ADR: Hợp đồng lỏng cho Đội ngũ chuyên gia Sysops về Ứng dụng Di động
Bối cảnh Ứng dụng di động được các chuyên gia của Đội Sysops sử dụng phải được phát hành qua cửa hàng ứng dụng công khai, điều này gây ra sự chậm trễ trong khả năng cập nhật hợp đồng.
Quyết định Chúng tôi sẽ sử dụng một hợp đồng cặp tên-giá trị linh hoạt để truyền thông tin từ và đến bộ điều phối và ứng dụng di động.
Chúng tôi sẽ xây dựng một cơ chế mở rộng để cho phép gia hạn tạm thời nhằm linh hoạt trong thời gian ngắn.
Hệ quả Quyết định cần được xem xét lại nếu chính sách của cửa hàng ứng dụng cho phép triển khai nhanh hơn (hoặc liên tục).
Nhiều logic để xác thực hợp đồng phải nằm trong bộ điều phối và ứng dụng di động.
Chapter 14. Managing Analytical Data
Thứ Ba, ngày 31 tháng 5, 13:23
Logan và Dana (kiến trúc sư dữ liệu) đang đứng ngoài phòng hội nghị lớn, trò chuyện sau cuộc họp tình hình hàng tuần.
"Chúng ta sẽ xử lý dữ liệu phân tích trong kiến trúc mới này như thế nào?" Dana hỏi. "Chúng ta đang chia nhỏ các cơ sở dữ liệu, nhưng chúng ta sẽ cần phải ghép tất cả dữ liệu đó lại với nhau để báo cáo và phân tích. Một trong những cải tiến mà chúng ta đang cố gắng thực hiện là lập kế hoạch dự đoán tốt hơn, điều này có nghĩa là chúng ta đang sử dụng nhiều khoa học dữ liệu và thống kê hơn để đưa ra các quyết định chiến lược hơn. Chúng ta bây giờ có một đội ngũ suy nghĩ về dữ liệu phân tích, và chúng ta cần một phần của hệ thống để đáp ứng nhu cầu này. Chúng ta có định xây dựng một kho dữ liệu không?"
Logan nói, “Chúng tôi đã xem xét việc tạo một kho dữ liệu, và trong khi nó giải quyết được vấn đề hợp nhất, nó còn có nhiều vấn đề khó khăn cho chúng tôi.”
Nhiều phần của cuốn sách này đã tập trung vào cách phân tích các sự đánh đổi trong các phong cách kiến trúc hiện có như microservices. Tuy nhiên, các kỹ thuật mà chúng tôi nhấn mạnh cũng có thể được sử dụng để hiểu các khả năng hoàn toàn mới khi chúng xuất hiện trong hệ sinh thái phát triển phần mềm; data mesh là một ví dụ xuất sắc.
Dữ liệu phân tích và dữ liệu vận hành có mục đích rất khác nhau trong các kiến trúc hiện đại (xem "Tầm quan trọng của dữ liệu trong kiến trúc"); phần lớn của cuốn sách này đã đề cập đến những đánh đổi khó khăn liên quan đến dữ liệu vận hành. Khi các hệ thống máy khách/máy chủ trở nên phổ biến và mạnh mẽ đủ cho các doanh nghiệp lớn, các kiến trúc sư và quản trị viên cơ sở dữ liệu đã tìm kiếm một giải pháp cho phép thực hiện các truy vấn chuyên biệt.
Previous Approaches
Sự tách biệt giữa dữ liệu vận hành và dữ liệu phân tích không phải là một vấn đề mới - sự khác biệt cơ bản trong việc sử dụng dữ liệu đã tồn tại từ rất lâu. Khi các phong cách kiến trúc ra đời và phát triển, các phương pháp xử lý dữ liệu cũng đã thay đổi và phát triển tương tự.
The Data Warehouse
Trở lại những thời kỳ trước đây của phát triển phần mềm (ví dụ, máy tính lớn hoặc máy tính cá nhân đầu tiên), các ứng dụng thường là đơn khối, bao gồm cả mã nguồn và dữ liệu trên cùng một hệ thống vật lý. Không ngạc nhiên khi, trong bối cảnh mà chúng ta đã đề cập cho đến thời điểm này, việc phối hợp giao dịch giữa các hệ thống vật lý khác nhau trở nên thách thức. Khi các yêu cầu về dữ liệu trở nên tham vọng hơn, cùng với sự ra đời của mạng cục bộ trong các văn phòng, điều này đã dẫn đến sự phát triển của các ứng dụng máy khách/máy chủ, trong đó một máy chủ cơ sở dữ liệu mạnh mẽ hoạt động trên mạng và các ứng dụng trên máy tính để bàn chạy trên các máy tính cục bộ, truy cập dữ liệu qua mạng. Sự tách biệt giữa xử lý ứng dụng và dữ liệu cho phép quản lý giao dịch, phối hợp tốt hơn và nhiều lợi ích khác, bao gồm khả năng bắt đầu sử dụng dữ liệu lịch sử cho các mục đích mới, như phân tích.
Các kiến trúc sư đã có một nỗ lực sớm để cung cấp dữ liệu phân tích có thể truy vấn với mẫu Data Warehouse. Vấn đề cơ bản mà họ cố gắng giải quyết đi đến cốt lõi của sự tách biệt giữa dữ liệu vận hành và dữ liệu phân tích: các định dạng và lược đồ của một bên không nhất thiết phải phù hợp (hoặc thậm chí cho phép sử dụng) bên kia. Ví dụ, nhiều vấn đề phân tích yêu cầu các phép tổng hợp và tính toán, đây là những thao tác tốn kém trên các cơ sở dữ liệu quan hệ, đặc biệt là những cơ sở dữ liệu đã hoạt động dưới tải giao dịch nặng.
Các mô hình Kho Dữ liệu đã phát triển với những biến thể nhẹ, chủ yếu dựa trên các sản phẩm và khả năng của nhà cung cấp. Tuy nhiên, mô hình này có nhiều đặc điểm chung. Giả định cơ bản là dữ liệu hoạt động được lưu trữ trong các cơ sở dữ liệu quan hệ có thể truy cập trực tiếp qua mạng. Dưới đây là các đặc điểm chính của mô hình Kho Dữ liệu:
- Data extracted from many sources
-
Khi dữ liệu hoạt động nằm trong các cơ sở dữ liệu riêng lẻ, một phần của mẫu này đã chỉ ra một cơ chế để trích xuất dữ liệu vào một kho dữ liệu (khổng lồ) khác, phần "kho" của mẫu. Việc truy vấn trên tất cả các cơ sở dữ liệu khác nhau trong tổ chức để xây dựng báo cáo là không thực tế, vì vậy dữ liệu được trích xuất vào kho chỉ vì mục đích phân tích.
- Transformed to single schema
-
Thường thì các sơ đồ vận hành không phù hợp với những gì cần thiết cho báo cáo. Chẳng hạn, một hệ thống vận hành cần cấu trúc sơ đồ và hành vi xung quanh các giao dịch, trong khi một hệ thống phân tích hiếm khi sử dụng dữ liệu OLTP (xem Chương 1) mà thường xử lý một lượng lớn dữ liệu, phục vụ cho báo cáo, tổng hợp, v.v. Vì vậy, hầu hết các kho dữ liệu sử dụng Mô hình Ngôi Sao để triển khai mô hình chiều, chuyển đổi dữ liệu từ các hệ thống vận hành với các định dạng khác nhau vào sơ đồ kho dữ liệu. Để tạo điều kiện cho tốc độ và đơn giản, các nhà thiết kế kho dữ liệu đã phi chuẩn hóa dữ liệu nhằm nâng cao hiệu suất và các truy vấn đơn giản hơn.
- Loaded into warehouse
-
Vì dữ liệu vận hành nằm trong các hệ thống riêng lẻ, kho dữ liệu phải xây dựng các cơ chế để thường xuyên trích xuất dữ liệu, chuyển đổi nó và đưa vào kho. Các nhà thiết kế thường sử dụng các cơ chế cơ sở dữ liệu quan hệ tích hợp sẵn như phân phối hoặc các công cụ chuyên dụng để xây dựng bộ dịch từ sơ đồ gốc sang sơ đồ kho. Tất nhiên, bất kỳ thay đổi nào đối với các sơ đồ hệ thống vận hành phải được nhân bản trong sơ đồ đã chuyển đổi, khiến việc phối hợp thay đổi trở nên khó khăn.
- Analysis done on the warehouse
-
Vì dữ liệu "sống" trong kho dữ liệu, nên tất cả phân tích được thực hiện ở đó. Điều này là mong muốn từ góc độ vận hành: máy móc của kho dữ liệu thường có khả năng lưu trữ và tính toán mạnh mẽ, giảm tải các yêu cầu nặng nề vào hệ sinh thái của nó.
- Used by data analysts
-
Kho dữ liệu sử dụng các nhà phân tích dữ liệu, công việc của họ bao gồm xây dựng các báo cáo và các tài sản trí tuệ kinh doanh khác. Tuy nhiên, việc xây dựng các báo cáo hữu ích đòi hỏi phải có sự hiểu biết về lĩnh vực, có nghĩa là chuyên môn về lĩnh vực phải tồn tại trong cả hệ thống dữ liệu vận hành và hệ thống phân tích, nơi mà các nhà thiết kế truy vấn phải sử dụng cùng một dữ liệu trong một lược đồ đã được chuyển đổi để tạo ra các báo cáo có ý nghĩa và trí tuệ kinh doanh.
- BI reports and dashboards
-
Dữ liệu đầu ra của kho dữ liệu bao gồm các báo cáo phân tích kinh doanh, bảng điều khiển cung cấp dữ liệu phân tích, các báo cáo và bất kỳ thông tin nào khác để cho phép công ty đưa ra quyết định tốt hơn.
- SQL-ish interface
-
Để khiến cho việc sử dụng dễ dàng hơn cho các quản trị viên cơ sở dữ liệu (DBA), hầu hết các công cụ truy vấn kho dữ liệu cung cấp những tính năng quen thuộc, chẳng hạn như ngôn ngữ giống SQL để hình thành truy vấn. Một trong những lý do cho bước chuyển đổi dữ liệu đã đề cập trước đó là để cung cấp cho người dùng một cách đơn giản hơn để truy vấn các tổng hợp phức tạp và các thông tin khác.
Mô hình Kho Dữ liệu cung cấp một ví dụ tốt về phân vùng kỹ thuật trong kiến trúc phần mềm: các nhà thiết kế kho dữ liệu biến đổi dữ liệu thành một sơ đồ giúp thuận tiện cho việc truy vấn và phân tích nhưng mất đi bất kỳ phân vùng miền nào, điều này phải được tái tạo trong các truy vấn khi cần thiết. Do đó, cần có các chuyên gia được đào tạo bài bản để hiểu cách xây dựng các truy vấn trong kiến trúc này.
Tuy nhiên, những điểm yếu chính của mô hình Kho Dữ liệu bao gồm sự dễ vỡ trong tích hợp, phân chia cực kỳ kiến thức miền, phức tạp và chức năng hạn chế cho mục đích dự kiến.
- Integration brittleness
-
Yêu cầu được xây dựng vào mô hình này để biến đổi dữ liệu trong giai đoạn tiêm tạo ra sự giòn gãy nghiêm trọng trong các hệ thống. Một sơ đồ cơ sở dữ liệu cho một miền vấn đề cụ thể có sự phụ thuộc cao đến ngữ nghĩa của vấn đề đó; những thay đổi trong miền yêu cầu thay đổi sơ đồ, mà ngược lại yêu cầu thay đổi logic nhập dữ liệu.
- Extreme partitioning of domain knowledge
-
Xây dựng các quy trình kinh doanh phức tạp yêu cầu kiến thức chuyên ngành. Việc tạo ra các báo cáo phức tạp và phân tích kinh doanh cũng đòi hỏi kiến thức chuyên ngành, kết hợp với các kỹ thuật phân tích chuyên biệt. Do đó, các biểu đồ Venn của chuyên môn lĩnh vực có sự giao thoa, nhưng chỉ một phần. Các kiến trúc sư, nhà phát triển, quản trị cơ sở dữ liệu và nhà khoa học dữ liệu phải phối hợp chặt chẽ trong việc thay đổi và phát triển dữ liệu, buộc phải tạo sự gắn kết chặt chẽ giữa những phần khác nhau trong hệ sinh thái.
- Complexity
-
Xây dựng một sơ đồ thay thế để cho phép phân tích nâng cao làm tăng độ phức tạp cho hệ thống, cùng với các cơ chế liên tục cần thiết để nạp và chuyển đổi dữ liệu. Một kho dữ liệu là một dự án riêng biệt bên ngoài các hệ thống vận hành bình thường của tổ chức, vì vậy phải được duy trì như một hệ sinh thái hoàn toàn tách biệt, nhưng vẫn rất gắn bó với các lĩnh vực bên trong các hệ thống vận hành. Tất cả những yếu tố này góp phần vào độ phức tạp.
- Limited functionality for intended purpose
-
Cuối cùng, hầu hết các kho dữ liệu đã thất bại vì chúng không mang lại giá trị thương mại tương xứng với nỗ lực cần thiết để tạo ra và duy trì kho dữ liệu. Bởi vì mô hình này phổ biến từ lâu trước khi có môi trường đám mây, nên khoản đầu tư vật lý vào hạ tầng là rất lớn, cùng với sự phát triển và bảo trì liên tục. Thường thì, những người tiêu dùng dữ liệu sẽ yêu cầu một loại báo cáo nhất định mà kho dữ liệu không thể cung cấp. Vì vậy, khoản đầu tư liên tục cho chức năng cuối cùng hạn chế đã khiến hầu hết các dự án này gặp thất bại.
- Synchronization creates bottlenecks
-
Nhu cầu trong một kho dữ liệu để đồng bộ hóa dữ liệu từ nhiều hệ thống vận hành khác nhau tạo ra cả những nút thắt vận hành và tổ chức—một vị trí nơi nhiều luồng dữ liệu độc lập phải hội tụ. Một tác động phụ phổ biến của kho dữ liệu là quá trình đồng bộ hóa ảnh hưởng đến các hệ thống vận hành mặc dù có mong muốn tách rời.
- Operational versus analytical contract differences
-
Hệ thống ghi chú có các nhu cầu hợp đồng cụ thể (được thảo luận trong Chương 13). Các hệ thống phân tích cũng có nhu cầu hợp đồng thường khác với các nhu cầu hoạt động. Trong một kho dữ liệu, các pipeline thường xử lý cả việc chuyển đổi cũng như nhập dữ liệu, dẫn đến sự giòn gãy hợp đồng trong quá trình chuyển đổi.
Bảng 14-1 cho thấy các thỏa hiệp cho mẫu kho dữ liệu.
Thứ Ba, ngày 31 tháng 5, 13:33
“Chúng tôi đã xem xét việc tạo một kho dữ liệu, nhưng nhận ra rằng nó phù hợp hơn với những loại kiến trúc cũ, đơn thể hơn là các kiến trúc phân tán hiện đại,” Logan nói. “Hơn nữa, bây giờ chúng tôi có rất nhiều trường hợp học máy mà chúng tôi cần phải hỗ trợ.”
“Ý tưởng về hồ dữ liệu mà tôi đã nghe nói đến thì sao?” Dana hỏi. “Tôi đã đọc một bài viết trên trang của Martin Fowler. Có vẻ như nó giải quyết nhiều vấn đề của kho dữ liệu và phù hợp hơn cho các trường hợp sử dụng ML.”
"Ôi, đúng rồi, tôi đã đọc bài viết đó khi nó ra mắt," Logan nói. "Trang web của anh ấy là một kho tàng thông tin hữu ích, và bài viết đó ra mắt ngay sau khi chủ đề microservices trở nên hot. Thực ra, tôi đã lần đầu tiên đọc về microservices trên chính trang web đó vào năm 2014, và một trong những câu hỏi lớn vào thời điểm đó là, Làm thế nào chúng ta quản lý báo cáo trong các kiến trúc như vậy? Data lake là một trong những câu trả lời ban đầu, chủ yếu như một phản biện đối với data warehouse, mà chắc chắn sẽ không hoạt động trong thứ gì như microservices."
“Tại sao không?” Dana hỏi.
The Data Lake
Như trong nhiều phản ứng phản động đối với sự phức tạp, chi phí và những thất bại của kho dữ liệu, chiếc pendulum thiết kế đã nghiêng về phía đối lập, được thể hiện qua mô hình Data Lake, về cơ bản là phản đề của mô hình kho dữ liệu. Trong khi nó giữ nguyên mô hình và đường ống trung tâm, nó lật ngược mô hình "biến đổi và tải" của kho dữ liệu thành mô hình "tải và biến đổi". Thay vì thực hiện công việc biến đổi khổng lồ, triết lý của mô hình Data Lake cho rằng, thay vì thực hiện những biến đổi vô ích có thể không bao giờ được sử dụng, không thực hiện bất kỳ biến đổi nào, cho phép người dùng doanh nghiệp truy cập dữ liệu phân tích ở định dạng tự nhiên của nó, mà thường yêu cầu biến đổi và điều chỉnh cho mục đích của họ. Do đó, gánh nặng công việc trở nên phản ứng thay vì chủ động - thay vì thực hiện công việc có thể không cần thiết, chỉ thực hiện công việc biến đổi khi có yêu cầu.
Quan sát cơ bản mà nhiều kiến trúc sư đã thực hiện là những sơ đồ đã được xây dựng sẵn trong các kho dữ liệu thường không phù hợp với loại báo cáo hoặc yêu cầu mà người dùng cần, dẫn đến việc phải mất thêm công sức để hiểu rõ sơ đồ kho dữ liệu đủ lâu để xây dựng một giải pháp. Hơn nữa, nhiều mô hình học máy hoạt động tốt hơn với dữ liệu “gần” với định dạng nửa thô hơn là phiên bản đã được biến đổi. Đối với các chuyên gia trong lĩnh vực đã hiểu rõ về miền, điều này tạo ra một quá trình đau đớn, trong đó dữ liệu bị tước bỏ sự phân tách và ngữ cảnh của miền để được chuyển đổi vào kho dữ liệu, chỉ để yêu cầu kiến thức miền để xây dựng các truy vấn mà không phù hợp tự nhiên với sơ đồ mới!
Các đặc điểm của mẫu Data Lake như sau:
- Data extracted from many sources
-
Dữ liệu vận hành vẫn được trích xuất theo mẫu này, nhưng quá trình chuyển đổi sang một lược đồ khác ít xảy ra hơn — thay vào đó, dữ liệu thường được lưu trữ ở dạng "thô", hoặc dạng gốc của nó. Một số chuyển đổi vẫn có thể diễn ra trong mẫu này. Ví dụ, một hệ thống đầu vào có thể đổ các tệp định dạng vào một hồ dữ liệu được tổ chức dựa trên các ảnh chụp theo cột.
- Loaded into the lake
-
Hồ, thường được sử dụng trong các môi trường đám mây, bao gồm các tệp dữ liệu định kỳ từ các hệ thống hoạt động.
- Used by data scientists
-
Các nhà khoa học dữ liệu và những người tiêu dùng khác của dữ liệu phân tích tìm kiếm dữ liệu trong hồ và thực hiện bất kỳ phép tổng hợp, phối hợp và các biến đổi khác cần thiết để trả lời các câu hỏi cụ thể.
Mô hình Data Lake, mặc dù là một cải tiến theo nhiều cách so với mô hình Data Warehouse, vẫn gặp phải nhiều hạn chế.
Mô hình này vẫn giữ quan điểm tập trung vào dữ liệu, nơi dữ liệu được trích xuất từ các cơ sở dữ liệu của hệ thống hoạt động và sao chép vào một kho dữ liệu có dạng tự do hơn hoặc ít hơn. Gánh nặng nằm trên người tiêu dùng để khám phá cách kết nối các bộ dữ liệu khác nhau, điều này thường xảy ra trong kho dữ liệu mặc dù đã có mức độ lập kế hoạch. Logic được theo sau là, nếu chúng ta phải thực hiện công việc chuẩn bị cho một số phân tích, hãy làm cho tất cả và bỏ qua khoản đầu tư lớn ban đầu.
Mặc dù mô hình Data Lake đã tránh được các vấn đề do sự chuyển đổi gây ra từ mô hình Data Warehouse, nhưng nó cũng không giải quyết hoặc tạo ra các vấn đề mới.
- Difficulty in discovery of proper assets
-
Nhiều hiểu biết về mối quan hệ dữ liệu trong một lĩnh vực bị biến mất khi dữ liệu chảy vào hồ không cấu trúc. Do đó, các chuyên gia trong lĩnh vực vẫn phải tham gia vào việc thiết kế phân tích.
- PII and other sensitive data
-
Mối quan ngại về thông tin cá nhân (PII) đã gia tăng cùng với khả năng của nhà khoa học dữ liệu khi họ có thể lấy những mảnh thông tin khác nhau và học được những kiến thức xâm phạm quyền riêng tư. Nhiều quốc gia hiện nay không chỉ hạn chế thông tin cá nhân mà còn cả thông tin có thể được kết hợp để học hỏi và xác định, phục vụ cho mục đích quảng cáo hoặc những mục đích ít được ưa chuộng hơn. Việc đổ dữ liệu không có cấu trúc vào một hồ dữ liệu thường có nguy cơ phơi bày thông tin có thể được liên kết lại với nhau để vi phạm quyền riêng tư. Tiếc là, cũng như trong quá trình khám phá, các chuyên gia trong lĩnh vực có kiến thức cần thiết để tránh những rủi ro phơi bày không mong muốn, buộc họ phải phân tích lại dữ liệu trong hồ.
- Still technically, not domain, partitioned
-
Xu hướng hiện tại trong kiến trúc phần mềm chuyển từ việc phân chia một hệ thống dựa trên các khả năng kỹ thuật sang phân chia dựa trên các miền, trong khi cả hai mẫu Data Warehouse và Data Lake đều tập trung vào việc phân chia kỹ thuật. Nói chung, các kiến trúc sư thiết kế mỗi giải pháp đó với các phân vùng khác nhau cho việc nạp dữ liệu, chuyển đổi, tải và phục vụ, mỗi phân vùng đều tập trung vào một khả năng kỹ thuật. Các mẫu kiến trúc hiện đại ưa chuộng việc phân chia theo miền, bao gồm cả chi tiết thực hiện kỹ thuật. Ví dụ, kiến trúc microservices cố gắng tách biệt các dịch vụ theo miền thay vì theo các khả năng kỹ thuật, bao gồm kiến thức miền, bao gồm dữ liệu, bên trong ranh giới dịch vụ. Tuy nhiên, cả hai mẫu Data Warehouse và Data Lake đều cố gắng tách dữ liệu như một thực thể riêng biệt, dẫn đến việc mất mát hoặc mờ đi các góc nhìn quan trọng của miền (chẳng hạn như dữ liệu PII) trong quá trình này.
