
Confluence

OceanofPDF.com translates to "Đại dương PDF".
Building Event-Driven Microservices
"Tận dụng Dữ liệu Tổ chức ở Quy mô Lớn"
Adam Bellemare
Building Event-Driven Microservices
bởi Adam Bellemare
Bản quyền © 2025 Adam Bellemare. Tất cả các quyền được bảo lưu.
In Ấn Độ Hoa Kỳ.
Xuất bản bởi O'Reilly Media, Inc., 1005 Gravenstein Highway Bắc, Sebastopol, CA 95472.
Sách O'Reilly có thể được mua cho mục đích giáo dục, kinh doanh hoặc khuyến mãi bán hàng. Phiên bản trực tuyến cũng có sẵn cho hầu hết các tựa sách (http://oreilly.com). Để biết thêm thông tin, hãy liên hệ với bộ phận bán hàng doanh nghiệp/cơ quan của chúng tôi: 800-998-9938 hoặc corporate@oreilly.com.
- Acquisitions Editor: Melissa Duffield
- Development Editor: Corbin Collins
- Production Editor: Clare Laylock
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- August 2020: First Edition
- September 2025: Second Edition
Revision History for the Early Release
- 2025-02-19: First Release
Xem http://oreilly.com/catalog/errata.csp?isbn=9781492057895 để biết chi tiết về phiên bản.
Logo O’Reilly là thương hiệu đã được đăng ký của O’Reilly Media, Inc. Xây dựng Microservices theo sự kiện, hình ảnh bìa và liên quan là thương hiệu của O’Reilly Media, Inc.
Ý kiến được trình bày trong tác phẩm này là của tác giả, và không đại diện cho quan điểm của nhà xuất bản. Mặc dù nhà xuất bản và tác giả đã nỗ lực tốt để đảm bảo rằng thông tin và hướng dẫn trong tác phẩm này là chính xác, nhà xuất bản và tác giả từ chối tất cả trách nhiệm đối với các sai sót hoặc thiếu sót, bao gồm cả trách nhiệm không giới hạn đối với thiệt hại phát sinh từ việc sử dụng hoặc tin tưởng vào tác phẩm này. Việc sử dụng thông tin và hướng dẫn trong tác phẩm này hoàn toàn do bạn tự quyết. Nếu bất kỳ mẫu mã hoặc công nghệ nào mà tác phẩm này chứa hoặc mô tả chịu sự điều chỉnh của các giấy phép mã nguồn mở hoặc quyền sở hữu trí tuệ của người khác, bạn có trách nhiệm đảm bảo rằng việc sử dụng chúng tuân thủ các giấy phép và/hoặc quyền đó.
Công việc này là một phần của sự hợp tác giữa O'Reilly và Confluence. Xem tuyên bố về sự độc lập biên tập của chúng tôi.
Chín bảy chín - tám - ba bốn một - sáu hai hai một - hai
[LSI]
Brief Table of Contents (Not Yet Final)
Lời giới thiệu (không có sẵn)
Chương 1. Tại sao lại là Microservices theo sự kiện? (không có sẵn)
Chương 2. Những nguyên tắc cơ bản về Sự kiện và Truyền phát Sự kiện
Chương 3. Các nguyên tắc cơ bản của Microservices theo sự kiện
Chương 4. Các sơ đồ và hợp đồng dữ liệu (không khả dụng)
Chương 5. Thiết kế Sự kiện
Chương 6. Tích hợp Kiến trúc Theo Sự kiện với các Hệ thống Hiện có
Chương 7. Sự kiện hóa và Hạ chuẩn (không có sẵn)
Chương 8. Xử lý luồng xác định (không có sẵn)
Chương 9. Streaming có trạng thái (không có sẵn)
Chương 10. Xây dựng Quy trình làm việc với Microservices (không có sẵn)
Chương 11. Tính nhất quán cuối cùng và hội tụ (không có sẵn)
Chương 12. Các dịch vụ vi mô nhà sản xuất và người tiêu dùng cơ bản (không có sẵn)
Chương 13. Microservices Sử dụng Function-as-a-Service (không có sẵn)
Chương 14. Microservices Khung Nặng (không khả dụng)
Chương 15. Khung Thực Thi Bền Vững (không có sẵn)
Chương 16. Microservices Khung Nhẹ (không có sẵn)
Chương 17. Truy vấn SQL trực tuyến dưới dạng dịch vụ vi mô (không có sẵn)
Chương 18. Tích hợp các dịch vụ vi mô kiểu sự kiện và kiểu yêu cầu - phản hồi (không có sẵn)
Chương 19. Trải nghiệm người dùng hướng đến sự kiện (không khả dụng)
Chương 20. Công cụ hỗ trợ (không có sẵn)
Chương 21. Kiểm tra Microservices Dựa trên Sự Kiện (không khả dụng)
Chương 22. Triển khai Microservices Dựa trên Sự Kiện (không có sẵn)
Chương 23. Kết luận (không có sẵn)
Chapter 1. Fundamentals of Events and Event Streams
Các luồng sự kiện được phục vụ bởi một trung gian sự kiện thường là chế độ chủ yếu cho các kiến trúc hướng sự kiện mạnh mẽ, tuy nhiên bạn sẽ thấy rằng hàng đợi và nhắn tin tạm thời cũng có vị trí của chúng. Chúng ta sẽ đề cập đến từng chế độ này một cách chi tiết hơn trong nửa sau của chương này.
Hiện tại, hãy cùng nhau xem xét kỹ lưỡng các sự kiện, bản ghi và tin nhắn, cũng như mối quan hệ giữa luồng sự kiện và trung gian sự kiện.
What’s an Event?
Một sự kiện có thể là bất cứ điều gì đã xảy ra trong khuôn khổ của cấu trúc giao tiếp kinh doanh. Nhận hóa đơn, đặt phòng họp, yêu cầu một cốc cà phê (vâng, bạn có thể kết nối một máy pha cà phê với một luồng sự kiện), tuyển dụng một nhân viên mới và hoàn thành thành công mã tùy ý đều là những ví dụ về các sự kiện xảy ra trong một doanh nghiệp. Điều quan trọng là nhận ra rằng các sự kiện có thể là bất cứ điều gì quan trọng đối với doanh nghiệp. Khi những sự kiện này bắt đầu được ghi lại, các hệ thống dựa trên sự kiện có thể được tạo ra để khai thác và sử dụng chúng trong toàn tổ chức.
Một sự kiện là một bản ghi lại những gì đã diễn ra, tương tự như cách mà thông tin và nhật ký lỗi của một ứng dụng ghi lại những gì xảy ra trong ứng dụng đó. Tuy nhiên, khác với những nhật ký này, sự kiện cũng là nguồn thông tin chính xác duy nhất, như đã đề cập trong [Liên kết sẽ đến sau]. Do đó, chúng phải chứa tất cả thông tin cần thiết để mô tả chính xác những gì đã xảy ra.
Các sự kiện sử dụng các lược đồ, điều này được trình bày chi tiết hơn trong [Liên kết sẽ có sau]. Hiện tại, hãy xem xét rằng các sự kiện có tên trường, kiểu dữ liệu và giá trị mặc định được xác định rõ ràng.
Tôi tránh sử dụng thuật ngữ "thông điệp" khi thảo luận về các dòng sự kiện và kiến trúc dựa trên sự kiện. Đó là một thuật ngữ có nhiều ý nghĩa khác nhau đối với từng người, và cũng bị ảnh hưởng mạnh mẽ bởi công nghệ bạn đang sử dụng. Hãy nghĩ về ý nghĩa của các thông điệp trong cuộc sống hàng ngày của chúng ta, đặc biệt nếu bạn sử dụng tin nhắn ngay lập tức. Một người gửi một thông điệp đến một người cụ thể hoặc đến một nhóm riêng tư cụ thể. Ngoài ra, các thông điệp có thể hoặc không thể bền vững - một số ứng dụng trò chuyện xóa các thông điệp sau khi đọc, trong khi những ứng dụng khác xóa sau một khoảng thời gian nhất định.
Sự kiện trong kiến trúc hướng sự kiện tương tự như một bài đăng mà bạn công bố trên một nền tảng mạng xã hội hoặc bảng tin. Bài đăng là công khai với tất cả mọi người, và mọi người đều có thể tự do đọc nó và sử dụng nó theo cách mà họ muốn. Nhiều người có thể đọc bài đăng, và tất nhiên bài đăng có thể được đọc đi đọc lại nhiều lần. Nó sẽ không bị xóa chỉ vì nó đã cũ. Dòng sự kiện thực chất là một buổi phát sóng để chia sẻ dữ liệu quan trọng, cho phép người khác đăng ký nhận thông tin và sử dụng nó theo cách họ thấy phù hợp.
Chỉ để rõ ràng, bạn có thể sử dụng luồng sự kiện để gửi tin nhắn. Tất cả các tin nhắn là sự kiện, nhưng không phải tất cả các sự kiện đều là tin nhắn. Nhưng để rõ ràng hơn, tôi sẽ sử dụng các thuật ngữ sự kiện và bản ghi thay vì tin nhắn cho những chương còn lại của cuốn sách này. Nhưng trước khi chúng ta đào sâu vào các sự kiện, hãy cùng nhìn qua một chút về luồng sự kiện.
What’s an Event Stream?
Một luồng sự kiện là một nhật ký bền vững và chỉ thêm, không thay đổi. Các bản ghi được thêm vào cuối nhật ký (đuôi) khi chúng được xuất bản bởi nhà sản xuất. Người tiêu dùng bắt đầu từ đầu nhật ký (đầu) và tiêu thụ các bản ghi với tốc độ xử lý của riêng họ.
Dưới hình thức cơ bản nhất, một luồng sự kiện là một chuỗi các sự kiện kinh doanh được đánh dấu thời gian liên quan đến một miền. Các sự kiện tạo thành cơ sở để giao tiếp dữ liệu kinh doanh quan trọng giữa các miền một cách đáng tin cậy và lặp đi lặp lại.
"Stream sự kiện có một số thuộc tính quan trọng cho phép chúng ta tin tưởng vào chúng cho các microservices hướng sự kiện, và như một cơ sở cho việc giao tiếp dữ liệu hiệu quả giữa các miền nói chung. Để rõ ràng, và với một chút lặp lại, các thuộc tính này bao gồm:"
- Immutability
-
Các sự kiện không thể được sửa đổi sau khi đã ghi vào nhật ký. Nội dung không thể bị thay đổi, cũng như vị trí bù, dấu thời gian hoặc bất kỳ siêu dữ liệu nào khác liên quan. Bạn chỉ có thể thêm các sự kiện mới.
- Partition Support
-
Các phân vùng cung cấp phương tiện để hỗ trợ các tập dữ liệu khổng lồ. Một người tiêu dùng có thể đăng ký một hoặc nhiều phân vùng từ một luồng sự kiện duy nhất, cho phép nhiều phiên bản của một dịch vụ vi mô tiêu thụ và xử lý luồng đó một cách song song.
- Indexed
-
Sự kiện được gán một chỉ mục không thể thay đổi khi được ghi vào nhật ký. Chỉ mục, thường được gọi là độ dịch, xác định duy nhất sự kiện.
- Strictly Ordered
-
Các bản ghi trong một phân vùng luồng sự kiện được phục vụ cho các khách hàng theo đúng thứ tự mà chúng được phát hành ban đầu.
- Durability and replayability
-
Các sự kiện là bền vững. Chúng có thể được tiêu thụ ngay lập tức hoặc trong tương lai. Các sự kiện có thể được phát lại bởi cả người tiêu dùng mới và hiện tại, miễn là môi giới sự kiện có đủ dung lượng lưu trữ để lưu giữ dữ liệu lịch sử. Các sự kiện không bị xóa sau khi được đọc, cũng như không bị loại bỏ đơn giản trong trường hợp không có người tiêu dùng.
- Indefinite Storage Support
-
Bạn có thể giữ lại tất cả các sự kiện trong luồng của mình lâu bất cứ khi nào cần thiết. Không có thời gian hết hiệu lực bắt buộc hay giới hạn thời gian lưu giữ, cho phép bạn tiêu thụ và tiêu thụ lại các sự kiện nhiều lần như bạn cần.
Hình 1-1 cho thấy một luồng sự kiện với ba phân vùng. Các sự kiện mới vừa được thêm vào phân vùng 0 (điểm bù 5) và phân vùng 1 (điểm bù 7). Microservice tiêu thụ các sự kiện này có hai phiên bản. Phiên bản 0 chỉ tiêu thụ phân vùng 0, trong khi phiên bản 1 tiêu thụ cả phân vùng 1 và phân vùng 2.
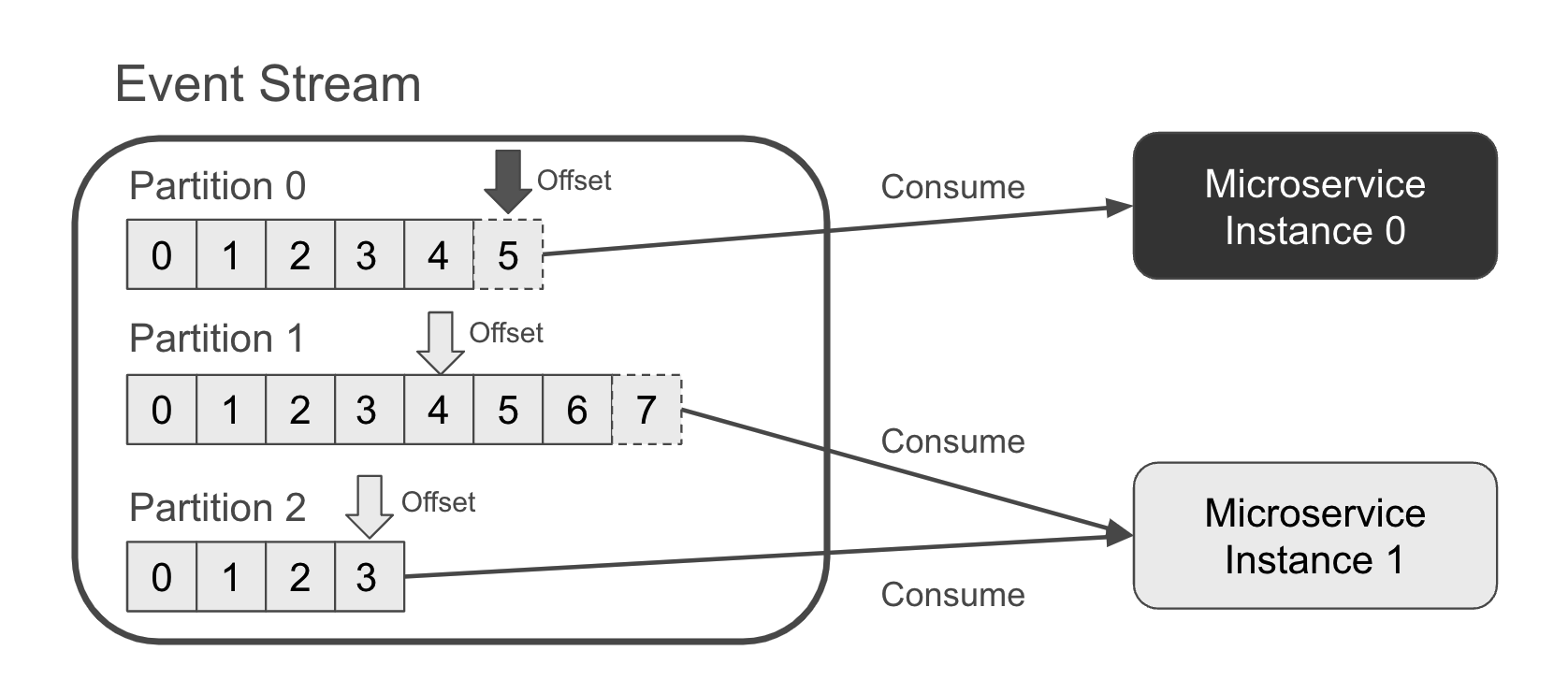
Figure 1-1. An event stream with two microservice instances consuming from a three partitions
With sufficient processing power, the consuming service will remain up to date with the event stream. Meanwhile, a new consumer beginning at an earlier offset (or the head) will need to process all of the events to catch up to current time.
Các luồng sự kiện được lưu trữ trên một trình môi giới sự kiện, với một trong những lựa chọn phổ biến nhất (và trở thành tiêu chuẩn de-facto) là Apache Kafka. Trình môi giới sự kiện, chẳng hạn như trong trường hợp của Kafka, cung cấp một cấu trúc được gọi là chủ đề mà chúng ta có thể ghi lại các sự kiện của mình. Nó cũng xử lý mọi thứ từ sao chép dữ liệu và cân bằng lại đến kết nối khách hàng và kiểm soát quyền truy cập. Các nhà phát hành ghi các sự kiện vào luồng sự kiện được lưu trữ trong trình môi giới, trong khi các nhà tiêu thụ đăng ký các luồng sự kiện và nhận các sự kiện.
Rất tiếc, do một lịch sử dài và thường rối rắm, các trình môi giới sự kiện thường bị nhầm lẫn với tin nhắn tạm thời và hàng đợi. Mỗi tùy chọn này đều khác nhau. Hãy cùng xem xét kỹ lưỡng từng loại và lý do tại sao luồng sự kiện tạo thành nền tảng của kiến trúc hướng sự kiện hiện đại.
Ephemeral Messaging
Một kênh là một nền tảng tạm thời để truyền tải thông điệp giữa một nhà sản xuất và một hoặc nhiều người đăng ký. Các thông điệp được gửi đến những người tiêu thụ cụ thể, và chúng không được lưu lại trong một khoảng thời gian đáng kể, cũng như không được ghi vào bộ lưu trữ lâu dài bởi môi giới. Trong trường hợp hệ thống gặp sự cố hoặc thiếu người đăng ký trên kênh, các thông điệp sẽ đơn giản bị loại bỏ, cung cấp việc giao hàng tối đa một lần. NATS.io Core (không phải JetStream) là một ví dụ cho hình thức triển khai này.
Hình 1-2 cho thấy một nhà sản xuất duy nhất gửi tin nhắn đến kênh tạm thời trong bộ trung gian sự kiện. Các tin nhắn tạm thời sau đó được chuyển đến các người tiêu dùng hiện đang đăng ký. Trong hình này, Người tiêu dùng 0 nhận được tin nhắn 7 và 8, nhưng Người tiêu dùng 1 không nhận được vì họ mới đăng ký và không có quyền truy cập vào dữ liệu lịch sử. Thay vào đó, Người tiêu dùng 1 sẽ chỉ nhận được tin nhắn 9 và bất kỳ tin nhắn nào tiếp theo.

Figure 1-2. An ephemeral message-passing broker forwarding messages
Giao tiếp tạm thời rất phù hợp cho việc giao tiếp trực tiếp giữa các dịch vụ với chi phí thấp. Đây là một kiến trúc truyền tin, và không nên nhầm lẫn với kiến trúc phát hành-đăng ký bền vững như được cung cấp bởi các luồng sự kiện.
Kiến trúc truyền tin cung cấp giao tiếp điểm-điểm giữa các hệ thống mà không nhất thiết phải đảm bảo giao hàng ít nhất một lần và có thể chịu đựng một số mất dữ liệu. Ví dụ, ứng dụng hẹn hò trực tuyến Tinder sử dụng NATS để thông báo cho người dùng về các cập nhật. Nếu tin nhắn không được nhận, điều đó không quá nghiêm trọng—một thông báo đẩy bị bỏ lỡ chỉ có tác động nhỏ (mặc dù tiêu cực) đến trải nghiệm của người dùng.
Các trung gian truyền tin tạm thời thiếu khả năng lưu giữ vô thời hạn, độ bền và khả năng phát lại sự kiện cần thiết mà chúng tôi cần để xây dựng các sản phẩm dữ liệu dựa trên sự kiện. Kiến trúc truyền tin hữu ích cho việc giao tiếp dựa trên sự kiện giữa các hệ thống phục vụ mục đích vận hành hiện tại nhưng hoàn toàn không phù hợp để cung cấp phương tiện giao tiếp cho các sản phẩm dữ liệu.
Queuing
Một hàng đợi là một chuỗi bền vững của các bản ghi được lưu trữ đang chờ được xử lý. Thông thường có nhiều người tiêu thụ đồng thời (và cạnh tranh) chọn, xử lý và xác nhận các bản ghi theo thứ tự ai đến trước được phục vụ trước. Đây là một trong những sự khác biệt chính khi so với các luồng sự kiện, sử dụng các đăng ký độc quyền phân vùng và xử lý theo thứ tự nghiêm ngặt.
Hàng đợi công việc là một trường hợp sử dụng phổ biến. Nhà sản xuất xuất bản các bản ghi "công việc cần làm", trong khi các máy tiêu thụ lấy ra các bản ghi, xử lý chúng, rồi báo hiệu cho môi giới hàng đợi rằng công việc đã hoàn thành. Sau đó, môi giới thường xóa các bản ghi đã được xử lý, đây là sự khác biệt lớn thứ hai khi so sánh với luồng sự kiện, vì luồng này giữ lại các bản ghi miễn là được chỉ định (bao gồm cả vô thời hạn).
Hình 1-3 cho thấy hai người đăng ký tiêu thụ các bản ghi từ một hàng đợi theo cách vòng tròn. Lưu ý rằng hàng đợi chứa các bản ghi đang được xử lý (đường nét đứt) và những bản ghi chưa được xử lý (đường liền).
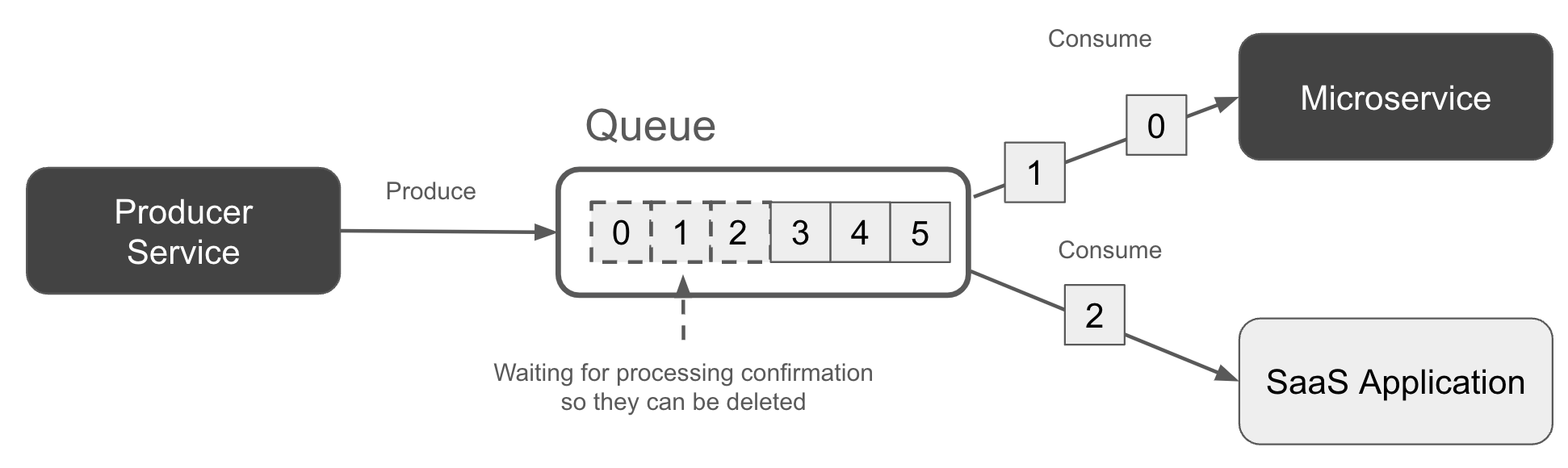
Figure 1-3. A queue with two subscribers each processing a subset of events
Hàng đợi thường cung cấp đảm bảo xử lý "ít nhất một lần". Các bản ghi có thể được xử lý nhiều hơn một lần, đặc biệt nếu một người đăng ký không cam kết tiến trình của mình trở lại với trung gian, chẳng hạn do bị treo, sau khi xử lý một bản ghi. Trong trường hợp này, một người đăng ký khác có thể lấy bản ghi và xử lý lại.
Nếu nhiều người tiêu dùng độc lập (ví dụ: các ứng dụng microservice) cần truy cập vào các bản ghi trong hàng đợi (chẳng hạn như để thực hiện một sự kiện Bán hàng), thì bạn phải sử dụng một dòng sự kiện hoặc tạo một hàng đợi cho mỗi dịch vụ tiêu thụ. Hình 1-4 cho thấy một ví dụ, trong đó dịch vụ sản xuất ghi một bản sao của mỗi bản ghi vào hai hàng đợi khác nhau để đảm bảo rằng mỗi người tiêu dùng có một bản sao của dữ liệu để xử lý.
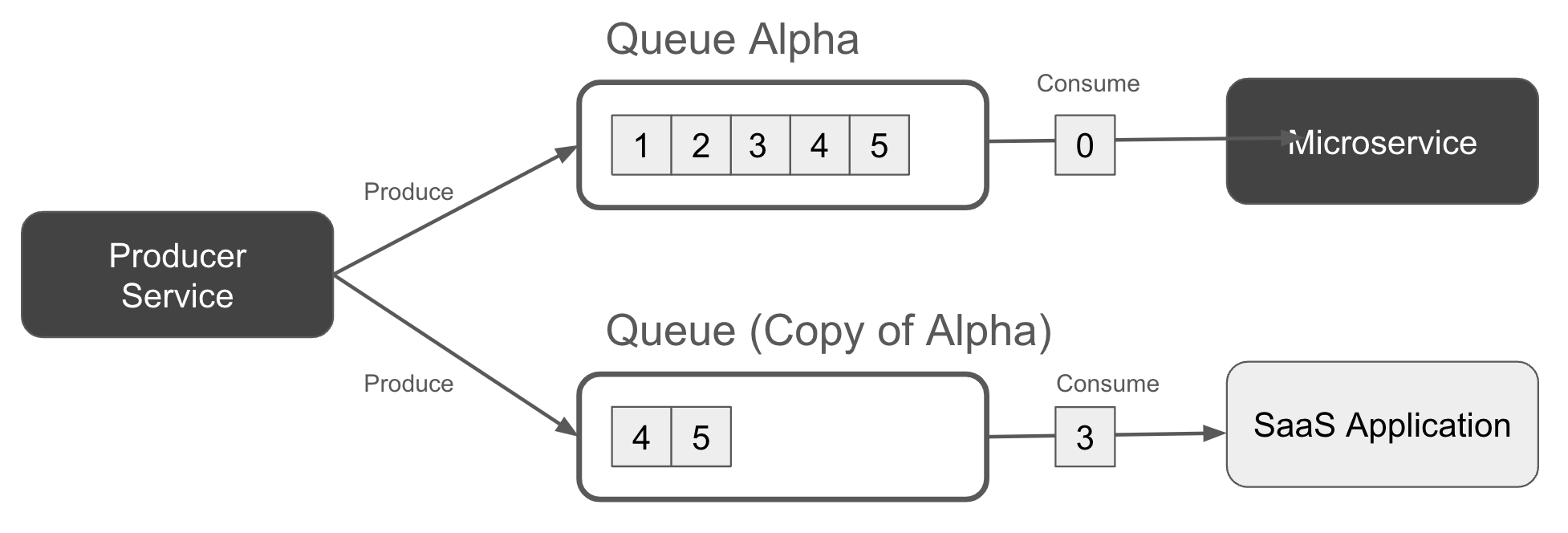
Figure 1-4. A producer writing to two duplicate queues, one or each consumer application.
Warning
Dịch vụ sản xuất của bạn có thể không thể ghi đồng thời vào nhiều hàng đợi hơn một lần. Bạn sẽ cần xem xét các hạn chế của khả năng ghi vào nhiều hàng đợi của broker của bạn. Nếu không làm như vậy, các hàng đợi có thể phân kỳ với nhau theo thời gian, khi điều kiện cạnh tranh và các lỗi tạm thời có thể khiến một bản ghi được ghi vào một hàng đợi, nhưng không ghi vào các hàng đợi khác.
Lịch sử, các nhà môi giới hàng đợi đã giới hạn thời gian tồn tại (TTL) để lưu trữ các bản ghi trong hàng đợi. Các bản ghi không được xử lý trong một khoảng thời gian nhất định sẽ bị đánh dấu là chết, bị xóa đi và không còn được gửi đến các người nhận - ngay cả khi chúng chưa được xử lý! Tương tự như các giao tiếp tạm thời, việc giữ lại dựa trên thời gian và dữ liệu không thể phát lại đã ảnh hưởng đến nhận thức sai lầm rằng các nhà môi giới (cả hàng đợi và sự kiện) không thể được sử dụng để giữ dữ liệu vô thời hạn.
Với điều đó được nói ra, quan trọng là lưu ý rằng TTL thấp không còn là tiêu chuẩn nữa, ít nhất là đối với các công nghệ hàng đợi hiện đại hơn. Ví dụ, cả RabbitMQ và ActiveMQ đều cho phép bạn đặt TTL không hạn chế cho các bản ghi của bạn, cho phép bạn giữ chúng trong hàng đợi miễn là cần thiết cho doanh nghiệp của bạn.
Note
Các trung gian hàng đợi hiện đại cũng có thể hỗ trợ khả năng phát lại và lưu trữ vô hạn các bản ghi thông qua các nhật ký ghi đè bền vững - về cơ bản giống như một luồng sự kiện. Chẳng hạn, cả Solace và RabbitMQ Streams đều cho phép các người tiêu dùng riêng lẻ phát lại các bản ghi đã được xếp hàng như thể đó là một luồng sự kiện.
Một điều cuối cùng trước khi chúng ta kết thúc phần này. Hàng đợi cũng có thể cung cấp thứ tự ghi dựa trên ưu tiên cho người tiêu dùng, để các bản ghi ưu tiên cao được đẩy lên phía trước, trong khi các bản ghi ưu tiên thấp sẽ ở lại phía sau hàng đợi cho đến khi tất cả các bản ghi ưu tiên cao hơn được xử lý. Hàng đợi cung cấp một cấu trúc dữ liệu lý tưởng cho việc sắp xếp theo ưu tiên, vì chúng không áp dụng một thứ tự vào trước, ra trước nghiêm ngặt như một luồng sự kiện.
Hàng đợi được sử dụng tốt nhất như một bộ đệm đầu vào cho một hệ thống hạ nguồn cụ thể. Bạn có thể dựa vào một hàng đợi để lưu trữ các bản ghi cần được xử lý bởi một hệ thống khác, cho phép ứng dụng sản xuất tiếp tục với các nhiệm vụ khác - bao gồm việc ghi thêm các bản ghi vào hàng đợi. Bạn có thể tin tưởng vào hàng đợi để lưu trữ bền bỉ tất cả các bản ghi cho đến khi dịch vụ tiêu thụ của bạn có thể làm việc với chúng. Thêm vào đó, dịch vụ tiêu thụ của bạn có thể mở rộng quy mô xử lý bằng cách đăng ký thêm các người tiêu dùng mới trên hàng đợi và chia sẻ việc xử lý theo hình thức vòng tròn.
The Structure of an Event
Sự kiện, như được ghi vào một luồng sự kiện, thường được đại diện bằng một khóa, một giá trị và một tiêu đề. Cả ba thành phần này cùng nhau tạo thành bản ghi thể hiện sự kiện.
Cấu trúc chính xác của bản ghi sẽ khác nhau tùy thuộc vào công nghệ bạn chọn. Ví dụ, các hàng đợi và thông điệp tạm thời thường sử dụng các quy tắc và thành phần tương tự nhưng khác nhau, chẳng hạn như khóa tiêu đề, khóa định tuyến và khóa ràng buộc, để kể tên một vài thứ. Nhưng phần lớn, định dạng bản ghi ba phần sau đây thường có thể áp dụng cho tất cả các sự kiện.
- The key
-
Chìa khóa là tùy chọn nhưng cực kỳ hữu ích. Nó thường được đặt thành một ID duy nhất đại diện cho dữ liệu của sự kiện đó, tương tự như khóa chính trong một cơ sở dữ liệu quan hệ. Nó cũng thường được sử dụng để định tuyến sự kiện đến một phân vùng cụ thể của luồng sự kiện. Sẽ có thêm thông tin về điều đó trong chương này.
- The value
-
Chứa phần lớn dữ liệu liên quan đến sự kiện. Nếu bạn coi khóa sự kiện như khóa chính của một dòng trong bảng cơ sở dữ liệu, thì hãy nghĩ giá trị như tất cả các trường khác trong dòng đó. Giá trị mang phần lớn dữ liệu của một sự kiện.
- The header (also known as “record properties”)
-
Chứa siêu dữ liệu về chính sự kiện, và thường là định dạng độc quyền tùy thuộc vào nhà môi giới sự kiện. Bản ghi thường được sử dụng để ghi lại thông tin như ngày giờ, ID theo dõi và các cặp khóa-giá trị do người dùng định nghĩa mà không thích hợp cho giá trị.
Một ví dụ về cấu trúc bản ghi được hiển thị trong Hình 1-5, chứa một tập hợp thông tin tối thiểu liên quan đến một đơn hàng thương mại điện tử.
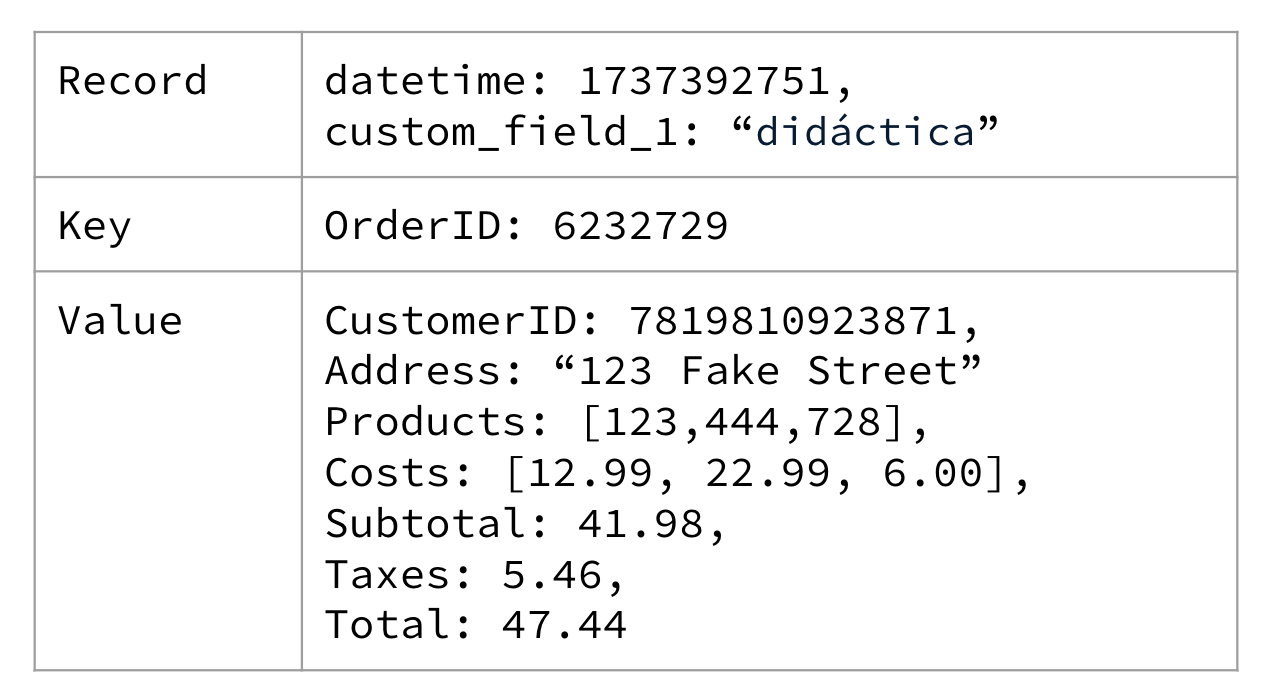
Figure 1-5. A simple e-commerce order showing the items purchased by a user, along with the total cost
Các sự kiện là bất biến. Bạn không thể sửa đổi một sự kiện sau khi nó được phát hành vào dòng sự kiện. Tính bất biến là một thuộc tính thiết yếu để đảm bảo rằng các người tiêu dùng đều có quyền truy cập vào cùng một dữ liệu. Việc thay đổi dữ liệu đã được đọc bởi nhiều người tiêu dùng thì không có lợi, vì không có cách nào dễ dàng để thông báo cho họ rằng họ phải thực hiện thay đổi đối với dữ liệu mà họ đã đọc. Tuy nhiên, bạn có thể tạo và phát hành các sự kiện mới chứa các sửa đổi hoặc cập nhật cần thiết, được trình bày rõ hơn trong chương [Liên kết sẽ đến].
Các sự kiện thường được phân loại thành ba loại chính: sự kiện không khóa, sự kiện có khóa và sự kiện thực thể. Hãy cùng xem xét kỹ lưỡng từng loại.
Unkeyed Event
Các sự kiện không có khóa không chứa khóa. Chúng thường được coi là hoàn toàn độc lập với nhau. Không có sự xử lý đặc biệt nào cho việc định tuyến tới một phân vùng cụ thể.
Các sự kiện không khóa thường là một dạng đo lường thô. Ví dụ, một chiếc máy ảnh chụp lại hình ảnh một chiếc ô tô chạy qua đèn đỏ có thể tạo ra một sự kiện không khóa, như được thể hiện trong Hình 1-6.
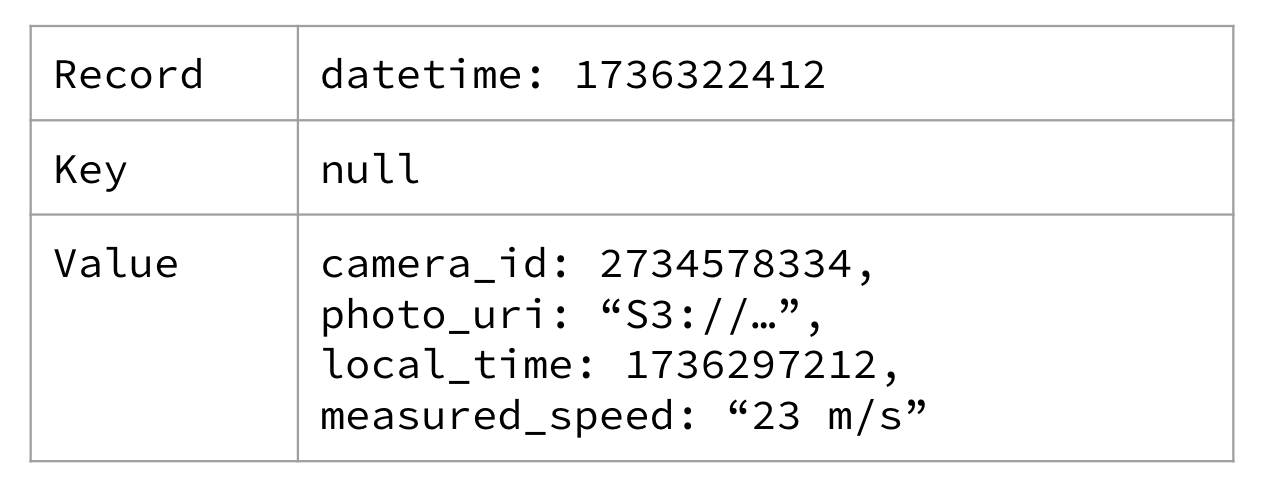
Figure 1-6. An unkeyed red light traffic camera event
Có thể camera tín hiệu đỏ đã tạo ra sự kiện với camera_id làm khóa không? Chắc chắn rồi! Nhưng nó đã không làm vậy, vì nó chỉ ghi lại dữ liệu theo định dạng cụ thể đó, và camera cụ thể này không hỗ trợ xử lý hậu kỳ tùy chỉnh. Bạn nhận được sự kiện theo định dạng mà nó chỉ định trong hướng dẫn sử dụng.
Nếu chúng ta muốn thêm một khóa, chúng ta sẽ phải thực hiện một số xử lý bổ sung và phát ra một luồng sự kiện mới, như bạn sẽ thấy trong phần tiếp theo.
Keyed Events
Các sự kiện có khóa chứa một khóa không null liên quan đến điều gì đó quan trọng về sự kiện. Khóa sự kiện được xác định bởi dịch vụ sản xuất khi nó tạo ra bản ghi và giữ nguyên không thay đổi sau khi được ghi vào luồng sự kiện.
Nếu chúng ta áp dụng một khóa cho dữ liệu camera giao thông tín hiệu đỏ, chúng ta có thể chọn sử dụng biển số xe của người lái. Bạn có thể xem một ví dụ về điều đó trong Hình 1-7.
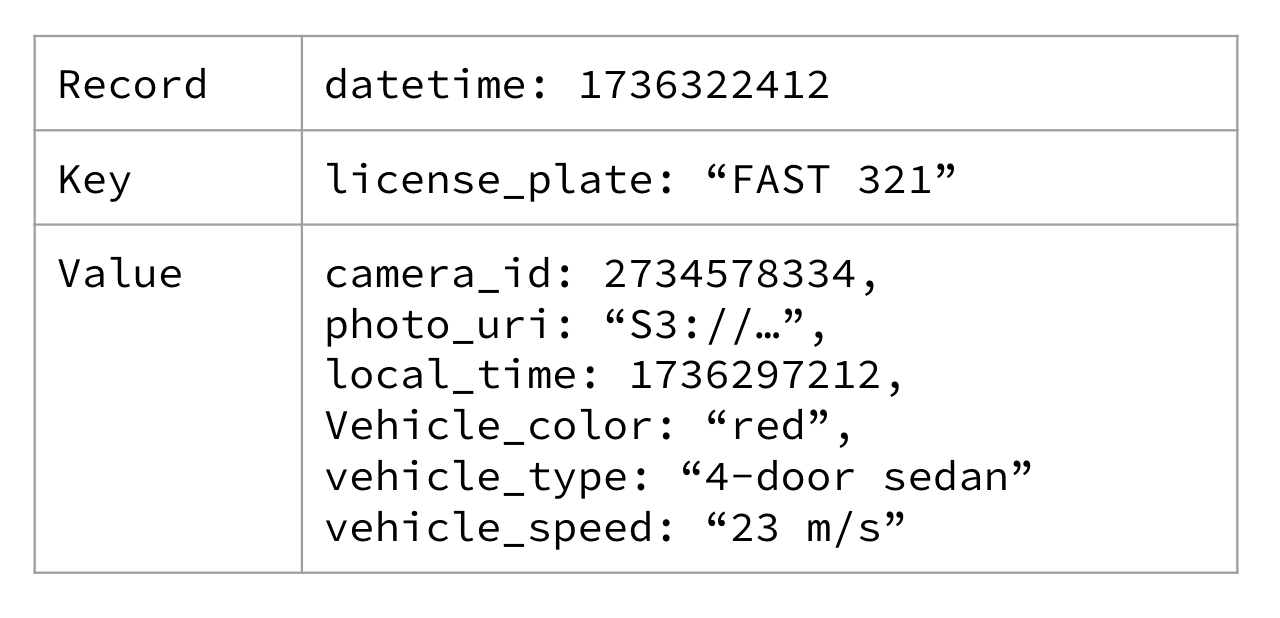
Figure 1-7. A red light traffic camera event keyed on the driver’s license plate
Một khóa cho phép nhà sản xuất phân vùng các bản ghi một cách xác định, với tất cả các bản ghi của cùng một khóa được đưa vào cùng một phân vùng sự kiện, như được mô tả trong Hình 1-8. Điều này cung cấp cho người tiêu dùng sự kiện của bạn một đảm bảo rằng tất cả dữ liệu của một khóa nhất định sẽ chỉ nằm trong một phân vùng duy nhất. Ngược lại, người tiêu dùng của bạn có thể dễ dàng phân chia công việc dựa trên từng phân vùng, biết rằng bất kỳ công việc nào dựa trên khóa mà họ thực hiện sẽ chỉ phụ thuộc vào việc đọc một phân vùng duy nhất, chứ không phải tất cả các sự kiện từ tất cả các phân vùng.
