
Functional Programming Patterns in Scala and Clojure
Write Lean Programs for the JVM
by Michael Bevilacqua-Linn
Version: P1.0 (October 2013)Copyright © 2013 The Pragmatic Programmers, LLC. This book is licensed to the individual who purchased it. We don't copy-protect it because that would limit your ability to use it for your own purposes. Please don't break this trust—you can use this across all of your devices but please do not share this copy with other members of your team, with friends, or via file sharing services. Thanks.—Dave & Andy.
Nhiều trong số các ký hiệu được sử dụng bởi các nhà sản xuất và người bán để phân biệt sản phẩm của họ được yêu cầu là nhãn hiệu thương mại. Khi các ký hiệu đó xuất hiện trong cuốn sách này, và Công ty TNHH Pragmatic Programmers đã biết về một yêu cầu nhãn hiệu, các ký hiệu đã được in bằng chữ cái đầu tiên in hoa hoặc bằng chữ hoa hoàn toàn. Bộ Khởi động Pragmatic, Lập trình viên Pragmatic, Lập trình Pragmatic, Giá sách Pragmatic và thiết bị liên kết là nhãn hiệu của Công ty TNHH Pragmatic Programmers.
Mọi biện pháp phòng ngừa đã được thực hiện trong việc chuẩn bị cuốn sách này. Tuy nhiên, Nhà xuất bản không chịu trách nhiệm về những lỗi hoặc thiếu sót, hoặc về những thiệt hại có thể xảy ra từ việc sử dụng thông tin (bao gồm cả danh sách chương trình) có trong đây.
Các khóa học, hội thảo và sản phẩm khác của chúng tôi có thể giúp bạn và đội ngũ của bạn tạo ra phần mềm tốt hơn và có nhiều niềm vui hơn. Để biết thêm thông tin, cũng như các tiêu đề Pragmatic mới nhất, hãy truy cập chúng tôi tại http://pragprog.com.
Table of Contents
| Acknowledgments |
| Preface |
| How This Book Is Organized |
| Pattern Template |
| Why Scala and Clojure |
| How to Read This Book |
| Online Resources |
| 1. | Patterns and Functional Programming |
| 1.1 | What Is Functional Programming? |
| 1.2 | Pattern Glossary |
| 2. | TinyWeb: Patterns Working Together |
| 2.1 | Introducing TinyWeb |
| 2.2 | TinyWeb in Java |
| 2.3 | TinyWeb in Scala |
| 2.4 | TinyWeb in Clojure |
| 3. | Replacing Object-Oriented Patterns |
| 3.1 | Introduction |
| Pattern 1. Replacing Functional Interface |
| Pattern 2. Replacing State-Carrying Functional Interface |
| Pattern 3. Replacing Command |
| Pattern 4. Replacing Builder for Immutable Object |
| Pattern 5. Replacing Iterator |
| Pattern 6. Replacing Template Method |
| Pattern 7. Replacing Strategy |
| Pattern 8. Replacing Null Object |
| Pattern 9. Replacing Decorator |
| Pattern 10. Replacing Visitor |
| Pattern 11. Replacing Dependency Injection |
| 4. | Functional Patterns |
| 4.1 | Introduction |
| Pattern 12. Tail Recursion |
| Pattern 13. Mutual Recursion |
| Pattern 14. Filter-Map-Reduce |
| Pattern 15. Chain of Operations |
| Pattern 16. Function Builder |
| Pattern 17. Memoization |
| Pattern 18. Lazy Sequence |
| Pattern 19. Focused Mutability |
| Pattern 20. Customized Control Flow |
| Pattern 21. Domain-Specific Language |
| 5. | The End |
| Bibliography |
Early Praise for Functional Programming Patterns
Cuốn sách này là một viên ngọc tuyệt vời và nên được coi là tài liệu cần thiết cho bất kỳ ai muốn chuyển từ lập trình hướng đối tượng sang lập trình hàm. Nó là một sợi dây an toàn được xây dựng rất tốt cho những ai đang qua cầu giữa hai thế giới rất khác biệt. Hãy coi đây là tài liệu bắt buộc phải đọc.
| → | Colin Yates, technical team leader at QFI Consulting, LLP |
Cuốn sách này tập trung vào những điều thiết yếu mà lập trình hàm có thể mang lại cho lập trình viên JVM theo hướng đối tượng. Các mẫu hàm được phân chia ở cuối cuốn sách, tách biệt với các thay thế hàm cho các mẫu hướng đối tượng, làm cho cuốn sách trở thành tài liệu tham khảo tiện lợi. Là một lập trình viên Scala, tôi thậm chí đã học thêm một số mẹo mới trong quá trình đọc.
| → | Justin James, developer with Full Stack Apps |
Cuốn sách này phù hợp cho những ai đã chạm vào Clojure hoặc Scala nhưng chưa thực sự thoải mái với nó; đối tượng lý tưởng là những lập trình viên lập trình hướng đối tượng có kinh nghiệm đang tìm cách áp dụng phong cách lập trình hàm, vì nó cung cấp cho các lập trình viên đó một hướng dẫn để chuyển mình ra khỏi các mẫu mà họ đã quen thuộc.
| → | Rod Hilton, Java developer and PhD candidate at the University of Colorado |
Acknowledgments
Tôi muốn cảm ơn cha mẹ tôi, những người nếu không có họ thì tôi sẽ không tồn tại.
Cảm ơn bạn gái tuyệt vời của tôi, người đã chịu đựng nhiều đêm và cuối tuần lắng nghe tôi lẩm bẩm về mẫu mã, cách sử dụng thì không nhất quán và câu văn kéo dài.
Cuốn sách này sẽ gặp rất nhiều khó khăn nếu không có sự hỗ trợ từ một nhóm các reviewer kỹ thuật tuyệt vời. Tôi xin gửi lời cảm ơn đến Rod Hilton, Michajlo “Mishu” Matijkiw, Venkat Subramaniam, Justin James, Dave Cleaver, Ted Neward, Neal Ford, Richard Minerich, Dustin Campbell, Dave Copeland, Josh Carter, Fred Daoud và Chris Smith.
Cuối cùng, tôi muốn cảm ơn Dave Thomas và Andy Hunt. Cuốn sách của họ, The Pragmatic Programmer, là một trong những cuốn sách đầu tiên tôi đọc khi bắt đầu sự nghiệp. Nó đã có ảnh hưởng lớn và tôi vẫn còn giữ cuốn sách ban đầu, với bìa nhăn nheo, đầy dấu vân tay, bị dập nát và cũ kỹ. Trong Pragmatic Bookshelf, họ đã tạo ra một nhà xuất bản thực sự tận tâm với việc sản xuất các cuốn sách kỹ thuật chất lượng cao và hỗ trợ các tác giả viết chúng.
Copyright © 2013, The Pragmatic Bookshelf.
Preface
Cuốn sách này nói về các mẫu và lập trình hàm trong Scala và Clojure. Nó chỉ ra cách thay thế, hoặc đơn giản hóa rất nhiều, các mẫu thông dụng mà chúng ta sử dụng trong lập trình hướng đối tượng, và giới thiệu một số mẫu thường được dùng trong thế giới hàm.
Sử dụng cùng nhau, những mẫu này cho phép lập trình viên giải quyết vấn đề nhanh hơn và theo phong cách khai báo ngắn gọn hơn so với lập trình hướng đối tượng một mình. Nếu bạn đang sử dụng Java và muốn thấy cách lập trình hàm có thể giúp bạn làm việc hiệu quả hơn, hoặc nếu bạn đã bắt đầu sử dụng Scala và Clojure nhưng vẫn chưa hiểu rõ về cách giải quyết vấn đề bằng lập trình hàm, thì đây là cuốn sách dành cho bạn.
Trước khi chúng ta bắt đầu, tôi muốn bắt đầu bằng một câu chuyện. Câu chuyện này là có thật, mặc dù một số tên đã được thay đổi để bảo vệ những người không hề trong trắng.
A Tale of Functional Programming by Michael Bevilacqua-Linn, software firefighterMichael Bevilacqua-LinnTrang web không bị sập, nhưng rất nhiều cảnh báo đang vang lên. Chúng tôi truy tìm nguyên nhân của các vấn đề đến từ những thay đổi mà ai đó đã thực hiện trên một API bên thứ ba mà chúng tôi sử dụng. Những thay đổi này đang gây ra các vấn đề dữ liệu lớn ở phía chúng tôi; cụ thể là, chúng tôi không biết những thay đổi đó là gì và không thể tìm thấy ai có thể cho chúng tôi biết. Hóa ra hệ thống giao tiếp với API sử dụng mã nguồn cũ, và người duy nhất biết cách làm việc với nó lại đang đi nghỉ. Đây là một hệ thống lớn: 500.000 dòng mã Java và OSGI.
Những cuộc gọi hỗ trợ đang ập đến, rất nhiều cuộc gọi. Những cuộc gọi hỗ trợ tốn kém từ các khách hàng thất vọng. Chúng ta cần nhanh chóng khắc phục vấn đề. Tôi khởi động một REPL Clojure và sử dụng nó để điều tra vấn đề của API.
Ông sếp của tôi thò đầu vào văn phòng. “Mọi chuyện thế nào?” ông hỏi. “Đang làm đây,” tôi nói. Mười phút sau, ông grandboss thò đầu vào văn phòng. “Mọi chuyện thế nào?” ông hỏi. “Đang làm đây,” tôi nói. Thêm mười phút trôi qua khi ông great-grandboss thò đầu vào văn phòng. “Mọi chuyện thế nào?” ông hỏi. “Đang làm đây,” tôi nói. Tôi có nửa giờ im lặng trước khi CTO thò đầu vào văn phòng. “Đang làm đây,” tôi nói trước khi ông mở miệng.
Một giờ trôi qua, và tôi nhận ra điều gì đã thay đổi. Tôi nhanh chóng nghĩ ra cách để giữ cho dữ liệu sạch cho đến khi nhà phát triển cũ quay lại và có thể đưa ra một bản sửa chữa đúng đắn. Tôi bàn giao chương trình nhỏ của mình cho đội ngũ vận hành, họ đưa nó vào chạy trong một JVM, ở một nơi an toàn. Các cuộc gọi hỗ trợ không còn nữa, và mọi người có phần thư giãn hơn.
Khoảng một tuần sau, tại một cuộc họp toàn thể, ông sếp lớn cảm ơn tôi vì chương trình Java mà tôi đã viết và đã cứu vãn tình hình. Tôi mỉm cười và nói: “Đó không phải là Java.”
REPL, môi trường lập trình tương tác của Clojure, đã hỗ trợ rất nhiều trong câu chuyện này. Tuy nhiên, nhiều ngôn ngữ không phải là chức năng đặc biệt cũng có những môi trường lập trình tương tác tương tự, vì vậy đó không phải là tất cả.
Hai trong số các mẫu mà chúng ta sẽ thấy trong cuốn sách này, Mẫu 21, Ngôn ngữ miền cụ thể, và Mẫu 15, Chuỗi hoạt động, đã đóng góp rất lớn vào cái kết hạnh phúc của câu chuyện này.
Trước đây, tôi đã viết một đoạn mã nhỏ của ngôn ngữ cụ thể cho miền để làm việc với những API đặc biệt này, điều đó đã giúp tôi khám phá chúng một cách nhanh chóng mặc dù chúng rất lớn và thật khó để xác định xem vấn đề nằm ở đâu. Thêm vào đó, những khả năng biến đổi dữ liệu mạnh mẽ mà lập trình hàm dựa vào, chẳng hạn như những ví dụ mà chúng ta sẽ thấy trong Mẫu 15, Chuỗi các phép toán, đã giúp tôi nhanh chóng viết mã để dọn dẹp hỗn độn.
How This Book Is Organized
Chúng ta sẽ bắt đầu với một giới thiệu về các mẫu và cách chúng liên quan đến lập trình hàm. Sau đó, chúng ta sẽ xem xét một ví dụ mở rộng, một khung web nhỏ gọi là TinyWeb. Chúng ta sẽ đầu tiên hiển thị TinyWeb được viết bằng cách sử dụng các mẫu lập trình hướng đối tượng cổ điển trong Java. Sau đó, chúng ta sẽ viết lại từng phần một theo một phong cách lai giữa lập trình hướng đối tượng và lập trình hàm, sử dụng Scala. Cuối cùng, chúng ta sẽ viết theo phong cách hàm sử dụng Clojure.
Ví dụ mở rộng TinyWeb có một số mục đích. Nó sẽ cho phép chúng ta thấy cách mà một số mẫu mà chúng ta đề cập trong cuốn sách này kết hợp với nhau một cách toàn diện. Chúng tôi cũng sử dụng nó để giới thiệu các khái niệm cơ bản về Scala và Clojure. Cuối cùng, vì chúng tôi sẽ chuyển đổi TinyWeb từ Java sang Scala và Clojure từng bước một, nó cho chúng ta cơ hội để khám phá cách dễ dàng tích hợp mã Java với Scala và Clojure.
Phần còn lại của cuốn sách được chia thành hai phần. Phần đầu tiên, Chương 3, Thay thế các Mẫu Hướng Đối Tượng, mô tả các giải pháp chức năng thay thế cho các mẫu hướng đối tượng. Những giải pháp này thay thế các mẫu hướng đối tượng nặng nề bằng các giải pháp chức năng ngắn gọn.
Peter Norvig, tác giả của cuốn sách Lisp cổ điển "Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp" [Nor92], hiện là giám đốc nghiên cứu tại Google và là một người rất thông minh, đã chỉ ra trong "Design Patterns in Dynamic Languages" rằng những ngôn ngữ biểu đạt như Lisp có thể làm cho các mẫu lập trình hướng đối tượng cổ điển trở nên vô hình.
Rất tiếc, không nhiều người trong thế giới phát triển phần mềm chính thống dường như đã đọc Norvig, nhưng khi chúng ta có thể thay thế một mẫu phức tạp bằng một cái gì đó đơn giản hơn, thì thật hợp lý khi chúng ta nên làm như vậy. Điều đó làm cho mã của chúng ta ngắn gọn hơn, dễ hiểu hơn và dễ bảo trì hơn.
Phần thứ hai, Chương 4, Các mẫu chức năng, mô tả các mẫu đặc trưng của thế giới chức năng. Các mẫu này trải dài từ nhỏ - những mẫu bao gồm một hoặc hai dòng mã - đến rất lớn - những mẫu xử lý toàn bộ chương trình.
Đôi khi các mẫu này được hỗ trợ bởi ngôn ngữ chính, nghĩa là có người khác đã làm công việc khó khăn này cho chúng ta. Ngay cả khi chúng không được hỗ trợ, chúng ta vẫn có thể sử dụng một mẫu cực kỳ mạnh mẽ, Mẫu 21, Ngôn ngữ chuyên ngành, để thêm vào. Điều này có nghĩa là các mẫu hàm nhẹ hơn so với các mẫu hướng đối tượng. Bạn vẫn cần hiểu mẫu trước khi có thể sử dụng nó, nhưng việc triển khai trở nên đơn giản chỉ với vài dòng mã.
Pattern Template
Mẫu được trình bày theo định dạng sau, với một số ngoại lệ. Chẳng hạn, một mẫu không có tên gọi khác sẽ không có phần "Cũng biết đến như" và các phần "Thay thế chức năng" chỉ áp dụng cho các mẫu trong Chương 3, "Thay thế các mẫu hướng đối tượng".
Intent
Tiểu mục Ý định cung cấp một giải thích nhanh về mục đích của mẫu này và vấn đề mà nó giải quyết.
Overview
Đây là nơi bạn sẽ tìm thấy động lực sâu sắc hơn cho mẫu hình và giải thích cách nó hoạt động.
Also Known As
Mục phụ này liệt kê các tên gọi khác phổ biến cho mẫu này.
Functional Replacement
Ở đây bạn sẽ tìm thấy cách thay thế mẫu này bằng các kỹ thuật lập trình hàm - đôi khi các mẫu lập trình hướng đối tượng có thể được thay thế bằng các tính năng ngôn ngữ hàm cơ bản và đôi khi bằng các mẫu đơn giản hơn.
Example Code
Phần phụ này chứa mẫu của mẫu thiết kế—đối với các mẫu hướng đối tượng, chúng tôi sẽ đầu tiên trình bày một phác thảo của giải pháp hướng đối tượng bằng cách sử dụng sơ đồ lớp hoặc phác thảo mã Java trước khi chỉ cho cách thay thế chúng bằng Clojure và Scala. Các mẫu hàm sẽ chỉ được trình bày bằng Clojure và Scala.
Discussion
Khu vực này cung cấp tóm tắt và thảo luận về những điểm thú vị liên quan đến mô hình.
For Further Reading
Xem ở đây để có danh sách tài liệu tham khảo cho thông tin thêm về mẫu.
Related Patterns
Điều này cung cấp danh sách các mẫu khác trong cuốn sách này có liên quan đến mẫu hiện tại.
Why Scala and Clojure
Nhiều mẫu trong cuốn sách này có thể được áp dụng bằng các ngôn ngữ khác có tính năng hàm, nhưng chúng tôi sẽ tập trung vào Clojure và Scala cho các ví dụ của mình. Chúng tôi tập trung vào hai ngôn ngữ này vì nhiều lý do, nhưng trước hết và quan trọng nhất là vì chúng đều là những ngôn ngữ thực tiễn phù hợp để lập trình trong các môi trường sản xuất.
Cả Scala và Clojure đều chạy trên máy ảo Java (JVM), vì vậy chúng tương tác tốt với các thư viện Java hiện có và không gặp vấn đề gì khi được đưa vào hạ tầng JVM. Điều này khiến chúng trở thành lựa chọn lý tưởng để chạy song song với các mã nguồn Java hiện có. Cuối cùng, trong khi cả Scala và Clojure đều có các tính năng lập trình hàm, chúng lại khá khác nhau. Học cách sử dụng cả hai sẽ giúp chúng ta tiếp cận một loạt các mô hình lập trình hàm rất phong phú.
Scala là một ngôn ngữ lập trình lai giữa hướng đối tượng và hàm. Nó có kiểu tĩnh và kết hợp một hệ thống kiểu rất tinh vi với suy diễn kiểu cục bộ, cho phép chúng ta thường xuyên bỏ qua các chú thích kiểu rõ ràng trong mã của mình.
Clojure là một cách tiếp cận hiện đại đối với Lisp. Nó có hệ thống macro mạnh mẽ của Lisp và kiểu dữ liệu động, nhưng Clojure đã thêm một số tính năng mới chưa thấy trong các phiên bản Lisp cũ. Quan trọng nhất là cách độc đáo của nó trong việc xử lý thay đổi trạng thái bằng cách sử dụng loại tham chiếu, một hệ thống bộ nhớ giao dịch phần mềm, và các cấu trúc dữ liệu bất biến hiệu quả.
Trong khi Clojure không phải là một ngôn ngữ lập trình hướng đối tượng, nó vẫn cung cấp cho chúng ta một số tính năng tốt thường thấy trong các ngôn ngữ hướng đối tượng, chỉ là không theo cách mà chúng ta có thể quen thuộc. Chẳng hạn, chúng ta vẫn có thể có tính đa hình thông qua các phương thức đa hình và giao thức của Clojure, và chúng ta có thể có các hệ thống phân cấp thông qua các hệ thống phân cấp tùy ý của Clojure.
Khi chúng tôi giới thiệu các mô hình, chúng tôi sẽ khám phá cả hai ngôn ngữ này và các tính năng của chúng, vì vậy cuốn sách này phục vụ như một sự giới thiệu tốt cho cả Scala và Clojure. Để biết thêm chi tiết về mỗi ngôn ngữ, những cuốn sách tôi yêu thích là Programming Clojure [Hal09] và The Joy of Clojure [FH11] cho Clojure, và Programming Scala: Tackle Multi-Core Complexity on the Java Virtual Machine [Sub09] và Scala In Depth [Sue12] cho Scala.
读累了记得休息一会哦~
Công chúng: Cụ Good Maoning Lý
- 电子书搜索下载
- 书单分享
- 书友学习交流
Trang web: Thư viện Trầm Kim https://www.chenjin5.com
- 电子书搜索下载
- 电子书打包资源分享
- 学习资源分享
How to Read This Book
Nơi tốt nhất để bắt đầu là với Chương 1, Mô hình và Lập trình hàm, chú trọng vào những điều cơ bản của lập trình hàm và mối quan hệ của nó với các mô hình. Tiếp theo, Chương 2, TinyWeb: Các mô hình hoạt động cùng nhau, giới thiệu các khái niệm cơ bản trong Scala và Clojure và chỉ ra cách mà một số mô hình trong cuốn sách này kết hợp với nhau.
Từ đó, bạn có thể nhảy qua lại, từng mẫu một, theo nhu cầu. Các mẫu được đề cập trước đó trong Chương 3, “Thay thế các mẫu hướng đối tượng”, và Chương 4, “Các mẫu hàm”, thường đơn giản hơn so với các mẫu sau, vì vậy chúng xứng đáng được đọc trước nếu bạn không có kinh nghiệm lập trình hàm trước đó.
Tóm tắt nhanh về mỗi mẫu có thể được tìm thấy trong Mục 1.2, Bảng chú giải mẫu, để dễ dàng tra cứu. Khi bạn đã hoàn thành phần giới thiệu, bạn có thể sử dụng nó để tìm kiếm một mẫu giải quyết vấn đề cụ thể mà bạn cần giải quyết.
Tuy nhiên, nếu bạn hoàn toàn mới với lập trình hàm, bạn nên bắt đầu với Mẫu 1, Thay thế Giao diện Hàm, Mẫu 2, Thay thế Giao diện Hàm Mang Trạng Thái, và Mẫu 12, Đệ quy Đuôi.
Online Resources
Khi bạn làm việc qua cuốn sách, bạn có thể tải xuống tất cả các tệp mã nguồn được bao gồm từ http://pragprog.com/titles/mbfpp/source_code. Trên trang chủ của cuốn sách tại http://pragprog.com/book/mbfpp, bạn có thể tìm thấy liên kết đến diễn đàn của cuốn sách và để báo lỗi. Ngoài ra, đối với những người mua ebook, việc nhấp vào hộp trên các đoạn mã sẽ tải xuống mã cho đoạn đó.
Footnotes
| [1] | http://norvig.com/design-patterns/ |
Chapter 1
Patterns and Functional Programming
Các mẫu thiết kế và lập trình hàm đi đôi với nhau theo hai cách. Đầu tiên, nhiều mẫu thiết kế hướng đối tượng đơn giản hơn khi triển khai với lập trình hàm. Điều này đúng vì một số lý do. Ngôn ngữ hàm cho chúng ta một cách ngắn gọn để truyền tải một phần tính toán mà không cần phải tạo một lớp mới. Ngoài ra, việc sử dụng biểu thức thay vì câu lệnh cho phép chúng ta loại bỏ các biến thừa, và tính chất khai báo của nhiều giải pháp hàm cho phép chúng ta thực hiện trong một dòng mã điều mà có thể mất năm dòng trong phong cách mệnh lệnh. Một số mẫu hướng đối tượng thậm chí có thể được thay thế bằng một ứng dụng đơn giản các tính năng của ngôn ngữ hàm.
Thứ hai, thế giới chức năng cũng có những mẫu hữu ích riêng của nó. Những mẫu này tập trung vào việc viết mã mà tránh tính biến đổi và ưa thích phong cách khai báo, giúp chúng ta viết mã đơn giản hơn, dễ bảo trì hơn. Hai phần chính của cuốn sách này đề cập đến hai bộ mẫu này.
Bạn có thể sẽ ngạc nhiên khi thấy bộ đầu tiên. Những mẫu mà chúng ta biết và yêu thích không mở rộng ra các ngôn ngữ hay sao? Không phải chúng đáng lẽ phải cung cấp những giải pháp chung cho những vấn đề chung bất kể bạn đang sử dụng ngôn ngữ nào hay sao? Câu trả lời cho cả hai câu hỏi là có, miễn là ngôn ngữ bạn đang sử dụng có hình dạng giống như Java hoặc tổ tiên của nó, C++.
Với sự xuất hiện của những tính năng ngôn ngữ phong phú hơn, nhiều mẫu mã này dần phai nhạt. Chính Java cũng có một ví dụ tuyệt vời về một tính năng ngôn ngữ thay thế một mẫu: foreach. Việc giới thiệu vòng lặp foreach vào Java 1.5 đã giảm bớt tính hữu ích của mẫu Iterator rõ ràng được mô tả trong cuốn sách Design Patterns: Elements of Reusable Object-Oriented Software [GHJV95], mặc dù vòng lặp foreach vẫn sử dụng nó ẩn sau.
Điều đó không có nghĩa là vòng lặp foreach hoàn toàn tương đương với Iterator. Một vòng lặp foreach sẽ không thay thế một Iterator trong tất cả các trường hợp. Những vấn đề mà chúng giải quyết được thực hiện đơn giản hơn. Các nhà phát triển thích sử dụng vòng lặp foreach tích hợp sẵn vì lý do hợp lý rằng chúng ít công sức hơn để triển khai và ít có khả năng xảy ra lỗi hơn.
Nhiều tính năng và kỹ thuật của ngôn ngữ lập trình hàm có tác dụng tương tự trên các dự án lập trình. Mặc dù chúng có thể không hoàn toàn tương đương với một mẫu cụ thể, nhưng chúng thường cung cấp cho các nhà phát triển một giải pháp thay thế tích hợp giải quyết cùng một vấn đề. Tương tự như ví dụ về Iterator foreach, các tính năng ngôn ngữ khác cung cấp cho lập trình viên những kỹ thuật ít công sức hơn và thường tạo ra mã nguồn ngắn gọn hơn và dễ hiểu hơn so với mã gốc.
Việc thêm các tính năng và kỹ thuật chức năng cung cấp thêm nhiều công cụ vào hộp công cụ lập trình của chúng ta, giống như Java 1.5 đã làm với vòng lặp foreach nhưng ở quy mô lớn hơn. Những công cụ này thường bổ sung cho các công cụ mà chúng ta đã biết và yêu thích từ thế giới lập trình hướng đối tượng.
Bộ mẫu thứ hai mà chúng tôi đề cập trong cuốn sách này, các mẫu chức năng bản địa, miêu tả những mẫu phát triển từ phong cách hàm. Những mẫu chức năng này khác với các mẫu hướng đối tượng mà bạn có thể quen thuộc theo một vài điểm chính. Điểm đầu tiên và rõ ràng nhất là hàm là đơn vị chính trong việc kết hợp, cũng giống như các đối tượng trong thế giới hướng đối tượng.
Một sự khác biệt quan trọng khác nằm ở độ chi tiết của các mẫu thiết kế. Các mẫu từ cuốn sách Design Patterns: Elements of Reusable Object-Oriented Software [GHJV95] (một trong những động lực ban đầu của phong trào mẫu phần mềm) thường là các khuôn mẫu định nghĩa một vài lớp và quy định cách chúng kết hợp với nhau. Hầu hết chúng có kích thước vừa phải. Chúng thường không quan tâm đến những vấn đề rất nhỏ chỉ bao gồm vài dòng mã hoặc những vấn đề rất lớn bao gồm toàn bộ chương trình.
Các mẫu chức năng trong cuốn sách này bao trùm một phạm vi rộng hơn nhiều, vì một số trong số đó có thể được thực hiện chỉ với một hoặc hai dòng mã. Những mẫu khác giải quyết những vấn đề lớn, chẳng hạn như tạo ra các ngôn ngữ lập trình mới, mini.
Phạm vi này phù hợp với cuốn sách đã khởi đầu phong trào các mẫu nói chung, A Pattern Language [AIS77]. Cuốn sách về các mẫu kiến trúc bắt đầu với mẫu "1—Các Khu Vực Độc Lập" rất lớn, nêu rõ lý do tại sao hành tinh nên được tổ chức thành các thực thể chính trị khoảng 10.000 người, và đi xuyên suốt đến mẫu "248—Gạch Mềm và Gạch Đất," giải thích cách tự làm gạch của bạn.
Trước khi chúng ta khám phá các mẫu khác nhau trong cuốn sách này, hãy dành một chút thời gian để làm quen với lập trình hàm.
1.1 What Is Functional Programming?
Ở cốt lõi, lập trình hàm là về bất biến và về việc kết hợp các hàm thay vì các đối tượng. Nhiều đặc điểm liên quan phát sinh từ phong cách này.
Các chương trình chức năng thực hiện những điều sau:
- Have first-class functions:
-
Hàm bậc nhất là những hàm có thể được truyền qua lại, được tạo ra một cách động, lưu trữ trong các cấu trúc dữ liệu, và được đối xử như bất kỳ đối tượng bậc nhất nào khác trong ngôn ngữ.
- Favor pure functions:
-
Hàm thuần túy là các hàm không có tác dụng phụ. Một tác dụng phụ là một hành động mà hàm thực hiện làm thay đổi trạng thái bên ngoài hàm đó.
- Compose functions:
-
Lập trình hàm ưu tiên xây dựng chương trình từ dưới lên bằng cách kết hợp các hàm với nhau.
- Use expressions:
-
Lập trình hàm ưu tiên biểu thức hơn câu lệnh. Biểu thức trả về giá trị. Câu lệnh thì không và chỉ tồn tại để điều khiển luồng của một chương trình.
- Use Immutability:
-
Vì lập trình hàm ưa chuộng các hàm thuần khiết, những hàm không thể thay đổi dữ liệu, nó cũng sử dụng mạnh mẽ dữ liệu không thay đổi. Thay vì sửa đổi một cấu trúc dữ liệu hiện có, một cấu trúc mới sẽ được tạo ra một cách hiệu quả.
- Transform, rather than mutate, data:
-
Lập trình hàm sử dụng các hàm để biến đổi dữ liệu không thể thay đổi. Một cấu trúc dữ liệu được đưa vào hàm, và một cấu trúc dữ liệu mới không thể thay đổi sẽ được tạo ra. Điều này hoàn toàn trái ngược với mô hình hướng đối tượng phổ biến, mà xem các đối tượng như những gói trạng thái và hành vi có thể thay đổi nhỏ.
Một sự tập trung vào dữ liệu không thay đổi dẫn đến các chương trình được viết theo kiểu tuyên bố nhiều hơn, vì chúng ta không thể sửa đổi một cấu trúc dữ liệu từng phần một. Đây là một cách lặp để lọc các số lẻ ra khỏi một danh sách, được viết bằng Java. Lưu ý rằng nó dựa vào sự thay đổi để thêm các số lẻ vào filteredList một cách từng cái một.
| JavaExamples/src/main/java/com/mblinn/mbfpp/intro/FilterOdds.java | |
| | public List<Integer> filterOdds(List<Integer> list) { |
| | List<Integer> filteredList = new ArrayList<Integer>(); |
| | for (Integer current : list) { |
| | if (isOdd(current)) { |
| | filteredList.add(current); |
| | } |
| | } |
| | return filteredList; |
| | } |
| | private boolean isOdd(Integer integer) { |
| | return 0 != integer % 2; |
| | } |
Và đây là một phiên bản chức năng, được viết bằng Clojure.
| | (filter odd? list-of-ints) |
Phiên bản hàm rõ ràng ngắn gọn hơn nhiều so với phiên bản hướng đối tượng. Như đã đề cập trước đây, điều này là do lập trình hàm có tính khai báo. Tức là, nó chỉ ra những gì cần thực hiện chứ không phải cách thức thực hiện. Đối với nhiều vấn đề mà chúng ta gặp phải trong lập trình, kiểu lập trình này cho phép chúng ta làm việc ở cấp độ tr-abstraction cao hơn.
Tuy nhiên, những vấn đề khác thì khó, nếu không muốn nói là không thể, được giải quyết bằng các kỹ thuật lập trình hàm thuần túy. Một trình biên dịch là một hàm thuần túy. Nếu bạn đưa một chương trình vào, bạn mong đợi nhận được cùng một mã máy ra mỗi lần. Nếu không, có thể là do lỗi trong trình biên dịch. Tuy nhiên, công cụ tìm kiếm của Google không phải là một hàm thuần túy. Nếu chúng ta nhận được cùng một kết quả từ một truy vấn tìm kiếm của Google mỗi lần, chúng ta sẽ bị kẹt với một cái nhìn của Web từ cuối những năm 1990, điều này thật bi thảm.
Vì lý do này, các ngôn ngữ lập trình hàm thường nằm trên một dải mức độ nghiêm ngặt. Một số ngôn ngữ thuần chức năng hơn những ngôn ngữ khác. Trong hai ngôn ngữ mà chúng ta đang sử dụng trong cuốn sách này, Clojure thuần hơn trong phổ chức năng; ít nhất là nếu chúng ta tránh các tính năng tương tác với Java của nó.
Ví dụ, trong Clojure theo cách diễn đạt thông thường, chúng ta không thay đổi dữ liệu như trong Java. Thay vào đó, chúng ta dựa vào một tập hợp các cấu trúc dữ liệu bất biến hiệu quả, một tập hợp các loại tham chiếu và một hệ thống bộ nhớ giao dịch phần mềm. Điều này cho phép chúng ta thu được lợi ích từ tính thay đổi mà không gặp phải các rủi ro. Chúng tôi sẽ giới thiệu những kỹ thuật này trong Mục 2.4, TinyWeb trong Clojure.
Scala có nhiều hỗ trợ cho dữ liệu có thể thay đổi, nhưng dữ liệu không thay đổi thì được ưu tiên. Chẳng hạn, Scala có cả phiên bản có thể thay đổi và không thể thay đổi của thư viện collections, nhưng các cấu trúc dữ liệu không thay đổi được nhập và sử dụng theo mặc định.
1.2 Pattern Glossary
Dưới đây là nơi chúng tôi giới thiệu tất cả các mẫu mà chúng tôi đề cập trong cuốn sách và cung cấp cái nhìn tổng quan ngắn gọn về từng mẫu. Đây là một danh sách tuyệt vời để lướt qua nếu bạn đã có một vấn đề cụ thể cần giải quyết theo cách hàm chức năng.
Replacing Object-Oriented Patterns
Phần này cho thấy cách thay thế các mẫu lập trình hướng đối tượng phổ biến bằng các tính năng của ngôn ngữ hàm. Điều này thường giảm bớt lượng mã mà chúng ta phải viết trong khi mang lại cho chúng ta mã ngắn gọn hơn để duy trì.
Pattern 1, Replacing Functional Interface
Ở đây chúng tôi thay thế các loại giao diện chức năng phổ biến, chẳng hạn như Runnable hoặc Comparator, bằng các tính năng chức năng nội tại.
Phần này giới thiệu hai loại đặc điểm chức năng cơ bản. Loại đầu tiên, hàm bậc cao, cho phép chúng ta truyền các hàm như dữ liệu hạng nhất. Loại thứ hai, hàm ẩn danh, cho phép chúng ta viết các hàm tạm thời mà không cần đặt tên cho chúng. Những đặc điểm này kết hợp lại cho phép chúng ta thay thế hầu hết các trường hợp của Giao diện Chức năng một cách cực kỳ ngắn gọn.
Pattern 2, Replacing State-Carrying Functional Interface
Với mẫu này, chúng ta thay thế các trường hợp của Giao diện Chức năng cần phải mang theo một chút trạng thái—chúng ta giới thiệu một tính năng chức năng mới khác, đóng gói (closures), cho phép chúng ta bao bọc một hàm và một số trạng thái để chuyển đi.
Pattern 3, Replacing Command
Lệnh Thay Thế đóng gói một hành động trong một đối tượng—ở đây chúng ta sẽ xem xét cách chúng ta có thể thay thế phiên bản có hướng đối tượng bằng các kỹ thuật đã được giới thiệu trong hai mẫu trước.
Pattern 4, Replacing Builder for Immutable Object
Ở đây, chúng tôi mang dữ liệu bằng cách sử dụng quy ước Java cổ điển, một lớp đầy đủ các phương thức getter và setter—cách tiếp cận này gắn liền với tính có thể thay đổi. Ở đây, chúng tôi sẽ chỉ cho bạn cách có được sự tiện lợi của một Java Bean cùng với những lợi ích của tính bất biến.
Pattern 5, Replacing Iterator
Thay thế Iterator cho chúng ta một cách để truy cập các mục trong một tập hợp theo thứ tự—tại đây, chúng ta sẽ thấy cách giải quyết nhiều vấn đề mà chúng ta đã giải quyết bằng Iterator bằng cách sử dụng các hàm bậc cao và các phép hiểu dãy, điều này mang lại cho chúng ta những giải pháp mang tính tuyên bố hơn.
Pattern 6, Replacing Template Method
Mẫu này xác định khung của một thuật toán trong một siêu lớp, để lại cho các lớp con thực hiện các chi tiết của nó. Ở đây chúng ta sẽ thấy cách sử dụng các hàm bậc cao và hợp thành hàm để thay thế mẫu dựa trên kế thừa này.
Pattern 7, Replacing Strategy
Trong mẫu này, chúng tôi định nghĩa một tập hợp các thuật toán mà tất cả đều triển khai một giao diện chung. Điều này cho phép lập trình viên dễ dàng thay thế một triển khai của thuật toán bằng một triển khai khác.
Pattern 8, Replacing Null Object
Trong mẫu này, chúng ta thảo luận về cách thay thế Null Object và nói về các loại xử lý null khác - trong Scala, chúng ta tận dụng hệ thống kiểu dữ liệu bằng cách sử dụng Option. Trong Clojure, chúng ta dựa vào nil và một số hỗ trợ ngôn ngữ để làm cho việc xử lý thuận tiện hơn.
Pattern 9, Replacing Decorator
Thay thế Decorator thêm hành vi mới cho một đối tượng mà không thay đổi lớp gốc. Ở đây, chúng ta sẽ xem cách đạt được hiệu ứng tương tự bằng cách kết hợp hàm.
Pattern 10, Replacing Visitor
Thay thế Visitor giúp dễ dàng thêm các thao tác vào một loại dữ liệu nhưng khó khăn trong việc thêm các triển khai mới của loại đó. Ở đây, chúng tôi trình bày các giải pháp trong Scala và Clojure mà cho phép thực hiện cả hai điều này.
Pattern 11, Replacing Dependency Injection
Mô hình này tiêm các phụ thuộc của một đối tượng vào nó, thay vì khởi tạo chúng trực tiếp—điều này cho phép chúng ta thay thế các triển khai của chúng. Chúng ta sẽ khám phá mô hình Cake của Scala, cung cấp cho chúng ta một mô hình giống như DI.
Introducing Functional Patterns
Pattern 12, Tail Recursion
Đệ quy đuôi về mặt chức năng tương đương với lặp và cung cấp một cách để viết một thuật toán đệ quy mà không cần yêu cầu một khung ngăn xếp cho mỗi lần gọi đệ quy. Mặc dù chúng tôi sẽ ưu tiên các giải pháp mang tính tuyên bố hơn trong suốt cuốn sách, đôi khi cách đơn giản nhất để giải quyết một vấn đề là lặp. Ở đây, chúng tôi sẽ cho thấy cách sử dụng Đệ quy đuôi cho những tình huống đó.
Pattern 13, Mutual Recursion
Đệ quy tương hỗ là một mẫu trong đó các hàm đệ quy gọi lẫn nhau. Cũng như với đệ quy đuôi, chúng ta cần có một cách để thực hiện điều này mà không tiêu tốn khung ngăn xếp để điều đó trở nên thực tiễn. Ở đây, chúng tôi sẽ chỉ cho bạn cách sử dụng một tính năng gọi là nhảy dây để thực hiện điều đó.
Pattern 14, Filter-Map-Reduce
Lọc, ánh xạ và giảm là ba trong những hàm bậc cao thường được sử dụng nhất. Khi được sử dụng cùng nhau, chúng là một công cụ rất mạnh mẽ cho việc thao tác dữ liệu và là nguồn cảm hứng cho mô hình xử lý dữ liệu phổ biến MapReduce. Trong mẫu này, chúng ta sẽ thấy cách chúng có thể được sử dụng ở quy mô nhỏ hơn.
Pattern 15, Chain of Operations
Lập trình hàm tránh sự thay đổi trạng thái; do đó, thay vì thay đổi một cấu trúc dữ liệu, chúng ta lấy một cấu trúc dữ liệu bất biến, thực hiện các phép toán trên nó và tạo ra một cái mới. Chuỗi các phép toán xem xét những cách khác nhau để làm điều đó trong Scala và Clojure.
Pattern 16, Function Builder
Các hàm bậc cao có thể tạo ra các hàm khác bằng cách sử dụng mẫu Xây dựng Hàm. Ở đây, chúng tôi sẽ trình bày một số trường hợp phổ biến của mẫu này được tích hợp sẵn trong nhiều ngôn ngữ hàm, và chúng tôi sẽ khám phá một vài trường hợp tùy chỉnh.
Pattern 17, Memoization
Mô hình này lưu trữ kết quả của một lần gọi hàm thuần để tránh phải thực hiện một phép tính tốn kém hơn một lần.
Pattern 18, Lazy Sequence
Chuỗi lười biếng là một mẫu trong đó một chuỗi được hiện thực hóa từng bit một chỉ khi cần thiết. Điều này cho phép chúng ta tạo ra những chuỗi dài vô hạn và dễ dàng làm việc với các luồng dữ liệu.
Pattern 19, Focused Mutability
Tính biến đổi tập trung làm cho một phần mã quan trọng nhỏ sử dụng các cấu trúc dữ liệu có thể thay đổi để tối ưu hóa hiệu suất. Nhu cầu cho điều này ít phổ biến hơn bạn nghĩ. Clojure và Scala, được hỗ trợ bởi JVM, cung cấp các cơ chế rất hiệu quả để làm việc với dữ liệu không thay đổi, vì vậy tính bất biến hiếm khi là nút thắt cổ chai.
Pattern 20, Customized Control Flow
Với hầu hết các ngôn ngữ, rất khó để thêm một cách mới để điều khiển luồng vào ngôn ngữ mà không phải sửa đổi chính ngôn ngữ đó. Tuy nhiên, các ngôn ngữ hàm thường cung cấp một cách để tạo ra các trừu tượng điều khiển tùy chỉnh phù hợp với các mục đích cụ thể.
Pattern 21, Domain-Specific Language
Mô hình Ngôn ngữ Chuyên biệt cho Miền cho phép chúng ta tạo ra một ngôn ngữ được xây dựng đặc biệt để giải quyết một vấn đề cụ thể. Việc sử dụng một triển khai được thiết kế tốt của ngôn ngữ chuyên biệt cho miền là giải pháp tốt nhất cho những vấn đề thường gặp, vì nó cho phép chúng ta lập trình gần gũi với miền vấn đề. Điều này giảm bớt lượng mã mà chúng ta phải viết và sự cản trở trong việc chuyển đổi ý tưởng của chúng ta thành mã.
Copyright © 2013, The Pragmatic Bookshelf. Chapter 2
TinyWeb: Patterns Working Together
2.1 Introducing TinyWeb
Chúng ta sẽ bắt đầu hành trình của mình bằng cách xem xét một ví dụ về một chương trình sử dụng nhiều mẫu hướng đối tượng cổ điển, đó là một framework web nhỏ gọi là TinyWeb. Sau khi giới thiệu về TinyWeb, chúng ta sẽ thấy cách viết lại nó theo phong cách kết hợp giữa hướng đối tượng và hàm trong Scala. Cuối cùng, chúng ta sẽ chuyển sang một phong cách hoàn toàn hàm trong Clojure.
Hãy tập trung vào một vài mục tiêu cho ví dụ này. Mục tiêu đầu tiên là xem nhiều mẫu làm việc cùng nhau trong một mã nguồn trước khi chúng ta đi vào chi tiết hơn.
Mục thứ hai là giới thiệu các khái niệm cơ bản về Scala và Clojure cho những người chưa quen thuộc với một trong hai hoặc cả hai ngôn ngữ. Một giới thiệu đầy đủ về các ngôn ngữ vượt quá phạm vi của cuốn sách này, nhưng phần này cung cấp cho bạn đủ các kiến thức cơ bản để hiểu phần lớn mã còn lại.
Cuối cùng, chúng tôi sẽ chuyển đổi mã Java hiện có thành mã nguồn Scala hoặc Clojure. Chúng tôi sẽ thực hiện điều này bằng cách lấy phiên bản Java của TinyWeb và biến đổi nó thành Scala và Clojure từng phần một.
TinyWeb tự nó là một khuôn khổ web nhỏ theo mô hình - điều khiển - trình xem (MVC). Nó còn xa mới hoàn thiện, nhưng nó sẽ cảm thấy quen thuộc với bất kỳ ai đã làm việc với bất kỳ khuôn khổ phổ biến nào, chẳng hạn như Spring MVC. Có một điểm khác biệt nhỏ với TinyWeb: vì đây là một cuốn sách về lập trình hàm, chúng tôi sẽ cố gắng hết sức để làm việc với dữ liệu bất biến, điều này có thể khá thách thức trong Java.
2.2 TinyWeb in Java
Phiên bản Java của TinyWeb là một khung web MVC cơ bản được viết theo phong cách lập trình hướng đối tượng cổ điển. Để xử lý các yêu cầu, chúng tôi sử dụng một **Controller** được triển khai bằng cách sử dụng phương pháp Template, mà chúng tôi sẽ đề cập chi tiết trong Mô hình 6, **Thay thế phương pháp Template**. Các View được triển khai bằng cách sử dụng mẫu Chiến lược, được đề cập trong Mô hình 7, **Thay thế Chiến lược**.
Khung của chúng tôi được xây dựng xung quanh các đối tượng dữ liệu cốt lõi, HttpRequest và HttpResponse. Chúng tôi muốn những đối tượng này là bất biến và dễ làm việc, vì vậy chúng tôi sẽ xây dựng chúng sử dụng mẫu Builder đã thảo luận trong Mẫu 4, Thay thế Builder cho Đối tượng Bất biến. Builder là một cách tiêu chuẩn để có được các đối tượng bất biến trong Java.
Cuối cùng, chúng tôi có các bộ lọc yêu cầu chạy trước khi một yêu cầu được xử lý và thực hiện một số công việc trên yêu cầu, chẳng hạn như sửa đổi nó. Chúng tôi sẽ triển khai các bộ lọc này sử dụng lớp Filter, một ví dụ đơn giản của Mẫu 1, Thay thế Giao diện Chức năng. Các bộ lọc của chúng tôi cũng cho thấy cách xử lý dữ liệu thay đổi bằng cách sử dụng các đối tượng bất biến.
Toàn bộ hệ thống được tóm tắt trong hình dưới đây.
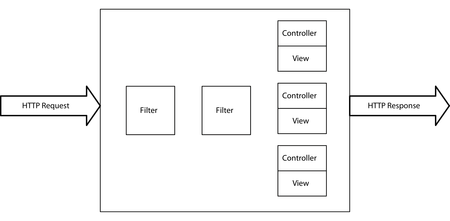
Figure 1. A TinyWeb Overview. A graphical overview of TinyWeb
Chúng ta sẽ bắt đầu với cái nhìn về các kiểu dữ liệu cốt lõi của chúng ta, HttpRequest và HttpResponse.
HttpRequest and HttpResponse
Hãy cùng khám phá mã, bắt đầu với HttpResponse. Trong ví dụ này, chúng ta chỉ cần một nội dung và mã phản hồi trong phản hồi của mình, vì vậy đó là những thuộc tính duy nhất mà chúng ta sẽ thêm vào. Khối mã sau đây cho thấy cách chúng ta có thể triển khai lớp này. Ở đây, chúng ta sử dụng trình xây dựng linh hoạt của loại đã trở nên phổ biến trong cuốn sách kinh điển Java, Effective Java [Blo08].
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/HttpResponse.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | public class HttpResponse { |
| | private final String body; |
| | private final Integer responseCode; |
| | |
| | public String getBody() { |
| | return body; |
| | } |
| | |
| | public Integer getResponseCode() { |
| | return responseCode; |
| | } |
| | |
| | private HttpResponse(Builder builder) { |
| | body = builder.body; |
| | responseCode = builder.responseCode; |
| | } |
| | |
| | public static class Builder { |
| | private String body; |
| | private Integer responseCode; |
| | |
| | public Builder body(String body) { |
| | this.body = body; |
| | return this; |
| | } |
| | |
| | public Builder responseCode(Integer responseCode) { |
| | this.responseCode = responseCode; |
| | return this; |
| | } |
| | |
| | public HttpResponse build() { |
| | return new HttpResponse(this); |
| | } |
| | |
| | public static Builder newBuilder() { |
| | return new Builder(); |
| | } |
| | } |
| | } |
Cách tiếp cận này bao encapsulates tất cả sự biến đổi bên trong một đối tượng Builder, mà sau đó xây dựng một HttpResponse không thể thay đổi. Mặc dù điều này mang lại cho chúng ta một cách làm sạch khi làm việc với dữ liệu không thay đổi, nhưng nó khá dài dòng. Ví dụ, chúng ta có thể tạo một yêu cầu kiểm tra đơn giản bằng cách sử dụng mã này:
| | HttpResponse testResponse = HttpResponse.Builder.newBuilder() |
| | .responseCode(200) |
| | .body("responseBody") |
| | .build(); |
Nếu không sử dụng Builder, chúng ta sẽ cần truyền tất cả các tham số trong constructor. Điều này là chấp nhận được cho ví dụ nhỏ của chúng ta, nhưng thực tiễn này trở nên khó quản lý khi làm việc với các lớp lớn hơn. Một lựa chọn khác là sử dụng lớp theo kiểu Java Bean với các phương thức getter và setter, nhưng điều đó sẽ yêu cầu tính biến đổi.
Hãy tiếp tục và nhanh chóng xem qua HttpRequest. Vì lớp này tương tự như HttpResponse (mặc dù cho phép chúng ta thiết lập một thân yêu cầu, tiêu đề và một đường dẫn), chúng ta sẽ không lặp lại mã hoàn toàn. Tuy nhiên, có một tính năng đáng đề cập.
Để hỗ trợ các bộ lọc yêu cầu "chỉnh sửa" yêu cầu đến, chúng ta cần tạo một yêu cầu mới dựa trên yêu cầu hiện có, vì các đối tượng yêu cầu của chúng ta không thể thay đổi. Chúng ta sẽ sử dụng builderFrom để làm điều đó. Phương thức này nhận một HttpRequest hiện có và sử dụng nó để thiết lập các giá trị khởi đầu cho một trình xây dựng mới. Mã cho builderFrom như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/HttpRequest.java | |
| | public static Builder builderFrom(HttpRequest request) { |
| | Builder builder = new Builder(); |
| | builder.path(request.getPath()); |
| | builder.body(request.getBody()); |
| | |
| | Map<String, String> headers = request.getHeaders(); |
| | for (String headerName : headers.keySet()) |
| | builder.addHeader(headerName, |
| | headers.get(headerName)); |
| | |
| | return builder; |
| | } |
Điều này có thể có vẻ lãng phí, nhưng JVM là một phép màu của kỹ thuật phần mềm hiện đại. Nó có khả năng thu gom rác cho các đối tượng ngắn hạn một cách rất hiệu quả, vì vậy phong cách lập trình này hoạt động rất tốt trong hầu hết các lĩnh vực.
Immutability: Not Just for Functional ProgrammersLập trình viên có kinh nghiệm về lập trình hướng đối tượng có thể phàn nàn về nỗ lực bổ sung để tạo ra các đối tượng bất biến, đặc biệt nếu chúng ta làm điều đó "chỉ để theo hướng chức năng." Tuy nhiên, dữ liệu bất biến không chỉ xuất phát từ lập trình chức năng; đó là một thực tiễn tốt có thể giúp chúng ta viết mã sạch hơn.
Một loại lỗi phần mềm lớn liên quan đến việc một phần mã sửa đổi dữ liệu ở phần khác theo cách không mong đợi. Loại lỗi này trở nên nghiêm trọng hơn trong thế giới đa nhân mà chúng ta đang sống hiện nay. Bằng cách làm cho dữ liệu của chúng ta trở nên không thay đổi, chúng ta có thể hoàn toàn tránh được loại lỗi này.
Sử dụng dữ liệu không thay đổi là một lời khuyên thường được nhắc đến trong thế giới Java; nó được đề cập trong cuốn Effective Java [Blo08]—Mục 15: Giảm thiểu tính biến đổi, cùng với nhiều nơi khác, nhưng nó hiếm khi được tuân theo. Điều này chủ yếu do thực tế là Java không được thiết kế với tính bất biến trong tâm trí, vì vậy cần rất nhiều nỗ lực của lập trình viên để đạt được điều đó.
Tuy nhiên, một số thư viện phổ biến và chất lượng cao, như Joda-Time và thư viện collections của Google, cung cấp hỗ trợ tuyệt vời cho việc lập trình với dữ liệu bất biến. Thực tế là cả hai thư viện phổ biến này đều cung cấp các thay thế cho chức năng có sẵn trong thư viện tiêu chuẩn của Java cho thấy tính hữu ích của dữ liệu bất biến.
May mắn thay, cả Scala và Clojure đều có hỗ trợ tốt hơn nhiều cho dữ liệu bất biến, đến mức thường thì việc sử dụng dữ liệu thay đổi lại khó hơn so với dữ liệu bất biến.
Views and Strategy
Hãy tiếp tục chuyến tham quan TinyWeb với cái nhìn về việc xử lý giao diện. Trong một khung đầy đủ tính năng, chúng ta sẽ bao gồm một số cách để tích hợp các engine mẫu vào giao diện của chúng ta, nhưng đối với TinyWeb, chúng ta sẽ chỉ giả định rằng chúng ta đang tạo ra nội dung phản hồi hoàn toàn bằng cách sử dụng thao tác chuỗi.
Trước tiên, chúng ta cần một giao diện View, mà có một phương thức duy nhất, render. Phương thức render nhận vào một mô hình dưới dạng Map<String, List<String>>, đại diện cho các thuộc tính và giá trị của mô hình. Chúng ta sẽ sử dụng List<String> cho các giá trị của mình để một thuộc tính đơn lẻ có thể có nhiều giá trị. Nó trả về một String đại diện cho giao diện đã được kết xuất.
Giao diện View nằm trong đoạn mã sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/View.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | public interface View { |
| | public String render(Map<String, List<String>> model); |
| | } |
Tiếp theo, chúng ta cần hai lớp được thiết kế để làm việc cùng nhau bằng cách sử dụng mẫu Chiến lược: StrategyView và RenderingStrategy.
`RenderingStrategy` chịu trách nhiệm thực hiện công việc thực sự của việc hiển thị một bố cục được thực hiện bởi người sử dụng khuôn khổ. Nó là một thể hiện của lớp `Strategy` trong mẫu chiến lược, và mã nguồn của nó như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/RenderingStrategy.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | public interface RenderingStrategy { |
| | |
| | public String renderView(Map<String, List<String>> model); |
| | |
| | } |
Bây giờ hãy xem xét lớp phân công cho RenderingStrategy, đó là StrategyView. Lớp này được thực hiện bởi framework và chăm sóc việc xử lý đúng cách các ngoại lệ được ném ra từ RenderingStrategy. Mã nguồn của nó như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/StrategyView.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | public class StrategyView implements View { |
| | |
| | private RenderingStrategy viewRenderer; |
| | |
| | public StrategyView(RenderingStrategy viewRenderer) { |
| | this.viewRenderer = viewRenderer; |
| | } |
| | |
| | @Override |
| | public String render(Map<String, List<String>> model) { |
| | try { |
| | return viewRenderer.renderView(model); |
| | } catch (Exception e) { |
| | throw new RenderingException(e); |
| | } |
| | } |
| | } |
Để triển khai một cái nhìn, người dùng framework tạo một lớp con mới của RenderingStrategy với logic hiển thị đúng, và framework sẽ chèn nó vào StrategyView.
Trong ví dụ đơn giản này, StrategyView đóng vai trò tối thiểu. Nó chỉ đơn giản là nuốt các ngoại lệ và bọc chúng trong RenderingException để có thể được xử lý đúng cách ở cấp cao hơn. Một khung hoàn chỉnh hơn có thể sử dụng StrategyView như một điểm tích hợp cho nhiều công cụ kết xuất khác nhau, trong số những thứ khác, nhưng chúng ta sẽ giữ cho nó đơn giản ở đây.
Controllers and Template Method
Tiếp theo là bộ điều khiển của chúng ta. Bộ điều khiển tự nó là một giao diện đơn giản với một phương thức duy nhất, handleRequest, nhận vào một HttpRequest và trả về một HttpResponse. Mã cho giao diện như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/Controller.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | public interface Controller { |
| | public HttpResponse handleRequest(HttpRequest httpRequest); |
| | } |
Chúng tôi sẽ sử dụng mẫu phương thức Template để người dùng có thể triển khai các bộ điều khiển của riêng họ. Lớp trung tâm cho việc triển khai này là TemplateController, lớp này có một phương thức trừu tượng doRequest, như được hiển thị trong mã sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/TemplateController.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | public abstract class TemplateController implements Controller { |
| | private View view; |
| | public TemplateController(View view) { |
| | this.view = view; |
| | } |
| | |
| | public HttpResponse handleRequest(HttpRequest request) { |
| | Integer responseCode = 200; |
| | String responseBody = ""; |
| | |
| | try { |
| | Map<String, List<String>> model = doRequest(request); |
| | responseBody = view.render(model); |
| | } catch (ControllerException e) { |
| | responseCode = e.getStatusCode(); |
| | } catch (RenderingException e) { |
| | responseCode = 500; |
| | responseBody = "Exception while rendering."; |
| | } catch (Exception e) { |
| | responseCode = 500; |
| | } |
| | |
| | return HttpResponse.Builder.newBuilder().body(responseBody) |
| | .responseCode(responseCode).build(); |
| | } |
| | protected abstract Map<String, List<String>> doRequest(HttpRequest request); |
| | } |
Để triển khai một bộ điều khiển, người dùng của framework mở rộng TemplateController và triển khai phương thức doRequest của nó.
Cả mẫu phương thức mẫu mà chúng tôi sử dụng cho các bộ điều khiển và mẫu chiến lược mà chúng tôi sử dụng cho các chế độ xem đều hỗ trợ các tác vụ tương tự. Chúng cho phép một số mã chung, có thể trong một thư viện hoặc framework, phân công cho một đoạn mã khác nhằm thực hiện một tác vụ cụ thể. Mẫu phương thức mẫu thực hiện điều này bằng cách sử dụng kế thừa, trong khi mẫu chiến lược thực hiện nó bằng cách sử dụng hợp thành.
Trong thế giới chức năng, chúng ta sẽ dựa nhiều vào sự kết hợp, điều này cũng là thực hành tốt trong thế giới hướng đối tượng. Tuy nhiên, đó sẽ là sự kết hợp của các hàm thay vì sự kết hợp của các đối tượng.
Filter and Functional Interface
Cuối cùng, hãy xem xét Filter. Lớp Filter là một Giao diện Chức năng cho phép chúng ta thực hiện một hành động nào đó trên HttpRequest trước khi nó được xử lý. Ví dụ, chúng ta có thể muốn ghi lại một số thông tin về yêu cầu hoặc thậm chí thêm một tiêu đề. Nó có một phương thức duy nhất, doFilter, nhận HttpRequest và trả về một phiên bản đã được lọc của nó.
Nếu một Filter của cá nhân cần thực hiện một hành động nào đó để sửa đổi một yêu cầu, nó chỉ cần tạo ra một yêu cầu mới dựa trên yêu cầu hiện có và trả về nó. Điều này cho phép chúng ta làm việc với một HttpRequest không thay đổi nhưng mang lại ảo giác rằng nó có thể được thay đổi.
Mã cho Bộ lọc như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/Filter.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | public interface Filter { |
| | public HttpRequest doFilter(HttpRequest request); |
| | } |
Bây giờ, chúng ta đã thấy tất cả các thành phần của TinyWeb, hãy xem chúng kết hợp với nhau như thế nào.
Tying It All Together
Để kết hợp mọi thứ lại với nhau, chúng ta sẽ sử dụng lớp chính, TinyWeb. Lớp này nhận hai tham số khởi tạo. Tham số đầu tiên là một Map, trong đó các khóa là các String đại diện cho các đường dẫn yêu cầu và các giá trị là các đối tượng Controller. Tham số thứ hai là một danh sách các Filter sẽ được chạy trên tất cả các yêu cầu trước khi chúng được chuyển đến bộ điều khiển thích hợp.
Lớp TinyWeb có một phương thức công khai duy nhất, handleRequest, nhận vào HttpRequest. Phương thức handleRequest sau đó xử lý yêu cầu qua các bộ lọc, tìm kiếm bộ điều khiển thích hợp để xử lý và trả về HttpResponse kết quả. Mã nguồn như dưới đây:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/TinyWeb.java | |
| | package com.mblinn.oo.tinyweb; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | public class TinyWeb { |
| | private Map<String, Controller> controllers; |
| | private List<Filter> filters; |
| | |
| | public TinyWeb(Map<String, Controller> controllers, List<Filter> filters) { |
| | this.controllers = controllers; |
| | this.filters = filters; |
| | } |
| | |
| | public HttpResponse handleRequest(HttpRequest httpRequest) { |
| | |
| | HttpRequest currentRequest = httpRequest; |
| | for (Filter filter : filters) { |
| | currentRequest = filter.doFilter(currentRequest); |
| | } |
| | |
| | Controller controller = controllers.get(currentRequest.getPath()); |
| | |
| | if (null == controller) |
| | return null; |
| | |
| | return controller.handleRequest(currentRequest); |
| | } |
| | } |
Một framework web Java đầy đủ tính năng sẽ không trực tiếp công khai một lớp như thế này như là phần cơ sở của framework. Thay vào đó, nó sẽ sử dụng một số tệp cấu hình và chú thích để kết nối mọi thứ lại với nhau. Tuy nhiên, chúng tôi sẽ dừng lại việc thêm vào TinyWeb ở đây và chuyển sang một ví dụ sử dụng nó.
Using TinyWeb
Hãy triển khai một chương trình ví dụ nhận một HttpRequest với danh sách tên cách nhau bằng dấu phẩy làm giá trị và trả về một thân chứa đầy lời chào thân thiện cho những tên đó. Chúng ta cũng sẽ thêm một bộ lọc để ghi lại đường dẫn đã được yêu cầu.
Chúng ta sẽ bắt đầu bằng cách xem GreetingController. Khi bộ điều khiển nhận một HttpRequest, nó lấy nội dung của yêu cầu, phân tách nó theo dấu phẩy và coi mỗi phần tử trong nội dung đã phân tách là một cái tên. Sau đó, nó tạo ra một lời chào thân thiện ngẫu nhiên cho mỗi tên và đưa các tên vào mô hình dưới khóa greetings. Mã cho GreetingController như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/example/GreetingController.java | |
| | package com.mblinn.oo.tinyweb.example; |
| | import java.util.ArrayList; |
| | import java.util.HashMap; |
| | import java.util.List; |
| | import java.util.Map; |
| | import java.util.Random; |
| | |
| | import com.mblinn.oo.tinyweb.HttpRequest; |
| | import com.mblinn.oo.tinyweb.TemplateController; |
| | import com.mblinn.oo.tinyweb.View; |
| | |
| | public class GreetingController extends TemplateController { |
| | private Random random; |
| | public GreetingController(View view) { |
| | super(view); |
| | random = new Random(); |
| | } |
| | |
| | @Override |
| | public Map<String, List<String>> doRequest(HttpRequest httpRequest) { |
| | Map<String, List<String>> helloModel = |
| | new HashMap<String, List<String>>(); |
| | helloModel.put("greetings", |
| | generateGreetings(httpRequest.getBody())); |
| | return helloModel; |
| | } |
| | |
| | private List<String> generateGreetings(String namesCommaSeperated) { |
| | String[] names = namesCommaSeperated.split(","); |
| | List<String> greetings = new ArrayList<String>(); |
| | for (String name : names) { |
| | greetings.add(makeGreeting(name)); |
| | } |
| | return greetings; |
| | } |
| | |
| | private String makeGreeting(String name) { |
| | String[] greetings = |
| | { "Hello", "Greetings", "Salutations", "Hola" }; |
| | String greetingPrefix = greetings[random.nextInt(4)]; |
| | return String.format("%s, %s", greetingPrefix, name); |
| | } |
| | } |
Tiếp theo, hãy cùng xem xét lớp GreetingRenderingStrategy. Lớp này lặp qua danh sách các lời chào thân thiện được tạo ra bởi bộ điều khiển và đặt mỗi lời chào vào thẻ <h2>. Sau đó, nó thêm vào phía trước các lời chào với một thẻ <h1> chứa nội dung "Những Lời Chào Thân Thiện:", như đoạn mã sau đây cho thấy:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/example/GreetingRenderingStrategy.java | |
| | package com.mblinn.oo.tinyweb.example; |
| | |
| | import java.util.List; |
| | import java.util.Map; |
| | |
| | import com.mblinn.oo.tinyweb.RenderingStrategy; |
| | |
| | public class GreetingRenderingStrategy implements RenderingStrategy { |
| | |
| | @Override |
| | public String renderView(Map<String, List<String>> model) { |
| | List<String> greetings = model.get("greetings"); |
| | StringBuffer responseBody = new StringBuffer(); |
| | responseBody.append("<h1>Friendly Greetings:</h1>\n"); |
| | for (String greeting : greetings) { |
| | responseBody.append( |
| | String.format("<h2>%s</h2>\n", greeting)); |
| | |
| | } |
| | return responseBody.toString(); |
| | } |
| | |
| | } |
Cuối cùng, hãy xem một ví dụ về bộ lọc. Lớp LoggingFilter chỉ ghi lại đường dẫn của yêu cầu mà nó đang được thực thi. Mã của nó như sau:
| JavaExamples/src/main/java/com/mblinn/oo/tinyweb/example/LoggingFilter.java | |
| | package com.mblinn.oo.tinyweb.example; |
| | |
| | import com.mblinn.oo.tinyweb.Filter; |
| | import com.mblinn.oo.tinyweb.HttpRequest; |
| | |
| | public class LoggingFilter implements Filter { |
| | |
| | @Override |
| | public HttpRequest doFilter(HttpRequest request) { |
| | System.out.println("In Logging Filter - request for path: " |
| | + request.getPath()); |
| | return request; |
| | } |
| | |
| | } |
Kết nối một bộ thử nghiệm đơn giản mà kết nối mọi thứ vào một TinyWeb, gửi một HttpRequest tới nó, và sau đó in phản hồi ra bảng điều khiển cho chúng ta kết quả sau đây. Điều này cho thấy mọi thứ đang hoạt động đúng cách:
| | In Logging Filter - request for path: greeting/ |
| | responseCode: 200 |
| | responseBody: |
| | <h1>Friendly Greetings:</h1> |
| | <h2>Hola, Mike</h2> |
| | <h2>Greetings, Joe</h2> |
| | <h2>Hola, John</h2> |
| | <h2>Salutations, Steve</h2> |
Bây giờ mà chúng ta đã xem qua framework TinyWeb trong Java, hãy cùng xem cách chúng ta sẽ sử dụng một số thay thế hàm cho các mẫu lập trình hướng đối tượng mà chúng ta sẽ khám phá trong cuốn sách này. Điều này sẽ mang lại cho chúng ta một TinyWeb có chức năng tương đương nhưng được viết với ít dòng mã hơn và theo phong cách khai báo dễ đọc hơn.
2.3 TinyWeb in Scala
Hãy lấy TinyWeb và chuyển đổi nó thành Scala. Chúng ta sẽ thực hiện điều này từng chút một để có thể cho thấy cách mã Scala của chúng ta có thể hoạt động với mã Java hiện có. Hình dạng tổng thể của khung sẽ tương tự như phiên bản Java, nhưng chúng ta sẽ tận dụng một số tính năng hàm của Scala để làm cho mã ngắn gọn hơn.
Step One: Changing Views
Chúng ta sẽ bắt đầu với mã nhìn của mình. Trong Java, chúng ta đã sử dụng mẫu Chiến lược cổ điển. Trong Scala, chúng ta sẽ giữ nguyên mẫu Chiến lược, nhưng sẽ sử dụng các hàm bậc cao cho các triển khai chiến lược của chúng ta. Chúng ta cũng sẽ thấy một số lợi ích của biểu thức so với câu lệnh trong việc điều khiển luồng.
Sự thay đổi lớn nhất mà chúng tôi sẽ thực hiện là đối với mã khả năng hiển thị. Thay vì sử dụng Giao diện Hàm dưới dạng RenderingStrategy, chúng tôi sẽ sử dụng một hàm bậc cao. Chúng tôi đi vào chi tiết về sự thay thế này trong Mẫu 1, Thay thế Giao diện Hàm.
Dưới đây là mã xem đã được sửa đổi của chúng tôi trong vẻ đẹp đầy đủ chức năng:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/stepone/View.scala | |
| | package com.mblinn.mbfpp.oo.tinyweb.stepone |
| | import com.mblinn.oo.tinyweb.RenderingException |
| | |
| | trait View { |
| | def render(model: Map[String, List[String]]): String |
| | } |
| | class FunctionView(viewRenderer: (Map[String, List[String]]) => String) |
| | extends View { |
| | def render(model: Map[String, List[String]]) = |
| | try |
| | viewRenderer(model) |
| | catch { |
| | case e: Exception => throw new RenderingException(e) |
| | } |
| | } |
Chúng ta bắt đầu với đặc tính View của mình. Nó định nghĩa một phương thức duy nhất, render, mà nhận một bản đồ đại diện cho dữ liệu trong mô hình của chúng ta và trả về một String đã được kết xuất.
| | trait View { |
| | def render(model: Map[String, String]): String |
| | } |
Tiếp theo, hãy xem xét phần thân của FunctionView. Đoạn mã dưới đây khai báo một lớp có một hàm khởi tạo với một tham số duy nhất, viewRenderer, cái mà thiết lập một trường không thể thay đổi với cùng tên.
| | class FunctionView(viewRenderer: (Map[String, String]) => String) extends View { |
| | classBody |
| | } |
Tham số hàm viewRenderer có một chú thích kiểu dữ liệu khá kỳ lạ, (Map[String, String]) => String. Đây là một kiểu hàm. Nó cho biết rằng viewRenderer là một hàm nhận một Map[String, String] và trả về một String, giống như renderView trong RenderingStrategy của chúng ta.
Tiếp theo, hãy xem xét phương thức render bản thân nó. Như chúng ta có thể thấy từ mã bên dưới, nó nhận vào một mô hình và chạy nó qua hàm viewRender .
| | def render(model: Map[String, String]) = |
| | try |
| | viewRenderer(model) |
| | catch { |
| | case e: Exception => throw new RenderingException(e) |
| | } |
Lưu ý rằng không có từ khoá return nào trong đoạn mã này? Điều này minh họa một khía cạnh quan trọng khác của lập trình hàm. Trong thế giới lập trình hàm, chúng ta chủ yếu lập trình bằng các biểu thức. Giá trị của một hàm chỉ là giá trị của biểu thức cuối cùng trong nó.
Trong ví dụ này, biểu thức đó thực sự là một khối try. Nếu không có ngoại lệ nào được ném ra, khối try sẽ nhận giá trị của nhánh chính; nếu không, nó sẽ nhận giá trị của trường hợp phù hợp trong nhánh catch.
Nếu chúng ta muốn cung cấp một giá trị mặc định thay vì bao bọc ngoại lệ trong một RenderException, chúng ta có thể làm như vậy chỉ bằng cách để nhánh trường hợp thích hợp nhận giá trị mặc định của chúng ta, như minh họa trong mã sau:
| | try |
| | viewRenderer(model) |
| | catch { |
| | case e: Exception => "" |
| | } |
Bây giờ khi một ngoại lệ được bắt, khối try nhận giá trị của chuỗi rỗng.
Step Two: A Controller First Cut
Bây giờ hãy xem xét việc chuyển đổi mã điều khiển của chúng ta sang Scala. Trong Java, chúng ta đã sử dụng giao diện Controller và lớp TemplateController. Các bộ điều khiển riêng lẻ được triển khai bằng cách kế thừa từ TemplateController.