Điểm cuối cùng là quan trọng - ngày càng nhiều kiến trúc sư thiết kế dựa trên miền thay vì phân chia kỹ thuật trong kiến trúc, và cả hai cách tiếp cận trước đó đều minh họa cho việc tách dữ liệu ra khỏi ngữ cảnh của nó. Những gì các kiến trúc sư và khoa học dữ liệu cần là một kỹ thuật bảo tồn loại phân chia vĩ mô phù hợp, đồng thời hỗ trợ tách biệt rõ ràng giữa dữ liệu phân tích và dữ liệu hoạt động. Bảng 14-2 liệt kê các đánh đổi cho mô hình Data Lake.
Các bất lợi liên quan đến sự giòn và sự kết nối bệnh lý của các pipeline vẫn còn tồn tại. Mặc dù chúng thực hiện ít biến đổi hơn trong mô hình Data Lake, nhưng việc này vẫn phổ biến, cũng như việc làm sạch dữ liệu.
Mô hình Data Lake chuyển việc kiểm tra tính toàn vẹn dữ liệu, chất lượng dữ liệu và các vấn đề chất lượng khác xuống các pipeline hồ dữ liệu phía hạ nguồn, điều này có thể tạo ra một số nút thắt hoạt động tương tự như những gì xảy ra trong mô hình Kho Dữ liệu.
Vì cả việc phân tách kỹ thuật và bản chất giống như lô, các giải pháp có thể gặp phải vấn đề về dữ liệu lỗi thời. Nếu không có sự phối hợp cẩn thận, các kiến trúc sư hoặc là phớt lờ những thay đổi trong các hệ thống ở phía upstream, dẫn đến dữ liệu lỗi thời, hoặc cho phép các pipeline liên kết bị hỏng.
Thứ Ba, ngày 31 tháng 5, 14:43
“Được rồi, vậy chúng ta cũng không thể sử dụng hồ dữ liệu nữa!” Dana kêu lên. “Bây giờ thì sao?”
"Rất may, một số nghiên cứu gần đây đã tìm ra cách để giải quyết vấn đề dữ liệu phân tích với các kiến trúc phân tán như microservices," Logan trả lời. "Nó tuân thủ các ranh giới miền mà chúng tôi đang cố gắng đạt được, nhưng cũng cho phép chúng tôi dự đoán dữ liệu phân tích theo cách mà các nhà khoa học dữ liệu có thể sử dụng. Và, nó loại bỏ các vấn đề liên quan đến thông tin cá nhân mà các luật sư của chúng tôi đang lo lắng."
“Rất tuyệt!” Dana trả lời. “Nó hoạt động như thế nào?”
The Data Mesh
Quan sát các xu hướng khác trong kiến trúc phân tán, Zhamak Dehghani và một số nhà đổi mới khác đã rút ra ý tưởng cốt lõi của mẫu Data Mesh từ việc phân tách theo miền của các microservices, service mesh và sidecars (xem “Sidecars và Service Mesh”), và áp dụng nó cho dữ liệu phân tích, với những điều chỉnh. Như chúng tôi đã đề cập trong Chương 8, Mẫu Sidecar cung cấp một cách tổ chức không gây rối để tổ chức liên kết chính xác (xem “Liên Kết Chính Xác”); sự tách biệt giữa dữ liệu vận hành và dữ liệu phân tích là một ví dụ xuất sắc khác về một liên kết như vậy, nhưng với độ phức tạp nhiều hơn so với liên kết vận hành đơn giản.
Definition of Data Mesh
Data mesh là một phương pháp xã hội-kỹ thuật để chia sẻ, truy cập và quản lý dữ liệu phân tích theo cách phi tập trung. Nó đáp ứng một loạt các trường hợp sử dụng phân tích, chẳng hạn như báo cáo, đào tạo mô hình học máy và tạo ra những hiểu biết. Trái ngược với kiến trúc trước đây, nó thực hiện điều này bằng cách căn chỉnh kiến trúc và quyền sở hữu dữ liệu với các lĩnh vực kinh doanh và cho phép việc tiêu thụ dữ liệu theo kiểu ngang hàng.
Data mesh được xây dựng dựa trên bốn nguyên tắc:
- Domain ownership of data
-
Dữ liệu thuộc sở hữu và được chia sẻ bởi các lĩnh vực quen thuộc nhất với dữ liệu: những lĩnh vực tạo ra dữ liệu hoặc là những người tiêu thụ chính của dữ liệu. Kiến trúc này cho phép chia sẻ và truy cập dữ liệu phân tán từ nhiều lĩnh vực theo cách peer-to-peer mà không cần trung gian hay kho dữ liệu tập trung, và không cần một đội ngũ dữ liệu chuyên dụng.
- Data as a product
-
Để ngăn chặn việc cô lập dữ liệu và khuyến khích các lĩnh vực chia sẻ dữ liệu của họ, mạng lưới dữ liệu đã giới thiệu khái niệm dữ liệu được phục vụ như một sản phẩm. Nó thiết lập các vai trò tổ chức và chỉ số thành công cần thiết để đảm bảo rằng các lĩnh vực cung cấp dữ liệu của họ theo cách mang lại trải nghiệm tốt cho người tiêu dùng dữ liệu trong toàn bộ tổ chức. Nguyên tắc này dẫn đến việc giới thiệu một định nghĩa kiến trúc mới gọi là quantum sản phẩm dữ liệu, để duy trì và phục vụ dữ liệu có thể khám phá, dễ hiểu, kịp thời, an toàn và chất lượng cao cho người tiêu dùng. Chương này giới thiệu khía cạnh kiến trúc của quantum sản phẩm dữ liệu.
- Self-serve data platform
-
Để trao quyền cho các đội miền xây dựng và duy trì sản phẩm dữ liệu của họ, data mesh giới thiệu một bộ khả năng nền tảng tự phục vụ mới. Các khả năng này tập trung vào việc cải thiện trải nghiệm của các nhà phát triển sản phẩm dữ liệu và người tiêu dùng. Nó bao gồm các tính năng như tạo sản phẩm dữ liệu theo kiểu khai báo, khả năng khám phá sản phẩm dữ liệu trên toàn bộ mesh thông qua tìm kiếm và duyệt, cũng như quản lý sự phát sinh của các đồ thị thông minh khác, chẳng hạn như di sản dữ liệu và đồ thị tri thức.
- Computational federated governance
-
Nguyên tắc này đảm bảo rằng, mặc dù quyền sở hữu dữ liệu phân quyền, các yêu cầu quản trị trên toàn tổ chức—như tuân thủ, bảo mật, quyền riêng tư và chất lượng dữ liệu, cũng như khả năng tương tác của các sản phẩm dữ liệu—được thực hiện nhất quán trên tất cả các lĩnh vực. Data mesh giới thiệu một mô hình ra quyết định liên bang bao gồm các chủ sở hữu sản phẩm dữ liệu theo miền. Các chính sách mà họ xây dựng được tự động hóa và nhúng dưới dạng mã trong từng sản phẩm dữ liệu. Ảnh hưởng kiến trúc của cách tiếp cận này đối với quản trị là một sidecar nhúng do nền tảng cung cấp trong từng quanta sản phẩm dữ liệu để lưu trữ và thực thi các chính sách tại điểm truy cập: đọc hoặc ghi dữ liệu.
Mạng lưới dữ liệu là một chủ đề rộng, được đề cập đầy đủ trong cuốn sách "Data Mesh" của Zhamak Dehghani (O’Reilly). Trong chương này, chúng tôi sẽ tập trung vào yếu tố kiến trúc cốt lõi, sản phẩm dữ liệu quantum.
Data Product Quantum
Tôn chỉ cốt lõi của lưới dữ liệu chồng lên các kiến trúc phân tán hiện đại như vi dịch vụ. Cũng giống như trong lưới dịch vụ, các nhóm xây dựng một sản phẩm dữ liệu lượng tử (DPQ) liền kề nhưng kết nối với dịch vụ của họ, như được minh họa trong Hình 14-1.
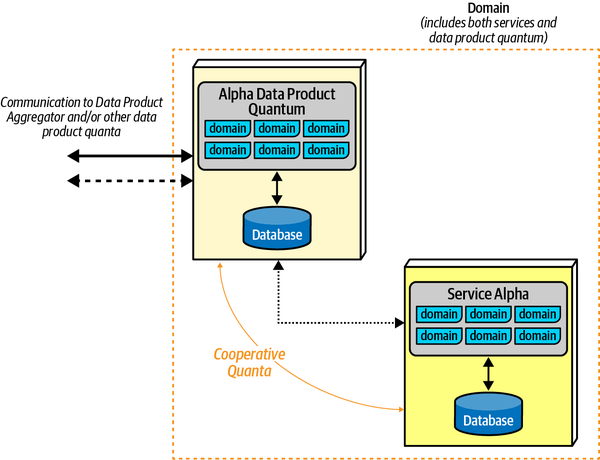
Figure 14-1. Structure of a data product quantum
Trong ví dụ này, dịch vụ Alpha chứa cả dữ liệu hành vi và dữ liệu giao dịch (vận hành). Miền này bao gồm một sản phẩm dữ liệu quantum, cũng chứa mã và dữ liệu, và hoạt động như một giao diện cho phần phân tích và báo cáo tổng thể của hệ thống. DPQ hoạt động như một tập hợp các hành vi và dữ liệu độc lập về mặt vận hành nhưng có liên kết chặt chẽ.
Nhiều loại DPQ thường tồn tại trong các kiến trúc hiện đại:
- Source-aligned (native) DPQ
-
Cung cấp dữ liệu phân tích thay mặt cho kiến trúc hợp tác quantum, thường là một microservice, hoạt động như một quantum hợp tác.
- Aggregate DQP
-
Tổng hợp dữ liệu từ nhiều đầu vào, có thể đồng bộ hoặc không đồng bộ. Ví dụ, đối với một số tổng hợp, yêu cầu không đồng bộ có thể đủ; đối với các trường hợp khác, DPQ tổng hợp có thể cần thực hiện các truy vấn đồng bộ để phù hợp với DPQ của nguồn.
- Fit-for-purpose DPQ
-
Một DPQ được thiết kế riêng để phục vụ một yêu cầu cụ thể, có thể bao gồm báo cáo phân tích, trí tuệ doanh nghiệp, học máy hoặc các khả năng hỗ trợ khác.
Mỗi lĩnh vực cũng góp phần vào phân tích và trí tuệ doanh nghiệp đều bao gồm một DPQ, như được minh họa trong Hình 14-2.
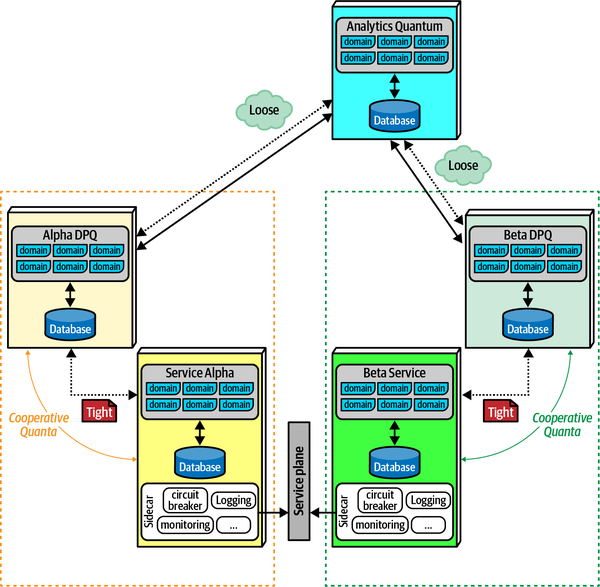
Figure 14-2. The data product quantum acts as a separate but highly coupled adjunct to a service
Ở đây, DPQ đại diện cho một thành phần thuộc sở hữu của nhóm miền chịu trách nhiệm triển khai dịch vụ. Nó chồng chéo lên thông tin được lưu trữ trong cơ sở dữ liệu và có thể có các tương tác với một số hành vi của miền theo cách bất đồng bộ. Sản phẩm dữ liệu lượng tử cũng có thể có hành vi cũng như dữ liệu phục vụ cho mục đích phân tích và trí tuệ kinh doanh.
Mỗi sản phẩm dữ liệu lượng tử hoạt động như một lượng tử hợp tác cho chính dịch vụ đó.
- Cooperative quantum
-
Một quantum hoạt động tách biệt giao tiếp với hợp tác viên của nó thông qua giao tiếp không đồng bộ và tính nhất quán cuối cùng, nhưng có sự liên kết hợp đồng chặt chẽ với hợp tác viên của nó và thường có liên kết hợp đồng lỏng lẻo hơn với quantum phân tích, dịch vụ chịu trách nhiệm cho báo cáo, phân tích, trí tuệ kinh doanh, và vân vân. Trong khi hai quantum hợp tác là độc lập về mặt hoạt động, chúng đại diện cho hai mặt của dữ liệu: dữ liệu hoạt động trong quantum và dữ liệu phân tích trong quantum sản phẩm dữ liệu.
Một phần của hệ thống sẽ đảm nhận trách nhiệm về phân tích và trí tuệ doanh nghiệp, điều này sẽ hình thành nên miền và lượng riêng của nó. Để hoạt động, lượng phân tích này có hợp tác lượng tĩnh với các sản phẩm dữ liệu riêng lẻ mà nó cần để lấy thông tin. Dịch vụ này có thể thực hiện các cuộc gọi đồng bộ hoặc bất đồng bộ đến DPQ, tùy thuộc vào loại yêu cầu. Chẳng hạn, một số DPQ sẽ có giao diện SQL đến DPQ phân tích, cho phép thực hiện các truy vấn đồng bộ. Các yêu cầu khác có thể tổng hợp thông tin từ nhiều DPQ khác nhau.
Data Mesh, Coupling, and Architecture Quantum
Bởi vì báo cáo phân tích có thể là một tính năng bắt buộc của một giải pháp, DPQ và cách triển khai giao tiếp của nó thuộc về sự kết nối tĩnh của một lượng kiến trúc. Ví dụ, trong kiến trúc vi dịch vụ, lớp dịch vụ phải có sẵn, cũng như một broker tin nhắn phải có sẵn nếu thiết kế yêu cầu lập trình nhắn tin. Tuy nhiên, giống như mẫu Sidecar trong một mesh dịch vụ, DPQ nên là điều không thuộc về các thay đổi triển khai bên trong dịch vụ, và duy trì một hợp đồng riêng với lớp dữ liệu.
Từ góc độ kết nối lượng tử động, sidecar dữ liệu luôn nên triển khai một trong các mô hình giao tiếp có cả tính nhất quán cuối cùng và tính bất đồng bộ: hoặc "Mô hình Saga Song song" hoặc "Mô hình Saga Tập hợp". Nói cách khác, một sidecar dữ liệu không bao giờ nên bao gồm một yêu cầu giao dịch để giữ cho dữ liệu vận hành và phân tích đồng bộ, điều này sẽ làm mất đi mục đích sử dụng DPQ để tách biệt một cách chính xác. Tương tự, giao tiếp với mặt dữ liệu nên thường là bất đồng bộ, nhằm giảm thiểu tác động đến các đặc điểm kiến trúc vận hành của dịch vụ miền.
When to Use Data Mesh
Giống như mọi thứ trong kiến trúc, mẫu này có những đánh đổi kèm theo, như được chỉ ra trong Bảng 14-3.
Nó phù hợp nhất trong các kiến trúc phân tán hiện đại như microservices với tính giao dịch được chứa đựng tốt và sự tách biệt rõ ràng giữa các dịch vụ. Nó cho phép các nhóm miền xác định lượng, nhịp độ, chất lượng và sự minh bạch của dữ liệu được tiêu thụ bởi các đơn vị khác.
Trong các kiến trúc mà dữ liệu phân tích và dữ liệu vận hành phải luôn đồng bộ, việc này trở nên khó khăn hơn, đặc biệt là trong các kiến trúc phân tán. Tìm ra các cách hỗ trợ tính nhất quán cuối cùng, có thể bằng các hợp đồng rất nghiêm ngặt, cho phép áp dụng nhiều mô hình mà không gây ra những khó khăn khác.
Data mesh là một ví dụ nổi bật về sự tiến hóa gia tăng liên tục xảy ra trong hệ sinh thái phát triển phần mềm; những khả năng mới tạo ra những quan điểm mới, mà từ đó giúp giải quyết một số vấn đề dai dẳng từ quá khứ, chẳng hạn như sự phân tách giả tạo giữa miền và dữ liệu, cả về mặt vận hành lẫn phân tích.
Sysops Squad Saga: Data Mesh
Thứ Sáu, ngày 10 tháng 6, 09:55
Logan, Dana và Addison đã gặp nhau trong phòng hội nghị lớn, nơi thường có đồ ăn thừa (hoặc, vào buổi sáng sớm này, bữa sáng) từ các cuộc họp trước đó.
“Tôi vừa trở về từ một cuộc họp với các nhà khoa học dữ liệu của chúng tôi, và họ đang cố gắng tìm ra cách giải quyết một vấn đề lâu dài của chúng tôi - chúng tôi cần trở nên dựa vào dữ liệu trong việc lập kế hoạch cung cấp chuyên gia, đối với nhu cầu về kỹ năng cho các vị trí địa lý khác nhau ở các thời điểm khác nhau. Khả năng đó sẽ giúp cho việc tuyển dụng, đào tạo và các chức năng liên quan đến cung ứng khác,” Logan nói.
“Em chưa tham gia nhiều vào việc triển khai data mesh—chúng ta đã tiến xa đến đâu rồi?” Addison hỏi.
“Mỗi dịch vụ mới mà chúng tôi đã triển khai đều bao gồm một DPQ. Đội miền có trách nhiệm chạy và duy trì hợp tác lượng tử DQP cho dịch vụ của họ. Chúng tôi chỉ vừa mới bắt đầu. Chúng tôi đang dần dần xây dựng các khả năng khi chúng tôi xác định nhu cầu. Tôi có một hình ảnh về miền Quản lý Vé trong Hình 14-3.”
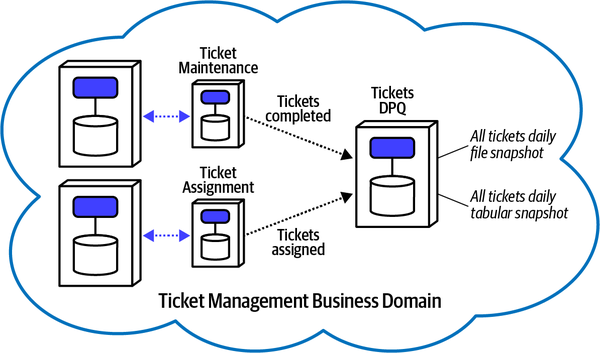
Figure 14-3. Ticket Management Domain, including two services with their own DPQs, with a Tickets DPQ
Logan nói, “Tickets DPQ là một kiến trúc lượng tử riêng, và hoạt động như một điểm tập hợp cho một vài cái nhìn về vé khác mà các hệ thống khác quan tâm.”
“Cả đội phải xây dựng bao nhiêu so với những gì đã được cung cấp?” Addison hỏi.
“Em có thể trả lời câu đó,” Dana nói. “Đội ngũ nền tảng dữ liệu mesh đang cung cấp cho các người dùng dữ liệu và nhà phát triển sản phẩm dữ liệu một bộ khả năng tự phục vụ. Điều đó cho phép bất kỳ nhóm nào muốn xây dựng một trường hợp phân tích mới có thể tìm kiếm và tìm thấy các sản phẩm dữ liệu mà mình chọn trong các khối kiến trúc hiện có, trực tiếp kết nối với chúng và bắt đầu sử dụng. Nền tảng cũng hỗ trợ các miền muốn tạo ra các sản phẩm dữ liệu mới. Nền tảng liên tục theo dõi mesh để phát hiện bất kỳ thời gian chết của sản phẩm dữ liệu nào, hoặc sự không tương thích với các chính sách quản trị và thông báo cho các nhóm miền để thực hiện các hành động.”
Logan nói, "Các chủ sở hữu sản phẩm dữ liệu miền, phối hợp với các chuyên gia trong lĩnh vực bảo mật, pháp lý, rủi ro và tuân thủ, cũng như các chủ sở hữu sản phẩm nền tảng, đã thành lập một nhóm quản trị liên kết toàn cầu, nhóm này quyết định các khía cạnh của DPQ cần phải được tiêu chuẩn hóa, chẳng hạn như hợp đồng chia sẻ dữ liệu, phương thức vận chuyển dữ liệu không đồng bộ, kiểm soát truy cập, và nhiều thứ khác. Nhóm nền tảng, trong một khoảng thời gian, làm phong phú thêm phần phụ trợ của DPQ với các khả năng thực thi chính sách mới và nâng cấp đồng nhất các phần phụ trợ trên toàn bộ lưới."
“Wow, chúng ta tiến xa hơn tôi nghĩ,” Dana nói. “Chúng ta cần dữ liệu gì để cung cấp thông tin cho vấn đề cung cấp chuyên gia?”
Logan trả lời, “Trong sự hợp tác với các nhà khoa học dữ liệu, chúng tôi đã xác định thông tin nào cần tổng hợp. Có vẻ như chúng tôi đã có thông tin chính xác: DPQ Tickets phục vụ cái nhìn dài hạn về tất cả các vé được tạo ra và giải quyết, DPQ Quản lý Người dùng cung cấp cái nhìn hàng ngày cho tất cả các hồ sơ chuyên gia, và DPQ Khảo sát cung cấp một nhật ký về tất cả các kết quả khảo sát từ khách hàng.”
“Thật tuyệt vời,” Addison nói. “Có lẽ chúng ta nên tạo ra một DPQ mới, có tên gì đó như DPQ Cung Cấp Chuyên Gia, mà nhận đầu vào không đồng bộ từ ba DPQ đó? Sản phẩm đầu tiên có thể được gọi là khuyến nghị cung cấp, sử dụng một mô hình ML được huấn luyện bằng dữ liệu tổng hợp từ các DPQ trong lĩnh vực khảo sát, vé và bảo trì. DPQ Cung Cấp Chuyên Gia sẽ cung cấp dữ liệu khuyến nghị hàng ngày, khi có dữ liệu mới về vé, khảo sát và hồ sơ chuyên gia. Thiết kế tổng thể trông giống như Hình 14-4.”