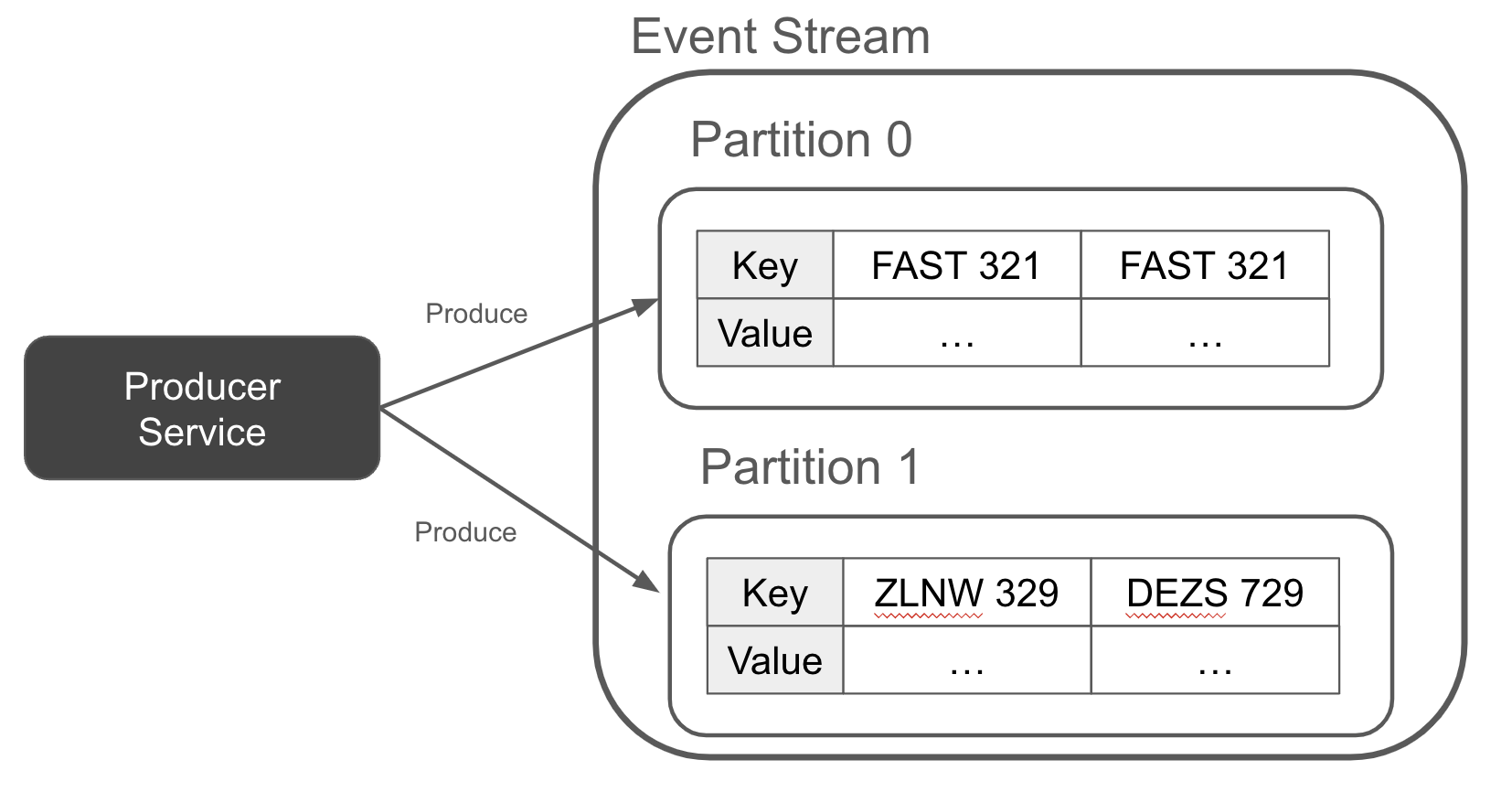
Figure 1-8. A red light traffic camera event keyed on the driver’s license plate
Như đã được minh họa trong chủ đề phân tách, bạn có thể thấy rằng có ít nhất hai sự kiện cho FAST 321. Mỗi sự kiện trong số này đại diện cho một lần xe chạy qua đèn đỏ. Hãy ghi nhớ điều này khi chúng ta đến với phân loại sự kiện cuối cùng, sự kiện thực thể.
Entity Event
Một sự kiện thực thể đại diện cho một thứ duy nhất và được xác định bằng ID duy nhất của thứ đó. Nó mô tả các thuộc tính và trạng thái của thực thể tại một thời điểm cụ thể. Các sự kiện thực thể cũng thỉnh thoảng được gọi là sự kiện trạng thái, vì chúng đại diện cho trạng thái của một thứ cụ thể tại một thời điểm nhất định.
Để có điều gì đó cụ thể hơn, và tiếp tục với phép loại suy về camera giao thông, bạn có thể mong đợi thấy một chiếc xe như một sự kiện thực thể. Bạn cũng có thể thấy các sự kiện thực thể cho Người lái xe, Lốp xe, Ngã tư, hoặc bất kỳ “thứ” nào khác liên quan đến tình huống. Một thực thể xe được trình bày trong Hình 1-9.
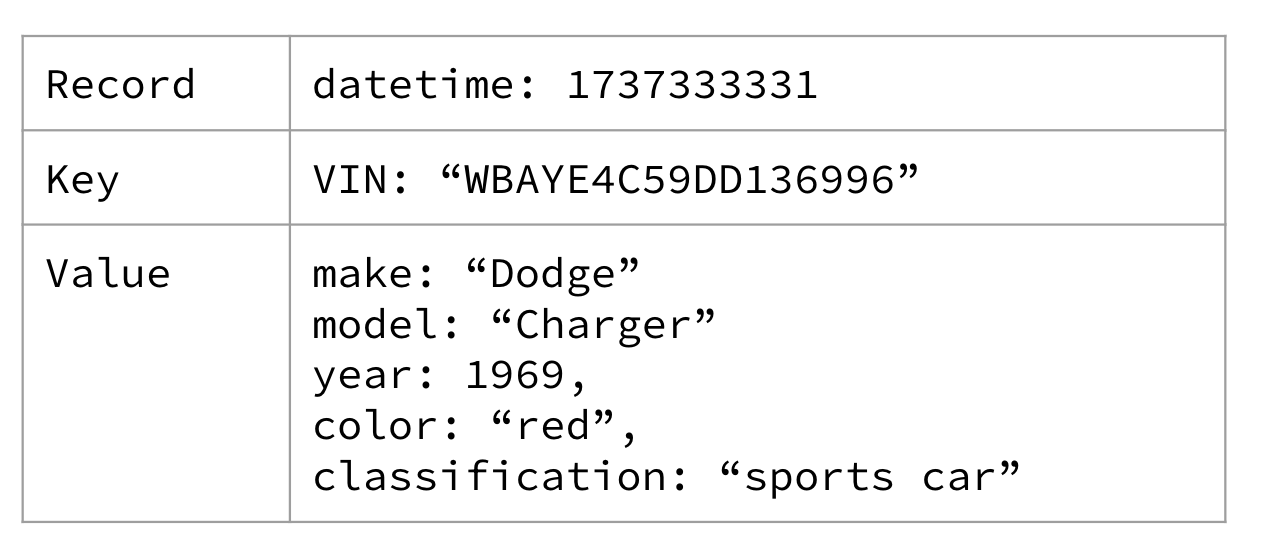
Figure 1-9. A Car entity describing the sports car that keeps running the red lights
Bạn có thể thấy hữu ích khi nghĩ về một sự kiện của thực thể giống như bạn nghĩ về một hàng trong bảng cơ sở dữ liệu. Cả hai đều có một khóa chính, và cả hai đại diện cho dữ liệu của khóa chính đó như nó đang ở thời điểm hiện tại. Và giống như một hàng trong cơ sở dữ liệu, dữ liệu chỉ hợp lệ trong khoảng thời gian dữ liệu đó vẫn không thay đổi. Do đó, nếu bạn sơn lại chiếc xe thành màu xanh, bạn có thể mong đợi thấy một sự kiện mới với màu sắc được cập nhật, như trong Hình 1-10.

Figure 1-10. The car has been repainted blue
Bạn cũng có thể nhận thấy rằng trường datetime đã được cập nhật để thể hiện khi chiếc xe được sơn màu xanh (hoặc ít nhất là khi nó được báo cáo). Bạn cũng sẽ nhận thấy rằng sự kiện thực thể cũng chứa tất cả dữ liệu không thay đổi. Điều này là có ý định, và thực sự cho phép chúng ta thực hiện một số điều khá mạnh mẽ với các sự kiện thực thể - nhưng chúng ta sẽ đề cập đến điều đó một cách chi tiết hơn trong Chương 3.
Tương tự như cách các sự kiện có khóa đều được gửi đến cùng một phân vùng, điều này cũng đúng với các sự kiện thực thể. Hình 1-11 cho thấy một luồng sự kiện với hai sự kiện cho FAST 321 - một khi nó màu đỏ (sự kiện cũ nhất), và một khi nó màu xanh (sự kiện mới nhất, được thêm vào cuối luồng).
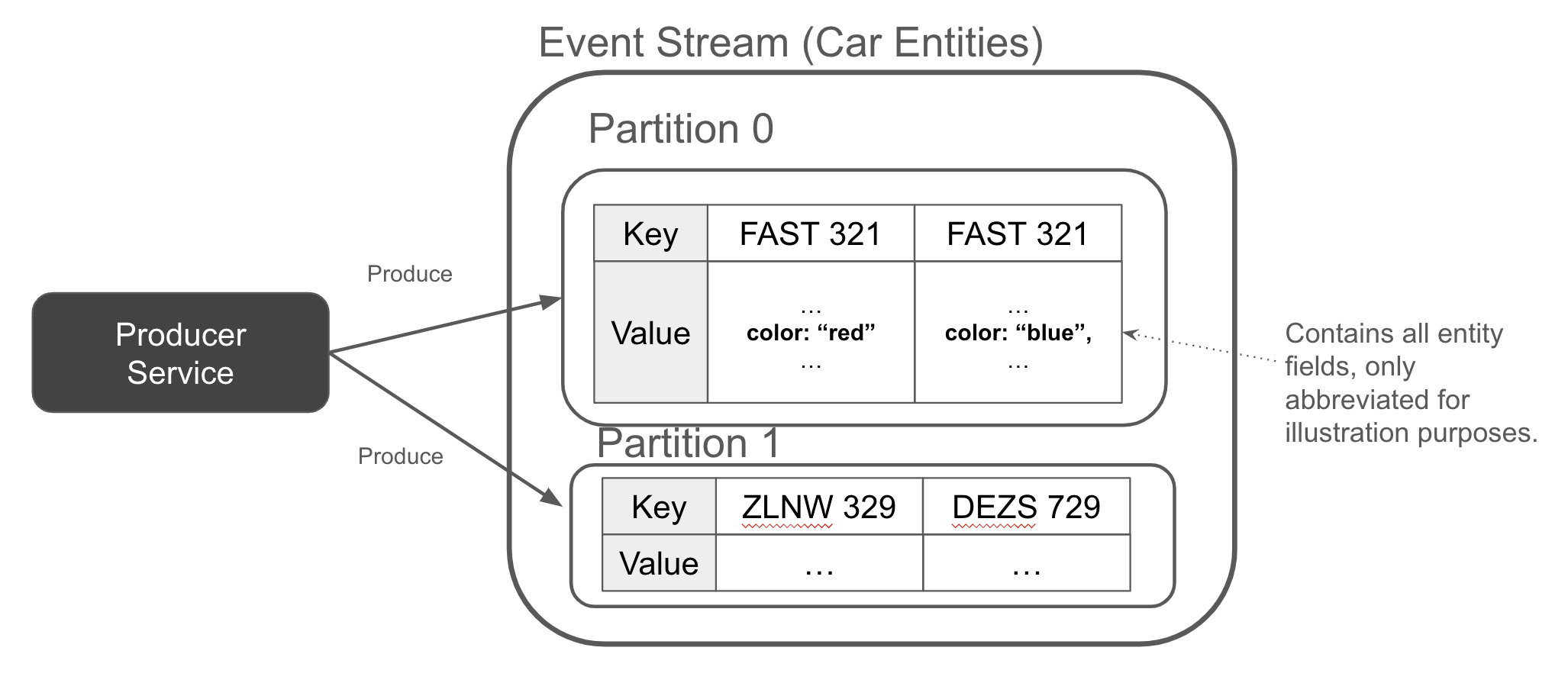
Figure 1-11. The producer appends a full entity event whenever an entity is created, updated, or deleted
Các sự kiện thực thể đặc biệt quan trọng trong các kiến trúc hướng sự kiện. Chúng cung cấp một lịch sử liên tục về trạng thái của một thực thể và có thể được sử dụng để hiện thực hóa trạng thái (được đề cập trong phần tiếp theo).
Có nhiều điều hơn nữa về thiết kế sự kiện so với những gì chúng ta đã đề cập trong chương này, nhưng chúng ta sẽ tạm hoãn việc đi sâu vào điều đó cho đến chương [Liên kết sẽ có]. Thay vào đó, hãy cùng xem cách chúng ta có thể sử dụng những sự kiện mà chúng ta vừa giới thiệu để xây dựng các dịch vụ vi mô dựa trên sự kiện trong thế giới thực.
Aggregating State from Keyed Events
Một phép tổng hợp là quá trình tiêu thụ hai hoặc nhiều sự kiện và kết hợp chúng thành một kết quả duy nhất. Các phép tổng hợp là một nguyên lý xử lý dữ liệu phổ biến cho các kiến trúc dựa trên sự kiện, và là một trong những cách chính để tạo ra trạng thái từ một loạt các sự kiện. Việc xây dựng một phép tổng hợp yêu cầu lưu trữ và duy trì trạng thái bền vững, sao cho tiến trình tổng hợp được bảo tồn nếu dịch vụ gặp sự cố. Trạng thái và phục hồi sẽ được đề cập trong chương [Link to Come].
Sự kiện được khóa đóng vai trò quan trọng trong việc tổng hợp, vì tất cả dữ liệu cùng một khóa nằm trong cùng một phân vùng. Do đó, bạn có thể đơn giản tổng hợp một khóa duy nhất bằng cách đọc một phân vùng duy nhất. Nếu bạn đang đọc nhiều chủ đề, thì bạn cần đảm bảo rằng chúng được phân vùng giống nhau - nếu không, bạn sẽ phải phân vùng lại dữ liệu để các luồng khớp với nhau. Việc phân vùng lại và đồng phân vùng sẽ được đề cập chi tiết hơn trong chương [Liên kết sẽ đến].
Một phép tổng hợp có thể đơn giản như một tổng, như được thể hiện trong Hình 1-12. Ví dụ, tổng hợp số vé phạt giao thông đã được cấp cho chủ sở hữu của một chiếc xe thể thao có tốc độ cao và tính tổng số tiền phải trả.
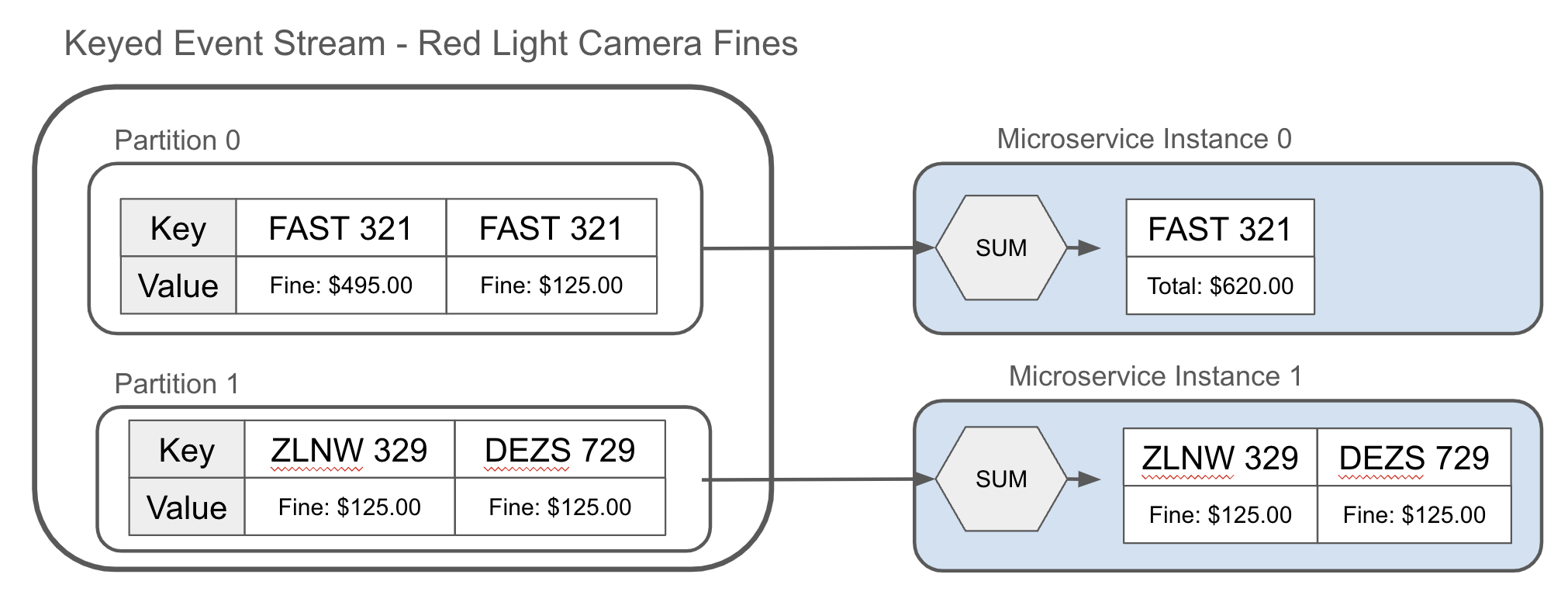
Figure 1-12. Aggregating the keyed events of the red light camera fines
Các phép tổng hợp cũng có thể phức tạp hơn, bao gồm nhiều luồng đầu vào, nhiều loại sự kiện và các máy trạng thái nội bộ để thu được kết quả phức tạp hơn. Chúng ta sẽ xem lại các phép tổng hợp trong suốt cuốn sách, nhưng bây giờ, hãy cùng xem xét việc vật chất hóa.
Materializing State from Entity Events
Một sự vật hóa là một dự báo của một luồng vào một bảng. Bạn vật hóa một bảng bằng cách áp dụng các sự kiện thực thể, theo thứ tự, từ một luồng sự kiện thực thể. Mỗi sự kiện thực thể được chèn hoặc cập nhật vào bảng, sao cho sự kiện được đọc gần đây nhất cho một khóa nhất định được đại diện. Điều này được minh họa trong Hình 1-13, nơi FAST 321 và SJFH 372 đều có giá trị mới nhất trong bảng đã được vật hóa của chúng.
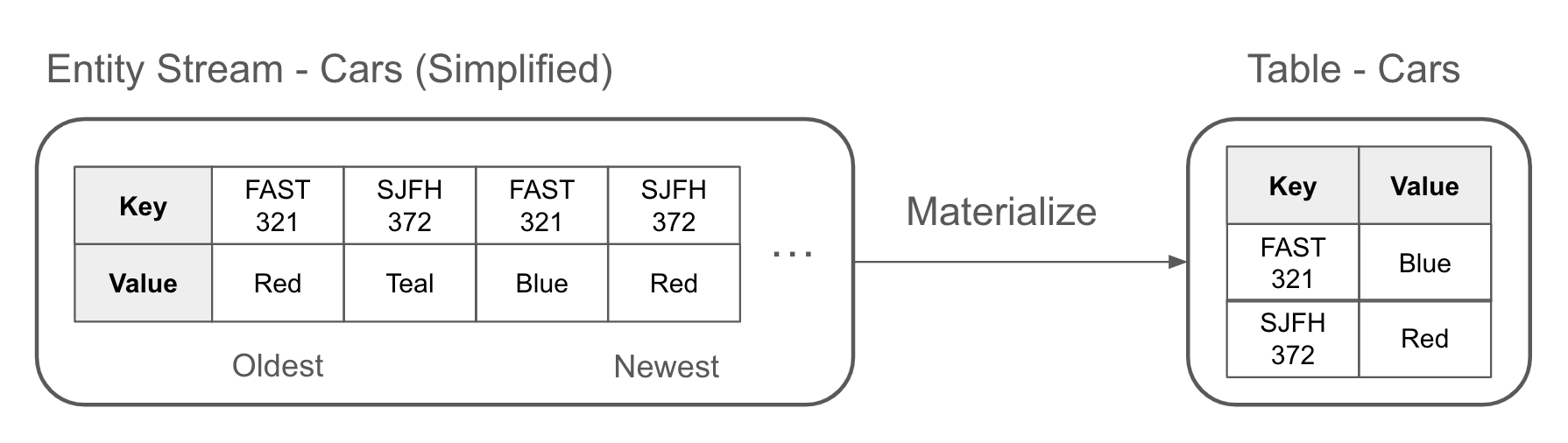
Figure 1-13. Materializing an event stream into a table
Bạn cũng có thể chuyển đổi một bảng thành một luồng sự kiện thực thể bằng cách công bố mỗi bản cập nhật vào luồng sự kiện.
Tip
Định lý đối xứng luồng-bảng là nguyên tắc rằng một luồng có thể được biểu diễn bằng một bảng, và một bảng có thể được biểu diễn dưới dạng luồng. Điều này rất cơ bản trong việc chia sẻ trạng thái giữa các dịch vụ vi mô theo sự kiện, mà không có bất kỳ sự ràng buộc trực tiếp nào giữa các dịch vụ sản xuất và tiêu thụ.
Theo cách tương tự, bạn có thể có một bảng ghi lại tất cả các cập nhật và qua đó tạo ra một luồng dữ liệu đại diện cho trạng thái của bảng theo thời gian. Trong ví dụ sau, BB được upsert hai lần, trong khi DD chỉ được upsert một lần. Luồng đầu ra trong Hình 1-14 cho thấy ba sự kiện upsert đại diện cho những thao tác này.
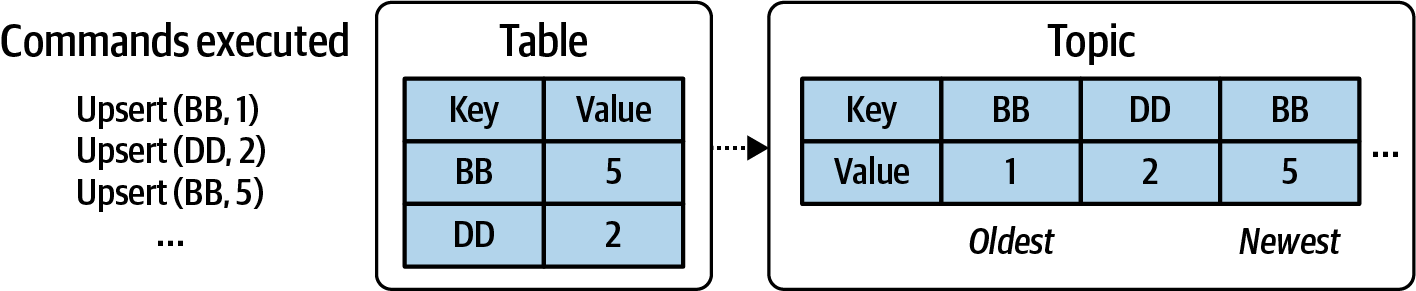
Figure 1-14. Generating an event stream from the changes applied to a table
Một bảng cơ sở dữ liệu quan hệ, chẳng hạn, được tạo ra và điền dữ liệu thông qua một loạt các lệnh chèn, cập nhật và xóa dữ liệu. Những lệnh này có thể được sản xuất dưới dạng sự kiện vào một nhật ký không thay đổi, chẳng hạn như một tệp chỉ thêm tại chỗ (như nhật ký nhị phân trong MySQL) hoặc một luồng sự kiện bên ngoài. Bằng cách phát lại toàn bộ nội dung của nhật ký, bạn có thể tái tạo chính xác bảng và tất cả dữ liệu của nó.
Deleting Events and Event Stream Compaction
Đầu tiên, tin xấu. Bạn không thể xóa một bản ghi khỏi luồng sự kiện như cách bạn xóa một hàng trong bảng cơ sở dữ liệu. Một phần lớn giá trị của luồng sự kiện là tính bất biến của nó. Nhưng bạn có thể phát hành một sự kiện mới, được gọi là tombstone, cho phép bạn xóa các bản ghi có cùng khóa. Tombstone thường được sử dụng nhiều nhất với các luồng sự kiện của thực thể.
Một bia mộ (tombstone) là một sự kiện có khóa với giá trị được đặt là null, đây là một quy ước được thiết lập bởi dự án Apache Kafka. Bia mộ phục vụ hai mục đích. Đầu tiên, chúng báo hiệu cho người tiêu dùng rằng dữ liệu liên quan đến khóa sự kiện đó bây giờ nên được xem là đã bị xóa. Để sử dụng phép so sánh với cơ sở dữ liệu, việc xóa một hàng từ bảng sẽ tương đương với việc phát hành một bia mộ vào một luồng sự kiện dành cho cùng một khóa chính.
Thứ hai, bia mộ cho phép việc nén. Nén là một quá trình của trình môi giới sự kiện nhằm giảm kích thước của các luồng sự kiện bằng cách chỉ giữ lại các sự kiện gần đây nhất cho một khóa nhất định. Các sự kiện cũ hơn bia mộ sẽ bị xóa, và các sự kiện còn lại được nén lại thành một tập hợp nhỏ hơn các tệp dễ đọc và nhanh chóng hơn. Các offset của luồng sự kiện được duy trì để không cần thay đổi từ phía người tiêu dùng. Hình 1-15 minh họa sự nén logic của một luồng sự kiện trong trình môi giới sự kiện.
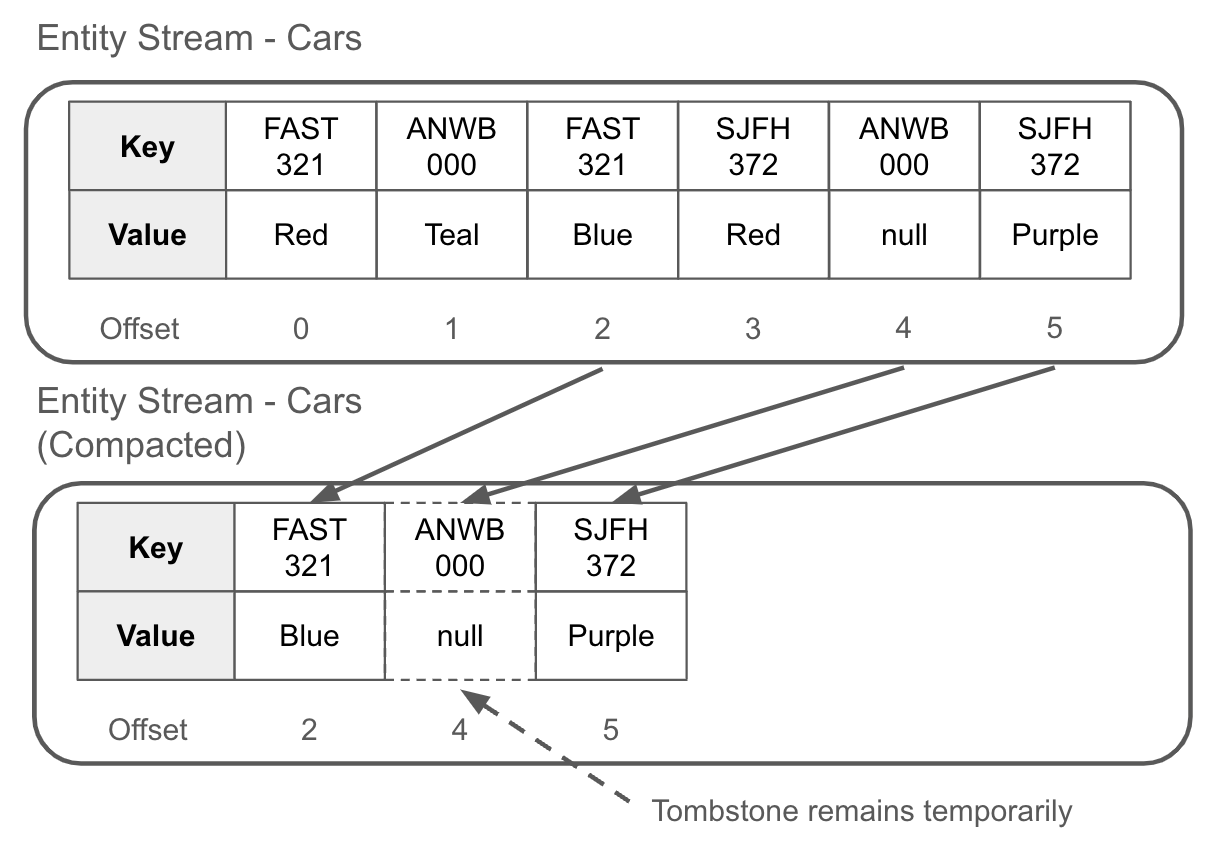
Figure 1-15. After a compaction, only the most recent record is kept for a given key — all predecessors records of the same key are deleted
Bản ghi tombstone thường chỉ tồn tại trong luồng sự kiện trong một khoảng thời gian ngắn. Trong trường hợp của Apache Kafka, giá trị mặc định là 24 giờ cho phép người tiêu dùng có cơ hội đọc tombstone trước khi nó cũng bị (asynchronously) dọn dẹp.
Quá trình nén là một quá trình không đồng bộ chỉ được thực hiện khi đáp ứng một tập hợp tiêu chí nhất định, bao gồm tỷ lệ bẩn hoặc số lượng bản ghi trong các phân đoạn không hoạt động. Bạn cũng có thể kích hoạt nén thủ công. Cách thức cụ thể của quá trình nén thay đổi tùy theo lựa chọn trình xử lý sự kiện, vì vậy bạn sẽ phải tham khảo tài liệu của mình cho phù hợp.
Nén giảm cả việc sử dụng đĩa và số lượng sự kiện cần được xử lý để đạt được trạng thái hiện tại, với cái giá là loại bỏ một phần lịch sử luồng sự kiện. Nén thường cung cấp một số cấu hình và đảm bảo hữu ích, bao gồm:
- Minimum Compaction Lag
-
Bạn có thể chỉ định khoảng thời gian tối thiểu mà một bản ghi phải tồn tại trong luồng sự kiện trước khi nó đủ điều kiện để được nén. Ví dụ, Apache Kafka cung cấp thuộc tính min.compaction.lag.ms cho các chủ đề của nó. Bạn có thể đặt giá trị này thành một giá trị hợp lý, chẳng hạn như 24 giờ hoặc 7 ngày, để đảm bảo rằng các người tiêu dùng của bạn có thể đọc dữ liệu trước khi nó bị nén đi.
- Offset Guarantees
-
Các offset không thay đổi trước, trong và sau khi nén. Nén sẽ tạo ra khoảng trống giữa các offset liên tiếp, nhưng sẽ không có hậu quả nào cho người tiêu dùng tiêu thụ tuần tự luồng sự kiện. Cố gắng đọc một offset cụ thể không còn tồn tại sẽ dẫn đến một lỗi.
- Consistency Guarantees
-
Một người tiêu dùng đọc từ đầu một chủ đề đã nén có thể tạo ra một bảng chính xác giống hệt như một người tiêu dùng đã chạy từ đầu.
Caution
Mặc dù bạn có thể tìm thấy các công cụ cho phép bạn xóa thủ công các bản ghi từ một luồng sự kiện, nhưng hãy rất cẩn thận. Việc xóa thủ công các bản ghi có thể dẫn đến những kết quả không mong muốn, đặc biệt nếu bạn có các kẻ tiêu thụ đã đọc dữ liệu. Chỉ xóa các bản ghi sẽ không sửa chữa được trạng thái do các kẻ tiêu thụ tạo ra. Việc ngăn chặn dữ liệu xấu là rất quan trọng, và chúng tôi sẽ đề cập đến điều đó nhiều hơn trong chương [Liên kết sẽ đến].
Sự đối xứng giữa stream và bảng cùng với việc vật chất hóa cho phép các dịch vụ của chúng tôi giao tiếp trạng thái với nhau. Việc nén cho phép chúng tôi giữ các luồng sự kiện của mình ở kích thước hợp lý, phù hợp với miền dữ liệu.
The Kappa Architecture
Kiến trúc Kappa lần đầu tiên được trình bày vào năm 2014 bởi Jay Kreps, người đồng sáng lập Apache Kafka và đồng sáng lập Confluent. Kiến trúc Kappa dựa vào các luồng sự kiện như là bản ghi duy nhất cho cả dữ liệu hiện tại và dữ liệu lịch sử. Người tiêu dùng chỉ cần bắt đầu tiêu thụ từ đầu luồng để có cái nhìn tổng quát về mọi thứ đã xảy ra kể từ khi bắt đầu, cuối cùng đến đầu luồng và các sự kiện mới nhất như trong Hình 1-16.
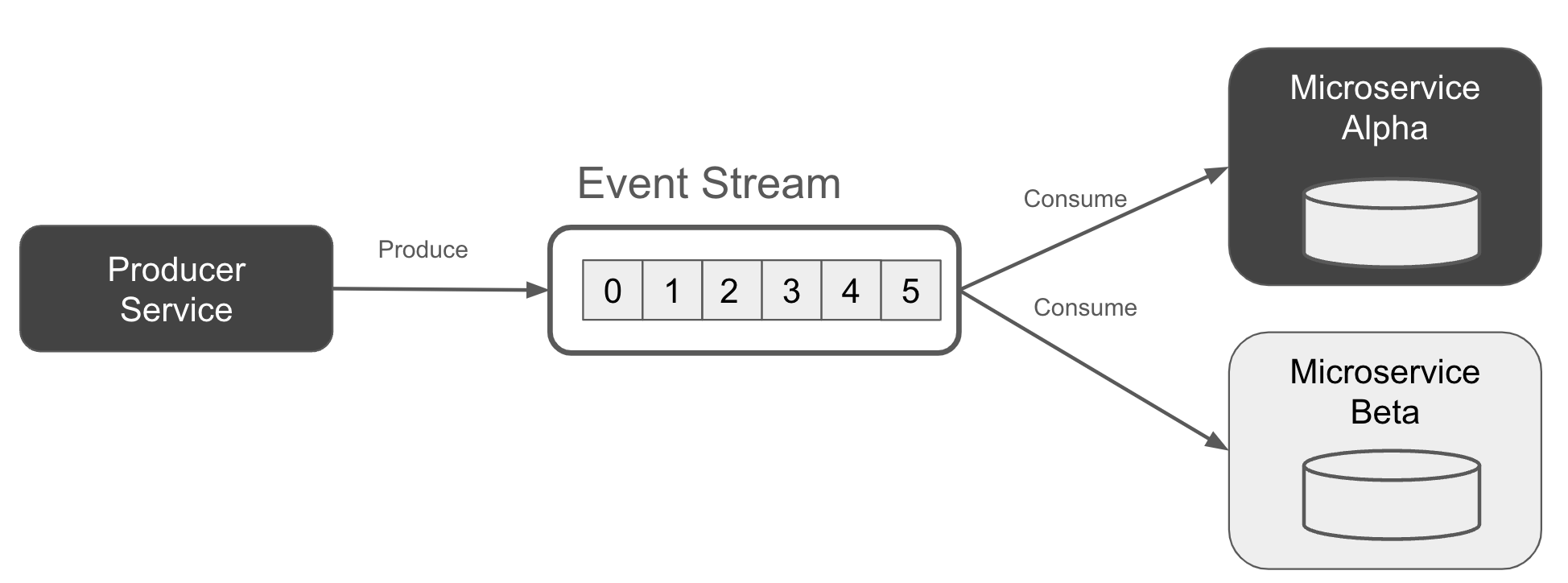
Figure 1-16. Kappa Architecture, with each service building its state from just an event stream
Kiến trúc Kappa không sử dụng kho lưu trữ thứ cấp cho dữ liệu lịch sử, như trong kiến trúc Lambda (sẽ bàn thêm về điều đó trong phần tiếp theo). Kappa hoàn toàn dựa vào luồng sự kiện để lưu trữ và phục vụ.
Các kiến trúc Kappa chỉ được hiện thực hóa với các trình môi giới sự kiện hiện đại, kết hợp với lưu trữ giá rẻ được đưa vào bởi cuộc cách mạng điện toán đám mây. Việc lưu trữ bao nhiêu dữ liệu tùy thích trong luồng trở nên dễ dàng và tiết kiệm chi phí, và bạn không còn bị giới hạn bởi các công nghệ môi giới áp dụng TTL bắt buộc, xóa các bản ghi của bạn sau vài giờ hoặc vài ngày.
Microservices theo hướng sự kiện chỉ cần tạo ra trạng thái của riêng chúng từ các luồng khi cần. Không cần truy cập dữ liệu từ một kho lưu trữ thứ cấp ở đâu đó, cũng như không có bất kỳ độ phức tạp nào trong việc quản lý quyền truy cập bổ sung. Nó sạch sẽ, đơn giản và dễ dàng lập trình.
Có một số đánh đổi với Kappa. Mỗi dịch vụ phải xây dựng trạng thái riêng của nó, và đối với các tập dữ liệu cực lớn, việc hiện thực hóa từ luồng sự kiện có thể mất một khoảng thời gian. Số lượng phân vùng thấp và sự song song không đủ có thể khiến dịch vụ của bạn mất nhiều giờ hoặc vài ngày để hiện thực hóa. Điều này thường được gọi là “thời gian hydrat hóa”, và bạn sẽ cần lên kế hoạch cho nó trong vòng đời dịch vụ của mình.
Bạn có thể giảm thiểu vấn đề thời gian hydrate bằng cách duy trì các bản chụp nhanh hoặc sao lưu trạng thái đã được tính toán và hóa thành. Khi tải ứng dụng của bạn, dịch vụ của bạn chỉ cần tải từ dữ liệu đã sao lưu và khôi phục quá trình từ nơi nó đã dừng lại. Mặc dù đây là trách nhiệm của chính ứng dụng, nhưng các bản chụp nhanh và sao lưu đi kèm với các công nghệ xử lý luồng hàng đầu như Apache Kafka Streams, Apache Flink và Apache Spark Streaming, chỉ là một vài trong số các công ty hàng đầu mã nguồn mở trong ngành.
Kiến trúc Kappa là chìa khóa để xây dựng các microservices phi tập trung dựa trên sự kiện, vì nó cung cấp cho các dịch vụ của bạn một đảm bảo mạnh mẽ duy nhất - rằng luồng sự kiện của bạn có thể đóng vai trò là nguồn thông tin duy nhất cho một tập hợp dữ liệu nhất định. Không cần phải tìm đến nơi khác để lấy dữ liệu từ kho thứ hai hoặc thứ ba. Tất cả dữ liệu bạn cần đều nằm trong luồng sự kiện đó, sẵn sàng cho các dịch vụ của bạn.
Kiến trúc Kappa trông như thế nào trong mã?
Ví dụ 1-1 cho thấy một ứng dụng Kafka Streams với hai KTables, mà chỉ là một stream được hiện thực hóa thành một bảng bằng cách sử dụng ECST. Tiếp theo, KTable tồn kho và KTable bán hàng được kết hợp bằng cách sử dụng INNER join không có cửa sổ để tạo ra một KTable chứa thông tin hàng tồn kho đã được chuẩn hóa và làm phong phú. Các framework xử lý stream giúp dễ dàng xử lý các luồng sự kiện, xây dựng trạng thái nội bộ bằng ECST và kết hợp, ghép dữ liệu từ nhiều sản phẩm dữ liệu khác nhau, chỉ trong vài dòng mã.
Example 1-1. Showcasing joins with Kafka Streams
StreamsBuilderbuilder=newStreamsBuilder();//Materializes the tables from the source Kafka topicsKTableproducts=builder.table("products")KTableproductReviews=builder.table("product_reviews")//Join events on the primary key, apply business logic as neededKTableproductsWithReviews=products.join(productReviews,businessLogic(..),...)builder.build();
Apache Flink có thể cung cấp một cái gì đó tương tự. Giả sử chúng ta muốn một cái gì đó giống như SQL hơn.
Example 1-2. Showcasing joins with Flink SQL
CREATETABLEPRODUCTS(product_idBIGINT,nameVARCHAR,brandVARCHAR,descriptionVARCHAR,timestampTIMESTAMP(3),PRIMARYKEY(product_id)NOTENFORCED,)WITH('connector'='kafka','topic'='products','format'='protobuf','properties.bootstrap.servers'='localhost:9092','properties.group.id'='foobar');CREATETABLEPRODUCT_REVIEWS(product_idBIGINT,reviewsVARCHAR,timestampTIMESTAMP(3),PRIMARYKEY(product_id)NOTENFORCED,)WITH('connector'='kafka','topic'='product_reviews','format'='protobuf','properties.bootstrap.servers'='localhost:9092','properties.group.id'='foobar');CREATETABLEPRODUCTS_WITH_REVIEWSASSELECT*FROMPRODUCTSINNERJOINPRODUCT_REVIEWSONPRODUCTS.product_id=PRODUCT_REVIEWS.product_id;
Cả hai mẫu mã Flink SQL và Kafka Streams đều đơn giản, rõ ràng và ngắn gọn. Chúng tôi sẽ đề cập đến việc xây dựng microservices với những công nghệ này sau trong cuốn sách này. Nhưng hiện tại, khi chúng ta xem xét kiến trúc Lambda, hãy nhớ rằng việc tận dụng kiến trúc Kappa thật dễ dàng. Chỉ cần vài dòng mã để chuyển đổi một luồng sự kiện thành một bảng tự cập nhật, có khả năng điều khiển mã microservice của bạn.
The Lambda Architecture
Kiến trúc Lambda dựa trên cả luồng sự kiện cho dữ liệu thời gian thực và một kho lưu trữ thứ cấp cho dữ liệu lịch sử. Kiến trúc Lambda được xây dựng trên khái niệm lỗi thời rằng bạn không thể lưu trữ sự kiện trong một luồng sự kiện vô thời hạn. Tuy nhiên, nó nhất quán với các công nghệ lỗi thời đã buộc phải đặt thời gian sống (TTL) trên các luồng sự kiện. Nó vẫn tiếp tục bướng bỉnh tồn tại trong tâm trí của nhiều người, vì vậy chúng tôi đưa nó vào cuốn sách này vì mục đích bối cảnh lịch sử, nhưng không phải là sự ủng hộ cho việc sử dụng.