Trong Scala, chúng ta dựa vào việc hợp nhất hàm giống như chúng ta đã làm với các view bằng cách truyền vào một hàm doRequest khi chúng ta tạo một Controller.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/steptwo/Controller.scala | |
| | package com.mblinn.mbfpp.oo.tinyweb.steptwo |
| | |
| | import com.mblinn.oo.tinyweb.HttpRequest |
| | import com.mblinn.oo.tinyweb.HttpResponse |
| | import com.mblinn.oo.tinyweb.ControllerException |
| | import com.mblinn.oo.tinyweb.RenderingException |
| | |
| | trait Controller { |
| | def handleRequest(httpRequest: HttpRequest): HttpResponse |
| | } |
| | |
| | class FunctionController(view: View, doRequest: (HttpRequest) => |
| | Map[String, List[String]] ) extends Controller { |
| | |
| | def handleRequest(request: HttpRequest): HttpResponse = { |
| | var responseCode = 200; |
| | var responseBody = ""; |
| | |
| | try { |
| | val model = doRequest(request) |
| | responseBody = view.render(model) |
| | } catch { |
| | case e: ControllerException => |
| | responseCode = e.getStatusCode() |
| | case e: RenderingException => |
| | responseCode = 500 |
| | responseBody = "Exception while rendering." |
| | case e: Exception => |
| | responseCode = 500 |
| | } |
| | |
| | HttpResponse.Builder.newBuilder() |
| | .body(responseBody).responseCode(responseCode).build() |
| | } |
| | } |
Mã này sẽ trông tương đối giống với mã trong view của chúng ta. Đây là một bản dịch tương đối sát nghĩa từ Java sang Scala, nhưng nó không thực sự mang tính hàm chức năng vì chúng ta đang sử dụng câu lệnh try-catch để thiết lập các giá trị của responseCode và responseBody.
Chúng tôi cũng đang tái sử dụng Java HttpRequest và HttpResponse của mình. Scala cung cấp một cách ngắn gọn hơn để tạo các lớp chứa dữ liệu này, gọi là case classes. Chuyển sang sử dụng try-catch như một câu lệnh, cũng như sử dụng case classes, có thể giúp giảm đáng kể mã nguồn của chúng tôi.
Chúng tôi sẽ thực hiện cả hai thay đổi này trong quá trình chuyển đổi tiếp theo của mình.
Immutable HttpRequest and HttpResponse
Hãy bắt đầu bằng cách chuyển sang sử dụng các lớp trường hợp thay vì sử dụng mẫu Builder. Nó đơn giản như mã dưới đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/stepthree/HttpData.scala | |
| | package com.mblinn.mbfpp.oo.tinyweb.stepthree |
| | |
| | case class HttpRequest(headers: Map[String, String], body: String, path: String) |
| | case class HttpResponse(body: String, responseCode: Integer) |
Chúng ta có thể dễ dàng tạo ra các đối tượng HttpRequest và HttpResponse mới, như kết quả REPL sau đây cho thấy:
| | scala> val request = HttpRequest(Map("X-Test" -> "Value"), "requestBody", "/test") |
| | request: com.mblinn.mbfpp.oo.tinyweb.stepfour.HttpRequest = |
| | HttpRequest(Map(X-Test -> Value),requestBody,/test) |
| | |
| | scala> val response = HttpResponse("requestBody", 200) |
| | response: com.mblinn.mbfpp.oo.tinyweb.stepfour.HttpResponse = |
| | HttpResponse(requestBody,200) |
Nhìn thoáng qua, điều này có thể giống như việc sử dụng một lớp Java với các tham số khởi tạo, ngoại trừ việc chúng ta không cần sử dụng từ khóa new. Tuy nhiên, trong Mẫu 4, Thay thế Builder cho Đối tượng Bất biến, chúng ta đi sâu hơn và thấy rằng khả năng của Scala trong việc cung cấp các tham số mặc định trong một bộ khởi tạo, tính bất biến tự nhiên của các lớp case, và khả năng dễ dàng tạo một thể hiện mới của một lớp case từ một thể hiện hiện có giúp chúng đáp ứng được ý định của mẫu Builder.
Hãy cùng xem xét thay đổi thứ hai của chúng ta. Bởi vì một khối try-catch trong Scala có giá trị, chúng ta có thể sử dụng nó như một biểu thức thay vì như một câu lệnh. Điều này có thể có vẻ hơi lạ vào đầu, nhưng điều quan trọng là chúng ta có thể sử dụng thực tế rằng try-catch trong Scala là một biểu thức để đơn giản hóa khối try-catch nhận giá trị của HttpResponse mà chúng ta đang trả về. Mã để thực hiện điều này như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/stepthree/Controller.scala | |
| | package com.mblinn.mbfpp.oo.tinyweb.stepthree |
| | import com.mblinn.oo.tinyweb.ControllerException |
| | import com.mblinn.oo.tinyweb.RenderingException |
| | |
| | trait Controller { |
| | def handleRequest(httpRequest: HttpRequest): HttpResponse |
| | } |
| | class FunctionController(view: View, doRequest: (HttpRequest) => |
| | Map[String, List[String]] ) extends Controller { |
| | def handleRequest(request: HttpRequest): HttpResponse = |
| | try { |
| | val model = doRequest(request) |
| | val responseBody = view.render(model) |
| | HttpResponse(responseBody, 200) |
| | } catch { |
| | case e: ControllerException => |
| | HttpResponse("", e.getStatusCode) |
| | case e: RenderingException => |
| | HttpResponse("Exception while rendering.", 500) |
| | case e: Exception => |
| | HttpResponse("", 500) |
| | } |
| | } |
Phong cách lập trình này có một vài lợi ích. Đầu tiên, chúng ta đã loại bỏ một vài biến không cần thiết, responseCode và responseBody. Thứ hai, chúng ta đã giảm số dòng mã mà lập trình viên cần quét để hiểu xem HttpRequest nào chúng ta đang trả về từ toàn bộ phương thức xuống còn một dòng.
Thay vì theo dõi các giá trị của responseCode và responseBody từ đầu phương thức qua khối try và cuối cùng vào HttpResponse, chúng ta chỉ cần xem xét phần thích hợp của khối try để hiểu giá trị cuối cùng của HttpResponse. Những thay đổi này kết hợp lại để mang đến cho chúng ta mã dễ đọc và ngắn gọn hơn.
Tying It Together
Bây giờ hãy thêm vào lớp kết nối tất cả lại với nhau, TinyWeb. Giống như phiên bản Java, TinyWeb được khởi tạo với một bản đồ các Controller và một bản đồ các bộ lọc. Không giống như Java, chúng ta không định nghĩa một lớp cho bộ lọc; chúng ta chỉ đơn giản sử dụng một danh sách các hàm bậc cao!
Cũng giống như phiên bản Java, Scala TinyWeb có một phương thức duy nhất, handleRequest, nhận vào một HttpRequest. Thay vì trả về một HttpResponse trực tiếp, chúng ta trả về một Option[HttpResponse], giúp chúng ta có cách xử lý gọn gàng khi không tìm thấy bộ điều khiển cho một yêu cầu cụ thể. Mã cho Scala TinyWeb như dưới đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/stepfour/Tinyweb.scala | |
| | package com.mblinn.mbfpp.oo.tinyweb.stepfour |
| | class TinyWeb(controllers: Map[String, Controller], |
| | filters: List[(HttpRequest) => HttpRequest]) { |
| | |
| | def handleRequest(httpRequest: HttpRequest): Option[HttpResponse] = { |
| | val composedFilter = filters.reverse.reduceLeft( |
| | (composed, next) => composed compose next) |
| | val filteredRequest = composedFilter(httpRequest) |
| | val controllerOption = controllers.get(filteredRequest.path) |
| | controllerOption map { controller => controller.handleRequest(filteredRequest) } |
| | } |
| | } |
Hãy xem xét nó chi tiết hơn bắt đầu với định nghĩa lớp.
| | class TinyWeb(controllers: Map[String, Controller], |
| | filters: List[(HttpRequest) => HttpRequest]) { |
| | classBody |
| | } |
Ở đây, chúng tôi đang định nghĩa một lớp nhận hai đối số tạo, một bản đồ các bộ điều khiển và một danh sách các bộ lọc. Lưu ý loại của đối số filters, List[(HttpRequest) => HttpRequest]. Điều này cho biết rằng filters là một danh sách các hàm từ HttpRequest đến HttpRequest.
Tiếp theo, chúng ta hãy xem chữ ký của phương thức handleRequest.
| | def handleRequest(httpRequest: HttpRequest): Option[HttpResponse] = { |
| | functionBody |
| | } |
Như đã quảng cáo, chúng tôi đang trả về một Option[HttpResponse] thay vì một HttpResponse. Loại Option là một loại chứa với hai loại con, Some và None. Nếu chúng ta có một giá trị để lưu trữ trong đó, chúng ta có thể lưu trữ nó trong một thể hiện của Some; nếu không, chúng ta sử dụng None để chỉ ra rằng chúng ta không có giá trị thực sự. Chúng tôi sẽ đề cập đến Option chi tiết hơn trong Mẫu 8, Thay Thế Đối Tượng Null.
Bây giờ chúng ta đã xem framework TinyWeb, hãy cùng nhìn nó hoạt động. Chúng ta sẽ sử dụng cùng một ví dụ từ phần Java, trả về một danh sách những lời chào thân thiện. Tuy nhiên, vì đây là Scala, chúng ta có thể thử nghiệm ví dụ của mình trong REPL khi tiến hành. Hãy bắt đầu với mã xem của chúng ta.
Using Scala TinyWeb
Hãy cùng xem xét việc sử dụng framework TinyWeb của chúng tôi trong Scala.
Chúng ta sẽ bắt đầu bằng cách tạo một FunctionView và hàm render mà chúng ta sẽ kết hợp vào đó. Mã dưới đây tạo ra hàm này, mà chúng ta sẽ đặt tên là greetingViewRenderer, và FunctionView tương ứng với nó:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/example/Example.scala | |
| | def greetingViewRenderer(model: Map[String, List[String]]) = |
| | "<h1>Friendly Greetings:%s".format( |
| | model |
| | getOrElse("greetings", List[String]()) |
| | map(renderGreeting) |
| | mkString ", ") |
| | |
| | private def renderGreeting(greeting: String) = |
| | "<h2>%s</h2>".format(greeting) |
| | |
| | def greetingView = new FunctionView(greetingViewRenderer) |
Chúng tôi đang sử dụng một vài thành phần mới của Scala ở đây. Đầu tiên, chúng tôi giới thiệu phương thức map, cho phép chúng tôi áp dụng một hàm cho tất cả các phần tử trong một chuỗi và trả về một chuỗi mới. Thứ hai, chúng tôi đang sử dụng một chút "đường dẫn cú pháp" mà Scala cung cấp, cho phép chúng tôi coi bất kỳ phương thức nào với một đối số đơn là một toán tử trung gian. Đối tượng ở bên trái của toán tử được coi là người nhận của cuộc gọi phương thức, và đối tượng ở bên phải là đối số.
Cú pháp này có nghĩa là chúng ta có thể bỏ qua cú pháp dấu chấm quen thuộc khi làm việc với Scala. Ví dụ, hai cách sử dụng của `map` bên dưới là tương đương:
| | scala> val greetings = List("Hi!", "Hola", "Aloha") |
| | greetings: List[java.lang.String] |
| | |
| | scala> greetings.map(renderGreeting) |
| | res0: List[String] = List(<h2>Hi!</h2>, <h2>Hola</h2>, <h2>Aloha</h2>) |
| | |
| | scala> greetings map renderGreeting |
| | res1: List[String] = List(<h2>Hi!</h2>, <h2>Hola</h2>, <h2>Aloha</h2>) |
Vì Scala là một ngôn ngữ lai, nó có cả hàm và phương thức. Phương thức được định nghĩa bằng cách sử dụng từ khóa def, như trong đoạn mã sau:
| | scala> def addOneMethod(num: Int) = num + 1 |
| | addOneMethod: (num: Int)Int |
Chúng ta có thể tạo một hàm và đặt tên cho nó bằng cách sử dụng cú pháp hàm ẩn danh của Scala, gán hàm kết quả cho một val, như trong đoạn mã sau:
| | scala> val addOneFunction = (num: Int) => num + 1 |
| | addOneFunction: Int => Int = <function1> |
Chúng ta hầu như luôn có thể sử dụng các phương thức như là các hàm bậc cao. Ví dụ, ở đây chúng ta truyền cả phương thức và phiên bản hàm của addOne vào map .
| | scala> val someInts = List(1, 2, 3) |
| | someInts: List[Int] = List(1, 2, 3) |
| | |
| | scala> someInts map addOneMethod |
| | res1: List[Int] = List(2, 3, 4) |
| | |
| | scala> someInts map addOneFunction |
| | res2: List[Int] = List(2, 3, 4) |
Vì định nghĩa phương thức có cú pháp rõ ràng hơn, chúng tôi sử dụng chúng khi cần định nghĩa một hàm, thay vì sử dụng cú pháp hàm. Khi cần chuyển đổi thủ công một phương thức thành một hàm, chúng tôi có thể làm điều đó với toán tử gạch dưới, như chúng tôi đã làm trong phiên REPL sau đây:
| | scala> addOneMethod _ |
| | res3: Int => Int = <function1> |
Nhưng nhu cầu để làm điều này rất hiếm, hầu hết Scala đủ thông minh để tự động thực hiện chuyển đổi.
Bây giờ chúng ta hãy xem qua mã của bộ điều khiển. Ở đây, chúng ta tạo ra hàm handleGreetingRequest để truyền vào Controller. Như một trợ giúp, chúng ta sử dụng makeGreeting, hàm này nhận vào một tên và tạo ra một lời chào thân thiện ngẫu nhiên.
Bên trong hàm handleGreetingRequest, chúng tôi tạo ra một danh sách các tên bằng cách tách nội dung yêu cầu, điều này trả về một mảng như trong Java, chuyển đổi mảng đó thành danh sách Scala và áp dụng phương thức makeGreeting lên nó. Sau đó, chúng tôi sử dụng danh sách đó làm giá trị cho khóa "greetings" trong bản đồ mô hình của chúng tôi:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/example/Example.scala | |
| | def handleGreetingRequest(request: HttpRequest) = |
| | Map("greetings" -> request.body.split(",").toList.map(makeGreeting)) |
| | |
| | private def random = new Random() |
| | private def greetings = Vector("Hello", "Greetings", "Salutations", "Hola") |
| | private def makeGreeting(name: String) = |
| | "%s, %s".format(greetings(random.nextInt(greetings.size)), name) |
| | |
| | def greetingController = new FunctionController(greetingView, handleGreetingRequest) |
Cuối cùng, hãy cùng xem xét bộ lọc ghi nhật ký của chúng tôi. Hàm này đơn giản chỉ ghi đường dẫn mà nó tìm thấy trong HttpRequest được truyền vào vào console và sau đó trả về đường dẫn mà không bị biến đổi.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/example/Example.scala | |
| | private def loggingFilter(request: HttpRequest) = { |
| | println("In Logging Filter - request for path: %s".format(request.path)) |
| | request |
| | } |
Để hoàn thành ví dụ, chúng ta cần tạo một phiên bản của TinyWeb với bộ điều khiển, giao diện, và bộ lọc mà chúng ta đã định nghĩa trước đó, và chúng ta cần tạo một phản hồi HttpResponse để kiểm tra:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tinyweb/example/Example.scala | |
| | def tinyweb = new TinyWeb( |
| | Map("/greeting" -> greetingController), |
| | List(loggingFilter)) |
| | def testHttpRequest = HttpRequest( |
| | body="Mike,Joe,John,Steve", |
| | path="/greeting") |
Chúng ta bây giờ có thể chạy yêu cầu thử nghiệm thông qua phương thức handleRequest của TinyWeb trong REPL và xem phản hồi HttpResponse tương ứng:
| | scala> tinyweb.handleRequest(testHttpRequest) |
| | In Logging Filter - request for path: /greeting |
| | res0: Option[com.mblinn.mbfpp.oo.tinyweb.stepfour.HttpResponse] = |
| | Some(HttpResponse(<h1>Friendly Greetings:<h2>Mike</h2>, <h2>Nam</h2>, <h2>John</h2>, |
| | 200)) |
Điều đó kết thúc phiên bản Scala của TinyWeb. Chúng tôi đã thực hiện một vài thay đổi về phong cách mà chúng tôi đã sử dụng trong phiên bản Java của mình. Đầu tiên, chúng tôi đã thay thế hầu hết mã lặp của mình bằng mã mang tính khai báo hơn. Thứ hai, chúng tôi đã thay thế các trình xây dựng cồng kềnh của mình bằng các lớp case của Scala, điều này cung cấp cho chúng tôi một cách tích hợp để xử lý dữ liệu không thay đổi. Cuối cùng, chúng tôi đã thay thế việc sử dụng Giao diện Chức năng bằng các hàm thông thường.
Tổng hợp lại, những thay đổi nhỏ này giúp chúng ta tiết kiệm khá nhiều mã và mang lại cho chúng ta một giải pháp ngắn gọn hơn và dễ đọc hơn. Tiếp theo, chúng ta sẽ xem xét TinyWeb trong Clojure.
读累了记得休息一会哦~
Công chúng: Cụ Good Mèo Ning Lý
- 电子书搜索下载
- 书单分享
- 书友学习交流
Trang web: Thư viện Trầm Kim https://www.chenjin5.com
- 电子书搜索下载
- 电子书打包资源分享
- 学习资源分享
2.4 TinyWeb in Clojure
Bây giờ hãy lấy TinyWeb và dịch nó sang Clojure. Đây sẽ là một bước nhảy lớn hơn so với việc dịch từ Java sang Scala, vì vậy chúng ta sẽ thực hiện từ từ.
Sự khác biệt rõ ràng nhất giữa Clojure và Java là cú pháp. Nó rất khác so với cú pháp lấy cảm hứng từ C được tìm thấy trong hầu hết các ngôn ngữ lập trình hiện đại. Điều này không phải là tình cờ: cú pháp cho phép một trong những tính năng mạnh mẽ nhất của Clojure, các macro, mà chúng ta sẽ đề cập trong Mô hình 21, Ngôn ngữ theo miền.
A Gentle Introduction to Clojure
Hiện tại, hãy để chúng ta chỉ có một sự giới thiệu nhẹ nhàng. Clojure sử dụng cú pháp tiền tố, có nghĩa là tên hàm đứng trước các đối số của hàm trong một cuộc gọi hàm. Ở đây, chúng ta gọi hàm count để lấy kích thước của một vector, một trong những cấu trúc dữ liệu bất biến của Clojure.
| | => (count [1 2 3 4]) |
| | 4 |
Giống như Scala, Clojure có khả năng tương tác tuyệt vời với mã Java hiện có. Gọi một phương thức trên một lớp Java trông gần như giống hệt như gọi một hàm Clojure; bạn chỉ cần thêm dấu chấm trước tên phương thức và đặt nó trước thể hiện của lớp thay vì sau. Ví dụ, đây là cách chúng ta gọi phương thức length trên một thể hiện của một chuỗi Java String:
| | => (.length "Clojure") |
| | 7 |
Thay vì tổ chức mã Clojure thành các đối tượng và phương thức trong Java hoặc thành các đối tượng, phương thức và hàm trong Scala, mã Clojure được tổ chức thành các hàm và không gian tên. Phiên bản Clojure của TinyWeb dựa trên các mô hình, giao diện, bộ điều khiển và bộ lọc, giống như các phiên bản Java và Scala; tuy nhiên, các thành phần này sẽ có hình thức khá khác biệt.
Quan điểm, bộ điều khiển và mã bộ lọc của chúng tôi chỉ là các hàm, và các mô hình của chúng tôi là các bản đồ. Để kết nối mọi thứ lại với nhau, chúng tôi sử dụng một hàm có tên là TinyWeb, hàm này nhận tất cả các thành phần của chúng tôi và trả về một hàm nhận một yêu cầu HTTP, xử lý nó qua các bộ lọc, và sau đó định tuyến nó đến bộ điều khiển và view phù hợp.
Controllers in Clojure
Hãy bắt đầu xem xét mã Clojure với các controller. Dưới đây, chúng tôi triển khai một controller đơn giản nhận nội dung của một yêu cầu HTTP đến và sử dụng nó để thiết lập một tên trong mô hình. Ở phiên bản đầu tiên này, chúng tôi sẽ sử dụng cùng một HttpRequest như mã Java của chúng tôi. Chúng tôi sẽ thay đổi nó để phù hợp hơn với phong cách Clojure sau.
| ClojureExamples/src/mbfpp/oo/tinyweb/stepone.clj | |
| | (ns mbfpp.oo.tinyweb.stepone |
| | (:import (com.mblinn.oo.tinyweb HttpRequest HttpRequest$Builder))) |
| | (defn test-controller [http-request] |
| | {:name (.getBody http-request)}) |
| | (def test-builder (HttpRequest$Builder/newBuilder)) |
| | (def test-http-request (.. test-builder (body "Mike") (path "/say-hello") build)) |
| | (defn test-controller-with-map [http-request] |
| | {:name (http-request :body)}) |
Hãy xem xét đoạn mã này từng phần một, bắt đầu với khai báo không gian tên.
| ClojureExamples/src/mbfpp/oo/tinyweb/stepone.clj | |
| | (ns mbfpp.oo.tinyweb.stepone |
| | (:import (com.mblinn.oo.tinyweb HttpRequest HttpRequest$Builder))) |
Ở đây, chúng tôi định nghĩa một không gian tên gọi là mbfpp.oo.tinyweb.stepone. Một không gian tên đơn giản là một bộ sưu tập các hàm tạo thành một thư viện có thể được nhập toàn bộ hoặc một phần bởi một không gian tên khác.
Trong phần định nghĩa, chúng tôi nhập một số lớp Java, HttpRequest và HttpRequest$Builder. Lớp thứ hai có thể trông hơi lạ, nhưng đó chỉ là tên đầy đủ cho lớp tĩnh con Builder mà chúng tôi đã tạo ra như một phần của HttpRequest. Clojure không có bất kỳ cú pháp đặc biệt nào để tham chiếu đến các lớp tĩnh con, vì vậy chúng tôi cần sử dụng tên đầy đủ của lớp.
Từ khóa :import là một ví dụ về từ khóa trong Clojure. Một từ khóa chỉ là một định danh cung cấp các kiểm tra độ chẵn rất nhanh và luôn được đặt trước bằng dấu hai chấm. Ở đây, chúng ta đang sử dụng từ khóa :import để chỉ định những lớp nào nên được nhập vào không gian tên mà chúng ta vừa khai báo, nhưng từ khóa còn có nhiều ứng dụng khác. Chúng thường được sử dụng như các khóa trong một bản đồ, chẳng hạn.
Bây giờ hãy xem xét bộ điều khiển của chúng ta, cái nhận một HttpRequest từ giải pháp Java gốc và sản xuất một bản đồ Clojure như một mô hình:
| ClojureExamples/src/mbfpp/oo/tinyweb/stepone.clj | |
| | (defn test-controller [http-request] |
| | {:name (.getBody http-request)}) |
Ở đây, chúng tôi gọi phương thức getBody trên HttpRequest để lấy nội dung của yêu cầu, và sử dụng nó để tạo một bản đồ với một cặp khóa-giá trị duy nhất. Khóa là từ khóa :name, và giá trị là nội dung kiểu String của HttpRequest.
Trước khi tiếp tục, hãy cùng xem xét các bản đồ Clojure một cách chi tiết hơn. Trong Clojure, việc sử dụng bản đồ để truyền dữ liệu là rất phổ biến. Cú pháp để tạo một bản đồ trong Clojure là bao gói các cặp khóa-giá trị bên trong dấu ngoặc nhọn. Ví dụ, ở đây chúng ta đang tạo một bản đồ với hai cặp khóa-giá trị. Khóa đầu tiên là từ khóa :name, và giá trị là chuỗi "Mike". Khóa thứ hai là từ khóa :sex, và giá trị là một từ khóa khác, :male:
| | => {:name "Mike" :sex :male} |
| | {:name "Mike" :sex :male} |
Bản đồ trong Clojure là các hàm của các khóa của chúng. Điều này có nghĩa là chúng ta có thể gọi một bản đồ như một hàm, truyền một khóa mà chúng ta mong đợi có trong bản đồ, và bản đồ sẽ trả về giá trị. Nếu khóa không có trong bản đồ, giá trị nil sẽ được trả về, như mã bên dưới cho thấy:
| | => (def test-map {:name "Mike"}) |
| | #'mbfpp.oo.tinyweb.stepone/test-map |
| | => (test-map :name) |
| | "Mike" |
| | => (test-map :orange) |
| | nil |
Từ khóa trong Clojure cũng là các hàm. Khi chúng được truyền một bản đồ, chúng sẽ tự tìm kiếm trong đó, như trong đoạn mã sau đây, cho thấy cách phổ biến nhất để tra cứu một giá trị từ một bản đồ:
| | => (def test-map {:name "Mike"}) |
| | #'mbfpp.oo.tinyweb.stepone/test-map |
| | => (:name test-map) |
| | "Mike" |
| | => (:orange test-map) |
| | nil |
Bây giờ hãy tạo một số dữ liệu thử nghiệm. Dưới đây, chúng ta tạo một HttpRequest$Builder và sử dụng nó để tạo một HttpRequest mới:
| ClojureExamples/src/mbfpp/oo/tinyweb/stepone.clj | |
| | (def test-builder (HttpRequest$Builder/newBuilder)) |
| | (def test-http-request (.. test-builder (body "Mike") (path "/say-hello") build)) |
Mã này có hai tính năng khác liên kết giữa Clojure và Java. Đầu tiên, dấu gạch chéo cho phép chúng ta gọi một phương thức tĩnh hoặc tham chiếu đến một biến tĩnh trong một lớp. Do đó, đoạn mã (HttpRequest$Builder/newBuilder) đang gọi phương thức newBuilder trên lớp HttpRequest$Builder. Là một ví dụ khác, chúng ta có thể sử dụng cú pháp này để phân tích một số nguyên từ một String bằng cách sử dụng phương thức parseInt trên lớp Integer.
| | => (Integer/parseInt "42") |
| | 42 |
Tiếp theo là macro .., một tính năng liên kết tiện lợi giúp việc gọi một chuỗi các phương thức trên một đối tượng Java trở nên dễ dàng. Nó hoạt động bằng cách nhận tham số đầu tiên của .. và truyền thực hiện qua các cuộc gọi đến các tham số còn lại.
Đoạn mã (.. test-builder (body "Mike") (path "/say-hello") build) đầu tiên gọi phương thức body trên test-builder với tham số "Mike". Sau đó, nó lấy kết quả đó và gọi phương thức path trên đó với tham số "say-hello" và cuối cùng gọi build trên kết quả đó để trả về một thể hiện của HttpResult.
Dưới đây là một ví dụ khác về việc sử dụng macro .. để chuyển chữ cái đầu tiên của chuỗi "mike" thành chữ in hoa và sau đó lấy ký tự đầu tiên của nó:
| | => (.. "mike" toUpperCase (substring 0 1)) |
| | "M" |
Maps for Data
Bây giờ chúng ta đã thấy một số kiến thức cơ bản về Clojure và khả năng tương tác giữa Clojure với Java, hãy tiến bước tiếp theo trong việc biến TinyWeb thành Clojure. Ở đây, chúng ta sẽ thay đổi test-controller sao cho yêu cầu HTTP mà nó nhận vào cũng là một bản đồ, giống như mô hình mà nó trả về. Chúng ta cũng sẽ giới thiệu một hàm view và một hàm render có trách nhiệm gọi các view. Mã cho phiên bản tiếp theo của chúng ta ở dưới đây:
| ClojureExamples/src/mbfpp/oo/tinyweb/steptwo.clj | |
| | (ns mbfpp.oo.tinyweb.steptwo |
| | (:import (com.mblinn.oo.tinyweb RenderingException))) |
| | |
| | (defn test-controller [http-request] |
| | {:name (http-request :body)}) |
| | |
| | (defn test-view [model] |
| | (str "<h1>Hello, " (model :name) "</h1>")) |
| | |
| | (defn- render [view model] |
| | (try |
| | (view model) |
| | (catch Exception e (throw (RenderingException. e))))) |
Hãy cùng xem xét kỹ lưỡng các phần, bắt đầu với test-controller mới của chúng tôi. Như chúng ta thấy trong mã, chúng tôi mong đợi http-request là một bản đồ với khóa :body đại diện cho nội dung của yêu cầu HTTP. Chúng tôi đang lấy giá trị cho khóa đó và đặt nó vào một bản đồ mới đại diện cho mô hình của chúng tôi:
| ClojureExamples/src/mbfpp/oo/tinyweb/steptwo.clj | |
| | (defn test-controller [http-request] |
| | {:name (http-request :body)}) |
Chúng ta có thể khám phá cách mà test-controller hoạt động rất dễ dàng bằng cách sử dụng REPL. Tất cả những gì chúng ta cần làm là định nghĩa một bản đồ test-http-request và truyền nó vào test-controller, điều này được thực hiện trong đầu ra REPL này:
| | => (def test-http-request {:body "Mike" :path "/say-hello" :headers {}}) |
| | #'mbfpp.oo.tinyweb.steptwo/test-http-request |
| | => (test-controller test-http-request) |
| | {:name "Mike"} |
Views in Clojure
Bây giờ khi chúng ta đã hoàn thiện cách tiếp cận controller, hãy xem qua một số mã view. Giống như các controller của chúng ta, views sẽ là các hàm. Chúng nhận một bản đồ đại diện cho mô hình mà chúng hoạt động trên và trả về một String đại diện cho đầu ra của view.
Đây là một đoạn mã cho một test-view đơn giản chỉ bao bọc một tên trong thẻ <h1>:
| ClojureExamples/src/mbfpp/oo/tinyweb/steptwo.clj | |
| | (defn test-view [model] |
| | (str "<h1>Hello, " (model :name) "</h1>")) |
Một lần nữa, chúng ta có thể thử điều này một cách đơn giản trong REPL bằng cách định nghĩa một mô hình thử nghiệm và truyền nó vào hàm:
| | => (def test-model {:name "Mike"}) |
| | #'mbfpp.oo.tinyweb.steptwo/test-model |
| | => (test-view test-model) |
| | "<h1>Hello, Mike</h1>" |
Chúng ta cần một phần nữa để hoàn thành mã xử lý giao diện của mình. Trong Java, chúng ta đã sử dụng Mẫu 7, Chiến lược Thay thế, để đảm bảo rằng bất kỳ ngoại lệ nào trong mã xử lý giao diện đều được bọc lại một cách đúng đắn trong một RenderException. Trong Clojure, chúng ta sẽ làm điều gì đó tương tự với các hàm bậc cao. Như mã dưới đây cho thấy, tất cả những gì chúng ta cần làm là truyền hàm giao diện của chúng ta vào hàm render, hàm này sẽ đảm nhận việc chạy giao diện và bọc bất kỳ ngoại lệ nào.
| ClojureExamples/src/mbfpp/oo/tinyweb/steptwo.clj | |
| | (defn- render [view model] |
| | (try |
| | (view model) |
| | (catch Exception e (throw (RenderingException. e))))) |
Tying It All Together
Bây giờ mà chúng ta đã nắm vững các view và controller trong Clojure, hãy hoàn thành ví dụ bằng cách thêm vào các bộ lọc và mã kết nối mọi thứ lại với nhau. Chúng ta sẽ thực hiện bước cuối cùng này trong một không gian đặt tên gọi là core. Đây là không gian đặt tên core tiêu chuẩn mà công cụ xây dựng của Clojure, Leiningen, tạo ra khi bạn tạo một dự án mới, vì vậy nó đã trở thành tiêu chuẩn de facto cho không gian đặt tên core trong các dự án Clojure.
Để làm điều này, chúng ta sẽ thêm một chức năng execute-request, chức năng này chịu trách nhiệm thực hiện một http-request. Hàm này nhận một http-request và một trình xử lý yêu cầu. Trình xử lý yêu cầu chỉ đơn giản là một bản đồ chứa bộ điều khiển và giao diện mà nên được sử dụng để xử lý yêu cầu.
Chúng tôi cũng sẽ cần apply-filters, hàm này nhận một http-request, áp dụng một loạt bộ lọc cho nó và trả về một http-request mới. Cuối cùng, chúng tôi sẽ cần hàm tinyweb.
Chức năng tinyweb là thứ kết nối mọi thứ lại với nhau. Nó nhận vào hai tham số: một bản đồ các bộ xử lý yêu cầu được định danh theo đường dẫn mà mỗi bộ xử lý sẽ xử lý và một dãy các bộ lọc. Sau đó, nó trả về một hàm nhận vào một http-request, áp dụng dãy bộ lọc lên nó, chuyển nó đến bộ xử lý yêu cầu phù hợp, và trả về kết quả.
Đây là mã cho thư viện Clojure TinyWeb đầy đủ:
| ClojureExamples/src/mbfpp/oo/tinyweb/core.clj | |
| | (ns mbfpp.oo.tinyweb.core |
| | (:require [clojure.string :as str]) |
| | (:import (com.mblinn.oo.tinyweb RenderingException ControllerException))) |
| | (defn- render [view model] |
| | (try |
| | (view model) |
| | (catch Exception e (throw (RenderingException. e))))) |
| | (defn- execute-request [http-request handler] |
| | (let [controller (handler :controller) |
| | view (handler :view)] |
| | (try |
| | {:status-code 200 |
| | :body |
| | (render |
| | view |
| | (controller http-request))} |
| | (catch ControllerException e {:status-code (.getStatusCode e) :body ""}) |
| | (catch RenderingException e {:status-code 500 |
| | :body "Exception while rendering"}) |
| | (catch Exception e (.printStackTrace e) {:status-code 500 :body ""})))) |
| | (defn- apply-filters [filters http-request] |
| | (let [composed-filter (reduce comp (reverse filters))] |
| | (composed-filter http-request))) |
| | (defn tinyweb [request-handlers filters] |
| | (fn [http-request] |
| | (let [filtered-request (apply-filters filters http-request) |
| | path (http-request :path) |
| | handler (request-handlers path)] |
| | (execute-request filtered-request handler)))) |
Phương thức render không thay đổi so với phiên bản trước, vì vậy hãy bắt đầu bằng cách kiểm tra hàm execute-request. Chúng ta đã định nghĩa hàm này trong thư viện Clojure TinyWeb đầy đủ. Để bắt đầu phân tích hàm execute-request, trước tiên hãy định nghĩa một số dữ liệu thử nghiệm trong REPL. Chúng ta sẽ cần test-controller và test-view mà chúng ta đã định nghĩa trong lần lặp trước để tạo một trình xử lý yêu cầu thử nghiệm, điều này được thực hiện bên dưới:
| | => (defn test-controller [http-request] |
| | {:name (http-request :body)}) |
| | |
| | (defn test-view [model] |
| | (str "<h1>Hello, " (model :name) "</h1>")) |
| | #'mbfpp.oo.tinyweb.core/test-controller |
| | #'mbfpp.oo.tinyweb.core/test-view |
| | => (def test-request-handler {:controller test-controller |
| | :view test-view}) |
| | #'mbfpp.oo.tinyweb.core/test-request-handler |
Bây giờ chúng ta chỉ cần test-http-request của mình, và chúng ta có thể xác nhận rằng execute-request thực thi request-handler đã truyền vào trên http-request đã truyền vào, như chúng ta mong đợi:
| | => (def test-http-request {:body "Mike" :path "/say-hello" :headers {}}) |
| | #'mbfpp.oo.tinyweb.steptwo/test-http-request |
| | => (execute-request test-http-request test-request-handler) |
| | {:status-code 200, :body "<h1>Hello, Mike</h1>"} |
Hãy xem xét các phần của execute-request một cách chi tiết hơn bằng cách thử nghiệm chúng trong REPL, bắt đầu với câu lệnh let để chọn controller và view từ request-handler, mà chúng tôi đã phác thảo ở đây:
| | (let [controller (handler :controller) |
| | view (handler :view)] |
| | let-body) |
Một câu lệnh let là cách bạn gán tên cục bộ trong Clojure, tương tự như một biến cục bộ trong Java. Tuy nhiên, khác với một biến, giá trị mà các tên này tham chiếu đến không được phép thay đổi. Trong câu lệnh let ở trên, chúng ta đang lấy các hàm view và controller từ map request-handler và đặt tên cho chúng là controller và view. Chúng ta có thể sau đó tham chiếu đến chúng bằng những tên đó bên trong câu lệnh let.
Hãy cùng xem một ví dụ đơn giản hơn về biểu thức let. Dưới đây, chúng ta sử dụng let để gán name với chuỗi "Mike" và gán greeting với chuỗi "Hello". Sau đó, bên trong phần thân của biểu thức let, chúng ta sử dụng chúng để tạo ra một lời chào:
| | => (let [name "Mike" |
| | greeting "Hello"] |
| | (str greeting ", " name)) |
| | "Hello, Mike" |
Bây giờ khi chúng ta đã nắm rõ về `let`, hãy xem xét biểu thức `try`, mà chúng tôi đã lặp lại bên dưới. Giống như trong Scala, `try` là một biểu thức có giá trị. Nếu không có ngoại lệ nào xảy ra, `try` sẽ có giá trị của phần thân của biểu thức đó; nếu không, nó sẽ lấy giá trị của một điều khoản catch.
| | (try |
| | {:status-code 200 |
| | :body |
| | (render |
| | view |
| | (controller http-request))} |
| | (catch ControllerException e {:status-code (.getStatusCode e) :body ""}) |
| | (catch RenderingException e {:status-code 500 |
| | :body "Exception while rendering"}) |
| | (catch Exception e (.printStackTrace e) {:status-code 500 :body ""}) |
Nếu không có ngoại lệ nào được ném ra, thì biểu thức try sẽ có giá trị là một bản đồ với hai cặp khóa-giá trị, đại diện cho phản hồi HTTP của chúng ta. Khóa đầu tiên là :status-code với giá trị là 200. Khóa thứ hai là :body. Giá trị của nó được tính toán bằng cách chuyển http-request vào controller và sau đó truyền kết quả đó vào hàm render cùng với giao diện sẽ được render.
Chúng ta có thể thấy điều này được thực hiện trong ví dụ sử dụng test-view và test-controller dưới đây:
| | => (render test-view (test-controller test-http-request)) |
| | "<h1>Hello, Mike</h1>" |
Trước khi chúng ta tiếp tục, hãy xem xét kỹ hơn cách xử lý ngoại lệ trong Clojure bằng một vài ví dụ đơn giản hơn. Dưới đây, chúng ta thấy một ví dụ về biểu thức try nơi phần thân chỉ là chuỗi "hello, world", vì vậy giá trị của toàn bộ biểu thức là "hello, world".
| | => (try |
| | "hello, world" |
| | (catch Exception e (.message e))) |
| | "hello, world" |
Dưới đây là một ví dụ đơn giản về cách mà biểu thức try hoạt động khi có sự cố xảy ra. Trong phần thân của biểu thức try bên dưới, chúng ta đang ném ra một RuntimeException với thông điệp "Nó bị hỏng!". Trong nhánh catch, chúng ta bắt Exception và chỉ lấy thông điệp ra, sau đó nó trở thành giá trị của nhánh catch và do đó là giá trị của toàn bộ biểu thức try:
| | => (try |
| | (throw (RuntimeException. "It's broke!")) |
| | (catch Exception e (.getMessage e))) |
| | "It's broke!" |
Tiếp theo, hãy cùng xem cách chúng tôi áp dụng các bộ lọc. Chúng tôi sử dụng một hàm apply-filters, hàm này nhận một chuỗi bộ lọc và một yêu cầu HTTP, kết hợp chúng thành một bộ lọc duy nhất và sau đó áp dụng nó cho yêu cầu HTTP. Đoạn mã ở dưới đây:
| | (defn- apply-filters [filters http-request] |
| | (let [composed-filter (reduce comp filters)] |
| | (composed-filter http-request))) |
Chúng tôi khám phá chức năng comp sâu hơn như một phần của Mẫu 16, Bộ Tạo Chức Năng.
Để hoàn thiện việc triển khai TinyWeb trong Clojure của chúng ta, chúng ta cần một hàm, tinyweb, để kết nối mọi thứ lại với nhau. Hàm này nhận vào một bản đồ các trình xử lý yêu cầu và một chuỗi bộ lọc. Nó trả về một hàm nhận một yêu cầu HTTP, sử dụng apply-filters để áp dụng tất cả các bộ lọc lên yêu cầu.
Sau đó, nó chọn đường dẫn từ yêu cầu HTTP, tìm trong bản đồ các bộ xử lý yêu cầu để tìm bộ xử lý phù hợp và sử dụng execute-request để thực thi nó. Dưới đây là mã cho tinyweb:
| | (defn tinyweb [request-handlers filters] |
| | (fn [http-request] |
| | (let [filtered-request (apply-filters filters http-request) |
| | path (:path http-request) |
| | handler (request-handlers path)] |
| | (execute-request filtered-request handler)))) |
Using TinyWeb
Hãy cùng xem xét việc sử dụng phiên bản TinyWeb bằng Clojure. Đầu tiên, hãy định nghĩa một yêu cầu HTTP thử nghiệm:
| | => (def request {:path "/greeting" :body "Mike,Joe,John,Steve"}) |
| | #'mbfpp.oo.tinyweb.core/request |
Bây giờ hãy cùng xem mã điều khiển của chúng ta, chỉ là một hàm đơn giản và hoạt động giống như phiên bản Scala của chúng ta:
| ClojureExamples/src/mbfpp/oo/tinyweb/example.clj | |
| | (defn make-greeting [name] |
| | (let [greetings ["Hello" "Greetings" "Salutations" "Hola"] |
| | greeting-count (count greetings)] |
| | (str (greetings (rand-int greeting-count)) ", " name))) |
| | |
| | (defn handle-greeting [http-request] |
| | {:greetings (map make-greeting (str/split (:body http-request) #","))}) |
Chạy yêu cầu kiểm tra của chúng tôi thông qua nó trả về bản đồ mô hình phù hợp, như thấy bên dưới:
| | => (handle-greeting request) |
| | {:greetings ("Greetings, Mike" "Hola, Joe" "Hola, John" "Hola, Steve")} |
Tiếp theo là mã view của chúng tôi. Mã này chuyển đổi mô hình thành HTML. Đó chỉ là một hàm khác nhận vào bản đồ mô hình thích hợp và trả về một chuỗi.
| ClojureExamples/src/mbfpp/oo/tinyweb/example.clj | |
| | (defn render-greeting [greeting] |
| | (str "<h2>"greeting"</h2>")) |
| | |
| | (defn greeting-view [model] |
| | (let [rendered-greetings (str/join " " (map render-greeting (:greetings model)))] |
| | (str "<h1>Friendly Greetings</h1> " rendered-greetings))) |
Nếu chúng ta chạy greeting-view trên đầu ra của handle-greeting, chúng ta sẽ nhận được HTML đã được hiển thị của mình:
| | => (greeting-view (handle-greeting request)) |
| | "<h1>Friendly Greetings</h1> |
| | <h2>Hola, Mike</h2> |
| | <h2>Hello, Joe</h2> |
| | <h2>Greetings, John</h2> |
| | <h2>Salutations, Steve</h2>" |
Tiếp theo, hãy xem xét bộ lọc ghi log của chúng ta. Đây chỉ là một hàm đơn giản ghi lại đường dẫn của yêu cầu trước khi trả về nó:
| ClojureExamples/src/mbfpp/oo/tinyweb/example.clj | |
| | (defn logging-filter [http-request] |
| | (println (str "In Logging Filter - request for path: " (:path http-request))) |
| | http-request) |
Cuối cùng, chúng ta sẽ kết nối mọi thứ lại với nhau thành một phiên bản của TinyWeb, như chúng ta làm trong mã sau:
| ClojureExamples/src/mbfpp/oo/tinyweb/example.clj | |
| | (def request-handlers |
| | {"/greeting" {:controller handle-greeting :view greeting-view}}) |
| | (def filters [logging-filter]) |
| | (def tinyweb-instance (tinyweb request-handlers filters)) |
Nếu chúng ta chạy yêu cầu kiểm tra của mình qua phiên bản của TinyWeb, nó sẽ được lọc và xử lý như mong đợi.
| | => (tinyweb-instance request) |
| | In Logging Filter - request for path: /greeting |
| | {:status-code 200, |
| | :body "<h1>Friendly Greetings</h1> |
| | <h2>Greetings, Mike</h2> |
| | <h2>Greetings, Joe</h2> |
| | <h2>Hello, John</h2> |
| | <h2>Hola, Steve</h2>"} |
Đó là kết thúc cái nhìn của chúng ta về TinyWeb! Mã trong chương này đã được giữ ở mức đơn giản; chúng tôi đã bám sát một tập hợp tính năng ngôn ngữ tối thiểu và bỏ qua nhiều xử lý lỗi và nhiều tính năng hữu ích. Tuy nhiên, nó cho thấy cách mà khá nhiều mẫu mà chúng ta sẽ xem xét trong cuốn sách này kết hợp với nhau.
Trong phần còn lại của cuốn sách, chúng ta sẽ xem xét kỹ lưỡng những mẫu này và nhiều mẫu khác khi tiếp tục hành trình của chúng ta qua lập trình hàm.
Copyright © 2013, The Pragmatic Bookshelf. Chapter 3
Replacing Object-Oriented Patterns
3.1 Introduction
Các mẫu lập trình hướng đối tượng là một phần thiết yếu trong kỹ thuật phần mềm hiện đại. Trong chương này, chúng ta sẽ xem xét một số mẫu phổ biến nhất và những vấn đề mà chúng giải quyết. Sau đó, chúng tôi sẽ giới thiệu những giải pháp chức năng hơn để giải quyết những vấn đề tương tự mà các mẫu lập trình hướng đối tượng giải quyết.
Đối với mỗi mẫu mà chúng tôi giới thiệu, trước tiên chúng tôi sẽ xem xét nó trong Java. Sau đó, chúng tôi sẽ xem xét một cách tiếp cận bằng Scala giải quyết những vấn đề tương tự, và cuối cùng, chúng tôi sẽ kết thúc bằng cách nhìn nhận một phiên bản Clojure cũng làm như vậy.
Đôi khi, các thay thế bằng Scala và Clojure sẽ khá giống nhau. Ví dụ, các giải pháp Scala và Clojure trong cả Mẫu 1, Thay thế Giao diện Chức năng, và Mẫu 7, Thay thế Chiến lược, về cơ bản là giống nhau. Những lúc khác, các giải pháp mà chúng tôi khám phá trong hai ngôn ngữ này sẽ khá khác nhau nhưng vẫn thể hiện cùng một khái niệm chức năng.
Các giải pháp mà chúng tôi xem xét trong Mẫu 4, Thay thế Builder cho Đối tượng Bất biến, chẳng hạn, rất khác nhau trong Scala và Clojure. Tuy nhiên, trong cả hai trường hợp, chúng đều cho thấy những cách làm đơn giản để làm việc với dữ liệu bất biến.
Bằng cách khám phá cả những điểm tương đồng và khác biệt giữa Scala và Clojure, bạn sẽ có được cảm nhận tốt về cách mỗi ngôn ngữ tiếp cận lập trình hàm và cách nó khác biệt với phong cách mệnh lệnh truyền thống mà bạn có thể đã quen thuộc.
Hãy bắt đầu với mẫu đầu tiên của chúng ta, Giao diện Chức năng!
| Pattern 1 | Replacing Functional Interface |
Intent
Để bao gói một chút logic chương trình để nó có thể được truyền đi, lưu trữ trong các cấu trúc dữ liệu và nói chung được đối xử như bất kỳ cấu trúc cấp một nào khác.
Overview
Giao diện chức năng là một mẫu thiết kế hướng đối tượng cơ bản. Nó bao gồm một giao diện với một phương thức duy nhất có tên như chạy, thực hiện, thi hành, áp dụng hoặc một động từ chung nào đó khác. Các triển khai của Giao diện chức năng thực hiện một hành động rõ ràng duy nhất, như bất kỳ phương thức nào cũng nên có.
Giao diện chức năng cho phép chúng ta gọi một đối tượng như thể nó là một hàm, điều này cho phép chúng ta truyền những động từ quanh chương trình của mình thay vì các danh từ. Điều này làm lật ngược một chút quan điểm truyền thống về lập trình hướng đối tượng. Trong quan điểm lập trình hướng đối tượng nghiêm ngặt, các đối tượng, là danh từ, là vua. Các động từ, hoặc phương thức, là công dân hạng hai, luôn gắn liền với một đối tượng, phải sống một cuộc đời phục tùng các bá vương danh từ của chúng.
Also Known As
Đối tượng hàm Functoid Hàm bậc 1
Functional Replacement
Một quan điểm nghiêm ngặt về lập trình hướng đối tượng làm cho một số vấn đề trở nên khó giải quyết hơn. Tôi đã mất số lần không đếm được khi viết năm hoặc sáu dòng mã mẫu để bọc một dòng mã hữu ích vào Runnable hoặc Callable, hai trong số các trường hợp giao diện chức năng phổ biến nhất của Java.
Để đơn giản hóa mọi thứ, chúng ta có thể thay thế Giao diện Chức năng bằng các hàm thuần túy. Có thể có vẻ lạ khi chúng ta có thể thay thế một đối tượng bằng các hàm có vẻ như nguyên thủy hơn, nhưng các hàm trong lập trình hàm mạnh mẽ hơn nhiều so với các hàm trong C hoặc các phương thức trong Java.
Trong các ngôn ngữ hàm, hàm là dạng hàm bậc cao: chúng có thể được trả về từ các hàm và được sử dụng làm tham số cho các hàm khác. Chúng là cấu trúc hạng nhất, có nghĩa là ngoài việc là hàm bậc cao, chúng cũng có thể được gán cho các biến, đặt vào các cấu trúc dữ liệu và hầu như có thể bị thao tác. Chúng có thể là những hàm không có tên, hay còn gọi là hàm ẩn danh, rất tiện lợi cho những đoạn mã nhỏ, dùng một lần. Thực tế, Giao diện Hàm (như tên gọi của nó có thể gợi ý) là một mẫu cách mà trong thế giới lập trình hướng đối tượng gần giống với hành vi của các hàm trong thế giới hàm.
Chúng tôi sẽ đề cập đến một vài biến thể khác nhau của việc thay thế Giao diện Chức năng trong phần này. Thay thế đầu tiên cho các trường hợp nhỏ hơn của mẫu - chẳng hạn như những trường hợp chỉ mất vài dòng mã - bằng một hàm vô danh. Điều này tương tự như việc sử dụng lớp ẩn danh để triển khai Giao diện Chức năng trong Java và được trình bày trong Mã mẫu: Hàm vô danh.
Phần thứ hai đề cập đến các trường hợp của mẫu có độ dài vượt quá vài dòng. Trong Java, chúng tôi sẽ triển khai chúng bằng cách sử dụng một lớp được đặt tên thay vì lớp vô danh; trong thế giới chức năng, chúng tôi sử dụng một hàm được đặt tên, như trong Mã mẫu: Hàm được đặt tên.
Sample Code: Anonymous Functions
Ví dụ đầu tiên của chúng ta minh họa các hàm ẩn danh và cách chúng ta có thể sử dụng chúng để thay thế các trường hợp nhỏ của Giao diện Hàm. Một tình huống phổ biến mà chúng ta sẽ làm điều này là khi chúng ta cần sắp xếp một tập hợp theo cách khác với thứ tự tự nhiên của nó, cách mà nó thường được sắp xếp.
Để làm được điều này, chúng ta cần tạo một phép so sánh tùy chỉnh để thuật toán sắp xếp biết phần tử nào đến trước. Trong Java cổ điển, chúng ta cần tạo một Comparator được triển khai dưới dạng một lớp ẩn danh. Trong Scala và Clojure, chúng ta đi thẳng vào vấn đề bằng cách sử dụng một hàm ẩn danh. Chúng ta sẽ xem xét một ví dụ đơn giản về việc sắp xếp khác với thứ tự tự nhiên cho một đối tượng: sắp xếp một Person theo tên gọi thay vì theo họ.
Classic Java
Trong Java cổ điển, chúng ta sẽ sử dụng một Giao diện Chức năng được gọi là Comparator để hỗ trợ việc sắp xếp. Chúng ta sẽ triển khai nó dưới dạng một hàm ẩn danh, vì chỉ có một phần nhỏ mã, và chúng ta sẽ truyền nó vào hàm sắp xếp. Cốt lõi của giải pháp nằm ở đây:
| JavaExamples/src/main/java/com/mblinn/mbfpp/oo/fi/PersonFirstNameSort.java | |
| | Collections.sort(people, new Comparator<Person>() { |
| | public int compare(Person p1, Person p2) { |
| | return p1.getFirstName().compareTo(p2.getFirstName()); |
| | } |
| | }); |
Điều này hoạt động, nhưng hầu hết mã là cú pháp thừa để bọc một dòng logic thực tế của chúng ta vào một lớp ẩn danh. Hãy xem cách các hàm ẩn danh có thể giúp đơn giản hóa điều này.
In Scala
Hãy cùng xem cách chúng ta sẽ giải quyết vấn đề sắp xếp theo họ trước thay vì tên trong Scala. Chúng ta sẽ sử dụng một lớp case để đại diện cho con người, và chúng ta sẽ bỏ qua Giao diện Hàm Comparator. Thay vào đó, chúng ta sẽ sử dụng một hàm thông thường.
Tạo một hàm ẩn danh trong Scala sử dụng cú pháp sau đây:
| | (arg1: Type1, arg2: Type2) => FunctionBody |
Chẳng hạn, phiên làm việc REPL sau đây tạo ra một hàm ẩn danh nhận hai tham số nguyên và cộng chúng lại với nhau.
| | scala> (int1: Int, int2: Int) => int1 + int2 |
| | res0: (Int, Int) => Int = <function2> |
Bây giờ khi chúng ta đã nắm vững cú pháp cơ bản, hãy xem cách sử dụng hàm ẩn danh để giải quyết vấn đề sắp xếp người. Để làm điều này, chúng ta sử dụng một phương pháp trong thư viện bộ sưu tập của Scala, đó là sortWith. Phương pháp sortWith nhận một hàm so sánh và sử dụng nó để giúp sắp xếp một bộ sưu tập, giống như Collections.sort nhận một Comparator để thực hiện điều tương tự.
Hãy bắt đầu với mã cho lớp trường hợp Person của chúng ta:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/PersonExample.scala | |
| | case class Person(firstName: String, lastName: String) |
Đây là một vector đầy đủ để sử dụng làm dữ liệu kiểm tra:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/PersonExample.scala | |
| | val p1 = Person("Michael", "Bevilacqua") |
| | val p2 = Person("Pedro", "Vasquez") |
| | val p3 = Person("Robert", "Aarons") |
| | |
| | val people = Vector(p3, p2, p1) |
Phương thức `sortWith` mong đợi hàm so sánh của nó trả về giá trị Boolean cho biết liệu đối số đầu tiên có lớn hơn đối số thứ hai hay không. Các toán tử so sánh `<` và `>` trong Scala làm việc trên chuỗi, vì vậy chúng ta có thể sử dụng chúng cho mục đích này.
Mã sau đây minh họa cách tiếp cận này. Chúng ta có thể bỏ qua các chú thích kiểu cho các tham số của hàm. Scala có khả năng suy ra chúng từ phương thức sortWith.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/PersonExample.scala | |
| | people.sortWith((p1, p2) => p1.firstName < p2.firstName) |
Chạy điều này trong REPL của Scala sẽ cho chúng ta đầu ra như sau.
| | res1: scala.collection.immutable.Vector[...] = |
| | Vector( |
| | Person(Michael,Bevilacqua), |
| | Person(Pedro,Vasquez), |
| | Person(Robert,Aarons)) |
Điều này ngắn gọn và đơn giản hơn so với việc sử dụng một hiện thực tương đương của Giao diện Chức năng!
In Clojure
Chúng ta định nghĩa một hàm vô danh trong Clojure bằng cách sử dụng dạng đặc biệt fn, như mã dưới đây cho thấy.
| | (fn [arg1 arg2] function-body) |
Hãy bắt đầu bằng cách tạo ra một số người thử nghiệm. Trong Clojure, chúng ta sẽ không định nghĩa một lớp để mang theo dữ liệu; chúng ta sẽ sử dụng một bản đồ khiêm tốn.
| ClojureExamples/src/mbfpp/rso/person.clj | |
| | (def p1 {:first-name "Michael" :last-name "Bevilacqua"}) |
| | (def p2 {:first-name "Pedro" :last-name "Vasquez"}) |
| | (def p3 {:first-name "Robert" :last-name "Aarons"}) |
| | |
| | (def people [p3 p2 p1]) |
Bây giờ chúng ta tạo một hàm sắp xếp ẩn danh và truyền nó vào hàm sort cùng với những người mà chúng ta muốn sắp xếp, như mã sau đây minh họa:
| | => (sort (fn [p1 p2] (compare (p1 :first-name) (p2 :first-name))) people) |
| | ({:last-name "Bevilacqua", :first-name "Michael"} |
| | {:last-name "Vasquez", :first-name "Pedro"} |
| | {:last-name "Aarons", :first-name "Robert"}) |
Bằng cách loại bỏ cú pháp thừa mà chúng ta cần trong Java để bao bọc hàm sắp xếp của mình trong một Comparator, chúng ta viết mã trực tiếp đến vấn đề.
Sample Code: Named Functions
Hãy mở rộng vấn đề phân loại người một chút. Chúng ta sẽ thêm một tên đệm cho mỗi người trong danh sách của mình và điều chỉnh thuật toán sắp xếp bất thường của chúng ta để sắp xếp theo tên gọi trước, sau đó là họ nếu tên gọi giống nhau, và cuối cùng là tên đệm nếu họ cũng giống nhau.
Điều này làm cho đoạn mã so sánh đủ dài để chúng ta không nên nhúng nó vào mã đang sử dụng. Trong Java, chúng ta di chuyển mã ra khỏi một lớp nội tại ẩn danh và vào một lớp đã đặt tên. Trong Clojure và Scala, chúng ta di chuyển nó vào một hàm đã đặt tên.
Classic Java
Các lớp và hàm ẩn danh rất hữu ích khi logic mà chúng bao bọc nhỏ, nhưng khi nó lớn hơn, việc nhúng trở nên rối rắm. Trong Java cổ điển, chúng ta chuyển sang sử dụng một lớp được đặt tên, như được phác thảo dưới đây:
| | public class ComplicatedNameComparator implements Comparator<Person> { |
| | public int compare(Person p1, Person p2) { |
| | complicatedSortLogic |
| | } |
| | } |
Với các hàm bậc cao, chúng ta sử dụng một hàm có tên.
In Scala
Chúng tôi bắt đầu bằng cách mở rộng lớp case Scala của mình để có tên đệm và định nghĩa một số dữ liệu thử nghiệm:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/PersonExpanded.scala | |
| | case class Person(firstName: String, middleName: String, lastName: String) |
| | val p1 = Person("Aaron", "Jeffrey", "Smith") |
| | val p2 = Person("Aaron", "Bailey", "Zanthar") |
| | val p3 = Person("Brian", "Adams", "Smith") |
| | val people = Vector(p1, p2, p3) |
Bây giờ chúng ta tạo một hàm so sánh có tên và truyền nó vào sortWith, như mã dưới đây thể hiện:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/PersonExpanded.scala | |
| | def complicatedSort(p1: Person, p2: Person) = |
| | if (p1.firstName != p2.firstName) |
| | p1.firstName < p2.firstName |
| | else if (p1.lastName != p2.lastName) |
| | p1.lastName < p2.lastName |
| | else |
| | p1.middleName < p2.middleName |
Và voilà! Chúng ta có thể dễ dàng sắp xếp người của mình bằng cách sử dụng một hàm được đặt tên tùy ý:
| | scala> people.sortWith(complicatedSort) |
| | res0: scala.collection.immutable.Vector[...] = |
| | Vector( |
| | Person(Aaron,Jeffrey,Smith), |
| | Person(Aaron,Bailey,Zanthar), |
| | Person(Brian,Adams,Smith)) |
In Clojure
Giải pháp Clojure tương tự khá nhiều so với giải pháp Scala. Chúng ta sẽ cần một hàm có tên có thể so sánh mọi người theo bộ quy tắc phức tạp hơn, và chúng ta sẽ cần thêm tên đệm cho mọi người.
Đây là mã cho thuật toán sắp xếp phức tạp của chúng tôi:
| ClojureExamples/src/mbfpp/rso/person_expanded.clj | |
| | (defn complicated-sort [p1 p2] |
| | (let [first-name-compare (compare (p1 :first-name) (p2 :first-name)) |
| | middle-name-compare (compare (p1 :middle-name) (p2 :middle-name)) |
| | last-name-compare (compare (p1 :last-name) (p2 :last-name))] |
| | (cond |
| | (not (= 0 first-name-compare)) first-name-compare |
| | (not (= 0 last-name-compare)) last-name-compare |
| | :else middle-name-compare))) |
Bây giờ chúng ta có thể gọi sort như trước, nhưng thay vì truyền vào một hàm ẩn danh, chúng ta truyền vào hàm đã đặt tên complicated-sort:
| ClojureExamples/src/mbfpp/rso/person_expanded.clj | |
| | (def p1 {:first-name "Aaron" :middle-name "Jeffrey" :last-name "Smith"}) |
| | (def p2 {:first-name "Aaron" :middle-name "Bailey" :last-name "Zanthar"}) |
| | (def p3 {:first-name "Brian" :middle-name "Adams" :last-name "Smith"}) |
| | (def people [p1 p2 p3]) |
| | => (sort complicated-sort people) |
| | ({:middle-name "Jeffrey", :last-name "Smith", :first-name "Aaron"} |
| | {:middle-name "Bailey", :last-name "Zanthar", :first-name "Aaron"} |
| | {:middle-name "Adams", :last-name "Smith", :first-name "Brian"}) |
Chỉ có vậy thôi.
Discussion
Giao diện chức năng thì có vẻ hơi kỳ quặc. Nó xuất phát từ sự khăng khăng của Java trong việc biến mọi thứ thành một đối tượng, một danh từ. Điều này giống như việc bạn phải sử dụng một ShoePutterOnner, một DoorOpener và một Runner chỉ để đi chạy! Việc thay thế mẫu này bằng các hàm bậc cao giúp chúng ta theo nhiều cách. Điều đầu tiên là nó giảm bớt chi phí cú pháp cho nhiều tác vụ thông thường, những thứ rườm rà mà bạn phải viết để thực hiện được mã mà bạn muốn viết.
Ví dụ, Comparator đầu tiên mà chúng tôi gặp trong phần này cần năm dòng mã Java (được định dạng hợp lý) để truyền đạt chỉ một dòng tính toán thực sự:
| | new Comparator<Person>() { |
| | public int compare(Person left, Person right) { |
| | return left.getFirstName().compareTo(right.getFirstName()); |
| | } |
| | } |
So sánh điều đó với một dòng mã Clojure.
| | (fn [left right] (compare (left :first-name) (right :first-name))) |
Quan trọng hơn, việc sử dụng các hàm bậc cao mang lại cho chúng ta một cách nhất quán để truyền tải những mảnh tính toán nhỏ. Với Giao diện Hàm, bạn cần phải tra cứu giao diện phù hợp cho từng vấn đề nhỏ mà bạn muốn giải quyết và tìm cách sử dụng nó. Chúng ta đã thấy Comparator trong chương này và đề cập đến một vài cách sử dụng phổ biến khác của mẫu này. Hàng trăm cái khác tồn tại trong các thư viện chuẩn của Java và các thư viện phổ biến khác, mỗi cái thì độc đáo như một bông tuyết, nhưng khó chịu hơn là khác biệt hơn là đẹp.
Giao diện chức năng và các thay thế của nó trong chương này có một số khác biệt không ảnh hưởng đến vấn đề cốt lõi mà nó nhằm giải quyết. Bởi vì Giao diện chức năng được triển khai bằng một lớp, nó xác định một kiểu và có thể sử dụng các tính năng hướng đối tượng chung như kế thừa và đa hình. Các hàm bậc cao thì không thể. Đây thực sự là một điểm mạnh của các hàm bậc cao so với Giao diện chức năng: bạn không cần một kiểu mới cho mỗi loại Giao diện chức năng khi mà chỉ cần các kiểu hàm hiện có là đủ.
For Further Reading
Hiệu quả Java—Mục 21: Sử dụng Đối tượng Hàm để Đại diện cho Chiến lược
JSR 335: Biểu thức Lambda cho ngôn ngữ lập trình Java
Related Patterns
Mẫu 3, Thay thế Lệnh
Mô hình 6, Thay thế phương thức mẫu
Mẫu 7, Chiến lược Thay thế
Mẫu 16, Công cụ xây dựng chức năng
| Pattern 2 | Replacing State-Carrying Functional Interface |
Intent
Để bao encapsulate một chút trạng thái cùng với logic chương trình để nó có thể được truyền đi, lưu trữ trong các cấu trúc dữ liệu và nói chung được đối xử như bất kỳ cấu trúc đầu tiên nào khác.
Overview
Trong Mẫu 1, Thay thế Giao diện Chức năng, chúng ta đã thấy cách thay thế Giao diện Chức năng bằng các hàm bậc cao, nhưng các ví dụ mà chúng ta xem xét không mang theo bất kỳ trạng thái chương trình nào. Trong mẫu này, chúng ta sẽ xem xét cách thay thế các cài đặt Giao diện Chức năng cần trạng thái bằng một cấu trúc mạnh mẽ được gọi là một **closure**.
Also Known As
Đối tượng Hàm Hàm tùy chỉnh Hàm đối tượng
Functional Replacement
Các hàm trong thế giới hàm là một phần của một cấu trúc mạnh mẽ được gọi là đóng . Một đóng bao bọc một hàm cùng với trạng thái có sẵn cho nó khi nó được tạo ra. Điều này có nghĩa là một hàm có thể tham chiếu đến bất kỳ biến nào có trong phạm vi khi hàm được tạo ra vào thời điểm nó được gọi. Lập trình viên không cần phải làm gì đặc biệt để tạo ra một đóng; biên dịch viên và thời gian chạy sẽ lo liệu việc này, và đóng tự động ghi lại tất cả trạng thái mà nó cần.
Trong Java cổ điển, chúng ta thường mang theo trạng thái bằng cách tạo các trường trong lớp và cung cấp các hàm setter cho chúng hoặc thiết lập chúng thông qua hàm khởi tạo. Trong thế giới chức năng, chúng ta có thể tận dụng các closure để xử lý điều này mà không cần thiết bị bổ sung nào. Closures có vẻ như ma thuật một chút, vì vậy đáng để xem xét chúng một cách chi tiết hơn trước khi chúng ta tiếp tục.
Một closure được cấu thành từ một hàm và trạng thái mà hàm đó có sẵn khi nó được tạo ra. Hãy cùng xem điều này có thể trông như thế nào theo hình ảnh, như được thể hiện trong hình.
Một closure là một cấu trúc bao gồm một hàm và ngữ cảnh của nó vào thời điểm nó được định nghĩa.
Figure 2. Structure of a Closure.
Ở đây chúng ta có thể thấy rằng closure có một hàm bên trong và một chuỗi phạm vi cho phép nó tra cứu bất kỳ biến nào mà nó cần để thực hiện công việc của mình. Dịch sang Clojure, nó trông như thế này:
| ClojureExamples/src/mbfpp/rso/closure_example.clj | |
| | (ns mbfpp.rso.closure-example) |
| | |
| | ; Scope 1 - Top Level |
| | (def foo "first foo") |
| | (def bar "first bar") |
| | (def baz "first baz") |
| | |
| | (defn make-printer [foo bar] ; Scope 2 - Function Arguments |
| | (fn [] |
| | (let [foo "third foo"] ; Scope 3 - Let Statement |
| | (println foo) |
| | (println bar) |
| | (println baz)))) |
Nếu chúng ta sử dụng đoạn mã này để tạo một hàm in và chạy nó, nó sẽ in ra foo, bar và baz từ phạm vi sâu nhất mà chúng được định nghĩa, giống như bất kỳ lập trình viên có kinh nghiệm nào cũng sẽ mong đợi:
| | => (def a-printer (make-printer "second foo" "second bar")) |
| | #'closure-example/a-printer |
| | => (a-printer) |
| | third foo |
| | second bar |
| | first baz |
| | nil |
Điều này có thể không gây ngạc nhiên, nhưng điều gì sẽ xảy ra nếu chúng ta lấy một a-printer và truyền nó qua chương trình của chúng ta, hoặc lưu trữ nó trong một vector để truy xuất và sử dụng sau? Nó vẫn sẽ in ra những giá trị giống nhau cho foo, bar và baz, điều này ngụ ý rằng những giá trị đó vẫn còn tồn tại ở đâu đó.
Trong bối cảnh, Clojure và Scala cần phải thực hiện rất nhiều phép thuật để làm cho điều đó hoạt động. Tuy nhiên, việc sử dụng một closure thực sự đơn giản như việc khai báo một hàm. Tôi thích giữ hình ảnh trước đó trong tâm trí khi làm việc với các closure vì nó là một mô hình tư duy tốt về cách mà chúng hoạt động.
Sample Code: Closure
Để minh họa về closures, chúng ta sẽ xem xét một lần nữa các phép so sánh, với một chút biến tấu. Lần này, chúng ta sẽ thấy cách tạo ra một phép so sánh được cấu thành từ một danh sách các phép so sánh khác, điều này có nghĩa là chúng ta cần một nơi để lưu trữ danh sách các phép so sánh này.
Trong Java, chúng ta sẽ chỉ truyền chúng vào như là các tham số cho một hàm khởi tạo trong việc triển khai Comparator tùy chỉnh của chúng ta, và chúng ta sẽ lưu trữ chúng trong một trường. Trong Scala và Clojure, chúng ta chỉ cần sử dụng một closure. Hãy bắt đầu với ví dụ Java trước.
Classic Java
Trong Java, chúng tôi tạo một triển khai tùy chỉnh của Comparator gọi là ComposedComparator, với một constructor duy nhất sử dụng varargs để lấy một mảng các Comparator và lưu trữ chúng trong một trường.
Khi phương thức compare trên một ComposedComparator được gọi, nó sẽ chạy qua tất cả các bộ so sánh trong mảng của nó và trả về kết quả khác không đầu tiên. Nếu tất cả các kết quả đều bằng không, nó sẽ trả về số không. Một phác thảo của giải pháp này trông như sau:
| | public class ComposedComparator<T> implements Comparator<T> { |
| | private Comparator<T>[] comparators; |
| | public ComposedComparator(Comparator<T>... comparators) { |
| | this.comparators = comparators; |
| | } |
| | @Override |
| | public int compare(T o1, T o2) { |
| | //Iterate through comparators and call each in turn. |
| | } |
| | |
| | } |
Trong thế giới chức năng, chúng ta có thể sử dụng closure thay vì phải tạo ra các lớp mới. Hãy cùng đào sâu cách thực hiện điều này trong Scala.
In Scala
Trong Scala, chúng ta sẽ tận dụng các closure để tránh việc theo dõi một cách rõ ràng danh sách so sánh trong phép so sánh kết hợp của chúng ta. Giải pháp Scala của chúng ta xoay quanh một hàm bậc cao, makeComposedComparison, sử dụng varargs để nhận vào một mảng các hàm so sánh và trả về một hàm thực hiện chúng theo thứ tự.
Một sự khác biệt nữa giữa các giải pháp Java và Scala là cách chúng ta trả về kết quả cuối cùng. Trong Java, chúng ta đã lặp qua danh sách các Comparator, và ngay khi thấy một phép so sánh không bằng không, chúng ta đã trả về nó.
