
Confluence

Building Event-Driven Microservices
Leveraging Organizational Data at Scale
Adam Bellemare
Building Event-Driven Microservices
by Adam Bellemare
Copyright © 2025 Adam Bellemare. All rights reserved.
Printed in the United States of America.
Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472.
O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com.
- Acquisitions Editor: Melissa Duffield
- Development Editor: Corbin Collins
- Production Editor: Clare Laylock
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- August 2020: First Edition
- September 2025: Second Edition
Revision History for the Early Release
- 2025-02-19: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781492057895 for release details.
The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Building Event-Driven Microservices, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc.
The views expressed in this work are those of the author, and do not represent the publisher’s views. While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
This work is part of a collaboration between O’Reilly and Confluence. See our statement of editorial independence.
979-8-341-62214-2
[LSI]
Brief Table of Contents (Not Yet Final)
Preface (unavailable)
Chapter 1. Why Event-Driven Microservices? (unavailable)
Chapter 2. Fundamentals of Events and Event Streaming
Chapter 3. Fundamentals of Event-Driven Microservices
Chapter 4. Schemas and Data Contracts (unavailable)
Chapter 5. Designing Events
Chapter 6. Integrating Event-Driven Architectures with Existing Systems
Chapter 7. Eventification and Denormalization (unavailable)
Chapter 8. Deterministic Stream Processing (unavailable)
Chapter 9. Stateful Streaming (unavailable)
Chapter 10. Building Workflows with Microservices (unavailable)
Chapter 11. Eventual Consistency and Convergence (unavailable)
Chapter 12. Basic Producer and Consumer Microservices (unavailable)
Chapter 13. Microservices Using Function-as-a-Service (unavailable)
Chapter 14. Heavyweight Framework Microservices (unavailable)
Chapter 15. Durable Execution Frameworks (unavailable)
Chapter 16. Lightweight Framework Microservices (unavailable)
Chapter 17. Streaming SQL Queries as Microservices (unavailable)
Chapter 18. Integrating Event-Driven and Request-Response Microservices (unavailable)
Chapter 19. The Event-Driven User-Experience (unavailable)
Chapter 20. Supportive Tooling (unavailable)
Chapter 21. Testing Event-Driven Microservices (unavailable)
Chapter 22. Deploying Event-Driven Microservices (unavailable)
Chapter 23. Conclusion (unavailable)
Chapter 1. Fundamentals of Events and Event Streams
Event streams served by an event broker tends to be the dominant mode for powerful event-driven architectures, though you’ll find that queues and ephemeral messaging also have a place. We’ll cover each of these modes in more detail in the second half of this chapter.For now, let’s now take a closer look at events, records, and messages, as well as the relationship between an event stream and an event broker.
What’s an Event?
An event can be anything that has happened within the scope of the business communication structure. Receiving an invoice, booking a meeting room, requesting a cup of coffee (yes, you can hook up a coffee machine to an event stream), hiring a new employee, and successfully completing arbitrary code are all examples of events that happen within a business. It is important to recognize that events can be anything that is important to the business. Once these events start being captured, event-driven systems can be created to harness and use them across the organization.An event is a recording of what happened, much like how an application’s information and error logs record what takes place in the application.
Unlike these logs, however, events are also the single source of truth, as covered in [Link to Come]. As such, they must contain all the information required to accurately describe what happened.Events use schemas, which is covered in more detail in [Link to Come]. For now, consider events to have well-defined field names, types, and default values.
I avoid using the term message when discussing event streams and event-driven architectures. It’s an overloaded term that has different meanings for different people, and is also heavily influenced by the technology you’re using. Think about what messages mean in our day-to-day life, particularly if you use instant messaging. One person sends a message to a specific person or to a specific private group. Additionally, the messages may or may not be durable - some chat applications delete the messages after read, others after a period of time.
Events in an event-driven architecture are more akin to a post that you publish to a social media platform or message board. The posting is public to all, and everyone is free to read it and use it as they see fit. More than one person can read the post, and of course the post can be read again and again. It isn’t deleted just because it’s old. Event streams are effectively a broadcast to share important data, letting others subscribe to it and use it however they see fit.
Just to be clear, you can use event streams to send messages. All messages are events, but not all events are messages. But for clarity’s sake, I’ll use the terms event and record instead of message for the remaining chapters of this book. But before we dig further into events, let’s take a brief look at the event stream.
What’s an Event Stream?
An event stream is durable and append-only immutable log. Records are added to the end of the log (the tail) as they are published by the producer. Consumers begin at the start of the log (the head) and consume records at their own processing rate.
In its most basic form, an event stream is a time-stamped sequence of business facts pertaining to a domain. Events form the basis for communicating important business data between domains reliably and repeatably.
Event streams have several critical properties that enable us to rely on them for event-driven microservices, and as the basis for effective inter-domain data communication as a whole. For clarity, and with a bit of repetition, these properties include:
- Immutability
-
Events cannot be modified once written to the log. The contents cannot be altered, nor can their offset position, timestamp, or any other associated metadata. You may only add new events.
- Partition Support
-
Partitions provide the means for supporting massive datasets. A consumer can subscribe to one or more paritions from a single event stream, allowing multiple instances of a single microservice to consume and process the stream in parallel.
- Indexed
-
Events are assigned an immutable index when written to the log. The index, also often called an offset, uniquely identifies the event.
- Strictly Ordered
-
Records in an event stream partition are served to clients in the exact same order that it was originally published.
- Durability and replayability
-
Events are durable. They can be consumed either immediately or in the future. Events can be replayed by new and existing consumers alike, provided the event broker has sufficient storage to host the historical data. Events are not deleted once they are read, nor are they simply discarded in the case of an absence of consumers.
- Indefinite Storage Support
-
You can retain all events in your stream for as long as necessary. There is no forced expiry or time-limited retention, allowing you to consume and reconsume events as often as you need.
Figure 1-1 shows an event stream with three partitions. New events have just been appended to partition 0 (offset 5) and partition 1 (offset 7). The microservice consuming these events has two instances. Instance 0 is consuming only partition 0, which instance 1 is consuming both partition 1 and partition 2.
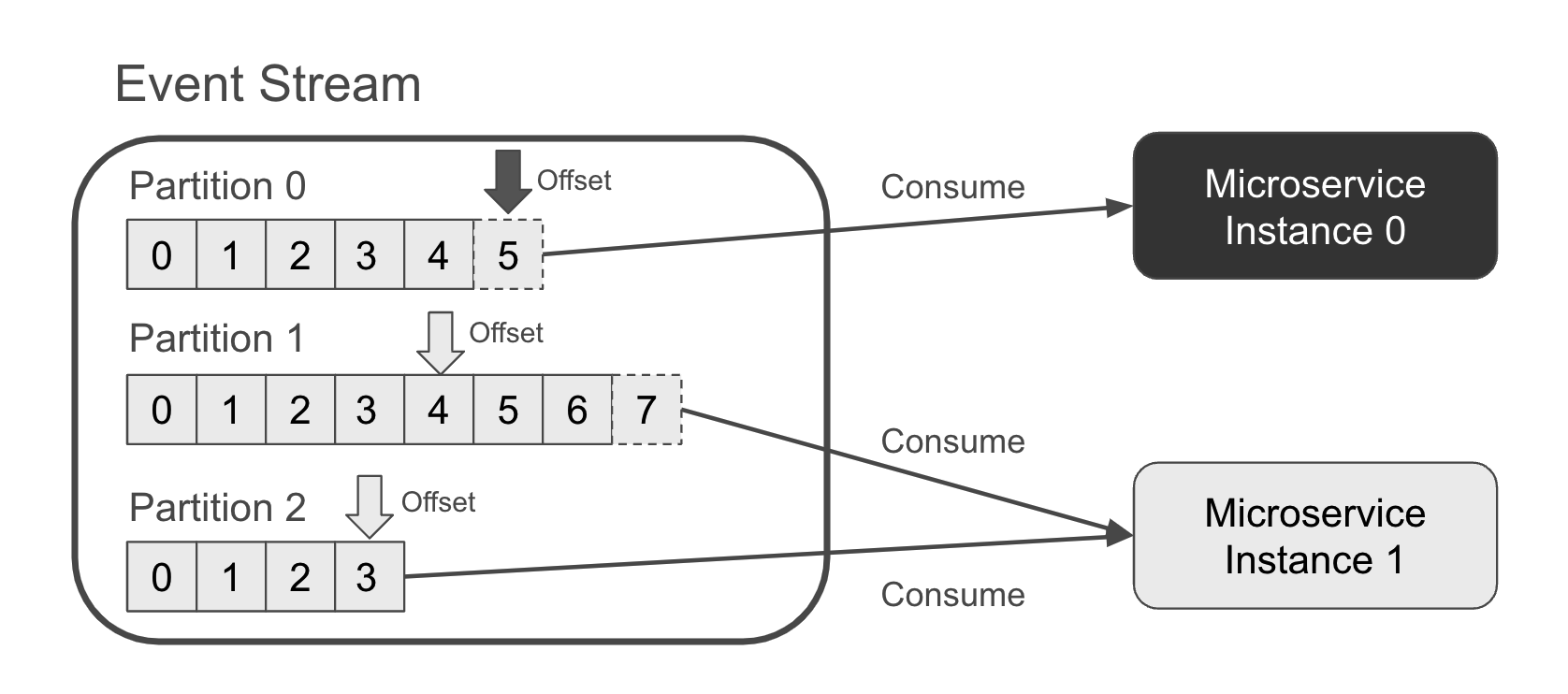
Figure 1-1. An event stream with two microservice instances consuming from a three partitions
With sufficient processing power, the consuming service will remain up to date with the event stream. Meanwhile, a new consumer beginning at an earlier offset (or the head) will need to process all of the events to catch up to current time.
Event streams are hosted on an event broker, with one of the most popular (and de-facto standard) being Apache Kafka. The event broker, such as in the case of Kafka, provides a structure known as a topic that we can write our events to. It also handles everything from data replication and rebalancing to client connections and access controls. Publishers write events to the event stream hosted in the broker, while consumers subscribe to event streams and receive the events.
Unfortunately, due to a long and often messy history, event brokers have often been confused with ephemeral messaging and queues. Each of these three options is different from the others. Let’s take a deeper look at each, and why event streams form the backbone of a modern event driven architectures.
Ephemeral Messaging
A channel is an ephemeral substrate for
communicating a message between one producer and one or more subscribers. Messages are directed to specific consumers, and they are not stored for any significant length of time, nor are they written to durable storage by the broker. In the case of a system failure or a lack of subscribers on the channel, the messages are simply discarded, providing at-most-once delivery. NATS.io Core (not JetStream) is an example of this form of implementation.Figure 1-2 shows a single producer sending messages to the ephemeral channel within the event broker. The ephemeral messages are then passed on to the currently subscribed consumers. In this figure, Consumer 0 obtains messages 7 and 8, but Consumer 1 does not because it is newly subscribed and has no access to historical data. Instead, Consumer 1 will receive only message 9 and any subsequent messages.

Figure 1-2. An ephemeral message-passing broker forwarding messages
Ephemeral communication lend itself well to direct service-to-service communication with low overhead. It is a message-passing architecture, and is not to be confused with a durable publish-subscribe architecture as provided by event streams.
Message-passing architectures provides point-to-point communication between systems that don’t necessarily need at-least-once delivery and can tolerate some data loss. As an example, the online dating application Tinder uses NATS to notify users of updates. If the message is not received, not a big deal—a missed push notification to the user only has a minor (though negative) effect on the user experience.
Ephemeral message-passing brokers lack the necessary indefinite retention, durability, and replayability of events that we need to build event-driven data products. Message-passing architectures are useful for event-driven communication between systems for current operational purposes but are completely unsuited for providing the means to communicate data products.
Queuing
A queue is a durable sequence of stored records awaiting processing. It is fairly common to have multiple consumers that asynchronously (and competitively) select, process, and acknowledge records on a first-come, first-served basis. This is one of the major differences when compared to event streams, which use partition-exclusive subscriptions and strict in-order processing.
A work queue is a common use cases. The producer publishes “work to do” records, while consumers dequeue records, processes them, then signals to the queue broker that the work is complete. The broker then typically deletes the processed records, which is the second major difference when compared to the event stream, as the latter retains the records as long as specified (including indefinitely).
Figure 1-3 shows two subscribers consuming records from a queue in a round-robin manner. Note that the queue contains records currently being processed (dashed lines) and those yet to be processed (solid lines).
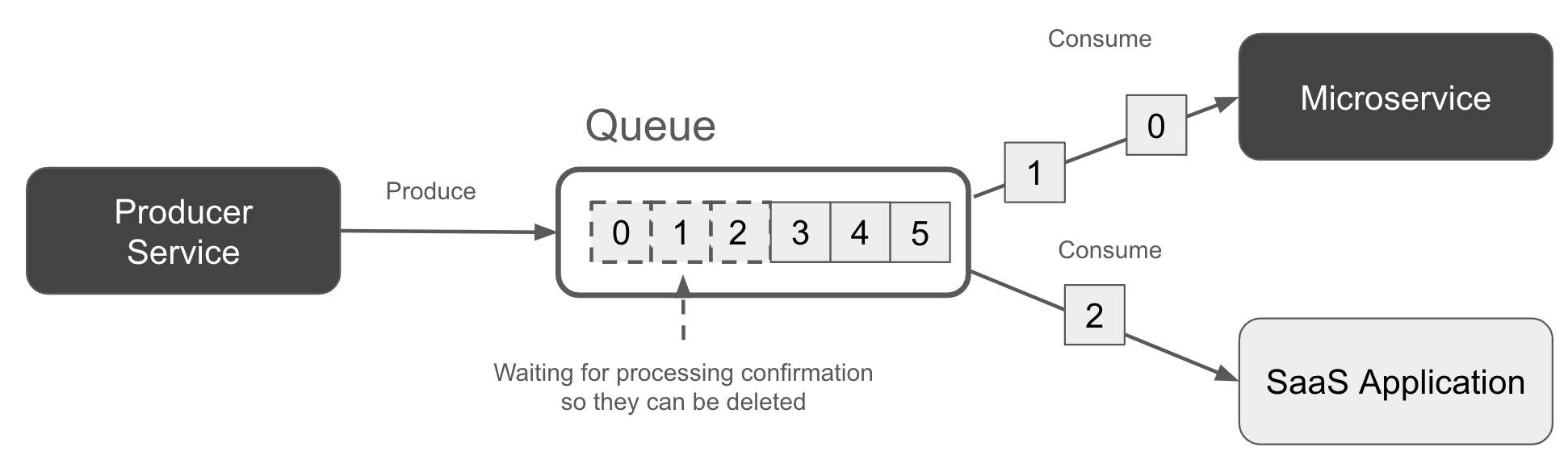
Figure 1-3. A queue with two subscribers each processing a subset of events
Queues typically provide “at-least once” processing guarantees. Records may be proccessed more than once, particularly if a subscriber fails to commit its progress back to the broker, say due to a crash, after processing a record. In this case, another subscriber may pick up the record and process it again.
If multiple independent consumers (e.g. microservice applications) need access to the records in the queue (say in fulfilling a Sales event), then you’d have to either use an event stream, or create a queue for each consuming service. Figure 1-4 shows an example where the producer service writes a copy of each record to two different queues to ensure that each consumer has a copy of the data to process.
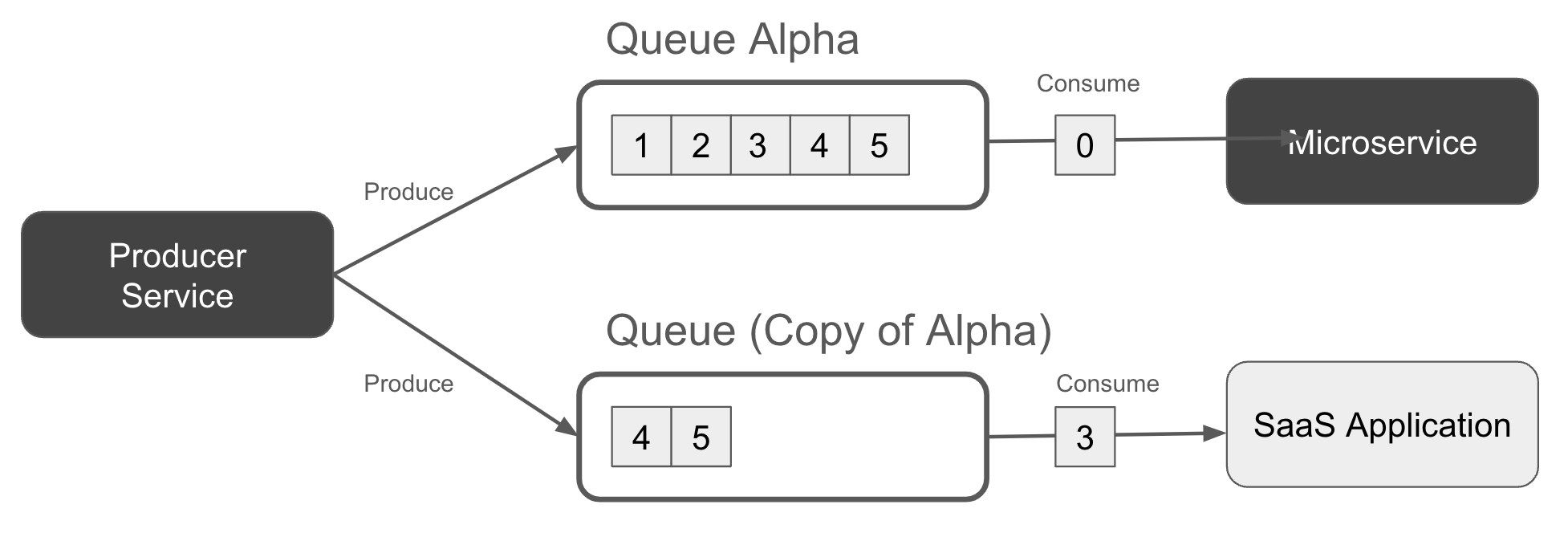
Figure 1-4. A producer writing to two duplicate queues, one or each consumer application.
Warning
Your producer service may not be able to atomically write to more than one queue at a time. You’ll need to review the limitations of your broker’s multi-queue write capabilities. A failure to do so may see the queues diverge from one another over time, as race conditions and intermittent failures may see a record written to one queue, but not the others.
Historically, queue brokers have limited the time-to-live (TTL) for storing records in the queue. Records not processed within a certain time frame are marked as dead, purged, and no longer delivered to the subscribers - even if they have not yet been processed! Similar to ephemeral communications, time-based retention and non-replayable data has influenced the false notion that brokers (queue and event alike) cannot be used to retain data indefinitely.
With that being said, it is important to note that low TTLs are no longer the norm, at least for the more modern queue technologies. For example, both RabbitMQ and ActiveMQ let you set unlimited TTL for your records, letting you keep them in the queue for as long as is necessary for your business.
Note
Modern queue brokers may also support replayability and infinite retention of records via durable append-only logs - effectively the same as an event stream. For example, both Solace and RabbitMQ Streams allow for individual consumers to replay queued records as though it were an event stream.
One last thing before we close out this section. Queues can also provide priority-based record ordering for its consumers, so that high priority records get pushed to the front, while low priority records remain in the back of the queue until all higher priority records are processed. Queues provide an ideal data structure for priority ordering, since they do not enforce a strict first-in, first-out ordering like an event stream.
Queues are best used as an input buffer for a specific downstream system. You can rely on a queue to buffer records that need processing by another system, allowing the producer application to get on with its other tasks - including writing more records to the queue. You can rely on the queue to durably store all the records until your consumer service can get to working on them. Additionally, your consumer can scale up its processing by registering new consumers on the queue, and sharing processing in a round-robin manner.
The Structure of an Event
Events, as written to an event stream, are typically represented using a key, a value, and a header. Together, these three components form the record representing the event.
The record’s exact structure will vary with your technology of choice. For example, queues and ephemeral-messaging tend to use similar yet different conventions and components, such as header keys, routing keys, and binding keys, to name a few. But for the most part, this following three-piece record format is generally applicable for all events.
- The key
-
The key is optional but extremely useful. It’s typically set to a unique ID that represents the data of the event itself, akin to a primary key in a relational database. It is also commonly used to route the event to a specific partition of the event stream. More on that later in this chapter.
- The value
-
Contains the bulk of the data relating to the event. If you think of the event key as the primary key of a database table’s row, then think of the value as all the other fields in that row. The value carries the majority of an event’s data.
- The header (also known as “record properties”)
-
Contains metadata about the event itself, and is often a proprietary format depending on the event broker. The record is usually used to record information such as datetimes, tracking IDs, and user-defined key-value pairs that aren’t suitable for the value.
An example of the record structure is shown in Figure 1-5, containing a minimal set of details pertaining to an e-commerce order.
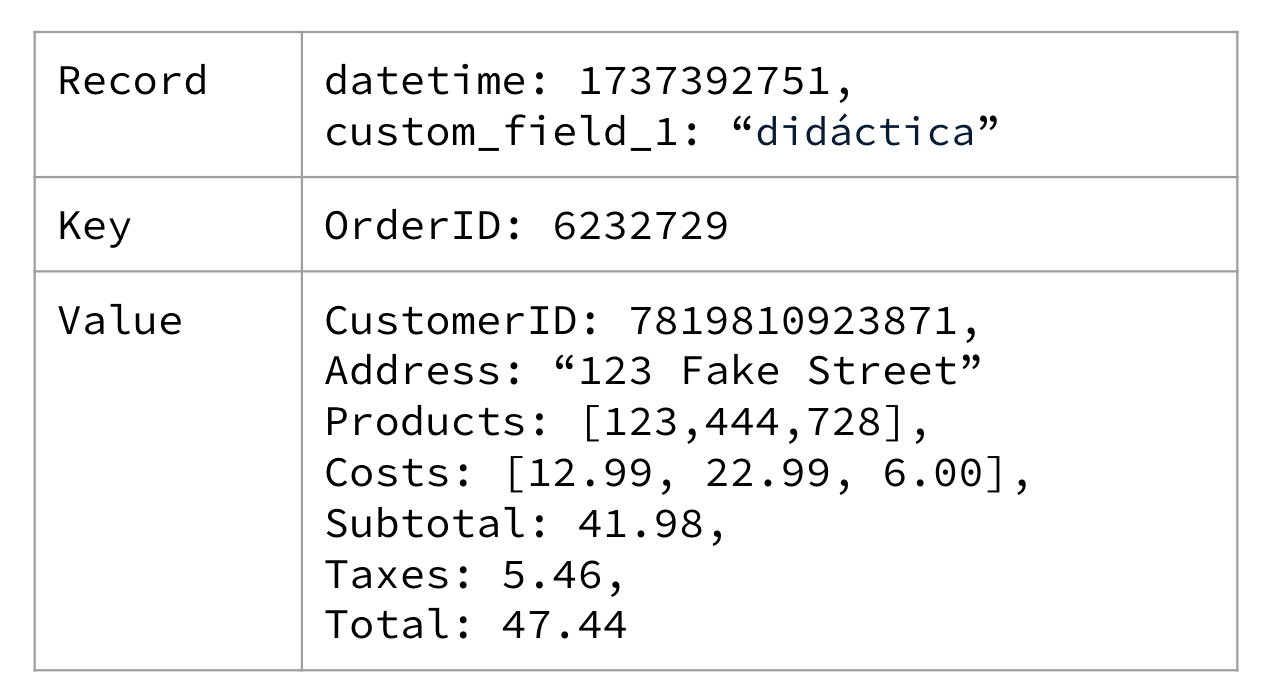
Figure 1-5. A simple e-commerce order showing the items purchased by a user, along with the total cost
Events are immutable. You can’t modify an event once it is published to the event stream. Immutability is an essential property for ensuring that consumers each have access to exactly the same data. Mutating data that has already been read by several consumers is of no benefit, since there is no way to easily notify them that they must make a change to data that they’re already read. You can, however, create and publish a new events containing the necessary corrections or updates, covered more in chapter [Link to Come].
Events tend to fall into three main classifications: unkeyed events, keyed events, and entity events. Let’s take a look closer look at each.
Unkeyed Event
Unkeyed events do not contain a key. They’re generally considered to be fully independent of one another. There is no special treatment for routing to a particular partition.Unkeyed events are commonly some form of raw measurement. For example, a camera that photographs an automobile running through a red light may creates an unkeyed event, as shown in Figure 1-6
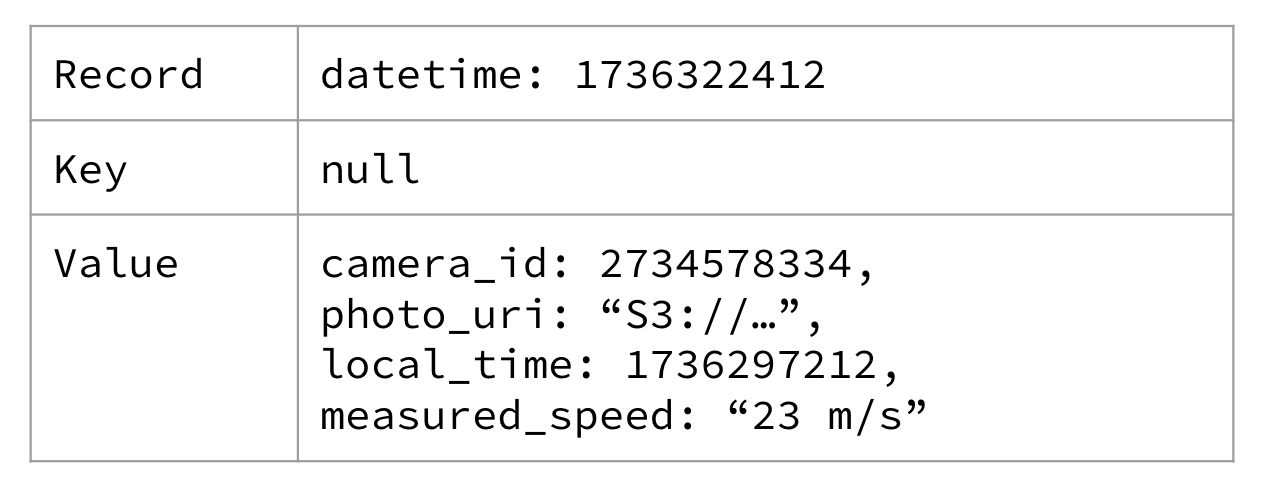
Figure 1-6. An unkeyed red light traffic camera event
Could the red light camera have produced the event with the camera_id as the key? Sure! But it didn’t, because it only records the data in that specific format, and this specific camera doesn’t support custom post-processing. You get the event in the format that it specifies in the user manual.
If we want to add a key, we’re going to have to do some additional processing and emit a new event stream, as you’ll see in this next section.
Keyed Events
Keyed events contain a non-null key related to something important about the event. The event key is specified by the producer service when it creates the record, and remains immutable once written to the event stream.
If we were to apply a key to the red light traffic camera data, we may choose to use the driver’s license plate. You can see an example of that in Figure 1-7.