Người tiêu dùng trong kiến trúc lambda phải lấy dữ liệu lịch sử từ kho lưu trữ lịch sử trước tiên, sau đó nạp nó vào các kho trạng thái tương ứng của họ. Sau đó, người tiêu dùng phải chuyển sang luồng sự kiện để nhận các cập nhật và thay đổi tiếp theo.
Có hai phiên bản chính của kiến trúc này. Trong phiên bản đầu tiên, kho dữ liệu lịch sử và luồng được xây dựng độc lập. Trong phiên bản thứ hai, kho dữ liệu lịch sử được xây dựng từ luồng. Hãy xem xét phiên bản đầu tiên trước.
Kho lưu trữ lịch sử chứa kết quả của các tập hợp, vật chất hóa, hoặc các phép tính phong phú hơn. Nó không chỉ là một vị trí khác để lưu trữ sự kiện. Nhìn từ góc độ lịch sử, kho lưu trữ lịch sử thường chỉ là cơ sở dữ liệu nội bộ của hệ thống nguồn. Nói cách khác, bạn sẽ yêu cầu hệ thống nguồn cung cấp dữ liệu lịch sử, tải nó vào hệ thống của bạn, sau đó chuyển sang luồng sự kiện. Điều này là một hình mẫu phản tác dụng vì nó đặt toàn bộ tải đầu cuối lên dịch vụ sản xuất, nhưng nó đủ phổ biến để đáng được đề cập.
"[Link to Come] cho thấy một cách triển khai đơn giản của kiến trúc Lambda. Nhà sản xuất ghi dữ liệu mới vào cả luồng sự kiện và kho dữ liệu lịch sử."
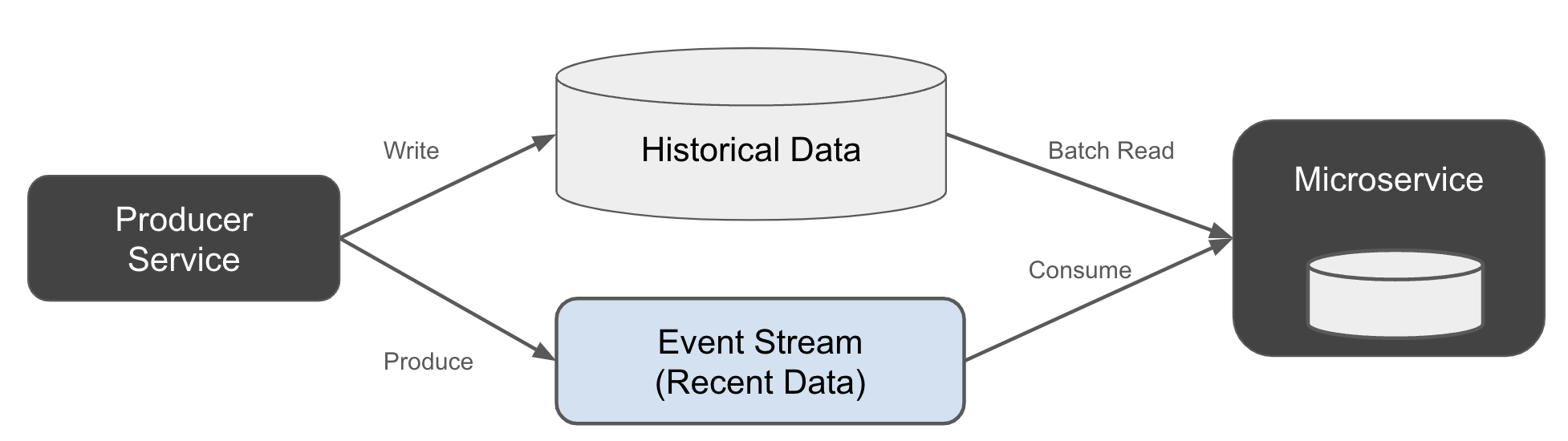
Figure 1-17. Lambda architecture, writing to both the stream and the historical data table at the same time
Một lỗi lớn trong kế hoạch này là dữ liệu không được ghi một cách nguyên tử. Thực tế là rất khó để đạt được hiệu suất cao cho các giao dịch phân tán trên nhiều hệ thống độc lập. Điều thường xảy ra trong thực tế là nhà sản xuất cập nhật một hệ thống trước (có thể là kho dữ liệu lịch sử), sau đó là hệ thống khác (dòng sự kiện). Một lỗi tạm thời trong quá trình ghi có thể khiến sự kiện được ghi vào kho dữ liệu lịch sử nhưng không vào dòng sự kiện - hoặc ngược lại, tùy thuộc vào mã của bạn.
Vấn đề là dữ liệu luồng và tập dữ liệu lịch sử của bạn sẽ phân kỳ, có nghĩa là bạn sẽ có kết quả khác biệt nếu xây dựng từ luồng so với việc bạn xây dựng từ dữ liệu lịch sử. Một người tiêu dùng cũ chỉ đọc từ luồng có thể tính toán ra một kết quả khác với một người tiêu dùng mới khởi động từ dữ liệu lịch sử. Điều này có thể gây ra những vấn đề nghiêm trọng trong tổ chức của bạn, và nó có thể rất khó để tìm ra lý do tại sao - đặc biệt là vì dữ liệu luồng sự kiện có giới hạn về thời gian, và bằng chứng về sự phân kỳ của nó sẽ bị xóa sau chỉ vài ngày.
Trong phiên bản thứ hai của kiến trúc Lambda, dữ liệu lịch sử được nạp trực tiếp từ luồng sự kiện ban đầu, như được trình bày trong Hình 1-18.
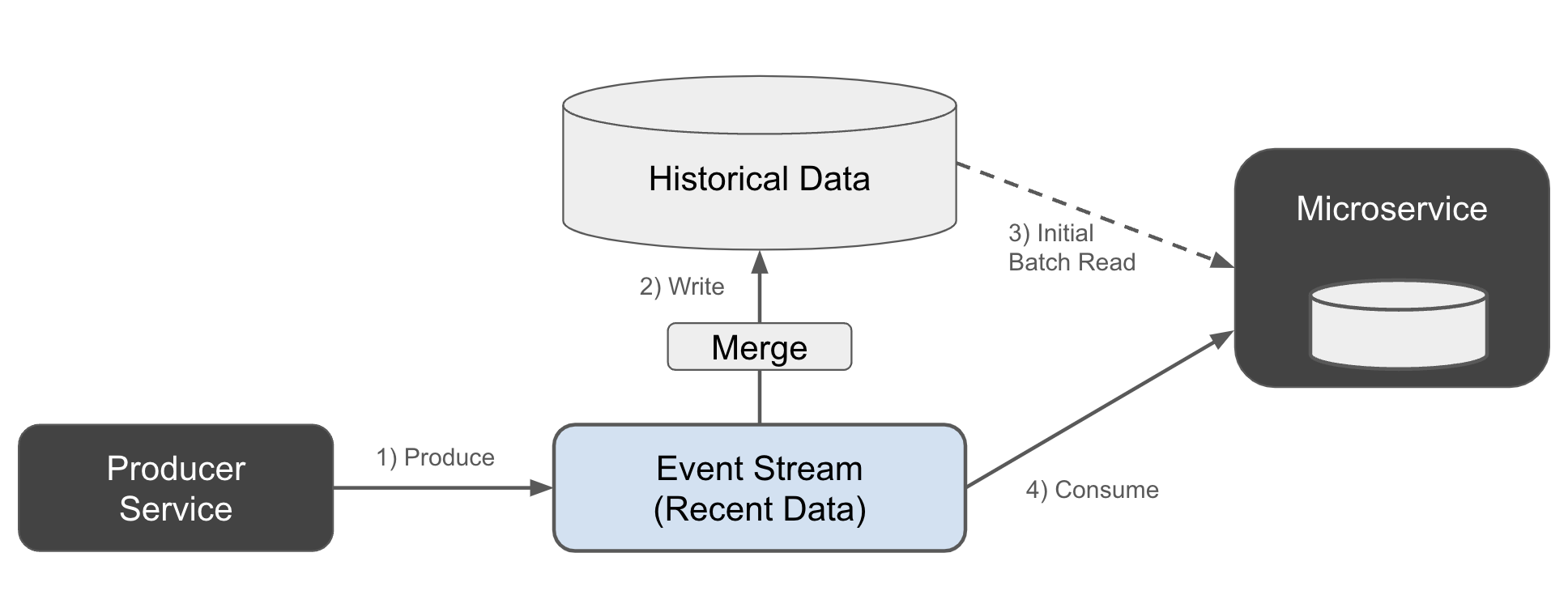
Figure 1-18. Historical lambda data build from the event stream
Nhà sản xuất ghi trực tiếp vào luồng sự kiện (1). Dữ liệu lịch sử được bổ sung bởi một quy trình thứ cấp kết hợp nó vào kho dữ liệu (2). Người tiêu dùng lần lượt đọc dữ liệu lịch sử trước (3), sau đó chuyển sang luồng sự kiện (4).
Nếu bạn nheo mắt một chút, bạn có thể thấy rằng phiên bản thứ hai này trông giống hệt như kiến trúc Kappa - ngoại trừ việc chúng tôi xây dựng kho trạng thái bên ngoài dịch vụ vi mô. Sự phức tạp duy nhất là chúng tôi đã giới thiệu một sự phân tách awkward giữa nhà môi giới sự kiện và kho dữ liệu lịch sử - một sản phẩm do quan niệm không còn hợp lệ rằng nhà môi giới sự kiện không thể lưu trữ sự kiện một cách vô thời hạn.
Nhìn chung, kiến trúc Lambda có vẻ đơn giản trong lý thuyết, nhưng thực tế lại rất khó để thực hiện tốt. Tại sao? Dưới đây là một vài trở ngại chính, khi chúng ta kết thúc phần này:
- The producer must maintain extra code
-
Mã viết vào luồng, và mã viết vào kho lưu trữ lịch sử.
- The consumer must maintain two code paths
-
Một đường dẫn đọc từ kho lưu trữ lịch sử, và một đường dẫn đọc từ luồng. Người tiêu dùng phải viết mã sao cho có thể chuyển đổi giữa hai đường dẫn mà không bỏ lỡ bất kỳ dữ liệu nào hoặc vô tình sao chép dữ liệu. Điều này có thể khá khó khăn trong thực tế, đặc biệt là với các hệ thống phân tán và các sự cố tạm thời.
- Streamed data may not converge to the same results as the historical data
-
Người tiêu dùng có thể không nhận được kết quả hoàn toàn giống nhau khi đọc từ luồng dữ liệu và từ bảng. Nhà sản xuất phải đảm bảo rằng dữ liệu giữa hai nguồn không khác biệt theo thời gian, nhưng điều này rất khó khăn mà không có các cập nhật nguyên tử cho cả luồng và kho dữ liệu lịch sử.
- The stream and historical data models must evolve in sync
-
Dữ liệu không phải là tĩnh. Nếu bạn cần cập nhật định dạng dữ liệu, điều đó sẽ yêu cầu thay đổi mã ở hai nơi - kho lưu trữ lịch sử và luồng.
- Merging multiple Lambda-powered data sets is almost impossible
-
Rất dễ để kết hợp nhiều tập dữ liệu Kappa, như được minh họa trong [Link sẽ đến]. Không có sự chồng chéo giữa các nguồn dữ liệu, vì vậy bạn chỉ cần phát trực tiếp dữ liệu từ luồng sự kiện và nhận được kết quả nhất quán. Tuy nhiên, không có quy định tự nhiên nào giữa luồng và tập dữ liệu lịch sử. Các bản ghi trong luồng sự kiện và dữ liệu lịch sử sẽ chồng chéo lên nhau, và các quy tắc để hợp nhất bản ghi trước vào sau sẽ khác nhau giữa các tập dữ liệu, cũng như các quy tắc để hết hạn các bản ghi từ luồng sự kiện.
Việc hòa giải lưu trữ song song giữa dữ liệu theo luồng và dữ liệu lịch sử là rất khó khăn cho chỉ một tập dữ liệu. Điều này còn khó khăn hơn khi bạn đưa nhiều tập dữ liệu vào, mỗi tập đều có ranh giới dữ liệu luồng/lịch sử riêng biệt.
Tóm lại, kiến trúc Lambda đơn giản là quá khó để quản lý ở bất kỳ quy mô hợp lý nào. Nó đặt toàn bộ gánh nặng truy cập dữ liệu lên phía người tiêu dùng, buộc họ phải hòa giải giữa hai nguồn không chỉ giữa dữ liệu dòng và dữ liệu lịch sử, mà còn giữa dữ liệu dòng và dữ liệu lịch sử của tất cả các tập dữ liệu khác mà họ muốn xử lý. Thay vào đó, dựa vào kiến trúc Kappa với một nguồn dữ liệu dòng duy nhất để cung cấp dữ liệu lịch sử thì dễ hơn rất nhiều, cả về nhận thức lẫn viết mã.
Event Data Definitions and Schemas
Dữ liệu sự kiện đóng vai trò là phương tiện lưu trữ dữ liệu lâu dài và không phụ thuộc vào việc triển khai, cũng như cơ chế giao tiếp giữa các dịch vụ. Do đó, rất quan trọng để cả nhà sản xuất và nhà tiêu thụ sự kiện đều có sự hiểu biết chung về ý nghĩa của dữ liệu. Lý tưởng nhất là, nhà tiêu thụ phải có khả năng diễn giải nội dung và ý nghĩa của một sự kiện mà không cần phải tham khảo với chủ sở hữu của dịch vụ sản xuất. Điều này đòi hỏi một ngôn ngữ chung cho việc giao tiếp giữa nhà sản xuất và nhà tiêu thụ và tương tự như định nghĩa API giữa các dịch vụ yêu cầu - phản hồi đồng bộ.
Sự lựa chọn về sơ đồ như Apache Avro và Protobuf của Google cung cấp hai tính năng mà các dịch vụ vi mô hướng sự kiện sử dụng rất nhiều. Đầu tiên, chúng cung cấp một khung phát triển, nơi một số tập hợp các thay đổi có thể được thực hiện một cách an toàn đối với các sơ đồ mà không yêu cầu các bên tiêu thụ ở phía hạ nguồn phải thay đổi mã. Thứ hai, chúng cũng cung cấp phương tiện để tạo ra các lớp kiểu (nơi có thể áp dụng) để chuyển đổi dữ liệu đã được sơ đồ hóa thành các đối tượng cũ trong ngôn ngữ mà bạn lựa chọn. Điều này làm cho việc tạo ra logic kinh doanh trở nên đơn giản và minh bạch hơn rất nhiều trong việc phát triển các dịch vụ vi mô. [Liên kết sẽ đến sau] sẽ đề cập đến những chủ đề này chi tiết hơn.
Powering Microservices with the Event Broker
Hệ thống môi giới sự kiện phù hợp với các doanh nghiệp quy mô lớn thường tuân theo cùng một mô hình. Nhiều môi giới sự kiện phân tán hoạt động cùng nhau trong một cụm để cung cấp nền tảng cho việc sản xuất và tiêu thụ các luồng sự kiện và hàng đợi. Mô hình này cung cấp một số tính năng thiết yếu cần thiết để vận hành một hệ sinh thái theo sự kiện ở quy mô lớn:
- Scalability
-
Các phiên bản broker sự kiện bổ sung có thể được thêm vào để tăng cường khả năng sản xuất, tiêu thụ và lưu trữ dữ liệu của cụm.
- Durability
-
Dữ liệu sự kiện được sao chép giữa các nút. Điều này cho phép một cụm các nhà môi giới vừa duy trì vừa tiếp tục phục vụ dữ liệu khi một nhà môi giới gặp sự cố.
- High availability
-
Một cụm các nút môi giới sự kiện cho phép các khách hàng kết nối với các nút khác trong trường hợp xảy ra lỗi môi giới. Điều này cho phép các khách hàng duy trì thời gian hoạt động liên tục.
- High-performance
-
Nhiều nút môi giới chia sẻ tải sản xuất và tiêu thụ. Ngoài ra, mỗi nút môi giới phải có hiệu suất cao để có thể xử lý hàng trăm nghìn ghi hoặc đọc mỗi giây.
Mặc dù có nhiều cách khác nhau để dữ liệu sự kiện có thể được lưu trữ, sao chép và truy cập trong hậu trường của một trung gian sự kiện, nhưng chúng đều cung cấp các cơ chế lưu trữ và truy cập tương tự cho khách hàng của mình.
Selecting an Event Broker
Trong khi cuốn sách này sẽ thường xuyên tham khảo Apache Kafka như một ví dụ, còn có những trình trung gian sự kiện khác có thể là lựa chọn phù hợp. Thay vì so sánh trực tiếp các công nghệ, hãy xem xét kỹ lưỡng các yếu tố sau đây khi chọn trình trung gian sự kiện của bạn.
Support tooling
Các công cụ hỗ trợ là rất cần thiết để phát triển hiệu quả các microservices theo sự kiện. Nhiều công cụ trong số này liên quan đến việc triển khai chính broker sự kiện. Một số trong số đó bao gồm:
-
Duyệt các bản ghi sự kiện luồng
-
Duyệt dữ liệu sơ đồ
-
Hạn ngạch, kiểm soát truy cập và quản lý chủ đề
-
Giám sát, thông lượng và đo lường độ trễ
Xem [Liên kết sẽ đến] để biết thêm thông tin về các công cụ bạn có thể cần.
Hosted services
Các dịch vụ được lưu trữ cho phép bạn thuê ngoài việc tạo ra và quản lý môi giới sự kiện của mình.
-
Có giải pháp lưu trữ nào không?
-
Bạn sẽ mua giải pháp được lưu trữ hay tự lưu trữ nội bộ?
-
Đại lý lưu trữ có cung cấp giám sát, mở rộng, phục hồi thảm họa, sao chép và triển khai đa khu vực không?
-
Nó có gắn bạn với một nhà cung cấp dịch vụ cụ thể nào không?
-
Có dịch vụ hỗ trợ chuyên nghiệp nào có sẵn không?
Client libraries and processing frameworks
Có nhiều triển khai trình trung gian sự kiện để chọn, mỗi cái có mức độ hỗ trợ khách hàng khác nhau. Điều quan trọng là các ngôn ngữ và công cụ thường được sử dụng của bạn phải hoạt động tốt với các thư viện khách hàng.
-
Các thư viện và framework client có tồn tại trong các ngôn ngữ cần thiết không?
-
Bạn có thể xây dựng các thư viện nếu chúng không tồn tại không?
-
Bạn có đang sử dụng các framework phổ biến hay đang cố gắng tự phát triển của riêng mình?
Community support
Hỗ trợ cộng đồng là một khía cạnh cực kỳ quan trọng trong việc chọn lựa một broker sự kiện. Một dự án mã nguồn mở và miễn phí, chẳng hạn như Apache Kafka, là một ví dụ đặc biệt tốt về một broker sự kiện với sự hỗ trợ cộng đồng lớn.
-
Có hỗ trợ cộng đồng trực tuyến không?
-
Công nghệ đã trưởng thành và sẵn sàng sản xuất chưa?
-
Công nghệ này có được sử dụng phổ biến ở nhiều tổ chức không?
-
Công nghệ có thu hút được nhân viên tiềm năng không?
-
Nhân viên có hào hứng để xây dựng với những công nghệ này không?
Indefinite and tiered storage
Lưu trữ không xác định cho phép bạn lưu trữ các sự kiện mãi mãi, với điều kiện bạn có đủ không gian lưu trữ để làm điều đó. Tùy thuộc vào kích thước của các luồng sự kiện và thời gian lưu giữ (ví dụ: không xác định), có thể tốt hơn nếu lưu trữ các đoạn dữ liệu cũ trong lưu trữ chậm hơn nhưng rẻ hơn.
Lưu trữ phân tầng cung cấp nhiều lớp hiệu suất truy cập, với một đĩa riêng được gán cho bộ môi giới sự kiện hoặc các nút phục vụ dữ liệu cung cấp tầng hiệu suất cao nhất. Các tầng tiếp theo có thể bao gồm các tùy chọn như dịch vụ lưu trữ quy mô lớn riêng biệt (ví dụ: Amazon S3, Google Cloud Storage và Azure Storage).
-
Lưu trữ phân lớp có được hỗ trợ tự động không?
-
Dữ liệu có thể được chuyển vào các bậc thấp hơn hoặc cao hơn dựa trên mức sử dụng không?
-
Dữ liệu có thể được truy xuất một cách liền mạch từ bất kỳ tầng nào mà nó được lưu trữ không?
Summary
Dòng sự kiện cung cấp khả năng truy cập dữ liệu bền bỉ, có thể phát lại và có khả năng mở rộng. Chúng có thể cung cấp một lịch sử đầy đủ của các sự kiện, cho phép người tiêu dùng của bạn đọc bất kỳ dữ liệu nào họ cần thông qua một API duy nhất. Mỗi người tiêu dùng được đảm bảo có một bản sao giống hệt của dữ liệu, với điều kiện họ đọc dòng sự kiện như nó đã được ghi lại.
Môi giới sự kiện của bạn là phần cốt lõi của kiến trúc dựa trên sự kiện. Nó chịu trách nhiệm lưu trữ các luồng sự kiện và cung cấp truy cập nhất quán, hiệu suất cao đến dữ liệu cơ bản. Nó đảm bảo độ bền, khả năng chịu lỗi và khả năng mở rộng, để bạn có thể tập trung vào việc xây dựng các dịch vụ của mình, không phải vật lộn với việc truy cập dữ liệu.
Dịch vụ sản xuất công bố một tập hợp các sự kiện kinh doanh quan trọng, phát sóng dữ liệu qua luồng sự kiện đến các dịch vụ tiêu dùng đã đăng ký. Nhà sản xuất không còn chịu trách nhiệm cho các nhu cầu truy vấn đa dạng của tất cả các dịch vụ khác trong tổ chức.
Người tiêu dùng không truy vấn dịch vụ sản xuất để lấy dữ liệu, loại bỏ các kết nối điểm-điểm không cần thiết khỏi kiến trúc của bạn. Trước đây, một nhóm có thể đơn giản viết các truy vấn SQL hoặc sử dụng API yêu cầu/đáp ứng để truy cập dữ liệu được lưu trữ trong cơ sở dữ liệu của một monolith. Trong kiến trúc hướng sự kiện, họ thay vào đó truy cập dữ liệu đó từ một luồng sự kiện, hiện thực hóa và tổng hợp trạng thái của riêng mình cho các nhu cầu kinh doanh của mình.
Việc áp dụng các vi dịch vụ theo sự kiện cho phép tạo ra các dịch vụ chỉ sử dụng trung gian sự kiện để lưu trữ và truy cập dữ liệu. Mặc dù các bản sao cục bộ của sự kiện có thể được sử dụng bởi logic kinh doanh của vi dịch vụ, nhưng trung gian sự kiện vẫn là nguồn thông tin chính duy nhất cho tất cả dữ liệu.
Chapter 2. Fundamentals of Event-Driven Microservices
Một microservice dựa trên sự kiện, như đã giới thiệu trong [Liên kết sẽ đến], là một ứng dụng như bao ứng dụng khác. Nó yêu cầu cùng một loại tài nguyên máy tính, lưu trữ và mạng như bất kỳ ứng dụng nào khác. Nó cũng cần một nơi để lưu trữ mã nguồn, công cụ để xây dựng và triển khai ứng dụng, và giám sát cũng như ghi nhật ký để đảm bảo hoạt động khỏe mạnh. Là một ứng dụng dựa trên sự kiện, nó đọc các sự kiện từ một luồng (hoặc nhiều luồng), thực hiện công việc dựa trên những sự kiện đó, và sau đó xuất ra kết quả - dưới dạng các sự kiện mới, các cuộc gọi API, hoặc các hình thức công việc khác.
`[Liên kết sẽ có] đã giới thiệu ngắn gọn các lợi ích chính của microservices dựa trên sự kiện. Trong chương này, chúng ta sẽ đề cập đến các nguyên tắc cơ bản của microservices dựa trên sự kiện, khám phá vai trò và trách nhiệm của chúng, cùng với các yêu cầu, quy tắc và khuyến nghị để xây dựng các ứng dụng khoẻ mạnh.`
The Basics
Tình huống điều khiển sự kiện có nghĩa là các sự kiện điều khiển logic kinh doanh, giống như nước từ một con suối quay bánh xe nước của một nhà máy (Hình 2-1). Các ứng dụng điều khiển sự kiện, dù lớn hay nhỏ, thường chỉ làm việc khi có các sự kiện xảy ra (hoặc khi một bộ đếm thời gian hết hạn - cũng là một sự kiện). Nếu không, chúng sẽ đứng yên cho đến khi có các sự kiện mới để xử lý.

Figure 2-1. The water stream powers the wheel, as event streams power the microservice Source - wikimedia
{kind=link}
Dịch vụ microservice tiêu dùng đọc các sự kiện từ luồng. Mỗi người tiêu dùng có trách nhiệm cập nhật các con trỏ của riêng mình đến các chỉ số đã đọc trước đó trong luồng sự kiện. Chỉ số này, được gọi là offset, là thước đo của sự kiện hiện tại từ đầu luồng sự kiện. Các offset cho phép nhiều người tiêu dùng tiêu thụ và theo dõi tiến trình của họ một cách độc lập với nhau, như được thể hiện trong Hình 2-2.
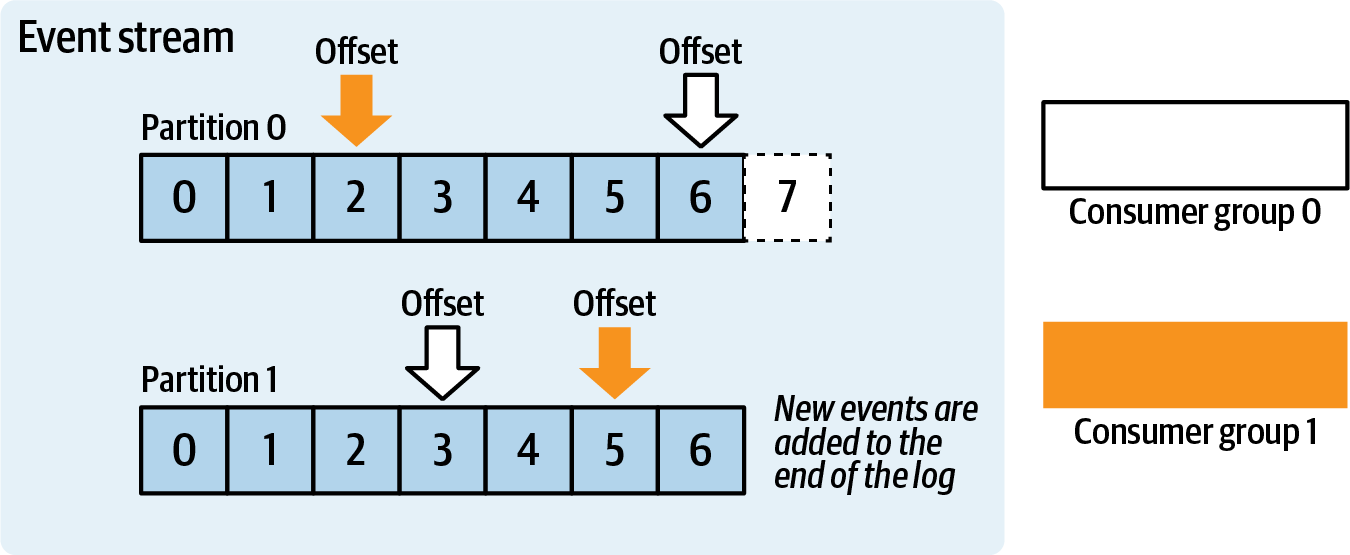
Figure 2-2. Consumer groups and their per-partition offsets
Nhóm người tiêu dùng cho phép nhiều người tiêu dùng được xem như một thực thể logic duy nhất và có thể được tận dụng để mở rộng quy mô ngang của việc tiêu thụ tin nhắn. Khi một phiên bản người tiêu dùng mới tham gia vào một nhóm người tiêu dùng, các phân vùng thường được tự động phân phối lại giữa các phiên bản đang hoạt động. Điều này cân bằng tải của các sự kiện đến giữa các người tiêu dùng đang hoạt động. Trạng thái, đặc biệt là trạng thái cục bộ, có thể làm cho việc phân bổ lại này trở nên khó khăn hơn, nhưng điều này sẽ được thảo luận thêm trong [Link to Come].
“Vậy điều gì cấu thành nên một microservice dựa trên sự kiện?” bạn có thể hỏi. Có lẽ điều tốt nhất là chỉ cần xem qua một vài ví dụ trước, và làm việc ngược lại từ đó. Hãy cùng xem xét một vài ví dụ về việc triển khai microservice.
The Basic Producer/Consumer
Ví dụ này được đặt tên là "nhà sản xuất / người tiêu dùng cơ bản" vì đó thực sự chỉ là như vậy - nhà sản xuất tạo ra các sự kiện, người tiêu dùng tiêu thụ các sự kiện, và bạn, nhà phát triển phần mềm, phải viết tất cả các hoạt động để kết nối logic kinh doanh. Chúng ta sẽ đi sâu vào mẫu này trong chương [Liên kết sẽ đến], nhưng bây giờ chúng ta sẽ bắt đầu với một ví dụ microservice Python cơ bản.
Dịch vụ này tiêu thụ các sự kiện từ một trình môi giới sự kiện Kafka (tên chủ đề là "input_topic", tổng hợp một tổng và phát ra tổng đã cập nhật tới một luồng sự kiện mới nếu giá trị vượt quá 1000.
Ứng dụng python tạo ra KafkaConsumer (1) và KafkaProducer (2). KafkaConsumer được đặt tên chính xác sẽ đọc các sự kiện từ chủ đề được chỉ định, chuyển đổi các sự kiện từ byte đã được tuần tự hóa thành các đối tượng mà ứng dụng hiểu - trong trường hợp này là khóa văn bản thuần và giá trị JSON. Để làm mới về các khóa và giá trị, bạn có thể nhìn lại “Cấu trúc của một sự kiện”.
fromkafkaimportKafkaConsumer,KafkaProducerimportjsonimporttime# 1) Initialize Kafka consumerconsumer=KafkaConsumer('input_topic_name',bootstrap_servers=['localhost:9092'],value_deserializer=lambdax:json.loads(x.decode('utf-8')),key_deserializer=lambdax:x.decode('utf-8'),group_id='ch03_python_example_consumer_group_name',auto_offset_reset='earliest')# 2) Initialize Kafka producerproducer=KafkaProducer(bootstrap_servers=['localhost:9092'],value_serializer=lambdax:json.dumps(x).encode('utf-8'),key_serializer=lambdax:x.encode('utf-8'))# 3) Connect to the state store (A simple dictionary to keep track of the sums per key)key_sums={}# 4) Polling loopwhileTrue:# 5 Poll for new eventsevent_batch=consumer.poll(timeout_ms=1000)# 6 Process each partition's eventsforpartition_batchinevent_batch.values():foreventinpartition_batch:key=event.keynumber=event.value['number']# 7) Update sum for this keyifkeynotinkey_sums:key_sums[key]=0key_sums[key]+=number# 8) Check if sum exceeds 1000ifkey_sums[key]>1000:# Prepare and send new eventoutput_event={'key':key,'total_sum':key_sums[key]}# 9) Write to topic named "key_sums"producer.send('key_sums',key=key,value=output_event)# 10) Flushes the events to the brokerproducer.flush()
Tiếp theo, mã sẽ tạo ra một kho trạng thái đơn giản (3). Bạn sẽ có khả năng cao muốn sử dụng một cái gì đó khác ngoài từ điển trong bộ nhớ, nhưng đây là một ví dụ đơn giản và bạn có thể thay thế nó bằng một RDBMS, một kho khóa-giá trị được quản lý hoàn toàn, hoặc một kho trạng thái bền bỉ khác.
Tip
Chọn kho trạng thái phù hợp nhất với trường hợp sử dụng của vi dịch vụ của bạn. Một số trường hợp sẽ được phục vụ tốt nhất bằng các kho lưu trữ khóa-giá trị hiệu suất cao, trong khi những trường hợp khác sẽ được phục vụ tốt hơn thông qua RDBMS, đồ thị hoặc tài liệu, chẳng hạn.
Bước thứ tư là vào một vòng lặp vô hạn (4) để lấy dữ liệu từ chủ đề đầu vào cho một lô sự kiện (5) và xử lý mỗi sự kiện trên cơ sở từng phân vùng (6). Đối với mỗi sự kiện, logic kinh doanh cập nhật tổng khóa (7), và nếu nó > 1000 (8), thì nó tạo ra một sự kiện với tổng để viết vào chủ đề đầu ra key_sums (9 và 10).
Đây là một ứng dụng rất đơn giản. Nhưng nó thể hiện các thành phần chính phổ biến trong phần lớn các dịch vụ vi mô dựa trên sự kiện: người tiêu dùng dòng sự kiện, nhà sản xuất, kho trạng thái và một vòng lặp xử lý liên tục được điều khiển bởi sự xuất hiện của các sự kiện mới trên các dòng đầu vào. Logic kinh doanh được nhúng trong vòng lặp xử lý, và mặc dù ví dụ này rất đơn giản, vẫn có nhiều hoạt động mạnh mẽ và phức tạp hơn mà chúng ta có thể thực hiện.
Hãy cùng xem thêm một vài ví dụ nữa.
The Stream-Processing Event-Driven Application
Ứng dụng xử lý sự kiện theo dòng được xây dựng bằng cách sử dụng một khung xử lý theo dòng. Một số ví dụ phổ biến bao gồm Apache Kafka Streams, Apache Flink, Apache Spark và Akka Streams. Một số ví dụ cũ mà tôi đã đề cập trong ấn bản đầu tiên không còn phổ biến nữa, nhưng đã bao gồm Apache Storm và Apache Samza.
Các khung phát trực tuyến cung cấp sự tích hợp chặt chẽ hơn với môi trường quản lý sự kiện và giảm bớt khối lượng công việc mà bạn phải đối mặt khi xây dựng EDM của mình. Ngoài ra, chúng thường cung cấp các tính toán mạnh mẽ hơn với các cấu trúc cấp cao hơn, chẳng hạn như cho phép bạn kết hợp các luồng và bảng vật liệu với rất ít nỗ lực từ phía bạn.
Một điểm khác biệt chính của các khung xử lý luồng so với mô hình sản xuất/tiêu thụ cơ bản là các bộ xử lý luồng yêu cầu hoặc một cụm độc lập riêng (như trong trường hợp của Flink và Spark), hoặc một sự tích hợp chặt chẽ với một trung gian sự kiện cụ thể (như trong trường hợp của Kafka Streams).
Flink và Spark (cùng với những cái khác như vậy) sử dụng các cụm xử lý độc quyền của riêng chúng để quản lý trạng thái, khả năng mở rộng, độ bền và định tuyến dữ liệu bên trong. Ngược lại, Kafka Streams chỉ dựa vào cụm Kafka để lưu trữ trạng thái bền vững của riêng nó, cung cấp khả năng tái phân vùng chủ đề và chức năng mở rộng ứng dụng.
Các chương tương lai (nhẹ, nặng) sẽ đề cập đến cả hai loại khung này một cách chi tiết hơn. Bây giờ, chúng ta hãy chuyển sang một ví dụ thực tiễn (và kết hợp) sử dụng Apache Flink.
// 1) TableEnvironment manages access and usage of the tables in the Flink applicationTableEnvironmenttableEnv=TableEnvironment.create(EnvironmentSettings.inStreamingMode());// 2) Create the output table for joined results, connecting to a Kafka broker.tableEnv.executeSql("CREATE TABLE PurchasesInnerJoinOrders ("+" order_id STRING,"+" /* Add all columns you want to output here */"+") WITH ("+" 'connector' = 'kafka',"+" 'topic' = 'PurchasesInnerJoinOrders',"+" 'properties.bootstrap.servers' = 'localhost:9092',"")");//Other table definitions removed for brevity. They are very similar.// 3) Reference the Sales and Purchase tables (assumes they are already created as tables in the catalog)Tablesales=tableEnv.from("Sales");Tablepurchases=tableEnv.from("Purchase");// 4) Perform inner join between Sales and Purchase tables on order_idTableresult=sales.join(purchases).where($("Sales.order_id").isEqual($("Purchase.order_id")));// 5) Insert the joined results into the output Kafka topicresult.executeInsert("PurchasesInnerJoinOrders");
Đây là một ứng dụng khá ngắn gọn, nhưng nó chứa đựng nhiều sức mạnh. Đầu tiên (1), chúng ta tạo kết nối tableEnv để quản lý công việc trong môi trường bảng của chúng ta. Tiếp theo, chúng ta khai báo bảng đầu ra (2), được kết nối với chủ đề Kafka PurchasesInnerJoinOrders. Bạn chỉ cần tạo điều này một lần. Tôi đã bỏ qua các khai báo khác để tiết kiệm thời gian.
Thứ ba (3), bạn tạo ra các tham chiếu đến bảng Bán hàng và Mua hàng để có thể sử dụng chúng trong ứng dụng của bạn. Những bảng này là dòng dữ liệu vật chất, như đã đề cập trong “Vật chất hóa trạng thái từ các sự kiện thực thể”.
Thứ tư (4), mã khai báo các biến đổi cần thực hiện trên các sự kiện làm đầy các bảng vật liệu. Một vài dòng này thực hiện nhiều công việc quan trọng. Không chỉ thực hiện các thao tác kết hợp hai bảng này với nhau, mà nó còn xử lý tính năng chống lỗi, cân bằng tải, xử lý theo thứ tự và tải dữ liệu lớn. Nó cũng dễ dàng kết hợp các luồng và bảng đã được phân vùng và định khóa hoàn toàn khác nhau, điều mà bạn có thể sẽ gặp phải.
Cuối cùng, ứng dụng ghi dữ liệu vào bảng đầu ra. Các cơ chế của framework streaming Flink sẽ xử lý phần còn lại để cam kết dữ liệu vào chủ đề Kafka.
Các khung phát trực tuyến cung cấp khả năng rất mạnh mẽ, nhưng thường đòi hỏi một khoản đầu tư ban đầu lớn hơn vào kiến trúc hỗ trợ. Chúng thường chỉ cung cấp hỗ trợ giới hạn cho các ngôn ngữ (Python và JVM là phổ biến nhất), mặc dù đã có một số tiến bộ trong việc hỗ trợ các ngôn ngữ khác kể từ khi phiên bản đầu tiên của cuốn sách này được xuất bản. Trên thực tế, các ngôn ngữ SQL (hoặc ngôn ngữ tương tự SQL) có thể là nhóm phát triển nhanh nhất. Hãy cùng xem xét những điều đó tiếp theo.
The “Streaming SQL” Query
“Liệu microservice của bạn có nên chỉ là một truy vấn SQL không?”
Đó là một câu hỏi hay, đặc biệt là với sự gia tăng của các dịch vụ quản lý SQL streaming. Chính những điều khiến SQL trở nên phổ biến trong thế giới cơ sở dữ liệu cũng làm cho nó được ưa chuộng trong thế giới streaming. Bản chất khai báo của nó có nghĩa là bạn chỉ cần khai báo kết quả mà bạn đang tìm kiếm. Bạn không cần phải chỉ định cách để thực hiện điều đó, vì đó là nhiệm vụ của động cơ xử lý bên dưới.
Ngoài ra, SQL cho phép bạn viết những câu lệnh rất rõ ràng và súc tích về những gì bạn muốn làm với dữ liệu của mình - trong trường hợp này, là luồng sự kiện. Dưới đây là một ví dụ về cùng một ứng dụng Flink, nhưng được viết bằng Flink SQL.
--Assumes we have already declares the materialized input tables and the output tableINSERTINTOPurchasesInnerJoinOrdersSELECT*FROMSalessINNERJOINPurchasepONs.order_id=p.order_id;
Đó là tất cả. Đơn giản nhưng mạnh mẽ. Truy vấn SQL Streaming này sẽ chạy mãi mãi, hoạt động như một microservice độc lập.
SQL luồng hiện chưa được chuẩn hóa. Có nhiều loại và hình thức khác nhau, vì vậy bạn sẽ phải tự mình nghiên cứu để tìm hiểu điều gì được hỗ trợ và điều gì không được hỗ trợ theo từng khung luồng. Thêm vào đó, SQL luồng thường yêu cầu một bộ API cấp thấp mạnh mẽ để hoạt động ngoài những ví dụ đơn giản. Dự án Flink, chẳng hạn như trong Hình 2-3, có nhiều lớp API, mỗi lớp phụ thuộc vào những lớp bên dưới nó.
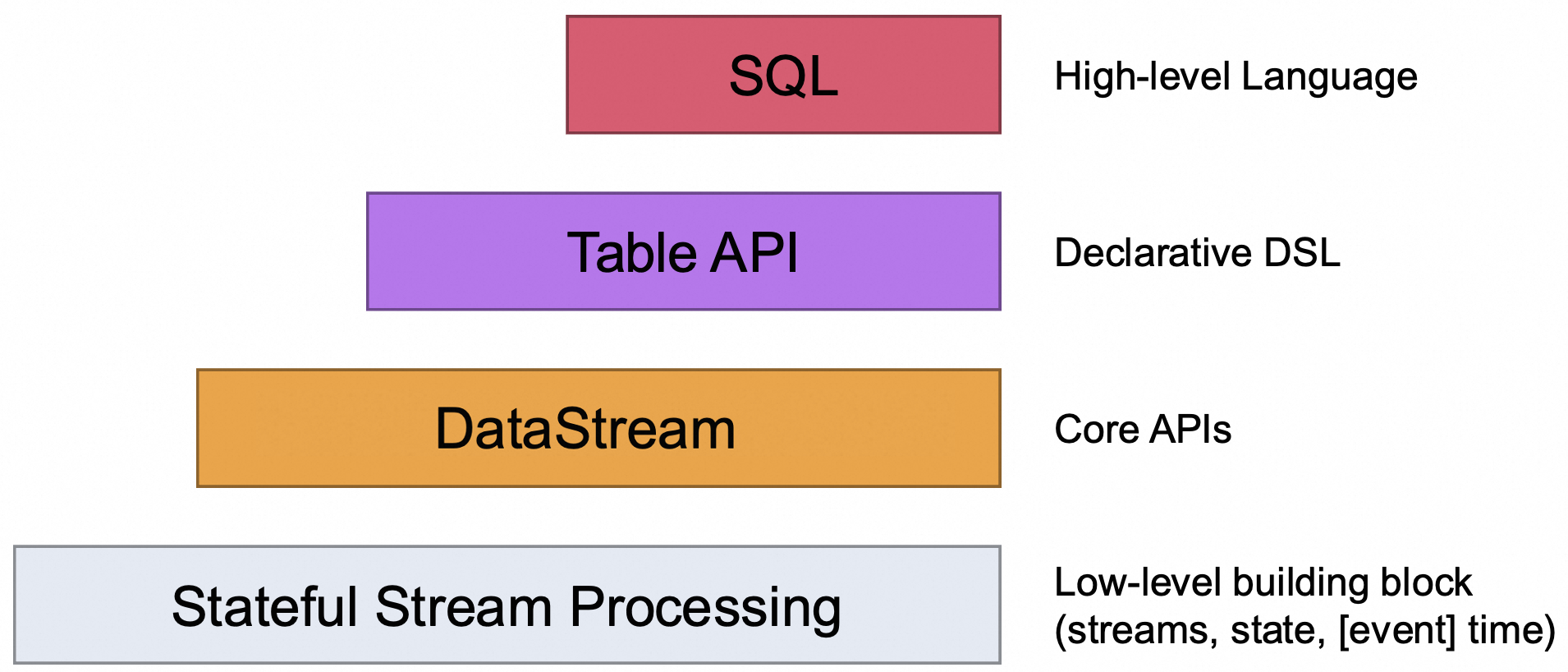
Figure 2-3. The four levels of Flink APIs - Source - apache.org
Nói tóm lại, hãy chú ý đến các cơ hội sử dụng SQL trong các microservices của bạn. Nó có thể giúp bạn tiết kiệm rất nhiều thời gian và công sức, và cho phép bạn tiếp tục với các công việc khác. Chúng ta sẽ xem xét SQL theo luồng chi tiết hơn một chút trong [Liên kết sẽ đến].