Chúng tôi sử dụng map để thực hiện các so sánh trên đầu vào của chúng tôi. Sau đó, chúng tôi tìm kiếm giá trị khác không đầu tiên. Nếu chúng tôi không tìm thấy giá trị khác không, tất cả các so sánh của chúng tôi đều giống nhau và chúng tôi trả về zero. Đây là mã cho makeComposedComparison:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/personexpanded/ClosureExample.scala | |
| | def makeComposedComparison(comparisons: (Person, Person) => Int*) = |
| | (p1: Person, p2: Person) => |
| | comparisons.map(cmp => cmp(p1, p2)).find(_ != 0).getOrElse(0) |
Bây giờ, chúng ta có thể lấy hai hàm so sánh và kết hợp chúng với nhau. Trong mã dưới đây, chúng ta định nghĩa firstNameComparison và lastNameComparison , và sau đó kết hợp chúng lại thành firstAndLastNameComparison :
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/personexpanded/ClosureExample.scala | |
| | def firstNameComparison(p1: Person, p2: Person) = |
| | p1.firstName.compareTo(p2.firstName) |
| | |
| | def lastNameComparison(p1: Person, p2: Person) = |
| | p1.lastName.compareTo(p2.lastName) |
| | |
| | val firstAndLastNameComparison = makeComposedComparison( |
| | firstNameComparison, lastNameComparison |
| | ) |
Hãy cùng xem hàm so sánh mà chúng ta đã xây dựng hoạt động như thế nào bằng cách định nghĩa một vài người và so sánh họ.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/fi/personexpanded/ClosureExample.scala | |
| | val p1 = Person("John", "", "Adams") |
| | val p2 = Person("John", "Quincy", "Adams") |
| | scala> firstAndLastNameComparison(p1, p2) |
| | res0: Int = 0 |
Một tối ưu hóa mà chúng ta có thể thực hiện là tạo ra một phiên bản rút gọn của phép so sánh kết hợp mà dừng lại việc chạy các phép so sánh ngay khi gặp kết quả khác không đầu tiên. Để thực hiện điều này, chúng ta có thể sử dụng một hàm đệ quy như những hàm mà chúng ta thảo luận trong Mẫu 12, Đệ quy đuôi, thay vì sử dụng comprehension for mà chúng ta sử dụng ở đây.
In Clojure
Chúng ta sẽ kết thúc các mẫu mã cho mẫu này bằng việc xem xét cách chúng ta sẽ tạo ra các so sánh hợp thành trong Clojure. Chúng ta sẽ dựa vào một so sánh make-composed, nhưng nó sẽ hoạt động hơi khác so với phiên bản Scala.
Trong Scala, chúng ta có thể sử dụng phương thức find để tìm kết quả không bằng không đầu tiên; trong Clojure, chúng ta có thể sử dụng hàm some. Điều này rất khác so với kiểu Some của Scala!
Trong Clojure, hàm some nhận một điều kiện và một dãy, và nó trả về giá trị đầu tiên mà điều kiện đó đúng. Ở đây, chúng ta sử dụng hàm some và for của Clojure để chạy tất cả các phép so sánh và chọn giá trị cuối cùng chính xác.
| ClojureExamples/src/mbfpp/rso/closure_comparison.clj | |
| | (defn make-composed-comparison [& comparisons] |
| | (fn [p1 p2] |
| | (let [results (for [comparison comparisons] (comparison p1 p2)) |
| | first-non-zero-result |
| | (some (fn [result] (if (not (= 0 result)) result nil)) results)] |
| | (if (nil? first-non-zero-result) |
| | 0 |
| | first-non-zero-result)))) |
Bây giờ chúng ta có thể tạo ra so sánh tên đầu tiên và so sánh họ, và ghép chúng lại với nhau:
| ClojureExamples/src/mbfpp/rso/closure_comparison.clj | |
| | (defn first-name-comparison [p1, p2] |
| | (compare (:first-name p1) (:first-name p2))) |
| | |
| | (defn last-name-comparison [p1 p2] |
| | (compare (:last-name p1) (:last-name p2))) |
| | |
| | (def first-and-last-name-comparison |
| | (make-composed-comparison |
| | first-name-comparison last-name-comparison)) |
Và chúng ta sẽ sử dụng chúng để so sánh hai người:
| ClojureExamples/src/mbfpp/rso/closure_comparison.clj | |
| | (def p1 {:first-name "John" :middle-name "" :last-name "Adams"}) |
| | (def p2 {:first-name "John" :middle-name "Quincy" :last-name "Adams"}) |
| | => (first-and-last-name-comparison p1 p2) |
| | 0 |
Điều đó khép lại cái nhìn của chúng ta về việc sử dụng closures để thay thế các triển khai Giao diện Hàm mang trạng thái. Trước khi di chuyển tiếp, hãy cùng thảo luận về mối quan hệ giữa closures và các lớp một cách chi tiết hơn.
Discussion
Có một câu đùa về closures và classes: classes là closure của người nghèo, và closures là class của người nghèo. Ngoài việc cho thấy các lập trình viên chức năng có lẽ không nên tham gia hài kịch, điều này minh họa một điều thú vị về mối quan hệ giữa classes và closures.
Ở một số khía cạnh, closure và lớp rất giống nhau. Chúng đều có thể mang theo trạng thái và hành vi. Ở những khía cạnh khác, chúng khá khác biệt. Lớp có rất nhiều cơ chế lập trình hướng đối tượng xung quanh, chúng định nghĩa các kiểu, chúng có thể là một phần của các hệ thống phân cấp, và nhiều hơn thế nữa. Closure thì đơn giản hơn nhiều - chúng chỉ bao gồm một hàm và ngữ cảnh mà nó được tạo ra.
Việc sử dụng closures làm cho việc giải quyết một loạt các tác vụ lập trình phổ biến trở nên đơn giản hơn rất nhiều, như chúng ta đã thấy trong phần này, đó là lý do tại sao các lớp được coi là một dạng closure kém. Tuy nhiên, các lớp có nhiều tính năng lập trình mà closures không có, đó là lý do tại sao closures lại được xem như một dạng lớp kém. Scala giải quyết vấn đề này bằng cách cung cấp cả lớp và closures, và Clojure giải quyết nó bằng cách tách lấy những điều hay từ các lớp, như tính đa hình và phân cấp kiểu, và cung cấp cho lập trình viên dưới các hình thức khác.
Việc có các closure và hàm bậc cao có thể đơn giản hóa nhiều mẫu phổ biến (Command, Template Method và Strategy là một vài ví dụ) đến mức chúng gần như biến mất. Chúng hữu ích đến mức các closure và hàm bậc cao là một trong những tính năng chính mới trong Java 8 sắp ra mắt dưới dạng JSR 335.
Đây là một sự thay đổi lớn đối với một ngôn ngữ đã trưởng thành mà hoàn toàn phải tương thích ngược, vì vậy đây không phải là một nhiệm vụ dễ dàng. Nó không phải là một việc mà các người giám hộ của Java thực hiện một cách nhẹ nhàng; nhưng vì các hàm bậc cao là một lợi thế lớn, nên việc đưa chúng vào được coi là quan trọng. Đã mất nhiều năm nỗ lực để xác định và triển khai, nhưng cuối cùng chúng cũng sắp ra mắt!
For Further Reading
Java hiệu quả [Blo08]—Mục 21: Sử dụng đối tượng hàm để đại diện cho các chiến lược
JSR 335: Biểu thức Lambda cho ngôn ngữ lập trình Java [Goe12] [3]
Related Patterns
Mẫu 3, Thay thế Lệnh
Mẫu 6, Thay thế phương thức mẫu
Mô hình 7, Chiến lược Thay thế
Mẫu 16, Trình xây dựng chức năng
| Pattern 3 | Replacing Command |
Intent
Để biến một cuộc gọi phương thức thành một đối tượng và thực thi nó ở một vị trí trung tâm nhằm theo dõi các cuộc gọi để có thể hoàn tác, ghi lại và các thao tác khác.
Overview
Lệnh bao gồm một hành động cùng với thông tin cần thiết để thực hiện nó. Mặc dù có vẻ đơn giản, nhưng mẫu này có khá nhiều phần chuyển động. Ngoài giao diện Lệnh và các thực thi của nó, còn có một khách hàng, chịu trách nhiệm tạo ra Lệnh; một người gọi, có nhiệm vụ thực hiện nó; và một người nhận, nơi mà Lệnh thực hiện hành động của mình.
Người gọi (invoker) đáng được nói đến một chút vì nó thường bị hiểu nhầm. Nó giúp tách biệt việc gọi một phương thức ra khỏi khách hàng yêu cầu nó được gọi và cung cấp cho chúng ta một vị trí trung tâm nơi tất cả các cuộc gọi phương thức diễn ra. Điều này, kết hợp với thực tế rằng cuộc gọi được đại diện bởi một đối tượng, cho phép chúng ta thực hiện những điều tiện lợi như ghi lại cuộc gọi phương thức để có thể hoàn tác hoặc có thể tuần tự hóa vào đĩa.
Hình 3, Phác thảo Lệnh mô tả cách mà Lệnh kết hợp lại với nhau.
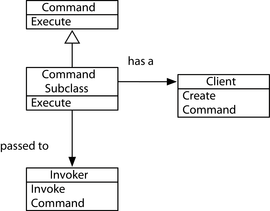
Figure 3. Command Outline. The outline of the Command pattern
Một ví dụ đơn giản là một lệnh ghi log. Ở đây, khách hàng là bất kỳ lớp nào cần thực hiện việc ghi log và người nhận là một phiên bản Logger. Bộ gọi là lớp mà khách hàng gọi thay vì gọi trực tiếp đến Logger.
Also Known As
Hành động
Functional Replacement
Lệnh có một số thành phần đang hoạt động, như cách thay thế chức năng của chúng tôi. Lớp Lệnh tự nó là một Giao diện Chức năng thường mang trạng thái, vì vậy chúng tôi sẽ thay thế nó bằng các closure mà chúng tôi đã giới thiệu trong Mẫu 2, Thay thế Giao diện Chức năng Mang trạng thái.
Tiếp theo, chúng ta sẽ thay thế bộ gọi lệnh bằng một hàm đơn giản có trách nhiệm thực thi các lệnh, mà tôi sẽ gọi là hàm thực thi. Cũng giống như bộ gọi lệnh, hàm thực thi cung cấp cho chúng ta một nơi trung tâm để kiểm soát việc thực thi các lệnh của chúng ta, vì vậy chúng ta có thể lưu trữ hoặc xử lý chúng theo nhu cầu.
Cuối cùng, chúng ta sẽ tạo một Mẫu 16, Trình Xây Dựng Chức Năng có trách nhiệm tạo ra các lệnh của chúng ta để chúng ta có thể tạo ra chúng một cách dễ dàng và đồng nhất.
Sample Code: Cash Register
Hãy cùng xem cách chúng ta sẽ triển khai một máy tính tiền đơn giản với Command. Máy tính tiền của chúng ta rất cơ bản: nó chỉ xử lý những đồng đô la nguyên, và nó chứa một tổng số tiền mặt. Tiền mặt chỉ có thể được thêm vào máy tính tiền.
Chúng tôi sẽ giữ một nhật ký giao dịch để có thể phát lại chúng. Chúng tôi sẽ xem xét cách thực hiện điều này với mẫu lệnh truyền thống trước khi chuyển sang các thay thế chức năng trong Scala và Clojure.
Classic Java
Một triển khai Java bắt đầu bằng cách định nghĩa một giao diện Command chuẩn. Đây là một ví dụ về Mẫu 1, Thay thế Giao diện Chức năng. Chúng tôi triển khai giao diện đó với một lớp Purchase.
Người nhận cho mẫu của chúng ta là lớp CashRegister. Một Purchase sẽ chứa một tham chiếu tới CashRegister mà nó sẽ được thực hiện. Để hoàn thiện mẫu, chúng ta sẽ cần một trình gọi, PurchaseInvoker, thực sự thực hiện các giao dịch mua của chúng ta.
Một sơ đồ của việc triển khai này nằm dưới đây, và mã nguồn đầy đủ có thể được tìm thấy trong các mẫu mã của cuốn sách này.
Figure 4. Cash Register Command. The structure of a cash register as a Command pattern in Java
Bây giờ chúng ta đã phác thảo một triển khai Java của mẫu Command, hãy xem cách chúng ta có thể đơn giản hóa nó bằng cách sử dụng lập trình hàm.
In Scala
Sự thay thế sạch nhất cho Command trong Scala tận dụng bản chất hỗn hợp của Scala. Chúng ta sẽ giữ lại một lớp CashRegister, giống như trong Java; tuy nhiên, thay vì tạo một giao diện và thực thi Command, chúng ta sẽ chỉ sử dụng các hàm bậc cao. Thay vì tạo một lớp riêng để làm bộ gọi, chúng ta sẽ chỉ tạo một hàm thực thi. Hãy cùng xem xét mã, bắt đầu với chính lớp CashRegister.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/command/register/Register.scala | |
| | class CashRegister(var total: Int) { |
| | def addCash(toAdd: Int) { |
| | total += toAdd |
| | } |
| | } |
Tiếp theo, chúng ta sẽ tạo hàm makePurchase để tạo ra các hàm mua hàng. Nó nhận amount và register làm tham số để thêm vào, và nó trả về một hàm thực hiện nhiệm vụ, như mã sau đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/command/register/Register.scala | |
| | def makePurchase(register: CashRegister, amount: Int) = { |
| | () => { |
| | println("Purchase in amount: " + amount) |
| | register.addCash(amount) |
| | } |
| | } |
Cuối cùng, hãy xem xét hàm thực thi của chúng ta, executePurchase. Nó chỉ thêm hàm mua sắm mà nó nhận được vào một Vector để theo dõi các giao dịch mua mà chúng ta đã thực hiện trước khi thực thi nó. Dưới đây là mã code:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/command/register/Register.scala | |
| | var purchases: Vector[() => Unit] = Vector() |
| | def executePurchase(purchase: () => Unit) = { |
| | purchases = purchases :+ purchase |
| | purchase() |
| | } |
Mã có một tham chiếu có thể thay đổi ở trung tâm.
| | var purchases: Vector[() => Unit] = Vector() |
Điều này có thể có vẻ hơi kỳ quặc trong một cuốn sách về lập trình hàm. Mọi thứ không nên là bất biến sao? Thực tế, việc mô hình hóa mọi thứ theo cách hoàn toàn hàm là khó khăn, mặc dù không phải là không thể. Việc theo dõi ngăn xếp đang thay đổi đặc biệt khó khăn.
Đừng lo lắng; tất cả những gì chúng ta đang làm ở đây là di chuyển một tham chiếu đến một phần dữ liệu không thay đổi. Điều này mang lại cho chúng ta hầu hết những lợi ích của tính không thay đổi. Ví dụ, chúng ta có thể an toàn tạo ra nhiều tham chiếu đến Vector gốc của mình mà không cần lo lắng về việc vô tình thay đổi bản gốc, như mã sau đây cho thấy:
| | scala> var v1 = Vector("foo", "bar") |
| | v1: scala.collection.immutable.Vector[String] = Vector(foo, bar) |
| | |
| | scala> val v1Copy = v1 |
| | v1Copy: scala.collection.immutable.Vector[String] = Vector(foo, bar) |
| | |
| | scala> v1 = v1 :+ "baz" |
| | v1: scala.collection.immutable.Vector[String] = Vector(foo, bar, baz) |
| | |
| | scala> v1Copy |
| | res0: scala.collection.immutable.Vector[String] = Vector(foo, bar) |
Có thể lập trình theo cách hoàn toàn hàm (functional) bằng cách sử dụng thư viện Scalaz tuyệt vời, nhưng cuốn sách này tập trung vào một hình thức lập trình hàm thực tiễn hơn.
Đây là giải pháp của chúng tôi đang hoạt động:
| | scala> val register = new CashRegister(0) |
| | register: CashRegister = CashRegister@53f7eb48 |
| | |
| | scala> val purchaseOne = makePurchase(register, 100) |
| | purchaseOne: () => Unit = <function0> |
| | |
| | scala> val purchaseTwo = makePurchase(register, 50) |
| | purchaseTwo: () => Unit = <function0> |
| | |
| | scala> executePurchase(purchaseOne) |
| | Purchase in amount: 100 |
| | |
| | scala> executePurchase(purchaseTwo) |
| | Purchase in amount: 50 |
Như bạn có thể thấy, đăng ký bây giờ đã có tổng số chính xác:
| | scala> register.total |
| | res2: Int = 150 |
Nếu chúng ta đặt lại thanh ghi về 0, chúng ta có thể phát lại các giao dịch mua bằng cách sử dụng những giao dịch mà chúng ta đã lưu trong vector mua hàng.
| | scala> register.total = 0 |
| | register.total: Int = 0 |
| | |
| | scala> for(purchase <- purchases){ purchase.apply() } |
| | Purchase in amount: 100 |
| | Purchase in amount: 50 |
| | |
| | scala> register.total |
| | res4: Int = 150 |
So với phiên bản Java, phiên bản Scala đơn giản hơn nhiều. Không cần đến lớp Command, Purchase hay lớp gọi khác khi bạn đã có các hàm bậc cao.
In Clojure
Cấu trúc tổng thể của giải pháp Clojure tương tự như giải pháp Scala. Chúng tôi sẽ sử dụng các hàm bậc cao cho các lệnh của mình, và chúng tôi sẽ sử dụng một hàm thực thi để thực hiện chúng. Sự khác biệt lớn nhất giữa giải pháp Scala và Clojure là chính cái máy tính tiền. Bởi vì Clojure không có các tính năng hướng đối tượng, chúng tôi không thể tạo ra một lớp CashRegister.
Thay vào đó, chúng ta sẽ sử dụng một atom trong Clojure để theo dõi số tiền trong quầy. Để làm điều này, chúng ta sẽ tạo một hàm make-cash-register trả về một atom mới để đại diện cho một quầy mới và một hàm add-cash nhận vào một quầy và một số tiền. Chúng ta cũng sẽ tạo ra một hàm reset để đặt lại quầy của chúng ta về số không.
Đây là mã cho máy tính tiền Clojure:
| ClojureExamples/src/mbfpp/oo/command/cash_register.clj | |
| | (defn make-cash-register [] |
| | (let [register (atom 0)] |
| | (set-validator! register (fn [new-total] (>= new-total 0))) |
| | register)) |
| | |
| | (defn add-cash [register to-add] |
| | (swap! register + to-add)) |
| | |
| | (defn reset [register] |
| | (swap! register (fn [oldval] 0))) |
Chúng ta có thể tạo một sổ đăng ký trống:
| | => (def register (make-cash-register)) |
| | #'mblinn.oo.command.ex1.version-one/register |
Và chúng tôi sẽ thêm một ít tiền mặt:
| | => (add-cash register 100) |
| | 100 |
Bây giờ khi chúng ta đã có máy thu ngân, hãy xem xét cách chúng ta sẽ tạo lệnh. Hãy nhớ rằng, trong Java, điều này sẽ yêu cầu chúng ta triển khai một giao diện Command. Trong Clojure, chúng ta chỉ cần sử dụng một hàm để đại diện cho các giao dịch mua.
Để tạo ra chúng, chúng ta sẽ sử dụng hàm make-purchase, hàm này nhận một register và một amount và trả về một hàm thêm amount vào register. Đây là mã nguồn:
| ClojureExamples/src/mbfpp/oo/command/cash_register.clj | |
| | (defn make-purchase [register amount] |
| | (fn [] |
| | (println (str "Purchase in amount: " amount)) |
| | (add-cash register amount))) |
Ở đây chúng tôi sử dụng nó để tạo ra một vài giao dịch mua sắm.
| | => (def register (make-cash-register)) |
| | #'mblinn.oo.command.ex1.version-one/register |
| | => @register |
| | 0 |
| | => (def purchase-1 (make-purchase register 100)) |
| | #'mblinn.oo.command.ex1.version-one/purchase-1 |
| | => (def purchase-2 (make-purchase register 50)) |
| | #'mblinn.oo.command.ex1.version-one/purchase-2 |
Và đây là chúng tôi điều hành chúng:
| | => (purchase-1) |
| | Purchase in amount: 100 |
| | 100 |
| | => (purchase-2) |
| | Purchase in amount: 50 |
| | 150 |
Để hoàn thành ví dụ, chúng ta sẽ cần hàm thực thi của mình, execute-purchase, hàm này lưu trữ các lệnh mua trước khi thực hiện chúng. Chúng ta sẽ sử dụng một atom, purchases, được bọc quanh một vector cho mục đích đó. Dưới đây là đoạn mã mà chúng ta cần:
| ClojureExamples/src/mbfpp/oo/command/cash_register.clj | |
| | (def purchases (atom [])) |
| | (defn execute-purchase [purchase] |
| | (swap! purchases conj purchase) |
| | (purchase)) |
Bây giờ chúng ta có thể sử dụng execute-purchase để thực hiện các giao dịch mua mà chúng ta đã định nghĩa ở trên để lần này chúng ta sẽ có chúng trong lịch sử mua hàng của mình. Chúng ta sẽ reset register trước:
| | => (execute-purchase purchase-1) |
| | Purchase in amount: 100 |
| | 100 |
| | => (execute-purchase purchase-2) |
| | Purchase in amount: 50 |
| | 150 |
Bây giờ nếu chúng ta đặt lại thanh ghi một lần nữa, chúng ta có thể xem lại lịch sử mua hàng của mình để thực hiện lại các giao dịch mua.
| | => (reset register) |
| | 0 |
| | => (doseq [purchase @purchases] (purchase)) |
| | Purchase in amount: 100 |
| | Purchase in amount: 50 |
| | nil |
| | => @register |
| | 150 |
Đó là giải pháp Clojure của chúng tôi! Một điểm thú vị mà tôi thấy về nó là cách chúng tôi mô hình hóa máy tính tiền mà không sử dụng đối tượng, chỉ đơn giản là đại diện nó như một mẩu dữ liệu và các hàm hoạt động trên đó. Điều này, tất nhiên, là phổ biến trong thế giới hàm và thường dẫn đến mã lệnh đơn giản hơn và hệ thống nhỏ hơn.
Điều này có thể có vẻ hạn chế đối với lập trình viên hướng đối tượng có kinh nghiệm ban đầu; ví dụ, điều gì sẽ xảy ra nếu bạn cần tính đa hình hoặc các hệ thống phân cấp kiểu? Đừng lo lắng, Clojure cung cấp cho lập trình viên tất cả những điều tuyệt vời từ thế giới lập trình hướng đối tượng, chỉ là dưới một hình thức khác, tách biệt hơn. Ví dụ, Clojure có cách để tạo ra các hệ thống phân cấp tạm thời, và các phương thức đa năng cùng với giao thức của nó cung cấp cho chúng ta tính đa hình. Chúng ta sẽ xem xét một số công cụ này chi tiết hơn trong Mẫu 10, Thay thế Visitor.
Discussion
Tôi nhận thấy rằng Mẫu Lệnh, mặc dù được sử dụng rộng rãi, là một trong những mẫu bị hiểu nhầm nhất trong cuốn Design Patterns: Elements of Reusable Object-Oriented Software [GHJV95]. Mọi người thường nhầm lẫn giao diện Command với mẫu Command. Giao diện Command chỉ là một phần nhỏ trong tổng thể mẫu và chính nó là một ví dụ của Mẫu 1, Thay thế Giao diện Chức năng. Điều này không có nghĩa là cách mà nó thường được sử dụng là sai, nhưng nó thường khác với cách mà nhóm Bốn người mô tả, điều này có thể dẫn đến một số nhầm lẫn khi nói về mẫu này.
Các ví dụ trong phần này đã triển khai một sự thay thế cho toàn bộ mẫu trong tất cả vinh quang của nó với các thành phần gọi, nhận và khách hàng, nhưng rất dễ dàng để loại bỏ những phần không cần thiết. Ví dụ, nếu chúng ta không cần lệnh của mình có thể làm việc với nhiều thanh ghi, chúng ta sẽ không phải truyền một thanh ghi vào makePurchase.
For Further Reading
Mô hình thiết kế: Các yếu tố của phần mềm hướng đối tượng có thể tái sử dụng [GHJV95]—Lệnh
Related Patterns
Mẫu 1, Thay thế Giao diện Chức năng
| Pattern 4 | Replacing Builder for Immutable Object |
Intent
Để tạo một đối tượng không thể thay đổi bằng cách sử dụng cú pháp thân thiện để thiết lập thuộc tính—vì chúng ta không thể sửa đổi chúng, chúng ta cũng cần một cách đơn giản để tạo ra các đối tượng mới dựa trên các đối tượng hiện có, thiết lập một số thuộc tính với các giá trị mới khi làm như vậy.
Overview
Trong phần này, chúng ta sẽ đề cập đến Fluent Builder, tạo ra các đối tượng không thể thay đổi. Đây là một mẫu phổ biến; thư viện chuẩn của Java sử dụng nó với StringBuilder và StringBuffer. Nhiều thư viện phổ biến khác cũng sử dụng nó, chẳng hạn như framework protocol buffers của Google.
Sử dụng các đối tượng không thay đổi là một thực tiễn tốt nhưng thường bị bỏ qua trong Java, nơi mà cách phổ biến nhất để mang dữ liệu là trong một lớp với nhiều hàm getter và setter. Điều này buộc các đối tượng dữ liệu trở nên có thể thay đổi, và tính biến đổi là nguồn gốc của nhiều lỗi thường gặp.
Cách dễ nhất để tạo một đối tượng không thay đổi trong Java là chỉ cần tạo một lớp nhận tất cả dữ liệu mà nó cần dưới dạng tham số của hàm xây dựng. Đáng tiếc, như mục 2 của cuốn sách hiệu quả Java [Blo08] đã chỉ ra, điều này dẫn đến một số vấn đề khi xử lý với nhiều thuộc tính.
Điều đầu tiên là một lớp Java với nhiều tham số khởi tạo rất khó để sử dụng. Một lập trình viên phải nhớ tham số nào nằm ở vị trí nào, thay vì tham chiếu theo tên. Điều thứ hai là không có cách dễ dàng để tạo giá trị mặc định cho các thuộc tính, vì tất cả các giá trị của thuộc tính cần phải được truyền vào hàm khởi tạo.
Một cách để giải quyết điều đó là tạo ra nhiều hàm tạo khác nhau chỉ nhận một tập hợp con các giá trị và mặc định các giá trị không được truyền vào. Đối với các đối tượng lớn, điều này dẫn đến vấn đề hàm tạo lồng ghép, nơi một lớp phải triển khai nhiều hàm tạo khác nhau và truyền các giá trị từ các hàm tạo nhỏ hơn cho các hàm tạo lớn hơn.
Mô hình builder mà chúng tôi xem xét trong phần này, được phác thảo trong cuốn Effective Java [Blo08], giải quyết cả hai vấn đề này với chi phí là một lượng mã khá lớn.
Functional Replacement
Kỹ thuật được sử dụng để thay thế hai mẫu này trong Scala và Clojure là khá khác nhau, nhưng cả hai đều chia sẻ một thuộc tính rất quan trọng là chúng làm cho việc tạo ra các đối tượng bất biến trở nên cực kỳ đơn giản. Hãy xem xét Scala trước.
In Scala
Chúng ta sẽ xem xét ba kỹ thuật khác nhau để tạo ra các cấu trúc dữ liệu bất biến trong Scala, mỗi kỹ thuật có những điểm mạnh và điểm yếu riêng.
Trước hết, chúng ta sẽ tìm hiểu cách tạo một lớp Scala chỉ bao gồm các giá trị bất biến. Chúng ta sẽ chỉ cho cách sử dụng tham số có tên và giá trị mặc định để đạt được điều gì đó rất giống với trình xây dựng trôi chảy cho một đối tượng bất biến trong Java, nhưng với một phần nhỏ chi phí.
Tiếp theo, chúng ta sẽ xem xét các lớp trường hợp (case classes) của Scala. Các lớp trường hợp được thiết kế đặc biệt để mang dữ liệu, vì vậy chúng đi kèm với một số phương thức tiện dụng đã được cài đặt sẵn, như equals và hashCode, và chúng có thể được sử dụng với việc khớp mẫu (pattern matching) của Scala để dễ dàng phân tách chúng. Điều này khiến chúng trở thành lựa chọn mặc định tốt cho nhiều mục đích chứa dữ liệu.
Trong cả hai trường hợp, chúng ta sẽ sử dụng các bộ khởi tạo của Scala để tạo ra các đối tượng. Các bộ khởi tạo của Scala không có những hạn chế giống như các bộ khởi tạo trong Java mà chúng ta đã thảo luận trước đó, vì chúng ta có thể đặt tên cho các tham số và cung cấp giá trị mặc định cho chúng. Điều này giúp chúng ta tránh được cả vấn đề bộ khởi tạo hình ống và các vấn đề liên quan đến việc truyền vào nhiều tham số không có tên và cố gắng nhớ cái nào là cái nào.
Cuối cùng, chúng ta sẽ đề cập đến các tuple trong Scala, là một cách tiện lợi để truyền các cấu trúc dữ liệu tổ hợp nhỏ mà không cần phải tạo ra một lớp mới.
In Clojure
Clojure hỗ trợ việc tạo các lớp mới, nhưng nó chỉ được sử dụng cho việc tương tác với Java. Thay vào đó, thường thì người ta sử dụng các bản đồ bất biến đơn giản để mô hình hóa dữ liệu tổng hợp.
Xuất phát từ thế giới Java, có thể đây có vẻ là một ý tưởng tồi, nhưng vì Clojure hỗ trợ rất tốt cho việc làm việc với các bản đồ, nên thực sự điều này rất tiện lợi. Sử dụng bản đồ để mô hình hóa dữ liệu cho phép chúng ta sử dụng toàn bộ sức mạnh của thư viện tuần tự của Clojure trong việc thao tác với dữ liệu đó, điều này thực sự rất mạnh mẽ.
Nhiều thư viện dựa vào việc kiểm tra các đối tượng dữ liệu để thực hiện các thao tác trên dữ liệu của chúng, chẳng hạn như XStream, cái mà tuần tự hóa các đối tượng dữ liệu thành XML, hoặc Hibernate, cái có thể tạo ra các truy vấn SQL bằng cách sử dụng chúng. Để thực hiện loại lập trình này trong Java, bạn cần sử dụng thư viện phản chiếu. Với Clojure, bạn chỉ cần sử dụng các thao tác bản đồ đơn giản.
Cách thứ hai để mô hình hóa dữ liệu trong Clojure là sử dụng record. Một record cung cấp giao diện giống như bản đồ; vì vậy bạn vẫn có thể sử dụng toàn bộ sức mạnh của thư viện chuỗi của Clojure trên đó, nhưng record có một vài lợi thế so với bản đồ.
Đầu tiên, bản ghi thường có hiệu suất tốt hơn. Ngoài ra, bản ghi định nghĩa một loại có thể tham gia vào tính đa hình của Clojure. Để sử dụng một câu nói cũ trong lập trình hướng đối tượng, nó cho phép chúng ta định nghĩa một hàm make-noise sẽ sủa khi nhận một con chó và kêu khi nhận một con mèo. Hơn nữa, bản ghi cho phép chúng ta giới hạn các thuộc tính mà chúng ta có thể đưa vào một cấu trúc dữ liệu.
Thông thường, một cách hiệu quả để làm việc với Clojure là bắt đầu bằng việc mô hình hóa dữ liệu của bạn bằng các bản đồ và sau đó chuyển sang các bản ghi khi bạn cần tốc độ bổ sung, khi bạn cần sử dụng tính đa hình, hoặc khi bạn chỉ muốn giới hạn các tên thuộc tính mà bạn đang xử lý.
Sample Code: Immutable Data
Trong phần này, chúng ta sẽ tìm hiểu cách biểu diễn dữ liệu trong Java bằng cách sử dụng một builder cho các đối tượng bất biến. Sau đó, chúng ta sẽ xem xét ba cách để thay thế chúng trong Clojure: các lớp thông thường với thuộc tính bất biến, lớp case, và tuple. Cuối cùng, chúng ta sẽ xem xét hai cách để thay thế chúng trong Clojure: bản đồ thông thường và bản ghi.
Classic Java
Trong Java cổ điển, chúng ta có thể sử dụng một bộ xây dựng lưu loát để tạo ra một đối tượng bất biến bằng cú pháp đẹp. Để giải quyết vấn đề của chúng ta, chúng ta tạo ra một lớp ImmutablePerson chỉ có các hàm getter cho các thuộc tính của nó. Lồng trong lớp đó, chúng ta tạo một lớp Builder, cho phép chúng ta xây dựng một đối tượng ImmutablePerson.
Khi chúng ta muốn tạo một ImmutablePerson, chúng ta không xây dựng nó trực tiếp; chúng ta tạo một Builder mới, đặt các thuộc tính mà chúng ta muốn thiết lập, và sau đó gọi build để nhận được một ImmutablePerson. Điều này được mô tả dưới đây:
| | public class ImmutablePerson { |
| | |
| | private final String firstName; |
| | // more attributes |
| | |
| | public String getFirstName() { |
| | return firstName; |
| | } |
| | // more getters |
| | |
| | private ImmutablePerson(Builder builder) { |
| | firstName = builder.firstName; |
| | // set more attributes |
| | } |
| | |
| | public static class Builder { |
| | private String firstName; |
| | // more attributes |
| | |
| | public Builder firstName(String firstName) { |
| | this.firstName = firstName; |
| | return this; |
| | } |
| | // more setters |
| | public ImmutablePerson build() { |
| | return new ImmutablePerson(this); |
| | } |
| | } |
| | public static Builder newBuilder() { |
| | return new Builder(); |
| | } |
| | } |
Nhược điểm là chúng ta có rất nhiều mã cho một công việc căn bản như vậy. Việc truyền dữ liệu tổng hợp là một trong những điều cơ bản nhất mà chúng ta làm được với tư cách là lập trình viên, vì vậy các ngôn ngữ nên cung cấp cho chúng ta một cách tốt hơn để thực hiện việc này. May mắn thay, cả Scala và Clojure đều làm được điều đó. Hãy cùng xem xét, bắt đầu với Scala.
In Scala
Chúng ta sẽ xem xét ba cách khác nhau để đại diện cho dữ liệu không thay đổi trong Scala: các lớp không thay đổi, lớp trường hợp và bộ. Các lớp không thay đổi là các lớp thông thường chỉ chứa các thuộc tính không thay đổi; lớp trường hợp là một loại lớp đặc biệt được thiết kế để làm việc với việc phân tích mẫu của Scala; và bộ là các cấu trúc dữ liệu không thay đổi cho phép chúng ta nhóm dữ liệu lại với nhau mà không cần định nghĩa một lớp mới.
Lớp không thay đổi
Hãy bắt đầu bằng cách xem cách tạo ra các đối tượng bất biến trong Scala. Tất cả những gì chúng ta cần làm là định nghĩa một lớp mà định nghĩa một số val như là tham số khởi tạo, điều này sẽ khiến các giá trị được truyền vào được gán cho các vals công khai. Đây là mã cho giải pháp này:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/javabean/Person.scala | |
| | class Person( |
| | val firstName: String, |
| | val middleName: String, |
| | val lastName: String) |
Bây giờ chúng ta có thể tạo một Person sử dụng các tham số khởi tạo theo vị trí:
| | scala> val p1 = new Person("John", "Quincy", "Adams") |
| | p1: Person = Person@83d2eb1 |
Hoặc chúng ta có thể sử dụng chúng làm các tham số có tên:
| | scala> val p2 = new Person(firstName="John", middleName="Quincy", lastName="Adams") |
| | p2: Person = Person@33d6798 |
Chúng ta có thể thêm giá trị mặc định cho các tham số, cho phép chúng ta bỏ qua chúng khi sử dụng dạng tham số có tên. Ở đây, chúng ta đang thêm một tên giữa mặc định là rỗng.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/javabean/Person.scala | |
| | class PersonWithDefault( |
| | val firstName: String, |
| | val middleName: String = "", |
| | val lastName: String) |
Điều này cho phép chúng tôi xử lý những người có thể không có tên đệm:
| | scala> val p3 = new PersonWithDefault(firstName="John", lastName="Adams") |
| | p3: PersonWithDefault = PersonWithDefault@6d0984e0 |
Điều này mang lại cho chúng ta một cách đơn giản để tạo ra các đối tượng không thay đổi trong Scala, nhưng nó có một số hạn chế. Nếu chúng ta muốn so sánh đối tượng, mã băm, hoặc một đại diện đẹp khi được in ra, chúng ta cần tự triển khai nó. Các lớp trường hợp cung cấp tất cả điều này ngay lập tức và được thiết kế để tham gia vào việc khớp mẫu của Scala. Tuy nhiên, chúng không thể được mở rộng, vì vậy chúng không phù hợp cho mọi mục đích.
Lớp trường hợp
Một lớp trường hợp được định nghĩa bằng cách sử dụng case class, như được thể hiện dưới đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/javabean/Person.scala | |
| | case class PersonCaseClass( |
| | firstName: String, |
| | middleName: String = "", |
| | lastName: String) |
Bây giờ chúng ta có thể tạo một PersonCaseClass theo cách giống như chúng ta tạo một lớp bình thường, ngoại trừ việc chúng ta không cần sử dụng toán tử new. Ở đây, chúng ta tạo một cái bằng cách sử dụng các tham số có tên và bỏ qua tên đệm:
| | scala> val p = PersonCaseClass(firstName="John", lastName="Adams") |
| | p: PersonCaseClass = PersonCaseClass(John,,Adams) |
Lưu ý cách lớp trường hợp hiển thị dưới dạng PersonCaseClass(John,,Adams), và chúng ta không cần phải triển khai một phương thức toString . Chúng ta cũng nhận được equals và hashCode miễn phí với các lớp trường hợp. Ở đây, chúng ta kiểm tra tính bằng nhau:
| | scala> val p2 = PersonCaseClass(firstName="John", lastName="Adams") |
| | p2: PersonCaseClass = PersonCaseClass(John,,Adams) |
| | |
| | scala> p.equals(p2) |
| | res1: Boolean = true |
| | |
| | scala> val p3 = PersonCaseClass( |
| | firstName="John", |
| | middleName="Quincy", |
| | lastName="Adams") |
| | p3: PersonCaseClass = PersonCaseClass(John,Quincy,Adams) |
| | |
| | scala> p2.equals(p3) |
| | res2: Boolean = false |
Các lớp case là bất biến, vì vậy chúng ta không thể chỉnh sửa chúng, nhưng chúng ta có thể đạt được hiệu ứng tương tự bằng cách sử dụng phương thức copy để tạo một lớp case mới dựa trên một lớp đã tồn tại, như chúng ta thực hiện trong phiên REPL sau đây:
| | scala> val p2 = p.copy(middleName="Quincy") |
| | p2: com.mblinn.mbfpp.oo.javabean.PersonCaseClass = |
| | PersonCaseClass(John,Quincy,Adams) |
Cuối cùng, các lớp trường hợp có thể được sử dụng với việc phân tích mẫu của Scala. Ở đây, chúng ta sử dụng một phép phân tích mẫu để tách rời tổng thống thứ sáu của Hoa Kỳ:
| | scala> p3 match { |
| | | case PersonCaseClass(firstName, middleName, lastName) => { |
| | | "First: %s - Middle: %s - Last: %s".format( |
| | firstName, middleName, lastName) |
| | | }} |
| | res0: String = First: John - Middle: Quincy - Last: Adams |
Có một cách cuối cùng phổ biến để biểu diễn dữ liệu trong Scala: các tuple. Tuples cho phép chúng ta đại diện cho một bản ghi có kích thước cố định, nhưng chúng không tạo ra một loại mới như các lớp và lớp trường hợp. Chúng rất tiện lợi cho việc phát triển khám phá; bạn có thể sử dụng chúng để mô hình hóa dữ liệu của mình trong các giai đoạn đầu khi bạn chưa chắc chắn về hình dạng của nó và sau đó chuyển sang các lớp hoặc lớp trường hợp sau. Hãy cùng xem chúng hoạt động như thế nào.
Cặp số
Để tạo một tuple, bạn bao gồm các giá trị mà nó chứa bên trong dấu ngoặc đơn, như sau:
| | scala> def p = ("John", "Adams") |
| | p: (java.lang.String, java.lang.String) |
Để lấy giá trị trở lại, hãy tham chiếu chúng theo vị trí, như chúng tôi đã làm bên dưới:
| | scala> p._1 |
| | res0: java.lang.String = John |
| | |
| | scala> p._2 |
| | res1: java.lang.String = Adams |
Cuối cùng, các bộ (tuples) có thể dễ dàng được sử dụng trong việc khớp mẫu, giống như các lớp trường hợp (case classes):
| | scala> p match { |
| | | case (firstName, lastName) => { |
| | | println("First name is: " + firstName) |
| | | println("Last name is: " + lastName) |
| | | }} |
| | First name is: John |
| | Last name is: Adams |
Điều đó bao gồm ba cách chính để làm việc với dữ liệu không thay đổi trong Scala.
Các lớp bất biến thông thường truyền thống rất hữu ích khi bạn có nhiều thuộc tính hơn hai mươi hai cái mà một lớp trường hợp có thể xử lý, mặc dù điều này có thể gợi ý rằng đã đến lúc bạn cần tinh chỉnh mô hình dữ liệu của mình hoặc các đối tượng dữ liệu của bạn cần có một số phương thức.
Các lớp case rất hữu ích khi bạn muốn sử dụng các phương thức tích hợp sẵn như equals , hashCode , và toString , hoặc khi bạn cần làm việc với việc khớp mẫu. Cuối cùng, các tuple rất tuyệt cho phát triển khám phá; bạn có thể sử dụng chúng để mô hình hóa dữ liệu của mình một cách đơn giản trước khi chuyển sang các lớp hoặc lớp case.
In Clojure
Chúng ta sẽ xem xét hai cách để biểu diễn dữ liệu không thay đổi (immutable) trong Clojure. Cách đầu tiên là đơn giản lưu trữ nó trong một bản đồ (map), và cách thứ hai sử dụng một bản ghi (record). Bản đồ là cấu trúc dữ liệu đơn giản mà chúng ta đều biết và yêu thích; bản ghi thì có chút khác biệt. Chúng cho phép chúng ta định nghĩa một kiểu dữ liệu và ràng buộc các thuộc tính mà nó chứa, nhưng vẫn cung cấp cho chúng ta một giao diện giống như bản đồ.
Bản đồ
Hãy bắt đầu bằng cách xem xét tùy chọn đơn giản hơn trong hai tùy chọn: sử dụng một bản đồ không thay đổi. Tất cả những gì chúng ta cần làm là tạo một bản đồ với các từ khóa làm khóa và dữ liệu của chúng ta làm giá trị, như chúng ta làm ở dưới đây:
| ClojureExamples/src/mbfpp/oo/javabean/person.clj | |
| | (def p |
| | {:first-name "John" |
| | :middle-name "Quincy" |
| | :last-name "Adams"}) |
Chúng ta có thể truy cập vào các thuộc tính như chúng ta làm với bất kỳ bản đồ nào:
| | => (p :first-name) |
| | "John" |
| | => (get p :first-name) |
| | "John" |
Một lợi ích mà có thể không rõ ràng là chúng ta có thể sử dụng toàn bộ tập hợp các phép toán mà bản đồ hỗ trợ, bao gồm cả những phép toán xử lý bản đồ như các chuỗi. Chẳng hạn, nếu chúng ta muốn viết hoa tất cả các phần của một tên, chúng ta có thể làm điều đó với mã sau:
| | => (into {} (for [[k, v] p] [k (.toUpperCase v)])) |
| | {:middle-name "QUINCY", :last-name "ADAMS", :first-name "JOHN"} |
Để làm điều gì đó tương tự với các đối tượng và các getter, chúng ta cần gọi tất cả các getter thích hợp. Điều đó có nghĩa là chúng ta đã lấy một giải pháp cho một vấn đề chung, vấn đề viết hoa tất cả các thuộc tính trong một cấu trúc dữ liệu đầy đủ các chuỗi, và giảm tính tổng quát của nó chỉ để viết hoa các thuộc tính của một loại cụ thể, điều này đồng nghĩa với việc chúng ta cần tái triển khai giải pháp đó cho mỗi loại đối tượng.
Sử dụng bản đồ bất biến như một trong những cách chính để mang dữ liệu có vài lợi ích khác. Việc tạo chúng sử dụng cú pháp đơn giản, vì vậy bạn không có giới hạn nào về các thuộc tính mà bạn có thể thêm vào. Điều này giúp chúng trở nên tuyệt vời cho lập trình khám phá.
Sự linh hoạt này có một số nhược điểm. Các bản đồ Clojure không hiệu quả bằng các lớp Java đơn giản, và một khi bạn đã làm rõ mô hình dữ liệu của mình, có thể hữu ích khi hạn chế các thuộc tính mà bạn đang xử lý.
Điều quan trọng nhất, tuy nhiên, là việc sử dụng bản đồ đơn giản khiến việc sử dụng polymorphism trở nên khó khăn, vì việc sử dụng một bản đồ không định nghĩa một kiểu mới. Hãy cùng xem xét một tính năng khác của Clojure giải quyết những vấn đề này nhưng vẫn cung cấp giao diện giống như bản đồ.
Awkward, Not ImpossibleTrước đây tôi đã nói rằng việc sử dụng bản đồ (maps) khi bạn muốn đa hình dựa trên kiểu (type-based polymorphism) là khó xử. Điều này đúng, nhưng Clojure đủ linh hoạt để chỉ khó xử chứ không phải là không thể. Chúng ta có thể mã hóa kiểu trong chính bản đồ và sử dụng các phương thức đa hình của Clojure, như mã dưới đây cho thấy:
| ClojureExamples/src/mbfpp/oo/javabean/sidebar.clj | |
| | (def cat {:type :cat |
| | :color "Calico" |
| | :name "Fuzzy McBootings"}) |
| | |
| | (def dog {:type :dog |
| | :color "Brown" |
| | :name "Brown Dog"}) |
| | |
| | (defmulti make-noise (fn [animal] (:type animal))) |
| | (defmethod make-noise :cat [cat] (println (str (:name cat)) "meows!")) |
| | (defmethod make-noise :dog [dog] (println (str (:name dog)) "barks!")) |
Nói chung, nếu bạn muốn có tính đa hình trên các kiểu dữ liệu, thì tốt nhất là chỉ nên sử dụng giao thức và giữ multimethod cho những trường hợp đa hình phức tạp hơn, khi bạn cần toàn bộ sức mạnh đi kèm với khả năng định nghĩa hàm phân phối riêng của mình.
Hồ sơ
Để minh họa các bản ghi, hãy mượn một ví dụ cũ về lập trình hướng đối tượng: tạo ra mèo và chó. Để tạo các loại Mèo và Chó của chúng ta, chúng ta sử dụng mã dưới đây:
| ClojureExamples/src/mbfpp/oo/javabean/catsanddogslivingtogether.clj | |
| | (defrecord Cat [color name]) |
| | |
| | (defrecord Dog [color name]) |
Chúng ta có thể coi chúng như bản đồ để có được sức mạnh toàn diện đã đề cập ở trên:
| | => (def cat (Cat. "Calico" "Fuzzy McBootings")) |
| | #'mbfpp.oo.javabean.catsanddogslivingtogether/cat |
| | => (def dog (Dog. "Brown" "Brown Dog")) |
| | #'mbfpp.oo.javabean.catsanddogslivingtogether/dog |
| | => (:name cat) |
| | "Fuzzy McBootings" |
| | => (:name dog) |
| | "Brown Dog" |
Họ có thể dễ dàng tham gia vào đa hình (polymorphism) bằng cách sử dụng các giao thức của Clojure. Ở đây, chúng tôi định nghĩa một giao thức có một hàm duy nhất, make-noise, và chúng tôi tạo ra một NoisyCat và NoisyDog để tận dụng điều đó:
| ClojureExamples/src/mbfpp/oo/javabean/catsanddogslivingtogether.clj | |
| | (defprotocol NoiseMaker |
| | (make-noise [this])) |
| | |
| | (defrecord NoisyCat [color name] |
| | NoiseMaker |
| | (make-noise [this] (str (:name this) "meows!"))) |
| | |
| | (defrecord NoisyDog [color name] |
| | NoiseMaker |
| | (make-noise [this] (str (:name this) "barks!"))) |
| | => (def noisy-cat (NoisyCat. "Calico" "Fuzzy McBootings")) |
| | #'mbfpp.oo.javabean.catsanddogslivingtogether/noisy-cat |
| | => (def noisy-dog (NoisyDog. "Brown" "Brown Dog")) |
| | #'mbfpp.oo.javabean.catsanddogslivingtogether/noisy-dog |
| | => (make-noise noisy-cat) |
| | "Fuzzy McBootingsmeows!" |
| | => (make-noise noisy-dog) |
| | "Brown Dogbarks!" |
Đó là hai cách chính để mang dữ liệu trong Clojure. Cách đầu tiên, bản đồ đơn giản, là một nơi tốt để bắt đầu. Khi bạn đã xác định rõ mô hình dữ liệu của mình hơn, hoặc nếu bạn muốn tận dụng tính đa hình của các giao thức trong Clojure, bạn có thể chuyển sang sử dụng bản ghi.
Discussion
Có một sự căng thẳng cơ bản giữa việc khóa chặt cấu trúc dữ liệu của bạn và giữ chúng linh hoạt. Giữ chúng linh hoạt giúp trong giai đoạn phát triển, khi mô hình dữ liệu của bạn đang thay đổi, nhưng việc khóa chúng chặt lại có thể giúp phát hiện lỗi sớm hơn, điều này quan trọng khi mã của bạn đã đi vào sản xuất. Điều này cũng phần nào phản ánh trong thế giới kỹ thuật rộng lớn hơn với một số tranh luận xung quanh các cơ sở dữ liệu quan hệ truyền thống, chúng áp đặt một sơ đồ nghiêm ngặt, và một số cơ sở dữ liệu phi quan hệ mới hơn, không có sơ đồ hoặc có sơ đồ lỏng lẻo hơn, với cả hai bên đều tuyên bố rằng cách tiếp cận của họ tốt hơn.
Trên thực tế, cả hai cách tiếp cận đều hữu ích, tùy thuộc vào tình huống. Clojure và Scala cung cấp cho chúng ta những lợi ích tốt nhất của cả hai thế giới bằng cách cho phép chúng ta giữ cho cấu trúc dữ liệu linh hoạt ở giai đoạn đầu (sử dụng bản đồ trong Clojure và tuple trong Scala) và cho phép chúng ta cố định chúng khi hiểu rõ hơn về dữ liệu của mình (sử dụng bản ghi trong Clojure và lớp hoặc lớp trường trong Scala).
For Further Reading
Java Hiệu Quả [Blo08]—Mục 2: Xem Xét Sử Dụng Builder Khi Đối Mặt Với Nhiều Tham Số Khởi Tạo
Hiệu quả Java [Blo08]—Mục 15: Giảm thiểu tính thay đổi
Related Patterns
Mô hình 19, Biến đổi Tập trung
| Pattern 5 | Replacing Iterator |
Intent
Để lặp qua các phần tử của một chuỗi theo thứ tự, mà không cần phải chỉ số vào nó.
Overview
Một bộ lặp là một đối tượng cho phép chúng ta lặp qua tất cả các đối tượng trong một chuỗi. Nó thực hiện điều này bằng cách duy trì một trạng thái nội bộ để theo dõi vị trí hiện tại trong chuỗi mà bộ lặp đang ở. Ở mức đơn giản nhất, một triển khai của Bộ lặp chỉ yêu cầu một phương thức trả về mục tiếp theo trong chuỗi, với một giá trị cảnh báo được trả về khi không còn mục nào nữa.
Hầu hết các cài đặt có một phương thức riêng để kiểm tra xem bộ lặp có còn mục nào nữa hay không, thay vì sử dụng một đối tượng đánh dấu để kiểm tra. Một số cài đặt của Iterator cho phép tập hợp cơ bản được chỉnh sửa bằng cách xóa mục hiện tại.
Also Known As
Con trỏ Bộ lặp
Functional Replacement
Trong phần này, chúng ta sẽ tập trung vào việc thay thế một bộ lặp bằng sự kết hợp của các hàm bậc cao và các phép hiểu chuỗi. Một phép hiểu chuỗi là một kỹ thuật thông minh cho phép chúng ta lấy một chuỗi và biến đổi nó thành một chuỗi khác theo những cách tinh vi. Chúng giống như hàm `map` nhưng mạnh mẽ hơn.
Nhiều cách sử dụng cơ bản của Iterator có thể được thay thế bằng các hàm bậc cao đơn giản. Ví dụ, việc cộng một dãy số có thể được thực hiện trong Clojure bằng cách sử dụng hàm bậc cao reduce.
Các cách sử dụng khác, phức tạp hơn có thể được xử lý bằng cách sử dụng comprehension chuỗi. Comprehension chuỗi cung cấp một cách ngắn gọn để tạo ra một chuỗi mới từ một chuỗi cũ, bao gồm khả năng loại bỏ các giá trị không mong muốn.
Trong phần này, chúng ta sẽ chỉ tập trung vào các ứng dụng của Iterator có thể được biểu diễn bằng cách sử dụng vòng lặp foreach của Java. Các ứng dụng khác, ít phổ biến hơn, có thể được thay thế bằng các mẫu chức năng Mẫu 12, Đệ quy đuôi, và Mẫu 13, Đệ quy tương hỗ.
Sample Code: Higher-Order Functions
Hãy bắt đầu bằng cách xem qua một số ứng dụng đơn giản của Iterator có thể được thay thế bằng các hàm bậc cao. Đầu tiên, chúng ta sẽ xem xét việc xác định các nguyên âm trong một chuỗi, sau đó chúng ta sẽ xem xét việc thêm tiền tố cho danh sách tên bằng "Xin chào, ", và cuối cùng chúng ta sẽ tổng hợp một dãy số.
Chúng ta sẽ xem xét những ví dụ này đầu tiên theo phong cách lặp lại được viết bằng Java, và sau đó chúng ta sẽ chuyển sang một phong cách khai báo hơn trong Scala và Clojure.
Classic Java
Để xác định tập hợp các nguyên âm trong một từ, chúng ta lặp qua các ký tự và kiểm tra từng ký tự với tập hợp tất cả các nguyên âm. Nếu nó thuộc về tập hợp tất cả các nguyên âm, chúng ta thêm nó vào vowelsInWorld và trả về nó. Mã dưới đây, giả sử có một phương thức trợ giúp isVowel, minh họa cho giải pháp này:
| JavaExamples/src/main/java/com/mblinn/oo/iterator/HigherOrderFunctions.java | |
| | public static Set<Character> vowelsInWord(String word) { |
| | |
| | Set<Character> vowelsInWord = new HashSet<Character>(); |
| | |
| | for (Character character : word.toLowerCase().toCharArray()) { |
| | if (isVowel(character)) { |
| | vowelsInWord.add(character); |
| | } |
| | } |
| | |
| | return vowelsInWord; |
| | } |
Có một mẫu cao hơn ở đây: chúng ta đang lọc ra một loại phần tử nào đó từ một chuỗi. Ở đây là các nguyên âm trong một chuỗi, nhưng nó có thể là số lẻ, những người có tên "Michael" hoặc bất kỳ điều gì khác. Chúng ta sẽ khai thác mẫu bậc cao này trong sự thay thế chức năng của mình, sử dụng hàm filter.
Tiếp theo, hãy thảo luận về việc thêm chuỗi “Hello, ” vào đầu danh sách tên. Ở đây, chúng ta nhận vào một danh sách tên, lặp qua từng tên, thêm “Hello, ” vào trước mỗi tên và thêm nó vào một danh sách mới. Cuối cùng, chúng ta trả về danh sách đó.
Mã dưới đây minh họa phương pháp này:
| JavaExamples/src/main/java/com/mblinn/oo/iterator/HigherOrderFunctions.java | |
| | public static List<String> prependHello(List<String> names) { |
| | List<String> prepended = new ArrayList<String>(); |
| | for (String name : names) { |
| | prepended.add("Hello, " + name); |
| | } |
| | return prepended; |
| | } |
Một lần nữa, có một mô hình cấp cao hơn đang ẩn chứa ở đây. Chúng ta đang ánh xạ một phép toán lên mỗi mục trong một chuỗi, ở đây là thêm trước một từ với chuỗi “Hello, ”. Chúng ta sẽ xem cách sử dụng hàm bậc cao map để thực hiện điều đó.
Hãy xem xét một vấn đề cuối cùng: tính tổng một chuỗi số. Trong Java cổ điển, chúng ta sẽ tính tổng bằng cách lặp qua một danh sách và cộng từng số vào một biến tổng, như trong đoạn mã dưới đây:
| JavaExamples/src/main/java/com/mblinn/oo/iterator/HigherOrderFunctions.java | |
| | public static Integer sumSequence(List<Integer> sequence) { |
| | Integer sum = 0; |
| | for (Integer num : sequence) { |
| | sum += num; |
| | } |
| | return sum; |
| | } |
Loại lặp này là một ví dụ của một mẫu khác, thực hiện một phép toán trên một chuỗi để giảm nó thành một giá trị duy nhất. Chúng ta sẽ tận dụng mẫu đó trong việc thay thế hàm của mình bằng cách sử dụng hàm reduce và một hàm liên quan chặt chẽ được gọi là fold.
In Scala
Hãy xem ví dụ đầu tiên của chúng ta, trả về tập hợp các nguyên âm trong một từ. Trong thế giới hàm, điều này có thể được thực hiện qua hai bước: đầu tiên, chúng ta sử dụng filter để lọc tất cả các nguyên âm ra khỏi một từ, và sau đó, chúng ta lấy chuỗi đó và biến nó thành một tập hợp để loại bỏ bất kỳ bản sao nào. Để thực hiện việc lọc, chúng ta có thể tận dụng thực tế rằng các tập hợp trong Scala có thể được gọi như các hàm điều kiện. Nếu tập hợp chứa đối số được truyền vào, nó sẽ trả về true; ngược lại, nó sẽ trả về false, như mã dưới đây cho thấy:
| | scala> val isVowel = Set('a', 'e', 'i', 'o', 'u') |
| | isVowel: scala.collection.immutable.Set[Char] = Set(e, u, a, i, o) |
| | |
| | scala> isVowel('a') |
| | res0: Boolean = true |
| | |
| | scala> isVowel('z') |
| | res1: Boolean = false |
Bây giờ chúng ta có thể sử dụng hàm isVowel ở trên, cùng với filter và toSet để lấy một tập hợp nguyên âm từ một chuỗi:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/iterator/HigherOrderFunctions.scala | |
| | val isVowel = Set('a', 'e', 'i', 'o', 'u') |
| | def vowelsInWord(word: String) = word.filter(isVowel).toSet |
Ở đây chúng ta có thể thấy nó hoạt động, lọc các nguyên âm ra khỏi một chuỗi:
| | scala> vowelsInWord("onomotopeia") |
| | res4: scala.collection.immutable.Set[Char] = Set(o, e, i, a) |
| | |
| | scala> vowelsInWord("yak") |
| | res5: scala.collection.immutable.Set[Char] = Set(a) |
Ví dụ tiếp theo của chúng ta - thêm “Hello, ” vào đầu danh sách tên - có thể được viết bằng cách ánh xạ một hàm thực hiện việc thêm này trên một chuỗi các chuỗi. Ở đây, ánh xạ có nghĩa là hàm được áp dụng cho từng phần tử trong một chuỗi và một chuỗi mới được trả về với kết quả. Ở đây, chúng ta ánh xạ một hàm thêm chuỗi "Hello, " vào đầu mỗi tên trong một chuỗi:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/iterator/HigherOrderFunctions.scala | |
| | def prependHello(names : Seq[String]) = |
| | names.map((name) => "Hello, " + name) |
Đoạn mã dưới đây thực hiện công việc này. Scala REPL chèn dấu phẩy giữa các phần tử trong một chuỗi, vì vậy nó đang chèn thêm một dấu phẩy giữa mỗi lời chào của chúng ta.
| | scala> prependHello(Vector("Mike", "John", "Joe")) |
| | res0: Seq[java.lang.String] = Vector(Hello, Mike, Hello, John, Hello, Joe) |
Cuối cùng, ví dụ cuối cùng của chúng ta - tổng hợp một chuỗi. Chúng ta đang sử dụng một phép toán, trong trường hợp này là phép cộng, để lấy một chuỗi và giảm nó xuống một giá trị duy nhất. Trong Scala, cách đơn giản nhất để làm điều này là sử dụng phương thức được đặt tên phù hợp là reduce, phương thức này nhận một đối số duy nhất, một hàm giảm.
Ở đây chúng tôi tạo ra một hàm giảm dần có tác dụng cộng các đối số lại với nhau, và chúng tôi sử dụng nó để tính tổng một chuỗi.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/iterator/HigherOrderFunctions.scala | |
| | def sumSequence(sequence : Seq[Int]) = |
| | if(sequence.isEmpty) 0 else sequence.reduce((acc, curr) => acc + curr) |
Hãy cùng xem nó hoạt động như thế nào:
| | scala> sumSequence(Vector(1, 2, 3, 4, 5)) |
| | res0: Int = 15 |
Đó là tất cả—không lặp lại, không biến đổi, chỉ là một hàm bậc cao đơn giản!
In Clojure
Ví dụ đầu tiên của chúng ta tận dụng cùng một mẹo mà chúng ta đã sử dụng trong Scala, nơi một tập hợp có thể được sử dụng như một hàm điều kiện. Nếu phần tử được truyền vào nằm trong tập hợp, nó sẽ được trả về (nhớ rằng, bất cứ điều gì ngoại trừ false và nil được coi là đúng trong Clojure); ngược lại nil sẽ được trả về.
Ở đây, chúng ta tận dụng thuộc tính của tập hợp trong Clojure để định nghĩa một predicate vowel?, mà sau đó chúng ta có thể sử dụng với filter để lọc ra các nguyên âm khỏi một chuỗi. Chúng ta sau đó sử dụng hàm set của Clojure để tạo ra một tập hợp mới từ một chuỗi có sẵn. Đoạn mã dưới đây kết hợp tất cả lại với nhau:
| ClojureExamples/src/mbfpp/oo/iterator/higher_order_functions.clj | |
| | (def vowel? #{\a \e \i \o \u}) |
| | (defn vowels-in-word [word] |
| | (set (filter vowel? word))) |
Bây giờ chúng ta có thể sử dụng nó để lọc ra các tập hợp nguyên âm từ một từ:
| | => (vowels-in-word "onomotopeia") |
| | #{\a \e \i \o} |
| | => (vowels-in-word "yak") |
| | #{\a} |
Tiếp theo là hàm prepend-hello thân thiện của chúng ta. Giống như ví dụ trong Scala, chúng ta đơn giản sử dụng map để ánh xạ một hàm thêm tiền tố "Hello, " vào mỗi tên trong một dãy tên. Đây là mã nguồn:
| ClojureExamples/src/mbfpp/oo/iterator/higher_order_functions.clj | |
| | (defn prepend-hello [names] |
| | (map (fn [name] (str "Hello, " name)) names)) |
Chúng ta có thể sử dụng điều này để tạo ra một bộ lời chào.
| | => (prepend-hello ["Mike" "John" "Joe"]) |
| | ("Hello, Mike" "Hello, John" "Hello, Joe") |
Cuối cùng, hãy xem cách chúng ta sẽ tính tổng một chuỗi trong Clojure. Giống như Scala, chúng ta có thể sử dụng hàm reduce, mặc dù chúng ta không cần phải tạo ra hàm riêng để cộng các số nguyên như đã làm trong Scala: chúng ta chỉ cần sử dụng hàm + của Clojure. Dưới đây là mã code:
| ClojureExamples/src/mbfpp/oo/iterator/higher_order_functions.clj | |
| | (defn sum-sequence [s] |
| | {:pre [(not (empty? s))]} |
| | (reduce + s)) |
Và ở đây chúng ta đang sử dụng nó để tính tổng một dãy số:
| | => (sum-sequence [1 2 3 4 5]) |
| | 15 |
Những người không quen với Clojure có thể thấy hơi lạ khi + chỉ là một hàm khác mà chúng ta có thể truyền vào reduce, nhưng đây là một trong những điểm mạnh của Clojure và các ngôn ngữ Lisp nói chung. Nhiều thứ mà sẽ là các toán tử đặc biệt trong các ngôn ngữ khác chỉ là hàm trong Clojure, điều này cho phép chúng ta sử dụng chúng làm tham số cho các hàm bậc cao như reduce.
Một lưu ý về hàm reduce trong Clojure và Scala: Mặc dù chúng ta có thể sử dụng chúng theo cùng một cách ở đây, nhưng thực tế chúng có một số khác biệt. Hàm reduce của Scala hoạt động trên một chuỗi của một kiểu nào đó, và nó trả về một mục duy nhất của kiểu đó. Ví dụ, việc giảm một List chứa các số Int sẽ trả về một số Int duy nhất.
Clojure, ngược lại, cho phép bạn trả về bất kỳ thứ gì từ hàm reduce của nó, bao gồm cả một tập hợp khác nào đó! Điều này tổng quát hơn (và thường rất tiện lợi), và Scala hỗ trợ ý tưởng tổng quát hơn này về sự giảm dưới một tên gọi khác, foldLeft.
Thường thì việc sử dụng `reduce` trong Scala dễ dàng và rõ ràng hơn khi bạn thực sự giảm một chuỗi nào đó về một thực thể duy nhất của loại đó, và sử dụng `foldLeft` trong những trường hợp khác.
Sample Code: Sequence Comprehensions
Cả Scala và Clojure đều hỗ trợ một tính năng rất tiện lợi gọi là tổng hợp chuỗi. Tổng hợp chuỗi cung cấp cho chúng ta một cú pháp tiện lợi cho phép chúng ta thực hiện một vài điều khác nhau cùng một lúc. Cũng giống như hàm map, tổng hợp chuỗi cho phép chúng ta biến đổi một chuỗi thành một chuỗi khác. Tổng hợp chuỗi cũng cho phép chúng ta bao gồm một bước lọc, và nó cung cấp một cách tiện lợi để truy cập các phần của dữ liệu tổng hợp, được gọi là destructuring.
Hãy cùng xem cách chúng ta sử dụng các phép hiểu dãy để giải quyết một vấn đề thú vị. Chúng ta có một danh sách những người đã yêu cầu được thông báo khi nhà hàng mới của chúng ta, The Lambda Bar and Grille, mở cửa, và chúng ta muốn gửi cho họ một lời mời tham dự bữa tiệc khai trương.
Chúng tôi có danh sách tên và địa chỉ, và chúng tôi nghĩ rằng những người sống gần Lambda sẽ có khả năng đến tham dự hơn, vì vậy chúng tôi muốn gửi lời mời đến họ trước. Cuối cùng, chúng tôi muốn loại bỏ những người sống quá xa mà chúng tôi hoàn toàn chắc chắn rằng họ sẽ không đến.
Chúng tôi quyết định giải quyết vấn đề như sau: chúng tôi sẽ phân loại khách hàng thành các nhóm dựa trên mã bưu điện, và chúng tôi sẽ gửi thư mời đến các nhóm người ở các mã bưu điện gần nhất với nhà hàng của chúng tôi trước tiên. Ngoài ra, chúng tôi sẽ giới hạn mình trong một nhóm nhỏ các mã bưu điện lân cận.
Hãy xem cách giải quyết vấn đề này. Chúng ta sẽ bắt đầu, như thường lệ, với giải pháp lặp lại trong Java, sau đó chúng ta sẽ chuyển sang các giải pháp hàm sử dụng biến hiểu chuỗi trong Scala và Clojure.
Classic Java
Trong Java, chúng ta tạo ra một Người và một Địa chỉ theo định dạng JavaBean thông thường, và chúng ta tạo ra một phương thức, peopleByZip, nhận vào một danh sách những người, lọc ra những người không sống gần đủ, và trả về một bản đồ có khóa là mã zip chứa danh sách những người trong mỗi mã zip.
Để thực hiện điều này, chúng tôi sử dụng một giải pháp lặp tiêu chuẩn với một vài phương pháp trợ giúp. Phương pháp đầu tiên, addPerson, thêm một người vào danh sách, tạo danh sách nếu nó chưa tồn tại, để chúng tôi có thể xử lý trường hợp khi gặp người đầu tiên trong một mã bưu điện.
Thứ hai, isCloseZip, trả về true nếu mã bưu chính đủ gần với Lambda Bar and Grille để nhận được lời mời đến buổi tiệc, và false trong trường hợp ngược lại. Để giữ cho ví dụ ngắn gọn, chúng tôi đã cố định chỉ một vài mã bưu chính trong đó, nhưng vì chúng tôi đã tách kiểm tra đó ra thành một phương thức riêng, nên sẽ dễ dàng thay đổi nó để lấy từ một nguồn dữ liệu động về các mã bưu chính mà chúng tôi quan tâm.
Để giải quyết vấn đề, chúng ta chỉ cần lặp qua danh sách những người. Đối với mỗi người, chúng ta kiểm tra xem họ có mã bưu điện gần gũi hay không, và nếu có, chúng ta sẽ thêm họ vào một bản đồ danh sách những người được phân loại theo mã bưu điện gọi là closePeople. Khi chúng ta hoàn thành việc lặp, chúng ta chỉ cần trả về bản đồ đó. Giải pháp này được phác thảo như sau:
| JavaExamples/src/main/java/com/mblinn/oo/iterator/TheLambdaBarAndGrille.java | |
| | public class TheLambdaBarAndGrille { |
| | |
| | public Map<Integer, List<String>> peopleByZip(List<Person> people) { |
| | Map<Integer, List<String>> closePeople = |
| | new HashMap<Integer, List<String>>(); |
| | |
| | for (Person person : people) { |
| | Integer zipCode = person.getAddress().getZipCode(); |
| | if (isCloseZip(zipCode)){ |
| | List<String> peopleForZip = |
| | closePeople.get(zipCode); |
| | closePeople.put(zipCode, |
| | addPerson(peopleForZip, person)); |
| | } |
| | } |
| | |
| | return closePeople; |
| | } |
| | |
| | private List<String> addPerson(List<String> people, Person person) { |
| | if (null == people) |
| | people = new ArrayList<String>(); |
| | people.add(person.getName()); |
| | return people; |
| | } |
| | private Boolean isCloseZip(Integer zipCode) { |
| | return zipCode == 19123 || zipCode == 19103; |
| | } |
| | } |
Đây là một biến đổi dữ liệu khá đơn giản, nhưng nó cần khá nhiều công sức khi thực hiện theo kiểu mệnh lệnh vì chúng ta phải chỉnh sửa để thêm các phần tử vào danh sách mới, và chúng ta không có cách nào hợp lý để lọc các phần tử từ danh sách hiện có. Các hiểu biết tuần tự mang tính khai báo hơn giúp chúng ta nâng cao mức độ trừu tượng ở đây. Bây giờ hãy cùng xem phiên bản của Scala.
In Scala
Trong Scala, chúng ta có thể sử dụng cú pháp của Scala cho phép hiểu dãy, cụ thể là phép hiểu for, để tạo ra những lời chào một cách gọn gàng hơn. Chúng ta sẽ sử dụng các lớp case cho Person và Address, và chúng ta sẽ viết một phép hiểu for nhận vào một dãy các Person và sinh ra một dãy các lời chào.
Bởi vì các comprehension rất tiện dụng cho điều này vì một vài lý do. Lý do đầu tiên là chúng ta có thể sử dụng cú pháp ghép mẫu của Scala bên trong chúng, điều này cho phép chúng ta tách một Person thành tên và địa chỉ một cách ngắn gọn.
Thứ hai, đối với các biểu thức hiểu (comprehensions), chúng ta sẽ bao gồm một bộ lọc trực tiếp trong chính biểu thức hiểu, được gọi là guard, để không cần một câu lệnh if riêng biệt để loại bỏ những người có mã bưu điện sai. Cuối cùng, các hiểu (comprehensions) được thiết kế để tạo ra các chuỗi mới, vì vậy không cần phải có một danh sách tạm thời để tích lũy các giá trị mới; chúng ta chỉ cần trả về giá trị của biểu thức hiểu.
Với một phép hiểu for, chúng ta vẫn sẽ sử dụng một phương pháp trợ giúp là isCloseZip, nhưng sẽ sử dụng nó như một phần của điều kiện trong chính phép hiểu for, và chúng ta sẽ loại bỏ danh sách lời chào thay đổi từ giải pháp Java hoàn toàn, vì giá trị mà chúng ta muốn chỉ là giá trị của phép hiểu for.
Mã cho toàn bộ giải pháp nằm bên dưới:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/iterator/TheLambdaBarAndGrille.scala | |
| | case class Person(name: String, address: Address) |
| | case class Address(zip: Int) |
| | def generateGreetings(people: Seq[Person]) = |
| | for (Person(name, address) <- people if isCloseZip(address.zip)) |
| | yield "Hello, %s, and welcome to the Lambda Bar And Grille!".format(name) |
| | def isCloseZip(zipCode: Int) = zipCode == 19123 || zipCode == 19103 |
Một điều có thể không rõ ràng khi sử dụng list comprehension là cách xử lý các tình huống khi chúng ta thực sự cần các tác dụng phụ. Vì chúng ta đang lập trình theo phong cách hàm, điều này nên khá hiếm. Như chúng ta đã thấy ở trên, chúng ta không cần một danh sách có thể thay đổi để tạo ra danh sách lời chào của mình. Một cách sử dụng đơn giản của các tác dụng phụ mà chúng ta vẫn cần trong thế giới hàm là in ra console.