Figure 14-4. Implementing the Experts Supply DPQ
"Được rồi, điều đó có vẻ hợp lý hoàn toàn," Dana nói. "Các dịch vụ đã được thực hiện; chúng ta chỉ cần đảm bảo rằng các điểm cuối cụ thể tồn tại trong mỗi DPQ nguồn, và triển khai DPQ Cung cấp Chuyên gia mới."
“Đúng vậy,” Logan nói. “Tuy nhiên, có một điều chúng ta cần lo lắng—phân tích xu hướng phụ thuộc vào dữ liệu đáng tin cậy. Điều gì sẽ xảy ra nếu một trong các hệ thống nguồn cung cấp trả về thông tin không đầy đủ trong một khoảng thời gian? Điều đó có làm sai lệch phân tích xu hướng không?”
“Đúng vậy—không có dữ liệu cho một khoảng thời gian nào thì tốt hơn là có dữ liệu không đầy đủ, vì điều đó khiến nó có vẻ như có ít lưu lượng hơn thực tế,” Dana nói. “Chúng ta chỉ cần loại bỏ một ngày không có dữ liệu, miễn là điều đó không xảy ra thường xuyên.”
“Được rồi, Addison, bạn biết điều đó có nghĩa là gì, đúng không?” Logan nói.
"Vâng, tôi chắc chắn là có - một ADR quy định thông tin đầy đủ hoặc không có gì, và một hàm thích nghi để đảm bảo chúng ta có dữ liệu đầy đủ."
ADR: Đảm bảo rằng các Nguồn Cung cấp DPQ Chuyên gia cung cấp dữ liệu của cả ngày hoặc không có gì.
Bối cảnh DPQ Cung cấp Chuyên gia thực hiện phân tích xu hướng trong các khoảng thời gian cụ thể. Dữ liệu không đầy đủ cho một ngày nhất định sẽ làm sai lệch kết quả xu hướng và nên tránh.
Quyết định Chúng tôi sẽ đảm bảo rằng mỗi nguồn dữ liệu cho DPQ Cung cấp Chuyên gia nhận được các bản chụp đầy đủ cho các xu hướng hàng ngày hoặc không có dữ liệu cho ngày hôm đó, cho phép các nhà khoa học dữ liệu loại trừ ngày đó.
Các hợp đồng giữa các nguồn dữ liệu và DPQ Cung cấp Chuyên gia nên được liên kết lỏng lẻo để tránh sự giòn gãy.
Hệ quả Nếu quá nhiều ngày được miễn vì lý do khả năng sẵn có hoặc các vấn đề khác, độ chính xác của xu hướng sẽ bị ảnh hưởng tiêu cực.
Hàm thích nghi:
Hoàn thành ảnh chụp hàng ngày. Kiểm tra thời gian trên các tin nhắn khi chúng đến. Với khối lượng tin nhắn thông thường, bất kỳ khoảng cách nào lớn hơn một phút đều cho thấy có sự gián đoạn trong việc xử lý, đánh dấu ngày đó là miễn trừ.
Hàm thích nghi hợp đồng do người tiêu dùng thúc đẩy cho DPQ vé và DPQ cung cấp chuyên gia. Để đảm bảo rằng sự phát triển nội bộ của miền vé không làm hỏng DPQ cung cấp chuyên gia.
Martin Fowler đã đăng một thông điệp có ảnh hưởng về mô hình Data Lake trên blog của ông vào năm 2015 tại https://martinfowler.com/bliki/DataLake.html.
Chapter 15. Build Your Own Trade-Off Analysis
Thứ Hai, ngày 10 tháng 6, 10:01
Phòng hội nghị dường như được chiếu sáng hơn so với ngày định mệnh đó vào tháng Chín, khi các nhà tài trợ doanh nghiệp của Đội Sysops chuẩn bị cắt đứt toàn bộ hợp đồng hỗ trợ. Mọi người trong phòng hội nghị đang trò chuyện với nhau trước khi cuộc họp bắt đầu, tạo ra một năng lượng chưa từng thấy trong phòng hội nghị suốt một thời gian dài.
“Chà,” Bailey, nhà tài trợ chính và trưởng ứng dụng ticketing của đội Sysops, nói, “Tôi nghĩ chúng ta nên bắt đầu. Như các bạn đã biết, mục đích của cuộc họp này là để thảo luận về cách mà bộ phận CNTT đã có thể đảo ngược tình thế và sửa chữa những gì cách đây chín tháng đã trở thành một thảm họa.”
“Chúng tôi gọi đó là một buổi tổng kết,” Addison nói. “Và nó thực sự hữu ích để khám phá cách làm mọi thứ tốt hơn trong tương lai, cũng như để thảo luận về những điều dường như hoạt động tốt.”
"Vậy thì, hãy cho chúng tôi biết, điều gì đã hoạt động rất tốt? Làm thế nào bạn đã xoay chuyển dòng kinh doanh này từ góc độ kỹ thuật?" hỏi Bailey.
“Thật sự không phải chỉ là một điều duy nhất,” Austen nói, “mà là sự kết hợp của nhiều điều khác nhau. Trước hết, chúng tôi trong lĩnh vực CNTT đã rút ra một bài học quý giá về việc nhìn nhận các yếu tố thúc đẩy kinh doanh như một cách để giải quyết vấn đề và tạo ra giải pháp. Trước đây, chúng tôi luôn chỉ tập trung vào các khía cạnh kỹ thuật của vấn đề, và kết quả là không bao giờ thấy được bức tranh tổng thể.”
“Đó chỉ là một phần của vấn đề,” Dana nói, “nhưng một trong những điều đã thay đổi tình hình cho tôi và nhóm cơ sở dữ liệu là bắt đầu làm việc cùng nhau nhiều hơn với các đội phát triển ứng dụng để giải quyết vấn đề. Bạn thấy đấy, trước đây, những người chúng tôi ở phía cơ sở dữ liệu làm việc theo cách riêng của mình, và các đội phát triển ứng dụng làm việc theo cách riêng của họ. Chúng tôi không bao giờ có thể đạt được những gì chúng tôi có hôm nay nếu không hợp tác và làm việc cùng nhau để di chuyển ứng dụng Squad Sysops.”
“Đối với tôi, đó là việc học cách phân tích đúng đắn các yếu tố đánh đổi,” Addison nói. “Nếu không có sự hướng dẫn, những hiểu biết và kiến thức của Logan, chúng tôi sẽ không có được vị trí như hiện tại. Chính nhờ Logan mà chúng tôi có thể biện minh cho các giải pháp của mình từ góc độ kinh doanh.”
“Về điều đó,” Bailey nói, “Tôi nghĩ tôi đại diện cho mọi người ở đây khi nói rằng những lập luận kinh doanh ban đầu của bạn chính là lý do khiến chúng tôi cho bạn một cơ hội cuối cùng để khắc phục tình hình rắc rối mà chúng tôi gặp phải. Đó là điều mà chúng tôi không quen thuộc, và, thật lòng mà nói, nó đã khiến chúng tôi bất ngờ—một cách tích cực.”
“Được rồi,” Parker nói, “vì bây giờ tất cả chúng ta đều đồng ý rằng mọi thứ có vẻ đang diễn ra tốt đẹp, làm thế nào để chúng ta duy trì được nhịp độ này? Làm thế nào để khuyến khích các bộ phận và phòng ban khác trong công ty không rơi vào tình trạng hỗn độn như trước đây?”
“Kỷ luật,” Logan nói. “Chúng ta tiếp tục thói quen mới tạo ra bảng đánh đổi cho tất cả các quyết định của mình, tiếp tục ghi chép và truyền đạt các quyết định của mình thông qua các bản ghi quyết định kiến trúc, và tiếp tục hợp tác với các đội khác về các vấn đề và giải pháp.”
“Nhưng điều đó chẳng phải chỉ là thêm rất nhiều quy trình và thủ tục vào sự kết hợp này sao?” Morgan, trưởng phòng marketing, hỏi.
“Không,” Logan nói. “Đó là kiến trúc. Và như bạn có thể thấy, nó hoạt động.”
Trong suốt cuốn sách này, ví dụ thống nhất minh họa cách thực hiện phân tích đánh đổi một cách tổng quát trong các kiến trúc phân tán. Tuy nhiên, các giải pháp tổng quát hiếm khi tồn tại trong kiến trúc và, nếu có, thường không đầy đủ cho các kiến trúc rất cụ thể và các vấn đề độc đáo mà chúng mang lại. Do đó, chúng tôi không nghĩ rằng phân tích giao tiếp được đề cập trong Chương 2 là toàn diện, mà chỉ là một điểm khởi đầu để bạn có thể thêm nhiều cột cho các yếu tố độc đáo liên quan đến không gian vấn đề của bạn.
Vì mục đích đó, chương này cung cấp một số lời khuyên về cách xây dựng phân tích trao đổi của riêng bạn, sử dụng nhiều kỹ thuật mà chúng tôi đã áp dụng để rút ra các kết luận được trình bày trong cuốn sách này.
Quy trình ba bước của chúng tôi để phân tích đánh đổi hiện đại, mà chúng tôi đã giới thiệu trong Chương 2, như sau:
-
Tìm những bộ phận nào bị rối vào nhau.
-
Phân tích cách chúng được kết nối với nhau.
-
Đánh giá các thỏa hiệp bằng cách xác định tác động của sự thay đổi đối với các hệ thống phụ thuộc lẫn nhau.
Chúng tôi sẽ thảo luận một số kỹ thuật và cân nhắc cho từng bước tiếp theo.
Finding Entangled Dimensions
Bước đầu tiên của một kiến trúc sư trong quá trình này là khám phá những kích thước nào đang liên quan hoặc đan xen với nhau. Điều này là duy nhất trong một kiến trúc cụ thể nhưng có thể được những nhà phát triển, kiến trúc sư, nhân viên vận hành và các vai trò khác quen thuộc với hệ sinh thái tổng thể hiện có cùng với những khả năng và giới hạn của nó phát hiện.
Coupling
Phần đầu tiên của phân tích trả lời câu hỏi này cho một kiến trúc sư: các phần trong một kiến trúc được liên kết với nhau như thế nào? Thế giới phát triển phần mềm có nhiều định nghĩa khác nhau về sự liên kết, nhưng chúng tôi sử dụng phiên bản đơn giản nhất, dễ hiểu nhất cho bài tập này: nếu ai đó thay đổi X, liệu điều đó có thể buộc Y phải thay đổi không?
Trong Chương 2, chúng tôi đã mô tả khái niệm về sự kết nối tĩnh giữa các quanta kiến trúc, cung cấp một sơ đồ cấu trúc toàn diện về sự kết nối kỹ thuật. Không có công cụ chung nào để xây dựng điều này vì mỗi kiến trúc đều độc đáo. Tuy nhiên, trong một tổ chức, một nhóm phát triển có thể xây dựng sơ đồ kết nối tĩnh, bằng cách thủ công hoặc thông qua tự động hóa.
Ví dụ, để tạo một sơ đồ liên kết tĩnh cho một microservice trong một kiến trúc, một kiến trúc sư cần thu thập các thông tin sau:
-
Các hệ điều hành/ phụ thuộc vào container
-
Các phụ thuộc được cung cấp qua quản lý phụ thuộc trung gian (khung, thư viện, v.v.)
-
Các phụ thuộc bền vững vào cơ sở dữ liệu, công cụ tìm kiếm, môi trường đám mây, v.v.
-
"Các điểm tích hợp kiến trúc cần thiết để dịch vụ có thể khởi động."
-
Hạ tầng nhắn tin (chẳng hạn như trình trung gian nhắn tin) cần thiết để cho phép giao tiếp với các quanta khác.
Sơ đồ liên kết tĩnh không xem xét các quanta khác mà điểm liên kết duy nhất của chúng là giao tiếp quy trình với quantum này. Ví dụ, nếu dịch vụ AssignTicket hợp tác với ManageTicket trong một quy trình làm việc nhưng không có điểm liên kết nào khác, chúng độc lập tĩnh (nhưng lại liên kết động trong quá trình làm việc thực tế).
Các nhóm đã xây dựng hầu hết các môi trường của họ thông qua tự động hóa có thể tích hợp vào cơ chế sinh ra đó một khả năng bổ sung để ghi lại các điểm kết nối khi hệ thống được xây dựng.
Đối với cuốn sách này, mục tiêu của chúng tôi là đo lường các đánh đổi trong việc kết nối và giao tiếp trong kiến trúc phân tán. Để xác định ba chiều của sự kết nối lượng tử động, chúng tôi đã xem xét hàng trăm ví dụ về các kiến trúc phân tán (cả microservices và các loại khác) để xác định các điểm kết nối chung. Nói cách khác, tất cả các ví dụ mà chúng tôi đã xem xét đều nhạy cảm với những thay đổi trong các chiều của giao tiếp, tính nhất quán và sự điều phối.
Quá trình này nhấn mạnh tầm quan trọng của thiết kế lặp đi lặp lại trong kiến trúc. Không có kiến trúc sư nào xuất sắc đến mức bản thảo đầu tiên của họ luôn hoàn hảo. Xây dựng các mẫu cấu trúc cho các quy trình công việc (giống như cách mà chúng ta làm trong cuốn sách này) cho phép một kiến trúc sư hoặc đội ngũ tạo ra một cái nhìn ma trận về các đánh đổi, cho phép phân tích nhanh hơn và kỹ lưỡng hơn so với các phương pháp ngẫu nhiên.
Analyze Coupling Points
Một khi một kiến trúc sư hoặc nhóm đã xác định các điểm kết nối mà họ muốn phân tích, bước tiếp theo là mô hình hóa các sự kết hợp có thể theo cách nhẹ nhàng. Một số sự kết hợp có thể không khả thi, cho phép kiến trúc sư bỏ qua việc mô hình hóa những sự kết hợp đó. Mục tiêu của phân tích là xác định những lực mà kiến trúc sư cần nghiên cứu - nói cách khác, những lực nào yêu cầu phân tích đánh đổi? Ví dụ, cho phân tích kết nối động lượng lượng tử của kiến trúc của chúng tôi, chúng tôi đã chọn kết nối, độ phức tạp, khả năng phản ứng/sẵn có và quy mô/độ đàn hồi là những mối quan tâm đánh đổi chính, bên cạnh việc phân tích ba lực giao tiếp, nhất quán và phối hợp, như được hiển thị trong bảng đánh giá cho “Mẫu Câu Chuyện Song Song”, xuất hiện lại trong Bảng 15-1.
| Parallel Saga | Ratings |
|---|---|
Giao tiếp | Bất đồng bộ |
Tính nhất quán | Cuối cùng |
Điều phối | Tập trung |
Ghép nối | Thấp |
Độ phức tạp | Thấp |
Sự phản hồi/sự có sẵn | Cao |
Quy mô/tính co giãn | Cao |
Khi xây dựng các danh sách xếp hạng này, chúng tôi đã xem xét từng giải pháp thiết kế (các mẫu mà chúng tôi đã đặt tên) một cách riêng biệt, chỉ kết hợp chúng vào cuối cùng để xem sự khác biệt, như được trình bày trong Bảng 15-2.
Một khi chúng tôi đã phân tích từng mẫu một cách độc lập, chúng tôi đã tạo ra một ma trận để so sánh các đặc điểm, dẫn đến những quan sát thú vị. Đầu tiên, hãy chú ý đến mối tương quan nghịch đảo trực tiếp giữa mức độ gắn kết và quy mô/độ co giãn: càng nhiều gắn kết có trong mẫu, khả năng mở rộng của nó càng kém. Điều này hợp lý theo trực giác; càng có nhiều dịch vụ tham gia vào một quy trình làm việc, thì càng khó cho một kiến trúc sư thiết kế cho việc mở rộng.
Thứ hai, chúng tôi đã có một quan sát tương tự về mức độ phản hồi/sẵn có và mức độ liên kết, điều này không trực tiếp như mối tương quan trước đó nhưng cũng quan trọng: mức độ liên kết cao dẫn đến khả năng phản hồi và sẵn có thấp hơn bởi vì càng có nhiều dịch vụ tham gia vào một quy trình làm việc, thì khả năng toàn bộ quy trình làm việc thất bại do một dịch vụ gặp sự cố càng cao.
Kỹ thuật phân tích này minh họa cho kiến trúc lặp đi lặp lại. Không có kiến trúc sư nào, bất kể sự thông minh của họ, có thể ngay lập tức hiểu được những sắc thái của một tình huống thực sự độc đáo - và những sắc thái này luôn xuất hiện trong các kiến trúc phức tạp. Việc xây dựng một ma trận các khả năng cung cấp thông tin cho các bài tập lập mô hình mà một kiến trúc sư có thể muốn thực hiện để nghiên cứu những hệ quả của việc hoán đổi một hoặc nhiều chiều để xem hiệu ứng kết quả.
Assess Trade-Offs
Khi bạn đã xây dựng một nền tảng cho phép các kịch bản "thử nghiệm" lặp đi lặp lại, hãy tập trung vào các đánh đổi cơ bản cho một tình huống nhất định. Ví dụ, chúng tôi đã tập trung vào giao tiếp đồng bộ và phi đồng bộ, một lựa chọn tạo ra hàng loạt khả năng và hạn chế - mọi thứ trong kiến trúc phần mềm đều là một sự đánh đổi. Do đó, việc chọn một chiều hướng cơ bản như đồng bộ hóa trước tiên sẽ hạn chế các lựa chọn trong tương lai. Khi chiều hướng đó đã được cố định, thực hiện cùng một loại phân tích lặp lại cho các quyết định tiếp theo được khuyến khích hoặc buộc phải theo quyết định đầu tiên. Một đội ngũ kiến trúc sư có thể lặp đi lặp lại quy trình này cho đến khi họ giải quyết được các quyết định khó khăn - nói cách khác, những quyết định có các chiều hướng liên quan chằng chịt. Những gì còn lại là thiết kế.
Trade-Off Techniques
Theo thời gian, các tác giả đã tạo ra một số phân tích đánh đổi và đã xây dựng một số lời khuyên về cách tiếp cận chúng.
Qualitative Versus Quantative Analysis
Bạn có thể đã nhận thấy rằng hầu như không có bảng đánh đổi nào của chúng tôi là định lượng - dựa trên con số - mà chủ yếu là định tính - đo lường chất lượng của một thứ gì đó thay vì số lượng, điều này là cần thiết vì hai kiến trúc sẽ luôn khác nhau đủ để ngăn cản các so sánh định lượng thực sự. Tuy nhiên, việc sử dụng phân tích thống kê trên một tập dữ liệu lớn cho phép phân tích định tính hợp lý.
Ví dụ, khi so sánh khả năng mở rộng của các mẫu, chúng tôi đã xem xét nhiều triển khai khác nhau của các tổ hợp giao tiếp, nhất quán và phối hợp, đánh giá khả năng mở rộng trong từng trường hợp, và cho phép chúng tôi xây dựng thang đo so sánh như được trình bày trong Bảng 15-2.
Tương tự, các kiến trúc sư trong một tổ chức cụ thể có thể thực hiện cùng một bài tập, xây dựng một ma trận chiều của các mối quan tâm liên kết, và xem xét các ví dụ đại diện (hoặc trong tổ chức hiện tại hoặc những điểm cục bộ để kiểm tra lý thuyết).
Chúng tôi khuyên bạn rèn luyện kỹ năng phân tích định tính, vì có rất ít cơ hội cho phân tích định lượng thực sự trong kiến trúc.
MECE Lists
Điều quan trọng đối với các kiến trúc sư là phải chắc chắn rằng họ đang so sánh những thứ tương tự chứ không phải những thứ hoàn toàn khác nhau. Ví dụ, không phải là một so sánh hợp lệ khi so sánh một hàng đợi tin nhắn đơn giản với một bus dịch vụ doanh nghiệp, cái mà bao gồm một hàng đợi tin nhắn nhưng còn có hàng tá các thành phần khác nữa.
Một khái niệm hữu ích được mượn từ thế giới chiến lược công nghệ giúp các kiến trúc sư tìm ra sự so sánh chính xác là danh sách MECE, viết tắt của "không chồng chéo, bao quát tổng thể".
- Mutually exclusive
-
Không có khả năng nào được phép chồng chéo giữa những mục được so sánh. Như trong ví dụ trước, việc so sánh một hàng đợi tin nhắn với toàn bộ ESB là không hợp lệ vì chúng thực sự không thuộc cùng một loại. Nếu bạn muốn chỉ so sánh các khả năng về tin nhắn mà không tính đến các phần khác, điều đó sẽ giảm so sánh xuống hai thứ có thể so sánh lẫn nhau.
- Collectively exhaustive
-
Điều này gợi ý rằng bạn đã xem xét tất cả các khả năng trong không gian quyết định và rằng bạn chưa bỏ qua bất kỳ khả năng rõ ràng nào. Ví dụ, nếu một nhóm kiến trúc sư đang đánh giá các hàng đợi tin nhắn hiệu suất cao và chỉ xem xét một ESB và hàng đợi tin nhắn đơn giản nhưng không xem xét Kafka, họ đã không xem xét tất cả các khả năng trong không gian này.
Mục tiêu của một danh sách MECE là bao phủ hoàn toàn không gian danh mục, không có lỗ hổng hoặc chồng chéo, như được trình bày bằng hình ảnh trong Hình 15-1.
Figure 15-1. A MECE list is mutually exclusive and collectively exhaustive
Hệ sinh thái phát triển phần mềm liên tục tiến hóa, khám phá ra những khả năng mới trong quá trình đó. Khi đưa ra quyết định có ảnh hưởng lâu dài, kiến trúc sư cần đảm bảo rằng một khả năng mới không vừa mới xuất hiện, làm thay đổi tiêu chí. Đảm bảo rằng các tiêu chí so sánh là đầy đủ và bao quát sẽ khuyến khích việc khám phá.
The “Out-of-Context” Trap
Khi đánh giá các sự đánh đổi, các kiến trúc sư phải đảm bảo giữ cho quyết định trong ngữ cảnh; nếu không, các yếu tố bên ngoài sẽ ảnh hưởng không đúng mực đến phân tích của họ. Thường thì, một giải pháp có nhiều khía cạnh có lợi, nhưng lại thiếu những khả năng quan trọng ngăn cản sự thành công. Các kiến trúc sư cần đảm bảo rằng họ cân bằng đúng tập hợp các sự đánh đổi, chứ không phải tất cả những cái có sẵn.