The Legacy Application
Các ứng dụng kế thừa thường không được viết với tư duy xử lý theo sự kiện. Chúng thường là những hệ thống cũ nhưng quan trọng, phục vụ cho các chức năng kinh doanh quan trọng, nhưng không còn được phát triển tích cực nữa. Các thay đổi đối với những dịch vụ này rất hiếm, và chỉ được thực hiện khi cần thiết tuyệt đối. Chúng cũng thường là những người giám sát dữ liệu kinh doanh quan trọng, được lưu trữ riêng biệt trong cơ sở dữ liệu hoặc kho tệp của hệ thống.
Ứng dụng kế thừa về cơ bản là một cấu trúc cứng nhắc mà bạn khó có thể thay đổi. Nhưng bạn vẫn có thể tích hợp nó vào kiến trúc sự kiện tổng thể của mình thông qua việc sử dụng các bộ kết nối, như được mô tả trong Hình 2-4.
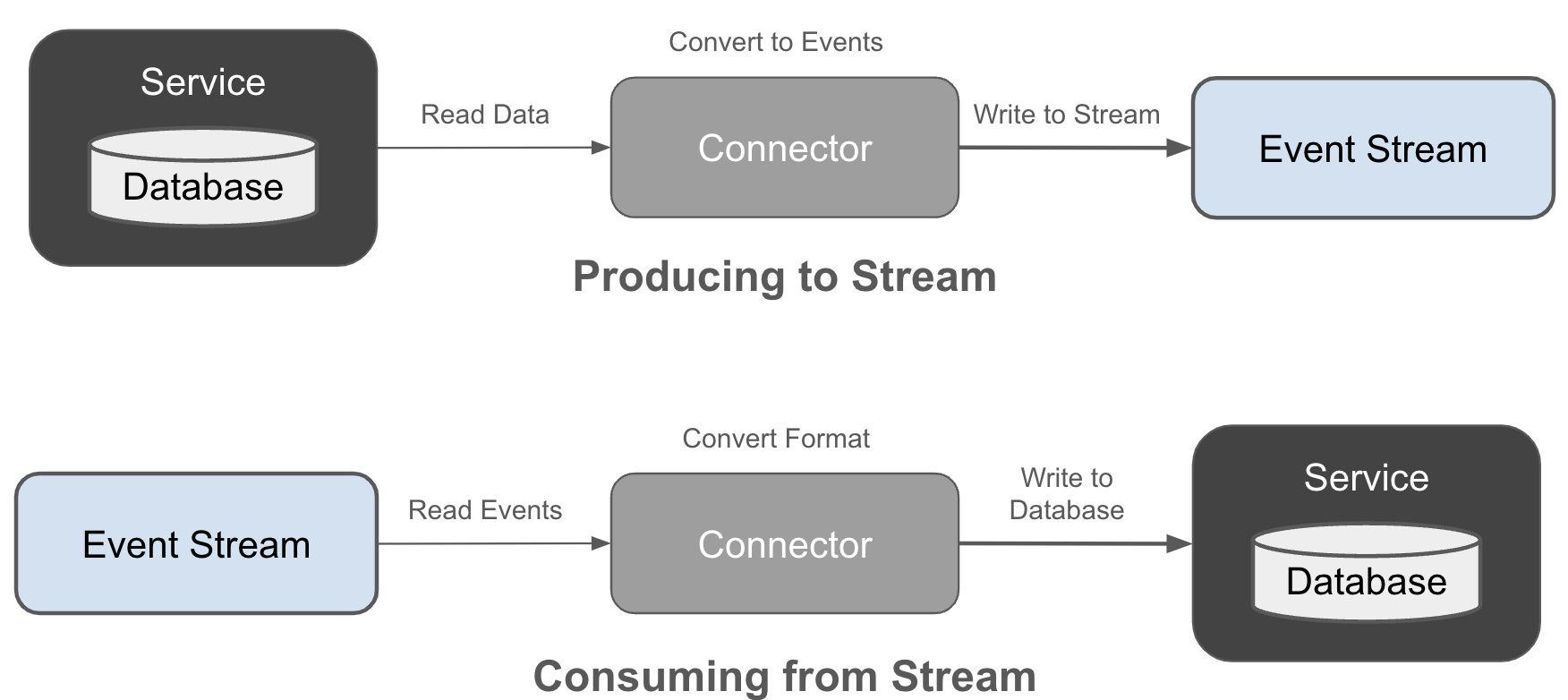
Figure 2-4. Producing and consuming event streams with connectors
Các connector có thể đọc sự kiện từ một hệ thống hoặc cơ sở dữ liệu nguồn, chuyển đổi dữ liệu thành sự kiện, và ghi chúng vào một luồng sự kiện. Tương tự, các connector cũng có thể đọc sự kiện từ một luồng, chuyển đổi chúng thành định dạng phù hợp, và ghi chúng vào API hoặc cơ sở dữ liệu của hệ thống kế thừa. Chúng cung cấp phương tiện để tích hợp những ứng dụng hiện có vào kiến trúc hướng sự kiện của bạn mà không cần phải thiết kế lại toàn bộ hệ thống như một kiến trúc hướng sự kiện nguyên bản.
Các kết nối cho phép bạn bắt đầu với các luồng sự kiện mà không cần phải tạo lại toàn bộ kiến trúc của mình. Chúng giúp bạn dễ dàng đưa dữ liệu vào các luồng, để bạn có thể bắt đầu nhận giá trị từ các microservices theo sự kiện của mình trong thời gian sớm nhất có thể. Chúng tôi sẽ trình bày chi tiết về các kết nối trong [Link to Come].
Bây giờ, bốn dịch vụ này có thể cần phải làm việc cùng nhau. Khác với một dịch vụ macro duy nhất (ví dụ: một khối đơn), microservices theo định nghĩa là một tập hợp các dịch vụ phụ thuộc vào nhau. Mặc dù chúng ta cố gắng đạt được sự tách biệt và giao tiếp bất đồng bộ, nhưng vào cuối ngày, mỗi dịch vụ này có thể (và thường là) phụ thuộc vào công việc được thực hiện bởi các dịch vụ khác. Do đó, chúng ta có một loại mối quan hệ mạng... chuyển sang Trách nhiệm.
Event-Driven Microservice Responsibilities
- Service Boundaries and Scope
-
Một tập hợp ranh giới được xác định rõ ràng. Ứng dụng này chịu trách nhiệm về điều gì? Và nó không chịu trách nhiệm về điều gì? Điều sau trở nên quan trọng hơn khi bạn có nhiều microservices hoạt động cùng nhau để hoàn thành một quy trình phức tạp hơn, nơi có thể hơi khó phân biệt trách nhiệm của mỗi dịch vụ. Bằng cách ánh xạ các microservices một cách sạch sẽ nhất có thể đến các bối cảnh ranh giới, chúng ta có thể tránh được nhiều sự suy đoán và mơ hồ có thể phát sinh.
- Scalability
-
Microservice có trách nhiệm đảm bảo rằng nó có khả năng mở rộng. Cụ thể, nó phải được viết theo cách cho phép nó mở rộng theo chiều ngang (nhiều phiên bản hơn) hoặc theo chiều dọc (phiên bản mạnh mẽ hơn), tùy thuộc vào yêu cầu của nó. Các khung EDM cung cấp khả năng mở rộng sẵn có thường có sức hấp dẫn lớn hơn do khả năng mở rộng tích hợp liền mạch. Tuy nhiên, sức mạnh xử lý cơ bản là thứ mà nền tảng microservice cung cấp. Chúng ta sẽ nói về điều đó ở phần cuối của chương này.
- State Management
-
Microservice chỉ chịu trách nhiệm cho việc tạo, đọc, cập nhật và xóa dữ liệu trong kho dữ liệu của nó. Bất kỳ hoạt động nào thay đổi trạng thái trong microservice đều hoàn toàn nằm trong ranh giới kiểm soát của nó. Mọi vấn đề với kho trạng thái, chẳng hạn như hết dung lượng đĩa hoặc không kiểm tra thay đổi ứng dụng cũng thuộc về không gian vấn đề của microservice. [Liên kết sẽ có sau] đi vào chi tiết hơn về cách xây dựng và quản lý trạng thái cho các microservice dựa trên sự kiện.
- Track Stream Input Progress
-
Mỗi microservice phải theo dõi tiến trình của nó trong việc đọc các luồng sự kiện đầu vào. Ví dụ, Apache Kafka theo dõi tiến trình này bằng cách sử dụng một nhóm tiêu thụ, một nhóm cho mỗi microservice logic. Các nhóm tiêu thụ cũng được nhiều broker sự kiện hàng đầu khác sử dụng, mặc dù một tiêu thụ vẫn có thể chọn thao tác thủ công với các offset của chính nó (chẳng hạn như để phát lại một số bản ghi) hoặc lưu chúng ở nơi khác, chẳng hạn như trong kho dữ liệu riêng của mình.
- Failure Recovery
-
Microservices chịu trách nhiệm đảm bảo rằng chúng có thể tự khôi phục trở lại trạng thái khỏe mạnh sau một sự cố. Các framework mà chúng tôi sẽ dựa vào để vận hành microservices thường khá hiệu quả trong việc đưa các dịch vụ chết trở lại hoạt động, nhưng các dịch vụ của chúng tôi sẽ có trách nhiệm khôi phục trạng thái, khôi phục tiến trình luồng sự kiện đầu vào và tiếp tục từ nơi chúng đã dừng lại trước khi xảy ra sự cố.
Ứng dụng cũng phải xem xét trạng thái đã lưu của nó liên quan đến tiến trình đầu vào dòng. Trong trường hợp bị sự cố, dịch vụ tiêu thụ sẽ tiếp tục từ các offset tốt nhất cuối cùng mà nó biết, điều này có thể dẫn đến việc xử lý trùng lặp và cập nhật trạng thái lưu trữ trùng lặp.
- The Single Writer Topic Principle
-
Mỗi luồng sự kiện chỉ có một microservice sản xuất duy nhất. Microservice này là chủ sở hữu của mỗi sự kiện được sản xuất cho luồng đó. Điều này cho phép nguồn gốc chính xác của sự thật luôn được biết đến cho bất kỳ sự kiện nào, bằng cách cho phép theo dõi nguồn gốc dữ liệu qua hệ thống. Các cơ chế kiểm soát truy cập, như đã thảo luận trong [Link to Come], nên được sử dụng để thực thi quyền sở hữu và ranh giới ghi.
- Partitioning and Event Keys
-
Microservice có trách nhiệm chọn khóa chính của bản ghi đầu ra (xem "Cấu trúc của một sự kiện") và cũng có trách nhiệm xác định phân vùng nào để gửi bản ghi đó đến. Các bản ghi có cùng khóa thường đi đến cùng một phân vùng, mặc dù bạn có thể chọn các chiến lược khác (ví dụ: round-robin, ngẫu nhiên hoặc tùy chỉnh). Cuối cùng, microservice của bạn có trách nhiệm chọn phân vùng nào để ghi sự kiện vào.
- Event Schema Definitions and Data Contracts
-
Cũng giống như lựa chọn của microservice của bạn trong việc chọn khóa bản ghi, nó cũng có quyền lựa chọn định dạng schema để ghi lại sự kiện. Ví dụ, bạn viết product_id dưới dạng String? Hay bạn viết nó dưới dạng Integer? Chương [Liên kết sẽ có] sẽ đề cập đến điều này chi tiết hơn, nhưng hiện tại, hãy lập kế hoạch sử dụng một schema Avro, Protobuf hoặc JSON đã được định nghĩa rõ ràng để ghi lại các bản ghi của bạn. Điều này sẽ giúp các luồng sự kiện của bạn dễ sử dụng hơn, cung cấp sự rõ ràng cho người tiêu dùng và tạo ra một hệ sinh thái dựa trên sự kiện khỏe mạnh hơn.
Một microservice cũng nên có kích thước hợp lý. Bạn có thấy điều đó mơ hồ không? Hãy đọc tiếp.
How small should a microservice be?
Đầu tiên, mục tiêu của kiến trúc vi dịch vụ không phải là tạo ra càng nhiều càng tốt. Bạn sẽ không nhận được bất kỳ giải thưởng nào cho việc có số lượng dịch vụ cao nhất, và trải nghiệm đó cũng sẽ không mang lại cho bạn sự thỏa mãn. Thực tế, bạn thậm chí có thể viết một blog về cách bạn đã tạo ra 1000 vi dịch vụ và mọi thứ đều tồi tệ.
Thực tế là mọi dịch vụ bạn xây dựng, dù là vi mô hay khác, đều phát sinh chi phí đi kèm. Tuy nhiên, chúng tôi cũng muốn tránh những đau khổ mà một kiến trúc đơn thể mang lại. Sự cân bằng nằm ở đâu?
Một microservice nên được quản lý bởi một đội duy nhất, và đội đó nên có khả năng để những người khác trong đội làm việc trên dịch vụ khi cần. Đội đó lớn bao nhiêu? Đội hai chiếc pizza là một thước đo phổ biến, mặc dù nó có thể là một hướng dẫn không đáng tin cậy chút nào tùy thuộc vào việc các lập trình viên của bạn đói bao nhiêu.
Một lập trình viên đơn lẻ trong đội này nên có khả năng nắm bắt không gian công việc mà dịch vụ đảm nhận trong đầu của họ. Một lập trình viên mới đến với microservice nên có khả năng tìm hiểu về các nhiệm vụ của dịch vụ đó và cách mà nó thực hiện các nhiệm vụ đó chỉ trong một hoặc hai ngày.
Cuối cùng, mối quan tâm thực sự là dịch vụ phục vụ một bối cảnh giới hạn cụ thể và đáp ứng nhu cầu kinh doanh. Kích thước, hoặc nó thực sự nhỏ như thế nào, trở thành một mối quan tâm thứ yếu. Bạn có thể kết thúc với các microservices vượt quá ranh giới tối đa mà tôi đã quy định ở đây, và điều đó là hoàn toàn chấp nhận được - phần quan trọng là bạn có thể xác định mối quan tâm kinh doanh cụ thể mà nó đáp ứng, các ranh giới của dịch vụ, và có thể duy trì một danh sách tư duy tốt về những gì dịch vụ nên làm và không nên làm.
Dưới đây là một vài mẹo nhanh:
-
Chỉ xây dựng b ст dịch vụ cần thiết. Nhiều hơn không tốt hơn.
-
Mỗi người nên có khả năng hiểu toàn bộ dịch vụ.
-
Đội ngũ của bạn sẽ cần chịu trách nhiệm sở hữu và duy trì dịch vụ cũng như các luồng sự kiện đầu ra.
-
Hãy xem xét việc thêm chức năng vào một dịch vụ hiện có trước. Điều này sẽ giảm bớt chi phí cho mỗi ứng dụng của bạn, như chúng ta sẽ thấy ở phần tiếp theo.
-
Đối với các microservices mà bạn xây dựng, hãy tập trung vào việc phát triển các thành phần mô-đun. Bạn có thể nhận thấy rằng khi doanh nghiệp của bạn phát triển, bạn sẽ cần tách ra một mô-đun để chuyển đổi thành microservice riêng của nó.
Trong phần tiếp theo, chúng ta sẽ xem xét cách quản lý microservices, bao gồm cả cách quản lý chúng khi mở rộng.
Managing Microservices at Scale
Quản lý microservices có thể trở nên ngày càng khó khăn khi số lượng dịch vụ tăng lên. Mỗi microservice yêu cầu các tài nguyên tính toán cụ thể, kho dữ liệu, cấu hình, biến môi trường, và nhiều thuộc tính khác đặc trưng cho microservice. Mỗi microservice cũng phải có thể quản lý và triển khai được bởi đội ngũ sở hữu nó. Việc container hóa và ảo hóa, cùng với các hệ thống quản lý liên quan, là những cách phổ biến để đạt được điều này. Cả hai tùy chọn cho phép các đội ngũ cá nhân tùy chỉnh yêu cầu của microservices thông qua một đơn vị triển khai duy nhất.
Putting Microservices into Containers
Containers, được phổ biến bởi Docker, cách ly các ứng dụng với nhau. Containers tận dụng hệ điều hành máy chủ hiện có thông qua mô hình kernel chia sẻ. Điều này cung cấp sự tách biệt cơ bản giữa các containers, trong khi container tự nó cách ly các biến môi trường, thư viện và các phụ thuộc khác. Containers cung cấp hầu hết các lợi ích của một máy ảo (được trình bày tiếp theo) với chi phí thấp hơn, thời gian khởi động nhanh và mức tiêu thụ tài nguyên thấp.
Cách tiếp cận hệ điều hành chia sẻ của các container có một số đánh đổi. Các ứng dụng đóng gói phải có khả năng chạy trên hệ điều hành của máy chủ. Nếu một ứng dụng yêu cầu một hệ điều hành chuyên biệt, thì cần phải thiết lập một máy chủ độc lập. An ninh là một trong những mối quan tâm chính, vì các container chia sẻ quyền truy cập vào hệ điều hành của máy chủ. Một lỗ hổng trong nhân có thể đặt tất cả các container trên máy chủ đó vào tình trạng rủi ro. Với các khối lượng công việc thân thiện, điều này khó có thể trở thành vấn đề, nhưng các mô hình chia sẻ không gian trong điện toán đám mây hiện tại đang bắt đầu biến nó thành một yếu tố quan trọng hơn.
Putting Microservices into Virtual Machines
Máy ảo (VM) khắc phục một số nhược điểm của container, mặc dù việc áp dụng chúng chậm hơn. VM truyền thống cung cấp sự cô lập hoàn toàn với một hệ điều hành tự chứa và phần cứng ảo hóa được chỉ định cho mỗi phiên bản. Mặc dù lựa chọn này cung cấp bảo mật cao hơn so với container, nhưng từ trước đến nay nó tốn kém hơn nhiều. Mỗi VM có chi phí quản lý cao hơn so với container, với thời gian khởi động chậm hơn và yêu cầu hệ thống lớn hơn.
Tip
Các nỗ lực đang được thực hiện để làm cho máy ảo (VM) rẻ hơn và hiệu quả hơn. Những sáng kiến hiện tại bao gồm gVisor của Google, Firecracker của Amazon và Kata Containers, chỉ đề cập đến một số ví dụ. Khi các công nghệ này được cải tiến, máy ảo sẽ trở thành một phương án cạnh tranh hơn nhiều với các container cho nhu cầu vi dịch vụ của bạn. Đáng để theo dõi lĩnh vực này nếu nhu cầu của bạn do yêu cầu bảo mật hàng đầu.
Managing Containers and Virtual Machines
Các container và máy ảo (VM) được quản lý thông qua nhiều phần mềm chuyên biệt được gọi là hệ thống quản lý container (CMS). Những hệ thống này kiểm soát việc triển khai container, phân bổ tài nguyên và tích hợp với các tài nguyên máy tính cơ bản. Những CMS phổ biến và thường được sử dụng bao gồm Kubernetes, Docker Engine, Mesos Marathon, Amazon ECS và Nomad.
Các microservices phải có khả năng mở rộng lên và xuống tùy thuộc vào khối lượng công việc thay đổi, các thỏa thuận cấp dịch vụ (SLA) và yêu cầu về hiệu suất. Cần hỗ trợ mở rộng theo chiều dọc, trong đó các tài nguyên tính toán như CPU, bộ nhớ và đĩa được tăng hoặc giảm trên mỗi phiên bản microservice. Cũng cần hỗ trợ mở rộng theo chiều ngang, với các phiên bản mới được thêm vào hoặc gỡ bỏ.
Mỗi microservice nên được triển khai như một đơn vị duy nhất. Đối với nhiều microservice, một thực thi đơn lẻ là tất cả những gì cần thiết để thực hiện các yêu cầu kinh doanh của nó, và nó có thể được triển khai trong một container duy nhất. Các microservice khác có thể phức tạp hơn, yêu cầu sự phối hợp giữa nhiều container và các kho dữ liệu bên ngoài. Đây là lúc khái niệm pod của Kubernetes phát huy tác dụng, cho phép nhiều container được triển khai và quay lại như một hành động duy nhất. Kubernetes cũng cho phép thực hiện các thao tác chỉ một lần; ví dụ, các thao tác di chuyển cơ sở dữ liệu có thể được thực hiện trong quá trình thực thi của việc triển khai đơn lẻ.
Quản lý VM được hỗ trợ bởi một số triển khai, nhưng hiện tại còn hạn chế hơn so với quản lý container. Kubernetes và Docker Engine hỗ trợ gVisor và Kata Containers của Google, trong khi nền tảng của Amazon hỗ trợ AWS Firecracker. Ranh giới giữa các container và VM sẽ tiếp tục mờ nhạt khi quá trình phát triển diễn ra. Hãy chắc chắn rằng CMS bạn chọn sẽ xử lý được các container và VM mà bạn yêu cầu.
Tip
Có rất nhiều tài nguyên phong phú có sẵn cho Kubernetes, Docker, Mesos, Amazon ECS và Nomad. Thông tin mà chúng cung cấp vượt xa những gì tôi có thể trình bày ở đây. Tôi khuyến khích bạn tìm hiểu thêm về những tài liệu này để biết thêm thông tin.
Paying the Microservice Tax
Thuế vi mô dịch vụ là tổng hợp các chi phí, bao gồm chi phí tài chính, nhân lực và cơ hội, liên quan đến việc triển khai các công cụ, nền tảng và thành phần của kiến trúc vi mô dịch vụ.
Thuế bao gồm các chi phí quản lý, triển khai và vận hành môi trường sự kiện, CMS, quy trình triển khai, giải pháp giám sát và dịch vụ ghi log. Những chi phí này là không thể tránh khỏi và được trả tiền theo cách trung tâm bởi tổ chức hoặc độc lập bởi từng đội nhóm triển khai microservices. Cách tiếp cận trước kết quả trong một khuôn khổ phát triển microservices có thể mở rộng, đơn giản và thống nhất, trong khi cách tiếp cận sau dẫn đến chi phí phình to, giải pháp trùng lặp, công cụ phân mảnh và tăng trưởng không bền vững.
Việc trả "thuế vi mô dịch vụ" không phải là một vấn đề đơn giản, và đây là một trong những trở ngại lớn nhất để bắt đầu với các dịch vụ vi mô hướng sự kiện. Các tổ chức nhỏ nên tốt hơn là giữ lại kiến trúc phù hợp hơn với nhu cầu kinh doanh của họ, chẳng hạn như một kiến trúc monolith mô-đun, và chỉ mở rộng ra các dịch vụ vi mô khi doanh nghiệp của họ gặp phải các vấn đề về quy mô và tăng trưởng.
Tin tốt là thuế không phải là một điều mà bạn phải lựa chọn hoàn toàn. Bạn có thể đầu tư vào các phần của nền tảng dịch vụ vi mô theo sự kiện tổng thể của mình như một sản phẩm độc lập, với các bổ sung dần dần và cải tiến theo từng bước.
May mắn thay, các dịch vụ tự lưu trữ, lưu trữ và hoàn toàn được quản lý có sẵn cho bạn lựa chọn. Thuế microservice đang được giảm dần nhờ vào các tích hợp mới giữa các CMS, trung gian sự kiện và các công cụ cần thiết khác.
Dịch vụ đám mây đáng được nhắc đến vì đã giảm đáng kể chi phí của thuế Microservices. Các dịch vụ đám mây và các giải pháp quản lý hoàn toàn đã cải thiện đáng kể kể từ khi phiên bản đầu tiên của cuốn sách này được phát hành vào năm 2020, và không có dấu hiệu nào cho thấy sẽ ngừng lại. Ví dụ, bạn có thể dễ dàng tìm thấy các hệ quản trị nội dung (CMS) hoàn toàn được quản lý, các trình môi giới sự kiện, các giải pháp giám sát, các danh mục dữ liệu và các dịch vụ tích hợp/triển khai mà không cần phải tự vận hành bất kỳ dịch vụ nào. Rất dễ dàng để bắt đầu sử dụng dịch vụ đám mây cho kiến trúc microservice của bạn hơn là xây dựng riêng, vì điều này cho phép bạn thử nghiệm và thử nghiệm các dịch vụ của mình trước khi cam kết đầu tư nghĩa vụ đáng kể.
Summary
Microservices hướng sự kiện là những ứng dụng giống như bất kỳ ứng dụng nào khác, dựa vào các sự kiện đến để thúc đẩy logic kinh doanh của chúng. Chúng có thể được viết bằng nhiều ngôn ngữ khác nhau, mặc dù chức năng mà bạn có sẵn sẽ khác nhau tương ứng. Các microservices cơ bản theo mô hình sản xuất/kết nối có thể được viết bằng nhiều ngôn ngữ, trong khi các khung phát trực tiếp được thiết kế riêng có thể chỉ hỗ trợ một hoặc hai ngôn ngữ. Các truy vấn SQL và kết nối cũng vẫn là lựa chọn, nhưng việc sử dụng chúng yêu cầu tích hợp sâu hơn với mã nguồn ứng dụng so với những gì đã được đề cập trong chương này.
Microservices có nhiều trách nhiệm, bao gồm quản lý mã nguồn, trạng thái và các thuộc tính thời gian chạy của chính nó. Các nhà phát triển dịch vụ có sự tự do để chọn công nghệ phù hợp nhất để giải quyết vấn đề kinh doanh, dù họ tất nhiên cần đảm bảo rằng dịch vụ có thể được bảo trì, cập nhật và gỡ lỗi bởi những người khác. Microservices thường được triển khai trong các container hoặc sử dụng máy ảo, dựa vào các hệ thống quản lý container/VM để giúp theo dõi và quản lý vòng đời của chúng.
Cuối cùng, hãy được cảnh báo rằng có một loại thuế microservice. Đó là tổng số công việc không liên quan đến kinh doanh mà bạn cần thực hiện để khiến việc sử dụng microservices trở thành một lựa chọn hợp lý. Không có công thức rõ ràng cho việc cái gì là và không phải là thuế microservice. Mỗi tổ chức có một bộ công nghệ khác nhau, và điều mà có thể là lời khuyên tốt cho một tổ chức có thể lại là một lựa chọn kém cho tổ chức khác. Dù vậy, hãy cố gắng sử dụng những gì bạn đã có trước khi mua sắm gì mới và làm việc theo từng bước. Đây không phải là một việc tất cả hoặc không có gì. Hãy làm việc để đưa microservice đầu tiên của bạn lên và chạy, học hỏi từ quá trình, sau đó lặp lại và cải thiện từ đó.
Chapter 3. Designing Events
An early version of this chapter previously appeared in Building an Event-Driven Data Mesh.
Có nhiều cách thiết kế sự kiện cho kiến trúc hướng sự kiện. Tuy nhiên, một số cách phù hợp hơn những cách khác. Chương này đề cập đến các chiến lược tốt nhất để thiết kế sự kiện cho các luồng sự kiện của bạn, bao gồm cách tránh những cạm bẫy mà bạn sẽ gặp phải dọc đường. Nó cũng cung cấp hướng dẫn về khi nào nên sử dụng các loại cụ thể và khi nào nên tránh sử dụng những loại khác, thêm vào đó là một số minh họa về lý do tại sao điều này lại như vậy.
Introduction to Event Types
Có hai loại sự kiện chính làm nền tảng cho tất cả thiết kế sự kiện: sự kiện trạng thái, được giới thiệu trong "Sự kiện thực thể", và sự kiện delta.
Hình 3-1 cho thấy một sóng vuông đơn giản trong trạng thái ổn định, thay đổi định kỳ từ trạng thái này sang trạng thái khác dựa trên một delta. Tương tự như sóng vuông này, chúng tôi mô hình hóa các sự kiện của mình để capture trạng thái chính nó hoặc biên chuyển tiếp từ trạng thái này sang trạng thái khác.
Figure 3-1. State and delta during a change
Có ba giai đoạn cho bất kỳ sự kiện nào trong một hệ thống:
-
Trạng thái ban đầu
-
Delta thay đổi trạng thái ban đầu để sản xuất trạng thái cuối cùng.
-
Trạng thái cuối cùng (cũng là trạng thái ban đầu cho chu kỳ thay đổi tiếp theo)
Phần lớn các sự kiện mà chúng ta gặp phải có thể được phân loại hoàn toàn thành hai loại là trạng thái hoặc biến đổi. Nhìn nhận các sự kiện theo cách này giúp tách biệt các mối quan tâm và tập trung nỗ lực thiết kế.
- State events
-
Sự kiện trạng thái mô tả đầy đủ trạng thái của một thực thể tại một thời điểm nhất định. Chúng giống như một hàng trong cơ sở dữ liệu, ghi lại toàn bộ trạng thái hiện tại của sự việc cho dữ liệu đó. Sự kiện trạng thái thường là loại sự kiện linh hoạt và hữu ích nhất để chia sẻ dữ liệu quan trọng giữa các đội, người và hệ thống. Sự kiện trạng thái đôi khi được gọi là sự kiện loại cấp độ, danh từ hoặc sự kiện sự thật.
- Delta events
-
Những điều này mô tả sự chuyển tiếp giữa các trạng thái và thường chỉ chứa thông tin về những gì đã thay đổi. Sự kiện delta thường được sử dụng hơn trong và giữa các hệ thống có mức độ liên kết rất cao, vì có mối quan hệ chặt chẽ giữa định nghĩa của sự kiện và cách nó được diễn giải. Delta cũng đôi khi được gọi là sự kiện cạnh, động từ hoặc loại hành động.
Bạn cũng có thể gặp các sự kiện hỗn hợp có những đặc điểm của cả hai, mặc dù những sự kiện này thường ít phổ biến hơn vì chúng có thể gây ra hiệu ứng kết hợp mạnh không mong muốn.
- Hybrid events
-
Các sự kiện này mô tả cả một trạng thái và sự chuyển tiếp. Chúng thường là một giải pháp tạm thời, được thực hiện khi không thể tiến hành một sự làm lại sâu hơn do các thời hạn như cố gắng đạt được mục tiêu lợi nhuận của quý. Nhưng vì mọi người vẫn sẽ sử dụng chúng, nên chúng được trình bày chi tiết hơn ở phần sau của chương này.
Hãy cùng xem các sự kiện của tiểu bang trước.
State Events and Event-Carried State Transfer
Một sự kiện trạng thái cung cấp trạng thái hiện tại của một thực thể tại một thời điểm cụ thể. Chi tiết khóa của bản ghi xác định định danh duy nhất của thực thể, trong khi giá trị chứa toàn bộ tập hợp dữ liệu được cung cấp cho tất cả các bên tiêu thụ.
Chuyển giao trạng thái mang sự kiện (ECST) là một miêu tả chính xác: Một sự kiện (trạng thái) mang trạng thái hiện tại của thực thể, và nó được chuyển vào miền của người tiêu dùng thông qua dòng sự kiện. Các sự kiện trạng thái cung cấp một số lợi ích quan trọng, bao gồm:
- Materialization
-
Các sự kiện trạng thái cho phép bạn hiện thực hóa dữ liệu một cách nhanh chóng và dễ dàng. Chỉ cần tiêu thụ luồng sự kiện và hiện thực hóa dữ liệu mà dịch vụ của bạn cần vào kho trạng thái của riêng nó.
- Strong Decoupling
-
Định nghĩa và thành phần của sự kiện trạng thái hoàn toàn nằm trong bối cảnh giới hạn của dịch vụ sản xuất. Không có sự kết nối nào với logic kinh doanh nội bộ của hệ thống tạo ra bản ghi.
- Infer Deltas from State
-
Người tiêu dùng có thể suy ra tất cả những thay đổi của các trường bằng cách so sánh sự kiện trạng thái hiện tại với sự kiện trạng thái trước đó đối với một khóa nhất định. Dịch vụ có thể phản ứng tương ứng mỗi khi có bất kỳ trường nào thay đổi, như đã được chỉ ra trong [Link to Come].
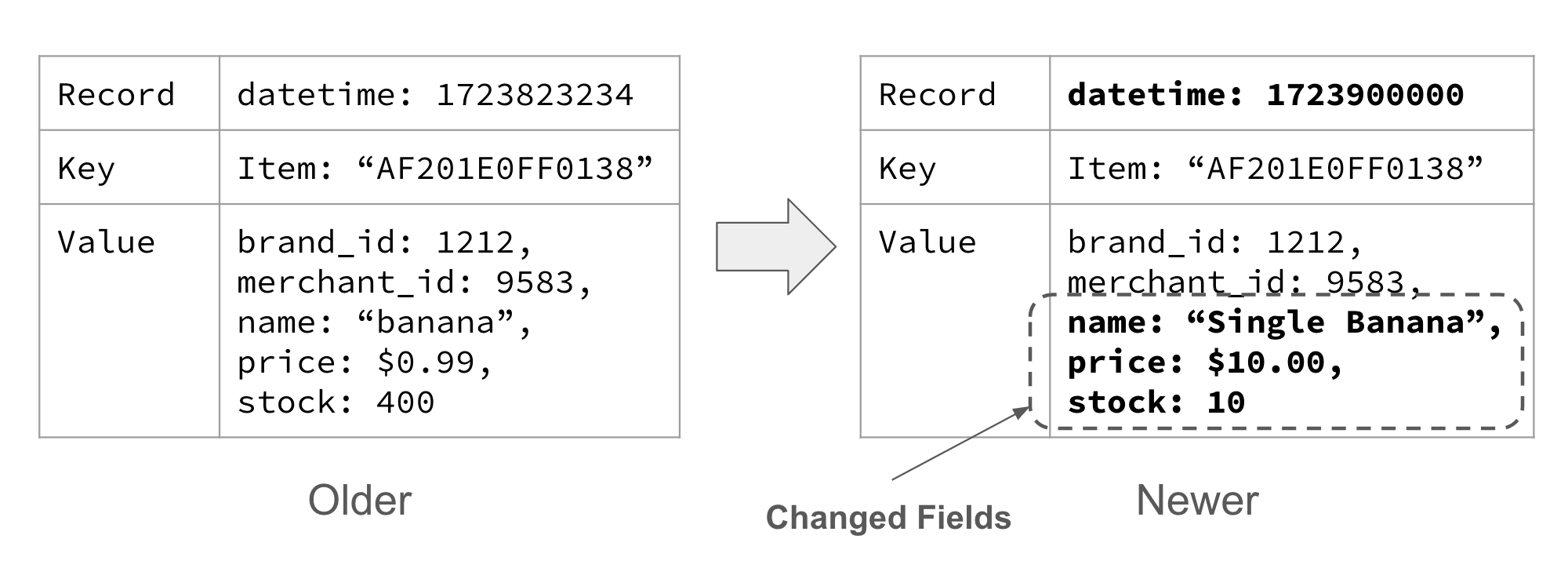
Figure 3-2. Two state events allow you to infer what has changed by comparing the newer event to the older event
Trong ví dụ này, bạn có thể thấy rằng sự kiện mới hơn đã được cập nhật tên, giá cả và kho hàng. Microservice của bạn có thể suy luận những thay đổi mà nó quan tâm và phản ứng tương ứng. Ví dụ, cập nhật biển hiệu, đặt hàng tồn kho mới, hoặc ưu tiên các tùy chọn thay thế trong kết quả tìm kiếm của khách hàng.
Các sự kiện trạng thái có thể chỉ chứa trạng thái "bây giờ" hoặc chúng có thể chứa trạng thái "trước/sau" (một mô hình được phổ biến với “Giải phóng Dữ liệu Sử dụng Capture Dữ liệu Thay đổi”). Cả hai lựa chọn đều có những ưu điểm và nhược điểm riêng, mà chúng ta sẽ xem xét lần lượt. Để bắt đầu, hãy xem xét cách mỗi lựa chọn này ảnh hưởng đến việc nén các luồng sự kiện.
Có hai chiến lược thiết kế chính để xác định cấu trúc và nội dung của các sự kiện trạng thái:
- Current state
-
Chứa trạng thái công khai đầy đủ vào thời điểm sự kiện được tạo ra.
- Before/after state
-
Chứa cả trạng thái công khai đầy đủ trước khi sự kiện diễn ra và trạng thái công khai đầy đủ sau khi sự kiện diễn ra.
Hãy cùng xem xét từng vấn đề này một cách chi tiết để hiểu rõ hơn về những đánh đổi của chúng.
Current State Events
Sự kiện chỉ chứa trạng thái hiện tại của thực thể và yêu cầu so sánh với sự kiện trạng thái trước đó để xác định những gì đã thay đổi. Ví dụ, một sự kiện tồn kho cho một item_id nhất định sẽ chỉ chứa giá trị mới nhất cho số lượng hàng tồn kho tại thời điểm đó. Chiến lược thiết kế này có một số lợi ích chính:
- Lean
-
Các sự kiện trạng thái tiêu thụ một lượng không gian tối thiểu trong luồng sự kiện. Lưu lượng mạng cũng được giảm thiểu.
- Simple
-
Nhà môi giới sự kiện lưu trữ bất kỳ sự kiện trạng thái trước đó nào cho thực thể đó, để nếu bạn cần trạng thái lịch sử, bạn chỉ cần tua lại và phát lại các bù đắp người tiêu dùng của mình. Bạn có thể đặt các chính sách nén độc lập cho mỗi luồng sự kiện tùy thuộc vào nhu cầu của người tiêu dùng về dữ liệu lịch sử.
- Compactable
-
Bạn có thể giữ số lượng sự kiện trong luồng tương ứng với không gian khóa của miền.
Nó cũng có một vài sắc thái không hẳn là nhược điểm, mà là những đặc tính cần xem xét:
- Agnostic to why the state changed
-
Người tiêu dùng ở hạ nguồn không được cung cấp lý do tại sao dữ liệu đã thay đổi, chỉ có trạng thái công khai mới. Lý do cho điều này là đơn giản: nó loại bỏ khả năng của người tiêu dùng trong việc phụ thuộc vào các chuyển đổi trạng thái nội bộ của miền nguồn. Hãy nghĩ về dữ liệu trong một bảng cơ sở dữ liệu quan hệ—chúng ta thường không truyền đạt lý do tại sao dữ liệu đó đã thay đổi trong chính dữ liệu, và điều này cũng đúng đối với các sự kiện trạng thái (Lưu ý: Chúng ta sẽ xem xét việc bẻ cong quy tắc này một chút với các sự kiện lai sau).
- Consumers must maintain state to detect transitions
-
Người tiêu dùng phải duy trì trạng thái của chính họ để phát hiện những thay đổi cụ thể đối với một số trường, bất kể logic kinh doanh của họ đơn giản hay phức tạp đến đâu. Ví dụ, một khách hàng thay đổi địa chỉ đến một quốc gia khác có thể yêu cầu bạn gửi cho họ các tài liệu pháp lý mới, mà có thể khác nhau tùy thuộc vào quốc gia họ đã rời và quốc gia họ đã chuyển đến. Bằng cách để người tiêu dùng tự chịu trách nhiệm trong việc hiện thực hóa trạng thái để theo dõi các chuyển tiếp, trách nhiệm tính toán những ranh giới này hoàn toàn nằm trong miền của người tiêu dùng. Điều này dẫn đến việc theo dõi phụ thuộc đơn giản hơn nhiều và ranh giới phân chia mã sạch hơn.
Before/After State Events
Chiến lược này dựa vào việc cung cấp trạng thái trước khi một chuyển đổi xảy ra và trạng thái sau khi nó đã xảy ra. Các hệ thống thu thập dữ liệu thay đổi (CDC), như đã đề cập trong “Giải phóng dữ liệu bằng cách sử dụng thu thập dữ liệu thay đổi”, thường xuyên sử dụng chiến lược trước/sau. Dưới đây là hai sự kiện người dùng trước/sau với một sơ đồ đơn giản gồm hai trường:
Key:26Value:{before:{name:"Adam",country:"Madagascar"},after:{name:"Adam",country:"Canada"}}
Một cuộc theo dõi trước/sau sự kiện trạng thái cho thấy việc xóa Key = 26. Lưu ý rằng dữ liệu cũ vẫn còn trong trường trước.
Key:26Value:{before:{name:"Adam",country:"Canada"},after:null}
Có một số lợi ích từ thiết kế này:
- Simple state transitions in a single event
-
Sự kiện trước/sau thể hiện tất cả các trường đã thay đổi trong một giao dịch duy nhất, cùng với tất cả các trường không thay đổi. Tuy nhiên, lý do cho sự thay đổi này không được bao gồm.
- Consumers can detect simple changes without maintaining state
-
Một số người tiêu dùng có thể từ bỏ việc duy trì trạng thái nếu họ chỉ quan tâm đến việc phát hiện một chuyển đổi trạng thái đơn giản. Ví dụ, nếu chúng ta muốn gửi tài liệu đến một người dùng di chuyển từ Madagascar đến Canada, thì người tiêu dùng của chúng ta có thể đơn giản kiểm tra xem các trường trước và sau của sự kiện có phù hợp với tiêu chí của họ hay không. Tuy nhiên, điều này không hiệu quả nếu Adam di chuyển từ Madagascar đến Ethiopia, và sau đó không lâu sau lại di chuyển đến Canada, dẫn đến việc xảy ra hai sự kiện. Lógica kinh doanh của người tiêu dùng sẽ không thể kích hoạt trong chuỗi sự kiện này vì nó không duy trì bất kỳ trạng thái nào. Trong thực tế, người tiêu dùng không trạng thái lý thuyết hiếm khi được hiện thực hóa, vì phần lớn các dịch vụ với bất kỳ độ phức tạp hợp lý nào đều cần duy trì trạng thái.
Cũng có một vài nhược điểm đối với thiết kế này:
- Compaction is difficult
-
Xóa một sự kiện sử dụng logic trước/sau dẫn đến trường sau được đặt thành null, nhưng toàn bộ giá trị bản thân không phải là null. Theo mặc định, các trình trung gian sự kiện như Apache Kafka sẽ không nhận ra điều này như một tombstone và do đó sẽ không xóa nó. Mặc dù về mặt kỹ thuật có thể tái viết logic nén, nhưng thường thì điều này không khả thi, đặc biệt nếu bạn đang phụ thuộc nhiều vào các giải pháp SaaS.