Ở đây chúng tôi đã viết lại ví dụ để chỉ in lời chào ra console, thay vì gom chúng lại thành một chuỗi.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/iterator/TheLambdaBarAndGrille.scala | |
| | def printGreetings(people: Seq[Person]) = |
| | for (Person(name, address) <- people if isCloseZip(address.zip)) |
| | println("Hello, %s, and welcome to the Lambda Bar And Grille!".format(name)) |
Chúng tôi chỉ mới đề cập đến những điều cơ bản của các phép hiểu for trong Scala; chúng là những công cụ rất mạnh mẽ. Chúng có thể được sử dụng với nhiều chuỗi và nhiều điều kiện đồng thời, bên cạnh nhiều tính năng khác, nhưng những gì chúng tôi đã đề cập ở đây cho phép chúng tôi xử lý những trường hợp phổ biến nhất mà chúng tôi sẽ sử dụng mẫu Iterator.
In Clojure
Clojure cũng có hiểu nghị chuỗi tích hợp sẵn sử dụng macro for. Cũng giống như trong Scala, điểm chính của một hiểu nghị chuỗi trong Clojure là để lấy một chuỗi và biến đổi nó thành một chuỗi khác với việc lọc tích hợp. Các hiểu nghị chuỗi trong Clojure cũng cung cấp một cách tiện lợi để tách rời dữ liệu tổng hợp bằng cách sử dụng hủy cấu trúc.
Vì sự hiểu biết giữa các phép hiểu tuần tự của Clojure và Scala tương tự nhau, ít nhất là với cách sử dụng cơ bản này, cấu trúc của giải pháp trông rất giống nhau. Chúng ta có một hàm close-zip? tận dụng tính năng hữu ích của Clojure cho phép sử dụng tập hợp như một hàm, và một hàm generate-greetings bao gồm một câu lệnh for duy nhất.
Câu lệnh `for` sử dụng `close-zip?` để lọc ra những người ở ngoài vùng mã bưu chính mà chúng ta quan tâm, sau đó tạo ra một lời chào cho những người còn lại. Mã nguồn bên dưới:
| ClojureExamples/src/mbfpp/oo/iterator/lambda_bar_and_grille.clj | |
| | (def close-zip? #{19123 19103}) |
| | |
| | (defn generate-greetings [people] |
| | (for [{:keys [name address]} people :when (close-zip? (address :zip-code))] |
| | (str "Hello, " name ", and welcome to the Lambda Bar And Grille!"))) |
Clojure cũng có cách sử dụng cú pháp tương tự như comprehension của chuỗi cho các tác dụng phụ, mặc dù Clojure tách nó ra thành macro doseq. Ở đây, chúng ta sử dụng doseq để in danh sách lời chào của chúng ta thay vì thu thập chúng lại.
| ClojureExamples/src/mbfpp/oo/iterator/lambda_bar_and_grille.clj | |
| | (defn print-greetings [people] |
| | (for [{:keys [name address]} people :when (close-zip? (address :zip-code))] |
| | (println (str "Hello, " name ", and welcome to the Lambda Bar And Grille!")))) |
Các biểu thức hiểu tuần tự của Scala và Clojure có sự tương đồng trong một số khía cạnh, mặc dù không phải tất cả. Câu lệnh for của Scala thường được sử dụng phổ biến hơn và thường theo những cách có thể bất ngờ đối với những người chưa có kinh nghiệm. Ví dụ, câu lệnh for có thể được sử dụng kết hợp với kiểu tùy chọn của Scala để cung cấp một giải pháp thanh lịch cho những bài toán mà sẽ yêu cầu nhiều kiểm tra null trong Java, như chúng tôi đã đề cập trong Mẫu 8, Thay thế Đối tượng Null.
Ngoài ra, trong khi khớp mẫu của Scala và phân tách của Clojure có một số điểm tương đồng, cả hai đều cho phép chúng ta phân tích các cấu trúc dữ liệu tổng hợp; khớp mẫu trong Scala ít linh hoạt hơn so với phân tách của Clojure. Phân tách cho phép chúng ta phân tích các bản đồ và vector tùy ý, trong khi khớp mẫu của Scala chỉ giới hạn ở các lớp trường hợp và một vài cấu trúc khác được định nghĩa tĩnh tại thời điểm biên dịch.
Discussion
Một sự khác biệt không rõ ràng giữa Iterator và các giải pháp mà chúng ta đã đề cập trong chương này là Iterator về cơ bản là mệnh lệnh vì nó phụ thuộc vào trạng thái có thể thay đổi. Mỗi iterator đều có một chút trạng thái bên trong để theo dõi vị trí hiện tại của nó. Điều này có thể gây rắc rối nếu bạn bắt đầu truyền các iterator xung quanh và một phần của chương trình bạn bất ngờ làm tiến bộ iterator, ảnh hưởng đến một phần khác.
Ngược lại, các giải pháp mà chúng ta đã thảo luận trong chương này dựa vào việc biến đổi một chuỗi bất biến thành một chuỗi khác. Thực tế, các hiểu biết về chuỗi mà chúng ta đã đề cập là cả hai ví dụ của một kỹ thuật được phổ biến bởi ngôn ngữ hàm cao Haskell, được biết đến với tên gọi là biến đổi đồng vị, dựa vào một khái niệm từ lý thuyết hạng mục được gọi là monads.
Giải thích về monads là một lĩnh vực khá phổ biến trong cộng đồng lập trình viên hàm và đã truyền cảm hứng cho nhiều bài blog cố gắng giải thích monads thông qua các phép ẩn dụ khác nhau, chẳng hạn như burritos, voi, bàn viết và Muppets. Chúng tôi sẽ không để bạn phải trải qua một giải thích như vậy nữa; không cần thiết phải hiểu monads để sử dụng các phép biện luận theo chuỗi, và cả Scala lẫn Clojure đều không đặc biệt nhấn mạnh tính chất monadic của các phép biện luận tương ứng của chúng.
Ở cấp độ rất cao, một trong những điều mà monads làm là cung cấp một cách thức để lập trình theo phong cách hàm một cách rất mạch lạc bằng cách biến đổi dữ liệu bất biến trong một đường ống thay vì phụ thuộc vào trạng thái có thể thay đổi. Những độc giả có sự tò mò về monads nên tham khảo cuốn sách tuyệt vời "Learn You a Haskell for Great Good! A Beginner’s Guide" [Lip11].
For Further Reading
"Mẫu thiết kế: Các yếu tố của phần mềm đối tượng tái sử dụng [GHJV95]—Bộ lặp"
Thư viện chuẩn Java
Related Patterns
Mẫu 12, Đệ quy đuôi
Mẫu 13, Đệ quy tương hỗ
Mẫu 14, Lọc-Đồ thị-Tổng hợp
| Pattern 6 | Replacing Template Method |
Intent
Để xác định khung của một thuật toán, cho phép người gọi cắm vào một số thông tin cụ thể.
Overview
Mẫu phương pháp (Template Method) bao gồm một lớp trừu tượng định nghĩa một số hoạt động, hoặc tập hợp các hoạt động, dưới dạng các tiểu hoạt động trừu tượng. Người sử dụng Mẫu phương pháp sẽ triển khai lớp mẫu trừu tượng để cung cấp việc hiện thực hóa các bước phụ. Một lớp mẫu trông giống như đoạn mã sau:
| | public abstract class TemplateExample{ |
| | |
| | public void anOperation(){ |
| | subOperationOne(); |
| | subOperationTwo(); |
| | } |
| | |
| | protected abstract void subOperationOne(); |
| | |
| | protected abstract void subOperationTwo(); |
| | } |
Để sử dụng nó, mở rộng TemplateExample và triển khai các thao tác con trừu tượng.
Ví dụ, để sử dụng Phương pháp Mẫu cho các trò chơi trên bàn, hãy tạo một mẫu Game xác định tập hợp các bước trừu tượng cần thiết để chơi một trò chơi trên bàn (setUpBoard, makeMove, declareWinner, và nhiều hơn nữa). Để triển khai bất kỳ trò chơi trên bàn cụ thể nào, mở rộng lớp Game trừu tượng và thực hiện các bước con phù hợp cho một trò chơi cụ thể.
Functional Replacement
Sự thay thế chức năng của chúng tôi cho Phương thức Mẫu sẽ đáp ứng mục đích của nó, đó là tạo ra một cấu trúc cho một số thuật toán và cho phép người gọi cắm vào các chi tiết. Thay vì sử dụng các lớp để triển khai các thao tác con, chúng tôi sẽ sử dụng các hàm bậc cao; và thay vì phụ thuộc vào việc kế thừa lớp, chúng tôi sẽ phụ thuộc vào sự kết hợp hàm. Chúng tôi sẽ làm điều đó bằng cách truyền các thao tác con vào một Mẫu 16, Người xây dựng hàm và để nó trả về một hàm mới thực hiện toàn bộ thao tác.
Một phác thảo của cách tiếp cận này trong Scala trông như sau:
| | def makeAnOperation( |
| | subOperationOne: () => Unit, |
| | subOperationTwo: () => Unit) = |
| | () => { |
| | subOperationOne() |
| | subOperationTwo() |
| | } |
Điều này cho phép chúng tôi lập trình một cách trực tiếp hơn, vì chúng tôi không còn cần phải định nghĩa các hoạt động phụ và lớp con.
Sample Code: Grade Reporter
Ví dụ, hãy xem một phương thức mẫu mà in báo cáo điểm. Nó thực hiện điều này theo hai bước. Bước đầu tiên lấy danh sách điểm ở dạng số và dịch chúng thành dạng chữ cái, và bước thứ hai định dạng và in báo cáo.
Vì hai bước đó có thể được thực hiện theo nhiều cách khác nhau, chúng tôi chỉ cần xác định cấu trúc cần thiết để tạo báo cáo điểm, dịch các điểm trước, rồi định dạng và in báo cáo, và chúng tôi sẽ để cho các triển khai cá nhân xác định chính xác cách thức dịch điểm và in báo cáo.
Chúng ta cũng sẽ xem xét hai cách triển khai như vậy. Cách đầu tiên chuyển đổi sang các điểm chữ cái đầy đủ A, B, C, D và F và in ra một biểu đồ đơn giản. Cách thứ hai thêm các điểm cộng và trừ vào một số chữ cái và in ra danh sách điểm đầy đủ.
Classic Java
Một phác thảo sử dụng phương thức mẫu để giải quyết vấn đề này trong Java cổ điển sử dụng các thành phần sau: một GradeReporterTemplate có một phương thức được triển khai hoàn toàn là reportGrades, và hai phương thức trừu tượng, numToLetter và printGradeReport.
Phương thức numToLetter xác định cách chuyển đổi một điểm số số thành điểm số chữ, và phương thức printGradeReport xác định cách định dạng và in báo cáo điểm số. Cả hai phương thức đều phải được người sử dụng mẫu triển khai. Sơ đồ lớp cung cấp một phác thảo:
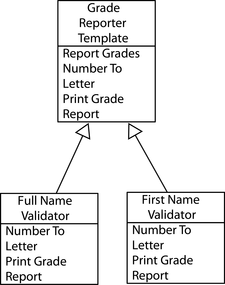
Figure 5. Grade Reporter Template. Using Template Method to report grades
Để có được các triển khai mẫu với những hành vi khác nhau, người sử dụng lớp Template tạo ra các lớp con khác nhau với các triển khai khác nhau của numToLetter và printGradeReport .
In Scala
Thay vì dựa vào kế thừa, phương pháp thay thế của Scala cho Phương thức Mẫu sử dụng Mẫu 16, Người xây dựng hàm để kết hợp các hoạt động con lại với nhau.
Nền tảng của giải pháp là hàm makeGradeReporter, nhận một hàm numToLetter để chuyển đổi điểm số số thành điểm chữ và một hàm printGradeReport để in báo cáo. Hàm makeGradeReporter trả về một hàm mới kết hợp các hàm đầu vào của nó lại với nhau.
Chúng tôi cũng sẽ cần một vài triển khai khác nhau của các hàm numToLetter và printGradeReport để chúng tôi có thể thấy giải pháp này trong thực tế.
Hãy bắt đầu bằng cách xem makeGradeReporter . Nó nhận numToLetter và printGradeReport làm tham số và tạo ra một hàm mới nhận một Seq[Double] để đại diện cho danh sách điểm số. Sau đó, nó sử dụng map để chuyển đổi từng điểm số thành điểm chữ và truyền danh sách mới vào printGradeReport . Dưới đây là mã:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | def makeGradeReporter( |
| | numToLetter: (Double) => String, |
| | printGradeReport: (Seq[String]) => Unit) = (grades: Seq[Double]) => { |
| | printGradeReport(grades.map(numToLetter)) |
| | } |
Bây giờ hãy xem xét các hàm mà chúng ta cần để chuyển đổi sang điểm chữ đầy đủ và in ra biểu đồ. Đầu tiên, fullGradeConverter, chỉ sử dụng một câu lệnh if-else lớn để thực hiện chuyển đổi điểm:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | def fullGradeConverter(grade: Double) = |
| | if(grade <= 5.0 && grade > 4.0) "A" |
| | else if(grade <= 4.0 && grade > 3.0) "B" |
| | else if(grade <= 3.0 && grade > 2.0) "C" |
| | else if(grade <= 2.0 && grade > 0.0) "D" |
| | else if(grade == 0.0) "F" |
| | else "N/A" |
Tiếp theo, hàm `printHistogram` phức tạp hơn một chút. Nó sử dụng một phương thức có tên là `groupBy` để nhóm các điểm số lại thành một `Map`, sau đó chuyển đổi nó thành một danh sách các bộ đôi đếm được bằng cách sử dụng phương thức `map`. Cuối cùng, nó sử dụng một biểu thức for để in ra biểu đồ, như mã dưới đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | def printHistogram(grades: Seq[String]) = { |
| | val grouped = grades.groupBy(identity) |
| | val counts = grouped.map((kv) => (kv._1, kv._2.size)).toSeq.sorted |
| | for(count <- counts) { |
| | val stars = "*" * count._2 |
| | println("%s: %s".format(count._1, stars)) |
| | } |
| | } |
Hãy xem xét đoạn mẫu này từng dòng một, bắt đầu với dòng đầu tiên trong thân hàm printHistogram:
| | val grouped = grades.groupBy(identity) |
Phương thức groupBy nhận vào một hàm và sử dụng nó để nhóm tất cả các phần tử của một chuỗi mà hàm trả về cùng một giá trị. Ở đây, chúng ta truyền vào hàm xác định, hàm này chỉ trả về những gì được truyền vào, để chúng ta có thể nhóm lại tất cả các điểm số giống nhau. Đầu ra REPL dưới đây cho chúng ta thấy cách sử dụng đoạn mã này để nhóm lại một vector các điểm số:
| | scala> val grades = Vector("A", "B", "A", "B", "B") |
| | grades: scala.collection.immutable.Vector[java.lang.String] = Vector(A, B, A, B, B) |
| | |
| | scala> val grouped = grades.groupBy(identity) |
| | grouped: scala.collection.immutable.Map[...] = |
| | Map(A -> Vector(A, A), B -> Vector(B, B, B)) |
Tiếp theo, chúng ta lấy bản đồ của các điểm được nhóm lại và sử dụng map và toSeq để biến nó thành một chuỗi các bộ, trong đó phần tử đầu tiên là điểm và phần tử thứ hai là số lượng điểm. Sau đó, chúng ta sắp xếp chuỗi đó. Mặc định, Scala sắp xếp các chuỗi bộ dựa trên phần tử đầu tiên của chúng, vì vậy điều này mang lại cho chúng ta một chuỗi số lượng điểm đã được sắp xếp.
| | val counts = grouped.map((kv) => (kv._1, kv._2.size)).toSeq.sorted |
Đầu ra REPL dưới đây cho chúng ta thấy việc sử dụng đoạn mã này để có được chuỗi các số lượng điểm.
| | scala> val counts = grouped.map((kv) => (kv._1, kv._2.size)).toSeq.sorted |
| | counts: Seq[(java.lang.String, Int)] = ArrayBuffer((A,2), (B,3)) |
Cuối cùng, chúng tôi sử dụng một comprehension for trên chuỗi các tuple để in ra biểu đồ histogram của điểm số, như đoạn mã dưới đây cho thấy:
| | for(count <- counts) { |
| | val stars = "*" * count._2 |
| | |
| | println("%s: %s".format(count._1, stars)) |
| | } |
Điều này làm nổi bật một cách sử dụng thú vị của toán tử * trong Scala. Nó có thể được sử dụng để lặp lại một chuỗi, như đầu ra REPL sau đây minh họa:
| | scala> "*" * 5 |
| | res0: String = ***** |
Bây giờ chúng ta chỉ cần sử dụng makeGradeReporter để kết hợp hai hàm của chúng ta lại với nhau để tạo ra fullGradeReporter, như đoạn mã sau đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | val fullGradeReporter = makeGradeReporter(fullGradeConverter, printHistogram) |
Sau đó, chúng ta có thể định nghĩa một số dữ liệu mẫu và chạy fullGradeReporter để in ra một biểu đồ.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | val sampleGrades = Vector(5.0, 4.0, 4.4, 2.2, 3.3, 3.5) |
| | scala> fullGradeReporter(sampleGrades) |
| | A: ** |
| | B: *** |
| | C: * |
Bây giờ, nếu chúng ta muốn thay đổi cách chuyển đổi điểm và in báo cáo, chúng ta chỉ cần tạo thêm các chức năng chuyển đổi và báo cáo. Chúng ta có thể sử dụng **makeGradeReporter** để kết hợp chúng lại với nhau.
Hãy xem cách viết lại ví dụ về Phương pháp Mẫu chuyển đổi thành các kiểu điểm cộng/trừ và in ra một danh sách đầy đủ các kiểu điểm đó. Như trước đây, chúng ta sẽ cần hai hàm. Hàm đầu tiên là **plusMinusGradeConverter** để thực hiện việc chuyển đổi điểm. Hàm thứ hai là **printAllGrades**, chỉ đơn giản là in ra một danh sách các điểm đã được chuyển đổi.
Dưới đây là mã cho hàm plusMinusGradeConverter:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | def plusMinusGradeConverter(grade: Double) = |
| | if(grade <= 5.0 && grade > 4.7) "A" |
| | else if(grade <= 4.7 && grade > 4.3) "A-" |
| | else if(grade <= 4.3 && grade > 4.0) "B+" |
| | else if(grade <= 4.0 && grade > 3.7) "B" |
| | else if(grade <= 3.7 && grade > 3.3) "B-" |
| | else if(grade <= 3.3 && grade > 3.0) "C+" |
| | else if(grade <= 3.0 && grade > 2.7) "C" |
| | else if(grade <= 2.7 && grade > 2.3) "C-" |
| | else if(grade <= 2.3 && grade > 0.0) "D" |
| | else if(grade == 0.0) "F" |
| | else "N/A" |
Và đây là mã cho printAllGrades :
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | def printAllGrades(grades: Seq[String]) = |
| | for(grade <- grades) println("Grade is: " + grade) |
Bây giờ chúng ta chỉ cần kết hợp chúng lại với nhau bằng cách sử dụng makeGradeReporter, và chúng ta có thể dùng nó để tạo ra một báo cáo điểm đầy đủ, như mã code dưới đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/tm/GradeReporter.scala | |
| | val plusMinusGradeReporter = |
| | makeGradeReporter(plusMinusGradeConverter, printAllGrades) |
| | scala> plusMinusGradeReporter(sampleGrades) |
| | Grade is: A |
| | Grade is: B |
| | Grade is: A- |
| | Grade is: D |
| | Grade is: C+ |
| | Grade is: B- |
Đó là phần kết thúc cho việc thay thế Phương thức Mẫu trong Scala. Tiếp theo, hãy cùng xem mọi thứ trông như thế nào trong Clojure.
In Clojure
Thay thế Clojure cho phương pháp Template tương tự như trong Scala. Cũng như trong Scala, chúng ta sẽ sử dụng Mẫu 16, Người xây dựng hàm, được đặt tên là make-grade-reporter, để kết hợp một hàm chuyển đổi điểm số thành điểm chữ và một hàm in báo cáo. Hàm make-grade-reporter trả về một hàm ánh xạ num-to-letter trên một chuỗi điểm số. Hãy cùng xem mã nguồn cho nó trước tiên:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (defn make-grade-reporter [num-to-letter print-grade-report] |
| | (fn [grades] |
| | (print-grade-report (map num-to-letter grades)))) |
Việc chuyển đổi điểm số dạng số thành điểm chữ đầy đủ chỉ là một vấn đề của một biểu thức điều kiện đơn giản, như chúng ta có thể thấy bên dưới:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (defn full-grade-converter [grade] |
| | (cond |
| | (and (<= grade 5.0) (> grade 4.0)) "A" |
| | (and (<= grade 4.0) (> grade 3.0)) "B" |
| | (and (<= grade 3.0) (> grade 2.0)) "C" |
| | (and (<= grade 2.0) (> grade 0)) "D" |
| | (= grade 0) "F" |
| | :else "N/A")) |
Việc in một biểu đồ histogram có thể được thực hiện giống như cách mà chúng ta đã làm trong Scala, sử dụng group-by để nhóm các điểm số lại với nhau, ánh xạ một hàm lên các điểm số đã nhóm để lấy số lượng, và sau đó sử dụng một phép hiểu chuỗi để in biểu đồ histogram cuối cùng. Đây là mã để in một biểu đồ histogram:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (defn print-histogram [grades] |
| | (let [grouped (group-by identity grades) |
| | counts (sort (map |
| | (fn [[grade grades]] [grade (count grades)]) |
| | grouped))] |
| | (doseq [[grade num] counts] |
| | (println (str grade ":" (apply str (repeat num "*"))))))) |
Bây giờ chúng ta có thể sử dụng make-grade-reporter để kết hợp full-grade-converter và print-histogram thành một chức năng mới, full-grade-reporter. Mã để thực hiện điều đó ở dưới đây:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (def full-grade-reporter (make-grade-reporter full-grade-converter print-histogram)) |
Chúng tôi đang chạy nó trên một số dữ liệu mẫu:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (def sample-grades [5.0 4.0 4.4 2.2 3.3 3.5]) |
| | => (full-grade-reporter sample-grades) |
| | A:** |
| | B:*** |
| | C:* |
Để thay đổi cách chúng ta chuyển đổi điểm và in báo cáo, chúng ta chỉ cần tạo các hàm mới để kết hợp với make-grade-reporter. Hãy tạo các hàm plus-minus-grade-converter và print-all-grades rồi sau đó kết hợp chúng lại thành một plus-minus-grade-reporter.
Chức năng báo cáo điểm cộng-trừ rất đơn giản; nó chỉ là một biểu thức cond đơn giản.
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (defn plus-minus-grade-converter [grade] |
| | (cond |
| | (and (<= grade 5.0) (> grade 4.7)) "A" |
| | (and (<= grade 4.7) (> grade 4.3)) "A-" |
| | (and (<= grade 4.3) (> grade 4.0)) "B+" |
| | (and (<= grade 4.0) (> grade 3.7)) "B" |
| | (and (<= grade 3.7) (> grade 3.3)) "B-" |
| | (and (<= grade 3.3) (> grade 3.0)) "C+" |
| | (and (<= grade 3.0) (> grade 2.7)) "C" |
| | (and (<= grade 2.7) (> grade 2.3)) "C" |
| | (and (<= grade 2.3) (> grade 0)) "D" |
| | (= grade 0) "F" |
| | :else "N/A")) |
Hàm print-all-grades chỉ sử dụng một biểu thức tuần tự để in ra từng điểm số:
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (defn print-all-grades [grades] |
| | (doseq [grade grades] |
| | (println "Grade is:" grade))) |
Bây giờ chúng ta có thể kết hợp chúng với make-grade-reporter và chạy chúng trên dữ liệu mẫu của chúng ta để in ra báo cáo điểm.
| ClojureExamples/src/mbfpp/oo/tm/grade_reporter.clj | |
| | (def plus-minus-grade-reporter |
| | (make-grade-reporter plus-minus-grade-converter print-all-grades)) |
| | => (plus-minus-grade-reporter sample-grades) |
| | Grade is: A |
| | Grade is: B |
| | Grade is: A- |
| | Grade is: D |
| | Grade is: C+ |
| | Grade is: B- |
Đó là tất cả cho phiên bản Clojure của phương pháp mẫu thay thế. Hãy kết thúc với một số cuộc thảo luận về cách mà phương pháp mẫu so với sự thay thế chức năng của nó.
Discussion
Thay thế chức năng của chúng tôi cho Phương pháp Mẫu thực hiện cùng một mục đích nhưng hoạt động khá khác biệt. Thay vì sử dụng các kiểu con để thực hiện các tiểu hoạt động cụ thể, chúng tôi sử dụng sự kết hợp hàm và các hàm bậc cao.
Điều này phản ánh sở thích cũ trong lập trình hướng đối tượng về việc sử dụng thành phần thay vì kế thừa. Ngay cả trong thế giới lập trình hướng đối tượng, tôi thích sử dụng mẫu được mô tả trong Mẫu 11, Thay thế Tiêm Phụ Thuộc để chèn các thao tác con vào một lớp, thay vì sử dụng phương pháp mẫu và kế thừa lớp.
Lý do lớn nhất cho điều này là nó giúp ngăn chặn việc trùng lặp mã. Chẳng hạn, trong ví dụ mà chúng tôi đã sử dụng trong chương này, nếu chúng tôi muốn một lớp in ra biểu đồ tần suất của điểm cộng/trừ, chúng tôi sẽ phải tạo ra một hệ thống kế thừa sâu hơn hoặc cắt và dán mã từ các hiện thực hiện có. Trong một hệ thống thực tế, điều này có thể trở nên mong manh rất nhanh chóng.
Composition cũng làm tốt hơn trong việc làm cho một API trở nên rõ ràng. Lớp Template Method có thể phơi bày các phương thức trợ giúp bảo vệ mà được sử dụng bởi mã khung nhưng không nên được sử dụng bởi một khách hàng. Cách duy nhất để chỉ ra điều này là thông qua các chú thích trong tài liệu API.
For Further Reading
Mẫu thiết kế: Các yếu tố của phần mềm hướng đối tượng tái sử dụng [GHJV95] – Phương thức mẫu
Related Patterns
Mẫu 1, Thay thế Giao diện Chức năng
Mẫu 7, Chiến lược Thay thế
Mẫu 16, Trình xây dựng chức năng
读累了记得休息一会哦~
Công chúng: Cổ Đức Miêu Ninh Lý
- 电子书搜索下载
- 书单分享
- 书友学习交流
Trang web: Thư viện Trầm Kim https://www.chenjin5.com
- 电子书搜索下载
- 电子书打包资源分享
- 学习资源分享
| Pattern 7 | Replacing Strategy |
Intent
Để định nghĩa một thuật toán theo cách trừu tượng để nó có thể được triển khai theo nhiều cách khác nhau, và để cho phép nó được tiêm vào các ứng dụng khách để có thể được sử dụng trên nhiều ứng dụng khách khác nhau.
Overview
Chiến lược có một vài phần. Phần đầu tiên là một giao diện đại diện cho một số thuật toán, chẳng hạn như một chút logic xác thực hoặc một quy trình sắp xếp. Phần thứ hai là một hoặc nhiều triển khai của giao diện đó; đây chính là các lớp chiến lược. Cuối cùng, một hoặc nhiều client sử dụng các đối tượng chiến lược.
Ví dụ, chúng ta có thể có nhiều cách khác nhau để xác thực một tập hợp dữ liệu nhập từ một mẫu trên trang web, và chúng ta có thể muốn sử dụng mã xác thực đó ở nhiều nơi. Chúng ta có thể tạo một giao diện Validator với phương thức validate để phục vụ như một đối tượng chiến lược, cùng với nhiều triển khai khác nhau có thể được tiêm vào mã của chúng ta ở các vị trí thích hợp.
Also Known As
Chính sách
Functional Replacement
Chiến lược liên quan chặt chẽ đến Mô hình 1, Thay thế Giao diện Chức năng, vì các đối tượng chiến lược thường là một giao diện chức năng đơn giản, nhưng mẫu Chiến lược chứa nhiều phần chuyển động hơn chỉ một Giao diện Chức năng. Tuy nhiên, điều này gợi ý một sự thay thế đơn giản cho Chiến lược trong thế giới chức năng.
Để thay thế các lớp chiến lược, chúng tôi sử dụng các hàm bậc cao để thực hiện các thuật toán cần thiết. Điều này tránh việc phải tạo ra và áp dụng các giao diện cho các triển khai chiến lược khác nhau. Từ đó, việc chuyển các hàm chiến lược xung quanh và sử dụng chúng ở những nơi cần thiết trở nên đơn giản.
Sample Code: Person Validation
Một ứng dụng phổ biến của Chiến lược là tạo ra các thuật toán khác nhau có thể được sử dụng để xác thực cùng một tập dữ liệu. Hãy cùng nhìn vào một ví dụ về việc sử dụng Chiến lược để làm điều đó.
Chúng tôi sẽ triển khai hai chiến lược xác thực khác nhau cho một người gồm một tên, một tên đệm và một họ. Chiến lược đầu tiên sẽ coi người đó hợp lệ nếu họ có một tên, chiến lược thứ hai chỉ coi người đó hợp lệ nếu tất cả ba tên đều được thiết lập. Thêm vào đó, chúng tôi sẽ xem xét một số mã lệnh đơn giản của khách hàng để thu thập những người hợp lệ.
In Java
Trong Java, chúng ta cần một giao diện PersonValidator, mà hai chiến lược xác thực của chúng ta, FirstNameValidator và FullNameValidator, sẽ thực hiện. Các bộ xác thực tự chúng rất đơn giản; chúng trả về true nếu chúng coi người đó hợp lệ và false nếu không.
Các bộ xác thực sau đó có thể được kết hợp trong lớp PersonCollector, lớp này sẽ thu thập các đối tượng People đáp ứng yêu cầu xác thực. Sơ đồ lớp dưới đây phác thảo giải pháp này:
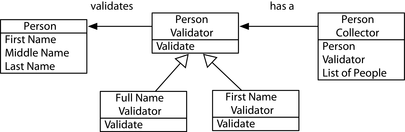
Figure 6. Person Validator Strategy. Using Strategy to validate a person
Điều này hoạt động tốt, nhưng nó liên quan đến việc phân bổ logic của chúng ta qua nhiều lớp mà không có lý do gì đặc biệt. Hãy xem cách chúng ta có thể đơn giản hóa Strategy bằng cách sử dụng các kỹ thuật hàm.
In Scala
Trong Scala, không cần thiết phải có giao diện PersonValidator mà chúng ta đã thấy trong các ví dụ Java. Thay vào đó, chúng ta sẽ chỉ sử dụng các hàm đơn giản để thực hiện việc xác thực. Để quản lý một người, chúng ta sẽ dựa vào một case class với các thuộc tính cho từng phần của tên người. Cuối cùng, thay vì sử dụng một lớp hoàn chỉnh cho bộ thu thập người, chúng ta sẽ sử dụng một hàm bậc cao tự nó trả về một hàm khác có trách nhiệm thu thập người.
Hãy bắt đầu với lớp trường hợp Person. Đây là một lớp trường hợp khá tiêu chuẩn, nhưng hãy chú ý cách chúng ta sử dụng Option[String] để biểu diễn tên thay vì chỉ dùng String, vì lớp trường hợp này đại diện cho một người có thể thiếu một phần tên.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/strategy/PeopleExample.scala | |
| | case class Person( |
| | firstName: Option[String], |
| | middleName: Option[String], |
| | lastName: Option[String]) |
Bây giờ hãy xem xét trình xác thực tên đầu tiên của chúng ta, một hàm gọi là isFirstNameValid. Như mã dưới đây cho thấy, chúng ta sử dụng phương thức isDefined trên Option của Scala, phương thức này trả về true nếu Option chứa Some và trả về false trong trường hợp ngược lại để kiểm tra xem người đó có tên đầu tiên hay không:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/strategy/PeopleExample.scala | |
| | def isFirstNameValid(person: Person) = person.firstName.isDefined |
Trình xác thực tên đầy đủ của chúng tôi là một hàm, isFullNameValid. Ở đây, chúng tôi sử dụng một câu lệnh match trong Scala để phân tích một Person, và sau đó chúng tôi đảm bảo rằng mỗi tên đều có mặt sử dụng isDefined. Mã nguồn nằm bên dưới:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/strategy/PeopleExample.scala | |
| | def isFullNameValid(person: Person) = person match { |
| | case Person(firstName, middleName, lastName) => |
| | firstName.isDefined && middleName.isDefined && lastName.isDefined |
| | } |
Cuối cùng, bộ thu thập người của chúng tôi, một chức năng được đặt tên một cách hợp lý là personCollector, nhận vào một hàm xác thực và tạo ra một hàm khác chịu trách nhiệm thu thập những người hợp lệ. Nó thực hiện điều này bằng cách chạy một người được truyền vào qua hàm xác thực. Sau đó, nó đính kèm nó vào một vector không thay đổi và lưu trữ một tham chiếu đến vector mới trong biến validPeople nếu nó vượt qua kiểm tra xác thực. Cuối cùng, nó trả về validPeople, như mã dưới đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/strategy/PeopleExample.scala | |
| | def personCollector(isValid: (Person) => Boolean) = { |
| | var validPeople = Vector[Person]() |
| | (person: Person) => { |
| | if(isValid(person)) validPeople = validPeople :+ person |
| | validPeople |
| | } |
| | } |
Hãy cùng xem các bộ xác minh và bộ thu thập người của chúng ta hoạt động, bắt đầu với việc tạo một bộ thu thập người mà coi tên đơn là hợp lệ và một bộ chỉ coi tên đầy đủ là hợp lệ:
| | scala> val singleNameValidCollector = personCollector(isFirstNameValid) |
| | singleNameValidCollector: ... |
| | |
| | scala> val fullNameValidCollector = personCollector(isFullNameValid) |
| | fullNameValidCollector: ... |
Chúng ta có thể định nghĩa một vài tên kiểm tra:
| | scala> val p1 = Person(Some("John"), Some("Quincy"), Some("Adams")) |
| | p1: com.mblinn.mbfpp.oo.strategy.PeopleExample.Person = ... |
| | |
| | scala> val p2 = Person(Some("Mike"), None, Some("Linn")) |
| | p2: com.mblinn.mbfpp.oo.strategy.PeopleExample.Person = ... |
| | |
| | scala> val p3 = Person(None, None, None) |
| | p3: com.mblinn.mbfpp.oo.strategy.PeopleExample.Person = ... |
Sau đó, chúng tôi chạy qua hai người thu thập, bắt đầu với singleNameValidCollector:
| | scala> singleNameValidCollector(p1) |
| | res0: scala.collection.immutable.Vector[...] = |
| | Vector(Person(Some(John),Some(Quincy),Some(Adams))) |
| | |
| | scala> singleNameValidCollector(p2) |
| | res1: scala.collection.immutable.Vector[...] = |
| | Vector( |
| | Person(Some(John),Some(Quincy),Some(Adams)), |
| | Person(Some(Mike),None,Some(Linn))) |
| | |
| | scala> singleNameValidCollector(p3) |
| | res2: scala.collection.immutable.Vector[...] = |
| | Vector( |
| | Person(Some(John),Some(Quincy),Some(Adams)), |
| | Person(Some(Mike),None,Some(Linn))) |
Và chúng ta sẽ kết thúc với fullNameValidCollector :
| | scala> fullNameValidCollector(p1) |
| | res3: scala.collection.immutable.Vector[...] = |
| | Vector(Person(Some(John),Some(Quincy),Some(Adams))) |
| | |
| | scala> fullNameValidCollector(p2) |
| | res4: scala.collection.immutable.Vector[...] = |
| | Vector(Person(Some(John),Some(Quincy),Some(Adams))) |
| | |
| | scala> fullNameValidCollector(p3) |
| | res5: scala.collection.immutable.Vector[...] = |
| | Vector(Person(Some(John),Some(Quincy),Some(Adams))) |
Như chúng ta thấy, hai bộ thu hoạt động như mong đợi, ủy thác cho các hàm xác thực mà đã được truyền vào khi chúng được tạo.
In Clojure
Trong Clojure, chúng ta sẽ giải quyết vấn đề thu thập người giống như trong Scala, sử dụng các hàm cho các trình xác thực và một hàm bậc cao nhận vào một trình xác thực và tạo ra một hàm thu thập người. Để đại diện cho mọi người, chúng ta sẽ sử dụng các map của Clojure. Vì Clojure là một ngôn ngữ động và không có kiểu Option như trong Scala, chúng ta sẽ sử dụng nil để đại diện cho việc không có tên.
Hãy bắt đầu bằng cách xem xét first-name-valid?. Nó kiểm tra xem :first-name của người đó có phải là nil không và trả về true nếu có; nếu không, nó sẽ trả về false.
| ClojureExamples/src/mbfpp/oo/strategy/people_example.clj | |
| | (defn first-name-valid? [person] |
| | (not (nil? (:first-name person)))) |
Hàm full-name-valid? sẽ lấy ra cả ba tên và trả về true chỉ khi tất cả chúng đều không phải là nil:
| ClojureExamples/src/mbfpp/oo/strategy/people_example.clj | |
| | (defn full-name-valid? [person] |
| | (and |
| | (not (nil? (:first-name person))) |
| | (not (nil? (:middle-name person))) |
| | (not (nil? (:last-name person))))) |
Cuối cùng, hãy cùng xem xét person-collector của chúng ta, cái mà nhận vào một hàm xác thực và tạo ra một hàm thu thập. Cách hoạt động của nó gần giống như phiên bản Scala, điểm khác biệt chính là chúng ta cần sử dụng một atom để lưu trữ tham chiếu đến vector bất biến của chúng ta trong một atom.
| ClojureExamples/src/mbfpp/oo/strategy/people_example.clj | |
| | (defn person-collector [valid?] |
| | (let [valid-people (atom [])] |
| | (fn [person] |
| | (if (valid? person) |
| | (swap! valid-people conj person)) |
| | @valid-people))) |
Trước khi kết thúc, hãy cùng xem bộ sưu tập người Clojure của chúng ta hoạt động như thế nào, bắt đầu bằng cách định nghĩa các hàm thu thập như chúng ta thực hiện bên dưới:
| | => (def first-name-valid-collector (person-collector first-name-valid?)) |
| | #'mbfpp.oo.strategy.people-example/first-name-valid-collector |
| | => (def full-name-valid-collector (person-collector full-name-valid?)) |
| | #'mbfpp.oo.strategy.people-example/full-name-valid-collector |
Bây giờ chúng ta cần một số dữ liệu kiểm tra:
| | => (def p1 {:first-name "john" :middle-name "quincy" :last-name "adams"}) |
| | #'mbfpp.oo.strategy.people-example/p1 |
| | => (def p2 {:first-name "mike" :middle-name nil :last-name "adams"}) |
| | #'mbfpp.oo.strategy.people-example/p2 |
| | => (def p3 {:first-name nil :middle-name nil :last-name nil}) |
| | #'mbfpp.oo.strategy.people-example/p3 |
Và chúng ta có thể chạy nó qua các bộ thu thập của mình, bắt đầu với bộ thu thập chỉ yêu cầu một tên đầu tiên cho người đó được coi là hợp lệ:
| | => (first-name-valid-collector p1) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"}] |
| | => (first-name-valid-collector p2) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"} |
| | {:middle-name nil, :last-name "adams", :first-name "mike"}] |
| | => (first-name-valid-collector p3) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"} |
| | {:middle-name nil, :last-name "adams", :first-name "mike"}] |
Sau đó, chúng ta hoàn thành với bộ thu thập yêu cầu tên đầy đủ của người để hợp lệ:
| | => (full-name-valid-collector p1) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"}] |
| | => (full-name-valid-collector p2) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"}] |
| | => (full-name-valid-collector p3) |
| | [{:middle-name "quincy", :last-name "adams", :first-name "john"}] |
Cả hai đều hoạt động như mong đợi, xác thực tên được truyền vào trước khi lưu trữ nếu hợp lệ và sau đó trả về toàn bộ tập hợp các tên hợp lệ.
Discussion
Chiến lược và Phương pháp Mẫu phục vụ những mục đích tương tự. Cả hai đều là cách để chèn một số đoạn mã tùy chỉnh vào một khung hoặc thuật toán lớn hơn. Chiến lược sử dụng thành phần, và Phương pháp Mẫu sử dụng kế thừa. Chúng tôi đã thay thế cả hai mẫu bằng những mẫu dựa trên tổ hợp hàm.
Mặc dù cả Clojure và Scala đều có những tính năng ngôn ngữ cho phép chúng ta xây dựng các cấu trúc phân cấp, chúng tôi đã thay thế cả Hai phương pháp Template và Chiến lược bằng các mẫu dựa trên việc kết hợp chức năng. Điều này dẫn đến những giải pháp đơn giản hơn cho các vấn đề phổ biến, phản ánh sở thích của lập trình hướng đối tượng cũ là ưu tiên kết hợp hơn là kế thừa.
For Further Reading
Mô hình Thiết kế: Các yếu tố của Phần mềm Hướng đối tượng Tái sử dụng [GHJV95]—Chiến lược
Related Patterns
Mẫu 1, Thay thế Giao diện Chức năng
Mẫu 6, Thay thế phương thức mẫu
| Pattern 8 | Replacing Null Object |
Intent
Để tránh rải rác các kiểm tra null trong mã của chúng tôi bằng cách bao bọc hành động được thực hiện cho các tham chiếu null vào một đối tượng null đại diện.
Overview
Một cách phổ biến để biểu diễn việc thiếu giá trị trong Java là sử dụng tham chiếu null. Điều này dẫn đến nhiều mã trông như sau:
| | if(null == someObject){ |
| | // default null handling behavior |
| | }else{ |
| | someObject.someMethod() |
| | } |
Phong cách này dẫn đến việc rải rác logic xử lý giá trị null trong toàn bộ mã của chúng tôi, thường là lặp lại nó. Nếu chúng tôi quên kiểm tra giá trị null, điều này có thể dẫn đến việc chương trình bị sập do lỗi NullPointerException, ngay cả khi có một hành vi mặc định hợp lý có thể xử lý việc thiếu một giá trị.
Một giải pháp phổ biến cho vấn đề này là tạo ra một đối tượng null singleton có cùng giao diện với các đối tượng thực của chúng ta, nhưng thực hiện hành vi mặc định của chúng ta. Chúng ta có thể sử dụng đối tượng này thay cho các tham chiếu null.
Hai lợi ích chính ở đây là:
-
Chúng ta có thể tránh việc rải rác các kiểm tra null trong toàn bộ mã của mình, điều này giúp mã sạch sẽ hơn và dễ đọc hơn.
-
Chúng ta có thể tập trung logic xử lý việc thiếu giá trị.
Sử dụng Đối tượng Null có những đánh đổi của nó. Việc sử dụng rộng rãi mẫu này có nghĩa là chương trình của bạn có khả năng không phát hiện lỗi ngay lập tức. Bạn có thể tạo ra một đối tượng null do lỗi và không nhận ra cho đến rất lâu sau trong quá trình thực thi của chương trình, điều này khiến việc theo dõi nguồn gốc của lỗi trở nên khó khăn hơn rất nhiều.
Trong Java, tôi thường sử dụng Null Object một cách thận trọng khi tôi biết rằng có lý do chính đáng tại sao tôi có thể không có giá trị cho một thứ gì đó và sử dụng kiểm tra null ở những nơi khác. Sự khác biệt giữa hai tình huống này có thể rất tinh tế.
Ví dụ, hãy tưởng tượng rằng chúng ta đang viết một phần của hệ thống tìm kiếm một người bằng ID độc nhất được sinh ra. Nếu các ID liên quan chặt chẽ đến hệ thống mà chúng ta đang viết và chúng ta biết rằng mọi lần tìm kiếm đều phải thành công và trả về một người, tôi sẽ giữ lại việc sử dụng các tham chiếu null. Bằng cách này, nếu có điều gì đó sai xảy ra và chúng ta không có người, chúng ta sẽ thất bại ngay lập tức và không chuyển vấn đề đó đi.
Tuy nhiên, nếu các ID không liên quan chặt chẽ đến chương trình của chúng tôi, tôi có thể sẽ sử dụng Null Object. Ví dụ, giả sử rằng các ID được tạo ra bởi một hệ thống khác và được nhập vào hệ thống của chúng tôi qua một quá trình hàng loạt, điều này có nghĩa là có một khoảng thời gian trễ giữa khi ID được tạo ra và khi nó trở nên có sẵn cho hệ thống của chúng tôi. Trong trường hợp này, việc xử lý một ID bị thiếu sẽ là một phần của hoạt động bình thường của chương trình của chúng tôi, và tôi sẽ sử dụng Null Object để giữ cho mã sạch sẽ và tránh các kiểm tra null không cần thiết.
Các sự thay thế chức năng mà chúng tôi xem xét sẽ khám phá những thỏa hiệp này.
Functional Replacement
Chúng ta sẽ xem xét một vài cách tiếp cận khác nhau ở đây. Trong Scala, chúng ta sẽ tận dụng kiểu tĩnh và kiểu Option để thay thế các tham chiếu đối tượng null. Trong Clojure, chúng ta sẽ chủ yếu tập trung vào cách xử lý của Clojure đối với nil, nhưng cũng sẽ đề cập đến hệ thống kiểu tĩnh tùy chọn của Clojure, cung cấp cho chúng ta một Option tương tự như của Scala.
In Scala
Chúng ta có tham chiếu null trong Scala cũng giống như trong Java; tuy nhiên, việc sử dụng chúng không phổ biến. Thay vào đó, chúng ta có thể tận dụng hệ thống loại để thay thế cả tham chiếu null và Đối tượng Null. Chúng ta sẽ xem xét hai loại container, Option và Either. Đầu tiên, Option cho phép chúng ta chỉ ra rằng chúng ta có thể không có giá trị theo cách an toàn với kiểu dữ liệu. Thứ hai, Either cho phép chúng ta cung cấp một giá trị khi chúng ta có và một giá trị mặc định hoặc lỗi khi chúng ta không có.
Hãy cùng xem xét kỹ hơn về loại Option trước. Các loại Option là các chứa, giống như một Map hoặc một Vector, ngoại trừ việc chúng chỉ có thể chứa tối đa một phần tử. Option có hai loại con quan trọng: Some, mang giá trị, và đối tượng đơn lẻ None, không mang giá trị. Trong đoạn mã sau, chúng ta tạo một Some[String] mang giá trị "foo" và một tham chiếu đến None:
| | scala> def aSome = Some("foo") |
| | aSome: Some[java.lang.String] |
| | |
| | scala> def aNone = None |
| | aNone: None.type |
Bây giờ chúng ta có thể làm việc với các thể hiện Option của mình theo nhiều cách khác nhau. Có lẽ cách đơn giản nhất là phương thức getOrElse. Phương thức getOrElse được gọi với một đối số duy nhất, một giá trị mặc định. Khi được gọi trên một thể hiện của Some, giá trị được mang theo sẽ được trả về; khi được gọi trên None, giá trị mặc định sẽ được trả về. Mã sau đây minh họa điều này:
| | scala> aSome.getOrElse("default value") |
| | res0: java.lang.String = foo |
| | |
| | scala> aNone.getOrElse("default value") |
| | res1: java.lang.String = default value |
Khi làm việc với Option, tốt nhất là coi một giá trị như một loại container khác. Ví dụ, nếu chúng ta cần thực hiện một hành động nào đó với một giá trị bên trong một Option, chúng ta có thể sử dụng người bạn cũ của mình, đó là map, như trong đoạn mã sau:
| | scala> aSome.map((s) => s.toUpperCase) |
| | res2: Option[java.lang.String] = Some(FOO) |
Chúng ta sẽ xem xét một số cách làm việc tinh vi hơn với Option trong các mẫu mã.
Một lưu ý cuối cùng về Option: Ở dạng đơn giản nhất, nó có thể được sử dụng tương tự như cách chúng ta sử dụng kiểm tra null trong Java, mặc dù có nhiều cách mạnh mẽ hơn để sử dụng nó. Tuy nhiên, ngay cả ở dạng đơn giản nhất, có một điểm khác biệt lớn.
Tùy chọn là một phần của hệ thống loại, vì vậy nếu chúng ta sử dụng nó một cách nhất quán, chúng ta biết chính xác ở những phần nào trong mã của mình có thể phải đối mặt với việc thiếu giá trị hoặc giá trị mặc định. Ở mọi nơi khác, chúng ta có thể viết mã với sự tự tin rằng chúng ta sẽ có một giá trị.
In Clojure
Trong Clojure, chúng ta không có kiểu Option mà hệ thống kiểu tĩnh của Scala cung cấp. Thay vào đó, chúng ta có nil, tương đương với null của Java ở cấp độ bytecode. Tuy nhiên, Clojure cung cấp một số tính năng tiện lợi giúp việc xử lý sự thiếu vắng giá trị bằng nil trở nên sạch sẽ hơn và mang lại cho chúng ta nhiều lợi ích tương tự như với Null Object.
Đầu tiên, nil được xử lý giống như false trong Clojure. Khi kết hợp với việc sử dụng biểu thức phổ biến, điều này làm cho việc kiểm tra nil trong Clojure dễ hơn rất nhiều so với việc kiểm tra null trong Java, như đoạn mã sau đây chứng minh:
| | => (if nil "default value" "real value") |
| | "real value" |
Thứ hai, các hàm mà chúng tôi sử dụng để lấy giá trị của các cấu trúc dữ liệu tổng hợp trong Clojure cung cấp một cách để lấy giá trị mặc định nếu phần tử mà chúng tôi cố gắng truy xuất không có mặt. Ở đây, chúng tôi sử dụng phương thức get để cố gắng truy xuất giá trị cho :foo từ một bản đồ rỗng, và chúng tôi nhận lại giá trị mặc định mà chúng tôi đã truyền vào.
| | => (get {} :foo "default value") |
| | "default value" |
Sự thiếu giá trị cho một khóa là khác biệt với một khóa có giá trị là nil, như đoạn mã này chứng minh:
| | => (get {:foo nil} :foo "default value") |
| | nil |
Hãy cùng khám phá một số mẫu mã!
Sample Code: Default Values
Chúng ta sẽ bắt đầu bằng cách xem cách sử dụng Null Object như một giá trị mặc định khi chúng ta không nhận được giá trị từ việc tra cứu bản đồ. Trong ví dụ này, chúng ta sẽ có một bản đồ đầy đủ những người được khóa bằng ID. Nếu chúng ta không tìm thấy một người cho ID nhất định, chúng ta cần trả về một người mặc định có tên là "John Doe."
Classic Java
Trong Java cổ điển, chúng ta sẽ tạo một giao diện Person với hai lớp con, RealPerson và NullPerson. Lớp đầu tiên, RealPerson, cho phép chúng ta thiết lập tên và họ, trong khi NullPerson được mã hóa cứng với giá trị là "John" và "Doe".
Nếu chúng ta nhận được giá trị null khi cố gắng lấy thông tin của một người bằng ID, chúng ta sẽ trả về một thể hiện của NullPerson; nếu không, chúng ta sẽ sử dụng RealPerson mà chúng ta đã lấy ra từ bản đồ. Mã sau đây phác thảo cách tiếp cận này:
| JavaExamples/src/main/java/com/mblinn/oo/nullobject/PersonExample.java | |
| | public class PersonExample { |
| | private Map<Integer, Person> people; |
| | |
| | public PersonExample() { |
| | people = new HashMap<Integer, Person>(); |
| | } |
| | |
| | public Person fetchPerson(Integer id) { |
| | Person person = people.get(id); |
| | if (null != person) |
| | return person; |
| | else |
| | return new NullPerson(); |
| | } |
| | // Code to add/remove people |
| | |
| | public Person buildPerson(String firstName, String lastName){ |
| | if(null != firstName && null != lastName) |
| | return new RealPerson(firstName, lastName); |
| | else |
| | return new NullPerson(); |
| | } |
| | } |
Hãy xem cách chúng ta có thể sử dụng Option của Scala để loại bỏ việc kiểm tra null rõ ràng mà chúng ta cần thực hiện trong Java.
In Scala
Trong Scala, phương thức get trên Map không trả về giá trị trực tiếp. Nếu khóa tồn tại, giá trị sẽ được trả về trong một Some, ngược lại sẽ trả về một None.
Ví dụ, trong đoạn mã sau, chúng ta tạo một bản đồ với hai khóa kiểu integer, 1 và 2, và chuỗi greetings làm giá trị. Khi chúng ta cố gắng lấy bất kỳ khóa nào trong số đó bằng cách sử dụng get, chúng ta sẽ nhận lại một chuỗi được bọc trong một Some. Đối với bất kỳ khóa nào khác, chúng ta sẽ nhận lại một None.
| | scala> def aMap = Map(1->"Hello", 2->"Aloha") |
| | aMap: scala.collection.immutable.Map[Int,java.lang.String] |
| | |
| | scala> aMap.get(1) |
| | res0: Option[java.lang.String] = Some(Hello) |
| | |
| | scala> aMap.get(3) |
| | res1: Option[java.lang.String] = None |
Chúng tôi có thể làm việc trực tiếp với loại Option, nhưng Scala cung cấp một cách viết tắt hữu ích cho phép chúng tôi lấy lại giá trị mặc định trực tiếp từ một bản đồ, getOrElse. Trong kết quả REPL tiếp theo, chúng tôi sử dụng nó để cố gắng lấy giá trị cho khóa 3 từ bản đồ. Vì nó không có ở đó, chúng tôi nhận được giá trị mặc định của mình thay thế.
| | scala> aMap.getOrElse(3, "Default Greeting") |
| | res3: java.lang.String = Default Greeting |
Bây giờ chúng ta hãy xem cách chúng ta có thể sử dụng tính năng tiện lợi này để triển khai ví dụ về việc lấy thông tin người. Ở đây, chúng ta đang sử dụng một trait làm kiểu cơ sở cho người, và chúng ta đang sử dụng các case class cho RealPerson và NullPerson. Sau đó, chúng ta có thể sử dụng một instance của NullPerson làm giá trị mặc định trong việc tra cứu. Đoạn mã sau đây minh họa cách tiếp cận này:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/nullobject/Examples.scala | |
| | case class Person(firstName: String="John", lastName: String="Doe") |
| | val nullPerson = Person() |
| | |
| | def fetchPerson(people: Map[Int, Person], id: Int) = |
| | people.getOrElse(id, nullPerson) |
Hãy định nghĩa một số dữ liệu thử nghiệm để chúng ta có thể thấy cách tiếp cận này hoạt động:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/nullobject/Examples.scala | |
| | val joe = Person("Joe", "Smith") |
| | val jack = Person("Jack", "Brown") |
| | val somePeople = Map(1 -> joe, 2 -> jack) |
Bây giờ nếu chúng ta sử dụng fetchPerson trên một khóa tồn tại, nó sẽ được trả về; nếu không, người mặc định của chúng ta sẽ được trả về:
| | scala> fetchPerson(somePeople, 1) |
| | res0: com.mblinn.mbfpp.oo.nullobject.Examples.Person = Person(Joe,Smith) |
| | |
| | scala> fetchPerson(somePeople, 3) |
| | res1: com.mblinn.mbfpp.oo.nullobject.Examples.Person = Person(John,Doe) |
Bây giờ hãy cùng xem cách chúng ta có thể thực hiện điều này trong Clojure.
In Clojure
Khi chúng ta cố gắng tra cứu một khóa không tồn tại từ một bản đồ trong Clojure, giá trị nil được trả về.
| | => ({} :foo) |
| | nil |
Clojure cung cấp một cách khác để tra cứu khóa từ một bản đồ, đó là hàm get, cho phép chúng ta cung cấp một giá trị mặc định tùy chọn. Đoạn mã REPL sau đây cho thấy một ví dụ đơn giản về việc sử dụng get trong thực tế.
| | => (get :foo {} "default") |
| | "default" |
Để viết ví dụ tra cứu người trong Clojure, tất cả những gì chúng ta cần làm là định nghĩa một null-person mặc định. Sau đó, chúng ta truyền nó vào get như một giá trị mặc định khi cố gắng thực hiện việc tra cứu, như mã và kết quả REPL dưới đây minh họa:
| ClojureExamples/src/mbfpp/oo/nullobject/examples.clj | |
| | (def null-person {:first-name "John" :last-name "Doe"}) |
| | (defn fetch-person [people id] |
| | (get id people null-person)) |
| | => (def people {42 {:first-name "Jack" :last-name "Bauer"}}) |
| | #'mbfpp.oo.nullobject.examples/people |
| | => (fetch-person 42 people) |
| | {:last-name "Bauer", :first-name "Jack"} |
| | => (fetch-person 4 people) |
| | {:last-name "Doe", :first-name "John"} |
Mã trong ví dụ này xử lý một cách sử dụng cơ bản của Đối tượng Null như một giá trị mặc định tại thời điểm tra cứu. Tiếp theo, hãy cùng xem cách chúng ta sẽ xử lý việc làm việc với Đối tượng Null và các thay thế của nó khi đến lúc cần chỉnh sửa chúng.
Sample Code: Something from Nothing
Hãy nhìn vào ví dụ về người của chúng ta từ một góc độ khác. Lần này, thay vì tra cứu một người có thể không tồn tại, chúng ta muốn tạo ra một người chỉ khi chúng ta có tên và họ hợp lệ. Nếu không, chúng ta sẽ sử dụng một giá trị mặc định.
Classic Java
Trong Java, chúng ta sẽ sử dụng cùng một đối tượng null mà chúng ta đã thấy trong Classic Java. Nếu chúng ta có cả họ và tên để sử dụng, chúng ta sẽ sử dụng một RealPerson; ngược lại, chúng ta sẽ sử dụng một NullPerson.
Để thực hiện điều này, chúng ta viết một hàm buildPerson nhận vào một firstName và một lastName . Nếu một trong hai giá trị là null, chúng ta sẽ trả về một NullPerson; ngược lại, chúng ta sẽ trả về một RealPerson được tạo ra với các tên đã được truyền vào. Đoạn mã sau phác thảo giải pháp này:
| JavaExamples/src/main/java/com/mblinn/oo/nullobject/PersonExample.java | |
| | public Person buildPerson(String firstName, String lastName){ |
| | if(null != firstName && null != lastName) |
| | return new RealPerson(firstName, lastName); |
| | else |
| | return new NullPerson(); |
| | } |
Cách tiếp cận này cho phép chúng ta giảm thiểu diện tích bề mặt của mã mà chúng ta cần xử lý với giá trị null, giúp giảm bớt các con trỏ null bất ngờ. Bây giờ hãy xem chúng ta có thể đạt được điều tương tự trong Scala mà không cần phải giới thiệu một đối tượng null không cần thiết.
In Scala
Cách tiếp cận của chúng tôi với Scala về vấn đề này sẽ tận dụng Option thay vì tạo ra một loại đối tượng Null đặc biệt. Các tham số firstName và lastName mà chúng tôi truyền vào buildPerson là Option[String], và chúng tôi trả về một Option[Person].
Nếu cả firstName và lastName đều là Some[String], thì chúng ta trả về một Some[Person]; ngược lại, chúng ta trả về một None. Cách đúng để làm điều này trong Scala là coi các Option như các container khác, chẳng hạn như một Map hoặc một Vector.
Trước đây, chúng ta đã xem một ví dụ đơn giản về việc sử dụng phương pháp map trên một thể hiện của Some. Hãy cùng xem cách chúng ta sử dụng công cụ thao tác chuỗi mạnh mẽ nhất của Scala, đó là hiểu biết chuỗi mà chúng ta đã giới thiệu trong Mã mẫu: Hiểu biết chuỗi, để thao tác với các loại Option.
Đầu tiên, hãy cho một số dữ liệu kiểm tra vào REPL của chúng ta. Trong đoạn mã sau, chúng ta định nghĩa một vector đơn giản và một vài kiểu tùy chọn:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/nullobject/Examples.scala | |
| | def vecFoo = Vector("foo") |
| | def someFoo = Some("foo") |
| | def someBar = Some("bar") |
| | def aNone = None |
Như chúng ta có thể thấy trong đoạn mã dưới đây, việc thao tác với một Some trông giống như thao tác với một Vector chứa một giá trị duy nhất.
| | scala> for(theFoo <- vecFoo) yield theFoo |
| | res0: scala.collection.immutable.Vector[java.lang.String] = Vector(foo) |
| | scala> for(theFoo <- someFoo) yield theFoo |
| | res1: Option[java.lang.String] = Some(foo) |
Sức mạnh thực sự của việc sử dụng comprehension với Option xuất hiện khi chúng ta làm việc với nhiều Option cùng lúc. Chúng ta có thể sử dụng nhiều bộ sinh, một cho mỗi option, để lấy giá trị trong mỗi option. Trong đoạn mã sau, chúng ta sử dụng kỹ thuật này để lấy các chuỗi từ someFoo và someBar và đưa chúng vào một tuple, mà sau đó chúng ta sẽ trả về.
| | scala> for(theFoo <- someFoo; theBar <- someBar) yield (theFoo, theBar) |
| | res2: Option[(java.lang.String, java.lang.String)] = Some((foo,bar)) |
Khi làm việc với các tùy chọn theo cách này, nếu bất kỳ trình sinh nào sản xuất ra một None, thì giá trị của toàn bộ biểu thức sẽ là None. Điều này mang lại cho chúng ta một cú pháp rõ ràng để làm việc với Some và None.
| | scala> for(theFoo <- someFoo; theNone <- aNone) yield (theFoo, theNone) |
| | res3: Option[(java.lang.String, Nothing)] = None |
Chúng ta có thể áp dụng điều này vào ví dụ xây dựng người của mình một cách khá đơn giản. Chúng ta sử dụng hai bộ sinh trong câu lệnh for comprehension, một cho tên đầu tiên và một cho họ. Sau đó, chúng ta trả về một đối tượng Person. Câu lệnh for comprehension bao bọc điều đó trong một Option, và chúng ta sử dụng getOrElse để lấy giá trị hoặc sử dụng một giá trị mặc định. Mã sau đây minh họa cho cách tiếp cận này:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/nullobject/Examples.scala | |
| | def buildPerson(firstNameOption: Option[String], lastNameOption: Option[String]) = |
| | (for( |
| | firstName <- firstNameOption; |
| | lastName <- lastNameOption) |
| | yield Person(firstName, lastName)).getOrElse(Person("John", "Doe")) |
Ở đây chúng ta có thể thấy nó hoạt động:
| | scala> buildPerson(Some("Mike"), Some("Linn")) |
| | res4: com.mblinn.mbfpp.oo.nullobject.Examples.Person = Person(Mike,Linn) |
| | |
| | scala> buildPerson(Some("Mike"), None) |
| | res5: com.mblinn.mbfpp.oo.nullobject.Examples.Person = Person(John,Doe) |
Hãy hoàn thành ví dụ bằng cách xem cách xử lý việc xây dựng đối tượng người trong Clojure.
In Clojure
Trong Clojure, ví dụ xây dựng người của chúng ta đơn giản hóa thành một kiểm tra nil. Chúng ta truyền first-name và last-name vào hàm build-person. Nếu cả hai đều không phải là nil, chúng ta sử dụng chúng để tạo ra một người; nếu không, chúng ta tạo ra một người mặc định.
Cách Clojure xử lý nil như một giá trị "giả" làm cho việc này trở nên thuận tiện, nhưng nhìn chung nó rất giống với cách tiếp cận của chúng ta trong Java. Mã nguồn như sau:
| ClojureExamples/src/mbfpp/oo/nullobject/examples.clj | |
| | (defn build-person [first-name last-name] |
| | (if (and first-name last-name) |
| | {:first-name first-name :last-name last-name} |
| | {:first-name "John" :last-name "Doe"})) |
Ở đây nó tạo ra một người thật và một người mặc định:
| | => (build-person "Mike" "Linn") |
| | {:first-name "Mike", :last-name "Linn"} |
| | => (build-person "Mike" nil) |
| | {:first-name "John", :last-name "Doe"} |
Hãy cùng xem xét lần cuối việc xử lý giá trị rỗng bằng cách xem xét một trường hợp trong đó chúng ta có nhiều phần của mã mà muốn xử lý sự thiếu vắng giá trị theo cùng một cách.
Discussion
Cách tiếp cận theo cách diễn đạt để xử lý sự thiếu vắng giá trị trong Clojure và Scala là rất khác nhau. Sự khác biệt này là do hệ thống kiểu tĩnh của Scala và hệ thống kiểu động của Clojure. Hệ thống kiểu tĩnh và các tham số kiểu của Scala làm cho kiểu Option trở nên khả thi.
Các sự đánh đổi mà Scala và Clojure thực hiện ở đây phản ánh những đánh đổi chung giữa kiểu tĩnh và kiểu động. Với cách tiếp cận của Scala, trình biên dịch giúp đảm bảo rằng chúng ta đang xử lý đúng trường hợp không (nothing) tại thời điểm biên dịch, tuy nhiên chúng ta phải cẩn thận để không để giá trị null của Java len lỏi vào mã Scala của chúng ta.
Với cách tiếp cận của Clojure, chúng ta có khả năng gặp con trỏ null hầu như ở khắp nơi, giống như trong Java. Chúng ta cần cẩn thận hơn để xử lý chúng một cách thích hợp, nếu không chúng ta có nguy cơ gặp lỗi tại thời gian chạy.
Sở thích của tôi là xử lý tất cả các tình huống không có giá trị ở lớp ngoài cùng của mã nguồn, bất kể tôi đang sử dụng kiểu dữ liệu Option của Scala hay null/nil mà Java và Clojure chia sẻ. Ví dụ, nếu tôi đang truy vấn một cơ sở dữ liệu để tìm một người có thể tồn tại hoặc không, tôi thích kiểm tra sự tồn tại của họ chỉ một lần: khi chúng tôi cố gắng lấy lại từ cơ sở dữ liệu. Sau đó, tôi sử dụng các kỹ thuật được nêu trong mẫu này để tạo ra một người mặc định nếu cần thiết. Điều này cho phép phần còn lại của mã nguồn của tôi tránh việc kiểm tra null hoặc xử lý kiểu dữ liệu Option. Tôi thấy rằng cách tiếp cận của Scala đối với kiểu dữ liệu Option giúp dễ dàng hơn nhiều để viết chương trình theo kiểu này, vì nó buộc chúng tôi phải xử lý rõ ràng việc thiếu giá trị bất cứ khi nào chúng tôi có thể không có giá trị và giả định rằng chúng tôi sẽ có giá trị ở mọi nơi khác.
For Further Reading
Ngôn ngữ Mẫu của Thiết kế Chương trình 3 [MRB97]—Đối tượng Null
Tái cấu trúc: Cải thiện thiết kế của mã hiện có [FBBO99]—Giới thiệu Đối tượng Null
| Pattern 9 | Replacing Decorator |
Intent
Để thêm hành vi cho một đối tượng cụ thể thay vì cho toàn bộ lớp đối tượng—điều này cho phép chúng ta thay đổi hành vi của một lớp đã tồn tại.
Overview
Decorator rất hữu ích khi chúng ta có một lớp (class) hiện có mà chúng ta cần thêm một số hành vi vào, nhưng chúng ta không thể thay đổi lớp hiện có đó. Chúng ta có thể muốn giới thiệu một thay đổi lớn, nhưng không thể thay đổi mọi phần khác của hệ thống nơi lớp đó được sử dụng. Hoặc lớp đó có thể là một phần của thư viện mà chúng ta không thể hoặc không muốn sửa đổi.
Trang trí sử dụng sự kết hợp của kế thừa và thành phần. Nó bắt đầu bằng một giao diện với ít nhất một cài đặt cụ thể. Cài đặt này là lớp mà chúng ta không thể hoặc không muốn thay đổi.
Chúng tôi sau đó triển khai giao diện với một lớp trang trí trừu tượng, lớp này nhận một thể hiện của lớp cụ thể hiện có được kết hợp vào nó. Lớp trang trí trừu tượng của chúng tôi có thể có nhiều triển khai, điều chỉnh hành vi của lớp hiện có bằng cách sử dụng sự kết hợp, như được mô tả trong hình này:
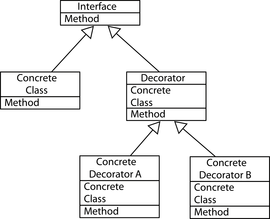
Figure 7. Decorator Diagram. A class diagram for the Decorator pattern
Điều này cho chúng ta một khả năng nhất định để thêm hoặc sửa đổi hành vi của các lớp hiện có, nhưng chủ yếu chúng ta chỉ bị giới hạn ở những điều chỉnh nhỏ vì chúng ta phụ thuộc vào hành vi cơ bản của lớp được kết hợp.
Also Known As
Bìa
Functional Replacement
Tinh chất của Decorator là bọc một lớp hiện tại bằng một lớp mới để lớp mới có thể điều chỉnh hành vi của lớp hiện tại. Trong thế giới hàm, một thay thế đơn giản là tạo ra một hàm bậc cao nhận vào hàm hiện tại và trả về một hàm mới đã được bọc.
Hàm được bọc thực hiện công việc của nó và sau đó ủy quyền cho hàm hiện có. Chẳng hạn, chúng ta có thể tạo một hàm `wrapWithLogger` mà bọc một hàm hiện có với một chút ghi log, trả về một hàm mới.
Sample Code: Logging Calculator
Hãy cùng xem việc sử dụng Decorator với một máy tính cơ bản có bốn chức năng. Máy tính này có bốn phép toán: cộng, trừ, nhân và chia. Để minh họa cho Decorator, chúng ta sẽ lấy một máy tính cơ bản và trang trí nó để ghi lại phép tính mà nó đang thực hiện ra console.
Classic Java
Trong Java, giải pháp của chúng tôi bao gồm một giao diện và hai lớp cụ thể. Giao diện Calculator được triển khai bởi cả CalculatorImp và LoggingCalculator. Lớp LoggingCalculator hoạt động như một bộ trang trí và cần một CalculatorImpl được kết hợp vào nó để thực hiện công việc của mình. Một phác thảo của cách tiếp cận này có thể được tìm thấy trong hình ảnh sau:
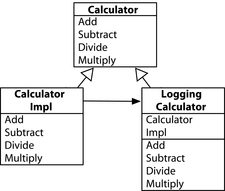
Lớp LoggingCalculator ủy quyền cho lớp CalculatorImpl đã được kết hợp và sau đó ghi lại phép tính ra console.
In Scala
Trong Scala, máy tính của chúng tôi chỉ là một tập hợp bốn hàm. Để giữ cho mọi thứ đơn giản, chúng tôi sẽ hạn chế các phép toán với số nguyên, vì việc triển khai các hàm số học tổng quát trong Scala có phần phức tạp. Mã cho máy tính Scala của chúng tôi như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/decorator/Examples.scala | |
| | def add(a: Int, b: Int) = a + b |
| | def subtract(a: Int, b: Int) = a - b |
| | def multiply(a: Int, b: Int) = a * b |
| | def divide(a: Int, b: Int) = a / b |
Để bao bọc các chức năng máy tính của chúng ta trong mã ghi log, chúng ta sử dụng makeLogger. Đây là một hàm bậc cao nhận vào một hàm máy tính và trả về một hàm mới thực hiện hàm máy tính gốc và in kết quả ra bảng điều khiển trước khi trả về nó.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/decorator/Examples.scala | |
| | def makeLogger(calcFn: (Int, Int) => Int) = |
| | (a: Int, b: Int) => { |
| | val result = calcFn(a, b) |
| | println("Result is: " + result) |
| | result |
| | } |
Để sử dụng makeLogger, chúng ta chạy các hàm máy tính gốc của mình qua nó và gán kết quả vào các giá trị mới, như đoạn mã sau đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/decorator/Examples.scala | |
| | val loggingAdd = makeLogger(add) |
| | val loggingSubtract = makeLogger(subtract) |
| | val loggingMultiply = makeLogger(multiply) |
| | val loggingDivide = makeLogger(divide) |
Bây giờ chúng ta có thể sử dụng hàm máy tính in của mình để thực hiện một số phép toán và in ra kết quả:
| | scala> loggingAdd(2, 3) |
| | Result is: 5 |
| | res0: Int = 5 |
| | |
| | scala> loggingSubtract(2, 3) |
| | Result is: -1 |
| | res1: Int = -1 |
Hãy cùng xem giải pháp máy tính của chúng ta bằng Clojure.