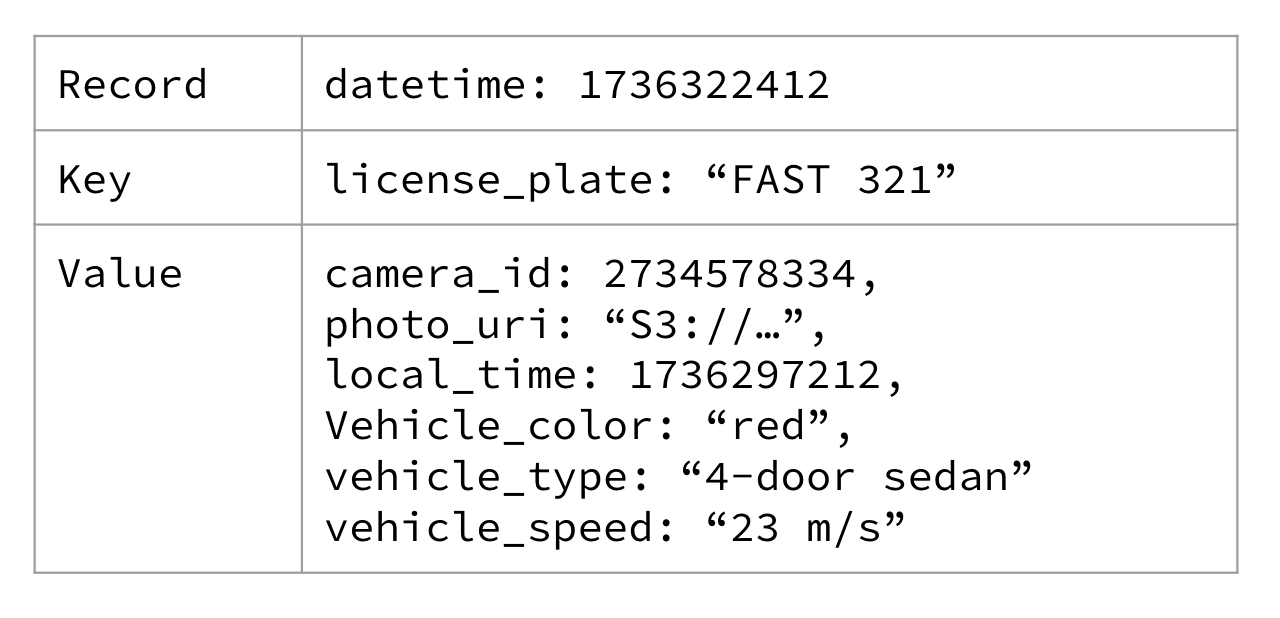
Figure 1-7. A red light traffic camera event keyed on the driver’s license plate
A key enables the producer to partition the records deterministically, with all records of the same key going to the same event stream partition, as per Figure 1-8. This provides your event consumers with a guarantee that all data of a given key will be in just a single partition. In turn, your consumers can easily divide up the work on a per-partition basis, knowing that any key-based work they perform will only rely on reading a single partition, and not all the events from all partitions.
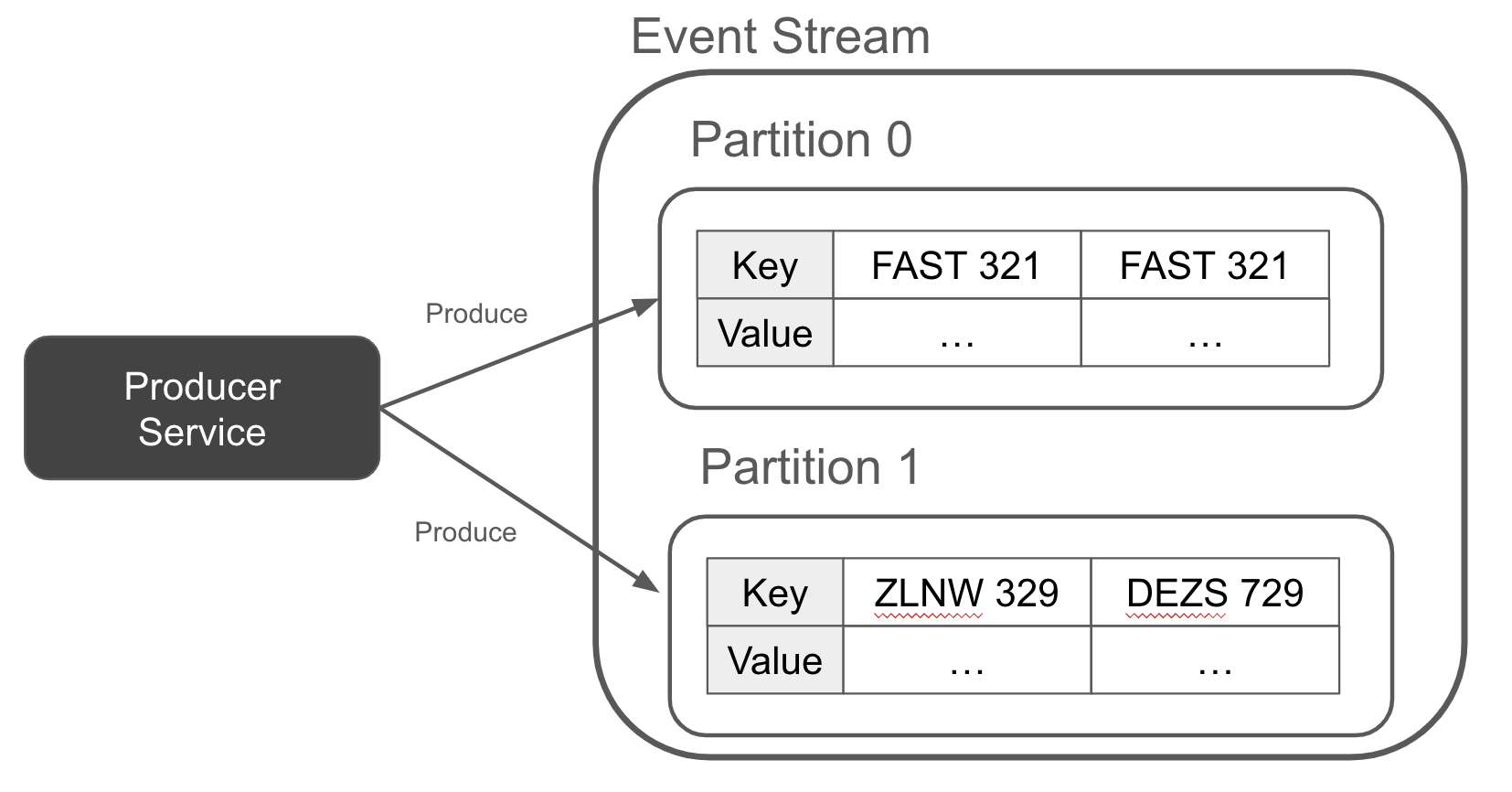
Figure 1-8. A red light traffic camera event keyed on the driver’s license plate
As illustrated in the partitioned topic, you can see that there are at least two events for FAST 321. Each of these events represents an instance of the car running through a red light. Keep this in mind as we go to our final event classification, the entity event.
Entity Event
An entity event represents a unique thing, and is keyed on the unique ID of that thing. It describes the properties and state of the entity at a specific point in time. Entity events are also sometimes called state events, as they represent the state of a given thing at a given point in time.
For something a bit more concrete, and to continue the red light camera analogy, you could expect to see a Car as an entity event. You may also see entity events for Driver, Tire, Intersection, or any other number of “things” involved in the scenario. A car entity is featured in Figure 1-9.
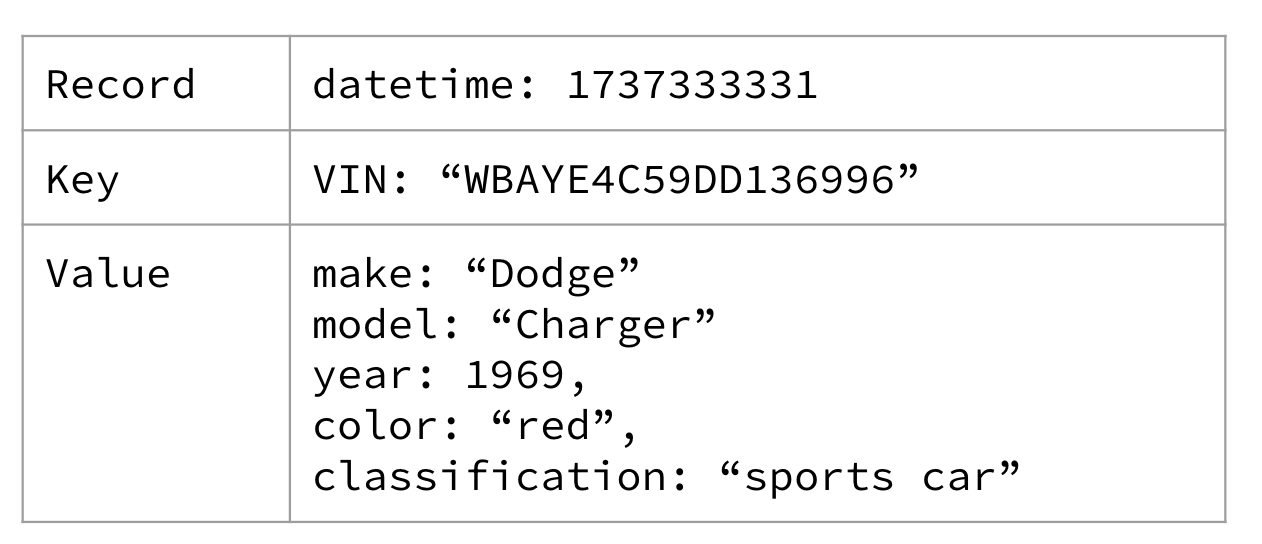
Figure 1-9. A Car entity describing the sports car that keeps running the red lights
You may find it helpful to think of an entity event like you would think of a row in a database table. Both have a primary key, and both represent the data for that primary key as it is at the current point in time. And much like a database row, the data is only valid for as long as the data remains unchanged. Thus, if you were to repaint the car to blue, you could expect to see a new event with the color updated, as in Figure 1-10.

Figure 1-10. The car has been repainted blue
You may also notice that the datetime field has been updated to represent when the car was painted blue (or at least when it was reported). You’ll also notice that the entity event also contains all the data that didn’t change. This is intentional, and it actually allows us to do some pretty powerful things with entity events - but we’ll cover that in a bit more detail in Chapter 3.
Similarly to how keyed events each go to the same partition, the same is true for entity events. Figure 1-11 shows an event stream with two events for the FAST 321 - one when it was red (the oldest event), and one while it is blue (the latest event, appended to the tail of the stream).
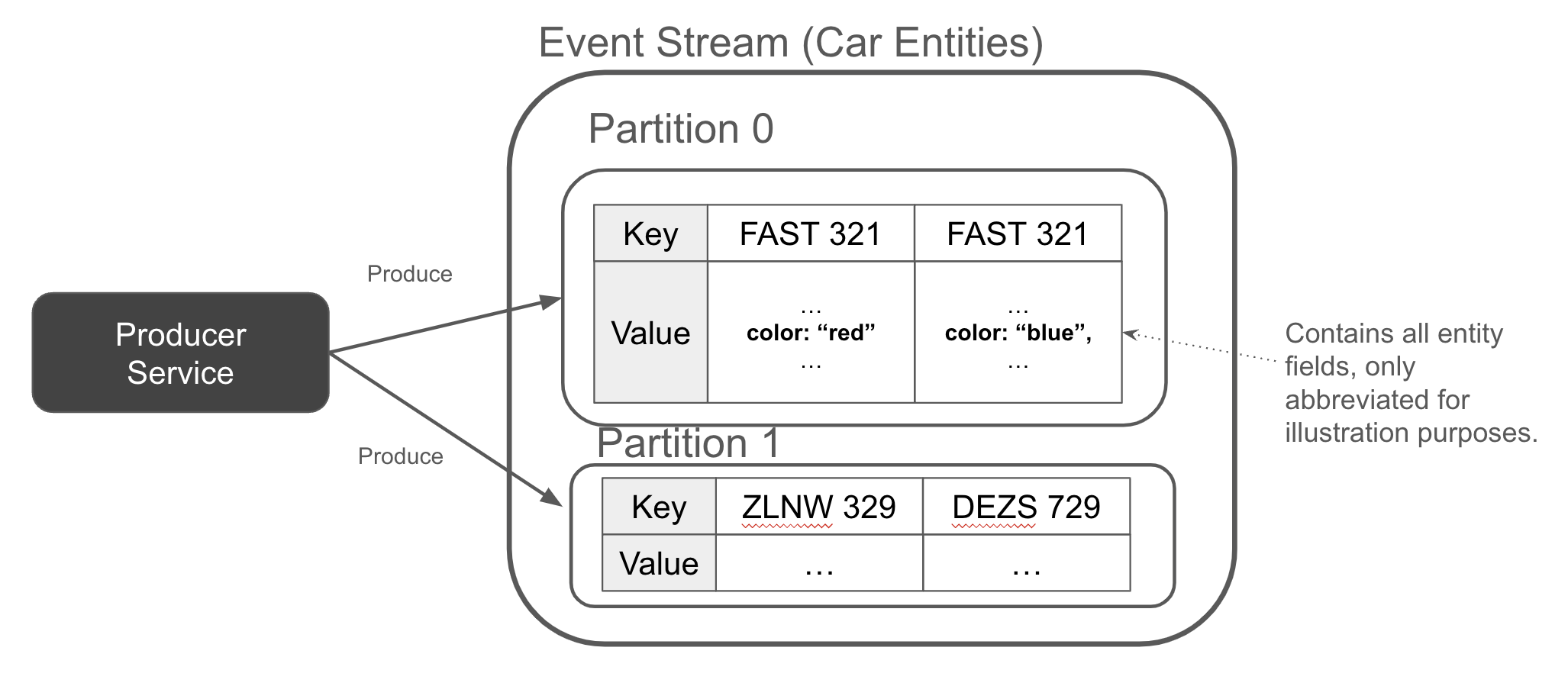
Figure 1-11. The producer appends a full entity event whenever an entity is created, updated, or deleted
Entity events are particularly important in event-driven architectures. They provide a continual history of the state of an entity and can be used to materialize state (covered in the next section).
There is more to event design than what we’ve covered in this chapter so far, but we’re going to defer going deeper into that until chapter [Link to Come]. Instead, lets look at how we might use these events that we’ve just introduced to build real world event-driven microservices.
Aggregating State from Keyed Events
An aggregation is the process of consuming two or more events and combining them into a single result. Aggregations are a common data processing primitive for event-driven architectures, and are one of the primary ways to generate state out of a series of events. Building an aggregation requires storing and maintaining durable state, such that aggregation progress is persisted if the service fails. State and recovery are covered in chapter [Link to Come].
The keyed event plays an important role in aggregations, since all the data of the same key is in the same partition. Thus, you can simply aggregate a single key by reading a single partition. If you’re reading multiple topics, then you’ll need to ensure that they’re partitioned identically - otherwise you’re going to have to repartition the data so that the streams match one another. Repartitioning and co-partitioning are covered further in chapter [Link to Come].
An aggregation may be as simple as a sum, as shown in Figure 1-12. For example, summing up the traffic infraction tickets that have been issued to the owner of a speeding sports car, and computing the total of the amount owed.
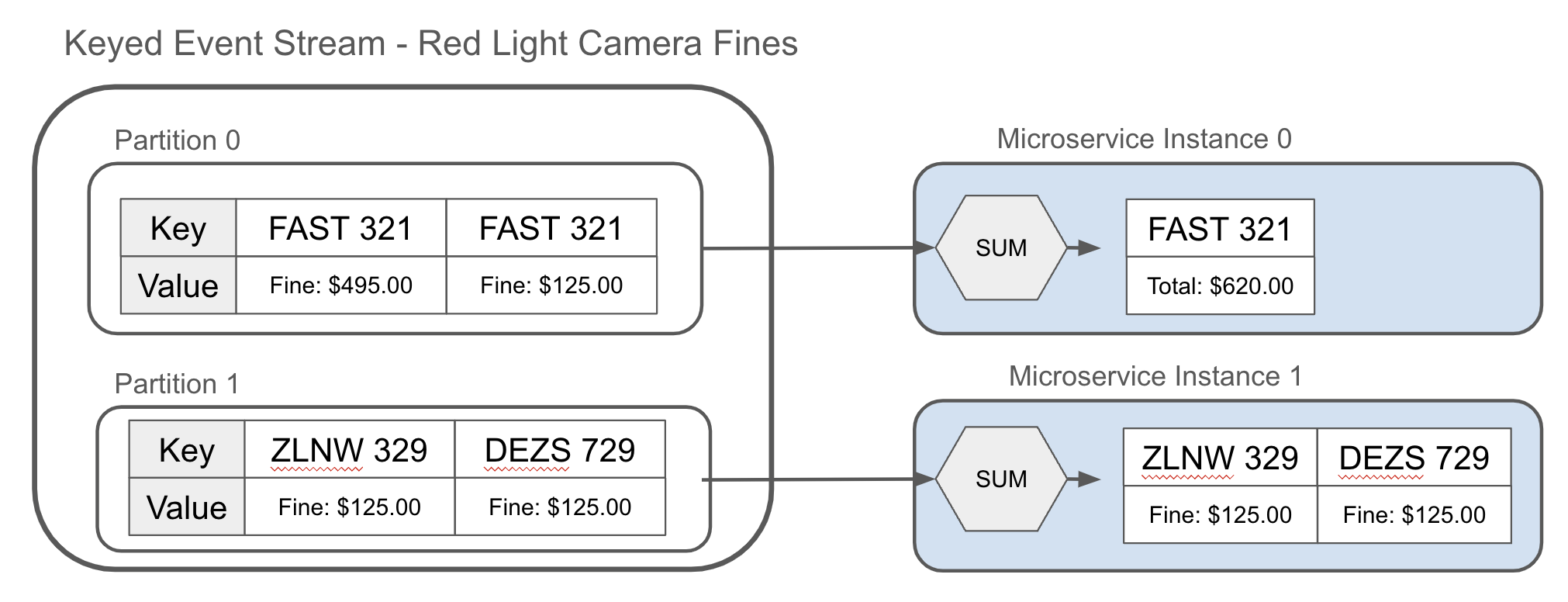
Figure 1-12. Aggregating the keyed events of the red light camera fines
Aggregations may also be more complex, incorporating multiple input streams, multiple event types, and internal state machines to derive more complex results. We’ll revisit aggregations throughout the book, but for now, let’s take a look at materializations.
Materializing State from Entity Events
A materialization is a projection of a stream into a table. You materialize a table by applying entity events, in order, from an entity event stream. Each entity event is upserted into the table, such that the most recently read event for a given key is represented. This is illustrated in Figure 1-13, where FAST 321 and SJFH 372 both have the newest values in their materialized table.
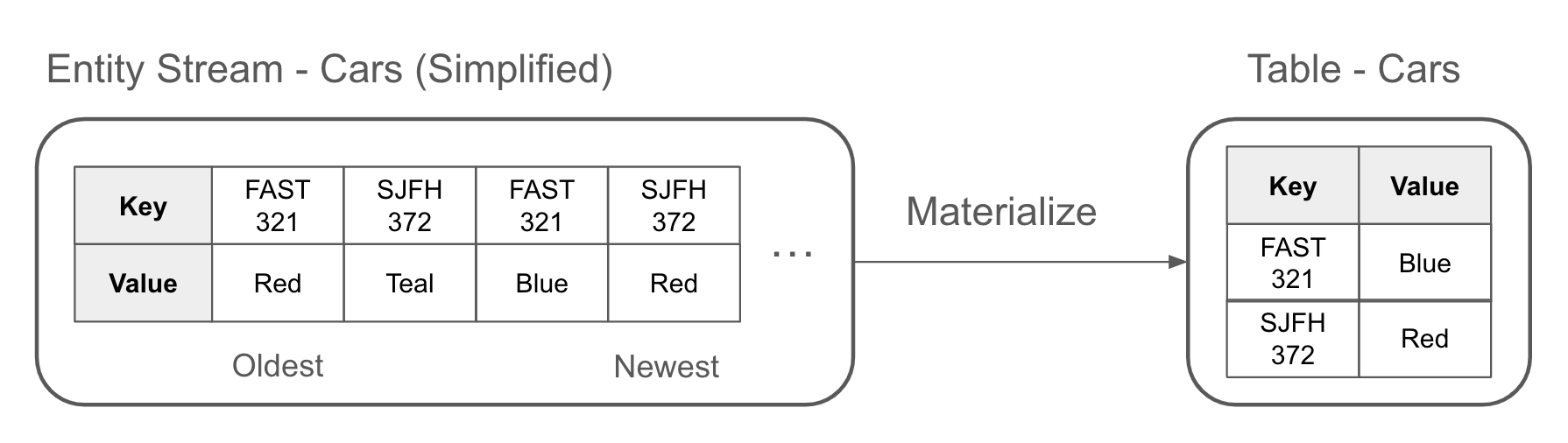
Figure 1-13. Materializing an event stream into a table
You can also convert a table into a stream of entity events by publishing each update to the event stream.
Tip
Stream-Table duality is the principle that a stream can be represented by a table, and a table can be represented as a stream. It is fundamental to the sharing of state between event-driven microservice, without any direct coupling between producer and consumer services.
In the same way, you can have a table record all updates and in doing so produce a stream of data representing the table’s state over time. In the following example, BB is upserted twice, while DD is upserted just once. The output stream in Figure 1-14 shows three upsert events representing these operations.
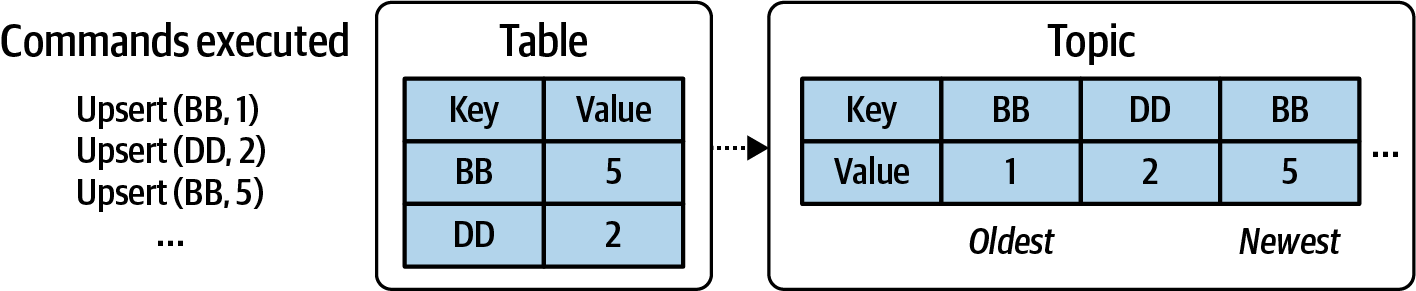
Figure 1-14. Generating an event stream from the changes applied to a table
Deleting Events and Event Stream Compaction
First, the bad news. You can’t delete a record from an event stream as you would a row in a database table. A major part of the value proposition of an event stream is its immutability. But you can issue a new event, known as a tombstone, that will allow you to delete records with the same key. Tombstones are most commonly used with entity event streams.
A tombstone is a keyed event with its value set to null, a convention established by the Apache Kafka project. Tombstones serve two purposes. First, they signal to the consumer that the data associated with that event key should now be considered deleted. To use the database analogy, deleting a row from a table would be equivalent to publishing a tombstone to an event stream for the same primary key.
Secondly, tombstones enable compaction. Compaction is an event broker process that reduces the size of the event streams by retaining only the most recent events for a given key. Events older than the tombstone will be deleted, and the remaining events are compacted down into a smaller set of files that are faster and easier to read. Event stream offsets are maintained such that no changes are required by the consumers. Figure 1-15 illustrates the logical compaction of an event stream in the event broker.
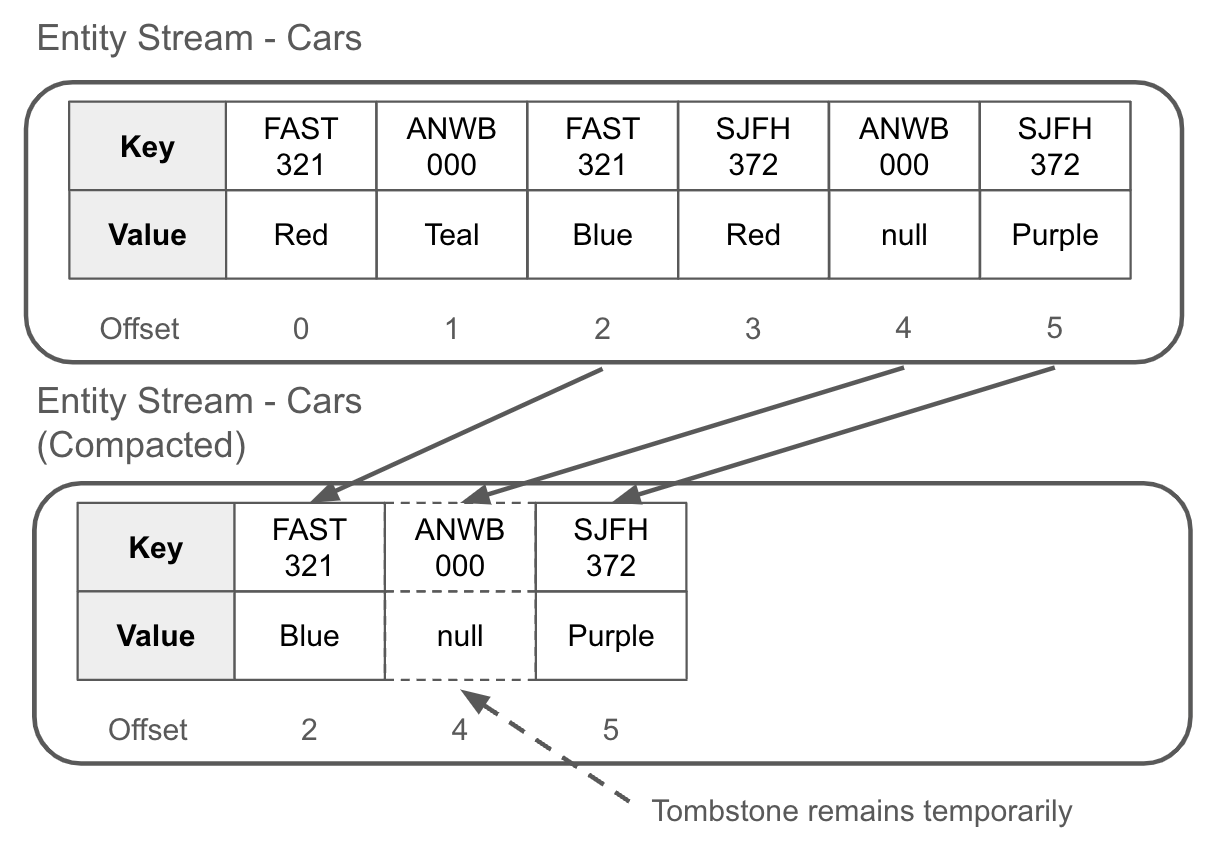
Figure 1-15. After a compaction, only the most recent record is kept for a given key — all predecessors records of the same key are deleted
The tombstone record typically remains in the event stream for a short period of time. In the case of Apache Kafka, the default value of 24 hours gives consumers a chance to read the tombstone before it too is (asynchronously) cleaned up.
Compaction is an asynchronous process performed only when a certain set of criteria is met, including dirty ratio, or record count in inactive segments. You can also manually trigger compaction. The precise mechanics of compaction vary with event broker selection, so you’ll have to consult your documentation accordingly.