Cuối cùng, bạn sẽ phải đảm bảo rằng bạn viết một sự kiện tombstone thứ cấp sau sự kiện ban đầu "trước/sau". Sau đó, bạn sẽ dựa vào việc trình quản lý sự kiện cuối cùng nén dữ liệu. Chiến lược sự kiện kép này thường được sử dụng bởi các hệ thống ghi nhận thay đổi dữ liệu, chẳng hạn như Debezium (một dịch vụ ghi nhận thay đổi dữ liệu sẽ được khám phá chi tiết hơn trong "Giải phóng Dữ liệu Sử dụng Ghi Nhận Thay Đổi Dữ Liệu"). Theo tài liệu của Debezium:
Một thao tác DELETE trong cơ sở dữ liệu khiến Debezium tạo ra hai bản ghi Kafka:
Một bản ghi chứa "op": "d", dữ liệu hàng trước và một số trường khác.
Một bản ghi bia mộ có cùng khóa với hàng đã xoá và giá trị là null. Bản ghi này là một dấu hiệu cho Apache Kafka. Nó chỉ ra rằng việc nén nhật ký có thể loại bỏ tất cả các bản ghi có khóa này.
- Risk of leftover information
-
Như chúng ta đã thấy trước đó, dữ liệu trước đó có thể vô tình được giữ lại vô thời hạn trong trường trước trừ khi bạn thực hiện một loạt các thao tác xóa.
- Doubled data storage and network usage
-
Trước/sau các sự kiện gấp đôi (trung bình) lượng dữ liệu truyền qua mạng và lưu trữ trên đĩa. Người tiêu dùng, người sản xuất và trung gian sự kiện đều gánh một phần của khối lượng này. Trong một số trường hợp, điều này có thể là không đáng kể. Các sự kiện ít được cập nhật hoặc có khối lượng thấp có lẽ không cần phải lo lắng, nhưng các luồng sự kiện có khối lượng cực cao có thể nhanh chóng làm tăng chi phí. Điều này có thể đặc biệt tốn kém tùy thuộc vào các khoản phí chuyển dữ liệu qua các vùng khác nhau liên quan đến việc triển khai sản xuất, tiêu thụ và trung gian sự kiện có độ khả dụng cao.
Các sự kiện trạng thái hiện tại có xu hướng là một lựa chọn tốt hơn nhiều so với mô hình trước/sau cho các dòng sự kiện. Người tiêu dùng vẫn cần phải duy trì trạng thái cho các bản ghi mà họ quan tâm trong các quy trình kinh doanh của họ, nhưng không gian lưu trữ tương đối rẻ, và họ chỉ cần giữ lại dữ liệu mà họ quan tâm. Điều này cũng làm đơn giản hóa hoạt động cho người trung gian sự kiện so với mô hình trước/sau, với chi phí lưu lượng mạng giữa các vùng thấp hơn, giảm nhu cầu sử dụng đĩa của người trung gian và giảm chi phí sao chép mạng của người trung gian. Hơn nữa, rủi ro rò rỉ dữ liệu do xóa nén không đúng cách được loại bỏ.
Trong phần tiếp theo, chúng ta sẽ xem xét các sự kiện delta, nơi một sự kiện được mô hình hóa dựa trên sự thay đổi chứ không phải trạng thái bản thân nó.
Delta Events
Sự kiện delta đại diện cho một thay đổi đã xảy ra trong một miền cụ thể, được thể hiện như là cạnh của một quá trình chuyển tiếp trong Hình 3-1. Các sự kiện delta chỉ chứa thông tin về sự thay đổi trạng thái, không phải trạng thái hiện tại hay quá khứ. Các sự kiện delta thường được diễn đạt dưới dạng động từ ở thì quá khứ, cho thấy rằng một điều gì đó đã xảy ra. Ví dụ:
-
mặt hàng đã được thêm vào giỏ hàng
-
món hàng đã bị xóa khỏi giỏ hàng
-
đơn hàng đã thanh toán
-
đơn hàng đã được giao
-
Đơn hàng đã được trả lại
-
người dùng đã di chuyển
-
Người dùng đã bị xóa
Bạn có thể nhận thấy rằng bạn quen thuộc hơn với những loại sự kiện này so với các loại trạng thái được sử dụng cho ECST. Các sự kiện delta đã từng khá phổ biến, đặc biệt trong bối cảnh kiến trúc Lambda (xem “Kiến trúc Lambda”). Các sự kiện delta cũng thường được sử dụng trong một miền cho việc lưu trữ sự kiện, một chủ đề mà chúng ta sẽ xem xét kỹ lưỡng hơn ngay bây giờ.
Delta Events for Event Sourcing
Event sourcing là một mẫu kiến trúc dựa trên việc ghi lại những gì đã xảy ra trong một miền dưới dạng một chuỗi các sự kiện không thay đổi và chỉ bổ sung. Những sự kiện này được tổng hợp để xây dựng trạng thái hiện tại bằng cách áp dụng chúng theo thứ tự mà chúng xảy ra, sử dụng logic cụ thể cho miền, từng cái một.
Kiến trúc này thường được quảng bá như một sự thay thế cho mô hình tạo, đọc, cập nhật, xóa (CRUD) truyền thống thường thấy trong các khung cơ sở dữ liệu quan hệ. Trong mô hình CRUD, trạng thái có thể thay đổi hoàn toàn của thực thể được sửa đổi trực tiếp sao cho chỉ trạng thái cuối cùng được giữ lại. Mặc dù các cơ sở dữ liệu hỗ trợ CRUD có thể tạo ra một nhật ký kiểm tra các thay đổi đã xảy ra, nhưng nhật ký này chủ yếu được sử dụng cho mục đích kiểm toán chứ không phải để thúc đẩy logic kinh doanh.
Có một số hạn chế đối với mô hình CRUD có thể khiến việc sử dụng nguồn sự kiện trở thành một lựa chọn hấp dẫn. Thứ nhất, các thao tác phải được xử lý trực tiếp trên kho dữ liệu ngay khi chúng được gọi. Khi sử dụng nhiều, điều này có thể làm chậm đáng kể các thao tác và dẫn đến thời gian chờ và thất bại. Thứ hai, các thao tác đồng thời cao trên cùng một thực thể có thể dẫn đến xung đột dữ liệu và giao dịch thất bại, làm tăng thêm tải lên hệ thống.
Nhưng mô hình CRUD cũng chứa đựng một số lợi thế rõ rệt. Mặc dù chủ yếu phụ thuộc vào cơ sở dữ liệu, hầu hết các triển khai CRUD đều cung cấp tính nhất quán mạnh mẽ sau khi ghi. Nó cũng khá trực quan và đơn giản để sử dụng, với rất nhiều công cụ và framework hỗ trợ. Đối với nhiều lập trình viên, đây là mô hình đầu tiên để duy trì trạng thái mà họ gặp phải. Hình 3-3 cho thấy một loạt các sự kiện CRUD (một lần tạo, hai lần cập nhật) áp dụng thay đổi cho trạng thái của tủ lạnh. Trạng thái hoàn toàn có thể thay đổi, và chỉ trạng thái đã được cập nhật được giữ lại sau khi lệnh tạo hoặc cập nhật được áp dụng.
Figure 3-3. Using CRUD commands to update the contents of the refrigerator, reflected in the database
Dưới kiến trúc sự kiện nguồn, các thao tác tạo, cập nhật và xóa được mô hình hóa như các sự kiện được ghi vào một nhật ký ghi thêm chỉ có thể duy trì vĩnh viễn. Không hiếm khi một bảng cơ sở dữ liệu duy nhất được sử dụng để hoạt động như một nhật ký ghi thêm chỉ. Cũng có thể sử dụng một trình trung gian sự kiện như Apache Kafka để lưu trữ nhật ký ghi thêm chỉ, mặc dù điều này có thể làm phát sinh độ trễ bổ sung. Trong cả hai trường hợp, trạng thái hiện tại được tạo ra bằng cách tiêu thụ các sự kiện theo thứ tự mà chúng được ghi trong nhật ký và áp dụng chúng từng cái một để tạo ra trạng thái cuối cùng.
Hình 3-4 cho thấy ví dụ về tủ lạnh tương tự, với các thao tác CRUD được mô hình hóa như các sự kiện miền. Và mặc dù các sự kiện mẫu này có đặc điểm giống CRUD, nhưng chủ sở hữu miền có quyền tự do thiết kế các deltas để phù hợp với các trường hợp sử dụng kinh doanh của họ. Chẳng hạn, họ có thể mở rộng tập hợp các sự kiện mà họ đang tạo ra để cũng bao gồm các deltas như:
-
bật đèn/tắt đèn
-
bật làm mát/tắt làm mát
-
mở_cửa/đóng_cửa
Figure 3-4. Building up the contents of a refrigerator using event sourcing
Bộ tổng hợp miền (2) tách biệt với quy trình ghi các sự kiện miền mới vào nhật ký (1), cho phép quy trình ghi và tổng hợp được mở rộng độc lập. Một miền cũng có thể chứa nhiều bộ tổng hợp miền và có thể tổng hợp cùng một nhật ký vào hai kho trạng thái nội bộ khác nhau tùy thuộc vào nhu cầu của miền.
Một trong những nhược điểm chính của nguồn sự kiện là nó nhất quán theo thời gian, điều này có thể là một rào cản đáng kể đối với một số trường hợp sử dụng. Luôn có một khoảng trễ giữa việc ghi sự kiện vào nhật ký và việc thấy kết quả hiện tại trong trạng thái. Và vì nhiều khách hàng đồng thời có thể ghi sự kiện về cùng một thực thể, nên sẽ rất khó để gán bất kỳ sự thay đổi cụ thể nào trong trạng thái cuối cùng cho sự thay đổi mà khách hàng của bạn vừa thêm vào. Điều này có thể khiến nó không phù hợp trong các ứng dụng yêu cầu tính nhất quán mạnh.
Sourcing sự kiện là một lựa chọn hợp lý thay thế cho mô hình CRUD để xây dựng trạng thái nội bộ. Vấn đề với sourcing sự kiện xảy ra khi nó bị lạm dụng như một phương tiện giao tiếp liên miền, phơi bày các delta miền nội bộ ra bên ngoài cho người khác để họ phụ thuộc vào (và hiểu sai). Những sự kiện cụ thể của miền này và mối quan hệ của chúng với tổng hợp và với nhau có thể thay đổi theo thời gian. Cũng như chúng ta không cho phép các dịch vụ bên ngoài miền của chúng ta phụ thuộc trực tiếp vào mô hình dữ liệu của chúng ta, chúng ta cũng không được phép để các dịch vụ phụ thuộc vào mô hình dữ liệu sự kiện miền riêng tư của chúng ta.
Điều này không có nghĩa là bạn không thể công khai bất kỳ sự kiện nào bên ngoài ranh giới miền, nhưng bất kỳ sự kiện nào mà bạn công khai đều trở thành một phần của hợp đồng dữ liệu công khai. Bạn sẽ cần đảm bảo rằng ý nghĩa ngữ nghĩa của nó không thay đổi theo thời gian và rằng dữ liệu không phát triển theo cách phá vỡ. Việc không duy trì ranh giới của “các sự kiện ở đây” và “các sự kiện ở ngoài” có thể dẫn đến sự kết nối rất phức tạp, khó khăn trong việc tái cấu trúc và các lỗi tinh vi do sự hiểu nhầm các sự kiện bởi các bên tiêu thụ bên ngoài.
The Problems with Delta Events
Những phần tiếp theo minh họa các vấn đề khi sử dụng các sự kiện delta cho microservices. Hãy cùng xem xét từng vấn đề một.
1) There is an infinite amount of delta event types
Trước hết và quan trọng nhất, có một lượng delta sự kiện vô hạn có thể xảy ra trong bất kỳ lĩnh vực nào. Điều này một mình nên ngăn hầu hết mọi người cố gắng tạo ra các luồng sự kiện với mô hình delta, nhưng không may là điều đó không xảy ra. Nhưng chắc chắn, liệu có thật sự là có một số lượng delta sự kiện vô hạn không?
Trên thực tế, tập hợp các sự kiện delta cần thiết cho lĩnh vực của bạn chắc chắn là hữu hạn. Vấn đề thực sự là mỗi người tiêu dùng sự kiện delta cần phải biết chính xác cách tải nó vào phiên bản trạng thái của riêng họ. Đối với nhiều sự kiện, điều này để lại sự mở cho việc diễn giải.
Hãy cùng xem một ví dụ. Hình 3-5 cho thấy một tập hợp đơn giản các sự kiện thương mại điện tử để xây dựng nội dung giỏ hàng.

Figure 3-5. Shopping cart delta events, used to construct the current state of the shopping cart
Thêm và xóa thì khá đơn giản: các mặt hàng có thể được thêm vào, hoặc chúng có thể bị xóa. Người tiêu dùng sẽ cần diễn giải và áp dụng từng sự kiện này, theo đúng thứ tự, để xây dựng tổng hợp của mình. Tuy nhiên, giả sử rằng một tính năng mới trong miền cho phép người dùng cập nhật số lượng mặt hàng họ có trong giỏ: nơi mà trước đây chủ sở hữu miền có thể đã phát hành một sự kiện xóa trước, rồi một sự kiện thêm với số lượng mới, thì bây giờ họ có thể đơn giản phát hành một sự kiện cập nhật.
Hình 3-6 cho thấy luồng sự kiện Cập nhật Số lượng Mặt hàng mới này được công bố ra thế giới. Bây giờ, nếu một người tiêu dùng cần một mô hình của giỏ hàng, họ cũng phải tính đến những sự kiện cập nhật này trong mã tổng hợp của họ. Khi phạm vi của miền thay đổi, ý nghĩa của các sự kiện và mối quan hệ của chúng với tổng hợp cũng thay đổi.
Figure 3-6. New updated event changes the way the shopping cart delta events are interpreted
Một trong những lí do phổ biến mà mọi người (sai lầm) chọn sử dụng sự kiện delta cho giao tiếp giữa các miền là họ không tin rằng những người tiêu dùng khác nên được yêu cầu duy trì trạng thái để kích hoạt các thay đổi cụ thể. Dải delta có thể gần như vô hạn làm cho điều này trở nên không thể chấp nhận, nhưng đó là một cái bẫy mà nhiều người không nhận ra cho đến khi họ đã hoàn toàn bị cuốn vào nó.
Một sự mở rộng đơn giản của lĩnh vực giỏ hàng để tích hợp các tính năng như phiếu giảm giá, ước lượng vận chuyển và đăng ký tăng lượng thông tin mà người tiêu dùng phải tính toán, như đã được thể hiện trong Hình 3-7.
Figure 3-7. The delta events defining the shopping cart sprawl as new business functionality is added
Việc công khai miền giỏ hàng mở rộng này cho người tiêu dùng yêu cầu rằng người tiêu dùng có thể xác định, sử dụng và xây dựng một tổng hợp chính xác từ các sự kiện này. Nhưng người tiêu dùng lấy thông tin cần thiết để diễn giải và tổng hợp dữ liệu này một cách chính xác từ đâu? Từ hệ thống sản xuất nguồn. Điều này dẫn chúng ta đến vấn đề chính tiếp theo của việc sử dụng các sự kiện delta.
2) The logic to interpret delta events must be replicated to each consumer
Làm thế nào một người tiêu dùng có thể biết họ đang giải thích đúng các sự kiện delta? Và làm thế nào để người tiêu dùng cập nhật khi có các sự kiện miền mới được giới thiệu? Chìa khóa là làm cho người tiêu dùng có thể hoạt động đúng mà không cần thường xuyên cập nhật logic của họ để tính đến các sự kiện delta mới và đa dạng.
Trong mô hình trạng thái, một người tiêu dùng chỉ cần hiện thực hóa các sự kiện trạng thái để biết rằng họ đang nhận được toàn bộ miền công khai. Họ có thể không biết tại sao sự chuyển tiếp xảy ra (chúng ta sẽ đề cập đến điều này nhiều hơn một chút ở phần sau của chương), nhưng họ có thể yên tâm rằng toàn bộ miền công khai có ở đó, và là một người tiêu dùng, họ không cần phải lo lắng về việc xây dựng một tập hợp chính xác.
Hình 3-8 cho thấy hai người tiêu dùng, mỗi người đã sao chép lại logic từ nhà sản xuất để xây dựng trạng thái tổng hợp. Người tiêu dùng có trách nhiệm xác định, hiểu và áp dụng đúng các sự kiện miền thêm, xóa và cập nhật để tạo ra trạng thái cuối cùng phù hợp của tổng hợp. Độ phức tạp của miền là rất quan trọng; các miền rất đơn giản có thể giải quyết vấn đề này, nhưng bất kỳ miền nào có độ phức tạp có ý nghĩa sẽ thấy giải pháp này không thể chấp nhận được.
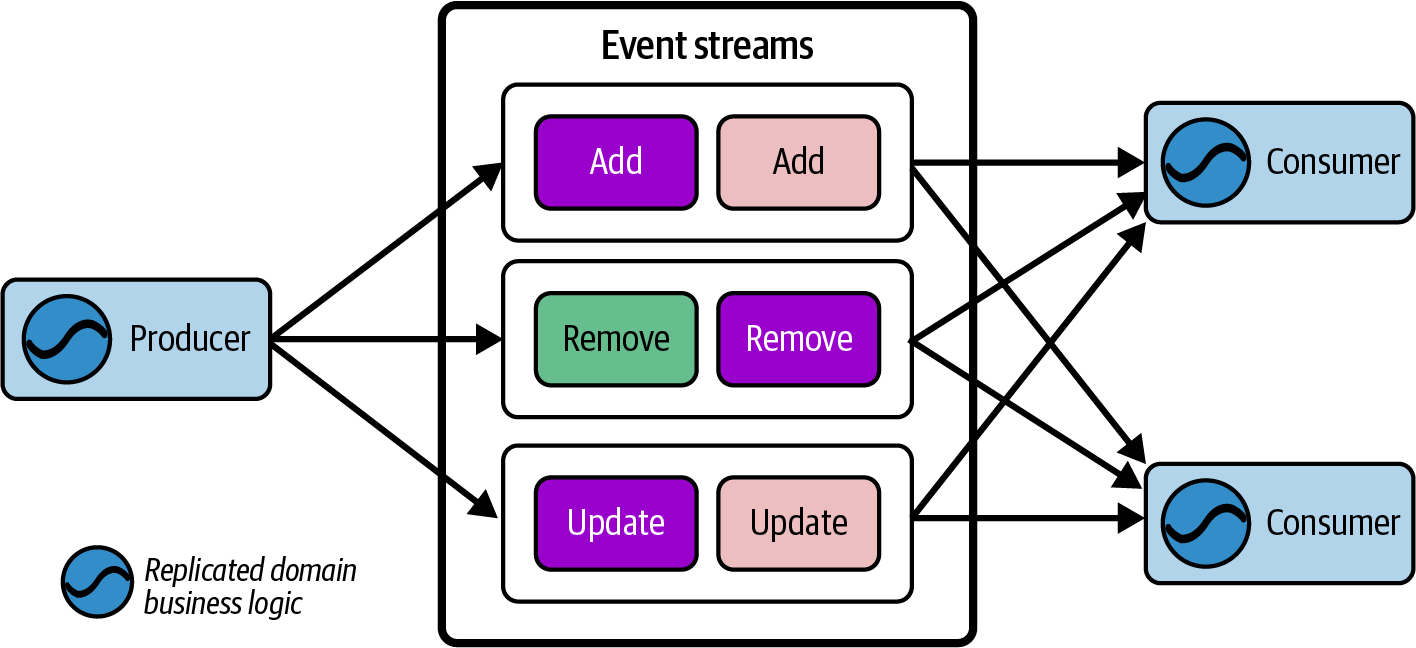
Figure 3-8. The logic to interpret delta events to build state is copied into multiple locations
Các vấn đề tạm thời có thể gây ra những phức tạp hơn—một luồng sự kiện được lưu trữ trên một môi giới chậm có thể gặp phải sự chậm trễ trong việc cung cấp một số sự kiện, dẫn đến việc người tiêu dùng nhận chúng theo thứ tự khác với các sự kiện trong các luồng khác. Các delta được áp dụng theo thứ tự sai thường dẫn đến các chuyển trạng thái không chính xác và có thể kích hoạt các hành động kinh doanh không đúng.
Hơn nữa, mỗi người tiêu dùng có thể thực hiện logic tổng hợp của riêng họ hơi khác nhau—thường là vì một người tiêu dùng không cập nhật logic tổng hợp khi miền phát triển. Một người tiêu dùng có thể chờ tối đa 30 giây cho các sự kiện đến muộn, trong khi một người tiêu dùng khác có thể không chờ đợi chút nào và đơn giản chỉ loại bỏ bất kỳ sự kiện đến muộn nào, dẫn đến các tổng hợp tương tự nhưng khác nhau.
Bất kỳ thay đổi nào đối với cách mà nhà sản xuất tổng hợp miền nội bộ của mình, bao gồm các sự kiện mới hoặc thay đổi trong ngữ nghĩa delta, đều phải được truyền đạt đến logic của người tiêu dùng—nếu bạn đã làm việc với các dịch vụ phân tán (hoặc vi dịch vụ) trước đây, bạn có thể sẽ run sợ với ý tưởng này. Việc sử dụng các sự kiện delta để giao tiếp giữa các miền làm cho nhà sản xuất, các định nghĩa sự kiện, và các người tiêu dùng gắn chặt với nhau, và cố gắng quản lý điều này là một bài tập trong sự vô vọng.
3) Delta events map poorly to event streams
Trong các vấn đề đã thảo luận cho đến nay, chúng tôi đã giả định rằng bất kỳ sự kiện delta mới nào sẽ được người tiêu dùng nhận diện và hiểu ngay lập tức, mặc dù họ có thể chưa hiểu cách áp dụng những sự kiện đó vào miền. Thực tế thì phức tạp hơn nhiều. Người tiêu dùng sự kiện delta phải được thông báo khi có delta mới được tạo ra để họ có thể cập nhật mã của mình nhằm tích hợp sự kiện vào mô hình dữ liệu của họ.
Sự phối hợp có thể khá khó khăn, đặc biệt khi có nhiều người tiêu dùng khác nhau. Đây là vấn đề chính của phần phụ này: làm thế nào để người tiêu dùng biết về các sự kiện miền mới mà họ phải xem xét trong mô hình của họ?
Một gợi ý phổ biến mà đáng tiếc là đã bỏ lỡ điểm chính là chỉ đơn giản "đưa tất cả vào cùng một luồng sự kiện để người tiêu dùng có thể truy cập và tự chọn xem họ có cần sử dụng hay không." Mặc dù các người tiêu dùng hiện tại sẽ nhận được các loại sự kiện mới này, nhưng đề xuất này không giải quyết gì cho các thay đổi mã và tích hợp mà người tiêu dùng cần để sử dụng dữ liệu đó.
Ngoài ra, khả năng gây ra lỗi cho người tiêu dùng là rất cao, có thể bị loại bỏ như "dữ liệu xấu" hoặc, tệ hơn nữa, gây ra lỗi xử lý âm thầm trong logic kinh doanh của người tiêu dùng. Điều này cũng vi phạm quy tắc sử dụng một schema có khả năng phát triển duy nhất cho mỗi dòng sự kiện, điều này là tiêu chuẩn mặc định cho nhiều khung và công nghệ xử lý dòng sự kiện.
Vấn đề quan trọng ở đây là các định nghĩa sự kiện mới cần phải làm việc với những người tổng hợp các sự kiện thành một mô hình. Nếu bạn đưa các sự kiện delta mới vào các luồng riêng lẻ mới, bạn sẽ làm cho việc phát hiện dễ dàng hơn và theo quy tắc một lược đồ cho mỗi luồng, nhưng người tiêu dùng của bạn vẫn cần được thông báo thủ công rằng luồng mới này tồn tại! Trong cả hai trường hợp, việc cập nhật mã là cần thiết để hiểu dữ liệu này, trong khi việc không tích hợp nó sẽ có nguy cơ dẫn đến việc tổng hợp sai.
Bây giờ hãy so sánh với mô hình trạng thái, nơi miền trạng thái có thể thay đổi theo nhu cầu và thành phần của sự kiện trạng thái được đóng gói hoàn toàn trong dịch vụ sản xuất. Mọi thay đổi được thực hiện đối với sự kiện trạng thái xảy ra ở một nơi và chỉ một nơi duy nhất, và được phản ánh trong mô hình dữ liệu đã cập nhật được công bố lên luồng sự kiện. Vâng, bạn có thể cần xử lý sự phát triển lược đồ của sự kiện mô hình trạng thái, nhưng chỉ trong những trường hợp gây ra sự thay đổi lớn cho mô hình dữ liệu thực thể.
4) Inversion of ownership: Consumers push their business logic into the producer
Vấn đề thứ tư với deltas liên quan đến quyền sở hữu và vị trí của logic kinh doanh. Ví dụ, một người tiêu dùng có thể cần biết khi nào một gói hàng đã được gửi đi để có thể gửi một email đến người nhận thông báo rằng gói hàng đang trên đường đến. Logic kinh doanh để xác định rằng gói hàng đã được gửi đi phải chắc chắn nằm trong phía nhà sản xuất, như trong Hình 3-9.
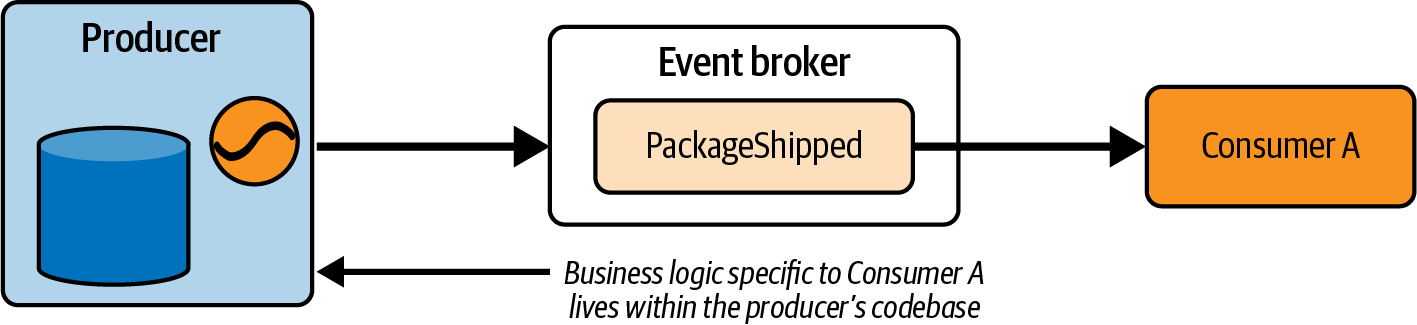
Figure 3-9. Consumer business requirements are pushed into the business logic of the producer; in this case, Consumer A only wants to know when a package is shipped, but not when the package has any other status
Tuy nhiên, điều này nhanh chóng trở nên không khả thi với sự mở rộng ngày càng tăng của các trường hợp sử dụng trong kinh doanh. Mỗi yêu cầu kinh doanh mới phụ thuộc vào sự chuyển tiếp trạng thái cũng sẽ cần phải đặt logic kinh doanh của nó trong dịch vụ sản xuất (xem Hình 3-10) để tạo ra sự kiện bất cứ khi nào “điểm rìa” đó xảy ra. Điều này rất khó khăn để mở rộng và quản lý, chưa nói đến việc theo dõi quyền sở hữu và các phụ thuộc.
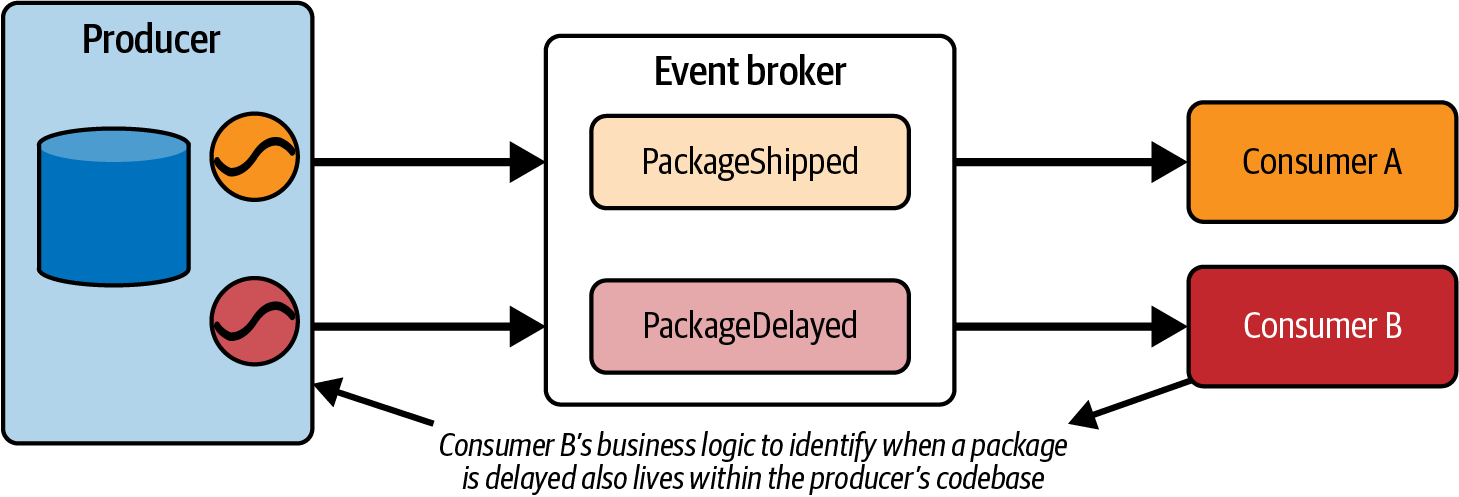
Figure 3-10. The scope of consumer requirements can grow quite large, as there are many possible deltas for most domains of any complexity
Toàn bộ mục đích của các sự kiện delta là tránh việc duy trì trạng thái trong dịch vụ tiêu dùng, nhưng chúng yêu cầu rằng nhà sản xuất hoàn toàn có khả năng và sẵn sàng thực hiện logic kinh doanh chỉ cho người tiêu dùng. Ví dụ, hãy xem xét những trường hợp sử dụng hợp lý sau đây:
-
Tôi muốn theo dõi các trường hợp trả hàng mà người dùng đã gọi điện để khiếu nại trước đó: một sự kiện userReturnedItemAfterTelephoneComplaint.
-
Tôi muốn biết liệu người dùng đã xem ít nhất ba quảng cáo về sản phẩm và sau đó đã mua nó hay chưa: một sự kiện userSawAtLeastThreeAdsThenPurchasedIt.
Những sự kiện mẫu này có vẻ hơi quá mức, nhưng thực tế là đây là những điều kiện mà các doanh nghiệp thực sự quan tâm. Trong mỗi trường hợp, người tiêu dùng nên duy trì trạng thái của riêng mình và xây dựng các tính toán riêng về những sự kiện này, nhưng thay vào đó lại tránh điều đó bằng cách chuyển trách nhiệm phát hiện rìa trở lại cho nhà sản xuất. Kết quả là có sự liên kết rất chặt chẽ giữa nhà sản xuất và người tiêu dùng, và dẫn đến việc phân tán độ phức tạp qua nhiều mã nguồn khác nhau.
Một yếu tố cuối cùng là một hệ thống đơn lẻ hiếm khi có thể cung cấp tất cả thông tin cần thiết cho những sự kiện chuyên biệt cao này. Hãy xem xét ví dụ trong Hình 3-11. Trong ví dụ này, người tiêu dùng cần hành động khi thông tin từ dịch vụ quảng cáo và dịch vụ thanh toán (cả hai đều trong lĩnh vực của riêng chúng) đáp ứng một tiêu chuẩn nhất định: người dùng phải được hiển thị quảng cáo ba lần và sau đó cuối cùng đã mua sản phẩm đó.
Ngay cả khi chúng tôi thuyết phục được đội ngũ quảng cáo sản xuất các sự kiện userSawAdvertisementThreeTimes và userReturnedItemAfterTelephoneComplaint, người tiêu dùng vẫn cần phải lưu trữ chúng trong kho trạng thái của riêng mình và chờ đợi giao dịch mua phù hợp từ dịch vụ thanh toán. Ngay cả định nghĩa sự kiện phức tạp và rối rắm nhất cũng không thể tính đến việc xử lý dữ liệu hoàn toàn nằm trong một miền khác. Người tiêu dùng vẫn phải có khả năng duy trì trạng thái, mặc dù chúng tôi đã nỗ lực tốt nhất để tránh điều đó.
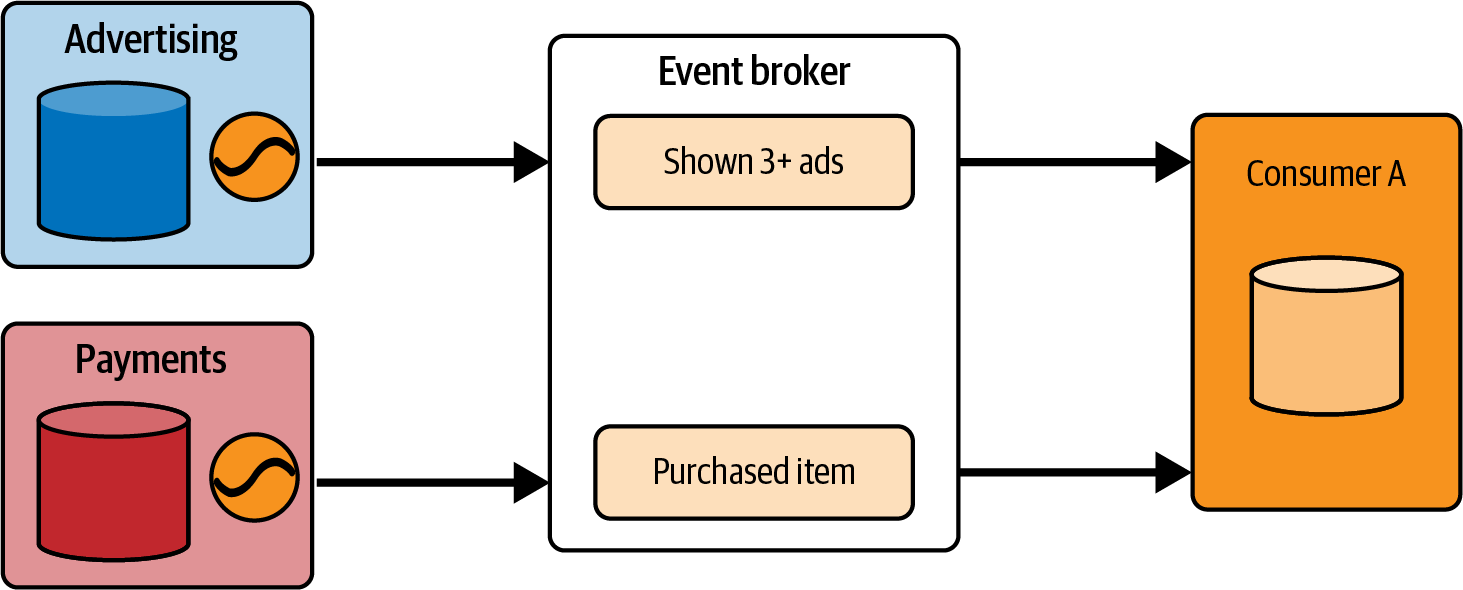
Figure 3-11. Consumer-specific delta event triggering logic is pushed upstream to both the advertising and payments service
Và nếu người tiêu dùng của chúng ta muốn thay đổi logic kinh doanh từ ba quảng cáo thành bốn? Một định nghĩa sự kiện hoàn toàn mới cần được thương lượng và đưa vào ranh giới của nhà sản xuất, điều này sẽ cho bạn một ý tưởng về việc ý tưởng này hoạt động kém như thế nào trong thực tế. Hợp lý hơn nhiều là nhà sản xuất xuất ra một tập hợp trạng thái đa mục đích và để cho người tiêu dùng tự quyết định xem họ muốn làm gì với những tập dữ liệu đó.
5) Inability to maintain historical data
Điểm thứ năm và cuối cùng chống lại sự kiện delta dựa trên sự khó khăn trong việc duy trì dữ liệu lịch sử có thể sử dụng. Các sự kiện trạng thái cũ có thể đơn giản được nén lại, nhưng sự kiện delta thì không. Việc quản lý log sự kiện ngày càng tăng trở nên khó khăn hơn nhiều khi xem xét như một nguồn thông tin lịch sử.
Mỗi sự kiện delta đều rất quan trọng để tổng hợp trạng thái cuối cùng. Và có thể không chỉ có một luồng sự kiện duy nhất để xử lý, mà còn có nhiều luồng delta khác nhau liên quan đến các delta khác nhau trong miền. Hình 3-12 cho thấy một ví dụ về ba sự kiện delta giỏ hàng đơn giản đã phát triển rất lớn trong suốt 10 năm qua—lớn đến mức một người tiêu dùng mới có thể mất, ví dụ, ba tuần xử lý không ngừng để vượt qua khối lượng dữ liệu, chỉ để bắt kịp với trạng thái hiện tại.
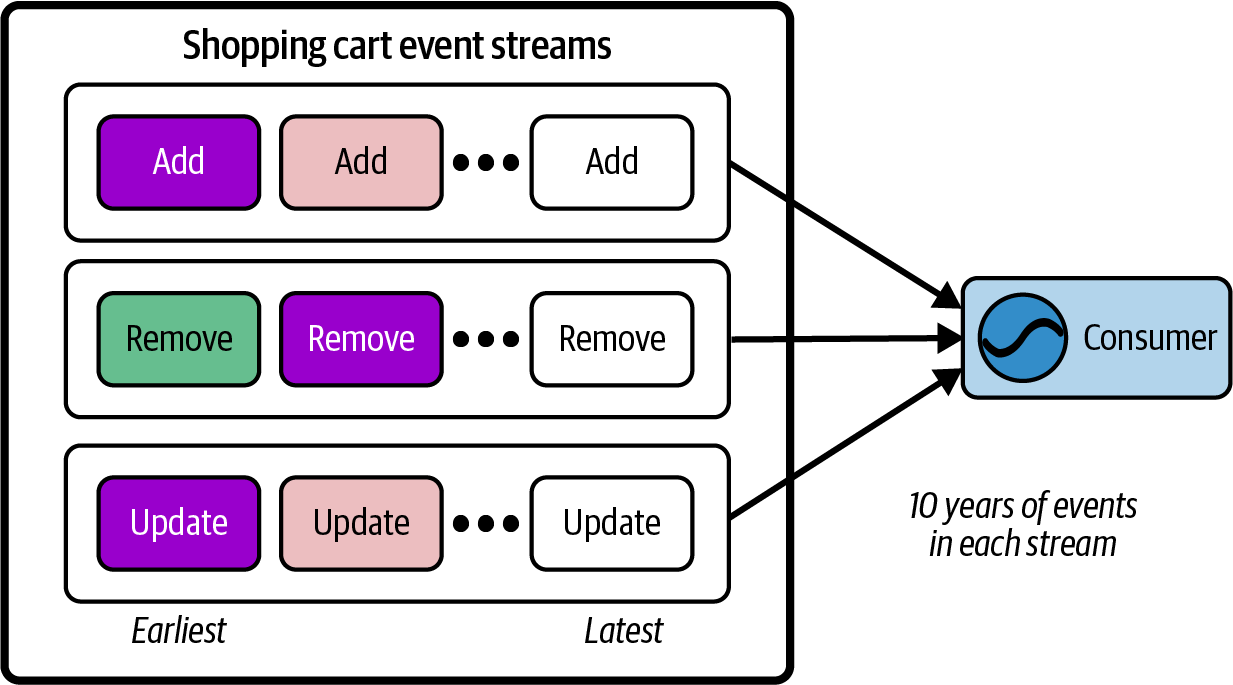
Figure 3-12. There are simply too many delta events in this stream for a new consumer to reasonably consume
Trong khi việc xóa dữ liệu cũ chắc chắn là một giải pháp, một giải pháp khác mà tôi đã thấy được thực hiện là chuyển các sự kiện cũ vào một kho trạng thái lớn bên ngoài, có thể được tải vào một người tiêu dùng mới. Ý tưởng ở đây là người tiêu dùng có thể tải tất cả các sự kiện này song song, khởi động nhanh hơn rất nhiều. Vấn đề là thứ tự mà các sự kiện này được áp dụng có thể quan trọng, và chỉ đơn giản là di chuyển các sự kiện sang một hệ thống không phát trực tiếp rồi lại phát chúng vào các người tiêu dùng mới có vẻ hơi vô lý. Vì vậy, giải pháp tiếp theo là xây dựng một ảnh chụp của trạng thái tại thời điểm đó dựa trên tất cả các sự kiện delta. Điều này được thể hiện trong Hình 3-13.
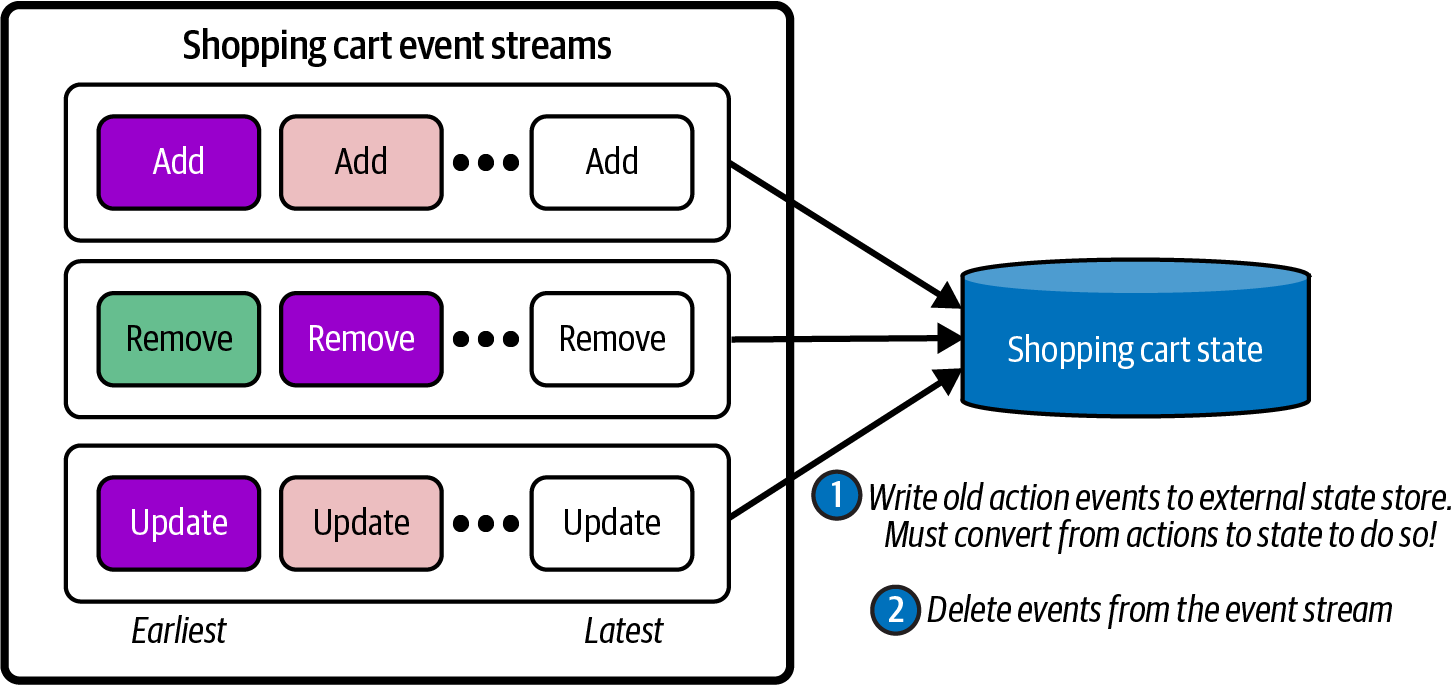
Figure 3-13. Loading the old events into a bootstrapping side store requires aggregating into a state model
Có một chút mỉa mai ở đây. Trong nỗ lực tránh tạo ra một định nghĩa về trạng thái có thể sử dụng công khai, chúng ta lại vô tình làm điều đó để lưu trữ dữ liệu trong một kho bên. Những người tiêu dùng mới chắc chắn có thể khởi động nhanh hơn nhiều khi sử dụng nó, nhưng bây giờ họ phải vừa đọc từ kho trạng thái snapshot vừa chuyển đổi hoàn hảo sang luồng sự kiện.