In Clojure
Cấu trúc giải pháp Clojure của chúng tôi tương tự như giải pháp Scala, điểm khác biệt chính là giải pháp Clojure của chúng tôi không bị giới hạn ở các số nguyên vì Clojure là ngôn ngữ kiểu động. Đoạn mã sau đây định nghĩa các hàm máy tính của chúng tôi:
| ClojureExamples/src/mbfpp/oo/decorator/examples.clj | |
| | (defn add [a b] (+ a b)) |
| | (defn subtract [a b] (- a b)) |
| | (defn multiply [a b] (* a b)) |
| | (defn divide [a b] (/ a b)) |
Tiếp theo, chúng ta cần một hàm bậc cao make-logger để bọc các hàm máy tính của chúng ta với mã ghi log:
| ClojureExamples/src/mbfpp/oo/decorator/examples.clj | |
| | (defn make-logger [calc-fn] |
| | (fn [a b] |
| | (let [result (calc-fn a b)] |
| | (println (str "Result is: " result)) |
| | result))) |
Cuối cùng, chúng ta có thể tạo một số hàm máy tính ghi chép và sử dụng chúng để thực hiện một số phép toán ghi chép:
| ClojureExamples/src/mbfpp/oo/decorator/examples.clj | |
| | (def logging-add (make-logger add)) |
| | (def logging-subtract (make-logger subtract)) |
| | (def logging-multiply (make-logger multiply)) |
| | (def logging-divide (make-logger divide)) |
| | => (logging-add 2 3) |
| | Result is: 5 |
| | 5 |
| | => (logging-subtract 2 3) |
| | Result is: -1 |
| | -1 |
Không phải ngẫu nhiên mà các giải pháp Scala và Clojure cho bài toán máy tính lại tương tự nhau: chúng đều chỉ dựa vào các hàm bậc cao cơ bản, mà tương tự nhau trong cả hai ngôn ngữ.
For Further Reading
Mô hình thiết kế: Các yếu tố của phần mềm hướng đối tượng có thể tái sử dụng [GHJV95]—Trang trí
Related Patterns
Mẫu 7, Chiến lược Thay thế
Mẫu 16, Trình xây dựng chức năng
| Pattern 10 | Replacing Visitor |
Intent
Để bao bọc một hành động sẽ được thực hiện trên một cấu trúc dữ liệu theo cách cho phép thêm các phép toán mới vào cấu trúc dữ liệu mà không cần phải sửa đổi nó.
Overview
Một điểm nghẽn phổ biến trong các chương trình lớn, lâu dài là cách mở rộng một kiểu dữ liệu. Chúng tôi muốn mở rộng theo hai khía cạnh. Đầu tiên, chúng tôi có thể muốn thêm các phép toán mới vào các triển khai hiện có của kiểu dữ liệu. Thứ hai, chúng tôi có thể muốn thêm các triển khai mới của kiểu dữ liệu.
Chúng tôi muốn có khả năng thực hiện điều này mà không cần biên dịch lại mã nguồn gốc, thực sự, có thể là ngay cả khi không có quyền truy cập vào nó. Đây là một vấn đề đã tồn tại từ khi lập trình được hình thành, và bây giờ được biết đến với tên gọi vấn đề biểu thức.
Ví dụ, hãy xem xét `Collection` của Java như một kiểu dữ liệu mẫu. Giao diện `Collection` định nghĩa nhiều phương thức, hay hoạt động, và có nhiều triển khai. Trong một thế giới hoàn hảo, chúng ta sẽ dễ dàng thêm cả các hoạt động mới vào `Collection` cũng như các triển khai mới của `Collection`.
Trong các ngôn ngữ lập trình hướng đối tượng, tuy nhiên, chỉ dễ dàng thực hiện cái sau. Chúng ta có thể tạo ra một triển khai mới của Collection bằng cách triển khai giao diện. Nếu chúng ta muốn thêm các thao tác mới vào Collection mà hoạt động với tất cả các triển khai hiện có của Collection, chúng ta sẽ gặp khó khăn.
Trong Java, chúng ta thường giải quyết vấn đề này bằng cách tạo một lớp đầy đủ các phương thức tiện ích tĩnh, thay vì thêm các thao tác trực tiếp vào kiểu dữ liệu. Một thư viện như vậy cho Collection là CollectionUtils của tổ chức Apache.
Visitor là một giải pháp một phần khác cho loại vấn đề này. Nó cho phép chúng ta thêm các thao tác mới vào một kiểu dữ liệu hiện có và thường được sử dụng với dữ liệu có cấu trúc cây. Visitor cho phép chúng ta khá dễ dàng thêm các thao tác mới vào một kiểu dữ liệu hiện có, nhưng nó khiến cho việc thêm các cài đặt mới cho kiểu dữ liệu trở nên khó khăn.
Visitor Pattern
Biểu đồ lớp Visitor (được hiển thị trong hình dưới đây) cho thấy các phần chính của mẫu Visitor. Kiểu dữ liệu của chúng ta ở đây là lớp DataElement, có hai triển khai. Thay vì thực hiện các thao tác trực tiếp trên các lớp con của DataElement, chúng ta tạo ra một phương thức accept nhận một Visitor và gọi visit, truyền chính nó vào.
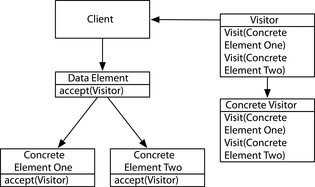
Figure 8. Visitor Classes. A sketch of the Visitor pattern
Điều này đảo ngược ràng buộc hướng đối tượng thông thường rằng việc thêm các triển khai mới của một kiểu dữ liệu là dễ dàng nhưng khó khăn để thêm các thao tác mới. Nếu chúng ta muốn thêm một thao tác mới, chúng ta chỉ cần tạo một visitor mới và viết mã sao cho nó biết cách ghé thăm từng phần tử cụ thể đã tồn tại.
Tuy nhiên, thật khó để thêm các triển khai mới của DataElement. Để làm điều đó, chúng ta cần sửa đổi tất cả các visitor hiện có để biết cách truy cập vào triển khai mới của DataElement. Nếu những lớp Visitor đó nằm ngoài sự kiểm soát của chúng ta, có thể sẽ không thể thực hiện được!
Functional Replacement
Mẫu Visitor cho phép thêm các thao tác mới vào một kiểu dữ liệu hướng đối tượng nhưng khiến việc thêm các triển khai mới của kiểu đó trở nên khó khăn, hoặc không thể. Trong thế giới lập trình hàm, đây là điều bình thường. Rất dễ để thêm một thao tác mới cho một kiểu dữ liệu bằng cách viết một hàm mới hoạt động trên nó, nhưng việc thêm các kiểu dữ liệu mới vào một thao tác đã tồn tại thì khó khăn.
Trong các phần thay thế của chúng tôi, chúng tôi sẽ xem xét một vài cách khác nhau để giải quyết vấn đề mở rộng này trong Scala và Clojure. Các giải pháp là khá khác nhau trong hai ngôn ngữ này. Một phần, điều này là do Scala là ngôn ngữ kiểu tĩnh trong khi Clojure là ngôn ngữ kiểu động. Điều này có nghĩa là Scala phải giải quyết vấn đề khó hơn vì nó cố gắng thực hiện các mở rộng đồng thời giữ nguyên tính an toàn kiểu tĩnh.
Sự khác biệt khác là cách tiếp cận của Scala đối với đa hình (polymorphism) là một sự mở rộng của mô hình hướng đối tượng truyền thống, sử dụng một hệ thống phân cấp các lớp con. Clojure có một cái nhìn mới mẻ và cung cấp đa hình theo cách tạm thời hơn. Bởi vì đa hình liên quan chặt chẽ đến khả năng mở rộng, điều này ảnh hưởng đến hình dạng tổng thể của các giải pháp.
In Scala
Vì Scala là một ngôn ngữ lai, việc mở rộng mã hiện có yêu cầu chúng ta phải dựa vào các tính năng lập trình hướng đối tượng của nó, đặc biệt là hệ thống kiểu của nó.
Đầu tiên, chúng ta sẽ xem một phương pháp mở rộng các thao tác trong một thư viện hiện có sử dụng hệ thống chuyển đổi ngầm của Scala. Điều này cho phép chúng ta thêm các thao tác mới vào các thư viện hiện có.
Thứ hai, chúng ta sẽ xem xét một giải pháp tận dụng tính kế thừa theo kiểu mix-in và các trait của Scala, cho phép chúng ta dễ dàng thêm cả các hoạt động mới và các triển khai mới vào một kiểu dữ liệu.
In Clojure
Trong Clojure, chúng ta sẽ xem xét cách mà ngôn ngữ này tiếp cận đa hình một cách độc đáo. Đầu tiên, chúng ta sẽ tìm hiểu về các kiểu dữ liệu và giao thức của Clojure. Những điều này cho phép chúng ta xác định kiểu dữ liệu và các phép toán thực hiện trên chúng độc lập, cũng như mở rộng kiểu dữ liệu với cả các triển khai mới và các phép toán mới, đồng thời tận dụng khả năng dispatch phương thức được tối ưu hóa cao của JVM.
Tiếp theo, chúng ta sẽ xem xét các phương thức đa dạng (multimethods) trong Clojure. Những phương thức này cho phép chúng ta cung cấp hàm phân phối (dispatch function) của riêng mình, cho phép chúng ta phân phối cuộc gọi phương thức theo cách mà chúng ta muốn. Chúng linh hoạt hơn so với các giao thức (protocols) nhưng chậm hơn, vì chúng yêu cầu một cuộc gọi hàm bổ sung tới hàm phân phối do người dùng cung cấp.
Các giải pháp Scala và Clojure mà chúng tôi xem xét không hoàn toàn giống nhau, nhưng chúng đều cung cấp những cách linh hoạt để mở rộng mã hiện có.
Sample Code: Extensible Persons
Trong ví dụ này, chúng ta sẽ xem xét một loại Người và xem cách chúng ta có thể mở rộng nó để có cả triển khai và hoạt động mới. Điều này không thay thế toàn bộ mẫu Visitor, nhưng nó là một ví dụ đơn giản về những loại vấn đề mà Visitor đề cập đến.
In Java
Mã mà chúng ta sẽ xem xét ở đây là một ví dụ cơ bản về việc mở rộng một thư viện hiện có mà không phải bao bọc các đối tượng gốc. Trong Java, sẽ rất dễ dàng để tạo ra các triển khai mới của loại Person, giả sử các tác giả của thư viện gốc đã định nghĩa một giao diện cho nó.
Việc thêm các phương thức mới vào Person sẽ khó hơn. Chúng ta không thể chỉ tạo một giao diện con của Person với các phương thức mới, vì điều đó sẽ không thể được sử dụng thay cho một đối tượng Person bình thường. Việc bao bọc Person trong một lớp mới cũng không khả thi vì lý do tương tự.
Java không có cách tốt để mở rộng một kiểu dữ liệu hiện có để có thêm các thao tác mới, vì vậy chúng ta thường phải giả lập điều đó bằng cách tạo ra các lớp chứa đầy các phương thức tiện ích tĩnh hoạt động trên kiểu dữ liệu đó. Scala và Clojure mang lại cho chúng ta nhiều linh hoạt hơn để mở rộng theo cả hai chiều.
In Scala
Trong Scala, Person của chúng ta được định nghĩa bởi một trait. Trait này chỉ định các phương thức để lấy tên, họ, số nhà và phố của một người. Ngoài ra, còn có một phương thức để lấy tên đầy đủ của người đó, như mã code dưới đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Examples.scala | |
| | trait Person { |
| | def fullName: String |
| | def firstName: String |
| | def lastName: String |
| | def houseNum: Int |
| | def street: String |
| | } |
Bây giờ hãy tạo một triển khai cho loại Person của chúng ta, SimplePerson. Chúng ta sẽ tận dụng thực tế rằng Scala sẽ tự động tạo các phương thức để truy cập các thuộc tính được truyền vào một constructor. Phương thức duy nhất mà chúng ta cần triển khai bằng tay là fullName, như đoạn mã sau đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Examples.scala | |
| | class SimplePerson(val firstName: String, val lastName: String, |
| | val houseNum: Int, val street: String) extends Person { |
| | def fullName = firstName + " " + lastName |
| | } |
Bây giờ chúng ta có thể tạo một SimplePerson và gọi phương thức fullName.
| | scala> val simplePerson = new SimplePerson("Mike", "Linn", 123, "Fake. St.") |
| | simplePerson: com.mblinn.mbfpp.oo.visitor.Examples.SimplePerson = ... |
| | scala> simplePerson.fullName |
| | res0: String = Mike Linn |
Nếu chúng ta muốn mở rộng kiểu Person để có thêm một thao tác, fullAddress thì sao? Một cách để làm điều đó là tạo ra một kiểu con mới với thao tác mới, nhưng sau đó chúng ta không thể sử dụng kiểu mới đó trong trường hợp cần một Person.
Trong Scala, một cách tốt hơn là định nghĩa một chuyển đổi ngầm (implicit conversion) mà chuyển đổi từ một đối tượng `Person` sang một lớp mới có phương thức `fullAddress`. Một chuyển đổi ngầm thay đổi từ một kiểu sang kiểu khác tùy thuộc vào ngữ cảnh.
Hầu hết các ngôn ngữ có một tập hợp các chuyển đổi rõ ràng hoặc ép kiểu được xây dựng sẵn. Chẳng hạn, nếu bạn sử dụng toán tử + trên một int và một String trong Java, int sẽ được chuyển đổi thành String và hai giá trị này sẽ được nối lại với nhau.
Scala cho phép lập trình viên định nghĩa các chuyển đổi ngầm của riêng họ. Một cách để làm như vậy là sử dụng một lớp ngầm. Một lớp ngầm cung cấp bộ xây dựng của nó như là một ứng viên cho các chuyển đổi ngầm. Đoạn mã sau đây tạo ra một lớp ngầm chuyển đổi từ một Person sang một ExtendedPerson với một fullAddress:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Examples.scala | |
| | implicit class ExtendedPerson(person: Person) { |
| | def fullAddress = person.houseNum + " " + person.street |
| | } |
Bây giờ khi chúng ta cố gắng gọi fullAddress trên một Person, trình biên dịch Scala sẽ nhận ra rằng kiểu Person không có phương thức như vậy. Sau đó, nó sẽ tìm kiếm một phép chuyển đổi ngầm định từ một Person sang một kiểu có phương thức đó và sẽ tìm thấy trong lớp ExtendedPerson.
Biên dịch viên sau đó sẽ xây dựng một ExtendedPerson bằng cách truyền đối tượng Person vào trình tạo chính của nó và gọi fullAddress trên đối tượng đó, như ví dụ đầu ra REPL sau đây minh họa:
| | scala> simplePerson.fullAddress |
| | res1: String = 123 Fake. St. |
Bây giờ khi chúng ta đã thấy mẹo cho phép chúng ta mô phỏng việc thêm các phương thức mới vào một kiểu dữ liệu hiện có, phần khó đã hoàn thành. Việc thêm một triển khai mới của kiểu dữ liệu này đơn giản như việc tạo ra một triển khai mới của trait Person ban đầu.
Hãy cùng xem một triển khai của Person có tên là ComplexPerson, sử dụng các đối tượng riêng biệt cho tên và địa chỉ của nó:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Examples.scala | |
| | class ComplexPerson(name: Name, address: Address) extends Person { |
| | def fullName = name.firstName + " " + name.lastName |
| | |
| | def firstName = name.firstName |
| | def lastName = name.lastName |
| | def houseNum = address.houseNum |
| | def street = address.street |
| | } |
| | class Address(val houseNum: Int, val street: String) |
| | class Name(val firstName: String, val lastName: String) |
Bây giờ chúng ta tạo một ComplexPerson mới:
| | scala> val name = new Name("Mike", "Linn") |
| | name: com.mblinn.mbfpp.oo.visitor.Examples.Name = .. |
| | |
| | scala> val address = new Address(123, "Fake St.") |
| | address: com.mblinn.mbfpp.oo.visitor.Examples.Address = .. |
| | |
| | scala> val complexPerson = new ComplexPerson(name, address) |
| | complexPerson: com.mblinn.mbfpp.oo.visitor.Examples.ComplexPerson = ... |
Chuyển đổi ngầm nhập hiện tại của chúng tôi vẫn sẽ hoạt động!
| | scala> complexPerson.fullName |
| | res2: String = Mike Linn |
| | |
| | scala> complexPerson.fullAddress |
| | res3: String = 123 Fake St. |
Điều này có nghĩa là chúng tôi đã có thể mở rộng một kiểu dữ liệu với cả một thao tác mới và một triển khai mới.
In Clojure
Hãy cùng xem ví dụ về người có thể mở rộng trong Clojure. Chúng ta sẽ bắt đầu bằng cách định nghĩa một giao thức với một phép toán duy nhất trong đó, extract-name. Phép toán này nhằm mục đích trích xuất một tên đầy đủ từ một người và được định nghĩa trong đoạn mã sau:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defprotocol NameExtractor |
| | (extract-name [this] "Extracts a name from a person.")) |
Bây giờ chúng ta có thể tạo một bản ghi Clojure, SimplePerson, sử dụng defrecord. Điều này tạo ra một kiểu dữ liệu với một vài trường trên đó:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defrecord SimplePerson [first-name last-name house-num street]) |
Chúng ta có thể tạo một thể hiện mới của SimplePerson bằng cách sử dụng hàm tạo ->SimplePerson, như chúng ta thực hiện trong đoạn mã sau:
| | => (def simple-person (->SimplePerson "Mike" "Linn" 123 "Fake St.")) |
| | #'mbfpp.oo.visitor.examples/simple-person |
Khi đã được tạo, chúng ta có thể truy cập các trường trong kiểu dữ liệu như thể nó là một bản đồ với các từ khóa làm khóa. Trong đoạn mã sau, chúng ta lấy tên riêng từ thể hiện người đơn giản của mình:
| | => (:first-name simple-person) |
| | "Mike" |
Lưu ý cách chúng ta định nghĩa kiểu dữ liệu và tập hợp các phép toán một cách độc lập? Để kết nối hai phần lại với nhau, chúng ta có thể sử dụng `extend-type` để cho phép `SimplePerson` thực thi giao thức `NameExtractor`, như trong đoạn mã sau:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (extend-type SimplePerson |
| | NameExtractor |
| | (extract-name [this] |
| | (str (:first-name this) " " (:last-name this)))) |
Bây giờ chúng ta có thể gọi extract-name trên một SimplePerson và để nó trích xuất tên đầy đủ của người đó:
| | => (extract-name simple-person) |
| | "Mike Linn" |
Bây giờ hãy xem cách tạo một loại mới, ComplexPerson, đại diện cho tên và địa chỉ của nó dưới dạng một bản đồ nhúng. Chúng ta sẽ sử dụng một phiên bản của defrecord cho phép chúng ta mở rộng loại này thành một giao thức ngay khi tạo nó. Đây chỉ là một sự tiện lợi; bản ghi và giao thức mà chúng ta đã tạo vẫn là những thực thể riêng biệt.
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defrecord ComplexPerson [name address] |
| | NameExtractor |
| | (extract-name [this] |
| | (str (-> this :name :first) " " (-> this :name :last)))) |
Bây giờ chúng ta có thể tạo một ComplexPerson và trích xuất tên đầy đủ của nó:
| | => (def complex-person (->ComplexPerson {:first "Mike" :last "Linn"} |
| | {:house-num 123 :street "Fake St."})) |
| | #'mbfpp.oo.visitor.examples/complex-person |
| | => (extract-name complex-person) |
| | "Mike Linn" |
Để thêm một hoạt động hoặc một tập hợp các hoạt động mới vào các kiểu hiện có của chúng tôi, chúng tôi chỉ cần tạo một giao thức mới và mở rộng các kiểu. Trong đoạn mã sau, chúng tôi tạo một giao thức cho phép chúng tôi trích xuất địa chỉ từ một người.
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defprotocol |
| | AddressExtractor |
| | (extract-address [this] "Extracts and address from a person.")) |
Bây giờ chúng ta có thể mở rộng các kiểu có sẵn của mình để tuân thủ giao thức mới, như chúng ta thực hiện trong mã sau:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (extend-type SimplePerson |
| | AddressExtractor |
| | (extract-address [this] |
| | (str (:house-num this) " " (:street this)))) |
| | |
| | (extend-type ComplexPerson |
| | AddressExtractor |
| | (extract-address [this] |
| | (str (-> this :address :house-num) |
| | " " |
| | (-> this :address :street)))) |
Như chúng ta có thể thấy từ đầu ra REPL dưới đây, cả hai kiểu dữ liệu của chúng ta hiện đều tuân thủ giao thức mới:
| | => (extract-address complex-person) |
| | "123 Fake St." |
| | => (extract-address simple-person) |
| | "123 Fake St." |
Trong khi chúng tôi đã sử dụng các phép chuyển đổi ngầm của Scala và các giao thức của Clojure để đạt được một kết quả tương tự ở đây, chúng không hoàn toàn giống nhau. Trong Scala, các phép toán mà chúng ta đã thấy là các phương thức được định nghĩa trên các lớp, có phần thuộc về một kiểu. Kỹ thuật chuyển đổi ngầm của Scala cho phép chúng ta chuyển đổi ngầm từ một kiểu sang kiểu khác, điều này làm cho nó trông như thể chúng ta có thể thêm các phép toán vào một kiểu đã tồn tại.
Các giao thức của Clojure, ngược lại, định nghĩa các tập hợp các thao tác và kiểu hoàn toàn độc lập thông qua các giao thức và bản ghi. Chúng ta sau đó có thể mở rộng bất kỳ bản ghi nào với bất kỳ số lượng giao thức nào, cho phép chúng ta dễ dàng mở rộng một giải pháp hiện có cả với các thao tác mới và các kiểu mới.
Sample Code: Extensible Geometry
Hãy nhìn vào một ví dụ phức tạp hơn. Chúng ta sẽ bắt đầu bằng cách định nghĩa hai hình dạng, một hình tròn và một hình chữ nhật, cùng với một phép toán tính chu vi của chúng.
Sau đó, chúng tôi sẽ trình bày cách mà chúng tôi có thể độc lập thêm các hình dạng mới hoạt động với phép toán chu vi hiện tại và các phép toán mới hoạt động với các hình dạng hiện có của chúng tôi. Cuối cùng, chúng tôi sẽ cho thấy cách kết hợp cả hai loại mở rộng này.
In Java
Trong Java, đây là một vấn đề không thể giải quyết tốt được. Mở rộng kiểu hình dạng để có thêm các triển khai là điều dễ dàng. Chúng ta tạo ra một giao diện Shape với nhiều triển khai khác nhau.
Nếu chúng ta muốn mở rộng `Shape` để có các triển khai mới, sẽ khó khăn hơn một chút, nhưng chúng ta có thể sử dụng Visitor như đã được trình bày trong sơ đồ Các lớp Visitor.
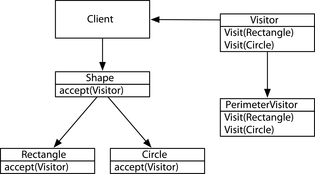
Figure 9. Shape Visitor. The Visitor pattern implemented
Tuy nhiên, nếu chúng ta đi theo hướng này, thì giờ đây việc có các triển khai mới sẽ trở nên khó khăn vì chúng ta sẽ phải sửa đổi tất cả các Visitor hiện có. Nếu các Visitor được triển khai bởi mã bên thứ ba, thì sẽ rất khó để mở rộng trong khía cạnh này mà không phải đưa ra các thay đổi không tương thích ngược.
Trong Java, chúng ta cần quyết định ngay từ đầu xem liệu chúng ta muốn thêm các thao tác mới vào hình dạng của chúng ta hay muốn có các triển khai mới của nó.
In Scala
Trong Scala, chúng tôi sử dụng một phiên bản giản lược của một kỹ thuật được giới thiệu trong một bài báo viết bởi nhà thiết kế Scala, Martin Odersky.
Chúng tôi sẽ tạo một trait, Hình dạng, làm cơ sở cho tất cả các hình dạng của chúng tôi. Chúng tôi sẽ bắt đầu với một phương thức duy nhất, chu vi , và hai triển khai, Hình tròn và Hình chữ nhật.
Để thực hiện phép toán mở rộng của chúng tôi, chúng tôi sẽ sử dụng một số tính năng nâng cao của hệ thống kiểu trong Scala. Đầu tiên, chúng tôi sẽ tận dụng lợi thế của việc có thể sử dụng các trait của Scala như các mô-đun. Ở mỗi bước, chúng tôi sẽ đóng gói mã của mình trong một trait ở cấp cao nhất tách biệt với trait mà chúng tôi đang sử dụng để đại diện cho Hình dạng (Shape).
Điều này cho phép chúng ta gộp các tập hợp kiểu dữ liệu và các thao tác lại với nhau và mở rộng những gói đó sau này bằng cách sử dụng kế thừa kết hợp của Scala. Sau đó, chúng ta có thể có một kiểu mới mở rộng nhiều trait khác nhau, một khả năng mà chúng ta tận dụng để kết hợp các mở rộng độc lập.
Hãy cùng đi sâu vào mã, bắt đầu với trait Shape ban đầu và hai triển khai đầu tiên:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | trait PerimeterShapes { |
| | trait Shape { |
| | def perimeter: Double |
| | } |
| | |
| | class Circle(radius: Double) extends Shape { |
| | def perimeter = 2 * Math.PI * radius |
| | } |
| | |
| | class Rectangle(width: Double, height: Double) extends Shape { |
| | def perimeter = 2 * width + 2 * height |
| | } |
| | } |
Ngoài về trait PerimeterShapes cấp cao nhất, đây là một khai báo khá đơn giản của trait Shape và một vài cài đặt. Để sử dụng mã hình dạng của chúng tôi, chúng ta có thể mở rộng một object bằng trait cấp cao nhất.
Điều này thêm đặc tính Hình dạng và các triển khai của nó vào đối tượng. Bây giờ chúng ta có thể sử dụng chúng trực tiếp hoặc dễ dàng nhập khẩu chúng vào REPL, như chúng ta làm trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | object FirstShapeExample extends PerimeterShapes { |
| | val aCircle = new Circle(4); |
| | val aRectangle = new Rectangle(2, 2); |
| | } |
Bây giờ chúng ta có thể nhập các hình dạng của mình vào REPL và thử nghiệm chúng, giống như trong đoạn mã sau:
| | import com.mblinn.mbfpp.oo.visitor.FirstShapeExample._ |
| | |
| | scala> aCircle.perimeter |
| | res1: Double = 25.132741228718345 |
| | |
| | scala> aRectangle.perimeter |
| | res2: Double = 8.0 |
Mở rộng hình dạng của chúng tôi với các phép toán mới là điều khó khăn trong hầu hết các ngôn ngữ lập trình hoàn toàn hướng đối tượng, vì vậy hãy giải quyết vấn đề đó trước. Để mở rộng tập hợp hình dạng ban đầu của chúng tôi, chúng tôi tạo một trait cấp cao mới gọi là AreaShapes, kế thừa từ PerimeterShapes.
Bên trong AreaShapes, chúng tôi mở rộng lớp Shape ban đầu của chúng tôi để có một phương thức area, và chúng tôi tạo ra một hình Circle mới và một hình Rectangle mới, cái mà thực hiện phương thức area. Mã cho các phần mở rộng của chúng tôi như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | trait AreaShapes extends PerimeterShapes { |
| | trait Shape extends super.Shape { |
| | def area: Double |
| | } |
| | |
| | class Circle(radius: Double) extends super.Circle(radius) with Shape { |
| | def area = Math.PI * radius * radius |
| | } |
| | |
| | class Rectangle(width: Double, height: Double) |
| | extends super.Rectangle(width, height) with Shape { |
| | def area = width * height |
| | } |
| | } |
Hãy cùng xem xét điều này một cách chi tiết hơn. Đầu tiên, chúng ta tạo ra trait cấp cao nhất AreaShapes, mà kế thừa từ PerimeterShapes. Điều này cho phép chúng ta dễ dàng tham chiếu và mở rộng các lớp và trait bên trong AreaShapes:
| | trait AreaShapes extends PerimeterShapes { |
| | area-shapes |
| | } |
Tiếp theo, chúng ta tạo một trait Shape mới bên trong AreaShapes và làm cho nó kế thừa trait cũ bên trong PerimeterShapes.
| | trait Shape extends super.Shape { |
| | def area: Double |
| | } |
Chúng ta cần tham chiếu đến lớp Shape trong PerimeterShapes dưới dạng super.Shape để phân biệt với lớp mà chúng ta vừa tạo trong AreaShapes.
Bây giờ chúng ta đã sẵn sàng để triển khai diện tích của mình. Để làm điều đó, trước tiên chúng ta mở rộng các lớp Hình tròn và Hình chữ nhật cũ của mình, sau đó chúng ta kết hợp vào trait Hình mới của mình, có phương thức diện tích.
Cuối cùng, chúng tôi thực hiện khu vực trên hình Tròn và Chữ nhật mới của chúng tôi, như được hiển thị trong đoạn mã sau:
| | class Circle(radius: Double) extends super.Circle(radius) with Shape { |
| | def area = Math.PI * radius * radius |
| | } |
| | |
| | class Rectangle(width: Double, height: Double) |
| | extends super.Rectangle(width, height) with Shape { |
| | def area = width * height |
| | } |
Bây giờ chúng ta có thể tạo một số hình mẫu và xem cả chu vi và diện tích trong hành động:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | object SecondShapeExample extends AreaShapes { |
| | val someShapes = Vector(new Circle(4), new Rectangle(2, 2)); |
| | } |
| | scala> for(shape <- someShapes) yield shape.perimeter |
| | res0: scala.collection.immutable.Vector[Double] = Vector(25.132741228718345, 8.0) |
| | |
| | scala> for(shape <- someShapes) yield shape.area |
| | res1: scala.collection.immutable.Vector[Double] = Vector(50.26548245743669, 4.0) |
Điều đó đã bao phủ phần khó, mở rộng Shape với một thao tác mới. Giờ hãy xem xét phần dễ hơn. Chúng ta sẽ mở rộng Shape để có một triển khai mới bằng cách tạo ra một lớp Square.
Trong phần đầu tiên của phần mở rộng của chúng tôi, chúng tôi tạo ra đặc tính cấp cao MorePerimeterShapes, mở rộng từ PerimeterShapes gốc. Bên trong, chúng tôi tạo ra một triển khai mới của hình vuông Square từ lớp đặc tính gốc của chúng tôi. Phần đầu tiên của phần mở rộng của chúng tôi nằm trong mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | trait MorePerimeterShapes extends PerimeterShapes { |
| | class Square(side: Double) extends Shape { |
| | def perimeter = 4 * side; |
| | } |
| | } |
Bây giờ chúng ta có thể tạo một đặc tính cấp cao mới khác, MoreAreaShapes, mở rộng từ AreaShapes ban đầu của chúng ta và kết hợp đặc tính MorePerimeterShapes mà chúng ta vừa tạo. Bên trong đặc tính này, chúng ta mở rộng lớp Square mà chúng ta vừa tạo để cũng có một phương thức area:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | trait MoreAreaShapes extends AreaShapes with MorePerimeterShapes { |
| | class Square(side: Double) extends super.Square(side) with Shape { |
| | def area = side * side |
| | } |
| | } |
Bây giờ chúng ta có thể thêm một hình vuông vào các hình thử nghiệm của mình và xem toàn bộ bộ hình dạng và các phép toán trong hành động, như chúng tôi đã làm trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/visitor/Shapes.scala | |
| | object ThirdShapeExample extends MoreAreaShapes { |
| | val someMoreShapes = Vector(new Circle(4), new Rectangle(2, 2), new Square(4)); |
| | } |
| | scala> for(shape <- someMoreShapes) yield shape.perimeter |
| | res2: scala.collection.immutable.Vector[Double] = |
| | Vector(25.132741228718345, 8.0, 16.0) |
| | |
| | scala> for(shape <- someMoreShapes) yield shape.area |
| | res3: scala.collection.immutable.Vector[Double] = |
| | Vector(50.26548245743669, 4.0, 16.0) |
Bây giờ chúng ta đã thành công trong việc thêm cả hai triển khai mới của Shape và các thao tác mới trên nó, và chúng ta đã làm điều đó một cách an toàn về kiểu dữ liệu!
In Clojure
Giải pháp Clojure của chúng tôi dựa vào multimethods, cho phép chúng tôi chỉ định một hàm dispatch tùy ý. Hãy xem xét một ví dụ đơn giản.
Trước tiên, chúng ta tạo ra một multimethod bằng cách sử dụng defmulti. Điều này không chỉ định bất kỳ thực hiện nào của phương thức; thay vào đó, nó chứa một hàm phân phối. Trong đoạn mã sau, chúng ta tạo một multimethod có tên là test-multimethod. Hàm phân phối là một hàm có một tham số, và nó trả về tham số đó không bị thay đổi. Tuy nhiên, nó có thể là một đoạn mã tùy ý.
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defmulti test-multimethod (fn [keyword] keyword)) |
Phương thức đa phương thức được triển khai bằng cách sử dụng defmethod. Việc định nghĩa phương thức giống như định nghĩa hàm, ngoại trừ việc chúng cũng chứa một giá trị phân phối, tương ứng với các giá trị được trả về từ hàm phân phối.
Trong đoạn mã dưới đây, chúng tôi định nghĩa hai triển khai của test-multimethod . Cái đầu tiên mong đợi giá trị phân phối là :foo, và cái thứ hai, :bar.
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defmethod test-multimethod :foo [a-map] |
| | "foo-method was called") |
| | |
| | (defmethod test-multimethod :bar [a-map] |
| | "bar-method was called") |
Khi phương thức đa hình được gọi, hàm dispatch được gọi trước tiên, sau đó Clojure chuyển giao cuộc gọi đến phương thức có giá trị dispatch phù hợp. Vì hàm dispatch của chúng ta trả về đầu vào của nó, chúng ta gọi nó với các giá trị dispatch mong muốn. Đầu ra REPL sau đây minh họa điều này:
| | => (test-multimethod :foo) |
| | "foo-method was called" |
| | => (test-multimethod :bar) |
| | "bar-method was called" |
Bây giờ, khi chúng ta đã thấy một ví dụ cơ bản về đa phương thức trong hành động, hãy đào sâu hơn một chút. Chúng ta sẽ định nghĩa phép toán chu vi của mình như một đa phương thức. Hàm dispatch mong đợi một bản đồ đại diện cho hình dạng của chúng ta. Một trong những khóa trong bản đồ là :shape-name, mà hàm dispatch trích xuất làm giá trị dispatch của chúng ta.
Phương pháp đa hình ở chu vi của chúng tôi được định nghĩa bên dưới, cùng với các triển khai cho hình tròn và hình chữ nhật:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defmulti perimeter (fn [shape] (:shape-name shape))) |
| | (defmethod perimeter :circle [circle] |
| | (* 2 Math/PI (:radius circle))) |
| | (defmethod perimeter :rectangle [rectangle] |
| | (+ (* 2 (:width rectangle)) (* 2 (:height rectangle)))) |
Bây giờ chúng ta có thể định nghĩa một vài hình dạng thử nghiệm:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (def some-shapes [{:shape-name :circle :radius 4} |
| | {:shape-name :rectangle :width 2 :height 2}]) |
Sau đó, chúng ta có thể áp dụng phương pháp chu vi lên chúng:
| | => (for [shape some-shapes] (perimeter shape)) |
| | (25.132741228718345 8) |
Để thêm các thao tác mới, chúng ta tạo một đa phương thức mới xử lý các giá trị phân phối hiện có. Trong đoạn mã dưới đây, chúng ta thêm hỗ trợ cho một thao tác tính diện tích:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defmulti area (fn [shape] (:shape-name shape))) |
| | (defmethod area :circle [circle] |
| | (* Math/PI (:radius circle) (:radius circle))) |
| | (defmethod area :rectangle [rectangle] |
| | (* (:width rectangle) (:height rectangle))) |
Bây giờ chúng ta cũng có thể tính diện tích cho các hình dạng của mình:
| | => (for [shape some-shapes] (area shape)) |
| | (50.26548245743669 4) |
Để thêm một hình dạng mới vào tập hợp các hình mà chúng ta có thể xử lý qua cả phép toán chu vi và diện tích, chúng ta thêm các triển khai mới của các phương thức đa hình mà xử lý các giá trị dispatch thích hợp. Trong mã sau, chúng ta thêm hỗ trợ cho các hình vuông:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (defmethod perimeter :square [square] |
| | (* 4 (:side square))) |
| | (defmethod area :square [square] |
| | (* (:side square) (:side square))) |
Hãy thêm một hình vuông vào vector các hình dạng kiểm tra của chúng ta:
| ClojureExamples/src/mbfpp/oo/visitor/examples.clj | |
| | (def more-shapes (conj some-shapes |
| | {:shape-name :square :side 4})) |
Và chúng tôi có thể xác nhận rằng các phép toán của chúng tôi hoạt động trên các hình vuông cũng vậy:
| | => (for [shape more-shapes] (perimeter shape)) |
| | (25.132741228718345 8 16) |
| | => (for [shape more-shapes] (area shape)) |
| | (50.26548245743669 4 16) |
Chúng ta chỉ mới chạm đến bề mặt của những gì mà đa phương thức (multimethods) có thể làm. Vì chúng ta có thể chỉ định một hàm phân phối tùy ý, nên chúng ta có thể phân phối dựa trên gần như bất kỳ điều gì. Clojure cũng cung cấp một cách để làm cho đa phương thức hoạt động với các hệ thống phân cấp do người dùng định nghĩa, tương tự như các hệ thống phân cấp lớp trong các ngôn ngữ lập trình theo hướng đối tượng. Tuy nhiên, ngay cả việc sử dụng đơn giản của đa phương thức mà chúng ta vừa thấy cũng đủ để thay thế những khía cạnh thú vị của mẫu Visitor.
Discussion
Scala phải đối mặt với một vấn đề khó khăn hơn ở đây, vì nó duy trì tính an toàn kiểu tĩnh trong khi cho phép mở rộng cả đối với các triển khai của một kiểu dữ liệu và các phép toán thực hiện trên đó. Do Clojure có kiểu động, nó không có yêu cầu như vậy.
Các sự thay thế của chúng tôi cho Visitor là một ví dụ tuyệt vời về những đánh đổi giữa một ngôn ngữ kiểu tĩnh biểu cảm như Scala và một ngôn ngữ kiểu động như Clojure. Chúng tôi phải bỏ ra nhiều công sức hơn trong Scala, và các giải pháp của chúng tôi không đơn giản như những giải pháp trong Clojure. Tuy nhiên, nếu chúng tôi cố gắng thực hiện một số thao tác trên một kiểu mà Clojure không thể xử lý, đó sẽ là một vấn đề tại thời điểm chạy thay vì tại thời điểm biên dịch.
For Further Reading
Mô hình thiết kế: Các yếu tố của phần mềm hướng đối tượng có thể tái sử dụng [GHJV95]—Khách thăm
Related Patterns
Mẫu 9, Thay thế Decorator
| Pattern 11 | Replacing Dependency Injection |
Intent
Để kết hợp các đối tượng với nhau bằng cách sử dụng cấu hình hoặc mã bên ngoài, thay vì để một đối tượng tự khởi tạo các phụ thuộc của nó - điều này cho phép chúng ta dễ dàng chèn các triển khai phụ thuộc khác nhau vào một đối tượng và cung cấp một nơi tập trung để hiểu rõ những phụ thuộc mà một đối tượng cụ thể có.
Overview
Đối tượng là đơn vị chính của thành phần trong thế giới lập trình hướng đối tượng. Tiêm phụ thuộc (Dependency Injection) là về việc kết hợp các đồ thị đối tượng với nhau. Ở dạng đơn giản nhất, điều liên quan trong Tiêm phụ thuộc chỉ là tiêm các phụ thuộc của một đối tượng thông qua một hàm khởi tạo hoặc phương thức thiết lập.
Ví dụ, lớp dưới đây phác thảo một dịch vụ phim có khả năng trả về danh sách phim yêu thích của người dùng. Nó phụ thuộc vào một dịch vụ yêu thích để lấy về danh sách các bộ phim yêu thích và một DAO phim để lấy thông tin chi tiết về từng bộ phim:
| JavaExamples/src/main/java/com/mblinn/mbfpp/oo/di/MovieService.java | |
| | package com.mblinn.mbfpp.oo.di; |
| | public class MovieService { |
| | |
| | private MovieDao movieDao; |
| | private FavoritesService favoritesService; |
| | public MovieService(MovieDao movieDao, FavoritesService favoritesService){ |
| | this.movieDao = movieDao; |
| | this.favoritesService = favoritesService; |
| | } |
| | } |
Ở đây, chúng tôi đang sử dụng việc tiêm phụ thuộc dựa trên hàm tạo, kiểu cổ điển. Khi được tạo, lớp MovieService cần phải có các phụ thuộc được truyền vào. Điều này có thể được thực hiện thủ công, nhưng thường thì nó được thực hiện bằng cách sử dụng một framework tiêm phụ thuộc.
Tiêm phụ thuộc có nhiều lợi ích. Nó giúp dễ dàng thay đổi triển khai cho một phụ thuộc nhất định, điều này đặc biệt hữu ích khi thay thế một phụ thuộc thực sự bằng một stub trong một bài kiểm tra đơn vị.
Với sự hỗ trợ của các container thích hợp, việc tiêm phụ thuộc cũng có thể giúp dễ dàng xác định một cách khai báo hình dạng tổng thể của hệ thống, khi mà mỗi thành phần có các phụ thuộc của nó được tiêm vào thông qua một tệp cấu hình hoặc một đoạn mã cấu hình.
Functional Replacement
Cần ít hơn một mẫu giống như Tiêm Phụ Thuộc khi lập trình theo phong cách lập trình hàm. Lập trình hàm một cách tự nhiên liên quan đến việc kết hợp các hàm, như chúng ta đã thấy trong các mẫu như Mẫu 16, Người xây dựng hàm. Vì việc này liên quan đến việc kết hợp các hàm tương tự như việc Tiêm Phụ Thuộc kết hợp các lớp, chúng ta nhận được một số lợi ích mà không cần nỗ lực nhiều chỉ từ việc kết hợp hàm.
Tuy nhiên, việc kết hợp hàm đơn giản không giải quyết tất cả các vấn đề mà Dependency Injection làm. Điều này đặc biệt đúng trong Scala vì đây là một ngôn ngữ lai, và các khối mã lớn thường được tổ chức thành các đối tượng.
In Scala
Tiêm phụ thuộc cổ điển có thể được sử dụng trong Scala. Chúng ta thậm chí có thể sử dụng các framework Java quen thuộc như Spring hoặc Guice. Tuy nhiên, chúng ta có thể đạt được nhiều mục tiêu tương tự mà không cần đến bất kỳ framework nào.
Chúng ta sẽ xem xét một mẫu Scala gọi là mẫu Cake. Mẫu này sử dụng các trait của Scala và chú thích self-type để đạt được loại kết hợp và cấu trúc tương tự như chúng ta có được với Tiêm phụ thuộc mà không cần đến một container.
In Clojure
Đơn vị tiêm trong Clojure là hàm, vì Clojure không theo hướng đối tượng. Hầu hết, điều này có nghĩa là những vấn đề mà chúng ta giải quyết bằng Dependency Injection trong một ngôn ngữ hướng đối tượng không tồn tại trong Clojure, vì chúng ta có thể hợp nhất các hàm với nhau một cách tự nhiên.
Tuy nhiên, một ứng dụng của Dependency Injection cần một chút điều chỉnh đặc biệt trong Clojure. Để thay thế các hàm cho mục đích kiểm thử, chúng ta có thể sử dụng một macro có tên là with-redfs, cho phép chúng ta tạm thời thay thế một hàm bằng một stub.
Sample Code: Favorite Videos
Hãy cùng xem xét kỹ hơn về phác thảo của một vấn đề mà chúng ta đã thấy trong phần Tổng quan. Ở đó, chúng ta đã tạo ra một dịch vụ phim cho phép thực hiện nhiều hành động liên quan đến phim. Mỗi video đều liên quan đến một bộ phim và cần được trang trí với các chi tiết liên quan đến bộ phim đó, chẳng hạn như tiêu đề của bộ phim.
Để thực hiện điều này, chúng tôi có một dịch vụ phim cấp cao phụ thuộc vào DAO phim để lấy thông tin chi tiết về phim và vào dịch vụ yêu thích để lấy danh sách yêu thích cho một người dùng nhất định.
Classic Java
Trong Java, dịch vụ cấp cao nhất của chúng tôi MovieService được phác thảo trong lớp sau đây. Chúng tôi sử dụng Tiêm Phụ Thuộc để tiêm một FavoritesService và một MovieDao thông qua một hàm khởi tạo:
| JavaExamples/src/main/java/com/mblinn/mbfpp/oo/di/MovieService.java | |
| | package com.mblinn.mbfpp.oo.di; |
| | public class MovieService { |
| | |
| | private MovieDao movieDao; |
| | private FavoritesService favoritesService; |
| | public MovieService(MovieDao movieDao, FavoritesService favoritesService){ |
| | this.movieDao = movieDao; |
| | this.favoritesService = favoritesService; |
| | } |
| | } |
Trong một chương trình đầy đủ, chúng tôi sẽ sử dụng một khung để kết nối các phụ thuộc của MovieService. Chúng tôi có khá nhiều cách để làm điều này, từ các file cấu hình XML đến các lớp cấu hình Java và các chú thích tự động kết nối các phụ thuộc.
Tất cả những điều này có một đặc điểm chung: chúng cần một khung bên ngoài để hiệu quả. Ở đây, chúng ta sẽ xem xét các tùy chọn Scala và Clojure không có sự hạn chế như vậy.
In Scala
Bây giờ, chúng ta sẽ xem xét một ví dụ về mẫu bánh (Cake pattern) trong Scala. Ý tưởng chính là chúng ta sẽ bao bọc các phụ thuộc mà chúng ta muốn tiêm bên trong các trait cấp cao, đại diện cho các thành phần có thể tiêm của chúng ta. Thay vì khởi tạo các phụ thuộc trực tiếp bên trong trait, chúng ta tạo ra các giá trị trừu tượng (abstract val) sẽ giữ các tham chiếu đến chúng khi chúng ta kết nối mọi thứ lại với nhau.
Chúng tôi sẽ sử dụng chú thích kiểu tự của Scala và kế thừa mixin để chỉ định cách kết nối một cách an toàn về kiểu. Cuối cùng, chúng tôi sử dụng một đối tượng Scala đơn giản làm bản đăng ký thành phần. Chúng tôi kết hợp tất cả các phụ thuộc của mình vào đối tượng container và khởi tạo chúng, giữ các tham chiếu đến chúng trong các giá trị trừu tượng val đã đề cập trước đó.
Cách tiếp cận này có một số đặc điểm tốt. Như chúng tôi đã đề cập trước đó, nó không yêu cầu một container bên ngoài để sử dụng. Thêm vào đó, việc kết nối các thành phần giữ được tính an toàn kiểu tĩnh.
Hãy bắt đầu với cái nhìn về dữ liệu mà chúng ta sẽ làm việc. Chúng ta có ba lớp trường hợp: một Bộ phim, một Video và một Bộ phim trang trí, đại diện cho một bộ phim được trang trí với một video về nó.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | case class Movie(movieId: String, title: String) |
| | case class Video(movieId: String) |
| | case class DecoratedMovie(movie: Movie, video: Video) |
Bây giờ, hãy định nghĩa một số đặc điểm dưới dạng giao diện cho các phụ thuộc của chúng ta, FavoritesService và MovieDao. Chúng ta sẽ nhúng những đặc điểm này trong một tập hợp khác của các đặc điểm đại diện cho các thành phần có thể tiêm. Chúng ta sẽ thấy lý do tại sao điều này là cần thiết trong ví dụ sau.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | trait MovieDaoComponent { |
| | trait MovieDao { |
| | def getMovie(id: String): Movie |
| | } |
| | } |
| | |
| | trait FavoritesServiceComponent { |
| | trait FavoritesService { |
| | def getFavoriteVideos(id: String): Vector[Video] |
| | } |
| | } |
Tiếp theo, chúng ta sẽ thực hiện các thành phần đã được giới thiệu trước đó. Ở đây, chúng ta sẽ định nghĩa tạm thời MovieDao và FavoritesService để trả về các phản hồi tĩnh bằng cách thực hiện các giao diện. Lưu ý rằng chúng ta cũng cần mở rộng các đặc điểm của thành phần mà chúng ta đã bọc lại.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | trait MovieDaoComponentImpl extends MovieDaoComponent { |
| | class MovieDaoImpl extends MovieDao { |
| | def getMovie(id: String): Movie = new Movie("42", "A Movie") |
| | } |
| | } |
| | |
| | trait FavoritesServiceComponentImpl extends FavoritesServiceComponent { |
| | class FavoritesServiceImpl extends FavoritesService { |
| | def getFavoriteVideos(id: String): Vector[Video] = Vector(new Video("1")) |
| | } |
| | } |
Bây giờ hãy xem xét lớp MovieServiceImpl, phụ thuộc vào FavoritesService và MovieDao đã được định nghĩa trước đó. Lớp này triển khai một phương thức duy nhất, getFavoriteDecoratedMovies, nhận một ID người dùng và trả về các bộ phim yêu thích của người đó được trang trí bằng một video của bộ phim đó.
Mã đầy đủ cho MovieServiceImpl, được bao bọc trong một đặc điểm MovieServiceComponentImpl cấp cao, như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | trait MovieServiceComponentImpl { |
| | this: MovieDaoComponent with FavoritesServiceComponent => |
| | |
| | val favoritesService: FavoritesService |
| | val movieDao: MovieDao |
| | |
| | class MovieServiceImpl { |
| | def getFavoriteDecoratedMovies(userId: String): Vector[DecoratedMovie] = |
| | for ( |
| | favoriteVideo <- favoritesService.getFavoriteVideos(userId); |
| | val movie = movieDao.getMovie(favoriteVideo.movieId) |
| | ) yield DecoratedMovie(movie, favoriteVideo) |
| | } |
| | } |
Hãy xem xét kỹ lưỡng từng phần này. Đầu tiên, chúng ta có chú thích kiểu tự trên trait MovieServiceComponentImpl. Đây là một phần của phép thuật Scala giúp mẫu Cake trở nên an toàn về kiểu.
| | this: MovieDaoComponent with FavoritesServiceComponent => |
Chú thích kiểu tự đảm bảo rằng mỗi khi `MovieServiceComponentImpl` được kết hợp vào một đối tượng hoặc lớp, tham chiếu này của đối tượng đó có kiểu `MovieDaoComponent` với `FavoritesServiceComponent`. Nói cách khác, nó đảm bảo rằng khi `MovieServiceComponentImpl` được kết hợp vào một thứ gì đó, `MovieDaoComponent` và `FavoritesServiceComponent` hoặc một trong những kiểu con của chúng cũng được kết hợp.
Tiếp theo là các biến rõ ràng mà chúng tôi sẽ lưu trữ tham chiếu đến các phụ thuộc của chúng tôi:
| | val favoritesService: FavoritesService |
| | val movieDao: MovieDao |
Điều này đảm bảo rằng khi chúng ta kết hợp MovieServiceComponentImpl vào đối tượng container của mình, chúng ta sẽ cần gán cho các giá trị trừu tượng val.
Cuối cùng, chúng ta có đối tượng phục vụ như một bảng đăng ký thành phần, ComponentRegistry. Bảng đăng ký mở rộng các triển khai của tất cả các phụ thuộc của chúng ta và khởi tạo chúng, lưu giữ tham chiếu đến chúng trong các biến trừu tượng val mà chúng ta đã định nghĩa trước đó:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | object ComponentRegistry extends MovieServiceComponentImpl |
| | with FavoritesServiceComponentImpl with MovieDaoComponentImpl { |
| | val favoritesService = new FavoritesServiceImpl |
| | val movieDao = new MovieDaoImpl |
| | |
| | val movieService = new MovieServiceImpl |
| | } |
Bây giờ chúng ta có thể lấy một dịch vụ MovieService đầy đủ từ registry khi cần thiết:
| | scala> val movieService = ComponentRegistry.movieService |
| | movieService: ... |
Trước đây, tôi đã khẳng định rằng việc này giữ an toàn kiểu tĩnh. Hãy cùng khám phá điều này một cách chi tiết hơn. Trước tiên, hãy xem điều gì xảy ra nếu chúng tôi chỉ mở rộng MovieServiceComponentImpl chính nó trongregistry đối tượng của chúng tôi, như trong phác thảo mã sau:
| | object BrokenComponentRegistry extends MovieServiceComponentImpl { |
| | |
| | } |
Điều này gây ra lỗi biên dịch, điều gì đó giống như sau:
di sản trái phép; kiểu tự com.mblinn.mbfpp.oo.di.ex1.Example.BrokenComponentRegistry.type không tuân thủ kiểu tự của com.mblinn.mbfpp.oo.di.ex1.Example.MovieServiceComponentImpl...
Ở đây, trình biên dịch cho chúng ta biết rằng BrokenComponentRegistry không tuân theo kiểu tự định nghĩa mà chúng ta đã khai báo cho MovieServiceComponentImpl, vì chúng ta cũng không kết hợp MovieDaoComponent và FavoritesServiceComponent.
Chúng ta có thể khắc phục lỗi đó bằng cách mở rộng FavoritesServiceComponentImpl và MovieDaoComponentImpl, như chúng ta làm trong đoạn mã sau:
| | object BrokenComponentRegistry extends MovieServiceComponentImpl |
| | with FavoritesServiceComponentImpl with MovieDaoComponentImpl { |
| | |
| | } |
Tuy nhiên, điều này sẽ khiến chúng ta gặp phải một lỗi biên dịch khác, bắt đầu như sau:
Tạo đối tượng không thể thực hiện, vì: nó có 2 thành viên chưa được triển khai...
Lỗi này nói rằng chúng tôi chưa triển khai các thành viên favoritesService và movieDao mà MovieServiceComponentImpl yêu cầu.
In Clojure
Clojure không có một tương đương trực tiếp với Tiêm phụ thuộc (Dependency Injection). Thay vào đó, chúng ta truyền các hàm trực tiếp vào các hàm khác khi cần thiết. Ví dụ, ở đây chúng ta khai báo các hàm get-movie và get-favorite-videos.
| ClojureExamples/src/mbfpp/functional/di/examples.clj | |
| | (defn get-movie [movie-id] |
| | {:id "42" :title "A Movie"}) |
| | |
| | (defn get-favorite-videos [user-id] |
| | [{:id "1"}]) |
Ở đây, chúng tôi truyền chúng vào get-favorite-decorated-videos nơi chúng được sử dụng:
| ClojureExamples/src/mbfpp/functional/di/examples.clj | |
| | (defn get-favorite-decorated-videos [user-id get-movie get-favorite-videos] |
| | (for [video (get-favorite-videos user-id)] |
| | {:movie (get-movie (:id video)) |
| | :video video})) |
Một khả năng khác là sử dụng Mẫu 16, Trình xây dựng chức năng, để đóng gói các chức năng phụ thuộc trong một đóng gói.
Tuy nhiên, trong Clojure, chúng tôi thường chỉ thực hiện kiểu tiêm trực tiếp này khi chúng tôi muốn người sử dụng hàm có quyền kiểm soát đối với các phụ thuộc được truyền vào. Chúng tôi không cần điều này để xác định hình dạng tổng thể của các chương trình của mình.
Thay vào đó, các chương trình trong Clojure và các ngôn ngữ Lisp khác thường được tổ chức dưới dạng một loạt các ngôn ngữ chuyên biệt theo miền. Chúng ta sẽ thấy một ví dụ về điều này ở Mô hình 21, Ngôn ngữ Chuyên biệt theo Miền.
Sample Code: Test Stubs
Trong khi Dependency Injection chủ yếu liên quan đến việc tổ chức chương trình nói chung, một lĩnh vực cụ thể mà nó đặc biệt hữu ích là tiêm các phụ thuộc giả mạo vào các bài kiểm tra.
Classic Java
Trong Java, chúng ta có thể chỉ cần lấy dịch vụ MovieService của mình và tiêm các stub hoặc mock một cách thủ công vào nó bằng cách sử dụng tiêm qua constructor. Một lựa chọn khác là sử dụng container tiêm phụ thuộc để khởi tạo một tập hợp các phụ thuộc kiểm tra.
Cách tiếp cận tốt nhất phụ thuộc vào loại bài kiểm tra mà chúng ta đang viết. Đối với các bài kiểm tra đơn vị, thường thì đơn giản hơn để chỉ cần tiêm từng mô phỏng một cách thủ công. Đối với các bài kiểm tra kiểu tích hợp lớn hơn, tôi thích sử dụng phương pháp toàn bộ container.
In Scala
Với mẫu Cake của Scala, chúng ta có thể dễ dàng tạo ra các phiên bản giả của các phụ thuộc của mình. Chúng ta thực hiện điều đó trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | trait MovieDaoComponentTestImpl extends MovieDaoComponent { |
| | class MovieDaoTestImpl extends MovieDao { |
| | def getMovie(id: String): Movie = new Movie("43", "A Test Movie") |
| | } |
| | } |
| | |
| | trait FavoritesServiceComponentTestImpl extends FavoritesServiceComponent { |
| | class FavoritesServiceTestImpl extends FavoritesService { |
| | def getFavoriteVideos(id: String): Vector[Video] = Vector(new Video("2")) |
| | } |
| | } |
Bây giờ chúng ta chỉ cần trộn và khởi tạo các thành phần giả thay vì các thành phần thực, và sau đó dịch vụ phim thử nghiệm của chúng ta đã sẵn sàng để sử dụng.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/oo/di/ex1/Services.scala | |
| | object TestComponentRegistery extends MovieServiceComponentImpl |
| | with FavoritesServiceComponentTestImpl with MovieDaoComponentTestImpl { |
| | val favoritesService = new FavoritesServiceTestImpl |
| | val movieDao = new MovieDaoTestImpl |
| | |
| | val movieService = new MovieServiceImpl |
| | } |
In Clojure
Với mã Clojure ví dụ của chúng tôi được viết như trong ví dụ trước, chúng tôi chỉ cần tạo các phiên bản kiểm thử của các hàm phụ thuộc và truyền chúng vào get-favorite-decorated-videos. Chúng tôi minh họa điều này trong đoạn mã sau:
| ClojureExamples/src/mbfpp/functional/di/examples.clj | |
| | (defn get-test-movie [movie-id] |
| | {:id "43" :title "A Test Movie"}) |
| | |
| | (defn get-test-favorite-videos [user-id] |
| | [{:id "2"}]) |
| | => (get-favorite-decorated-videos "2" get-test-movie get-test-favorite-videos) |
| | ({:movie {:title "A Test Movie", :id "43"}, :video {:id "2"}}) |
Tuy nhiên, vì chúng ta không luôn cấu trúc toàn bộ chương trình Clojure bằng cách truyền vào mọi phụ thuộc dưới dạng hàm bậc cao, nên chúng ta thường cần một phương pháp thay thế để giả lập các phụ thuộc trong bài kiểm tra. Hãy xem một phiên bản khác của get-favorite-decorated-videos mà phụ thuộc vào các phụ thuộc của nó trực tiếp, thay vì phải truyền chúng vào.
| ClojureExamples/src/mbfpp/functional/di/examples.clj | |
| | (defn get-favorite-decorated-videos-2 [user-id] |
| | (for [video (get-favorite-videos user-id)] |
| | {:movie (get-movie (:id video)) |
| | :video video})) |
Nếu chúng ta gọi get-favorite-decorated-videos-2, nó sẽ sử dụng các phụ thuộc đã được mã hóa cứng:
| | => (get-favorite-decorated-videos-2 "1") |
| | ({:movie {:title "A Movie", :id "42"}, :video {:id "1"}}) |
Chúng ta có thể sử dụng `with-redefs` để tạm thời định nghĩa lại các phụ thuộc đó, như chúng ta thể hiện dưới đây:
| | => (with-redefs |
| | [get-favorite-videos get-test-favorite-videos |
| | get-movie get-test-movie] |
| | (doall (get-favorite-decorated-videos-2 "2"))) |
| | ({:movie {:title "A Test Movie", :id "43"}, :video {:id "2"}}) |
Lưu ý rằng chúng ta đã bọc cuộc gọi đến get-favorite-decorated-videos-2 trong một cuộc gọi đến doall. Hình thức doall buộc chuỗi lười biếng được tạo ra bởi get-favorite-decorated-videos-2 phải được hiện thực hóa.
Chúng ta cần sử dụng nó ở đây vì sự lười biếng và `with-redefs` có một tương tác tinh tế có thể gây nhầm lẫn. Nếu không buộc chuỗi được hiện thực hóa, nó sẽ không được hiện thực hóa hoàn toàn cho đến khi REPL cố gắng in nó. Lúc đó, các liên kết hàm đã rebound sẽ quay trở lại các liên kết gốc của chúng.
`with-redefs` của Clojure là một công cụ khá thô. Như bạn có thể đoán, việc thay thế định nghĩa hàm ngay lập tức có thể rất nguy hiểm, vì vậy điều này tốt nhất chỉ nên được sử dụng cho mã kiểm thử.
Related Patterns
Mẫu 16, Trình tạo chức năng
Mẫu 21, Ngôn ngữ miền cụ thể
Footnotes
| [2] | Tôi không thể truy cập nội dung từ liên kết mà bạn đã cung cấp. Tuy nhiên, nếu bạn có một đoạn văn cần dịch, xin vui lòng sao chép và dán ở đây. Tôi sẽ rất vui lòng giúp bạn dịch nó sang tiếng Việt. |
| [3] | Xin chào, tôi không thể truy cập vào liên kết mà bạn cung cấp. Tuy nhiên, nếu bạn có đoạn văn bản cụ thể cần dịch, hãy chia sẻ với tôi và tôi sẽ giúp bạn dịch sang tiếng Việt. |
| [4] | https://code.google.com/p/scalaz/ |
| [5] | Tài liệu này mô tả giao diện `Iterator` trong Java. Giao diện `Iterator` cho phép duyệt qua các phần tử trong một tập hợp mà không cần phải tiết lộ cách thức tổ chức của tập hợp đó. Dưới đây là các thành phần chính mà tài liệu này đề cập: 1. **Tổng quan**: - `Iterator` là một thành phần quan trọng trong Java Collections Framework, cho phép lặp qua các tập hợp như danh sách, tập hợp, và mảng. 2. **Phương thức chính**: - `boolean hasNext()`: Kiểm tra xem có còn phần tử tiếp theo không. - `E next()`: Trả về phần tử tiếp theo trong tập hợp. - `void remove()`: Xóa phần tử gần nhất được trả về bởi phương thức `next()`. 3. **Sử dụng**: - Giao diện này thường được sử dụng trong vòng lặp để duyệt qua các tập hợp mà không cần biết chi tiết về cấu trúc dữ liệu bên trong. 4. **Lưu ý**: - Phương thức `remove()` chỉ có thể được gọi một lần sau mỗi lần gọi `next()` và sẽ ném ra `IllegalStateException` nếu không được gọi đúng cách. Giao diện `Iterator` rất hữu ích cho việc thao tác với các cấu trúc dữ liệu và giúp mã trở lên rõ ràng và dễ hiểu hơn. |
Chapter 4
Functional Patterns
4.1 Introduction
Lập trình hàm có những mẫu riêng đã phát triển từ phong cách hàm.
Những mẫu này phụ thuộc nhiều vào tính bất biến. Ví dụ, Mẫu 12, Đệ quy đuôi, cho thấy một thay thế đa mục đích cho vòng lặp mà không phụ thuộc vào một biến đếm có thể thay đổi, trong khi Mẫu 15, Chuỗi các phép toán, cho thấy cách làm việc với dữ liệu bất biến bằng cách nối các phép biến đổi trên một cấu trúc dữ liệu bất biến.
Một chủ đề khác trong những mô hình này là việc sử dụng các hàm bậc cao như một đơn vị chính để kết hợp. Điều này khá ăn khớp với chủ đề đầu tiên, tính bất biến và sự biến đổi của dữ liệu bất biến. Bằng cách sử dụng các hàm bậc cao, chúng ta có thể dễ dàng thực hiện những biến đổi này, như chúng tôi đã minh họa trong Mô hình 14, Lọc-Ánh xạ-Giảm.
Một chủ đề cuối cùng mà chúng ta sẽ khám phá là khả năng của các ngôn ngữ hàm được điều chỉnh để tạo ra các ngôn ngữ nhỏ giải quyết các vấn đề cụ thể. Loại lập trình này đã lan rộng ra ngoài phong cách hàm, nhưng nó bắt đầu từ truyền thống Lisp mà Clojure tiếp nối. Chúng ta sẽ thấy điều này trong Mẫu 12, Đệ quy đuôi, và Mẫu 21, Ngôn ngữ chuyên biệt cho miền.
Hãy xem xét mẫu đầu tiên của chúng ta, Đệ quy cuối.
| Pattern 12 | Tail Recursion |
Intent
Để lặp lại một phép tính mà không sử dụng trạng thái thay đổi và không tràn ngăn xếp.
Overview
Lặp là một kỹ thuật cần thiết yêu cầu trạng thái có thể thay đổi. Ví dụ, hãy xem xét một vấn đề đơn giản, viết một hàm sẽ tính tổng từ một đến một số tùy ý, bao gồm cả số đó. Đoạn mã bên dưới thực hiện chính xác điều đó, nhưng nó yêu cầu cả i và sum phải có thể thay đổi.
| JavaExamples/src/main/java/com/mblinn/functional/tailrecursion/Sum.java | |
| | public static int sum(int upTo) { |
| | int sum = 0; |
| | for (int i = 0; i <= upTo; i++) |
| | sum += i; |
| | return sum; |
| | } |
Vì thế giới hàm nhấn mạnh tính bất biến, vòng lặp không được sử dụng. Thay vào đó, chúng ta có thể sử dụng đệ quy, không yêu cầu tính bất biến. Tuy nhiên, đệ quy cũng có những vấn đề của nó; đặc biệt, mỗi lần gọi đệ quy sẽ dẫn đến một khung khác trên ngăn xếp gọi của chương trình.
Để khắc phục điều đó, chúng ta có thể sử dụng một dạng đệ quy đặc biệt gọi là đệ quy đuôi, có thể được tối ưu hóa để sử dụng một khung duy nhất trên ngăn xếp, một quá trình được gọi là tối ưu hóa gọi đuôi hoặc TCO.
Hãy suy nghĩ về cách chúng ta sẽ viết hàm tổng như một hàm đệ quy, sumRecursive. Đầu tiên, chúng ta cần quyết định khi nào đệ quy của chúng ta phải dừng lại và bắt đầu. Vì chúng ta đang cộng tất cả các số lại với nhau cho đến một số tùy ý nào đó, nên thật hợp lý khi làm việc từ số đó và dừng lại ở số không. Điểm dừng này được gọi là trường hợp cơ sở của chúng ta.
Tiếp theo, chúng ta cần xác định những gì cần làm để thực hiện phép tính thực tế. Trong trường hợp này, chúng ta lấy số mà chúng ta đang làm việc và cộng nó với kết quả của việc gọi tailRecursive với số đó trừ đi một. Cuối cùng, chúng ta giảm xuống trường hợp cơ bản của số không, tại thời điểm đó, ngăn xếp sẽ giải phóng, trả về các tổng từng phần khi nó đi qua, cho đến khi nó quay trở lại đỉnh và trả về tổng cuối cùng. Đoạn mã bên dưới minh họa giải pháp này:
| JavaExamples/src/main/java/com/mblinn/functional/tailrecursion/Sum.java | |
| | public static int sumRecursive(int upTo) { |
| | if (upTo == 0) |
| | return 0; |
| | else |
| | return upTo + sumRecursive(upTo - 1); |
| | } |
Tuy nhiên, có một vấn đề với điều này. Mỗi cuộc gọi đệ quy thêm một khung vào ngăn xếp, điều này có nghĩa là giải pháp này chiếm bộ nhớ tương ứng với kích thước của dãy số mà chúng ta đang cộng, như được chỉ ra trong hình dưới đây.
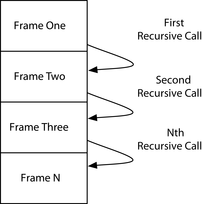
Figure 10. Simple Stack. An illustration of the stack during normal recursive calls—each recursive call adds a call to the stack; these frames represent memory that cannot be reclaimed until after the recursion is done.
Rõ ràng là điều này không thực tế, nhưng chúng ta có thể làm tốt hơn. Nguyên nhân chính dẫn đến việc sử dụng ngăn xếp tăng cao là mỗi lần chúng ta thực hiện một cuộc gọi đệ quy, chúng ta cần kết quả của cuộc gọi đó để hoàn thành phép toán mà chúng ta đang thực hiện trong cuộc gọi hiện tại. Điều này có nghĩa là runtime không có lựa chọn nào khác ngoài việc lưu trữ các kết quả trung gian trên ngăn xếp.
Nếu chúng ta đảm bảo rằng lời gọi đệ quy là điều cuối cùng xảy ra trong mỗi nhánh của hàm, được gọi là vị trí đuôi, thì điều này sẽ không còn đúng nữa. Việc này yêu cầu chúng ta phải truyền các giá trị trung gian đã được lưu trữ trên ngăn xếp qua chuỗi các lời gọi. Mã dưới đây minh họa điều này:
| JavaExamples/src/main/java/com/mblinn/functional/tailrecursion/Sum.java | |
| | public static int sumTailRecursive(int upTo, int currentSum) { |
| | if (upTo == 0) |
| | return currentSum; |
| | else |
| | return sumTailRecursive(upTo - 1, currentSum + upTo); |
| | } |
Khi chúng ta viết lại hàm để trở thành đệ quy đuôi, có thể sử dụng TCO để chạy nó trong chỉ một khung ngăn xếp, như được thể hiện trong hình này.
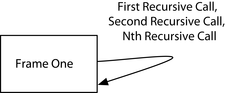
Figure 11. Stack with TCO. With TCO, recursive calls in the tail position don’t generate a new stack frame. Instead, each call uses the existing stack frame, removing whatever data was there from the previous call.
Rất tiếc, JVM không hỗ trợ TCO trực tiếp, vì vậy Scala và Clojure cần sử dụng một số mẹo để biên dịch các cuộc gọi đệ quy đuôi xuống cùng một mã byte được dùng cho lặp. Trong trường hợp của Clojure, điều này được thực hiện bằng cách cung cấp hai dạng đặc biệt, loop và recur, thay vì sử dụng các cuộc gọi hàm chung.
Trong trường hợp của Scala, trình biên dịch Scala sẽ cố gắng dịch các lời gọi đệ quy đuôi thành vòng lặp ẩn sau, và Scala cung cấp một chú thích, @tailrec, có thể được đặt trên các hàm dự kiến sẽ được sử dụng theo cách đệ quy đuôi. Nếu hàm được gọi đệ quy mà không ở vị trí đuôi, trình biên dịch sẽ tạo ra một lỗi.
Code Sample: Recursive People
Hãy cùng xem xét một giải pháp đệ quy cho một bài toán đơn giản. Chúng ta có một chuỗi các tên và một chuỗi các họ, và chúng ta muốn kết hợp chúng lại để tạo thành những người. Để giải quyết điều này, chúng ta cần đi qua cả hai chuỗi đồng bộ. Chúng ta sẽ giả định rằng một phần khác của chương trình đã xác minh rằng hai chuỗi có cùng kích thước.
Tại mỗi bước trong quá trình đệ quy, chúng ta sẽ lấy phần tử đầu tiên trong cả hai chuỗi và ghép chúng lại để tạo thành một tên đầy đủ. Sau đó, chúng ta sẽ truyền phần còn lại của mỗi chuỗi vào cuộc gọi đệ quy tiếp theo cùng với một chuỗi những người mà chúng ta đã tạo ra cho đến nay. Hãy xem nó trông như thế nào trong Scala.