Compaction reduces both disk usage and the quantity of events that must be processed to reach the current state, at the expense of eliminating a portion of the event stream history. Comapaction typically provides several useful configurations and guarantees, including:
- Minimum Compaction Lag
-
You can specify the minimum amount of time a record must live in the event stream before it is eligible for compaction. For example, Apache Kafka provides a min.compaction.lag.ms property on its topics. You can set this to a reasonable value, say 24 hours or 7 days, to ensure that your consumers can read the data before it is compacted away.
- Offset Guarantees
-
Offsets remain unchanged before, during, and after compaction. Compaction will introduce gaps between sequential offsets, but there remains no consequences for consumers sequentially consuming the event stream. Trying to read a specific offset that no longer exists will result in an error.
- Consistency Guarantees
-
A consumer reading from the start of a compacted topic can materialize exactly the same table as a consumer that has been running since the beginning.
Caution
While you may be able to find tools that allow you to delete records from an event stream manually, be very careful. Manually deleting records can lead to unexpected results, particularly if you have consumers that have already read the data. Simply deleting the records won’t fix the consumers derived state. Prevention of bad data is essential, and we’ll cover that more in chapter [Link to Come].
Stream-table duality and materialization allow our services to communicate state between one another. Compaction lets us keep our event streams to a reasonable size, in line with the domain of the data.
The Kappa Architecture
The Kappa architecture was first presented in 2014 by Jay Kreps, cocreator of Apache Kafka and cofounder of Confluent. The Kappa architecture relies on event streams as the sole record for both current and historical data. Consumers simply start consuming from the start of the stream to get a full picture of everything that has happened since inception, eventually reaching the head of the stream and the latest events as per Figure 1-16.
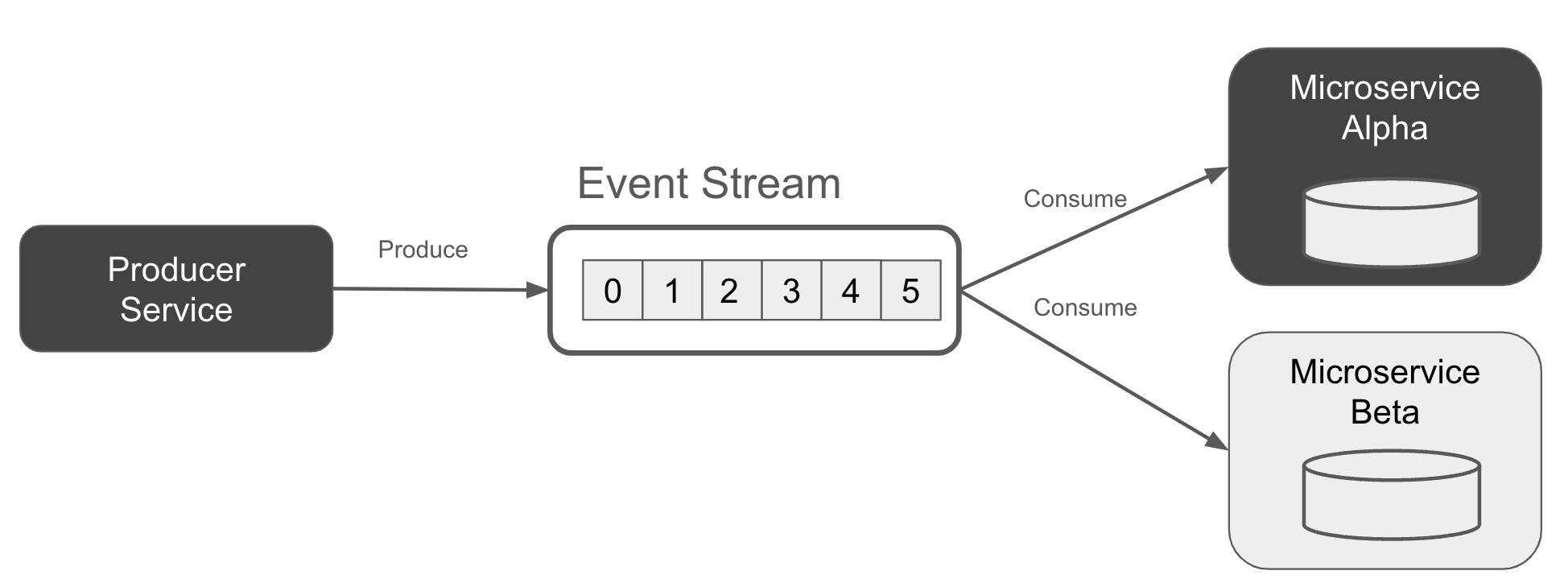
Figure 1-16. Kappa Architecture, with each service building its state from just an event stream
Kappa architectures do not use a secondary store for historical data, as is the case in the Lambda architecture (more on that in the next section). Kappa relies entirely on the event stream for storage and serving.
Kappa architectures have only been realized with modern event brokers, in combination with cheap storage ushered in with the Cloud computing revolution. It is affordable and easy to store as much data as you need in the stream, and you are no longer limited by broker technologies that applied mandatory TTLs, deleting your records after a few hours or days.
Event-driven microservices simply materialize their own state from the streams as they need. There is no need to access data from a secondary store somewhere else, nor any of the complexity overhead in managing extra permissions. It’s clean, simple, and easy to code.
There are some trade-offs with Kappa. Each service must build its own state, and for extremely large data sets it may take some time to materialize from the event stream. A low partition count and insufficient parallelization may see your service take many hours or days to materialize. This is often called “hydration time”, and you’ll need to plan for it in your service life cycle.
You can mitigate the hydration time problem by maintaining snapshots or backups of your materialized and computed state. Then, when loading your application, your service simply loads from its backed up data and restores processing from where it left off. While this is a responsibility of the application itself, snapshots and backups come with leading stream-processing technologies such as Apache Kafka Streams, Apache Flink, and Apache Spark Streaming, just to name a few of the open source industry leaders.
The Kappa architecture is key to building decoupled event-driven microservices as it provides your services with a single powerful guarantee - that your event stream can act as a single source of truth for a given set of data. There is no need to go elsewhere to a secondary or tertiary store. All the data you need is in that event stream, ready to go for your services.
What does the Kappa architecture look like in code?
Example 1-1 shows a Kafka Streams
application with twoKTables, which is just a stream materialized into a table using ECST. Next, the inventory KTable and the sales KTable are joined using a non-windowed INNER join to create a KTable of denormalized and enriched item inventory. Stream-processing frameworks make it very easy to handle event streams, build up internal state using ECST, and merge and join data from various data products, in just a few lines of code. Example 1-1. Showcasing joins with Kafka Streams
StreamsBuilderbuilder=newStreamsBuilder();//Materializes the tables from the source Kafka topicsKTableproducts=builder.table("products")KTableproductReviews=builder.table("product_reviews")//Join events on the primary key, apply business logic as neededKTableproductsWithReviews=products.join(productReviews,businessLogic(..),...)builder.build();
Apache Flink can provide something similar. Let’s say we wanted something more SQL-like.
Example 1-2. Showcasing joins with Flink SQL
CREATETABLEPRODUCTS(product_idBIGINT,nameVARCHAR,brandVARCHAR,descriptionVARCHAR,timestampTIMESTAMP(3),PRIMARYKEY(product_id)NOTENFORCED,)WITH('connector'='kafka','topic'='products','format'='protobuf','properties.bootstrap.servers'='localhost:9092','properties.group.id'='foobar');CREATETABLEPRODUCT_REVIEWS(product_idBIGINT,reviewsVARCHAR,timestampTIMESTAMP(3),PRIMARYKEY(product_id)NOTENFORCED,)WITH('connector'='kafka','topic'='product_reviews','format'='protobuf','properties.bootstrap.servers'='localhost:9092','properties.group.id'='foobar');CREATETABLEPRODUCTS_WITH_REVIEWSASSELECT*FROMPRODUCTSINNERJOINPRODUCT_REVIEWSONPRODUCTS.product_id=PRODUCT_REVIEWS.product_id;
Both the Flink SQL and the Kafka Streams code samples are simple, clear, and concise. We’ll cover building microservices with these technologies later in this book. But for now, as we go to look at the Lambda architecture, just keep in mind how easy it is to leverage the Kappa architecture. It just takes a few lines of code to transform a stream of events into a self-updating table capable of driving your microservice code.
The Lambda Architecture
The Lambda architecture relies on both an event stream for real-time data and a secondary repository for storage of historical data. The Lambda architecture is predicated on the outdated notion that you cannot store events in an event stream indefinitely. It is, however, consistent with the outdated technologies that enforced mandatory TTLs on event streams. It remains stubbornly persistent in the minds of many, and so we include it in this book for the sake of historical context, but not as an endorsement for use.
Consumers in a lambda architecture must obtain their historical data from the historical repository first, loading it into their respective state stores. Then, the consumers must swap over to the event stream for further updates and changes.
There are two main versions of this architecture. In the first, the historical repository and the stream are built independently. In the second, the historical repository is built from the stream. Let’s take a look at the first, first.
The historical repository contains the results of aggregations, materializations, or richer computations. It’s not just another location to store events. Historically speaking, the historical repository has often simply been just the internal database of the source system. In other words, you’d ask the source system for the historical data, load it in to your system, then swap over to the event stream. This is a bit of a anti-pattern as it puts the entire consumer load on the producer service, but it’s common enough that it’s worth mentioning.
[Link to Come] shows a simplified implementation of the Lambda architecture. The producer writes new data to both the event stream and the historical data store.
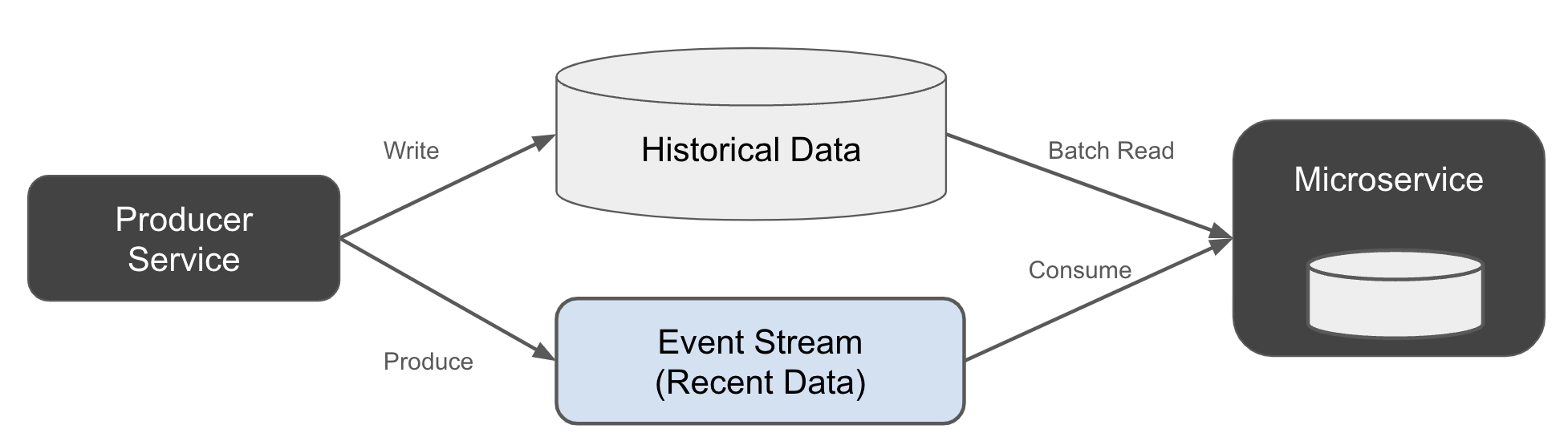
Figure 1-17. Lambda architecture, writing to both the stream and the historical data table at the same time
A major flaw in this plan is that the data is not written atomically. The reality is that it’s very difficult to get high performance distributed transactions across multiple independent systems. What tends to happen in reality is that the producer updates one system first (say the historical data store), then the other (the event stream). An intermittent failure during the writes may see the event written to the historical store but not the stream - or vice verse, depending on your code.
The problem is that your stream and historical data set will diverge, meaning that you get different results than if you build from the stream than you would from the the historical data. An old consumer reading solely from the stream may compute a different result than a new consumer bootstrapping itself from the historical data. This can cause serious problems in your organization, and it can be very difficult to track down the reason why - particularly since the event stream data is time-limited, and evidence of its divergence is deleted after just a few days.
In the second version of Lambda architecture, the historical data is populated directly from the initial event stream, as shown in Figure 1-18.
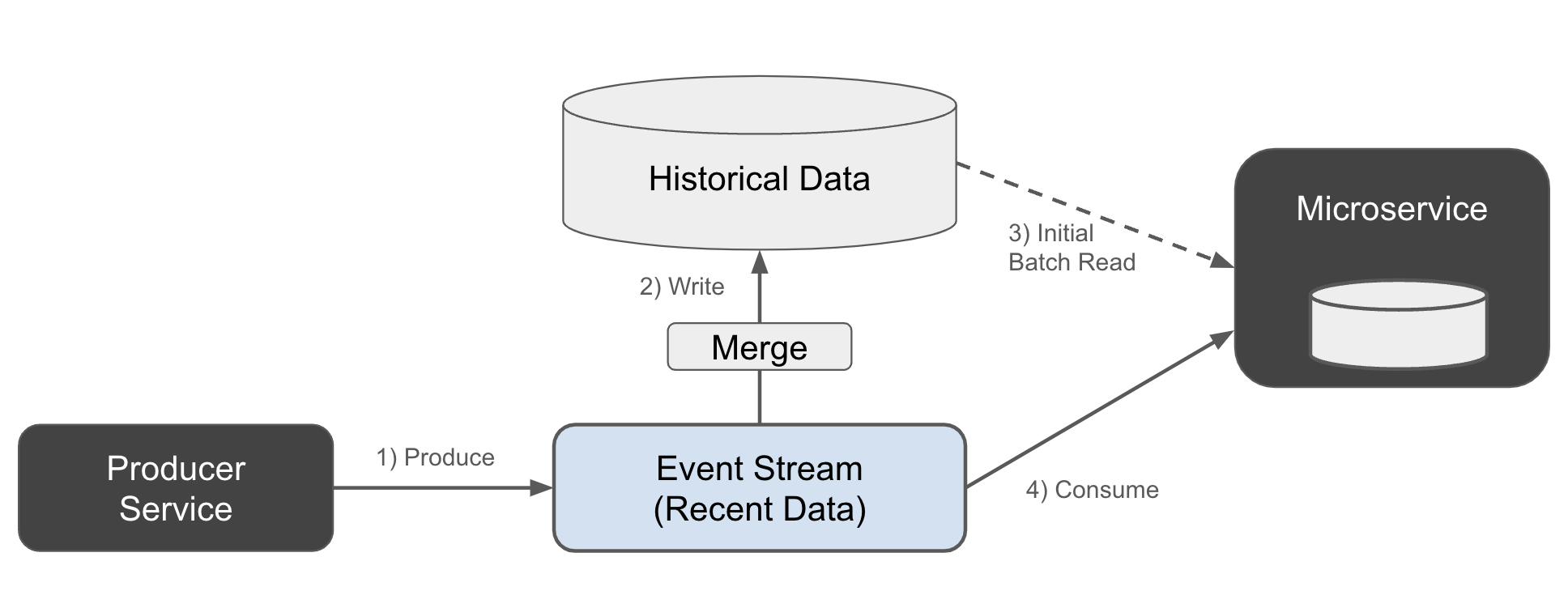
Figure 1-18. Historical lambda data build from the event stream
The producer writes directly to the event stream (1). The historical data is populated by a secondary process that merges it into the data store (2). The consumer in turn reads the historical data first (3), then switches over to the event stream (4).
If you squint a little, you may find that this second version looks an awful lot like the Kappa architecture - except that we’re builing the state store outside of the microservice. The only complication is that we’ve introduced this awkward split between the event broker and the historic data store - an artifact due to the now-invalid notion that an event broker cannot store events indefinitely.
Overall, the Lambda architecture may seem simple in theory, but it ends up being very difficult to do well in practice. Why? Here are a few of the major obstacles, as we wrap this section up:
- The producer must maintain extra code
-
The code that writes to the stream, and the code that writes to the historical store.
- The consumer must maintain two code paths
-
One path reads from the historical store, and one path reads from the stream. The consumer must write code that seamlessly switches from one to the other, without missing any data or accidentally duplicating data. This can be quite challenging in practice, particularly with distributed systems and intermittent failures.
- Streamed data may not converge to the same results as the historical data
-
Consumers may not get exactly the same results if reading from the stream as the table. The producer must ensure that the data between the two does not diverge over time, but this is challenging without atomic updates to both the stream and the historical data store.
- The stream and historical data models must evolve in sync
-
Data isn’t static. If you have to update the data format, it will require code changes in two places - the historical store and the stream.
- Merging multiple Lambda-powered data sets is almost impossible
-
It’s easy to merge multiple Kappa data sets, as illustrated in [Link to Come]. There is no crossover from one source to another, so you can simply stream the data from the event stream and get consistent results. But there’s no natural governance between the stream and the historical data set. Event stream records and historical data will overlap, the rules for merging the former into the latter will differ by data set, as will rules for expiring records from the event stream.
Reconciling the dual storage of stream and historical is difficult for just a single data set. It’s even more challenging when you bring multiple data sets into the mix, each with its own unique stream/historical data boundaries.
The long and the short of it is that Lambda architecture is simply too difficult to manage at any reasonable scale. It puts the entire onus of accessing data onto the consumer, forcing them to reconcile two the seams not only between the stream and the historical data, but also the steams and historial data seams of all the other data sets they want to process too. It is far easier, both cognitively and coding-wise, to rely on the Kappa architecture with the single stream source for providing historical data.
Event Data Definitions and Schemas
Event data serves as the means of long term and implementation agnostic data storage, as well as the communication mechanism between services. Therefore, it is important that both the producers and consumers of events have a common understanding of the meaning of the data. Ideally, the consumer must be able to interpret the contents and meaning of an event without having to consult with the owner of the producing service. This requires a common language for communication between producers and consumers and is analogous to an API definition between synchronous request-response services.Schematization selections such as Apache Avro and Google’s Protobuf provide two features that are leveraged heavily in event-driven microservices. First, they provide an evolution framework, where certain sets of changes can be safely made to the schemas without requiring downstream consumers to make a code change. Second, they also provide the means to generate typed classes (where applicable) to convert the schematized data into plain old objects in the language of your choice. This makes the creation of business logic far simpler and more transparent in the development of microservices. [Link to Come] covers these topics in greater detail.
Powering Microservices with the Event Broker
Event broker systems suitable for large-scale enterprises all generally follow the same model. Multiple, distributed event brokers work together in a cluster to provide a platform for the production and consumption of event streams and queues. This model provides several essential features that are required for running an event-driven ecosystem at scale:
- Scalability
-
Additional event broker instances can be added to increase the cluster’s production, consumption, and data storage capacity.
- Durability
-
Event data is replicated between nodes. This permits a cluster of brokers to both preserve and continue serving data when a broker fails.
- High availability
-
A cluster of event broker nodes enables clients to connect to other nodes in the case of a broker failure. This permits the clients to maintain full uptime.
- High-performance
-
Multiple broker nodes share the production and consumption load. In addition, each broker node must be highly performant to be able to handle hundreds of thousands of writes or reads per second.
Though there are different ways in which event data can be stored, replicated, and accessed behind the scenes of an event broker, they all generally provide the same mechanisms of storage and access to their clients.
Selecting an Event Broker
While this book will make frequent reference to Apache Kafka as an example, there are other event brokers that could make suitable selections. Instead of comparing technologies directly, consider the following factors closely when selecting your event broker.
Support tooling
Support tools are essential for effectively developing event-driven microservices. Many of these tools are bound to the implementation of the event broker itself. Some of these include:
-
Browsing event stream records
-
Browsing schema data
-
Quotas, access control, and topic management
-
Monitoring, throughput, and lag measurements
See [Link to Come] for more information regarding tooling you may need.
Hosted services
Hosted services allow you to outsource the creation and management of your event broker.-
Do hosted solutions exist?
-
Will you purchase a hosted solution or host it internally?
-
Does the hosting agent provide monitoring, scaling, disaster recovery, replication, and multizone deployments?
-
Does it couple you to a single specific service provider?
-
Are there professional support services available?
Client libraries and processing frameworks
There are multiple event broker implementations to select from, each of which has varying levels of client support. It is important that your commonly used languages and tools work well with the client libraries.-
Do client libraries and frameworks exist in the required languages?
-
Will you be able to build the libraries if they do not exist?
-
Are you using commonly used frameworks or trying to roll your own?
Community support
Community support is an extremely important aspect of selecting an event broker. An open source and freely available project, such as Apache Kafka, is a particularly good example of an event broker with large community support.-
Is there online community support?
-
Is the technology mature and production-ready?
-
Is the technology commonly used across many organizations?
-
Is the technology attractive to prospective employees?
-
Will employees be excited to build with these technologies?
Indefinite and tiered storage
Indefinite storage lets you store events forever, provided you have the storage space to do so. Depending on the size of your event streams and the retention duration (e.g. indefinite), it may be preferable to store older data segments in slower but cheaper storage.
Tiered storage provides multiple layers of access performance, with a dedicated disk local to the event broker or its data-serving nodes providing the highest performance tier. Subsequent tiers can include options such as dedicated large-scale storage layer services (e.g., Amazon’s S3, Google Cloud Storage, and Azure Storage).
-
Is tiered storage automatically supported?
-
Can data be rolled into lower or higher tiers based on usage?
-
Can data be seamlessly retrieved from whichever tier it is stored in?
Summary
Event streams provide durable, replayable, and scalable data access. They can provide a full history of events, allowing your consumers to read whatever data they need via a single API. Every consumer is guaranteed an identical copy of the data, provided they read the stream as it was written.
Your event broker forms the core of your event-driven architectures. It’s responsible for hosting the event streams, and providing consistent, high-performance access to the underlying data. It’s responsible for durability, fault-tolerance, and scaling, to ensure that you can focus on building your services, not struggling with data access.
The producer service publishes a set of important business facts, broadcasting the data via the event stream to subscribed consumer services. The producer is no longer responsible for the varied query needs of all other services across the organization.
Consumers do not query the producer service for data, eliminating unnecessary point-to-point connections from your architecture. Previously a team may simply have written SQL queries or used request/response APIs to access data stored in a monolith’s database. In an event-driven architecture they instead access that data from an event stream, materializing and aggregating their own state for their own business needs.
The adoption of event-driven microservices enables the creation of services that use only the event broker to store and access data. While local copies of the events may certainly be used by the business logic of the microservice, the event broker remains the single source of truth for all data.
Chapter 2. Fundamentals of Event-Driven Microservices
An event-driven microservice, as introduced back in [Link to Come], is an application like any other. It requires the exact same type of compute, storage, and network resources as any other application. It also requires a place to store the source code, tools to build and deploy the application, and monitoring and logging to ensure healthy operation. As an event-driven application, it reads events from a stream (or streams), does work based on those events, and then outputs results - in the form of new events, API calls, or other forms of work.
[Link to Come] briefly introduced the main benefits of event-driven microservices. In this chapter, we’ll cover the fundamentals of event-driven microservices, exploring their roles and responsibilities, along with the requirements, rules, and recommendations for building healthy applications.
The Basics
Event-Driven means that the events drive the business logic, just as water from a stream turns the water wheel of a mill (Figure 2-1). Event-driven applications, be they micro or macro, typically only do work when there are events coming through it (or a timer expires - also an event). Otherwise, they sit idle until there are new events to process.

Figure 2-1. The water stream powers the wheel, as event streams power the microservice Source - wikimedia
{kind=link}
The consumer microservice reads events from the stream. Each consumer is responsible for updating its own pointers to previously read indices within the event stream. This index, known as the offset, is the measurement of the current event from the beginning of the event stream. Offsets permit multiple consumers to consume and track their progress independently of one another, as shown in Figure 2-2.
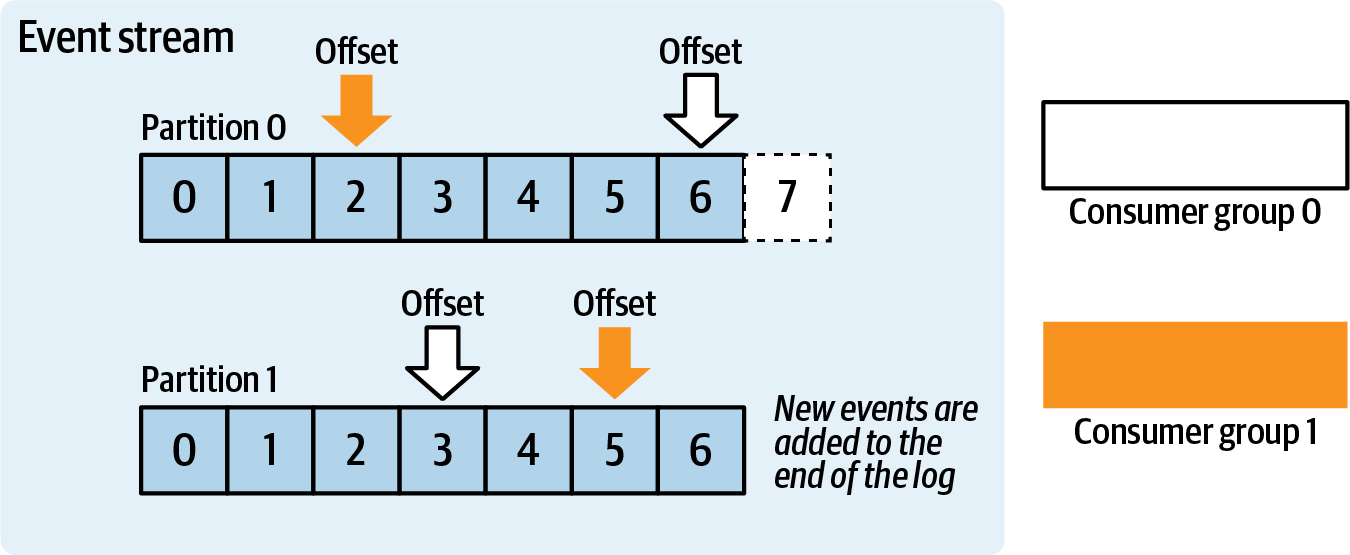
Figure 2-2. Consumer groups and their per-partition offsets
“So what makes up an event-driven microservice?” you may ask. Perhaps the best thing to do is just look at a few examples first, and work backwards from there. Let’s take a look at a few examples of microservice implementations.
The Basic Producer/Consumer
This example is entitled a “basic producer/consumer” because that’s all it really is - the producer produces events, the consumer consumes events, and you, the software dev, must write all the operations to stitch together the business logic. We’ll go more into this pattern in chapter [Link to Come], but for now we’ll start with a basic Python microservice example.
This service consumes events from a Kafka event broker (topic name “input_topic”, tallies a sum, and emits the updated total to a new event stream if the value exceeds 1000.