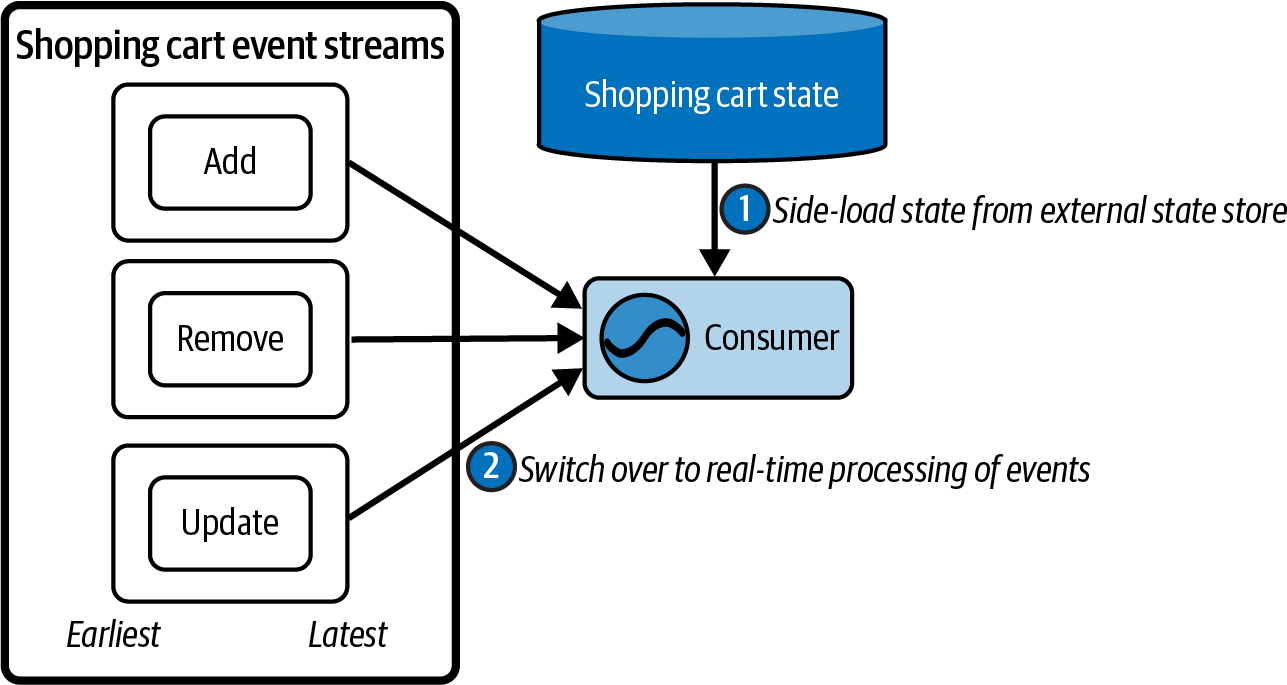
Figure 3-14. This brings us back around to the Lambda architecture involving both delta events, aggregated state, and the need to handle both batch and streaming
Hình 3-14 cho thấy chúng ta đã quay về điểm khởi đầu, trở lại với kiến trúc Lambda mà chúng ta đã cố gắng tránh suốt thời gian qua, cùng với tất cả những phức tạp trong vận hành và các vấn đề vốn có của nó.
Các lý do sau đây thật không may là những lập luận phổ biến nhưng không đủ cho việc sử dụng các sự kiện delta trong giao tiếp liên miền:
Việc duy trì trạng thái trùng lặp là lãng phí, nó sẽ chiếm quá nhiều dung lượng đĩa.
Người tiêu dùng sẽ biết sự kiện đó có ý nghĩa gì. Làm sao họ có thể hiểu sai được?
Thôi nào, tôi thực sự chỉ quan tâm đến một cú chuyển tiếp này, không sao đâu nếu tôi kết hợp vào nó. Chỉ cần phát hành một sự kiện tùy chỉnh cho tôi.
Người đó không muốn sử dụng các sự kiện của nhà nước.
Các sự kiện Delta là hợp lệ trong ranh giới nội bộ của một miền riêng tư, nơi sự kết hợp chặt chẽ giữa các định nghĩa sự kiện và logic cần thiết để giải thích và áp dụng chúng có thể được thực hiện một cách nhất quán.
Tuy nhiên, việc sử dụng cùng một sự kiện delta qua các ranh giới miền là rất nguy hiểm, và việc sử dụng chúng như một phương tiện để xây dựng trạng thái trong các ứng dụng khác là hoàn toàn không khả thi. Hãy tập trung vào việc sử dụng sự kiện trạng thái cho phần lớn các luồng sự kiện của bạn.
Hybrid Events—State with a Bit of Delta
Sự kiện lai là sự kết hợp giữa trạng thái và delta. Tốt nhất là nghĩ về những điều này như các sự kiện trạng thái có thể chứa một ít thông tin về lý do hoặc cách mà một điều gì đó xảy ra. Hãy xem một ví dụ để làm rõ.
Exposing "how" or "why" something has occurred with a hybrid event may lead to strong consumer coupling on the producer system. Proceed with caution.
Xem xét kịch bản sau. Một công ty cung cấp dịch vụ trực tuyến yêu cầu người dùng đăng ký trước khi sử dụng. Có một số cách mà người dùng có thể đăng ký:
-
Thông qua nút đăng ký chính trên trang chủ
-
Qua một liên kết quảng cáo qua email
-
Sử dụng tài khoản bên thứ ba (ví dụ, tài khoản Google)
-
Tài khoản đã được tạo thủ công cho họ bởi một quản trị viên.
Người tiêu dùng muốn biết cách mà người dùng đã đăng ký. Đối với các trường hợp sử dụng vận hành, chúng tôi muốn biết quy trình onboarding nào sẽ phục vụ họ khi họ đăng nhập lần tiếp theo. Vì mục đích phân tích, chúng tôi có thể muốn biết phương pháp đăng ký nào của chúng tôi là phổ biến nhất để có thể phân bổ tài nguyên phát triển.
Một cách để mô hình hóa việc đăng ký này là với một sự kiện trạng thái người dùng, với một tập hợp liệt kê duy nhất chỉ ra cơ chế đăng ký (sau cùng, bạn chỉ có thể đăng ký một lần!). Một ví dụ về bản ghi sẽ trông như sau:
Key:"USERID-9283716596927463"Value:{name:"RandolphL.Bandito",signup_time:"2022-02-22T22:22:22Z",birthday:"2000-01-01T00:00:00Z",//An enum of (MAIN,VIA_AD_EMAIL,THIRD_PARTY,or ADMIN)method_of_signup:"VIA_AD_EMAIL"}
Để tạo ra sự kiện hybrid, chúng tôi đã kết hợp những gì sẽ là các sự kiện delta vào một sự kiện trạng thái duy nhất. Thay vì các sự kiện signed_up_via_email, signed_up_via_homepage, signed_up_via_third_party và signed_up_via_admin, chúng tôi đã giản lược chúng thành một enum duy nhất và thêm chúng vào thực thể người dùng. Miền giá trị trong sự kiện trạng thái người dùng cần xem xét tất cả các cài đặt enum có thể: ví dụ, chúng tôi cũng có thể muốn bao gồm thông tin về nhà cung cấp đăng nhập bên thứ ba nào đã được sử dụng hoặc chiến dịch email nào đã khiến người dùng đăng ký.
Và đây là vấn đề chính với các sự kiện kết hợp. Cơ chế chính xác của việc một điều gì đó trở thành thuộc về một miền chủ yếu là một chi tiết riêng tư, nhưng bằng cách công khai thông tin này, chúng ta cũng phơi bày quy trình logic kinh doanh nội bộ để các người tiêu dùng ở hạ nguồn kết nối.
Rủi ro chính đối với người tiêu dùng thông tin này là cách người dùng đăng ký sẽ thay đổi theo thời gian. Điều này có thể là một sự thay đổi về ý nghĩa (cách nào là cách "chính" để đăng ký hiện tại so với 5 năm trước và 5 năm tới?), cũng như sự mở rộng hoặc thu hẹp các giá trị trong enum. Những ngữ nghĩa này thường chỉ là mối quan tâm của miền nguồn, nhưng bằng cách phơi bày những khía cạnh tập trung vào biến đổi này, chúng trở thành mối quan tâm của người tiêu dùng.
Cũng có khả năng (hoặc xác suất) rằng nhà sản xuất phải cập nhật sự kiện hybrid để tính đến một phương thức đăng ký mới: thông qua ứng dụng di động vừa được công ty phát hành (thêm VIA_MOBILE_APP vào enum method_of_signup). Người tiêu dùng của sự kiện này phải được thông báo về những thay đổi sắp tới và phải xác nhận rằng họ có thể xử lý phương thức đăng ký mới này trước khi định nghĩa sự kiện được cập nhật. Nếu không, người tiêu dùng sẽ đối mặt với nguy cơ chạm phải lỗi nghiêm trọng trong quá trình xử lý, vì logic kinh doanh của họ sẽ không tính đến loại mới này. Đây chỉ là một khía cạnh khác của cùng một vấn đề mà chúng ta đã thấy trong “2) Logic để diễn giải các sự kiện delta phải được nhân đôi cho mỗi người tiêu dùng”.
Tuy nhiên, trong ví dụ này, rủi ro đối với người tiêu dùng là thấp nhưng không bằng không, vì các lý do sau:
-
Cách một người tiêu dùng đăng ký là không thể thay đổi. Rủi ro thực sự nằm ở chỗ ý nghĩa của phương thức đăng ký có thể thay đổi theo thời gian. Người sở hữu sự kiện có thể ngăn chặn điều này bằng cách cung cấp tài liệu rất rõ ràng về ý nghĩa của các liệt kê (ví dụ, trong chính sơ đồ sự kiện) và tuân thủ chặt chẽ các định nghĩa của chính họ.
-
Logic của việc điền thông tin phương thức đăng ký thì khá đơn giản tổng thể, vì vậy ít có khả năng thay đổi theo thời gian hơn. Đăng ký qua liên kết email là một biến đổi nhị phân – bạn hoặc đã đăng ký qua liên kết email hoặc không. Ngược lại, một enum dựa trên sự kiện biến đổi userReturnedItemAfterTelephoneComplaint từ phần trước có nhiều phụ thuộc tuần tự hơn và nhiều cách để diễn giải sai, và dễ dàng có khả năng thay đổi ý nghĩa theo thời gian hơn.
Một sự kiện hybrid là một sự đánh đổi. Rủi ro bạn phải đối mặt khi sử dụng một sự kiện hybrid tỷ lệ thuận với độ phức tạp của delta mà bạn đang cố gắng theo dõi và khả năng nó sẽ thay đổi theo thời gian (dù có chủ ý hay không). Tôi khuyên bạn nên cố gắng tách rời hơn nữa các hệ thống sản xuất và tiêu thụ của bạn để tránh việc phải thông báo chi tiết lý do hoặc cách mà dữ liệu đã thay đổi. Nếu bạn chọn bao gồm một trường kiểu delta trong sự kiện của mình, hãy nhận thức rằng nó sẽ trở thành một phần của hợp đồng dữ liệu của bạn và hãy cân nhắc kỹ lưỡng về sự gắn kết mà nó mang lại với hệ thống nguồn.
Measurement Events
Sự kiện đo lường thường thấy ở nhiều lĩnh vực và bao gồm một bản ghi đầy đủ về một sự kiện xảy ra tại một thời điểm. Có những ví dụ phổ biến về điều này trong thế giới hàng ngày của chúng ta: phân tích trang web, có lẽ được thể hiện rõ nhất qua Google Analytics, là một ví dụ. Theo dõi hành vi người dùng xảy ra trên từng trang web, trải nghiệm mạng xã hội và ứng dụng di động là một ví dụ khác. Mỗi khi bạn nhấp vào một nút, xem một quảng cáo, hoặc dừng lại trên một bài đăng mạng xã hội, điều đó được ghi lại như một sự kiện đo lường.
Một sự kiện đo lường trông như thế nào? Dưới đây là một ví dụ về sự kiện hành vi người dùng ghi lại sự kiện người dùng nhìn thấy một quảng cáo trên trang web:
Key:"USERID-8271949472726174"Value:{utc_timestamp:"2022-01-22T15:39:19Z",ad_id:1739487875123,page_id:364198769786,url:https://www.somewebsite.com/welcome.html}
Một phép đo là một bức ảnh của trạng thái tại một thời điểm cụ thể. Tuy nhiên, các phép đo có một vài đặc điểm phân biệt chúng với các sự kiện trạng thái mà chúng ta đã thảo luận trước đó.
Measurement Events Enable Aggregations
Các chỉ số thường được sử dụng để tạo ra các tập hợp dữ liệu xung quanh một khóa cụ thể. Ví dụ, chỉ số userViewedAd có thể được sử dụng để tính toán nhiều tập dữ liệu, trả lời các câu hỏi như “ID trang nào phổ biến nhất?”, “Khi nào người dùng xem nhiều quảng cáo nhất?”, và “Mỗi người dùng trung bình xem bao nhiêu quảng cáo trong một phiên?”
Measurement Event Sources May Be Lossy
Không hiếm khi mất dữ liệu đo lường ở đâu đó giữa quá trình tạo ra và tiếp nhận vào luồng sự kiện. Ví dụ, các trình chặn quảng cáo rất hiệu quả trong việc chặn các sự kiện phân tích trên web, khiến cho các báo cáo và bảng điều khiển của bạn khó có thể hoàn toàn chính xác. Tuy nhiên, chúng thường đủ tốt cho nhiều mục đích phân tích.
Measurement Events Can Power Time-Sensitive Applications
Xem xét một nhà máy đo nhiệt độ, độ ẩm và các chỉ số chất lượng không khí khác trên dây chuyền lắp ráp của mình. Một trường hợp sử dụng phân tích cho những phép đo này có thể là theo dõi và xác định các xu hướng lâu dài của môi trường nhà máy. Nhưng một trường hợp sử dụng hoạt động có thể là phản ứng nhanh chóng trong trường hợp các giá trị cảm biến khác biệt, thay đổi thông lượng dây chuyền lắp ráp hoặc tắt nó hoàn toàn nếu các điều kiện môi trường không đáp ứng yêu cầu.
Trong trường hợp có sự cố kết nối mạng, có thể các cảm biến đang chờ để gửi dữ liệu đã cũ từ 30 đến 60 giây, trong khi dữ liệu mới đang xếp hàng phía sau. Tùy thuộc vào mục đích của luồng đo lường và các mục tiêu dịch vụ đã thương lượng trước, nó có thể chọn bỏ qua các sự kiện cũ và chỉ công bố những cái mới nhất. Điều này phụ thuộc rất nhiều vào việc liệu dữ liệu này có được sử dụng cho mục đích thời gian thực hay không, hoặc liệu nó đang được sử dụng để xây dựng một bức tranh lịch sử toàn diện mà có khả năng chịu đựng sự gián đoạn và độ trễ, như trong trường hợp phân tích web.
Notification Events
Còn một loại sự kiện cuối cùng cần thảo luận trước khi chúng ta kết thúc chương. Một thông báo chứa một bộ thông tin tối thiểu rằng điều gì đó đã xảy ra và một liên kết hoặc URI đến tài nguyên chứa thêm thông tin. Điện thoại di động có lẽ là nguồn quen thuộc nhất của các thông báo—bạn có một tin nhắn mới, ai đó đã thích bài đăng của bạn, hoặc bạn có đủ trái tim để tiếp tục trò chơi miễn phí của mình—nhấp vào đây để truy cập vào đó.
Một ví dụ về thông báo đơn giản phía sau mà bạn có thể nhận trên điện thoại di động của mình có thể trông giống như sau. Ứng dụng nhắn tin tức thì của bạn gửi đi thông báo "TIN NHẮN MỚI", bao gồm trạng thái (để hiển thị biểu tượng), tên của ứng dụng và một URI để nhấp vào ứng dụng đó.
Value:{status:"NEW_MESSAGE",source:"messaging_app",application_uri:"/user/chat/192873163812392"}
"Các sự kiện thông báo thường bị lạm dụng như một phương tiện để cố gắng truyền đạt trạng thái mà không gửi trạng thái thực tế. Thay vào đó, một con trỏ đến trạng thái được gửi trong thông báo, với kỳ vọng rằng người nhận sẽ đăng nhập vào máy chủ nguồn và lấy dữ liệu. Dưới đây là một ví dụ như vậy, trong đó thông báo bao gồm việc trạng thái đã thay đổi, và có một URI truy cập để tìm trạng thái hiện tại hoàn chỉnh:"
Key:12309131238218Value:{status:"PARTIAL_RETURN",utc_timestamp:"2021-21-13T13:11:42Z",access_uri:"serverURI:8080/orders/values/12309131238218"}
Nhìn thoáng qua, điều này có vẻ là một giải pháp gọn gàng và hợp lý: nó cho phép người tiêu dùng chỉ cần truy vấn toàn bộ trạng thái công cộng khi nhận được sự kiện mà không cần sao chép hoặc tiết lộ dữ liệu đó ở nơi khác. Một trong những vấn đề lớn là sự kiện thực sự không cung cấp một bản ghi của trạng thái tại thời điểm đó—trừ khi dữ liệu chứa tại access_uri hoàn toàn bất biến (thường thì không phải vậy). Bởi vì mô hình chống kiểu này thường được xây dựng trên một kho lưu trữ trạng thái có thể thay đổi, nên vào thời điểm bạn nhận được thông báo PARTIAL_RETURN, trạng thái liên quan tại access_uri có thể đã được cập nhật lại thành một trạng thái mới.
Tình trạng race condition này làm cho việc thông báo trở thành một cơ chế không đáng tin cậy để truyền đạt trạng thái. Ví dụ, một giao dịch có các cập nhật trạng thái từ SOLD -> PARTIAL_RETURN -> FULL_RETURN sẽ phát ra ba sự kiện riêng biệt, một cho mỗi trạng thái. Một người tiêu dùng chậm trong việc xử lý có thể không truy cập được trạng thái PARTIAL_RETURN trước khi nó chuyển biến thành FULL_RETURN và do đó hoàn toàn bỏ lỡ quá trình chuyển trạng thái đầy đủ. Tệ hơn nữa, một người tiêu dùng mới xử lý backlog sẽ không thấy được bất kỳ trạng thái nào trước đó—chỉ có bất kỳ điều gì được lưu trữ trong access_uri tại thời điểm đồng hồ hiện tại.
Một điểm cuối cùng về thiết kế này là nó tạo ra nguyên tắc phức tạp hơn rất nhiều. Không chỉ chủ sở hữu miền của thông báo phải phát hành các sự kiện, mà họ cũng phải phục vụ các yêu cầu đồng bộ liên quan đến trạng thái đó. Điều này bao gồm việc quản lý kiểm soát truy cập, ủy quyền và mở rộng hiệu suất cho cả nhà sản xuất luồng sự kiện và API truy vấn đồng bộ.
Thay vào đó, tốt hơn nhiều chỉ để tạo ra trạng thái cần thiết của sự kiện như một bản ghi không thay đổi của thời điểm đó. Nó tốn rất ít nỗ lực và làm đơn giản hóa rất nhiều việc truyền dữ liệu giữa các miền.
Summary
Chúng ta đã đề cập đến nhiều điều trong chương này, vì vậy hãy dành một chút thời gian để tóm tắt trước khi tiếp tục.
Các sự kiện có thể được định nghĩa chủ yếu là trạng thái hoặc delta. Các sự kiện trạng thái cho phép chuyển giao trạng thái mang theo sự kiện và là lựa chọn tốt nhất của bạn để truyền tải dữ liệu giữa các miền. Các sự kiện trạng thái phụ thuộc vào các tính năng của trình môi giới sự kiện, chẳng hạn như lưu giữ không giới hạn, trạng thái bền vững, và nén để giúp chúng ta quản lý khối lượng sự kiện. Thiết kế trạng thái cho phép chúng ta tận dụng trình môi giới sự kiện như là nguồn dữ liệu chính, cho phép sử dụng kiến trúc Kappa và khéo léo tránh những cạm bẫy liên quan đến người tiền nhiệm của nó, kiến trúc Lambda.
Các sự kiện delta là một cách phổ biến để suy nghĩ về kiến trúc hướng sự kiện, nhưng chúng không đủ cho giao tiếp giữa các miền khác nhau. Delta thuộc về nhóm nhận thức rõ ràng trong việc lưu trữ sự kiện và giao tiếp giữa các ứng dụng khăng khít. Chúng có thể rất quý giá cho việc giao tiếp trong một bối cảnh giới hạn duy nhất. Việc lạm dụng sự kiện delta xảy ra khi việc kết nối từ các bên bên ngoài được phép. Điều này dẫn đến việc lộ ra logic kinh doanh nội bộ, quy trình và sự kiện mà lẽ ra nên giữ kín. Nói một cách đơn giản, không nên sử dụng sự kiện delta cho việc kết nối giữa các miền khác nhau.
Các sự kiện đo lường ghi lại các sự cố, chẳng hạn như từ người dùng, hệ thống phân tán và các thiết bị Internet of Things (IoT). Các sự kiện đo lường có nguồn gốc từ lĩnh vực phân tích dữ liệu và bao gồm một bức ảnh chụp trạng thái cục bộ tại một thời điểm chính xác. Những sự kiện này thường được sử dụng để tạo ra các tổng hợp chi tiết hoặc để phản ứng với những thay đổi đo lường nhanh chóng.
Cả sự kiện kết hợp và sự kiện thông báo đều nên được sử dụng cẩn thận, nếu có thể. Sự kiện kết hợp chủ yếu là sự kiện trạng thái nhưng có thể tiết lộ thông tin liên quan đến lý do tại sao một chuyện gì đó xảy ra, tương tự như sự kiện delta. Điều này tạo ra một mối nối có thể gây ra sự kết nối chặt chẽ, đặc biệt khi lý do thay đổi theo thời gian, và có thể dẫn đến sự kết nối chặt chẽ và các phụ thuộc trải rộng qua nhiều dịch vụ.
Chapter 4. Integrating Event-Driven Architectures with Existing Systems
Việc chuyển đổi một tổ chức sang kiến trúc hướng sự kiện đòi hỏi phải tích hợp các hệ thống hiện có vào hệ sinh thái. Tổ chức của bạn có thể có một hoặc nhiều ứng dụng cơ sở dữ liệu quan hệ dạng đơn khối. Có thể tồn tại các kết nối điểm-điểm giữa các triển khai khác nhau. Có thể đã có những cơ chế giống như sự kiện để chuyển dữ liệu khối giữa các hệ thống, chẳng hạn như việc đồng bộ định kỳ các bản sao cơ sở dữ liệu thông qua một vị trí lưu trữ tệp trung gian. Trong trường hợp bạn đang xây dựng một kiến trúc vi dịch vụ hướng sự kiện từ đầu và không có hệ thống kế thừa, tuyệt vời! Bạn có thể bỏ qua phần này (mặc dù có thể bạn nên xem xét rằng kiến trúc EDM có thể không phù hợp với dự án mới của bạn). Tuy nhiên, nếu bạn có các hệ thống kế thừa hiện có cần được hỗ trợ, hãy tiếp tục đọc.
Trong bất kỳ lĩnh vực kinh doanh nào, đều có những thực thể và sự kiện thường được yêu cầu qua nhiều tiểu lĩnh vực khác nhau. Ví dụ, một nhà bán lẻ thương mại điện tử sẽ cần cung cấp thông tin sản phẩm, giá cả, tồn kho và hình ảnh cho nhiều ngữ cảnh giới hạn khác nhau. Có thể khoản thanh toán được thu bởi một hệ thống nhưng cần phải được xác thực trong một hệ thống khác, với phân tích về các mẫu mua hàng được thực hiện trong một hệ thống thứ ba. Việc làm cho dữ liệu này có sẵn tại một vị trí trung tâm như là nguồn thông tin chính mới cho phép mỗi hệ thống tiêu thụ nó khi nó trở nên khả dụng. Việc chuyển sang kiến trúc microservices dựa trên sự kiện yêu cầu có sẵn dữ liệu lĩnh vực kinh doanh cần thiết trong trạm phát sự kiện, có thể tiêu thụ dưới dạng luồng sự kiện. Việc này được gọi là giải phóng dữ liệu, và liên quan đến việc tìm nguồn dữ liệu từ các hệ thống hiện có và các kho trạng thái chứa nó.
Dữ liệu được sản xuất ra từ một dòng sự kiện có thể được truy cập bởi bất kỳ hệ thống nào, dù là ứng dụng hướng sự kiện hay không. Trong khi các ứng dụng hướng sự kiện có thể sử dụng các khung phát trực tuyến và người tiêu dùng gốc để đọc các sự kiện, các ứng dụng kế thừa có thể không truy cập chúng dễ dàng do nhiều yếu tố khác nhau, chẳng hạn như giới hạn về công nghệ và hiệu suất. Trong trường hợp này, bạn có thể cần chuyển các sự kiện từ một dòng sự kiện vào một kho trạng thái hiện có.
Có một số mô hình và khung để tìm kiếm và xử lý dữ liệu sự kiện. Đối với mỗi kỹ thuật, chương này sẽ đề cập đến lý do tại sao nó cần thiết, cách thực hiện và những đánh đổi liên quan đến các phương pháp khác nhau. Sau đó, chúng ta sẽ xem xét cách giải phóng dữ liệu và xử lý dữ liệu phù hợp với tổ chức nói chung, các tác động mà chúng mang lại và những cách để cấu trúc nỗ lực của bạn cho thành công.
What Is Data Liberation?
Giải phóng dữ liệu là việc xác định và công bố các tập dữ liệu liên miền tương ứng với các luồng sự kiện của chúng và là một phần của chiến lược di chuyển cho kiến trúc hướng sự kiện. Các tập dữ liệu liên miền bao gồm bất kỳ dữ liệu nào được lưu trữ trong một kho dữ liệu mà các hệ thống bên ngoài khác cần. Các phụ thuộc điểm đến điểm giữa các dịch vụ hiện có và các kho dữ liệu thường làm nổi bật dữ liệu liên miền mà nên được giải phóng, như được chỉ ra trong Hình 4-1, nơi ba dịch vụ phụ thuộc đang truy vấn trực tiếp hệ thống kế nhiệm.
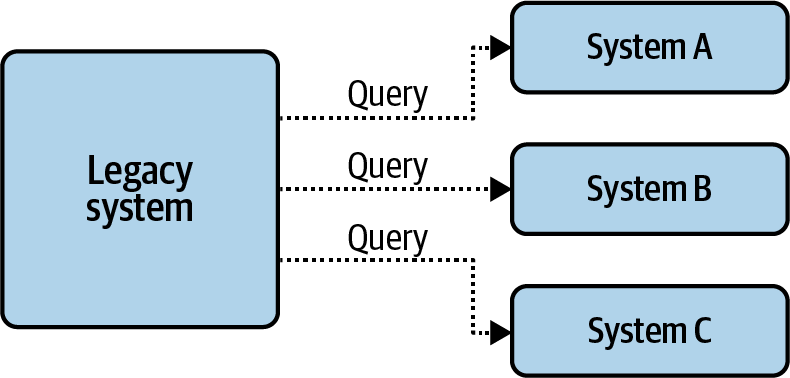
Figure 4-1. Point-to-point dependencies, accessing data directly from the underlying service
Giải phóng dữ liệu thực thi hai đặc điểm chính của kiến trúc hướng sự kiện: nguồn thông tin duy nhất và loại bỏ sự gắn kết trực tiếp giữa các hệ thống. Các luồng sự kiện được giải phóng cho phép xây dựng các microservices hướng sự kiện mới như là người tiêu thụ, với các hệ thống hiện có được di chuyển theo thời gian. Các khung và dịch vụ hướng sự kiện phản ứng giờ đây có thể được sử dụng để tiêu thụ và xử lý dữ liệu, và người tiêu thụ ở hạ nguồn không còn cần phải gắn kết trực tiếp với hệ thống dữ liệu nguồn.
Bằng cách đóng vai trò là một nguồn thông tin duy nhất, các luồng này cũng chuẩn hóa cách mà các hệ thống trong tổ chức truy cập dữ liệu. Các hệ thống không còn cần phải kết nối trực tiếp với các kho dữ liệu và ứng dụng cơ sở nữa, mà thay vào đó có thể chỉ kết nối dựa trên hợp đồng dữ liệu của các luồng sự kiện. Quy trình làm việc sau khi được giải phóng được hiển thị trong Hình 4-2.
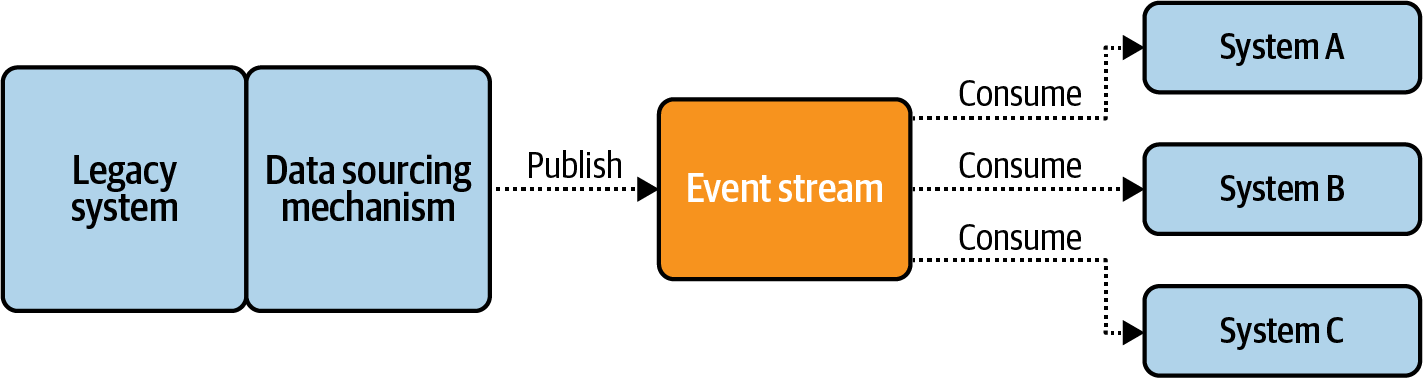
Figure 4-2. Post-data-liberation workflow
Compromises for Data Liberation
Một tập dữ liệu và luồng sự kiện đã giải phóng của nó phải được giữ hoàn toàn đồng bộ, mặc dù yêu cầu này bị giới hạn bởi tính tương thích cuối cùng do độ trễ trong việc truyền sự kiện. Một luồng sự kiện đã giải phóng phải được hình thành trở lại thành một bản sao chính xác của bảng nguồn, và thuộc tính này được sử dụng rộng rãi cho các dịch vụ vi mô hướng sự kiện (như sẽ được đề cập trong [Liên kết sẽ đến]). Ngược lại, các hệ thống kế thừa không tái tạo tập dữ liệu của chúng từ bất kỳ luồng sự kiện nào, mà thay vào đó thường có các cơ chế sao lưu và phục hồi riêng và hoàn toàn không đọc lại gì từ luồng sự kiện đã giải phóng.
Trong một thế giới hoàn hảo, tất cả trạng thái sẽ được tạo ra, quản lý, duy trì và phục hồi từ nguồn tin cậy duy nhất của các luồng sự kiện. Mọi trạng thái chung nên được công bố tới trình môi giới sự kiện trước và được hiện thực hóa lại cho bất kỳ dịch vụ nào cần hiện thực hóa trạng thái, bao gồm cả dịch vụ đã sản xuất dữ liệu ngay từ đầu, như được mô tả trong Hình 4-3.
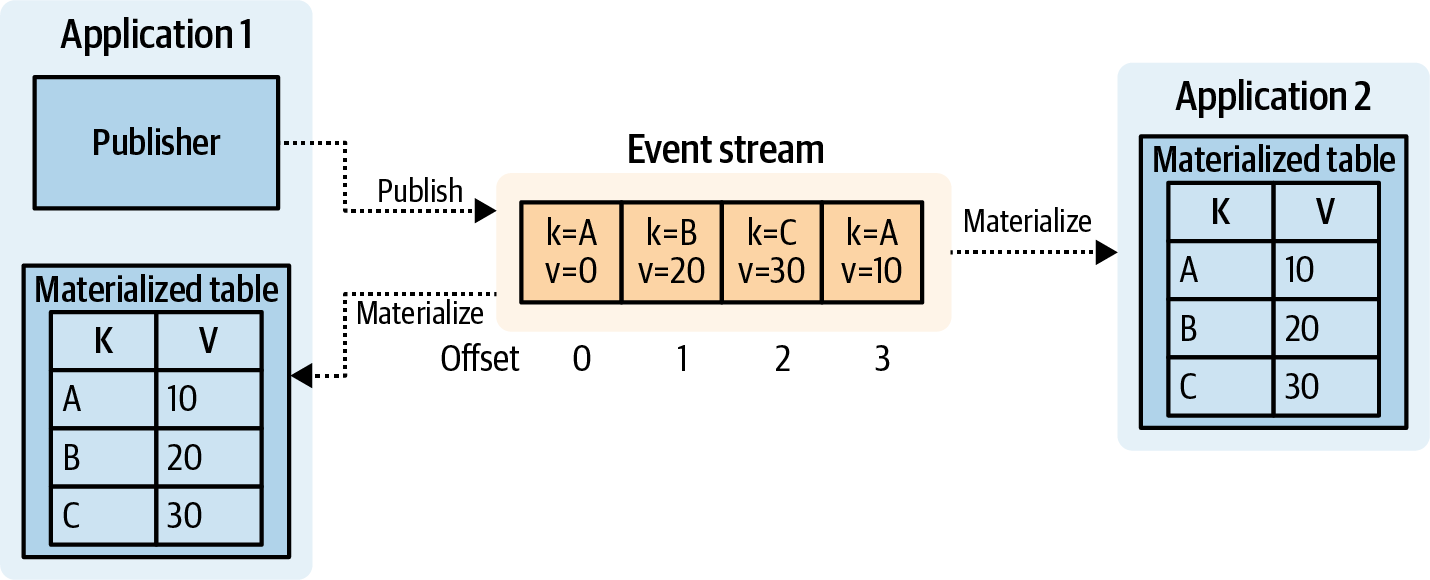
Figure 4-3. Publish to stream before materializing
Trong khi lý tưởng duy trì trạng thái trong broker sự kiện có sẵn cho các microservices mới và các ứng dụng kế thừa đã được tái cấu trúc, điều này không nhất thiết phải khả dụng hoặc thực tế cho tất cả các ứng dụng. Điều này đặc biệt đúng với các dịch vụ mà có khả năng không bao giờ được tái cấu trúc hoặc thay đổi sau khi tích hợp ban đầu với các cơ chế ghi lại thay đổi dữ liệu. Các hệ thống kế thừa có thể rất quan trọng đối với tổ chức và khó tái cấu trúc một cách cản trở, trong đó những hệ thống tồi tệ nhất thường được coi là một "cục bùn lớn". Bất chấp sự phức tạp của hệ thống, dữ liệu nội bộ của chúng vẫn cần được truy cập bởi các hệ thống mới khác. Mặc dù việc tái cấu trúc có thể chắc chắn là mong muốn, nhưng còn một số vấn đề ngăn cản điều này xảy ra trong thực tế.
- Limited developer support
-
Nhiều hệ thống cũ có sự hỗ trợ của nhà phát triển tối thiểu và yêu cầu các giải pháp ít tốn công sức để tạo ra dữ liệu tự do.
- Expense of refactoring
-
Việc tái cấu trúc các quy trình ứng dụng hiện có thành một sự kết hợp giữa logic ứng dụng web theo mô hình MVC (Model-View-Controller) đồng bộ và hướng sự kiện bất đồng bộ có thể tốn kém quá mức, đặc biệt với các hệ thống kế thừa phức tạp.
- Legacy support risk
-
Các thay đổi được thực hiện đối với các hệ thống kế thừa có thể có những hậu quả không mong muốn, đặc biệt khi trách nhiệm của hệ thống không rõ ràng do nợ kỹ thuật và các kết nối điểm đến điểm chưa được xác định với các hệ thống khác.
Có một cơ hội để thỏa hiệp ở đây. Bạn có thể sử dụng các mẫu giải phóng dữ liệu để trích xuất dữ liệu ra khỏi kho dữ liệu và tạo ra các luồng sự kiện cần thiết. Đây là một hình thức kiến trúc hướng sự kiện đơn hướng, vì hệ thống kế thừa sẽ không đọc lại từ luồng sự kiện đã được giải phóng, như được mô tả trong Hình 4-3. Thay vào đó, mục tiêu cơ bản là giữ cho bộ dữ liệu nội bộ đồng bộ với luồng sự kiện bên ngoài thông qua việc phát hành dữ liệu sự kiện được kiểm soát chặt chẽ. Luồng sự kiện sẽ nhất quán cuối cùng với bộ dữ liệu nội bộ của ứng dụng kế thừa, như được hiển thị trong Hình 4-4.
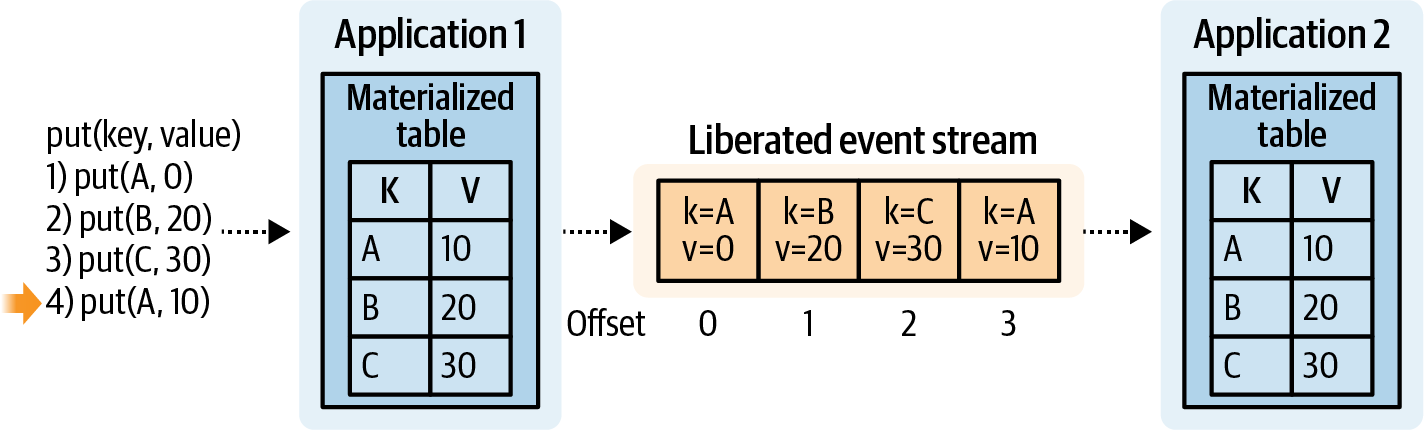
Figure 4-4. Liberating and materializing state between two services
Converting Liberated Data to Events
Dữ liệu được giải phóng, giống như bất kỳ sự kiện nào khác, cũng chịu sự chi phối của những khuyến nghị về việc lập mô hình mà đã được giới thiệu trong [Liên kết sẽ có]. Một trong những đặc điểm của một dòng sự kiện được xác định rõ ràng là có một lược đồ được định nghĩa rõ ràng và tương thích với sự phát triển cho các sự kiện mà nó chứa. Bạn nên đảm bảo rằng người tiêu dùng có các đảm bảo về chất lượng dữ liệu cơ bản như một phần của hợp đồng dữ liệu được xác định bởi lược đồ. Các thay đổi đối với lược đồ chỉ có thể được thực hiện theo các quy tắc phát triển.
Tip
Sử dụng cùng một định dạng tiêu chuẩn cho cả dữ liệu sự kiện đã giải phóng và dữ liệu sự kiện gốc trong toàn tổ chức của bạn.
Theo định nghĩa, dữ liệu có liên quan nhất và được sử dụng rộng rãi trong doanh nghiệp là dữ liệu cần được giải phóng nhất. Những thay đổi được thực hiện đối với định nghĩa dữ liệu của nguồn, chẳng hạn như tạo các trường mới, thay đổi các trường hiện có hoặc xóa bỏ các trường khác, có thể dẫn đến dữ liệu thay đổi động được truyền sang phía tiêu thụ. Việc không sử dụng một sơ đồ được xác định rõ cho dữ liệu đã được giải phóng sẽ buộc các người tiêu thụ phía sau phải giải quyết bất kỳ sự không tương thích nào. Điều này cực kỳ vấn đề cho việc cung cấp nguồn thông tin duy nhất đáng tin cậy, vì người tiêu thụ phía dưới không nên tự cố gắng phân tích hoặc diễn giải dữ liệu. Việc cung cấp một sơ đồ đáng tin cậy và cập nhật của dữ liệu đã được sản xuất và xem xét cẩn thận sự phát triển của dữ liệu theo thời gian là vô cùng quan trọng.
Data Liberation Patterns
Có ba mô hình giải phóng dữ liệu chính mà bạn có thể sử dụng để trích xuất dữ liệu từ kho lưu trữ dữ liệu cơ bản. Vì dữ liệu đã được giải phóng nhằm tạo thành nguồn sự thật duy nhất mới, nên nó phải chứa toàn bộ tập hợp dữ liệu từ kho lưu trữ dữ liệu. Thêm vào đó, dữ liệu này phải được cập nhật với các chèn, cập nhật và xóa mới.
- Query-based
-
Bạn trích xuất dữ liệu bằng cách truy vấn kho lưu trữ trạng thái cơ sở. Điều này có thể được thực hiện trên bất kỳ kho dữ liệu nào.
- Log-based
-
Bạn trích xuất dữ liệu bằng cách theo dõi nhật ký chỉ thêm cho các thay đổi đối với các cấu trúc dữ liệu cơ bản. Tùy chọn này chỉ có sẵn cho một số kho dữ liệu nhất định mà duy trì nhật ký của các sửa đổi được thực hiện trên dữ liệu.
- Table-based
-
Trong mẫu này, bạn đầu tiên đưa dữ liệu vào một bảng được sử dụng làm hàng đợi đầu ra. Một luồng khác hoặc một tiến trình riêng biệt truy vấn bảng, phát ra dữ liệu vào luồng sự kiện liên quan, sau đó xóa các mục liên quan. Phương pháp này đòi hỏi kho dữ liệu phải hỗ trợ cả giao dịch và cơ chế hàng đợi đầu ra, thường là một bảng độc lập được cấu hình để sử dụng như một hàng đợi.