In Scala
Điều đầu tiên chúng ta cần là một lớp case trong Scala để đại diện cho những người của chúng ta. Ở đây chúng ta có một lớp với tên và họ.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/tr/Names.scala | |
| | case class Person(firstNames: String, lastNames: String) |
Tiếp theo là hàm đệ quy của chúng ta. Thật ra, nó được chia thành hai hàm. Hàm đầu tiên có tên là makePeople, nhận vào hai dãy, firstNames và lastNames. Hàm thứ hai là một hàm trợ giúp nằm bên trong makePeople, bổ sung một tham số thêm để truyền danh sách người qua các cuộc gọi đệ quy. Hãy xem xét toàn bộ hàm trước khi chúng ta chia nhỏ nó thành các phần nhỏ hơn:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/tr/Names.scala | |
| | def makePeople(firstNames: Seq[String], lastNames: Seq[String]) = { |
| | @tailrec |
| | def helper(firstNames: Seq[String], lastNames: Seq[String], |
| | people: Vector[Person]): Seq[Person] = |
| | if (firstNames.isEmpty) |
| | people |
| | else { |
| | val newPerson = Person(firstNames.head, lastNames.head) |
| | helper(firstNames.tail, lastNames.tail, people :+ newPerson) |
| | } |
| | helper(firstNames, lastNames, Vector[Person]()) |
| | } |
Đầu tiên, hãy xem xét chữ ký của hàm makePeople:
| | def makePeople(firstNames: Seq[String], lastNames: Seq[String]) = { |
| | function-body |
| | } |
Điều này có nghĩa là `makePeople` nhận hai `Seq` của `String`. Vì chúng ta không chỉ định kiểu trả về, trình biên dịch sẽ suy luận từ phần thân hàm.
Tiếp theo, hãy xem xét chữ ký của hàm helper. Hàm này chịu trách nhiệm cho các lời gọi đệ quy đuôi thực tế. Hàm helper được chú thích bằng anotasi @tailrec, điều này sẽ khiến trình biên dịch tạo ra lỗi nếu nó được gọi đệ quy nhưng không phải đệ quy đuôi. Chữ ký hàm chỉ thêm một đối số bổ sung, vector people, để tích lũy kết quả thông qua các lời gọi đệ quy.
Lưu ý rằng chúng tôi đã chỉ định một kiểu trả về ở đây, mặc dù chúng tôi thường bỏ qua điều này trong các ví dụ Scala của mình. Điều này là vì trình biên dịch không thể suy luận kiểu cho các hàm được gọi đệ quy.
| | def helper(firstNames: Seq[String], lastNames: Seq[String], |
| | people: Vector[Person]): Seq[Person] = |
| | function-body |
Bây giờ là phần thân của hàm trợ giúp. Nếu chuỗi firstNames rỗng, chúng ta sẽ trả về danh sách người mà chúng ta đã xây dựng. Ngược lại, chúng ta sẽ chọn tên đầu tiên và họ đầu tiên từ các chuỗi tương ứng của chúng, tạo ra một Person từ chúng, và gọi lại hàm trợ giúp với phần còn lại của hai chuỗi và người mới được thêm vào danh sách người:
| | if (firstNames.isEmpty) |
| | people |
| | else { |
| | val newPerson = Person(firstNames.head, lastNames.head) |
| | helper(firstNames.tail, lastNames.tail, people :+ newPerson) |
| | } |
Cuối cùng, chúng tôi chỉ cần gọi helper với các chuỗi tên và một Vector rỗng để chứa những người của chúng tôi:
| | helper(firstNames, lastNames, Vector[Person]()) |
Một ghi chú cuối về cú pháp: việc sử dụng một số tính năng lập trình hướng đối tượng của Scala, cụ thể là các phương thức, sẽ giúp chúng ta giảm bớt sự dài dòng đi kèm với việc định nghĩa hàm đệ quy. Các chữ ký phương thức sẽ như sau:
| | def makePeopleMethod(firstNames: Seq[String], lastNames: Seq[String]) = { |
| | @tailrec |
| | def helper(firstNames: Seq[String], lastNames: Seq[String], |
| | people: Vector[Person]): Seq[Person] = |
| | method-body |
| | } |
| | } |
Vì chúng ta chủ yếu tập trung vào các khía cạnh hàm của Scala trong cuốn sách này, nên chúng ta sử dụng hàm cho hầu hết các ví dụ thay vì phương thức. Phương thức có thể thường được sử dụng như các hàm bậc cao trong Scala, nhưng đôi khi việc này có thể gặp khó khăn.
In Clojure
Trong Clojure, các cuộc gọi đệ quy đuôi không bao giờ được tối ưu hóa, vì vậy ngay cả một cuộc gọi đệ quy đuôi cũng sẽ tiêu tốn một khung ngăn xếp. Thay vì cung cấp TCO, Clojure cho chúng ta hai dạng, loop và recur. Dạng loop định nghĩa một điểm đệ quy, và từ khóa recur nhảy trở lại đó, truyền các giá trị mới.
Trong thực tế, điều này trông gần giống như việc xác định một hàm trợ giúp riêng tư, vì vậy hình thức của giải pháp của chúng tôi tương tự như giải pháp trong Scala, mặc dù chúng tôi sẽ sử dụng một bản đồ đơn giản để lưu trữ những người của chúng tôi, như thường lệ trong Clojure. Hãy cùng xem xét mã bạn nhé:
| ClojureExamples/src/mbfpp/functional/tr/names.clj | |
| | (defn make-people [first-names last-names] |
| | (loop [first-names first-names last-names last-names people []] |
| | (if (seq first-names) |
| | (recur |
| | (rest first-names) |
| | (rest last-names) |
| | (conj |
| | people |
| | {:first (first first-names) :last (first last-names)})) |
| | people))) |
Đoạn mã thú vị đầu tiên ở đây là khai báo vòng lặp. Ở đây, chúng ta xác định điểm đệ quy và các giá trị mà chúng ta sẽ bắt đầu đệ quy: chuỗi tên và họ được truyền vào và một vector rỗng mà chúng ta sẽ sử dụng để tích lũy người khi chúng ta đệ quy.
| | (loop [first-names first-names last-names last-names people []] |
| | loop-body |
| | ) |
Mã nguồn `first-names first-names last-names last-names people []` có thể trông hơi kỳ lạ, nhưng điều nó làm là khởi tạo các `first-names` và `last-names` mà chúng ta đang định nghĩa trong `vòng lặp` để trở thành các giá trị đã được truyền vào hàm và `people` là một vector rỗng.
Đại phần của ví dụ nằm trong biểu thức if. Nếu chuỗi tên đầu tiên vẫn còn các mục trong đó, thì chúng ta sẽ lấy mục đầu tiên từ mỗi chuỗi, tạo một bản đồ để đại diện cho người đó, và conj nó vào bộ tích lũy people của chúng ta.
Khi chúng tôi đã đưa người mới vào vector người, chúng tôi sử dụng recur để quay lại điểm đệ quy mà chúng tôi đã xác định với loop. Điều này tương tự như cuộc gọi đệ quy mà chúng tôi đã thực hiện trong ví dụ Scala.
Nếu chúng ta không quay lại, chúng ta biết rằng chúng ta đã trải qua các chuỗi tên, và chúng ta trả về những người mà chúng ta đã xây dựng.
| | (if (seq first-names) |
| | (recur |
| | (rest first-names) |
| | (rest last-names) |
| | (conj |
| | people |
| | {:first (first first-names) :last (first last-names)})) |
| | people) |
Có thể không ngay lập tức rõ ràng tại sao phép kiểm tra trong biểu thức if ở trên hoạt động. Đó là vì `seq` của một tập hợp rỗng là nil, điều này đánh giá là sai, trong khi `seq` của bất kỳ tập hợp nào khác cho ra một chuỗi không rỗng. Đoạn mã dưới đây minh họa điều này:
| | => (seq []) |
| | nil |
| | => (seq [:hi]) |
| | (:hi) |
Sử dụng `nil` làm trường hợp cơ sở cho đệ quy khi bạn xử lý các chuỗi là điều phổ biến trong Clojure.
Discussion
Đệ quy đuôi tương đương với vòng lặp. Thực tế, các trình biên dịch Scala và Clojure sẽ biên dịch cách xử lý đệ quy đuôi của chúng xuống cùng loại bytecode mà vòng lặp trong Java sẽ tạo ra. Lợi thế chính của đệ quy đuôi so với vòng lặp đơn giản là nó loại bỏ một nguồn tính biến đổi trong ngôn ngữ, đó là lý do tại sao nó rất phổ biến trong thế giới hàm.
Tôi cá nhân thích đệ quy đuôi hơn vòng lặp vì một vài lý do nhỏ khác. Lý do đầu tiên là nó loại bỏ một biến chỉ số phụ. Lý do thứ hai là nó làm rõ chính xác các cấu trúc dữ liệu nào đang được thao tác và các cấu trúc dữ liệu nào đang được tạo ra, vì chúng đều được truyền dưới dạng tham số qua chuỗi gọi.
Trong một giải pháp lặp, nếu chúng ta đang cố gắng hoạt động trên hai chuỗi theo cách đồng bộ và tạo ra một cấu trúc dữ liệu khác, tất cả sẽ bị trộn lẫn trong thân của một hàm có thể đang làm những việc khác. Tôi nhận thấy rằng việc sử dụng đệ quy đuôi thay vì lặp lại là một yếu tố thúc đẩy tốt để cấu trúc các hàm của chúng ta một cách hợp lý, vì tất cả dữ liệu mà chúng ta đang hoạt động phải được truyền qua chuỗi gọi, và thật khó để làm điều đó nếu bạn có hơn một vài mảnh dữ liệu.
Vì đệ quy đuôi tương đương với vòng lặp, nên nó thực sự là một thao tác khá mức thấp. Thông thường, có một cách giải quyết vấn đề ở mức cao hơn, mang tính tuyên bố hơn là sử dụng đệ quy đuôi. Ví dụ, đây là một phiên bản ngắn gọn hơn của giải pháp cho ví dụ về việc tạo người mà tận dụng một số hàm bậc cao trong Clojure:
| ClojureExamples/src/mbfpp/functional/tr/names.clj | |
| | (defn shorter-make-people [first-names last-names] |
| | (for [[first last] (partition 2 (interleave first-names last-names))] |
| | {:first first :last last})) |
Việc chọn giải pháp nào là vấn đề sở thích, nhưng các lập trình viên chức năng có kinh nghiệm thường ưa chuộng những giải pháp ngắn gọn và tuyên bố hơn. Chúng dễ đọc hơn cho lập trình viên chức năng dày dạn kinh nghiệm chỉ trong một cái nhìn. Nhược điểm của những giải pháp này là chúng khó hiểu hơn đối với người mới, vì có thể yêu cầu kiến thức về nhiều hàm thư viện bậc cao.
Mỗi khi tôi sắp viết một giải pháp yêu cầu đệ quy đuôi, tôi thích tìm kiếm trong tài liệu API các hàm bậc cao, hoặc sự kết hợp của các hàm bậc cao, để thực hiện điều tôi muốn. Nếu tôi không thể tìm thấy một hàm bậc cao nào hoạt động, hoặc nếu giải pháp tôi nghĩ ra bao gồm nhiều hàm bậc cao được kết hợp theo cách phức tạp, thì tôi sẽ quay lại với đệ quy đuôi.
Related Patterns
Mẫu 5, Thay thế Bộ lặp
Mẫu 13, Đệ quy Tương hỗ
Mẫu 14, Lọc-Áp dụng-Biến đổi
| Pattern 13 | Mutual Recursion |
Intent
Sử dụng các hàm đệ quy lẫn nhau để diễn đạt một số thuật toán, chẳng hạn như duyệt các cấu trúc dữ liệu kiểu cây, phân tích cú pháp theo chiều sâu đệ quy và thao tác trên máy trạng thái.
Overview
Trong Mẫu 12, Đệ quy đuôi, chúng ta đã xem xét việc sử dụng đệ quy đuôi để duyệt qua các chuỗi dữ liệu và những mẹo mà Clojure và Scala sử dụng để tránh tiêu tốn khung ngăn xếp trong quá trình này, vì JVM không hỗ trợ trực tiếp đệ quy đuôi.
Đối với hầu hết các trường hợp, đệ quy đuôi đơn giản mà chúng ta đã xem trong Mẫu 12, Đệ quy đuôi, nơi mà các lời gọi đệ quy chỉ là tự đệ quy, là tất cả những gì chúng ta cần. Tuy nhiên, một số vấn đề phức tạp hơn yêu cầu các giải pháp mà trong đó các hàm có thể gọi nhau đệ quy.
Chẳng hạn, các máy trạng thái hữu hạn là một cách tuyệt vời để mô hình hóa nhiều loại vấn đề, và đệ quy lẫn nhau là một cách tuyệt vời để lập trình chúng. Các giao thức mạng, nhiều hệ thống vật lý như máy bán hàng tự động và thang máy, cùng với việc phân tích văn bản bán cấu trúc đều có thể thực hiện bằng máy trạng thái.
Trong mẫu này, chúng ta sẽ xem xét một số vấn đề có thể được giải quyết một cách rõ ràng bằng cách sử dụng đệ quy qua lại. Vì JVM không hỗ trợ tối ưu hóa đệ quy đuôi, Scala và Clojure phải sử dụng một thủ thuật khéo léo để hỗ trợ đệ quy qua lại thực tế, giống như họ đã làm với đệ quy đuôi thông thường, nhằm tránh hết không gian ngăn xếp.
Đối với đệ quy tương hỗ, thủ thuật này được gọi là một trampoline. Thay vì gọi trực tiếp các hàm đệ quy lẫn nhau, chúng ta trả về một hàm sẽ thực hiện cuộc gọi mong muốn, và để cho trình biên dịch hoặc thời gian chạy xử lý phần còn lại.
Hỗ trợ của Scala cho trampolining che giấu nhiều chi tiết và cung cấp cho chúng ta cả một phương thức tailcall để thực hiện các cuộc gọi đệ quy lẫn nhau và một phương thức done để gọi khi chúng ta đã hoàn thành đệ quy.
Điều đó có thể nghe có vẻ kỳ quặc, nhưng thực ra rất đơn giản. Để chứng minh điều này, hãy cùng xem qua "Hello, World" cho đệ quy tương hỗ, một cách rất đẹp mắt về mặt toán học nhưng lại vô cùng kém hiệu quả để xác định một số là chẵn hay lẻ, trước khi chúng ta đi vào những ví dụ thực tiễn hơn.
Dưới đây là cách nó hoạt động: chúng ta cần hai hàm, isEven và isOdd. Mỗi hàm nhận một đối số đơn là Long n. Hàm isEven kiểm tra xem n có bằng zero hay không, và nếu có, nó trả về true. Nếu không, nó giảm n đi 1 và gọi hàm isOdd. Hàm isOdd kiểm tra xem n có bằng zero hay không và nếu có thì trả về false. Nếu không, nó giảm n đi 1 và gọi hàm isEven.
Điều này rõ ràng nhất trong mã, vì vậy đây là nó:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mr/EvenOdd.scala | |
| | def isOdd(n: Long): Boolean = if (n == 0) false else isEven(n - 1) |
| | |
| | def isEven(n: Long): Boolean = if (n == 0) true else isOdd(n - 1) |
| | scala> isEven(0) |
| | res0: Boolean = true |
| | |
| | scala> isOdd(1) |
| | res1: Boolean = true |
| | |
| | scala> isEven(1000) |
| | res2: Boolean = true |
| | |
| | scala> isOdd(1001) |
| | res3: Boolean = true |
Điều đó hoạt động tốt với những con số nhỏ, nhưng nếu chúng ta thử với một con số lớn hơn thì sao?
| | scala> isOdd(100001) |
| | java.lang.StackOverflowError |
| | ... |
Như chúng ta thấy, mỗi cuộc gọi đệ quy tương hỗ tiêu tốn một khung ngăn xếp, vì vậy điều này gây ra tràn ngăn xếp của chúng ta! Hãy xem cách khắc phục điều đó bằng cách sử dụng trampoline của Scala.
Hỗ trợ cho trampolining trong Scala nằm trong scala.util.control.TailCalls, và nó gồm hai phần. Phần đầu tiên là một hàm done, được sử dụng để trả về kết quả cuối cùng từ các cuộc gọi đệ quy. Phần thứ hai là một hàm tailcall, được sử dụng để thực hiện các cuộc gọi đệ quy.
Ngoài ra, các kết quả trả về bởi các hàm đệ quy đuôi được bọc trong một loại TailRec thay vì được trả trực tiếp. Để lấy chúng ra ở cuối, chúng ta có thể gọi result trên thể hiện cuối cùng của TailRec.
Dưới đây là mã chẵn/lẻ của chúng tôi, được viết lại để tận dụng tính năng nhảy dù của Scala:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mr/EvenOdd.scala | |
| | def isOddTrampoline(n: Long): TailRec[Boolean] = |
| | if (n == 0) done(false) else tailcall(isEvenTrampoline(n - 1)) |
| | |
| | def isEvenTrampoline(n: Long): TailRec[Boolean] = |
| | if (n == 0) done(true) else tailcall(isOddTrampoline(n - 1)) |
| | scala> isEvenTrampoline(0).result |
| | res0: Boolean = true |
| | |
| | scala> isEvenTrampoline(1).result |
| | res1: Boolean = false |
| | |
| | scala> isEvenTrampoline(1000).result |
| | res2: Boolean = true |
| | |
| | scala> isEvenTrampoline(1001).result |
| | res3: Boolean = false |
Hãy thử chạy nó:
| | scala> isOddTrampoline(100001).result |
| | res4: Boolean = true |
Lần này, không có tràn ngăn xếp với những số lớn, mặc dù nếu bạn thử với một số lớn đủ, bạn nên chuẩn bị chờ đợi rất lâu, vì thời gian chạy của thuật toán này tỉ lệ thuận với kích thước của số!
Also Known As
Đệ quy gián tiếp
Example Code: Phases of Matter
Trong ví dụ này, chúng ta sẽ sử dụng Đệ quy Tương hỗ để xây dựng một máy trạng thái đơn giản, nhận một chuỗi các chuyển đổi giữa các trạng thái khác nhau của vật chất—lỏng, rắn, hơi và plasma—và xác minh rằng chuỗi đó là hợp lệ. Ví dụ, có thể chuyển từ rắn sang lỏng, nhưng không thể chuyển từ rắn sang plasma.
Mỗi trạng thái trong máy được đại diện bởi một hàm, và các chuyển tiếp được đại diện bởi một chuỗi các tên chuyển tiếp, như ngưng tụ và bốc hơi. Một hàm trạng thái chọn chuyển tiếp đầu tiên ra khỏi chuỗi và, nếu nó hợp lệ, gọi hàm đưa nó đến nơi nó nên chuyển tiếp, truyền cho nó phần còn lại của các chuyển tiếp. Nếu chuyển tiếp không hợp lệ, chúng ta dừng lại và trả về false.
Ví dụ, nếu chúng ta ở trạng thái rắn và sự chuyển tiếp mà chúng ta thấy là đông tan, thì chúng ta gọi hàm lỏng. Nếu đó là ngưng tụ, điều này không phải là một chuyển tiếp hợp lệ ra khỏi trạng thái rắn, thì chúng ta ngay lập tức trả về false.
Trước khi đi vào mã, hãy cùng xem một bức tranh về máy trạng thái các giai đoạn của vật chất.
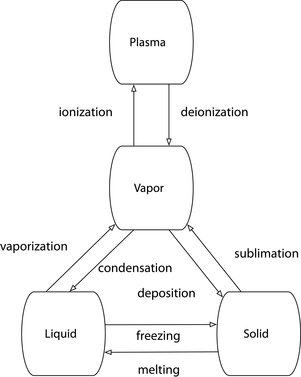
Figure 12. The Phases of Matter. The phases of matter and the transitions between them
Các nút trong đồ thị này đại diện cho các hàm mà chúng ta sẽ cần để mô hình hóa máy trạng thái này bằng cách sử dụng Đệ quy Tương hỗ, và các cạnh đại diện cho các chuyển tiếp mà các hàm đó sẽ hoạt động trên. Hãy cùng xem mã, bắt đầu với Scala.
In Scala
Giải pháp Scala của chúng tôi dựa trên bốn hàm, mỗi hàm cho mỗi trạng thái của vật chất: plasma, hơi, lỏng và rắn. Ngoài ra, chúng tôi sẽ cần một tập hợp các đối tượng case để thể hiện các chuyển tiếp: Ion hóa, Khử ion, Bốc hơi và các trạng thái khác.
Mỗi trong bốn hàm nhận một đối số duy nhất và một danh sách các chuyển tiếp, và mỗi hàm sử dụng phương pháp khớp mẫu của Scala để phân tích. Nếu danh sách là Nil, thì chúng ta biết rằng đã đến cuối một cách thành công và chúng ta gọi done, với tham số là true.
Nếu không, chúng tôi kiểm tra trạng thái chuyển tiếp đầu tiên trong danh sách để xem nó có hợp lệ không. Nếu có, chúng tôi chuyển sang trạng thái mà nó chỉ định và tiếp tục với các chuyển tiếp còn lại. Nếu chuyển tiếp đầu tiên không hợp lệ, chúng tôi gọi done, truyền vào false.
Hãy xem xét mã, bắt đầu với các đối tượng trường hợp để đại diện cho các chuyển tiếp của chúng ta. Chúng khá đơn giản; mỗi chuyển tiếp là một đối tượng riêng, và tất cả chúng đều kế thừa từ lớp Transition.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mr/Phases.scala | |
| | class Transition |
| | case object Ionization extends Transition |
| | case object Deionization extends Transition |
| | case object Vaporization extends Transition |
| | case object Condensation extends Transition |
| | case object Freezing extends Transition |
| | case object Melting extends Transition |
| | case object Sublimation extends Transition |
| | case object Deposition extends Transition |
Bây giờ hãy xem xét phần chính của ví dụ, các hàm đại diện cho các trạng thái vật chất của chúng ta. Như đã hứa, có bốn trạng thái: plasma, hơi nước, lỏng, và rắn. Dưới đây là tập hợp đầy đủ các hàm mà chúng ta sẽ cần:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mr/Phases.scala | |
| | def plasma(transitions: List[Transition]): TailRec[Boolean] = transitions match { |
| | case Nil => done(true) |
| | case Deionization :: restTransitions => tailcall(vapor(restTransitions)) |
| | case _ => done(false) |
| | } |
| | def vapor(transitions: List[Transition]): TailRec[Boolean] = transitions match { |
| | case Nil => done(true) |
| | case Condensation :: restTransitions => tailcall(liquid(restTransitions)) |
| | case Deposition :: restTransitions => tailcall(solid(restTransitions)) |
| | case Ionization :: restTransitions => tailcall(plasma(restTransitions)) |
| | case _ => done(false) |
| | } |
| | |
| | def liquid(transitions: List[Transition]): TailRec[Boolean] = transitions match { |
| | case Nil => done(true) |
| | case Vaporization :: restTransitions => tailcall(vapor(restTransitions)) |
| | case Freezing :: restTransitions => tailcall(solid(restTransitions)) |
| | case _ => done(false) |
| | } |
| | |
| | def solid(transitions: List[Transition]): TailRec[Boolean] = transitions match { |
| | case Nil => done(true) |
| | case Melting :: restTransitions => tailcall(liquid(restTransitions)) |
| | case Sublimation :: restTransitions => tailcall(vapor(restTransitions)) |
| | case _ => done(false) |
| | } |
Chúng tôi đã mô tả cách chúng hoạt động ở mức độ tổng quan, vì vậy hãy phân tích một trong số chúng, vapor, một cách chi tiết, bắt đầu với chữ ký của nó:
| | def vapor(transitions: List[Transition]): TailRec[Boolean] = transitions match { |
| | function-body |
| | } |
Như chúng ta có thể thấy, nó chỉ nhận vào một danh sách các Transition được đặt tên là transitions và thực hiện các phép so khớp mẫu trên đó. Thay vì trả về một giá trị Boolean trực tiếp, nó trả về một TailRec của Boolean, vì vậy chúng ta có thể tận dụng hỗ trợ của Scala cho trampolining.
Chuyển sang điều khoản trường hợp đầu tiên trong biểu thức khớp, chúng ta thấy nó gọi `done` để trả về true nếu danh sách trống, hoặc `Nil`. Đây là trường hợp cơ sở của đệ quy; nếu chúng ta đến đây, nghĩa là chúng ta đã xử lý thành công tất cả các chuyển tiếp ban đầu trong chuỗi.
| | case Nil => done(true) |
Tiếp theo là ba mệnh đề ở giữa. Chúng sử dụng khớp mẫu để chọn phần đầu của chuỗi nếu đó là một chuyển tiếp hợp lệ và gọi hàm để chuyển sang trạng thái thích hợp, truyền phần còn lại của các chuyển tiếp:
| | case Condensation :: restTransitions => tailcall(liquid(restTransitions)) |
| | case Deposition :: restTransitions => tailcall(solid(restTransitions)) |
| | case Ionization :: restTransitions => tailcall(plasma(restTransitions)) |
Cuối cùng, điều khoản cuối cùng, là một điều khoản bao trùm. Nếu chúng ta rơi vào đây, chúng ta biết rằng chúng ta chưa xử lý tất cả các chuyển đổi và chuyển đổi mà chúng ta thấy không hợp lệ, vì vậy chúng ta gọi hàm done và truyền vào giá trị false.
| | case _ => done(false) |
Hãy cùng xem nó hoạt động, trước tiên với một danh sách hợp lệ bắt đầu từ trạng thái rắn:
| | scala> val validSequence = List(Melting, Vaporization, Ionization, Deionization) |
| | validSequence: List[com.mblinn.mbfpp.functional.mr.Phases.Transition] = |
| | List(Melting, Vaporization, Ionization, Deionization) |
| | |
| | scala> solid(validSequence).result |
| | res0: Boolean = true |
Tiếp theo, chúng ta có một danh sách không hợp lệ bắt đầu từ trạng thái lỏng:
| | scala> val invalidSequence = List(Vaporization, Freezing) |
| | invalidSequence: List[com.mblinn.mbfpp.functional.mr.Phases.Transition] = |
| | List(Vaporization, Freezing) |
| | |
| | scala> liquid(invalidSequence).result |
| | res1: Boolean = false |
Điều này kết thúc cái nhìn đầu tiên của chúng ta về Đệ quy tương hỗ trong Scala. Hãy xem nó trông như thế nào trong Clojure.
In Clojure
Mã Clojure tương tự như mã Scala, ít nhất là ở mức độ cao. Chúng tôi có các hàm plasma, vapor, liquid và solid, mỗi hàm đều nhận một chuỗi các biến đổi.
Chúng tôi sử dụng kỹ thuật phá cấu trúc trong Clojure để tách rời chuỗi thành trạng thái chuyển đổi hiện tại, mà chúng tôi gán cho transition và các trạng thái chuyển đổi còn lại trong rest-transitions.
Nếu chuyển tiếp là nil, chúng tôi biết rằng chúng tôi đã đạt đến cuối thành công và trả về true. Nếu không, chúng tôi kiểm tra xem đó có phải là một chuyển tiếp hợp lệ không, và nếu có, chúng tôi chuyển sang giai đoạn phù hợp. Nếu không, chúng tôi trả về false. Dưới đây là mã đầy đủ:
| ClojureExamples/src/mbfpp/functional/mr/phases.clj | |
| | (declare plasma vapor liquid solid) |
| | |
| | (defn plasma [[transition & rest-transitions]] |
| | #(case transition |
| | nil true |
| | :deionization (vapor rest-transitions) |
| | :false)) |
| | |
| | (defn vapor [[transition & rest-transitions]] |
| | #(case transition |
| | nil true |
| | :condensation (liquid rest-transitions) |
| | :deposition (solid rest-transitions) |
| | :ionization (plasma rest-transitions) |
| | false)) |
| | |
| | (defn liquid [[transition & rest-transitions]] |
| | #(case transition |
| | nil true |
| | :vaporization (vapor rest-transitions) |
| | :freezing (solid rest-transitions) |
| | false)) |
| | |
| | (defn solid [[transition & rest-transitions]] |
| | #(case transition |
| | nil true |
| | :melting (liquid rest-transitions) |
| | :sublimation (vapor rest-transitions) |
| | false)) |
Lưu ý rằng không có lời gọi nào đến done hoặc tailcall như trong phiên bản Scala? Thay vì sử dụng tailcall, chúng ta chỉ trả về một hàm sẽ thực hiện cuộc gọi mà chúng ta muốn. Trong trường hợp này, chúng ta đang sử dụng cách viết tắt của Clojure cho các hàm ẩn danh để làm điều đó.
Khi chúng ta thực sự muốn bắt đầu chuỗi các cuộc gọi đệ quy lẫn nhau, chúng ta truyền hàm mà chúng ta muốn gọi vào trampoline, cùng với các tham số của nó:
| | => (def valid-sequence [:melting :vaporization :ionization :deionization]) |
| | #'mbfpp.functional.mr.phases/valid-sequence |
| | => (trampoline solid valid-sequence) |
| | true |
| | => (def invalid-sequence [:vaporization :freezing]) |
| | #'mbfpp.functional.mr.phases/invalid-sequence |
| | => (trampoline liquid invalid-sequence) |
| | false |
Điều này trả về đúng cho chuỗi hợp lệ và sai cho chuỗi không hợp lệ, như chúng ta mong đợi.
Trước khi rời khỏi ví dụ này, tôi muốn nói một chút về Nil trong Scala và nil trong Clojure. Mã mà chúng ta đã viết trông khá giống nhau, nhưng có một sự khác biệt tinh tế giữa hai nil mà đáng để đề cập đến.
Trong Scala, Nil chỉ là một từ đồng nghĩa với danh sách rỗng, như chúng ta có thể thấy nếu nhập nó vào REPL của Scala:
| | scala> Nil |
| | res0: scala.collection.immutable.Nil.type = List() |
Trong Clojure, nil chỉ có nghĩa là “không có gì”: nó có nghĩa là chúng ta không có giá trị, và nó khác với danh sách rỗng. Các ngôn ngữ lập trình chức năng khác nhau đã xử lý nil khác nhau qua các năm, vì vậy mỗi khi bạn gặp một ngôn ngữ mới, luôn đáng để dành một chút thời gian để hiểu chính xác ngôn ngữ đó định nghĩa nil như thế nào.
Discussion
Đệ quy lẫn nhau có thể rất hữu ích, nhưng thường chỉ trong những hoàn cảnh cụ thể. Máy trạng thái là một trong những hoàn cảnh này; chúng thực sự là những công cụ hữu ích. Không may, hầu hết các lập trình viên chỉ nhớ đến chúng từ những năm đại học khi họ phải chứng minh sự tương đương giữa máy trạng thái hữu hạn và biểu thức chính quy, điều này thì thú vị nhưng không hữu ích với hầu hết các lập trình viên.
Các máy trạng thái đã trở nên phổ biến hơn trong những năm gần đây. Chúng là một phần quan trọng của mô hình diễn viên, một mô hình cho lập trình đồng thời và phân tán, được sử dụng bởi thư viện Akka của Scala và bởi Erlang, một ngôn ngữ chức năng khác. Ruby có một gem thông minh để tạo ra chúng, được đặt tên một cách hợp lý là state_machine.
Một điều nữa đáng chú ý là cái bạt nhún mà chúng ta thấy ở đây, trong cả Scala và Clojure, chỉ là một cách thực hiện Đệ quy Tương hỗ. Nó chỉ cần thiết vì JVM không trực tiếp thực hiện tối ưu hóa gọi đuôi.
Related Patterns
Mẫu 5, Thay thế Bộ lặp
Mẫu 14, Lọc-Ánh xạ-Giảm
读累了记得休息一会哦~
Tài khoản công chúng: Cổ Đích Miêu Ninh Lý
- 电子书搜索下载
- 书单分享
- 书友学习交流
Website: Thư viện Trầm Kim https://www.chenjin5.com
- 电子书搜索下载
- 电子书打包资源分享
- 学习资源分享
| Pattern 14 | Filter-Map-Reduce |
Intent
Để thao tác với một chuỗi (danh sách, vector, v.v.) một cách khai báo sử dụng filter, map và reduce để tạo ra một chuỗi mới — đây là một cách mạnh mẽ và ở cấp độ cao để thực hiện nhiều thao tác trên chuỗi mà nếu không sẽ rất dài dòng.
Overview
Cách chúng ta thao tác với các chuỗi trong ngôn ngữ lập trình tuần tự có mối liên hệ chặt chẽ hơn với cách mà máy tính hoạt động hơn là cách mà con người suy nghĩ. Lặp lại là một bước tiến trên câu lệnh goto đáng ghét, và nó được thiết kế để dễ dàng được chuyển thành mã máy hơn là để dễ sử dụng.
Filter-Map-Reduce cho chúng ta một cách tiếp cận khai báo hơn để thực hiện nhiều thao tác trên chuỗi. Thay vì viết mã để sắp xếp hoặc thay đổi các yếu tố trong một chuỗi bằng cách làm việc theo cách lặp lại qua từng phần tử, chúng ta có thể làm việc ở mức độ cao hơn bằng cách sử dụng hàm filter để chọn các phần tử mà chúng ta quan tâm: map để biến đổi từng phần tử và reduce, đôi khi được biết đến với tên gọi fold, để kết hợp các kết quả.
Filter-Map-Reduce thay thế nhiều, mặc dù không phải tất cả, các thuật toán lặp đi lặp lại được sử dụng bởi các lập trình viên hướng đối tượng bằng mã khai báo.
Lợi thế chính của Filter-Map-Reduce so với việc lặp lại là sự rõ ràng của mã. Một đoạn mã Filter-Map-Reduce được viết tốt chỉ chiếm một phần mã so với một giải pháp lặp lại tương đương. Nó thường có thể được đọc ngay lập tức, giống như văn xuôi, bởi một chuyên gia có kinh nghiệm, trong khi giải pháp lặp lại yêu cầu phải phân tích ít nhất một vòng lặp và một điều kiện.
Một nhược điểm là không phải tất cả các vòng lặp đều có thể được thay thế bằng Filter-Map-Reduce. Một nhược điểm khác là đôi khi có thể khó khăn hoặc không rõ ràng để tạo ra một chuỗi cho phép sử dụng Filter-Map-Reduce. Trong những trường hợp này, một trong các mẫu trong danh sách các Mẫu Liên Quan có thể phù hợp hơn.
Code Sample: Calculate Discount
Việc thực hiện Filter-Map-Reduce kết hợp filter, map và reduce, mặc dù không phải lúc nào cũng theo thứ tự đó. Hãy xem một ví dụ về cách tính toán tổng số tiền giảm giá trên một chuỗi giá, trong đó bất kỳ giá nào từ hai mươi đô la trở lên sẽ được giảm giá mười phần trăm, và bất kỳ giá nào dưới hai mươi sẽ được tính theo giá đầy đủ.
In Scala
Filter-Map-Reduce trong Scala rất giống với triển khai trong Clojure. Chúng ta bắt đầu với hàm filter để chọn những giá lớn hơn hai mươi đô la:
| | scala> Vector(20.0, 4.5, 50.0, 15.75, 30.0, 3.5) filter (price => price >= 20) |
| | res0: scala.collection.immutable.Vector[Double] = Vector(20.0, 50.0, 30.0) |
Chúng tôi sử dụng map để lấy mười phần trăm trong số đó:
| | scala> Vector(20.0, 50.0, 30.0) map (price => price * 0.10) |
| | res1: scala.collection.immutable.Vector[Double] = Vector(2.0, 5.0, 3.0) |
Và chúng ta cộng chúng lại với nhau bằng cách sử dụng reduce.
| | scala> Vector(2.0, 5.0, 3.0) reduce ((total, price) => total + price) |
| | res2: Double = 10.0 |
Ghép lại với nhau chúng ta có tínhToánGiảmGiá:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mfr/Discount.scala | |
| | def calculateDiscount(prices : Seq[Double]) : Double = { |
| | prices filter(price => price >= 20.0) map |
| | (price => price * 0.10) reduce |
| | ((total, price) => total + price) |
| | } |
| | scala> calculateDiscount(Vector(20.0, 4.5, 50.0, 15.75, 30.0, 3.5)) |
| | res1: Double = 10.0 |
Bạn cũng có thể sử dụng các hàm có tên nếu điều đó phù hợp hơn với phong cách của bạn, mặc dù tôi thích phiên bản hàm ẩn danh ở đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/mfr/Discount.scala | |
| | def calculateDiscountNamedFn(prices : Seq[Double]) : Double = { |
| | def isGreaterThan20(price : Double) = price >= 20.0 |
| | def tenPercent(price : Double) = price * 0.10 |
| | def sumPrices(total: Double, price : Double) = total + price |
| | |
| | prices filter isGreaterThan20 map tenPercent reduce sumPrices |
| | } |
In Clojure
Hãy tạo một hàm calculate-discount sử dụng Filter-Map-Reduce để tính toán tổng số tiền chiết khấu. Để làm ví dụ, chúng ta sẽ sử dụng một vector chứa các số thực để đại diện cho các mức giá. Chúng ta cần lọc trước tiên để chỉ giữ lại những mức giá lớn hơn hai mươi đô la, như thế này:
| | => (filter (fn [price] (>= price 20)) [20.0 4.5 50.0 15.75 30.0 3.50]) |
| | (20.0 50.0 30.0) |
Sau đó, chúng ta cần lấy giá đã được lọc và nhân chúng với 0.10 để tính mười phần trăm của mỗi giá, sử dụng map:
| | => (map (fn [price] (* price 0.10)) [20.0 50.0 30.0]) |
| | (2.0 5.0 3.0) |
Cuối cùng, chúng ta cần kết hợp những kết quả đó bằng cách sử dụng reduce và phép cộng:
| | => (reduce + [2.0 5.0 3.0]) |
| | 10.0 |
Ghép lại với nhau, chúng ta có tính toán-chiết-khấu:
| ClojureExamples/src/mbfpp/functional/mfr/discount.clj | |
| | (defn calculate-discount [prices] |
| | (reduce + |
| | (map (fn [price] (* price 0.10)) |
| | (filter (fn [price] (>= price 20.0)) prices)))) |
Có một mẹo để đọc mã Lisp cho phép những người có kinh nghiệm trong Lisp có thể đọc nhanh chóng nhưng lại gây khó chịu cho những người chưa quen. Để đọc dễ dàng, bạn cần làm từ trong ra ngoài. Bắt đầu với hàm filter, sau đó chuyển sang map, và cuối cùng là reduce.
Trong văn xuôi, điều này sẽ là: “Lọc các giá sao cho chỉ những giá lớn hơn hai mươi còn lại, nhân các giá còn lại với một phần mười và cộng chúng lại với nhau.” Với một chút luyện tập, việc đọc loại mã này không chỉ tự nhiên mà còn vì nó ở mức độ cao hơn và gần với ngôn ngữ tự nhiên, nên nhanh hơn nhiều so với giải pháp lặp tương đương.
Chúng ta có thể thực hiện một sửa đổi nhỏ cho mẫu bằng cách đặt tên cho các hàm map và filter, như được thể hiện trong mã dưới đây:
| ClojureExamples/src/mbfpp/functional/mfr/discount.clj | |
| | (defn calculate-discount-namedfn [prices] |
| | (letfn [(twenty-or-greater? [price] (>= price 20.0)) |
| | (ten-percent [price] (* price 0.10))] |
| | (reduce + 0.0 (map ten-percent (filter twenty-or-greater? prices))))) |
Điều này khiến cho mô hình đọc giống như văn xuôi hơn, mặc dù cần thêm một số mã. Khi các hàm map và filter chỉ được sử dụng một lần như trong trường hợp này, tôi thích phiên bản gốc với các hàm ẩn danh, nhưng cả hai phong cách đều phổ biến. Việc chọn phong cách nào là do sở thích.
Discussion
Mẫu Filter-Map-Reduce dựa vào việc thao tác dữ liệu theo cách khai báo, điều này ở mức cao hơn so với các giải pháp lặp và thường cao hơn so với các giải pháp đệ quy rõ ràng. Nó giống như sự khác biệt giữa việc sử dụng SQL để tạo báo cáo từ dữ liệu trong cơ sở dữ liệu quan hệ so với việc lặp qua các dòng trong một tệp phẳng với cùng dữ liệu. Một phiên bản SQL được viết tốt sẽ thường ngắn gọn và rõ ràng hơn, vì nó sử dụng một ngôn ngữ được tạo ra đặc biệt để thao tác với dữ liệu. Việc sử dụng Map-Reduce-Filter mang lại cho chúng ta phần lớn sức mạnh khai báo đó.
Một điều khác cần lưu ý là cách chúng tôi xây dựng các giải pháp từ dưới lên, bắt đầu bằng việc tạo ra các hàm map, reduce và filter trong REPL và sau đó kết hợp chúng lại. Quy trình làm việc từ dưới lên này rất phổ biến trong lập trình hàm. Khả năng thử nghiệm trong REPL và xây dựng các chương trình thông qua khám phá là cực kỳ mạnh mẽ, và chúng ta sẽ thấy nhiều ví dụ hơn nữa về điều này trong các mẫu hàm.
Related Patterns
Mẫu 5, Thay thế Bộ lặp
Mẫu 12, Đệ quy đuôi
Mẫu 13, Đệ quy lẫn nhau
| Pattern 15 | Chain of Operations |
Intent
Để liên kết một chuỗi các phép toán lại với nhau—điều này cho phép chúng ta làm việc một cách sạch sẽ với dữ liệu không thay đổi mà không cần lưu trữ nhiều kết quả tạm thời.
Overview
Gửi một chút dữ liệu thông qua một tập hợp các thao tác là một kỹ thuật hữu ích. Điều này đặc biệt đúng khi làm việc với dữ liệu không thay đổi. Bởi vì chúng ta không thể thay đổi một cấu trúc dữ liệu, chúng ta cần gửi một cấu trúc không thay đổi qua một loạt biến đổi nếu chúng ta muốn thực hiện nhiều thay đổi hơn một lần.
Một lý do khác mà chúng ta kết hợp các phép toán là vì điều đó dẫn đến mã nguồn ngắn gọn. Ví dụ, trình tạo mà chúng ta đã thấy trong Mẫu 4, Thay thế Trình tạo cho Đối tượng Bất biến, kết hợp các phép đặt để giữ cho mã nguồn của chúng ta gọn gàng, như đoạn mã sau đây cho thấy:
| JavaExamples/src/main/java/com/mblinn/oo/javabean/PersonHarness.java | |
| | ImmutablePerson.Builder b = ImmutablePerson.newBuilder(); |
| | ImmutablePerson p = b.firstName("Peter").lastName("Jones").build(); |
Đôi khi, chúng ta kết hợp các lệnh gọi phương thức để tránh tạo ra các giá trị tạm thời gây tiếng ồn. Trong đoạn mã dưới đây, chúng ta lấy một giá trị String từ một List và biến nó thành chữ hoa trong một lần thực hiện:
| JavaExamples/src/main/java/com/mblinn/mbfpp/functional/coo/Examples.java | |
| | List<String> names = new ArrayList<String>(); |
| | names.add("Michael Bevilacqua Linn"); |
| | names.get(0).toUpperCase(); |
Phong cách lập trình này còn mạnh mẽ hơn trong thế giới hàm, nơi mà chúng ta có các hàm bậc cao. Ví dụ, đây là một đoạn mã Scala tạo ra các chữ cái viết tắt từ một tên:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | val name = "michael bevilacqua linn" |
| | val initials = name.split(" ") map (_.toUpperCase) map (_.charAt(0)) mkString |
Nó thực hiện điều này bằng cách gọi phương thức split trên tên, biến nó thành một mảng, sau đó ánh xạ các hàm lên đó để viết hoa các chuỗi và chọn ký tự đầu tiên trong mỗi chuỗi. Cuối cùng, chúng ta biến mảng trở lại thành một chuỗi.
Điều này ngắn gọn và tuyên bố rõ ràng, vì vậy nó dễ đọc.
Sample Code: Function Call Chaining
Hãy cùng xem xét một mẫu bao gồm nhiều cuộc gọi hàm liên kết. Mục tiêu là viết mã sao cho khi chúng ta đọc nó, chúng ta có thể dễ dàng theo dõi luồng dữ liệu từ bước này sang bước khác.
Chúng tôi sẽ lấy một vector các video đại diện cho lịch sử xem video của một người, và chúng tôi sẽ tính tổng thời gian đã dành để xem video mèo. Để làm điều này, chúng tôi cần chọn chỉ các video mèo ra khỏi vector, lấy độ dài của chúng, và cuối cùng cộng chúng lại với nhau.
In Scala
Đối với giải pháp Scala của chúng tôi, chúng tôi sẽ đại diện cho video dưới dạng một case class với tiêu đề, loại video và độ dài. Mã để định nghĩa class này và điền một số dữ liệu thử nghiệm như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | case class Video(title: String, video_type: String, length: Int) |
| | |
| | val v1 = Video("Pianocat Plays Carnegie Hall", "cat", 300) |
| | val v2 = Video("Paint Drying", "home-improvement", 600) |
| | val v3 = Video("Fuzzy McMittens Live At The Apollo", "cat", 200) |
| | |
| | val videos = Vector(v1, v2, v3) |
Để tính tổng thời gian đã dành để xem video về mèo, chúng ta lọc ra những video mà video_type bằng "cat", trích xuất trường length từ những video còn lại, và sau đó tính tổng chiều dài của chúng. Mã lệnh để thực hiện điều này như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | def catTime(videos: Vector[Video]) = |
| | videos. |
| | filter((video) => video.video_type == "cat"). |
| | map((video) => video.length). |
| | sum |
Bây giờ chúng ta có thể áp dụng catTime cho dữ liệu kiểm tra của mình để tính tổng thời gian đã dành cho video về mèo:
| | scala> catTime(videos) |
| | res0: Int = 500 |
Giải pháp này được diễn đạt một cách mạch lạc từ trên xuống dưới, gần giống như văn xuôi. Nó làm được điều đó mà không cần thêm biến hay bất kỳ sự biến đổi nào, vì vậy rất lý tưởng trong thế giới lập trình hàm.
In Clojure
Hãy xem xét vấn đề xem video của chúng ta trong Clojure. Ở đây, chúng ta sẽ sử dụng bản đồ cho các video của mình. Đoạn mã sau tạo ra một số dữ liệu thử nghiệm:
| ClojureExamples/src/mbfpp/functional/coo/examples.clj | |
| | (def v1 |
| | {:title "Pianocat Plays Carnegie Hall" |
| | :type :cat |
| | :length 300}) |
| | |
| | (def v2 |
| | {:title "Paint Drying" |
| | :type :home-improvement |
| | :length 600}) |
| | |
| | (def v3 |
| | {:title "Fuzzy McMittens Live At The Apollo" |
| | :type :cat |
| | :length 200}) |
| | |
| | (def videos [v1 v2 v3]) |
Hãy thử viết chương trình cat-time bằng Clojure. Như trước đây, chúng ta sẽ lọc vector các video và trích xuất độ dài của chúng. Để tổng hợp chuỗi độ dài, chúng ta sẽ sử dụng apply và hàm +. Mã cho giải pháp này như sau:
| ClojureExamples/src/mbfpp/functional/coo/examples.clj | |
| | (defn cat-time [videos] |
| | (apply + |
| | (map :length |
| | (filter (fn [video] (= :cat (:type video))) videos)))) |
Để hiểu mã này, hãy bắt đầu với hàm filter, sau đó chuyển sang map, và cuối cùng là apply. Đối với các chuỗi dài, điều này có thể trở nên phức tạp. Một lựa chọn là đặt tên cho các kết quả trung gian bằng cách sử dụng let để làm cho mọi thứ dễ hiểu hơn.
Một tùy chọn khác trong tình huống này là sử dụng các macro -> và ->> trong Clojure. Các macro này có thể được sử dụng để luồn một mảnh dữ liệu qua một chuỗi các lời gọi hàm.
Macro -> lồng ghép một biểu thức qua một loạt các biểu mẫu, chèn nó làm mục thứ hai trong mỗi biểu mẫu. Ví dụ, trong đoạn mã dưới đây, chúng ta sử dụng -> để lồng ghép một số nguyên qua hai phép trừ:
| | => (-> 4 (- 2) (- 2)) |
| | 0 |
Macro đầu tiên ghép số 4 vào vị trí thứ hai trong (-2), từ đó trừ 2 khỏi 4 để được 2. Sau đó, kết quả đó được ghép vào vị trí thứ hai trong (-2) tiếp theo để có kết quả cuối cùng là 0.
Nếu chúng ta sử dụng ->>, chúng ta sẽ nhận được một kết quả khác, như đoạn mã sau đây cho thấy:
| | => (->> 4 (- 2) (- 2)) |
| | 4 |
Ở đây, sợi chỉ 4 được đưa vào vị trí cuối cùng trong số đầu tiên (-2), do đó 4 được trừ đi từ 2 để có kết quả là -2. Giá trị -2 đó sau đó được đưa vào vị trí cuối cùng của số thứ hai (-2), làm giảm -2 từ 2 để có kết quả cuối cùng là 4.
Bây giờ mà chúng ta đã thấy các toán tử threading, chúng ta có thể sử dụng ->> để làm cho catTime của chúng ta đọc từ trên xuống dưới. Chúng ta thực hiện điều này trong đoạn mã sau:
| ClojureExamples/src/mbfpp/functional/coo/examples.clj | |
| | (defn more-cat-time [videos] |
| | (->> videos |
| | (filter (fn [video] (= :cat (:type video)))) |
| | (map :length) |
| | (apply +))) |
Điều này hoạt động giống như phiên bản ban đầu của chúng tôi:
| | => (more-cat-time videos) |
| | 500 |
Một hạn chế của các macro luồng là nếu chúng ta muốn sử dụng chúng để nối các cuộc gọi hàm, thì dữ liệu mà chúng ta truyền qua chuỗi các cuộc gọi hàm phải nhất quán ở vị trí đầu tiên hoặc cuối cùng.
Sample Code: Chaining Using Sequence Comprehensions
Một công dụng phổ biến của Chuỗi Hoạt Động là chúng ta cần thực hiện nhiều phép toán trên các giá trị bên trong một số loại container. Điều này đặc biệt phổ biến trong các ngôn ngữ kiểu tĩnh như Scala.
Ví dụ, chúng ta có thể có một loạt các giá trị Option mà chúng ta muốn kết hợp thành một giá trị duy nhất, trả về None nếu bất kỳ giá trị nào trong số đó là None. Có nhiều cách để thực hiện điều này, nhưng cách ngắn gọn nhất là sử dụng comprehension for để chọn các giá trị và trả về kết quả.
In Scala
Chúng tôi đã gặp hiểu biết về cách hiểu dãy trong Mã Mẫu: Cách Hiểu Dãy, như là một sự thay thế cho Iterator. Ở đây, chúng tôi sẽ tận dụng thực tế rằng chúng có thể hoạt động trên nhiều dãy cùng một lúc, điều này làm cho chúng hữu ích cho Chuỗi Hoạt Động.
Hãy xem xét một sự hiểu biết về chuỗi hoạt động trên hai véc-tơ, mỗi véc-tơ có một số nguyên đơn. Chúng ta sẽ sử dụng nó để cộng các giá trị trong các véc-tơ lại với nhau. Các véc-tơ thử nghiệm của chúng ta được định nghĩa trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | val vec1 = Vector(42) |
| | val vec2 = Vector(8) |
Dưới đây là cách mà chúng tôi sử dụng chúng để hiểu. Chúng tôi chọn i1 từ véc-tơ đầu tiên và i2 từ véc-tơ thứ hai, và chúng tôi sử dụng yield để cộng chúng lại với nhau:
| | scala> for { i1 <- vec1; i2 <- vec2 } yield(i1 + i2) |
| | res0: scala.collection.immutable.Vector[Int] = Vector(50) |
Từ đó, chỉ cần một bước ngắn để sử dụng for với Option. Trong đoạn mã dưới đây, chúng ta định nghĩa một vài giá trị tùy chọn:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | val o1 = Some(42) |
| | val o2 = Some(8) |
Bây giờ chúng ta có thể cộng chúng lại với nhau như chúng ta đã làm với các giá trị trong các vector của mình.
| | scala> for { v1 <- o1; v2 <- o2 } yield(v1 + v2) |
| | res1: Option[Int] = Some(50) |
Một lợi thế là chúng ta không cần phải gọi get hoặc so khớp mẫu để lấy giá trị từ Option. Sức mạnh của phương pháp này trở nên rõ ràng hơn khi chúng ta thêm một None vào trong hỗn hợp:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | val o3: Option[Int] = None |
| | scala> for { v1 <- o1; v3 <- o3 } yield(v1 + v3) |
| | res2: Option[Int] = None |
Hiện tại, sự hiểu biết của chúng tôi cho ra một giá trị không.
Một chuỗi các phép toán, mỗi phép toán có thể trả về giá trị `None`, là rất phổ biến trong Scala. Hãy xem một ví dụ mà qua đó thực hiện một loạt các phép toán để lấy danh sách video yêu thích của người dùng trên một trang web phim.
Để có được danh sách video, trước tiên chúng ta cần tra cứu một người dùng bằng ID, sau đó chúng ta cần tra cứu danh sách video yêu thích của người đó. Cuối cùng, chúng ta cần tra cứu danh sách video liên quan đến bộ phim đó, chẳng hạn như phỏng vấn dàn diễn viên, trailer và có thể là video dài của chính bộ phim.
Chúng ta sẽ bắt đầu bằng cách tạo ra một vài lớp để đại diện cho một Người dùng và một Bộ phim:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | case class User(name: String, id: String) |
| | case class Movie(name: String, id: String) |
Bây giờ chúng ta sẽ định nghĩa một tập hợp các phương thức để lấy thông tin người dùng, một bộ phim yêu thích và danh sách video cho bộ phim đó. Mỗi hàm sẽ trả về None nếu không thể tìm thấy phản hồi cho đầu vào của nó. Đối với ví dụ đơn giản này, chúng ta sẽ sử dụng các giá trị được mã hóa sẵn, nhưng trong thực tế, điều này có thể liên quan đến việc tra cứu từ cơ sở dữ liệu hoặc dịch vụ.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | def getUserById(id: String) = id match { |
| | case "1" => Some(User("Mike", "1")) |
| | case _ => None |
| | } |
| | |
| | def getFavoriteMovieForUser(user: User) = user match { |
| | case User(_, "1") => Some(Movie("Gigli", "101")) |
| | case _ => None |
| | } |
| | |
| | def getVideosForMovie(movie: Movie) = movie match { |
| | case Movie(_, "101") => |
| | Some(Vector( |
| | Video("Interview With Cast", "interview", 480), |
| | Video("Gigli", "feature", 7260))) |
| | case _ => None |
| | } |
Bây giờ chúng ta có thể viết một hàm để lấy video yêu thích của người dùng bằng cách liên kết các lệnh gọi đến các hàm mà chúng ta đã định nghĩa trước đó trong một câu lệnh for.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/coo/Examples.scala | |
| | def getFavoriteVideos(userId: String) = |
| | for { |
| | user <- getUserById(userId) |
| | favoriteMovie <- getFavoriteMovieForUser(user) |
| | favoriteVideos <- getVideosForMovie(favoriteMovie) |
| | } yield favoriteVideos |
Nếu chúng ta gọi getFavoriteVideos với một ID người dùng hợp lệ, nó sẽ trả về danh sách các video yêu thích.
| | scala> getFavoriteVideos("1") |
| | res3: Option[scala.collection.immutable.Vector[...] = |
| | Some(Vector(Video(Interview With Cast,interview,480), |
| | Video(Gigli,feature,7260))) |
Nếu chúng ta gọi nó với một người dùng không tồn tại, toàn bộ chuỗi sẽ trả về None thay vào đó:
| | scala> getFavoriteVideos("42") |
| | res4: Option[scala.collection.immutable.Vector[...]] = None |
In Clojure
Vì Clojure không phải là ngôn ngữ kiểu tĩnh, nó không có bất cứ thứ gì giống như Option của Scala như một phần cốt lõi của ngôn ngữ.
Tuy nhiên, các biểu thức thứ tự trong Clojure hoạt động rất giống như trong Scala đối với các loại container khác. Ví dụ, chúng ta có thể sử dụng for để chọn nội dung của chúng và cộng chúng lại với nhau, như chúng ta đã làm trong ví dụ của Scala. Trong đoạn mã dưới đây, chúng ta làm chính xác như vậy:
| ClojureExamples/src/mbfpp/functional/coo/examples.clj | |
| | (def v1 [42]) |
| | (def v2 [8]) |
| | => (for [i1 v1 i2 v2] (+ i1 i2)) |
| | (50) |
Nếu một trong các vector của chúng ta là vector rỗng, thì cho sẽ tạo ra một dãy rỗng. Đoạn mã dưới đây minh họa:
| ClojureExamples/src/mbfpp/functional/coo/examples.clj | |
| | (def v3 []) |
| | => (for [i1 v1 i3 v3] (+ i1 i3)) |
| | () |
Mặc dù sự hiểu biết về chuỗi trong Clojure hoạt động tương tự như trong Scala, nhưng việc thiếu kiểu tĩnh và kiểu Option có nghĩa là kiểu chuỗi mà chúng ta thấy trong Scala không phải là cách sử dụng thông thường. Thay vào đó, chúng tôi thường dựa vào việc kết nối các hàm với các kiểm tra null rõ ràng.
Tính linh hoạt của Lisp cho phép thêm vào ngay cả những thứ cơ bản như một trình kiểm tra kiểu tĩnh dưới dạng thư viện. Một thư viện như vậy hiện đang trong quá trình phát triển trong thư viện core.typed, thư viện cung cấp kiểu tĩnh tùy chọn.
Khi thư viện này phát triển, kiểu chuỗi mà chúng ta thấy trong các ví dụ Scala có thể trở nên phổ biến hơn.
Discussion
Các ví dụ mà chúng ta đã thấy trong Mã mẫu: Kết nối Sử dụng Sự thông hiểu Dãy, là ví dụ về monad dãy hoặc monad danh sách. Trong khi chúng ta chưa định nghĩa chính xác monad là gì, chúng ta đã cho thấy một ví dụ cơ bản về loại vấn đề mà chúng có thể giải quyết. Chúng làm cho việc kết nối các phép toán trên một loại chứa trở nên tự nhiên trong khi thao tác dữ liệu bên trong của loại chứa đó.
Trong thế giới lập trình, monad thường được biết đến như một cách để đưa IO và các tính năng không thuần túy khác vào một ngôn ngữ lập trình thuần hàm. Từ những ví dụ mà chúng ta đã thấy ở trên, có thể không ngay lập tức rõ ràng rằng monad có mối liên hệ gì với IO trong một ngôn ngữ lập trình thuần hàm.
Vì cả Scala lẫn Clojure đều không sử dụng monad theo cách này, chúng tôi sẽ không đi sâu vào chi tiết ở đây. Tuy nhiên, lý do chung là loại container monadic có thể mang theo một số thông tin bổ sung thông qua chuỗi gọi. Chẳng hạn, một monad để thực hiện IO sẽ thu thập tất cả các IO được thực hiện qua Chuỗi Các Hoạt Động và sau đó chuyển nó cho một runtime khi hoàn tất. Runtime sau đó sẽ chịu trách nhiệm thực hiện IO.
Phong cách lập trình này được khởi xướng bởi Haskell. Người đọc tò mò có thể tìm thấy một hướng dẫn tuyệt vời về nó trong cuốn sách "Learn You a Haskell for Great Good!: A Beginner’s Guide" [Lip11].
For Further Reading
Hãy học Haskell để có điều tốt đẹp!: Hướng dẫn cho người mới bắt đầu
Related Patterns
Mẫu 4, Thay thế Builder cho Đối tượng Bất biến
Mẫu 5, Thay thế Iterator
Mô hình 14, Lọc-Bản đồ-Giảm
Mẫu 16, Trình tạo chức năng
| Pattern 16 | Function Builder |
Intent
Để tạo ra một hàm mà chính nó tạo ra các hàm, cho phép chúng ta tổng hợp hành vi ngay lập tức.
Overview
Đôi khi chúng ta có một hàm thực hiện một hành động hữu ích, và chúng ta cần một hàm thực hiện một hành động khác liên quan. Chúng ta có thể có một hàm kiểm tra nguyên âm (vowel?) trả về true khi một nguyên âm được truyền vào và cần một hàm kiểm tra phụ âm (consonant?) làm điều tương tự cho các phụ âm.
Đôi khi, chúng ta có một số dữ liệu mà chúng ta cần biến thành hành động. Chúng ta có thể có một tỷ lệ chiết khấu và cần một hàm có thể áp dụng chiết khấu đó cho một tập hợp các mặt hàng.
Với Trình xây dựng hàm, chúng ta viết một hàm nhận dữ liệu hoặc hàm của chúng ta (mặc dù, như chúng ta đã thấy, sự phân biệt giữa hàm và dữ liệu là không rõ ràng) và sử dụng nó để tạo ra một hàm mới.
Để sử dụng Function Builder, chúng ta viết một hàm bậc cao trả về một hàm. Triển khai Function Builder mã hóa một số mẫu mà chúng tôi đã phát hiện.
Ví dụ, để tạo ra một predicate phụ âm? từ predicate nguyên âm?, chúng ta tạo ra một hàm mới gọi đến nguyên âm? và phủ định kết quả. Để tạo ra lẻ? từ chẵn?, chúng ta tạo một hàm gọi đến chẵn? và phủ định kết quả. Để tạo ra chết? từ sống?, chúng ta tạo một hàm gọi đến chết? và phủ định kết quả.
Có một mẫu rõ ràng ở đây. Chúng ta có thể mã hóa nó bằng một triển khai Bộ xây dựng Hàm có tên là negate. Hàm negate nhận vào một hàm và trả về một hàm mới gọi hàm đã truyền vào và phủ định kết quả.
Một ứng dụng phổ biến khác cho Function Builder là khi chúng ta có một mảnh dữ liệu tĩnh cần sử dụng làm cơ sở cho một hành động nào đó. Ví dụ, chúng ta có thể chuyển đổi một tỷ lệ phần trăm tĩnh thành một hàm tính toán tỷ lệ phần trăm bằng cách viết một hàm nhận vào tỷ lệ phần trăm và trả về một hàm nhận một đối số. Hàm này nhận vào một số để tính toán tỷ lệ phần trăm của nó và sử dụng tỷ lệ phần trăm được lưu trữ trong closure của nó để thực hiện.
Chúng ta sẽ xem một số ví dụ về cả hai loại Function Builder một chút sau đây.
Code Sample: Functions from Static Data
Một cách để sử dụng Function Builder là tạo ra các hàm từ dữ liệu tĩnh. Điều này cho phép chúng ta lấy một ít dữ liệu—một danh từ—và biến nó thành một hành động—một động từ. Hãy cùng xem một vài ví dụ, bắt đầu với một hàm nhận vào một tỷ lệ phần trăm và tạo ra một hàm tính giá sau khi được giảm giá dựa trên những tỷ lệ phần trăm đó.
Discount Calculator Builder
Trình tạo Hàm giảm giá nhận vào một tỷ lệ phần trăm từ 0 đến 100 và trả về một hàm sẽ tính toán giá sau khi giảm giá dựa trên tỷ lệ đó. Khi truyền vào 50, giảm giá trả về một hàm tính giảm giá 50%, 25 sẽ giúp chúng ta giảm giá 25%, và cứ như thế. Hãy cùng xem phiên bản Scala.
Trong Scala
Mã Scala của chúng tôi định nghĩa discount, nhận vào một Double, tên là percent, và kiểm tra để đảm bảo rằng nó nằm trong khoảng từ 0 đến 100. Sau đó, nó tạo ra một hàm sử dụng discountPercentage để tính toán một khoản giảm giá. Dưới đây là mã nguồn:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/DiscountBuilder.scala | |
| | def discount(percent: Double) = { |
| | if(percent < 0.0 || percent > 100.0) |
| | throw new IllegalArgumentException("Discounts must be between 0.0 and 100.0.") |
| | (originalPrice: Double) => |
| | originalPrice - (originalPrice * percent * 0.01) |
| | } |
Hãy cùng xem nó hoạt động như thế nào. Cách đơn giản nhất để sử dụng giá cả giảm giá là để nó tạo ra một hàm ẩn danh, mà chúng ta gọi trực tiếp. Ở đây, chúng ta sử dụng nó để tính toán một mức giảm giá 50 phần trăm trên một giá 200:
| | scala> discount(50)(200) |
| | res0: Double = 100.0 |
Và ở đây chúng tôi sử dụng nó để tính toán giảm giá 0% (giá đầy đủ) và giảm giá 100% (miễn phí!), tương ứng:
| | scala> discount(0)(200) |
| | res1: Double = 200.0 |
| | |
| | scala> discount(100)(200) |
| | res2: Double = 0.0 |
Nếu chúng ta cần sử dụng hàm giảm giá nhiều hơn một lần, chúng ta có thể đặt tên cho nó. Ở đây chúng ta làm như vậy và sử dụng nó để tính tổng giá đã giảm trên một vài vectơ hàng hóa.
| | scala> val twentyFivePercentOff = discountedPrice(25) |
| | twentyFivePercentOff: Double => Double = <function1> |
| | |
| | scala> Vector(100.0, 25.0, 50.0, 25.0) map twentyFivePercentOff sum |
| | res3: Double = 150.0 |
| | |
| | scala> Vector(75.0, 25.0) map twentyFivePercentOff sum |
| | res4: Double = 75.0 |
Trong Clojure
Ví dụ này hoạt động tương tự như trong Clojure. Sự khác biệt thú vị duy nhất là chúng ta có thể sử dụng các điều kiện tiên quyết của Clojure để đảm bảo rằng mức giảm giá nằm trong phạm vi hợp lệ. Hãy cùng xem xét đoạn mã:
| ClojureExamples/src/mbfpp/functional/fb/discount_builder.clj | |
| | (defn discount [percentage] |
| | {:pre [(and (>= percentage 0) (<= percentage 100))]} |
| | (fn [price] (- price (* price percentage 0.01)))) |
Chúng tôi có thể tạo một mức giá giảm và gọi nó là một hàm ẩn danh:
| | => ((discount 50) 200) |
| | 100.0 |
Như đã quảng cáo, việc cố gắng tạo ra một mức giảm giá nằm ngoài phạm vi chấp nhận sẽ gây ra một ngoại lệ:
| | => (discount 101) |
| | AssertionError Assert failed: ... |
Nếu chúng ta muốn đặt tên cho hàm giảm giá của mình để sử dụng nhiều lần, chúng ta có thể làm như vậy:
| | => (def twenty-five-percent-off (discount 25)) |
| | => (apply + (map twenty-five-percent-off [100.0 25.0 50.0 25.0])) |
| | 150.0 |
| | => (apply + (map twenty-five-percent-off [75.0, 25.0])) |
| | 75.0 |
Máy tính giảm giá là một ví dụ khá đơn giản; chúng ta sẽ xem xét một ví dụ phức tạp hơn ở phần tiếp theo.
Map Key Selector
Hãy cùng xem xét một cách triển khai phức tạp hơn của Function Builder. Vấn đề mà chúng ta đang cố gắng giải quyết là: chúng ta có một cấu trúc dữ liệu bao gồm các bản đồ lồng ghép vào nhau, và chúng ta muốn tạo ra các hàm giúp chúng ta chọn ra các giá trị, có thể từ các phần lồng ghép sâu.
Theo một cách nào đó, điều này giống như viết một ngôn ngữ khai báo rất đơn giản để chọn các giá trị từ các bản đồ lồng ghép sâu. Điều này giống như cách mà XPath cho phép chúng ta chọn một phần tử tùy ý từ một cấu trúc XML lồng ghép sâu, hoặc cách mà bộ chọn CSS cho phép chúng ta làm điều tương tự với HTML.
Giải pháp của chúng tôi bắt đầu bằng cách tạo một hàm, selector, nhận một đường dẫn đến dữ liệu mà chúng tôi đang tìm kiếm. Ví dụ, nếu chúng tôi có một bản đồ đại diện cho một người, trong đó có một khóa name có giá trị là một bản đồ khác, chứa khóa first có giá trị là tên, chúng tôi muốn có khả năng tạo một selector cho tên đầu tiên như sau: selector(’name, ’first). Chúng tôi có thể thấy điều này trong mã dưới đây:
| | scala> val person = Map('name -> Map('first -> "Rob")) |
| | person: ... |
| | |
| | scala> val firstName = selector('name, 'first) |
| | firstName: scala.collection.immutable.Map[Symbol,Any] => Option[Any] = <function1> |
| | |
| | scala> firstName(person) |
| | res0: Option[Any] = Some(Rob) |
Cấu trúc này rất tiện lợi khi làm việc với dữ liệu có cấu trúc như XML hoặc JSON. Dữ liệu có thể được phân tích thành một cấu trúc lồng ghép, và loại Công cụ Tạo Hàm này có thể giúp tách nó ra.
Trong Scala
Phiên bản Scala của selector tạo ra các hàm có thể chọn giá trị từ các bản đồ lồng nhau sâu, như đã mô tả trước đó. Các selector mà nó tạo ra sẽ trả về Some(Any) nếu nó có thể tìm thấy giá trị lồng nhau; nếu không, nó sẽ trả về None.
Để tạo một bộ chọn, chúng ta cần truyền vào một số Symbol tương ứng với các khóa trong đường dẫn mà chúng ta muốn chọn. Vì đây là tất cả những gì chúng ta cần truyền vào selector, chúng ta có thể sử dụng hỗ trợ varargs của Scala thay vì truyền vào một danh sách rõ ràng; điều này có nghĩa là việc tạo một selector để chọn tên đường từ địa chỉ của một người trông như thế này:
| | scala> selector('address, 'street, 'name) |
| | res0: scala.collection.immutable.Map[Symbol,Any] => Option[Any] = <function1> |
Khi được tạo, một bản đồ sẽ được chuyển vào bộ lựa chọn, và nó cố gắng chọn một giá trị dựa trên đường dẫn mà nó đã được cung cấp khi được tạo ra bằng cách đệ quy đi qua bản đồ. Đây là một đoạn mã hơi phức tạp, vì vậy hãy xem xét toàn bộ nội dung và sau đó phân tích nó thành các phần nhỏ hơn:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/Selector.scala | |
| | def selector(path: Symbol*): (Map[Symbol, Any] => Option[Any]) = { |
| | |
| | if(path.size <= 0) throw new IllegalArgumentException("path must not be empty") |
| | |
| | @tailrec |
| | def selectorHelper(path: Seq[Symbol], ds: Map[Symbol, Any]): Option[Any] = |
| | if(path.size == 1) { |
| | ds.get(path(0)) |
| | }else{ |
| | val currentPiece = ds.get(path.head) |
| | currentPiece match { |
| | case Some(currentMap: Map[Symbol, Any]) => |
| | selectorHelper(path.tail, currentMap) |
| | case None => None |
| | case _ => None |
| | } |
| | } |
| | |
| | (ds: Map[Symbol, Any]) => selectorHelper(path.toSeq, ds) |
| | } |
Hãy bắt đầu bằng cách xem xét chữ ký của selector:
| | def selector(path: Symbol*): (Map[Symbol, Any] => Option[Any]) = { |
| | selector-body |
| | } |
Điều này có nghĩa là selector nhận một số lượng biến các đối số kiểu Symbol và trả về một hàm. Hàm mà nó trả về lại nhận một bản đồ từ Symbol đến Any và trả về một Option[Any].