Ví dụ, có thể một kiến trúc sư đang cố gắng quyết định xem có nên sử dụng dịch vụ chia sẻ hay thư viện chia sẻ cho các chức năng chung trong một kiến trúc phân tán, như được minh họa trong Hình 15-2.
Figure 15-2. Deciding between shared service or library in a distributed architecture
Kiến trúc sư đối mặt với quyết định này sẽ bắt đầu nghiên cứu hai giải pháp có thể, cả thông qua các đặc điểm chung được phát hiện qua nghiên cứu và thông qua dữ liệu thực nghiệm từ tổ chức của họ. Kết quả của quá trình khám phá đó dẫn đến một ma trận đánh đổi như ma trận được trình bày trong Hình 15-3.
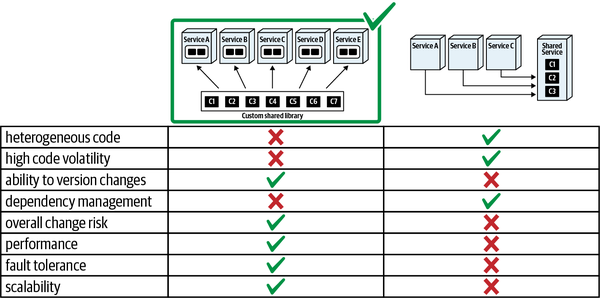
Figure 15-3. Trade-off analysis for two solutions
Kiến trúc sư dường như có lý do chính đáng khi chọn phương pháp thư viện chia sẻ, vì ma trận rõ ràng ưu tiên giải pháp đó... tổng thể. Tuy nhiên, quyết định này minh họa cho vấn đề ngoài ngữ cảnh - khi ngữ cảnh bổ sung cho vấn đề trở nên rõ ràng, tiêu chí quyết định thay đổi, như được minh họa trong Hình 15-4.

Figure 15-4. Shifting decision based on additional context
Kiến trúc sư tiếp tục nghiên cứu không chỉ vấn đề chung về dịch vụ so với thư viện, mà còn bối cảnh thực tế áp dụng trong tình huống này. Hãy nhớ rằng, các giải pháp chung hiếm khi hữu ích trong các kiến trúc thực tế mà không áp dụng thêm bối cảnh cụ thể cho tình huống.
Quá trình này nhấn mạnh hai quan sát quan trọng. Đầu tiên, việc tìm ra bối cảnh tốt nhất cho một quyết định cho phép kiến trúc sư xem xét ít lựa chọn hơn, từ đó đơn giản hóa quy trình ra quyết định. Một lời khuyên phổ biến từ những bậc thầy về phần mềm là “chấp nhận các thiết kế đơn giản,” mà không bao giờ giải thích cách đạt được mục tiêu đó. Tìm ra bối cảnh hẹp đúng cho các quyết định cho phép kiến trúc sư suy nghĩ ít hơn, trong nhiều trường hợp đơn giản hóa thiết kế.
Thứ hai, điều quan trọng là các kiến trúc sư phải hiểu tầm quan trọng của thiết kế lặp lại trong kiến trúc, lập sơ đồ các giải pháp kiến trúc mẫu để chơi các trò chơi “nếu - thì” định tính nhằm xem xét cách các chiều kích kiến trúc ảnh hưởng lẫn nhau. Bằng cách sử dụng thiết kế lặp lại, các kiến trúc sư có thể khám phá các giải pháp khả thi và phát hiện bối cảnh phù hợp mà quyết định đó thuộc về.
Model Relevant Domain Cases
Các kiến trúc sư không nên đưa ra quyết định trong khoảng trống, mà không có các yếu tố liên quan giúp gia tăng giá trị cho giải pháp cụ thể. Việc đưa những yếu tố trong miền trở lại quy trình ra quyết định có thể giúp kiến trúc sư sàng lọc các tùy chọn có sẵn và tập trung vào những đánh đổi thực sự quan trọng.
Ví dụ, hãy xem xét quyết định của một kiến trúc sư về việc tạo ra một dịch vụ thanh toán đơn lẻ hay một dịch vụ riêng biệt cho từng loại thanh toán, như được minh họa trong Hình 15-5.
Figure 15-5. Choosing between a single payment service or one per payment type
Như chúng ta đã thảo luận trong Chương 7, các kiến trúc sư có thể lựa chọn từ nhiều bộ tích hợp và phân tách để hỗ trợ quyết định này. Tuy nhiên, những lực lượng đó là tổng quát—một kiến trúc sư có thể thêm nhiều sắc thái vào quyết định bằng cách mô hình hóa một số kịch bản có thể xảy ra.
Ví dụ, xem xét kịch bản đầu tiên, được minh họa trong Hình 15-6, để cập nhật dịch vụ xử lý thẻ tín dụng.
Trong kịch bản này, việc có các dịch vụ riêng biệt mang lại khả năng bảo trì, khả năng kiểm tra và khả năng triển khai tốt hơn, tất cả đều dựa trên sự phân lập ở mức lượng tử của các dịch vụ. Tuy nhiên, nhược điểm của các dịch vụ riêng biệt thường là mã bị trùng lặp để ngăn chặn sự liên kết tĩnh lượng tử giữa các dịch vụ, điều này làm giảm lợi ích của việc có các dịch vụ riêng biệt.
Figure 15-6. Scenario 1: update credit card processing service
Trong kịch bản thứ hai, kiến trúc sư mô phỏng những gì xảy ra khi hệ thống thêm một loại thanh toán mới, như được thể hiện trong Hình 15-7.
Figure 15-7. Scenario 2: adding a payment type
Kiến trúc sư thêm một loại thanh toán điểm thưởng để xem nó ảnh hưởng như thế nào đến các đặc điểm kiến trúc quan tâm, nhấn mạnh khả năng mở rộng như một lợi ích của các dịch vụ riêng biệt. Cho đến nay, các dịch vụ riêng biệt trông có vẻ hấp dẫn.
Tuy nhiên, giống như trong nhiều trường hợp, những quy trình phức tạp hơn làm nổi bật những phần khó khăn của kiến trúc, như được trình bày trong kịch bản thứ ba ở Hình 15-8.
Trong kịch bản này, kiến trúc sư bắt đầu hiểu rõ hơn về những sự đánh đổi thực sự liên quan đến quyết định này. Việc sử dụng các dịch vụ riêng biệt đòi hỏi phải có sự phối hợp cho quy trình làm việc, điều này tốt nhất được xử lý bởi một bộ điều phối. Tuy nhiên, như chúng ta đã thảo luận trong Chương 11, việc chuyển sang một bộ điều phối có thể tác động tiêu cực đến hiệu suất và khiến cho việc duy trì tính nhất quán dữ liệu trở nên thách thức hơn. Kiến trúc sư có thể tránh sử dụng bộ điều phối, nhưng logic quy trình làm việc phải được lưu trữ ở đâu đó—hãy nhớ rằng, sự kết nối ngữ nghĩa chỉ có thể được tăng lên thông qua việc triển khai, chứ không bao giờ giảm xuống.
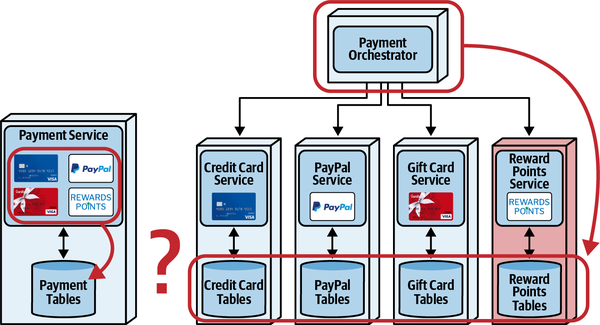
Figure 15-8. Scenario 3: using multiple types for payment
Sau khi mô phỏng ba kịch bản này, kiến trúc sư nhận ra rằng phân tích sự đánh đổi thực sự phụ thuộc vào việc điều gì quan trọng hơn: hiệu suất và tính nhất quán của dữ liệu (một dịch vụ thanh toán duy nhất) hay khả năng mở rộng và tính linh hoạt (các dịch vụ riêng lẻ).
Suy nghĩ về các vấn đề kiến trúc một cách tổng quát và trừu tượng chỉ giúp kiến trúc sư tiến xa đến mức độ nào đó. Vì kiến trúc thường né tránh các giải pháp tổng quát, nên điều quan trọng là các kiến trúc sư cần rèn luyện kỹ năng mô hình hóa các kịch bản trong lĩnh vực liên quan để có thể thực hiện phân tích và quyết định về các thỏa hiệp tốt hơn.
Prefer Bottom Line over Overwhelming Evidence
Dễ dàng cho các kiến trúc sư tích lũy một lượng thông tin khổng lồ trong quá trình tìm hiểu tất cả các khía cạnh của một phân tích đánh đổi cụ thể. Thêm vào đó, bất kỳ ai học được điều gì mới thường muốn chia sẻ với người khác, đặc biệt nếu họ nghĩ rằng bên kia sẽ quan tâm. Tuy nhiên, nhiều chi tiết kỹ thuật mà các kiến trúc sư phát hiện ra lại khó hiểu với những bên liên quan không có chuyên môn, và lượng chi tiết quá nhiều có thể vượt quá khả năng của họ trong việc đóng góp những hiểu biết có ý nghĩa vào quyết định.
Thay vì trình bày tất cả thông tin mà họ đã thu thập, một kiến trúc sư nên giản lược phân tích các sự đánh đổi xuống một vài điểm chính, đôi khi là tổng hợp của các sự đánh đổi cá nhân.
Xem xét vấn đề phổ biến mà một kiến trúc sư có thể gặp phải trong kiến trúc vi dịch vụ về việc lựa chọn giao tiếp đồng bộ hay bất đồng bộ, được minh họa trong Hình 15-9.
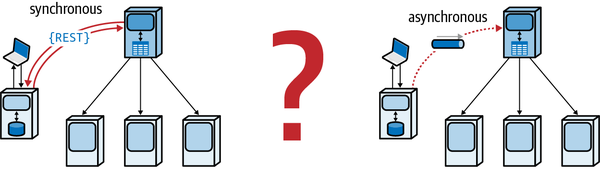
Figure 15-9. Deciding between communication types
Bộ điều phối giải pháp đồng bộ thực hiện các cuộc gọi REST đồng bộ để giao tiếp với các cộng tác viên trong quy trình, trong khi giải pháp không đồng bộ sử dụng hàng đợi tin nhắn để triển khai giao tiếp không đồng bộ.
Sau khi xem xét các yếu tố chung chỉ ra sự lựa chọn này hoặc sự lựa chọn khác, kiến trúc sư tiếp theo sẽ nghĩ về những kịch bản cụ thể trong lĩnh vực mà các bên liên quan không kỹ thuật quan tâm. Để đạt được mục đích đó, kiến trúc sư sẽ xây dựng một bảng so sánh giao dịch giống như Bảng 15-3.
Sau khi mô hình hóa những kịch bản này, kiến trúc sư có thể đưa ra quyết định cuối cùng cho các bên liên quan: điều nào quan trọng hơn, là đảm bảo rằng quy trình phê duyệt tín dụng bắt đầu ngay lập tức hay khả năng phản hồi và chống lỗi? Việc loại bỏ các chi tiết kỹ thuật khó hiểu cho phép các bên liên quan không phải kỹ thuật tập trung vào kết quả thay vì các quyết định thiết kế, giúp tránh việc làm cho họ bị chìm trong biển thông tin chi tiết.
Avoiding Snake Oil and Evangelism
Một tác động đáng tiếc của sự nhiệt tình với công nghệ là sự truyền bá, điều này lẽ ra nên là một đặc quyền dành riêng cho những người dẫn dắt công nghệ và các nhà phát triển nhưng thường khiến các kiến trúc sư gặp rắc rối.
Rắc rối xảy ra vì khi ai đó truyền bá một công cụ, kỹ thuật, phương pháp, hay bất kỳ điều gì khác mà mọi người xây dựng sự hào hứng, họ bắt đầu nâng cao những điểm tốt và giảm thiểu những điểm xấu. Thật không may, trong kiến trúc phần mềm, những thỏa hiệp cuối cùng luôn trở lại để làm phức tạp mọi thứ.
Một kiến trúc sư cũng nên cẩn trọng với bất kỳ công cụ hoặc kỹ thuật nào hứa hẹn những khả năng mới đáng kinh ngạc, thường xuất hiện và biến mất một cách định kỳ. Luôn yêu cầu những người truyền bá công cụ hoặc kỹ thuật đó cung cấp một đánh giá trung thực về cái tốt và cái xấu - không có gì trong kiến trúc phần mềm là hoàn toàn tốt - điều này cho phép quyết định được cân bằng hơn.
Ví dụ, hãy xem xét một kiến trúc sư đã thành công trong quá khứ với một phương pháp cụ thể và trở thành một người ủng hộ cho nó, như được minh họa trong Hình 15-10.
Figure 15-10. An architect evangelist who thinks they have found a silver bullet
Kiến trúc sư này có lẽ đã làm việc với những vấn đề trong quá khứ mà khả năng mở rộng là một đặc điểm kiến trúc chính và tin rằng khả năng đó sẽ luôn thúc đẩy quá trình quyết định. Tuy nhiên, các giải pháp trong kiến trúc hiếm khi mở rộng ra ngoài giới hạn hẹp của một không gian vấn đề cụ thể. Mặt khác, bằng chứng từ kinh nghiệm thường rất thuyết phục. Làm thế nào để bạn có thể tìm ra sự đánh đổi thực sự ẩn sau sự tán dương theo phản xạ?
Mặc dù kinh nghiệm là hữu ích, phân tích kịch bản là một trong những công cụ mạnh mẽ nhất của một kiến trúc sư để cho phép thiết kế lặp lại mà không cần phải xây dựng toàn bộ hệ thống. Bằng cách mô hình hóa các kịch bản có thể xảy ra, một kiến trúc sư có thể phát hiện xem một giải pháp cụ thể có thực sự hoạt động tốt hay không.
Trong ví dụ được thể hiện trong Hình 15-10, một hệ thống hiện tại sử dụng một chủ đề duy nhất để phát sóng các thay đổi. Mục tiêu của kiến trúc sư là thêm lịch sử đấu giá vào quy trình công việc—đội ngũ nên giữ nguyên cách tiếp cận phát và đăng ký hiện tại hay chuyển sang nhắn tin theo từng điểm kết nối cho mỗi người tiêu dùng?
Để khám phá các sự đánh đổi cho vấn đề cụ thể này, kiến trúc sư nên mô hình hóa các kịch bản miền có khả năng xảy ra bằng cách sử dụng hai topologies. Việc thêm lịch sử giao dịch vào thiết kế xuất bản và đăng ký hiện có xuất hiện trong Hình 15-11.
Figure 15-11. Scenario 1: Adding bid history to the existing topic
Trong khi giải pháp này hoạt động, nó cũng có những vấn đề. Thứ nhất, nếu các đội cần các hợp đồng khác nhau cho mỗi người tiêu dùng thì sao? Việc xây dựng một hợp đồng lớn duy nhất bao trùm mọi thứ thực hiện mẫu chống ví dụ “Kết nối hình dấu cho Quản lý Quy trình làm việc”; việc buộc mỗi đội phải thống nhất theo một hợp đồng duy nhất tạo ra một điểm kết nối tình cờ trong kiến trúc—nếu một đội thay đổi thông tin cần thiết, tất cả các đội phải phối hợp với thay đổi đó. Thứ hai, vấn đề về bảo mật dữ liệu thì sao? Việc sử dụng một chủ đề xuất bản và đăng ký duy nhất cho phép mỗi người tiêu dùng truy cập vào tất cả dữ liệu, điều này có thể tạo ra cả vấn đề bảo mật và các vấn đề liên quan đến PII (Thông tin nhận dạng cá nhân, được thảo luận trong Chương 14). Thứ ba, kiến trúc sư nên xem xét sự khác biệt về đặc điểm kiến trúc hoạt động giữa các người tiêu dùng khác nhau. Ví dụ, nếu đội vận hành muốn theo dõi độ sâu hàng đợi và sử dụng tự động mở rộng cho việc ghi lại giá thầu và theo dõi giá thầu nhưng không cho hai dịch vụ còn lại, việc sử dụng một chủ đề duy nhất sẽ ngăn cản khả năng đó—các người tiêu dùng giờ đây đã được kết nối hoạt động với nhau.
Để giảm thiểu những thiếu sót này, kiến trúc sư nên lập mô hình giải pháp thay thế để xem liệu nó có giải quyết được các vấn đề trước đó (và không gây ra những vấn đề nan giải mới). Phiên bản hàng đợi riêng lẻ xuất hiện trong Hình 15-12.
Figure 15-12. Using individual queues to capture bid information
Mỗi phần của quy trình làm việc này (bắt thầu, theo dõi thầu, phân tích thầu và lịch sử thầu) sử dụng các hàng đợi tin nhắn riêng và giải quyết nhiều vấn đề trước đó. Đầu tiên, mỗi tác nhân tiêu thụ có thể có hợp đồng riêng của họ, tách biệt các tác nhân tiêu thụ với nhau. Thứ hai, quyền truy cập an ninh và kiểm soát dữ liệu nằm trong hợp đồng giữa nhà sản xuất và từng tác nhân tiêu thụ, cho phép có những khác biệt về thông tin cũng như tỷ lệ thay đổi. Thứ ba, mỗi hàng đợi bây giờ có thể được theo dõi và mở rộng độc lập.
Chắc chắn rồi, đến thời điểm này trong cuốn sách, bạn nên nhận ra rằng hệ thống dựa trên điểm đến điểm cũng không hoàn hảo nhưng cung cấp một tập hợp khác về các sự đánh đổi.
Khi kiến trúc sư đã mô hình hóa cả hai phương pháp, có vẻ như sự khác biệt chủ yếu nằm ở những lựa chọn được hiển thị trong Bảng 15-4.
Cuối cùng, kiến trúc sư nên tham khảo ý kiến của các bên liên quan (hoạt động, kiến trúc sư doanh nghiệp, chuyên viên phân tích kinh doanh, v.v.) để xác định bộ đánh đổi nào trong số này là quan trọng hơn.
Đôi khi một kiến trúc sư không chọn cách truyền bá điều gì đó mà bị ép buộc phải đóng vai trò đối lập, đặc biệt đối với những thứ không có lợi thế rõ ràng. Các công nghệ phát triển những người hâm mộ, đôi khi là những người rất nhiệt thành, họ thường làm giảm thiểu những bất lợi và phóng đại những ưu điểm.
Ví dụ, gần đây một người đứng đầu kỹ thuật trong một dự án đã cố gắng lôi kéo một trong những tác giả vào một cuộc tranh luận về monorepo so với phát triển dựa trên trunk. Cả hai đều có những khía cạnh tốt và xấu, một quyết định kiến trúc phần mềm cổ điển. Người đứng đầu kỹ thuật là một người ủng hộ nhiệt tình cho phương pháp monorepo, và đã cố gắng buộc tác giả phải giữ lập trường đối lập - không có cuộc tranh luận nào nếu không có hai bên tồn tại.
Thay vào đó, kiến trúc sư chỉ ra rằng đó là một sự đánh đổi, nhẹ nhàng giải thích rằng nhiều lợi ích mà trưởng nhóm kỹ thuật đã ca ngợi đòi hỏi một mức độ kỷ luật mà trước đây chưa bao giờ thể hiện trong nhóm, nhưng chắc chắn sẽ cải thiện.
Thay vì bị buộc phải nhận vị trí đối lập, kiến trúc sư đã thực hiện một phân tích đánh đổi thực tế, không dựa trên các giải pháp chung chung. Kiến trúc sư đồng ý thử phương pháp Monorepo nhưng cũng thu thập số liệu để đảm bảo rằng những khía cạnh tiêu cực của giải pháp không xảy ra. Ví dụ, một trong những mẫu phản tác dụng mà họ muốn tránh là sự gắn bó tình cờ giữa hai dự án vì sự gần gũi của kho lưu trữ, vì vậy kiến trúc sư và đội ngũ đã xây dựng một loạt các hàm kiểm tra để đảm bảo rằng, mặc dù về mặt kỹ thuật có thể tạo ra một điểm gắn bó, nhưng hàm kiểm tra đã ngăn chặn điều đó.
Tip
Đừng để người khác ép bạn phải truyền bá điều gì đó—hãy quay lại với sự đánh đổi.
Chúng tôi khuyên các kiến trúc sư nên tránh việc truyền bá và cố gắng trở thành người phán quyết khách quan về các lựa chọn. Một kiến trúc sư mang lại giá trị thực sự cho một tổ chức không phải bằng cách theo đuổi những giải pháp hoàn hảo mà là bằng cách mài giũa kỹ năng phân tích các sự đánh đổi khi chúng xuất hiện.
Sysops Squad Saga: Epilogue
Thứ Hai, ngày 20 tháng 6, 16:55
“Được rồi, tôi nghĩ tôi cuối cùng đã hiểu. Chúng ta không thể thực sự dựa vào những lời khuyên chung cho kiến trúc của mình - nó khác biệt quá nhiều so với những cái khác. Chúng ta phải liên tục thực hiện công việc khó khăn của việc phân tích sự đánh đổi.”
"Đúng vậy. Nhưng đó không phải là một bất lợi - đó là một lợi thế. Khi tất cả chúng ta học cách phân tách các khía cạnh và thực hiện phân tích trao đổi, chúng ta đang học được những điều cụ thể về kiến trúc của mình. Ai quan tâm đến những cái khác, chung chung? Nếu chúng ta có thể giảm số lượng các trao đổi cho một vấn đề xuống một con số đủ nhỏ để thực sự mô hình hóa và thử nghiệm chúng, chúng ta sẽ có được những kiến thức quý giá về hệ sinh thái của mình. Bạn biết đấy, các kỹ sư kết cấu đã xây dựng rất nhiều toán học và các công cụ dự đoán khác, nhưng việc xây dựng những thứ đó thì khó khăn và tốn kém. Phần mềm thì… ồ, mềm mại hơn nhiều. Tôi luôn nói rằng việc kiểm tra là sự nghiêm ngặt trong kỹ thuật của phát triển phần mềm. Mặc dù chúng ta không có loại toán học như các kỹ sư khác, nhưng chúng ta có thể từng bước xây dựng và thử nghiệm các giải pháp của mình, cho phép linh hoạt hơn nhiều và tận dụng lợi thế của một phương tiện linh hoạt hơn. Việc kiểm tra với các kết quả khách quan cho phép phân tích trao đổi của chúng ta chuyển từ định tính sang định lượng - từ suy đoán sang kỹ thuật. Càng nhiều sự thật cụ thể mà chúng ta có thể học được về hệ sinh thái độc đáo của mình, phân tích của chúng ta càng trở nên chính xác hơn."