Trong khi mỗi mẫu là độc nhất, có một điểm chung giữa ba mẫu. Mỗi mẫu nên tạo ra các sự kiện theo thứ tự thời gian đã sắp xếp, sử dụng thời gian updated_at mới nhất của bản ghi nguồn trong tiêu đề bản ghi sự kiện đầu ra của nó. Điều này sẽ tạo ra một luồng sự kiện được đánh dấu thời gian theo thời điểm sự kiện xảy ra, chứ không phải theo thời gian mà nhà sản xuất công bố sự kiện. Điều này đặc biệt quan trọng đối với việc giải phóng dữ liệu, vì nó chính xác thể hiện thời điểm các sự kiện thực sự xảy ra trong quy trình làm việc. Việc xen kẽ các sự kiện dựa trên dấu thời gian sẽ được thảo luận thêm trong [Liên kết sẽ đến].
Data Liberation Frameworks
Một phương pháp để giải phóng dữ liệu liên quan đến việc sử dụng một khung trung tâm chuyên dụng để trích xuất dữ liệu thành các luồng sự kiện. Các ví dụ về khung trung tâm để ghi lại các luồng sự kiện bao gồm Kafka Connect (chỉ dành cho nền tảng Kafka), Debezium.io và Apache NiFi. Chúng sẽ kết nối với một loạt các kho dữ liệu, ứng dụng và điểm cuối SaaS khác nhau với các tùy chọn kết nối có sẵn. Một số khung kết nối cũng cho phép bạn viết các kết nối riêng cho các trường hợp sử dụng ít phổ biến hơn.
Mỗi khung công tác cho phép bạn thực thi một truy vấn đối với tập dữ liệu nền tảng, với kết quả được chuyển tiếp đến các luồng sự kiện đầu ra của bạn. Mỗi tùy chọn cũng có khả năng mở rộng, cho phép bạn thêm nhiều phiên bản hơn để tăng khả năng thực hiện các công việc ghi nhận thay đổi dữ liệu (CDC). Chúng hỗ trợ nhiều cấp độ tích hợp với đăng ký lược đồ được cung cấp bởi Confluent (Apache Kafka), nhưng cũng có thể tùy chỉnh để hỗ trợ các đăng ký lược đồ khác. Xem [Liên kết sẽ đến] để biết thêm thông tin.
Hãy cùng xem cơ chế đầu tiên để đưa dữ liệu vào luồng: ghi nhận thay đổi dữ liệu.
Liberating Data Using Change-Data Capture
Một trong những phương pháp chính để giải phóng dữ liệu dựa trên nhật ký không thay đổi cơ bản của kho dữ liệu (ví dụ: nhật ký nhị phân cho MySQL, nhật ký ghi trước cho PostgreSQL). Cấu trúc dữ liệu chỉ thêm này bảo vệ tính toàn vẹn dữ liệu của kho dữ liệu. Một bản ghi được chèn sẽ được ghi vào nhật ký bền vững trước khi được áp dụng vào mô hình dữ liệu cơ bản. Nếu cơ sở dữ liệu gặp sự cố giữa chừng khi ghi, thì nhật ký bền vững sẽ được phát lại vào đĩa, để đảm bảo rằng không có thông tin nào bị mất và mô hình dữ liệu vẫn nhất quán.
Change-Data Capture, hay CDC, là một quy trình đọc (hoặc theo dõi) các log này, chuyển đổi các thay đổi của từng kho dữ liệu thành các sự kiện, và ghi chúng vào luồng sự kiện. Những thay đổi này bao gồm việc tạo, xóa và cập nhật các bản ghi cá nhân, cũng như việc tạo, xóa và thay đổi các tập dữ liệu cá nhân và các sơ đồ của chúng. Trong khi nhiều cơ sở dữ liệu cung cấp một số hình thức truy cập chỉ đọc đối với các log bền bỉ, thì những cơ sở dữ liệu khác, như MongoDB, cung cấp các sự kiện CDC trực tiếp thay vì theo dõi log.
Nhật ký của kho dữ liệu hiếm khi chứa toàn bộ lịch sử dữ liệu. Để chuyển toàn bộ tập dữ liệu của kho dữ liệu thành một luồng sự kiện, bạn sẽ cần tạo một bức ảnh chụp trạng thái hiện tại từ tập dữ liệu đó. Chúng ta sẽ tìm hiểu thêm về điều này trong phần tiếp theo về "chụp ảnh".
Không phải tất cả các kho dữ liệu đều thực hiện ghi nhật ký bất biến của các thay đổi, và trong số những kho dữ liệu có tính năng này, không phải tất cả đều có các kết nối sẵn có để trích xuất dữ liệu. Cách tiếp cận này chủ yếu áp dụng cho một số cơ sở dữ liệu quan hệ như MySQL và PostgreSQL, mặc dù bất kỳ kho dữ liệu nào có một tập hợp các nhật ký thay đổi toàn diện đều là ứng viên phù hợp. Nhiều kho dữ liệu hiện đại khác cung cấp API sự kiện hoạt động như một proxy cho ghi trước vật lý. Ví dụ, MongoDB cung cấp giao diện Change Streams, trong khi Couchbase cung cấp quyền truy cập sao chép qua giao thức sao chép nội bộ của nó.

Figure 4-5. The end-to-end workflow of a Debezium capturing data from a MySQL database’s binary log, and writing it to event streams in Kafka
Hình 4-5 cho thấy một cơ sở dữ liệu MySQL phát ra bản ghi thay đổi nhị phân của nó. Một dịch vụ Kafka Connect, chạy một connector Debezium, đang tiêu thụ bản ghi nhị phân thô. Debezium phân tích dữ liệu và chuyển đổi nó thành các sự kiện tách biệt. Tiếp theo, một bộ định tuyến sự kiện phát ra mỗi sự kiện đến một luồng sự kiện cụ thể trong Kafka, tùy thuộc vào bảng nguồn của sự kiện đó. Các người tiêu dùng ở phía hạ nguồn bây giờ có thể truy cập nội dung cơ sở dữ liệu bằng cách tiêu thụ các luồng sự kiện liên quan từ Kafka.
CDC cung cấp cho bạn mọi sự thay đổi được thực hiện trong cơ sở dữ liệu. Bạn sẽ không bỏ lỡ bất kỳ chuyển tiếp nào, và luồng sự kiện mà bạn tạo ra sẽ chứa mọi cập nhật. Các framework CDC cung cấp các tệp cấu hình cho phép bạn chỉ định những trường nào sẽ được bao gồm trong sự kiện của bạn, cho phép bạn lọc ra dữ liệu nội bộ từ thế giới bên ngoài. Bạn cũng có thể chọn bao gồm siêu dữ liệu như serverId, transactionId và các nội dung cụ thể khác của cơ sở dữ liệu hoặc kết nối. Bạn cũng có thể bao gồm các trường trước và sau mô tả trạng thái đầy đủ của hàng hoặc tài liệu trước khi thay đổi và trạng thái đầy đủ sau khi thay đổi. Chúng tôi sẽ xem xét chủ đề này và các tác động đằng sau nó nhiều hơn trong [Liên kết sẽ đến].
Bạn phải kiểm tra tiến độ khi ghi lại các sự kiện từ các bản thay đổi, mặc dù tùy thuộc vào công cụ bạn sử dụng, điều này có thể đã được tích hợp sẵn. Trong trường hợp cơ chế ghi lại thay đổi dữ liệu bị lỗi, điểm kiểm tra sẽ được sử dụng để khôi phục chỉ mục bản ghi thay đổi cuối cùng đã lưu. Cách tiếp cận này chỉ có thể cung cấp việc sản xuất tối thiểu một lần cho các bản ghi, điều này thường phù hợp với bản chất dựa trên thực thể của việc giải phóng dữ liệu. Việc sản xuất một bản ghi bổ sung là không quan trọng vì việc cập nhật dữ liệu thực thể là idempotent.
Trong khi có nhiều tùy chọn để lấy dữ liệu từ các nhật ký thay đổi, Debezium vẫn là giải pháp phổ biến nhất và là người dẫn đầu trong lĩnh vực này. Nó hỗ trợ nhiều kho dữ liệu phổ biến nhất, và có thể tạo ra các bản ghi cho cả Apache Kafka và Apache Pulsar.
Sau khi đã trình bày các khái niệm cơ bản về CDC, bây giờ chúng ta hãy chuyển sự chú ý đến cách chúng ta có thể đưa tập dữ liệu ban đầu vào luồng sự kiện.
Snapshotting the Initial Data Set State
Nhật ký lưu trữ dữ liệu có khả năng không chứa tất cả các thay đổi từ thời điểm bắt đầu, vì nó chủ yếu là cơ chế để đảm bảo tính nhất quán của lưu trữ dữ liệu. Lưu trữ dữ liệu liên tục hợp nhất dữ liệu từ nhật ký vào mô hình lưu trữ dữ liệu cơ sở, chỉ giữ lại một khoảng dữ liệu ngắn (ví dụ: vài GB).
Snapshotting là quá trình chúng ta tải tất cả dữ liệu hiện tại vào dòng sự kiện, trực tiếp từ kho dữ liệu (chứ không phải từ nhật ký). Đây có thể là một hoạt động tiêu tốn tài nguyên rất lớn, vì bạn phải truy vấn, trả về, sao chép, chuyển đổi thành sự kiện và ghi vào dòng sự kiện cho mỗi thực thể dữ liệu từ tập dữ liệu nguồn. Chỉ khi nào bạn hoàn thành snapshot của mình, bạn mới có thể chuyển sang việc ghi lại các bản ghi trực tiếp.
Bản chụp thường liên quan đến một truy vấn lớn, có ảnh hưởng đến hiệu suất trên bảng và thường được gọi là khởi tạo. Bạn phải đảm bảo rằng có sự chồng chéo giữa các bản ghi trong kết quả truy vấn khởi tạo và các bản ghi trong nhật ký, để bạn không bỏ lỡ bất kỳ bản ghi nào khi chuyển sang CDC trực tiếp.
Còn nhiều phức tạp hơn ngoài kích thước của truy vấn. Một kho dữ liệu thường phục vụ cho các trường hợp sử dụng kinh doanh trực tiếp và không thể bị gián đoạn hoặc giảm hiệu suất mà không gặp phải một số hậu quả nhất định. Tuy nhiên, mà không đi quá sâu vào chi tiết, việc chụp ảnh thường yêu cầu một tập dữ liệu không đổi để đảm bảo tính nhất quán, và để đạt được điều đó, nó thường khóa bảng mà nó đang truy vấn. Điều này có nghĩa là bảng sản xuất quan trọng của bạn có thể bị khóa trong vài giờ trong khi quá trình chụp ảnh hoàn tất. Tôi cá rằng quản trị viên cơ sở dữ liệu của bạn sẽ rất hài lòng. Và ngay cả khi nó chỉ diễn ra trong thời gian ngắn, nó vẫn có thể là không chấp nhận được. Vậy chúng ta có thể làm gì?
Một tùy chọn là chụp ảnh từ một bản sao chỉ đọc. Bạn thực hiện chụp ảnh trên bản sao, để lại kho dữ liệu sản xuất không bị ảnh hưởng. Khi hoàn tất, bạn có thể mở khóa bảng, bảng này sau đó sẽ được cập nhật bởi các thay đổi được sao chép từ kho dữ liệu sản xuất. Vào lúc này, bạn có thể chuyển sang việc ghi lại thay đổi hoặc thực hiện truy vấn định kỳ như chúng ta sẽ thấy trong phần tiếp theo.
Một số khung CDC, như Debezium.io, cung cấp một cơ chế cho phép chụp ảnh một số kho dữ liệu mà không làm khóa bảng. Các thao tác đọc và ghi thông thường có thể tiếp tục không bị gián đoạn, với bức ảnh chụp kết quả sẽ đồng nhất với trạng thái hiện tại của bảng. Một bài viết trên blog của Debezium giải thích về sự đổi mới này. Nó dựa trên một tài liệu từ Netflix mà nêu rõ:
DBLog sử dụng một phương pháp dựa trên watermark cho phép chúng tôi xen kẽ các sự kiện nhật ký giao dịch với các hàng mà chúng tôi chọn trực tiếp từ các bảng để nắm bắt trạng thái đầy đủ. Giải pháp của chúng tôi cho phép các sự kiện nhật ký tiếp tục tiến triển mà không bị ngừng lại trong khi xử lý các lệnh chọn. Các lệnh chọn có thể được kích hoạt bất cứ lúc nào trên tất cả các bảng, một bảng cụ thể hoặc cho các khóa chính cụ thể của một bảng. DBLog thực hiện các lệnh chọn theo từng phần và theo dõi tiến độ, cho phép chúng tạm dừng và tiếp tục. Phương pháp watermark không sử dụng khóa và có ảnh hưởng tối thiểu đến nguồn dữ liệu.
Andreas Andreakis và Ioannis Papapanagiotou, Netflix
Các bảng snapshot trực tiếp không làm giảm hiệu suất hoặc chặn các trường hợp sử dụng sản xuất là một cải tiến lớn so với các công nghệ CDC đầu tiên. Điều này cho phép bạn tập trung vào việc sử dụng dữ liệu để xây dựng các ứng dụng dựa trên sự kiện, thay vì chỉ khua khoắng dữ liệu ra khỏi kho dữ liệu.
Hệ thống CDC kết hợp kết quả ảnh chụp gia tăng với các bản ghi nhật ký, sao cho các kết quả cũ (chẳng hạn từ bảng) không ghi đè lên các kết quả mới đến từ nhật ký. Sau đó, nó chuyển đổi các bản ghi thành định dạng phù hợp và ghi ra luồng sự kiện tương ứng. Và, khi hoàn tất, quy trình CDC tiếp tục theo dõi nhật ký của kho dữ liệu mà không bị gián đoạn.
Dưới đây là một vài lợi ích và bất lợi chính của việc sử dụng CDC với nhật ký lưu trữ dữ liệu.
Benefits of Change-Data Capture Using Data Store Logs
Một số lợi ích của việc sử dụng nhật ký lưu trữ dữ liệu bao gồm:
- Delete tracking
-
Nhật ký lưu trữ dữ liệu chứa thông tin về các lần xóa, để bạn có thể thấy khi nào một bản ghi đã bị xóa khỏi kho dữ liệu. Những thông tin này có thể được chuyển đổi thành sự kiện bia mộ để cho phép xóa ở phía dưới và nén luồng dữ liệu.
- Minimal effect on data store performance
-
Đối với các kho dữ liệu dựa trên nhật ký, việc thu thập dữ liệu thay đổi có thể được thực hiện mà không ảnh hưởng đến hiệu suất của kho dữ liệu. Đối với những kho sử dụng bảng thay đổi, chẳng hạn như trong SQL Server, tác động sẽ liên quan đến khối lượng dữ liệu.
- Low-latency updates
-
Cập nhật được lan truyền ngay khi sự kiện được ghi vào nhật ký kho dữ liệu, dẫn đến các luồng sự kiện với độ trễ tương đối thấp.
- Nonblocking snapshots
-
CDC có thể tạo các bản sao mà không làm gián đoạn hoạt động bình thường của kho dữ liệu nguồn.
Drawbacks of Change-Data Capture Using Data Store Logs
Dưới đây là một số nhược điểm khi sử dụng nhật ký lưu trữ dữ liệu:
- Exposure of internal data models
-
Mô hình dữ liệu nội bộ hoàn toàn được hiển thị trong các bản ghi thay đổi. Việc cách ly mô hình dữ liệu cơ sở phải được quản lý cẩn thận và có chọn lọc.
- Denormalization outside of the data store
-
Nhật ký thay đổi chỉ chứa dữ liệu sự kiện. Một số cơ chế CDC có thể trích xuất từ các view vật liệu hóa, nhưng đối với nhiều cơ chế khác, việc chuẩn hóa dữ liệu phải xảy ra bên ngoài kho dữ liệu. Điều này có thể dẫn đến việc tạo ra các luồng sự kiện được chuẩn hóa rất cao, yêu cầu các microservice phía dưới xử lý các phép kết hợp khóa ngoại và chuẩn hóa dữ liệu.
- Brittle dependency between data set schema and output event schema
-
Các thay đổi mô hình dữ liệu hợp lệ trong kho dữ liệu nguồn, chẳng hạn như thay đổi một tập dữ liệu hoặc định nghĩa lại kiểu trường, có thể gây ra sự thay đổi cố gắng cho các người tiêu dùng ở hạ nguồn.
Liberating Data with a Polling Query
Với việc giải phóng dữ liệu dựa trên truy vấn, bạn truy vấn kho dữ liệu, nhận kết quả, chuyển đổi chúng thành sự kiện và ghi chúng vào dòng sự kiện. Bạn có thể viết mã của riêng mình để thực hiện việc này, hoặc bạn có thể dựa vào các công cụ như Kafka Connect hoặc Debezium, như đã đề cập trước đó. Với sự phong phú của các bộ kết nối hiện có ngày nay, tôi khuyên bạn nên bắt đầu với một khung công tác được thiết kế riêng thay vì cố gắng xây dựng lại của riêng mình.
Query-based data liberation doesn't use the underlying data store log. Both snapshots and incremental iterations are consumerd entirely via the data store query API.
Có hai giai đoạn chính trong mẫu truy vấn định kỳ: bức tranh ban đầu và giai đoạn gia tăng.
Quá trình chụp lại giống hệt như đã tìm thấy trong “Chụp lại trạng thái tập dữ liệu ban đầu”, mặc dù không có nhật ký kho dữ liệu nào để thay thế khi hoàn thành. Giai đoạn lặp lại bắt đầu từ nơi mà ảnh chụp đã dừng lại.
Polling dựa trên truy vấn yêu cầu xác định các bản ghi đã thay đổi kể từ lần lặp trước đó. Ví dụ, trường updated_at hoặc modified_at là lựa chọn phổ biến để đánh giá trong truy vấn của bạn, như được minh họa bởi connector JDBC của Kafka Connect. Đối với mỗi lần lặp trong vòng lặp polling của bạn, nó sử dụng timestamp updated_at cao nhất từ kết quả của truy vấn trước đó, sau đó nhập nó như là điểm bắt đầu cho vòng lặp polling tiếp theo. Các hàng được trả về sẽ được chuyển đổi thành sự kiện và connector cập nhật timestamp updated_at đã lưu trữ của mình cho vòng lặp tiếp theo. Bạn cũng có thể chọn sử dụng ID tự tăng nếu nó có sẵn trong bảng của bạn.
Các lược đồ sự kiện được suy diễn tự động từ kết quả truy vấn - ít nhất là đối với các khung công tác có sẵn. Nếu bạn tự xây dựng truy vấn polling của riêng mình, thì bạn sẽ cần phải tạo ra một lược đồ phù hợp với nhu cầu của mình. Điều đó nói lên rằng, nếu mô hình lưu trữ dữ liệu ở phía trên thay đổi, thì bạn có nguy cơ lược đồ sự kiện của bạn cũng sẽ thay đổi.
Polling dựa trên truy vấn, đặc biệt khi tự triển khai, phụ thuộc nặng nề vào việc khóa bảng để có được trạng thái nhất quán. Đây là một quá trình lỗi thời cho việc khởi động, và mặc dù vẫn hợp lệ về mặt kỹ thuật, nhưng việc sử dụng CDC thì phổ biến hơn rất nhiều so với các truy vấn lặp. Kể từ phiên bản đầu tiên của cuốn sách này, CDC đã cải thiện đáng kể, trong khi polling dựa trên truy vấn chủ yếu bị relegated vào các kho dữ liệu và API mà không cung cấp quyền truy cập vào nhật ký kho dữ liệu cơ bản.
Incremental Updating
Bước đầu tiên của bất kỳ cập nhật gia tăng nào là đảm bảo rằng dấu thời gian cần thiết hoặc ID tự tăng cấp có sẵn trong các bản ghi của tập dữ liệu của bạn. Phải có một trường mà truy vấn có thể sử dụng để lọc ra các bản ghi mà nó đã xử lý từ những bản ghi mà nó vẫn chưa xử lý. Các tập dữ liệu không có các trường này sẽ cần phải được thêm vào, và kho dữ liệu sẽ cần được cấu hình để điền vào dấu thời gian updated_at cần thiết hoặc trường ID tự tăng cấp. Nếu các trường không thể được thêm vào tập dữ liệu, thì các cập nhật gia tăng sẽ không thể thực hiện được với một mẫu dựa trên truy vấn.
Bước thứ hai là xác định tần suất lấy dữ liệu và độ trễ của các bản cập nhật. Các bản cập nhật có tần suất cao hơn cung cấp độ trễ thấp hơn cho việc cập nhật dữ liệu ở phía hạ nguồn, mặc dù điều này đi kèm với chi phí là tổng tải lớn hơn cho kho dữ liệu. Cũng cần phải xem xét liệu khoảng thời gian giữa các yêu cầu có đủ để hoàn tất việc tải tất cả dữ liệu hay không. Bắt đầu một truy vấn mới trong khi truy vấn cũ vẫn đang tải có thể dẫn đến điều kiện đua, nơi dữ liệu cũ ghi đè lên dữ liệu mới trong các dòng sự kiện đầu ra.
Khi đã chọn trường cập nhật gia tăng và xác định tần suất cập nhật, bước cuối cùng là thực hiện một lần tải dữ liệu lớn trước khi kích hoạt cập nhật gia tăng. Tải dữ liệu này phải truy vấn và sản xuất tất cả dữ liệu hiện có trong bộ dữ liệu trước khi thực hiện các cập nhật gia tăng tiếp theo.
Benefits of Query-Based Updating
Cập nhật dựa trên truy vấn có một số lợi ích, bao gồm:
- Customizability
-
Bất kỳ kho dữ liệu nào cũng có thể được truy vấn, và toàn bộ tùy chọn của khách hàng cho việc truy vấn đều có sẵn.
- Independent polling periods
-
Các truy vấn cụ thể có thể được thực hiện thường xuyên hơn để đáp ứng các SLA (thỏa thuận mức dịch vụ) chặt chẽ hơn, trong khi các truy vấn tốn kém hơn có thể được thực hiện ít thường xuyên hơn để tiết kiệm tài nguyên.
- Isolation of internal data models
-
Các cơ sở dữ liệu quan hệ có thể cung cấp sự tách biệt khỏi mô hình dữ liệu nội bộ bằng cách sử dụng các view hoặc view vật liệu từ dữ liệu nền tảng. Kỹ thuật này có thể được sử dụng để ẩn thông tin mô hình miền không nên được công khai bên ngoài kho dữ liệu.
Caution
Hãy nhớ rằng dữ liệu được giải phóng sẽ là nguồn thông tin chính xác duy nhất. Cân nhắc xem liệu có dữ liệu nào bị che giấu hoặc bị bỏ qua cần được giải phóng hay không, hoặc liệu mô hình dữ liệu nguồn cần được tái cấu trúc. Điều này thường xảy ra trong quá trình giải phóng dữ liệu từ các hệ thống cũ, nơi dữ liệu kinh doanh và dữ liệu thực thể đã trở nên giao thoa với nhau theo thời gian.
Drawbacks of Query-Based Updating
Cũng có một số nhược điểm đối với việc cập nhật dựa trên truy vấn:
- Required
updated-attimestamp -
Bảng hoặc không gian tên cơ sở của các sự kiện cần truy vấn phải có một cột chứa dấu thời gian cập nhật của chúng. Điều này là cần thiết để theo dõi thời gian cập nhật cuối cùng của dữ liệu và để thực hiện các bản cập nhật gia tăng.
- Only detects soft deletes
-
Việc xóa hoàn toàn một bản ghi khỏi kho dữ liệu sẽ không dẫn đến việc bất kỳ sự kiện nào xuất hiện trong truy vấn. Do đó, bạn phải sử dụng xóa mềm, trong đó các bản ghi được đánh dấu là đã xóa bằng một cột is_deleted cụ thể.
- Brittle dependency between data set schema and output event schema
-
Các thay đổi về cấu trúc tập dữ liệu có thể xảy ra mà không tương thích với các quy tắc định dạng lược đồ sự kiện phía hạ lưu. Sự cố xảy ra ngày càng nhiều nếu cơ chế giải phóng tách biệt khỏi mã nguồn của ứng dụng kho dữ liệu, điều này thường xảy ra đối với các hệ thống dựa trên truy vấn.
- May miss intermittent data values
-
Dữ liệu chỉ được đồng bộ tại các khoảng thời gian kiểm tra, vì vậy một chuỗi các thay đổi cá nhân đối với cùng một bản ghi có thể chỉ hiển thị như một sự kiện duy nhất.
- Production resource consumption
-
Các truy vấn sử dụng tài nguyên hệ thống cơ sở để thực thi, điều này có thể gây ra sự chậm trễ không thể chấp nhận được trên hệ thống sản xuất. Vấn đề này có thể được giảm thiểu bằng cách sử dụng bản sao chỉ đọc, nhưng sẽ có thêm chi phí tài chính và độ phức tạp của hệ thống.
- Query performance varies due to data size
-
Số lượng dữ liệu được truy vấn và trả về thay đổi tùy thuộc vào các thay đổi được thực hiện trên dữ liệu gốc. Trong trường hợp xấu nhất, toàn bộ dữ liệu có thể bị thay đổi mỗi khi. Điều này có thể dẫn đến tình trạng đua tranh khi một truy vấn chưa hoàn thành trước khi truy vấn tiếp theo bắt đầu.
Liberating Data Using Transactional Outbox Tables
Một bảng outbox giao dịch đóng vai trò như một bộ đệm tạm thời cho dữ liệu sẽ được ghi vào luồng sự kiện. Khi bạn cập nhật mô hình miền nội bộ của mình, bạn chỉ chọn các dữ liệu mà bạn muốn công khai ra thế giới bên ngoài và ghi nó vào outbox. Sau đó, một quy trình đồng bộ hóa riêng biệt, chẳng hạn như một đầu nối CDC chuyên dụng, sẽ tiêu thụ dữ liệu từ outbox và ghi nó vào luồng sự kiện. Hình 4-6 cho thấy quy trình làm việc từ đầu đến cuối.
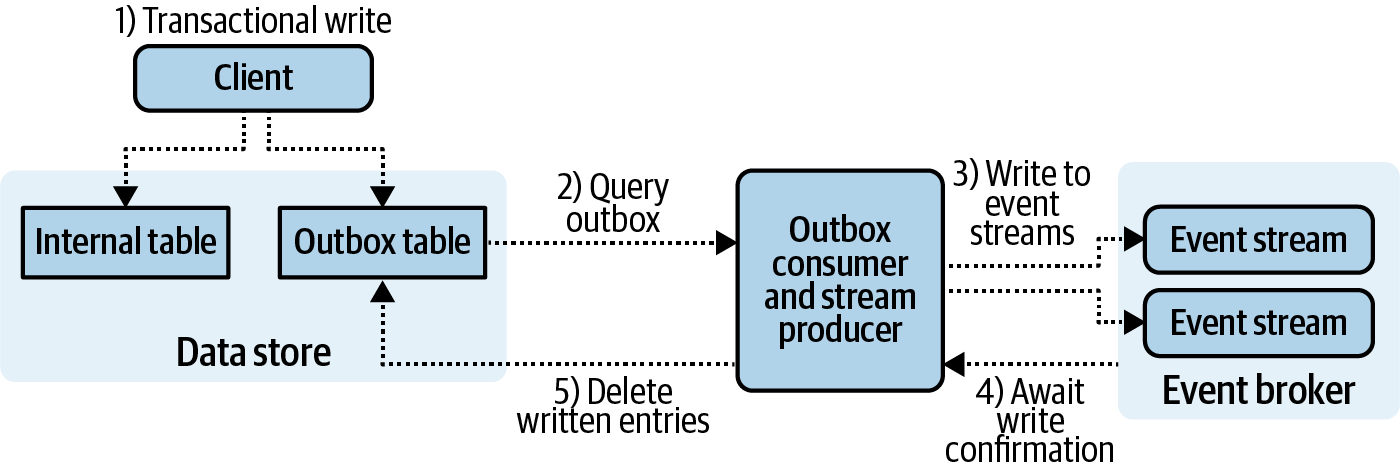
Figure 4-6. The end-to-end workflow of an outbox table CDC solution
Cả cập nhật bảng nội bộ và cập nhật hộp thư đi ra phải được gộp lại trong một giao dịch duy nhất, để mỗi cập nhật chỉ xảy ra nếu toàn bộ giao dịch thành công. Việc không làm như vậy có thể dẫn đến sự khác biệt với luồng sự kiện là nguồn thông tin chính, điều này có thể khó phát hiện và sửa chữa. Hình 4-7 cho thấy cái nhìn tổng quan về quy trình từ đầu đến cuối.
Figure 4-7. Getting events from a database using a transactional outbox and a dedicated connector
Một luồng hoặc tiến trình ứng dụng riêng biệt (ví dụ, một kết nối CDC) liên tục truy vấn các hộp thư đi và sản xuất dữ liệu vào các luồng sự kiện tương ứng. Khi hoàn tất sản xuất thành công, các bản ghi tương ứng trong hộp thư đi sẽ được xóa. Trong trường hợp có bất kỳ lỗi nào, cho dù là ở kho dữ liệu, người tiêu dùng/nhà sản xuất, hoặc ngay cả chính môi giới sự kiện, các bản ghi trong hộp thư đi vẫn sẽ được giữ lại mà không có nguy cơ mất mát. Mô hình này cung cấp việc giao hàng ít nhất một lần.
Bảng outbox giao dịch là một cách tiếp cận thay đổi dữ liệu mạnh mẽ hơn vì nó yêu cầu sửa đổi cả kho dữ liệu hoặc lớp ứng dụng, cả hai đều cần sự tham gia của các nhà phát triển kho dữ liệu. Mẫu bảng outbox tận dụng tính bền vững của kho dữ liệu để cung cấp một nhật ký viết trước cho các sự kiện đang chờ được công bố lên các luồng sự kiện bên ngoài.
Các bản ghi trong bảng hộp thư đi cần một định danh thứ tự nghiêm ngặt để đảm bảo rằng các trạng thái trung gian được ghi lại và phát ra theo đúng thứ tự mà chúng xảy ra. Ngoài ra, bạn cũng có thể chọn cách đơn giản hơn là chỉ thực hiện upsert theo khóa chính, ghi đè lên các mục trước đó và từ bỏ trạng thái trung gian. Trong trường hợp này, các bản ghi đã bị ghi đè sẽ không được phát ra vào luồng sự kiện.
Một ID tự động tăng, được gán tại thời điểm chèn, là tốt nhất để xác định thứ tự mà các sự kiện sẽ được công bố. Cột timestamp created_at cũng nên được duy trì, vì nó phản ánh thời gian sự kiện mà bản ghi được tạo ra trong kho dữ liệu và có thể được sử dụng thay cho thời gian thực trong quá trình công bố tới luồng sự kiện. Điều này sẽ cho phép sự xen kẽ chính xác bởi bộ lập lịch sự kiện như đã thảo luận trong [Link to Come].
Performance Considerations
Việc đưa vào các bảng outbox tạo thêm gánh nặng cho kho dữ liệu và các ứng dụng xử lý yêu cầu của nó. Đối với các kho dữ liệu nhỏ với ít gánh nặng, chi phí bổ sung có thể hoàn toàn không bị phát hiện. Ngược lại, điều này có thể rất tốn kém với các kho dữ liệu lớn, đặc biệt là những kho có tải trọng đáng kể và nhiều bảng đang được theo dõi. Chi phí của cách tiếp cận này nên được đánh giá dựa trên từng trường hợp cụ thể và được cân nhắc so với chi phí của một chiến lược phản ứng như phân tích nhật ký thay đổi dữ liệu.
Isolating Internal Data Models
Một bảng outbox không nhất thiết phải ánh xạ 1:1 với một bảng nội bộ. Thực tế, một trong những lợi ích chính của outbox là client dữ liệu có thể tách biệt mô hình dữ liệu nội bộ khỏi các người tiêu dùng hạ nguồn. Mô hình dữ liệu nội bộ của miền có thể sử dụng nhiều bảng đã được chuẩn hóa cao, được tối ưu hóa cho các thao tác quan hệ nhưng chủ yếu không phù hợp để tiêu thụ bởi các người tiêu dùng hạ nguồn. Ngay cả những miền đơn giản cũng có thể bao gồm nhiều bảng, mà nếu được công bố dưới dạng các luồng độc lập, thì sẽ yêu cầu tái cấu trúc để sử dụng bởi các người tiêu dùng hạ nguồn. Điều này nhanh chóng trở nên cực kỳ tốn kém về chi phí vận hành, vì nhiều nhóm hạ nguồn sẽ phải tái cấu trúc mô hình miền và xử lý dữ liệu quan hệ trong các luồng sự kiện.
Warning
Việc công khai mô hình dữ liệu nội bộ cho các bên tiêu thụ phía dưới là một mẫu chống lại. Các bên tiêu thụ phía dưới chỉ nên truy cập dữ liệu được định dạng với các hợp đồng dữ liệu công khai như đã mô tả trong [Liên kết sẽ đến sau].
Khách hàng của kho dữ liệu có thể thay vào đó thực hiện việc phi chuẩn hóa dữ liệu tại thời điểm chèn sao cho hộp thư ra phản ánh hợp đồng dữ liệu công khai dự định, mặc dù điều này sẽ làm tăng chi phí về hiệu suất và dung lượng lưu trữ. Một tùy chọn khác là duy trì sự ánh xạ 1:1 của các thay đổi với các luồng sự kiện đầu ra và phi chuẩn hóa các luồng này với một bộ xử lý sự kiện bên dưới chuyên trách cho nhiệm vụ này. Đây là một quy trình mà tôi gọi là sự kiện hóa, vì nó chuyển đổi dữ liệu quan hệ đã được chuẩn hóa cao thành các bản cập nhật sự kiện đơn giản dễ tiêu thụ. Điều này bắt chước những gì khách hàng của kho dữ liệu có thể làm nhưng thực hiện bên ngoài kho dữ liệu để giảm tải. Một ví dụ về điều này được trình bày trong Hình 4-8, nơi một Người dùng được phi chuẩn hóa dựa trên Người dùng, Vị trí và Nhà tuyển dụng.
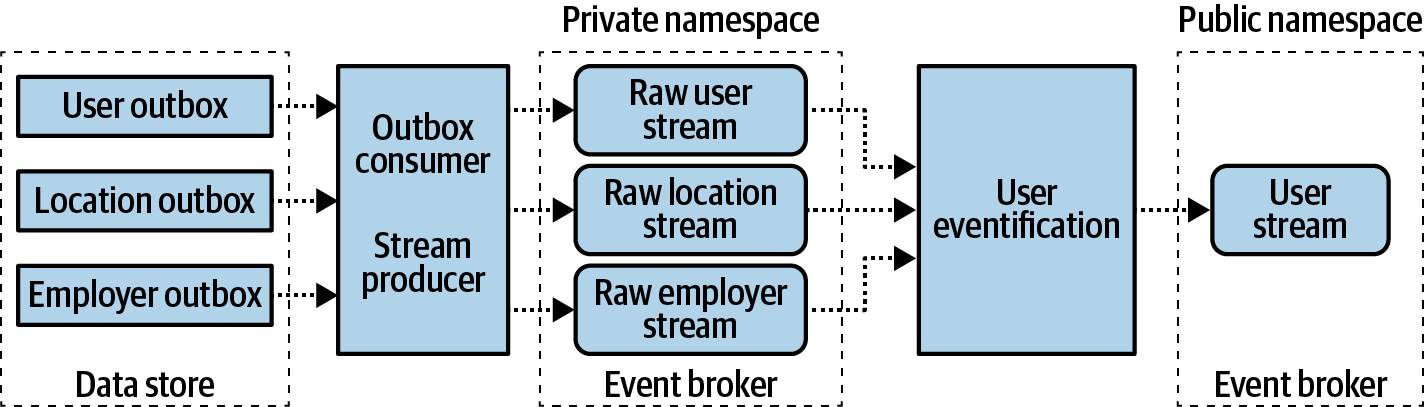
Figure 4-8. Eventification of public User events using private User, Location, and Employer event streams
Trong ví dụ này, Người dùng có tham chiếu khóa ngoại đến thành phố, tiểu bang/tỉnh và quốc gia họ sống, cũng như tham chiếu khóa ngoại đến nhà tuyển dụng hiện tại của họ. Thật hợp lý khi một người tiêu dùng downstream của sự kiện Người dùng có thể muốn tất cả thông tin về mỗi người dùng trong một sự kiện duy nhất, thay vì bị ép buộc phải hiện thực hóa từng luồng vào một kho trạng thái và sử dụng công cụ quan hệ để phi chuẩn hóa nó. Các sự kiện thô, đã chuẩn hóa được nguồn từ các hộp thư ra vào các luồng sự kiện riêng của chúng, nhưng những luồng này được giữ trong một không gian tên riêng biệt so với phần còn lại của tổ chức (được đề cập trong [Liên kết sẽ đến]) để bảo vệ mô hình dữ liệu nội bộ.
Việc sự kiện hóa người dùng được thực hiện bằng cách chuẩn hóa thực thể Người dùng và loại bỏ bất kỳ cấu trúc mô hình dữ liệu nội bộ nào. Quá trình này yêu cầu duy trì các bảng vật liệu về Người dùng, Địa điểm và Nhà tuyển dụng, sao cho bất kỳ cập nhật nào cũng có thể tái thực hiện logic nối và phát ra các cập nhật cho tất cả Người dùng bị ảnh hưởng. Sự kiện cuối cùng được phát ra trong không gian công cộng của tổ chức để bất kỳ người tiêu dùng nào phía dưới có thể tiêu thụ.
Mức độ mà các mô hình dữ liệu nội bộ được tách biệt khỏi người tiêu dùng bên ngoài thường trở thành một điểm tranh cãi trong các tổ chức chuyển hướng sang kiến trúc microservices dựa trên sự kiện. Việc cô lập mô hình dữ liệu nội bộ là cần thiết để đảm bảo sự tách rời và độc lập của các dịch vụ, đồng thời đảm bảo rằng hệ thống chỉ cần thay đổi do các yêu cầu kinh doanh mới, chứ không phải do thay đổi mô hình dữ liệu nội bộ upstream.
Ensuring Schema Compatibility
Việc tuần tự hóa (và do đó, xác thực) sơ đồ cũng có thể được tích hợp vào quy trình làm việc của hộp thư giao dịch. Việc xác thực sơ đồ có thể được thực hiện trước hoặc sau khi sự kiện được ghi vào bảng hộp thư. Thành công có nghĩa là sự kiện có thể tiến hành trong quy trình, trong khi thất bại có thể yêu cầu can thiệp thủ công để xác định nguyên nhân gốc rễ và tránh mất mát dữ liệu.
Việc tuần tự hóa trước khi cam kết giao dịch vào bảng outbox cung cấp sự đảm bảo mạnh mẽ nhất về tính nhất quán dữ liệu. Một sự cố tuần tự hóa sẽ khiến giao dịch thất bại và hoàn nguyên bất kỳ thay đổi nào đã thực hiện trên các bảng nội bộ, đảm bảo rằng bảng outbox và các bảng nội bộ luôn đồng bộ. Quá trình này được minh họa trong Hình 4-9. Một xác thực thành công sẽ thấy sự kiện được tuần tự hóa và sẵn sàng cho việc xuất bản dòng sự kiện. Lợi ích chính của phương pháp này là giảm thiểu đáng kể sự không nhất quán dữ liệu giữa trạng thái nội bộ và dòng sự kiện đầu ra. Dữ liệu dòng sự kiện được coi là một công dân hàng đầu, và việc xuất bản dữ liệu chính xác được xem là quan trọng không kém gì việc duy trì trạng thái nội bộ nhất quán.
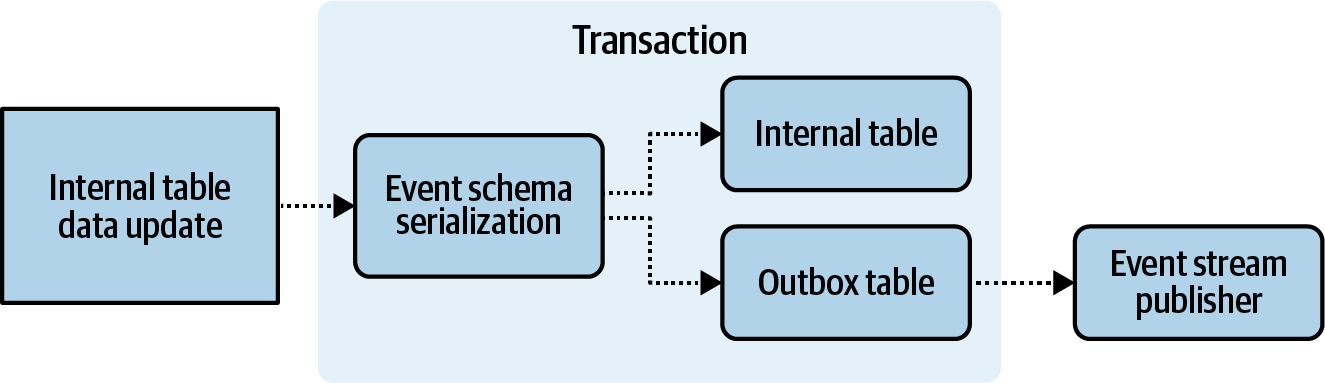
Figure 4-9. Serializing change-data before writing to outbox table
Việc tuần tự hóa trước khi ghi vào hộp thư đi ra cũng cung cấp cho bạn tùy chọn sử dụng một hộp thư đi ra duy nhất cho tất cả các giao dịch. Định dạng đơn giản, vì nội dung chủ yếu là dữ liệu đã được tuần tự hóa với ánh xạ luồng sự kiện đầu ra mục tiêu. Điều này được minh họa trong Hình 4-10.

Figure 4-10. A single output table with events already validated and serialized (note the output_stream entry for routing purposes)
Một nhược điểm của việc tuần tự hóa trước khi xuất bản là hiệu suất có thể bị giảm do chi phí tuần tự hóa. Điều này có thể không có ý nghĩa với tải nhẹ nhưng có thể có những tác động đáng kể hơn đối với tải nặng. Bạn sẽ cần đảm bảo rằng các nhu cầu hiệu suất của bạn vẫn được đáp ứng.
Ngược lại, việc tuần tự hóa có thể được thực hiện sau khi sự kiện đã được ghi vào bảng outbox, như được chỉ ra trong Hình 4-9.