Dòng đầu tiên chỉ đơn giản kiểm tra để đảm bảo rằng đường dẫn có ít nhất một phần tử và ném ra một ngoại lệ nếu không có.
| | if(path.size <= 0) throw new IllegalArgumentException("path must not be empty") |
Thịt của hàm là một hàm trợ giúp lồng nhau và đệ quy. Hãy xem xét chữ ký kiểu của nó:
| | @tailrec |
| | def selectorHelper(path: Seq[Symbol], ds: Map[Symbol, Any]): Option[Any] = |
| | selector-helper-body |
| | } |
`Điều này nói rằng selectorHelper nhận một chuỗi các Symbol như một đường dẫn và một cấu trúc dữ liệu bao gồm một bản đồ từ Symbol đến Any. Nó trả về một Option[Any], đại diện cho giá trị cuối cùng mà chúng ta đang cố gắng tìm với selector. Trong ví dụ ở trên, điều này sẽ là tên của con phố của một người.`
Tiếp theo, chúng ta có trường hợp cơ sở cho đệ quy của mình. Điều này xảy ra khi chúng ta đến cuối con đường. Chúng ta tìm thấy giá trị mà chúng ta đang tìm và trả về nó. Phương thức get trả về None nếu giá trị không tồn tại:
| | if(path.size == 1) { |
| | ds.get(path(0)) |
| | } |
Mảnh mã lớn nhất chứa lời gọi đệ quy đuôi. Ở đây, chúng ta lấy mảnh hiện tại của cấu trúc dữ liệu. Nếu nó tồn tại, chúng ta sẽ gọi hàm trợ giúp một cách đệ quy với phần còn lại của đường đi và cấu trúc dữ liệu mà chúng ta vừa chọn ra. Nếu nó không tồn tại, hoặc nếu nó không có kiểu đúng, chúng ta trả về None.
| | else{ |
| | val currentPiece = ds.get(path.first) |
| | currentPiece match { |
| | case Some(currentMap: Map[Symbol, Any]) => |
| | selectorHelper(path.tail, currentMap) |
| | case None => None |
| | case _ => None |
| | } |
| | } |
Cuối cùng, đây là dòng cuối cùng, chỉ trả về một hàm gọi selectorHelper với các đối số thích hợp:
| | (ds: Map[Symbol, Any]) => selectorHelper(path.toSeq, ds) |
Hãy cùng xem xét kỹ lưỡng cách chúng ta có thể sử dụng selector, bắt đầu với một ví dụ rất đơn giản, một bản đồ có một cặp khóa-giá trị duy nhất:
| | scala> val simplePerson = Map('name -> "Michael Bevilacqua-Linn") |
| | simplePerson: scala.collection.immutable.Map[Symbol,java.lang.String] = |
| | Map('name -> Michael Bevilacqua-Linn) |
| | |
| | scala> val name = selector('name) |
| | name: scala.collection.immutable.Map[Symbol,Any] => Option[Any] = <function1> |
| | |
| | scala> name(simplePerson) |
| | res0: Option[Any] = Some(Michael Bevilacqua-Linn) |
Tất nhiên, sức mạnh thực sự chỉ trở nên rõ ràng khi chúng ta bắt đầu làm việc với các cấu trúc dữ liệu lồng nhau, như thế này:
| | scala> val moreComplexPerson = |
| | Map('name -> Map('first -> "Michael", 'last -> "Bevilacqua-Linn")) |
| | moreComplexPerson: scala.collection.immutable.Map[...] = |
| | Map('name -> Map('first -> Michael, 'last -> Bevilacqua-Linn)) |
| | |
| | scala> val firstName = selector('name, 'first) |
| | firstName: scala.collection.immutable.Map[Symbol,Any] => Option[Any] = <function1> |
| | |
| | scala> firstName(moreComplexPerson) |
| | res1: Option[Any] = Some(Michael) |
Nếu bộ chọn không khớp với bất kỳ thứ gì, một giá trị None sẽ được trả về:
| | scala> val middleName = selector('name, 'middle) |
| | middleName: scala.collection.immutable.Map[Symbol,Any] => Option[Any] = <function1> |
| | |
| | scala> middleName(moreComplexPerson) |
| | res2: Option[Any] = None |
Trong Clojure
Phiên bản Clojure của selector đơn giản hơn nhiều so với phiên bản Scala. Một phần là vì Clojure được gán kiểu động, vì vậy chúng ta không phải lo lắng về hệ thống kiểu như chúng ta đã làm trong Scala. Thêm vào đó, Clojure có một hàm tiện lợi gọi là get-in, được thiết kế riêng để lấy giá trị từ các bản đồ lồng nhau sâu.
Hãy cùng xem qua hàm get-in trước khi chúng ta đào sâu vào mã. Hàm get-in nhận một bản đồ lồng ghép làm tham số đầu tiên và một chuỗi đại diện cho đường dẫn đến giá trị mà bạn đang tìm kiếm. Dưới đây là một ví dụ về việc sử dụng nó để lấy tên đường từ một bản đồ lồng ghép:
| | => (def person {:address {:street {:name "Fake St."}}}) |
| | #'mbfpp.functional.fb.selector/person |
| | => (get-in person [:address :street :name]) |
| | "Fake St." |
Việc xây dựng bộ chọn trên get-in là vô cùng đơn giản. Chúng ta chỉ cần thêm một bộ xác thực để đảm bảo rằng đường dẫn không trống và sử dụng varargs cho đường dẫn. Dưới đây là mã:
| ClojureExamples/src/mbfpp/functional/fb/selector.clj | |
| | (defn selector [& path] |
| | {:pre [(not (empty? path))]} |
| | (fn [ds] (get-in ds path))) |
Sử dụng nó dễ dàng như phiên bản Scala. Ở đây, chúng tôi chọn một cái tên từ một bản đồ phẳng:
| | => (def person {:name "Michael Bevilacqua-Linn"}) |
| | #'mbfpp.functional.fb.selector/person |
| | => (def personName (selector :name)) |
| | #'mbfpp.functional.fb.selector/personName |
| | => (personName person) |
| | "Michael Bevilacqua-Linn" |
Và ở đây chúng ta chọn một tên đường từ một tên đường ở vị trí sâu hơn:
| | => (def person {:address {:street {:name "Fake St."}}}) |
| | #'mbfpp.functional.fb.selector/person |
| | => (def streetName (selector :address :street :name)) |
| | #'mbfpp.functional.fb.selector/streetName |
| | => (streetName person) |
| | "Fake St." |
Trước khi chúng ta tiếp tục, đây là một ghi chú nhanh về độ phức tạp tương đối giữa các phiên bản Scala và Clojure của ví dụ này. Thực tế là Clojure có hàm get-in, thực hiện gần như chính xác những gì chúng ta muốn, giúp cho phiên bản Clojure ngắn gọn hơn rất nhiều. Yếu tố khác là Clojure là một ngôn ngữ kiểu động. Bởi vì các bản đồ lồng nhau có thể chứa giá trị của bất kỳ loại nào, điều này đòi hỏi một số động tác với hệ thống kiểu để xử lý trong Scala, ngôn ngữ có kiểu tĩnh.
Trong Clojure, việc sử dụng các bản đồ để lưu giữ dữ liệu như thế này là rất điển hình. Trong Scala, thường thì người ta sẽ sử dụng các lớp hoặc lớp trường hợp (case classes). Tuy nhiên, đối với loại vấn đề rất động này, tôi thích giữ mọi thứ trong một bản đồ hơn. Việc sử dụng bản đồ có nghĩa là chúng ta có thể thao tác với cấu trúc dữ liệu bằng tất cả các công cụ tích hợp sẵn để thao tác với bản đồ và tập hợp.
Functions from Other Functions
Bởi vì các hàm trong thế giới hàm là những phần dữ liệu có thể được thao tác, nên thường sử dụng Function Builder để biến đổi một hàm thành một hàm khác. Điều này có thể được thực hiện rất dễ dàng bằng cách tạo một hàm mới thao tác trên giá trị trả về của một hàm khác. Chẳng hạn, nếu chúng ta có một hàm isVowel và chúng ta muốn có một hàm isNotVowel, chúng ta có thể đơn giản ủy quyền cho isVowel và phủ định kết quả. Điều này tạo ra một hàm bổ sung, như mã Scala cho thấy:
| | scala> def isNotVowel(c: Char) = !isVowel(c) |
| | isNotVowel: (c: Char)Boolean |
| | |
| | scala> isNotVowel('b') |
| | res0: Boolean = true |
Trong ví dụ này, chúng ta sẽ xem xét kỹ lưỡng hai cách khác để tạo ra các hàm từ các hàm có sẵn: hợp thành hàm và ứng dụng một phần hàm. Hợp thành hàm cho phép chúng ta lấy nhiều hàm và kết hợp chúng lại với nhau. Ứng dụng một phần hàm cho phép chúng ta lấy một hàm và một số đối số của nó để tạo ra một hàm mới với ít đối số hơn. Đây là hai trong số những cách hữu ích nhất để tạo ra các hàm từ các hàm khác.
Function Composition
Tổ hợp hàm là cách để kết hợp các lời gọi hàm lại với nhau. Kết hợp một danh sách các hàm lại với nhau sẽ cho chúng ta một hàm mới, hàm này gọi hàm đầu tiên, truyền đầu ra của nó cho hàm tiếp theo, hàm đó lại truyền cho hàm tiếp theo, và cứ tiếp tục như vậy cho đến khi có kết quả được trả về.
Theo nhiều cách, thành phần hàm tương tự như cách mà Mẫu 9, Thay thế Decorator, được sử dụng. Với mẫu Decorator, nhiều decorator được xâu chuỗi lại với nhau, mỗi cái thực hiện một phần của một tác vụ nào đó. Ở đây, nhiều hàm được xâu chuỗi lại với nhau.
Có thể sử dụng hợp thành hàm bằng cách đơn giản là kết nối các hàm với nhau bằng tay, nhưng vì đây là một tác vụ rất phổ biến, các ngôn ngữ lập trình hàm cung cấp hỗ trợ hạng nhất cho nó. Clojure và Scala cũng không phải là ngoại lệ, vì vậy hãy cùng xem xét điều này.
Trong Scala
Trong Scala, chúng ta có thể ghép các hàm lại với nhau bằng toán tử compose. Như một ví dụ đơn giản, hãy định nghĩa ba hàm, appendA, appendB và appendC, mà lần lượt thêm các chuỗi "a", "b" và "c", như mã nguồn cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/CompositionExamples.scala | |
| | val appendA = (s: String) => s + "a" |
| | val appendB = (s: String) => s + "b" |
| | val appendC = (s: String) => s + "c" |
Bây giờ nếu chúng ta muốn một hàm nối tất cả ba chữ cái lại với nhau, chúng ta có thể định nghĩa nó như sau bằng cách sử dụng phép hợp thành hàm:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/CompositionExamples.scala | |
| | val appendCBA = appendA compose appendB compose appendC |
Như tên gọi cho thấy, điều này bổ sung các chữ cái c, b và a theo thứ tự đó. Nó tương đương với việc viết một hàm nhận một đối số, truyền nó vào appendC, lấy giá trị trả về và truyền nó vào appendB, và cuối cùng truyền giá trị trả về đó vào appendA:
| | scala> appendCBA("z") |
| | res0: java.lang.String = zcba |
Đây là một ví dụ đơn giản, nhưng nó minh họa một điều quan trọng về phép hợp thành hàm, đó là thứ tự mà các hàm được hợp thành được gọi. Hàm cuối cùng trong chuỗi hợp thành được gọi trước, và hàm đầu tiên được gọi sau cùng, đó là lý do tại sao chữ c là chữ cái đầu tiên được thêm vào chuỗi của chúng ta.
Hãy cùng xem một ví dụ phức tạp hơn. Một tình huống phổ biến xuất hiện trong các framework ứng dụng web là sự cần thiết phải chuyển một yêu cầu HTTP qua một loạt các đoạn mã do người dùng định nghĩa. Bộ lọc servlet của J2EE, vốn chuyển yêu cầu qua một chuỗi các bộ lọc trước khi được xử lý, là một ví dụ điển hình cho chuỗi bộ lọc như vậy.
Chuỗi bộ lọc cho phép mã ứng dụng thực hiện bất kỳ thao tác nào cần thiết trước khi xử lý yêu cầu, như giải mã và giải nén yêu cầu, kiểm tra thông tin xác thực của người dùng, ghi vào nhật ký yêu cầu, và nhiều thứ khác. Hãy phác thảo cách chúng ta sẽ thực hiện điều này bằng cách kết hợp các hàm. Đầu tiên, chúng ta sẽ cần một cách để đại diện cho các yêu cầu HTTP. Để phục vụ cho ví dụ này, chúng ta sẽ giữ cho nó đơn giản và chỉ sử dụng một bảng các tiêu đề yêu cầu và một chuỗi nội dung yêu cầu:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/CompositionExamples.scala | |
| | case class HttpRequest( |
| | headers: Map[String, String], |
| | payload: String, |
| | principal: Option[String] = None) |
Tiếp theo, hãy xác định một số bộ lọc. Mỗi bộ lọc là một hàm nhận vào một HttpRequest, thực hiện một số thao tác, và trả về một HttpRequest. Đối với ví dụ đơn giản này, chúng ta trả về cùng một HttpRequest; nhưng nếu bộ lọc cần sửa đổi hoặc thêm thông tin gì đó vào yêu cầu, nó có thể thực hiện điều đó bằng cách tạo một HttpRequest mới với các sửa đổi của nó.
Dưới đây là một vài bộ lọc ví dụ - cái đầu tiên giả lập việc kiểm tra tiêu đề Authorization và thêm một nguyên tắc người dùng vào yêu cầu nếu nó hợp lệ, và cái thứ hai giả lập việc ghi lại dấu vết yêu cầu để khắc phục sự cố:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/CompositionExamples.scala | |
| | def checkAuthorization(request: HttpRequest) = { |
| | val authHeader = request.headers.get("Authorization") |
| | val mockPrincipal = authHeader match { |
| | case Some(headerValue) => Some("AUser") |
| | case _ => None |
| | } |
| | request.copy(principal = mockPrincipal) |
| | } |
| | |
| | def logFingerprint(request: HttpRequest) = { |
| | val fingerprint = request.headers.getOrElse("X-RequestFingerprint", "") |
| | println("FINGERPRINT=" + fingerprint) |
| | request |
| | } |
Cuối cùng, chúng ta cần một hàm nhận một chuỗi bộ lọc và kết hợp chúng lại với nhau. Chúng ta có thể làm điều này bằng cách đơn giản là giảm hàm kết hợp qua chuỗi.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/CompositionExamples.scala | |
| | def composeFilters(filters: Seq[Function1[HttpRequest, HttpRequest]]) = |
| | filters.reduce { |
| | (allFilters, currentFilter) => allFilters compose currentFilter |
| | } |
Hãy xem nó hoạt động bằng cách kết hợp các bộ lọc mẫu thành một chuỗi bộ lọc duy nhất và chạy một yêu cầu HttpRequest qua nó:
| | scala> val filters = Vector(checkAuthorization, logFingerprint) |
| | filters: ... |
| | |
| | scala> val filterChain = composeFilters(filters) |
| | filterChain: ... |
| | |
| | scala> val requestHeaders = |
| | Map("Authorization" -> "Auth", "X-RequestFingerprint" -> "fingerprint") |
| | requestHeaders: ... |
| | |
| | scala> val request = HttpRequest(requestHeaders, "body") |
| | request: ... |
| | |
| | scala> filterChain(request) |
| | FINGERPRINT=fingerprint |
| | res0: com.mblinn.mbfpp.functional.fb.ScalaExamples.HttpRequest = |
| | HttpRequest( |
| | Map(Authorization -> Auth, X-RequestFingerprint -> fingerprint), |
| | body, |
| | Some(AUser)) |
Như chúng ta có thể thấy, chuỗi bộ lọc chạy đúng cách đối tượng HttpRequest qua từng bộ lọc trong chuỗi, điều này thêm một người dùng chính vào yêu cầu và ghi lại dấu vân tay của chúng ta vào bảng điều khiển.
Trong Clojure
Cách dễ nhất để thực hiện phép hợp nhất hàm trong Clojure là sử dụng comp. Ở đây, chúng ta đang sử dụng nó để hợp nhất các hàm kết nối chuỗi lại với nhau:
| ClojureExamples/src/mbfpp/functional/fb/composition_examples.clj | |
| | (defn append-a [s] (str s "a")) |
| | (defn append-b [s] (str s "b")) |
| | (defn append-c [s] (str s "c")) |
| | |
| | (def append-cba (comp append-a append-b append-c)) |
Điều này hoạt động tương tự như phiên bản Scala:
| | => (append-cba "z") |
| | "zcba" |
Trong Clojure, chúng ta sẽ mô hình hóa yêu cầu HTTP cũng như các tiêu đề dưới dạng một bản đồ. Một yêu cầu mẫu trông như sau:
| ClojureExamples/src/mbfpp/functional/fb/composition_examples.clj | |
| | (def request |
| | {:headers |
| | {"Authorization" "auth" |
| | "X-RequestFingerprint" "fingerprint"} |
| | :body "body"}) |
Các hàm bộ lọc mẫu của chúng tôi chọn các khóa từ một bản đồ và sử dụng nil thay cho None để đại diện cho các giá trị bị thiếu. Dưới đây là chúng, cùng với bộ tạo hàm, compose-filters, để kết hợp chúng thành một chuỗi bộ lọc:
| ClojureExamples/src/mbfpp/functional/fb/composition_examples.clj | |
| | (defn check-authorization [request] |
| | (let [auth-header (get-in request [:headers "Authorization"])] |
| | (assoc |
| | request |
| | :principal |
| | (if-not (nil? auth-header) |
| | "AUser")))) |
| | |
| | (defn log-fingerprint [request] |
| | (let [fingerprint (get-in request [:headers "X-RequestFingerprint"])] |
| | (println (str "FINGERPRINT=" fingerprint)) |
| | request)) |
| | |
| | (defn compose-filters [filters] |
| | (reduce |
| | (fn [all-filters, current-filter] (comp all-filters current-filter)) |
| | filters)) |
Và đây là chuỗi bộ lọc đang hoạt động, chạy qua các bộ lọc, thực hiện chúng và cuối cùng trả lại yêu cầu HTTP.
| | => (def filter-chain (compose-filters [check-authorization log-fingerprint])) |
| | #'mbfpp.functional.fb.composition-examples/filter-chain |
| | => (filter-chain request) |
| | FINGERPRINT=fingerprint |
| | {:principal "AUser", |
| | :headers {"X-RequestFingerprint" "fingerprint", "Authorization" "auth"}, |
| | :body "body"} |
Biến đổi hàm là một phép toán rất tổng quát, và chúng ta chỉ mới chạm đến một vài ứng dụng của nó ở đây. Bất cứ khi nào bạn thấy mình gọi cùng một tập hợp các hàm theo cùng một thứ tự nhiều lần, hoặc bạn có một danh sách các hàm được tạo động cần được kết hợp với nhau, biến đổi hàm là một giải pháp tốt để xem xét.
Partially Applied Functions
Trong khi hợp thành hàm kết hợp nhiều hàm lại với nhau, việc áp dụng một phần của hàm chỉ lấy một hàm và một tập hợp con của các đối số mà hàm đó nhận, sau đó trả về một hàm mới. Hàm mới này có ít đối số hơn hàm gốc và giữ lại tập hợp con đã được truyền vào khi hàm được áp dụng một phần được tạo ra, để có thể sử dụng chúng sau này khi nhận được phần còn lại của các đối số.
Hãy xem nó hoạt động như thế nào trong Scala.
Trong Scala
Ứng dụng một phần của hàm là một tính năng hàm khác quan trọng đủ để được hỗ trợ chính thức trong Scala. Cách mà nó hoạt động là bạn gọi một hàm và thay thế các tham số mà bạn hiện không có giá trị bằng dấu gạch dưới. Ví dụ, nếu chúng ta có một hàm cộng hai số nguyên lại với nhau và chúng ta muốn một hàm cộng 42 với một số nguyên duy nhất, chúng ta có thể tạo nó như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/PartialExamples.scala | |
| | def addTwoInts(intOne: Int, intTwo: Int) = intOne + intTwo |
| | |
| | val addFortyTwo = addTwoInts(42, _: Int) |
Như mã dưới đây cho thấy, addFortyTwo là một hàm có một đối số, mà hàm này cộng 42 vào đối số đó.
| | scala> addFortyTwo(100) |
| | res0: Int = 142 |
Việc tạo ra các hàm áp dụng một phần là đơn giản, nhưng việc nhận ra khi nào sử dụng chúng có thể hơi khó khăn. Dưới đây là một ví dụ mà chúng rất hữu ích. Giả sử chúng ta có một hàm tính thuế thu nhập theo tiểu bang, và chúng ta muốn tạo ra các hàm cho phép chúng ta tính thuế thu nhập cho một tiểu bang cụ thể. Chúng ta có thể sử dụng một hàm áp dụng một phần để thực hiện việc này, như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fb/PartialExamples.scala | |
| | def taxForState(amount: Double, state: Symbol) = state match { |
| | // Simple tax logic, for example only! |
| | case ('NY) => amount * 0.0645 |
| | case ('PA) => amount * 0.045 |
| | // Rest of states... |
| | } |
| | val nyTax = taxForState(_: Double, 'NY) |
| | val paTax = taxForState(_: Double, 'PA) |
Điều này tính thuế cho các bang khác nhau một cách chính xác:
| | scala> nyTax(100) |
| | res0: Double = 6.45 |
| | |
| | scala> paTax(100) |
| | res1: Double = 4.5 |
Trong Clojure
Áp dụng một phần các hàm trong Clojure tương tự như cách thực hiện trong Scala, nhưng có một điểm khác. Để giữ cho cú pháp đơn giản, Clojure chỉ cho phép các tham số mà hàm đang được áp dụng một phần xuất hiện ở đầu danh sách tham số. Ví dụ, chúng ta vẫn có thể viết add-forty-two, giống như cách chúng ta đã làm trong Scala, như đoạn mã này cho thấy:
| ClojureExamples/src/mbfpp/functional/fb/partial_examples.clj | |
| | (defn add-two-ints [int-one int-two] (+ int-one int-two)) |
| | |
| | (def add-fourty-two (partial add-two-ints 42)) |
| | => (add-forty-two 100) |
| | 142 |
Nhưng để viết ny-tax và pa-tax, chúng ta sẽ phải hoán đổi các đối số của tax-for-state lại với nhau, như thế này:
| ClojureExamples/src/mbfpp/functional/fb/partial_examples.clj | |
| | (defn tax-for-state [state amount] |
| | (cond |
| | (= :ny state) (* amount 0.0645) |
| | (= :pa state) (* amount 0.045))) |
| | |
| | (def ny-tax (partial tax-for-state :ny)) |
| | (def pa-tax (partial tax-for-state :pa)) |
| | => (ny-tax 100) |
| | 6.45 |
| | => (pa-tax 100) |
| | 4.5 |
Các hàm được áp dụng một phần rất dễ sử dụng, nhưng tôi thường cảm thấy hơi khó khăn khi biết khi nào nên sử dụng chúng. Tôi thường bắt gặp mình gọi cùng một hàm lặp đi lặp lại, với một tập hợp các đối số vẫn giữ nguyên. Rồi một ý tưởng nảy ra và tôi nhận ra rằng tôi có thể làm cho điều đó gọn gàng hơn một chút bằng cách sử dụng một hàm được áp dụng một phần.
Discussion
Trong phần này, chúng tôi đã đề cập đến một số cách tổng quát hơn để sử dụng Function Builder, nhưng đây không phải là những cách duy nhất. Thư viện Clojure và Scala chứa nhiều ví dụ khác, vì đây là một mẫu rất phổ biến trong thế giới hàm.
Trong khi hầu hết các ví dụ về Clojure và Scala rất giống nhau, các ví dụ trong phần Chọn Khóa Bản Đồ lại khác biệt rõ rệt. Cụ thể, phiên bản Scala đã dài dòng hơn rất nhiều. Một phần nguyên nhân là do Clojure có một hàm rất tiện lợi là get-in thực hiện gần như chính xác những gì chúng ta cần; tuy nhiên, một phần lớn sự khác biệt là do hệ thống kiểu của Scala.
Vì Scala là ngôn ngữ kiểu tĩnh, chúng tôi phải chỉ định kiểu cho nội dung của các bản đồ mà chúng tôi xử lý. Các nút nội bộ là các bản đồ, trong khi các nút lá có thể là bất kỳ thứ gì. Điều này dẫn đến một chút phức tạp trong hệ thống kiểu mà chúng tôi phải thực hiện trong phiên bản Scala.
Đây là một sự đánh đổi tổng quát giữa kiểu tĩnh và kiểu động. Ngay cả với một hệ thống kiểu mạnh mẽ như của Scala, vẫn có chi phí cho việc kiểu tĩnh xét về độ phức tạp mà nó có thể tạo ra và chỉ để hiểu cách mà hệ thống kiểu hoạt động. Sự đánh đổi là chúng ta có thể phát hiện nhiều lỗi tại thời điểm biên dịch mà nếu không sẽ trở thành lỗi thời gian chạy với một hệ thống kiểu động.
Related Patterns
Mẫu 1, Thay thế Giao diện Chức năng
Mẫu 9, Thay thế Trang trí
| Pattern 17 | Memoization |
Intent
Để lưu trữ kết quả của một cuộc gọi hàm thuần túy nhằm tránh thực hiện cùng một phép tính nhiều hơn một lần.
Overview
Vì các hàm thuần túy luôn trả về cùng một giá trị cho các đối số nhất định, nên có thể thay thế một lời gọi hàm thuần túy bằng các kết quả đã được lưu trữ.
Chúng ta có thể thực hiện điều này một cách thủ công bằng cách viết một hàm lưu giữ các tham số trước đó của nó. Khi được gọi, nó sẽ kiểm tra bộ nhớ cache của mình để xem liệu nó đã được gọi với các tham số đã truyền vào hay chưa. Nếu có, nó sẽ trả về giá trị đã được lưu cache. Ngược lại, nó sẽ thực hiện phép tính.
Một số ngôn ngữ cung cấp hỗ trợ đầu tiên cho Memorization bằng cách sử dụng các hàm bậc cao. Clojure, chẳng hạn, có một hàm gọi là memoize nhận một hàm và trả về một hàm mới sẽ lưu trữ kết quả. Scala không có hàm memoization tích hợp sẵn, vì vậy chúng ta sẽ sử dụng một triển khai thủ công đơn giản.
Sample Code: Simple Caching
Một ứng dụng của Memoization là làm bộ nhớ đệm đơn giản cho các hàm tốn kém hoặc mất thời gian, đặc biệt khi hàm đó được gọi nhiều lần với cùng một tham số. Trong ví dụ này, chúng ta sẽ mô phỏng thao tác mất thời gian bằng cách cho nó tạm dừng luồng.
In Scala
Hãy bắt đầu với việc xem xét cuộc gọi hàm tốn kém mô phỏng của chúng ta. Làm ví dụ, chúng ta sử dụng một tra cứu theo ID từ một kho dữ liệu nào đó (có khả năng chậm). Để giả lập điều đó ở đây, chúng ta làm ngưng luồng trong một giây trước khi trả về giá trị từ một bản đồ tĩnh. Chúng ta cũng in ID mà chúng ta đang tra cứu ra console để minh họa khi nào hàm đang được thực thi:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/memoization/Examples.scala | |
| | def expensiveLookup(id: Int) = { |
| | Thread.sleep(1000) |
| | println(s"Doing expensive lookup for $id") |
| | Map(42 -> "foo", 12 -> "bar", 1 -> "baz").get(id) |
| | } |
Cũng như chúng ta mong đợi, hàm dài được thực thi mỗi lần chúng ta gọi nó, như chúng ta có thể thấy từ đầu ra trên bảng điều khiển:
| | scala> expensiveLookup(42) |
| | Doing expensive lookup for 42 |
| | res0: Option[String] = Some(foo) |
| | |
| | scala> expensiveLookup(42) |
| | Doing expensive lookup for 42 |
| | res1: Option[String] = Some(foo) |
Bây giờ hãy xem xét một phiên bản ghi nhớ đơn giản của expensiveLookup. Để tạo ra nó, chúng ta sẽ sử dụng memoizeExpensiveLookup, khởi tạo một bộ nhớ đệm và trả về một hàm mới bọc các cuộc gọi đến memoizeExpensiveFunction.
Hàm mới đầu tiên kiểm tra bộ nhớ cache của nó để xem có kết quả từ một cuộc gọi hàm trước đó hay không. Nếu có, nó trả về các kết quả đã lưu trong bộ nhớ. Ngược lại, nó thực hiện tìm kiếm tốn kém và lưu trữ các kết quả trước khi trả về chúng.
Cuối cùng, chúng ta gọi memoizeExpensiveFunction và lưu trữ một tham chiếu đến hàm mà nó trả về vào một biến mới. Giải pháp đầy đủ có trong mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/memoization/Examples.scala | |
| | def memoizeExpensiveLookup() = { |
| | var cache = Map[Int, Option[String]]() |
| | (id: Int) => |
| | cache.get(id) match { |
| | case Some(result: Option[String]) => result |
| | case None => { |
| | val result = expensiveLookup(id) |
| | cache += id -> result |
| | result |
| | } |
| | } |
| | } |
| | val memoizedExpensiveLookup = memoizeExpensiveLookup |
Như chúng ta có thể thấy từ đầu ra REPL sau đây, hàm tốn kém chỉ được gọi lần đầu tiên cho một đối số nhất định. Sau đó, nó trả về bản sao đã được lưu trữ.
| | scala> memoizedExpensiveLookup(42) |
| | Doing expensive lookup for 42 |
| | res2: Option[String] = Some(foo) |
| | |
| | scala> memoizedExpensiveLookup(42) |
| | res3: Option[String] = Some(foo) |
Một điều kỳ quặc với ví dụ này là ở dòng cuối cùng:
| | val memoizedExpensiveLookup = memoizeExpensiveLookup |
Ở đây, chúng tôi đang có memoizeExpensiveLookup trả về một hàm mới, và chúng tôi đang lưu giữ một tham chiếu đến nó. Điều này cho phép chúng tôi đóng gói bộ nhớ cache trong một closure để chỉ có hàm mới có tham chiếu đến nó. Nếu chúng tôi cần một bộ nhớ cache khác, chúng tôi có thể tạo nó như sau:
| | scala> val memoizedExpensiveLookup2 = memoizeExpensiveLookup |
| | memoizedExpensiveLookup2: Int => Option[String] = <function1> |
| | |
| | scala> memoizedExpensiveLookup2(42) |
| | Doing expensive lookup for 42 |
| | res4: Option[String] = Some(foo) |
Giải pháp Scala của chúng tôi có một chút vụng về vì chúng tôi đã thực hiện nó một cách thủ công cho một trường hợp cụ thể, nhưng nó phục vụ như một mô hình tốt cho cách mà memoization hoạt động ở hậu trường. Hãy cùng xem cách chúng tôi có thể sử dụng hàm memoize của Clojure để giải quyết cùng một vấn đề.
In Clojure
Trong Clojure, chúng ta sẽ bắt đầu với một hàm giả lập tốn kém tương tự. Tuy nhiên, chúng ta sẽ không ghi nhớ nó một cách thủ công. Thay vào đó, chúng ta sẽ sử dụng hàm memoize của Clojure để tự động trả về phiên bản đã được ghi nhớ của hàm, như mã này cho thấy:
| ClojureExamples/src/mbfpp/functional/memoization/examples.clj | |
| | (defn expensive-lookup [id] |
| | (Thread/sleep 1000) |
| | (println (str "Lookup for " id)) |
| | ({42 "foo" 12 "bar" 1 "baz"} id)) |
| | |
| | (def memoized-expensive-lookup |
| | (memoize expensive-lookup)) |
Như chúng ta có thể thấy từ đầu ra REPL sau đây, nó hoạt động tương tự như phiên bản Scala và chỉ thực hiện thao tác tốn kém một lần.
| | => (memoized-expensive-lookup 42) |
| | Lookup for 42 |
| | "foo" |
| | => (memoized-expensive-lookup 42) |
| | "foo" |
Ở hậu trường, hàm memoize tạo ra một hàm mới giống như ví dụ thủ công mà chúng ta đã thấy trong Scala, sử dụng một bản đồ làm bộ nhớ đệm.
Discussion
Một ứng dụng của phương pháp Memoization mà chúng tôi chưa đề cập đến ở đây là trong việc giải quyết các bài toán lập trình động, đây là một trong những ứng dụng ban đầu của nó. Các bài toán lập trình động là những bài toán có thể được phân tách thành các bài toán con đơn giản hơn theo cách đệ quy. Một ví dụ cổ điển, dễ hiểu là tính toán một số Fibonacci.
Công thức để tính số Fibonacci thứ n cộng hai số trước đó trong chuỗi. Một hàm Clojure đơn giản để tính một số Fibonacci theo định nghĩa này như sau:
| ClojureExamples/src/mbfpp/functional/memoization/examples.clj | |
| | (def slow-fib |
| | (fn [n] |
| | (cond |
| | (<= n 0) 0 |
| | (< n 2) 1 |
| | :else (+ (slow-fib (- n 1)) (slow-fib (- n 2)))))) |
Điều thú vị về hàm này là nó phản ánh định nghĩa toán học. Tuy nhiên, nó cần phải tính toán đệ quy các phần con của nó một cách lặp đi lặp lại, vì vậy hiệu suất của nó rất kém đối với ngay cả những số lớn vừa phải. Nếu chúng ta lưu trữ (memoize) hàm, như chúng ta làm trong mã sau, thì các phần con được lưu vào bộ nhớ đệm và hàm có thể hoạt động hợp lý.
| ClojureExamples/src/mbfpp/functional/memoization/examples.clj | |
| | (def mem-fib |
| | (memoize |
| | (fn [n] |
| | (cond |
| | (<= n 0) 0 |
| | (< n 2) 1 |
| | :else (+ (mem-fib (- n 1)) (mem-fib (- n 2))))))) |
Chạy hai hàm cho thấy sự khác biệt lớn về hiệu suất:
| | => (time (slow-fib 40)) |
| | "Elapsed time: 6689.204 msecs" |
| | 102334155 |
| | => (time (mem-fib 40)) |
| | "Elapsed time: 0.402 msecs" |
| | 102334155 |
Các bài toán lập trình động rất phong phú và hấp dẫn; tuy nhiên, chúng chỉ xuất hiện trong một số lĩnh vực hạn chế. Tôi thường thấy việc ghi nhớ được sử dụng như một bộ nhớ đệm đơn giản, tiện lợi cho các phép toán tốn kém hoặc lâu dài hơn là như một công cụ lập trình động.
| Pattern 18 | Lazy Sequence |
Intent
Để tạo ra một chuỗi mà các phần tử được tính toán chỉ khi cần thiết - điều này cho phép chúng ta dễ dàng phát dữ liệu từ một phép tính và làm việc với các chuỗi vô hạn.
Overview
Chúng ta thường xử lý các phần tử của một chuỗi một lần tại một thời điểm. Vì vậy, chúng ta thường không cần phải có toàn bộ chuỗi được hiện thực hóa trước khi bắt đầu xử lý. Ví dụ, chúng ta có thể muốn truyền dòng của một tệp từ đĩa và xử lý chúng mà không bao giờ giữ toàn bộ tệp trong bộ nhớ. Chúng ta có thể sử dụng Mẫu 12, Đệ quy đuôi, để tìm kiếm qua tệp, nhưng Chuỗi lười cung cấp một sự trừu tượng sạch hơn cho loại tính toán phát trực tiếp này.
Chuỗi lười chỉ tạo một phần tử trong chuỗi khi nó được yêu cầu. Trong ví dụ đọc tệp, các dòng chỉ được đọc từ đĩa khi được yêu cầu, và chúng có thể được thu gom rác khi chúng ta hoàn thành việc xử lý, mặc dù chúng ta cần phải cẩn thận một chút để đảm bảo rằng điều đó xảy ra.
Khi chúng ta tạo ra một phần tử, chúng ta gọi đó là việc **hiện thực hóa** phần tử. Một khi đã được hiện thực hóa, các phần tử sẽ được đưa vào bộ nhớ đệm bằng cách sử dụng Mô hình 17, **Ghi nhớ**, có nghĩa là chúng ta chỉ cần hiện thực hóa mỗi phần tử trong chuỗi một lần. Điều này được minh họa trong Hình 13, **Chuỗi lười biếng**.
Figure 13. Lazy Sequence. An instance of Lazy Sequence before and after the third element has been realized.
Chuỗi Lười cũng cho phép chúng ta tạo ra một trừu tượng cực kỳ hữu ích: một chuỗi vô hạn. Điều này có thể không có vẻ hữu ích ngay từ cái nhìn đầu tiên, nhưng vì toàn bộ chuỗi không được hiện thực hóa cùng một lúc, chúng ta có thể làm việc với phần đầu của chuỗi và hoãn lại việc tạo ra phần còn lại. Điều này cho phép chúng ta tạo ra, chẳng hạn, một chuỗi số pseudo ngẫu nhiên vô hạn mà chúng ta chỉ hiện thực hóa một phần.
Sample Code: Built-In Lazy Sequences
Hãy bắt đầu với một vài ví dụ đơn giản từ thư viện tích hợp sẵn. Trong ví dụ đầu tiên, chúng ta sẽ thể hiện cách làm việc với một danh sách số nguyên vô hạn. Trong ví dụ thứ hai, chúng ta sẽ cho thấy cách sử dụng Dãy Lười để tạo ra một chuỗi dữ liệu thử nghiệm ngẫu nhiên.
Hãy bắt đầu với việc khám phá mã Scala.
In Scala
Scala có hỗ trợ tích hợp cho Chuỗi Lười trong thư viện Stream của nó. Có lẽ điều đơn giản nhất mà chúng ta có thể làm với một chuỗi lười là tạo ra một chuỗi vô hạn của tất cả các số nguyên. Thư viện Stream của Scala có một phương thức thực hiện chính xác điều đó, gọi là from . Theo tài liệu ScalaDoc, nó sẽ “tạo ra một dòng vô hạn bắt đầu từ giá trị bắt đầu và tăng thêm bước nhảy.”
Ở đây, chúng tôi sử dụng từ để tạo ra một chuỗi tất cả các số nguyên, bắt đầu từ 0:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ls/LazySequence.scala | |
| | val integers = Stream.from(0) |
Điều này có thể có vẻ lạ, nhưng chúng ta có thể sử dụng một phương pháp khác, lấy, để làm việc với vài số đầu tiên trong chuỗi. Ở đây, chúng ta đang sử dụng nó để lấy năm số nguyên đầu tiên từ danh sách vô hạn của chúng ta và sau đó in chúng ra.
| | scala> val someints = integers take 5 |
| | someints: scala.collection.immutable.Stream[Int] = Stream(0, ?) |
| | |
| | scala> someints foreach println |
| | 0 |
| | 1 |
| | 2 |
| | 3 |
| | 4 |
Hãy cùng xem một ví dụ hơi tinh vi hơn về Lazy Sequence, sử dụng một phương thức khác trong thư viện Sequence của Scala. Phương thức continually tạo ra một chuỗi vô hạn bằng cách liên tục đánh giá biểu thức được truyền vào đây.
Hãy sử dụng điều này để tạo ra một chuỗi số giả ngẫu nhiên có độ dài vô hạn. Để làm điều đó, chúng ta tạo ra một máy phát số ngẫu nhiên mới trong val generate, và sau đó chúng ta truyền generate.nextInt vào phương thức continually, như được minh họa trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ls/LazySequence.scala | |
| | val generate = new Random() |
| | val randoms = Stream.continually(generate.nextInt) |
Chúng ta có thể lấy một vài số ngẫu nhiên từ danh sách vô hạn của mình:
| | scala> val aFewRandoms = randoms take 5 |
| | aFewRandoms: scala.collection.immutable.Stream[Int] = Stream(326862669, ?) |
| | |
| | scala> aFewRandoms foreach println |
| | 326862669 |
| | -473217479 |
| | -1619928859 |
| | 785666088 |
| | 1642217833 |
Nếu chúng ta muốn thêm một vài số ngẫu nhiên nữa, chúng ta có thể sử dụng lại hàm take với một số lớn hơn:
| | scala> val aFewMoreRandoms = randoms take 6 |
| | aFewMoreRandoms: scala.collection.immutable.Stream[Int] = Stream(326862669, ?) |
| | |
| | scala> aFewMoreRandoms foreach println |
| | 326862669 |
| | -473217479 |
| | -1619928859 |
| | 785666088 |
| | 1642217833 |
| | 1819425161 |
Lưu ý rằng năm số đầu tiên ở đây được lặp lại. Điều này là do thư viện Stream dựa vào Mẫu 17, Giữ nhớ, để lưu trữ các bản sao mà nó đã thấy. Năm giá trị đầu tiên đã được nhận diện khi chúng ta in ra aFewRandoms, giá trị thứ sáu chỉ được in ra một lần khi chúng ta in aFewMoreRandoms.
In Clojure
Dãy lười được tích hợp vào Clojure, nhưng không tập trung trong một thư viện đơn lẻ. Thay vào đó, hầu hết các chức năng thao tác dãy cơ bản của Clojure hoạt động theo cách lười biếng. Hàm range thông thường của Clojure, chẳng hạn, hoạt động với Dãy lười. Mã dưới đây tạo ra một danh sách tất cả các số nguyên dương nằm trong một Integer:
| ClojureExamples/src/mbfpp/functional/ls/examples.clj | |
| | (def integers (range Integer/MAX_VALUE)) |
Chúng ta có thể sử dụng hàm take để lấy vài số nguyên từ đầu danh sách dài của chúng ta:
| | => (take 5 integers) |
| | (0 1 2 3 4) |
Để tạo danh sách số nguyên ngẫu nhiên của chúng tôi, chúng tôi có thể sử dụng hàm `repeatedly` trong Clojure. Hàm này nhận một hàm với một đối số và lặp lại nó vô hạn lần, như đoạn mã dưới đây cho thấy:
| ClojureExamples/src/mbfpp/functional/ls/examples.clj | |
| | (def randoms (repeatedly (fn [] (rand-int Integer/MAX_VALUE)))) |
Để lấy một vài thứ, chúng ta có thể sử dụng từ "take" một lần nữa:
| | => (take 5 randoms) |
| | (2147483647 2147483647 2147483647 2147483647 2147483647) |
Nếu chúng ta muốn thêm một số nữa, chúng ta sử dụng take với một tham số lớn hơn. Một lần nữa, năm số nguyên ngẫu nhiên đầu tiên sẽ không được tính toán lại, chúng sẽ được lấy từ bộ nhớ tạm.
| | => (take 6 randoms) |
| | (2147483647 2147483647 2147483647 2147483647 2147483647 2147483647) |
Scala và cách xử lý lazily trong Clojure có một số điểm khác biệt chính. Hầu hết các hàm xử lý chuỗi của Clojure đều là lazy, nhưng chúng nhận diện chuỗi theo từng khối mười hai. Nếu chúng ta lấy một số từ một chuỗi lazy của các số nguyên, Clojure sẽ nhận diện ba mươi hai số nguyên đầu tiên mặc dù chúng ta chỉ yêu cầu một số.
Chúng ta có thể thấy điều này nếu chúng ta thêm một tác dụng phụ vào việc tạo ra chuỗi lười biếng. Ở đây, chúng ta có thể thấy rằng take nhận diện ba mươi hai số nguyên, mặc dù nó chỉ trả về số đầu tiên.
| | => (defn print-num [num] (print (str num " "))) |
| | #'mbfpp.functional.ls.examples/print-num |
| | => (take 1 (map print-num (range 100))) |
| | (0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
| | 19 20 21 22 23 24 25 26 27 28 29 30 31 nil) |
Một sự khác biệt tinh tế hơn lại xuất hiện khi sử dụng Lazy Sequence trong REPL. Khi REPL của Scala gặp một thể hiện của Lazy Sequence dưới dạng một Stream, nó sẽ không cố gắng hiện thực hóa toàn bộ.
Điều này dễ thấy nhất khi chúng ta có một tác dụng phụ rõ ràng. Trong đoạn mã Scala bên dưới, chúng ta sử dụng liên tục để in "xin chào" ra console và lưu trữ một tham chiếu đến Stream được tạo ra trong printHellos. Như chúng ta thấy, "xin chào" đầu tiên được in ra khi chúng ta gọi liên tục, điều này cho thấy phương thức nhận thức phần tử đầu tiên trong dòng chảy:
| | scala> val printHellos = Stream.continually(println("hello")) |
| | hello |
| | printHellos: scala.collection.immutable.Stream[Unit] = Stream((), ?) |
Nếu bây giờ chúng ta gọi `take` trên `printHellos`, chúng ta sẽ không nhận được thêm bất kỳ "hello" nào được in ra console, điều này có nghĩa là REPL không cố gắng thực hiện Stream đã trả về.
| | scala> printHellos take 5 |
| | res0: scala.collection.immutable.Stream[Unit] = Stream((), ?) |
Nếu chúng ta muốn buộc phần còn lại của các "hello" được hiện thực hóa, chúng ta có thể sử dụng bất kỳ phương pháp nào lặp lại trên Stream, hoặc chúng ta chỉ cần sử dụng force:
| | scala> printHellos take 5 force |
| | hello |
| | hello |
| | hello |
| | hello |
| | res1: scala.collection.immutable.Stream[Unit] = Stream((), (), (), (), ()) |
Điều này không phải là điều mà bạn thường cần làm, nhưng việc hiểu khi nào các phần tử của Chuỗi Lười được hiện thực hóa là rất quan trọng.
Ngược lại, REPL của Clojure sẽ cố gắng hiện thực hóa một thể hiện của Lazy Sequence; tuy nhiên, việc định nghĩa một thể hiện của Lazy Sequence có thể không hiện thực hóa phần tử đầu tiên! Ở đây, chúng tôi định nghĩa một print-hellos giống như phiên bản Scala. Lưu ý rằng "hello" không được in ra màn hình.
| | (def print-hellos (repeatedly (fn [] (println "hello")))) |
Tuy nhiên, nếu chúng ta lấy năm phần tử, REPL sẽ buộc việc đánh giá phiên bản Lazy Sequence kết quả phải in ra console.
| | => (take 5 print-hellos) |
| | (hello |
| | hello |
| | nil hello |
| | nil hello |
| | nil hello |
| | nil nil) |
Điều này phản ánh sự khác biệt trong cách Scala và REPL của Clojure đánh giá Dãy Tư duy Lười. Nó cũng nêu bật điều gì đó cần chú ý khi sử dụng Dãy Tư duy Lười. Vì bạn có thể tạo ra các dãy vô hạn, chúng ta cần đảm bảo rằng không cố gắng hiện thực hóa toàn bộ một dãy vô hạn cùng một lúc. Ví dụ, nếu chúng ta quên sử dụng take trong ví dụ Clojure và chỉ đánh giá (repeatedly (fn [] (println "hello"), chúng ta sẽ cố gắng hiện thực hóa một dãy vô hạn của việc in ra "hello"!
Sample Code: Paged Response
Trong ví dụ đầu tiên của chúng ta, chúng ta đã xem qua một vài hàm bậc cao cho phép chúng ta tạo một thể hiện của Chuỗi Lười. Bây giờ hãy cùng xem cách chúng ta có thể tạo một cái từ đầu.
Ví dụ mà chúng tôi sẽ sử dụng ở đây là một chuỗi lười cho phép chúng tôi duyệt qua một tập hợp dữ liệu phân trang. Trong ví dụ đơn giản của chúng tôi, chúng tôi sẽ mô phỏng dữ liệu phân trang bằng cách gọi hàm cục bộ, mặc dù trong một chương trình thực tế, điều này có lẽ sẽ đến từ một nguồn bên ngoài như một dịch vụ web. Hãy bắt đầu với việc xem xét mã Scala.
In Scala
Giải pháp Scala của chúng tôi có hai phần: chuỗi chính nó, `pagedSequence`, và một phương thức để tạo ra một số dữ liệu phân trang mẫu, `getPage`.
Chúng ta cần định nghĩa giải pháp cho vấn đề của mình một cách đệ quy, giống như trong Mẫu 12, Đệ quy đuôi. Tuy nhiên, thay vì truyền chuỗi của chúng ta qua ngăn xếp gọi, chúng ta sẽ thêm vào nó trong mỗi cuộc gọi đệ quy bằng cách sử dụng toán tử `#::`.
Mã sau đây là giải pháp hoàn chỉnh cho vấn đề dữ liệu phân trang của chúng tôi:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ls/LazySequence.scala | |
| | def pagedSequence(pageNum: Int): Stream[String] = |
| | getPage(pageNum) match { |
| | case Some(page: String) => page #:: pagedSequence(pageNum + 1) |
| | case None => Stream.Empty |
| | } |
| | |
| | def getPage(page: Int) = |
| | page match { |
| | case 1 => Some("Page1") |
| | case 2 => Some("Page2") |
| | case 3 => Some("Page3") |
| | case _ => None |
| | } |
Hãy cùng tìm hiểu thêm về pagedSequence, bắt đầu với toán tử #::, cho phép chúng ta chèn một giá trị vào đầu một Stream. Ở đây, chúng ta sử dụng nó để thêm các chuỗi "foo" và "bar" vào một Stream mới:
| | scala> val aStream = "foo" #:: "bar" #:: Stream[String]() |
| | aStream: scala.collection.immutable.Stream[String] = Stream(foo, ?) |
Chúng ta có thể lấy phần đầu và phần cuối của Stream, giống như chúng ta có thể với các dãy số khác.
| | scala> aStream.head |
| | res0: String = foo |
| | |
| | scala> aStream.tail |
| | res1: scala.collection.immutable.Stream[String] = Stream(bar, ?) |
Hãy cùng xem xét kỹ lưỡng trái tim của giải pháp của chúng tôi trong đoạn mã sau đây:
| | getPage(pageNum) match { |
| | case Some(page: String) => page #:: pagedSequence(pageNum + 1) |
| | case None => Stream.Empty |
| | } |
Chúng tôi gọi hàm `getPage` và so khớp kết quả. Nếu chúng tôi so khớp với một giá trị `Some`, thì chúng tôi biết rằng chúng tôi đã nhận được một trang hợp lệ. Chúng tôi thêm nó vào đầu chuỗi và sau đó gọi đệ quy phương thức tạo chuỗi, truyền vào trang tiếp theo mà chúng tôi đang cố gắng lấy.
Nếu chúng ta nhận được một None, chúng ta biết rằng đã đi qua tất cả các trang, và chúng ta thêm dòng trống, Stream.Empty, vào chuỗi lười biếng của chúng ta. Điều này báo hiệu sự kết thúc của chuỗi.
Bây giờ chúng ta có thể làm việc với pagedSequence giống như cách chúng ta đã làm với một số chuỗi trong ví dụ trước. Ở đây, chúng ta lấy hai trang từ chuỗi, bắt đầu từ phần tử đầu tiên:
| | scala> pagedSequence(1) take 2 force |
| | res2: scala.collection.immutable.Stream[String] = Stream(Page1, Page2) |
Ở đây, chúng tôi buộc toàn bộ điều này phải được thực hiện, điều này là an toàn vì chuỗi này, mặc dù lười biếng, nhưng không phải là vô hạn.
| | scala> pagedSequence(1) force |
| | res3: scala.collection.immutable.Stream[String] = Stream(Page1, Page2, Page3) |
Đó là kết thúc ví dụ về chuỗi phân trang Scala của chúng ta. Bây giờ hãy cùng xem cách thực hiện điều này trong Clojure.
In Clojure
Trong Clojure, chúng ta có thể xây dựng một thể hiện của Chuỗi Trễ từ đầu bằng cách sử dụng lazy-sequence và thêm vào đó bằng cons, như được thể hiện trong đoạn mã sau:
| | => (cons 1 (lazy-seq [2])) |
| | (1 2) |
Chúng ta có thể sử dụng các cuộc gọi hàm đệ quy để xây dựng các chuỗi hữu ích. Để viết ví dụ về chuỗi trang của chúng ta trong Clojure, trước tiên chúng ta định nghĩa một hàm get-page để mô phỏng dữ liệu theo trang. Phần cốt lõi của giải pháp của chúng ta nằm trong hàm paged-sequence.
Hàm paged-sequence được gọi với trang bắt đầu, và nó xây dựng một chuỗi lười biếng một cách đệ quy bằng cách truy cập trang đó, thêm vào chuỗi, và sau đó gọi chính nó với số của trang tiếp theo. Toàn bộ giải pháp như sau:
| ClojureExamples/src/mbfpp/functional/ls/examples.clj | |
| | (defn get-page [page-num] |
| | (cond |
| | (= page-num 1) "Page1" |
| | (= page-num 2) "Page2" |
| | (= page-num 3) "Page3" |
| | :default nil)) |
| | |
| | (defn paged-sequence [page-num] |
| | (let [page (get-page page-num)] |
| | (when page |
| | (cons page (lazy-seq (paged-sequence (inc page-num))))))) |
Bây giờ chúng ta có thể làm việc với chuỗi lười biếng của mình như bất kỳ chuỗi nào khác. Nếu chúng ta gọi paged-sequence trong REPL, chúng ta sẽ nhận được toàn bộ chuỗi:
| | => (paged-sequence 1) |
| | ("Page1" "Page2" "Page3") |
Nếu chúng ta sử dụng "take", chúng ta có thể lấy một phần của nó:
| | => (take 2 (paged-sequence 1)) |
| | ("Page1" "Page2") |
Điều này có thể mang lại cho chúng ta một cách rất rõ ràng để làm việc với dữ liệu truyền phát.
Discussion
Một điều cần chú ý khi sử dụng các chuỗi lười (lazy sequences) là vô tình giữ lại phần đầu của chuỗi khi bạn không có ý định như vậy, như hình 14, "Giữ Lại Phần Đầu" minh họa.
Figure 14. Holding on to the Head. Holding on to the head of a lazy sequence will keep the entire sequence in memory.
Trong Scala, thật dễ dàng để vô tình làm điều này chỉ bằng cách gán chuỗi lười vào một val, như chúng ta thực hiện trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ls/LazySequence.scala | |
| | val holdsHead = { |
| | def pagedSequence(pageNum: Int): Stream[String] = |
| | getPage(pageNum) match { |
| | case Some(page: String) => { |
| | println("Realizing " + page) |
| | page #:: pagedSequence(pageNum + 1) |
| | } |
| | case None => Stream.Empty |
| | } |
| | pagedSequence(1) |
| | } |
Nếu chúng ta cố gắng thực thi chuỗi nhiều hơn một lần, chúng ta có thể thấy rằng lần thứ hai sử dụng bản sao đã được lưu vào bộ nhớ đệm, như đầu ra REPL sau đây chứng minh:
| | scala> holdsHead force |
| | Realizing Page1 |
| | hello |
| | Realizing Page2 |
| | Realizing Page3 |
| | res0: scala.collection.immutable.Stream[String] = Stream(Page1, Page2, Page3) |
| | scala> holdsHead force |
| | res1: scala.collection.immutable.Stream[String] = Stream(Page1, Page2, Page3) |
Nếu chúng ta không muốn giữ đầu của chuỗi, chúng ta có thể sử dụng def thay vì val, như trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ls/LazySequence.scala | |
| | def doesntHoldHead = { |
| | def pagedSequence(pageNum: Int): Stream[String] = |
| | getPage(pageNum) match { |
| | case Some(page: String) => { |
| | println("Realizing " + page) |
| | page #:: pagedSequence(pageNum + 1) |
| | } |
| | case None => Stream.Empty |
| | } |
| | pagedSequence(1) |
| | } |
Điều này buộc chuỗi phải được thực hiện mới mỗi khi nó bị ép và không giữ lại phần đầu.
| | scala> doesntHoldHead force |
| | Realizing Page1 |
| | Realizing Page2 |
| | Realizing Page3 |
| | res2: scala.collection.immutable.Stream[String] = Stream(Page1, Page2, Page3) |
| | |
| | scala> doesntHoldHead force |
| | Realizing Page1 |
| | Realizing Page2 |
| | Realizing Page3 |
| | res3: scala.collection.immutable.Stream[String] = Stream(Page1, Page2, Page3) |
Việc giữ lại đầu của một chuỗi một cách tình cờ thực sự không bí ẩn hơn việc giữ lại một tham chiếu đến bất kỳ đối tượng nào khi bạn không có ý định, nhưng nó có thể gây bất ngờ nếu bạn không chú ý đến nó.
| Pattern 19 | Focused Mutability |
Intent
Sử dụng các cấu trúc dữ liệu có thể thay đổi trong những phần nhỏ, nhạy cảm về hiệu suất của một chương trình ẩn bên trong một hàm, trong khi vẫn sử dụng dữ liệu bất biến trong phần lớn còn lại.
Overview
Lập trình với dữ liệu bất biến hiệu năng cao trên các máy tính được xây dựng từ các thành phần cơ bản thay đổi được, như bộ nhớ chính và đĩa, gần như là điều kỳ diệu. Một loạt công nghệ đã góp phần làm cho điều này trở nên khả thi, đặc biệt là trên JVM. Sức mạnh của bộ xử lý ngày càng tăng và kích thước bộ nhớ ngày càng lớn làm cho việc tận dụng tối đa hiệu suất của một máy ngày càng trở nên không cần thiết.
Các đối tượng nhỏ, tạm thời thì rẻ để tạo ra và để phá hủy, nhờ vào bộ thu gom rác thế hệ xuất sắc của JVM. Cả Scala và Clojure đều sử dụng những cấu trúc dữ liệu cực kỳ thông minh cho phép các tập hợp bất biến chia sẻ trạng thái. Điều này loại bỏ nhu cầu sao chép toàn bộ tập hợp khi một phần của nó bị thay đổi, có nghĩa là các tập hợp có dấu chân bộ nhớ hợp lý và có thể được sửa đổi khá nhanh chóng.
Tuy nhiên, việc sử dụng dữ liệu không thay đổi có một số chi phí về hiệu suất. Ngay cả những cấu trúc dữ liệu thông minh mà Clojure và Scala sử dụng có thể chiếm nhiều bộ nhớ hơn so với các đối tác có thể thay đổi, và chúng thường có hiệu suất kém hơn chút. Những lợi ích của dữ liệu không thay đổi, giúp không chỉ lập trình đồng thời mà còn đơn giản hóa việc lập trình hệ thống lớn nói chung, thường vượt trội hơn chi phí. Tuy nhiên, đôi khi bạn thật sự cần hiệu suất tăng thêm đó, thường là trong một vòng lặp chặt chẽ ở một phần của chương trình mà được gọi thường xuyên.
Tính biến đổi tập trung cho thấy cách sử dụng dữ liệu có thể thay đổi trong những tình huống này bằng cách tạo ra các hàm nhận vào một số cấu trúc dữ liệu bất biến, thực hiện các thao tác trên dữ liệu có thể thay đổi bên trong hàm, và sau đó trả về một cấu trúc dữ liệu bất biến khác. Điều này cho phép chúng ta có được hiệu suất cao hơn mà không để tính biến đổi làm rối loạn chương trình của chúng ta, vì chúng ta giới hạn nó bên trong một hàm, nơi mà không có gì khác có thể nhìn thấy.
Một điều cần xem xét khi sử dụng Tính biến đổi Tập trung là chi phí để chuyển đổi một cấu trúc dữ liệu biến đổi thành một cấu trúc dữ liệu bất biến là bao nhiêu. Clojure cung cấp hỗ trợ hạng nhất với một tính năng gọi là transient. Transient cho phép chúng ta lấy một cấu trúc dữ liệu bất biến, chuyển đổi nó thành một cấu trúc dữ liệu biến đổi trong thời gian hằng số, và sau đó chuyển đổi nó trở lại thành một cấu trúc dữ liệu bất biến khi chúng ta sử dụng xong, cũng trong thời gian hằng số.
Trong Scala, điều này hơi phức tạp hơn, vì không có hỗ trợ chính thức cho những thứ như transients trong Clojure. Chúng ta phải sử dụng các phiên bản có thể thay đổi của các cấu trúc dữ liệu trong Scala và sau đó chuyển đổi chúng thành các phiên bản không thay đổi bằng cách sử dụng các phương thức chuyển đổi trong thư viện collections. May mắn thay, Scala có thể thực hiện việc chuyển đổi này một cách khá hiệu quả.
Code Sample: Adding to Indexed Sequence
Hãy bắt đầu bằng cách xem xét một mẫu rất đơn giản, đó là thêm một dãy số vào một chuỗi có chỉ số. Điều này không phải là một việc làm thực tế hữu ích, nhưng nó là một ví dụ rất đơn giản, điều này giúp dễ dàng thực hiện một số phân tích hiệu suất cơ bản.
Trong ví dụ này, chúng ta sẽ so sánh thời gian cần để thêm một triệu phần tử vào một chuỗi chỉ mục có thể thay đổi và sau đó chuyển đổi nó thành một chuỗi bất biến với thời gian cần để xây dựng chuỗi bất biến đó trực tiếp. Điều này liên quan đến việc thử nghiệm vi mô, vì vậy chúng ta sẽ thực hiện nhiều lần thử cho mỗi bài kiểm tra để cố gắng phát hiện các giá trị ngoại lai do thu gom rác, vấn đề bộ nhớ cache, và vân vân.
Điều này chắc chắn không phải là một cách hoàn hảo để thực hiện một microbenchmark, nhưng nó đủ tốt để chúng ta có thể cảm nhận được các giải pháp nào nhanh hơn và nhanh hơn bao nhiêu.
In Scala
Trong Scala, chúng ta sẽ so sánh kết quả của việc thêm các phần tử vào một Vector không thể thay đổi trực tiếp với kết quả của việc thêm chúng vào một ArrayBuffer có thể thay đổi và sau đó chuyển đổi nó thành một Vector không thể thay đổi. Ngoài các hàm kiểm tra của chúng ta, những hàm này sẽ thêm các phần tử vào một Vector và một ArrayBuffer, chúng ta sẽ cần một chút mã hạ tầng để hỗ trợ việc đo thời gian và thực hiện các bài kiểm tra.
Hãy xem xét phần không thay đổi trước. Mã sau đây định nghĩa một hàm, testImmutable, mà thêm các phần tử count vào một Vector không thay đổi và cập nhật tham chiếu để trỏ đến vector mới mỗi khi một phần tử mới được thêm vào:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | def testImmutable(count: Int): IndexedSeq[Int] = { |
| | var v = Vector[Int]() |
| | for (c <- Range(0, count)) |
| | v = v :+ c |
| | v |
| | } |
Bây giờ hãy cùng xem xét testMutable, tương tự nhưng nó thêm các yếu tố vào một ArrayBuffer có thể thay đổi, giống như một ArrayList của Java. Mã code ở đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | def testMutable(count: Int): IndexedSeq[Int] = { |
| | val s = ArrayBuffer[Int](count) |
| | for (c <- Range(0, count)) |
| | s.append(c) |
| | s.toIndexedSeq |
| | } |
Bây giờ chúng ta chỉ cần một cách để lấy thông tin thời gian từ các lần chạy của các hàm kiểm tra của chúng ta. Chúng ta sẽ đo thời gian chạy bằng cách ghi lại thời gian hệ thống trước và sau khi chạy kiểm tra. Thay vì nhúng điều này vào chính các hàm kiểm tra, chúng ta sẽ tạo một hàm bậc cao có thể thực hiện việc đo thời gian, time, và một hàm khác, timeRuns, sẽ chạy nhiều bài kiểm tra cùng một lúc. Dưới đây là mã cho cả hai:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | def time[R](block: => R): R = { |
| | val start = System.nanoTime |
| | val result = block |
| | val end = System.nanoTime |
| | val elapsedTimeMs = (end - start) * 0.000001 |
| | println("Elapsed time: %.3f msecs".format(elapsedTimeMs)) |
| | result |
| | } |
| | |
| | def timeRuns[R](block: => R, count: Int) = |
| | for (_ <- Range(0, count)) time { block } |
Khi mọi thứ đã sẵn sàng, chúng ta có thể chạy một số bài kiểm tra. Hãy thử năm lần thử nghiệm với số đếm là một triệu đối với phiên bản không thay đổi của chúng ta:
| | scala> val oneMillion = 1000000 |
| | scala> timeRuns(testImmutable(oneMillion), 5) |
| | Elapsed time: 127.499 msecs |
| | Elapsed time: 127.479 msecs |
| | Elapsed time: 130.501 msecs |
| | Elapsed time: 142.875 msecs |
| | Elapsed time: 123.623 msecs |
Như chúng ta có thể thấy, thời gian dao động từ khoảng 123 mili giây đến khoảng 142 mili giây. Bây giờ hãy thử nghiệm với phiên bản có thể thay đổi của chúng ta, chỉ chuyển đổi sang cấu trúc dữ liệu không thay đổi khi có sự thay đổi.
| | scala> timeRuns(testMutable(oneMillion), 5) |
| | Elapsed time: 98.339 msecs |
| | Elapsed time: 105.240 msecs |
| | Elapsed time: 88.800 msecs |
| | Elapsed time: 65.997 msecs |
| | Elapsed time: 54.918 msecs |
Ở đây, thời gian dao động từ khoảng 54 mili giây đến khoảng 105 mili giây. So sánh thời gian chạy ngắn nhất từ phiên bản bất biến của chúng tôi, 123 mili giây, với thời gian chạy ngắn nhất từ phiên bản có thể thay đổi, 54 mili giây, cho thấy mức cải thiện khoảng 230 phần trăm. So sánh thời gian chạy lâu nhất, 142 mili giây với 105 mili giây, cho thấy mức cải thiện khoảng 140 phần trăm.
Mặc dù hiệu suất của bạn có thể thay đổi tùy thuộc vào máy của bạn, phiên bản JVM của bạn, việc điều chỉnh thu gom rác, và nhiều yếu tố khác, nhưng microbenchmark cơ bản này cho thấy phiên bản có thể thay đổi thường nhanh hơn phiên bản bất biến, như chúng ta mong đợi.
In Clojure
Clojure hỗ trợ sẵn cho Tính biến đổi Tập trung thông qua một tính năng có tên là transients. Transients cho phép chúng ta biến đổi một cấu trúc dữ liệu bất biến thành một cấu trúc có thể thay đổi một cách kỳ diệu. Để sử dụng, cấu trúc dữ liệu bất biến được chuyển vào dạng transient!. Ví dụ, điều này sẽ cho chúng ta một vector tạm thời, biến đổi, (def t (transient [])).
Như tên gọi gợi ý, các đối tượng tạm thời (transients) được cho là tạm thời, nhưng theo cách rất khác so với từ khóa transient trong Java. Các đối tượng tạm thời trong Clojure là tạm thời theo nghĩa bạn sử dụng chúng một cách ngắn gọn bên trong một hàm và sau đó chuyển đổi chúng trở lại thành một cấu trúc dữ liệu bất biến trước khi truyền chúng đi.
Các đối tượng tạm thời có thể được bổ sung với một phiên bản đặc biệt của conj gọi là conj!. Việc sử dụng dấu chấm than cho các phép toán trên dữ liệu biến đổi là một truyền thống cũ trong Lisp nhằm truyền đạt rằng bạn sắp thực hiện điều gì đó thú vị và nguy hiểm!
Hãy xem xét ví dụ về Tính biến đổi Tập trung cơ bản của chúng ta, đã được viết lại để sử dụng các biến tạm của Clojure. Đầu tiên, chúng ta cần hàm có thể biến đổi của mình. Trong Clojure, chúng ta sẽ xây dựng chuỗi số của mình bằng một hàm đệ quy mà qua đó truyền một vector qua chuỗi gọi và thêm (conj) một số đơn lẻ vào vector trong mỗi lần gọi. Mã code ở đây:
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defn test-immutable [count] |
| | (loop [i 0 s []] |
| | (if (< i count) |
| | (recur (inc i) (conj s i)) |
| | s))) |
Phiên bản có thể thay đổi của chúng tôi trông gần như giống hệt nhau; sự khác biệt duy nhất là chúng tôi tạo ra một vector tạm thời bằng cách sử dụng `transient` để được sửa đổi bên trong hàm. Sau đó, chúng tôi chuyển nó quay trở lại một cấu trúc dữ liệu bất biến với `persistent!` khi hoàn tất, như mã code đã cho.
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defn test-mutable [count] |
| | (loop [i 0 s (transient [])] |
| | (if (< i count) |
| | (recur (inc i) (conj! s i)) |
| | (persistent! s)))) |
Cuối cùng, chúng ta cần một cách để đo thời gian cho các ví dụ của mình. Clojure có một hàm time tích hợp tương tự như hàm mà chúng ta đã viết cho Scala, nhưng vẫn cần một cách để thực hiện nhiều thử nghiệm cùng một lúc. Macro trông hơi khó hiểu ở đây đáp ứng yêu cầu đó. Nếu bạn chưa quen với các macro của Lisp, chúng tôi sẽ thảo luận về chúng trong Mẫu 21, Ngôn ngữ Đặc thù Miền.
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defmacro time-runs [fn count] |
| | `(dotimes [_# ~count] |
| | (time ~fn))) |
Bây giờ chúng ta có thể kiểm tra giải pháp Clojure của mình. Đầu tiên, đây là phiên bản bất biến:
| | => (time-runs (test-immutable one-million) 5) |
| | "Elapsed time: 112.03 msecs" |
| | "Elapsed time: 114.174 msecs" |
| | "Elapsed time: 117.223 msecs" |
| | "Elapsed time: 114.976 msecs" |
| | "Elapsed time: 300.29 msecs" |
Tiếp theo, cái có thể thay đổi:
| | => (time-runs (test-mutable one-million) 5) |
| | "Elapsed time: 84.752 msecs" |
| | "Elapsed time: 73.398 msecs" |
| | "Elapsed time: 196.601 msecs" |
| | "Elapsed time: 70.859 msecs" |
| | "Elapsed time: 70.402 msecs" |
Những thời gian này khá giống với thời gian ở Scala, điều này không có gì ngạc nhiên vì các cấu trúc dữ liệu bất biến của Scala và các cấu trúc dữ liệu bất biến của Clojure đều dựa trên cùng một bộ kỹ thuật. So sánh thời gian chạy ngắn nhất và dài nhất của cả hai phiên bản cho chúng ta thấy tốc độ nhanh hơn khoảng 1,5 lần cho phiên bản có thể thay đổi, điều này cũng khá ổn.
Một điều thú vị khác cần lưu ý về ví dụ này là hai điểm bất thường, 300,29 ms cho lần chạy không thay đổi và 196,601 ms cho lần chạy có thay đổi, đều chậm gấp đôi so với lần chạy nhanh nhất cho các giải pháp tương ứng của chúng.
Một chút đào sâu vào những ví dụ này với một công cụ phân tích cho thấy rằng kẻ gây ra vấn đề chính là một lần thu gom rác lớn đã diễn ra trong các mẫu đó và không phải trong những mẫu khác. Hậu quả của việc thu gom rác trong ví dụ này có thể được giảm bớt bằng cách tinh chỉnh, nhưng thật đáng tiếc, điều đó sẽ là một cuốn sách riêng!
Code Sample: Event Stream Manipulation
Hãy xem một ví dụ có chút nặng ký hơn. Ở đây, chúng ta sẽ xử lý một luồng sự kiện đại diện cho các giao dịch mua sắm. Mỗi sự kiện chứa một số cửa hàng, một số khách hàng và một số mặt hàng. Quy trình xử lý của chúng ta sẽ rất đơn giản; chúng ta sẽ tổ chức luồng sự kiện thành một bản đồ được khóa theo số cửa hàng để có thể sắp xếp các giao dịch mua sắm theo cửa hàng.
Ngoài mã xử lý chính, chúng ta sẽ cần một cách đơn giản để tạo dữ liệu kiểm thử. Để làm điều đó, chúng ta sẽ sử dụng Mẫu 18, Chuỗi lười, để tạo ra một chuỗi giao dịch thử nghiệm dài vô tận, từ đó chúng ta sẽ lấy số lượng tùy ý mà chúng ta cần. Hãy cùng xem nào!
In Scala
Giải pháp Scala của chúng tôi bắt đầu bằng một lớp trường hợp Purchase để giữ các giao dịch mua của chúng tôi. Chúng tôi cũng sẽ cần một chuỗi các giao dịch mua thử nghiệm, cũng như các phiên bản bất biến và có thể thay đổi của các hàm thử nghiệm của chúng tôi. Trong cả hai trường hợp, chúng tôi sẽ duyệt qua các giao dịch mua thử nghiệm của mình trong một sự hiểu biết for, lấy số cửa hàng từ giao dịch mua và thêm nó vào danh sách các giao dịch mua khác từ cửa hàng đó, sau đó chúng tôi sẽ đưa vào một bản đồ được khoá bằng số cửa hàng.