“Ừ, điều đó có lý. Bạn có muốn đi dự buổi gặp gỡ sau giờ làm việc để ăn mừng sự thay đổi lớn không?”
“Chắc chắn.”
Appendix A. Concept and Term References
Trong cuốn sách này, chúng tôi đã đề cập đến một số thuật ngữ hoặc khái niệm được giải thích chi tiết trong cuốn sách trước đó của chúng tôi, Cơ sở của Kiến trúc Phần mềm. Dưới đây là một tham chiếu trước cho những thuật ngữ và khái niệm đó:
Độ phức tạp cyclomatic: Chương 6, trang 81
Liên kết thành phần: Chương 7, trang 92
Tính kết dính của thành phần: Chương 7, trang 93
Chia tách kỹ thuật so với chia tách miền: Chương 8, trang 103
Kiến trúc phân lớp: Chương 10, trang 135
Kiến trúc dựa trên dịch vụ: Chương 13, trang 163
Kiến trúc microservices: Chương 12, trang 151
Appendix B. Architecture Decision Record References
Mỗi quyết định của Nhóm Sysops trong cuốn sách này đều đi kèm với một Hồ sơ Quyết định Kiến trúc tương ứng. Chúng tôi đã tập hợp tất cả các ADR ở đây để tiện tham khảo:
“ADR: Một cụm danh từ ngắn gọn chứa quyết định kiến trúc”
"ADR: Di chuyển ứng dụng Sysops Squad sang kiến trúc phân tán"
“ADR: Di cư sử dụng phương pháp phân tích dựa trên thành phần”
“ADR: Sử dụng Cơ sở Dữ liệu Tài liệu cho Khảo sát Khách hàng”
“ADR: Dịch vụ hợp nhất cho việc phân công và định tuyến vé”
“ADR: Dịch vụ hợp nhất cho các chức năng liên quan đến khách hàng”
“ADR: Sử dụng Sidecar để Kết nối Vận hành”
“ADR: Sử dụng Thư viện Chia sẻ cho Logic Cơ sở Dữ liệu Vé Chung”
“ADR: Quyền sở hữu bảng đơn cho các bối cảnh giới hạn”
“ADR: Dịch vụ Khảo sát Sở hữu Bảng Khảo sát”
"ADR: Sử dụng bộ nhớ cache nhân bản trong bộ nhớ cho dữ liệu hồ sơ chuyên gia"
“ADR: Sử dụng Orchestration cho Quy trình Ticket Chính”
“ADR: Hợp đồng lỏng cho nhóm chuyên gia Sysops Ứng dụng di động”
Appendix C. Trade-Off References
Tính tập trung chính của cuốn sách này là phân tích sự đánh đổi; để đạt được điều đó, chúng tôi đã tạo ra một số bảng và hình ảnh phân tích sự đánh đổi trong Phần II để tóm tắt các sự đánh đổi xoay quanh một mối quan tâm về kiến trúc cụ thể. Phụ lục này tóm tắt tất cả các bảng và hình ảnh phân tích sự đánh đổi để tham khảo dễ dàng.
Hình 6-25, “Cơ sở dữ liệu quan hệ được đánh giá theo các đặc điểm áp dụng khác nhau”
Hình 6-26, “Cơ sở dữ liệu khóa-giá trị được đánh giá theo các đặc tính chấp nhận khác nhau”
Hình 6-27, "Cơ sở dữ liệu tài liệu được đánh giá theo các đặc điểm chấp nhận khác nhau"
Hình 6-28, “Cơ sở dữ liệu kiểu cột được đánh giá theo các đặc tính nhận được khác nhau”
Hình 6-30, “Cơ sở dữ liệu đồ thị được đánh giá theo các đặc điểm áp dụng khác nhau”
Hình 6-31, “Các cơ sở dữ liệu SQL mới được đánh giá theo các đặc điểm chấp nhận khác nhau”
Hình 6-32, “Cơ sở dữ liệu gốc đám mây được đánh giá cho các đặc điểm áp dụng khác nhau”
Hình 6-33, “Cơ sở dữ liệu chuỗi thời gian đánh giá theo các đặc điểm áp dụng khác nhau”
Bảng 8-1, "Những trade-off cho kỹ thuật sao chép mã"
Bảng 8-2, “Các lựa chọn thay thế cho kỹ thuật thư viện chia sẻ”
Bảng 8-3, “Các sự đánh đổi cho kỹ thuật dịch vụ chia sẻ”
Bảng 8-4, “Sự đánh đổi cho mô hình Sidecar / kỹ thuật mạng dịch vụ”
Bảng 9-1, “Kỹ thuật chia tách bảng sở hữu chung - các biện pháp thương lượng”
Bảng 9-2, “Thương lượng trade-off kỹ thuật miền dữ liệu đồng sở hữu”
Bảng 9-3, "Các thỏa hiệp kỹ thuật của kỹ thuật ủy quyền sở hữu chung"
Bảng 9-4, "Kỹ thuật hợp nhất dịch vụ sở hữu chung - các trade-off"
Bảng 9-5, “Các thỏa thuận trong mẫu đồng bộ nền”
Bảng 9-6, “Thỏa hiệp trong mẫu yêu cầu dựa trên tổ chức”
Bảng 9-7, “Thỏa hiệp về mẫu dựa trên sự kiện”
Bảng 10-1, “Các đánh đổi cho mẫu truy cập dữ liệu giao tiếp liên dịch vụ”
Bảng 10-2, “Các đánh đổi cho mô hình truy cập dữ liệu sao chép cột”
Bảng 10-3, “Các đánh đổi liên quan đến mẫu truy cập dữ liệu lưu trữ đệm được sao chép”
Bảng 10-4, “Các sự đánh đổi liên quan đến mẫu truy cập dữ liệu miền dữ liệu”
Bảng 11-1, “Sự đánh đổi cho việc phối hợp”
Bảng 11-2, “Sự đánh đổi cho mẫu Front Controller”
Bảng 11-3, “Thương thảo không trạng thái”
Bảng 11-4, "Thỏa hiệp về liên kết con dấu"
Bảng 11-5, "Sự đánh đổi cho kiểu giao tiếp phối hợp"
Bảng 11-6, "Sự đánh đổi giữa tổ chức và nhảy múa cho quy trình làm vé"
Bảng 11-7, “Các thương lượng cập nhật giữa điều phối và khiêu vũ cho quy trình làm việc với vé”
Bảng 11-8, “Những đánh đổi cuối cùng giữa điều phối và khiêu vũ cho quy trình làm việc vé”
Bảng 12-11, “Những đánh đổi liên quan đến việc quản lý trạng thái thay vì các giao dịch phân tán nguyên tử với các cập nhật bù trừ”
Bảng 12-12, “Sự đánh đổi liên quan đến giao dịch phân tán nguyên tử và cập nhật bồi thường”
"Bảng 13-1, “Trao đổi cho hợp đồng nghiêm ngặt”"
Bảng 13-2, “Thương lượng cho hợp đồng lỏng lẻo”
Bảng 13-3, “Các đánh đổi cho hợp đồng do người tiêu dùng điều khiển”
Bảng 13-4, “Sự trao đổi giữa các kiểu ghép nối dấu”
Bảng 14-1, “Các thỏa hiệp cho mô hình Kho dữ liệu”
Bảng 14-2, “Các đánh đổi cho mẫu Data Lake”
Bảng 14-3, “Cân nhắc đối với mô hình Data Mesh”
Bảng 15-2, "So sánh hợp nhất các mẫu liên kết động"
Bảng 15-3, “Các thỏa hiệp giữa giao tiếp đồng bộ và bất đồng bộ trong xử lý thẻ tín dụng”
Bảng 15-4, “Sự cân nhắc giữa nhắn tin điểm-đến-điểm và nhắn tin công bố-và-đăng ký”
Index
A
- abstractness of codebase, Abstractness and Instability
- distance from main sequence, Distance from the Main Sequence
- ACID (atomicity, consistency, isolation, durability) transactions
- about, Distributed Transactions-Distributed Transactions
- distributed transactions versus, Distributed Transactions
- example, Distributed Transactions
- BASE transactions versus, Distributed Transactions
- database types
- cloud native databases, Cloud Native Databases
- document databases, Document Databases
- graph databases, Graph Databases
- NewSQL databases, NewSQL Databases
- relational databases, Relational Databases, Relational Databases
- time series databases, Time-Series Databases
- about, Distributed Transactions-Distributed Transactions
- afferent coupling, Afferent and Efferent Coupling, Abstractness and Instability
- aggregate orientation, Relational Databases
- GraphQL read-only aggregated data, Strict Versus Loose Contracts
- key-value databases, Key-Value Databases
- NoSQL databases understanding, Column Family Databases
- agility
- modularity providing, Architectural Modularity, Modularity Drivers
- speed-to-market via, Modularity Drivers
- testability for, Testability
- versioning shared libraries, Versioning Strategies
- Amazon DynamoDB key-value database, Key-Value Databases
- Ambler, Scott, Decomposing Monolithic Data
- analytical data
- about, The Importance of Data in Architecture, Managing Analytical Data
- data meshes, The Data Mesh-When to Use Data Mesh
- analytical reporting coupled, Data Mesh, Coupling, and Architecture Quantum
- when to use, When to Use Data Mesh
- definition, The Importance of Data in Architecture
- domain over technical partitioning, The Data Lake
- previous approaches
- data lakes, The Data Lake-The Data Lake
- data warehouses, The Data Warehouse-The Data Warehouse
- Sysops Squad saga, Managing Analytical Data, The Data Warehouse, The Data Lake
- annotations
- distributed transaction management, Techniques for Managing Sagas
- metadata for, Code Replication
- Anthology Saga pattern, Anthology Saga(aec) Pattern-Anthology Saga(aec) Pattern
- Apache Cassandra column family database, Column Family Databases
- Apache Ignite replicated caching, Replicated Caching Pattern
- APIs
- endpoint versioning for shared services, Change Risk
- platforms for code reuse, Reuse via Platforms
- Architectural Decision Records (ADRs), Architectural Decision Records
- architectural decomposition
- about, Architectural Decomposition
- eating the elephant, Architectural Decomposition
- codebase analysis
- about, Is the Codebase Decomposable?
- abstractness and instability, Abstractness and Instability
- afferent and efferent coupling, Afferent and Efferent Coupling
- distance from main sequence, Distance from the Main Sequence
- component-based, Component-Based Decomposition-Component-Based Decomposition
- about, Architectural Decomposition, Component-Based Decomposition Patterns
- about patterns, Component-Based Decomposition, Component-Based Decomposition Patterns
- architecture stories, Component-Based Decomposition Patterns
- create component domains, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- create domain services, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- determine component dependencies, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- flatten components, Flatten Components Pattern-Fitness function: No source code should reside in a root namespace
- gather common domain components, Gather Common Domain Components Pattern-Fitness function: Find common code across components
- identify and size components, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- services built from components, Component-Based Decomposition
- data
- about, Pulling Apart Operational Data
- about decomposing monolithic, Decomposing Monolithic Data
- assign tables to data domains, Step 2: Assign Tables to Data Domains-Step 2: Assign Tables to Data Domains
- create data domains, Step 1: Analyze Database and Create Data Domains
- drivers of decomposition, Data Decomposition Drivers-Database transactions
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- schemas to separate servers, Step 4: Move Schemas to Separate Database Servers
- separate connections to data domains, Step 3: Separate Database Connections to Data Domains
- switch over to independent servers, Step 5: Switch Over to Independent Database Servers
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- tactical forking, Component-Based Decomposition-Trade-Offs
- about, Architectural Decomposition
- trade-offs, Trade-Offs
- volatility-based decomposition, Code Volatility
- about, Architectural Decomposition
- architectural fitness functions (see fitness functions for governance)
- architecture
- architecture governance, Architecture Fitness Functions
- Big Ball of Mud anti-pattern, Is the Codebase Decomposable?
- Equifax data breach, Using Fitness Functions
- fitness functions, Using Fitness Functions
- (see also fitness functions)
- architecture quantum, Architecture (Quantum | Quanta)
- (see also architecture quantum)
- brittleness, Code Reuse: When Does It Add Value?
- data warehouses, The Data Warehouse
- strict contracts creating, Strict Versus Loose Contracts
- composition versus inheritance, Shared Service
- data importance, The Importance of Data in Architecture
- (see also data)
- definitions of terms, Architecture Versus Design: Keeping Definitions Simple
- architecture definition, Why “The Hard Parts”?
- design versus, Architecture Versus Design: Keeping Definitions Simple-Architecture Versus Design: Keeping Definitions Simple
- security controlled through design, Sysops Squad Saga: Customer Registration Granularity
- evolution of, Giving Timeless Advice About Software Architecture, Architecture Fitness Functions, Architectural Modularity
- (see also modularity)
- iterative nature of analysis, Analyze Coupling Points
- why more important than how, Architecture Versus Design: Keeping Definitions Simple
- architecture governance, Architecture Fitness Functions
- architecture governance, Architecture Fitness Functions
- Big Ball of Mud anti-pattern, Is the Codebase Decomposable?
- Equifax data breach, Using Fitness Functions
- fitness functions, Using Fitness Functions
- (see also fitness functions)
- architecture quantum
- about, Architecture (Quantum | Quanta), Architectural quantum
- coupling, static versus dynamic, Architecture (Quantum | Quanta)
- dynamic quantum coupling, Dynamic Quantum Coupling-Coordination
- high static coupling, High Static Coupling-High Static Coupling
- user interface, High Static Coupling
- data disintegration driver, Architectural quantum
- separate databases, Step 4: Move Schemas to Separate Database Servers
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- data product quantum, Definition of Data Mesh-Data Product Quantum
- high functional cohesion, High Functional Cohesion
- database, Architectural quantum
- independently deployable, Independently Deployable
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
- architecture stories, Component-Based Decomposition Patterns
- ArchUnit tool, Fitness function: All components in <some domain service> should start with the same namespace
- Aslett, Matthew, NewSQL Databases
- asynchronous communication
- about complexity of, Fantasy Fiction Saga(aao) Pattern, Horror Story(aac) Pattern
- definition, Architecture Versus Design: Keeping Definitions Simple
- delegate technique of data ownership, Delegate Technique
- distributed data access, Column Schema Replication Pattern
- fault tolerance, Availability/Fault Tolerance
- performance issues, Performance
- messaging mitigating, Performance
- publish-and-subscribe messaging, Event-Based Pattern
- dead letter queue, Event-Based Pattern
- durable subscribers, Event-Based Pattern
- synchronous versus, Communication, Sysops Squad Saga: Understanding Quanta
- atomic fitness functions, Using Fitness Functions
- atomic workflow
- consistency, Consistency
- definition, Architecture Versus Design: Keeping Definitions Simple
- eventual consistency versus, Architecture Versus Design: Keeping Definitions Simple, Consistency
- atomicity in ACID transactions, Distributed Transactions
- distributed transactions versus, Distributed Transactions
- attributes for distributed transaction management, Techniques for Managing Sagas
- availability
- basic availability of BASE transactions, Distributed Transactions
- coupling relationship, Analyze Coupling Points
- database types
- about availability, Selecting a Database Type
- cloud native databases, Cloud Native Databases
- column family databases, Column Family Databases
- document databases, Document Databases
- graph databases, Graph Databases
- key-value databases, Key-Value Databases
- NewSQL databases, NewSQL Databases
- relational databases, Relational Databases
- time series databases, Time-Series Databases
- modularity and, Availability/Fault Tolerance
- AWS Redshift cloud native database, Cloud Native Databases
- Azure CosmosDB cloud native database, Cloud Native Databases
B
- backpressure information link, Sysops Squad Saga: Ticket Assignment Granularity
- backup and restore databases, Step 4: Move Schemas to Separate Database Servers
- bandwidth and stamp coupling, Bandwidth
- BASE (basic availability, soft state, eventual consistency) transactions, Distributed Transactions
- Beck, Kent, Architecture Fitness Functions
- Berners-Lee, Tim, The Importance of Data in Architecture
- best practices nonexistent, What Happens When There Are No “Best Practices”?
- Big Ball of Mud anti-pattern, Is the Codebase Decomposable?
- tactical forking, Component-Based Decomposition-Trade-Offs
- bounded context in microservices, The Importance of Data in Architecture, Discerning Coupling in Software Architecture, Change control
- architecture quanta, High Static Coupling
- architecture quantum versus, Sysops Squad Saga: Understanding Quanta
- breaking database changes controlled, Change control-Change control
- database abstraction, Change control-Change control
- data domains, Decomposing Monolithic Data
- combining data domains, Step 2: Assign Tables to Data Domains
- data requirement in some architectures, Pulling Apart Operational Data
- data sovereignty per service, Step 3: Separate Database Connections to Data Domains
- granularity and, Data Relationships
- high functional cohesion, High Functional Cohesion
- ownership of data (see ownership of data)
- breaking changes to data structure, Change control
- bounded context controlling, Change control-Change control
- database abstraction, Change control-Change control
- bounded context controlling, Change control-Change control
- brittleness in architecture, Code Reuse: When Does It Add Value?
- data warehouses, The Data Warehouse
- strict contracts creating, Strict Versus Loose Contracts
- broker style event-driven architecture quantum, High Static Coupling, Sysops Squad Saga: Understanding Quanta
- Brooks, Fred, What Happens When There Are No “Best Practices”?
- business case for modularity, Sysops Squad Saga: Creating a Business Case-Sysops Squad Saga: Creating a Business Case
C
- caching for distributed data access, Replicated Caching Pattern-Replicated Caching Pattern
- Chain of Responsibility design pattern, Time Travel Saga(sec) Pattern
- The Checklist Manifesto (Gawande), Using Fitness Functions
- choreographed coordination, Choreography Communication Style-Choreography Communication Style
- about coordination, Coordination, Managing Distributed Workflows
- about orchestrated versus, Managing Distributed Workflows, Phone Tag Saga(sac) Pattern
- definition, Architecture Versus Design: Keeping Definitions Simple
- service granularity and, Workflow and Choreography-Workflow and Choreography
- stamp coupling for management, Stamp Coupling for Workflow Management
- workflow state management, Workflow State Management-Workflow State Management
- Front Controller pattern, Workflow State Management
- stamp coupling, Workflow State Management
- stateless choreography, Workflow State Management
- client/server applications, The Data Warehouse
- cloud native databases, Cloud Native Databases
- Cockburn, Alistair, Sidecars and Service Mesh
- CockroachDB NewSQL database, NewSQL Databases
- code replication as reuse pattern, Code Replication-When to Use
- code reuse patterns
- about, Reuse Patterns
- code replication, Code Replication-When to Use
- granularity and shared code, Shared Code-Shared Code, Dependency Management and Change Control
- orthogonal reuse pattern, Sidecars and Service Mesh
- shared libraries
- about, Shared Library
- granularity and, Dependency Management and Change Control
- versioning strategies, Versioning Strategies-When To Use
- shared services, Shared Service-When to Use
- change risk, Change Risk
- fault tolerance, Fault Tolerance
- performance, Performance
- scalability, Scalability
- versioning via API endpoints, Change Risk
- sidecars and service mesh, Sidecars and Service Mesh-When to Use
- Sysops Squad saga, Sysops Squad Saga: Common Infrastructure Logic
- strict contracts and, Strict Versus Loose Contracts
- Sysops Squad saga, Reuse Patterns
- shared domain functionality, Sysops Squad Saga: Shared Domain Functionality
- sidecars and service mesh, Sysops Squad Saga: Common Infrastructure Logic
- value added, Code Reuse: When Does It Add Value?