The python application creates the KafkaConsumer (1) and KafkaProcucer (2). The aptly named KafkaConsumer will read events from the specified topic, convert the events from serialized bytes to objects that application understands - in this case, plain text keys and JSON value. For a refresher on keys and values, you can look back to “The Structure of an Event”.
fromkafkaimportKafkaConsumer,KafkaProducerimportjsonimporttime# 1) Initialize Kafka consumerconsumer=KafkaConsumer('input_topic_name',bootstrap_servers=['localhost:9092'],value_deserializer=lambdax:json.loads(x.decode('utf-8')),key_deserializer=lambdax:x.decode('utf-8'),group_id='ch03_python_example_consumer_group_name',auto_offset_reset='earliest')# 2) Initialize Kafka producerproducer=KafkaProducer(bootstrap_servers=['localhost:9092'],value_serializer=lambdax:json.dumps(x).encode('utf-8'),key_serializer=lambdax:x.encode('utf-8'))# 3) Connect to the state store (A simple dictionary to keep track of the sums per key)key_sums={}# 4) Polling loopwhileTrue:# 5 Poll for new eventsevent_batch=consumer.poll(timeout_ms=1000)# 6 Process each partition's eventsforpartition_batchinevent_batch.values():foreventinpartition_batch:key=event.keynumber=event.value['number']# 7) Update sum for this keyifkeynotinkey_sums:key_sums[key]=0key_sums[key]+=number# 8) Check if sum exceeds 1000ifkey_sums[key]>1000:# Prepare and send new eventoutput_event={'key':key,'total_sum':key_sums[key]}# 9) Write to topic named "key_sums"producer.send('key_sums',key=key,value=output_event)# 10) Flushes the events to the brokerproducer.flush()
Next, the code creates a simple state store (3). You will most likely want to use something other than an in-memory dictionary, but this is a simple example and you could swap this for a RDBMS, a fully managed key-value store, or some other durable state store.
Tip
Choose the state store that’s most suitable for your microservice’s use case. Some are best served with high performance key-value stores, while other use cases are best served via RDBMS, graph, or document, for example.
The fourth step is to enter an endless loop (4) that polls the input topic for a batch of events (5) and processes each event on a per-partition basis (6). For each event, the business logic updates the key sum (7), and if it’s > 1000 (8), then it creates an event with the sum to write to the output topic key_sums (9 and 10).
This is a very simple application. But it showcases the key components common to the vast majority of event-driven microservices: event stream consumers, producers, state stores, and a continual processing loop driven by the arrival of new events on the input streams. The business logic is embedded within the processing loop, and though this example is very simple, there are far more powerful and complex operations that we can perform.
Let’s take a look at a few more examples.
The Stream-Processing Event-Driven Application
The Stream-Processing event-driven application is built using a stream-processing framework. Popular examples include Apache Kafka Streams, Apache Flink, Apache Spark, and Akka Streams. Some older examples that I cited in the first edition aren’t as common anymore, but included Apache Storm and Apache Samza.
The streaming frameworks provide a tighter integration with the event broker, and reduce the amount of overhead you have to deal with when building your EDM. Additionally, they tend to provide more powerful computations with higher level constructs, such as letting you join streams and materialized tables with very little effort on your part.
A key differentiator of stream-processing frameworks from the basic producer/consumer is that stream-processors require either a separate standalone cluster of its own (such as in the case of Flink and Spark), or a tight implementation with a specific event broker (such as the case of Kafka Streams).
Flink and Spark (and others like it) use their own proprietary processing clusters to manage state, scaling, durability, and the routing of data internally. Kafka Streams, on the other hand, relies on just the Kafka cluster to store their own durable state, provide topic repartitioning, and provide application scaling functionality.
Future chapters (lightweight, heavyweight) will cover both these types of frameworks in more detail. For now, let’s turn to a practical (and concatenated) example using Apache Flink.
// 1) TableEnvironment manages access and usage of the tables in the Flink applicationTableEnvironmenttableEnv=TableEnvironment.create(EnvironmentSettings.inStreamingMode());// 2) Create the output table for joined results, connecting to a Kafka broker.tableEnv.executeSql("CREATE TABLE PurchasesInnerJoinOrders ("+" order_id STRING,"+" /* Add all columns you want to output here */"+") WITH ("+" 'connector' = 'kafka',"+" 'topic' = 'PurchasesInnerJoinOrders',"+" 'properties.bootstrap.servers' = 'localhost:9092',"")");//Other table definitions removed for brevity. They are very similar.// 3) Reference the Sales and Purchase tables (assumes they are already created as tables in the catalog)Tablesales=tableEnv.from("Sales");Tablepurchases=tableEnv.from("Purchase");// 4) Perform inner join between Sales and Purchase tables on order_idTableresult=sales.join(purchases).where($("Sales.order_id").isEqual($("Purchase.order_id")));// 5) Insert the joined results into the output Kafka topicresult.executeInsert("PurchasesInnerJoinOrders");
This is a fairly terse application, but it packs a lot of power. First (1), we create the tableEnv connection that will manage our table environment work. Next, we declare the output table (2), which is connected to the Kafka topic PurchasesInnerJoinOrders. You’ll only have to create this once. I’ve omitted the other declarations for brevity.
Third (3), you create references to the Sales and Purchases tables so that you can use them in your application. These tables are materialized streams, as covered in “Materializing State from Entity Events”.
Fourth (4), the code declares the transformations to perform on the events populating the materialized tables. These few lines perform a lot of important work. Not only does it perform the operations of joining these two tables together, but it also handles fault-tolerance, load balancing, in-order processing, and big-data scale loads. It can also easily join streams and tables that are partitioned and keyed completely differently,something that you are likely to encounter on your own.
Fifth (5) and finally, the application writes the data to the output table. The machinations of the Flink streaming framework will handle the rest for committing the data to the Kafka topic.
Streaming frameworks provide very powerful capabilities, but typically require a larger upfront investment into supporting architecture. They also typically only provide limited language support (Python and JVM being the most popular), though some progress has on supporting other languages since the first edition of this book has been published. In fact, SQL (or SQL-like) languages have been possible the fastest growing of the bunch. Let’s take a look at those next.
The “Streaming SQL” Query
“Should your microservice actually just be a SQL query?”
It’s a good question, particularly with the rise of SQL streaming as managed services. The very same things that make SQL popular in the database world make it popular in the streaming world. It’s declarative nature means that you just declare the results you’re looking for. You don’t have to specify how to get it done, as that’s the job of the underlying processing engine.
Additionally, SQL lets you write very clear and concise statements about what it is you want to do with your data - in this case, the event stream. Here’s an example of the very same Flink application, but written using Flink SQL.
--Assumes we have already declares the materialized input tables and the output tableINSERTINTOPurchasesInnerJoinOrdersSELECT*FROMSalessINNERJOINPurchasepONs.order_id=p.order_id;
That’s it. Simple but powerful. This Streaming SQL query will run indefinitely, acting as a stand-alone microservice unto itself.
Streaming SQL is not yet standardized. There are many different flavors and types, and so you’ll have to do your own due diligence to find out what is and what isn’t supported per streaming framework. Additionally, streaming SQL tends to require a robust lower-level set of APIs to function beyond just toy examples. The Flink project, for example in Figure 2-3, has several layers of APIs, each which depends on the ones below it
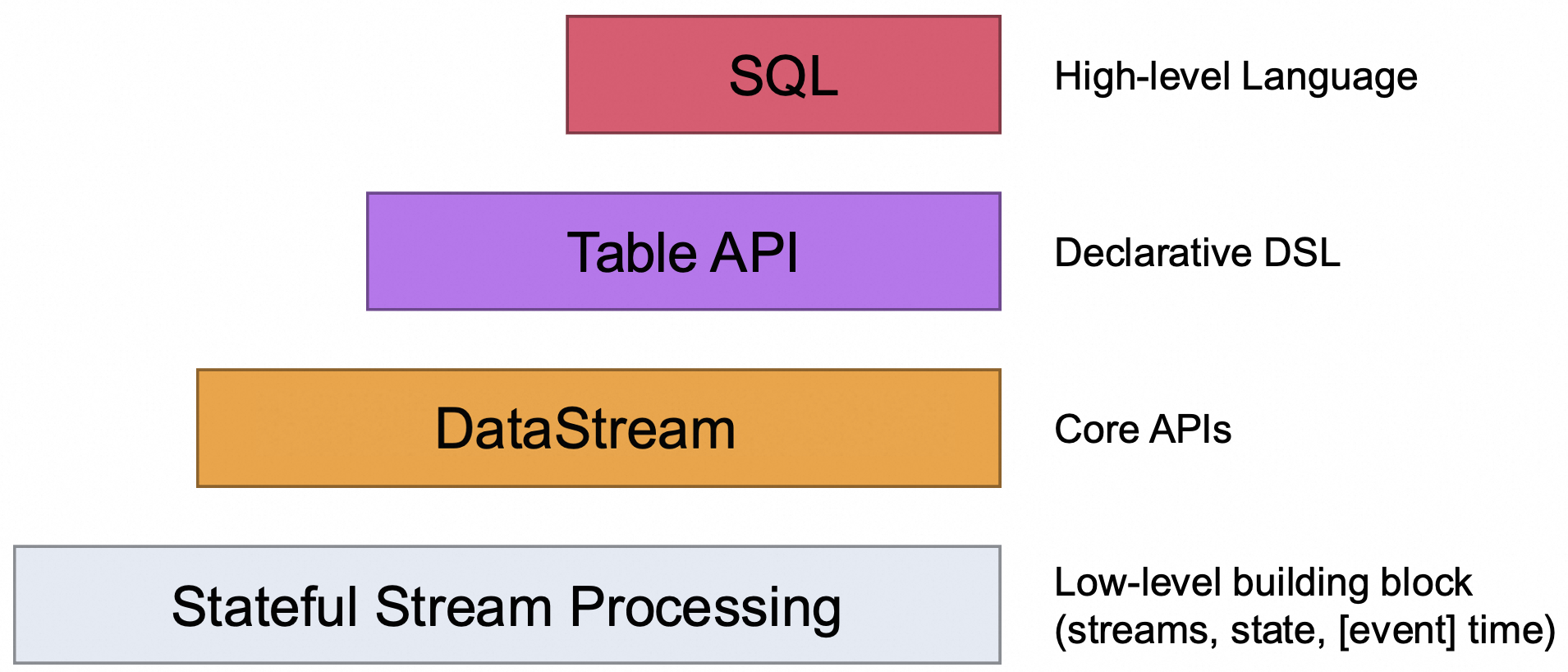
Figure 2-3. The four levels of Flink APIs - Source - apache.org
In short, keep your eyes open for opportunities to use SQL within your microservices. It can save you a ton of time and effort, and let you get on with other work. We’ll look at streaming SQL in a bit more detail in the [Link to Come].
The Legacy Application
Legacy applications typically aren’t written with event-driven processing in mind. They’re usually old but important systems that serve critical business functions, but that aren’t under active development anymore. Changes to these services are rare, and are only performed when absolutely necessary. They’re also often the gatekeepers to important business data, siloed away inside the database or file stores of the system.
The legacy application is basically a rigid structure that you’re unlikely to be able to change. But you can still integrate it into your overarching event-driven architecture through the use of connectors, as shown in Figure 2-4.
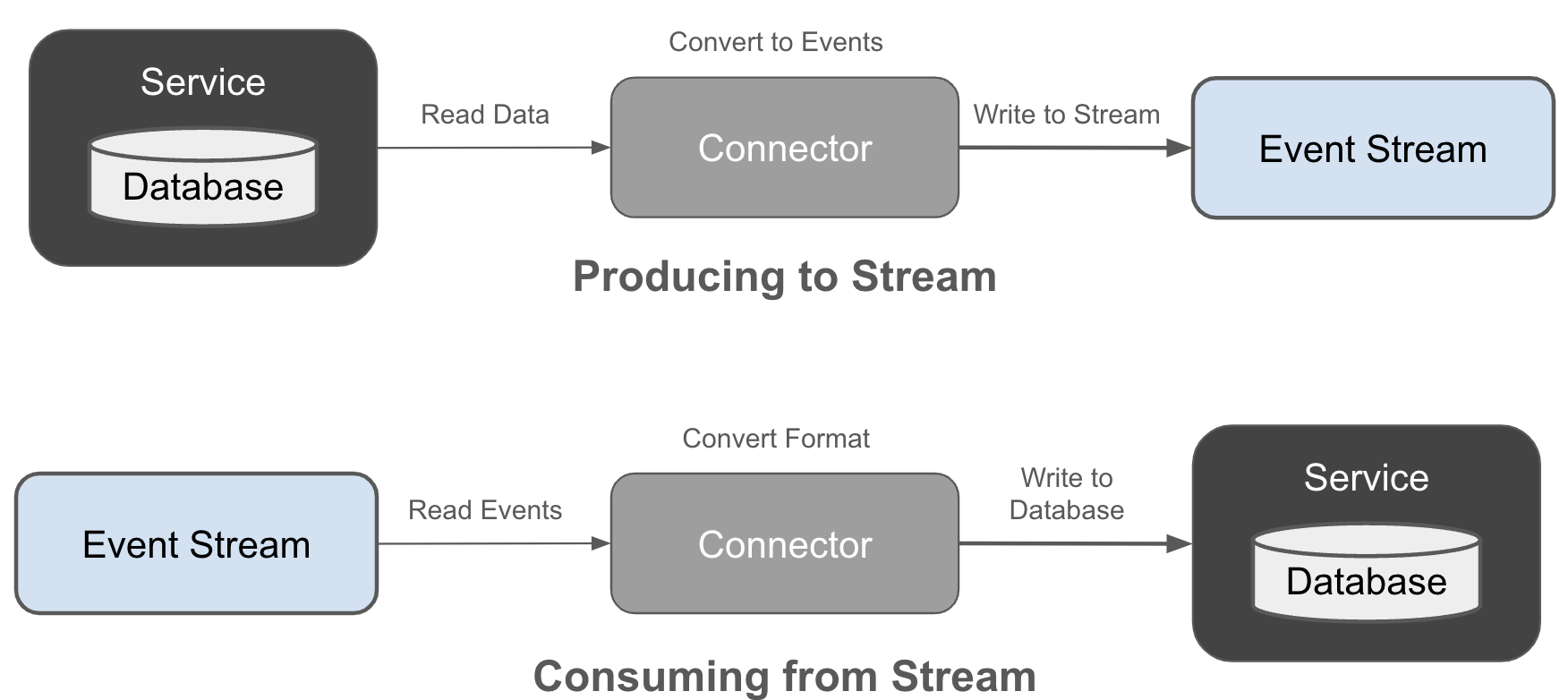
Figure 2-4. Producing and consuming event streams with connectors
Connectors can read events from a source system or database, convert the data to events, and write it into an event stream. Similarly, connectors can also read events from a stream, convert them into a suitable format, and write them to a legacy system’s API or database. They provide the means for integrating these existing applications into your event-driven architecture without having to redesign the whole system as a native event-driven architecture.
Connectors enable you to get started with event streams without having to reinvent your entire architecture. They make it easy to get data into streams, so that you can start getting value from your event-driven microservices as soon as possible. With that, we’ll cover connectors in more detail in [Link to Come].
Now, these four services may all need to work together with one another. Unlike a single macro-service (e.g. a singular monolith), microservices are, by definition, a collection of services that rely on one another. Although we strive for decoupled and asynchronous communication, at the end of the day, each of these services may be (and often are) dependent on the work done by the other services. Thus we have some sort of network relationship… segway into Responsibilities
Event-Driven Microservice Responsibilities
- Service Boundaries and Scope
-
A well-defined set of boundaries. What is this application responsible for? And what is it not? The latter becomes more important when you have multiple microservices working together to fulfil a more complicated workflow, where it can be a bit difficult to discern the responsibilities of each service. By mapping microservices as cleanly as possible to bounded contexts, we can avoid much of the guesswork and ambiguity that may otherwise crop up.
- Scalability
-
The microservice is responsible for ensuring that it is scalable. Specifically, it must be written in such a way that allows it to scale horizontally (more instances) or vertically (a more powerful instance), depending on its requirements. EDM frameworks that provide scaling out of the box tend to have far greater appeal due to the seamless built-in scaling capabilities. The underlying processing power, however, is something that is provided by the microservice platform. We’ll talk about the more towards the end of this chapter.
- State Management
-
The microservice is solely responsible for the creates, reads, updates, and deletes made to its data store. Any operations that modify the state in the microservice remain entirely within its boundary of control. Any problems with the state store, such as running out of disk or failing to test applications changes also fall within the microservice’s problem space. [Link to Come] goes into greater detail on how to build and manage state for event-driven microservices.
- Track Stream Input Progress
-
Each microservice must keep track of its progress in reading the input event streams. For example, Apache Kafka tracks this progress using a
consumer groupone per logical microservice. Consumer groups are also used by many other leading event brokers, though a consumer can still choose to manually manipulate its own offsets (say to replay some records) or store them elsewhere, such as in their own data store. - Failure Recovery
-
Microservices are responsible for ensuring that they can get themselves back to a healthy state after a failure. The frameworks that we’ll rely on to run our microservices are usually quite good at bringing dead services back to life, but our services will be responsible for restoring state, restoring the input event stream progress, and picking back up where they left off before the failure.
The application must also take into consideration its stored state in relation to its stream input progress. In the case of a crash, the consuming service will resume from its last known good offsets, which could mean duplicate processing and duplicate state store updates.
- The Single Writer Topic Principle
-
Each event stream has one and only one producing microservice. This microservice is the owner of each event produced to that stream. This allows for the authoritative source of truth to always be known for any given event, by permitting the tracing of data lineage through the system. Access control mechanisms, as discussed in [Link to Come], should be used to enforce ownership and write boundaries.
- Partitioning and Event Keys
-
The microservice is responsible for choosing the output record’s primary key (see “The Structure of an Event”), and is also responsible for determining which partition to send that record to. Records of the same key typically go to the same partition, though you can choose other strategies (e.g. round-robin, random, or custom). Ultimately, it is your microservice that is responsible for selecting which partition to write the event to.
- Event Schema Definitions and Data Contracts
-
Just as it’s your microservice’s choice for choosing the record key, it’s also its choice for choosing the schema format for writing the event. For example, do you write
product_idas aString? Or do you write it as aInteger? Chapter [Link to Come] covers this in far more detail, but for now, plan to use a well-defined Avro, Protobuf, or JSON schema to write your records. It will make your event streams much easier to use, provide clarity for your consumers, and enable a much healthier event-driven ecosystem.
A microservice should also be reasonably sized. Does that sound ambiguous to you? Well read on.
How small should a microservice be?
First up, the goal of a microservice architecture isn’t to make as many as possible. You won’t win any awards for having the highest service count, nor would you even find the experience rewarding. In fact, you’d probably end up writing a blog about how you made a 1000 microservices and everything was awful.
The reality is that every service you build, micro or otherwise, incurs overhead. However, we also want to avoid the pains that come with a single monolith. Where’s the balance?
A microservice should be manageable by a single team, and the team should be able to have others within it work on the service as needed. How big is that team? The two-pizza team is a popular measurement, though it can be a bit of an unreliable guide depending on how hungry your developers are.
A single developer on this team should be able to fit the space of duties that the service has in their own head. A new developer coming to the microservice should be able to figure out the duties of that service, and how it accomplishes those duties, in just a day or two.
Ultimately, the real concern is that the service serves a particular bounded context and satisfies a business need. The size, or how micro it really is, comes as a secondary concern. You may end up with microservices that push the upper boundary of what I’ve prescribed here, and that’s okay - the important part is that you can identify the specific business concern it meets, the boundaries of the service, and be able to maintain a good mental list of what the service should do and should not.
Here are a couple of quick tips:
-
Only build as many services as are necessary. More is not better.
-
One person should be able to understand the whole service.
-
Your team will need to be responsible for owning and maintaining the service and the output event streams.
-
Look to add functionality to an existing service first. It reduces your per-application overhead, as we’ll see next in the next section.
-
For the microservices you do build, focus on building modular components. You may find that as your business develops that you need to break off a module to convert to its own microservice.
In the next section we’ll take a look at how to manage microservices, including how to manage them at scale.
Managing Microservices at Scale
Managing microservices can become increasingly difficult as the quantity of services grows. Each microservice requires specific compute resources, data stores, configurations, environment variables, and a whole host of other microservice-specific properties. Each microservice must also be manageable and deployable by the team that owns it. Containerization and virtualization, along with their associated management systems, are common ways to achieve this. Both options allow individual teams to customize the requirements of their microservices through a single unit of deployability.Putting Microservices into Containers
Containers, as popularized by Docker, isolate applications from one another. Containers leverage the existing host operating system via a shared kernel model. This provides basic separation between containers, while the container itself isolates environment variables, libraries, and other dependencies. Containers provide most of the benefits of a virtual machine (covered next) at a fraction of the cost, with fast startup times and low resource overhead.Containers’ shared operating system approach does have some tradeoffs. Containerized applications must be able to run on the host OS. If an application requires a specialized OS, then an independent host will need to be set up. Security is one of the major concerns, since containers share access to the host machine’s OS. A vulnerability in the kernel can put all the containers on that host at risk. With friendly workloads this is unlikely to be a problem, but current shared tenancy models in cloud computing are beginning to make it a bigger consideration.
Putting Microservices into Virtual Machines
Virtual machines (VMs) address some of the shortcomings of containers, though their adoption has been slower. Traditional VMs provide full isolation with a self-contained OS and virtualized hardware specified for each instance. Although this alternative provides higher security than containers, it has historically been much more expensive. Each VM has higher overhead costs compared to containers, with slower startup times and larger system footprints.Tip
Efforts are under way to make VMs cheaper and more efficient. Current initiatives include Google’s gVisor, Amazon’s Firecracker, and Kata Containers, to mention just a few. As these technologies improve, VMs will become a much more competitive alternative to containers for your microservice needs. It is worth keeping an eye on this domain should your needs be driven by security-first requirements.
Managing Containers and Virtual Machines
Containers and VMs are managed through a variety of purpose-built software known as container management systems (CMS). These control container deployment, resource allocation, and integration with the underlying compute resources. Popular and commonly used CMSes include Kubernetes, Docker Engine, Mesos Marathon, Amazon ECS, and Nomad.Microservices must be able to scale up and down depending on changing workloads, service-level agreements (SLAs), and performance requirements. Vertical scaling must be supported, in which compute resources such as CPU, memory, and disk are increased or decreased on each microservice instance. Horizontal scaling must also be supported, with new instances added or removed.
Each microservice should be deployed as a single unit. For many microservices, a single executable is all that is needed to perform its business requirements, and it can be deployed within a single container. Other microservices may be more complex, requiring coordination between multiple containers and external data stores. This is where something like Kubernetes’s pod concept comes into play, allowing for multiple containers to be deployed and reverted as a single action. Kubernetes also allows for single-run operations; for example, database migrations can be run during the execution of the single deployable.
VM management is supported by a number of implementations, but is currently more limited than container management. Kubernetes and Docker Engine support Google’s gVisor and Kata Containers, while Amazon’s platform supports AWS Firecracker. The lines between containers and VMs will continue to blur as development continues. Make sure that the CMS you select will handle the containers and VMs that you require of it.Tip
There are rich sets of resources available for Kubernetes, Docker, Mesos, Amazon ECS, and Nomad. The information they provide goes far beyond what I can present here. I encourage you to look into these materials for more information.
Paying the Microservice Tax
The microservice tax is the sum of costs, including financial, manpower, and opportunity, associated with implementing the tools, platforms, and components of a microservice architecture.The tax includes the costs of managing, deploying, and operating the event broker, CMS, deployment pipelines, monitoring solutions, and logging services. These expenses are unavoidable and are paid either centrally by the organization or independently by each team implementing microservices. The former results in a scalable, simplified, and unified framework for developing microservices, while the latter results in excessive overhead, duplicate solutions, fragmented tooling, and unsustainable growth.
Paying the microservice tax is not a trivial matter, and it is one of the largest impediments to getting started with event-driven microservices. Small organizations be best to stick with an architecture that better suits their business needs, such as a modular monolith, and only expand into microservices once their business runs into scaling and growth issues.
The good news is that the tax is not an all-or-nothing thing. You can invest in parts of your overall event-driven microservices platform as a product all its own, with incremental additions and iterative improvements.
Fortunately, self-hosted, hosted, and fully managed services are available for you to choose from. The microservice tax is being steadily reduced with new integrations between CMSes, event brokers, and other commonly needed tools.
Cloud services are worth an explicit mention for greatly reducing the cost of the Microservices tax. Cloud services and fully managed offerings have significantly improved since the first version of this book was released in 2020, and show no sign of abating. For example, you can easily find fully managed CMSes, event brokers, monitoring solutions, data catalogs, and integration/deployment pipeline services without having to run any of them yourself. It is much easier to get started with using cloud services for your microservice architecture than building your own, as it lets you experiment and trial your services before committing significant resources.
Summary
Event-driven microservices are applications like any other, relying on incoming events to drive their business logic. They can be written in many different languages, though the functionality you have available to you will vary accordingly. Basic producer/consumer microservices may be written in a wide range of languages, while purpose-built streaming frameworks may only support one or two languages. SQL queries and connectors also remain options, but their use requires further integration with application source code than what was covered in this chapter.
Microservices have a host of responsibilities, including managing their own code, state, and runtime properties. The service creators have the freedom to choose the technologies best suited to solving the business problem, though they of course need to ensure that the service can be maintained, updated, and debugged by others. Microservices are typically deployed in containers or using virtual machines, relying on container/VM management systems to help monitor and manage their life cycles.
Last, be warned that there is a microservice tax. It is the total sum of non-business work you need to do to make using microservices a reasonable choice. There isn’t a clear recipe for what is and isn’t in the microservice tax. Every organization has a different technology stack, and what could be good advice for one organization may be a poor choice for another. That being said, try to use what you already have before buying something new, and work incrementally. It’s not an all or nothing thing. Work on getting your first microservice up and running, learn from the process, then iterate and improve from there.
Chapter 3. Designing Events
An early version of this chapter previously appeared in Building an Event-Driven Data Mesh.
There are many ways to design events for event-driven architectures However, some are more suitable than others. This chapter covers the best strategies for designing events for your event streams including how to avoid the numerous pitfalls that you will encounter along the way. It also provides guidelines of when to use certain types and when to avoid using others, plus some illustrations as to why this is the case.
Introduction to Event Types
There are two main types of events
that underpin all event design: the state event, introduced in “Entity Event”, and the delta event.Figure 3-1 shows a simple square wave in steady state, periodically altering from one state to another based on a delta. Similar to this square wave, we model our events to either capture the state itself or the edge that transitions from one state to another.
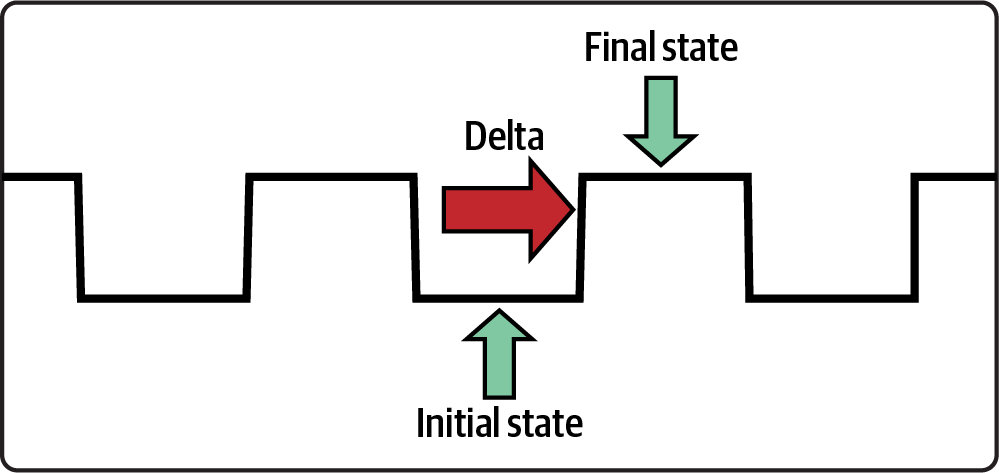
Figure 3-1. State and delta during a change
There are three stages to any occurrence in a system:
-
The initial state
-
The delta that alters the initial state to produce the final state
-
The final state (which is also the initial state for the next change cycle)
The majority of events we encounter can be fully categorized as either state or delta. Looking at events in this way helps separate concerns and focus design efforts:
- State events
-
State events fully describe the
state of an entity at a given point in time. They are akin to a row in a database, chronicling the entire current state of affairs for the given data. State events are typically the most flexible and useful event type for sharing important business data between teams, people, and systems. State events are sometimes called level, noun, or fact type events. - Delta events
-
These describe the transition
between states and typically only contain information about what has changed. Delta events are more commonly used in and between systems with very high degrees of coupling, as there is a close relationship between the definition of the event and how it is interpreted. Deltas are also sometimes called edge, verb, or action type events.