Để thực hiện đồng bộ, chúng ta sẽ sử dụng lại đoạn mã từ ví dụ trên. Hãy bắt đầu với lớp Purchase, một lớp case đơn giản:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | case class Purchase(storeNumber: Int, customerNumber: Int, itemNumber: Int) |
Việc tạo dữ liệu kiểm tra của chúng ta có thể được thực hiện với một chuỗi lười biếng vô tận, từ đó chúng ta sẽ lấy bao nhiêu mẫu như chúng ta cần. Không sao nếu bạn không hiểu chi tiết ở đây; chúng có thể được tìm thấy trong Mẫu 18, Chuỗi Lười Biếng. Điểm mấu chốt cho ví dụ hiện tại của chúng ta là chúng ta có thể dễ dàng tạo ra dữ liệu kiểm tra với infiniteTestPurchases , từ đó chúng ta có thể sử dụng take . Đây là mã:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | val r = new Random |
| | def makeTestPurchase = Purchase(r.nextInt(100), r.nextInt(1000), r.nextInt(500)) |
| | def infiniteTestPurchases: Stream[Purchase] = |
| | makeTestPurchase #:: infiniteTestPurchases |
Nếu chúng ta muốn lấy, ví dụ, năm món từ chuỗi vô hạn của mình, chúng ta làm như sau với từ take, như thế này:
| | scala> val fiveTestPurchases = infiniteTestPurchases.take(5) |
| | fiveTestPurchases: ... |
| | |
| | scala> for(purchase <- fiveTestPurchases) println(purchase) |
| | Purchase(71,704,442) |
| | Purchase(23,718,87) |
| | Purchase(39,736,3) |
| | Purchase(33,3,233) |
| | Purchase(86,985,152) |
Bây giờ mà chúng ta đã có cách tạo dữ liệu kiểm tra, hãy sử dụng nó một cách hiệu quả trong giải pháp bất biến của chúng ta, immutableSequenceEventProcessing. Hàm này nhận số lượng giao dịch mua thử nghiệm, lấy các giao dịch mua thử nghiệm từ chuỗi dữ liệu thử nghiệm vô tận của chúng ta và thêm chúng vào một bản đồ được lập chỉ mục theo cửa hàng, như đã mô tả trước đó.
Để thêm một giao dịch mua mới vào bản đồ, chúng tôi lấy số cửa hàng từ giao dịch mua và cố gắng lấy bất kỳ giao dịch mua nào tồn tại cho cửa hàng đó từ bản đồ. Nếu chúng tồn tại, chúng tôi sẽ thêm giao dịch mua mới vào danh sách hiện có và tạo một bản đồ mới với khóa đã cập nhật. Đoạn mã để thực hiện điều này ở đây:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | def immutableSequenceEventProcessing(count: Int) = { |
| | val testPurchases = infiniteTestPurchases.take(count) |
| | var mapOfPurchases = immutable.Map[Int, List[Purchase]]() |
| | |
| | for (purchase <- testPurchases) |
| | mapOfPurchases.get(purchase.storeNumber) match { |
| | case None => mapOfPurchases = |
| | mapOfPurchases + (purchase.storeNumber -> List(purchase)) |
| | case Some(existing: List[Purchase]) => mapOfPurchases = |
| | mapOfPurchases + (purchase.storeNumber -> (purchase :: existing)) |
| | } |
| | } |
Phiên bản có thể thay đổi của chúng tôi khá giống với phiên bản không thể thay đổi, ngoại trừ việc chúng tôi sửa đổi một bản đồ có thể thay đổi và sau đó chuyển nó thành một bản đồ không thể thay đổi khi hoàn thành, như mã này cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/fm/FocusedMutation.scala | |
| | def mutableSequenceEventProcessing(count: Int) = { |
| | val testPurchases = infiniteTestPurchases.take(count) |
| | val mapOfPurchases = mutable.Map[Int, List[Purchase]]() |
| | |
| | for (purchase <- testPurchases) |
| | mapOfPurchases.get(purchase.storeNumber) match { |
| | case None => mapOfPurchases.put(purchase.storeNumber, List(purchase)) |
| | case Some(existing: List[Purchase]) => |
| | mapOfPurchases.put(purchase.storeNumber, (purchase :: existing)) |
| | } |
| | |
| | mapOfPurchases.toMap |
| | } |
Vậy hai giải pháp này hoạt động như thế nào? Hãy cùng xem xét bằng cách chạy nó trên 500.000 mẫu, bắt đầu với phiên bản không thay đổi trước.
| | scala> timeRuns(immutableSequenceEventProcessing(fiveHundredThousand), 5) |
| | Elapsed time: 647.948 msecs |
| | Elapsed time: 523.477 msecs |
| | Elapsed time: 551.897 msecs |
| | Elapsed time: 505.083 msecs |
| | Elapsed time: 538.568 msecs |
Và bây giờ đây là cái biến đổi:
| | scala> timeRuns(mutableSequenceEventProcessing(fiveHundredThousand), 5) |
| | Elapsed time: 584.002 msecs |
| | Elapsed time: 283.623 msecs |
| | Elapsed time: 546.839 msecs |
| | Elapsed time: 286.259 msecs |
| | Elapsed time: 568.298 msecs |
Như chúng ta thấy, phiên bản có thể thay đổi chỉ nhanh hơn một chút. Một chút phân tích cho thấy điều này chủ yếu là do phần lớn thời gian trong ví dụ được dành cho việc tạo dữ liệu thử nghiệm, chứ không phải thao tác với bản đồ.
Nếu chúng ta đang đọc các sự kiện từ hệ thống tệp hoặc qua mạng, mức độ chậm trễ này sẽ lớn hơn nữa, và sự khác biệt giữa hai giải pháp sẽ nhỏ hơn! Mặt khác, ngay cả một khoảng thời gian nhỏ được cắt bớt trong mỗi lần xử lý sự kiện có thể trở nên quan trọng nếu tập dữ liệu đủ lớn.
In Clojure
Giải pháp Clojure của chúng tôi khá giống với giải pháp Scala. Cũng như trong Scala, chúng tôi sẽ sử dụng Mô hình 18, Chuỗi Lười, để tạo ra một chuỗi mua sắm kiểm tra vô hạn từ đó chúng tôi sẽ lấy một số hữu hạn. Chúng tôi sẽ xem xét hai triển khai của các hàm kiểm tra của chúng tôi. Cái đầu tiên sử dụng một bản đồ bất biến bình thường, và cái thứ hai sử dụng một bản đồ tạm thời, có thể thay đổi.
Hãy bắt đầu với việc xem xét mã cho phép chúng ta tạo dữ liệu thử nghiệm. Chúng ta có thể sử dụng một hàm tên là repeatedly, như tên gọi cho thấy, sẽ gọi hàm nhiều lần và sử dụng kết quả để tạo ra một chuỗi lười. Ngoài ra, chúng ta chỉ cần một hàm để tạo ra các giao dịch thử nghiệm. Đây là mã cho cả hai:
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defn make-test-purchase [] |
| | {:store-number (rand-int 100) |
| | :customer-number (rand-int 100) |
| | :item-number (rand-int 500)}) |
| | (defn infinite-test-purchases [] |
| | (repeatedly make-test-purchase)) |
Bây giờ chúng ta cần các hàm kiểm tra của mình. Chúng ta sẽ sử dụng reduce để chuyển một chuỗi giao dịch mua thành một bản đồ được chỉ mục theo số cửa hàng. Cũng giống như trong ví dụ Scala, chúng ta sẽ sử dụng take để lấy một số giao dịch mua hữu hạn từ chuỗi vô hạn của chúng. Sau đó, chúng ta sẽ giảm qua chuỗi đó, xây dựng bản đồ giao dịch mua của chúng ta được chỉ mục theo số cửa hàng.
Như trước đây, chúng ta cần xử lý trường hợp khi lần đầu tiên chúng ta thấy số cửa hàng, điều này chúng ta có thể làm bằng cách truyền vào một danh sách rỗng mặc định cho hàm get. Mã ở đây:
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defn immutable-sequence-event-processing [count] |
| | (let [test-purchases (take count (infinite-test-purchases))] |
| | (reduce |
| | (fn [map-of-purchases {:keys [store-number] :as current-purchase}] |
| | (let [purchases-for-store (get map-of-purchases store-number '())] |
| | (assoc map-of-purchases store-number |
| | (conj purchases-for-store current-purchase)))) |
| | {} |
| | test-purchases))) |
Vì Clojure có các transient hữu ích, giải pháp có thể thay đổi trông rất giống nhau, ngoại trừ việc chúng ta cần biến đổi bản đồ của mình thành và từ một transient và rằng chúng ta cần sử dụng assoc! để thêm vào nó, như mã cho thấy:
| ClojureExamples/src/mbfpp/functional/fm/examples.clj | |
| | (defn mutable-sequence-event-processing [count] |
| | (let [test-purchases (take count (infinite-test-purchases))] |
| | (persistent! (reduce |
| | (fn [map-of-purchases {:keys [store-number] :as current-purchase}] |
| | (let [purchases-for-store (get map-of-purchases store-number '())] |
| | (assoc! map-of-purchases store-number |
| | (conj purchases-for-store current-purchase)))) |
| | (transient {}) |
| | test-purchases)))) |
Bây giờ chúng ta hãy thử nghiệm, bắt đầu với phiên bản có thể thay đổi:
| | => (time-runs (mutable-sequence-event-processing five-hundred-thousand) 5) |
| | "Elapsed time: 445.841 msecs" |
| | "Elapsed time: 457.66 msecs" |
| | "Elapsed time: 452.743 msecs" |
| | "Elapsed time: 374.041 msecs" |
| | "Elapsed time: 403.498 msecs" |
| | nil |
Bây giờ đến cái bất biến:
| | => (time-runs (immutable-sequence-event-processing five-hundred-thousand) 5) |
| | "Elapsed time: 481.547 msecs" |
| | "Elapsed time: 413.121 msecs" |
| | "Elapsed time: 460.379 msecs" |
| | "Elapsed time: 441.686 msecs" |
| | "Elapsed time: 445.772 msecs" |
| | nil |
Như chúng ta có thể thấy, sự khác biệt là khá tối thiểu, nhưng phiên bản có thể biến đổi thì nhanh hơn một chút.
Discussion
Tính biến đổi có trọng tâm là một mẫu tối ưu hóa. Đây là điều mà lời khuyên cũ về việc tránh tối ưu hóa sớm nhấn mạnh. Như chúng ta đã thấy trong chương này, cấu trúc dữ liệu bất biến của Scala và Clojure hoạt động rất tốt - không tệ hơn nhiều so với cách tương ứng có thể thay đổi! Nếu bạn đang sửa đổi nhiều cấu trúc dữ liệu bất biến trong một lần và nếu bạn đang làm điều đó với một lượng lớn dữ liệu, bạn có khả năng thấy sự cải thiện đáng kể. Tuy nhiên, cấu trúc dữ liệu bất biến nên là mặc định - chúng thường đủ nhanh.
Trước khi sử dụng Đột biến Tập trung hoặc bất kỳ tối ưu hóa hiệu suất quy mô nhỏ nào, bạn nên kiểm tra hiệu suất ứng dụng của mình và đảm bảo rằng bạn đang tối ưu hóa đúng chỗ; nếu không, bạn có thể thấy rằng mình đang dành thời gian tối ưu hóa một phần mã mà hiếm khi được gọi, điều này sẽ ít ảnh hưởng đến hiệu suất tổng thể của chương trình.
| Pattern 20 | Customized Control Flow |
Intent
Để tạo ra các trừu tượng luồng điều khiển tùy chỉnh có trọng tâm.
Overview
Sử dụng sự trừu tượng kiểm soát luồng phù hợp cho công việc có thể giúp chúng ta viết mã rõ ràng hơn. Ví dụ, Ruby bao gồm một toán tử unless, có thể được sử dụng để làm điều gì đó trừ khi một điều kiện là đúng. Mã Ruby tốt sử dụng toán tử này thay vì toán tử if và not, vì nó rõ ràng hơn khi đọc.
Không có ngôn ngữ nào có sẵn mọi trừu tượng điều khiển luồng hữu ích, tuy nhiên, các ngôn ngữ lập trình hàm cung cấp cho chúng ta một cách để tạo ra của riêng mình bằng cách sử dụng các hàm bậc cao. Ví dụ, để tạo ra một cấu trúc điều khiển luồng thực hiện một đoạn mã n lần và in ra thời gian trung bình cho các lần chạy, chúng ta có thể viết một hàm nhận một hàm khác và gọi nó n lần.
Tuy nhiên, chỉ sử dụng các hàm bậc cao khiến cú pháp cho luồng điều khiển tùy chỉnh của chúng ta trở nên dài dòng. Chúng ta có thể làm tốt hơn. Trong Clojure, chúng ta có thể sử dụng hệ thống macro, và trong Scala, chúng ta có một loạt các thủ thuật bao gồm các tham số khối và theo tên .
Sample Code: Choose One of Three
Hãy bắt đầu bằng việc xem xét một cấu trúc điều khiển tùy chỉnh cơ bản, choose, cho phép chọn giữa ba tùy chọn khác nhau. Chúng ta sẽ khám phá hai cách triển khai khác nhau: cách thứ nhất sẽ sử dụng các hàm bậc cao và cách thứ hai sẽ tìm hiểu cách cải thiện giải pháp đầu tiên của chúng ta bằng cách cung cấp một số cú pháp ngắn gọn hơn.
In Scala
Hàm `choose` của chúng tôi nhận một số nguyên từ 1 đến 3 và ba hàm. Sau đó, nó thực thi hàm tương ứng, như mã sau đây cho thấy:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ccf/Choose.scala | |
| | def choose[E](num: Int, first: () => E, second: () => E, third: () => E) = |
| | if (num == 1) first() |
| | else if (num == 2) second() |
| | else if (num == 3) third() |
Đây là một cách sử dụng hàm bậc cao đơn giản. Hãy cùng xem cách chúng ta sẽ sử dụng nó:
| | scala> simplerChoose(2, |
| | | () => println("hello, world"), |
| | | () => println("goodbye, cruel world"), |
| | | () => println("meh, indifferent world")) |
| | goodbye, cruel world |
Nó hoạt động như chúng tôi mong đợi; tuy nhiên, việc phải gói gọn các hành động của chúng tôi trong các hàm là khá phiền phức. Một cú pháp tốt hơn sẽ là nếu chúng tôi có thể chỉ cần truyền các biểu thức không được bọc vào trong choose , như chúng tôi đã làm trong phiên REPL tưởng tượng sau đây:
| | scala> simplerChoose(2, |
| | | println("hello, world"), |
| | | println("goodbye, cruel world"), |
| | | println("meh, indifferent world")) |
| | goodbye, cruel world |
Hãy xem cách thực hiện cú pháp này thật, bắt đầu với một trường hợp rất đơn giản. Trong đầu ra REPL sau đây, chúng ta định nghĩa một hàm thử nghiệm với một đối số duy nhất, biểu thức. Thân hàm chỉ cố gắng thực thi biểu thức đó. Chúng ta sau đó gọi hàm thử nghiệm với đối số duy nhất là println("hello, world").
| | scala> def test[E](expression: E) = expression |
| | test: (expression: Unit)Unit |
| | |
| | scala> test(println("hello, world")) |
| | hello, world |
Có vẻ như điều này hoạt động và biểu thức của chúng ta được đánh giá, vì "hello, world" được in ra màn hình console. Nhưng điều gì xảy ra nếu chúng ta thử thực thi biểu thức của mình hai lần? Hãy cùng tìm hiểu trong đoạn mã REPL sau đây:
| | scala> def testTwice[E](expression: E) = { |
| | | expression |
| | | expression |
| | | } |
| | testTwice: (expression: Unit)Unit |
| | |
| | scala> testTwice(println("hello, world")) |
| | hello, world |
Chuỗi "hello, world" chỉ được in ra console một lần! Điều này là do Scala, theo mặc định, sẽ đánh giá một biểu thức vào thời điểm nó được truyền vào một hàm và sau đó truyền vào giá trị của biểu thức đã được đánh giá. Điều này được gọi là **truyền theo giá trị**, và thường là điều chúng ta mong muốn và kỳ vọng. Chẳng hạn, trong ví dụ sau, điều này ngăn biểu thức được đánh giá hai lần:
| | scala> def printTwice[E](expression: E) = { |
| | | println(expression) |
| | | println(expression) |
| | | } |
| | printTwice: [E](expression: E)Unit |
| | |
| | scala> printTwice(5 * 5) |
| | 25 |
| | 25 |
Tuy nhiên, điều này hoàn toàn trái ngược với những gì chúng ta cần khi viết các cấu trúc điều khiển tùy chỉnh. Scala cung cấp cho chúng ta một lựa chọn về ngữ nghĩa gọi được gọi là **truyền theo tên**. Sử dụng truyền theo tên có nghĩa là chúng ta truyền một tên cho biểu thức vào hàm thay vì giá trị đã được đánh giá của biểu thức đó. Sau đó, chúng ta có thể tham chiếu đến tên đó bên trong thân hàm để nó được đánh giá khi cần thiết.
Để thực hiện việc truyền đối số hàm theo cách tên thay vì theo giá trị, chúng ta có thể sử dụng => sau tên tham số và trước chú thích kiểu. Đoạn mã REPL sau đã viết lại hàm kiểm tra của chúng ta để sử dụng cách gọi truyền theo tên:
| | scala> def testByName[E](expression: => E) { |
| | | expression |
| | | expression |
| | | } |
| | testByName: [E](expression: => E)Unit |
| | |
| | scala> testByName(println("hello, world")) |
| | hello, world |
| | hello, world |
Bây giờ chúng ta đã hiểu sự khác biệt giữa truyền theo giá trị và truyền theo tên, chúng ta có thể viết một hàm simplerChoose nhận các biểu thức chưa được bọc. Đoạn mã sau đây thực hiện điều đó:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ccf/Choose.scala | |
| | def simplerChoose[E](num: Int, first: => E, second: => E, third: => E) = |
| | if (num == 1) first |
| | else if (num == 2) second |
| | else if (num == 3) third |
Bây giờ chúng ta có thể sử dụng cú pháp biểu thức trần trụi của mình, như trong đầu ra REPL sau đây:
| | scala> simplerChoose(2, |
| | | println("hello, world"), |
| | | println("goodbye, cruel world"), |
| | | println("meh, indifferent world")) |
| | goodbye, cruel world |
Cách tiếp cận của Clojure đối với điều khiển luồng tùy chỉnh là khá khác biệt và liên quan đến hệ thống macro mạnh mẽ của nó. Hãy cùng xem xét!
In Clojure
Hãy bắt đầu mẫu Clojure của chúng ta với một cái nhìn về phiên bản đơn giản của choose dựa vào các hàm bậc cao. Chúng ta sẽ nhận ba hàm và một số nguyên cho biết hàm nào cần chạy, như mã sau đây cho thấy:
| ClojureExamples/src/mbfpp/functional/ccf/ccf_examples.clj | |
| | (defn choose [num first second third] |
| | (cond |
| | (= 1 num) (first) |
| | (= 2 num) (second) |
| | (= 3 num) (third))) |
Để sử dụng nó, chúng ta truyền vào các đối số số nguyên và hàm của mình:
| | => (choose 2 |
| | (fn [] (println "hello, world")) |
| | (fn [] (println "goodbye, cruel world")) |
| | (fn [] (println "meh, indifferent world"))) |
| | goodbye, cruel world |
| | nil |
Tuy nhiên, chúng tôi muốn tránh việc bọc các hành động của mình thành các hàm và thay vào đó viết mã trông giống như phiên REPL sau:
| | => (choose 2 |
| | (println "hello, world") |
| | (println "goodbye, cruel world") |
| | (println "meh, indifferent world")) |
| | goodbye, cruel world |
| | nil |
Để xem làm thế nào chúng ta có thể đến đó, chúng ta sẽ cần đi một vòng ngắn vào một trong những tính năng mạnh mẽ nhất của Clojure, hệ thống macro của nó. Trên đường đi, chúng ta sẽ trả lời câu hỏi đã tồn tại từ lâu về việc tại sao Lisp lại có cú pháp khác biệt như vậy.
Macros Clojure
Macros là một dạng lập trình siêu: chúng là những đoạn mã biến đổi các đoạn mã khác. Khái niệm này có độ sâu bất ngờ trong Clojure và các ngôn ngữ Lisp khác.
Để hiểu tại sao, hãy thực hiện một thí nghiệm tư duy. Người xây dựng mà chúng ta đã giới thiệu trong Mẫu 4, Thay thế Người xây dựng cho Đối tượng Bất biến, thì rất dài dòng khi viết. Một cách để giảm bớt tính dài dòng là tạo ra một lớp Java khung với chỉ các thuộc tính trong đó, sau đó viết mã để tạo ra người xây dựng dựa trên các thuộc tính đó.
Một sơ đồ khối của phương pháp này được mô tả trong hình dưới đây:

Figure 15. Metaprogramming in Java. Code generating a Builder class
Ở đây, trình tạo builder là một đoạn mã chịu trách nhiệm lấy một lớp Java sơ khai chỉ có các thuộc tính và tạo ra một builder dựa trên nó. Điều này tương tự như sự hỗ trợ mà các IDE có để sinh ra các phương thức getter và setter.
Để làm điều này, người tạo bộ xây dựng cần một số hiểu biết về mã Java đầu vào. Đối với một nhiệm vụ đơn giản như vậy, người tạo bộ xây dựng có thể chỉ coi tệp như văn bản và đọc tệp đầu vào từng dòng một, xác định các dòng nào tương ứng với khai báo biến khi tiến hành.
Tuy nhiên, nếu chúng ta cần thao tác mã Java đầu vào của mình theo cách phức tạp hơn thì sao? Giả sử chúng ta muốn sửa đổi một số phương thức để ghi lại thời gian chúng được gọi. Điều này sẽ khó thực hiện: làm thế nào chúng ta biết khi nào một phương thức bắt đầu và kết thúc nếu chỉ đơn giản là duyệt qua tệp từng dòng một?
Khó khăn là trình tạo mã đơn giản của chúng tôi đang xử lý tệp Java như văn bản thông thường. Các ứng dụng ngôn ngữ phức tạp như trình biên dịch sẽ trải qua một loạt các bước để tạo ra một cây cú pháp trừu tượng hoặc AST. Sơ đồ sau là một đại diện đơn giản hóa của quy trình này.
Figure 16. Simplified Compiler. Stages in a simplified compiler
AST đại diện cho mã ở mức độ trừu tượng hơn về các khía cạnh như phương thức và lớp, thay vì chỉ là dữ liệu văn bản đơn giản. Ví dụ, một trình biên dịch Java viết bằng Java có thể có các lớp Method và VariableDefinition như là một phần của AST, bên cạnh nhiều thứ khác.
Điều này khiến việc biểu diễn AST của mã trở thành cách biểu diễn thuận tiện nhất để thao tác lập trình. Tuy nhiên, trong hầu hết các ngôn ngữ lập trình, AST bị ẩn giấu bên trong trình biên dịch và cần có kiến thức sâu sắc về trình biên dịch để thao tác.
Các ngôn ngữ Lisp, bao gồm cả Clojure, là khác nhau. Cú pháp của Clojure được xác định dựa trên các cấu trúc dữ liệu cơ bản của Clojure, như danh sách và vector. Ví dụ, hãy cùng xem xét một định nghĩa hàm giản dị:
| | (defn say-hello [name] (println (str "Hello, " name))) |
Đây chỉ là một danh sách với bốn phần tử trong đó. Phần tử đầu tiên là ký hiệu defn, phần tử thứ hai là ký hiệu say-hello, phần tử thứ ba là một vector, và phần tử thứ tư là một danh sách khác. Khi Clojure đánh giá một danh sách, nó giả định rằng phần tử đầu tiên là một cái gì đó có thể được gọi, như một hàm, một macro, hoặc một phần tích hợp sẵn của trình biên dịch, và nó giả định rằng phần còn lại của danh sách bao gồm các đối số.
Ngoài ra, nó chỉ là một danh sách như mọi danh sách khác! Chúng ta có thể thấy điều này bằng cách sử dụng dấu nháy đơn, điều này tắt việc đánh giá trên dạng mà nó được áp dụng. Trong đoạn mã sau, chúng ta lấy phần tử đầu tiên từ hai danh sách - danh sách đầu tiên là một danh sách gồm bốn số nguyên, danh sách thứ hai là định nghĩa hàm mà chúng ta vừa giới thiệu:
| | => (first '(1 2 3 4)) |
| | 1 |
| | => (first '(defn say-hello [name] (println (str "Hello, " name)))) |
| | defn |
Vì mã Clojure chỉ là dữ liệu Clojure, nên rất dễ dàng để viết mã nhằm thao tác với nó. Hệ thống macro của Clojure cung cấp một điểm móc thuận tiện để thực hiện thao tác này tại thời điểm biên dịch, như hình minh họa.
Figure 17. Read, Evaluate, Compile. Going from Clojure text to bytecode
Hãy cùng tìm hiểu sâu hơn về quy trình này. Trong Clojure, quá trình chuyển từ một chuỗi ký tự thành các cấu trúc dữ liệu được gọi là việc đọc , như được mô tả trong ô đầu tiên của sơ đồ. Thay vì là một điều kỳ diệu ẩn giấu bên trong trình biên dịch, đó là một tính năng có sẵn cho lập trình viên.
Một số biểu mẫu có sẵn có thể đọc từ nhiều nguồn, chẳng hạn như tệp hoặc chuỗi. Ở đây, chúng tôi sử dụng phiên bản chuỗi của read để đọc một vector từ một chuỗi và lấy phần tử đầu tiên của nó:
| | => (first (read-string "[1 2 3]")) |
| | 1 |
Biểu thức read có một đối tác, eval, như được hiển thị ở bước thứ hai của sơ đồ. Điều này nhận một cấu trúc dữ liệu và đánh giá nó theo một bộ quy tắc đánh giá đơn giản mà chúng tôi thảo luận trong Mục 2.4, TinyWeb trong Clojure. Trong đoạn mã sau, chúng tôi sử dụng eval để đánh giá một def sau khi đã đọc nó từ một chuỗi:
| | => (eval (read-string "(def foo 1)")) |
| | #'user/foo |
| | => foo |
| | 1 |
Bạn có thể đã thấy `eval` trong các ngôn ngữ như Ruby hoặc Javascript; tuy nhiên, có một điểm khác biệt quan trọng giữa `eval` đó và `eval` trong Clojure. Trong Clojure và các ngôn ngữ Lisp khác, `eval` hoạt động trên các cấu trúc dữ liệu đã được đọc vào, chứ không phải trên các chuỗi.
Điều này có nghĩa là có thể thực hiện những thao tác phức tạp hơn, vì chúng ta không cần phải xây dựng mã của mình bằng cách sử dụng thao tác chuỗi thô. Bước mở rộng macro như đã mô tả trong sơ đồ cung cấp một điểm gắn thuận tiện cho chúng ta để thực hiện chính xác điều này.
Một macro chỉ đơn giản là một hàm với một vài điểm khác biệt quan trọng. Các đối số của macro không được đánh giá, giống như các đối số gọi theo tên mà chúng ta đã sử dụng trong Scala. Một macro được chạy trước thời gian biên dịch và nó trả về mã nguồn sẽ được biên dịch. Điều này cung cấp cho chúng ta một cách chính thức và tích hợp để thực hiện các loại thao tác mà chúng ta đã giới thiệu trong thí nghiệm suy nghĩ về xây dựng và tạo mã Java của mình.
Chúng tôi định nghĩa một macro với built-in defmacro. Ngoài ra, một vài tính năng khác của Clojure giúp chúng ta xây dựng macro bằng cách kiểm soát việc đánh giá. Đó là dấu backtick, ‘, còn được biết đến là syntax quote, và dấu ngã, ~, còn được gọi là unquote.
Cùng nhau, những tính năng này cho phép chúng ta xây dựng các mẫu mã để sử dụng trong macro. Câu lệnh syntax quote tắt việc đánh giá bên trong dạng mà nó được áp dụng, và nó mở rộng bất kỳ tên biểu tượng nào thành tên đầy đủ được xác định bởi không gian tên của nó. Unquote, như tên gợi ý, cho phép chúng ta bật lại việc đánh giá bên trong một câu lệnh syntax quote.
Trong đoạn mã sau, chúng ta sử dụng cú pháp báo giá và bỏ báo giá cùng nhau. Biểu tượng foo và biểu thức (+ 1 1) không được đánh giá, nhưng vì chúng ta áp dụng bỏ báo giá cho number-one, nó được đánh giá.
| | => (def number-one 1) |
| | #'mbfpp.functional.ccf.ccf-examples/number-one |
| | => `(foo (+ 1 1) ~number-one) |
| | (mbfpp.functional.ccf.cff-examples/foo (clojure.core/+ 1 1) 1) |
Đầu ra trông có vẻ hơi ồn ào vì cú pháp trích dẫn có foo và + được xác định theo không gian tên.
Bây giờ chúng ta đã giới thiệu về macro, hãy xem cách chúng ta có thể sử dụng chúng để đơn giản hóa hàm choose. Chúng ta thực hiện điều này bằng cách viết một macro, simplerChoose. Macro simplerChoose nhận vào một số và ba biểu thức, và nó trả về một biểu thức cond đánh giá biểu thức phù hợp. Đoạn mã cho simplerChoose nằm trong đoạn mã sau:
| ClojureExamples/src/mbfpp/functional/ccf/ccf_examples.clj | |
| | (defmacro simpler-choose [num first second third] |
| | `(cond |
| | (= 1 ~num) ~first |
| | (= 2 ~num) ~second |
| | (= 3 ~num) ~third)) |
Trước khi chạy nó, chúng ta có thể sử dụng macroexpand-1 để xem mã mà macro tạo ra, như chúng ta đã làm trong phiên REPL sau đây:
| | => (macroexpand-1 |
| | '(simpler-choose 1 (println "foo") (println "bar") (println "baz"))) |
| | (clojure.core/cond |
| | (clojure.core/= 1 1) (println "foo") |
| | (clojure.core/= 2 1) (println "bar") |
| | (clojure.core/= 3 1) (println "baz")) |
Như chúng ta có thể thấy, macro được mở rộng thành một câu lệnh cond, như chúng ta mong đợi. Bây giờ nếu chúng ta thực thi nó, nó hoạt động như chúng ta mong đợi, mà không cần phải đóng gói hành động của mình trong các hàm!
| | => (simpler-choose 2 |
| | (println "hello, world") |
| | (println "goodbye, cruel world") |
| | (println "meh, indifferent world")) |
| | goodbye, cruel world |
| | nil |
Hệ thống macro của Clojure là một trong những tính năng mạnh mẽ nhất của nó, và điều này giải thích tại sao Clojure có cú pháp như vậy. Để phép màu hoạt động, mã Clojure phải được viết dựa trên các cấu trúc dữ liệu Clojure đơn giản, một thuộc tính được gọi là tính đồng hình.
Sample Code: Average Timing
Hãy cùng xem một ví dụ phức tạp hơn về Luồng Điều Khiển Tùy Chỉnh. Ở đây, chúng ta sẽ tạo ra một trừu tượng điều khiển tùy chỉnh thực thi một biểu thức một số lần nhất định và trả về thời gian trung bình của các lần thực thi. Điều này rất hữu ích cho việc kiểm tra hiệu suất nhanh và đơn giản.
In Scala
Trong Scala, giải pháp của chúng tôi là hai hàm. Hàm đầu tiên, timeRun, nhận một biểu thức, thực thi nó, và trả về thời gian mà nó mất. Hàm thứ hai, avgTime, nhận một biểu thức và số lần để đánh giá nó, sau đó trả về thời gian trung bình mà nó mất. Nó sử dụng timeRun như một hàm trợ giúp.
Mã cho giải pháp Scala của chúng tôi như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/ccf/Choose.scala | |
| | def timeRun[E](toTime: => E) = { |
| | val start = System.currentTimeMillis |
| | toTime |
| | System.currentTimeMillis - start |
| | } |
| | def avgTime[E](times: Int, toTime: => E) = { |
| | val allTimes = for (_ <- Range(0, times)) yield timeRun(toTime) |
| | allTimes.sum / times |
| | } |
Như đã quảng cáo, điều này cho chúng ta một cách để có được thời gian chạy trung bình cho một câu lệnh:
| | scala> avgTime(5, Thread.sleep(1000)) |
| | res0: Long = 1001 |
Hãy phân tích điều này thêm một chút bằng cách sử dụng REPL. Phần chính của avgTime là biểu thức sau:
| | val allTimes = for (_ <- Range(0, times)) yield timeRun(toTime) |
Nếu chúng ta thay thế một số biểu thức bằng tay, chúng ta có thể thấy điều này tạo ra một chuỗi thời gian chạy. Dấu gạch dưới trong binding for cho thấy rằng chúng ta thực sự không quan tâm đến giá trị của biểu thức Range được gán, vì chúng ta chỉ sử dụng nó để thực hiện câu lệnh của mình một số lần nhất định.
| | scala> val allTimes = for (_ <- Range(0, 5)) yield timeRun(Thread.sleep(1000)) |
| | allTimes: scala.collection.immutable.IndexedSeq[Long] = |
| | Vector(1000, 1001, 1000, 1001, 1001) |
Từ đó, chúng tôi sử dụng tổng để tính tổng thời gian chạy và chia cho số lần chạy để có được trung bình:
| | scala> allTimes.sum / 5 |
| | res2: Long = 1000 |
Một yếu tố thú vị khác của giải pháp này là cách mà chúng ta truyền tham số theo tên qua hai hàm khác nhau. Tham số toTime được truyền vào avgTime, và từ đó vào timeRun. Nó không được đánh giá cho đến khi nó được sử dụng trong timeRun.
Khả năng nối các cuộc gọi với nhau bằng cách sử dụng các tham số theo tên là quan trọng vì nó cho phép chúng ta phân tách mã cho những trường hợp phức tạp hơn của Luồng Điều Khiển Tùy Chỉnh.
In Clojure
Trong Clojure, giải pháp của chúng tôi bao gồm một macro, avg-time, và một hàm, time-run. Macro avg-time sinh ra mã sử dụng time-run để theo dõi thời gian thực hiện các câu lệnh được truyền vào và sau đó tính toán trung bình của chúng.
Mã cho giải pháp Clojure của chúng tôi như sau:
| ClojureExamples/src/mbfpp/functional/ccf/ccf_examples.clj | |
| | (defn time-run [to-time] |
| | (let [start (System/currentTimeMillis)] |
| | (to-time) |
| | (- (System/currentTimeMillis) start))) |
| | |
| | (defmacro avg-time [times to-time] |
| | `(let [total-time# |
| | (apply + (for [_# (range ~times)] (time-run (fn [] ~to-time))))] |
| | (float (/ total-time# ~times)))) |
Ở đây, chúng tôi sử dụng nó để tính toán thời gian trung bình cho một câu lệnh kiểm tra:
| | => (avg-time 5 (Thread/sleep 1000)) |
| | 1000.8 |
Hãy cùng tìm hiểu cách time-run hoạt động chi tiết hơn, bắt đầu với một tính năng Clojure mà chúng tôi giới thiệu trong mẫu này: các ký hiệu được tự động tạo, hay còn gọi là gensyms . Để tránh việc vô tình bắt biến trong các macro, bất cứ khi nào chúng ta cần một ký hiệu trong mã được tạo ra của mình, chúng ta cần tạo ra một ký hiệu duy nhất.
Cách chúng tôi thực hiện điều này trong Clojure là thêm một ký hiệu tên với một dấu hash khi chúng tôi sử dụng một cái bên trong một cú pháp báo giá. Như đoạn mã bên dưới cho thấy, Clojure sẽ mở rộng gensym thành một ký hiệu khá độc đáo.
| | => `(foo# foo#) |
| | (foo__2230__auto__ foo__2230__auto__) |
Chúng tôi sử dụng gensyms cho total-time và _. Cái thứ hai có thể có vẻ hơi kỳ lạ, bởi vì chúng tôi chỉ sử dụng dấu gạch dưới để chỉ ra rằng chúng tôi không quan tâm đến các giá trị trong phạm vi, giống như chúng tôi đã làm trong Scala.
Nếu chúng ta không biến nó thành một ký hiệu được tạo ra, Clojure sẽ xác định ký hiệu đó trong không gian tên hiện tại, nhưng việc biến nó thành một gensym khiến Clojure tạo ra một ký hiệu duy nhất cho nó. Chúng tôi sẽ minh hoạ điều này bên dưới:
| | => `(_) |
| | (mbfpp.functional.ccf.ccf-examples/_) |
| | => `(-#) |
| | (-__1308__auto__) |
Bây giờ hãy xem xét cốt lõi của avg-time. Câu lệnh let được trích dẫn cú pháp dưới đây phục vụ như một mẫu cho mã mà macro sẽ tạo ra. Như chúng ta thấy, phần chính của giải pháp là một câu lệnh for bao bọc biểu thức trong to-time trong một hàm và chạy nó qua time-run số lần yêu cầu:
| | `(let [total-time# |
| | (apply + (for [_# (range ~times)] |
| | (time-run (fn [] ~to-time))))] (float (/ total-time# ~times)))) |
Để kiểm tra điều này, chúng ta có thể sử dụng macroexpand-1 để xem mã mà nó tạo ra, như chúng ta đã thực hiện trong phiên REPL sau:
| | => (macroexpand-1 '(avg-time 5 (Thread/sleep 100))) |
| | (clojure.core/let |
| | [total-time__1489__auto__ |
| | (clojure.core/apply |
| | clojure.core/+ |
| | (clojure.core/for |
| | [___1490__auto__ (clojure.core/range 5)] |
| | (mbfpp.functional.ccf.cff-examples/time-run |
| | (clojure.core/fn [] (Thread/sleep 1000)))))] |
| | (clojure.core/float (clojure.core// total-time__1489__auto__ 5))) |
| | nil |
Vì tất cả các ký hiệu đều là gensyms hoặc được định danh đầy đủ bởi không gian tên của chúng, điều này có thể hơi khó đọc! Nếu tôi gặp khó khăn trong việc hiểu cách một macro hoạt động, tôi thích chuyển đổi thủ công đầu ra từ macroexpand-1 thành mã mà tôi sẽ viết bằng tay. Để làm điều này, bạn thường chỉ cần loại bỏ không gian tên khỏi các ký hiệu được định danh đầy đủ và phần được tạo ra của gensyms. Tôi đã làm như vậy trong đoạn mã sau:
| | (let |
| | [total-time |
| | (apply + (for [n (range 5)] (time-run (fn [] (Thread/sleep 100)))))] |
| | (float (/ total-time 5))) |
Như bạn có thể thấy, đầu ra được cải thiện này đơn giản hơn nhiều để hiểu. Tôi cũng nhận thấy rằng quá trình kiểm tra mã được tạo ra bằng tay sẽ giúp phát hiện bất kỳ lỗi nào trong macro.
Discussion
Cả Scala và Clojure đều cho phép chúng ta tạo ra các trừu tượng điều khiển luồng tùy chỉnh, nhưng cách thức chúng làm điều đó thì rất khác nhau. Trong Scala, chúng là các trừu tượng thời gian chạy. Chúng ta chỉ cần viết các hàm và truyền các lệnh vào chúng. Mánh khóe là chúng ta có thể kiểm soát thời điểm các lệnh đó được đánh giá bằng cách sử dụng các tham số kiểu by-name.
Trong Clojure, chúng ta sử dụng hệ thống macro, tận dụng tính chất đồng hình của Clojure. Macros là một vấn đề ở thời điểm biên dịch thay vì thời điểm thực thi. Như chúng ta đã thấy, chúng cho phép chúng ta khá dễ dàng viết mã mà viết mã khác bằng cách sử dụng dấu nháy cú pháp như là một mẫu cho mã mà chúng ta muốn tạo ra.
Cách tiếp cận của Clojure là tổng quát hơn, nhưng điều đó chỉ có thể vì tính đồng hình của Clojure. Để mô phỏng các macro kiểu Clojure trong một ngôn ngữ không đồng hình như Scala, ngôn ngữ đó cần phải cung cấp các điểm móc vào trình biên dịch cho phép lập trình viên thao tác với AST và các đối tượng khác của trình biên dịch.
Đây là một nhiệm vụ khó khăn, nhưng Scala có hỗ trợ thử nghiệm cho loại macro biên dịch này trong Scala 1.10. Việc sử dụng kiểu macro này khó hơn so với việc sử dụng macro kiểu Clojure, vì nó yêu cầu một số kiến thức về phần lõi của trình biên dịch.
Vì các macro của Scala còn đang trong giai đoạn thử nghiệm và Scala cung cấp các cách khác để triển khai Luồng Điều Kiển Tùy Chỉnh, chúng tôi sẽ không đề cập đến chúng ở đây.
| Pattern 21 | Domain-Specific Language |
Intent
Để tạo ra một ngôn ngữ lập trình thu nhỏ được thiết kế để giải quyết một vấn đề cụ thể.
Overview
Ngôn ngữ đặc thù miền là một mẫu rất phổ biến có hai loại chính: DSL bên ngoài và DSL bên trong.
Một DSL bên ngoài là một ngôn ngữ lập trình hoàn chỉnh với cú pháp và trình biên dịch riêng. Nó không được thiết kế để sử dụng chung, mà nhằm giải quyết một số vấn đề cụ thể. Ví dụ, SQL là một ví dụ của Ngôn ngữ Đặc thù Miền nhằm vào việc thao tác dữ liệu. ANTLR là một ví dụ khác, nhằm mục đích tạo ra các trình phân tích cú pháp.
Mặt khác, chúng ta có các DSL nội bộ, còn được gọi là ngôn ngữ nhúng. Những ví dụ này của mẫu này tận dụng ngôn ngữ chung và sống trong những ràng buộc của cú pháp của ngôn ngữ chủ.
Trong cả hai trường hợp, mục đích là như nhau. Chúng tôi đang cố gắng tạo ra một ngôn ngữ cho phép chúng tôi diễn đạt các giải pháp cho các vấn đề theo cách gần gũi hơn với lĩnh vực đang bàn đến. Điều này dẫn đến ít mã hơn và các giải pháp rõ ràng hơn so với những gì được tạo ra trong một ngôn ngữ lập trình đa mục đích. Nó cũng thường cho phép những người không phải là nhà phát triển phần mềm giải quyết một số vấn đề trong lĩnh vực đó.
Trong phần này, chúng ta sẽ xem xét việc xây dựng các DSL nội bộ trong Scala và Clojure. Các kỹ thuật mà chúng ta sẽ sử dụng để xây dựng một DSL rất khác nhau trong hai ngôn ngữ này, nhưng mục đích vẫn giữ nguyên.
In Scala
Lứa DSL Scala hiện tại dựa vào cú pháp linh hoạt của Scala và một số mẹo khác của Scala. DSL Scala mà chúng tôi xem xét ở đây sẽ tận dụng một số khả năng nâng cao của Scala.
Trước hết, chúng ta sẽ xem khả năng của Scala trong việc sử dụng các phương thức ở vị trí postfix và infix. Điều này cho phép chúng ta định nghĩa các phương thức hoạt động như các toán tử.
Thứ hai, chúng ta sẽ sử dụng các phép chuyển đổi ngầm trong Scala, được giới thiệu trong Mô hình 10, Thay thế Visitor. Những phép chuyển đổi này dường như cho phép chúng ta thêm hành vi mới vào các kiểu dữ liệu hiện có.
Cuối cùng, chúng ta sẽ sử dụng một đối tượng bạn đồng hành trong Scala như một nhà máy cho lớp mà nó được ghép cặp.
In Clojure
Các DSL nội bộ là một kỹ thuật cũ trong Lisp mà Clojure tiếp nối. Trong Clojure và các ngôn ngữ Lisp khác, ranh giới giữa Ngôn ngữ chuyên biệt cho miền và các framework hoặc API là rất mờ nhạt.
Mã Clojure tốt thường được cấu trúc thành các lớp DSL, lớp này chồng lên lớp khác, mỗi lớp đều giỏi trong việc giải quyết một vấn đề ở một lớp nhất định của hệ thống.
Ví dụ, một hệ thống nhiều lớp có thể để xây dựng ứng dụng web trong Clojure bắt đầu với một thư viện gọi là Ring. Thư viện này cung cấp một lớp trừu tượng trên HTTP, biến các yêu cầu HTTP thành các bản đồ Clojure. Trên nền tảng đó, chúng ta có thể sử dụng một DSL có tên Compojure để định tuyến các yêu cầu HTTP đến các hàm xử lý. Cuối cùng, chúng ta có thể sử dụng một DSL có tên Enlive để tạo ra các mẫu cho các trang của mình.
Các DSL của Clojure thường được xây dựng xung quanh một tập hợp các hàm bậc cao cốt lõi, với các macro cung cấp cú pháp ngữ nghĩa bổ sung. Đây là cách tiếp cận mà chúng tôi sẽ sử dụng cho DSL Clojure mà chúng tôi sẽ xem xét ở đây.
Code Sample: DSL for a Shell
Đôi khi tôi thấy mình cắt và dán từ shell vào REPL khi lập trình bằng Scala và Clojure. Hãy cùng xem xét một DSL đơn giản để làm cho điều này tự nhiên hơn bằng cách cho phép chúng ta chạy các lệnh shell trực tiếp trong REPL.
Ngoài việc chạy các lệnh, chúng ta cũng muốn ghi lại trạng thái thoát, đầu ra chuẩn và lỗi chuẩn của chúng. Cuối cùng, chúng ta sẽ muốn kết nối các lệnh với nhau, giống như trong một shell bình thường.
In Scala
Mục tiêu cuối cùng của ví dụ này là có thể chạy các lệnh shell một cách tự nhiên bên trong Scala REPL. Đối với từng lệnh, chúng tôi muốn có thể chạy chúng như sau:
| | scala> "ls" run |
Và chúng tôi muốn thực hiện các lệnh như sau:
| | scala> "ls" pipe "grep some-file" run |
Hãy bắt đầu hành trình DSL shell của chúng ta bằng cách xem xét những gì chúng ta muốn một lệnh trả về. Chúng ta cần có khả năng kiểm tra mã trạng thái của lệnh shell và cả luồng đầu ra chuẩn và luồng lỗi của nó. Trong đoạn mã sau, chúng tôi đã đóng gói những thông tin này vào một lớp trường hợp có tên là CommandResult.
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | case class CommandResult(status: Int, output: String, error: String) |
Bây giờ hãy xem cách thực sự chạy một lệnh. Chúng ta có thể sử dụng lớp ProcessBuilder của Java cho việc này.
Lớp constructor ProcessBuilder nhận một số lượng biến các tham số kiểu chuỗi, đại diện cho lệnh cần chạy và các tham số của nó. Trong đoạn mã REPL sau đây, chúng tôi tạo một ProcessBuilder cho phép chúng tôi chạy lệnh ls -la :
| | scala> val lsProcessBuilder = new ProcessBuilder("ls", "-la") |
| | lsProcessBuilder: ProcessBuilder = java.lang.ProcessBuilder@5674c175 |
Để chạy quy trình, chúng ta gọi start trên ProcessBuilder mà chúng ta vừa tạo. Điều này trả về một đối tượng Process cung cấp cho chúng ta một tay cầm về quy trình đang chạy:
| | scala> val lsProcess = lsProcessBuilder.start |
| | lsProcess: Process = java.lang.UNIXProcess@61a7c7e7 |
Đối tượng Process cung cấp cho chúng ta quyền truy cập vào tất cả thông tin cần thiết, nhưng đầu ra từ standard out và standard error nằm trong các đối tượng InputStream thay vì trong các chuỗi. Chúng ta có thể sử dụng fromInputStream trên đối tượng Source của Scala để lấy chúng ra, như chúng tôi minh họa trong đoạn mã sau:
| | scala> Source.fromInputStream(lsProcess.getInputStream()).mkString("") |
| | res0: String = |
| | "total 96 |
| | drwxr-xr-x 12 mblinn staff 408 Mar 17 10:23 . |
| | drwxr-xr-x 8 mblinn staff 272 Apr 6 15:12 .. |
| | -rw-r--r-- 1 mblinn staff 35583 Jun 9 16:35 .cache |
| | -rw-r--r-- 1 mblinn staff 1200 Mar 17 10:10 .classpath |
| | -rw-r--r-- 1 mblinn staff 328 Mar 17 10:08 .project |
| | drwxr-xr-x 3 mblinn staff 102 Mar 16 13:29 .settings |
| | drwxr-xr-x 9 mblinn staff 306 Jun 9 15:58 .svn |
| | drwxr-xr-x 2 mblinn staff 68 Mar 13 20:34 bin |
| | -rw-r--r-- 1 mblinn staff 262 Jun 9 13:12 build.sbt |
| | drwxr-xr-x 6 mblinn staff 204 Mar 13 20:33 project |
| | drwxr-xr-x 5 mblinn staff 170 Mar 13 19:52 src |
| | drwxr-xr-x 6 mblinn staff 204 Mar 16 13:33 target |
| | " |
Lưu ý rằng phương thức nhận đầu ra từ chuẩn ra được gọi là getInputStream() một cách hơi khó hiểu? Đó không phải là một lỗi đánh máy; tên phương thức dường như đề cập đến việc đầu ra chuẩn đang được ghi vào một Java InputStream mà mã gọi có thể tiêu thụ.
Bây giờ chúng ta có thể xây dựng lớp Command. Lớp Command nhận một danh sách các chuỗi đại diện cho lệnh và các tham số của nó, sau đó sử dụng danh sách đó để xây dựng một ProcessBuilder. Sau đó, nó chạy tiến trình, chờ cho tiến trình hoàn thành và lấy ra các luồng đầu ra và mã trạng thái của tiến trình đã hoàn thành. Mã sau đây triển khai lớp Command:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | class Command(commandParts: List[String]) { |
| | def run() = { |
| | val processBuilder = new ProcessBuilder(commandParts) |
| | val process = processBuilder.start() |
| | val status = process.waitFor() |
| | val outputAsString = |
| | Source.fromInputStream(process.getInputStream()).mkString("") |
| | val errorAsString = |
| | Source.fromInputStream(process.getErrorStream()).mkString("") |
| | CommandResult(status, outputAsString, errorAsString) |
| | } |
| | } |
Để làm cho các lớp Command dễ dàng hơn trong việc xây dựng, chúng tôi thêm một phương thức nhà máy nhận một chuỗi và tách nó thành đối tượng bạn đồng hành của Command:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | object Command { |
| | def apply(commandString: String) = new Command(commandString.split("\\s").toList) |
| | } |
Như phiên REPL sau đây cho thấy, điều này giúp chúng ta tiến gần hơn một chút đến cú pháp mong muốn của chúng ta để chạy một lệnh đơn.
| | scala> Command("ls -la").run |
| | res1: com.mblinn.mbfpp.functional.dsl.ExtendedExample.CommandResult = |
| | CommandResult(0,total 96 |
| | drwxr-xr-x 12 mblinn staff 408 Mar 17 10:23 . |
| | drwxr-xr-x 8 mblinn staff 272 Apr 6 15:12 .. |
| | -rw-r--r-- 1 mblinn staff 35592 Jun 9 16:57 .cache |
| | -rw-r--r-- 1 mblinn staff 1200 Mar 17 10:10 .classpath |
| | -rw-r--r-- 1 mblinn staff 328 Mar 17 10:08 .project |
| | drwxr-xr-x 3 mblinn staff 102 Mar 16 13:29 .settings |
| | drwxr-xr-x 9 mblinn staff 306 Jun 9 15:58 .svn |
| | drwxr-xr-x 2 mblinn staff 68 Mar 13 20:34 bin |
| | -rw-r--r-- 1 mblinn staff 262 Jun 9 13:12 build.sbt |
| | drwxr-xr-x 6 mblinn staff 204 Mar 13 20:33 project |
| | drwxr-xr-x 5 mblinn staff 170 Mar 13 19:52 src |
| | drwxr-xr-x 6 mblinn staff 204 Mar 16 13:33 target |
| | ,) |
Để đi đến phần còn lại, chúng ta sẽ sử dụng các chuyển đổi ngầm mà chúng ta đã giới thiệu trong Mẫu 10, Thay thế Visitor. Chúng ta sẽ tạo ra một chuyển đổi biến một Chuỗi thành một CommandString với một phương thức chạy. Một CommandString biến Chuỗi mà nó đang chuyển đổi thành một Command mà phương thức chạy của nó gọi. Nó được triển khai trong đoạn mã sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | implicit class CommandString(commandString: String) { |
| | def run() = Command(commandString).run |
| | } |
Bây giờ chúng ta đã có cú pháp mong muốn để chạy các lệnh đơn, như chúng ta minh họa với đầu ra REPL sau đây:
| | scala> "ls -la" run |
| | res2: com.mblinn.mbfpp.functional.dsl.ExtendedExample.CommandResult = |
| | CommandResult(0,total 96 |
| | drwxr-xr-x 12 mblinn staff 408 Mar 17 10:23 . |
| | drwxr-xr-x 8 mblinn staff 272 Apr 6 15:12 .. |
| | -rw-r--r-- 1 mblinn staff 35592 Jun 9 16:57 .cache |
| | -rw-r--r-- 1 mblinn staff 1200 Mar 17 10:10 .classpath |
| | -rw-r--r-- 1 mblinn staff 328 Mar 17 10:08 .project |
| | drwxr-xr-x 3 mblinn staff 102 Mar 16 13:29 .settings |
| | drwxr-xr-x 9 mblinn staff 306 Jun 9 15:58 .svn |
| | drwxr-xr-x 2 mblinn staff 68 Mar 13 20:34 bin |
| | -rw-r--r-- 1 mblinn staff 262 Jun 9 13:12 build.sbt |
| | drwxr-xr-x 6 mblinn staff 204 Mar 13 20:33 project |
| | drwxr-xr-x 5 mblinn staff 170 Mar 13 19:52 src |
| | drwxr-xr-x 6 mblinn staff 204 Mar 16 13:33 target |
| | ,) |
Hãy mở rộng DSL của chúng ta để bao gồm các ống dẫn. Cách tiếp cận mà chúng ta sẽ sử dụng là thu thập các chuỗi lệnh thông qua ống dẫn vào một vector và thực thi chúng khi chúng ta đã xây dựng xong chuỗi ống dẫn đầy đủ.
Hãy bắt đầu bằng cách xem xét các phần mở rộng mà chúng ta cần thực hiện cho CommandString. Hãy nhớ rằng, chúng ta muốn có thể chạy một chuỗi lệnh như sau: "ls -la" pipe "grep build" run. Điều này có nghĩa là chúng ta cần thêm một phương thức pipe, nhận một tham số chuỗi đơn, vào quá trình chuyển đổi ngầm của CommandString. Khi nó được gọi, nó sẽ lấy chuỗi mà nó chuyển đổi thành CommandString và tham số mà nó đã nhận, và nó sẽ đưa cả hai vào một Vector. Mã cho CommandString mở rộng của chúng ta như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | implicit class CommandString(firstCommandString: String) { |
| | def run = Command(firstCommandString).run |
| | def pipe(secondCommandString: String) = |
| | Vector(firstCommandString, secondCommandString) |
| | } |
Bây giờ chuyển đổi của chúng ta sẽ chuyển câu lệnh "ls -la" | "grep build" thành một vector với cả hai câu lệnh shell trong đó.
| | scala> "ls -la" pipe "grep build" |
| | res2: scala.collection.immutable.Vector[String] = Vector(ls -la, grep build) |
Bước tiếp theo là thêm một chuyển đổi ngầm định khác để chuyển đổi một Vector[String] thành một CommandVector, tương tự như những gì chúng ta đã làm cho các chuỗi riêng lẻ. Lớp CommandVector có một phương thức run và một phương thức pipe.
Phương thức pipe thêm một lệnh mới vào Vector các lệnh và trả về nó, và phương thức run biết cách duyệt qua các lệnh và thực thi chúng, chuyển output từ lệnh này sang lệnh khác. Mã cho CommandVector và một phương thức factory mới trên đối tượng đồng hành Command được sử dụng bởi CommandVector như sau:
| ScalaExamples/src/main/scala/com/mblinn/mbfpp/functional/dsl/Example.scala | |
| | implicit class CommandVector(existingCommands: Vector[String]) { |
| | def run = { |
| | val pipedCommands = existingCommands.mkString(" | ") |
| | Command("/bin/sh", "-c", pipedCommands).run |
| | } |
| | def pipe(nextCommand: String): Vector[String] = { |
| | existingCommands :+ nextCommand |
| | } |
| | } |
| | object Command { |
| | def apply(commandString: String) = new Command(commandString.split("\\s").toList) |
| | def apply(commandParts: String*) = new Command(commandParts.toList) |
| | } |
Bây giờ chúng ta đã có ngôn ngữ DSL đầy đủ, bao gồm cả ống dẫn! Trong phiên REPL tiếp theo, chúng ta sẽ sử dụng nó để chạy một số lệnh có piped:
| | scala> "ls -la" pipe "grep build" run |
| | res3: com.mblinn.mbfpp.functional.dsl.ExtendedExample.CommandResult = |
| | CommandResult(0,-rw-r--r-- 1 mblinn staff 262 Jun 9 13:12 build.sbt |
| | ,) |
| | |
| | scala> "ls -la" pipe "grep build" pipe "wc" run |
| | res4: com.mblinn.mbfpp.functional.dsl.ExtendedExample.CommandResult = |
| | CommandResult(0, 1 9 59 |
| | ,) |
Một vài lưu ý về DSL này. Đầu tiên, nó tận dụng khả năng của Scala trong việc sử dụng các phương thức như là toán tử hậu tố. Điều này rất dễ bị lạm dụng, vì vậy Scala 2.10 sẽ phát sinh cảnh báo khi bạn làm như vậy, và điều này sẽ bị vô hiệu hóa mặc định trong một phiên bản tương lai của Scala. Để sử dụng toán tử hậu tố mà không có cảnh báo, bạn có thể nhập scala.language.postfixOps vào tệp cần sử dụng chúng.
Thứ hai là một DSL đơn giản, phù hợp cho việc sử dụng cơ bản tại Scala REPL. Scala đã có một phiên bản hoàn chỉnh hơn của một DSL tương tự được tích hợp sẵn trong gói scala.sys.process.
In Clojure
Trong Clojure, DSL của chúng ta sẽ bao gồm một hàm lệnh tạo ra một hàm thực thi một lệnh shell. Sau đó, chúng ta sẽ tạo một hàm ống cho phép chúng ta kết hợp nhiều lệnh với nhau thông qua việc hợp thành hàm. Cuối cùng, chúng ta sẽ tạo hai macro, def-command và def-pipe, để dễ dàng đặt tên cho các ống và lệnh.
Trước khi chúng ta đi vào mã DSL chính, hãy xem cách chúng ta sẽ tương tác với shell. Chúng ta sẽ sử dụng một thư viện tích hợp sẵn trong Clojure thuộc không gian tên clojure.java.shell, cung cấp một lớp bọc mỏng xung quanh phương thức Runtime.exec() của Java.
Trong phiên REPL tiếp theo, chúng ta sử dụng hàm sh trong clojure.java.shell để thực thi lệnh ls. Như chúng ta có thể thấy, đầu ra của hàm là một bản đồ bao gồm mã trạng thái của quá trình và bất cứ điều gì quá trình ghi vào các luồng đầu ra tiêu chuẩn và lỗi tiêu chuẩn của nó dưới dạng một chuỗi:
| | => (shell/sh "ls") |
| | {:exit 0, :out "README.md\nclasses\nproject.clj\nsrc\ntarget\ntest\n", :err ""} |
Điều này không dễ đọc, vì vậy hãy tạo một hàm sẽ in nó theo cách dễ đọc hơn trước khi trả về bản đồ đầu ra. Mã để làm điều đó như sau:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defn- print-output [output] |
| | (println (str "Exit Code: " (:exit output))) |
| | (if-not (str/blank? (:out output)) (println (:out output))) |
| | (if-not (str/blank? (:err output)) (println (:err output))) |
| | output) |
Chúng ta bây giờ có thể sử dụng sh để chạy ls -a và nhận được đầu ra dễ đọc:
| | => (print-output (shell/sh "ls" "-a")) |
| | Exit Code: 0 |
| | . |
| | .. |
| | .classpath |
| | .project |
| | .settings |
| | .svn |
| | README.md |
| | classes |
| | project.clj |
| | src |
| | target |
| | test |
| | |
| | {:exit 0, |
| | :out ".\n..\n.classpath\n.project\n.settings\n.svn\n |
| | README.md\nclasses\nproject.clj\nsrc\ntarget\ntest\n", |
| | :err ""} |
Hãy chuyển sang phần đầu tiên của DSL của chúng ta, chức năng command. Chức năng này nhận lệnh mà chúng ta muốn thực thi dưới dạng chuỗi, phân tách nó theo khoảng trắng để có một chuỗi các phần lệnh, và sau đó sử dụng apply để áp dụng hàm sh cho chuỗi đó.
Cuối cùng, nó chạy đầu ra được trả về qua hàm print-output của chúng tôi, gói tất cả lại trong một hàm bậc cao và trả về kết quả. Mã cho command theo sau:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defn command [command-str] |
| | (let [command-parts (str/split command-str #"\s+")] |
| | (fn [] |
| | (print-output (apply shell/sh command-parts))))) |
Bây giờ, nếu chúng ta chạy một hàm được trả về bởi lệnh, nó sẽ thực thi lệnh shell mà nó bao gồm:
| | => ((command "pwd")) |
| | Exit Code: 0 |
| | /Users/mblinn/Documents/mbfpp/Book/code/ClojureExamples |
Nếu chúng ta muốn đặt tên cho lệnh, chúng ta có thể làm điều đó bằng cách sử dụng def:
| | => (def pwd (command "pwd")) |
| | #'mbfpp.functional.dsl.examples/pwd |
| | => (pwd) |
| | Exit Code: 0 |
| | /Users/mblinn/Documents/mbfpp/Book/code/ClojureExamples |
Bây giờ chúng ta có thể chạy một lệnh riêng lẻ, hãy xem điều gì sẽ cần thiết để kết nối chúng lại với nhau. Một ống (pipe) trong shell Unix chuyển đầu ra từ một lệnh sang đầu vào của lệnh khác. Vì đầu ra của một lệnh ở đây được lưu trữ trong một chuỗi, nên tất cả những gì chúng ta cần là một cách sử dụng chuỗi đó làm đầu vào cho một lệnh khác.
Hàm sh cho phép chúng ta làm như vậy với tùy chọn :in:
| | => (shell/sh "wc" :in "foo bar baz") |
| | {:exit 0, :out " 0 3 11\n", :err ""} |
Hãy sửa đổi hàm `command` của chúng ta để nhận đầu ra bản đồ từ một lệnh khác và sử dụng chuỗi đầu ra chuẩn của nó làm đầu vào. Để thực hiện điều này, chúng ta sẽ thêm một arity thứ hai cho `command` mà mong đợi nhận một bản đồ đầu ra.
Chức năng command phân tích cấu trúc bản đồ để lấy ra đầu ra của nó và truyền vào sh như là đầu vào. Mã cho command mới của chúng ta như sau:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defn command [command-str] |
| | (let [command-parts (str/split command-str #"\s+")] |
| | (fn |
| | ([] (print-output (apply shell/sh command-parts))) |
| | ([{old-out :out}] |
| | (print-output (apply shell/sh (concat command-parts [:in old-out]))))))) |
Bây giờ chúng ta có thể định nghĩa một lệnh khác, như lệnh sau đây để tìm kiếm từ README:
| | => (def grep-readme (command "grep README")) |
| | #'mbfpp.functional.dsl.examples/grep-readme |
Sau đó, chúng ta có thể truyền đầu ra của lệnh ls vào đó, và đầu ra của ls sẽ được chuyển vào grep. Mỗi lệnh sẽ in đầu ra của nó ra chuẩn, như phiên làm việc REPL sau đây cho thấy:
| | => (grep-readme (ls)) |
| | Exit Code: 0 |
| | README.md |
| | classes |
| | project.clj |
| | src |
| | target |
| | test |
| | |
| | Exit Code: 0 |
| | README.md |
| | |
| | {:exit 0, :out "README.md\n", :err ""} |
Với chức năng lệnh đã được sửa đổi của chúng tôi, chúng tôi có thể tạo ra một chuỗi lệnh bằng cách kết hợp nhiều lệnh với nhau bằng cách sử dụng `comp`. Nếu chúng tôi muốn viết các lệnh theo cùng một thứ tự như chúng tôi sẽ làm trong một shell, chúng tôi chỉ cần đảo ngược thứ tự của các lệnh trước khi kết hợp chúng, như trong triển khai `pipe` sau đây:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defn pipe [commands] |
| | (apply comp (reverse commands))) |
Bây giờ chúng ta có thể tạo một chuỗi lệnh, như chúng ta đã làm trong phiên REPL sau đây:
| | => (def grep-readme-from-ls |
| | (pipe |
| | [(command "ls") |
| | (command "grep README")])) |
| | #'mbfpp.functional.dsl.examples/grep-readme-from-ls |
Điều này có tác dụng giống như việc chạy lệnh ls và chuyển đầu ra của nó vào grep-readme.
| | => (grep-readme-from-ls) |
| | Exit Code: 0 |
| | README.md |
| | classes |
| | project.clj |
| | src |
| | target |
| | test |
| | |
| | Exit Code: 0 |
| | README.md |
| | |
| | {:exit 0, :out "README.md\n", :err ""} |
Bây giờ chúng ta có thể định nghĩa các lệnh và ống nối, hãy sử dụng macro để thêm một số cú pháp đẹp giúp mọi thứ dễ dàng hơn. Để tìm hiểu về macro trong Clojure, hãy xem Clojure Macros. Trước tiên, chúng ta sẽ tạo một macro có tên def-command. Macro này nhận một tên và một chuỗi lệnh, sau đó định nghĩa một hàm thực thi chuỗi lệnh đó. Đoạn mã cho def-command như sau:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defmacro def-command [name command-str] |
| | `(def ~name ~(command command-str))) |
Bây giờ chúng ta có thể định nghĩa một lệnh và đặt tên cho nó bằng một lần gọi macro duy nhất, như chúng ta thấy trong đầu ra REPL sau đây:
| | => (def-command pwd "pwd") |
| | #'mbfpp.functional.dsl.examples/pwd |
| | |
| | => (pwd) |
| | Exit Code: 0 |
| | /Users/mblinn/Documents/mbfpp/Book/code/ClojureExamples |
| | |
| | {:exit 0, :out "/Users/mblinn/Documents/mbfpp/Book/code/ClojureExamples\n", :err ""} |
Bây giờ hãy làm điều tương tự cho các lệnh piped của chúng ta như chúng ta đã làm cho các lệnh đơn với macro def-pipe. Macro này nhận một tên lệnh và một số chuỗi lệnh không xác định, biến mỗi chuỗi lệnh thành một lệnh và cuối cùng tạo ra một pipe với tên đã cho. Dưới đây là mã cho def-pipe:
| ClojureExamples/src/mbfpp/functional/dsl/examples.clj | |
| | (defmacro def-pipe [name & command-strs] |
| | (let [commands (map command command-strs) |
| | pipe (pipe commands)] |
| | `(def ~name ~pipe))) |
Bây giờ chúng ta có thể tạo một ống chỉ trong một lần, như chúng ta làm ở dưới đây:
| | => (def-pipe grep-readme-from-ls "ls" "grep README") |
| | #'mbfpp.functional.dsl.examples/grep-readme-from-ls |
| | => (grep-readme-from-ls) |
| | Exit Code: 0 |
| | README.md |
| | classes |
| | project.clj |
| | src |
| | target |
| | test |
| | |
| | Exit Code: 0 |
| | README.md |
| | |
| | {:exit 0, :out "README.md\n", :err ""} |
Đó là kết thúc cái nhìn của chúng ta về các DSL của Clojure!
Discussion
Hiện tại, Scala và Clojure có cách tiếp cận rất khác nhau đối với Ngôn ngữ Chuyên Biệt Miền. Scala sử dụng cú pháp linh hoạt và nhiều thủ thuật khác nhau. Clojure sử dụng các hàm bậc cao và macro.
Cách tiếp cận của Clojure tổng quát hơn. Thực tế, hầu hết ngôn ngữ Clojure tự nó được viết dưới dạng một tập hợp các hàm và macro của Clojure! Những người viết DSL nâng cao bằng Scala có thể gặp phải những hạn chế trong cách tiếp cận hiện tại của Scala.
Vì lý do này, các macro đang được thêm vào Scala. Tuy nhiên, như đã đề cập trong phần Thảo luận, chúng khó được triển khai và sử dụng hơn nhiều mà không có cú pháp đơn giản và tính đồng hình có sẵn trong Clojure và các ngôn ngữ khác trong gia đình Lisp.
Related Patterns
Mẫu 20, Luồng điều khiển tùy chỉnh
For Further Reading
`DSLs trong hành động [Gho10]`
Footnotes
| [6] | https://github.com/clojure/core.typed |
| [7] | http://www.oracle.com/technetwork/java/filters-137243.html |
Chapter 5
The End
Đó là tất cả những gì chúng ta đã khám phá về các mẫu trong lập trình hàm. Hy vọng bây giờ bạn đã thấy cách các công cụ lập trình hàm có thể giúp bạn viết mã ngắn hơn và rõ ràng hơn, cũng như cách dữ liệu bất biến có thể loại bỏ nhiều nguồn lỗi lớn trong chương trình của bạn.
Tôi hy vọng bạn cũng đã có cơ hội làm quen với cả Scala và Clojure. Mặc dù cả hai đều bao gồm các đặc điểm chức năng, nhưng chúng khá khác biệt nhau. Bằng cách xem các ví dụ được viết bằng cả Scala và Clojure, bạn đã được tiếp xúc với một loạt các kỹ thuật chức năng đa dạng.
Hơn hết, tôi hy vọng bạn có thể áp dụng những gì bạn đã học trong cuốn sách này để cải thiện trải nghiệm lập trình hàng ngày của bạn.
Cảm ơn bạn đã đọc!
Copyright © 2013, The Pragmatic Bookshelf.
Bibliography
- [AIS77]
- Christopher Alexander, Sara Ishikawa, and Murray Silverstein. A Pattern Language: Towns, Buildings, Construction. Oxford University Press, New York, NY, 1977.
- [Blo08]
- Joshua Bloch. Effective Java. Addison-Wesley, Reading, MA, 2008.
- [FBBO99]
- Martin Fowler, Kent Beck, John Brant, William Opdyke, and Don Roberts. Refactoring: Improving the Design of Existing Code. Addison-Wesley, Reading, MA, 1999.
- [FH11]
- Michael Fogus and Chris Houser. The Joy of Clojure. Manning Publications Co., Greenwich, CT, 2011.
- [GHJV95]
- Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, Reading, MA, 1995.
- [Gho10]
- Debasish Ghosh. DSLs in Action. Manning Publications Co., Greenwich, CT, 2010.
- [Goe12]
- Brian Goetz. JSR 335: Lambda Expressions for the Java Programming Language. Java Community Process, http://jcp.org, 2012.
- [Hal09]
- Stuart Halloway. Programming Clojure. The Pragmatic Bookshelf, Raleigh, NC and Dallas, TX, 2009.
- [Lip11]
- Miran Lipovaca. Learn You a Haskell for Great Good!: A Beginner’s Guide. No Starch Press, San Francisco, CA, 2011.
- [MRB97]
- Robert C. Martin, Dirk Riehle, and Frank Buschmann. Pattern Languages of Program Design 3. Addison-Wesley, Reading, MA, 1997.
- [Nor92]
- Peter Norvig. Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp. Morgan Kaufmann Publishers, San Francisco, CA, 1992.
- [Sub09]
- Venkat Subramaniam. Programming Scala: Tackle Multi-Core Complexity on the Java Virtual Machine. The Pragmatic Bookshelf, Raleigh, NC and Dallas, TX, 2009.
- [Sue12]
- Joshua Suereth. Scala In Depth. Manning Publications Co., Greenwich, CT, 2012.
读累了记得休息一会哦~
Tài khoản công khai: Cổ Đức Miêu Ninh Lý
- 电子书搜索下载
- 书单分享
- 书友学习交流
Trang web: Thư viện Trầm Kim https://www.chenjin5.com
- 电子书搜索下载
- 电子书打包资源分享
- 学习资源分享
You May Be Interested In…
Nhấp vào bìa để biết thêm thông tin