- reuse via platforms, Reuse via Platforms
- code volatility as granularity driver, Code Volatility
- cohesion
- high functional cohesion, High Functional Cohesion
- database architecture quantum, Architectural quantum
- maintainability and, Maintainability
- metrics information link, Service Scope and Function
- service granularity, Service Scope and Function, Fault Tolerance
- high functional cohesion, High Functional Cohesion
- column family databases, Column Family Databases
- communication
- about synchronous versus asynchronous, Communication, Sysops Squad Saga: Understanding Quanta
- analytical data mesh, Data Mesh, Coupling, and Architecture Quantum
- coordination required, Coordination
- database connection pool, Connection management
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- distributed data access, Column Schema Replication Pattern
- dynamic coupling as, Pulling Things Apart, Architecture (Quantum | Quanta)
- communication dependencies, Architecture (Quantum | Quanta)
- saga pattern matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- east-west communication, Workflow and Choreography-Workflow and Choreography
- interservice communication, Workflow and Choreography-Workflow and Choreography
- API endpoint versioning for shared services, Change Risk
- bounded context data, Data Relationships
- data ownership, Common Ownership Scenario, Delegate Technique
- distributed data access, Interservice Communication Pattern
- performance issues, Performance
- latency with distributed data, Interservice Communication Pattern
- publish-and-subscribe messaging, Event-Based Pattern
- dead letter queue, Event-Based Pattern
- durable subscribers, Event-Based Pattern
- service scalability and elasticity, Scalability
- compensating updates in distributed transactions, Orchestrated Request-Based Pattern, Epic Saga(sao) Pattern
- state management instead, State Management and Eventual Consistency, Saga State Machines
- Sysops Squad saga, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- competitive advantage as modularity driver, Modularity Drivers
- compile-based versus runtime changes, Change Risk
- component-based decomposition, Component-Based Decomposition-Component-Based Decomposition
- about, Architectural Decomposition, Component-Based Decomposition Patterns
- about components, Component-Based Decomposition
- patterns
- about, Component-Based Decomposition, Component-Based Decomposition Patterns
- architecture stories, Component-Based Decomposition Patterns
- create component domains, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- create domain services, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- determine component dependencies, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- flatten components, Flatten Components Pattern-Fitness function: No source code should reside in a root namespace
- gather common domain components, Gather Common Domain Components Pattern-Fitness function: Find common code across components
- identify and size components, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- components
- Create Component Domains pattern, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- fitness functions, Fitness Functions for Governance
- definition, Architecture Versus Design: Keeping Definitions Simple, Maintainability, Component-Based Decomposition, Pattern Description
- dependencies determination, Pattern Description
- Identify and Size Components pattern, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- maintainability and, Maintainability
- names, Pattern Description
- namespaces, Pattern Description
- size determination, Pattern Description
- size and granularity, Service Scope and Function
- Create Component Domains pattern, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- composite architecture characteristics, Using Fitness Functions
- composition versus inheritance in design, Shared Service
- connection management
- connection quotas, Connection management
- data disintegration driver, Connection management-Connection management
- scalability includes connections, Scalability
- database per service, Scalability
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- consistency
- about, Consistency, Selecting a Database Type
- ACID transactions, Distributed Transactions
- distributed transactions versus, Distributed Transactions
- database types
- cloud native ACID, Cloud Native Databases
- column family tunable, Column Family Databases
- document ACID, Document Databases
- graph ACID, Graph Databases
- key-value tunable, Key-Value Databases
- NewSQL ACID, NewSQL Databases
- relational ACID, Relational Databases
- time series ACID or tunable, Time-Series Databases
- dynamic coupling relationship matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- eventual consistency
- about patterns, Eventual Consistency Patterns
- atomic workflow versus, Architecture Versus Design: Keeping Definitions Simple, Consistency
- background synchronization pattern, Background Synchronization Pattern-Background Synchronization Pattern
- BASE transactions, Distributed Transactions
- event-based pattern, Event-Based Pattern-Event-Based Pattern
- finite state machines for, State Management and Eventual Consistency
- orchestrated request-based pattern, Orchestrated Request-Based Pattern-Orchestrated Request-Based Pattern
- majority quorum, Key-Value Databases, Document Databases
- tunable consistency, Key-Value Databases, Column Family Databases
- Constantine, Larry, Afferent and Efferent Coupling, Putting Things Back Together
- consumer-driven contracts, Consumer-driven contracts
- context for trade-off analysis, The “Out-of-Context” Trap-The “Out-of-Context” Trap
- contracts
- about, Contracts
- bounded context data ownership, Change control-Change control
- contract fidelity and microservices, Coupling levels
- consumer-driven contracts, Consumer-driven contracts
- definition, Architecture Versus Design: Keeping Definitions Simple
- distributed data access
- Data Domain not requiring, Data Domain Pattern
- Interservice Communication requiring, Interservice Communication Pattern, Data Domain Pattern
- Replicated Cache requiring, Data Domain Pattern
- high static coupling, High Static Coupling
- loose contracts, Strict Versus Loose Contracts
- decoupling via, Strict Versus Loose Contracts, Loose contracts
- fitness functions required, Loose contracts
- trade-offs, Loose contracts
- microservice contracts, Contracts in Microservices
- stamp coupling
- about, Stamp Coupling
- bandwidth, Bandwidth
- over-coupling via, Over-Coupling via Stamp Coupling
- workflow management, Stamp Coupling for Workflow Management
- strict contracts, Strict Versus Loose Contracts
- JSON example, Strict Versus Loose Contracts
- trade-offs, Strict contracts
- Sysops Squad saga, Contracts, Sysops Squad Saga: Managing Ticketing Contracts
- cooperative quantum, Data Product Quantum
- coordination of workflow
- about, Coordination, Managing Distributed Workflows
- about trade-offs, Trade-Offs Between Orchestration and Choreography
- choreographed coordination, Choreography Communication Style-Choreography Communication Style
- about orchestration versus, Managing Distributed Workflows, Phone Tag Saga(sac) Pattern
- definition, Architecture Versus Design: Keeping Definitions Simple
- stamp coupling for management, Stamp Coupling for Workflow Management
- workflow state management, Workflow State Management
- dynamic coupling relationship matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- orchestrated coordination, Orchestration Communication Style-Orchestration Communication Style
- about choreographed versus, Managing Distributed Workflows, Phone Tag Saga(sac) Pattern
- definition, Architecture Versus Design: Keeping Definitions Simple
- workflow state management, Workflow State Management
- stamp coupling for management, Stamp Coupling for Workflow Management
- Sysops Squad saga, Managing Distributed Workflows, Sysops Squad Saga: Managing Workflows-Sysops Squad Saga: Managing Workflows
- coupling
- about static versus dynamic, Architecture (Quantum | Quanta)
- dynamic coupling, Pulling Things Apart, Architecture (Quantum | Quanta)
- static coupling, Pulling Things Apart, Architecture (Quantum | Quanta)
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
- architectural decomposition
- afferent coupling, Afferent and Efferent Coupling, Abstractness and Instability
- common domain functionality consolidated, Sysops Squad Saga: Gathering Common Components
- determining component dependencies, Pattern Description
- efferent coupling, Afferent and Efferent Coupling, Abstractness and Instability
- architecture quantum, Architecture (Quantum | Quanta), High Static Coupling
- dynamic quantum coupling, Dynamic Quantum Coupling-Coordination
- high static coupling, High Static Coupling-High Static Coupling
- independently deployable, Independently Deployable
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
- user interface, High Static Coupling
- availability relationship, Analyze Coupling Points
- data relationships, Data relationships
- definition, Architecture Versus Design: Keeping Definitions Simple, Discerning Coupling in Software Architecture
- interservice communication pattern, Interservice Communication Pattern
- loose contracts for decoupling, Strict Versus Loose Contracts, Loose contracts
- consumer-driven contracts, Consumer-driven contracts
- microservices, Coupling levels
- microservices and contract fidelity, Coupling levels
- strict contract tight coupling, Strict contracts
- maintainability and, Maintainability
- operational coupling, Sidecars and Service Mesh-When to Use
- Sysops Squad saga, Sysops Squad Saga: Common Infrastructure Logic
- orchestration, Orchestration Communication Style
- choreography versus, Phone Tag Saga(sac) Pattern
- orthogonal coupling, Sidecars and Service Mesh
- scaling relationship, Phone Tag Saga(sac) Pattern, Analyze Coupling Points
- semantic coupling, Choreography Communication Style
- implementation coupling, Choreography Communication Style
- stamp coupling, Stamp Coupling for Workflow Management
- stamp coupling
- bandwidth, Bandwidth
- choreography state management, Workflow State Management
- over-coupling via, Over-Coupling via Stamp Coupling
- workflow management, Stamp Coupling for Workflow Management
- trade-off analysis, Discerning Coupling in Software Architecture-Discerning Coupling in Software Architecture, Coupling-Analyze Coupling Points
- coupling points, Analyze Coupling Points
- static coupling diagram, Coupling
- about static versus dynamic, Architecture (Quantum | Quanta)
- Create Component Domains pattern, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- Create Domain Services pattern, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- fitness functions, Fitness Functions for Governance
- Sysops Squad saga, Sysops Squad Saga: Creating Domain Services
- credit card data (see PCI (Payment Card Industry) data)
- custom attributes for distributed transaction management, Techniques for Managing Sagas
- cyclomatic complexity and maintainability, Maintainability
D
- data
- about importance of, The Importance of Data in Architecture
- about operational versus analytical, The Importance of Data in Architecture
- analytical data
- about, The Importance of Data in Architecture, Managing Analytical Data
- data lakes, The Data Lake-The Data Lake
- data meshes, The Data Mesh-When to Use Data Mesh
- data meshes coupled to reporting, Data Mesh, Coupling, and Architecture Quantum
- data warehouses, The Data Warehouse-The Data Warehouse
- definition, The Importance of Data in Architecture
- domain over technical partitioning, The Data Lake
- Sysops Squad saga, Managing Analytical Data, The Data Warehouse, The Data Lake, Sysops Squad Saga: Data Mesh-Sysops Squad Saga: Data Mesh
- breaking changes, Change control
- bounded contexts controlling, Change control-Change control
- coupling
- microservices, High Static Coupling
- multiple quanta event-driven architecture, High Static Coupling
- relationships among data, Data relationships
- data domains (see data domains)
- database-per-service, Scalability
- breaking apart database to achieve, Data relationships
- decomposition of operational data
- about, Pulling Apart Operational Data
- about decomposing monolithic, Decomposing Monolithic Data
- assign tables to data domains, Step 2: Assign Tables to Data Domains-Step 2: Assign Tables to Data Domains
- create data domains, Step 1: Analyze Database and Create Data Domains
- data access in other domains, Step 3: Separate Database Connections to Data Domains
- database-per-service requiring, Data relationships
- dependencies, Decomposing Monolithic Data-Decomposing Monolithic Data
- drivers of, Data Decomposition Drivers-Database transactions
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- schemas to separate servers, Step 4: Move Schemas to Separate Database Servers
- separate connections to data domains, Step 3: Separate Database Connections to Data Domains
- switch over to independent servers, Step 5: Switch Over to Independent Database Servers
- Sysops Squad saga, Pulling Apart Operational Data, Sysops Squad Saga: Justifying Database Decomposition
- disintegration drivers
- about, Data Disintegrators
- architecture quantum, Architectural quantum
- connection management, Connection management-Connection management
- database change control, Change control-Change control
- database type optimization, Database type optimization
- fault tolerance, Fault tolerance
- scalability, Scalability
- distributed data access (see distributed data access)
- granularity and data relationships, Data Relationships-Data Relationships
- integration drivers
- about, Data Integrators
- database transactions, Database transactions
- relationships, Data relationships
- latency with distributed data, Interservice Communication Pattern
- ownership
- about, Data Ownership and Distributed Transactions
- assigning, Assigning Data Ownership
- common ownership, Common Ownership Scenario
- data mesh domain ownership, Definition of Data Mesh
- data sovereignty per service, Step 3: Separate Database Connections to Data Domains
- distributed data access, Column Schema Replication Pattern, Replicated Caching Pattern
- joint ownership, Joint Ownership Scenario-Delegate Technique
- service consolidation technique, Service Consolidation Technique
- single ownership, Single Ownership Scenario
- summary, Data Ownership Summary
- Sysops Squad saga, Data Ownership and Distributed Transactions, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing
- security
- services sharing, Pulling Apart Operational Data
- changes to database, Change control
- connection management, Connection management-Connection management
- single point of failure, Fault tolerance
- single point of failure vulnerability, Fault tolerance
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- Sysops Squad data model, Sysops Squad Data Model
- data domains, Decomposing Monolithic Data
- data domain technique of joint ownership, Data Domain Technique-Data Domain Technique
- data domains
- about, Decomposing Monolithic Data
- about decomposing monolithic data, Decomposing Monolithic Data
- assign tables to data domains, Step 2: Assign Tables to Data Domains-Step 2: Assign Tables to Data Domains
- bounded context rules, Decomposing Monolithic Data
- create data domains, Step 1: Analyze Database and Create Data Domains
- schemas to separate servers, Step 4: Move Schemas to Separate Database Servers
- separate connections to data domains, Step 3: Separate Database Connections to Data Domains
- switch over to independent servers, Step 5: Switch Over to Independent Database Servers
- combining
- service consolidation, Service Consolidation Technique
- tables tightly coupled, Step 2: Assign Tables to Data Domains
- data access in other domains, Step 3: Separate Database Connections to Data Domains
- data schemas versus, Step 2: Assign Tables to Data Domains
- synonyms for tables, Step 2: Assign Tables to Data Domains
- distributed data access, Data Domain Pattern-Data Domain Pattern
- joint ownership of data, Data Domain Technique-Data Domain Technique
- soccer ball visualization, Decomposing Monolithic Data
- Sysops Squad data model, Decomposing Monolithic Data
- data lakes, The Data Lake-The Data Lake
- Data Mesh (Dehghani), Definition of Data Mesh
- data meshes
- about, The Data Mesh
- Data Mesh (Dehghani), Definition of Data Mesh
- data product quantum, Definition of Data Mesh-Data Product Quantum
- Sysops Squad saga, Sysops Squad Saga: Data Mesh-Sysops Squad Saga: Data Mesh
- when to use, When to Use Data Mesh
- data product quantum (DPQ), Definition of Data Mesh-Data Product Quantum
- aggregate DPQ, Data Product Quantum
- cooperative quantum, Data Product Quantum
- fit-for-purpose DPQ, Data Product Quantum
- source-aligned (native) DPQ, Data Product Quantum
- data warehouses, The Data Warehouse-The Data Warehouse
- Star Schema, The Data Warehouse, The Data Warehouse
- technical partitioning, The Data Warehouse
- database abstraction via bounded context, Change control-Change control
- Database as a Service (DBaaS), Relational Databases
- NewSQL databases, NewSQL Databases
- database refactoring book, Decomposing Monolithic Data
- database structure Sysops Squad saga, Sysops Squad Saga: Polyglot Databases-Sysops Squad Saga: Polyglot Databases
- database transactions and granularity, Database Transactions
- database types, Time-Series Databases
- about characteristics rated, Selecting a Database Type
- aggregate orientation, Relational Databases
- cloud native databases, Cloud Native Databases
- column family databases, Column Family Databases
- database type optimization, Database type optimization
- document databases, Document Databases
- graph databases, Graph Databases-Graph Databases
- key-value databases, Key-Value Databases-Key-Value Databases
- NewSQL databases, NewSQL Databases
- NoSQL databases, Key-Value Databases
- relational databases, Relational Databases-Relational Databases
- schema-less databases, Document Databases
- Sysops Squad saga, Sysops Squad Saga: Polyglot Databases
- time series databases, Time-Series Databases-Time-Series Databases
- database-per-service, Scalability
- breaking apart database to achieve, Data relationships
- databases separated physically, Step 4: Move Schemas to Separate Database Servers
- Datomic cloud native database, Cloud Native Databases
- DDD (see Domain-Driven Design)
- De La Torre, Fausto, Tactical Forking
- dead letter queue (DLQ), Event-Based Pattern
- decision making, Discerning Coupling in Software Architecture-Discerning Coupling in Software Architecture
- (see also trade-off analysis)
- decomposition (see architectural decomposition)
- Decorator Design Pattern, When to Use
- Dehghani, Zhamak, The Data Mesh, Definition of Data Mesh
- delegate technique of joint data ownership, Delegate Technique-Delegate Technique
- dependencies
- Determine Component Dependencies pattern, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- dynamic coupling as communication dependencies, Architecture (Quantum | Quanta)
- monolithic data domains, Decomposing Monolithic Data-Decomposing Monolithic Data
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- synonyms for tables, Step 2: Assign Tables to Data Domains
- shared libraries, Dependency Management and Change Control, Versioning Strategies
- static coupling as operational dependencies, Pulling Things Apart, Architecture (Quantum | Quanta)
- tools
- JDepend, Using Fitness Functions, Afferent and Efferent Coupling
- NetArchTest, Using Fitness Functions
- visualization importance, Pattern Description
- visualization tools resource, Pattern Description
- deployment
- architectural modularity described, Testability
- deployability in modularity, Deployability
- fault tolerance, Availability/Fault Tolerance
- cloud native Production Topology, Cloud Native Databases
- independent deployability, Independently Deployable
- architectural modularity described, Testability
- deprecation strategies for shared libraries, Versioning Strategies
- design
- architecture versus, Architecture Versus Design: Keeping Definitions Simple-Architecture Versus Design: Keeping Definitions Simple
- security controlled through design, Sysops Squad Saga: Customer Registration Granularity
- Chain of Responsibility, Time Travel Saga(sec) Pattern
- composition versus inheritance, Shared Service
- Decorator Design Pattern, When to Use
- Pipes and Filters, Time Travel Saga(sec) Pattern, Anthology Saga(aec) Pattern
- architecture versus, Architecture Versus Design: Keeping Definitions Simple-Architecture Versus Design: Keeping Definitions Simple
- Determine Component Dependencies pattern, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- fitness functions, Fitness Functions for Governance
- Sysops Squad saga, Sysops Squad Saga: Identifying Component Dependencies-Sysops Squad Saga: Identifying Component Dependencies
- dimensional models of Star Schema, The Data Warehouse
- distance from main sequence, Distance from the Main Sequence
- zones of uselessness and pain, Distance from the Main Sequence
- distributed architectures
- bounded context in microservices, Discerning Coupling in Software Architecture
- (see also bounded context)
- code reuse patterns, Reuse Patterns
- (see also code reuse patterns)
- data importance, The Importance of Data in Architecture
- (see also data)
- data sovereignty per service, Step 3: Separate Database Connections to Data Domains
- database connection pool, Connection management
- connection management, Connection management
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- dynamic coupling matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- eventual consistency, Eventual Consistency Patterns
- (see also eventual consistency)
- evolution of architecture, Giving Timeless Advice About Software Architecture
- sagas as transactional behavior, Introducing the Sysops Squad Saga
- (see also sagas)
- sharing data, Data Domain Technique
- side effects, Sysops Squad Saga: Atomic Transactions and Compensating Updates
- state machines, Saga State Machines-Saga State Machines
- static coupling, High Static Coupling
- multiple quanta, High Static Coupling
- single quantum, High Static Coupling
- transactionality challenges, Consistency
- bounded context in microservices, Discerning Coupling in Software Architecture
- distributed data access
- Column Schema Replication pattern, Column Schema Replication Pattern
- Data Domain pattern, Data Domain Pattern-Data Domain Pattern
- Interservice Communication pattern, Interservice Communication Pattern
- Replicated Caching pattern, Replicated Caching Pattern-Replicated Caching Pattern
- Sysops Squad saga, Distributed Data Access, Sysops Squad Saga: Data Access for Ticket Assignment-Sysops Squad Saga: Data Access for Ticket Assignment
- distributed transactions
- about, Distributed Transactions, Epic Saga(sao) Pattern
- ACID transactions, Distributed Transactions-Distributed Transactions
- example, Distributed Transactions
- BASE transactions, Distributed Transactions
- compensating updates, Orchestrated Request-Based Pattern, Epic Saga(sao) Pattern
- eventual consistency, Eventual Consistency Patterns
- (see also eventual consistency)
- managing sagas, Techniques for Managing Sagas
- (see also transactional saga patterns)
- Sysops Squad sagas, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- distributed workflows
- about, Managing Distributed Workflows
- about coordination, Coordination, Managing Distributed Workflows
- about trade-offs, Trade-Offs Between Orchestration and Choreography
- choreography, Choreography Communication Style-Choreography Communication Style
- about orchestration versus, Managing Distributed Workflows
- definition, Architecture Versus Design: Keeping Definitions Simple
- workflow state management, Workflow State Management-Workflow State Management
- orchestration, Orchestration Communication Style-Orchestration Communication Style
- about choreographed versus, Managing Distributed Workflows
- definition, Architecture Versus Design: Keeping Definitions Simple
- workflow state management, Workflow State Management
- semantic coupling, Choreography Communication Style
- implementation coupling, Choreography Communication Style
- service granularity and workflow, Workflow and Choreography-Workflow and Choreography
- stamp coupling for management, Stamp Coupling for Workflow Management
- Sysops Squad saga, Managing Distributed Workflows, Sysops Squad Saga: Managing Workflows-Sysops Squad Saga: Managing Workflows
- transactional saga patterns, Transactional Sagas
- (see also transactional saga patterns)
- document databases, Document Databases
- documentation for managing distributed transactions, Code Replication, Techniques for Managing Sagas
- domain partitioned architecture, Modularity Drivers
- data domains, Decomposing Monolithic Data
- data lakes losing relationships, The Data Lake
- data mesh domain ownership, Definition of Data Mesh
- granularity and shared domain functionality, Shared Code
- maintainability and, Maintainability
- technical partitioning
- data warehouses as, The Data Warehouse
- domain preferred, The Data Lake
- domain workflows, Choreography Communication Style
- domain services
- about, Create Domain Services Pattern
- component domains into, Pattern Description
- Create Domain Services pattern, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- fitness function for namespace, Fitness function: All components in <some domain service> should start with the same namespace
- domain cohesion and granularity, Fault Tolerance
- Front Controller in choreography, Workflow State Management
- service-based architecture definition, Component-Based Decomposition, Create Domain Services Pattern
- domain versus infrastructure shared functionality, Pattern Description
- Domain-Driven Design (DDD)
- bounded context, The Importance of Data in Architecture
- architecture quantum, Sysops Squad Saga: Understanding Quanta
- high functional cohesion and, High Functional Cohesion
- information link, Pattern Description
- namespaces from applications prior to, Pattern Description
- bounded context, The Importance of Data in Architecture
- durability in ACID transactions, Distributed Transactions
- distributed transactions versus, Distributed Transactions
- durable subscribers in pub/sub messaging, Event-Based Pattern
- dynamic coupling, Pulling Things Apart, Architecture (Quantum | Quanta)
- about dimensions of, Managing Distributed Workflows, Coupling
- analytical data communication pattern, Data Mesh, Coupling, and Architecture Quantum
- communication, Communication, Sysops Squad Saga: Understanding Quanta
- consistency, Consistency
- coordination, Coordination
- relationships among factors, Coordination, Transactional Saga Patterns
- (see also sagas)
- static versus, Architecture (Quantum | Quanta)
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
E
- east-west communication, Workflow and Choreography-Workflow and Choreography
- efferent coupling, Afferent and Efferent Coupling, Abstractness and Instability
- elasticity
- coupling, Sysops Squad Saga: Understanding Quanta
- definition, Scalability
- mean time to startup and, Scalability
- scalability versus, Sysops Squad Saga: Understanding Quanta, Scalability
- Enterprise Integration Patterns (Hohpe and Woolf), Step 1: Analyze Database and Create Data Domains
- enterprise service bus (ESB) global orchestrator, Orchestration Communication Style
- Epic Saga pattern, Epic Saga(sao) Pattern-Epic Saga(sao) Pattern
- Equifax data breach, Using Fitness Functions
- Evans, Erik, Relational Databases
- event-based eventual consistency, Event-Based Pattern-Event-Based Pattern
- publish-and-subscribe messaging, Event-Based Pattern
- dead letter queue, Event-Based Pattern
- durable subscribers, Event-Based Pattern
- publish-and-subscribe messaging, Event-Based Pattern
- event-driven architecture (EDA)
- multiple architecture quanta, High Static Coupling
- single architecture quantum
- broker style as, High Static Coupling, Sysops Squad Saga: Understanding Quanta
- mediator style as, High Static Coupling
- eventual consistency
- about consistency, Consistency
- about patterns, Eventual Consistency Patterns
- atomic workflow versus, Architecture Versus Design: Keeping Definitions Simple, Consistency
- background synchronization pattern, Background Synchronization Pattern-Background Synchronization Pattern
- BASE transactions, Distributed Transactions
- event-based pattern, Event-Based Pattern-Event-Based Pattern
- publish-and-subscribe messaging, Event-Based Pattern
- finite state machines for, State Management and Eventual Consistency
- orchestrated request-based pattern, Orchestrated Request-Based Pattern-Orchestrated Request-Based Pattern
- extensibility as granularity driver, Extensibility
- eXtreme Programming (XP), Architecture Fitness Functions
F
- Fairy Tale Saga pattern, Fairy Tale Saga(seo) Pattern-Fairy Tale Saga(seo) Pattern
- Fantasy Fiction Saga pattern, Fantasy Fiction Saga(aao) Pattern-Fantasy Fiction Saga(aao) Pattern
- fault tolerance
- choreography, Workflow State Management
- data disintegration driver, Fault tolerance
- definition, Availability/Fault Tolerance, Fault tolerance, Fault Tolerance
- granularity disintegration driver, Fault Tolerance
- granularity integration driver, Workflow and Choreography-Workflow and Choreography
- modularity driver, Modularity Drivers, Availability/Fault Tolerance
- orchestration, Orchestration Communication Style
- shared libraries, Fault Tolerance
- shared services, Fault Tolerance
- single point of failure, Fault tolerance
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- fitness functions for governance
- about, Using Fitness Functions-Using Fitness Functions
- atomic, Using Fitness Functions
- composite architecture characteristics, Using Fitness Functions
- holistic, Using Fitness Functions
- manual versus automated, Using Fitness Functions
- outcomes, Using Fitness Functions
- overuse avoided, Using Fitness Functions
- dynamic coupling monitored, Architecture (Quantum | Quanta)
- examples
- component cycles avoided, Using Fitness Functions
- layer relationship verification, Using Fitness Functions
- loose coupling requiring, Loose contracts
- patterns for component-based decomposition
- create component domains, Fitness Functions for Governance
- create domain services, Fitness Functions for Governance
- determine component dependencies, Fitness Functions for Governance
- flatten components, Fitness Functions for Governance
- gather common domain components, Fitness Functions for Governance
- identify and size components, Fitness Functions for Governance-Fitness function: No component shall exceed <some number of standard deviations> from the mean component size
- zero-day exploits, Using Fitness Functions
- about, Using Fitness Functions-Using Fitness Functions
- Flatten Components pattern, Flatten Components Pattern-Fitness function: No source code should reside in a root namespace
- fitness functions, Fitness Functions for Governance
- metrics for shared components, Pattern Description
- Sysops Squad saga, Sysops Squad Saga: Flattening Components-Sysops Squad Saga: Flattening Components
- Foote, Brian, Is the Codebase Decomposable?