You may also encounter hybrid events that have characteristics of each, though these tend to be less common because they can cause an undesirable strong coupling effect.
- Hybrid events
-
These events describe both a state and transition. They are usually a bit of a kludge, implemented when a deeper rework isn’t possible due to deadlines such as trying to make the quarter’s profit goal. But since people will still use them, they are covered in more detail later in this chapter.
Let’s take a look at state events first.
State Events and Event-Carried State Transfer
A state event provides the current state of an entity at a specific moment in time. The record’s key details the unique identifier of the entity, while the value contains the entire set of data made available to all consumers.
Event-carried state transfer (ECST) is a precise description: A (state) event carries the entity’s current state, and it is transferred into the domain of the consumers through the event stream. State events provide several critical benefits, including:
- Materialization
-
State events let you materialize data quickly and easily. Simply consume the event stream, and materialize the data your service needs into its own state store.
- Strong Decoupling
-
The definition and composition of the state event remains entirely within the producer service’s bounded context. There is no coupling on the internal business logic of the system that produces the record.
- Infer Deltas from State
-
Consumers can infer all field changes by comparing the current state event to the previous state event for a given key. The service can react accordingly whenever any fields change, as shown in [Link to Come].
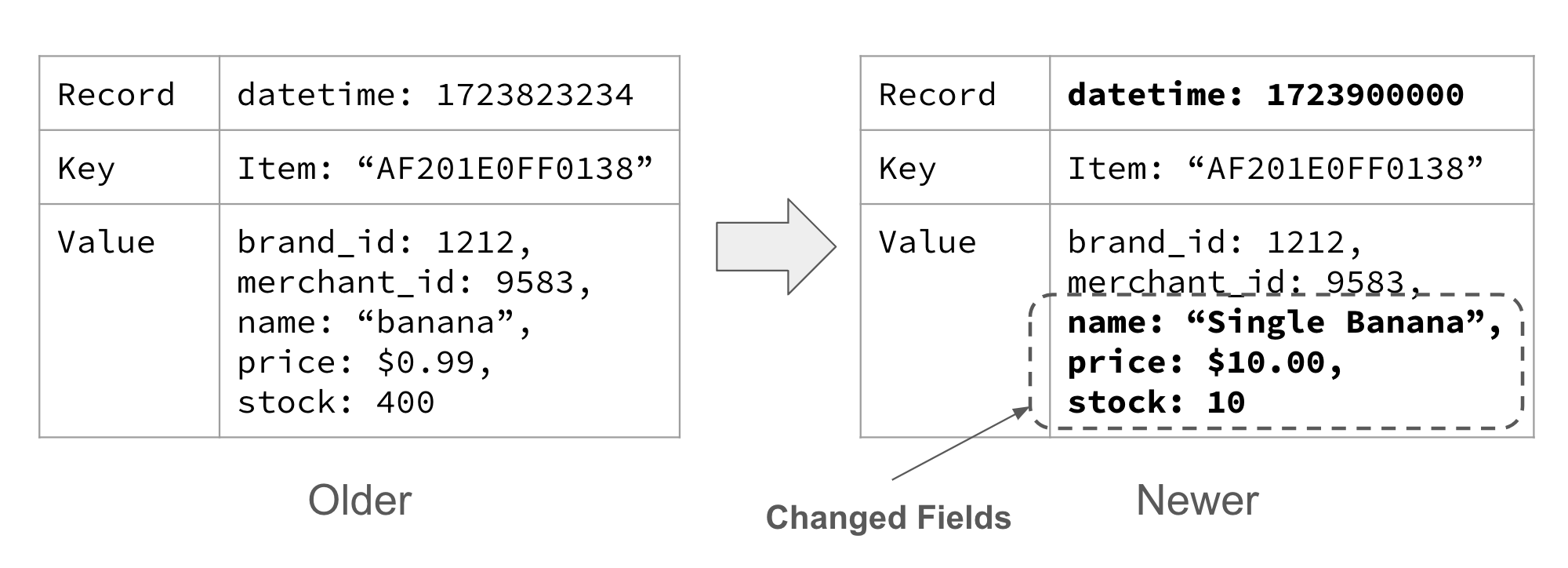
Figure 3-2. Two state events allow you to infer what has changed by comparing the newer event to the older event
In this example, you can see that the newer event has had its name, price, and stock updated. Your microservice can infer the changes that it cares about, and react accordingly. For e.g., updating signage, ordering new inventory, or prioritizing alternate options in the customer’s search results.
State events may contain just
the “now” state or they may contain the “before/after” state (a pattern made popular with “Liberating Data Using Change-Data Capture”). Both options have their own advantages and disadvantages, which we’ll examine in turn. For starters, let’s take a look at how each of these options affects compaction of event streams.There are two main design strategies for defining the structure and contents of state events:
- Current state
-
Contains the full public
state at the moment the event was created. - Before/after state
-
Contains
both the full public state before the event occurred and the full public state after the event occurred.
Let’s look into each of these in detail to get a better understanding of their trade-offs.
Current State Events
The event contains only the
current state of the entity and requires comparison with a previous state event to determine what has changed. For example, aninventory event for a given item_id will contain only the latest value for the quantity in stock at that point in time. This design strategy has several main benefits: - Lean
-
The state events consume a minimal amount of space in the event stream. Network traffic is also minimized.
- Simple
-
The event broker stores any previous state events for that entity, such that if you need historical state, you simply rewind and replay your consumer offsets. You can set independent compaction policies for each event stream depending on your consumer’s needs for historical data.
- Compactable
-
You can keep the number of events in the stream proportional to the key space of the domain.
It also has a few nuances that are not quite drawbacks, but rather properties to consider:
- Agnostic to why the state changed
-
The downstream consumer is not provided with the reason why the data has changed, only with the new public state. The reason for this is simple: it removes the ability of consumers to couple on the internal state transitions of the source domain. Think about data in a relational database table—we typically do not communicate why that data has changed in the data itself, and the same holds true for state events (Note: We’ll look at bending this rule a bit with hybrid events a bit later).
- Consumers must maintain state to detect transitions
-
A consumer must maintain its
own state to detect specific changes to certain fields, regardless of how simple or complex its business logic is. For example, a customer changing their address to another country may require you to send them new legal documents, which can differ depending on the country they left and the country they moved to. By making it the consumer’s responsibility to materialize state for tracking transitions, the onus of computing these edges is placed entirely within the domain of the consumer. This leads to far simpler dependency tracking, and cleaner modularization boundaries for code.
Before/After State Events
This strategy relies on providing the state
before a transition occurs and the state after it has occurred. Change-data capture (CDC) systems, as covered in “Liberating Data Using Change-Data Capture”, regularly make use of the before/after strategy. The following showcases two before/afteruser events with a simple two-field schema: Key:26Value:{before:{name:"Adam",country:"Madagascar"},after:{name:"Adam",country:"Canada"}}
A follow-up before/after state event that shows the deletion of Key = 26. Note that old data still remains in the before field:
Key:26Value:{before:{name:"Adam",country:"Canada"},after:null}
There are some benefits to this design:
- Simple state transitions in a single event
-
The before/after event showcases every
field that has changed within a single transaction, in addition to all of the fields that have not changed. The reason for the change, however, is not included. - Consumers can detect simple changes without maintaining state
-
Some consumers can forgo maintaining state if they are only interested in detecting a simple state transition. For example, if we want to send documents to a user who moves from Madagascar to Canada, then our consumer can simply check to see if the
beforeandafterfields of the event match their criteria. However, this doesn’t work if Adam moves from Madagascar to Ethiopia, and then soon thereafter moves to Canada, causing two events to occur. The consumer business logic would not be able to trigger on this sequence of events since it doesn’t maintain any state. In practice, the theoretical stateless consumer is seldom realized, since the vast majority of services of any reasonable complexity need to maintain state.
There are also a few drawbacks to this design:
- Compaction is difficult
-
Deleting an event using the before/after logic
results in theafterfield being set to null—but the entire value itself is not null. By default, event brokers like Apache Kafka will not recognize this as a tombstone and thus will not delete it. While it may be technically possible to rewrite the compaction logic, it usually isn’t feasible, especially if you are relying heavily on SaaS solutions.
In the end you’ll have to ensure that you write a secondary tombstone event after your initial “before/after” event. Then, you’ll rely on the event broker eventually compacting the data away. This double-event strategy is often used by change-data capture systems, such as Debezium (a change-data capture service that will be explored in more detail in “Liberating Data Using Change-Data Capture”). According to Debezium’s documentation:
A database
DELETEoperation causes Debezium to generate two Kafka records:
A record that contains
"op": "d", thebeforerow data, and some other fields.A tombstone record that has the same key as the deleted row and a value of
null. This record is a marker for Apache Kafka. It indicates that log compaction can remove all records that have this key.
- Risk of leftover information
-
As we saw earlier, previous data may be
accidentally maintained indefinitely in thebeforefield unless you issue a series of deletions. - Doubled data storage and network usage
-
Before/after events double (on average) the amount of data going over the wire and stored on disk. Consumers, producers, and the event broker each bear part of this load. In some cases this may be trivial. Seldom-updated events or those with low volume are probably nothing to worry about, but extremely high volume event streams can quickly add up the costs. This can be particularly expensive depending on the cross-regional data transfer fees associated with high-availability producer, consumer, and event broker deployments.
Current state events tend to be a far better option than the before/after model for event-streams. Consumers will still need to maintain state for the records they care about for their business processes, but disk space is relatively cheap, and they need only keep the data that they care about. This also simplifies operations for the event broker when compared to before/after, with lower cross-region traffic costs, less broker disk usage, and less broker network usage replication overhead. Further, the risk of leaking data from improper compaction deletion is eliminated.
In the next section, we’ll take a look at delta
events, where an event is modeled after the change and not the state itself.Delta Events
The delta event represents a change that
has occurred within a specific domain, represented as the edge of a transition in Figure 3-1. Delta events contain only the information about the state change, not the past or current state. Delta events are usually phrased as verbs in the past tense, indicating that something has occurred. For example:-
itemAddedToCart -
itemRemovedFromCart -
orderPaid -
orderShipped -
orderReturned -
userMoved -
userDeleted
You may find that you’re more familiar with these types of events than you are with the state types used for ECST. Delta events have historically been fairly common, particularly in the context of the Lambda architecture (see “The Lambda Architecture”). Delta events are also commonly used inside a domain for event sourcing, a subject we’ll now take a look at in more detail.
Delta Events for Event Sourcing
Event sourcing is an architectural pattern
based on recording what happened within a domain as a sequence of immutable append-only events. These events are aggregated to build up the current state by applying them in the order that they occurred, using domain specific logic, one after another.This architecture is often promoted as an alternative to the traditional create, read, update, delete (CRUD) model commonly
found in relational-database type frameworks. In the CRUD model, the fully mutable state of the entity is directly modified such that only the final state is retained. Though the databases underpinning CRUD can generate an audit log of the changes that occurred, this log is used primarily for auditing purposes and not for driving business logic.There are some limitations to the CRUD model that may make event sourcing an attractive alternative. For one, operations must be processed directly against the data store as they are invoked. Under heavy use, this can significantly slow down operations and result in timeouts and failures. Second, high concurrency operations on the same entities can result in data conflicts and failed transactions, further increasing load on the system.
But the CRUD model also contains several distinct advantages. Though it depends largely on the database, most CRUD implementations offer strong read-after-write consistency. It’s also fairly intuitive and simple to use, with lots of tools and frameworks supporting it. For many software developers, this is the first model of maintaining state that they encounter. Figure 3-3 shows a series of CRUD events (one create, two updates) applying changes to the refrigerator state. The state is completely mutable, and only the updated state is retained after a create or update command is applied.
Figure 3-3. Using CRUD commands to update the contents of the refrigerator, reflected in the database
Under the event sourcing architecture, these create, update, and destroy operations are instead modeled as events that are written to a durable append-only log that retains them indefinitely. It is not uncommon to use a single database table to act as the append-only log. It is also possible to use an event broker like Apache Kafka to host the append-only log, although this does introduce additional latency. In either case, the current state is generated by consuming events in the order they are written in the log and applying them one at a time to create the final state.
Figure 3-4 shows the same refrigerator example, with the CRUD operations instead modeled as domain events. And although these sample events are CRUD-like, the domain owner has free reign over designing the deltas to suit their own business use cases. For instance, they could extend the set of events they’re creating to also incorporate deltas such as:
-
turn_lights_on/turn_lights_off -
turn_cooling_on/turn_cooling_off -
open_door/close_door
Figure 3-4. Building up the contents of a refrigerator using event sourcing
The domain aggregator (2) is separate from the process that writes the new domain events into the log (1), and allows the write and aggregation processes to be scaled independently. A domain can also contain multiple domain aggregators and may aggregate the same log to two different internal state stores depending on the domain needs.
One of the main drawbacks of event sourcing is that it is eventually consistent, which can be a significant obstacle for some use cases. There will always be some delay between writing the event to the log and seeing the materialized result in the state. And because multiple concurrent clients can each write events about the same entity, it becomes difficult to attribute any specific modification in final state to the delta your client just appended. This can make it unsuitable in applications that require strong consistency.
Event sourcing is a reasonable alternative
to the CRUD model for building up internal state. The problem with event sourcing comes when it is misused as a means for interdomain communication, exposing the internal domain deltas to the outside world for others to couple on (and misinterpret). These domain-specific events and their relationship to the aggregate and to each other can change over time. Just as we do not allow services outside of our domain to couple directly on our data model, we also must not allow services to couple on our private domain events data model.This isn’t to say you cannot expose any events outside of the domain boundary, but any event that you expose becomes part of the public data contract. You’ll need to ensure that its semantic meaning doesn’t drift over time and that the data doesn’t evolve in a breaking way. A failure to maintain the boundaries of “events in here” and “events out there” can lead to very tangled coupling, excessive difficulty in refactoring, and subtle errors due to
misinterpretation of events by outside consumers.The Problems with Delta Events
The next few sections illustrate the problems with using delta events for microservices. Let’s take a look at each issue in turn.
1) There is an infinite amount of delta event types
First and foremost, there is an infinite amount of delta events that can occur in any domain. This alone should stop most folks from trying to create event-streams with the delta model, but unfortunately it does not. But surely, can it really be the case that there is an infinite number of delta events?
In reality, the actual set of delta events necessary for your domain is undoubtedly finite. The real problem is that every consumer of a delta event needs to know precisely how to load it into their own version of state. For many events, this leaves it open to interpretation.
Let’s take a look at an example. Figure 3-5 shows a simple set of ecommerce events for constructing the contents of a shopping cart.

Figure 3-5. Shopping cart delta events, used to construct the current state of the shopping cart
Add and remove are fairly simple: items can be added, or they can be removed. The consumer will need to interpret and apply each of these events, in the correct order, to build up its aggregate. Suppose, though, that a new feature in the domain allows users to update the quantity of items they have in their cart: where previously the domain owner may have issued a remove event first, then an add event with the new quantity, now they may instead simply issue an update.
Figure 3-6 shows this new Update Item Quantity event stream published to the world. Now if a consumer needs a model of the shopping cart, they must also account for these updated events in their aggregation code. As the scope of the domain changes, so do the meaning of the events and their relationship to the aggregate.
Figure 3-6. New updated event changes the way the shopping cart delta events are interpreted
One of the common reasons that people (incorrectly) choose to use delta events for cross-domain communication is that they don’t believe that other consumers should be required to maintain state to trigger on specific changes. The near-infinite range of possible deltas makes this untenable, but it’s a trap that many don’t recognize until they’re firmly in its grasp.
A simple expansion of the shopping cart domain to incorporate features such as coupons, shipping estimates, and subscriptions increases the amount of information that a consumer must account for, as shown in Figure 3-7.
Figure 3-7. The delta events defining the shopping cart sprawl as new business functionality is added
Exposing this expanded shopping cart domain to consumers requires that the consumers can identify, use, and build a correct aggregate out of these events. But where do the consumers get the information they need to correctly interpret and aggregate this data? From the source producer system. Which leads us to the next major problem of using delta events.
2) The logic to interpret delta events must be replicated to each consumer
How can a consumer know they’re correctly interpreting the delta events? And how does the consumer stay up to date when new domain events are introduced? The key is to make it possible for a consumer to correctly operate without having to continually update their logic to account for new and varied delta events.
In the state model, a consumer only needs to materialize the state events to know they’re getting the complete public domain. They may not know why the transition occurred (we’ll touch on this a bit more later in the chapter), but they can be assured that the entire public domain is there, and that as a consumer, they don’t need to worry about correctly building an aggregation.
Figure 3-8 shows two consumers, each of which has replicated the logic from the producer for building up the aggregate state. Consumers are responsible for identifying, understanding, and correctly applying the add, remove, and update domain events to generate the appropriate final state of the aggregate. The complexity of the domain is paramount; very simple domains may be able to account for this, but any domain of meaningful complexity will find this solution untenable.
Figure 3-8. The logic to interpret delta events to build state is copied into multiple locations
Intermittent issues can cause further complexities—an event stream hosted on a lagging broker may experience delays in providing some events, resulting in the consumer receiving them out of order from events in other streams. Deltas applied in the wrong order often yield incorrect state transitions and may trigger incorrect business actions.
Additionally, each consumer may implement its own aggregation logic slightly differently—often because a consumer fails to update the aggregation logic as the domain evolves. One consumer may wait up to 30 seconds for late-arriving events, while another consumer may not wait at all and simply discard any late arrivals, resulting in similar yet different aggregates.
Any changes to how the producer aggregates its internal domain, including new events or changed delta semantics, must be propagated to the consumer logic—if you have worked on distributed services (or microservices) before, you may be shuddering at this idea. Using delta events to communicate between domains tightly couples the producer, the event definitions, and the consumers together, and trying to manage this is an exercise in futility.
3) Delta events map poorly to event streams
In the problems discussed so far, we’ve operated under the assumption that any new delta events will be immediately identifiable and understandable to consumers, though they may not yet understand how to apply those events to the domain. The reality is far messier. Delta event consumers must be notified when new deltas are created so that they can update their code to integrate the event into their data model.
Coordination can be quite difficult, particularly when there are many different consumers. Herein lies the main problem of this subsection: how do consumers know about the new domain events that they must consider in their model?
One common suggestion that unfortunately misses the point is to simply “put it all in the same event stream so that the consumers have access to it and can choose if they need to use it.” Although existing consumers will end up receiving these new event types, this proposal does nothing to solve the code changes and integrations for consumers to use that data.
Additionally, it is far more likely to cause the consumer to throw an exception, get thrown away as “bad data,” or, worse yet, cause silent processing errors in the consumer’s business logic. This also violates the convention of using a single evolvable schema per event stream, which is a de facto standard for many of the frameworks and technologies that process event streams.
The critical issue here is that new event definitions require working with those that aggregate the events into a model. If you put the new delta events into new individual streams, you make discovery easier and follow the one-schema-per-stream convention, but your consumers will still need to be manually notified that this new stream exists! In either case, a code update is required to make any sense of this data, while a failure to incorporate it runs the risk of an incorrect aggregate.
Now contrast it with the state model, where the state domain can change as needed and the composition of the state event is encapsulated entirely within the producer service. Any modifications made to the state event occur in one place and one place only, and is reflected in the updated data model published to the event stream. Yes, you may need to handle a schema evolution of the state model event, but only in circumstances that cause a breaking change to the entity data model.
4) Inversion of ownership: Consumers push their business logic into the producer
The fourth problem with deltas revolves around the ownership and location of business logic. For example, a consumer may need to know when a package has been shipped so that it can send out an email to the intended recipient notifying them that it’s on its way. The business logic for determining that the package has shipped must necessarily live in the producer, as in Figure 3-9.
Figure 3-9. Consumer business requirements are pushed into the business logic of the producer; in this case, Consumer A only wants to know when a package is shipped, but not when the package has any other status
However, this quickly becomes untenable with the growing scope of business use cases. Each new business requirement that relies on state transition will similarly need to place its business logic within the producer service (see Figure 3-10) to generate events whenever that “edge” happens. This is prohibitively difficult to scale and manage, let alone track ownership and dependencies.
Figure 3-10. The scope of consumer requirements can grow quite large, as there are many possible deltas for most domains of any complexity
The entire purpose of delta events is to avoid maintaining state in the consumer service, but they require that the producer be fully able and willing to fulfill business logic solely for the consumer. For example, consider these reasonably plausible use cases:
-
I want to track returns where a user had previously called in to complain: a
userReturnedItemAfterTelephoneComplaintevent. -
I want to know if the user has seen at least three ads for the item and then subsequently purchased it: a
userSawAtLeastThreeAdsThenPurchasedItevent.
These sample events may seem a bit over the top, but the reality is that these are the sorts of conditions that businesses do care about. In each case, the consumer should maintain its own state and build up its own computations of these occurrences but instead avoids it by pushing the responsibility of detecting the edge back to the producer. The resultant is a very tight coupling between the producer and the consumer, and leads to spreading the complexity across multiple code bases.
A final factor is that a single system is seldom able to provide all of the information necessary for these highly specialized events. Consider the example of Figure 3-11. In this example, the consumer needs to act when state from the advertising service and the payments service (both within their own domains) meet a certain criterion: the user must have been shown an advertisement three times and then eventually have purchased that item.
Even if we convinced the advertising team to produce userSawAdvertisementThreeTimes and userRe turnedItemAfterTelephoneComplaint events, the consumer would still need to store it in its own state store and await the matching purchase from the payments service. Even the most complex and convoluted event definition cannot account for handling data that resides entirely in another domain. The consumer must still be able to maintain state, despite our best efforts to avoid it.
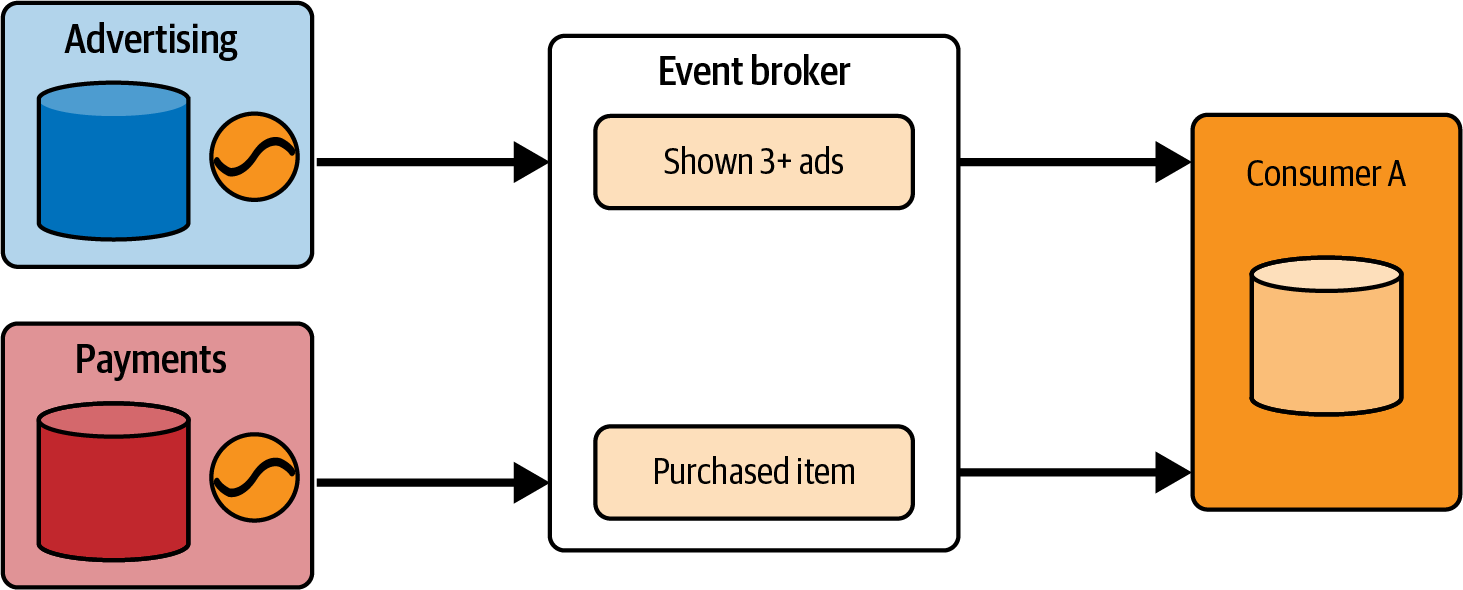
Figure 3-11. Consumer-specific delta event triggering logic is pushed upstream to both the advertising and payments service
And what if our consumer wants to change its business logic from three ads to four? A whole new event definition needs to be negotiated and put in the producer’s boundary, which should give you an idea of how poorly this idea fares in practice. It is far more reasonable that the producer output a set of general purpose state and let the consumer figure out what it wants to do with those data sets.
5) Inability to maintain historical data
The fifth and final point against delta events is based on the difficulty of maintaining usable historical data. Old state events can simply be compacted, but delta events cannot. It becomes substantially more difficult to manage the ever-increasing log of events as a source of historical information.
Each delta event is essential for aggregating the final state. And there may not only be a single event stream to deal with, but multiple delta streams relating to different deltas within the domain. Figure 3-12 shows an example of three simple shopping cart delta events that have grown very large over the past 10 years—so large that a new consumer might take, say, three weeks of nonstop processing to make it through the volume of data, just to catch up to the current state.