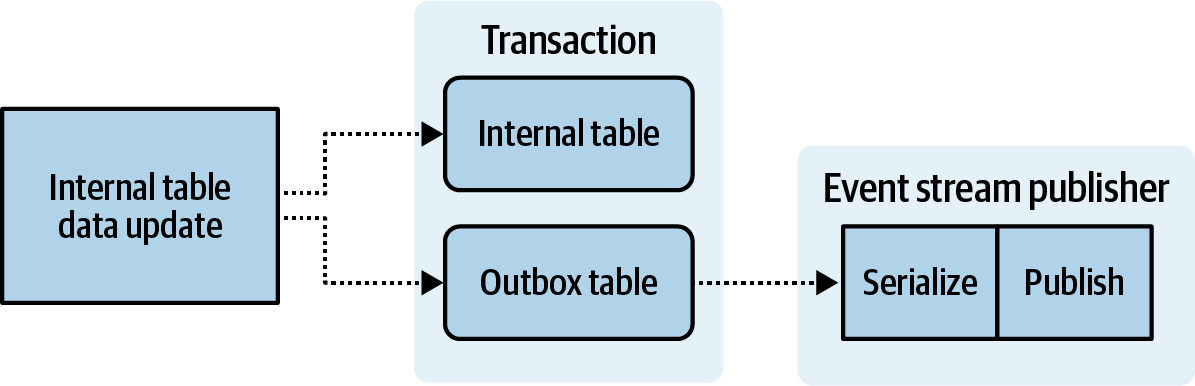
Figure 4-11. Serializing change-data after writing to outbox table, as part of the publishing process
Với chiến lược này, bạn thường có các outbox độc lập, mỗi cái cho một mô hình miền, được ánh xạ đến nội dung công khai của luồng sự kiện đầu ra tương ứng. Quá trình phát hành đọc sự kiện chưa được tuần tự hóa từ outbox và cố gắng tuần tự hóa nó với lược đồ liên quan trước khi phát ra luồng sự kiện đầu ra. Hình 4-12 cho thấy một ví dụ về nhiều outbox, một cho thực thể Người dùng và một cho thực thể Tài khoản.
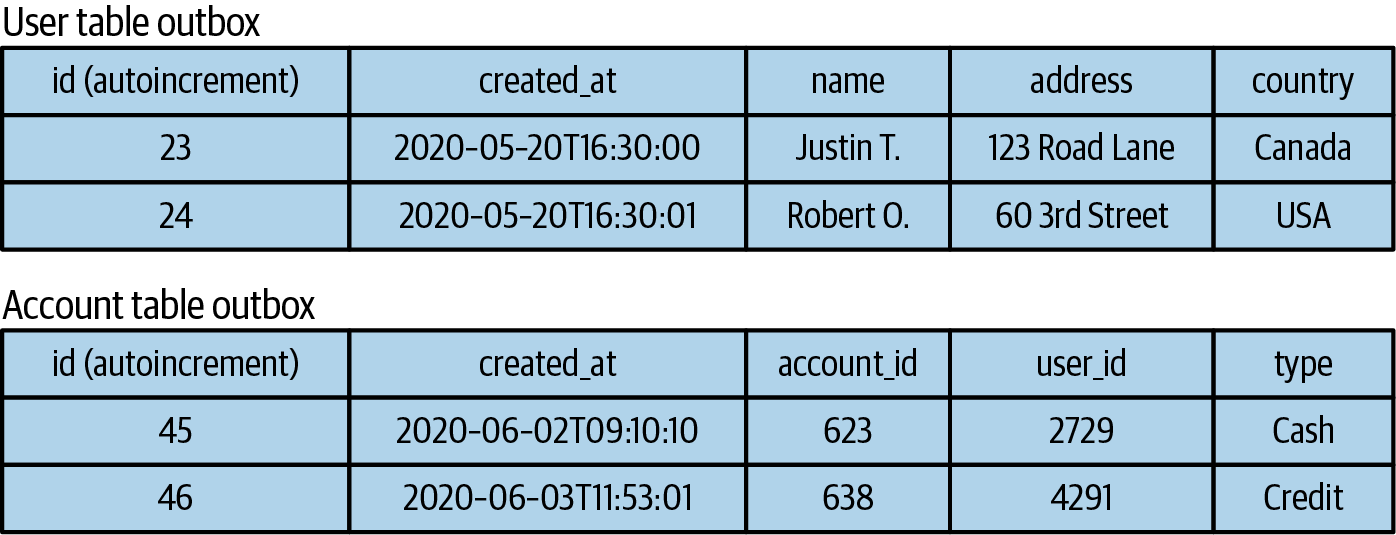
Figure 4-12. Multiple outbox tables (note that the data is not serialized, which means that it may not be compatible with the schema of the output event stream)
Một sự thất bại trong việc tuần tự hóa chỉ ra rằng dữ liệu của sự kiện không tuân thủ theo lược đồ đã được định nghĩa và do đó không thể được phát hành. Đây là lúc tùy chọn tuần tự hóa sau khi ghi trở nên khó duy trì hơn, vì một giao dịch đã hoàn thành sẽ đưa dữ liệu không tương thích vào bảng outbox, và không có đảm bảo rằng giao dịch có thể được đảo ngược.
Trên thực tế, bạn thường sẽ kết thúc với một số lượng lớn các sự kiện không thể tuần tự hóa trong hộp thư đi của bạn. Can thiệp từ con người có thể sẽ được yêu cầu để cố gắng cứu lại một số dữ liệu, nhưng việc giải quyết vấn đề sẽ mất thời gian và khó khăn, thậm chí có thể cần phải dừng hoạt động để ngăn chặn các vấn đề bổ sung. Điều này càng trở nên phức tạp bởi thực tế là một số sự kiện có thể thực sự tương thích và đã được xuất bản, dẫn đến khả năng thứ tự sai lệch của các sự kiện trong các luồng đầu ra.
Tip
Trước khi xảy ra, việc tuần tự hóa cung cấp sự đảm bảo mạnh mẽ hơn chống lại dữ liệu không tương thích so với sau khi xảy ra và ngăn chặn sự lan truyền của các sự kiện vi phạm hợp đồng dữ liệu của chúng. Sự đánh đổi là việc triển khai này cũng sẽ ngăn cản quy trình kinh doanh hoàn thành nếu việc tuần tự hóa thất bại, vì giao dịch phải được hoàn tác.
Xác nhận và tuần tự hóa trước khi ghi đảm bảo rằng dữ liệu được coi như một công dân hạng nhất và cung cấp một cam kết rằng các sự kiện trong luồng sự kiện đầu ra cuối cùng nhất quán với dữ liệu bên trong kho dữ liệu nguồn, đồng thời bảo toàn tính tách biệt của mô hình dữ liệu nội bộ của nguồn. Đây là cam kết mạnh mẽ nhất mà một giải pháp lấy dữ liệu thay đổi có thể cung cấp.
Benefits of event-production with outbox tables
Có nhiều lợi ích khi sử dụng hộp thư giao dịch:
Việc sản xuất sự kiện thông qua bảng outbox mang lại một số lợi thế quan trọng.
- Multilanguage support
-
Cách tiếp cận này được hỗ trợ bởi bất kỳ khách hàng hoặc framework nào cung cấp khả năng giao dịch.
- Exactly-once outbox semantics
-
Các giao dịch đảm bảo rằng cả mô hình nội bộ và dữ liệu hòm thư đều được tạo ra một cách nguyên tử. Bạn sẽ không bỏ lỡ bất kỳ thay đổi nào trong cơ sở dữ liệu của mình nếu bạn bao bọc các cập nhật trong một giao dịch.
- Early schema enforcement
-
Bảng hộp thư đi có thể cung cấp một sơ đồ định nghĩa rõ ràng thể hiện sơ đồ của luồng sự kiện. Ngoài ra, có thể xác thực các sơ đồ tại thời gian chạy bằng cách tuần tự hóa dữ liệu được ghi vào hộp thư đi.
- Internal Data Model Isolation
-
Các nhà phát triển ứng dụng lưu trữ dữ liệu có thể chọn các trường để ghi vào bảng outbox, giữ cho các trường nội bộ được cách ly.
- Denormalization
-
Dữ liệu có thể được chuẩn hóa lại theo nhu cầu trước khi được ghi vào bảng outbox.
Drawbacks of event production with outbox tables
Việc sản xuất sự kiện thông qua các bảng outbox cũng có một số nhược điểm:
- Database must support transactions
-
Cơ sở dữ liệu của bạn phải hỗ trợ giao dịch. Nếu nó không hỗ trợ, bạn sẽ phải chọn một mẫu truy cập dữ liệu khác.
- Application code changes
-
Mã ứng dụng phải được thay đổi để kích hoạt mẫu này, điều này cần có nguồn lực phát triển và kiểm tra từ những người duy trì ứng dụng.
- Business process performance impact
-
Ảnh hưởng đến hiệu suất của quy trình kinh doanh có thể không tầm thường, đặc biệt khi xác thực các sơ đồ thông qua quá trình tuần tự hóa. Các giao dịch thất bại cũng có thể ngăn cản hoạt động kinh doanh tiếp tục.
- Data store performance impact
-
Tác động đến hiệu suất của kho dữ liệu có thể không thể bỏ qua, đặc biệt là khi một số lượng lớn bản ghi đang được ghi, đọc và xóa từ hộp thư đi.
Note
Các tác động đến hiệu suất phải được cân nhắc so với các chi phí khác. Ví dụ, một số tổ chức đơn giản phát ra các sự kiện bằng cách phân tích nhật ký ghi lại thay đổi dữ liệu và để các đội ngũ hạ nguồn tự dọn dẹp các sự kiện sau đó. Điều này phát sinh một loạt các chi phí riêng dưới hình thức chi phí tính toán cho việc xử lý và tiêu chuẩn hóa các sự kiện, cũng như chi phí lao động con người trong việc giải quyết các sơ đồ không tương thích và đối phó với các tác động của việc kết nối mạnh với các mô hình dữ liệu nội bộ. Chi phí tiết kiệm được ở phía nhà sản xuất thường bị che mờ bởi các chi phí phát sinh ở phía người tiêu dùng cho việc xử lý những vấn đề này.
Capturing Change-Data Using Triggers
Hỗ trợ trigger đã có trước nhiều mẫu kiểm toán, binlog và nhật ký ghi trước được xem xét trong các phần trước. Nhiều cơ sở dữ liệu quan hệ cũ sử dụng trigger như một phương tiện để tạo ra các bảng kiểm toán. Như tên gọi của chúng, trigger được thiết lập để xảy ra tự động khi có một điều kiện cụ thể. Nếu nó thất bại, lệnh đã gây ra trigger được thực thi cũng sẽ thất bại, đảm bảo tính nguyên tử của việc cập nhật.
Bạn có thể ghi lại các thay đổi theo hàng vào một bảng kiểm toán bằng cách sử dụng trigger AFTER. Ví dụ, sau bất kỳ lệnh INSERT, UPDATE hoặc DELETE nào, trigger sẽ ghi một hàng tương ứng vào bảng thay đổi dữ liệu. Điều này đảm bảo rằng các thay đổi được thực hiện trên một bảng cụ thể được theo dõi một cách hợp lệ.
Xem xét ví dụ được hiển thị trong Hình 4-13. Dữ liệu người dùng đang được cập nhật hoặc chèn vào bảng người dùng, với một trigger ghi lại các sự kiện khi chúng xảy ra. Lưu ý rằng trigger cũng ghi lại thời gian mà việc chèn xảy ra cũng như một ID tuần tự tự động tăng cho quá trình phát hành sự kiện sử dụng.
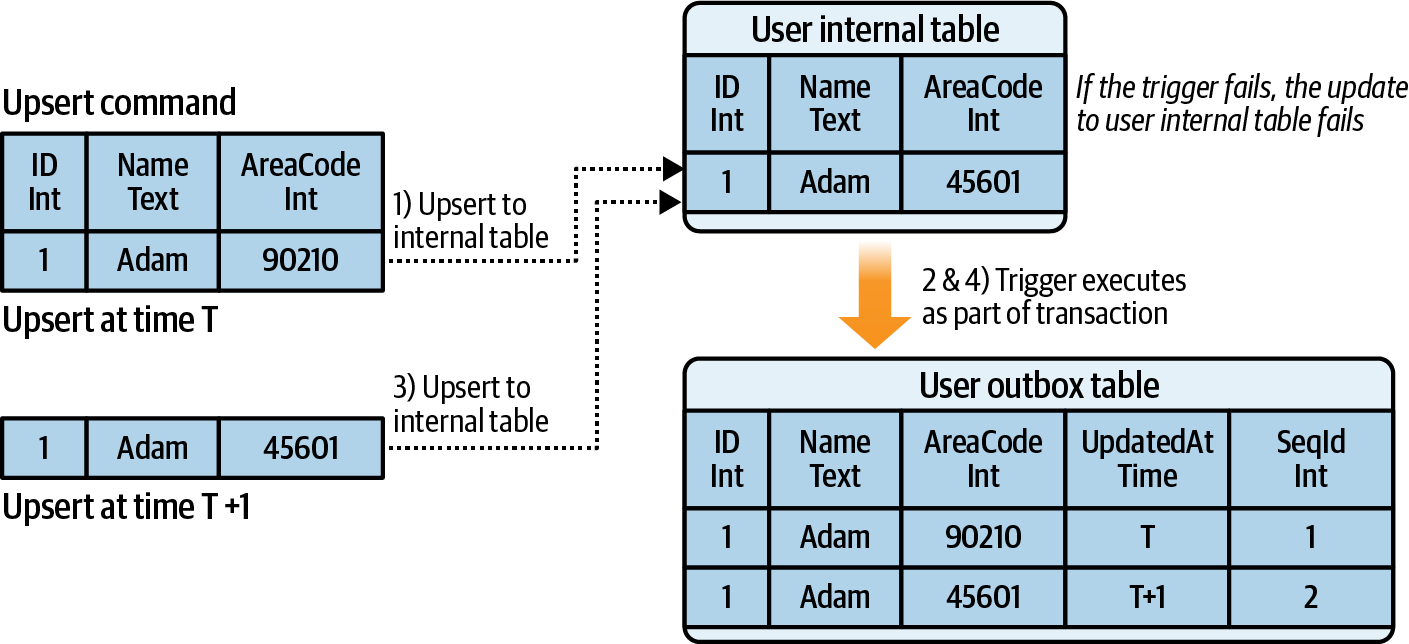
Figure 4-13. Using a trigger to capture changes to a user table
Bạn thường không thể xác thực dữ liệu thay đổi với sơ đồ sự kiện trong quá trình thực thi một trigger, mặc dù không phải là không thể. Một vấn đề chính là nó có thể đơn giản không được hỗ trợ, vì các trigger thực thi trong chính cơ sở dữ liệu, và nhiều trigger bị giới hạn vào những dạng ngôn ngữ mà chúng có thể hỗ trợ. Trong khi PostgreSQL hỗ trợ C, Python và Perl, có thể được sử dụng để viết các hàm do người dùng định nghĩa để thực hiện xác thực sơ đồ, nhiều cơ sở dữ liệu khác không cung cấp hỗ trợ đa ngôn ngữ. Cuối cùng, ngay cả khi một trigger được hỗ trợ, nó có thể đơn giản là quá tốn kém. Mỗi trigger được kích hoạt độc lập và yêu cầu một lượng chi phí không nhỏ để lưu trữ dữ liệu cần thiết, sơ đồ và logic xác thực, và đối với nhiều tải hệ thống, chi phí là quá cao.
Hình 4-14 cho thấy một sự tiếp tục của ví dụ trước. Việc xác thực và tuần tự hóa dữ liệu thay đổi được thực hiện sau khi sự kiện xảy ra, với dữ liệu đã được xác thực thành công được xuất ra luồng sự kiện. Dữ liệu không thành công sẽ cần được xử lý lỗi theo yêu cầu của doanh nghiệp, nhưng có khả năng sẽ cần can thiệp của con người.
Sơ đồ bảng capture dữ liệu thay đổi là cầu nối giữa sơ đồ bảng nội bộ và sơ đồ luồng sự kiện đầu ra. Sự tương thích giữa cả ba là rất quan trọng để đảm bảo rằng dữ liệu có thể được sản xuất ra luồng sự kiện đầu ra. Vì việc xác thực sơ đồ đầu ra thường không được thực hiện trong quá trình thực thi trigger, nên tốt nhất là giữ cho bảng capture dữ liệu thay đổi đồng bộ với định dạng của sơ đồ sự kiện đầu ra.
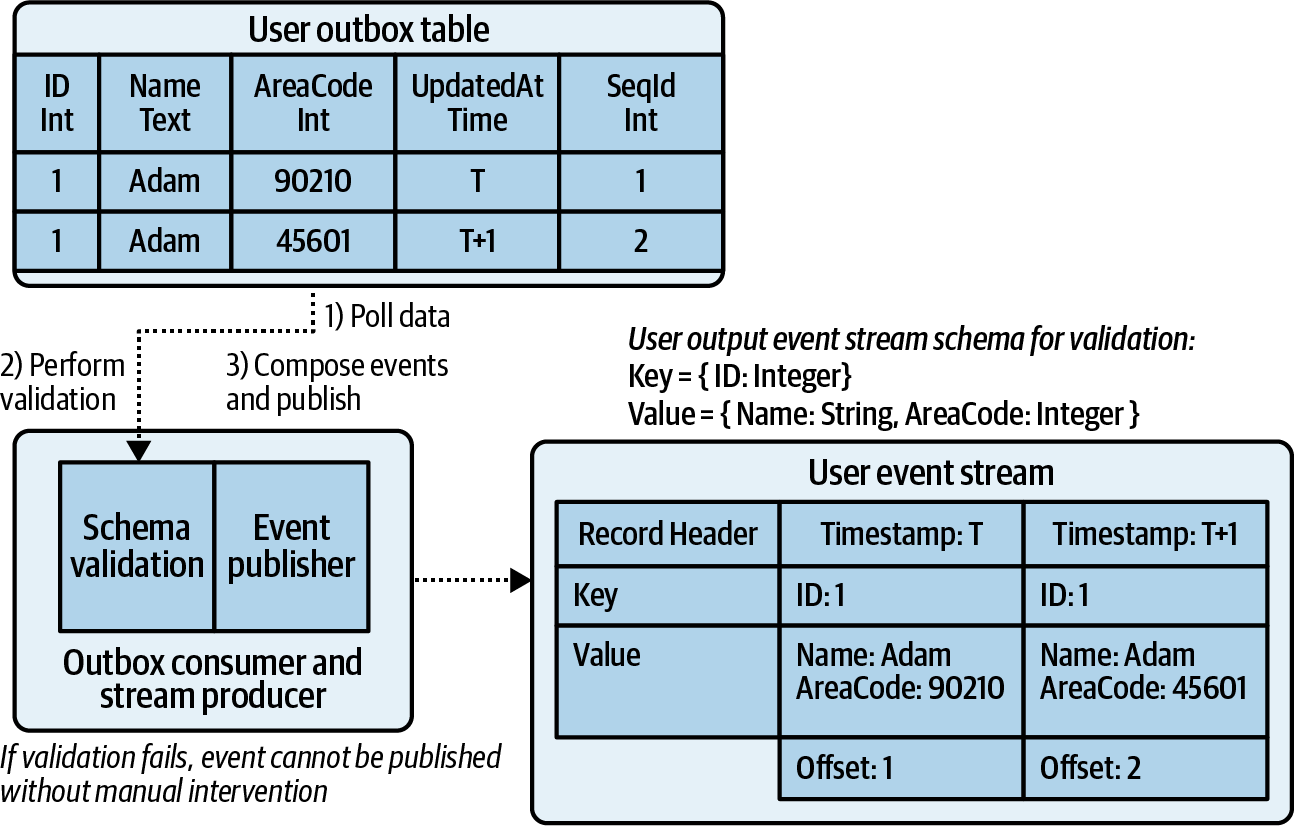
Figure 4-14. After-the-fact validation and production to the output event stream
Tip
So sánh định dạng của lược đồ sự kiện đầu ra với bảng dữ liệu thay đổi trong quá trình thử nghiệm. Điều này có thể làm lộ ra các sự không tương thích trước khi triển khai vào sản xuất.
Nói như vậy, các trigger có thể hoạt động rất tốt trong nhiều hệ thống kế thừa. Hệ thống kế thừa thường sử dụng, theo định nghĩa, công nghệ cũ; các trigger đã tồn tại trong một thời gian dài và có thể rất dễ dàng cung cấp cơ chế thu thập dữ liệu thay đổi cần thiết. Các mô hình truy cập và tải thường được xác định rõ ràng và ổn định, do đó tác động của việc thêm trigger có thể được ước lượng chính xác. Cuối cùng, mặc dù việc xác thực schema khó có thể xảy ra trong quá trình kích hoạt, nhưng cũng khó có khả năng rằng các schema sẽ thay đổi, đơn giản là do tính chất kế thừa của hệ thống. Việc xác thực sau đó chỉ là một vấn đề nếu các schema được mong đợi sẽ thay đổi thường xuyên.
Warning
Hãy cố gắng tránh sử dụng triggers nếu bạn có thể, thay vào đó hãy sử dụng các chức năng hiện đại hơn để tạo ra hoặc truy cập dữ liệu thay đổi, chẳng hạn như một hệ thống CDC được chỉ định. Bạn không nên đánh giá thấp hiệu suất và công tác quản lý cần thiết cho một giải pháp dựa trên trigger, đặc biệt là khi có nhiều chục hoặc hàng trăm bảng và mô hình dữ liệu liên quan.
Benefits of using triggers
Lợi ích của việc sử dụng trigger bao gồm các điều sau:
- Supported by most databases
-
Các trigger tồn tại cho hầu hết các cơ sở dữ liệu quan hệ.
- Low overhead for small data sets
-
Bảo trì và cấu hình khá dễ dàng cho một số lượng nhỏ các tập dữ liệu.
- Customizable logic
-
Mã kích hoạt có thể được tùy chỉnh để chỉ hiển thị một tập hợp con của các trường cụ thể. Điều này có thể cung cấp một số mức độ tách biệt về dữ liệu được hiển thị cho các người tiêu dùng ở phía hạ nguồn.
Drawbacks of using triggers
Một số nhược điểm khi sử dụng trigger là:
- Performance overhead
-
Các trigger thực thi đồng bộ với các hành động trên các bảng cơ sở dữ liệu và có thể tiêu tốn tài nguyên xử lý không nhỏ. Tùy thuộc vào yêu cầu hiệu suất và SLA của các dịch vụ của bạn, cách tiếp cận này có thể gây ra một khối lượng tải không chấp nhận được.
- Change management complexity
-
Các thay đổi đối với mã ứng dụng và định nghĩa tập dữ liệu có thể cần các sửa đổi tương ứng cho trigger. Các sửa đổi cần thiết đối với các trigger cơ sở có thể bị các nhà quản lý hệ thống bỏ qua, dẫn đến kết quả giải phóng dữ liệu không nhất quán với các tập dữ liệu nội bộ. Cần thực hiện thử nghiệm toàn diện để đảm bảo các quy trình trigger hoạt động theo như mong đợi.
- Poor scaling
-
Số lượng kích hoạt cần thiết tăng theo tỷ lệ với số lượng tập dữ liệu cần được ghi lại. Điều này không bao gồm bất kỳ kích hoạt bổ sung nào có thể đã tồn tại trong logic kinh doanh, chẳng hạn như những cái được sử dụng để thực thi các phụ thuộc giữa các bảng.
- After-the-fact schema enforcement
-
Sự thực thi schema cho sự kiện đầu ra chỉ xảy ra sau khi bản ghi đã được xuất bản vào bảng outbox. Điều này có thể dẫn đến các sự kiện không thể xuất bản trong bảng outbox.
Tip
Một số cơ sở dữ liệu cho phép kích hoạt các trigger được thực hiện bằng các ngôn ngữ có thể xác thực tính tương thích với các lược đồ sự kiện đầu ra trong quá trình thực hiện trigger (ví dụ: Python cho PostgreSQL). Điều này có thể làm tăng độ phức tạp và chi phí, nhưng giảm đáng kể rủi ro về sự không tương thích giữa các lược đồ ở phía dưới.
Making Data Definition Changes to Data Sets Under Capture
Việc tích hợp các thay đổi định nghĩa dữ liệu có thể gặp khó khăn trong một khung dữ liệu tự do. Di chuyển dữ liệu là một thao tác phổ biến cho nhiều ứng dụng cơ sở dữ liệu quan hệ và cần được hỗ trợ qua việc ghi lại. Các thay đổi định nghĩa dữ liệu cho một cơ sở dữ liệu quan hệ có thể bao gồm việc thêm, xóa và đổi tên các cột; thay đổi kiểu của một cột; và thêm hoặc xóa các giá trị mặc định. Mặc dù tất cả các thao tác này đều là các thay đổi hợp lệ của tập dữ liệu, nhưng chúng có thể gây ra vấn đề cho việc sản xuất dữ liệu đến các luồng sự kiện tự do.
Note
Định nghĩa dữ liệu là mô tả chính thức về tập dữ liệu. Ví dụ, một bảng trong cơ sở dữ liệu quan hệ được định nghĩa bằng cách sử dụng ngôn ngữ định nghĩa dữ liệu (DDL). Bảng kết quả, các cột, tên, loại và chỉ mục đều là một phần của định nghĩa dữ liệu của nó.
Ví dụ, nếu yêu cầu tính tương thích với sự phát triển toàn bộ của sơ đồ, bạn không thể xóa một cột không thể null mà không có giá trị mặc định khỏi tập dữ liệu đang được theo dõi, vì các bên tiêu thụ sử dụng sơ đồ đã định nghĩa trước đó sẽ mong đợi một giá trị cho trường đó. Các bên tiêu thụ sẽ không thể quay lại bất kỳ giá trị mặc định nào vì không có giá trị nào được chỉ định tại thời điểm định nghĩa hợp đồng, vì vậy họ sẽ rơi vào trạng thái mơ hồ. Nếu một thay đổi không tương thích là hoàn toàn cần thiết và sự vi phạm hợp đồng dữ liệu là không thể tránh khỏi, thì nhà sản xuất và các bên tiêu thụ dữ liệu phải đồng ý về một hợp đồng dữ liệu mới.
Caution
Những thay đổi hợp lệ đối với tập dữ liệu đang đượcthu thập có thể không phải là những thay đổi hợp lệ cho lược đồ sự kiện đã được giải phóng. Sự không tương thích này sẽ gây ra những thay đổi lược đồ nghiêm trọng ảnh hưởng đến tất cả các bên tiêu thụ dòng sự kiện ở phía hạ nguồn.
Việc ghi nhận các thay đổi DDL phụ thuộc vào mô hình tích hợp được sử dụng để ghi lại dữ liệu thay đổi. Vì các thay đổi DDL có thể tác động đáng kể đến những người tiêu dùng dữ liệu ở hạ nguồn, nên rất quan trọng để xác định xem các mẫu ghi nhận của bạn có phát hiện ra các thay đổi đối với DDL trước hay sau khi chúng xảy ra. Chẳng hạn, mẫu truy vấn và mẫu nhật ký CDC chỉ có thể phát hiện các thay đổi DDL sau khi chúng đã xảy ra—tức là, khi chúng đã được áp dụng vào tập dữ liệu. Ngược lại, mẫu bảng dữ liệu thay đổi được tích hợp với chu kỳ phát triển của hệ thống nguồn, đến mức các thay đổi được thực hiện trên tập dữ liệu yêu cầu xác thực với bảng dữ liệu thay đổi trước khi phát hành ra sản xuất.
Handling After-the-Fact Data Definition Changes for the Query and CDC Log Patterns
Đối với mẫu truy vấn, lược đồ có thể được lấy tại thời gian truy vấn, và một lược đồ sự kiện có thể được suy diễn. Lược đồ sự kiện mới có thể được so sánh với lược đồ luồng sự kiện đầu ra, với các quy tắc tương thích lược đồ được sử dụng để cho phép hoặc cấm việc công bố dữ liệu sự kiện. Cơ chế sinh lược đồ này được nhiều kết nối truy vấn sử dụng, chẳng hạn như các kết nối được cung cấp với khung Kafka Connect.
Đối với mô hình nhật ký CDC, các cập nhật định nghĩa dữ liệu thường được ghi lại vào một phần riêng của nhật ký CDC. Những thay đổi này cần được trích xuất từ các nhật ký và suy diễn vào một lược đồ đại diện cho tập dữ liệu. Khi lược đồ được tạo ra, nó có thể được xác thực so với lược đồ sự kiện phía hạ nguồn. Tuy nhiên, hỗ trợ cho chức năng này còn hạn chế. Hiện tại, kết nối Debezium chỉ hỗ trợ các thay đổi định nghĩa dữ liệu của MySQL.
Handling Data Definition Changes for Change-Data Table Capture Patterns
Bảng thay đổi dữ liệu hoạt động như một cầu nối giữa lược đồ luồng sự kiện đầu ra và lược đồ trạng thái nội bộ. Mọi sự không tương thích trong mã xác thực của ứng dụng hoặc chức năng kích hoạt của cơ sở dữ liệu sẽ ngăn dữ liệu được ghi vào bảng thay đổi dữ liệu, với lỗi được gửi ngược lên ngăn xếp. Những thay đổi được thực hiện đối với bảng ghi lại thay đổi dữ liệu sẽ yêu cầu một sự tiến hóa lược đồ tương thích với luồng sự kiện đầu ra, theo các quy tắc tương thích lược đồ của nó. Điều này bao gồm một quy trình gồm hai bước, giảm đáng kể khả năng các thay đổi không mong muốn lọt vào sản xuất.
Sinking Event Data to Data Stores
Việc hạ dữ liệu từ các luồng sự kiện bao gồm việc tiêu thụ dữ liệu sự kiện và chèn nó vào một kho dữ liệu. Điều này được thực hiện qua một framework tập trung hoặc một dịch vụ vi mô độc lập. Bất kỳ loại dữ liệu sự kiện nào, cho dù là sự kiện thực thể, sự kiện có khóa hay sự kiện không có khóa, đều có thể được hạ xuống kho dữ liệu.
Quá trình sink sự kiện đặc biệt hữu ích cho việc tích hợp các ứng dụng không dựa trên sự kiện với các luồng sự kiện. Quá trình sink đọc các luồng sự kiện từ nhà môi giới sự kiện và chèn dữ liệu vào kho dữ liệu đã chỉ định. Nó theo dõi các offset tiêu thụ của chính nó và ghi dữ liệu sự kiện khi nó đến tại đầu vào, hoạt động hoàn toàn độc lập với ứng dụng không dựa trên sự kiện.
Một cách sử dụng điển hình của việc "event sinking" là thay thế các mối liên kết trực tiếp giữa các hệ thống kế thừa. Khi dữ liệu của hệ thống nguồn được giải phóng thành các luồng sự kiện, nó có thể được truyền đến hệ thống đích với ít thay đổi khác. Quá trình "sink" hoạt động cả bên ngoài và một cách vô hình đối với hệ thống đích.
Dữ liệu giảm tải cũng thường được các nhóm sử dụng để thực hiện phân tích big-data theo lô. Họ thường thực hiện điều này bằng cách giảm tải dữ liệu vào Hệ thống Tệp Phân phối Hadoop, cung cấp các công cụ phân tích big-data.
Sử dụng một nền tảng chung như Kafka Connect cho phép bạn xác định các điểm đích với cấu hình đơn giản và chạy chúng trên hạ tầng chung. Các điểm đích microservice độc lập cung cấp một giải pháp thay thế. Các nhà phát triển có thể tạo và chạy chúng trên nền tảng microservice và quản lý độc lập.
The Impacts of Sinking and Sourcing on a Business
Một khuôn khổ tập trung cho phép các quy trình có chi phí thấp hơn để giải phóng dữ liệu. Khuôn khổ này có thể được vận hành quy mô bởi một đội duy nhất, điều này hỗ trợ nhu cầu giải phóng dữ liệu của các đội khác trong tổ chức. Các đội muốn tích hợp chỉ cần quan tâm đến việc cấu hình và thiết kế kết nối, không phải lo lắng về bất kỳ nhiệm vụ vận hành nào. Cách tiếp cận này hoạt động tốt nhất trong các tổ chức lớn, nơi dữ liệu được lưu trữ trong nhiều kho dữ liệu khác nhau giữa nhiều đội, vì nó cho phép bắt đầu nhanh chóng việc giải phóng dữ liệu mà không cần mỗi đội phải tự xây dựng giải pháp riêng của mình.
Có hai cạm bẫy chính mà bạn có thể mắc phải khi sử dụng một khung trung tâm. Đầu tiên, trách nhiệm về nguồn dữ liệu và tiêu thụ dữ liệu giờ đây được chia sẻ giữa các đội nhóm. Đội nhóm vận hành khung trung tâm có trách nhiệm về sự ổn định, khả năng mở rộng và sức khỏe của cả khung và mỗi trường hợp kết nối. Trong khi đó, đội nhóm vận hành hệ thống đang bị ghi lại là độc lập và có thể đưa ra những quyết định làm thay đổi hiệu suất và sự ổn định của trình kết nối, chẳng hạn như thêm và bớt các trường, hoặc thay đổi logic ảnh hưởng đến khối lượng dữ liệu được truyền qua trình kết nối. Điều này tạo ra sự phụ thuộc trực tiếp giữa hai đội nhóm này. Những thay đổi này có thể làm hỏng các trình kết nối, nhưng có thể chỉ được phát hiện bởi đội nhóm quản lý trình kết nối, dẫn đến sự phụ thuộc giữa các đội nhóm theo chiều ngang, tăng theo cấp số nhân. Điều này có thể trở thành gánh nặng khó quản lý khi số lượng thay đổi tăng lên.
Vấn đề thứ hai có phần phổ biến hơn, đặc biệt là trong một tổ chức mà các nguyên tắc hướng sự kiện chỉ được áp dụng một phần. Các hệ thống có thể trở nên quá phụ thuộc vào các khung và bộ kết nối để thực hiện công việc hướng sự kiện của chúng. Khi dữ liệu đã được giải phóng khỏi các kho trạng thái nội bộ và được xuất bản ra các luồng sự kiện, tổ chức có thể trở nên tự mãn về việc tiến tới các dịch vụ vi mô hướng sự kiện bản địa. Các nhóm có thể trở nên quá phụ thuộc vào khung bộ kết nối để lấy và lưu trữ dữ liệu, và chọn không tái cấu trúc các ứng dụng của họ hoặc phát triển các dịch vụ hướng sự kiện mới. Trong kịch bản này, họ thay vào đó thích chỉ yêu cầu các nguồn và bể dữ liệu mới khi cần thiết, để lại toàn bộ ứng dụng nền tảng của họ hoàn toàn không biết đến các sự kiện.
Warning
Các công cụ CDC không phải là điểm đến cuối cùng trong việc chuyển sang kiến trúc hướng sự kiện, mà chủ yếu nhằm mục đích khởi động quá trình. Giá trị thực sự của bộ trung gian sự kiện như là lớp giao tiếp dữ liệu nằm ở việc cung cấp một nguồn dữ liệu sự kiện mạnh mẽ, đáng tin cậy và trung thực không bị ràng buộc với các lớp triển khai, và bộ trung gian chỉ tốt như chất lượng và độ tin cậy của dữ liệu của nó.
Cả hai vấn đề này có thể được giảm thiểu thông qua việc hiểu đúng vai trò của khung thay đổi dữ liệu (change-data capture - CDC). Có thể trái ngược với trực giác, nhưng việc tối thiểu hóa việc sử dụng khung CDC và yêu cầu các nhóm tự triển khai việc thay đổi dữ liệu của riêng họ (chẳng hạn như mẫu outbox) là rất quan trọng, mặc dù điều này có thể đòi hỏi thêm công sức ban đầu. Các nhóm trở nên hoàn toàn chịu trách nhiệm về việc công bố và các sự kiện trong hệ thống của họ, loại bỏ sự phụ thuộc giữa các nhóm và giảm thiểu tính dễ tổn thương của việc kết nối dựa trên CDC. Điều này giảm bớt công việc mà đội ngũ khung CDC cần thực hiện và cho phép họ tập trung vào việc hỗ trợ các sản phẩm thực sự cần thiết.
Việc giảm thiểu sự phụ thuộc vào khung CDC cũng tạo ra một tâm lý "sự kiện trước tiên". Thay vì nghĩ về các luồng sự kiện như một cách để chuyển đổi dữ liệu giữa các monolith, bạn xem mỗi hệ thống như một nhà xuất bản và người tiêu dùng sự kiện trực tiếp, tham gia vào hệ sinh thái điều khiển bởi sự kiện. Bằng cách trở thành một người tham gia tích cực trong hệ sinh thái EDM, bạn bắt đầu suy nghĩ về khi nào và như thế nào hệ thống cần sản xuất các sự kiện, về dữ liệu ở bên ngoài thay vì chỉ về dữ liệu ở bên trong. Đây là một phần quan trọng của sự chuyển mình văn hóa hướng tới việc triển khai thành công EDM.
Đối với các sản phẩm có nguồn lực hạn chế và những sản phẩm chỉ hoạt động bảo trì, một hệ thống kết nối nguồn và bể chứa tập trung có thể là một lợi ích đáng kể. Đối với các sản phẩm khác, đặc biệt là những sản phẩm phức tạp hơn, có yêu cầu về luồng sự kiện đáng kể và đang trong quá trình phát triển tích cực, việc duy trì và hỗ trợ các kết nối là không bền vững. Trong những trường hợp này, tốt nhất là nên lên kế hoạch thời gian để tái cấu trúc mã nguồn khi cần thiết để cho phép ứng dụng trở thành một ứng dụng thực sự dựa trên sự kiện.
Cuối cùng, hãy xem xét cẩn thận những đánh đổi của từng chiến lược CDC. Điều này thường trở thành một lĩnh vực thảo luận và tranh cãi trong một tổ chức, khi các đội cố gắng xác định trách nhiệm và ranh giới mới của họ liên quan đến việc sản xuất các sự kiện của họ như một nguồn thông tin chính xác duy nhất. Chuyển sang kiến trúc dựa trên sự kiện đòi hỏi đầu tư vào lớp giao tiếp dữ liệu, và tính hữu ích của lớp này chỉ có thể tốt như chất lượng dữ liệu bên trong nó. Mọi người trong tổ chức phải thay đổi cách suy nghĩ để xem xét tác động của dữ liệu tự do của họ đối với phần còn lại của tổ chức và đưa ra các thỏa thuận dịch vụ rõ ràng về các sơ đồ, mô hình dữ liệu, thứ tự, độ trễ và độ chính xác cho các sự kiện mà họ đang sản xuất.
Summary
Giải phóng dữ liệu là một bước quan trọng hướng tới việc cung cấp một lớp giao tiếp dữ liệu trưởng thành và dễ tiếp cận. Các hệ thống kế thừa thường chứa phần lớn các mô hình miền kinh doanh cốt lõi, được lưu trữ trong một hình thức cấu trúc giao tiếp triển khai tập trung nào đó. Dữ liệu này cần được giải phóng khỏi các hệ thống kế thừa để cho phép các lĩnh vực khác của tổ chức tạo ra các sản phẩm và dịch vụ mới, tách biệt.
Có nhiều khung, công cụ và chiến lược có sẵn để trích xuất và chuyển đổi dữ liệu từ các kho dữ liệu triển khai của chúng. Mỗi cái đều có những lợi ích, nhược điểm và sự đánh đổi riêng. Các trường hợp sử dụng của bạn sẽ ảnh hưởng đến việc bạn lựa chọn những tùy chọn nào, hoặc bạn có thể thấy rằng bạn phải tạo ra các cơ chế và quy trình riêng của mình.
Mục tiêu của việc giải phóng dữ liệu là cung cấp một nguồn dữ liệu duy nhất rõ ràng và nhất quán cho những dữ liệu quan trọng đối với tổ chức. Việc truy cập dữ liệu được tách rời khỏi quá trình sản xuất và lưu trữ nó, loại bỏ nhu cầu về các cấu trúc giao tiếp triển khai phải phục vụ cho hai mục đích. Hành động đơn giản này giảm bớt rào cản truy cập dữ liệu quan trọng từ nhiều hệ thống kế thừa và trực tiếp thúc đẩy sự phát triển của các sản phẩm và dịch vụ mới.
Có một loạt các chiến lược giải phóng dữ liệu. Ở một đầu là việc tích hợp cẩn thận với hệ thống nguồn, nơi các sự kiện được phát ra cho trình môi giới sự kiện khi chúng được ghi vào kho dữ liệu thực hiện. Một số hệ thống thậm chí còn có thể sản xuất vào luồng sự kiện trước khi tiêu thụ nó cho nhu cầu của chính mình, từ đó củng cố thêm luồng sự kiện như là nguồn trung thực duy nhất. Nhà sản xuất nhận thức được vai trò của mình như một công dân sản xuất dữ liệu tốt và đặt ra các biện pháp bảo vệ để ngăn chặn các thay đổi đột ngột không mong muốn. Các nhà sản xuất cố gắng làm việc với các người tiêu dùng để đảm bảo một luồng dữ liệu chất lượng cao, được xác định rõ ràng, giảm thiểu các thay đổi gây rối và đảm bảo rằng các thay đổi đối với hệ thống tương thích với các lược đồ của các sự kiện mà họ đang sản xuất.
Ở phía đối diện của quang phổ, bạn sẽ thấy các chiến lược phản ứng cao. Các chủ sở hữu dữ liệu nguồn trong triển khai hầu như không có hoặc có rất ít sự nhìn thấy vào việc sản xuất dữ liệu vào bên trung gian sự kiện. Họ hoàn toàn dựa vào các khung để lấy dữ liệu trực tiếp từ các tập dữ liệu nội bộ của họ hoặc phân tích nhật ký thay đổi dữ liệu. Các sơ đồ bị hỏng gây rối cho các người tiêu dùng downstream là điều phổ biến, cũng như việc lộ diện các mô hình dữ liệu nội bộ từ triển khai nguồn. Mô hình này không bền vững trong dài hạn, vì nó bỏ qua trách nhiệm của chủ sở hữu dữ liệu trong việc đảm bảo sản xuất các sự kiện miền một cách sạch sẽ và nhất quán.
Văn hóa của tổ chức quyết định mức độ thành công của các sáng kiến giải phóng dữ liệu trong việc chuyển đổi sang kiến trúc dựa trên sự kiện. Các chủ sở hữu dữ liệu phải nghiêm túc xem xét sự cần thiết phải tạo ra các luồng sự kiện sạch sẽ và đáng tin cậy, và hiểu rằng các cơ chế thu thập dữ liệu là không đủ như một điểm đến cuối cùng cho việc giải phóng dữ liệu sự kiện.
About the Author
Adam Bellemare là một kỹ sư nhân viên cho nền tảng dữ liệu tại Shopify. Anh đã giữ vị trí này từ năm 2020. Trước đó, anh làm việc tại Flipp từ năm 2014 đến 2020 với vai trò kỹ sư nhân viên. Trước khi đó, anh đã làm việc ở vị trí lập trình viên phần mềm tại BlackBerry, nơi anh lần đầu tiên bắt đầu với hệ thống hướng sự kiện.
Chuyên môn của anh ấy bao gồm DevOps (Kafka, Spark, Mesos, Kubernetes, Solr, Elasticsearch, HBase và các cụm Zookeeper, xây dựng, mở rộng, giám sát theo chương trình); lãnh đạo kỹ thuật (giúp doanh nghiệp tổ chức lớp giao tiếp dữ liệu của họ, tích hợp các hệ thống hiện có, phát triển các hệ thống mới và tập trung vào việc cung cấp sản phẩm); phát triển phần mềm (xây dựng các dịch vụ vi mô theo sự kiện trong Java và Scala sử dụng các thư viện Beam, Flink, Spark và Kafka Streams); và kỹ thuật dữ liệu (thay đổi cách thức thu thập dữ liệu hành vi từ các thiết bị người dùng và chia sẻ trong tổ chức).