- Ford, Neal, Preface, Concept and Term References
- Fowler, Martin, Key-Value Databases, Shared Service
- Front Controller in choreography, Workflow State Management
- Fundamentals of Software Architecture (Richards and Ford), Preface, Concept and Term References-Trade-Off References
G
- Gather Common Domain Components pattern, Gather Common Domain Components Pattern-Fitness function: Find common code across components
- fitness functions, Fitness Functions for Governance
- Sysops Squad saga, Sysops Squad Saga: Gathering Common Components-Sysops Squad Saga: Gathering Common Components
- Gawande, Atul, Using Fitness Functions
- Gee, Trisha, Code Replication
- granularity
- balancing trade-offs, Finding the Right Balance
- definition, Scalability
- disintegrators of granularity
- about, Service Granularity, Granularity Disintegrators
- code volatility, Code Volatility
- extensibility, Extensibility
- fault tolerance, Fault Tolerance
- scalability and throughput, Scalability and Throughput
- security, Security
- service scope and function, Service Scope and Function
- elasticity as function of, Scalability
- integrators of granularity
- about, Service Granularity, Granularity Integrators
- data relationships, Data Relationships-Data Relationships
- database transactions, Database Transactions
- shared code, Shared Code-Shared Code
- workflow and choreography, Workflow and Choreography-Workflow and Choreography
- metrics, Service Granularity
- microservice single responsibility, Service Granularity, Service Scope and Function
- modularity versus, Service Granularity
- shared data and, Data Domain Technique
- shared libraries, Dependency Management and Change Control
- Sysops Squad saga, Service Granularity, Sysops Squad Saga: Ticket Assignment Granularity-Sysops Squad Saga: Customer Registration Granularity
- graph databases, Graph Databases-Graph Databases
- GraphQL loose contracts, Strict Versus Loose Contracts
- Gremlin database language, Graph Databases
- gRPC protocol
- information link, Change Risk
- performance mitigation by, Performance
- strict contracts by default, Strict Versus Loose Contracts
H
- hard parts of architecture, Why “The Hard Parts”?
- hash table data structure, Key-Value Databases
- Hello2morrow, Maintainability
- Henney, Kevlin, Code Replication
- Hexagonal Architecture, Sidecars and Service Mesh
- high functional cohesion, High Functional Cohesion
- database architecture quantum, Architectural quantum
- Hohpe, Gregor, Step 1: Analyze Database and Create Data Domains, Sysops Squad Saga: Atomic Transactions and Compensating Updates
- Horror Story pattern, Horror Story(aac) Pattern-Horror Story(aac) Pattern
I
- Identify and Size Components pattern, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- implementation coupling, Choreography Communication Style
- independent deployability, Independently Deployable
- InfluxDB time series database, Time-Series Databases
- infrastructure versus domain shared functionality, Pattern Description
- inheritance versus composition in design, Shared Service
- instability of codebase, Abstractness and Instability
- distance from main sequence, Distance from the Main Sequence
- interservice communication, Workflow and Choreography-Workflow and Choreography
- API endpoint versioning for shared services, Change Risk
- bounded context data, Data Relationships
- data ownership
- common ownership, Common Ownership Scenario
- delegate technique of joint ownership, Delegate Technique
- distributed data access, Interservice Communication Pattern
- isolation in ACID transactions, Distributed Transactions
- distributed transactions versus, Distributed Transactions
- importance of, Sysops Squad Saga: Atomic Transactions and Compensating Updates
- isomorphic diagrams, Transactional Saga Patterns
J
- Java Message Service (Richards), Performance
- JDepend tool, Using Fitness Functions
- Eclipse plug-in, Afferent and Efferent Coupling
- joint ownership of data
- about, Joint Ownership Scenario
- data domain technique, Data Domain Technique-Data Domain Technique
- delegate technique, Delegate Technique-Delegate Technique
- service consolidation technique, Service Consolidation Technique
- table split technique, Table Split Technique-Table Split Technique
K
- key-value databases, Key-Value Databases-Key-Value Databases
- Kx time series database, Time-Series Databases
L
- latency in communication, Interservice Communication Pattern
- LATEST caution for versioning, Versioning Strategies
- layered architecture
- architecture governance, Using Fitness Functions
- modular architecture
- maintainability, Maintainability
- scalability and elasticity, Scalability
- testability, Testability
- loose contracts
- decoupling via, Strict Versus Loose Contracts
- fitness functions required, Loose contracts
- REST and GraphQL, Strict Versus Loose Contracts
- trade-offs, Loose contracts
M
- maintainability of modular architecture, Maintainability-Maintainability
- metric for tracking, Maintainability
- majority quorum, Key-Value Databases, Document Databases
- Martin, Robert C., Abstractness and Instability, Service Scope and Function
- mean time to startup and elasticity, Scalability
- MECE (Mutually Exclusive, Collectively Exhaustive) lists, MECE Lists
- mediator in orchestration, Orchestration Communication Style
- mediator style event-driven architecture quantum, High Static Coupling
- MemcacheDB key-value database, Key-Value Databases
- messaging asynchronicity, Performance
- Java Message Service (Richards), Performance
- metadata annotations, Code Replication
- microkernel architecture, Modularity Drivers
- microservices
- architecture quantum, Architecture (Quantum | Quanta), Independently Deployable
- decoupled services, High Static Coupling
- high functional cohesion, High Functional Cohesion
- user interface coupling, High Static Coupling
- bounded context, The Importance of Data in Architecture, Discerning Coupling in Software Architecture
- architecture quanta, High Static Coupling
- architecture quantum versus, Sysops Squad Saga: Understanding Quanta
- breaking database changes controlled, Change control-Change control
- data domains, Decomposing Monolithic Data
- data domains combined, Step 2: Assign Tables to Data Domains
- data requirement, Pulling Apart Operational Data
- database abstraction, Change control-Change control
- granularity and, Data Relationships
- high functional cohesion, High Functional Cohesion
- ownership of data (see ownership of data)
- contracts
- about, Contracts in Microservices
- consumer-driven contracts, Consumer-driven contracts
- contract fidelity, Coupling levels
- coupling levels, Coupling levels
- coordination, Coordination
- (see also coordination)
- definition, Service Scope and Function
- domain partitioning of, The Data Lake
- modularity, Maintainability
- deployability, Deployability
- scalability and elasticity, Scalability
- operational coupling, Sidecars and Service Mesh-When to Use
- orchestrator per workflow, Orchestration Communication Style
- saga pattern, Transactional Sagas
- service-based architecture as stepping-stone, Component-Based Decomposition, Pattern Description, Pattern Description
- shared database changed, Change control
- single responsibility principle and granularity, Service Granularity, Service Scope and Function
- architecture quantum, Architecture (Quantum | Quanta), Independently Deployable
- Microservices Patterns (Richardson), Transactional Sagas
- Microsoft SQL Server relational database, Relational Databases
- modularity
- about, Architectural Modularity, Modularity Drivers
- about change, Architectural Modularity
- architectural governance, Using Fitness Functions
- drivers of
- about, Modularity Drivers
- agility, Architectural Modularity, Modularity Drivers
- deployability, Deployability
- fault tolerance, Availability/Fault Tolerance
- maintainability, Maintainability-Maintainability
- scalability, Architectural Modularity, Scalability-Scalability
- testability, Testability
- granularity versus, Service Granularity
- monolithic architectures
- about modularity, Modularity Drivers
- about need for modularity, Architectural Modularity
- deployability, Deployability
- fault tolerance, Availability/Fault Tolerance
- maintainability, Maintainability
- modular monoliths, Modularity Drivers
- scalability and elasticity, Scalability
- Sysops Squad saga, Architectural Modularity, Sysops Squad Saga: Creating a Business Case-Sysops Squad Saga: Creating a Business Case
- testability, Testability
- water glass analogy, Architectural Modularity
- about, Architectural Modularity, Modularity Drivers
- monolithic architectures
- architectural decomposition (see architectural decomposition)
- Big Ball of Mud anti-pattern, Is the Codebase Decomposable?
- tactical forking, Component-Based Decomposition-Trade-Offs
- data decomposition
- about, Decomposing Monolithic Data
- assign tables to data domains, Step 2: Assign Tables to Data Domains-Step 2: Assign Tables to Data Domains
- create data domains, Step 1: Analyze Database and Create Data Domains
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- schemas to separate servers, Step 4: Move Schemas to Separate Database Servers
- separate connections to data domains, Step 3: Separate Database Connections to Data Domains
- switch over to independent servers, Step 5: Switch Over to Independent Database Servers
- data importance, The Importance of Data in Architecture
- database connection pool, Connection management
- database type optimization, Database type optimization
- Epic Saga mimicking, Epic Saga(sao) Pattern-Epic Saga(sao) Pattern
- modular architecture
- about need for, Architectural Modularity
- deployability, Deployability
- fault tolerance, Availability/Fault Tolerance
- maintainability, Maintainability
- modular monoliths, Modularity Drivers
- scalability and elasticity, Scalability
- Sysops Squad saga, Architectural Modularity, Sysops Squad Saga: Creating a Business Case-Sysops Squad Saga: Creating a Business Case
- testability, Testability
- water glass analogy, Architectural Modularity
- namespaces prior to Domain-Driven Design, Pattern Description
- patterns for migration to service-based
- about, Component-Based Decomposition, Component-Based Decomposition Patterns
- architecture stories, Component-Based Decomposition Patterns
- create component domains, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- create domain services, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- determine component dependencies, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- flatten components, Flatten Components Pattern-Fitness function: No source code should reside in a root namespace
- gather common domain components, Gather Common Domain Components Pattern-Fitness function: Find common code across components
- identify and size components, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- single architecture quantum, Independently Deployable
- functional cohesion, High Functional Cohesion
- static coupling, High Static Coupling
- Monorepo, Avoiding Snake Oil and Evangelism
- MySQL relational database, Relational Databases
N
- namespaces
- component domains, Pattern Description
- applications prior to Domain-Driven Design, Pattern Description
- fitness functions for governance, Fitness Functions for Governance
- components, Pattern Description
- extend then prior a subdomain, Pattern Description
- fitness function, Fitness function: All components in <some domain service> should start with the same namespace
- root namespace definition, Pattern Description
- component domains, Pattern Description
- Neo4j graph database, Graph Databases
- NetArchTest tool, Using Fitness Functions
- network latency, Interservice Communication Pattern
- NewSQL databases, NewSQL Databases
- 97 Things Every Java Programmer Should Know (Henney and Gee), Code Replication
- NoSQL databases
- aggregate orientation understood, Column Family Databases
- column family databases, Column Family Databases
- document databases, Document Databases
- key-value databases, Key-Value Databases
- NoSQL Distilled (Sadalage and Fowler), Key-Value Databases
- schema-less databases, Document Databases
- Nygard, Michael, Architectural Decision Records
O
- online resources (see resources online)
- Online Transactional Processing (OLTP), The Importance of Data in Architecture
- operational coupling, Sidecars and Service Mesh-When to Use
- Sysops Squad saga, Sysops Squad Saga: Common Infrastructure Logic
- operational data definition, The Importance of Data in Architecture
- Oracle Coherence replicated caching, Replicated Caching Pattern
- Oracle relational database, Relational Databases
- orchestrated coordination, Orchestration Communication Style-Orchestration Communication Style
- about choreographed versus, Managing Distributed Workflows, Phone Tag Saga(sac) Pattern
- about coordination, Coordination, Managing Distributed Workflows
- definition, Architecture Versus Design: Keeping Definitions Simple
- orchestrator, Orchestration Communication Style
- workflow state management, Workflow State Management
- orchestrated request-based eventual consistency, Orchestrated Request-Based Pattern-Orchestrated Request-Based Pattern
- Orchestrated Saga pattern, Epic Saga(sao) Pattern-Epic Saga(sao) Pattern
- orphaned classes definition, Pattern Description
- orthogonal code reuse pattern, Sidecars and Service Mesh
- orthogonal coupling, Sidecars and Service Mesh
- out-of-context trap, The “Out-of-Context” Trap-The “Out-of-Context” Trap
- ownership of data
- about, Data Ownership and Distributed Transactions
- assigning, Assigning Data Ownership
- common ownership, Common Ownership Scenario
- data mesh domain ownership, Definition of Data Mesh
- data sovereignty per service, Step 3: Separate Database Connections to Data Domains
- distributed data access, Column Schema Replication Pattern, Replicated Caching Pattern
- joint ownership
- about, Joint Ownership Scenario
- data domain technique, Data Domain Technique-Data Domain Technique
- delegate technique, Delegate Technique-Delegate Technique
- table split technique, Table Split Technique-Table Split Technique
- service consolidation technique, Service Consolidation Technique
- single ownership, Single Ownership Scenario
- summary, Data Ownership Summary
- Sysops Squad saga, Data Ownership and Distributed Transactions, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing
P
- Page-Jones, Meilir, Pulling Things Apart
- Parallel Saga pattern, Parallel Saga(aeo) Pattern-Parallel Saga(aeo) Pattern
- PCI (Payment Card Industry) data
- security and granularity, Security
- Personally Identifiable Information (PII), The Data Lake
- Phone Tag Saga pattern, Phone Tag Saga(sac) Pattern-Phone Tag Saga(sac) Pattern
- PII (Personally Identifiable Information), The Data Lake
- Pipes and Filters design pattern, Time Travel Saga(sec) Pattern, Anthology Saga(aec) Pattern
- platforms for code reuse, Reuse via Platforms
- Ports and Adaptors Pattern, Sidecars and Service Mesh
- PostgreSQL relational database, Relational Databases
- publish-and-subscribe messaging, Event-Based Pattern
- dead letter queue, Event-Based Pattern
- durable subscribers, Event-Based Pattern
- pull model consumer-driven contracts, Consumer-driven contracts
- push model definition, Consumer-driven contracts
Q
- quanta, Architecture (Quantum | Quanta)
- (see also architecture quantum)
- quorum mechanism, Key-Value Databases, Document Databases
R
- Redis key-value database, Key-Value Databases
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- relational databases (RDBMS), Relational Databases-Relational Databases
- links to most popular, Relational Databases
- transactions and service granularity, Database Transactions
- replicate databases, Step 4: Move Schemas to Separate Database Servers
- replicated in-memory caching, Replicated Caching Pattern-Replicated Caching Pattern
- resources online
- ArchUnit tool, Fitness function: All components in <some domain service> should start with the same namespace
- book website, Using Code Examples
- cohesion metrics information, Service Scope and Function
- database links
- cloud native databases, Cloud Native Databases
- NoSQL databases, Key-Value Databases
- relational databases, Relational Databases
- dependency tools
- JDepend, Using Fitness Functions, Afferent and Efferent Coupling
- NetArchTest, Using Fitness Functions
- visualization, Pattern Description
- Refactoring Databases (Ambler and Sadalage), Decomposing Monolithic Data
- Saga Pattern (Richardson), Transactional Sagas
- stamp coupling information, Stamp Coupling
- static code analysis tools, Pattern Description
- REST (representational state transfer) loose contracts, Strict Versus Loose Contracts
- reuse patterns (see code reuse patterns)
- Riak KV key-value database, Key-Value Databases
- Richards, Mark, Preface, Performance, Concept and Term References
- Richardson, Chris, Transactional Sagas
- root namespace definition, Pattern Description
- runtime versus compile-based changes, Change Risk
S
- Sadalage, Pramod, Decomposing Monolithic Data, Key-Value Databases
- sagas
- about, Transactional Sagas
- definition, Introducing the Sysops Squad Saga
- dynamic coupling matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- microservice saga pattern, Transactional Sagas
- state machines, Saga State Machines-Saga State Machines
- Sysops Squad saga background, Introducing the Sysops Squad Saga
- (see also Sysops Squad sagas)
- techniques for managing, Techniques for Managing Sagas
- transactional saga patterns
- about, Coordination, Transactional Saga Patterns
- about state management, State Management and Eventual Consistency
- Anthology Saga, Anthology Saga(aec) Pattern-Anthology Saga(aec) Pattern
- Epic Saga, Epic Saga(sao) Pattern-Epic Saga(sao) Pattern
- Fairy Tale Saga, Fairy Tale Saga(seo) Pattern-Fairy Tale Saga(seo) Pattern
- Fantasy Fiction Saga, Fantasy Fiction Saga(aao) Pattern-Fantasy Fiction Saga(aao) Pattern
- Horror Story, Horror Story(aac) Pattern-Horror Story(aac) Pattern
- Parallel Saga, Parallel Saga(aeo) Pattern-Parallel Saga(aeo) Pattern
- Phone Tag Saga, Phone Tag Saga(sac) Pattern-Phone Tag Saga(sac) Pattern
- Sysops Squad saga, Transactional Sagas, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- Time Travel Saga, Time Travel Saga(sec) Pattern-Time Travel Saga(sec) Pattern
- scalability
- choreography, Workflow State Management, Phone Tag Saga(sac) Pattern
- connection management, Scalability
- database-per-service, Scalability
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- coupling relationship, Phone Tag Saga(sac) Pattern, Analyze Coupling Points
- data disintegration driver, Scalability
- database types
- cloud native scalable, Cloud Native Databases
- column family scalable, Column Family Databases
- document scalable, Document Databases
- graph read versus write, Graph Databases
- key-value scalable, Key-Value Databases
- NewSQL scalable, NewSQL Databases
- relational complexity, Relational Databases
- time series scalable, Time-Series Databases
- definition, Scalability
- elasticity versus, Sysops Squad Saga: Understanding Quanta, Scalability
- granularity disintegration driver, Scalability and Throughput
- modularity providing, Architectural Modularity, Scalability
- modularity driver, Modularity Drivers, Scalability-Scalability
- orchestration, Orchestration Communication Style
- choreography versus, Phone Tag Saga(sac) Pattern
- service consolidation for data ownership, Service Consolidation Technique
- shared services, Scalability
- schemas for database tables, Step 2: Assign Tables to Data Domains
- cross-schema access resolved, Step 3: Separate Database Connections to Data Domains
- data domain versus data schema, Step 2: Assign Tables to Data Domains
- databases separated physically, Step 4: Move Schemas to Separate Database Servers
- schema-less databases, Document Databases
- synonyms for tables, Step 2: Assign Tables to Data Domains
- Scylla column family database, Column Family Databases
- security
- granularity disintegration driver, Security
- PCI data Sysops Squad saga, Sysops Squad Saga: Customer Registration Granularity-Sysops Squad Saga: Customer Registration Granularity
- security latency, Interservice Communication Pattern
- semantic coupling, Choreography Communication Style
- implementation coupling, Choreography Communication Style
- stamp coupling to manage workflow, Stamp Coupling for Workflow Management
- service consolidation technique of joint ownership, Service Consolidation Technique
- service granularity (see granularity)
- service mesh, Sidecars and Service Mesh-When to Use
- Sysops Squad saga, Sysops Squad Saga: Common Infrastructure Logic
- service-based architecture
- about, High Static Coupling, Component-Based Decomposition, Pattern Description
- data access in other domains, Step 3: Separate Database Connections to Data Domains
- data shared by services, Pulling Apart Operational Data
- changes to database, Change control
- connection management, Connection management-Connection management
- single point of failure, Fault tolerance
- domain services from component domains, Pattern Description
- Create Domain Services pattern, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- evolution of architecture, Giving Timeless Advice About Software Architecture
- modular architecture scalability and elasticity, Scalability
- monolithic migration to
- about, Component-Based Decomposition, Component-Based Decomposition Patterns
- architecture stories, Component-Based Decomposition Patterns
- create component domains, Create Component Domains Pattern-Fitness function: All namespaces under <root namespace node> should be restricted to <list of domains>
- create domain services, Create Domain Services Pattern-Fitness function: All components in <some domain service> should start with the same namespace
- determine component dependencies, Determine Component Dependencies Pattern-Fitness function: <some component> should not have a dependency on <another component>
- flatten components pattern, Flatten Components Pattern-Fitness function: No source code should reside in a root namespace
- gather common domain components, Gather Common Domain Components Pattern-Fitness function: Find common code across components
- identify and size components, Identify and Size Components Pattern-Sysops Squad Saga: Sizing Components
- static coupling, High Static Coupling
- stepping-stone to microservices, Component-Based Decomposition, Pattern Description, Pattern Description
- services
- bounded contexts (see bounded context)
- choreographed coordination definition, Architecture Versus Design: Keeping Definitions Simple
- component-based decomposition, Component-Based Decomposition
- Create Component Domains pattern, Create Component Domains Pattern
- coupling definition, Architecture Versus Design: Keeping Definitions Simple
- (see also coupling)
- data access in other domains, Step 3: Separate Database Connections to Data Domains
- data shared by services, Pulling Apart Operational Data
- changes to database, Change control
- connection management, Connection management-Connection management
- single point of failure, Fault tolerance
- database connection pool, Connection management
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- database-per-service, Scalability
- definition, Architecture Versus Design: Keeping Definitions Simple
- distributed data access
- Column Schema Replication pattern, Column Schema Replication Pattern
- Data Domain pattern, Data Domain Pattern-Data Domain Pattern
- Interservice Communication Pattern, Interservice Communication Pattern
- Replicated Caching pattern, Replicated Caching Pattern-Replicated Caching Pattern
- Sysops Squad saga, Distributed Data Access, Sysops Squad Saga: Data Access for Ticket Assignment-Sysops Squad Saga: Data Access for Ticket Assignment
- extensibility, Extensibility
- granularity (see granularity)
- identifying in sagas, Techniques for Managing Sagas
- modularity
- deployability, Deployability
- scalability and elasticity, Scalability
- testability, Testability
- orchestrated coordination definition, Architecture Versus Design: Keeping Definitions Simple
- ownership of data
- assigning, Assigning Data Ownership
- common ownership, Common Ownership Scenario
- data sovereignty per service, Step 3: Separate Database Connections to Data Domains
- distributed data access, Column Schema Replication Pattern, Replicated Caching Pattern
- joint ownership, Joint Ownership Scenario-Delegate Technique
- service consolidation technique, Service Consolidation Technique
- single ownership, Single Ownership Scenario
- summary, Data Ownership Summary
- Sysops Squad saga, Data Ownership and Distributed Transactions, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing
- service mesh, Sidecars and Service Mesh-When to Use
- shared services for code reuse, Shared Service-When to Use
- Sidecar pattern, Sidecars and Service Mesh-When to Use
- sharding in databases, Key-Value Databases
- document databases, Document Databases
- NewSQL databases, NewSQL Databases
- shared code and granularity, Shared Code-Shared Code
- (see also code reuse patterns)
- shared libraries, Dependency Management and Change Control
- shared domain functionality
- granularity and, Shared Code
- shared infrastructure functionality versus, Pattern Description
- Sysops Squad saga, Sysops Squad Saga: Shared Domain Functionality
- shared libraries
- about, Shared Library
- fault tolerance, Fault Tolerance
- granularity and, Dependency Management and Change Control
- versioning strategies, Versioning Strategies-When To Use
- shared services for code reuse, Shared Service-When to Use
- change risk, Change Risk
- fault tolerance, Fault Tolerance
- performance, Performance
- scalability, Scalability
- Sysops Squad saga, Sysops Squad Saga: Shared Domain Functionality
- versioning via API endpoints, Change Risk
- side effects in distributed architectures, Sysops Squad Saga: Atomic Transactions and Compensating Updates
- Sidecar pattern, Sidecars and Service Mesh-When to Use
- Sysops Squad saga, Sysops Squad Saga: Common Infrastructure Logic
- silver-bullet solutions, What Happens When There Are No “Best Practices”?