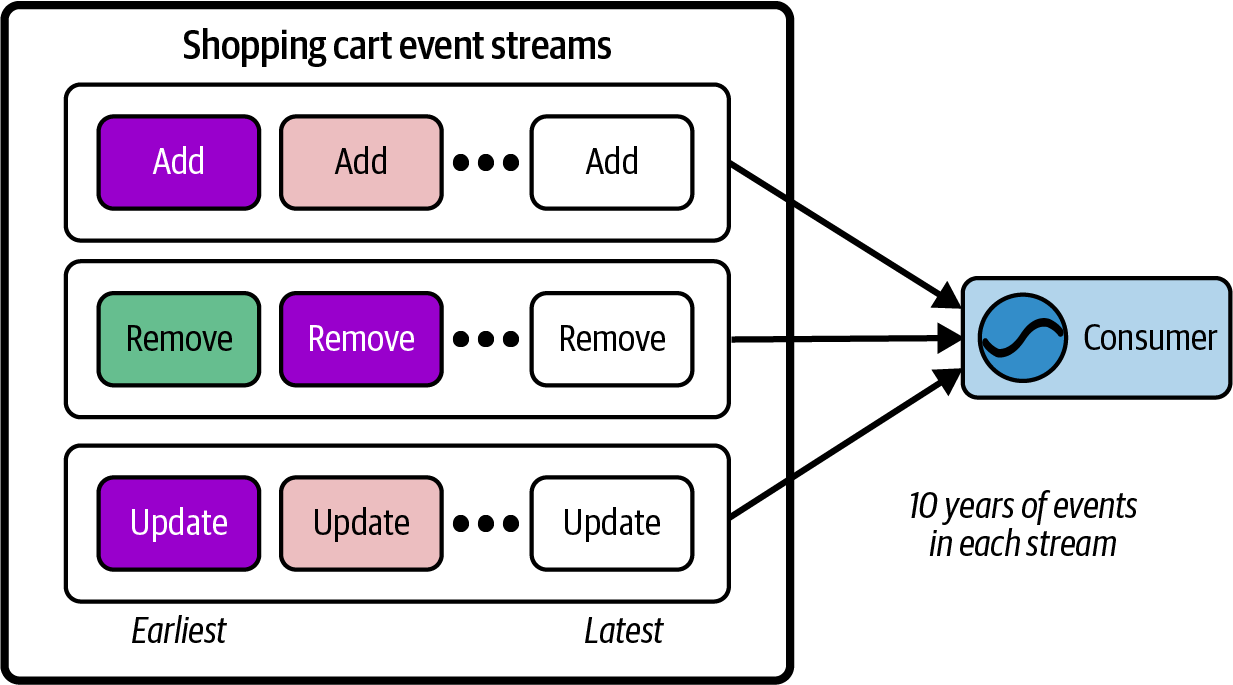
Figure 3-12. There are simply too many delta events in this stream for a new consumer to reasonably consume
While purging old data is certainly one solution, another solution that I have seen attempted is to offload older events into a large side state store, which can be sideloaded into a new consumer. The idea here is that the consumer can load all of these events in parallel, booting up far more quickly. The problem is that the order in which these events are applied can matter, and just moving the events to a nonstreaming system only to stream them back into new consumers is a bit nonsensical. So the next solution is to build a snapshot of the state at that point in time based on all of the delta events. This is shown in Figure 3-13.
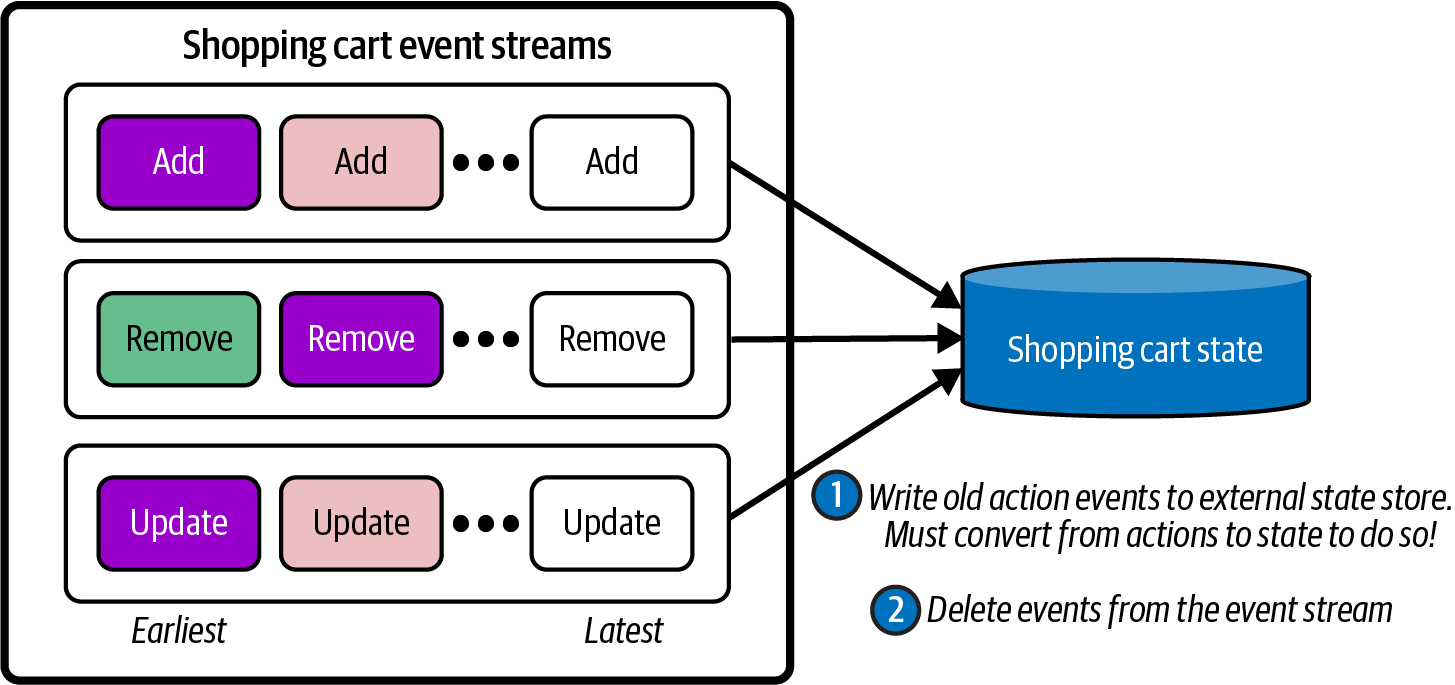
Figure 3-13. Loading the old events into a bootstrapping side store requires aggregating into a state model
There is a bit of irony here. In the attempt to avoid creating a publicly usable definition of state, we find ourselves doing exactly this to store the data in a side store. New consumers can certainly boot up far more quickly using it, but now they have to both read from the snapshot state store and then switch over perfectly to the event stream.
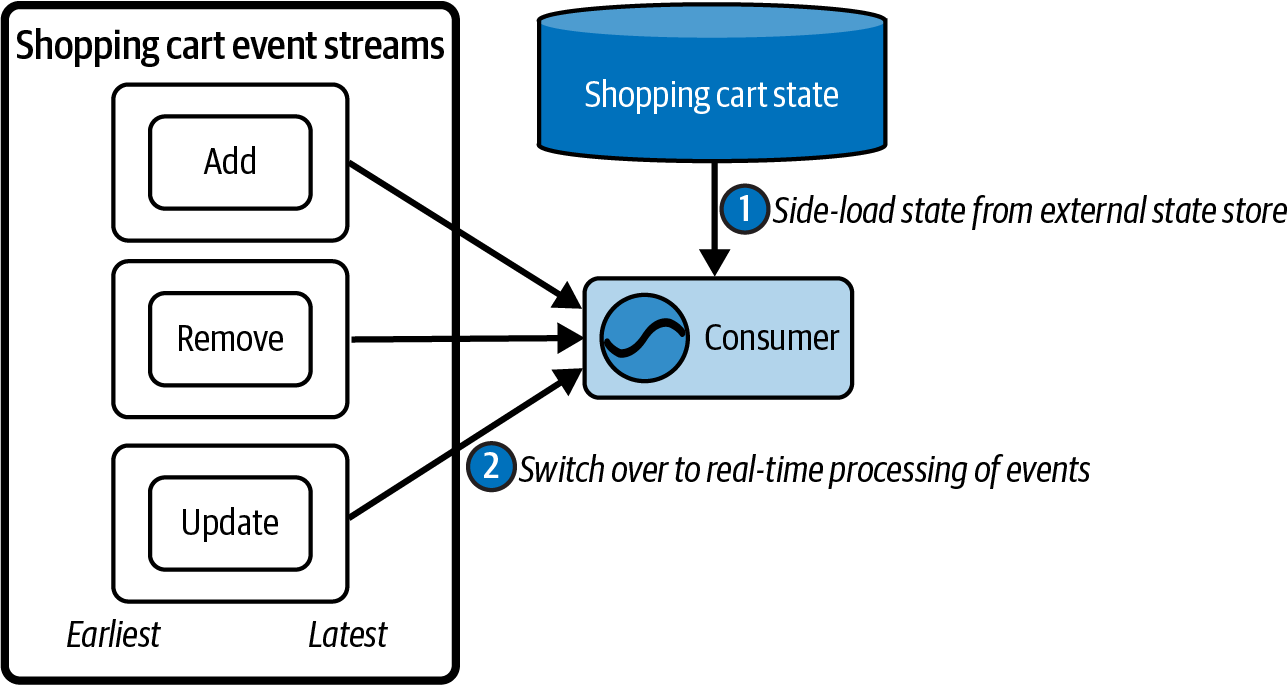
Figure 3-14. This brings us back around to the Lambda architecture involving both delta events, aggregated state, and the need to handle both batch and streaming
Figure 3-14 shows that we have now come full circle, back to the very Lambda architectures that we have been trying to avoid this whole time, along with all its operational complexity and inherent problems.
The following are unfortunately common yet insufficient arguments for using delta events for interdomain communication:
Maintaining duplicate state is wasteful, it’s going to take up too much disk.
The consumers will know what the event means. How could they possibly misinterpret it?
C’mon, I really only care about this one transition, it’s not a big deal if I couple on it. Just publish a custom event for me.
That person who doesn’t want to use state events
Delta events are fine within the internal boundary of a private domain, where the tight coupling of the event definitions and the logic required to interpret and apply them can be applied consistently.
However, using the same delta events across domain boundaries is perilous, and using them as the means to build up state in other applications is really out of the question. Focus on using state events for the bulk of your event-streams.
Hybrid Events—State with a Bit of Delta
Hybrid events are a mixture of state
and delta. It’s best to think of these as state events that may contain a bit of information about why or how something happened. Let’s look at an example for clarity.Exposing "how" or "why" something has occurred with a hybrid event may lead to strong consumer coupling on the producer system. Proceed with caution.
Consider the following scenario. A company provides an online service that requires a user to sign up before using it. There are several that a user can sign up:
-
Via the main sign up button on the home page
-
Via an email advertising link
-
Using a third-party account (a Google account, for example)
-
The account was manually created for them by an administrator
The consumer wants to know how the user signed up. For operational use cases, we want to know which onboarding workflow to serve them when they next log in. For analytical purposes, we may want to know which of our methods of sign-up are the most common so we can allocate our development resources.
One way to model this sign-up is with a user state event, with a single enumeration indicating the sign-up mechanism (after all, you can only sign up once!). An example of the record would look like this:
Key:"USERID-9283716596927463"Value:{name:"RandolphL.Bandito",signup_time:"2022-02-22T22:22:22Z",birthday:"2000-01-01T00:00:00Z",//An enum of (MAIN,VIA_AD_EMAIL,THIRD_PARTY,or ADMIN)method_of_signup:"VIA_AD_EMAIL"}
To create the hybrid event, we incorporated what would otherwise be delta events into a single state event. Instead of signed_up_via_email, signed_up_via_homepage, signed_up_via_third_party, and signed_up_via_admin events, we flattened them down into a single enum and appended them to the user entity. The domain of values in the user state event needs to account for each of the possible enum settings: for example, we may also want to include information about which third-party sign-in provider was used or which email campaign got the user to sign up.
And herein lies the main issue with hybrid events. The precise mechanism of how something came to be in a domain is by and large a private detail, but by exposing this information we also expose the internal business logic process for coupling on by downstream consumers.
The main risk to the consumer of this information is that how a user signs up will change over time. This can be both a semantic change in meaning (what exactly is the “main” way to sign up now versus 5 years ago and 5 years in the future?), as well as the expansion or contraction of values in the enum. These semantics are usually only the concern of the source domain, but by exposing these delta-centric seams, they become a concern of the consumer.
There is also the chance (or likelihood) that the producer must update the hybrid event to account for a new means of sign-up: via the company’s newly released mobile application (add VIA_MOBILE_APP to the method_of_signup enum). Consumers of this event must be kept informed of impending changes to this event and must confirm that they can handle processing of this new method_of_signup before the event definition is updated. If not, the consumers run the risk of encountering fatal errors during processing, because their business logic won’t account for the new type. This is just another aspect of the same issue we saw in “2) The logic to interpret delta events must be replicated to each consumer”.
However, in this example, the risk to the consumer is low, but not zero, for the following reasons:
-
How a consumer signed up is immutable. The real risk lies in the meaning of
method_of_signupdrifting over time. The owner of the event can prevent this by providing very clear documentation of the enumeration’s meaning (e.g., in the event schema itself) and adhering closely to its own definitions. -
The logic that populates
method_of_signupis fairly simple overall, and so is much less likely to drift over time. Registering via an email link is a binary delta—you either registered via the email link or you didn’t. In contrast, an enum based on theuserReturnedItemAfterTelephoneComplaintdelta event from earlier in the chapter has many more sequential dependencies and ways of misinterpreting it, and is far more likely to drift in meaning over time.
A hybrid event is a trade-off. The risk you incur in using a hybrid event is proportional to the complexity of the delta you are trying to track and the likelihood that it will change over time (intentionally or not). I advise that you try to further decouple your producer and consumer systems to avoid communicating the details of why or how data has changed. If you choose to include a delta-type field in your event, be aware that it becomes part of your data contract, and carefully consider the
coupling it introduces with the source system.Measurement Events
Measurement events are commonly found
in many domains and consist of a complete record of an occurrence at a point in time. There are common examples of this in our everyday world: website analytics, perhaps most familiarly embodied by Google Analytics, is one. The user behavior tracking that occurs on every single website, social media experience, and mobile application is another. Every time you click a button, view an ad, or linger on a social media post, it is recorded as a measurement event.What does a measurement event look like? Here’s an example of a user behavior event recording the event of a user seeing an advertisement on a webpage:
Key:"USERID-8271949472726174"Value:{utc_timestamp:"2022-01-22T15:39:19Z",ad_id:1739487875123,page_id:364198769786,url:https://www.somewebsite.com/welcome.html}
A measurement is a snapshot of state at a specific point in time. However, measurements have a few characteristics that differentiate them from the state events we discussed earlier.
Measurement Events Enable Aggregations
Measurements are often used to create aggregations around a particular key. For example, the userViewedAd measurement could be used to compute a multitude of data sets, answering questions like “What is the most popular page_id?”, “When do users see the most ads?”, and “How many ads does each user see, on average, in a session?”
Measurement Event Sources May Be Lossy
It is not uncommon to lose measurements somewhere between their creation and ingestion into the event stream. For example, ad-blockers are very good at blocking web analytical events, such that your reports and dashboards are unlikely to be completely accurate. They are, however, often good enough for many analytical purposes.
Measurement Events Can Power Time-Sensitive Applications
Consider a factory that measures temperature, humidity,
and other air quality metrics on its assembly line. One analytical use case for these measurements may be to track and identify long-term trends of the factory environment. But an operational use case may be to react quickly in the case of divergent sensor values, altering the assembly line throughput or shutting it down altogether if the environmental conditions fail to meet specifications.In the case of network connectivity issues, it may be the case that the sensors are waiting to publish data that is now 30 to 60 seconds old, while new data piles up behind it. Depending on the purpose of the measurement stream and its pre-negotiated service-level objectives, it may choose to discard the old events and simply publish the latest. It really depends heavily on whether this data is being used for real-time purposes or whether it’s being used to build a comprehensive historical picture that is tolerant of outages and delays, as is the case in web analytics.
Notification Events
There’s one last event type to discuss before we wrap
up the chapter. A notification contains a minimal set of information that something has happened and a link or URI to the resource containing more information. Mobile phones are probably the most familiar source of notifications—you have a new message, someone liked your post, or you have enough hearts to resume your free-to-play game—click here to go to it.An example of a simple behind-the-scenes notification you may receive on your cell phone could look something like the following. Your instant message application sends out a “NEW_MESSAGE” notification, including a status (for icon display), the name of the application, and a click-through URI to the application itself:
Value:{status:"NEW_MESSAGE",source:"messaging_app",application_uri:"/user/chat/192873163812392"}
Notification events are often misused as a means of trying to communicate state without sending state itself. Instead, a pointer to the state is sent in the notification, with the expectation that the recipient will log into the source server and obtain the data. The following shows just such an example, where the notification includes that the status has changed, and there is an access URI to find the complete current state:
Key:12309131238218Value:{status:"PARTIAL_RETURN",utc_timestamp:"2021-21-13T13:11:42Z",access_uri:"serverURI:8080/orders/values/12309131238218"}
At first glance, this seems to be a neat and trim solution: it allows the consumer to simply query for the full public state upon receiving the event without copying or exposing that data elsewhere. One of the major issues is that the event doesn’t actually provide a record of the state at that point in time—unless the data contained at access_uri is completely immutable (it usually isn’t). Since this anti-pattern is usually built on top of a mutable state store, by the time you receive the PARTIAL_RETURN notification, the associated state at access_uri may have already been updated again to a new state.
This race condition makes notifications an unreliable mechanism for communicating state. For example, a sale with status updates of SOLD -> PARTIAL_RETURN -> FULL_RETURN will emit three distinct events, one for each state. A consumer lagging behind on its processing may not be able to access the PARTIAL_RETURN state before it finalizes to FULL_RETURN and thus completely miss that full state transition. To make matters worse, a new consumer processing the backlog will not see any of the previous state—only whatever is stored in the access_uri at the current wall-clock time.
A final blow to this design is that it adds far more complexity. Not only must the domain owner of the notification publish events, but it must also serve synchronous requests pertaining to that state. This includes managing access control, authorization, and performance scaling for both the event-stream producer and the synchronous query API.
Instead, it is far better just to produce the necessary state of the event as an immutable record of that point in time. It takes very little effort and greatly simplifies data communication
between domains.Summary
We covered a lot of ground in this chapter, so let’s take a moment to recap before moving on.
Events can primarily be defined as state or delta. State events enable event-carried state transfer and are your best option for communicating data between domains. State events rely on event broker features, such as indefinite retention, durable state, and compaction to help us manage the volume of events. The state design allows us to leverage the event broker as the primary source of data, enables the use of the Kappa architecture, and deftly avoids the pitfalls associated with its predecessor, the Lambda architecture.
Delta events are a common way of thinking about event-driven architectures, but they are insufficient for cross-domain communication. Deltas belong firmly in the camp of the event sourcing and tightly-coupled inter-application communication. They can be invaluable for communication within a singular bounded context. Misuse of delta events occurs when coupling by external parties is allowed. This results in the exposure of internal business logic, processes, and events that should remain private. Simply put, do not use delta events for cross-domain coupling.
Measurement events record occurrences, such as those from human users, distributed systems, and Internet of Things (IoT) devices. Measurement events have their roots in the data analytics domain and consist of a snapshot of the localized state at a precise moment in time. These events are frequently used to compose detailed aggregates or to react to rapid measurement changes.
Both hybrid and notification events should be used with caution, if at all. Hybrid events are primarily a state event but can expose information pertaining to why something happened, akin to a delta event. This forms a seam that introduces tight coupling, particularly when the why changes with time, and can lead to tight coupling and dependencies spread across multiple services.
Chapter 4. Integrating Event-Driven Architectures with Existing Systems
Transitioning an organization to an event-driven architecture requires the integration of existing systems into the ecosystem. Your organization may have one or more monolithic relational database applications. Point-to-point connections between various implementations are likely to exist. Perhaps there are already event-like mechanisms for transferring bulk data between systems, such as regular syncing of database dumps via an intermediary file store location. In the case that you are building an event-driven microservice architecture from the ground up and have no legacy systems, great! You can skip this section (though perhaps you should consider that EDM may not be right for your new project). However, if you have existing legacy systems that need to be supported, read on.In any business domain, there are entities and events that are commonly required across multiple subdomains. For example, an ecommerce retailer will need to supply product information, prices, stock, and images to various bounded contexts. Perhaps payments are collected by one system but need to be validated in another, with analytics on purchase patterns performed in a third system. Making this data available in a central location as the new single source of truth allows each system to consume it as it becomes available. Migrating to event-driven microservices requires making the necessary business domain data available in the event broker, consumable as event streams. Doing so is a process known as data liberation, and involves sourcing the data from the existing systems and state stores that contain it.
Data produced to an event stream can be accessed by any system, event-driven or otherwise. While event-driven applications can use streaming frameworks and native consumers to read the events, legacy applications may not be able to access them as easily due to a variety of factors, such as technology and performance limitations. In this case, you may need to sink the events from an event stream into an existing state store.
There are a number of patterns and frameworks for sourcing and sinking event data. For each technique, this chapter will cover why it’s necessary, how to do it, and the tradeoffs associated with different approaches. Then, we’ll review how data liberation and sinking fit in to the organization as a whole, the impacts they have, and ways to structure your efforts for success.
What Is Data Liberation?
Data liberation is the identification and publication of cross-domain data sets to their corresponding event streams and is part of a migration strategy for event-driven architectures. Cross-domain data sets include any data stored in one data store that is required by other external systems. Point-to-point dependencies between existing services, and data stores often highlight the cross-domain data that should be liberated, as shown in Figure 4-1, where three dependent services are querying the legacy system directly.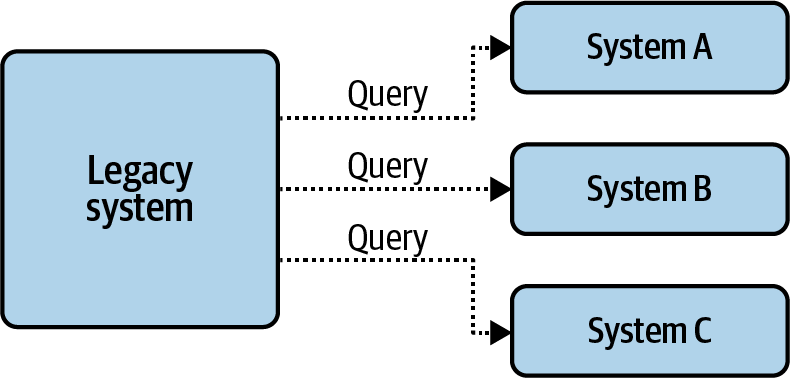
Figure 4-1. Point-to-point dependencies, accessing data directly from the underlying service
By serving as a single source of truth, these streams also standardize the way in which systems across the organization access data. Systems no longer need to couple directly to the underlying data stores and applications, but instead can couple solely on the data contracts of event streams. The post-liberation workflow is shown in Figure 4-2.
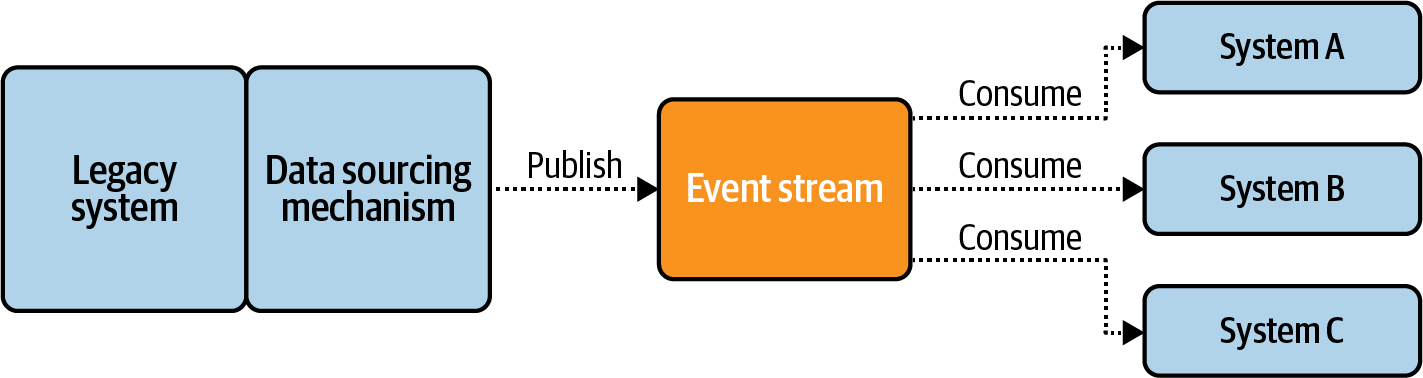
Figure 4-2. Post-data-liberation workflow
Compromises for Data Liberation
A data set and its liberated event stream must be kept fully in sync, although this requirement is limited to eventual consistency due to the latency of event propagation. A stream of liberated events must materialize back into an exact replica of the source table, and this property is used extensively for event-driven microservices (as covered in [Link to Come]). In contrast, legacy systems do not rebuild their data sets from any event streams, but instead typically have their own backup and restore mechanisms and read absolutely nothing back from the liberated event stream. In the perfect world, all state would be created, managed, maintained, and restored from the single source of truth of the event streams. Any shared state should be published to the event broker first and materialized back to any services that need to materialize the state, including the service that produced the data in the first place, as shown in Figure 4-3.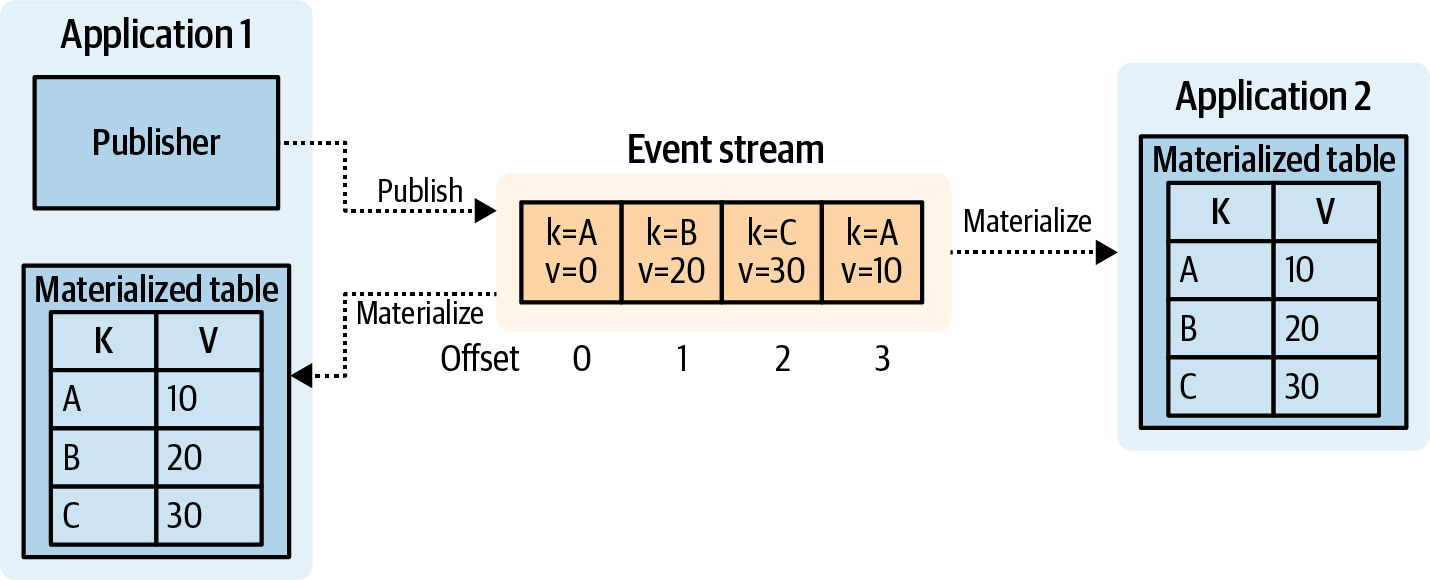
Figure 4-3. Publish to stream before materializing
- Limited developer support
-
Many legacy systems have minimal developer support and require low-effort solutions to generate liberated data.
- Expense of refactoring
-
Reworking the preexisting application workflows into a mix of asynchronous event-driven and synchronous MVC (Model-View-Controller) web application logic may be prohibitively expensive, especially for complex legacy monoliths.
- Legacy support risk
-
Changes made to legacy systems may have unintended consequences, especially when the system’s responsibilities are unclear due to technical debt and unidentified point-to-point connections with other systems.
There is an opportunity for compromise here. You can use data liberation patterns to extract the data out of the data store and create the necessary event streams. This is a form of unidirectional event-driven architecture, as the legacy system will not be reading back from the liberated event stream, as shown in Figure 4-3. Instead, the fundamental goal is to keep the internal data set synchronized with the external event stream through strictly controlled publishing of event data. The event stream will be eventually consistent with the internal data set of the legacy application, as shown in Figure 4-4.
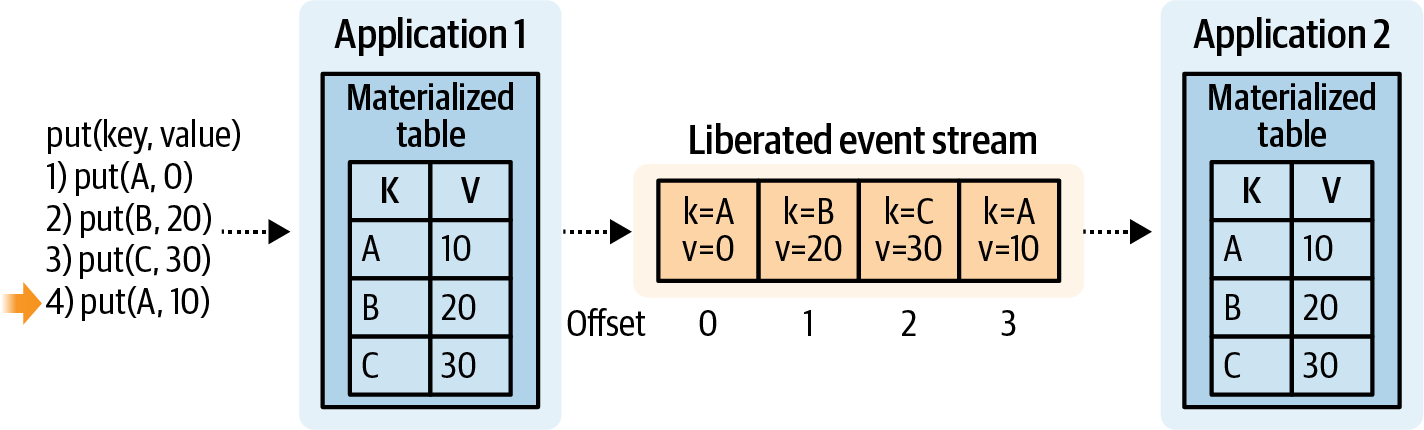
Figure 4-4. Liberating and materializing state between two services
Converting Liberated Data to Events
Liberated data, much like any other event, is subject to the same recommendations of schematization that were introduced in [Link to Come]. One of the properties of a well-defined event stream is that there is an explicitly defined and evolutionarily compatible schema for the events it contains. You should ensure that consumers have basic data quality guarantees as part of the data contract defined by the schema. Changes to the schema can only be made according to evolutionary rules.Tip
Use the same standard format for both liberated event data and native event data across your organization.
By definition, the data that is most relevant and used across the business is the data that is most necessary to liberate. Changes made to the data definitions of the source, such as creating new fields, altering existing ones, or dropping others, can result in dynamically changing data being propagated downstream to consumers. Failing to use an explicitly defined schema for liberated data will force downstream consumers to resolve any incompatibilities. This is extremely problematic for the provision of the single source of truth, as downstream consumers should not be attempting to parse or interpret data on their own. It is extremely important to provide a reliable and up-to-date schema of the produced data and to carefully consider the evolution of the data over time.Data Liberation Patterns
There are three main data liberation patterns that you can use to extract data from the underlying data store. Since liberated data is meant to form the new single source of truth, it follows that it must contain the entire set of data from the data store. Additionally, this data must be kept up to date with new insertions, updates, and deletes.- Query-based
-
You extract data by querying the underlying state store. This can be performed on any data store.
- Log-based
-
You extract data by following the append-only log for changes to the underlying data structures. This option is available only for select data stores that maintain a log of the modifications made to the data.
- Table-based
-
In this pattern, you first push data to a table used as an output queue. Another thread or separate process queries the table, emits the data to the relevant event stream, and then deletes the associated entries. This method requires that the data store support both transactions and an output queue mechanism, usually a standalone table configured for use as a queue.
While each pattern is unique, there is one commonality among the three. Each should produce its events in sorted timestamp order, using the source record’s most recent updated_at time in its output event record header. This will generate an event stream timestamped according to the event’s occurrence, not the time that the producer published the event. This is particularly important for data liberation, as it accurately represents when events actually happened in the workflow. Timestamp-based interleaving of events is discussed further in [Link to Come].
Data Liberation Frameworks
One method of liberating data involves the usage of a dedicated, centralized framework to extract data into event streams. Examples of centralized frameworks for capturing event streams include Kafka Connect (exclusively for the Kafka platform), Debezium.io, and Apache NiFi. They’ll connect to a whole suite of different data stores, applications, and SaaS endpoints with off-the shelf connection options. And some connector frameworks will also let you write your own connectors for less common use cases.Each framework allows you to execute a query against the underlying data set with the results piped through to your output event streams. Each option is also scalable, such that you can add further instances to increase the capacity for executing change-data capture (CDC) jobs.
They support various levels of integration with the schema registry offered by Confluent (Apache Kafka), but customization can certainly be performed to support other schema registries. See [Link to Come] for more information.Let’s take a look at our first mechanism for getting data into streams: change-data capture.
Liberating Data Using Change-Data Capture
One of the chief methods for liberating data relies on the data store’s own underlying immutable log (e.g. binary log for MySQL, write-ahead logs for PostgreSQL). This immutable append-only data structure preserves the data store’s data integrity. An inserted record is first written into the durable log before being applied to the underlying data model. If the database were to fail mid-write, then the durable log is replayed to the disk, to ensure that no information is lost and the data model remains consistent.
Change-Data Capture, or CDC, is a process that reads (or tails) these logs, converts the individual data store changes into events, and write them to the event stream. These changes include the creation, deletion, and updating of individual records, as well as the creation, deletion, and altering of the individual data sets and their schemas. While many databases provide some form of read-only access to the durable logs, others, like MongoDB, provide CDC events directly instead of tailing the log.
The data store’s log seldom contains the entire history of data. To turn the entire data store dataset into an event stream, you’ll need to create a snapshot of the existing state from the data set itself. We’ll cover that more in the next section on “snapshotting”.
Not all data stores implement an immutable logging of changes, and of those that do, not all of them have off-the-shelf connectors available for extracting the data.
This approach is mostly applicable to select relational databases, such as MySQL and PostgreSQL, though any data store with a set of comprehensive changelogs is a suitable candidate. Many other modern data stores expose event APIs that act as a proxy for a physical write-ahead log. For example, MongoDB provides a Change Streams interface, whereas Couchbase provides replication access via its internal replication protocol.
Figure 4-5. The end-to-end workflow of a Debezium capturing data from a MySQL database’s binary log, and writing it to event streams in Kafka
Figure 4-5 shows a MySQL database emitting its binary changelog. A Kafka Connect service, running a Debezium connector, is consuming the raw binary log. Debezium parses the data and converts it into discrete events. Next, an event router emits each event to a specific event stream in Kafka, depending on the source table of that event. Downstream consumers are now able to access the database content by consuming the relevant event streams from Kafka.
CDC gives you every change made in the database. You will not miss any transitions, and your derived event stream will contain every update. CDC frameworks provide configuration files that let you specify which fields to include in your event, letting you filter out internal data from the outside world. You can also choose to include metadata like the serverId, transactionId, and other database or connector-specific content. You can also include before and after fields that detail the full state of the row or document before the change and the full state after the change. We’re going to look at this subject and the implications behind it more in [Link to Come].
Having covered the basics of CDC, let’s now turn our attention to how we can get the initial data set into the event stream.
Snapshotting the Initial Data Set State
The data store log is unlikely to contain all changes since the beginning of time, as it’s primarily a mechanism to ensure data store consistency. The data store continually merges the log data down into the underlying data store model, only keeping a short window of data (e.g. several GBs).
Snapshotting is where we load all the current data into the event stream, directly from the data store (and not the log). It can be a very resource intensive activity, as you must query, return, copy, convert to events, and write to event streams every entity of data from the source data set. Only once you’ve completed your snapshot can you move to live capturing of records.
The snapshot usually involves a large, performance-impacting query on the table and is commonly referred to as bootstrapping. You must ensure that there is overlap between the records in the bootstrapped query results and the records in the log, so that you do not miss any record when you swich over to live CDC.
There are further complications beyond the size of the query. A data store typically serves live business use cases and cannot be interrupted or degraded without some sort of consequence. However, and without getting too into the weeds, snapshotting typically requires an unchanging set of data to ensure consistency, and to accomplish that, it usually locks the table that it is querying. This means that your important production table may be locked for several hours while the snapshot completes. I bet your database administrator will be thrilled. And even if it’s brief, it may still be unacceptable. So what can we do?
One option is to snapshot from a read-only replica. You take the snapshot against the replica, leaving the production data store alone. Once completed, you can unlock the table, which will then be populated by the replicated updates from the production data store. At this point, you can swap over to change-date capture, or a periodic query as we’ll see in the next section.
Some CDC frameworks, like Debezium.io, provide a mechanism that a way to snapshot certain data stores without locking the table. Normal operational reads and writes can continue uninterrupted with the resultant snapshot being eventually consistent with the current table’s state. A Debezium blog post, explains this innovation. It is based on a paper from Netflix that states
:DBLog utilizes a watermark based approach that allows us to interleave transaction log events with rows that we directly select from tables to capture the full state. Our solution allows log events to continue progress without stalling while processing selects. Selects can be triggered at any time on all tables, a specific table, or for specific primary keys of a table. DBLog executes selects in chunks and tracks progress, allowing them to pause and resume. The watermark approach does not use locks and has minimum impact on the source.
Andreas Andreakis and Ioannis Papapanagiotou, Netflix
Live table snapshots that don’t degrade performance or block production use cases are a massive improvement from early CDC technologies. This let you focus on using the data to build event-driven applications, instead of just wrangling the data out of the data store.
The CDC system merges the incremental snapshot results with the log records, such that old results (say from the table) aren’t overwritting new results coming from the log. Then, it converts the records into a suitable format and writes it out to the corresponding event stream. And, once completed, the CDC process continues to tail the data store’s log uninterrupted.
Here are a few of the main benefits and drawbacks of using the CDC with data store logs.
Benefits of Change-Data Capture Using Data Store Logs
Some benefits of using data store logs include:- Delete tracking
-
Data store logs contain deletions, so that you can see when a record has been deleted from the data store. These can be converted into tombstone events to enable downstream deletions and stream compaction.
- Minimal effect on data store performance
-
For data stores predicated on logs, change-data capture can be performed without any impact to the data store’s performance. For those that use change tables, such as in SQL Server, the impact is related to the volume of data.
- Low-latency updates
-
Updates propagate as soon as the event is written to the data store log, resulting in the event streams with relatively low latency.
- Nonblocking snapshots
-
CDC can create snapshots without interfering with the normal operations of the source data store.
Drawbacks of Change-Data Capture Using Data Store Logs
The following are some of the downsides to using data store logs:
- Exposure of internal data models
-
The internal data model is completely exposed in the changelogs. Isolation of the underlying data model must be carefully and selectively managed.
- Denormalization outside of the data store
-
Changelogs contain only the event data. Some CDC mechanisms can extract from materialized views, but for many others, denormalization must occur outside of the data store. This may lead to the creation of highly normalized event streams, requiring downstream microservices to handle foreign-key joins and denormalization.
- Brittle dependency between data set schema and output event schema
-
Valid data model changes in the source data store, such as altering a data set or redefining a field type, may cause breaking changes to downstream consumers.
Liberating Data with a Polling Query
With query-based data liberation you query the data store, get the results, convert them into events, and write them to the event stream. You can write your own code to do this for you, or you can rely on the likes of Kafka Connect or Debezium, as mentioned previously. Given the wealth of connectors available today, I recommend that you start with a purpose-built framework instead of trying to rebuild your own.
Query-based data liberation doesn't use the underlying data store log. Both snapshots and incremental iterations are consumerd entirely via the data store query API.
There are two main stages to the periodic query pattern: the initial snapshot, and the incremental phase.
The snapshot process is identical to that found in “Snapshotting the Initial Data Set State”, though there is no data store log to swap over to once completed. The iterative phase starts where the snapshot left off.
Query-based polling requires identifying which records have changed since the last polling iteration. For example, an updated_at or modified_at timestamp is a common choice of field to evaluate in your query, as illustrated by the Kafka Connect JDBC connector. For each iteration of your polling loop, it uses the highest updated_at timestamp from the last query’s results, then inputs it as the starting point for the next polling loop. The returned rows are converted into events and the connector updates its stored updated_at timestamp for the next loop. You may also choose to use an auto-incrementing ID if it is available in your table.
The event schemas are automatically inferred from the query results - at least for the off-the-shelf frameworks. If you’re rolling your own polling query, then you’ll need to generate a schema that suits your needs. That being said, if the upstream data store model changes, then you run the risk that your event schema will also change.
Query-based polling, particularly when rolling your own, relies heavily on locking tables to get a consistent state. It is overall a dated process for bootstrapping, and while it’s still technically valid, it’s far more common to use CDC over iterative queries. Since the first edition of this book CDC has substantially improved, with query-based polling relegated mostly to data stores and APIs that provide no underlying data store log access.
Incremental Updating
The first step of any incremental update is to ensure that the necessary timestamp or Auto-incrementing ID is available in the records of your data set. There must be a field that the query can use to filter out records it has already processed from those it has yet to process. Data sets that lack these fields will need to have them added, and the data store will need to be configured to populate the necessaryupdated_at timestamp or the Auto-incrementing ID field. If the fields cannot be added to the data set, then incremental updates will not be possible with a query-based pattern. The second step is to determine the frequency of polling and the latency of the updates. Higher-frequency updates provide lower latency for data updates downstream, though this comes at the expense of a larger total load on the data store. It’s also important to consider whether the interval between requests is sufficient to finish loading all of the data. Beginning a new query while the old one is still loading can lead to race conditions, where older data overwrites newer data in the output event streams.
Once the incremental update field has been selected and the frequency of updates determined, the final step is to perform a single bulk load before enabling incremental updates. This bulk load must query and produce all of the existing data in the data set prior to further incremental updates.
Benefits of Query-Based Updating
Query-based updating has a number of advantages, including:- Customizability
-
Any data store can be queried, and the entire range of client options for querying is available.
- Independent polling periods
-
Specific queries can be executed more frequently to meet tighter SLAs (service-level agreements), while other more expensive queries can be executed less frequently to save resources.
- Isolation of internal data models
-
Relational databases can provide isolation from the internal data model by using views or materialized views of the underlying data. This technique can be used to hide domain model information that should not be exposed outside of the data store.
Caution
Remember that the liberated data will be the single source of truth. Consider whether any concealed or omitted data should instead be liberated, or if the source data model needs to be refactored. This often occurs during data liberation from legacy systems, where business data and entity data have become intertwined over time.Drawbacks of Query-Based Updating
There are some downsides to query-based updating as well:- Required
updated-attimestamp -
The underlying table or namespace of events to query must have a column containing their
updated-attimestamp. This is essential for tracking the last update time of the data and for making incremental updates. - Only detects soft deletes
-
Outright deleting a record from the data store will not result in any events showing up in the query. Thus, you must use a soft delete, where the records are marked as deleted by a specific
is_deletedcolumn. - Brittle dependency between data set schema and output event schema
-
Data set schema changes may occur that are incompatible with downstream event format schema rules. Breakages are increasingly likely if the liberation mechanism is separate from the code base of the data store application, which is usually the case for query-based systems.
- May miss intermittent data values
-
Data is synced only at polling intervals, and so a series of individual changes to the same record may only show up as a single event.
- Production resource consumption
-
Queries use the underlying system resources to execute, which can cause unacceptable delays on a production system. This issue can be mitigated by the use of a read-only replica, but additional financial costs and system complexity will apply.
- Query performance varies due to data size
-
The quantity of data queried and returned varies depending on changes made to the underlying data. In the worst-case scenario, the entire body of data is changed each time. This can result in race conditions when a query is not finished before the next one starts.
Liberating Data Using Transactional Outbox Tables
A transactional outbox table acts as a temporary buffer for data to be written to the event stream. When you update your internal domain model, you select only the data that you want to expose to the outside world and write it to the outbox. Then, a separate asynchronous process, such as a dedicated CDC connector, consumes the data from the outbox and writes it to the event stream. Figure 4-6 shows the end-to-end workflow.
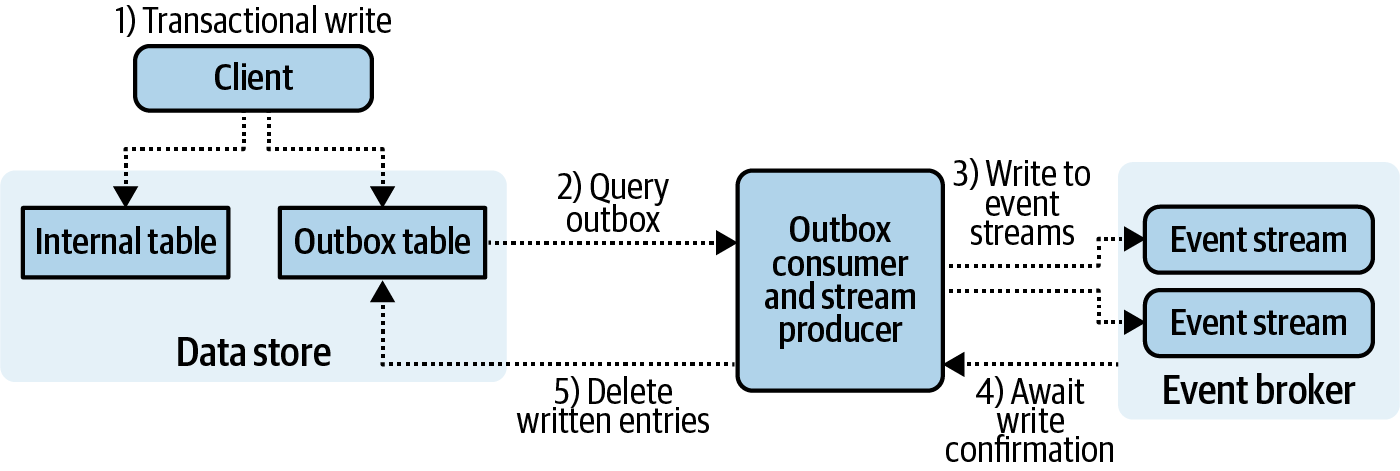
Figure 4-6. The end-to-end workflow of an outbox table CDC solution
Both the internal table updates and the outbox updates must be bundled into a single transaction, such that each occurs only if the entire transaction succeeds. A failure to do so may eventually result in divergence with the event stream as the single source of truth, which can be difficult to detect and repair. Figure 4-7 shows a high level view of the end-to-end process.
Figure 4-7. Getting events from a database using a transactional outbox and a dedicated connector
A separate application thread or process (e.g. a CDC connector) continually polls the outboxes and produce the data to the corresponding event streams. Once successfully produced, the corresponding records in the outbox are deleted. In the case of any failure, be it the data store, the consumer/producer, or the event broker itself, outbox records will still be retained without risk of loss. This pattern provides at-least-once delivery.
The transactional outbox table is a more invasive approach to change-data capture as it requires modification to either the data store or the application layer, both of which require the involvement of the data store developers. The outbox table pattern leverages the durability of the data store to provide a write-ahead log for events awaiting to be published to external event streams.
The records in outbox tables require a strict ordering identifier to ensure that intermediate states are recorded and emitted in the same order they occurred. Alternatively, you may choose instead to simply upsert by primary key, overwriting previous entries and forgoing intermediate state. In this case, overwritten records will not be emitted into the event stream.
An Auto-incrementing ID, assigned at insertion time, is best used to determine the order in which the events are to be published. Acreated_at timestamp column should also be maintained, as it reflects the event time that the record was created in the data store and can be used instead of the wall-clock time during publishing to the event stream. This will allow accurate interleaving by the event scheduler as discussed in [Link to Come]. Performance Considerations
The inclusion of outbox tables introduces additional load on the data store and its request-handling applications. For small data stores with minimal load, the overhead may go completely unnoticed. Alternately, it may be quite expensive with very large data stores, particularly those with significant load and many tables under capture. The cost of this approach should be evaluated on a case-by-case basis and balanced against the costs of a reactive strategy such as parsing the change-data capture logs.
Isolating Internal Data Models
An outbox table need not map 1:1 with an internal table. In fact, one of the major benefits of the outbox is that the data store client can isolate the internal data model from downstream consumers. The internal data model of the domain may use a number of highly normalized tables that are optimized for relational operations but are largely unsuitable for consumption by downstream consumers. Even simple domains may comprise multiple tables, which if exposed as independent streams, would require reconstruction for usage by downstream consumers. This quickly becomes extremely expensive in terms of operational overhead, as multiple downstream teams will have to reconstruct the domain model and deal with handling relational data in event streams.
Warning
Exposing the internal data model to downstream consumers is an anti-pattern. Downstream consumers should only access data formatted with public-facing data contracts as described in [Link to Come]. The data store client can instead denormalize data upon insertion time such that the outbox mirrors the intended public data contract, though this does come at the expense of additional performance and storage space. Another option is to maintain the 1:1 mapping of changes to output event streams and denormalize the streams with a downstream event processor dedicated to just this task. This is a process that I call eventification, as it converts highly normalized relational data into easy-to-consume single event updates. This mimics what the data store client could do but does it externally to the data store to reduce load. An example of this is shown in Figure 4-8, where a User is denormalized based on User, Location, and Employer.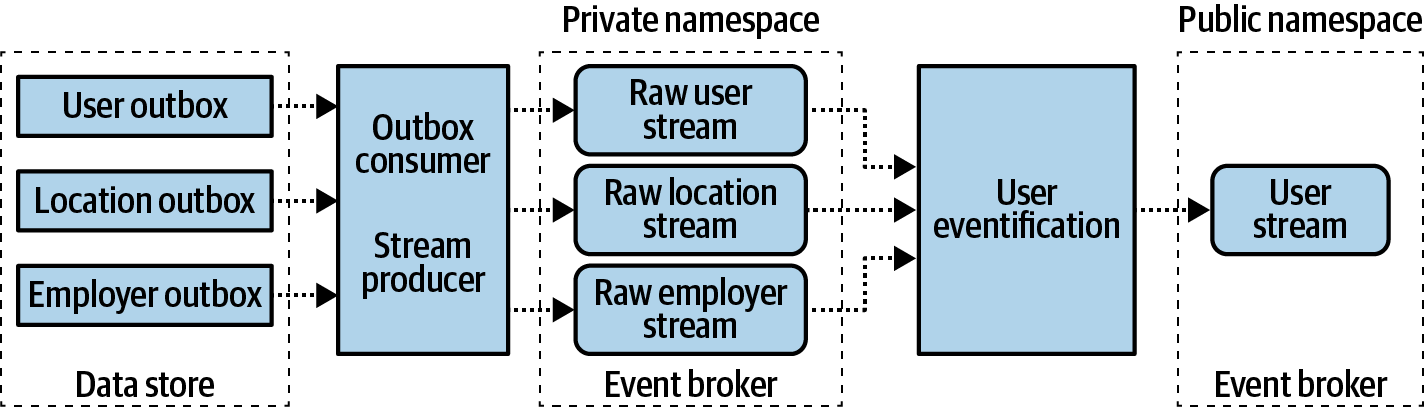
Figure 4-8. Eventification of public User events using private User, Location, and Employer event streams
In this example, the User has a foreign-key reference to the city, state/province, and country they live in, as well as a foreign-key reference to their current employer. It is reasonable that a downstream consumer of a User event may simply want everything about each user in a single event, instead of being forced to materialize each stream into a state store and use relational tooling to denormalize it. The raw, normalized events are sourced from the outboxes into their own event streams, but these streams are kept in a private namespace from the rest of the organization (covered in [Link to Come]) to protect the internal data model.
Eventification of the user is performed by denormalizing the User entity and shedding any internal data model structures. This process requires maintaining materialized tables of User, Location, and Employer, such that any updates can re-exercise the join logic and emit updates for all affected Users. The final event is emitted to the public namespace of the organization for any downstream consumer to consume. The extent to which the internal data models are isolated from external consumers tends to become a point of contention in organizations moving toward event-driven microservices. Isolating the internal data model is essential for ensuring decoupling and independence of services and to ensure that systems need only change due to new business requirements, and not upstream internal data-model changes.Ensuring Schema Compatibility
Schema serialization (and therefore, validation) can also be built into the transactional outbox workflow. Schema validation can be performed either before or after the event is written to the outbox table. Success means the event can be proceed in the workflow, whereas a failure may require manual intervention to determine the root cause and avoid data loss.Serializing prior to committing the transaction to the outbox table provides the strongest guarantee of data consistency. A serialization failure will cause the transaction to fail and roll back any changes made to the internal tables, ensuring that the outbox table and internal tables stay in sync. This process is shown in Figure 4-9. A successful validation will see the event serialized and ready for event stream publishing. The main advantage of this approach is that data inconsistencies between the internal state and the output event stream are significantly reduced. The event stream data is treated as a first-class citizen, and publishing correct data is considered just as important as maintaining consistent internal state.
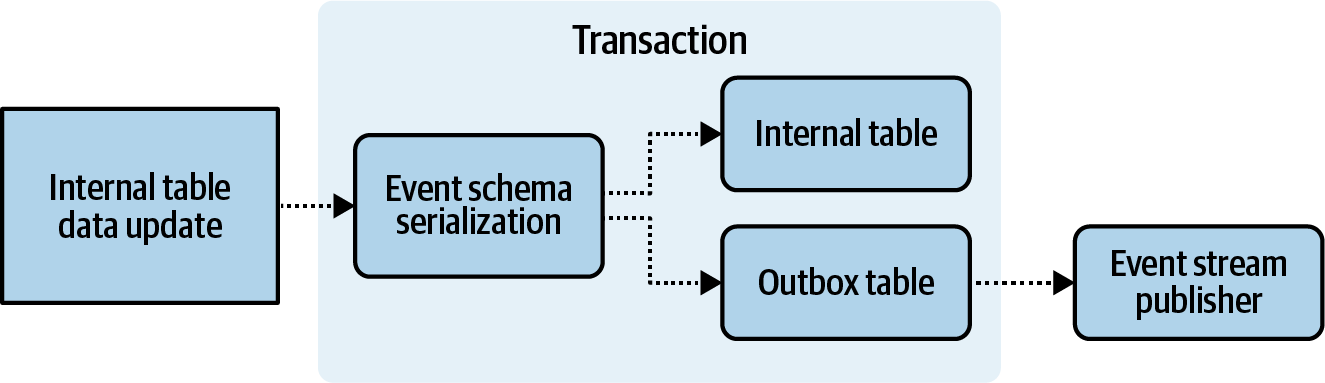
Figure 4-9. Serializing change-data before writing to outbox table
Serializing before writing to the outbox also provides you with the option of using a single outbox for all transactions. The format is simple, as the content is predominantly serialized data with the target output event stream mapping. This is shown in Figure 4-10.