- single point of failure (SPOF), Fault tolerance
- Sysops Squad saga, Sysops Squad Saga: Justifying Database Decomposition
- single responsibility principle, Service Scope and Function
- granularity and, Service Granularity, Service Scope and Function
- SMS information link, Service Scope and Function
- Snowflake cloud native database, Cloud Native Databases
- soft state of BASE transactions, Distributed Transactions
- software architecture (see architecture)
- SOLID principles (Martin), Service Scope and Function
- SonarQube code hygiene tool, Using Fitness Functions
- speed-to-market as modularity driver, Modularity Drivers
- stamp coupling
- about, Stamp Coupling
- bandwidth, Bandwidth
- choreography state management, Workflow State Management, Phone Tag Saga(sac) Pattern
- over-coupling via, Over-Coupling via Stamp Coupling
- workflow management, Stamp Coupling for Workflow Management
- standard deviation calculation, Fitness function: No component shall exceed <some number of standard deviations> from the mean component size
- Star Schema of data warehouses, The Data Warehouse, The Data Warehouse
- Starbucks Does Not Use Two-Phase Commit (Hohpe), Sysops Squad Saga: Atomic Transactions and Compensating Updates
- state machines, Saga State Machines-Saga State Machines
- state management
- compensating updates versus, Saga State Machines
- finite state machines for, State Management and Eventual Consistency
- about state machines, Saga State Machines-Saga State Machines
- orchestration, Orchestration Communication Style
- stamp coupling for workflow management, Stamp Coupling for Workflow Management
- workflow state management, Workflow State Management-Workflow State Management
- stateless choreography, Workflow State Management
- statements counted, Pattern Description, Service Granularity
- static code analysis tools resource, Pattern Description
- static coupling, Pulling Things Apart, Architecture (Quantum | Quanta)
- architecture quantum, High Static Coupling
- high static coupling, High Static Coupling-High Static Coupling
- independently deployable, Independently Deployable
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
- dynamic versus, Architecture (Quantum | Quanta)
- Sysops Squad saga, Sysops Squad Saga: Understanding Quanta
- operational dependencies as, Pulling Things Apart, Architecture (Quantum | Quanta)
- trade-off analysis, Coupling
- coupling points, Analyze Coupling Points
- static coupling diagram, Coupling
- architecture quantum, High Static Coupling
- Stine, Matt, Deployability
- strict contracts, Strict Versus Loose Contracts
- JSON example, Strict Versus Loose Contracts
- trade-offs, Strict contracts
- Structured Design (Yourdon and Constantine), Afferent and Efferent Coupling
- survey database structure, Sysops Squad Saga: Polyglot Databases-Sysops Squad Saga: Polyglot Databases
- synchronous communication
- asynchronous versus, Communication, Sysops Squad Saga: Understanding Quanta
- definition, Architecture Versus Design: Keeping Definitions Simple
- delegate technique of data ownership, Delegate Technique
- fault tolerance, Availability/Fault Tolerance
- granularity and, Workflow and Choreography-Workflow and Choreography
- scalability and elasticity versus, Scalability
- synonyms for tables, Step 2: Assign Tables to Data Domains
- Sysops Squad sagas
- about, Introducing the Sysops Squad Saga
- nonticketing workflow, Nonticketing Workflow
- problem, A Bad Scenario
- ticketing workflow, Ticketing Workflow
- analytical data, Managing Analytical Data, The Data Warehouse, The Data Lake
- architectural components, Sysops Squad Architectural Components
- architecture quantum, Sysops Squad Saga: Understanding Quanta
- contracts, Contracts, Sysops Squad Saga: Managing Ticketing Contracts
- data model, Sysops Squad Data Model
- ACID transaction example, Distributed Transactions
- data domains, Decomposing Monolithic Data
- distributed data access, Distributed Data Access, Sysops Squad Saga: Data Access for Ticket Assignment-Sysops Squad Saga: Data Access for Ticket Assignment
- Column Schema Replication pattern, Column Schema Replication Pattern
- Data Domain pattern, Data Domain Pattern-Data Domain Pattern
- Interservice Communication Pattern, Interservice Communication Pattern
- Replicated Caching pattern, Replicated Caching Pattern-Replicated Caching Pattern
- distributed transactions, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing
- distributed workflows, Managing Distributed Workflows, Sysops Squad Saga: Managing Workflows-Sysops Squad Saga: Managing Workflows
- epilogue, Sysops Squad Saga: Epilogue
- eventual consistency
- about, Eventual Consistency Patterns
- background synchronization, Background Synchronization Pattern-Background Synchronization Pattern
- event-based pattern, Event-Based Pattern-Event-Based Pattern
- orchestrated request-based pattern, Orchestrated Request-Based Pattern-Orchestrated Request-Based Pattern
- monolithic application broken apart, Architectural Modularity
- 6. create domain services, Pattern Description
- business case for, Sysops Squad Saga: Creating a Business Case-Sysops Squad Saga: Creating a Business Case
- code reuse patterns, Reuse Patterns, Sysops Squad Saga: Common Infrastructure Logic, Sysops Squad Saga: Shared Domain Functionality
- create component domains, Sysops Squad Saga: Creating Component Domains-Sysops Squad Saga: Creating Component Domains
- create domain services, Sysops Squad Saga: Creating Domain Services
- data pulled apart, Pulling Apart Operational Data, Sysops Squad Saga: Justifying Database Decomposition
- database structure, Sysops Squad Saga: Polyglot Databases-Sysops Squad Saga: Polyglot Databases
- database types, Sysops Squad Saga: Polyglot Databases
- decomposition method, Architectural Decomposition, Sysops Squad Saga: Choosing a Decomposition Approach
- decomposition pattern, Component-Based Decomposition Patterns
- determine component dependencies, Sysops Squad Saga: Identifying Component Dependencies-Sysops Squad Saga: Identifying Component Dependencies
- flatten components, Sysops Squad Saga: Flattening Components-Sysops Squad Saga: Flattening Components
- gather common domain components, Sysops Squad Saga: Gathering Common Components-Sysops Squad Saga: Gathering Common Components
- granularity, Service Granularity, Sysops Squad Saga: Ticket Assignment Granularity-Sysops Squad Saga: Customer Registration Granularity
- identify and size components, Sysops Squad Saga: Sizing Components-Sysops Squad Saga: Sizing Components
- ownership of data, Data Ownership and Distributed Transactions, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing
- state machines, Saga State Machines-Saga State Machines
- trade-off analysis, Build Your Own Trade-Off Analysis, Sysops Squad Saga: Epilogue
- transactional sagas, Transactional Sagas, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- about, Introducing the Sysops Squad Saga
T
- table split technique of joint ownership, Table Split Technique-Table Split Technique
- tactical forking, Component-Based Decomposition-Trade-Offs
- about, Architectural Decomposition
- trade-offs, Trade-Offs
- technical partitioning
- data warehouses as, The Data Warehouse
- domain partitioning preferred, The Data Lake
- domain workflows, Choreography Communication Style
- maintainability and, Maintainability
- testability as modularity driver, Testability
- Thoughtworks
- Architectural Decision Records, Architectural Decision Records
- composition versus inheritance, Shared Service
- time series databases, Time-Series Databases-Time-Series Databases
- Time Travel Saga pattern, Time Travel Saga(sec) Pattern-Time Travel Saga(sec) Pattern
- TimeScale time series database, Time-Series Databases
- tools
- ArchUnit, Fitness function: All components in <some domain service> should start with the same namespace
- dependencies
- JDepend, Using Fitness Functions, Afferent and Efferent Coupling
- NetArchTest, Using Fitness Functions
- visualization, Afferent and Efferent Coupling, Pattern Description, Pattern Description
- SonarQube code hygiene tool, Using Fitness Functions
- static code analysis, Pattern Description
- visualization
- about importance of, Pattern Description
- afferent and efferent coupling, Afferent and Efferent Coupling
- data domains via soccer ball, Decomposing Monolithic Data
- dependencies, Afferent and Efferent Coupling, Pattern Description, Pattern Description
- distance from main sequence, Distance from the Main Sequence
- domain diagramming exercise, Sysops Squad Saga: Creating Component Domains
- graph databases, Graph Databases-Graph Databases
- isomorphic diagrams, Transactional Saga Patterns
- static coupling diagram, Coupling
- trade-off analysis, Discerning Coupling in Software Architecture-Discerning Coupling in Software Architecture
- assessing trade-offs, Assess Trade-Offs
- least worst combination, What Happens When There Are No “Best Practices”?
- building your own, Build Your Own Trade-Off Analysis-Analyze Coupling Points
- consistency and availability, Time-Series Databases
- coordination, Trade-Offs Between Orchestration and Choreography
- coupling, Discerning Coupling in Software Architecture-Discerning Coupling in Software Architecture, Coupling-Analyze Coupling Points
- coupling points, Analyze Coupling Points
- dynamic quantum coupling factors, Coordination
- static coupling diagram, Coupling
- documenting versus governing, Architectural Decision Records
- granularity, Finding the Right Balance
- iterative nature of, Analyze Coupling Points
- loose contracts, Loose contracts
- strict contracts, Strict contracts
- Sysops Squad saga, Build Your Own Trade-Off Analysis, Sysops Squad Saga: Epilogue
- tactical forking, Trade-Offs
- techniques of
- bottom line decision, Prefer Bottom Line over Overwhelming Evidence
- MECE lists, MECE Lists
- modeling relevant domain cases, Model Relevant Domain Cases-Model Relevant Domain Cases
- out-of-context trap, The “Out-of-Context” Trap-The “Out-of-Context” Trap
- qualitative versus quantitative analysis, Qualitative Versus Quantative Analysis
- snake oil and evangelism, Avoiding Snake Oil and Evangelism
- assessing trade-offs, Assess Trade-Offs
- transactional saga patterns
- about, Transactional Saga Patterns
- pattern matrix, Coordination, Transactional Saga Patterns, Analyze Coupling Points
- about sagas, Transactional Sagas
- management techniques, Techniques for Managing Sagas
- about state management, State Management and Eventual Consistency
- about state machines, Saga State Machines-Saga State Machines
- compensating updates versus, Saga State Machines
- Anthology Saga, Anthology Saga(aec) Pattern-Anthology Saga(aec) Pattern
- Epic Saga, Epic Saga(sao) Pattern-Epic Saga(sao) Pattern
- Fairy Tale Saga, Fairy Tale Saga(seo) Pattern-Fairy Tale Saga(seo) Pattern
- Fantasy Fiction Saga, Fantasy Fiction Saga(aao) Pattern-Fantasy Fiction Saga(aao) Pattern
- Horror Story, Horror Story(aac) Pattern-Horror Story(aac) Pattern
- Parallel Saga, Parallel Saga(aeo) Pattern-Parallel Saga(aeo) Pattern
- Phone Tag Saga, Phone Tag Saga(sac) Pattern-Phone Tag Saga(sac) Pattern
- Sysops Squad saga, Transactional Sagas, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- Time Travel Saga, Time Travel Saga(sec) Pattern-Time Travel Saga(sec) Pattern
- about, Transactional Saga Patterns
- transactionality
- distributed architecture challenge, Consistency
- security versus, Sysops Squad Saga: Customer Registration Granularity-Sysops Squad Saga: Customer Registration Granularity
- transactions
- data integration driver, Database transactions
- database transactions and granularity, Database Transactions
- distributed transactions
- about, Distributed Transactions, Epic Saga(sao) Pattern
- ACID transactions, Distributed Transactions-Distributed Transactions
- BASE transactions, Distributed Transactions
- compensating updates, Orchestrated Request-Based Pattern, Epic Saga(sao) Pattern
- eventual consistency, Eventual Consistency Patterns
- (see also eventual consistency)
- Sysops Squad saga, Sysops Squad Saga: Data Ownership for Ticket Processing-Sysops Squad Saga: Data Ownership for Ticket Processing, Sysops Squad Saga: Atomic Transactions and Compensating Updates-Sysops Squad Saga: Atomic Transactions and Compensating Updates
- Trunk-based Development, Avoiding Snake Oil and Evangelism
- tunable consistency, Key-Value Databases, Column Family Databases
U
- user interface quantum, High Static Coupling
V
- version control systems
- code change frequency metric, Code Volatility
- LATEST caution, Versioning Strategies
- shared code libraries, Versioning Strategies-When To Use
- granularity and, Shared Code, Shared Code
- shared service API endpoint versioning, Change Risk
- strict contracts requiring, Strict contracts
- visualization tools
- afferent and efferent coupling, Afferent and Efferent Coupling
- data domains via soccer ball, Decomposing Monolithic Data
- dependencies, Pattern Description
- importance of visualization, Pattern Description
- JDepend Eclipse plug-in, Afferent and Efferent Coupling
- distance from main sequence, Distance from the Main Sequence
- domain diagramming exercise, Sysops Squad Saga: Creating Component Domains
- graph databases, Graph Databases-Graph Databases
- isomorphic diagrams, Transactional Saga Patterns
- static coupling diagram, Coupling
- volatility-based decomposition, Code Volatility
W
- What Every Programmer Should Know About Object-Oriented Design (Page-Jones), Pulling Things Apart
- why more important than how, Architecture Versus Design: Keeping Definitions Simple
- wide column databases, Column Family Databases
- Woolf, Bobby, Step 1: Analyze Database and Create Data Domains
- workflow and service granularity, Workflow and Choreography-Workflow and Choreography
- (see also distributed workflows)
Y
- Yourdon, Edward, Afferent and Efferent Coupling
Z
- zero-day exploits, Using Fitness Functions
- Zitzewitz, Alexander von, Maintainability
- zones of uselessness and pain, Distance from the Main Sequence
About the Authors
Neal Ford là một giám đốc, kiến trúc sư phần mềm và người quản lý meme tại Thoughtworks, một công ty phần mềm và cộng đồng của những cá nhân đam mê, có mục đích, những người suy nghĩ một cách đổi mới để cung cấp công nghệ giải quyết những thách thức khó khăn nhất, đồng thời tìm kiếm cách mạng hóa ngành CNTT và tạo ra sự thay đổi xã hội tích cực. Ông là một chuyên gia đã được công nhận quốc tế về phát triển và cung cấp phần mềm, đặc biệt là ở giao điểm giữa các kỹ thuật kỹ sư Agile và kiến trúc phần mềm. Neal đã viết bảy cuốn sách (và vẫn tiếp tục), một số bài báo tạp chí, và hàng chục bài trình bày video và đã phát biểu tại hàng trăm hội nghị lập trình viên trên toàn thế giới. Các chủ đề của ông bao gồm kiến trúc phần mềm, giao hàng liên tục, lập trình hàm, các đổi mới phần mềm tiên tiến, và một cuốn sách và video tập trung vào doanh nghiệp về việc cải thiện các bài thuyết trình kỹ thuật. Hãy truy cập vào trang web của ông, Nealford.com.
Mark Richards là một kiến trúc sư phần mềm giàu kinh nghiệm, tham gia vào kiến trúc, thiết kế và triển khai các kiến trúc microservices, kiến trúc hướng dịch vụ và hệ thống phân tán trên nhiều công nghệ khác nhau. Ông đã làm việc trong ngành công nghiệp phần mềm từ năm 1983 và có nhiều kinh nghiệm cũng như chuyên môn đáng kể trong kiến trúc ứng dụng, tích hợp và doanh nghiệp. Mark là tác giả của nhiều cuốn sách và video kỹ thuật, bao gồm "Các nguyên tắc cơ bản của Kiến trúc Phần mềm", loạt video "Các nguyên tắc cơ bản của Kiến trúc Phần mềm", và một số cuốn sách cũng như video về microservices cũng như truyền thông doanh nghiệp. Mark cũng là một diễn giả và giảng viên tại hội nghị, và đã phát biểu tại hàng trăm hội nghị và nhóm người sử dụng trên toàn thế giới về nhiều chủ đề kỹ thuật liên quan đến doanh nghiệp.
Pramod Sadalage là giám đốc dữ liệu và DevOps tại Thoughtworks. Chuyên môn của ông bao gồm phát triển ứng dụng, phát triển cơ sở dữ liệu Agile, thiết kế cơ sở dữ liệu tiến hóa, thiết kế thuật toán và quản trị cơ sở dữ liệu.
Zhamak Dehghani là giám đốc công nghệ mới nổi tại Thoughtworks. Trước đây, cô làm việc tại Silverbrook Research với vai trò kỹ sư phần mềm chính, và tại Fox Technology với vai trò kỹ sư phần mềm cao cấp.
Colophon
Động vật trên bìa của cuốn sách "Phần Khó Trong Kiến Trúc Phần Mềm" là một loài gõ kiến lưng đen vàng (Dinopium benghalense), một loài gõ kiến nổi bật được tìm thấy trên khắp các đồng bằng, chân đồi, rừng và khu vực đô thị của tiểu lục địa Ấn Độ.
Lưng vàng của con chim này được đặt trên một vai và đuôi đen, là lý do cho cái tên lấy cảm hứng từ lửa của nó. Những con trưởng thành có vương miện đỏ với đầu và ngực có đốm đen-trắng, với một sọc đen chạy từ mắt đến phía sau đầu. Giống như những con gõ kiến nhỏ, mỏ thẳng khác, gõ kiến lưng vàng đuôi đen có mỏ nhọn thẳng, đuôi cứng để hỗ trợ chống lại thân cây, và có bốn ngón chân—hai ngón hướng về phía trước và hai ngón hướng về phía sau. Như thể các dấu hiệu của nó không đủ đặc biệt, gõ kiến lưng vàng đuôi đen thường được phát hiện qua tiếng kêu “ki-ki-ki-ki-ki,” tăng dần về tốc độ.
Con gõ kiến này ăn côn trùng, chẳng hạn như kiến đỏ và ấu trùng bọ, dưới vỏ cây bằng mỏ nhọn và lưỡi dài. Chúng đã được quan sát ghé thăm các đống mối và thậm chí ăn mật hoa. Con gõ kiến lưng vàng cũng thích nghi tốt với các môi trường đô thị, sống dựa vào trái cây rụng và thức ăn thừa dễ kiếm.
Được coi là tương đối phổ biến ở Ấn Độ, tình trạng bảo tồn hiện tại của loài chim này được xếp vào loại "ít lo ngại." Nhiều loài động vật trên bìa sách của O’Reilly đang bị đe dọa; tất cả chúng đều quan trọng đối với thế giới.
Hình ảnh bìa là một minh họa màu của Karen Montgomery, dựa trên một bức khắc đen trắng từ Zoology của Shaw. Phông chữ bìa là URW Typewriter và Guardian Sans. Phông chữ văn bản là Adobe Minion Pro và Myriad Pro; phông chữ tiêu đề là Adobe Myriad Condensed; và phông chữ mã là Ubuntu Mono của Dalton Maag.