Figure 4-10. A single output table with events already validated and serialized (note the output_stream entry for routing purposes)
One drawback of serializing before publishing is that performance may suffer due to the serialization overhead. This may be inconsequential for light loads but could have more significant implications for heavier loads. You will need to ensure your performance needs remain met.
Alternately, serialization can be performed after the event has been written to the outbox table, as is shown in Figure 4-9.
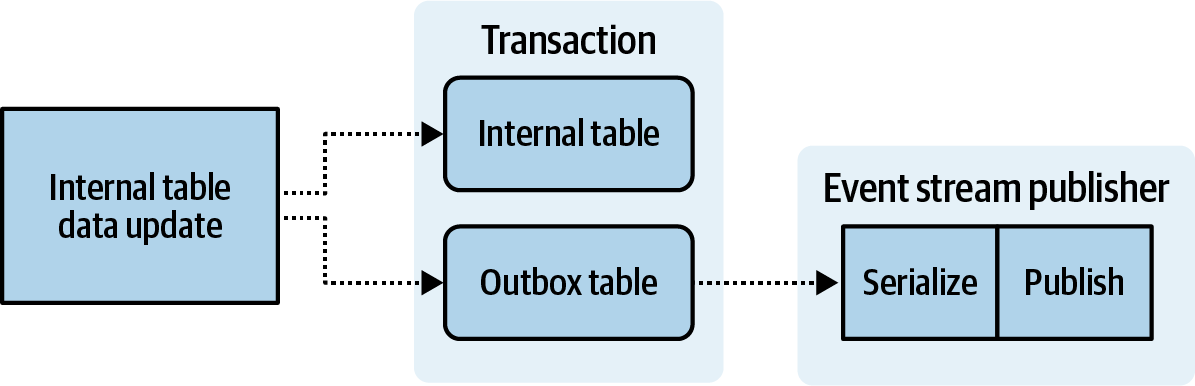
Figure 4-11. Serializing change-data after writing to outbox table, as part of the publishing process
With this strategy you typically have independent outboxes, one for each domain model, mapped to the public schema of the corresponding output event stream. The publisher process reads the unserialized event from the outbox and attempts to serialize it with the associated schema prior to producing it to the output event stream. Figure 4-12 shows an example of multiple outboxes, one for a User entity and one for an Account entity.
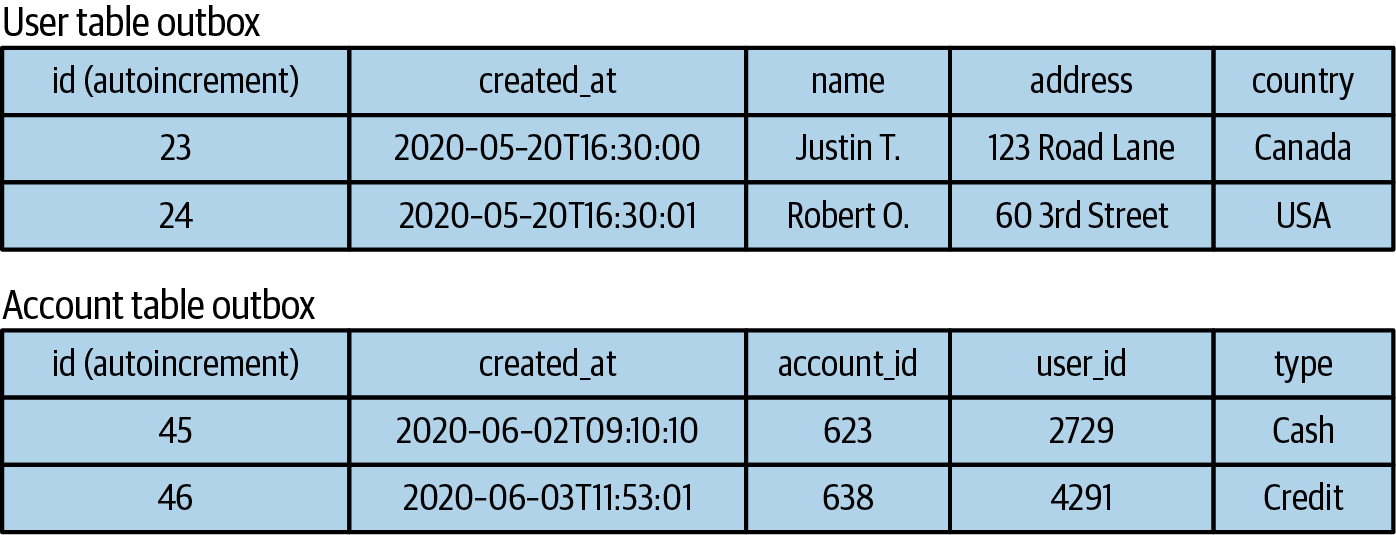
Figure 4-12. Multiple outbox tables (note that the data is not serialized, which means that it may not be compatible with the schema of the output event stream)
A failure to serialize indicates that the data of the event does not comply with its defined schema and so cannot be published. This is where the serialization-after-write option becomes more difficult to maintain, as an already completed transaction will have pushed incompatible data into the outbox table, and there is no guarantee that the transaction can be reversed.
In reality, you will typically end up with a large number of unserializable events in your outbox. Human intervention will most likely be required to try to salvage some of the data, but resolving the issue will be time-consuming and difficult and may even require downtime to prevent additional issues. This is compounded by the fact that some events may indeed be compatible and have already been published, leading to possible incorrect ordering of events in output streams.
Tip
Before-the-fact serialization provides a stronger guarantee against incompatible data than after-the-fact and prevents propagation of events that violate their data contract. The tradeoff is that this implementation will also prevent the business process from completing should serialization fail, as the transaction must be rolled back.
Validating and serializing before writing ensures that the data is being treated as a first-class citizen and offers a guarantee that events in the output event stream are eventually consistent with the data inside the source data store, while also preserving the isolation of the source’s internal data model. This is the strongest guarantee that a change-data capture solution can offer.
Benefits of event-production with outbox tables
There are a number of pros to using a transactional outbox:
Producing events via outbox tables allow for a number of significant advantages:
- Multilanguage support
-
This approach is supported by any client or framework that exposes transactional capabilities.
- Exactly-once outbox semantics
-
Transactions ensure that both the internal model and the outbox data are created atomically. You will not miss any changes in your database provided you wrap the updates in a transaction.
- Early schema enforcement
-
The outbox table can provide a strongly defined schema that represents the event stream’s schema. Alternatively, valide schemas at runtime by serializing the data written into the outbox.
- Internal Data Model Isolation
-
Data store application developers can select which fields to write to the outbox table, keeping internal fields isolated.
- Denormalization
-
Data can be denormalized as needed before being written to the outbox table.
Drawbacks of event production with outbox tables
Producing events via outbox tables has several disadvantages as well:
- Database must support transactions
-
Your database must support transactions. If it does not, you’ll have to choose a different data access pattern.
- Application code changes
-
The application code must be changed to enable this pattern, which requires development and testing resources from the application maintainers.
- Business process performance impact
-
The performance impact to the business workflow may be nontrivial, particularly when validating schemas via serialization. Failed transactions can also prevent business operations from proceeding.
- Data store performance impact
-
The performance impact to the data store may be nontrivial, especially when a significant quantity of records are being written, read, and deleted from the outbox.
Note
Performance impacts must be balanced against other costs. For instance, some organizations simply emit events by parsing change-data capture logs and leave it up to downstream teams to clean up the events after the fact. This incurs its own set of expenses in the form of computing costs for processing and standardizing the events, as well as human-labor costs in the form of resolving incompatible schemas and attending to the effects of strong coupling to internal data models. Costs saved at the producer side are often dwarfed by the expenses incurred at the consumer side for dealing with these issues.
Capturing Change-Data Using Triggers
Trigger support predates many of the auditing, binlog, and write-ahead log patterns examined in the previous sections. Many older relational databases use triggers as a means of generating audit tables. As their name implies, triggers are set up to occur automatically on a particular condition. If it fails, the command that caused the trigger to execute also fails, ensuring update atomicity. You can capture row-level changes to an audit table by using anAFTER trigger. For example, after any INSERT, UPDATE, or DELETE command, the trigger will write a corresponding row to the change-data table. This ensures that changes made to a specific table are tracked accordingly. Consider the example shown in Figure 4-13. User data is being upserted to a user table, with a trigger capturing the events as they occur. Note that the trigger is also capturing the time at which the insertion occurred as well as an Auto-incrementing sequence ID for the event publisher process to use.
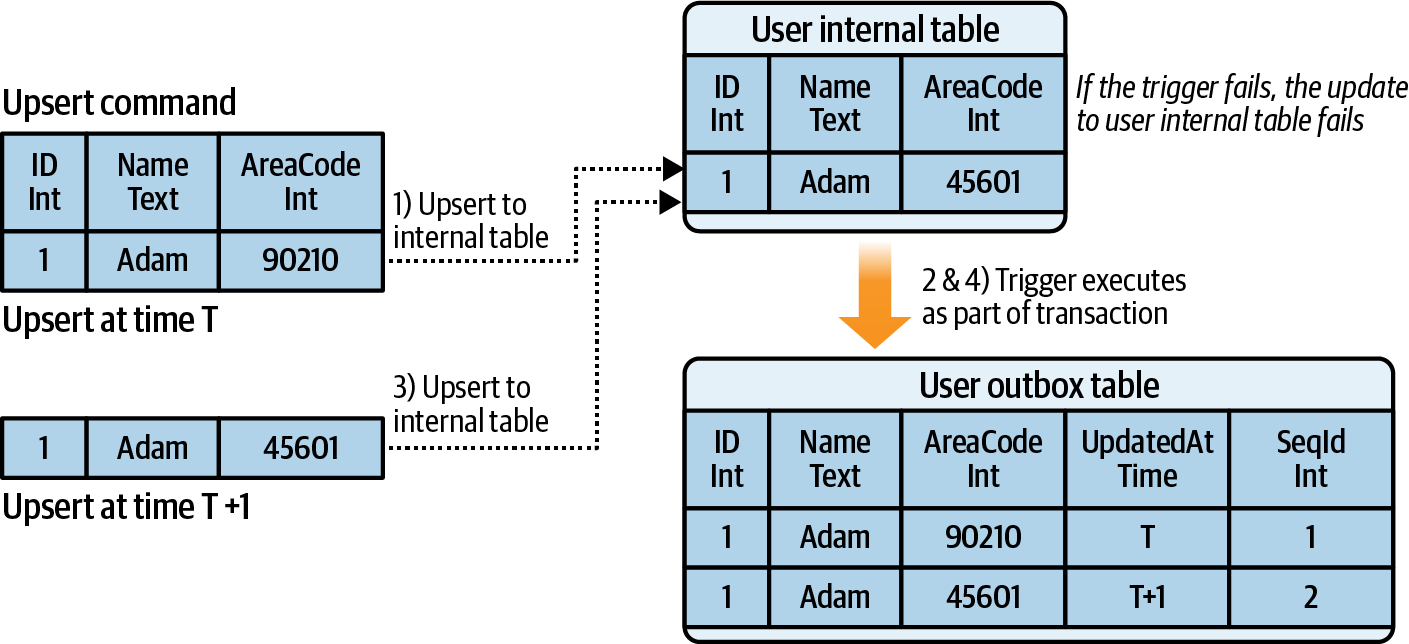
Figure 4-13. Using a trigger to capture changes to a user table
Figure 4-14 shows a continuation of the previous example. After-the-fact validation and serialization is performed on the change-data, with successfully validated data produced to the output event stream. Unsuccessful data would need to be error-handled according to business requirements, but would likely require human intervention.
The change-data capture table schema is the bridge between the internal table schema and the output event stream schema. Compatibility among all three is essential for ensuring that data can be produced to the output event stream. Because output schema validation is typically not performed during trigger execution, it is best to keep the change-data table in sync with the format of the output event schema.
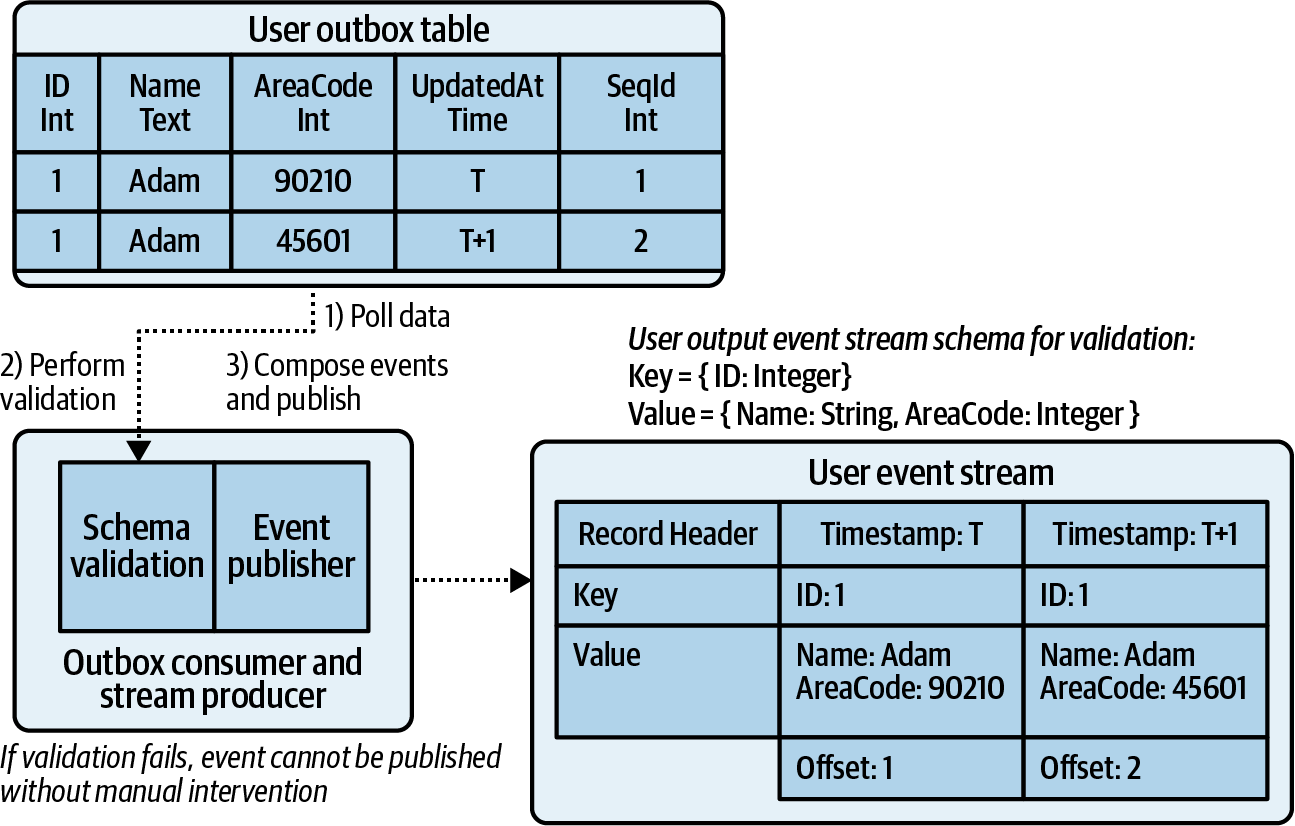
Figure 4-14. After-the-fact validation and production to the output event stream
Tip
Compare the format of the output event schema with the change-data table during testing. This can expose incompatibilities before production deployment.That being said, triggers can work great in many legacy systems. Legacy systems tend to use, by definition, old technology; triggers have existed for a very long time and may very well be able to provide the necessary change-data capture mechanism. The access and load patterns tend to be well defined and stable, such that the impact of adding triggering can be accurately estimated. Finally, although schema validation is unlikely to occur during the triggering process itself, it may be equally unlikely that the schemas themselves are going to change, simply due to the legacy nature of the system. After-the-fact validation is only an issue if schemas are expected to change frequently.
Warning
Try to avoid the use of triggers if you can instead use more modern functionality for generating or accessing change-data, such as a designated CDC system. You should not underestimate the overhead performance and management required for a trigger-based solution, particularly when many dozens or hundreds of tables and data models are involved.
Benefits of using triggers
Benefits of using triggers include the following:
- Supported by most databases
-
Triggers exist for most relational databases.
- Low overhead for small data sets
-
Maintenance and configuration is fairly easy for a small number of data sets.
- Customizable logic
-
Trigger code can be customized to expose only a subset of specific fields. This can provide some isolation into what data is exposed to downstream consumers.
Drawbacks of using triggers
Some cons of using triggers are:
- Performance overhead
-
Triggers execute inline with actions on the database tables and can consume non-trivial processing resources. Depending on the performance requirements and SLAs of your services, this approach may cause an unacceptable load.
- Change management complexity
-
Changes to application code and to data set definitions may require corresponding trigger modifications. Necessary modifications to underlying triggers may be overlooked by the system maintainers, leading to data liberation results that are inconsistent with the internal data sets. Comprehensive testing should be performed to ensure the trigger workflows operate as per expectations.
- Poor scaling
-
The quantity of triggers required scales linearly with the number of data sets to be captured. This excludes any additional triggers that may already exist in the business logic, such as those used for enforcing dependencies between tables.
- After-the-fact schema enforcement
-
Schema enforcement for the output event occurs only after the record has been published to the outbox table. This can lead to unpublishable events in the outbox table.
Tip
Some databases allow for triggers to be executed with languages that can validate compatibility with output event schemas during the trigger’s execution (e.g., Python for PostgreSQL). This can increase the complexity and expense, but significantly reduces the risk of downstream schema incompatibilities.Making Data Definition Changes to Data Sets Under Capture
Integrating data definition changes can be difficult in a data liberation framework. Data migrations are a common operation for many relational database applications and need to be supported by capture. Data definition changes for a relational database can include adding, deleting, and renaming columns; changing the type of a column; and adding or removing defaults. While all of these operations are valid data set changes, they can create issues for the production of data to liberated event streams.Note
Data definition is the formal description of the data set. For example, a table in a relational database is defined using a data definition language (DDL). The resultant table, columns, names, types, and indices are all part of its data definition.For example, if full schema evolution compatibility is required, you cannot drop a non-nullable column without a default value from the data set under capture, as consumers using the previously defined schema expect a value for that field. Consumers would be unable to fall back to any default because none was specified at contract definition time, so they would end up in an ambiguous state. If an incompatible change is absolutely necessary and a breach of data contract is inevitable, then the producer and consumers of the data must agree upon a new data contract.
Caution
Valid alterations to the data set under capture may not be valid changes for the liberated event schema. This incompatibility will cause breaking schema changes that will impact all downstream consumers of the event stream.
Capturing DDL changes depends on the integration pattern used to capture change-data. As DDL changes can have a significant impact on downstream consumers of the data, it’s important to determine if your capture patterns detect changes to the DDL before or after the fact. For instance, the query pattern and CDC log pattern can detect DDL changes only after the fact—that is, once they have already been applied to the data set. Conversely, the change-data table pattern is integrated with the development cycle of the source system, such that changes made to the data set require validation with the change-data table prior to production release.Handling After-the-Fact Data Definition Changes for the Query and CDC Log Patterns
For the query pattern, the schema can be obtained at query time, and an event schema can be inferred. The new event schema can be compared with the output event stream schema, with schema compatibility rules used to permit or prohibit publishing of the event data. This mechanism of schema generation is used by numerous query connectors, such as those provided with the Kafka Connect framework.For the CDC log pattern, data definition updates are typically captured to their own part of the CDC log. These changes need to be extracted from the logs and inferred into a schema representative of the data set. Once the schema is generated, it can be validated against the downstream event schema. Support for this functionality, however, is limited.
Currently, the Debezium connector supports only MySQL’s data definition changes.Handling Data Definition Changes for Change-Data Table Capture Patterns
The change-data table acts as a bridge between the output event stream schema and the internal state schema. Any incompatibilities in the application’s validation code or the database’s trigger function will prevent the data from being written to the change-data table, with the error sent back up the stack. Alterations made to the change-data capture table will require a schema evolution compatible with the output event stream, according to its schema compatibility rules. This involves a two-step process, which significantly reduces the chance of unintentional changes finding their way into production.Sinking Event Data to Data Stores
Sinking data from event streams consists of consuming event data and inserting it into a data store. This is facilitated either by the centralized framework or by a standalone microservice. Any type of event data, be it entity, keyed events, or unkeyed events, can be sunk to a data store.
Event sinking is particularly useful for integrating non-event-driven applications with event streams. The sink process reads the event streams from the event broker and inserts the data into the specified data store. It keeps track of its own consumption offsets and writes event data as it arrives at the input, acting completely independently of the non-event-driven application.
A typical use of event sinking is replacing direct point-to-point couplings between legacy systems. Once the data of the source system is liberated into event streams, it can be sunk to the destination system with few other changes. The sink process operates both externally and invisibly to the destination system.
Data sinking is also employed frequently by teams that need to perform batch-based big-data analysis.
They usually do this by sinking data to a Hadoop Distributed File System, which provides big-data analysis tools. Using a common platform like Kafka Connect allows you to specify sinks with simple configurations and run them on the shared infrastructure. Standalone microservice sinks provide an alternative solution. Developers can create and run them on the microservice platform and manage them independently.The Impacts of Sinking and Sourcing on a Business
A centralized framework allows for lower-overhead processes for liberating data. This framework may be operated at scale by a single team, which in turn supports the data liberation needs of other teams across the organization. Teams looking to integrate then need only concern themselves with the connector configuration and design, not with any operational duties. This approach works best in larger organizations where data is stored in multiple data stores across multiple teams, as it allows for a quick start to data liberation without each team needing to construct its own solution.
There are two main traps that you can fall into when using a centralized framework. First, the data sourcing/sinking responsibilities are now shared between teams. The team operating the centralized framework is responsible for the stability, scaling, and health of both the framework and each connector instance. Meanwhile, the team operating the system under capture is independent and may make decisions that alter the performance and stability of the connector, such as adding and removing fields, or changing logic that affects the volume of data being transmitted through the connector. This introduces a direct dependency between these two teams. These changes can break the connectors, but may be detected only by the connector management team, leading to linearly scaling, cross-team dependencies. This can become a difficult-to-manage burden as the number of changes grows.
The second issue is a bit more pervasive, especially in an organization where event-driven principles are only partially adopted. Systems can become too reliant upon frameworks and connectors to do their event-driven work for them. Once data has been liberated from the internal state stores and published to event streams, the organization may become complacent about moving onward into native event-driven microservices. Teams can become overly reliant upon the connector framework for sourcing and sinking data, and choose not to refactor their applications or develop new event-driven services. In this scenario they instead prefer to just requisition new sources and sinks as necessary, leaving their entire underlying application completely ignorant to events.
Warning
CDC tools are not the final destination in moving to an event-driven architecture, but instead are primarily meant to help bootstrap the process. The real value of the event broker as the data communication layer is in providing a robust, reliable, and truthful source of event data decoupled from the implementation layers, and the broker is only as good as the quality and reliability of its data.
Both of these issues can be mitigated through a proper understanding of the role of the change-data capture framework. Perhaps counterintuitively, it’s important to minimize the usage of the CDC framework and have teams implement their own change-data capture (such as the outbox pattern) despite the additional up-front work this may require. Teams become solely responsible for publishing and their system’s events, eliminating cross-team dependencies and brittle connector-based CDC. This minimizes the work that the CDC framework team needs to do and allows them to focus on supporting products that truly need it.
Reducing the reliance on the CDC framework also propagates an “event-first” mind-set. Instead of thinking of event streams as a way to shuffle data between monoliths, you view each system as a direct publisher and consumer of events, joining in on the event-driven ecosystem. By becoming an active participant in the EDM ecosystem, you begin to think about when and how the system needs to produce events, about the data out there instead of just the data in here. This is an important part of the cultural shift toward successful implementation of EDM.
For products with limited resources and those under maintenance-only operation, a centralized source and sink connector system can be a significant boon. For other products, especially those that are more complex, have significant event stream requirements, and are under active development, ongoing maintenance and support of connectors is unsustainable. In these circumstances it is best to schedule time to refactor the codebase as necessary to allow the application to become a truly native event-driven application.
Finally, carefully consider the tradeoffs of each of the CDC strategies. This often becomes an area of discussion and contention within an organization, as teams try to figure out their new responsibilities and boundaries in regard to producing their events as the single source of truth. Moving to an event-driven architecture requires investment into the data communication layer, and the usefulness of this layer can only ever be as good as the quality of data within it. Everyone within the organization must shift their thinking to consider the impacts of their liberated data on the rest of the organization and come up with clear service-level agreements as to the schemas, data models, ordering, latency, and correctness for the events they are producing.Summary
Data liberation is an important step toward providing a mature and accessible data communication layer. Legacy systems frequently contain the bulk of the core business domain models, stored within some form of centralized implementation communication structure. This data needs to be liberated from these legacy systems to enable other areas of the organization to compose new, decoupled products and services.
There are a number of frameworks, tools, and strategies available to extract and transform data from their implementation data stores. Each has its own benefits, drawbacks, and tradeoffs. Your use cases will influence which options you select, or you may find that you must create your own mechanisms and processes.
The goal of data liberation is to provide a clean and consistent single source of truth for data important to the organization. Access to data is decoupled from the production and storage of it, eliminating the need for implementation communication structures to serve double duty. This simple act reduces the boundaries for accessing important domain data from the numerous implementations of legacy systems and directly promotes the development of new products and services.
There is a full spectrum of data liberation strategies. On one end you will find careful integration with the source system, where events are emitted to the event broker as they are written to the implementation data store. Some systems may even be able to produce to the event stream first before consuming it back for their own needs, further reinforcing the event stream as the single source of truth. The producer is cognizant of its role as a good data-producing citizen and puts protections in place to prevent unintentional breaking changes. Producers seek to work with the consumers to ensure a high-quality, well-defined data stream, minimize disruptive changes, and ensure changes to the system are compatible with the schemas of the events they are producing.
On the other end of the spectrum, you’ll find the highly reactive strategies. The owners of the source data in the implementation have little to no visibility into the production of data into the event broker. They rely completely on frameworks to either pull the data directly from their internal data sets or parse the change-data capture logs. Broken schemas that disrupt downstream consumers are common, as is exposure of internal data models from the source implementation. This model is unsustainable in the long run, as it neglects the responsibility of the owner of the data to ensure clean, consistent production of domain events.
The culture of the organization dictates how successful data liberation initiatives will be in moving toward an event-driven architecture. Data owners must take seriously the need to produce clean and reliable event streams, and understand that data capture mechanisms are insufficient as a final destination for liberating event data.
About the Author
Adam Bellemare is a staff engineer for the data platform at Shopify. He’s held this position since 2020. Previously, he worked at Flipp from 2014 to 2020 as a staff engineer. Prior to that, he held a software developer position at BlackBerry, where he first got started in event-driven systems.
His expertise includes DevOps (Kafka, Spark, Mesos, Kubernetes, Solr, Elasticsearch, HBase, and Zookeeper clusters, programmatic building, scaling, monitoring); technical leadership (helping businesses organize their data communication layer, integrate existing systems, develop new systems, and focus on delivering products); software development (building event-driven microservices in Java and Scala using Beam, Flink, Spark, and Kafka Streams libraries); and data engineering (reshaping the way that behavioral data is collected from user devices and shared within the organization).